
Enhancing Diagnostic Decision-Making: Ensemble Learning Techniques for Reliable Stress Level Classification

 ,
,  , and
, and
Abstract
:1. Introduction
- (i)
- The research proposes a unique ensemble learning strategy designed primarily for classifying students’ levels of stress. While earlier research focused on stress prediction as outlined in Section 2, the work presented here ingeniously blends decision trees, random forest classifiers, AdaBoost, gradient boost, and ensemble learning techniques to provide a thorough model for precisely classifying stress levels.
- (ii)
- In contrast to other approaches outlined in Section 2, the article incorporates survey data from the student population to thoroughly analyze stress causes. The method also uses oversampling methods to correct the imbalance in the dataset of stress levels. A more reliable and accurate stress prediction model is produced because of the integration of survey-based insights with imbalance management.
- (iii)
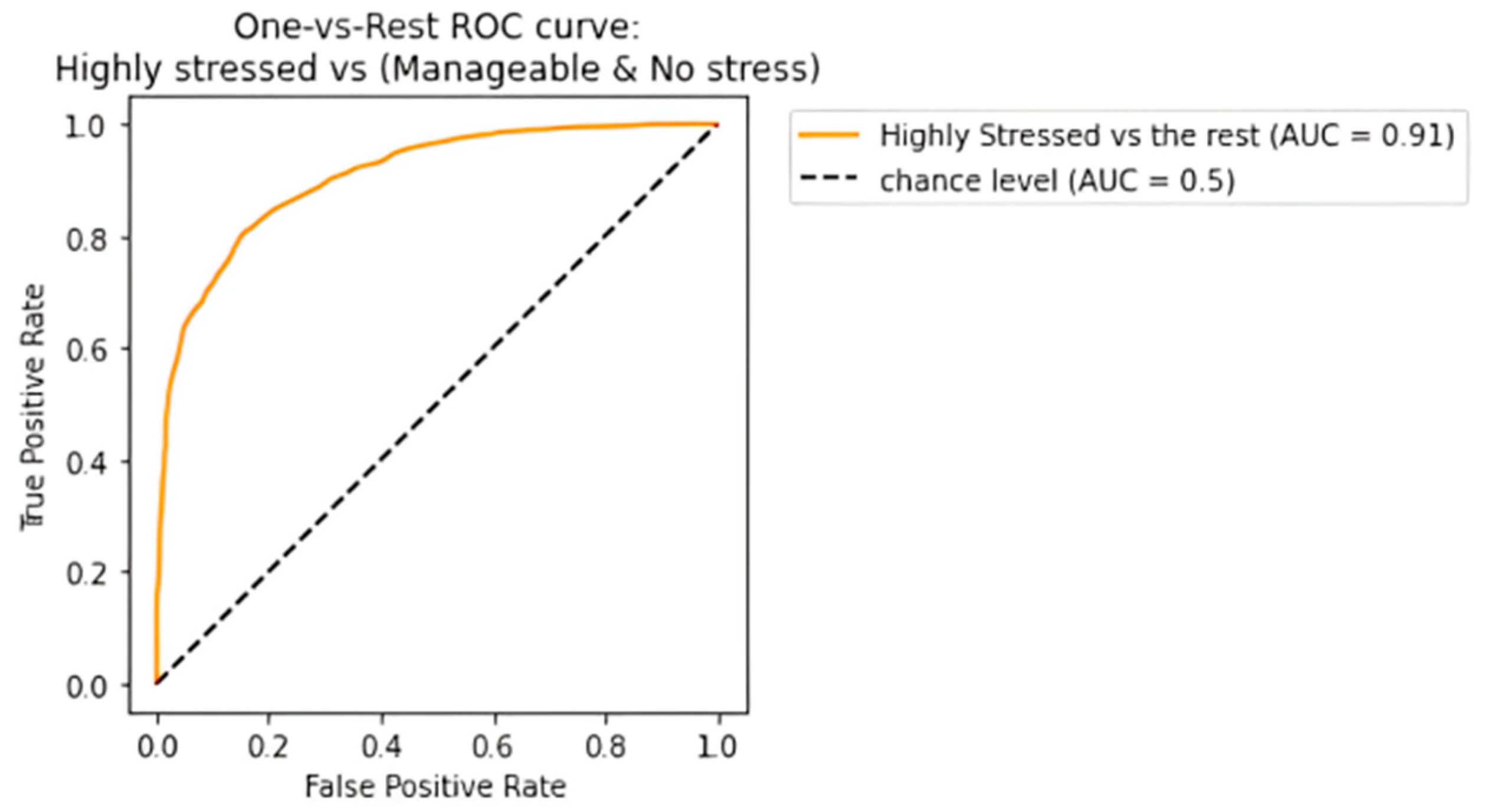
- The work uses a number of performance assessment criteria, such as accuracy, precision, recall, and F1 score, to go beyond intuitive measurements. The results’ validity is further strengthened by the use of fivefold cross-validation. The addition of receiver operating characteristic (ROC) curve analysis also offers a full review of the model’s performance for each category of stress level, demonstrating a comprehensive and in-depth examination of the suggested strategy.
