
Boosting the Performance of Artificial Intelligence-Driven Models in Predicting COVID-19 Mortality in Ethiopia



Abstract
:1. Introduction
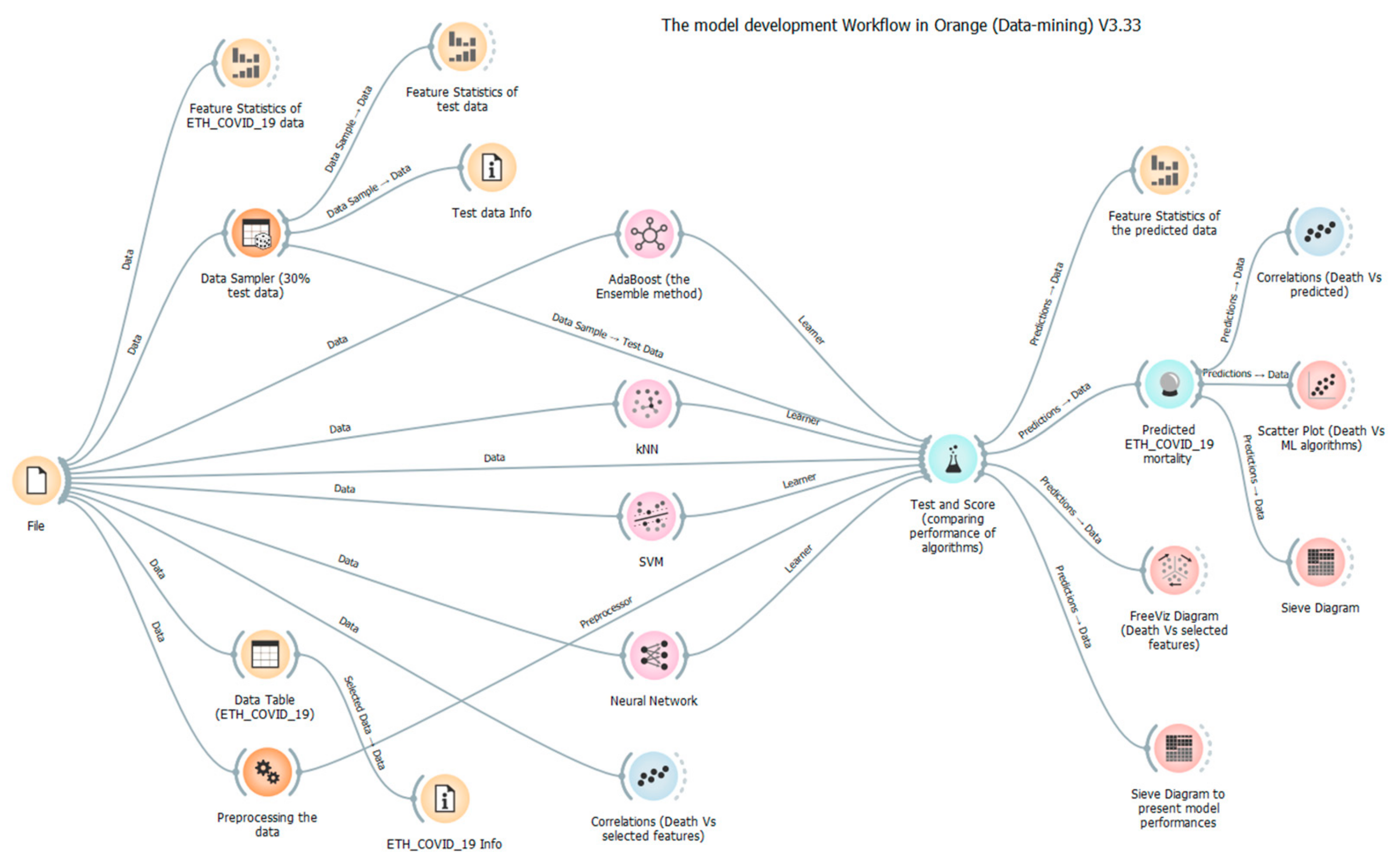
2. Materials and Methods
2.1. Study Area
2.2. Data Source
2.3. Feature Selection, Data Pre-Processing, and Analysis
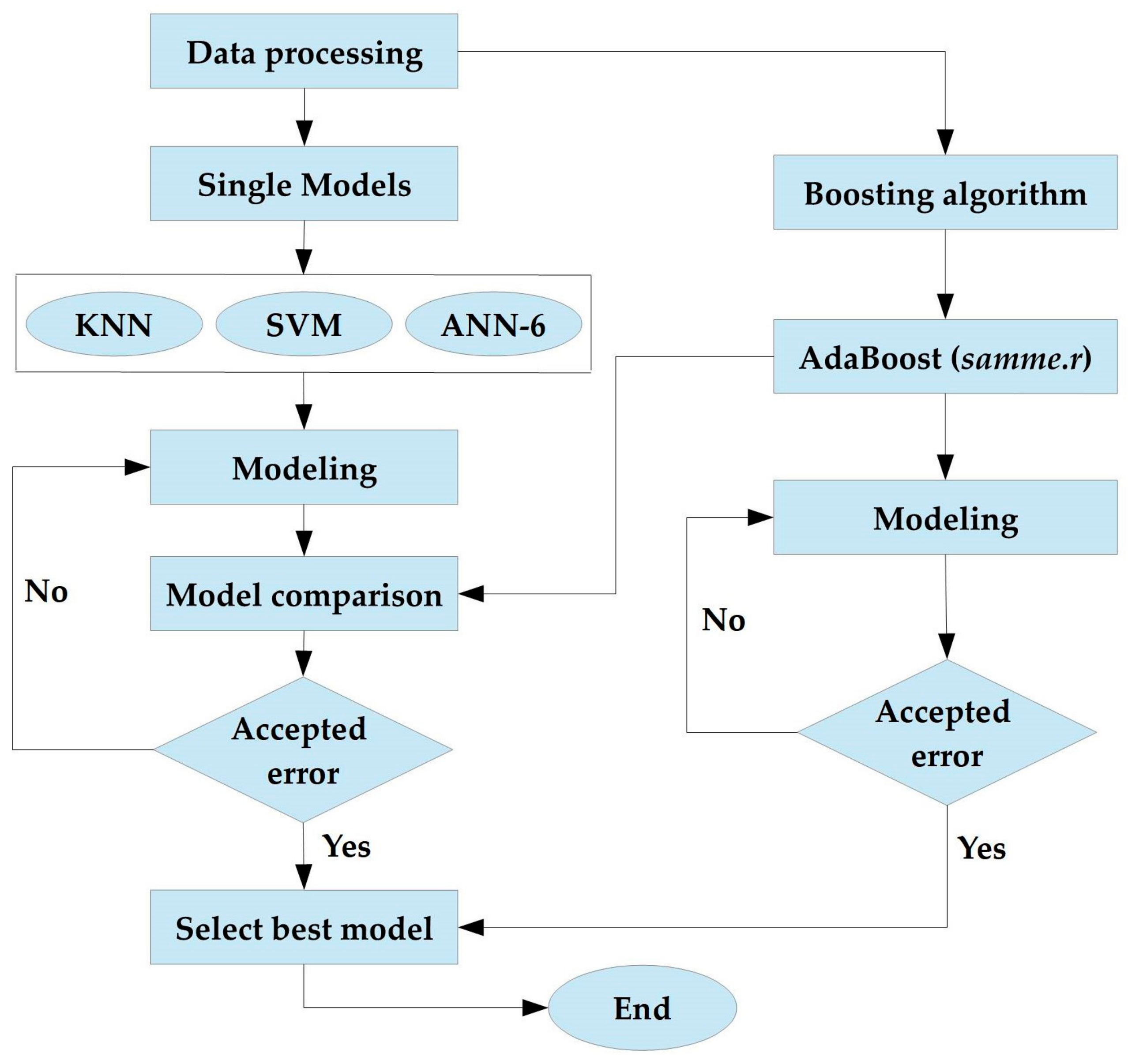
2.4. Proposed Methods
2.4.1. AI-Driven Models
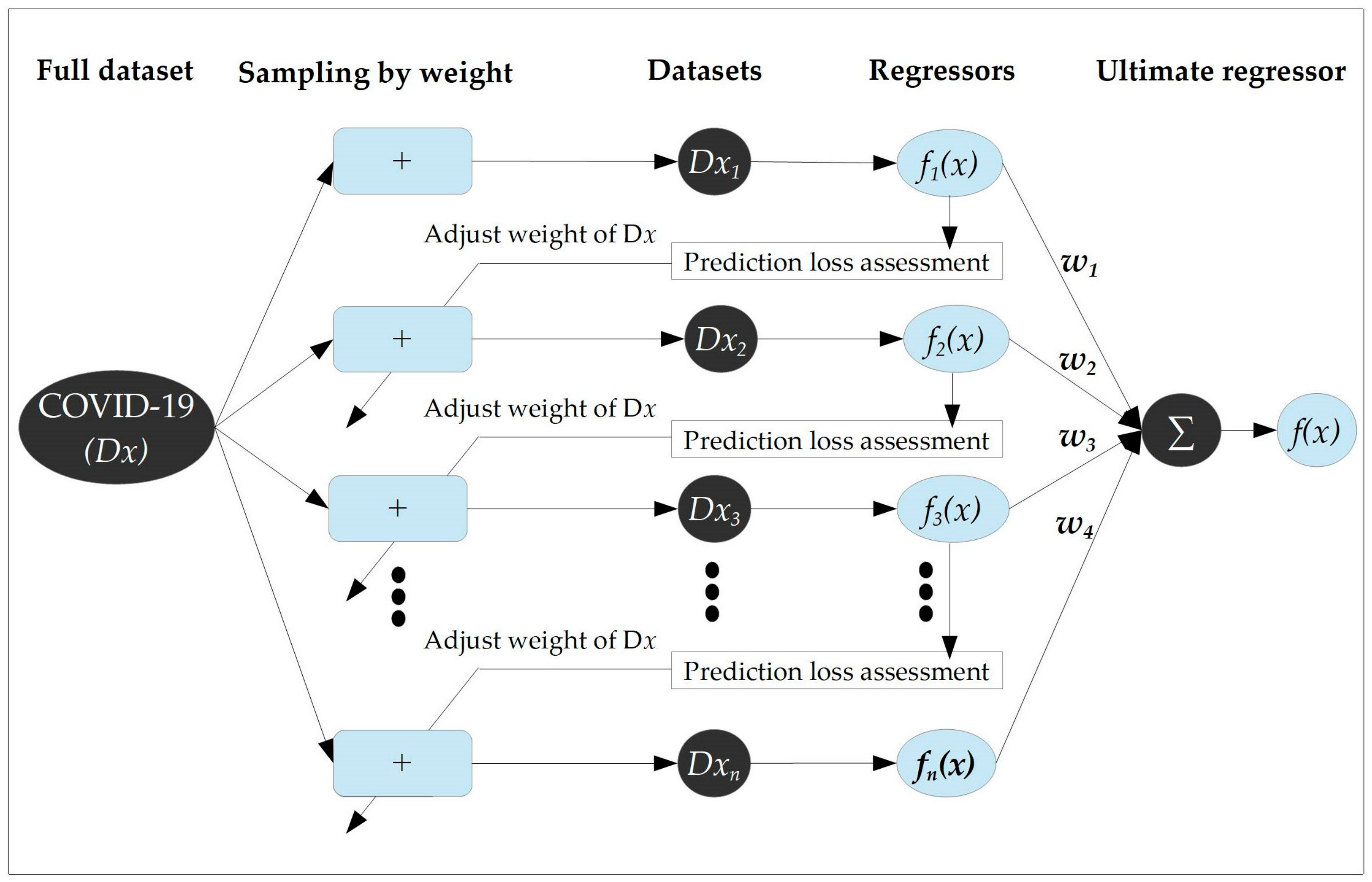
Adaptive Boosting Regression (AdaBoost Regression)
K-Nearest Neighbors Regression (KNN Regression)
The Artificial Neural Network (ANN-6)
The Support Vector Machine (SVM)
2.4.2. Data Normalization and Model Performance Evaluation
3. Results and Discussion
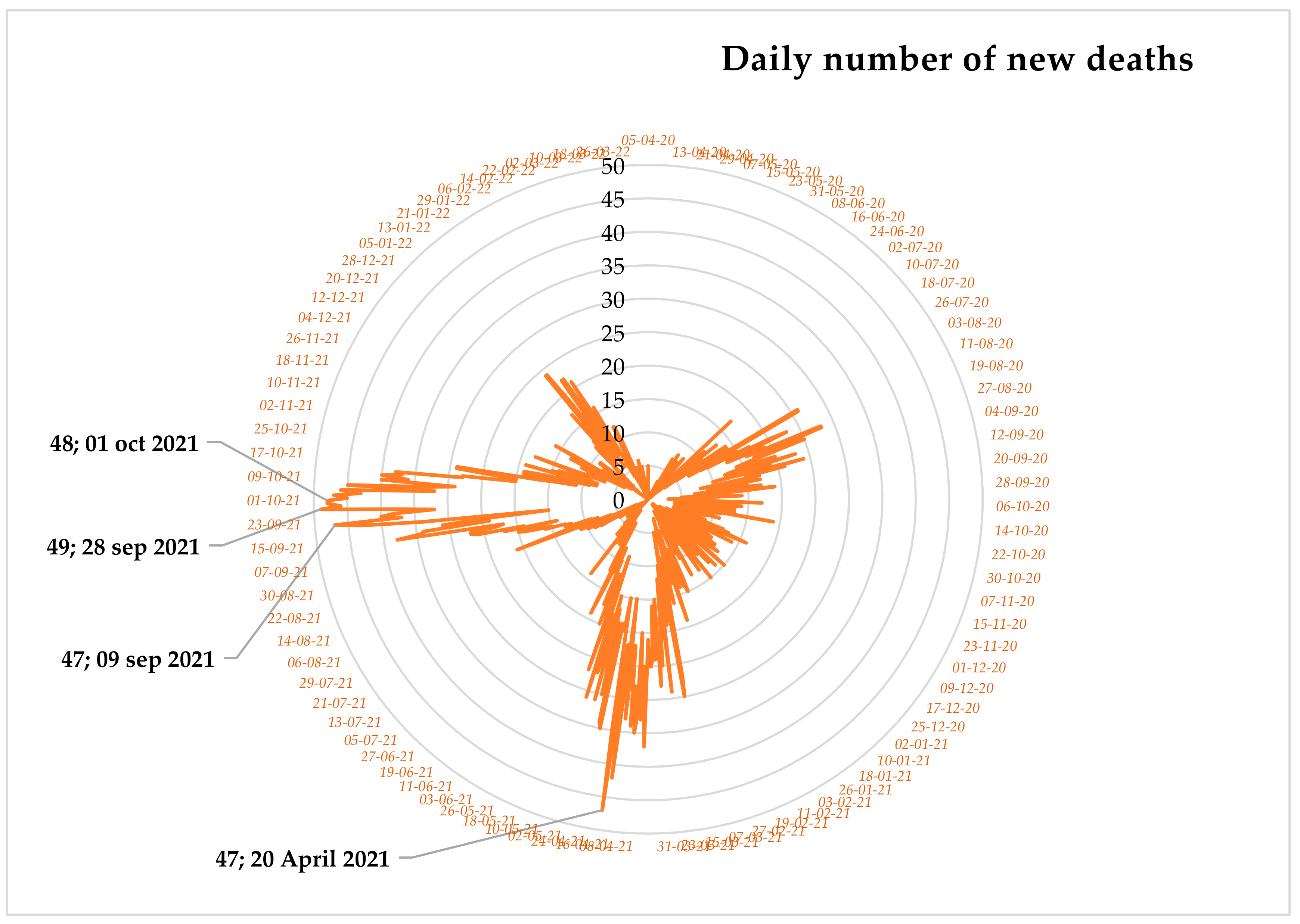
3.1. Feature Statistics
3.2. The Sensitivity Analysis
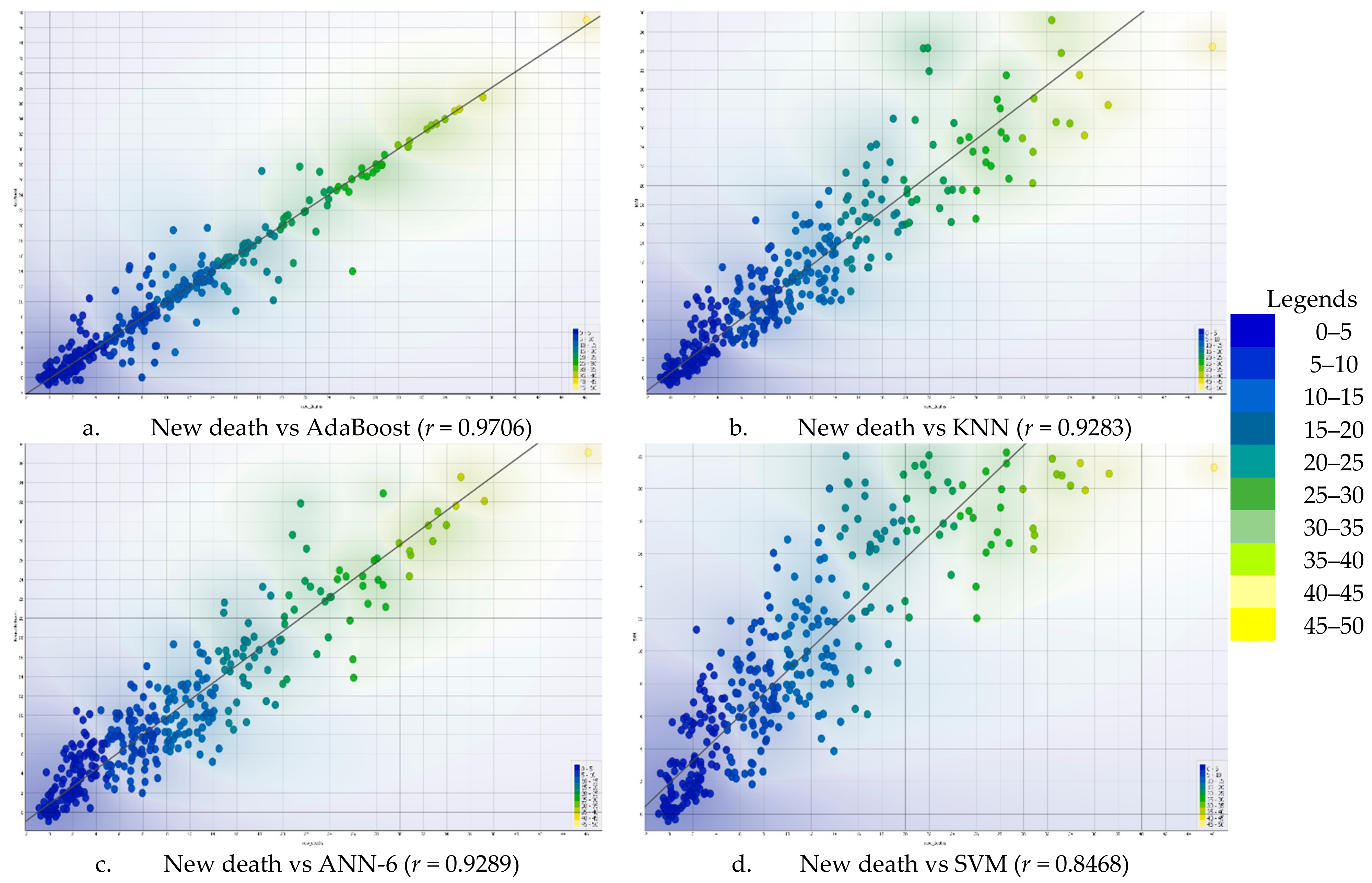
3.3. Prediction of COVID-19 Using Single AI-Driven Models
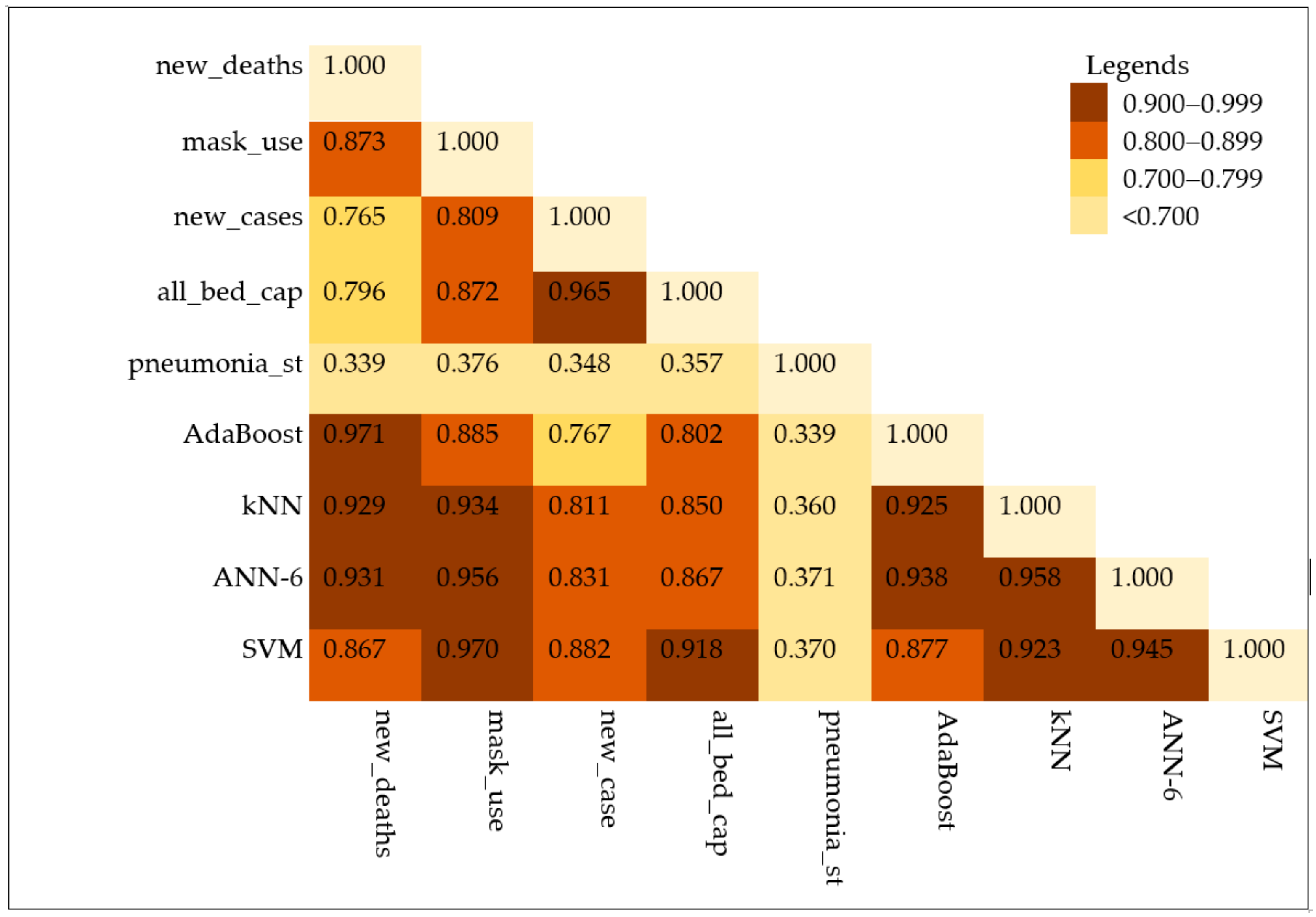
3.4. The Correlation Analysis
3.5. Comparison of AdaBoost with Single AI-Driven Model
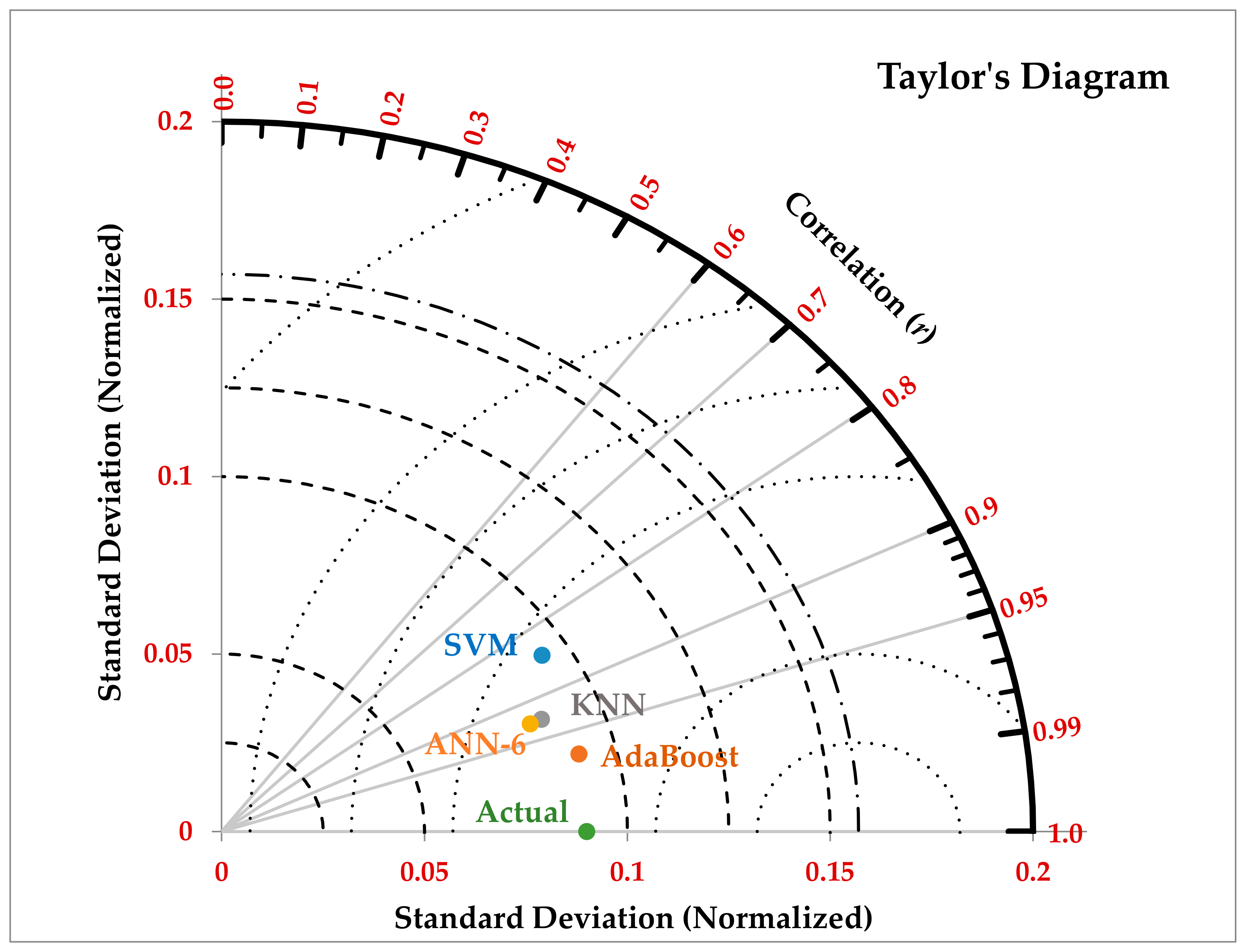
3.6. The Taylor’s Diagram
