
Quantitative Prediction of SYNTAX Score for Cardiovascular Artery Disease Patients via the Inverse Problem Algorithm Technique as Artificial Intelligence Assessment in Diagnostics
 and
and
Abstract
:1. Introduction
2. Methodology
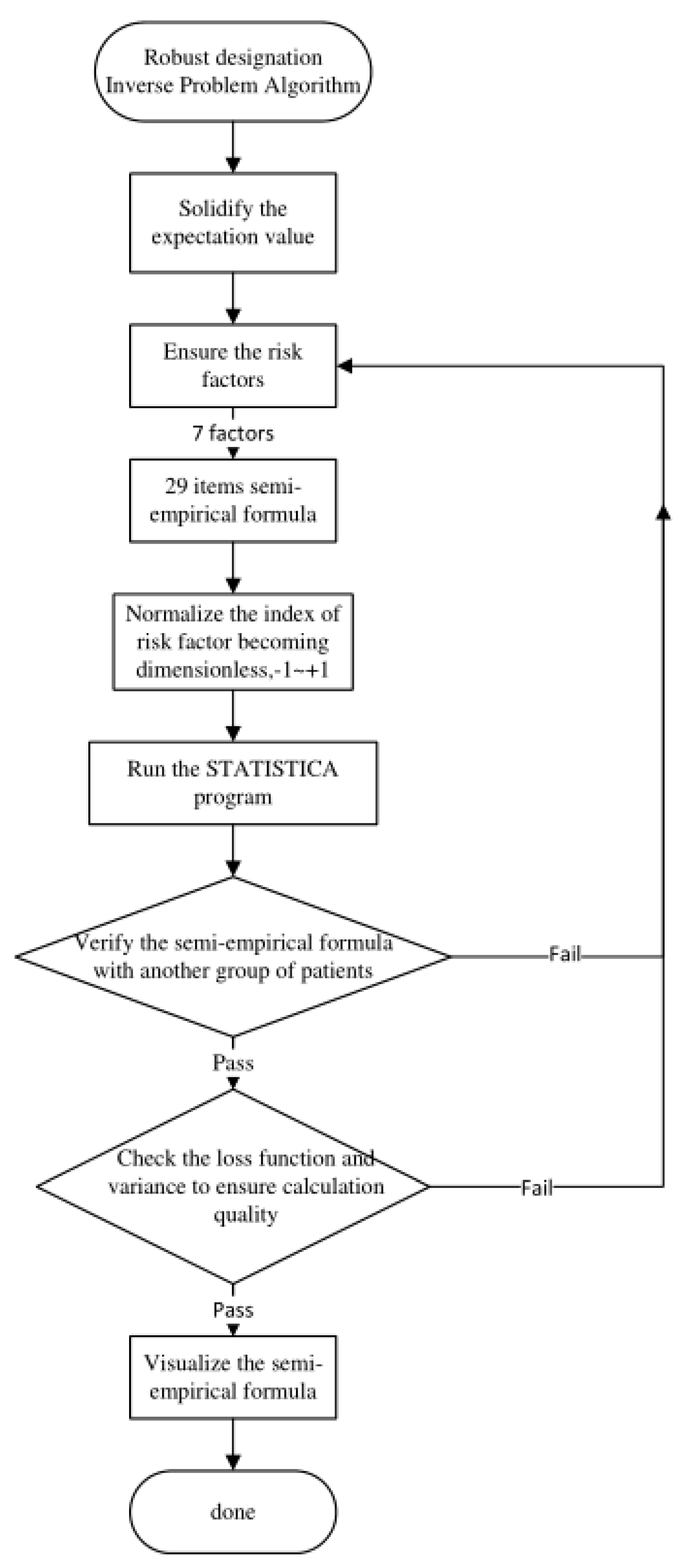
2.1. Basics of the Inverse Problem Algorithm
2.2. The IPA Flowchart
2.3. Semi-Empirical Formula Elaboration
2.4. SYNTAX Score and Seven Risk Factors
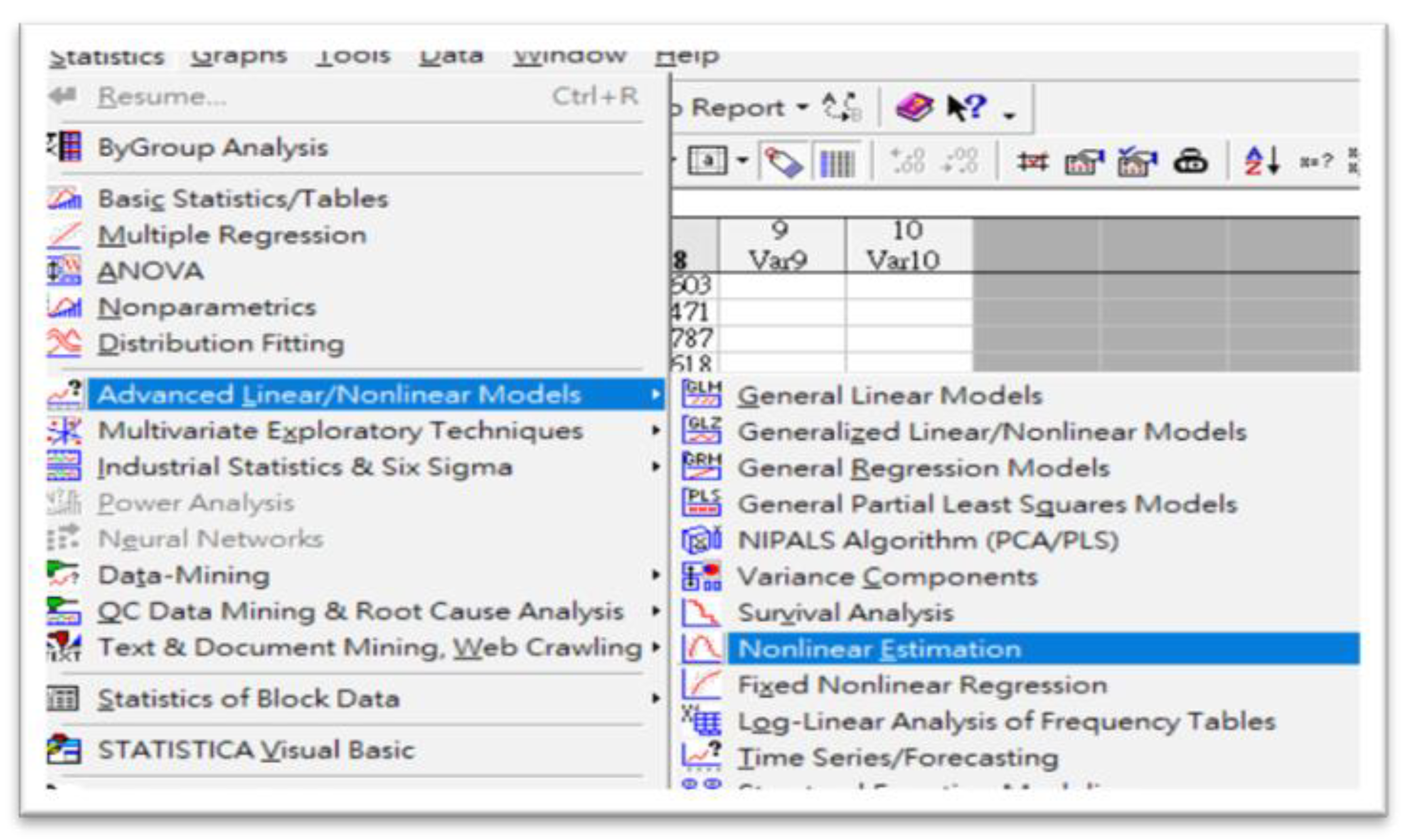
2.5. Running STATISTICA 7.0 Program
3. Results
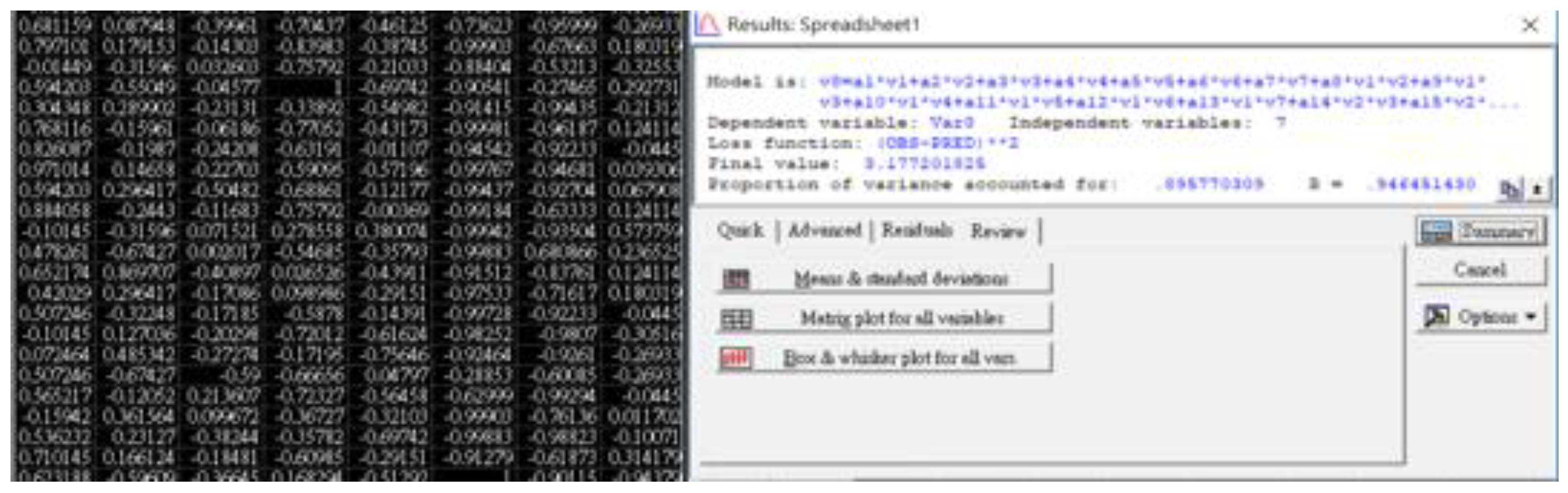
3.1. STATISTICA 7.0 Outcomes
3.2. Quantified Performance
4. Discussion
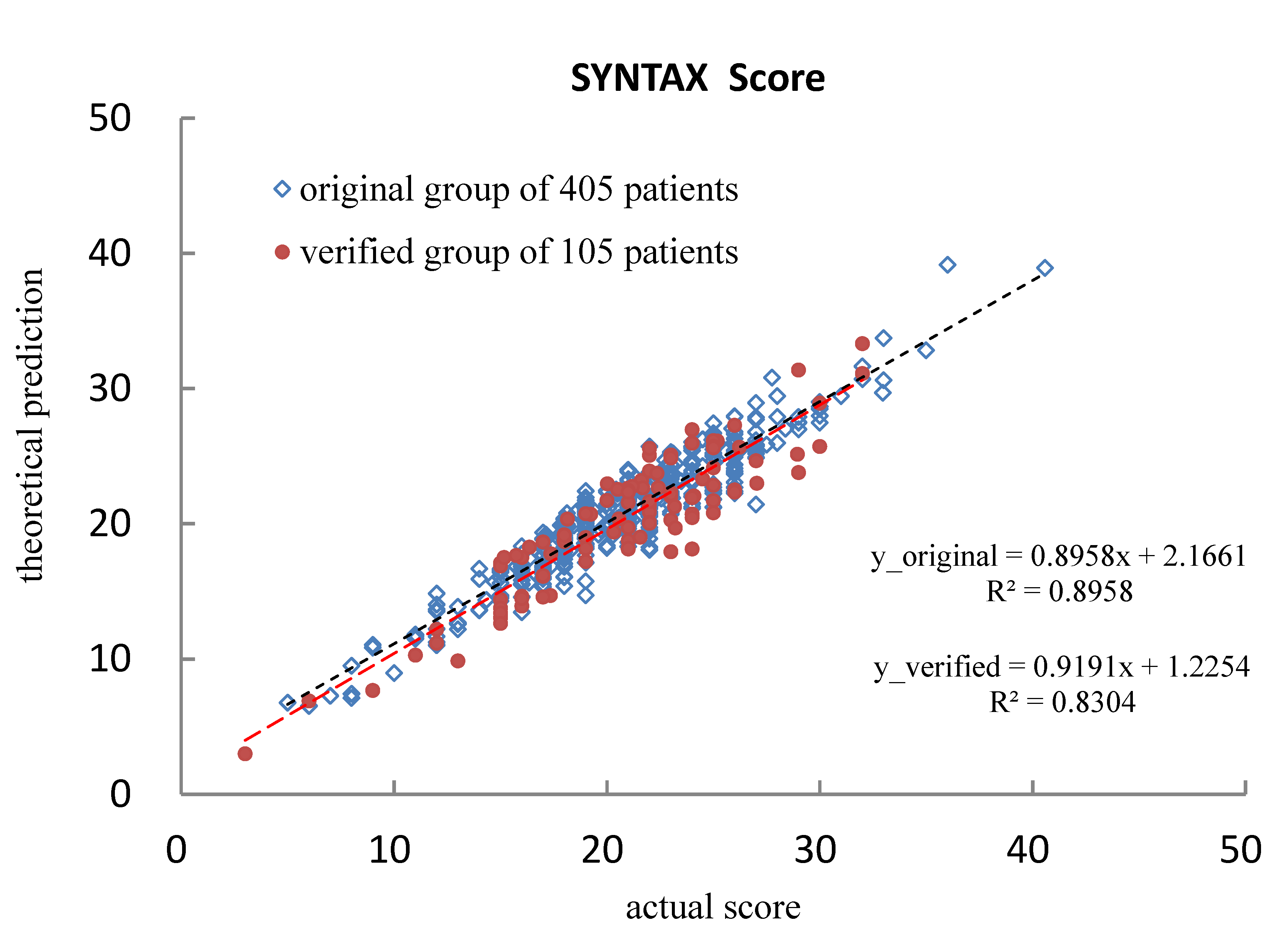
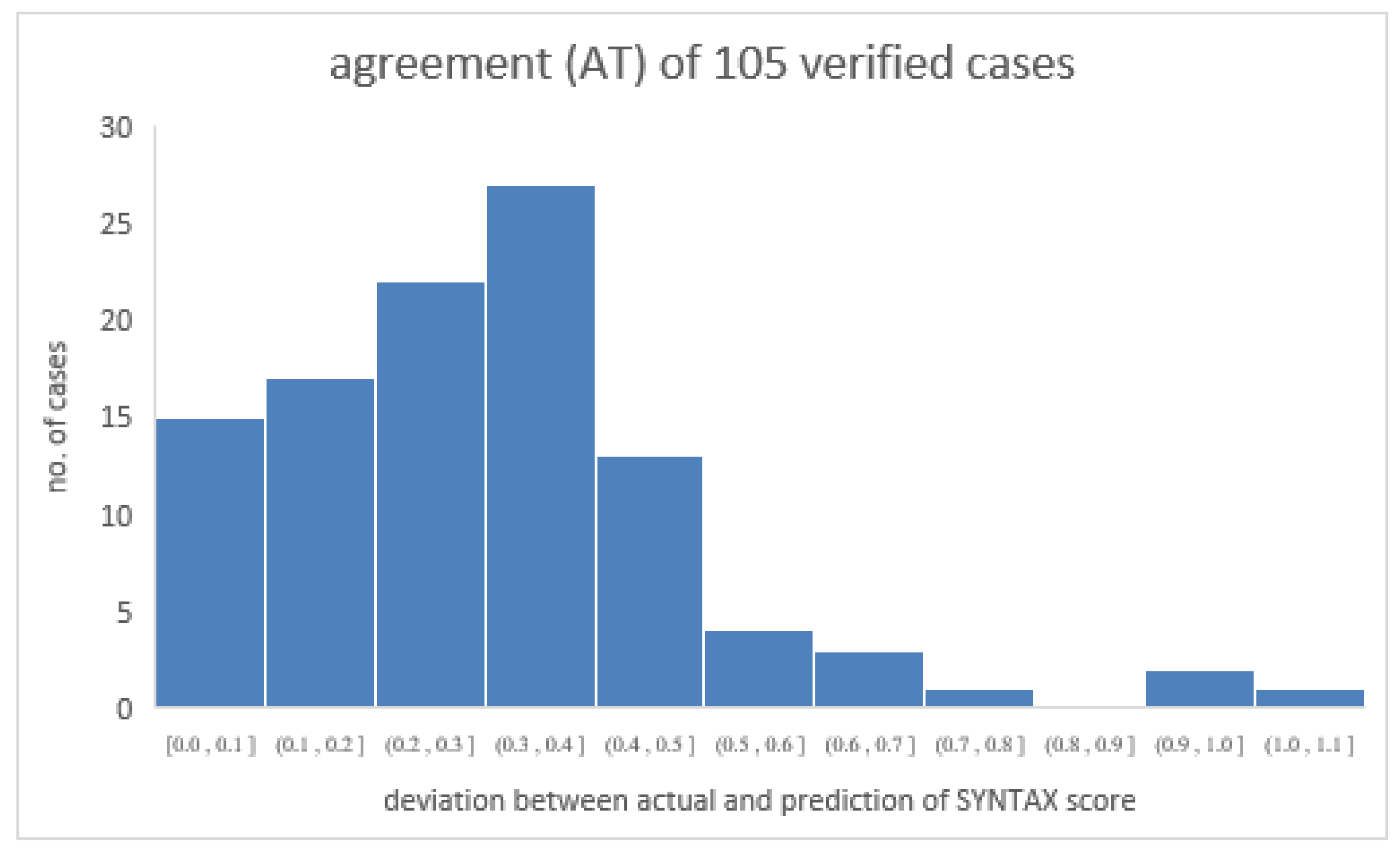
4.1. Verifying the Predicted SYNTAX Score
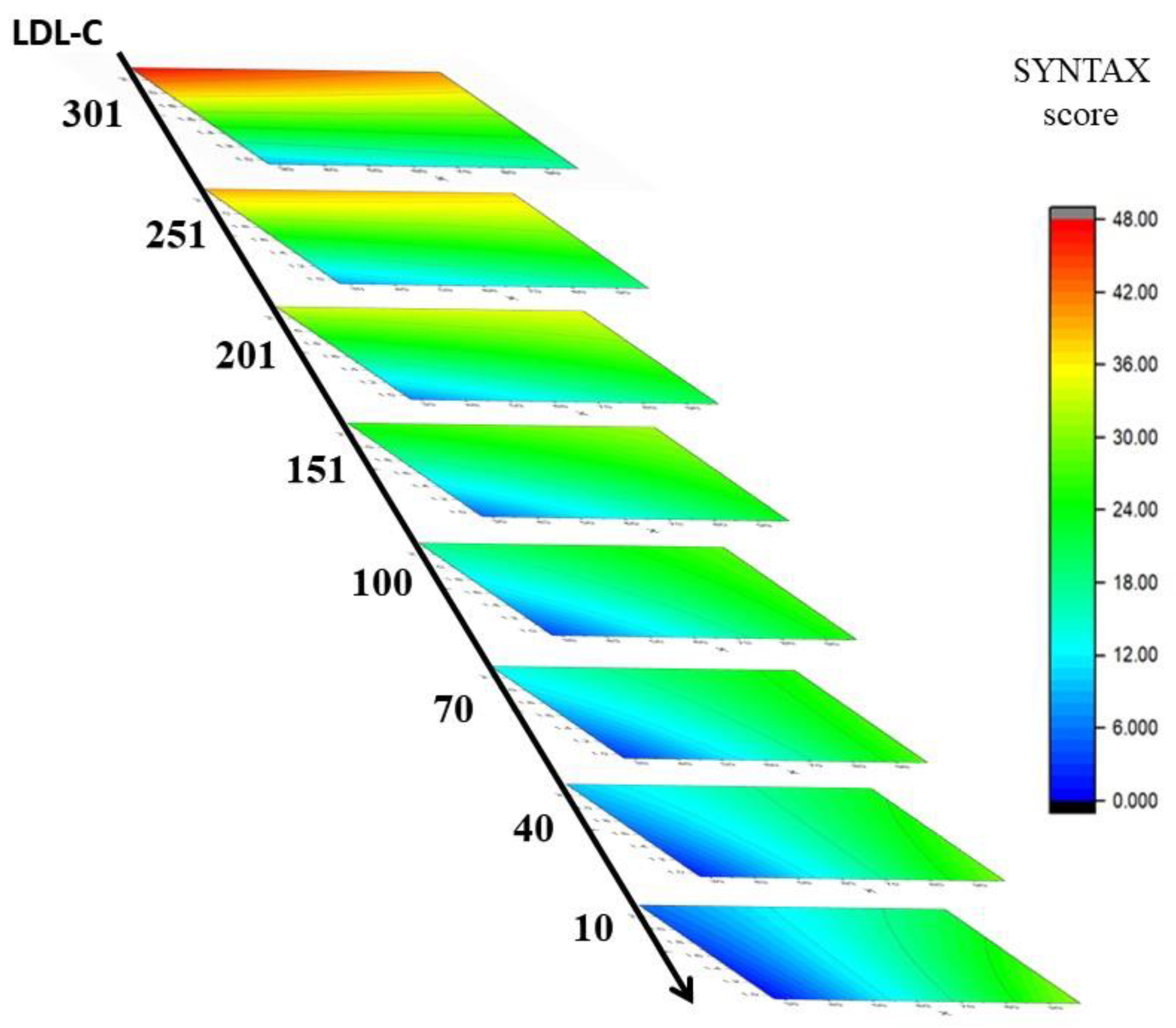