2. Related Works
2.1. Deep Learning Algorithms
2.2. Supervised and Ensemble Learning
2.3. Analysis of Stress Factors
3. Problem Statement
4. Proposed Work
| Algorithm 1: Oversampling the minority class in survey data to remove bias | |
| Step 1 | The minority class, “No stress” class, is oversampled to remove bias. |
| Step 2 | Oversampling the data due to the imbalance in the dataset for the “No stress” class. No stress data ← take subset (data, where stress level = “No stress”) Sampling “no stress” subset data to generate duplicate rows ← Sample ‘n’ rows (no-stress data, specify additional data point count) |
| Step 3 | Merge the additional duplicate records created with the initial data New data ← Row binding the data frame (data, Sampled “no stress” data) Shuffled data ← new data (sample (1: total data point count of new obtained data)) |
| Step 4 | Use the obtained data to train machine learning models |
4.1. Decision Tree Classification to Classify Stress Levels
| Algorithm 2: Implementing decision tree classifier to classify stress levels | |
| Step 1 | Read the surveyed dataset |
| Step 2 | Transforming data to feed them to the machine learning model Data ← transform (data, sleep = convert as integer (sleep), productivity ← convert as factor (productivity), screentime ← convert as factor (screentime), assignments ← convert as integer (assignments), deadline ← convert as factor(deadline), study ← convert as factor (study), stress ← convert as factor (stress)) |
| Step 3 | Training the decision tree model using the unbiased dataset Sample ← sample rows (1: total data point count (data), split into 80–20 ratio) Train ← data[sample,] Test ← data[-sample,] Decision tree model ← feed data (stress ~., data = training data) |
| Step 4 | Interpreting the results |
4.2. Random Forest Classification to Classify Stress Levels
| Algorithm 3: Feeding the data to random forest classifier | |
| Step 1 | Implement the similar transformation steps used in decision tree classifier |
| Step 2 | Random forest model ← random forest (stress~., data = training data, mtry = 2) |
| Step 3 | Evaluate the model using performance metrics |
| Step 4 | Interpreting the results |
4.3. Stress Level Classification Using Adaboost Algorithm
| Algorithm 4: Feeding the data to the AdaBoost classifier | |
| Step 1 | Implement the similar transformation steps used in decision tree classifier |
| Step 2 | Model ← boosting (stress~., data = training data, boost = TRUE, mfinal = 100) predictions ← predict (model, test) |
| Step 3 | Evaluate the model using performance metrics |
| Step 4 | Interpreting the results |
4.4. Stress Level Classification Using Gradient Boost Algorithm
| Algorithm 5: Feeding the data to gradient boost classifier | |
| Step 1 | Implement the similar transformation steps used in decision tree classifier |
| Step 2 | Model gbm = gbm (stress~., data = training_data, distribution = “multinomial”, cv.folds = 10, shrinkage = 0.01, n.minobsinnode = 10, n.trees = 200) |
| Step 3 | Evaluate the model using performance metrics |
| Step 4 | Interpreting the results |
5. Experimental Setup and Analysis
5.1. Exploratory Analysis
- Number of hours of sleep every night;
- Most productive time in the day—early bird/night owl;
- Screen time per day;
- Number of weekly assignments assigned to the student;
- Submission status of the weekly assignments;
- Study plan—regular or procrastinated;
- Stress level as assessed by the student.