4. Conclusions and Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arora, N.; Banerjee, A.K.; Narasu, M.L. The role of artificial intelligence in tackling COVID-19. Future Virol. 2020, 15, 717–724. [Google Scholar] [CrossRef]
- Abegaz, K.H.; Etikan, İ. Artificial Intelligence-Driven Ensemble Model for Predicting Mortality Due to COVID-19 in East Africa. Diagnostics 2022, 12, 2861. [Google Scholar] [CrossRef]
- WHO. Coronavirus (COVID-19) Dashboard; World Health Organization: Geneva, Switzerland, 2020; Available online: https://covid19.who.int/ (accessed on 11 January 2023).
- Baik, S.M.; Lee, M.; Hong, K.S.; Park, D.J. Development of Machine-Learning Model to Predict COVID-19 Mortality: Application of Ensemble Model and Regarding Feature Impacts. Diagnostics 2022, 12, 1464. [Google Scholar] [CrossRef] [PubMed]
- Karaarslan, E.; Aydın, D. An Artificial Intelligence-Based Decision Support and Resource Management System for COVID-19 Pandemic. In Data Science for COVID-19; Academic Press: Cambridge, MA, USA, 2021; pp. 25–49. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Taherkhani, A.; Cosma, G.; McGinnity, T.M. AdaBoost-CNN: An adaptive boosting algorithm for convolutional neural networks to classify multi-class imbalanced datasets using transfer learning. Neurocomputing 2020, 404, 351–366. [Google Scholar] [CrossRef]
