
Assist-Dermo: A Lightweight Separable Vision Transformer Model for Multiclass Skin Lesion Classification




Abstract
:1. Introduction
1.1. Research Highlights
- We used cross validation to test our model and the results showed that it worked much better than the methods already being used.
- This study proposes a new classification model (Assist-Dermo) to recognize multiclass PSLs.
- A new preprocessing step is integrated into the perceptual-oriented color space to enhance contrast and adjust the light.
- The proposed Assist-Dermo model is constructed with many layers and various filter sizes but fewer filters, and these parameters are selected by using lightweight SqueezeNet on a depthwise separable CNN.
- It is assessed using experimental findings from the many datasets that were gathered with regards to sensitivity, specificity, and other metrics.
- The Assist-Dermo can reduce overfitting because the dense connection better protects against the overfitting problem, especially when learning from small amounts of data.
1.2. Research Outline
2. Review of Related Research
3. Materials and Methods
3.1. Acquisition and Preparation of Dataset
3.2. Preprocessing
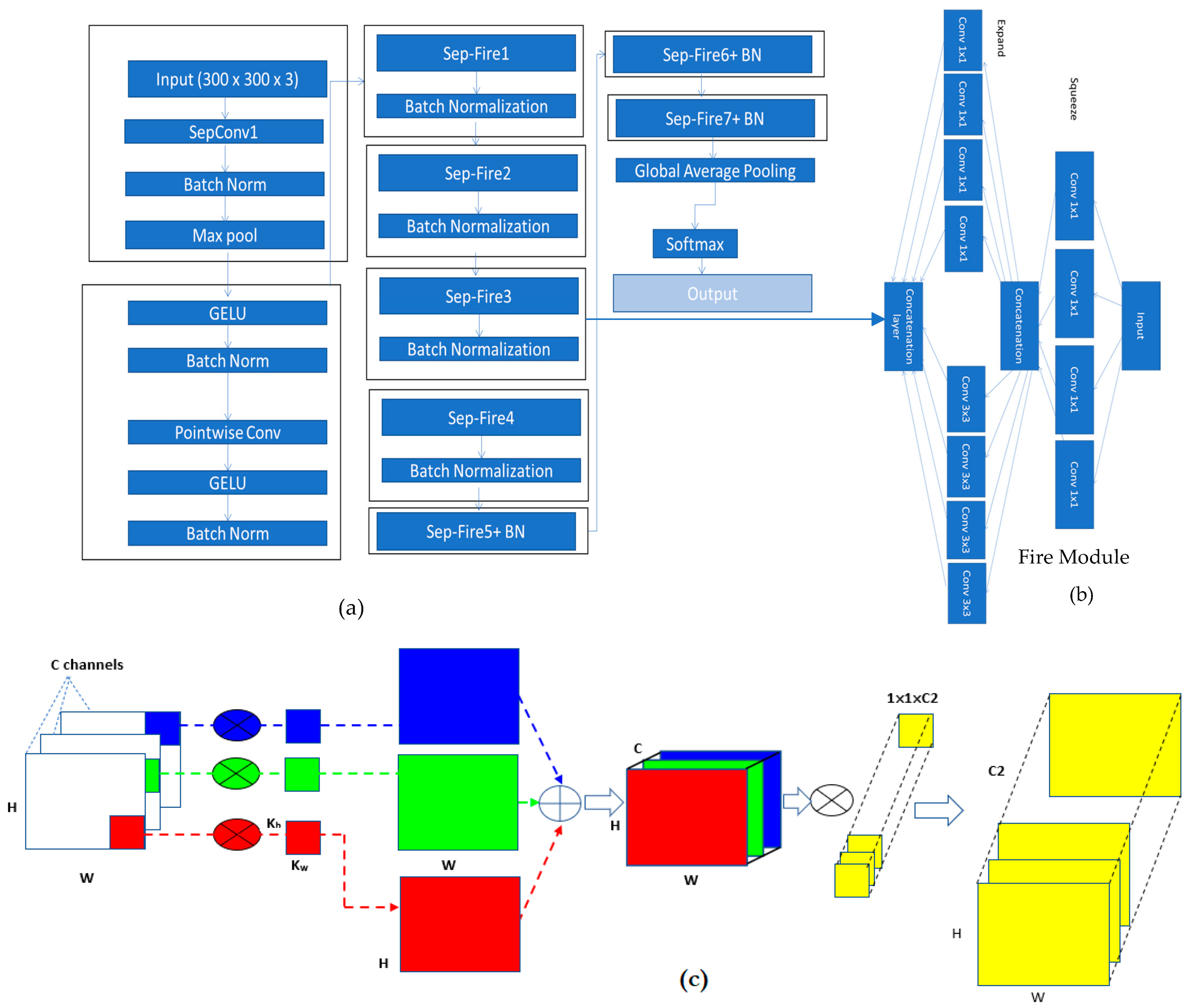
3.3. Architecture of SqueezeNet-Light
| Algorithm 1: ShuffleNet-Light Architecture for Features Extraction and Classification of PSLs |
| Input: Input Tensor (), 2-D of (256 × 256 × 3) PSLs training dataset. Output: Obtained and Classified feature mapaugmented 2-D image Main Process: Step 1. Define number of stages = 4 Step 2. Iterate for Each Stage
Step 4. Fcat(i) = concatenation (# features-maps) Step 5. channel = shuffle (x) [End Step 2] Step 6. Model Construction
Step 8. Test samples are predicted to the class label using the decision function of the below equation. |
3.3.1. SqueezeNet Neural Network
- (1)
- To decrease network parameters, a smaller 1 × 1 convolution kernel is used in place of the 3 × 3 convolution (Conv) kernel;
- (2)
- The parameters and model volume are reduced using SqueezeNet’s developed fire layer;
- (3)
- A thinner (a smaller number of) pooling layer resulted; only three maxpooling levels and a global pooling-layer are present in SqueezeNet.