5.2. Data Preprocessing
5.3. Evaluation Metrics
6. Results
6.1. Statistical Test Results
6.2. Experimental Results
6.3. Comparison of Algorithms
7. Discussion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, X.; Hegde, S.; Son, C.; Keller, B.; Smith, A.; Sasangohar, F. Investigating Mental Health of US College Students During the COVID-19 Pandemic: Cross-Sectional Survey Study. J. Med. Internet 2020, 22, e22817. [Google Scholar] [CrossRef]
- Bedewy, D.; Gabriel, A. Examining perceptions of academic stress and its sources among university students: The Perception of Academic Stress Scale. Health Psychol. Open 2015, 2, 2055102915596714. [Google Scholar] [CrossRef]
- Kulkarni, S.; O’Farrell, I.; Erasi, M.; Kochar, M.S. Stress and hypertension. WMJ Off. Publ. State Med. Soc. Wis. 1998, 97, 34–38. [Google Scholar]
- Chemers, M.M.; Hu, L.T.; Garcia, B.F. Academic self-efficacy and first year college student performance and adjustment. J. Educ. Psychol. 2001, 93, 55. [Google Scholar] [CrossRef]
- Aristovnik, A.; Keržič, D.; Ravšelj, D.; Tomaževič, N.; Umek, L. Impacts of the COVID-19 pandemic on life of higher education students: A global perspective. Sustainability 2020, 12, 8438. [Google Scholar] [CrossRef]
- Acikmese, Y.; Alptekin, S.E. Prediction of stress levels with LSTM and passive mobile sensors. Procedia Comput. Sci. 2019, 159, 658–667. [Google Scholar] [CrossRef]
- Shaw, A.; Simsiri, N.; Deznaby, I.; Fiterau, M.; Rahaman, T. Personalized student stress prediction with deep multitask network. arXiv 2019, arXiv:1906.11356. [Google Scholar]
- Wang, R.; Chen, F.; Chen, Z.; Li, T.; Harari, G.; Tignor, S.; Zhou, X.; Ben-Zeev, D.; Campbell, A.T. StudentLife. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing–UbiComp ’14 Adjunct, Washington, DC, USA, 13–17 September 2014. [Google Scholar] [CrossRef]
- Raichur, N.; Lonakadi, N.; Mural, P. Detection of Stress Using Image Processing and Machine Learning Techniques. Int. J. Eng. Technol. 2017, 9, 1–8. [Google Scholar] [CrossRef]
- Reddy, U.S.; Thota, A.V.; Dharun, A. Machine Learning Techniques for Stress Prediction in Working Employees. In Proceedings of the 2018 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 13–15 December 2018. [Google Scholar] [CrossRef]
- Gamage, S.N.; Asanka, P.P.G.D. Machine Learning Approach to Predict Mental Distress of IT Workforce in Remote Working Environments. In Proceedings of the 2022 International Research Conference on Smart Computing and Systems Engineering (SCSE), Colombo, Sri Lanka, 1 September 2022; pp. 211–216. [Google Scholar] [CrossRef]
- Rahman, A.A.; Siraji, M.I.; Khalid, L.I.; Faisal, F.; Nishat, M.M.; Ahmed, A.; Al Mamun, M.A. Perceived Stress Analysis of Undergraduate Students during COVID-19: A Machine Learning Approach. In Proceedings of the 2022 IEEE 21st Mediterranean Electrotechnical Conference (MELECON), Palermo, Italy, 14–16 June 2022; pp. 1129–1134. [Google Scholar]
