3.2.1. The Data Pre-Processing Method
In many machine learning algorithms, statistical models always work with vectors and matrices. To use real-world data as input to machine learning algorithms, it is necessary to convert it into a suitable format. This study has used the Count Vectorizer and TFIDF (Term Frequency Inverse Document Frequency) method.
In this study, EEG signals were normalized and converted to text format. For the data converted to text format to be run in machine learning algorithms, it is necessary to vectorize it. Count Vectorizer converts a text into a vector depending on the frequency of each word in the entire text [
22].
Table 1 shows eight unique words as columns of the table and three text examples as rows. In each cell of the table, there is the number of words in the text in question. All words were converted to lower-case before the study, as there would be a distinction between upper- and lower-case letters. The words in the column are listed alphabetically.
Thus, the words in the three different sentences have been converted into numerical data. According to this table, the text expressions in the sentence have been quantified according to their frequency.
During Count Vectorizer, data is not kept as words. For this reason, numerical indices are given to the words seen in the columns of
Table 1. As seen in
Table 2, the vectorization process of the texts has been completed.
TFIDF is the weighting factor that shows the importance of a term in the document. At the same time, TFIDF can be defined as the calculation of how relevant a word in a text string is to the text. It is calculated using the formulas in Equations (1) and (2) [
23,
24].
3.2.2. The Classification (Machine Learning Algorithms)
Classification is creating a machine learning model by learning by the computer in cases where the classes of the past data are known and determining which class the new and unknown data will be found through this model. Machine learning studies consist of two steps called training and testing. First, a learning model is created over the data sets where the intended results are known in the training phase. The test phase passes the data with known results through the model and estimates. The success rate is determined by checking the estimated and actual results [
23,
25]. If the model’s success is at acceptable levels, using this model, estimation is carried out on data whose results are unknown.
In this paper, among the classification algorithms, Naïve Bayes, LGBM (Light Gradient Boosting Machine), SVM (Support Vector Machine Classification—Support Vector Machine), DTC (Decision Tree Classification—Decision Tree Classification), K-NN (K-Nearest Neighbor)—K-Nearest Neighbors), L.R. (Logistic Regression), RFC (Random Forest Classification) were used.
- a)
Naive Bayes Classification Algorithm:
Thomas Bayes developed the Naive Bayes algorithm in the 18th century [
26]. The mathematical representation of the Naïve Bayes algorithm is given in Equation (3).
Here, the expression “P(A)” means the probability of occurrence of event A, the expression “P(B)” means the probability of occurrence of event B “, the expression P(B\A)” means the probability of occurrence of event B when event “A” occurs [
27].
- b)
Light Gradient Strengthening Machine (LGBM) Classification Algorithm:
LGBM is an algorithm that creates strong models in data sets where weak learning will occur. It has been published as open-source by Microsoft since 2017 [
28]. LGBM has a structure that improves the properties of decision trees in terms of running time and memory usage while maintaining predictive success. The algorithm is successful in big data processing thanks to its histogram-based studies [
28]. Furthermore, since LightGBM works in a leaf-based structure, the tree primarily grows horizontally, and the tree depth does not increase much. In this way, excessive learning can be prevented [
29].
- c)
Random Forest Classification (RFC) Algorithm:
It is a formation discovered by Leo Breiman in 2001. However, the method itself was developed by Tin Kam Ho, a statistician at Bell Labs, as an extension of the “bagging” method, which Breiman had also independently developed. Breiman took the idea of “bagging” and applied it to decision trees and named this new ensemble method as “Random Forest. The Random Forest algorithm is used by applying the decision trees algorithm “n” times to increase the prediction success rate [
30]. It is used in classification, regression, and feature extraction processes. In the R.F. algorithm, there are two parameters, the number of trees “N” and the value “M”, which determines the number of variables in the nodes. The test condition known as the appropriate cut-off value of the preferred variable for branching is determined by the “gini coefficient”. The Gini Coefficient is calculated as in Equation (4) [
31].