3.3.2. Depthwise Separable Convolution
3.3.3. Network Parameter Optimization
4. Experimental Results
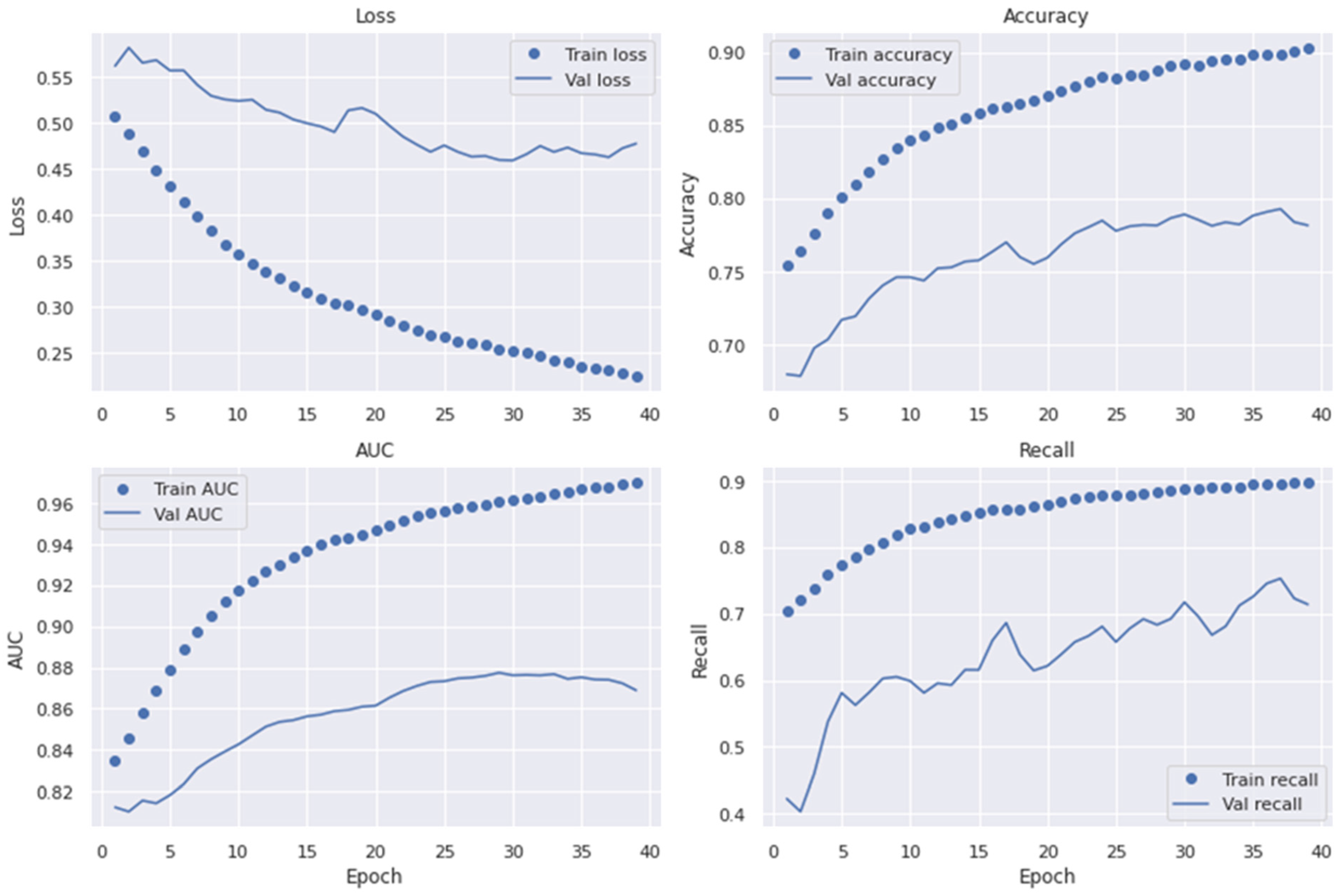
4.1. Experimental Setup
4.2. Model Evaluation Metrics
4.3. Network Settings
4.4. Computational Cost
4.5. Visual Feature Representation
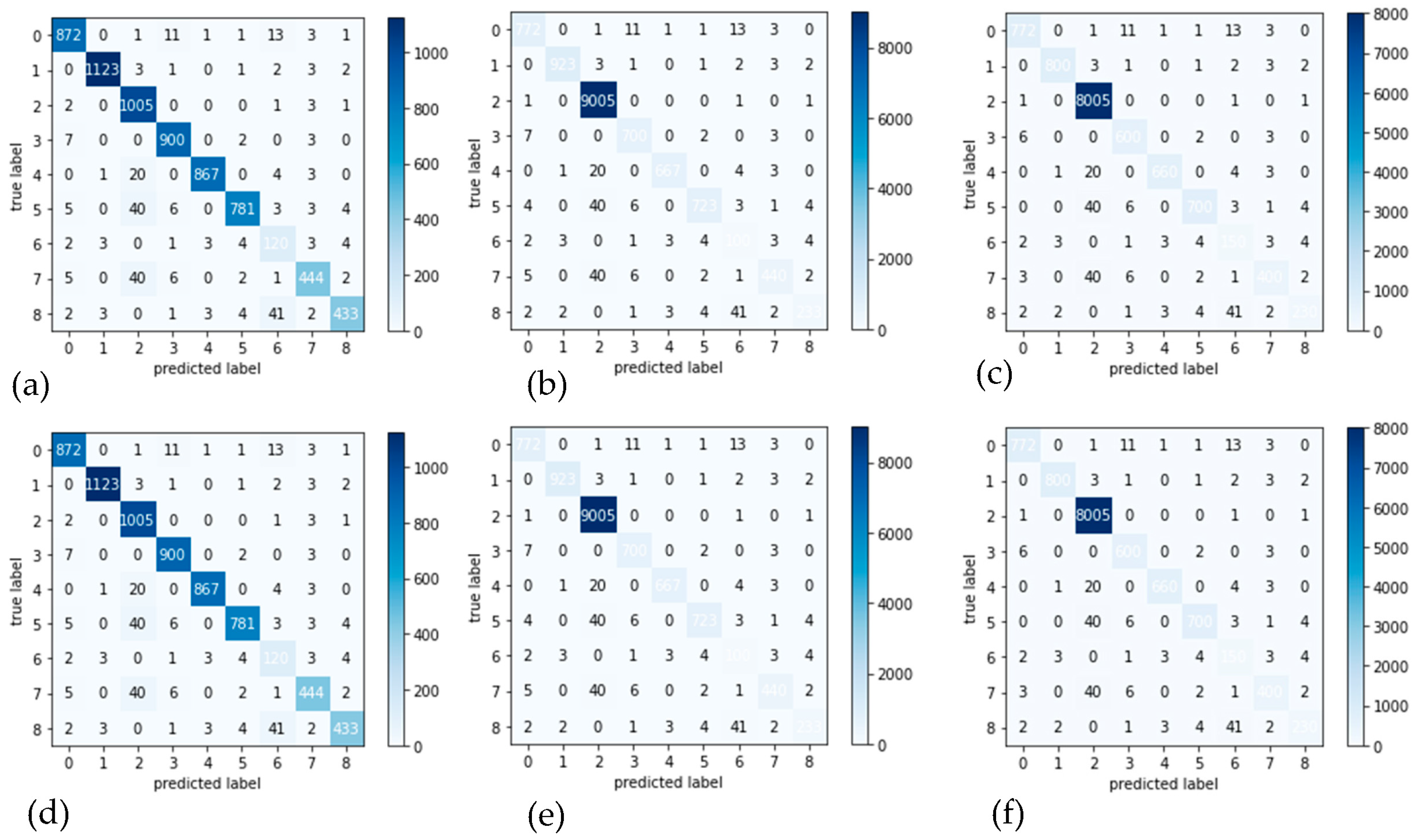
4.6. Performance of Proposed System