- El Affendi, M.A.; Al Rajhi, K.H. Text encoding for deep learning neural networks: A reversible base 64 (Tetrasexagesimal) Integer Transformation (RIT64) alternative to one hot encoding with applications to Arabic morphology. In Proceedings of the 2018 Sixth International Conference on Digital Information, Networking, and Wireless Communications (DINWC), Beirut, Lebanon, 25–27 April 2018; pp. 70–74. [Google Scholar]
- Priya, A.; Garg, S.; Tigga, N.P. Predicting Anxiety, Depression and Stress in Modern Life using Machine Learning Algorithms. Procedia Comput. Sci. 2020, 167, 1258–1267. [Google Scholar] [CrossRef]
- Rois, R.; Ray, M.; Rahman, A.; Roy, S.K. Prevalence and predicting factors of perceived stress among Bangladeshi university students using machine learning algorithms. J. Health Popul. Nutr. 2021, 40, 50. [Google Scholar] [CrossRef] [PubMed]
- Jaques, N.; Taylor, S.; Azaria, A.; Ghandeharioun, A.; Sano, A.; Picard, R. Predicting students’ happiness from physiology, phone, mobility, and behavioral data. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015. [Google Scholar] [CrossRef]
- Flesia, L.; Monaro, M.; Mazza, C.; Fietta, V.; Colicino, E.; Segatto, B.; Roma, P. Predicting Perceived Stress Related to the COVID-19 Outbreak through Stable Psychological Traits and Machine Learning Models. J. Clin. Med. 2020, 9, 3350. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Zheng, E.; Zhong, Z.; Xu, C.; Roma, N.; Lamkin, S.; Von Visger, T.T.; Chang, Y.-P.; Xu, W. Stress prediction using micro-EMA and machine learning during COVID-19 social isolation. Smart Health 2022, 23, 100242. [Google Scholar] [CrossRef]
- Pabreja, K.; Singh, A.; Singh, R.; Agnihotri, R.; Kaushik, S.; Malhotra, T. Stress Prediction Model Using Machine Learning. In Proceedings of International Conference on Artificial Intelligence and Applications; Bansal, P., Tushir, M., Balas, V., Srivastava, R., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2021; Volume 1164. [Google Scholar] [CrossRef]
- Bisht, A.; Vashisth, S.; Gupta, M.; Jain, E. Stress Prediction in Indian School Students Using Machine Learning. In Proceedings of the 2022 3rd International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 27–29 April 2022; pp. 770–774. [Google Scholar] [CrossRef]
- Martino, F.D.; Delmastro, F. High-Resolution Physiological Stress Prediction Models based on Ensemble Learning and Recurrent Neural Networks. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020. [Google Scholar] [CrossRef]
- Pariat, M.L.; Rynjah, M.A.; Joplin, M.; Kharjana, M.G. Stress Levels of College Students: Interrelationship between Stressors and Coping Strategies. IOSR J. Humanit. Soc. Sci. 2014, 19, 40–45. [Google Scholar] [CrossRef]
