
Development and Verification of a Deep Learning Algorithm to Evaluate Small-Bowel Preparation Quality


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Design
2.2. Materials
2.3. Training and Testing
2.3.1. Pre-Processing of Input Data
2.3.2. Repetition of Training and Testing
2.4. Validation Set
2.5. Methodology
3. Results
3.1. Performance Evaluation
3.2. External Validation and Cut-Off Value
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Iddan, G.; Meron, G.; Glukhovsky, A.; Swain, P. Wireless capsule endoscopy. Nat. Cell Biol. 2000, 405, 417. [Google Scholar] [CrossRef] [PubMed]
- Ragu, G.S.; Gerson, L.; Das, A.; Lewis, B. American Gastroenterological Association. American Gastroenterological Associa-tion (AGA) Institute medical position statement on obscure gastrointestinal bleeding. Gastroenterology 2007, 133, 1694–1696. [Google Scholar]
- Spada, C.; McNamara, D.; Despott, E.J.; Adler, S.; Cash, B.D.; Fernández-Urién, I.; Ivekovic, H.; Keuchel, M.; McAlindon, M.; Saurin, J.-C.; et al. Performance measures for small-bowel endoscopy: A European Society of Gastrointestinal Endoscopy (ESGE) Quality Improvement Initiative. Endoscopy 2019, 51, 574–598. [Google Scholar] [CrossRef] [Green Version]
- Amornyotin, S. Sedation-related complications in gastrointestinal endoscopy. World J. Gastrointest. Endosc. 2013, 5, 527–533. [Google Scholar] [CrossRef]
- Muguruma, N.; Tanaka, K.; Teramae, S.; Takayama, T. Colon capsule endoscopy: Toward the future. Clin. J. Gastroenterol. 2017, 10, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Spada, C.; Hassan, C.; Costamagna, G. Magnetically controlled capsule endoscopy for the evaluation of the stomach. Are we ready for this? Dig. Liver Dis. 2018, 50, 1047–1048. [Google Scholar] [CrossRef]
- Brotz, C.; Nandi, N.; Conn, M.; Daskalakis, C.; DiMarino, M.; Infantolino, A.; Katz, L.C.; Schroeder, T.; Kastenberg, D. A validation study of 3 grading systems to evaluate small-bowel cleansing for wireless capsule endoscopy: A quantitative index, a qualitative evaluation, and an overall adequacy assessment. Gastrointest. Endosc. 2009, 69, 262–270.e1. [Google Scholar] [CrossRef]