The GINI index is calculated at each node and continues until it reaches zero. When it is zero, branching ends, the tree with the lowest error rate has the highest weight, and the tree with the highest error rate has the lowest weight. Afterward, classes vote according to the weight of the trees, and these votes are collected. The tree structure with the highest votes is determined, and that tree is preferred [
31,
32]
- d)
K-Nearest Neighbors (K-NN) Classification Algorithm:
The K Nearest Neighbors algorithm, known as KNN (K-Nearest Neighbors), was developed by T.M. COVER and P.E. It was revealed using the “Nearest Neighbor Decision Rule” created by HART. KNN determines to which classification cluster unclassified data is closest among the classified data [
33,
34,
35,
36]
- e)
Support Vector Machines (SVM) Classification Algorithm:
SVM is a machine learning method using hyperplanes. Apart from other linear methods, it is to determine the gap that provides the separation of hyperplanes so that it is the largest. The distinction is not a single linear equation but a range that can be expressed by many equations [
37,
38]
The SVM algorithm was created by Vladimir Vapnik and Alexey Chervonenkis in 1963 [
39]. This method has been used in many fields, such as chemistry [
40], physics [
41], biology, and technology. To perform the classification process, SVM determines the optimum hyperplane, that is, the decision plane, which separates the classes from each other [
42,
43]. In the test phase, the position of the data points to the plane, which will be estimated to be included in which class is examined.
- f)
Decision Tree Classification (DTC) Algorithm:
The Decision Tree algorithm is a frequently used machine learning method. The Decision Trees algorithm is used for regression and classification problems. It is widely used because it is an algorithm that is cheap to create, easy to interpret, and highly reliable. DTC is a method of iterating the group into groups with a clustering algorithm until all values have the same class label [
44]. The decision tree classification method performs the prediction process using the tree structure. In this tree structure, there are decision variables at the nodes of the tree and target values to be predicted at the leaves [
44]. The features in the data set are from the nodes in the decision trees, and these nodes answer the node questions as true-false or yes-no and are divided into two. After the data is divided, the influencing feature vectors affecting the features are examined, and the nodes with high success information enter the algorithm to branch [
45]. There are problems such as the unstable structure of decision trees, differentiation of the result in the slightest change in the data, and over-learning problems [
46]. Decision trees are a machine learning method with statistical and probability structures behind them. The entropy value called the complexity value in statistics, is very important. Entropy is the probability of experiencing unexpected events. In other words, entropy is required to predict possible deviations in the algorithm.
- g)
Logistic Regression (L.R.) Algorithm:
Logistic regression was introduced by Raymond Pearl and Lowell Reed in 1940 [
47]. Logistic regression is used to classify independent variables to examine the probability of a categorical outcome [
48]. Equation (5) shows the logistic regression equation.
In Equation (5), the expression “Ω” indicates the upper limit of the saturation level of “
W”, the expression “α” the value of the curve on the “x” axis, and the expression “β” the slope of the curve. With this method, the relationship between the independent variables in terms of probability and the regressions resulting from the regression is determined and calculated [
48]. Logistic regression algorithm is frequently used in fields such as health [
49], social sciences [
50], and political sciences [
51].
3.2.3. The Testing Process and Performance Metrics
After the machine learning algorithms complete the training phase, the estimation process is made with the data whose results are unknown. It is difficult to control the accuracy once the predicted effects of the unknown data have been determined. In such cases, to test the success of the models, two-thirds of the training data is trained, and the remaining one-third is tested. In this study, training and testing are done by dividing the training data. Thus, the model is tested with data not included in the training, revealing its success.
- a)
The confusion matrix is a square matrix used to test the accuracy of predictions of classification models. Many machine learning algorithms are used in this study, and these algorithms are put to the test. The user checks the test results, and the most suitable algorithm is selected for the study. The confusion matrix shows the number of correct and incorrect predictions of the models [
52,
53].
Table 3 shows the confusion matrix.
In this study, hearing the sounds during the hearing test was expressed as “actually positive situation”, not being heard as “actually negative situation”, “predicted positive situation” for the model to be heard as “predicted negative situation”, and “predicted negative situation” for not being heard.
- b)
The classification error rate is the data that the model predicts incorrectly. It is calculated with the formula in Equation (6) [
54].
- c)
The classification accuracy rate is the value found by subtracting the prediction error rate from the number 1, which is the total probability value. It can also be calculated with the formula in Equation (7). The accuracy rate is the ratio of the values that the machine learning model predicts correctly [
55].
- d)
Recall is the rate at which positive situations are predicted positively by the model. It is calculated as in Equation (8) [
56].
- e)
Precision shows how many of the data used in the study predicted correctly, and it is calculated as in Equation (9) [
57].
- f)
Specificity is the ratio of correctly predicted negative true values to all true negative values. It is calculated with the formula in Equation (10) [
58].
