

Predicting Cardiovascular Rehabilitation of Patients with Coronary Artery Disease Using Transfer Feature Learning
 , , , , , , , , and
, , , , , , , , and
Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
3.1. Patients and Cardiovascular Rehabilitation Center
3.2. Variables
3.2.1. Retrospective Data
3.2.2. Prospective Data
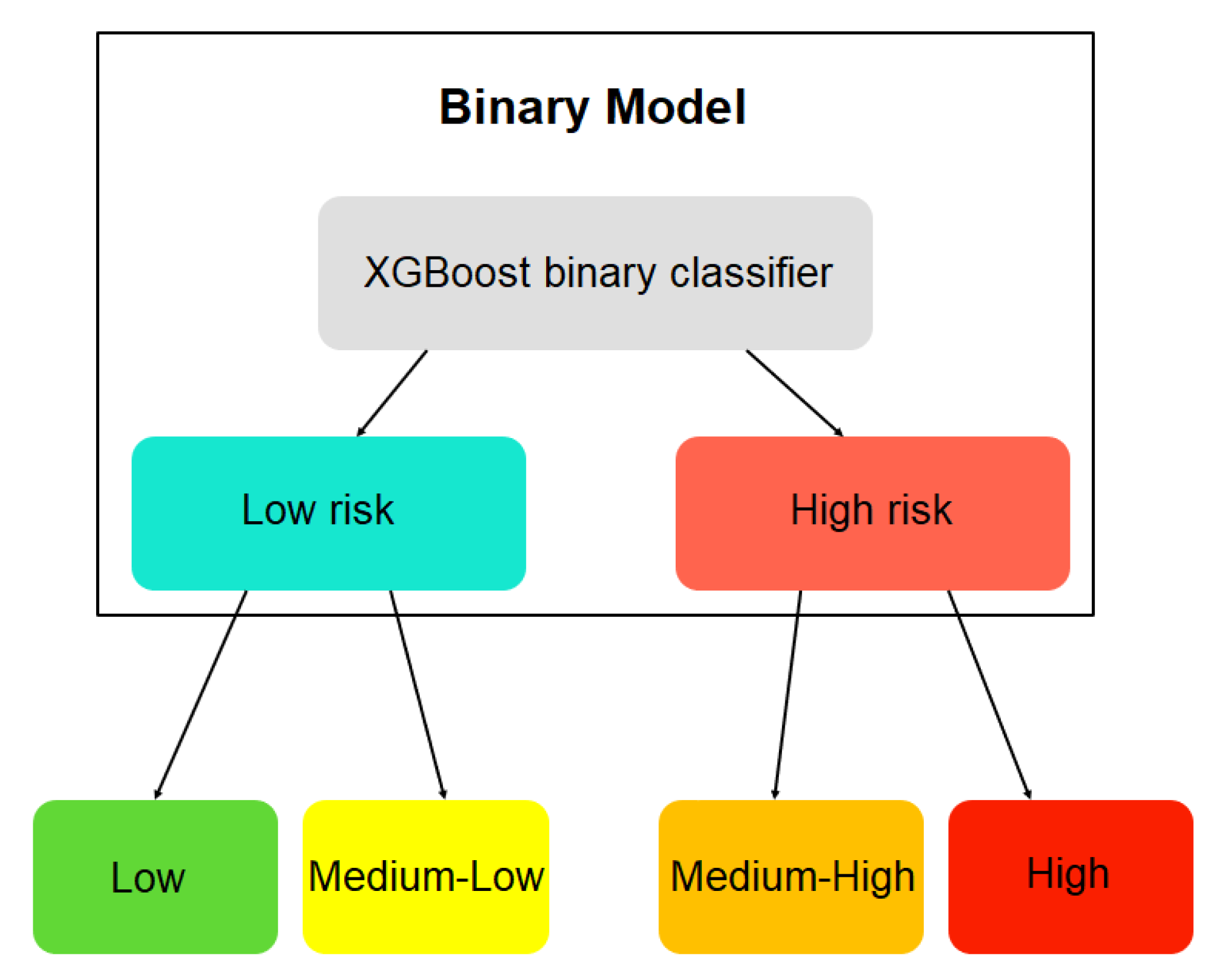
3.2.3. Labeling of Patients
- Level of cardiovascular rehabilitation and adherence:
- –
- 0–25: Low level;
- –
- 25–50: Medium-low level;
- –
- 51–75: Medium-high level;
- –
- 76–100: High level.
