1. Introduction
Breast cancer is one of the most dangerous and fatal diseases in women around the world. Breast cancer has been ranked the number one cancer among Indian females. It has an age-adjusted rate as high as 25.8 per 100,000 women and a mortality rate of 12.7 per 100,000 women. The breast cancer projection for India in 2020 suggests the number will go as high as 1,797,900. Better health awareness and availability of breast cancer screening programs and treatment facilities would cause a favorable and positive clinical picture in the country [
1]. According to the American Cancer Society (ACS), breast cancer is the most common cancer found in American women, except for skin cancers. The average risk of a woman in the U.S. developing breast cancer sometime in her life is about 12% or a 1 in 8 chance. The chance that a woman will die from breast cancer is about 2.6% or a 1 in 38 chance. According to a 2013 World Health Organisation (WHO) report, in 2011, around half a million women worldwide succumbed to breast cancer. The mortality rate of breast cancer is very high compared to other types of cancer [
2]. The prognosis for cancer patients varies depending on the type of cancer. Patients with small-cell lung carcinoma have the worst prognosis. Surgery, chemotherapy, radiation, targeted therapy, and immunotherapy are currently used to treat cancer. These methods of curative treatment are only available to people with localized disease or treatment-sensitive malignancies; therefore, their contributions to cancer curability are limited [
3]. However, early diagnosis significantly increases treatment success. Specifically, during the diagnosis procedure, specialists evaluate both overall and local tissue organization via whole-slide and microscopy images. However, the large amount of data and complexity of the images make this task time-consuming and non-trivial. As a result, the development of automatic detection and diagnosis tools is both difficult and necessary in this field. Breast cancer diagnosis consists of a screening test such as mammography or ultrasound whenever a lump is detected, followed by a biopsy and histopathological examination to make a definite diagnosis of any malignant growth in the breast tissue. The tissues can either be normal, benign, or malignant. Malignant lesions can be classified as either “in situ,” where the cells are restrained inside the mammary ductal-lobular system, or “invasive,” where the cells spread beyond that structure.
Breast-cancer prediction is usually performed by image analysis. Radiologists use different types of imaging techniques to predict the severity of breast cancer, which include diagnostic mammography, thermography, ultrasound, histology, or magnetic resonance imaging (MRI).
A mammography test is called a mammogram, which helps detect and diagnose breast cancer in women early [
4]. It involves small doses of X-rays to produce a breast image [
5]. Mammography is the cornerstone of population-level breast cancer screening and can detect more in situ lesions and smaller invasive cancers than other screening approaches, such as MRI and ultrasound [
6]. Ultrasound uses a small range of frequencies to create images of the breast but keeps the contrast very small. Ultrasound can detect and identify breast mass nodes and is mostly used due to its ease, volume, non-invasiveness, and low cost [
7].
MRI uses magnetic fields to construct very accurate 3-dimensional (3D) transverse images. Human body MRI requires a high dose of radiation to get accurate breast 3D images. Hence, the differences in the infected region are very vivid when we use an MRI and thus reveal cancer that cannot be seen in any other way. However, the problem is that MRI is much more costly compared to other cancer detection techniques [
8].
Thermography is an effective screening test that can detect breast cancer by showing the body parts with irregular temperature shifts in a thermal image. Thermal images are captured using a thermal infrared camera that captures the infrared radiation emitted by the breast region and transforms this infrared radiation into electrical signals [
8].
Histopathological images are microscopic images of the tissues used in disease analysis. The nature of histopathological images, therefore, makes this job lengthy, and the findings may be subject to the pathologist’s subjectivity. Therefore, the production of automated and precise methods of histopathological image analysis is a crucial area of research [
9], and computer-aided analysis of histopathological images plays a significant role in the diagnosis of breast cancer and its prognosis [
10,
11]. However, the process of developing tools for performing this analysis is impeded by the following challenges. To be specific, histopathological images of breast cancer are fine-grained, high-resolution images that depict rich geometric structures and complex textures. The variability within a class and the consistency between classes can make classification extremely difficult, especially when dealing with multiple classes. Due to this, the extraction of discriminative features for histopathological images of breast cancer becomes a challenging task.
The state-of-the-art methods can be broadly categorized into two most common approaches for designing image-based recognition systems: (i) using visual feature descriptors or handcrafted features and (ii) DL-based methods using CNNs. The traditional approach involves using handcrafted features for segmentation of nuclei and cells from the breast-histology images to extract discernible features to distinguish between malignant and non-malignant tissues. These handcrafted features revolve around using active contours, thresholding, graph cuts, watershed segmentation, pixel-wise classification and clustering, or a combination of these. Rajathi in 2020 [
12] used a radial basis neural network for classification purposes. The radial basis neural network was designed with the help of the optimization algorithm. The optimization tunes the classifier to reduce the error rate with the least amount of time spent on the training process. The cuckoo search algorithm was used for this purpose. Roy et al. [
13] ensembled texture and statistical features using a stacking method. In this, redundant features were discarded using the Pearson’s correlation coefficient-based feature selection method. The majority of these methods concentrated on a two-class classification task of malignant or non-malignant tissues [14, 15]. For instance, Basavanhally et al. in 2011 [
14] used the O’Callaghan neighborhood to solve the problem of tubule identification on hematoxylin and eosin (H & E)-stained breast cancer (BCa) histopathology images, where a tubule is characterized by a central lumen surrounded by cytoplasm and a ring of nuclei around the cytoplasm. The detection of tubules is important because tubular density is an important predictor in determining the grade of cancer. The potential lumen areas are segmented using a hierarchical normalized cut (HNCut) and an initialized color-gradient-based active contour model (CGAC). Evaluation of 1226 potential lumen areas from 14 patient studies produced an area under the receiver operating characteristic curve (AUC) of 0.91, along with the ability to classify true lumens with 86% accuracy. Dundar et al. in 2011 [
15] evaluated digitized slides of tissues for certain cytological criteria and classified the tissues based on the quantitative features derived from the images. The system was trained using a total of 327 regions of interest (ROIs) collected across 62 patient cases and tested with a sequestered set of 149 ROIs collected from 33 patient cases. An overall accuracy of 87.9% was achieved on the test data. The test accuracy of 84.6% was obtained in the borderline case. Melekoodapattu et al. (2022) [
16] implemented a system for autonomously diagnosing cancer using an integration method, which includes CNN and image texture attribute extraction. The nine-layer customized convolutional neural network is used to categorize data in the CNN stage. To improve the effectiveness of categorization in the extraction-based phase, texture features are defined and their dimensions are reduced using Uniform Manifold Approximation and Projection (UMAP). The findings of each phase were combined by an ensemble algorithm to arrive at the ultimate conclusion. The final categorization is presumed to be malignant if any of the stage’s output is malignant. In the MIAS repository, the ensemble method’s testing specificity and accuracy were 97.8% and 98%, respectively, whereas on the DDSM repository, they were 98.3% and 97.9%. However, these handcrafted features and engineering techniques suffered from some major drawbacks. This is because extracting high quality features from low resolution images is very difficult. Then comes another drawback of combining patch-level classification with image-level classification. Usually, patch-level classification is not very effective; to obtain good image-level accuracy, the patch features have to be used in a proper and efficient way.
Breast cancer is one of the few cancers for which an effective screening test is available. Breast cancer detection has been one of the most important fields in the computer vision field. Many DL-based networks have been used by researchers in the past [
17,
18,
19,
20,
21,
22,
23]. There are basically two ways of making breast cancer predictions: using DL models and using feature descriptors. In current scenarios where computational capability is increasing exponentially, it is becoming quite natural to utilize it to the fullest to save both time and human effort. Moreover, since huge amounts of computational power are required for prediction using DL models, there is no scope for compromising with human efficiency. Moreover, machines, when trained, can gather vast amounts of information and use it to predict in a short amount of time.