4.2. Dominant Factors of the SYNTAX Score Prediction
4.3. Reducing the Number of Risk Factors
4.4. Discussion of Similar Research Results Based on Various Risk Factors
4.5. IPA Technique in Artificial Intelligence Applications
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Alidoosti, M.; Shafiee, A.; Salarifar, M.; Poorhosseini, H.; Nematipour, E.; Safarian, H. The SYNTAX score can predict major adverse cardiac events following percutaneous coronary intervention. Hear. Views 2014, 15, 99–105. [Google Scholar] [CrossRef] [PubMed]
- Kastrati, A.; Schömig, A.; Elezi, S.; Dirschinger, J.; Mehilli, J.; Schühlen, H.; Blasini, R.; Neumann, F.-J. Prognostic Value of the Modified American College of Cardiology/American Heart Association Stenosis Morphology Classification for Long-Term Angiographic and Clinical Outcome After Coronary Stent Placement. Circulation 1999, 100, 1285–1290. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghebreyesus, T.A. Monitoring Health for the Sustainable Development Goals; Electronic Version; World Health Organization: Geneva, Switzerland, 2020; ISBN 978-92-4-000510-5. [Google Scholar]
- Chen, S.Z. Population Health and Welfare Quality Indicators Report 2017, 1st ed.; Ministry of Health and Welfare: Taiwan, China, 2019; ISBN 978-986-05-8656-5. [Google Scholar]
- Akboga, M.K.; Balci, K.G.; Maden, O.; Ertem, A.G.; Kirbas, O.; Yayla, C.; Acar, B.; Aras, D.; Kisacik, H.; Aydogdu, S. Usefulness of monocyte to HDL-cholesterol ratio to predict high SYNTAX score in patients with stable coronary artery disease. Biomark. Med. 2016, 10, 375–383. [Google Scholar] [CrossRef] [PubMed]