- Kim, J.; McKenzie, L. The Impacts of Physical Exercise on Stress Coping and Well-Being in University Students in the Context of Leisure. Health 2014, 6, 2570–2580. [Google Scholar] [CrossRef]
- Pryjmachuk, S.; Richards, D.A. Predicting stress in preregistration nursing students. Br. J. Health Psychol. 2007, 12, 125–144. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, S.; Sharma, N.; Singh, M. Employing CBPR to understand the well-being of higher education students during COVID-19 lockdown in India. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining AdaBoost. In Empirical Inference; Schölkopf, B., Luo, Z., Vovk, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Newman-Keuls test and Tukey test. Encycl. Res. Des. 2010, 2, 897–902. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Scope | Works | Key Contributions | Algorithms Used |
|---|---|---|---|---|
| 1. | Deep Learning | Acikmese, Y., et al. (2019) [6] | Worked on the StudentLife project, which collects passive and automatic data from students’ phones in Dartmouth. | Recurrent Neural Networks using LSTMs |
| Shaw, A. (2019) [7] | Worked on personalized stress prediction of students in SmartLife study in Dartmouth. | Deep Multitask Network using LSTMs | ||
| Wang, R. (2014) [8] | Worked on StudentLife dataset and analyzed stress factors | LSTMs and Correlation of factors | ||
| Raichur, N., et al. (2017) [9] | Detected stress from facial expressions presented in an image of subjects. | Deep learning models using theano package in python and linear regression | ||
| 2. | Supervised and Ensemble Learning | Reddy, U. S., et al. (2018) [10] | Predicted stress levels in working employees from the OSMI Mental Health in Tech 2017 dataset. | Logistic Regression, KNN, Decision Tree, Random Forest, Bagging, Boosting |
| Gamage, S. N., et al. (2022) [11] | Predicting mental distress in the IT workforce during the height of the pandemic in a remote environment. | Random Forests, SVM, XGBoost, CatBoost, Decision Tree, Naïve Bayes | ||
| Rahman, A. A., et al. (2022) [12] | Analysis of stress in undergraduate students from Jordan at the height of the pandemic. | Linear Regression, Logistic Regression | ||
| Priya, A., et al. (2020) [14] | Detected anxiety, depression, and stress using DASS 21. | Decision Trees, Random Forests, Naïve Bayes. SVMs, KNNs | ||
| Rois, R., et al. (2021) [15] | Researched causes of stress in Bangladesh university students. | Decision Tree, Random Forest, SVM, Logistic Regression | ||
| Jaques, N., et al. (2015) [16] | Modeled students’ happiness by monitoring their phones. | SVMs, Random Forests, Logistic Regression, KNN, Naïve Bayes, Adaboost. | ||
| Flesia, L., et al. (2020) [17] | Predicted perceived stress on adults caused by the pandemic. | SVMs, Logistic Regression, Random Forests, Naïve Bayes | ||
| Li, H., et al. (2022) [18] | Predicted perceived stress based on micro-EMA history data of adults. | Elastic Net Regression, Super Vector Regression, Gradient Boosted Regression Trees | ||