- Sun, W.; Gao, Q. Exploration of energy saving potential in China power industry based on Adaboost back propagation neuralnetwork. J. Clean. Prod. 2019, 217, 257–266. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Detecting tomatoes in greenhouse scenes by combining AdaBoost classifier andcolor analysis. Biosyst. Eng. 2016, 148, 127–137. [Google Scholar] [CrossRef]
- Fernandes, A.M.; Oliveira, P.; Moura, J.P.; Oliveira, A.A.; Falco, V.; Correia, M.J.; Melo-Pinto, P. Determination of anthocyaninconcentration in whole grape skins using hyperspectral imaging and adaptive boosting neural networks. J. Food Eng. 2011, 105, 216–226. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Li, Y.F.; Zhang, L. Comparison of four Adaboost algorithm based artificial neural networks in wind speedpredictions. Energy Convers. Manag. 2015, 92, 67–81. [Google Scholar] [CrossRef]
- Sun, J.; Fujita, H.; Chen, P.; Li, H. Dynamic financial distress prediction with concept drift based on time weighting combinedwith AdaBoost support vector machine ensemble. Knowl.-Based Syst. 2017, 120, 4–14. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, Y.; Duan, W.; Zhao, H. Nonlinear systems modelling based on self-organizing fuzzy neural network with hierarchical pruning scheme. Appl. Soft Comput. 2020, 95, 106516. [Google Scholar] [CrossRef]
- Zhou, H.; Li, Y.; Zhang, Q.; Xu, H.; Su, Y. Soft-sensing of effluent total phosphorus using adaptive recurrent fuzzy neural network with Gustafson-Kessel clustering. Expert Syst. Appl. 2022, 203, 117589. [Google Scholar] [CrossRef]
- Abegaz, K.H.; Habtewold, E.M. Trend and barriers of antenatal care utilization from 2000 to 2016 Ethiopian DHS: A data mining approach. Sci. Afr. 2019, 3, e00063. [Google Scholar] [CrossRef]
- Sahle, G. Ethiopic maternal care data mining: Discovering the factors that affect postnatal care visit in Ethiopia. Heal. Inf. Sci. Syst. 2016, 4, 4. [Google Scholar] [CrossRef] [PubMed]
- Abegaz, K.H.; Atomssa, E.M. Data mining of access to tetanus toxoid immunization among women of childbearing age in Ethiopia. Mach. Learn. Res. 2017, 2, 54–60. [Google Scholar]