- Ikeda, N.; Saba, L.; Molinari, F.; Piga, M.; Meiburger, K.M.; Sugi, K.; Porcu, M.; Bocchiddi, L.; Acharya, U.R.; Nakamura, M.; et al. Automated carotid intima-media thickness and its link for prediction of SYNTAX score in Japanese coronary artery disease patients. Int. Angiol. 2013, 32, 339–348. [Google Scholar] [PubMed]
- Ikeda, N.; Kogame, N.; Iijima, R.; Nakamura, M.; Sugi, K. Carotid artery intima-media thickness and plaque score can predict the SYNTAX score. Eur. Heart J. 2011, 33, 113–119. [Google Scholar] [CrossRef] [PubMed]
- Ikeda, N.; Kogame, N.; Iijima, R.; Nakamura, M.; Sugi, K. Impact of Carotid Artery Ultrasound and Ankle-Brachial Index on Prediction of Severity of SYNTAX Score. Circ. J. 2013, 77, 712–716. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahmani, R.; Majidi, B.; Ariannejad, H.; Shafiee, A. The Value of the GRACE Score for Predicting the SYNTAX Score in Patients with Unstable Angina/Non-ST Elevation Myocardial Infarction. Cardiovasc. Revasc. Med. 2020, 21, 514–517. [Google Scholar] [CrossRef] [PubMed]
- Priess, M.C.; Conway, R.; Choi, J.; Popovich, J.M.; Radcliffe, C. Solutions to the Inverse LQR Problem With Application to Biological Systems Analysis. IEEE Trans. Control Syst. Technol. 2015, 23, 770–777. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- StatSoft. STATISTICA, Version 12; StatSoft: Tulsa, OK, USA, 2012; Available online: http://www.statsoft.com (accessed on 15 May 2013).