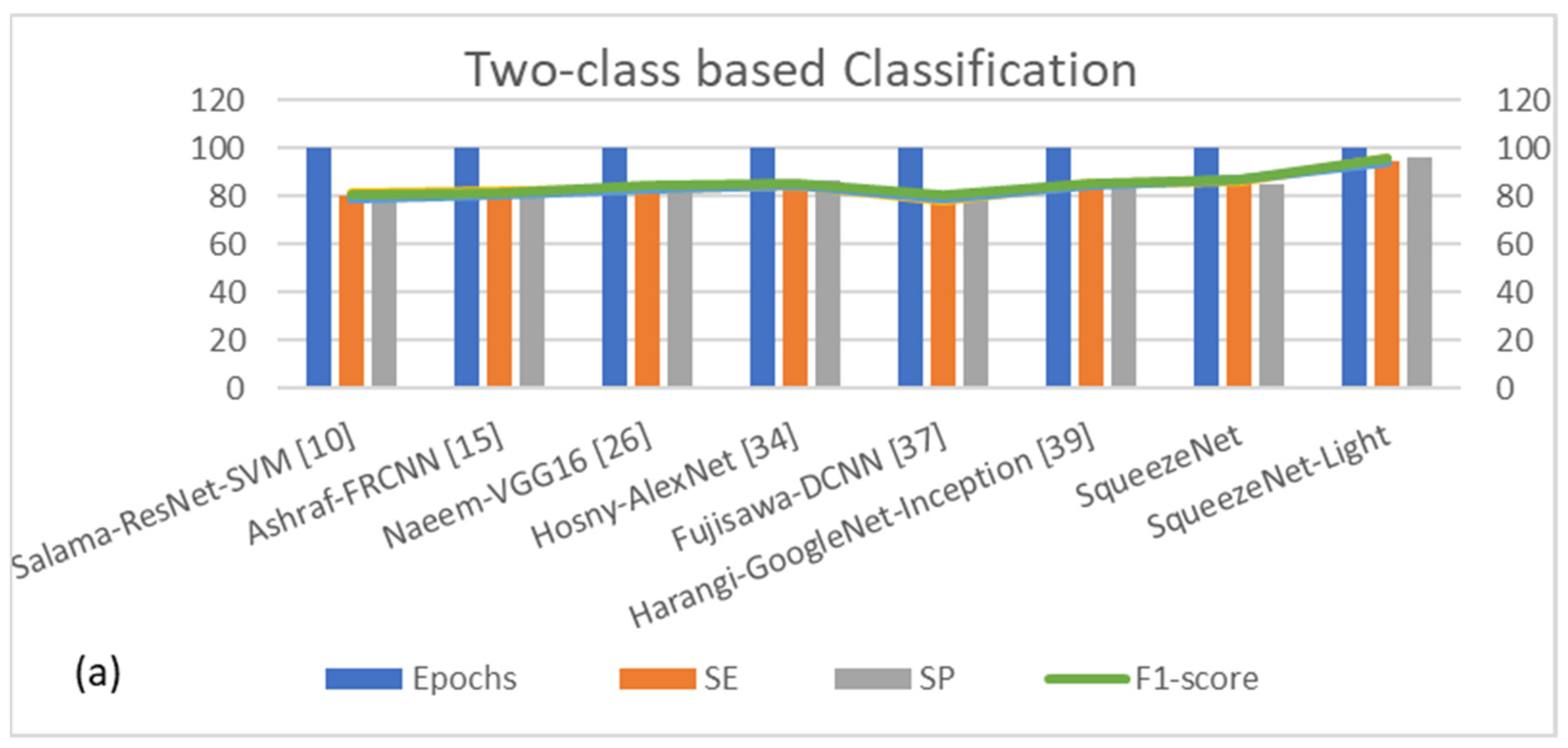
4.7. Comparisons with SOTA
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- American Cancer Society. Cancer Facts and Figures. 2022. Available online: https://www.cancer.org/content/dam/cancer-org/research/cancer-facts-and-statistics/annual-cancer-facts-and-figures/2022/2022-cancer-facts-and-figures.pdf (accessed on 12 February 2023).