- Gkolfakis, P.; Tziatzios, G.; Dimitriadis, G.D.; Triantafyllou, K. Meta-analysis of randomized controlled trials challenging the usefulness of purgative preparation before small-bowel video capsule endoscopy. Endoscopy 2018, 50, 671–683. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goyal, J.; Goel, A.; McGwin, G.; Weber, F. Analysis of a grading system to assess the quality of small-bowel preparation for capsule endoscopy: In search of the Holy Grail. Endosc. Int. Open 2014, 2, E183–E186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, S.C.; Keum, B.; Hyun, J.J.; Seo, Y.S.; Kim, Y.S.; Jeen, Y.T.; Chun, H.J.; Um, S.H.; Kim, C.D.; Ryu, H.S. A novel cleansing score system for capsule endoscopy. World J. Gastroenterol. 2010, 16, 875–880. [Google Scholar] [CrossRef]
- Van Weyenberg, S.J.B.; De Leest, H.T.J.I.; Mulder, C.J.J. Description of a novel grading system to assess the quality of bowel preparation in video capsule endoscopy. Endoscopy 2011, 43, 406–411. [Google Scholar] [CrossRef] [Green Version]
- Ponte, A.; Pinho, R.; Rodrigues, A.; Silva, J.; Rodrigues, J.; Carvalho, J. Validation of the computed assessment of cleansing score with the Mirocam® system. Rev. Esp. Enferm. Dig. 2016, 108, 709–715. [Google Scholar] [CrossRef]
- Nam, J.H.; Hwang, Y.; Oh, D.J.; Park, J.; Kim, K.B.; Jung, M.K.; Lim, Y.J. Development of a deep learning-based software for calculating cleansing score in small bowel capsule endoscopy. Sci. Rep. 2021, 11, 4417. [Google Scholar] [CrossRef] [PubMed]
- Esaki, M.; Matsumoto, T.; Kudo, T.; Yanaru-Fujisawa, R.; Nakamura, S.; Iida, M. Bowel preparations for capsule endoscopy: A comparison between simethicone and magnesium citrate. Gastrointest. Endosc. 2009, 69, 94–101. [Google Scholar] [CrossRef]
- Pogorelov, K.; Randel, K.R.; de Lange, T.; Eskeland, S.L.; Griwodz, C.; Johansen, D.; Spampinato, C.; Taschwer, M.; Lux, M.; Schmidt, P.T.; et al. Nerthus: A bowel preparation quality video dataset. In Proceedings of the 8th ACM on Multimedia Systems Conference, Taipei, Taiwan, 20–23 June 2017; pp. 170–174. [Google Scholar]
- Zhou, J.; Wu, L.; Wan, X.; Shen, L.; Liu, J.; Zhang, J.; Jiang, X.; Wang, Z.; Yu, S.; Kang, J.; et al. A novel artificial intelligence system for the assessment of bowel preparation (with video). Gastrointest. Endosc. 2020, 91, 428–435.e2. [Google Scholar] [CrossRef] [PubMed]
- Ching, H.-L.; Hale, M.F.; Sidhu, R.; Beg, S.; Ragunath, K.; McAlindon, M.E. Magnetically assisted capsule endoscopy in suspected acute upper GI bleeding versus esophagogastroduodenoscopy in detecting focal lesions. Gastrointest. Endosc. 2019, 90, 430–439. [Google Scholar] [CrossRef] [PubMed]