- Yeh, D.-M.; Chen, C.-Y.; Tang, J.-F.; Pan, L.-K. A quantitative evaluation of multiple biokinetic models using an assembled water phantom: A feasibility study. PLoS ONE 2017, 12, e0189244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, C.-C.; Lin, Y.-H.; Kittipayak, S.; Hwua, Y.-S.; Wang, S.-Y.; Pan, L.-K. Biokinetic model of radioiodine I-131 in nine thyroid cancer patients subjected to in-vivo gamma camera scanning: A simplified five-compartmental model. PLoS ONE 2020, 15, e0232480. [Google Scholar] [CrossRef] [PubMed]
- Pan, L.-F.; Chiang, C.-Y.; Huang, C.-C.; Kao, H.-T.; Chen, C.-F.; Peng, B.-R.; Pan, L.-K. Thyroid Biokinetics for Radioactive I-131 in Twelve Thyroid Cancer Patients via the Refined Nine-Compartmental Model. Appl. Sci. 2022, 12, 5538. [Google Scholar] [CrossRef]
- Peng, B.-R.; Pan, L.-F.; Huang, S.-H.; Chen, C.-Y.; Lin, C.-S.; Chiang, F.-T. Practical application of TAGUCHI optimization methodology to medical facilities: An integrated study. J. Mech. Med. Biol. 2022, 22, 2240025. [Google Scholar] [CrossRef]
- Kurtul, A.; Murat, S.N.; Yarlioglues, M.; Duran, M.; Ocek, A.H.; Koseoglu, C.; Celık, I.E.; Kilic, A.; Aksoy, O. Usefulness of Serum Albumin Concentration to Predict High Coronary SYNTAX Score and In-Hospital Mortality in Patients With Acute Coronary Syndrome. Angiology 2015, 67, 34–40. [Google Scholar] [CrossRef] [PubMed]
- Sebastianski, M.; Narasimhan, S.; Graham, M.M.; Toleva, O.; Shavadia, J.; Abualnaja, S.; Tsuyuki, R.T.; McMurtry, M.S. Usefulness of the Ankle-Brachial Index to Predict High Coronary SYNTAX Scores, Myocardium at Risk, and Incomplete Coronary Revascularization. Am. J. Cardiol. 2014, 114, 1745–1749. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Moussa, M.; Wassef, A.W.; Hiebert, B.M.; Hussain, F.; Jassal, D.S. The Utility of Systolic and Diastolic Echocardiographic Parameters for Predicting Coronary Artery Disease Burden as Defined by the SYNTAX Score. Echocardiography 2016, 33, 14–22. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.-H.; Chiu, S.-W.; Lin, Y.-C.; Lin, C.-C.; Pan, L.-K. Inverse problem algorithm application to semi-quantitative analysis of 272 patients with ischemic stroke symptoms: Carotid stenosis risk assessment for five risk factors. J. Mech. Med. Biol. 2020, 20, 2040021. [Google Scholar] [CrossRef]
- Liang, C.-C.; Pan, L.-F.; Chen, M.-H.; Deng, J.; Yang, D.-H.; Lin, C.-S. Timing Optimization of head and neck ct angiography via the inverse problem algorithm: In vivo survey for 1001 patients in 2020–2021. J. Mech. Med. Biol. 2021, 21, 2140055. [Google Scholar] [CrossRef]