| Pabreja, K., et al. (2021) [19] | Predicted stress in students transitioning from adolescent teens to adults. | Random Forests | ||
| Bisht, A., et al. (2022) [20] | Analyzed stress in over 190 school kids aged 14–18. | Decision Trees, Logistic Regression, KNN, Random Forest | ||
| Martino, F. D., et al. (2020) [21] | Developed a tool to predict high-resolution stress for health systems to aid in clinical treatments. | Random Forests, Least-Squares Gradient Boosting, Nonlinear AutoRegressive Network | ||
| 3. | Stress Factors Analysis | Pariat, M. L., et al. (2014) [22] | Tried to find relationship between stressors. | Logistic Regression, Correlation |
| Kim, J., et al. (2014) [23] | Analyzed the impact of exercise on stress and mental well-being of university students. | Correlation | ||
| Pryjmachuk, S., et al. (2007) [24] | Predicted stress in nursing students from a top English university. | Logistic Regression, Correlation. |
| S. No. | Scope | Works | Stress Parameters | |||
|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S4 | |||
| 1. | Deep Learning | Acikmese, Y., et al. (2019) [6] | Yes | No | No | No |
| Shaw, A. (2019) [7] | Yes | No | No | No | ||
| Wang, R. (2014) [8] | Yes | No | No | No | ||
| Raichur, N., et al. (2017) [9] | Yes | No | No | No | ||
| Supervised and Ensemble Learning | Reddy, U. S., et al. (2018) [10] | No | Yes | Yes | No | |
| Gamage, S. N., et al. (2022) [11] | No | Yes | Yes | No | ||
| Rahman, A. A., et al. (2022) [12] | Yes | No | No | Yes | ||
| Priya, A., et al. (2020) [14] | No | No | Yes | No | ||
| Rois, R., et al. (2021) [15] | Yes | No | Yes | No | ||
| Jaques, N., et al. (2015) [16] | Yes | No | Yes | No | ||
| Flesia, L., et al. (2020) [17] | No | No | Yes | Yes | ||
| Li, H., et al. (2022) [18] | No | No | Yes | Yes | ||
| Pabreja K., et al. (2021) [19] | Yes | No | Yes | No | ||
| Bisht, A., et al. (2022) [20] | Yes | No | Yes | Yes | ||
| Martino, F. D., et al. (2020) [21] | No | No | Yes | No | ||
| 3. | Analysis of Stress Factors | Pariat, M. L., et al. (2014) [22] | Yes | No | Yes | No |
| Kim, J., et al. (2014) [23] | Yes | No | Yes | No | ||
| Pryjmachuk, S., et al. (2007) [24] | Yes | No | Yes | No | ||
| Sleep (Hours) | Highly Stressed | Manageable | No Stress |
|---|---|---|---|
| <=4 | 23 | 3 | 0 |
| 5 | 17 | 6 | 4 |
| 6 | 23 | 35 | 5 |
| 7 | 12 | 24 | 11 |
| >=8 | 6 | 11 | 17 |
| Weekly Assignments (Count)/Screen Time (Hours) | 1 h | 2 h | 3 h | 4 h | 5+ h |
|---|---|---|---|---|---|
| 2 | 1 | 0 | 2 | 0 | 1 |
| 3 | 0 | 7 | 1 | 1 | 2 |
| 4 | 4 | 8 | 9 | 3 | 1 |
| 5 | 5 | 8 | 21 | 5 | 1 |
| 6 | 3 | 6 | 9 | 11 | 10 |
| 7 | 2 | 2 | 5 | 9 | 11 |
| 8+ | 3 | 7 | 7 | 10 | 22 |
| Assignments | Highly Stressed | Manageable | No Stress |
|---|---|---|---|
| 1 | 8 | 4 | 6 |
| 2 | 14 | 10 | 14 |