For instance, in this paper [
24], Melekoodappattu et al. proposed a model using extreme learning machines (ELM) with the fruitfly optimization algorithm (ELM-FOA) to tune the input weight to obtain optimal output at the ELM’s hidden node to obtain the solution analytically. The testing sensitivity and precision of ELM-FOA were 97.5% and 100%, respectively. The developed method can detect calcifications and tumors with 99.04% accuracy. Nirmala et al. in 2021 [
25] proposed a new methodology for integrating the run-length features with the bat-optimized learning machine—BORN. BORN also features the most efficient visual saliency segmentation process to obtain a highly efficient diagnosis. BORN was tested with two different datasets, MIAS and DDSM, with different learning kernels, and compared to other intelligent algorithms, such as RF-ELM, EGAM, and associate classifiers. The proposed classifier achieved 99.5% accuracy. In [
26], a soft computing classifier for the seven different CNN models was proposed for breast cancer histopathology-image classification. The proposed methodology uses the basic CNN with four convolutional layers, the basic CNN with five layers (with data augmentation), the VGG-19 transfer-learned model (with and without data augmentation), the VGG-16 transfer-learned model (without data augmentation), and the Xception transfer-learned model (with and without data augmentation). It uses seven models to extract features and then passes them through the classifier to make the final predictions. The dataset used in this research was the ICIAR BACH dataset for experimentation, and the model achieved a maximum accuracy of 96.91%. The primary drawback of this method is that training using the seven CNN models takes a huge amount of memory and time. Preetha et al. [
27] proposed a PCA–LDA-based feature extraction and reduction (FER) technique that reduces the original feature space to a large extent. For classification, an ANNFIS classifier that uses the neural network concept with some fuzzy rule logic was used. In another paper [
28], the authors combined two DCNNs to extract distinguished image features using the concept of transfer learning. The pre-trained Inception and Xceptions models were used in parallel. Then, the feature maps were combined and reduced by dropout before being fed to the last fully connected layer for classification. Then followed sub-image classification and whole-image classification based on a majority vote and maximum probability rules.
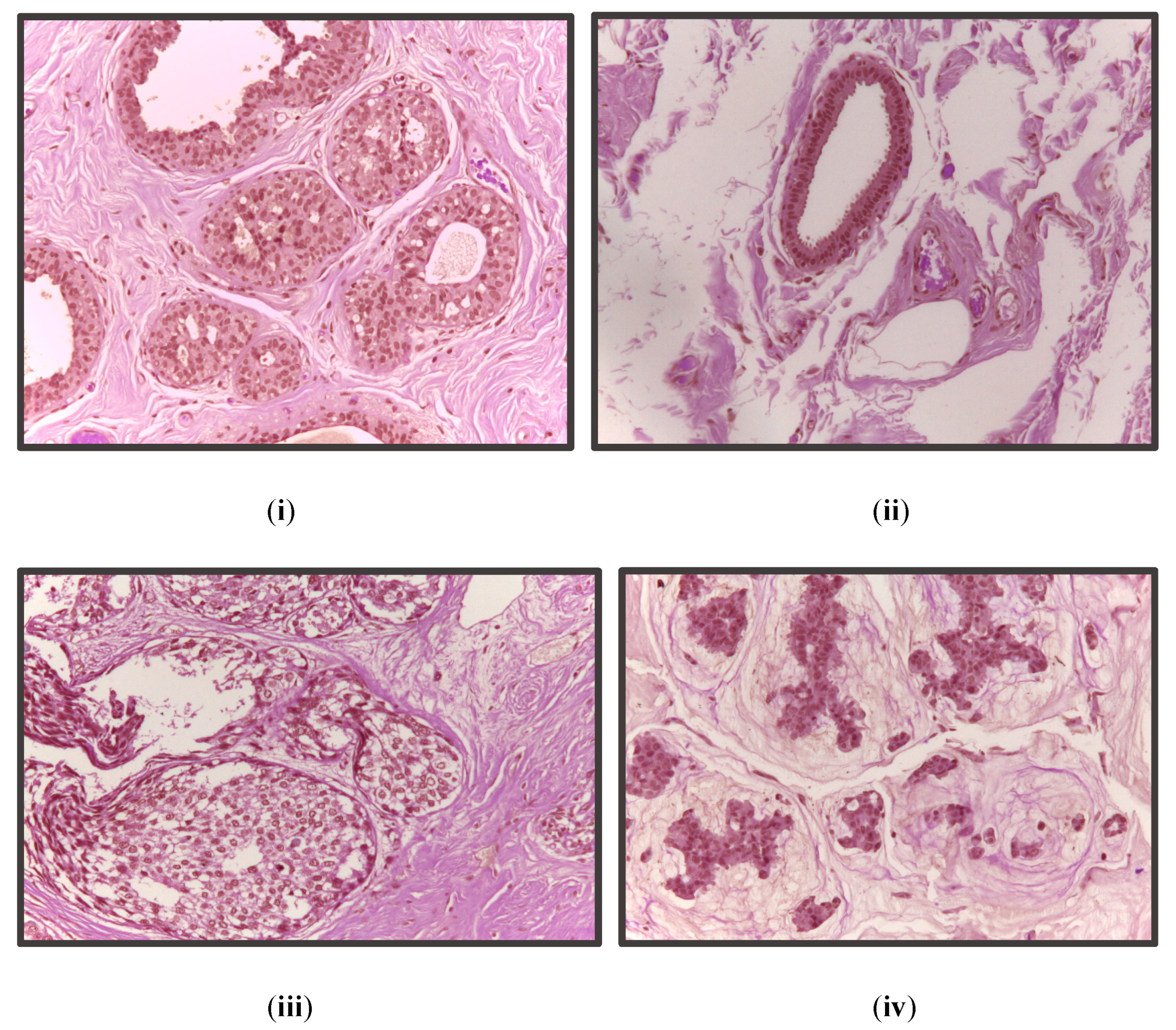
In this work, four tissue malignancy levels are considered: normal, benign, in situ carcinoma, and invasive carcinoma. The experiments were performed on the BACH dataset. The overall accuracy for the sub-image classification was 97.29%, and for the carcinoma cases, the sensitivity achieved was 99.58%. Wang et al. [
29] proposed a hybrid model with a CNN (for feature extraction) and support vector machine (SVM) (for classification) to classify breast cancer histology images into four classes, benign, normal, in situ, and invasive, for the ICIAR BACH dataset. In addition to traditional image augmentation techniques, this study introduced deformation to microscopic images and then used a multi-model vote to obtain a validation accuracy of 92.5% and a test accuracy of 91.7%. This model used Xception and Inception ResNet v2 as the backbone models of the CNN. Nazeri et al. [