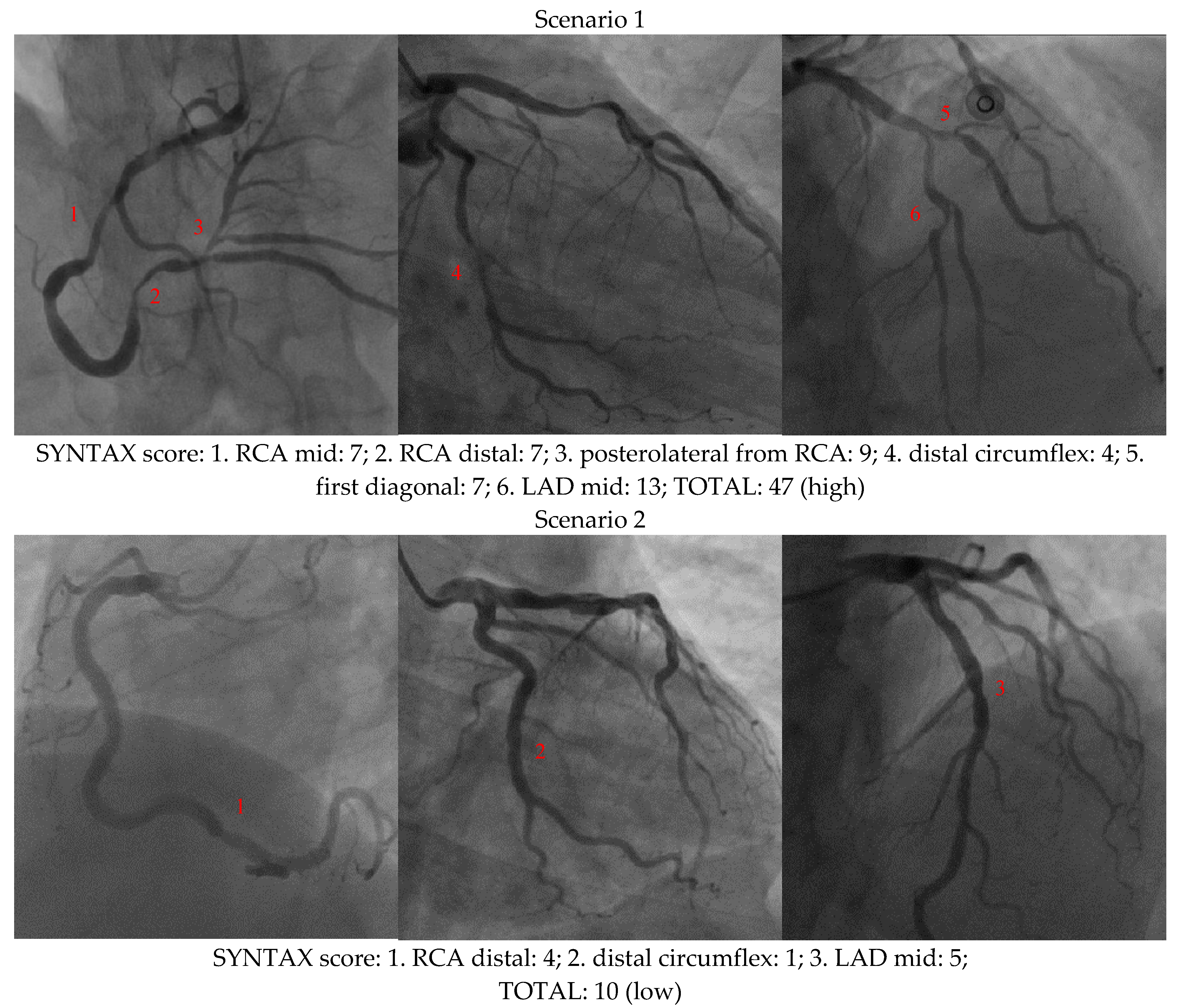{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Range | Derived Data | |||
|---|---|---|---|---|---|
| Case No./Max. | Case No./Min. | Mean | Median | St. Dev | |
| Age (yr) | 75/98 | 71/29 | 70 | 71 | 14.1 |
| MAP (mmHg) | 386/153 | 276/50 | 101 | 101 | 18 |
| BSA (m2) | 264/2.40 | 63/1.09 | 1.70 | 1.70 | 0.20 |
| Glucose AC (mg/dL) | 15/689 | 272/54 | 156.6 | 126.5 | 87.4 |
| LDL-C (mg/dL) | 125/283 | 92/12 | 100.4 | 98.0 | 39.5 |
| cTnI (ng/mL) | 224/102.98 | 265/0.01 | 5.09 | 0.22 | 16.67 |
| CRP (mg/dL) | 193/42.50 | 368/0.01 | 5.51 | 2.47 | 7.19 |
| SYNTAX score | 191/41 | 267/5 | 20.8 | 21.0 | 4.9 |
| Factor | Range after Normalized | Derived Data after Normalized | |||
|---|---|---|---|---|---|
| Case No./Max. | Case No./Min. | Mean | Median | St. Dev | |
| Age (yr) | 75/+1 | 71/−1 | 0.17 | 0.22 | 0.41 |
| MAP (mmHg) | 386/+1 | 276/−1 | 0.00 | 0.00 | 0.36 |
| BSA (m2) | 264/+1 | 63/−1 | 0.07 | 0.07 | 0.31 |
| Glucose AC (mg/dL) | 15/+1 | 272/−1 | 0.68 | 0.77 | 0.28 |
| LDL-C (mg/dL) | 125/+1 | 92/−1 | 0.35 | 0.37 | 0.29 |
| cTnI (ng/mL) | 224/+1 | 265/−1 | 0.90 | 1.00 | 0.32 |
| CRP (mg/dL) | 193/+1 | 368/−1 | 0.74 | 0.88 | 0.34 |
| SYNTAX score | 191/+1 | 267/−1 | 0.11 | 0.10 | 1.00 |
| Biological Index | Factor | Coefficient | After Normalization | |
|---|---|---|---|---|
| Value | Rank | |||
| Age | A | a1 | 0.912696 | 3 |
| MAP | B | a2 | 0.618889 | 8 |
| BSA | C | a3 | 0.831829 | 5 |
| Glucose AC | D | a4 | 0.825880 | 6 |
| LDL-C | E | a5 | 1.175788 | 2 |
| cTnI | F | a6 | 0.202330 | 20 |
| CRP | G | a7 | −0.103741 | 27 |
| Age × MAP | A × B | a8 | 0.183358 | 21 |
| Age × BSA | A × C | a9 | −0.169841 | 22 |
| Age × Glucose AC | A × D | a10 | −0.304887 | 16 |
| Age × LDL-C | A × E | a11 | −0.295175 | 17 |
| Age × cTnI | A × F | a12 | −0.145316 | 24 |
| Age × CRP | A × G | a13 | 1.252458 | 1 |
| MAP × BSA | B × C | a14 | −0.219970 | 18 |
| MAP × Glucose AC | B × D | a15 | 0.376565 | 13 |
| MAP × LDL-C | B × E | a16 | 0.757553 | 7 |
| MAP × cTnI | B × F | a17 | −0.135202 | 25 |
| MAP × CRP | B × G | a18 | 0.398636 | 11 |
| BSA × Glucose AC | C × D | a19 | 0.532427 | 9 |
| BSA × LDL-C | C × E | a20 | 0.401664 | 10 |
| BSA × cTnI | C × F | a21 | 0.124982 | 26 |
| BSA × CRP | C × G | a22 | 0.021501 | 29 |
| Glucose AC × LDL-C | D × E | a23 | 0.338031 | 15 |