- Ferlay, J.; Colombet, M.; Soerjomataram, I.; Dyba, T.; Randi, G.; Bettio, M.; Gavin, A.; Visser, O.; Bray, F. Cancer incidence and mortality patterns in Europe: Estimates for 40 countries and 25 major cancers in 2018. Eur. J. Cancer 2018, 103, 356–387. [Google Scholar] [CrossRef] [PubMed]
- Baig, A.R.; Abbas, Q.; Almakki, R.; Ibrahim, M.E.; AlSuwaidan, L.; Ahmed, A.E. Light-Dermo: A Lightweight Pretrained Convolution Neural Network for the Diagnosis of Multiclass Skin Lesions. Diagnostics 2023, 13, 385. [Google Scholar] [CrossRef] [PubMed]
- Alsahafi, Y.S.; Kassem, M.A.; Hosny, K.M. Skin-Net: A novel deep residual network for skin lesions classification using multilevel feature extraction and cross-channel correlation with detection of outlier. J. Big Data 2023, 10, 105. [Google Scholar] [CrossRef]
- Menghani, G. Efficient deep learning: A survey on making deep learning models smaller, faster, and better. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- Abbas, Q.; Ibrahim, M.E.A.; Jaffar, M.A. Video scene analysis: An overview and challenges on deep learning algorithms. Multimed. Tools Appl. 2019, 77, 20415–20453. [Google Scholar] [CrossRef]
- Maron, R.C.; Schlager, J.G.; Haggenmüller, S.; von Kalle, C.; Utikal, J.S.; Meier, F.; Gellrich, F.F.; Hobelsberger, S.; Hauschild, A.; French, L.; et al. A benchmark for neural network robustness in skin cancer classification. Eur. J. Cancer 2021, 155, 191–199. [Google Scholar] [CrossRef]
- Nadipineni, H. Method to Classify Skin Lesions using Dermoscopic images. arXiv 2020, arXiv:2008.09418. [Google Scholar]
- Sikkandar, M.Y.; Alrasheadi, B.A.; Prakash, N.B.; Hemalakshmi, G.R.; Mohanarathinam, A.; Shankar, K. Deep learning based an automated skin lesion segmentation and intelligent classification model. J. Ambient Intell. Humaniz. Comput. 2020, 12, 3245–3255. [Google Scholar] [CrossRef]
- Salama, W.M.; Aly, M.H. Deep learning design for benign and malignant classification of skin lesions: A new approach. Multimed. Tools Appl. 2021, 80, 26795–26811. [Google Scholar] [CrossRef]
- Mahbod, A.; Schaefer, G.; Ellinger, I.; Ecker, R.; Pitiot, A.; Wang, C. Fusing fine-tuned deep features for skin lesion classification. Comput. Med. Imaging Graph. 2019, 71, 19–29. [Google Scholar] [CrossRef] [Green Version]
- Yu, Z.; Jiang, X.; Zhou, F.; Qin, J.; Ni, D.; Chen, S.; Lei, B.; Wang, T. Melanoma recognition in dermoscopy images via aggregated deep convolutional features. IEEE Trans. Biomed. Eng. 2018, 66, 1006–1016. [Google Scholar] [CrossRef] [PubMed]
- Tan, T.Y.; Zhang, L.; Lim, C.P. Adaptive melanoma diagnosis using evolving clustering, ensemble and deep neural networks. Knowl. Based Syst. 2020, 187, 104807. [Google Scholar] [CrossRef]
- Dorj, U.O.; Lee, K.K.; Choi, J.Y.; Lee, M. The skin cancer classification using deep convolutional neural network. Multimed. Tools Appl. 2018, 77, 9909–9924. [Google Scholar] [CrossRef]
- Ashraf, R.; Afzal, S.; Rehman, A.U.; Gul, S.; Baber, J.; Bakhtyar, M.; Mehmood, I.; Song, O.-Y.; Maqsood, M. Region-of-interest based transfer learning assisted framework for skin cancer detection. IEEE Access 2020, 8, 147858–147871. [Google Scholar] [CrossRef]
- Abbas, Q.; Celebi, M.E. DermoDeep-A classification of melanoma-nevus skin lesions using multi-feature fusion of visual features and deep neural network. Multimed. Tools Appl. 2019, 78, 23559–23580. [Google Scholar] [CrossRef]
- Jinnai, S.; Yamazaki, N.; Hirano, Y.; Sugawara, Y.; Ohe, Y.; Hamamoto, R. The development of a skin cancer classification system for pigmented skin lesions using deep learning. Biomolecules 2020, 10, 1123. [Google Scholar] [CrossRef]
- Mijwil, M.M. Skin cancer disease images classification using deep learning solutions. Multimed. Tools Appl. 2021, 80, 26255–26271. [Google Scholar] [CrossRef]
- Kadampur, M.A.; Al Riyaee, S. Skin cancer detection: Applying a deep learning based model driven architecture in the cloud for classifying dermal cell images. Inform. Med. Unlocked 2020, 18, 100282. [Google Scholar] [CrossRef]
- Iqbal, I.; Younus, M.; Walayat, K.; Kakar, M.U.; Ma, J. Automated multi-class classification of skin lesions through deep convolutional neural network with dermoscopic images. Comput. Med. Imaging Graph. 2021, 88, 101843. [Google Scholar] [CrossRef]
- Tognetti, L.; Bonechi, S.; Andreini, P.; Bianchini, M.; Scarselli, F.; Cevenini, G.; Moscarella, E.; Farnetani, F.; Longo, C.; Lallas, A.; et al. A new deep learning approach integrated with clinical data for the dermoscopic differentiation of early melanomas from atypical nevi. J. Dermatol. Sci. 2021, 101, 115–122. [Google Scholar] [CrossRef]
- Ningrum, D.N.A.; Yuan, S.-P.; Kung, W.-M.; Wu, C.-C.; Tzeng, I.-S.; Huang, C.-Y.; Li, J.Y.-C.; Wang, Y.-C. Deep Learning Classifier with Patient’s Metadata of Dermoscopic Images in Malignant Melanoma Detection. J. Multidiscip. Healthc. 2021, 14, 877. [Google Scholar] [CrossRef] [PubMed]
- Jasil, S.P.; Ulagamuthalvi, V. Deep learning architecture using transfer learning for classification of skin lesions. J. Ambient. Intell. Humaniz. Comput. 2021, 1–8. [Google Scholar] [CrossRef]