30] proposed two consecutive CNNs to predict the classes of breast-cancer images. Firstly, due to the high resolution of the images, the images were converted to 512 × 512 resolution patches, and patch features were extracted by the first CNN. The second CNN utilized these patch features to obtain final image classification. It obtained 95% accuracy on the validation dataset. Training the patch-wise network with the same labels as the image-wise network is a disadvantage to the model’s performance because not every patch in an image represents the same category. Golatkar et al. [
31] proposed a nuclei-based patch extraction strategy and fine-tuned a pretrained Inception-v3 network to classify the patches. It obtained an average accuracy of 85% for the four classes and 93% for non-cancer (i.e., normal or benign) vs. malignant (in situ or invasive carcinoma). The authors used majority voting in the patch predictions to classify the images. Sanyal et al. [
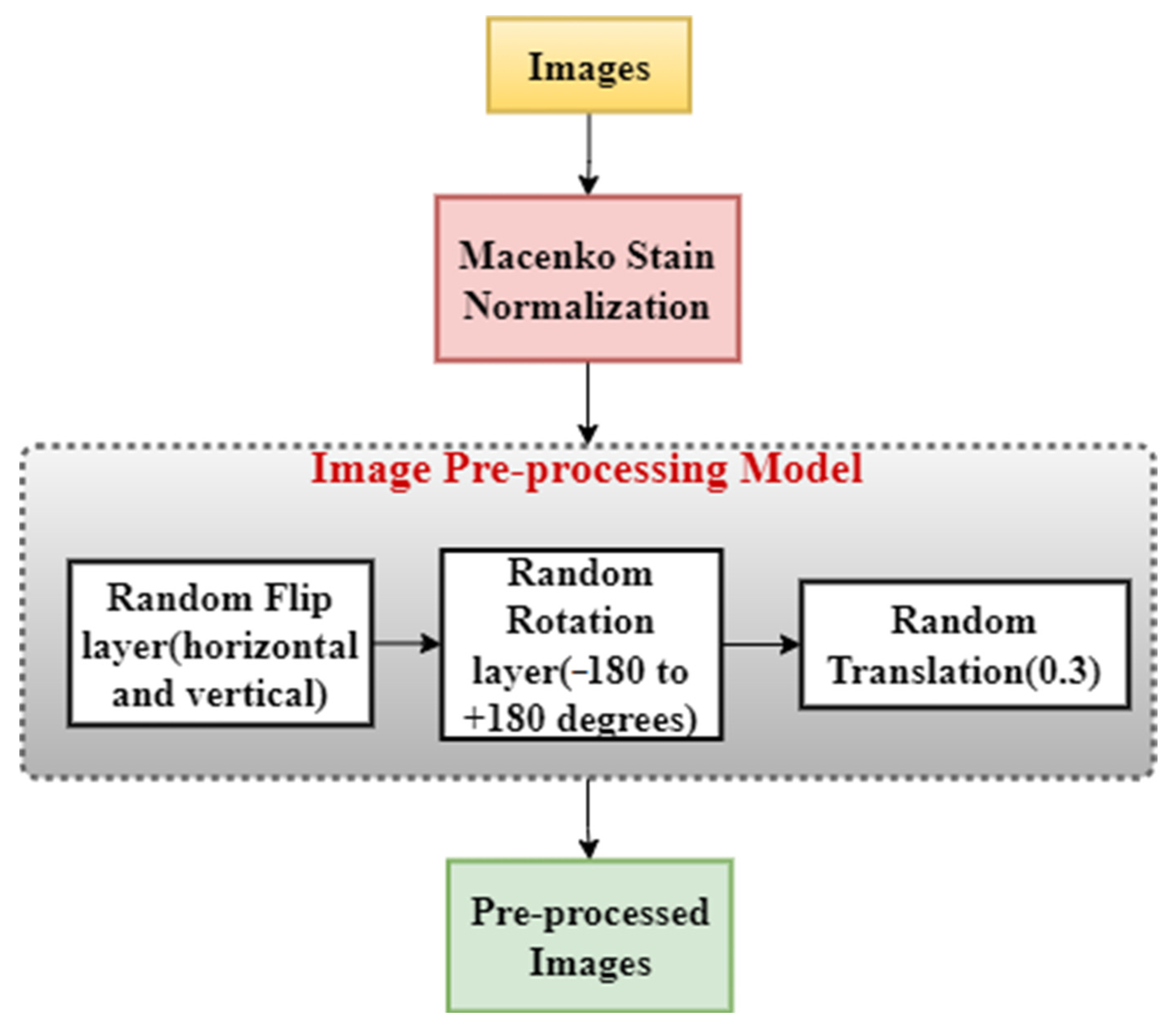
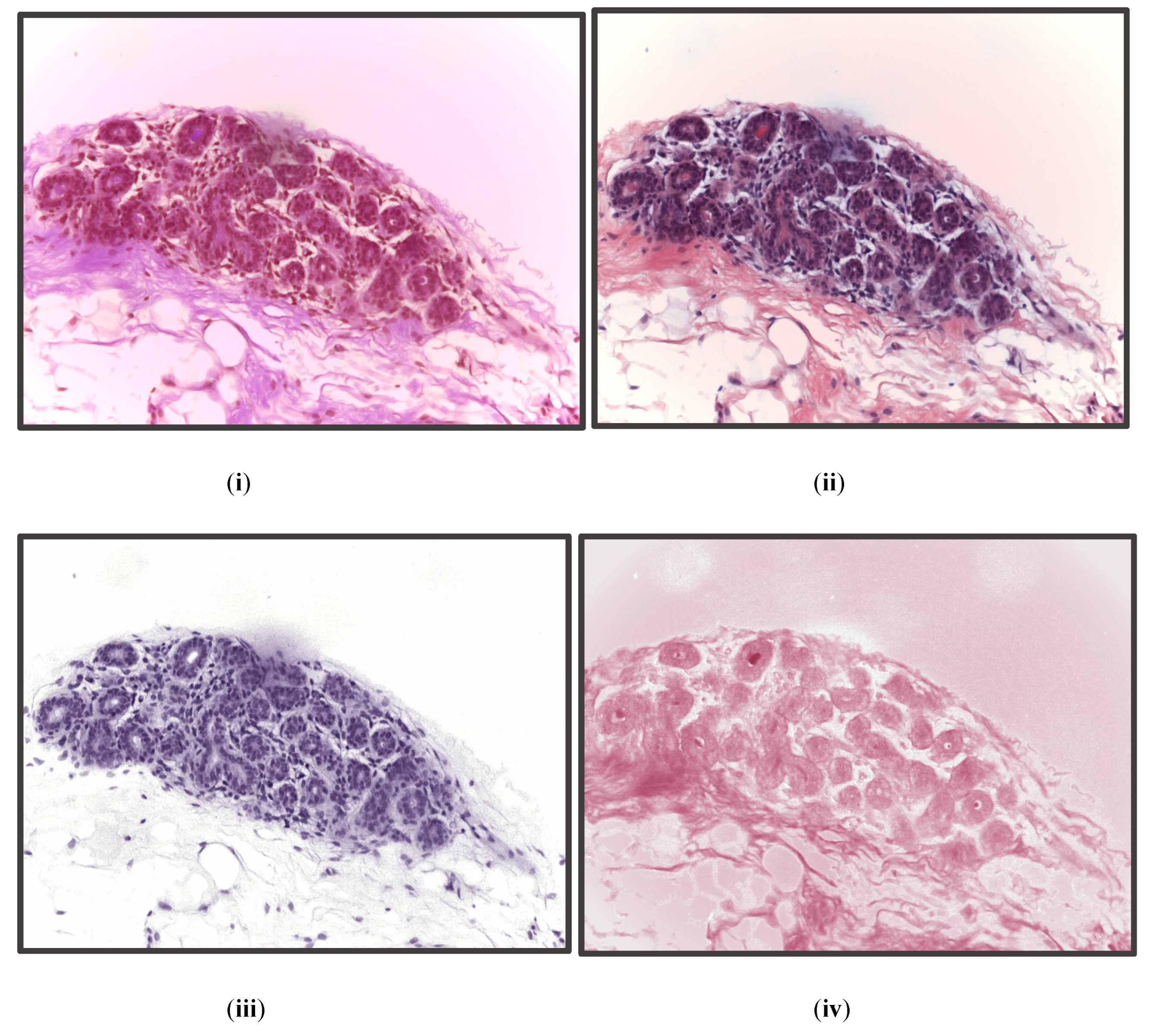
32] used a patch classification ensemble technique for the ICIAR BACH Dataset 2018. At first, the patches are stain-normalized and then passed through VGG-19, Inception-ResNet v2, Inception v3, and ResNet101, and the posterior probabilities are then classified using the XGBoost classifier. Then, all five classifications (four from the models and one from the classifier) are ensembled to obtain the patch-prediction probabilities. After that, in the image-wise pipeline, the patch probabilities were ensembled using mean, product, weighted mean, weighted product, and majority voting to obtain the final image classification. This model obtained a 4-class classification accuracy of 95% and a 2-class classification accuracy of 98.75%.
To capture more discriminant deep features for pathological breast-cancer images, Zou et al. [
33] introduced a novel attention high-order deep network (AHoNet) by simultaneously embedding attention mechanisms and high-order statistical representation into a residual convolutional network. AHoNet first employed an efficient channel attention module with non-dimensionality reduction and local cross-channel interaction to achieve local salient deep features of pathological breast-cancer images. Then, their second-order covariance statistics were further estimated through matrix power normalization, which provides a more robust global feature presentation of pathological breast-cancer images. AHoNet achieved optimal patient-level classification accuracy of 85% on the BACH database. Vang et al. [
34] fine-tuned a pre-trained Inception-v3 network on the extracted patches. To obtain image-wise prediction, the patch-wise prediction was ensembled using majority voting, logistic regression, and gradient boosting trees. Mohamed et al. [
35] proposed a deep learning approach to detect breast cancer from biopsy microscopy images, in which they examined the effects of different data preprocessing techniques on the performances of deep learning models. They introduced an ensemble method for aggregating the best models in order to improve performance. They showed that Densenet 169, Resnet 50, and Resnet 101 were the three best models, achieving accuracy scores of 62%, 68%, and 85%, respectively, without data pre-processing. With the help of data augmentation and segmentation, the accuracy of these models increased by 20%, 17%, and 6%, respectively. Additionally, the ensemble learning technique improved the accuracy of the models even further. The results show that the best accuracy achieved was 92.5%.