| Glucose AC × cTnI | D × F | a24 | 0.155761 | 23 |
| Glucose AC × CRP | D × G | a25 | 0.202936 | 19 |
| LDL-C × cTnI | E × F | a26 | 0.873143 | 4 |
| LDL-C × CRP | E × G | a27 | −0.347644 | 14 |
| cTnI × CRP | F × G | a28 | 0.067604 | 28 |
| Constant | a29 | 0.378574 | 12 | |
| Factor | Range | Derived Data | |||
|---|---|---|---|---|---|
| Case No./Max. | Case No./Min. | Mean | Median | St. Dev | |
| Age (yr) | 88/88 | 6/34 | 66 | 69 | 12.0 |
| MAP (mmHg) | 7/148 | 6/60 | 100 | 99 | 17.0 |
| BSA (m2) | 89/4.47 | 39/1.30 | 1.76 | 1.71 | 0.32 |
| Glucose AC (mg/dL) | 74/385 | 85/66 | 127.2 | 109.6 | 54.9 |
| LDL-C (mg/dL) | 84/187 | 95/45 | 104.9 | 99.9 | 41.5 |
| cTnI (ng/mL) | 74/102.98 | 1/0.01 | 3.69 | 0.09 | 14.74 |
| CRP (mg/dL) | 63/35.72 | 82/0.03 | 6.69 | 2.68 | 7.81 |
| SYNTAX score | 87/32 | 7/3 | 20.8 | 21.6 | 5.0 |
| Number of Factors | Number of Terms in the Regression Equation | Loss Function, Φ | Variance of Regression, s2 | Linear Regression y = Ax + B | Correlation Coefficient, r2 |
|---|---|---|---|---|---|
| 7 | 29 | 3.1772 | 0.8958 | 0.8958x + 2.1661 | 0.8958 |
| 6 | 22 | 9.6870 | 0.6822 | 0.6822x + 6.6042 | 0.6822 |
| 5 | 16 | 11.6247 | 0.6186 | 0.6185x + 7.9252 | 0.6186 |
| 4 | 11 | 16.1963 | 0.4687 | 0.4687x + 11.041 | 0.4687 |
| 3 | 7 | 20.1177 | 0.3400 | 0.3400x + 13.715 | 0.3400 |
| 2 | 4 | 21.5750 | 0.2922 | 0.2922x + 14.709 | 0.2922 |
| 1 | 2 | 28.5206 | 0.6437 | 0.0644x + 19.444 | 0.0644 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, M.-C.; Tseng, V.S.; Lin, C.-S.; Chiu, S.-W.; Pan, L.-K.; Pan, L.-F. Quantitative Prediction of SYNTAX Score for Cardiovascular Artery Disease Patients via the Inverse Problem Algorithm Technique as Artificial Intelligence Assessment in Diagnostics. Diagnostics 2022, 12, 3180. https://doi.org/10.3390/diagnostics12123180
Lin M-C, Tseng VS, Lin C-S, Chiu S-W, Pan L-K, Pan L-F. Quantitative Prediction of SYNTAX Score for Cardiovascular Artery Disease Patients via the Inverse Problem Algorithm Technique as Artificial Intelligence Assessment in Diagnostics. Diagnostics. 2022; 12(12):3180. https://doi.org/10.3390/diagnostics12123180
Chicago/Turabian StyleLin, Meng-Chiung, Vincent S. Tseng, Chih-Sheng Lin, Shao-Wen Chiu, Lung-Kwang Pan, and Lung-Fa Pan. 2022. "Quantitative Prediction of SYNTAX Score for Cardiovascular Artery Disease Patients via the Inverse Problem Algorithm Technique as Artificial Intelligence Assessment in Diagnostics" Diagnostics 12, no. 12: 3180. https://doi.org/10.3390/diagnostics12123180