- Wei, L.; Ding, K.; Hu, H. Automatic Skin Cancer Detection in Dermoscopy Images Based on Ensemble Lightweight Deep Learning Network. IEEE Access 2020, 8, 99633–99647. [Google Scholar] [CrossRef]
- Hasan, M.K.; Elahi MT, E.; Alam, M.A.; Jawad, M.T.; Martí, R. DermoExpert: Skin lesion classification using a hybrid convolutional neural network through segmentation, transfer learning, and augmentation. Inform. Med. Unlocked 2022, 28, 100819. [Google Scholar] [CrossRef]
- Naeem, A.; Anees, T.; Fiza, M.; Naqvi, R.A.; Lee, S.W. SCDNet: A Deep Learning-Based Framework for the Multiclassification of Skin Cancer Using Dermoscopy Images. Sensors 2022, 22, 5652. [Google Scholar] [CrossRef]
- Yu, L.; Chen, H.; Dou, Q.; Qin, J.; Heng, P.A. Automated melanoma recognition in dermoscopy images via very deep residual networks. IEEE Trans. Med. Imaging 2016, 36, 994–1004. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Albahar, M.A. Skin lesion classification using convolutional neural network with novel regularizer. IEEE Access 2019, 7, 38306–38313. [Google Scholar] [CrossRef]
- Chaturvedi, S.S.; Tembhurne, J.V.; Diwan, T. A multi-class skin Cancer classification using deep convolutional neural networks. Multimed. Tools Appl. 2020, 79, 28477–28498. [Google Scholar] [CrossRef]
- Singha, S.; Roy, P. Skin Cancer Classification and Comparison of Pretrained Models Performance using Transfer Learning. J. Inf. Syst. Eng. Bus. Intell. 2022, 8, 218–225. [Google Scholar] [CrossRef]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Halpern, A.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv 2019, arXiv:1902.03368. [Google Scholar]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2022, 5, 180161. [Google Scholar] [CrossRef] [PubMed]
- Hosny, K.M.; Kassem, M.A.; Foaud, M.M. Skin cancer classification using deep learning and transfer learning. In Proceedings of the 2018 9th Cairo International Biomedical Engineering Conference (CIBEC), Cairo, Egypt, 20–22 December 2018; pp. 90–93. [Google Scholar]
- Harangi, B. Skin lesion classification with ensembles of deep convolutional neural networks. J. Biomed. Inform. 2018, 86, 25–32. [Google Scholar] [CrossRef] [PubMed]
- Rahman, Z.; Hossain, M.S.; Islam, M.R.; Hasan, M.M.; Hridhee, R.A. An approach for multiclass skin lesion classification based on ensemble learning. Inform. Med. Unlocked 2021, 25, 100659. [Google Scholar] [CrossRef]
- Fujisawa, Y.; Otomo, Y.; Ogata, Y.; Nakamura, Y.; Fujita, R.; Ishitsuka, Y.; Watanabe, R.; Okiyama, N.; Ohara, K.; Fujimoto, M. Deep-learning-based, computer-aided classifier developed with a small dataset of clinical images surpasses board-certified dermatologists in skin tumour diagnosis. Br. J. Dermatol. 2019, 180, 373–381. [Google Scholar] [CrossRef]
- Calderón, C.; Sanchez, K.; Castillo, S.; Arguello, H. BILSK: A bilinear convolutional neural network approach for skin lesion classification. Comput. Methods Programs Biomed. Update 2021, 1, 100036. [Google Scholar] [CrossRef]
- Harangi, B.; Baran, A.; Hajdu, A. Assisted deep learning framework for multi-class skin lesion classification considering a binary classification support. Biomed. Signal Process. Control 2020, 62, 102041. [Google Scholar] [CrossRef]
- Han, S.S.; Park, I.; Chang, S.E.; Lim, W.; Kim, M.S.; Park, G.H.; Chae, J.B.; Huh, C.H.; Na, J.-I. Augmented intelligence dermatology: Deep neural networks empower medical professionals in diagnosing skin cancer and predicting treatment options for 134 skin disorders. J. Investig. Dermatol. 2020, 140, 1753–1761. [Google Scholar] [CrossRef]
- Hekler, A.; Utikal, J.S.; Enk, A.H.; Solass, W.; Schmitt, M.; Klode, J.; Schadendorf, D.; Sondermann, W.; Franklin, C.; Bestvater, F.; et al. Deep learning outperformed 11 pathologists in the classification of histopathological melanoma images. Eur. J. Cancer 2019, 118, 91–96. [Google Scholar] [CrossRef] [Green Version]
- Combalia, M.; Codella, N.C.; Rotemberg, V.; Helba, B.; Vilaplana, V.; Reiter, O.; Carrera, C.; Barreiro, A.; Halpern, A.C.; Puig, S.; et al. Bcn20000: Dermoscopic lesions in the wild. arXiv 2019, arXiv:1908.02288. [Google Scholar]
- Rotemberg, V.; Kurtansky, N.; Betz-Stablein, B.; Caffery, L.; Chousakos, E.; Codella, N.; Combalia, M.; Dusza, S.; Guitera, P.; Gutman, D.; et al. A patient-centric dataset of images and metadata for identifying melanomas using clinical context. Sci. Data 2019, 8, 34. [Google Scholar] [CrossRef] [PubMed]
- Mendonça, T.; Ferreira, P.M.; Marques, J.S.; Marcal, A.R.; Rozeira, J. PH2-A dermoscopic image database for research and benchmarking. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 5437–5440. [Google Scholar]
- Maron, R.C.; Weichenthal, M.; Utikal, J.S.; Hekler, A.; Berking, C.; Hauschild, A.; Enk, A.H.; Haferkamp, S.; Klode, J.; Schadendorf, D.; et al. Systematic outperformance of 112 dermatologists in multiclass skin cancer image classification by convolutional neural networks. Eur. J. Cancer 2017, 119, 57–65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, Q.C.; Cohen, L.D. Global and local contrast adaptive enhancement for non-uniform illumination color images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 3023–3030. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zhuang, J.; Tang, T.; Ding, Y.; Tatikonda, S.C.; Dvornek, N.; Papademetris, X.; Duncan, J. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. Adv. Neural Inf. Process Syst. 2017, 33, 18795–18806. [Google Scholar]