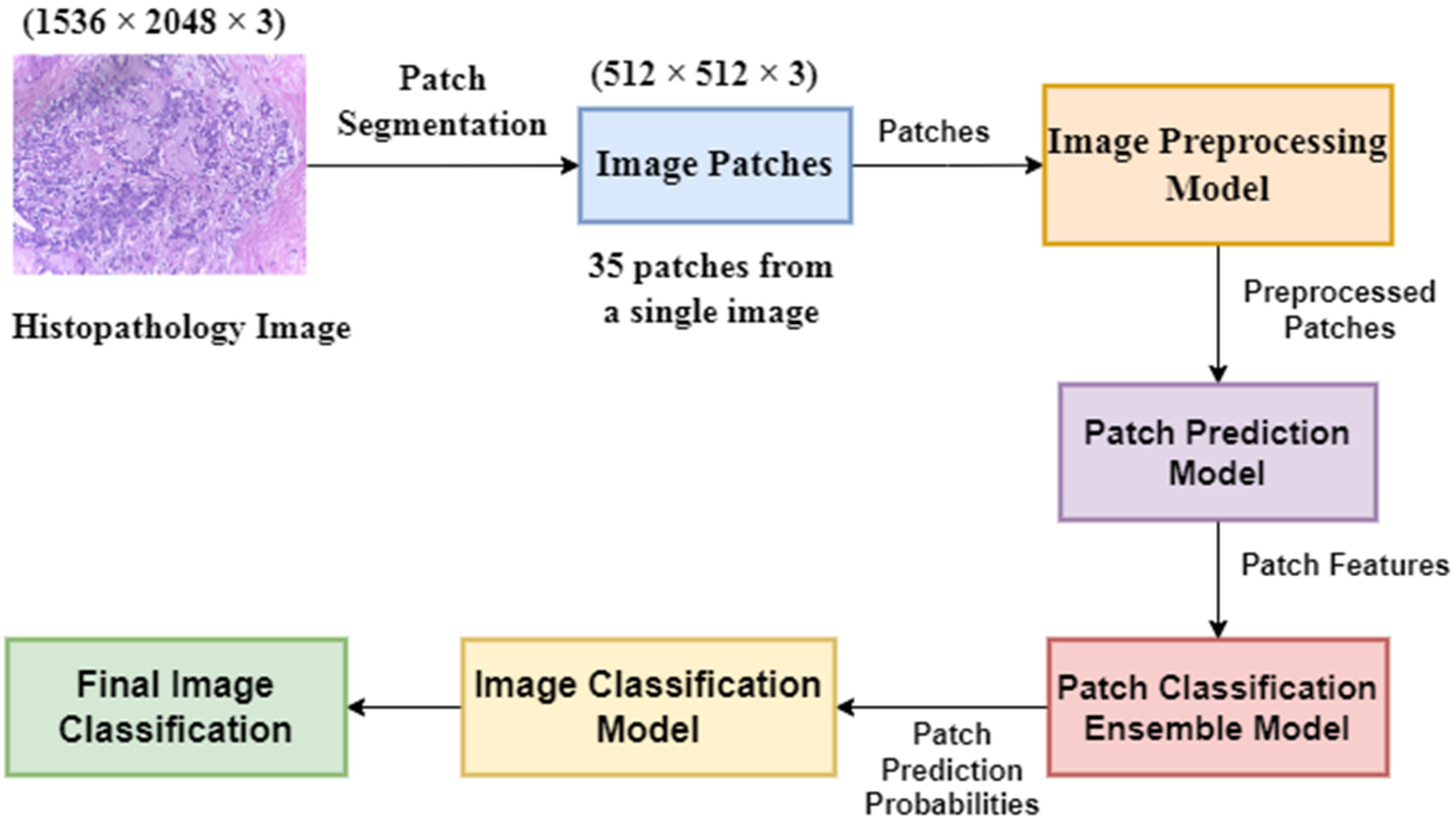
Many methods have been proposed to classify histology images for the ICIAR BACH 2018 dataset, which is an extension of the Bio-imaging 2015 dataset. In all these papers [12–16, 24–27], the high-resolution histology images (1536 × 2048) were pre-processed using different techniques and then segmented into patches. The patches were then passed through fine-tuned, pre-trained deep learning models such as VGG-19, Inception, Xception, and ResNet, and the patch-level results were obtained. After that, the patch-level results were used to obtain image-level results using different functions specific to each paper. Awan et al. [
36] fine-tuned the ResNet model for patch-wise classification. Then, the trained ResNet model was used to extract deep feature representations from the patches. After that, the flattened features of 2 × 2 overlapping blocks of patches were used to train an SVM classifier, followed by a majority voting scheme for image-wise classification. Rakhlin et al. [
37] proposed a transfer learning approach without fine-tuning based on extracting deep convolutional features from pre-trained networks. The authors used pre-trained CNNs to encode the patches to obtain sparse feature descriptors of low dimensionality, which were trained using a LightGBM classifier to classify the histopathology images.
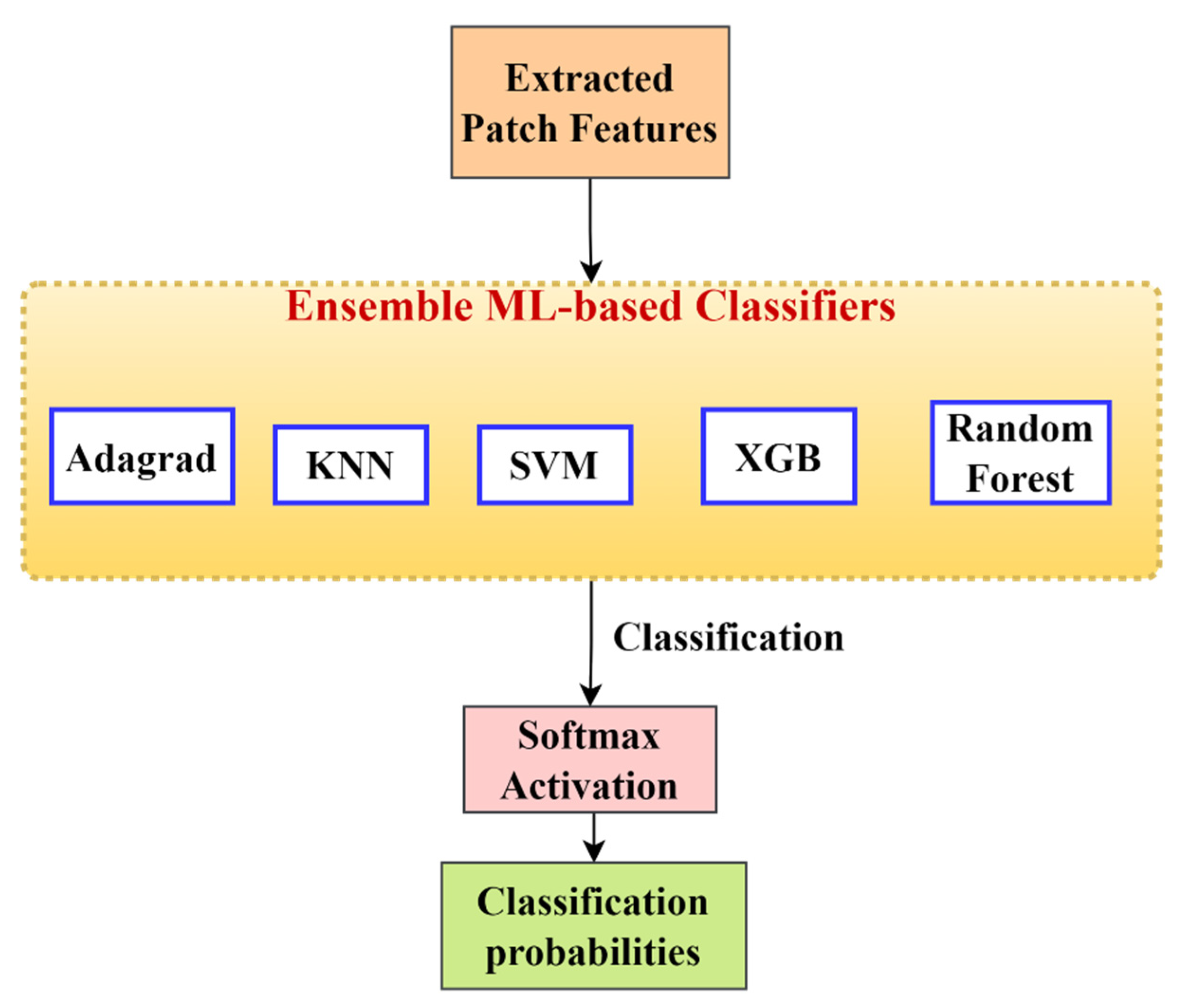
With the advent of DL models, researchers have started to use these techniques for histopathological breast image classification and have achieved state-of-the-art results. DL is a subcategory of machine learning but is more efficient than machine learning classifiers due to its ability to learn new functions, unlike them, where there is a predefined classifier function. In this study, we used deep CNN models and multiple classification algorithms to form an ensemble for histopathology image classification. The main problem with this sort of learning algorithm is that high-resolution images take a huge amount of time to learn. Moreover, such images are difficult to train because different parts of the image require different attention weights. Hence, a viable alternative is to use learning from patches of the whole image and then ensemble it for the final image prediction.