| 3 | 5 | 36 | 12 |
| 4 | 19 | 18 | 2 |
| 5+ | 34 | 11 | 3 |
| Sleep (Hours) | Early Morning Risers | Late-Night Workers |
|---|---|---|
| 4 | 4 | 21 |
| 5 | 5 | 22 |
| 6 | 27 | 36 |
| 7 | 21 | 26 |
| 8+ | 23 | 11 |
| Highly Stressed | Manageable | No Stress |
|---|---|---|
| 81 | 79 | 37 |
| Highly Stressed | Manageable | No Stress |
|---|---|---|
| 81 | 79 | 70 |
| Parameter | F Score |
|---|---|
| Sleep | 16.25 |
| Assignments | 17.09 |
| Screentime | 8.48 |
| Stress Level | Mean | Groups |
|---|---|---|
| Highly stressed | 3.19753 | A |
| No stress | 2.37838 | B |
| Manageable | 2.10127 | B |
| Category | MeanDiff | SEM | q Value | Prob | Alpha | Sig | LCL | UCL |
|---|---|---|---|---|---|---|---|---|
| Manageable/Highly Stressed | 0.91186 | 0.17409 | 7.40733 | <0.0001 | 0.05 | 1 | 0.50068 | 1.32304 |
| No Stress/Highly Stressed | 1.58959 | 0.21846 | 10.29021 | <0.0001 | 0.05 | 1 | 1.07362 | 2.10556 |
| No Stress/Manageable | 0.67773 | 0.21933 | 4.36997 | 0.00647 | 0.05 | 0 | 0.15971 | 1.19574 |
| Stress Level | Mean | Groups |
|---|---|---|
| No stress | 3.86486 | A |
| Manageable | 3.20253 | B |
| Highly stressed | 2.34568 | C |
| Category | MeanDiff | SEM | q Value | Prob | Alpha | Sig | LCL | UCL |
|---|---|---|---|---|---|---|---|---|
| Manageable/Highly Stressed | −0.42522 | 0.192 | 3.13214 | 0.07121 | 0.05 | 1 | −0.87869 | 0.02824 |
| No Stress/Highly Stressed | −1.19019 | 0.24093 | 6.9863 | <0.0001 | 0.05 | 1 | −1.75922 | −0.62116 |
| No Stress/Manageable | −0.76497 | 0.24188 | 4.47257 | 0.00514 | 0.05 | 1 | −1.33625 | −0.19368 |
| Stress Level | Mean | Groups |
|---|---|---|
| No stress | 3.75676 | A |
| Manageable | 3.34177 | A |
| Highly stressed | 2.53086 | B |
| Category | MeanDiff | SEM | q Value | Prob | Alpha | Sig | LCL | UCL |
|---|---|---|---|---|---|---|---|---|
| Manageable/Highly Stressed | −0.90999 | 0.24621 | 5.22682 | 8.29298 × 10−4 | 0.05 | 1 | −1.4915 | −0.32847 |
| No Stress/Highly Stressed | −1.33934 | 0.30896 | 6.13056 | <0.0001 | 0.05 | 1 | −2.06906 | −0.60962 |
| No Stress/Manageable | −0.42935 | 0.31019 | 1.95753 | 0.35117 | 0.05 | 0 | −1.16196 | 0.30326 |
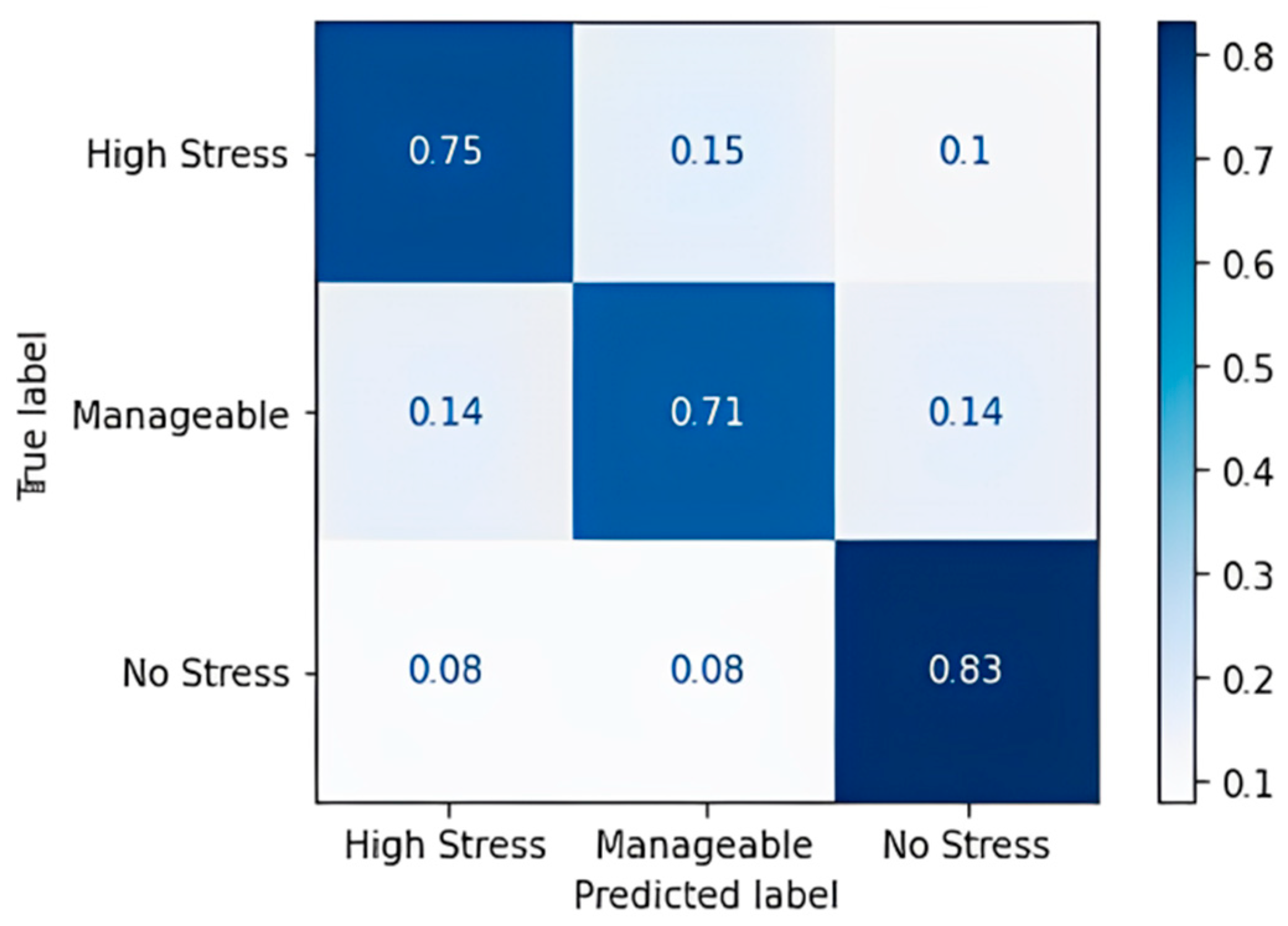
| Label | Highly Stressed | Manageable | No Stress |
|---|---|---|---|
| Highly Stressed | 15 | 3 | 2 |
| Manageable | 2 | 10 | 2 |
| No Stress | 1 | 1 | 10 |
| Label | Highly Stressed | Manageable | No Stress |
|---|---|---|---|
| Highly Stressed | 17 | 2 | 1 |
| Manageable | 1 | 12 | 1 |
| No Stress | 0 | 1 | 11 |
| Label | Highly Stressed | Manageable | No Stress |
|---|---|---|---|
| Highly Stressed | 13 | 4 | 3 |
| Manageable | 2 | 10 | 2 |
| No Stress | 2 | 3 | 7 |
| Label | Highly Stressed | Manageable | No Stress |
|---|---|---|---|
| Highly Stressed | 11 | 6 | 3 |
| Manageable | 3 | 10 | 1 |
| No Stress | 0 | 1 | 11 |
| S. No | Algorithm | Accuracy | F1 Score |
|---|---|---|---|
