
Brain Stroke Classification via Machine Learning Algorithms Trained with a Linearized Scattering Operator



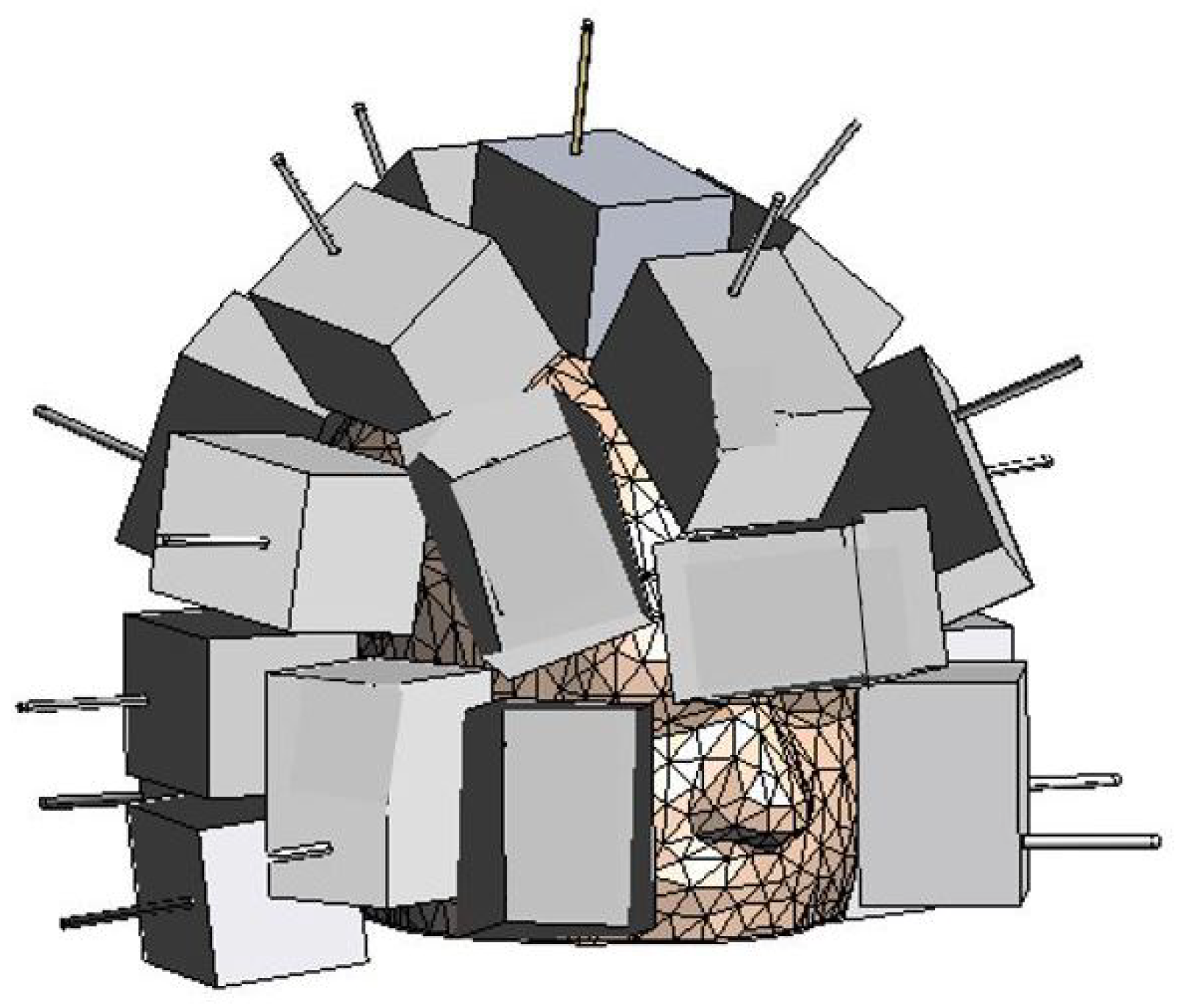{kind=link}
{kind=link}
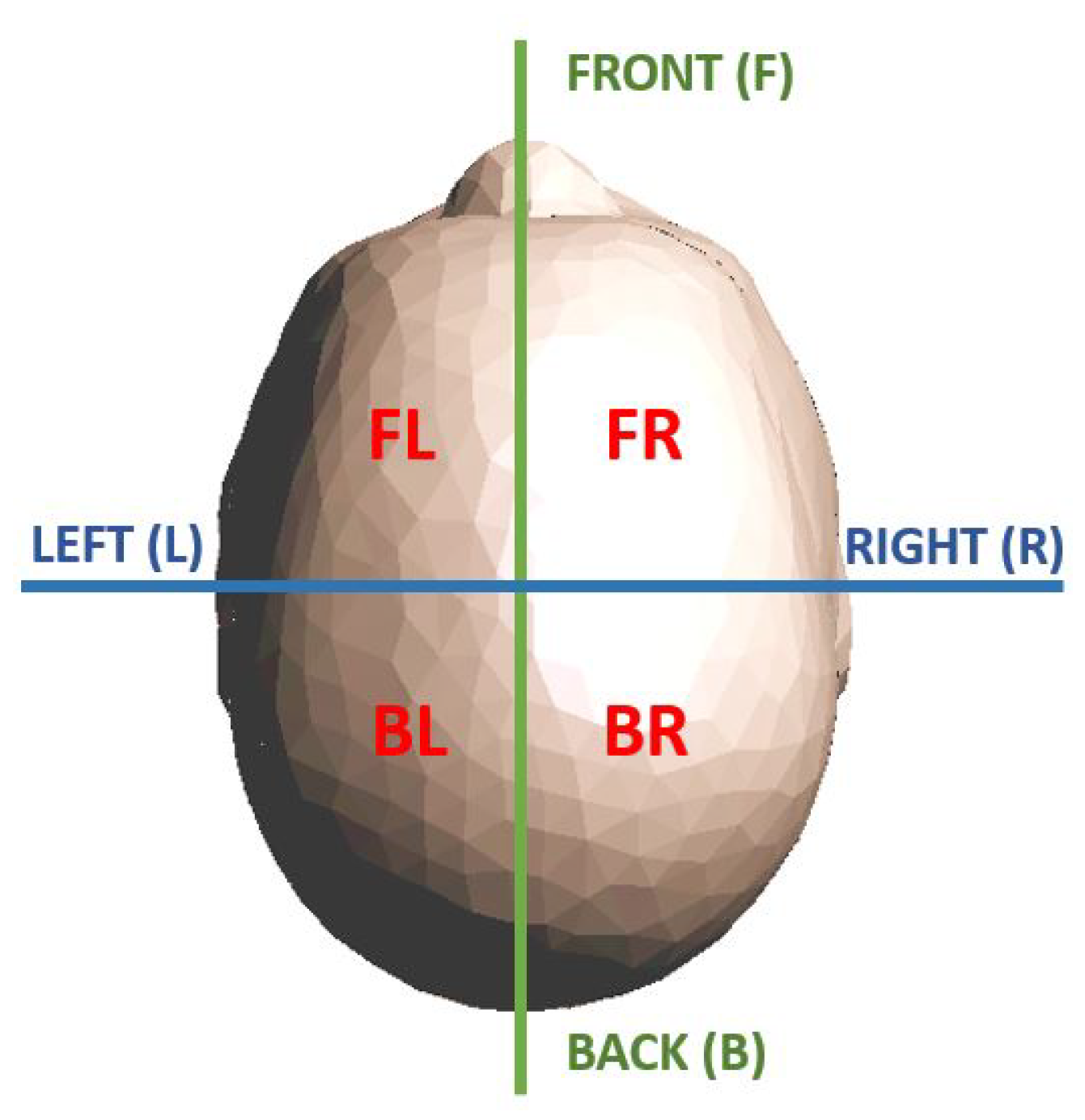{kind=link}
{kind=link}
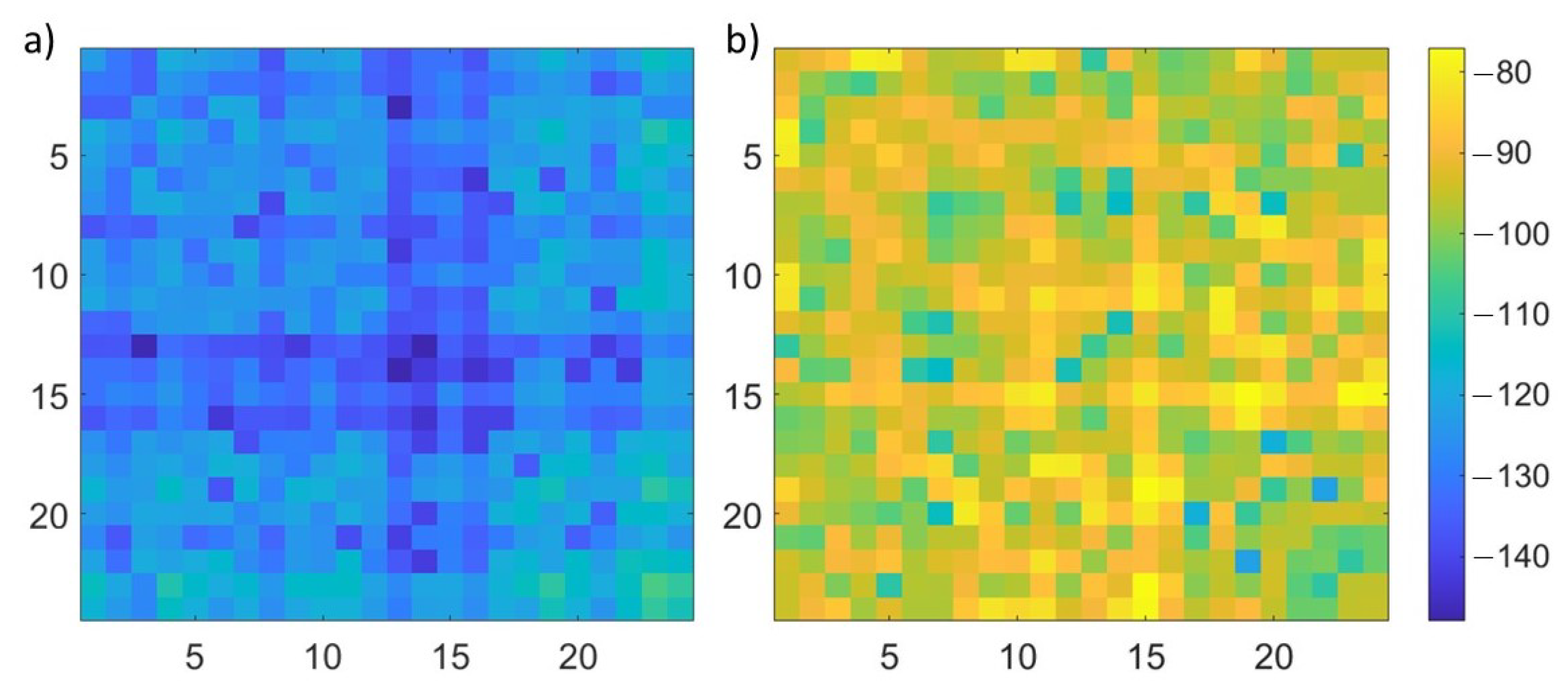{kind=link}
{kind=link}
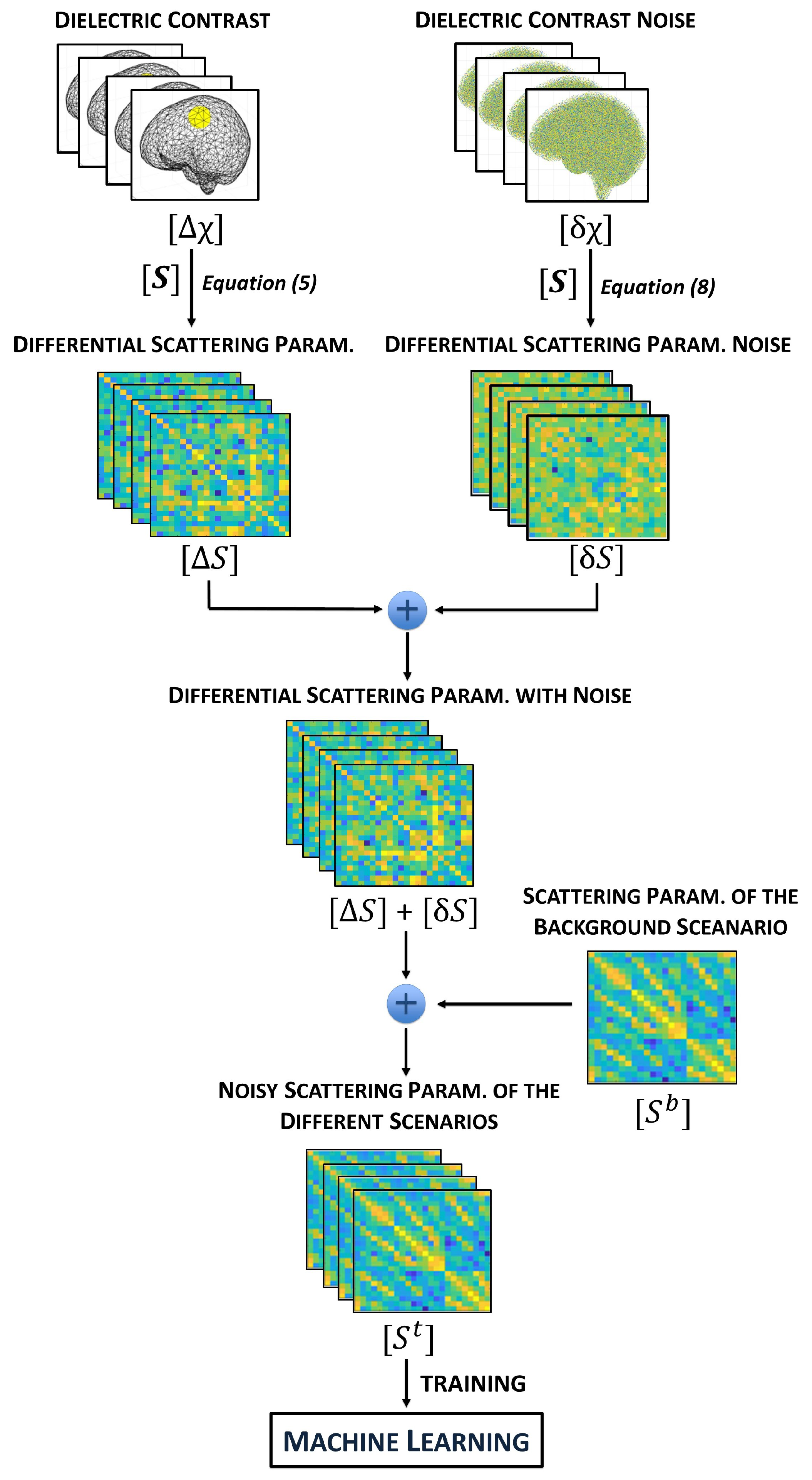{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Microwave Imaging System and Head Model
3. Machine Learning Algorithms
4. Training Set Generation and Testing Procedure
4.1. Linearized Scattering Operator
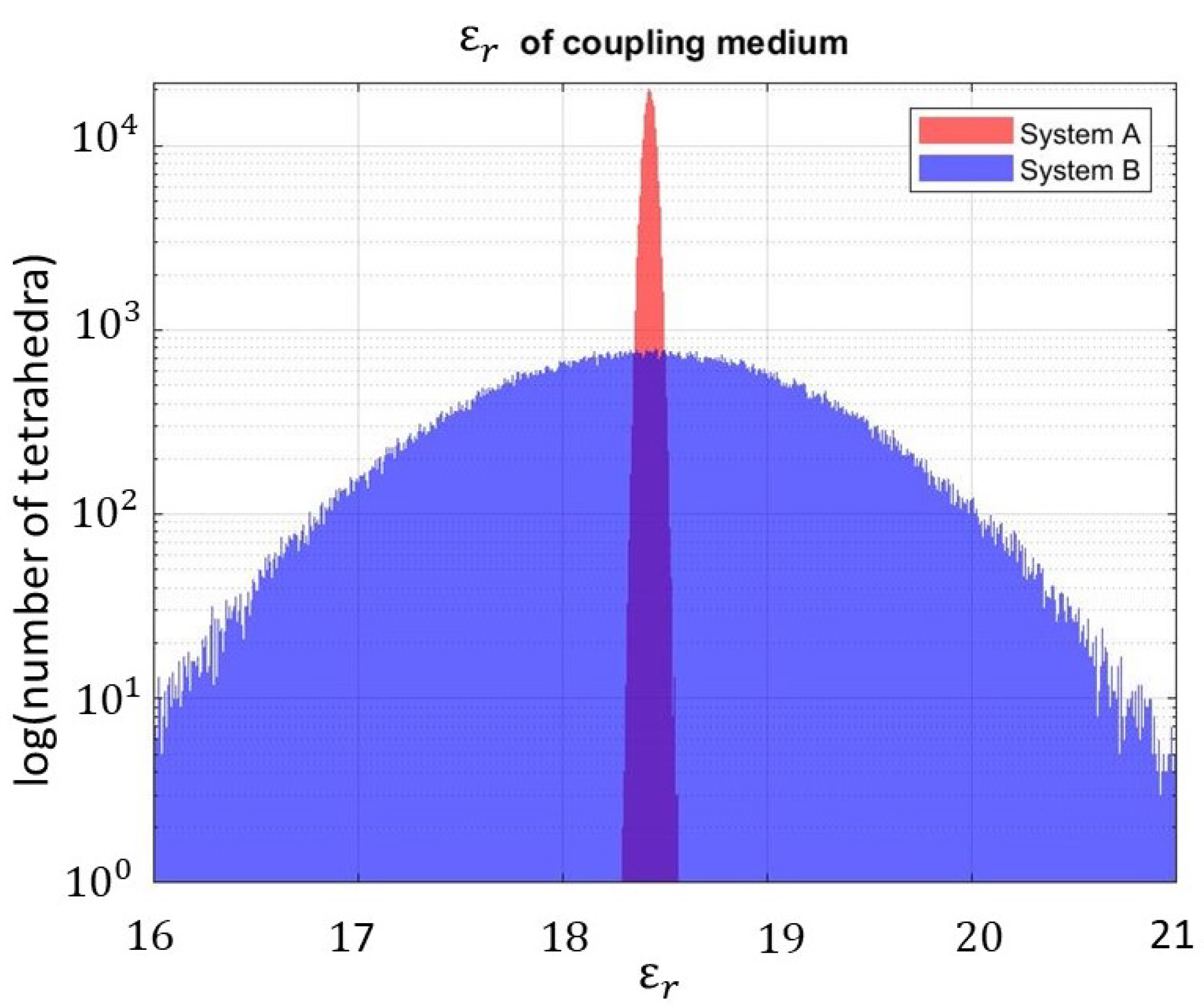
4.2. Training Set Generation
4.3. Testing Procedure
5. Numerical Results
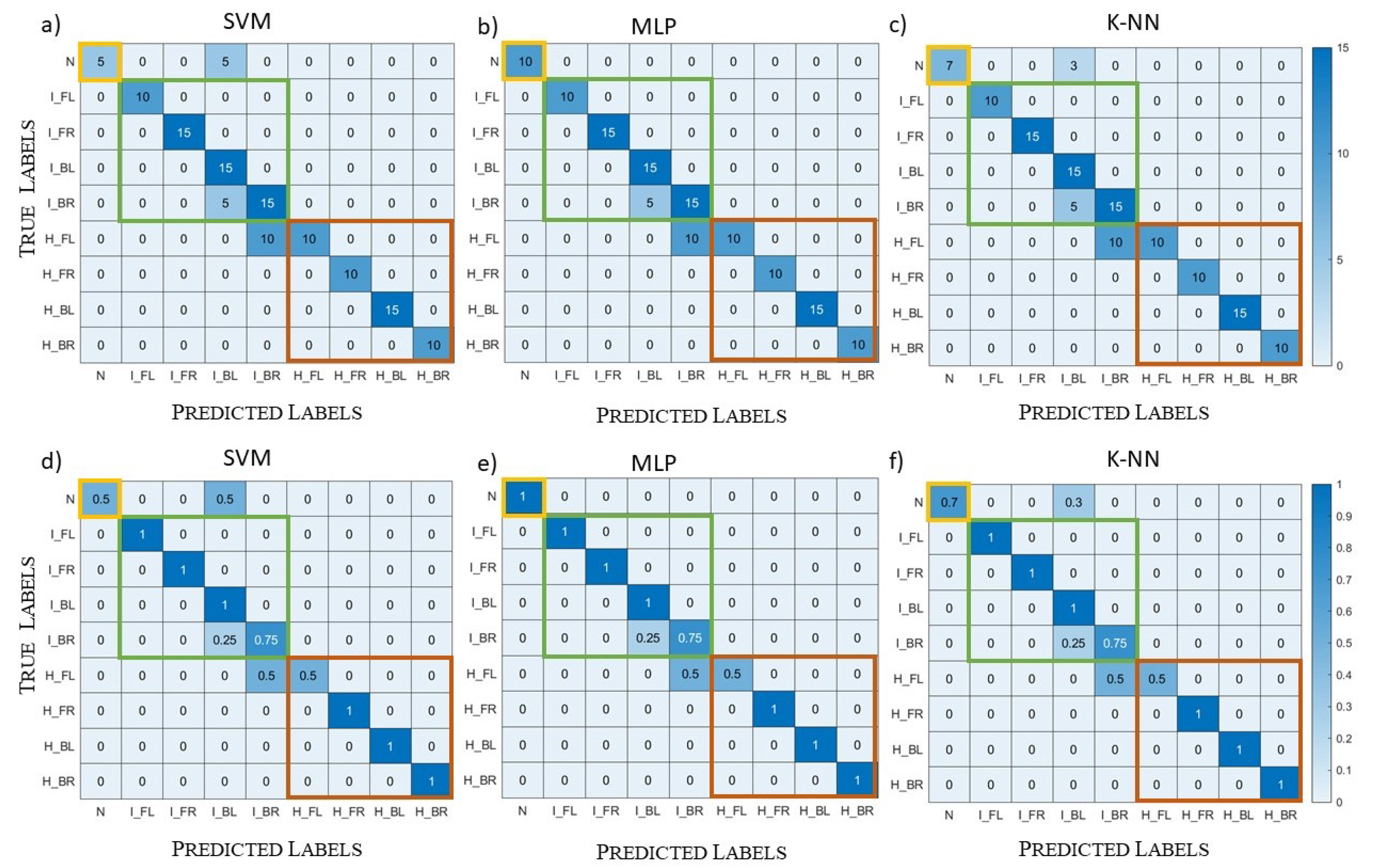
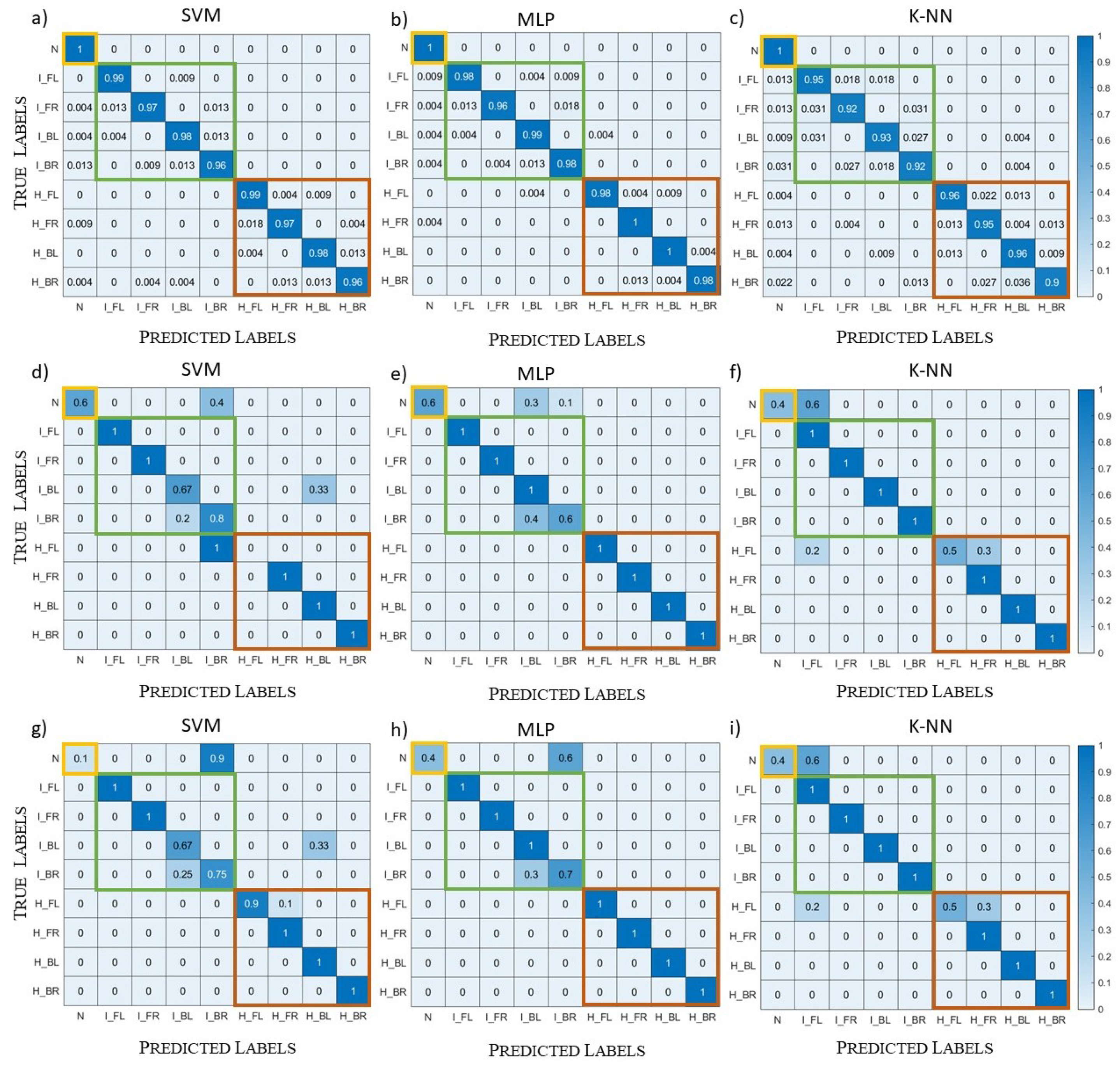
5.1. Complex Datasets
5.2. Amplitude Dataset
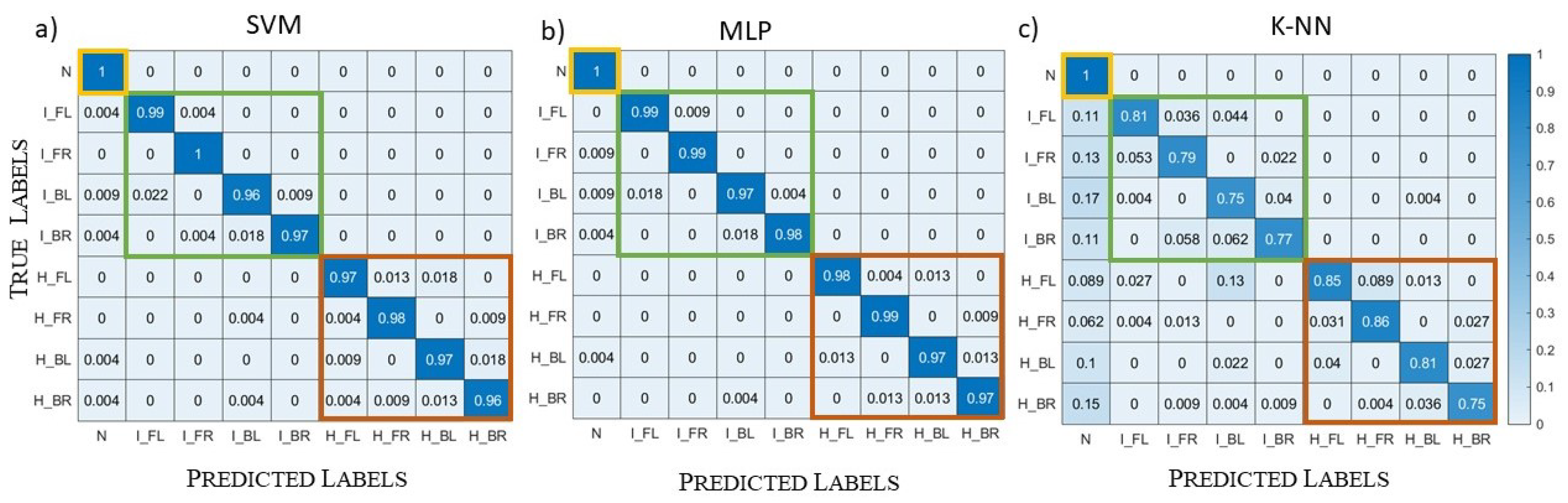
5.3. Different Head Models’ Datasets
6. Conclusions and Perspectives
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MRI | Magnetic resonance imaging |