- Zhu, R.; Cui, Y.; Huang, J.; Hou, E.; Zhao, J.; Zhou, Z.; Li, H. YOLOv5s-SA: Light-Weighted and Improved YOLOv5s for Sperm Detection. Diagnostics 2023, 13, 1100. [Google Scholar] [CrossRef]
- Li, W.; Zhang, L.; Wu, C.; Cui, Z.; Niu, C. A new lightweight deep neural network for surface scratch detection. Int. J. Adv. Manuf. Technol. 2022, 123, 1999–2015. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Diagnosis | Segment? | Classification | DL Model | Datasets | Result (%) ** | Limitations |
|---|---|---|---|---|---|---|---|
| [9] | Proposed a hybrid Inception adaptive-neuro-fuzzy (ANF) model for discriminating dermoscopic photos into different seven labels. | Yes | 7 classes | Inception-v4 | ISIC-2018 | ACC: 97.91% SE: 93.4% SP: 98.7% | Classes imbalance problem, evaluated on single dataset, classifies only seven classes, and computationally expensive. |
| [10] | Suggested a hybrid ResNet-SVM framework for efficient binary classification of skin lesions. | No | Binary | ResNet50, VGG-16 and SVM | ISIC 2017 ISBI 2016 | ACC: 99.19% | Classes imbalance problem, binary classification only two classes, and computationally expensive. |
| [15] | Offered an augmented ROI -based CNN system to recognize and separate melanoma from nevus malignancy. | Yes | Binary | CNN + Transfer learning | DermIS, DermQuest | ACC: 97.9% ACC: 97.4% | Classes imbalance problem, evaluated on single dataset, classifies only two classes, and computationally expensive. |
| [17] | Introduced a six-class cutaneous lesions classification system based on CNN. | No | 6 classes | Faster region-based CNN (FRCNN) | Private (5846 images) | ACC: Six-classes 86.2% Two-classes 91.5% | Image processing, handcrafted-based feature extraction approach, which limits the detection accuracy, 6 classes only, and computationally expensive |
| [19] | Suggested a hybrid ResNet-SVM framework for efficient binary classification of skin lesions. | No | Binary | SqueezeNet, DenseNet, inception v3 and ResNet | HAM10000 | AUC: 0.997 | Evaluated on one dataset, classifies only two classes, and computationally expensive. |
| [20] | Implemented a CNN model with many layers, various filter sizes, lower number of filters and settings for skin cancer categorization. | No | 3 classes | DCNN | ISIC 2017 ISIC 2018 ISIC 2019 | AUC: 0.964 | Three classes of PSLs and reduced hyper-parameters, so computationally expensive. |
| [25] | Suggested a hybrid-CNN made up of three different feature extracting modules that were combined to produce lesion feature vectors with better depth. | Yes | 7 classes | CNN | ISIC-2016, ISIC-2017, ISIC-2018 | AUC: ISIC-2016: 0.96 ISIC-2017: 0.95 ISIC-2018: 0.97 | Seven classes only and used only one limited dataset, classifier is not generalized. |
| [26] | Presented the classification of four different forms of skin cancer using the SCDNet, a vgg16-based framework. | No | 4 classes | Vgg16 | ISIC 2019 | ACC: 96.91% | Four classes only, many hyper-parameters required, and tested on signal dataset, so classifier is not generalized. |
| [29] | Proposed a new regularization technique for CNN model to binary classify skin lesions. | No | Binary | CNN | ISIC-2018 | ACC: 97.49% | Two classes (benign vs. malignant), required huge parameters, evaluate on single dataset, and computationally expensive. |
| [31] | Examined how well three of the best pretrained DL models classified skin cancer in binary form. | No | Binary | ResNet, VGG16, MobileNetV2 | ISIC 2020 | ACC: 98.39% | Two classes (benign vs. malignant), required huge parameters, evaluate on single dataset, and computationally expensive. |
| [34] | Used transfer learning and a pre-trained deep learning architecture to classify three skin lesions. | No | 3 classes | AlexNet | ph2 | Acc: 98.61% SE: 98.33% SP: 98.93% | Three classes only, required huge parameters, evaluate on single dataset, and computationally expensive. |
| [35] | Described the creation of an ensemble of deep CNNs to further improve the efficiency of each CNN while identifying dermoscopy photos into three categories | No | 3 classes | GoogLeNet, AlexNet, ResNet, VGGNet | ISBI 2017 | AUC: 0.891 | Single dataset used, three classes of PSLs and reduced hyper-parameters, so computationally expensive. |
| [36] | Suggested an architecture based on weighted mean ensemble learning to categorize seven different kinds of skin infections | No | 7 classes | ResNeXt, SeResNeXt, DenseNet, Xception, ResNet | HAM10000 ISIC 2019 | ACC/recall: avg.: 87%/93% weight avg.: 88%/94% | Seven classes with two datasets used, three classes of PSLs and reduced hyper-parameters, so computationally expensive. |