- Cardiovascular risk level (CVR):
- –
- 0–25: Low CVR;
- –
- 25–50: Medium-low CVR;
- –
- 51–75: Medium-high CVR;
- –
- 76–100: High CVR.
3.3. Stacked Machine Learning with Transfer Feature Learning
3.3.1. Stacked Machine Learning Using Retrospective Data
3.3.2. Transfer Feature Learning for Incorporating Prospective Data
3.4. Model Explainability
3.5. Performance Metrics
- Normalized mean square error (NMSE):where is the vector of observed rehabilitation probability values and is the vector of predicted rehabilitation probability values.
- Mean absolute error (MAE):
- Mean absolute percentage error (MAPE):
- Coefficient of determination ():where corresponds to the average of the predicted rehabilitation probability values.
- Spearman correlation coefficient (r):where corresponds to the ranks of the values, is the covariance and is the standard deviation. The results range in .
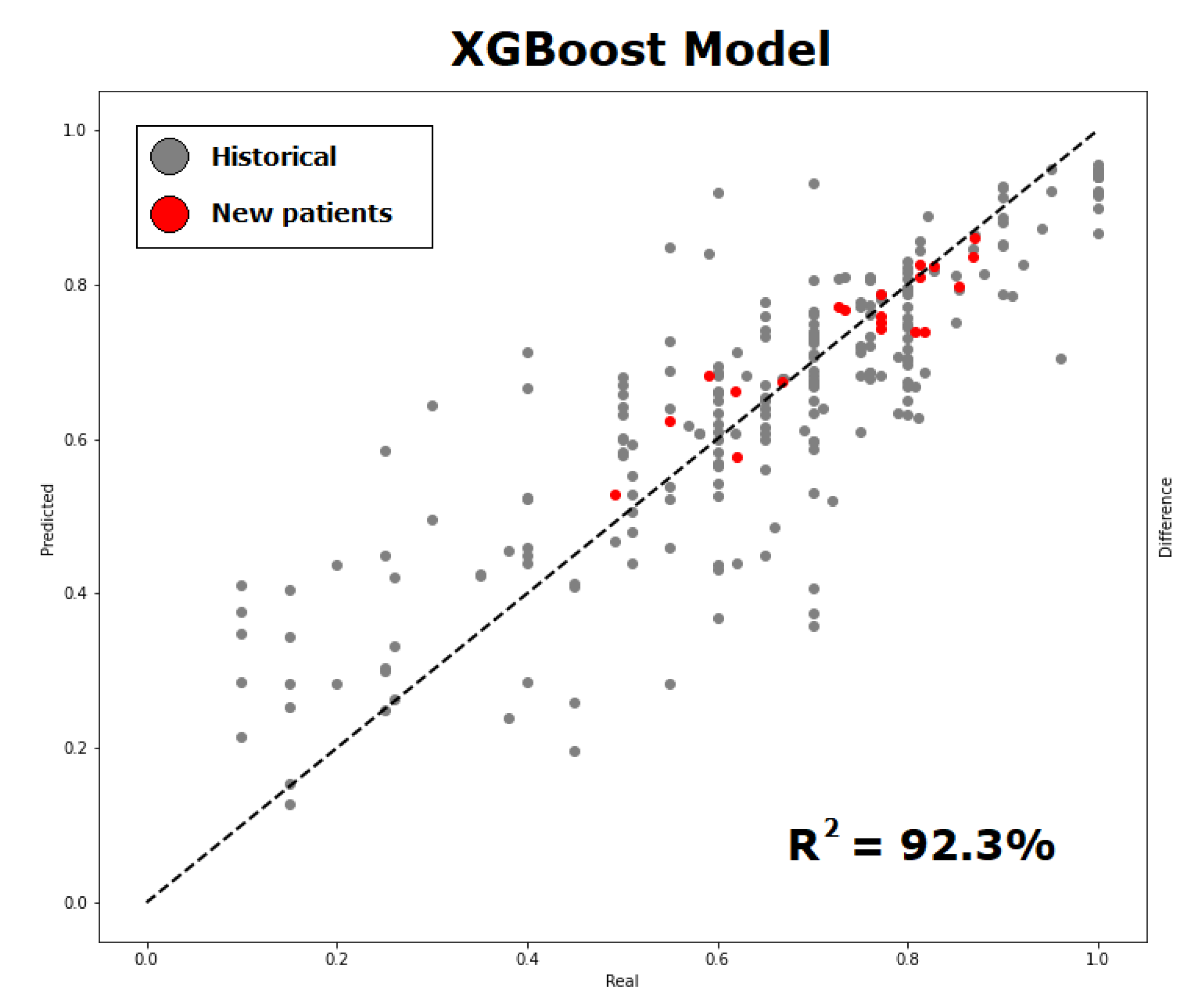
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Amiel, S.A.; Aschner, P.; Childs, B.; Cryer, P.E.; de Galan, B.E.; Frier, B.M.; Gonder-Frederick, L.; Heller, S.R.; Jones, T.; Khunti, K.; et al. Hypoglycaemia, cardiovascular disease, and mortality in diabetes: Epidemiology, pathogenesis, and management. Lancet Diabetes Endocrinol. 2019, 7, 385–396. [Google Scholar] [CrossRef] [PubMed]
- Ministerio de Salud (MINSAL). Departamento de Estadísticas e Información de Salud (DEIS). Indicadores Básicos de Salud en Chile; DEIS: Santiago de Chile, Chile, 2019. [Google Scholar]
- López-Jiménez, F.; Pérez-Terzic, C.; Zeballos, P.C.; Anchique, C.V.; Burdiat, G.; González, K.; González, G.; Fernández, R.; Santibáñez, C.; Herdy, A.; et al. Consenso de rehabilitación cardiovascular y prevención secundaria de las Sociedades Interamericana y Sudamericana de Cardiología. Rev. Urug. Cardiol. 2013, 28, 189–224. [Google Scholar]
- Tessler, J.; Bordoni, B. Cardiac Rehabilitation; StatPearls Publishing LLC: Treasure Island, FL, USA, 2019. [Google Scholar]
- Pina, A.; Castelletti, S. COVID-19 and Cardiovascular Disease: A Global Perspective. Curr. Cardiol. Rep. 2021, 23, 135. [Google Scholar] [CrossRef] [PubMed]
- Besnier, F.; Gayda, M.; Nigam, A.; Juneau, M.; Bherer, L. Cardiac rehabilitation during quarantine in COVID-19 pandemic: Challenges for center-based programs. Arch. Phys. Med. Rehabil. 2020, 101, 1835–1838. [Google Scholar] [CrossRef]
- Nicholls, S.J.; Nelson, M.; Astley, C.; Briffa, T.; Brown, A.; Clark, R.; Colquhoun, D.; Gallagher, R.; Hare, D.L.; Inglis, S.; et al. Optimising secondary prevention and cardiac rehabilitation for atherosclerotic cardiovascular disease during the COVID-19 pandemic: A position statement from the Cardiac Society of Australia and New Zealand (CSANZ). Hear. Lung Circ. 2020, 29, e99–e104. [Google Scholar] [CrossRef]