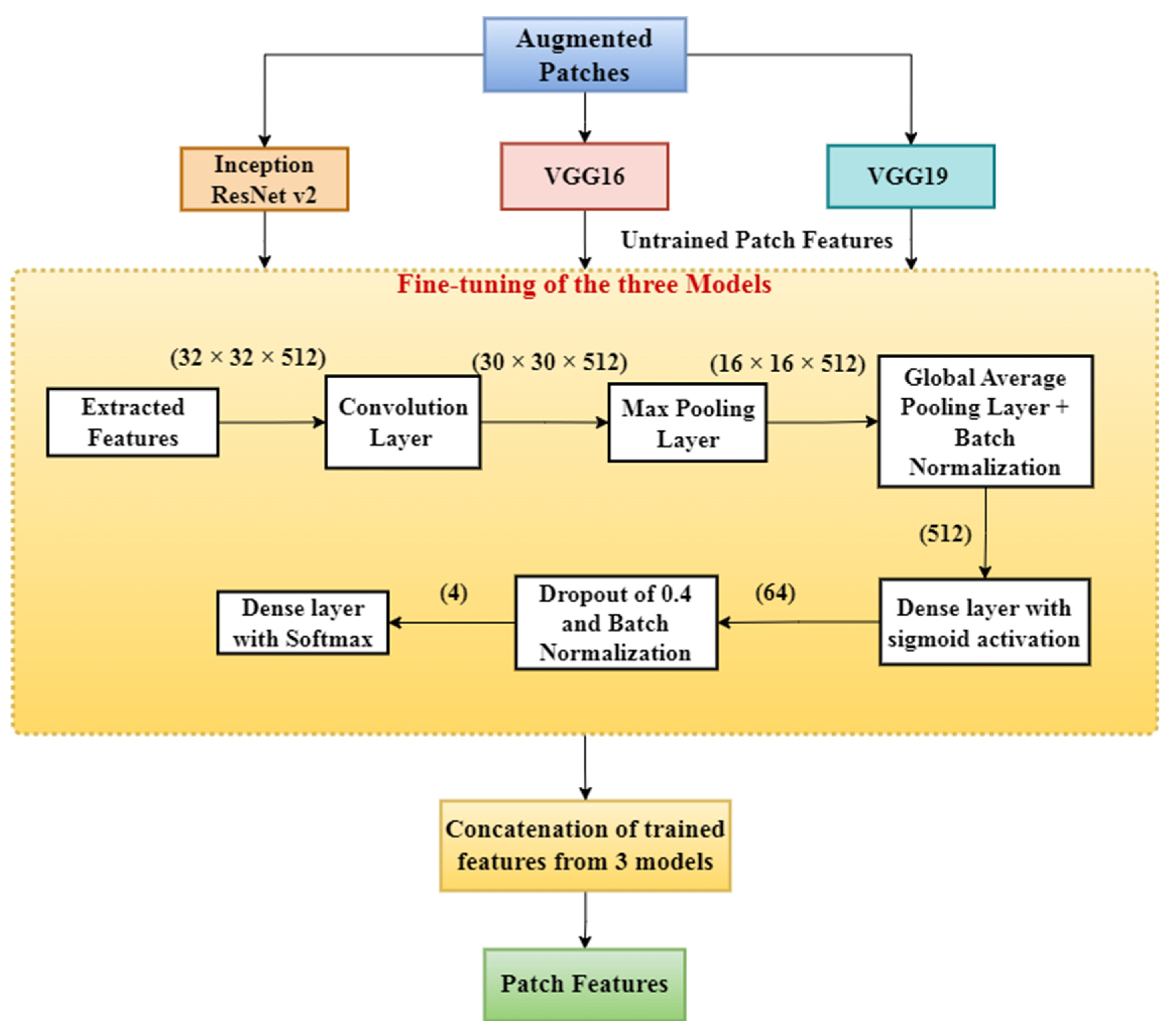
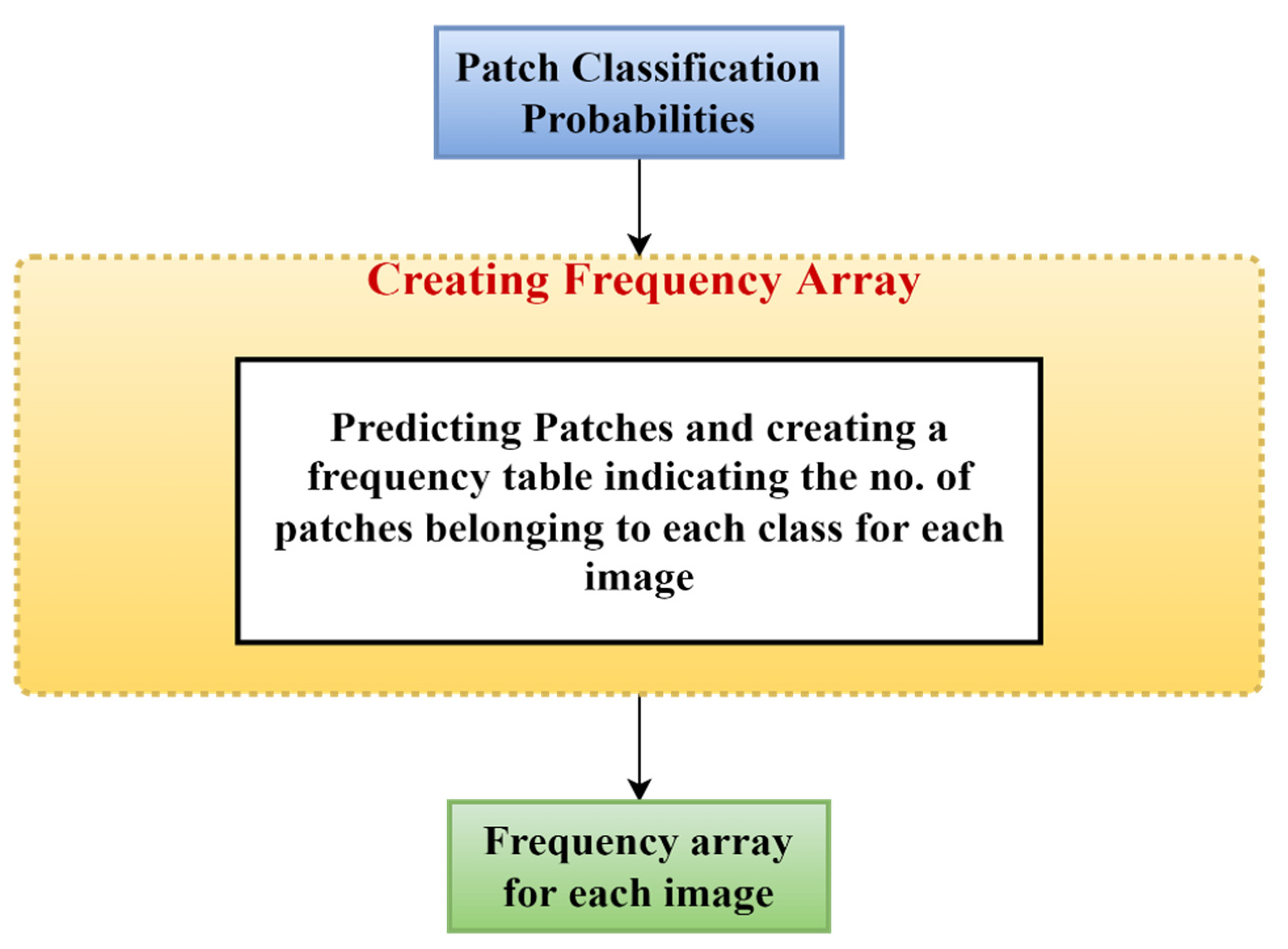
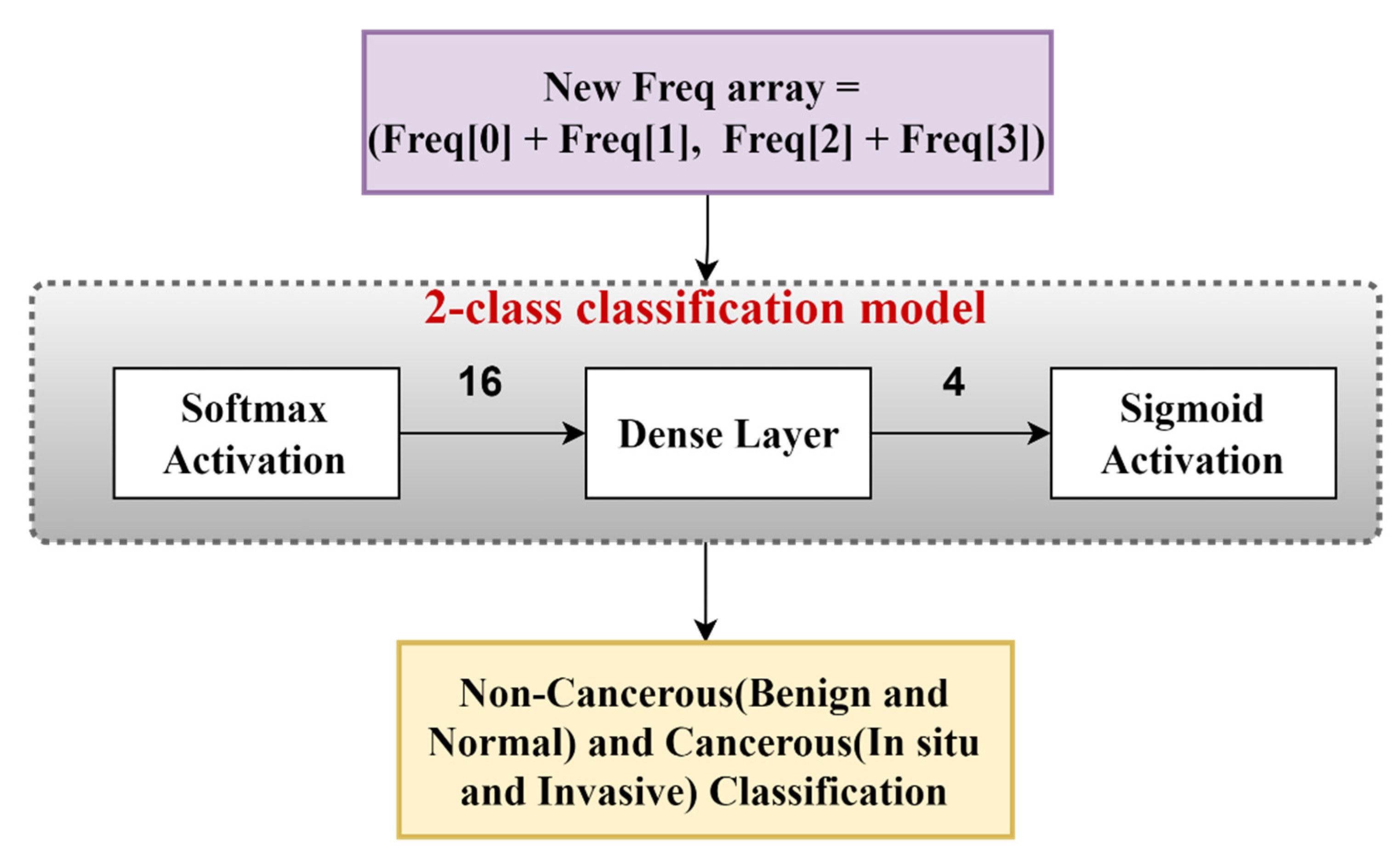
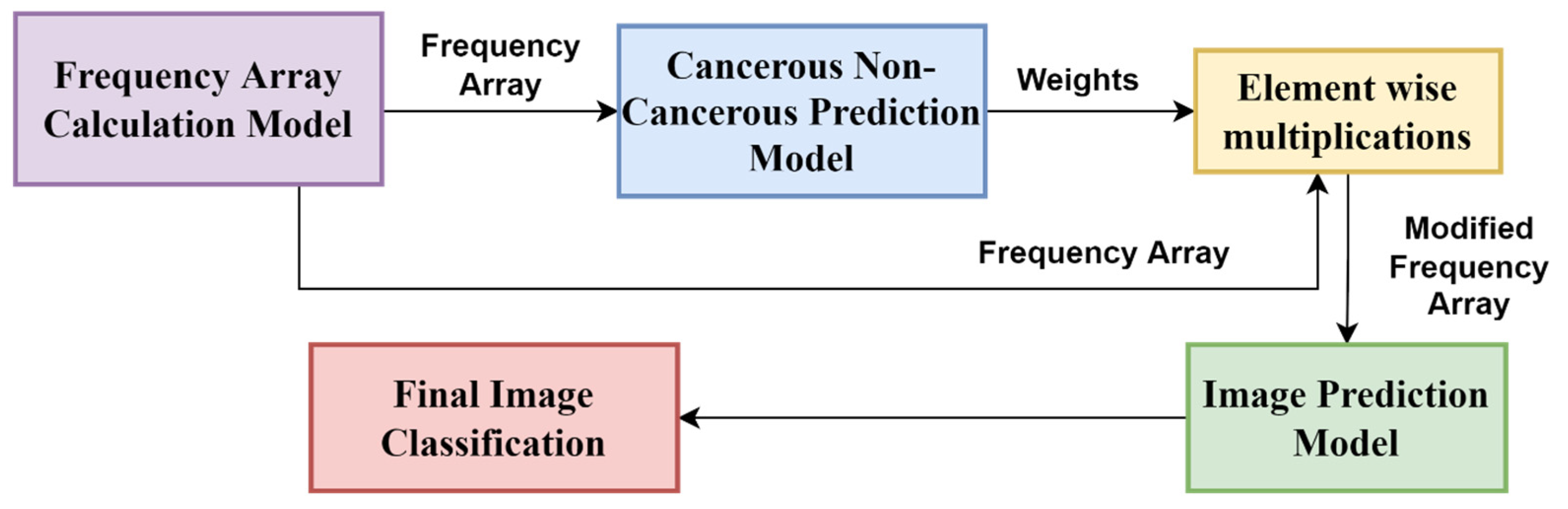
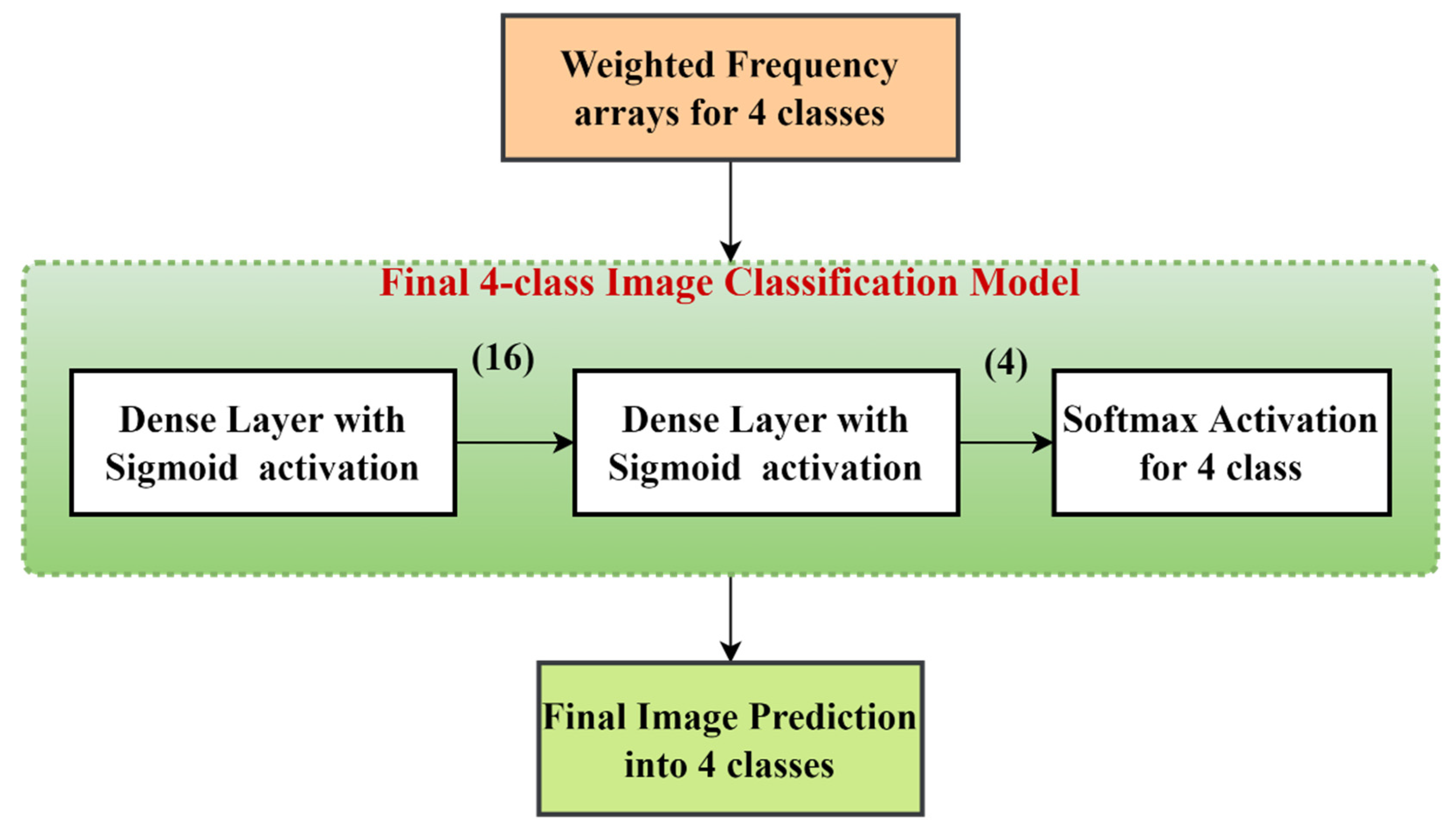
In the present work, we propose a DL-based method to classify high-resolution breast histology images into one of the four classes: normal, benign, in situ, and invasive. We consider the images and divide them into training, testing, and validation sets. Then, we perform patch-level classification. The issue here is that we do not know what the patch labels are. What we know are the image labels. Thus, at the beginning, we assign each patch the same label as that of its