| CT | Computerized tomography |
| MWI | Microwave imaging |
| ML | Machine learning |
| EM | Electromagnetic |
| SVM | Support vector machine |
| MLP | Multilayer perceptron |
| k-NN | k-nearest neighbours |
| DoI | Domain of interest |
| FEM | Finite element method |
References
- Mackay, J.; Mensah, G. The Atlas of Heart Disease and Stroke; World Health Organization: Geneva, Switzerland, 2004. [Google Scholar]
- Walsh, K.B. Non-invasive sensor technology for prehospital stroke diagnosis: Current status and future directions. Int. J. Stroke 2019, 14, 592–602. [Google Scholar] [CrossRef] [PubMed]
- Crocco, L.; Karanasiou, I.; James, M.; Conceicao, R.C. (Eds.) Emerging Electromagnetic Technologies for Brain Diseases Diagnostics, Monitoring and Therapy; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Fhager, A.; Candefjord, S.; Elam, M.; Persson, M. Microwave Diagnostics Ahead: Saving Time and the Lives of Trauma and Stroke Patients. IEEE Microw. Mag. 2018, 19, 78–90. [Google Scholar] [CrossRef]
- Li, M.; Guo, R.; Zhang, K.; Lin, Z.; Yang, F.; Xu, S.; Chen, X.; Massa, A.; Abubakar, A. Machine Learning in Electromagnetics With Applications to Biomedical Imaging: A Review. IEEE Antennas Propag. Mag. 2021, 63, 39–51. [Google Scholar] [CrossRef]
- Persson, M.; Fhager, A.; Trefná, H.D.; Yu, Y.; McKelvey, T.; Pegenius, G.; Karlsson, J.E.; Elam, M. Microwave-Based Stroke Diagnosis Making Global Prehospital Thrombolytic Treatment Possible. IEEE Trans. Biomed. Eng. 2014, 61, 2806–2817. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salucci, M.; Polo, A.; Vrba, J. Multi-Step Learning-by-Examples Strategy for Real-Time Brain Stroke Microwave Scattering Data Inversion. Electronics 2021, 10, 95. [Google Scholar] [CrossRef]
- Tal, O.; Shapira, S. Early Diagnosis of Stroke and Internal Hemorrhage via Deep Neural Network Inference of Microwave Signals. In Proceedings of the 