- Markos, Z.; Doyore, F.; Yifiru, M.; Haidar, J. Predicting Under nutrition status of under-five children using data mining techniques: The Case of 2011 Ethiopian Demographic and Health Survey. J. Health Med. Inform. 2014, 5, 2. [Google Scholar] [CrossRef]
- Mariam, B.G.; Mariam, T.H. Application of data mining techniques for predicting CD4 status of patients on ART in Jimma and Bonga Hospitals, Ethiopia. J. Health Med. Inf. 2015, 6, 1–9. [Google Scholar]
- Dejene, B.E.; Abuhay, T.M.; Bogale, D.S. Predicting the level of anemia among Ethiopian pregnant women using homogeneous ensemble machine learning algorithm. BMC Med. Inf. Decis. Mak. 2022, 22, 247. [Google Scholar] [CrossRef]
- Bitew, F.H.; Nyarko, S.H.; Potter, L.; Sparks, C.S. Machine learning approach for predicting under-five mortality determinants in Ethiopia: Evidence from the 2016 Ethiopian Demographic and Health Survey. Genus 2020, 76, 1–16. [Google Scholar] [CrossRef]
- Erdaw, Y.; Tachbele, E. Machine Learning Model Applied on Chest X-Ray Images Enables Automatic Detection of COVID-19 Cases with High Accuracy. Int. J. Gen. Med. 2021, 14, 4923–4931. [Google Scholar] [CrossRef]