| [37] | Employed 4867 clinical photos from 1842 patients who had been diagnosed with skin tumors as a dataset to train a DCNN architecture. | No | Binary | DCNN | Private (4867 images) | ACC: 92.4% | Two classes (benign vs. malignant), required huge parameters, evaluate on single dataset, and computationally expensive. |
| [38] | a bilinear CNN strategy that made use of transfer learning, a soft-adjustment step, and data augmentation to enhance classification performance while lowering the computing cost. | No | 7 classes | ResNet50 and VGG16 | HAM10000 | ACC: 93.21% | Three classes only and used only one limited dataset, classifier is not generalized. |
| [39] | classified dermoscopy images into seven classes comprising the advantage of binary support. | No | 7 classes | GoogLeNet and Inception-v3 | ISIC 2018 | BMA: 67.7% | Seven classes, required huge parameters, evaluate on single dataset, and computationally expensive. |
| [41] | Deep learning’s efficiency to that of derma specialists in categorizing histopathologic melanoma photos. | No | Binary | CNN | Private (695 lesions) | ACC: 68% SE: 76% SP: 60% | Two classes (benign vs. malignant), required huge parameters, evaluate on single dataset, and computationally expensive. |
| Dataset | Ref. | Images | Selected Images | Number of Classes * |
|---|---|---|---|---|
| HAM10000 | [32,33] | 10,015 | 10,015 | 7 (“AK, BCC, BKL, DF, NV, MEL, VASC”) |
| ISIC 2019 | [42] | 25,331 | 25,331 | 8 (“MEL, NV, BCC, AKIEC, BKL, DF, VASC, SCC”) |
| ISIC 2020 | [43] | 33,126 | 33,126 | 9 (“MEL, NV, BCC, AKIEC, BKL, DF, VASC, SCC, PBK”) |
| Ph2 | [44] | 200 | 200 | 2(NV, and Mel) |
| ISBI 2017 | [45] | 2750 | 2750 | 3 (NV, Mel, and SK) |
| Classes * | No. of Images | Size |
|---|---|---|
| AK | 700 | (512,512,3) |
| BCC | 3300 | (512,512,3) |
| BKL | 2600 | (512,512,3) |
| DF | 200 | (512,512,3) |
| NV | 12,000 | (512,512,3) |
| MEL | 4000 | (512,512,3) |
| SCC | 600 | (512,512,3) |
| VASC | 300 | (512,512,3) |
| PBK | 300 | (512,512,3) |
| Total | 24,000 | (512,512,3) |
| Parameters | Angle | Brightness | Zoom | Shear | Mode | Horizontal | Vertical | Rescale | Noise |
|---|---|---|---|---|---|---|---|---|---|
| Values | 30° | [0.9, 1.1] | 0.1 | 0.1 | Constant | Flip | Flip | 1./255 | 0.45 |
| Tensor Flow | GPU | Learning Rate | Optimizer | Number of Epoch | Batch size | Validation |
|---|---|---|---|---|---|---|
| 2.9.1 | GeForce GTX 1050 Ti | 1 × 10−3 | AdaBelief | 40 | 16 | 10-fold |
| Method | Preprocessing | Feature Extraction | Training | Prediction | Overall |
|---|---|---|---|---|---|
| VGG16 | 20.5 s | 14.4 s | 200.5 s | 10.8 s | 246.2 s |
| AlexNet | 18.6 s | 12.2 s | 190.5 s | 8.8 s | 230.1 s |
| InceptionV3 | 16.3 s | 14.8 s | 178.5 s | 7.8 s | 217.4 s |
| GoogleNet | 17.2 s | 17.3 s | 170.5 s | 6.8 s | 211.8 s |
| Xception | 18.1 s | 15.1 s | 165.5 s | 8.8 s | 207.5 s |
| MobileNet | 14.1 s | 13.3 s | 160.5 s | 7.8 s | 195.7 s |
| SqueezeNet | 10.8 s | 8.3 s | 168.5 s | 5.8 s | 193.4 s |
| Proposed | 1.8 s | 1.9 s | 165.5 s | 1.5 s | 184.5 s |
| Models | Image Size | Parameters | Validation Accuracy |
|---|---|---|---|
| VGG16 | 512 × 512 × 3 256 × 256 × 3 200 × 200 × 3 | 14,714,688 14,865,222 14,911,302 | 79 |
| AlexNet | 512 × 512 × 3 256 × 256 × 3 200 × 200 × 3 | 23,587,712 14,911,302 | 81.3 |
| InceptionV3 | 512 × 512 × 3 256 × 256 × 3 200 × 200 × 3 | 42,658,176 14,911,302 | 82.7 |
| GoogleNet | 512 × 512 × 3 256 × 256 × 3 200 × 200 × 3 | 14,714,688 14,865,222 14,911,302 | 83.5 |
| Xception | 512 × 512 × 3 256 × 256 × 3 200 × 200 × 3 | 14,714,688 14,865,222 14,911,302 | 82.4 |
| MobileNet | 512 × 512 × 3 256 × 256 × 3 200 × 200 × 3 | 3,228,864 14,865,222 14,911,302 | 84.3 |
| SqueezeNet | 512 × 512 × 3 256 × 256 × 3 200 × 200 × 3 | 7,037,504 14,911,302 | 87.6 |
| SqueezeNet-Light | 512 × 512 × 3 256 × 256 × 3 200 × 200 × 3 | 3,182,412 3,182,412 3,182,412 | 95.6 |
| Model | Epochs | SE | SP | ACC | PR | F1-Score | MCC |
|---|---|---|---|---|---|---|---|
| VGG16 | 40 | 78 | 80 | 79 | 76 | 79 | 80 |
| AlexNet | 40 | 79 | 82 | 81.3 | 80 | 80.4 | 81.1 |
| InceptionV3 | 40 | 81 | 80 | 82.7 | 82 | 82.7 | 83.5 |
| GoogleNet | 40 | 83 | 81 | 83.5 | 83 | 83.5 | 84.5 |
| Xception | 40 | 82 | 83 | 82.4 | 83 | 84.3 | 85.4 |
| MobileNet | 40 | 84 | 84.2 | 84.3 | 84 | 85.2 | 86.3 |
| SqueezeNet | 40 | 85 | 86.2 | 87.6 | 85 | 86.1 | 87.2 |
| Squeeze-Light | 40 | 94 | 96 | 95.6 | 94.12 | 95.2 | 96.7 |
| Model | Epochs | SE | SP | ACC | PR | F1-Score | MCC |
|---|---|---|---|---|---|---|---|
| VGG16 | 40 | 78 | 80 | 79 | 76 | 79 | 80 |
| AlexNet | 40 | 79 | 82 | 81.1 | 80 | 80.0 | 81.0 |
| InceptionV3 | 40 | 81 | 80 | 82.3 | 82 | 82.2 | 83.4 |
| GoogleNet | 40 | 83 | 81 | 83.6 | 83 | 83.3 | 84.3 |
| Xception | 40 | 82 | 83 | 82.6 | 83 | 84.4 | 85.2 |
| MobileNet | 40 | 84 | 84.0 | 84.3 | 84 | 85.1 | 86.1 |
| SqueezeNet | 40 | 85 | 86.1 | 87.2 | 85 | 86.0 | 87.0 |
| Squeeze-Light | 40 | 94 | 96 | 95.6 | 94.12 | 95.2 | 96.7 |
| Model | Epochs | SE | SP | ACC | PR | F1-Score | MCC |
|---|---|---|---|---|---|---|---|
| VGG16 | 40 | 78 | 80 | 80 | 76 | 79 | 80.5 |
| AlexNet | 40 | 80 | 81 | 80.3 | 80 | 80.4 | 82.3 |