parent image and design a model that outputs the probability of how likely it is that that patch label will be the same as that of the parent image. After that, we extract the deep features using a DL model. Lastly, we classify the patch as either normal, benign, in situ, or invasive using different classifiers and ensemble them. The final step is to convert the patch-level classification into an image-level classification. We take each image and create an array containing the number of patches corresponding to the four classes predicted by the patch prediction model for that image. Then, we pass this frequency array through a two-stage model to obtain the final prediction of four classes.
The key points of this work are as follows:
We aimed to increase the image-level breast histopathology classification accuracy using a patch-level classification.
We designed an efficient patch-level training model that is computationally fast. We fine-tuned a pre-trained model (pre-trained on the ImageNet dataset) with convolution, max pooling, and dense layers at the end. We obtained the patch features from this model.
We introduce a two-stage model using a neural network to map the patch-level information to image-level prediction into two classes (cancerous and non-cancerous) and four classes (normal, benign, in situ, and invasive).
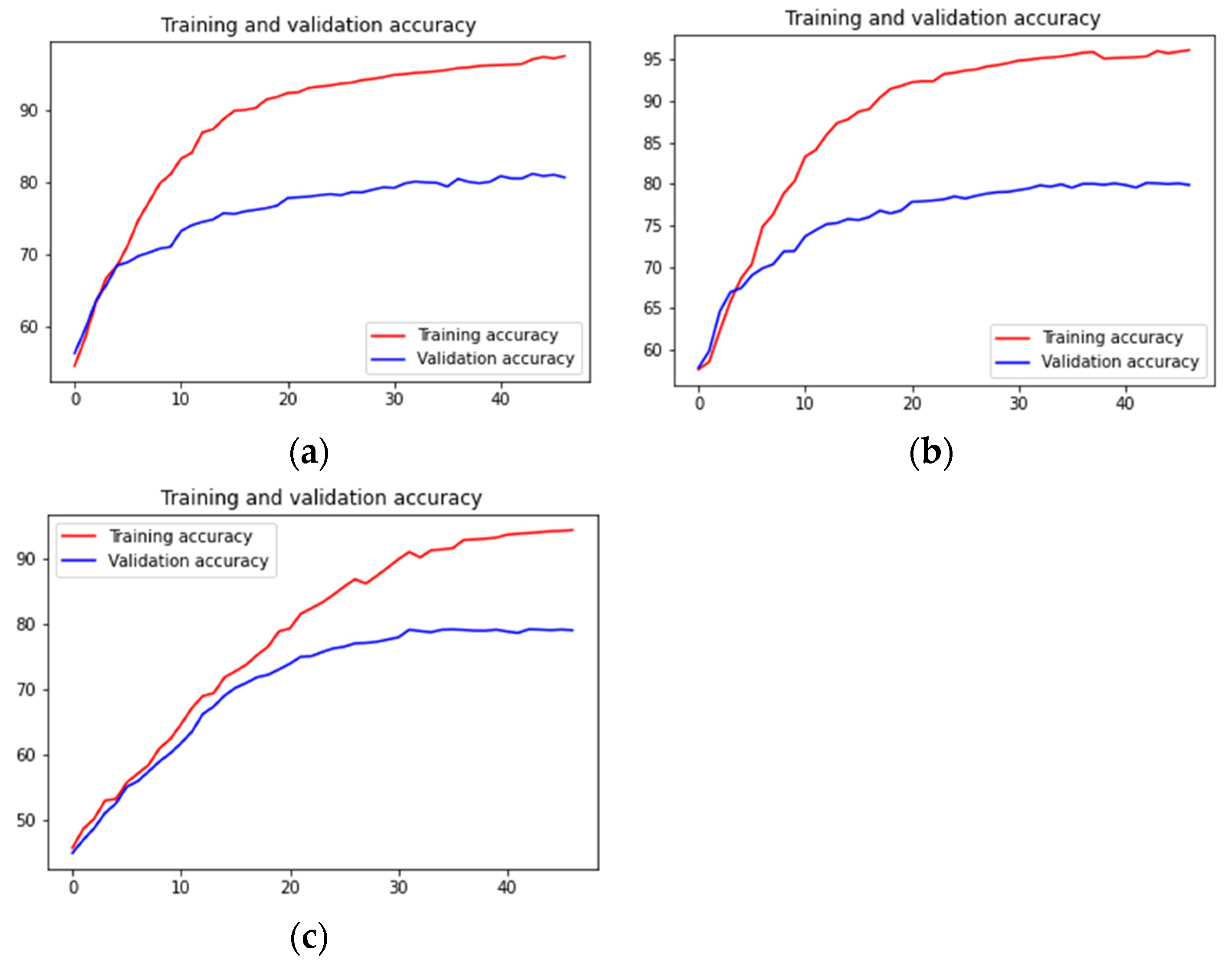
