
Robustness of Deep Learning Algorithm to Varying Imaging Conditions in Detecting Low Contrast Objects in Computed Tomography Phantom Images: In Comparison to 12 Radiologists

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. CT Phantom and Protocol for Training Set
2.2. CT Phantom and Protocol for Testing Set
2.3. Performance of the DLA in the Testing Set
2.4. Performance of Radiologists in the Testing Set
2.5. Performance Using Classic Computer Vision Approach–Template Matching
2.6. Statistical Analysis
3. Results
3.1. Primary Analysis
3.2. Secondary Analysis by Object Size
3.3. Post-Hoc Analysis
3.4. Template Matching Method
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADMIRE | Advanced modeled iterative reconstruction |
| CNN | convolutional neural network |
| DL | Deep learning |
| DLA | Deep learning-based algorithm |
| FBP | Filtered back projection |
| GUI | Graphical user interface |
| MRMC | Multi-reader multi-case |
References
- McDonald, R.J.; Schwartz, K.M.; Eckel, L.J.; Diehn, F.E.; Hunt, C.H.; Bartholmai, B.J.; Erickson, B.J.; Kallmes, D.F. The effects of changes in utilization and technological advancements of cross-sectional imaging on radiologist workload. Acad. Radiol. 2015, 22, 1191–1198. [Google Scholar] [CrossRef] [PubMed]
- Chetlen, A.L.; Chan, T.L.; Ballard, D.H.; Frigini, L.A.; Hildebrand, A.; Kim, S.; Brian, J.M.; Krupinski, E.A.; Ganeshan, D. Addressing burnout in radiologists. Acad. Radiol. 2019, 26, 526–533. [Google Scholar] [CrossRef] [PubMed]
- Dreyer, K.J.; Geis, J.R. When machines think: Radiology’s next frontier. Radiology 2017, 285, 713–718. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soffer, S.; Ben-Cohen, A.; Shimon, O.; Amitai, M.M.; Greenspan, H.; Klang, E. Convolutional neural networks for radiologic images: A radiologist’s guide. Radiology 2019, 290, 590–606. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Causey, J.L.; Zhang, J.; Ma, S.; Jiang, B.; Qualls, J.A.; Politte, D.G.; Prior, F.; Zhang, S.; Huang, X. Highly accurate model for prediction of lung nodule malignancy with CT scans. Sci. Rep. 2018, 8, 9286. [Google Scholar] [CrossRef] [PubMed]
- Vorontsov, E.; Cerny, M.; Régnier, P.; Jorio, L.D.; Pal, C.J.; Lapointe, R.; Vandenbroucke-Menu, F.; Turcotte, S.; Kadoury, S.; Tang, A. Deep learning for automated segmentation of liver lesions at CT in patients with colorectal cancer liver metastases. Radiol. Artific. Intell. 2019, 1, 180014. [Google Scholar] [CrossRef]