2019 IEEE International Conference on Microwaves, Antennas, Communications and Electronic Systems (COMCAS), Tel Aviv, Israel, 4–6 November 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Zhu, G.; Bialkowski, A.; Guo, L.; Mohammed, B.; Abbosh, A. Stroke Classification in Simulated Electromagnetic Imaging Using Graph Approaches. IEEE J. Electromagn. Microw. Med. Biol. 2021, 5, 46–53. [Google Scholar] [CrossRef]
- Brankovic, A.; Zamani, A.; Trakic, A.; Bialkowski, K.; Mohammed, B.; Cook, D.; Walsham, J.; Abbosh, A.M. Unsupervised Algorithm for Brain Anomalies Localization in Electromagnetic Imaging. IEEE Trans. Comput. Imaging 2020, 6, 1595–1606. [Google Scholar] [CrossRef]
- Lin, X.; Chen, Y.; Gong, Z.; Zhang, H. Brain Stroke Classification using a Microwave Transmission Line Approach. In Proceedings of the 2020 IEEE Asia-Pacific Microwave Conference (APMC), Hong Kong, China, 8–11 December 2020; pp. 1092–1094. [Google Scholar] [CrossRef]
- Mariano, V.; Vasquez, J.A.T.; Casu, M.R.; Vipiana, F. Model-Based Data Generation for Support Vector Machine Stroke Classification. In Proceedings of the 2021 IEEE International Symposium on Antennas and Propagation and USNC-URSI Radio Science Meeting (APS/URSI), Singapore, 4–10 December 2021; pp. 1685–1686. [Google Scholar] [CrossRef]
- Mariano, V.; Casu, M.R.; Vipiana, F. Simulation-based Machine Learning Training for Brain Anomalies Localization at Microwaves. In Proceedings of the 2022 16th European Conference on Antennas and Propagation (EuCAP), Madrid, Spain, 27 March–1 April 2022; pp. 1–3. [Google Scholar] [CrossRef]
- Mariano, V.; Tobon Vasquez, J.A.; Casu, M.R.; Vipiana, F. Efficient Data Generation for Stroke Classification via Multilayer Perceptron. In Proceedings of the 2022 IEEE International Symposium on Antennas and Propagation and USNC-URSI Radio Science Meeting (AP-S/URSI), Denver, CO, USA, 10–15 July 2022; pp. 890–891. [Google Scholar] [CrossRef]