- g)
F-1 Score is a unit of measure that shows the success of machine learning classification algorithms, also called F-1 Score (F-1 Score) or F-Measure (F-Measure), and is calculated with precision and recall values. It is calculated as in Equation (11) [
59].
- h)
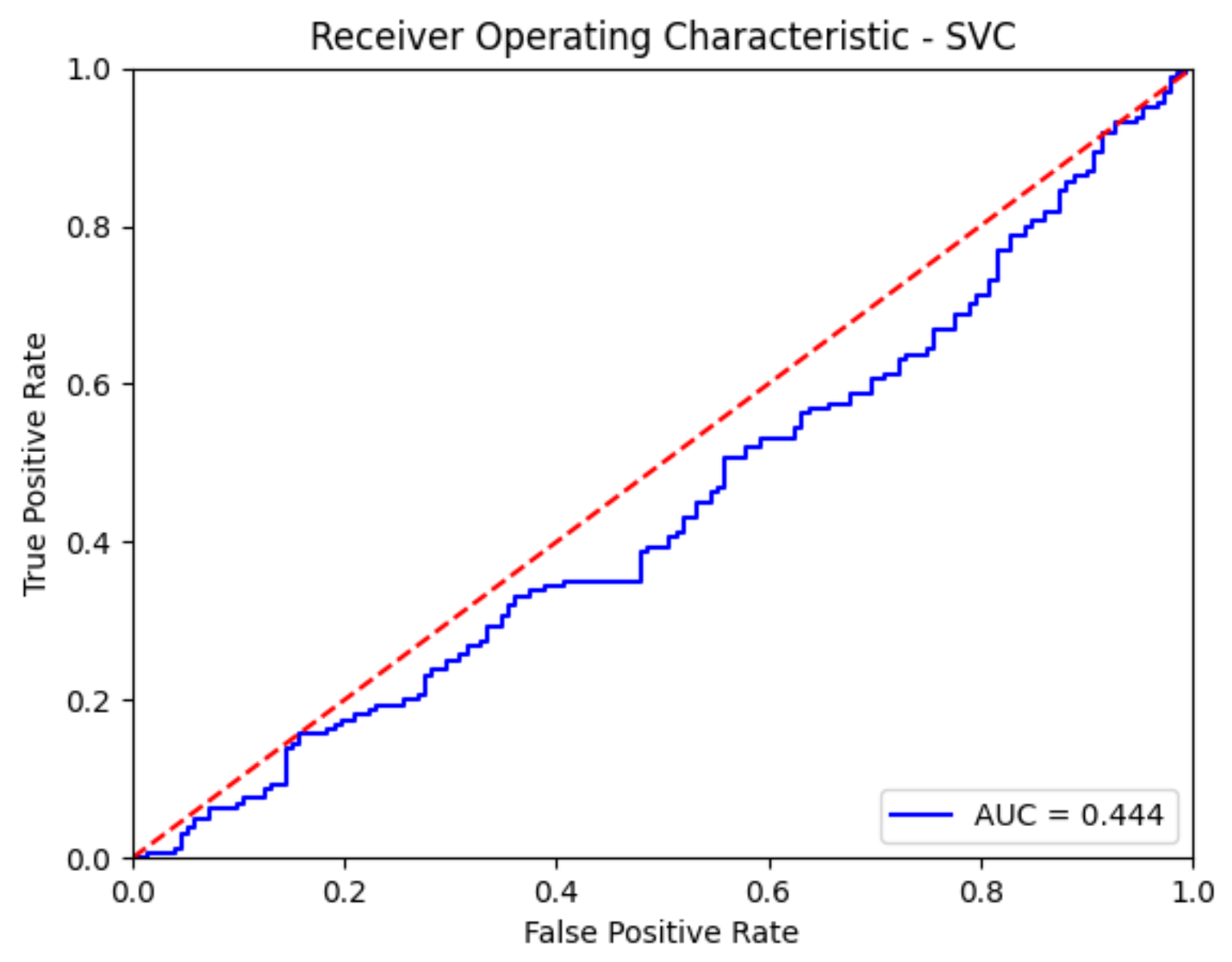
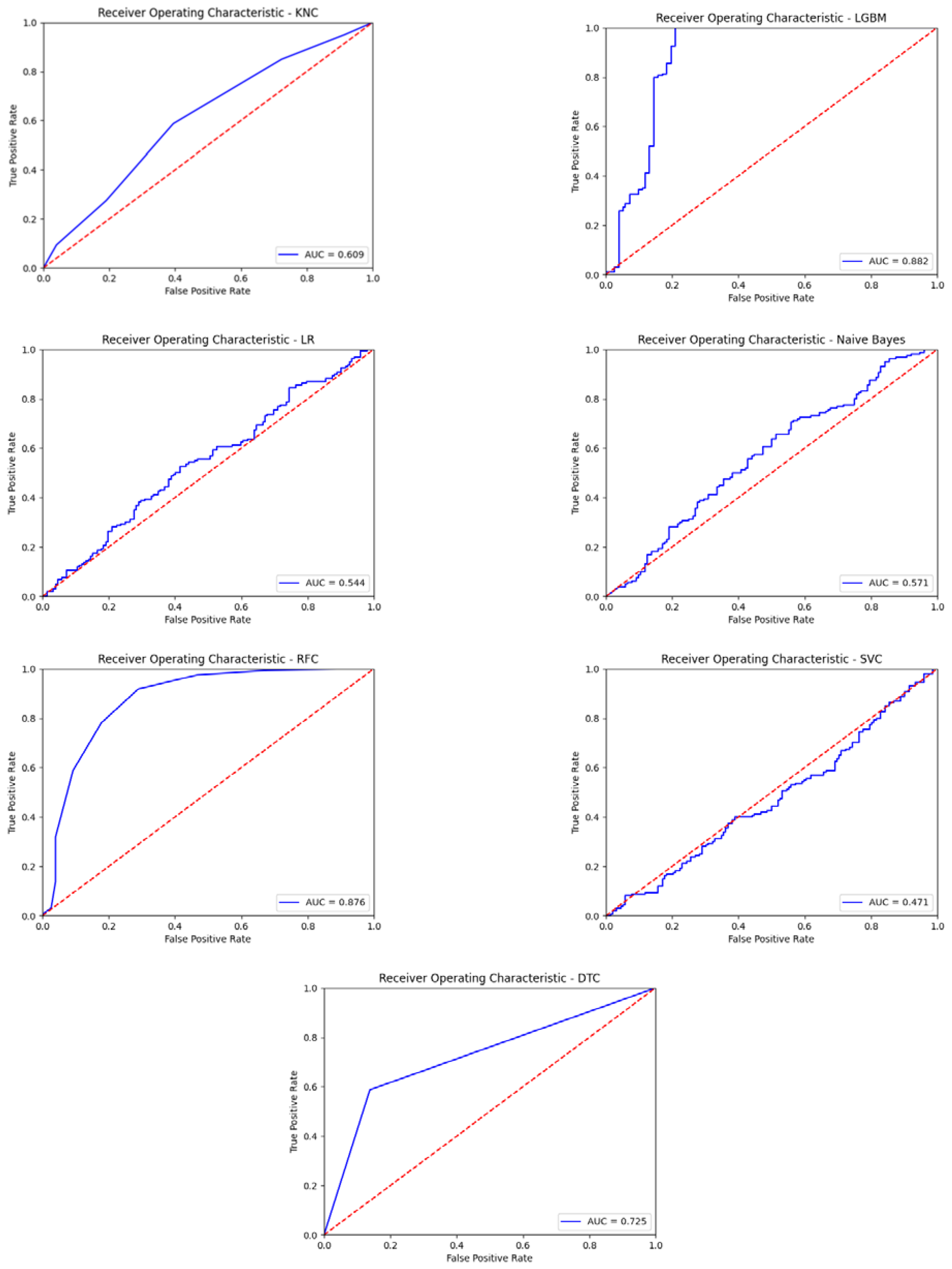
The ROC curve graphically shows the relationship between expressions of sensitivity and specificity for a data test. The ROC curve is obtained by plotting the false positive rates (1-specificity) values versus the sensitivity value. In other words, it is a graphic representation of the relationship between the T.P. value and the F.P. value. The area under the ROC curve is expressed as AUC (Area Under Curve), and it is understood that the classification success of the model increases as it is closer to 1 [
60].