- Ozdemir, O.; Russell, R.L.; Berlin, A.A. A 3D probabilistic deep learning system for detection and diagnosis of lung cancer using low-dose CT scans. IEEE Trans. Med. Imag. 2020, 39, 1419–1429. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, K.; Li, Q.; Ma, J.; Zhou, Z.; Sun, M.; Deng, Y.; Tu, W.; Wang, Y.; Fan, L.; Xia, C.; et al. Evaluating a fully automated pulmonary nodule detection approach and its impact on radiologist performance. Radiol. Artific. Intell. 2019, 1, e180084. [Google Scholar] [CrossRef]
- Mileto, A.; Guimaraes, L.S.; McCollough, C.H.; Fletcher, J.G.; Yu, L. State of the art in abdominal CT: The limits of iterative reconstruction algorithms. Radiology 2019, 293, 491–503. [Google Scholar] [CrossRef] [PubMed]
- Fletcher, J.G.; Fidler, J.L.; Venkatesh, S.K.; Hough, D.M.; Takahashi, N.; Yu, L.; Johnson, M.; Leng, S.; Holmes, D.R., 3rd; Carter, R.; et al. Observer performance with varying radiation dose and reconstruction methods for detection of hepatic metastases. Radiology 2018, 289, 455–464. [Google Scholar] [CrossRef] [PubMed]
- Solomon, J.; Mileto, A.; Ramirez-Giraldo, J.C.; Samei, E. Diagnostic performance of an advanced modeled iterative reconstruction algorithm for low-contrast detectability with a third-generation dual-source multidetector CT scanner: Potential for radiation dose reduction in a multireader study. Radiology 2015, 275, 735–745. [Google Scholar] [CrossRef] [PubMed]
- Saiprasad, G.; Filliben, J.; Peskin, A.; Siegel, E.; Chen, J.; Trimble, C.; Yang, Z.; Christianson, O.; Samei, E.; Krupinski, E.; et al. Evaluation of low-contrast detectability of iterative reconstruction across multiple institutions, CT scanner manufacturers, and radiation exposure levels. Radiology 2015, 277, 124–133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mileto, A.; Zamora, D.A.; Alessio, A.M.; Pereira, C.; Liu, J.; Bhargava, P.; Carnell, J.; Cowan, S.M.; Dighe, M.K.; Gunn, M.L.; et al. CT detectability of small low-contrast hypoattenuating focal lesions: Iterative reconstructions versus filtered back projection. Radiology 2018, 289, 443–454. [Google Scholar] [CrossRef] [PubMed]
- Youngjune, K.; Dong Yul, O.; Won, C.; Eunhee, K.; Jong Chul, Y.; Kyeorye, L.; Hae Young, K.; Young Hoon, K.; Ji Hoon, P.; Yoon Jin, L.; et al. Deep learning-based denoising algorithm in comparison to iterative reconstruction and filtered back projection: A 12-reader phantom study. Eur. Radiol. 2021. to be published. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Rensink, R.A. Change detection. Ann. Rev. Psychol. 2002, 53, 245–277. [Google Scholar] [CrossRef] [PubMed]