- Jin, K.; Khonsari, S.; Gallagher, R.; Gallagher, P.; Clark, A.M.; Freedman, B.; Briffa, T.; Bauman, A.; Redfern, J.; Neubeck, L. Telehealth interventions for the secondary prevention of coronary heart disease: A systematic review and meta-analysis. Eur. J. Cardiovasc. Nurs. 2019, 18, 260–271. [Google Scholar] [CrossRef]
- Valero, P.; Salas, R.; Pardo, F.; Cornejo, M.; Fuentes, G.; Vega, S.; Grismaldo, A.; Hillebrands, J.L.; van der Beek, E.M.; van Goor, H.; et al. Glycaemia dynamics in gestational diabetes mellitus. Biochim. Biophys. Acta (BBA)-Gen. Subj. 2022, 1866, 130134. [Google Scholar] [CrossRef]
- Bertini, A.; Gárate, B.; Pardo, F.; Pelicand, J.; Sobrevia, L.; Torres, R.; Chabert, S.; Salas, R. Impact of Remote Monitoring Technologies for Assisting Patients with Gestational Diabetes Mellitus: A Systematic Review. Front. Bioeng. Biotechnol. 2022, 10, 35310000. [Google Scholar] [CrossRef]
- Jimenez, F.; Torres, R. Building an IoT-aware healthcare monitoring system. In Proceedings of the 2015 34th International Conference of the Chilean Computer Science Society (SCCC), Santiago, Chile, 9–13 November 2015; IEEE: New York, NY, USA, 2015; pp. 1–4. [Google Scholar]
- Silva-Cardoso, J.; Juanatey, J.R.G.; Comin-Colet, J.; Sousa, J.M.; Cavalheiro, A.; Moreira, E. The future of telemedicine in the management of heart failure patients. Card. Fail. Rev. 2021, 7, e11. [Google Scholar] [CrossRef]
- Ganguli, I.; Gordon, W.J.; Lupo, C.; Sands-Lincoln, M.; George, J.; Jackson, G.; Rhee, K.; Bates, D.W. Machine learning and the pursuit of high-value health care. NEJM Catal. Innov. Care Deliv. 2020, 1, 94. [Google Scholar] [CrossRef]
- Barrett, M.; Boyne, J.; Brandts, J.; Rocca, B.L.; De Maesschalck, L.; De Wit, K.; Dixon, L.; Eurlings, C.; Fitzsimons, D.; Golubnitschaja, O.; et al. Artificial intelligence supported patient self-care in chronic heart failure: A paradigm shift from reactive to predictive, preventive and personalised care. Epma J. 2019, 10, 445–464. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Ling, C. A strategy to apply machine learning to small datasets in materials science. Npj Comput. Mater. 2018, 4, 25. [Google Scholar] [CrossRef] [Green Version]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine learning algorithm validation with a limited sample size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef]
- Science, D.; Laboratory, T. Machine Learning with Limited Data. Def. Sci. Technol. Lab. 2020. [Google Scholar]
- Liu, W.; Liu, W.D.; Gu, J. Predictive model for water absorption in sublayers using a Joint Distribution Adaption based XGBoost transfer learning method. J. Pet. Sci. Eng. 2020, 188, 106937. [Google Scholar] [CrossRef]
- Yang, K.; Lu, J.; Wan, W.; Zhang, G.; Hou, L. Transfer learning based on sparse Gaussian process for regression. Inf. Sci. 2022, 605, 286–300. [Google Scholar] [CrossRef]