- Tobon Vasquez, J.A.; Scapaticci, R.; Turvani, G.; Bellizzi, G.; Rodriguez-Duarte, D.O.; Joachimowicz, N.; Vipiana, F. A Prototype Microwave System for 3D Brain Stroke Imaging. Sensors 2020, 20, 2607. [Google Scholar] [CrossRef]
- Scapaticci, R.; Tobon, J.; Bellizzi, G.; Vipiana, F.; Crocco, L. Design and Numerical Characterization of a Low-Complexity Microwave Device for Brain Stroke Monitoring. IEEE Trans. Antennas Propag. 2018, 66, 7328–7338. [Google Scholar] [CrossRef]
- Rodriguez-Duarte, D.O.; Tobon Vasquez, J.A.; Scapaticci, R.; Crocco, L.; Vipiana, F. Brick Shaped Antenna Module for Microwave Brain Imaging Systems. IEEE Antennas Wirel. Propag. Lett. 2020, 19, 2057–2061. [Google Scholar] [CrossRef]
- Scapaticci, R.; Donato, L.D.; Catapano, I.; Crocco, L. A feasibility study on Microwave Imaging for brain stroke monitoring. Prog. Electromagn. Res. B 2012, 40, 305–324. [Google Scholar] [CrossRef] [Green Version]
- Makarov, S.N.; Noetscher, G.M.; Yanamadala, J.; Piazza, M.W.; Louie, S.; Prokop, A.; Nazarian, A.; Nummenmaa, A. Virtual Human Models for Electromagnetic Studies and Their Applications. IEEE Rev. Biomed. Eng. 2017, 10, 95–121. [Google Scholar] [CrossRef] [PubMed]
- Download Visible Human Project Data. Available online: https://www.nlm.nih.gov/databases/download/vhp.html (accessed on 17 October 2022).
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. 2003. Available online: https://www.csie.ntu.edu.tw/~cjlin/ (accessed on 17 October 2022).
- Lakshmi, R.P.; Babu, M.S.; Vijayalakshmi, V. Voxel based lesion segmentation through SVM classifier for effective brain stroke detection. In Proceedings of the 2017 International Conference WiSPNET, Chennai, India, 22–24 March 2017; pp. 1064–1067. [Google Scholar] [CrossRef]
- Nielsen, M.A. Neural Networks and Deep Learning. 2019. Available online: http://neuralnetworksanddeeplearning.com/index.html (accessed on 17 October 2022).