- Nam, S.-J.; Lim, Y.J.; Nam, J.H.; Lee, H.S.; Hwang, Y.; Park, J.; Chun, H.J. 3D reconstruction of small bowel lesions using stereo camera-based capsule endoscopy. Sci. Rep. 2020, 10, 6025. [Google Scholar] [CrossRef] [PubMed]
- Almalioglu, Y.; Ozyoruk, K.B.; Gokce, A.; Incetan, K.; Gokceler, G.I.; Simsek, M.A.; Ararat, K.; Chen, R.J.; Durr, N.J.; Mahmood, F.; et al. EndoL2H: Deep Super-Resolution for Capsule Endoscopy. IEEE Trans. Med. Imaging 2020, 39, 4297–4309. [Google Scholar] [CrossRef]
- Park, J.; Hwang, Y.; Yoon, J.-H.; Park, M.-G.; Kim, J.; Lim, Y.J.; Chun, H.J. Recent Development of Computer Vision Technology to Improve Capsule Endoscopy. Clin. Endosc. 2019, 52, 328–333. [Google Scholar] [CrossRef]
- Aoki, T.; Yamada, A.; Aoyama, K.; Saito, H.; Fujisawa, G.; Odawara, N.; Kondo, R.; Tsuboi, A.; Ishibashi, R.; Nakada, A.; et al. Clinical usefulness of a deep learning-based system as the first screening on small-bowel capsule endoscopy reading. Dig. Endosc. 2020, 32, 585–591. [Google Scholar] [CrossRef]
- Tsuboi, A.; Oka, S.; Aoyama, K.; Saito, H.; Aoki, T.; Yamada, A.; Matsuda, T.; Fujishiro, M.; Ishihara, S.; Nakahori, M.; et al. Artificial intelligence using a convolutional neural network for automatic detection of small-bowel angioectasia in capsule endoscopy images. Dig. Endosc. 2020, 32, 382–390. [Google Scholar] [CrossRef]
- Ding, Z.; Shi, H.; Zhang, H.; Meng, L.; Fan, M.; Han, C.; Zhang, K.; Ming, F.; Xie, X.; Liu, H.; et al. Gastroenterologist-Level Identification of Small-Bowel Diseases and Normal Variants by Capsule Endoscopy Using a Deep-Learning Model. Gastroenterology 2019, 157, 1044–1054.e5. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Hwang, Y.; Nam, J.H.; Oh, D.J.; Kim, K.B.; Song, H.J.; Kim, S.H.; Kang, S.H.; Jung, M.K.; Lim, Y.J. Artificial intelligence that determines the clinical significance of capsule endoscopy images can increase the efficiency of reading. PLoS ONE 2020, 15, e0241474. [Google Scholar] [CrossRef] [PubMed]
- Al-shebani, Q.; Premaratne, P.; McAndrew, D.J.; Vial, P.J.; Abey, S. A frame reduction system based on a color structural sim-ilarity (CSS) method and Bayer images analysis for capsule endoscopy. AI Med. 2019, 94, 18–27. [Google Scholar]