- Ayalew, A.M.; Salau, A.O.; Abeje, B.T.; Enyew, B. Detection and classification of COVID-19 disease from X-ray images using convolutional neural networks and histogram of oriented gradients. Biomed. Signal Process. Control. 2022, 74, 103530. [Google Scholar] [CrossRef] [PubMed]
- Statista. African Country with the Largest Population as of 2020. Available online: https://www.statista.com/statistics/1121246/population-in-africa-by-country/ (accessed on 29 December 2022).
- International trade administration (ITA). Ethiopia-Country commercial guide. Available online: https://www.trade.gov/country-commercial-guides/ethiopia-healthcare (accessed on 29 December 2022).
- Mathieu, E.; Ritchie, H.; Ortiz-Ospina, E.; Roser, M.; Hasell, J.; Appel, C.; Giattino, C.; Rodés-Guirao, L. A global database of COVID-19 vaccinations. Nat. Hum. Behav. 2021, 5, 947–953. [Google Scholar] [CrossRef] [PubMed]
- Hasell, J.; Mathieu, E.; Beltekian, D.; Macdonald, B.; Giattino, C.; Ortiz-Ospina, E.; Roser, M.; Ritchie, H. A cross-country database of COVID-19 testing. Sci. Data 2020, 7, 345. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Rojas, R. AdaBoost and the super bowl of classifiers a tutorial introduction to adaptive boosting. Freie Univ. Berlin Tech. Rep. 2009, 1–6. [Google Scholar]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J. Jpn. Soc. Artif. Intell. 1999, 14, 771–780. [Google Scholar]
- Min, H.; Luo, X. Calibration of soft sensor by using Just-in-time modeling and AdaBoost learning method. Chin. J. Chem. Eng. 2016, 24, 1038–1046. [Google Scholar] [CrossRef]
- Gareth, J.; Daniela, W.; Trevor, H.; Robert, T. An Introduction to Statistical Learning: With Applications in R; Spinger: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Tanty, R.; Desmukh, T.S. Application of artificial neural network in hydrology: A review. Int. J. Eng. Technol. Res. 2015, 4, 184–188. [Google Scholar]
- Nourani, V.; Gökçekuş, H.; Umar, I.K. Artificial intelligence-based ensemble model for prediction of vehicular traffic noise. Environ. Res. 2020, 180, 108852. [Google Scholar] [CrossRef]
- BogoToBogo. Artificial Neural Network (ANN) 6 Training via BFGS. Available online: https://www.bogotobogo.com/python/scikit-learn/Artificial-Neural-Network-ANN-6-Training-via-BFGS-Broyden-Fletcher-Goldfarb-Shanno-algorithm-a-variant-of-gradient-descent.php (accessed on 11 January 2023).