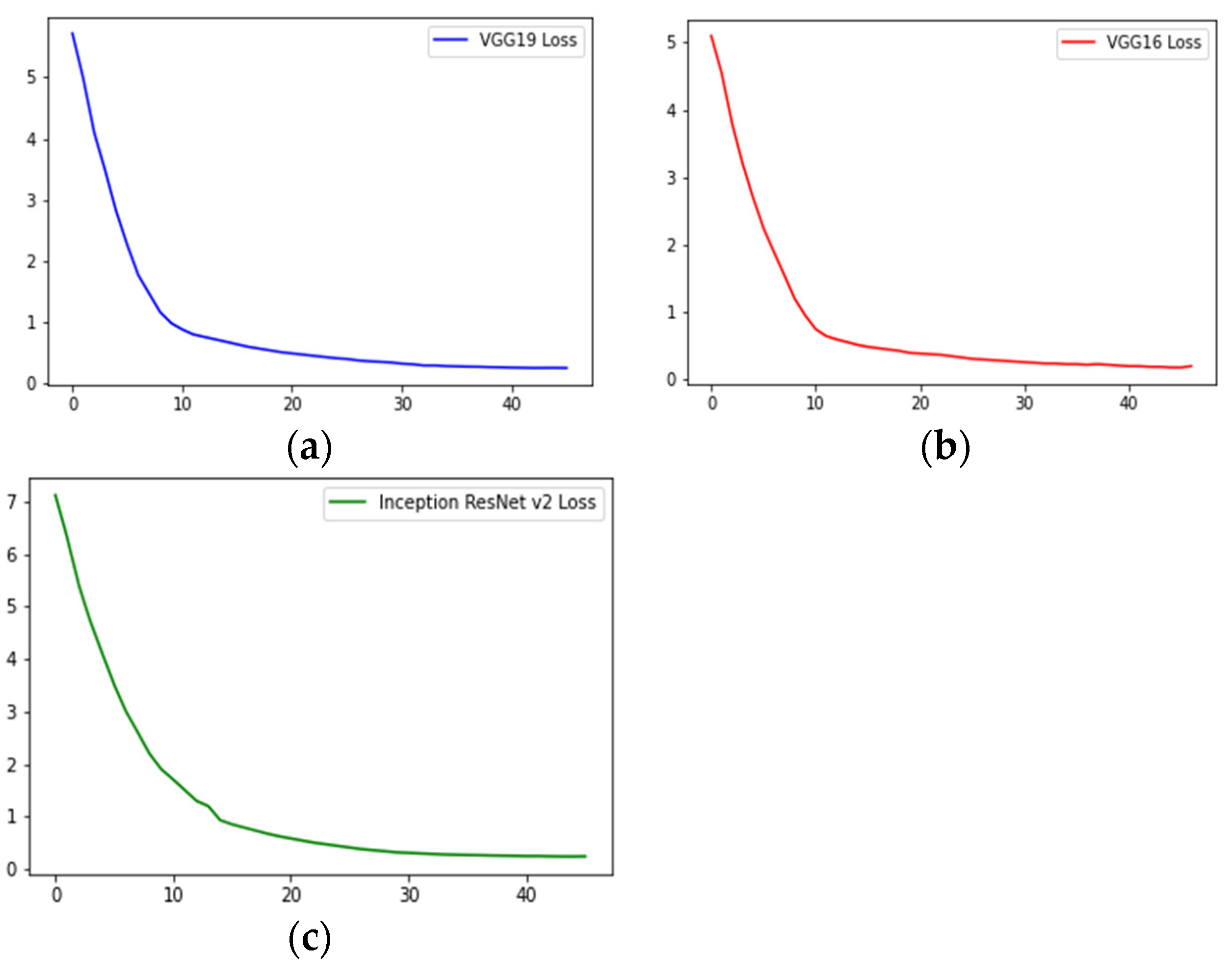
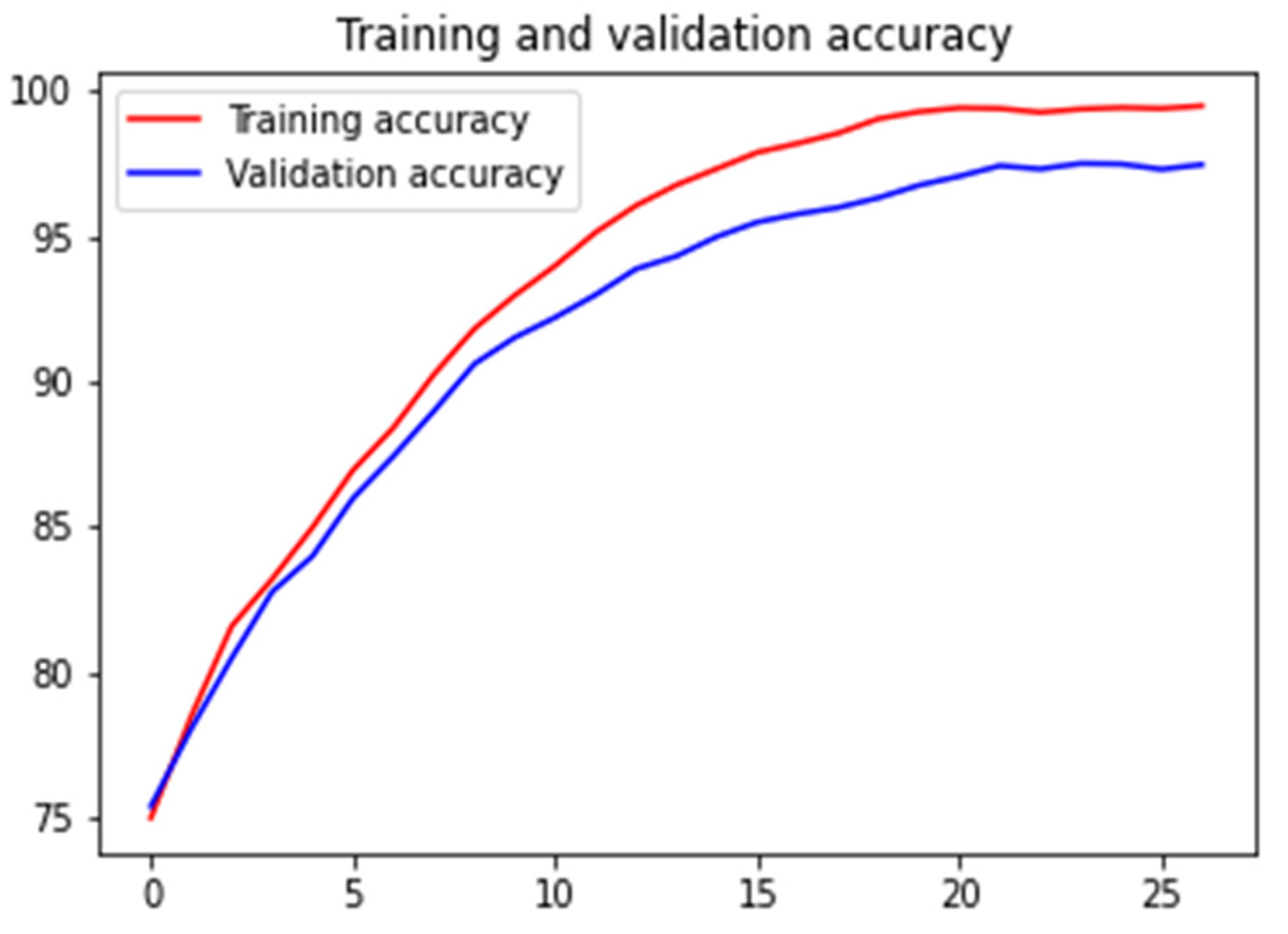
We evaluated our model on a publicly available BACH histopathological dataset and achieved state-of-the-art classification accuracy of 97.50% for four classes and 98.6% for two classes.
The remainder of the paper is structured as follows. The proposed method is described in
Section 2. The experimental results and analysis of the proposed method are presented in
Section 3, where the discussion of the results is also presented. Finally, we conclude our work and state the limitations and some future possibilities in
Section 4.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}