- i)
The MCC (Matthews Correlation Coefficient) is a correlation coefficient between actual values and predicted values. The MCC value takes a value between −1 and +1. It is calculated with the formula in Equation (12). It is understood that the classification success of the model increases as the MCC value approaches 1 [
61]
- j)
Log Loss, also called Logistic Regression Loss or Cross-Entropy Loss, takes into account uncertainty in addition to how much the model estimates differ from the true value. The more the estimated estimates deviate from the true values, the higher the Log Loss value [
62]
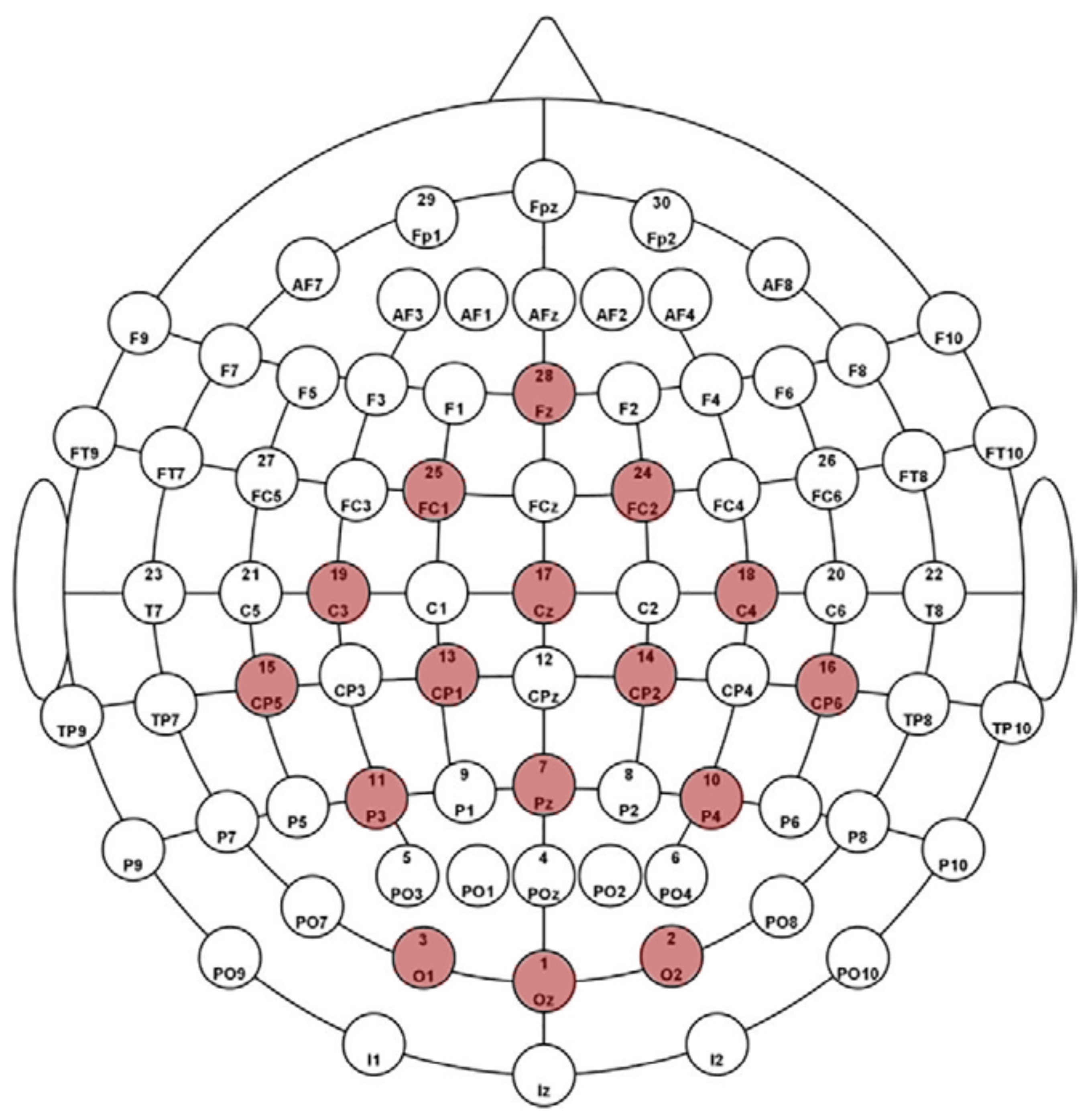
When the prepared dataset is visualized, the P300 signal created on the EEG signals by the given sound stimulus is shown in blue, and the EEG signals obtained in the absence of the sound stimulus as orange, the P300 effect in the data obtained from all experimental studies is shown in
Figure 7. As seen in
Figure 7, while there is a separation between the signals heard and those not heard in channels 1–13, this separation is seen more clearly in channels 1–8. Therefore, artificial intelligence studies were applied and evaluated for 16 channels, 1–13 and 1–8.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}