- Ricci, M.; Štitić, B.; Urbinati, L.; Di Guglielmo, G.; Vasquez, J.A.T.; Carloni, L.P.; Vipiana, F.; Casu, M.R. Machine-Learning Based Microwave Sensing: A Case Study for the Food Industry. IEEE J. Emerg. Sel. Top. Circuits Syst. 2021, 11, 503–514. [Google Scholar] [CrossRef]
- Taunk, K.; De, S.; Verma, S.; Swetapadma, A. A Brief Review of Nearest Neighbor Algorithm for Learning and Classification. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 1255–1260. [Google Scholar] [CrossRef]
- Google Colab. Available online: https://colab.research.google.com/ (accessed on 17 October 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Scikit-Learn Machine Learning in Python. Available online: https://scikit-learn.org/stable/ (accessed on 17 October 2022).
- Beaverstone, A.S.; Shumakov, D.S.; Nikolova, N.K. Frequency-Domain Integral Equations of Scattering for Complex Scalar Responses. IEEE Trans. Microw. Theory Tech. 2017, 65, 1120–1132. [Google Scholar] [CrossRef]
- Tajik, D.; Foroutan, F.; Shumakov, D.S.; Pitcher, A.D.; Nikolova, N.K. Real-Time Microwave Imaging of a Compressed Breast Phantom With Planar Scanning. IEEE J. Electromagn. Microw. Med. Biol. 2018, 2, 154–162. [Google Scholar] [CrossRef]
- Rodriguez-Duarte, D.O.; Tobon Vasquez, J.A.; Scapaticci, R.; Crocco, L.; Vipiana, F. Assessing a Microwave Imaging System for Brain Stroke Monitoring via High Fidelity Numerical Modelling. IEEE J. Electromagn. Microw. Med. Biol. 2021, 5, 238–245. [Google Scholar] [CrossRef]
- Attardo, E.A.; Borsic, A.; Vecchi, G.; Meaney, P.M. Whole-System Electromagnetic Modeling for Microwave Tomography. IEEE Antennas Wirel. Propag. Lett. 2012, 11, 1618–1621. [Google Scholar] [CrossRef]
- Laredo, C.; Zhao, Y.; Rudilosso, S.; Renu, A.; Pariente, J.; Chamorro, A.; Urra, X. Prognostic Significance of Infarct Size and Location: The Case of Insular Stroke. Sci. Rep. 2018, 8, 9498. [Google Scholar] [CrossRef] [Green Version]
- Bruno, A.; Shah, N.; Akinwuntan, A.E.; Close, B.; Switzer, J.A. Stroke Size Correlates with Functional Outcome on the Simplified Modified Rankin Scale Questionnaire. J. Stroke Cerebrovasc. Dis. 2013, 22, 781–783. [Google Scholar] [CrossRef]
- Saver, J.L. Time is brain–quantified. Stoke 2006, 37, 263–266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saver, J.L.; Johnston, K.C.; Homer, D.; Wityk, R.; Koroshetz, W.; Truskowski, L.L.; Haley, E.C. Infarct Volume as a Surrogate or Auxiliary Outcome Measure in Ischemic Stroke Clinical Trials. Stroke 1999, 30, 293–298. [Google Scholar] [CrossRef] [PubMed]
- Semenov, S.; Huynh, T.; Williams, T.; Nicholson, B.; Vasilenko, A. Dielectric properties of brain tissue in acute ischemic stroke: Experimental study on swine. Bioelectromagnetics 2017, 38, 158–163. [Google Scholar] [CrossRef] [PubMed]
- Keysight Technologies. Keysight Streamline Series USB Vector Network Analyzer P937XA 2-Port, Up to 26.5 GHz; Data Sheet; Keysight Technologies: Santa Rosa, CA, USA, 2018; p. 5. [Google Scholar]
- Gilmore, C.; Mojabi, P.; Zakaria, A.; Ostadrahimi, M.; Kaye, C.; Noghanian, S.; Shafai, L.; Pistorius, S.; LoVetri, J. A Wideband Microwave Tomography System With a Novel Frequency Selection Procedure. IEEE Trans. Biomed. Eng. 2010, 57, 894–904. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Duarte, D.O.; Vasquez, J.A.T.; Scapaticci, R.; Turvani, G.; Cavagnaro, M.; Casu, M.R.; Crocco, L.; Vipiana, F. Experimental Validation of a Microwave System for Brain Stroke 3D Imaging. Diagnostics 2021, 1232, 1232. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Orr, G.; Muller, K. Efficient backprop. In Neural Networks: Tricks of the Trade; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; Chapter 1; pp. 9–48. [Google Scholar]
















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mariano, V.; Tobon Vasquez, J.A.; Casu, M.R.; Vipiana, F. Brain Stroke Classification via Machine Learning Algorithms Trained with a Linearized Scattering Operator. Diagnostics 2023, 13, 23. https://doi.org/10.3390/diagnostics13010023
Mariano V, Tobon Vasquez JA, Casu MR, Vipiana F. Brain Stroke Classification via Machine Learning Algorithms Trained with a Linearized Scattering Operator. Diagnostics. 2023; 13(1):23. https://doi.org/10.3390/diagnostics13010023
Chicago/Turabian StyleMariano, Valeria, Jorge A. Tobon Vasquez, Mario R. Casu, and Francesca Vipiana. 2023. "Brain Stroke Classification via Machine Learning Algorithms Trained with a Linearized Scattering Operator" Diagnostics 13, no. 1: 23. https://doi.org/10.3390/diagnostics13010023