- Louridi, N.; Amar, M.; El Ouahidi, B. Identification of cardiovascular diseases using machine learning. In Proceedings of the 2019 7th Mediterranean Congress of Telecommunications (CMT), Fez, Morocco, 24–25 October 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Singh, N.; Singh, P. Cardiac arrhythmia classification using machine learning techniques. In Engineering Vibration, Communication and Information Processing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 469–480. [Google Scholar]
- Rodriguez-Segura, M.; Nicolis, O.; Peralta-Marquez, B.; Carrillo-Azocar, J. Predicting cardiovascular disease by combining optimal feature selection methods with machine learning. In Proceedings of the 2020 39th International Conference of the Chilean Computer Science Society (SCCC), Coquimbo, Chile, 16–20 November 2020; IEEE: New York, NY, USA, 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Kańtoch, E. Recognition of sedentary behavior by machine learning analysis of wearable sensors during activities of daily living for telemedical assessment of cardiovascular risk. Sensors 2018, 18, 3219. [Google Scholar] [CrossRef] [Green Version]
- Fang, Y.; Zou, Y.; Xu, J.; Chen, G.; Zhou, Y.; Deng, W.; Zhao, X.; Roustaei, M.; Hsiai, T.K.; Chen, J. Ambulatory Cardiovascular Monitoring via a Machine-Learning-Assisted Textile Triboelectric Sensor. Adv. Mater. 2021, 33, 2104178. [Google Scholar] [CrossRef]
- López Bernal, S.; Martínez Valverde, J.; Huertas Celdrán, A.; Martínez Pérez, G. SENIOR: An Intelligent Web-Based Ecosystem to Predict High Blood Pressure Adverse Events Using Biomarkers and Environmental Data. Appl. Sci. 2021, 11, 2506. [Google Scholar] [CrossRef]
- Huang, W.; Ying, T.W.; Chin, W.L.C.; Baskaran, L.; Marcus, O.E.H.; Yeo, K.K.; Kiong, N.S. Application of ensemble machine learning algorithms on lifestyle factors and wearables for cardiovascular risk prediction. Sci. Rep. 2022, 12, 1033. [Google Scholar] [CrossRef]
- Wallert, J.; Gustafson, E.; Held, C.; Madison, G.; Norlund, F.; von Essen, L.; Olsson, E.M.G. Predicting adherence to internet-delivered psychotherapy for symptoms of depression and anxiety after myocardial infarction: Machine learning insights from the U-CARE heart randomized controlled trial. J. Med. Internet Res. 2018, 20, e10754. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Norlund, F.; Olsson, E.M.; Burell, G.; Wallin, E.; Held, C. Treatment of depression and anxiety with internet-based cognitive behavior therapy in patients with a recent myocardial infarction (U-CARE Heart): Study protocol for a randomized controlled trial. Trials 2015, 16, 154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jahandideh, S.; Jahandideh, M.; Barzegari, E. Individuals’ Intention to Engage in Outpatient Cardiac Rehabilitation Programs: Prediction Based on an Enhanced Model. J. Clin. Psychol. Med. Settings 2021, 28, 798–807. [Google Scholar] [CrossRef] [PubMed]