- Schiaffino, S.; Codari, M.; Cozzi, A.; Albano, D.; Alì, M.; Arioli, R.; Avola, E.; Bnà, C.; Cariati, M.; Carriero, S.; et al. Machine learning to predict in-hospital mortality in COVID-19 patients using computed tomography-derived pulmonary and vascular features. J. Pers. Med. 2021, 11, 501. [Google Scholar] [CrossRef]
- Kalteh, A.M. Monthly river flow forecasting using artificial neural network and support vector regression models coupled with wavelet transform. Comput. Geosci. 2013, 54, 1–8. [Google Scholar] [CrossRef]
- Wang, W. -C.; Xu, D.-M.; Chau, K.-W.; Chen, S. Improved annual rainfall-runoff forecasting using PSO-SVM model based on EEMD. J. Hydroinf. 2013, 15, 1377–1390. [Google Scholar] [CrossRef]
- Nourani, V.; Elkiran, G.; Abba, S.I. Wastewater treatment plant performance analysis using artificial intelligence—An ensemble approach. Water Sci. Technol. 2018, 78, 2064–2076. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AI-Driven Models | Model Parameters |
|---|---|
| AdaBoost | Base estimator: tree, Number of estimators: 4, Algorithm: Samme.r, and Loss (regression): Square |
| KNN | Number of neighbours: 2, Metric: Manhattan, and Weight: Uniform |
| SVM | SVM type: SVM, C = 1.0, ε = 0.10000000000000003, Kernel: RBF, exp(-auto|x-y|2), Numerical tolerance: 0.001, and Iteration limit: 300 |
| ANN-6 | Hidden layers: 200, Activation: tanh, Solver: L-BFGS-B, Alpha: 1, Max iterations: 500, and Replicable training: True |
| Variables | Training Dataset (n = 584, 70% of the Data) | Testing Dataset (n = 146, 30% of the Data) | ||||
|---|---|---|---|---|---|---|
| Mean ± SD | Min | Max | Mean ± SD | Min | Max | |
| New deaths | 9.1298 ± 8.2090 | 0 | 47 | 13.2667 ± 12.7766 | 0 | 49 |
| New cases | 604.0812 ± 539.7915 | 0 | 2372 | 756.019 ± 1063.059 | 7 | 5185 |
| Bed capacity | 0.1647 ± 0.0235 | 0.1245 | 0.1856 | 0.1729 ± 0.0213 | 0.1345 | 0.1741 |
| Mask use | 0.4279 ± 0.1633 | 0.0000 | 0.6689 | 0.4163 ± 0.1641 | 0.0000 | 0.8679 |
| Pneumonia_st | 0.9615 ± 0.0961 | 0.8213 | 1.0929 | 0.9629 ± 0.0963 | 0.8132 | 1.1294 |
| Features Included | Longer Description of Feature Variables | DC | Rank |
|---|---|---|---|
| ‘mask_use’ | Percent of population reporting always wearing a mask | 0.867 | 1st |
| ‘all_bed_capacity’ | Total number of beds that exists at the location | 0.815 | 2nd |
| ‘new_cases’ | Daily number of new cases | 0.796 | 3rd |
| ‘pneumonia_st’ | Ratio of pneumonia deaths to the average annual deaths | 0.768 | 4th |
| ‘icu_bed_capacity’ | Total number of ICU beds that exists at the location | 0.421 | 5th |
| ‘hosp_admission’ | Daily COVID-19 hospital admission | 0.401 | 6th |
| ‘daily_infection’ | The number of daily infections | 0.253 | 7th |
| Model | Feature Combinations | Model Parameters | Training Dataset | Testing Dataset | ||
|---|---|---|---|---|---|---|
| RMSE | DC | RMSE | DC | |||
| AdaBoost | mask, all_bed, cases, pneumonia | Samme.r | 1.9358 | 0.9449 | 2.0549 | 0.9422 |
| KNN | mask, all_bed, cases, pneumonia | Uniform | 3.0834 | 0.8601 | 3.1858 | 0.8618 |
| SVM | mask, all_bed, cases, pneumonia | RBF | 4.3482 | 0.7218 | 4.5461 | 0.7171 |
| ANN-6 | mask, all_bed, cases, pneumonia | L-BFGS-B | 1.9358 | 0.8553 | 3.1749 | 0.8629 |
| Boosted Model vs. Single Model | Difference in Percentage | |
|---|---|---|
| Training Dataset | Testing Dataset | |
| AdaBoost vs. KNN | 8.48% | 7.94% |
| AdaBoost vs. SVM | 22.31% | 22.51% |
| AdaBoost vs. ANN-6 | 8.96% | 8.02% |
| KNN vs. SVM | 13.83% | 14.57% |
| KNN vs. ANN-6 | 0.48% | 0.08% |
| ANN-6 vs. SVM | 13.35% | 14.49% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abegaz, K.H.; Etikan, İ. Boosting the Performance of Artificial Intelligence-Driven Models in Predicting COVID-19 Mortality in Ethiopia. Diagnostics 2023, 13, 658. https://doi.org/10.3390/diagnostics13040658
Abegaz KH, Etikan İ. Boosting the Performance of Artificial Intelligence-Driven Models in Predicting COVID-19 Mortality in Ethiopia. Diagnostics. 2023; 13(4):658. https://doi.org/10.3390/diagnostics13040658
Chicago/Turabian StyleAbegaz, Kedir Hussein, and İlker Etikan. 2023. "Boosting the Performance of Artificial Intelligence-Driven Models in Predicting COVID-19 Mortality in Ethiopia" Diagnostics 13, no. 4: 658. https://doi.org/10.3390/diagnostics13040658