- Kim, S.H.; Lim, Y.J.; Park, J.; Shim, K.-N.; Yang, D.-H.; Chun, J.; Kim, J.S.; Lee, H.S.; Chun, H.J.; Research Group for Capsule Endoscopy/Small Bowel Endoscopy. Changes in performance of small bowel capsule endoscopy based on nationwide data from a Korean Capsule Endoscopy Registry. Korean J. Intern. Med. 2020, 35, 889–896. [Google Scholar] [CrossRef] [PubMed]
- Ponte, A.; Pinho, R.; Rodrigues, A.; Silva, J.; Rodrigues, J.; Sousa, M.; Carvalho, J. Predictive factors of an incomplete examination and inadequate small-bowel cleanliness during capsule endoscopy. Rev. Esp. Enferm. Dig. 2018, 110, 605–611. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
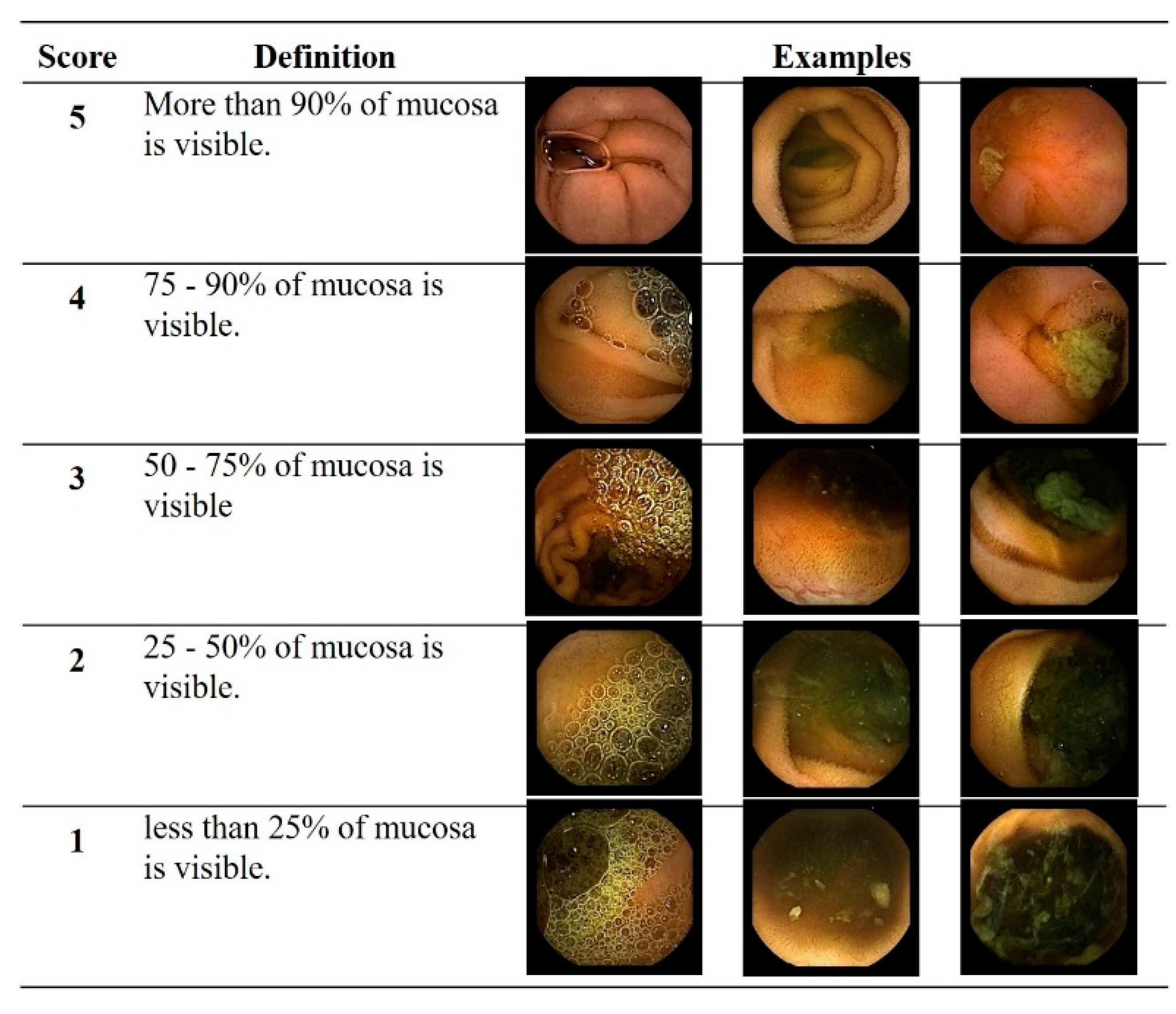{kind=link}
{kind=link}
{kind=link}
| Segmental Grading (Mucosal Invisibility of Each Segment) | |
|---|---|
| Grade 1 | <5% of video images exhibiting >50% invisible mucosa due to air bubbles, bile, or debris |
| Grade 2 | 5–15% |
| Grade 3 | 15–25% |
| Grade 4 | >25% |
| Overall grading (overall cleansing quality) | |
| Grade A | Total grades 3–5 |
| Grade B | 6–8 |
| Grade C | 9–12 |
| Clinically adequate preparation | |
| Adequate | Grade A or B |
| Inadequate | Grade C |
| 51,380 Frames, n (%) | Mean Score | |||||
|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S4 | S5 | ||
| Deep learning | 3227 (6.3) | 17,876 (34.8) | 16,264 (31.7) | 9354 (18.2) | 4659 (9.1) | 2.9 |
| Clinicians | 3761 (7.3) | 16,696 (32.5) | 14,723 (28.7) | 4603 (9.0) | 11,597 (22.6) | 3.1 |
| Overall Grading | n (%) | Score, Mean ± SD | 95% CI | p Value * |
|---|---|---|---|---|
| A | 11 (22.0) | 2.9 ± 0.3 | 3.6–4.1 | <0.001 |
| B | 20 (40.0) | 3.2 ± 0.5 | 3.0–3.4 | <0.001 |
| C | 19 (38.0) | 2.5 ± 0.5 | 2.2–2.7 | Ref. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nam, J.H.; Oh, D.J.; Lee, S.; Song, H.J.; Lim, Y.J. Development and Verification of a Deep Learning Algorithm to Evaluate Small-Bowel Preparation Quality. Diagnostics 2021, 11, 1127. https://doi.org/10.3390/diagnostics11061127
Nam JH, Oh DJ, Lee S, Song HJ, Lim YJ. Development and Verification of a Deep Learning Algorithm to Evaluate Small-Bowel Preparation Quality. Diagnostics. 2021; 11(6):1127. https://doi.org/10.3390/diagnostics11061127
Chicago/Turabian StyleNam, Ji Hyung, Dong Jun Oh, Sumin Lee, Hyun Joo Song, and Yun Jeong Lim. 2021. "Development and Verification of a Deep Learning Algorithm to Evaluate Small-Bowel Preparation Quality" Diagnostics 11, no. 6: 1127. https://doi.org/10.3390/diagnostics11061127