- Ro, T.; Russell, C.; Lavie, N. Changing faces: A detection advantage in the flicker paradigm. Psychol. Sci. 2001, 12, 94–99. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.; Lee, H.; Kim, K.J.; Seo, J.; Park, S.; Shin, Y.G.; Kim, S.H.; Lee, K.H. Comparison of three image comparison methods for the visual assessment of the image fidelity of compressed computed tomography images. Med. Phys. 2011, 38, 836–844. [Google Scholar] [CrossRef] [PubMed]
- Hanley, J.A.; McNeil, B.J. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 1983, 148, 839–843. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Q.; Li, Q.-C.; Cao, R.-T.; Wang, X.; Chen, R.-T.; Liu, K.; Fan, L.; Xiao, Y.; Zhang, Z.-T.; Fu, C.-C.; et al. Detectability of pulmonary nodules by deep learning: Results from a phantom study. Chin. J. Acad. Radiol. 2019, 2, 1–12. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Data |
|---|---|
| Reference Tube Current-Time Product of Training set | 200 |
| Reference Tube Current-Time Product of Testing set | 200, 100, 50, 26 |
| Tube potential (kVp) | 100 |
| Collimation (mm) | 128 × 0.6 |
| Section thickness (mm) | 4 |
| Rotation time (s) | 0.5 |
| Pitch (mm) | 0.6 |
| Scan field of view (cm) | 60 |
| Display field of view (cm) | 50 |
| Reconstruction in Training set | FBP |
| Reconstruction in Testing set | Both ADMIRE-3, FBP |
| Kernel for FBP | I40f, B40f |
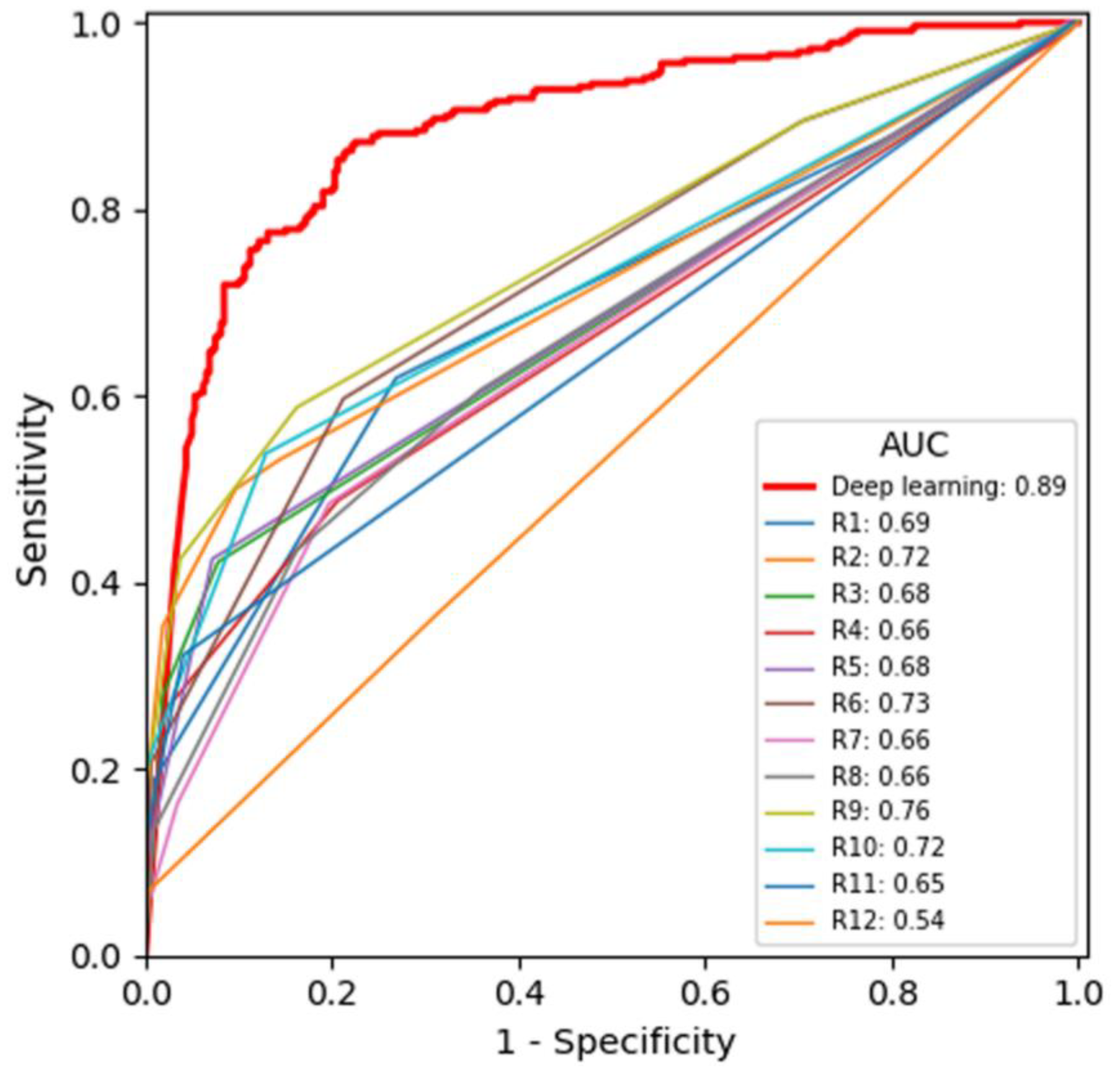
| - | DLA | Radiologists | Difference (95% CI) | p-Value |
|---|---|---|---|---|
| Total | 0.886 (0.859–0.912) | 0.678 (0.638–0.717) | 0.208 (0.205–0.213) | <0.0001 |
| Radiation Dose | ||||
| 26 mAs | 0.825 (0.759–0.890) | 0.570 (0.526–0.614) | 0.255 (0.248–0.264) | <0.0001 |
| 50 mAs | 0.789 (0.719–0.859) | 0.613 (0.561–0.664) | 0.176 (0.168–0.183) | <0.0001 |
| 100 mAs | 0.926 (0.882–0.970) | 0.725 (0.671–0.778) | 0.201 (0.188–0.211) | <0.0001 |
| 200 mAs | 0.982 (0.966–0.998) | 0.812 (0.760–0.864) | 0.170 (0.166–0.180) | <0.0001 |
| Reconstruction | ||||
| FBP | 0.885 (0.849–0.921) | 0.653 (0.611–0.695) | 0.232 (0.227–0.241) | <0.0001 |
| ADMIRE | 0.904 (0.870–0.904) | 0.705 (0.658–0.752) | 0.199 (0.195–0.204) | <0.0001 |
| Object Size | ||||
| 5 mm | 0.763 (0.711–0.816) | 0.581 (0.549–0.613) | 0.182 (0.177–0.190) | <0.0001 |
| 9 mm | 0.979 (0.965–0.993) | 0.776 (0.720–0.833) | 0.203 (0.196–0.211) | <0.0001 |
| - | DLA | Radiologists | Difference (95% CI) | p-Value |
|---|---|---|---|---|
| For Detection of 9 mm Objects | ||||
| Total | 0.979 (0.965–0.993) | 0.776 (0.720–0.833) | 0.203 (0.159–0.247) | <0.0001 |
| Radiation Dose | ||||
| 26 mAs | 0.965 (0.930–1.000) | 0.602 (0.535–0.668) | 0.363 (0.359–0.367) | <0.0001 |
| 50 mAs | 0.945 (0.890–1.000) | 0.679 (0.594–0.764) | 0.266 (0.260–0.272) | <0.0001 |