| InceptionV3 | 40 | 82 | 82 | 81.7 | 82 | 82.7 | 84.0 |
| GoogleNet | 40 | 82 | 83 | 82.5 | 83 | 82.5 | 85.0 |
| Xception | 40 | 84 | 84 | 83.4 | 83 | 83.3 | 86.0 |
| MobileNet | 40 | 83 | 82.2 | 85.3 | 84 | 84.2 | 83.0 |
| SqueezeNet | 40 | 85 | 85.2 | 86.6 | 85 | 85.1 | 86.1 |
| Squeeze-Light | 40 | 94 | 96 | 95.6 | 94.12 | 95.2 | 96.7 |
| Optimization | SE | SP | ACC | PR | F1-Score | MCC |
|---|---|---|---|---|---|---|
| SGD with Momentum | 80.2 | 81.8 | 82.9 | 85 | 80 | 82.2 |
| Adam | 82 | 83 | 82.5 | 83 | 82.5 | 85.0 |
| RMSProp | 84 | 84 | 83.4 | 83 | 83.3 | 86.0 |
| AdaGrad | 83 | 82.2 | 85.3 | 84 | 84.2 | 83.0 |
| AdaBelief | 94 | 96 | 95.6 | 94.12 | 95.2 | 96.7 |
| Loss Functions | SE | SP | ACC | PR | F1-Score | MCC |
|---|---|---|---|---|---|---|
| Cross Entropy Loss | 82.2 | 97.8 | 96.9 | 76 | 79 | 82.2 |
| Weighted Cross Entropy Loss | 94 | 96 | 95.6 | 94.12 | 95.2 | 96.7 |
| DL Architectures | Complexity (MFLOPs) | Model Size (MB) | GPU Speed (S) |
|---|---|---|---|
| SqueezeNet-Light | 68.3 | 9.3 | 0.7 |
| SqueezeNet | 96.9 | 14.5 | 1.6 |
| MobileNet | 95.4 | 12.3 | 1.3 |
| GoogleNet | 272.8 | 15.2 | 2.7 |
| Xception | 281.8 | 16.3 | 2.6 |
| InceptionV3 | 554.3 | 17.5 | 3.0 |
| AlexNet | 65.9 | 14.5 | 2.8 |
| VGG16 | 295.8 | 12.3 | 3.4 |
| Batch Size | Epochs | CPU/TPU/GPU (mS) |
|---|---|---|
| 64 | 40 | 700/500/400 |
| 128 | 40 | 750/400/500 |
| 256 | 40 | 750/400/500 |
| 512 | 40 | 750/400/500 |
| 1024 | 40 | 750/400/500 |
| Model | Epochs | SE | SP | ACC | PR | F1-Score | Trainable Parameters |
|---|---|---|---|---|---|---|---|
| SqueezeNet-Light | 100 | 94 | 96 | 95.6 | 94.12 | 95.2 | 3,182,412 |
| SqueezeNet | 100 | 87 | 85 | 87.6 | 87 | 87 | 7,037,504 |
| Salama-ResNet-SVM [10] | 100 | 80 | 82 | 81 | 79 | 80 | 53,982,272 |
| Ashraf-FRCNN [15] | 100 | 82 | 83 | 82 | 80 | 81 | 50,213,111 |
| Naeem-VGG16 [26] | 100 | 83 | 85 | 83 | 83 | 84 | 48,222,341 |
| Hosny-AlexNet [34] | 100 | 84 | 86 | 84 | 84 | 85 | 49,112,242 |
| Fujisawa-DCNN [37] | 100 | 79 | 80 | 78 | 79 | 80 | 52,128,141 |
| Harangi-GoogleNet-Inception [39] | 100 | 85 | 86 | 85 | 84 | 85 | 50,440,122 |
| SOTA Architectures | Complexity (MFLOPs) | Parameters (M) | Model Size (MB) | GPU Speed (S) |
|---|---|---|---|---|
| SqueezeNet-Light | 68.3 | 20.18 | 9.3 | 0.7 |
| SqueezeNet | 96.9 | 38.11 | 14.5 | 2.6 |
| Salama-ResNet-SVM [10] | 120.3 | 53.98 | 22.3 | 2.7 |
| Ashraf-FRCNN [15] | 140.9 | 50.21 | 20.5 | 5.6 |
| Naeem-VGG16 [26] | 150.3 | 48.22 | 19.3 | 4.7 |
| Hosny-AlexNet [34] | 122.3 | 49.11 | 17.3 | 4.7 |
| Fujisawa-DCNN [37] | 120.9 | 52.13 | 16.5 | 3.6 |
| Harangi-GoogleNet-Inception [39] | 150.3 | 50.44 | 19.3 | 3.7 |
| TL Architectures | Limitations | Advantages |
|---|---|---|
| SqueezeNet-Light | It should be trained on more different datasets and this classifier can be tested on different modality of images to check the generalizability of the model. | Tiny model, high speed, several datasets are evaluated, and identifies nine classes |
| SqueezeNet | It is small model but requires hyper-parameter tuning | It is better classifier compared to other pretrained TL models. |
| Salama-ResNet-SVM [10] | Classes imbalance, binary classification only two classes, and computationally expensive. | Integration of SVM and ResNet and good for binary decision. |
| Ashraf-FRCNN [15] | Classes imbalance, evaluated on single dataset, classify only two classes, and computationally expensive. | This approach used CNN and is better for features extraction. |
| Naeem-VGG16 [26] | Four classes only, many hyper-parameters required, and tested on signal dataset so classifier is not generalized. | This method used pre-trained TL VG-16 to recognize four classes of PSLs |
| Hosny-AlexNet [34] | Three classes only, required huge parameters, evaluate on single dataset, and computationally expensive. | This approach used CNN and is better for features extraction. |
| Fujisawa-DCNN [37] | Two classes (benign vs. malignant), required huge parameters, evaluate on single dataset, and computationally expensive. | This approach used CNN and is better for features extraction. |
| Harangi-GoogleNet-Inception [39] | Seven classes, required huge parameters, evaluate on single dataset, and computationally expensive. | Combining the GoogleNet and Inception pretrained TL to recognize nine classes. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, Q.; Daadaa, Y.; Rashid, U.; Ibrahim, M.E.A. Assist-Dermo: A Lightweight Separable Vision Transformer Model for Multiclass Skin Lesion Classification. Diagnostics 2023, 13, 2531. https://doi.org/10.3390/diagnostics13152531
Abbas Q, Daadaa Y, Rashid U, Ibrahim MEA. Assist-Dermo: A Lightweight Separable Vision Transformer Model for Multiclass Skin Lesion Classification. Diagnostics. 2023; 13(15):2531. https://doi.org/10.3390/diagnostics13152531
Chicago/Turabian StyleAbbas, Qaisar, Yassine Daadaa, Umer Rashid, and Mostafa E. A. Ibrahim. 2023. "Assist-Dermo: A Lightweight Separable Vision Transformer Model for Multiclass Skin Lesion Classification" Diagnostics 13, no. 15: 2531. https://doi.org/10.3390/diagnostics13152531