| 1. | Decision Tree | 76.09% | 75.67% |
| 2. | Random Forest | 86.96% | 86.67% |
| 3. | Gradient Boost | 65.22% | 64.3% |
| 4. | AdaBoost | 69.57% | 70.3% |
| S. No | Ensemble Combination | Accuracy | Precision | F1 Score | Recall |
|---|---|---|---|---|---|
| 1. | RF + DT | 88.34% | 85.12% | 87.26% | 90.67% |
| 2. | XGB + RF | 86.57% | 82.35% | 84.55% | 92.34% |
| 3. | AB + RF | 87.96% | 86.61% | 87.26% | 90.14% |
| 4. | RF + GB + DT | 82.90% | 82.17% | 84.39% | 88.96% |
| 5. | XGB + GB + AB | 78.67% | 79.29% | 80.54% | 86.34% |
| 6. | DT + XGB + AB | 86.57% | 83.65% | 85.89% | 91.47% |
| 7. | DT + RF + AB | 93.48% | 92.99% | 93.14% | 93.30% |
| 8. | XGB + AB + RF | 90.23% | 88.32% | 90.11% | 93.76% |
| Label | Highly Stressed | Manageable | No Stress |
|---|---|---|---|
| Highly Stressed | 18 | 1 | 0 |
| Manageable | 0 | 13 | 1 |
| No Stress | 0 | 1 | 12 |
| Algorithm | Fivefold Validation Accuracy |
|---|---|
| Decision Tree | 80.31% |
| Random Forest Classifier | 88.96% |
| Gradient Boosting | 70.43% |
| AdaBoost Algorithm | 72.1% |
| Ensemble Learning (DT + RF + AB) | 93.45% |
| S. No. | Work | Algorithm | Accuracy | F1 Score |
|---|---|---|---|---|
| 1. | Acikmese, Y., et al. (2019) [6] | LSTM | 63% | 63% |
| 2. | Shaw, A. (2019) [7] | CALM-Net | 65% | 59% |
| 3. | Raichur, N., et al. (2017) [9] | Theano Deep Learning Model | 60% | 60% |
| 4. | Reddy, U. S., et al. (2018) [10] | Boosting | 75% | 65% |
| 5. | Gamage, S. N., et al. (2022) [11] | Cat Boost | 85% | 81% |
| 6. | Rahman, A. A., et al. (2022) [12] | Logistic Regression | 79% | 75% |
| 7. | Rois, R., et al. (2021) [15] | Random Forests | 80% | 76% |
| 8. | Jaques, N., et al. (2015) [16] | Support Vector Machines | 70% | 65% |
| 9. | Flesia, L., et al. (2020) [17] | Naïve Bayes Classifier | 72% | 63% |
| 10. | Li, H., et al. (2022) [18] | Elastic Net Regularization | 75% | 78% |
| 11. | Bisht, A., et al. (2022) [20] | K Nearest Neighbours | 78% | 80% |
| 12. | Ensemble Learning Academic Stress Classifier | DT + RF + AB | 93.48% | 93.14% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anand, R.V.; Md, A.Q.; Urooj, S.; Mohan, S.; Alawad, M.A.; C., A. Enhancing Diagnostic Decision-Making: Ensemble Learning Techniques for Reliable Stress Level Classification. Diagnostics 2023, 13, 3455. https://doi.org/10.3390/diagnostics13223455
Anand RV, Md AQ, Urooj S, Mohan S, Alawad MA, C. A. Enhancing Diagnostic Decision-Making: Ensemble Learning Techniques for Reliable Stress Level Classification. Diagnostics. 2023; 13(22):3455. https://doi.org/10.3390/diagnostics13223455
Chicago/Turabian StyleAnand, Raghav V., Abdul Quadir Md, Shabana Urooj, Senthilkumar Mohan, Mohamad A. Alawad, and Adittya C. 2023. "Enhancing Diagnostic Decision-Making: Ensemble Learning Techniques for Reliable Stress Level Classification" Diagnostics 13, no. 22: 3455. https://doi.org/10.3390/diagnostics13223455