| 100 mAs | 0.999 (0.996–1.000) | 0.866 (0.797–0.936) | 0.133 (0.131–0.135) | <0.0001 |
| 200 mAs | 0.998 (0.992–1.000) | 0.964 (0.941–0.988) | 0.034 (0.033–0.035) | <0.0001 |
| Reconstruction | ||||
| FBP | 0.980 (0.964–0.997) | 0.744 (0.683–0.805) | 0.236 (0.234–0.238) | <0.0001 |
| ADMIRE | 0.986 (0.968–1.000) | 0.813 (0.749–0.877) | 0.173 (0.171–0.175) | <0.0001 |
| For Detection of 5 mm Objects | ||||
| Total | 0.763 (0.711–0.816) | 0.581 (0.549–0.613) | 0.182 (0.179–0.185) | <0.0001 |
| Radiation Dose | ||||
| 26 mAs | 0.658 (0.534–0.781) | 0.541 (0.498–0.584) | 0.117 (0.105–0.129) | <0.0001 |
| 50 mAs | 0.615 (0.491–1.738) | 0.549 (0.500–0.598) | 0.066 (0.054–0.078) | <0.0001 |
| 100 mAs | 0.820 (0.722–0.917) | 0.577 (0.531–0.623) | 0.243 (0.233–0.253) | <0.0001 |
| 200 mAs | 0.956 (0.916–0.996) | 0.661 (0.593–0.729) | 0.295 (0.288–0.302) | <0.0001 |
| Reconstruction | ||||
| FBP | 0.763 (0.689–0.837) | 0.564 (0.534–0.595) | 0.199 (0.197–0.201) | <0.0001 |
| ADMIRE | 0.785 (0.714–0.855) | 0.599 (0.554–0.643) | 0.186 (0.183–0.189) | <0.0001 |
| AUC Reduction | DLA | Radiologists | Difference (95% CI) | p-Value |
|---|---|---|---|---|
| Between 200 mAs and 26 mAs | 0.032 | 0.362 | −0.330 (−0.366 to −0.294) | <0.0001 |
| Between 200 mAs and 50 mAs | 0.052 | 0.284 | −0.233 (−0.290 to −0.170) | <0.0001 |
| Between 200 mAs and 100 mAs | 0.003 | 0.98 | −0.095 (−0.112 to −0.078) | <0.0001 |
| Between ADMIRE and FBP | 0.011 | 0.069 | −0.058 (−0.09 to −0.034) | <0.0001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.Y.; Lee, K.; Chang, W.; Kim, Y.; Lee, S.; Oh, D.Y.; Sunwoo, L.; Lee, Y.J.; Kim, Y.H. Robustness of Deep Learning Algorithm to Varying Imaging Conditions in Detecting Low Contrast Objects in Computed Tomography Phantom Images: In Comparison to 12 Radiologists. Diagnostics 2021, 11, 410. https://doi.org/10.3390/diagnostics11030410
Kim HY, Lee K, Chang W, Kim Y, Lee S, Oh DY, Sunwoo L, Lee YJ, Kim YH. Robustness of Deep Learning Algorithm to Varying Imaging Conditions in Detecting Low Contrast Objects in Computed Tomography Phantom Images: In Comparison to 12 Radiologists. Diagnostics. 2021; 11(3):410. https://doi.org/10.3390/diagnostics11030410
Chicago/Turabian StyleKim, Hae Young, Kyeorye Lee, Won Chang, Youngjune Kim, Sungsoo Lee, Dong Yul Oh, Leonard Sunwoo, Yoon Jin Lee, and Young Hoon Kim. 2021. "Robustness of Deep Learning Algorithm to Varying Imaging Conditions in Detecting Low Contrast Objects in Computed Tomography Phantom Images: In Comparison to 12 Radiologists" Diagnostics 11, no. 3: 410. https://doi.org/10.3390/diagnostics11030410