- Tripoliti, E.E.; Karanasiou, G.S.; Kalatzis, F.G.; Bechlioulis, A.; Goletsis, Y.; Naka, K.; Fotiadis, D.I. HEARTEN KMS—A knowledge management system targeting the management of patients with heart failure. J. Biomed. Inform. 2019, 94, 103203. [Google Scholar] [CrossRef]
- Desai, F.; Chowdhury, D.; Kaur, R.; Peeters, M.; Arya, R.C.; Wander, G.S.; Gill, S.S.; Buyya, R. HealthCloud: A system for monitoring health status of heart patients using machine learning and cloud computing. Internet Things 2022, 17, 100485. [Google Scholar] [CrossRef]
- Alshurafa, N.; Sideris, C.; Pourhomayoun, M.; Kalantarian, H.; Sarrafzadeh, M.; Eastwood, J.A. Remote health monitoring outcome success prediction using baseline and first month intervention data. IEEE J. Biomed. Health Inform. 2016, 21, 507–514. [Google Scholar] [CrossRef]
- De Cannière, H.; Corradi, F.; Smeets, C.J.; Schoutteten, M.; Varon, C.; Van Hoof, C.; Van Huffel, S.; Groenendaal, W.; Vandervoort, P. Wearable monitoring and interpretable machine learning can objectively track progression in patients during cardiac rehabilitation. Sensors 2020, 20, 3601. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: Las Vegas, NV, USA, 2016; pp. 785–794. [Google Scholar]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Huang, Y.; Lei, H.; Li, X.; Yang, G. Quantum maximum mean discrepancy GAN. Neurocomputing 2021, 454, 88–100. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Su-In, L. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Model Description |
|---|---|
| Louridi et al. [20] | Naive Bayes. |
| Singh and Singh [21] | Random forest. |
| Huang et al. [26] | Naive Bayes, random forest and support-vector classifier. |
| Kántoch [23] | Binary decision trees, discriminant analysis model, naive Bayes, k-nearest neighbors classification, support-vector machines and artificial neural networks. |
| Fang et al. [24] | Neural Networks. |
| López et al. [25] | Random forest, decision tree, support-vector regression, Bayesian ridge, linear regression, and polynomial regression. |
| Wallert et al. [27] | Random forest. |
| Jahandideh et al. [29] | Ordinal logistic regression and random forest. |
| Desai et al. [31] | Support-vector machine, k-nearest neighbors, neural networks, logistic regression, and gradient boosting trees. |
| Alshurafa et al. [32] | Logistic regression, C4.5 decision trees, k-nearest neighbors and naive Bayes. |
| De Cannière et al. [33] | Support vector machine. |
| Tripoliti et al. [30] | Random forests, logistic model trees, J48, rotation forest, support-vector machines, radial basis function network, Bayesian network, nive Bayes. |
| Kinesiology | Nutrition | Psychology |
|---|---|---|
| Oxygen uptake (L/min) | Weight (kg) | Function (score 0–100) |
| Oxygen uptake (mL/Kg/min) | Height (meters) | Physical role (score 0–100) |
| Maximum heart rate (beat/min) | Body mass index (kg/m2) | Bodily pain (score 0–100) |
| O2 pulse (mL/beat) | Waist-hip index | General health (score 0–100) |
| Ventilation/CO2 production ratio | Lean mass (%) | Vitality (score 0–100) |
| Metabolic Equivalent Task (MET) | Body mass (%) | Social function (score 0–100) |
| Fat mass (%) | Emotional role (score 0–100) | |
| Visceral fat mass (%) | Mental health (score 0–100) |
| Source | Variable |
|---|---|
| Pressure Holter | Overall mean systolic, overall mean diastolic, overall mean heart rate, overall mean blood pressure, overall mean pulse pressure. |
| Accelerometry | Kilocalories, step count, MET, total moderate to vigorous physical activities (MVPA), Borg strength, resting heart rate. |
| Blood test | Glycemia, total cholesterol. |
| Nursing evaluation | Description of the prescribed diet, description of the prescribed medication, identification of the disease process, and description of the prescribed activity. |
| Echocardiogram | Tricuspid annular plane systolic excursion (TAPSE), fractional shortening (FS), ejection fraction (EF), stretch and shortening measure (A). |
| Base Models | NMSE | r | MAE | MAPE | |
|---|---|---|---|---|---|
| Random forest | 0.0354 ± 0.011 | 0.562 ± 0.109 | 0.749 ± 0.115 | 0.092 ± 0.016 | 0.252 ± 0.094 |
| XgBoost | 0.030 ± 0.013 | 0.630 ± 0.189 | 0.760 ± 0.162 | 0.086 ± 0.021 | 0.212 ± 0.120 |
| Gradient boosting | 0.037 ± 0.011 | 0.525 ± 0.119 | 0.714 ± 0.107 | 0.094 ± 0.017 | 0.257 ± 0.094 |
| KNN | 0.063 ± 0.018 | 0.209 ± 0.088 | 0.462 ± 0.079 | 0.125 ± 0.020 | 0.357 ± 0.126 |
| SVM | 0.059 ± 0.015 | 0.232 ± 0.137 | 0.456 ± 0.091 | 0.126 ± 0.019 | 0.312 ± 0.104 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torres, R.; Zurita, C.; Mellado, D.; Nicolis, O.; Saavedra, C.; Tuesta, M.; Salinas, M.; Bertini, A.; Pedemonte, O.; Querales, M.; et al. Predicting Cardiovascular Rehabilitation of Patients with Coronary Artery Disease Using Transfer Feature Learning. Diagnostics 2023, 13, 508. https://doi.org/10.3390/diagnostics13030508
Torres R, Zurita C, Mellado D, Nicolis O, Saavedra C, Tuesta M, Salinas M, Bertini A, Pedemonte O, Querales M, et al. Predicting Cardiovascular Rehabilitation of Patients with Coronary Artery Disease Using Transfer Feature Learning. Diagnostics. 2023; 13(3):508. https://doi.org/10.3390/diagnostics13030508
Chicago/Turabian StyleTorres, Romina, Christopher Zurita, Diego Mellado, Orietta Nicolis, Carolina Saavedra, Marcelo Tuesta, Matías Salinas, Ayleen Bertini, Oneglio Pedemonte, Marvin Querales, and et al. 2023. "Predicting Cardiovascular Rehabilitation of Patients with Coronary Artery Disease Using Transfer Feature Learning" Diagnostics 13, no. 3: 508. https://doi.org/10.3390/diagnostics13030508