Deep Learning Techniques for Automatic Detection of Embryonic Neurodevelopmental Disorders



Abstract
:1. Introduction
2. Materials and Methods
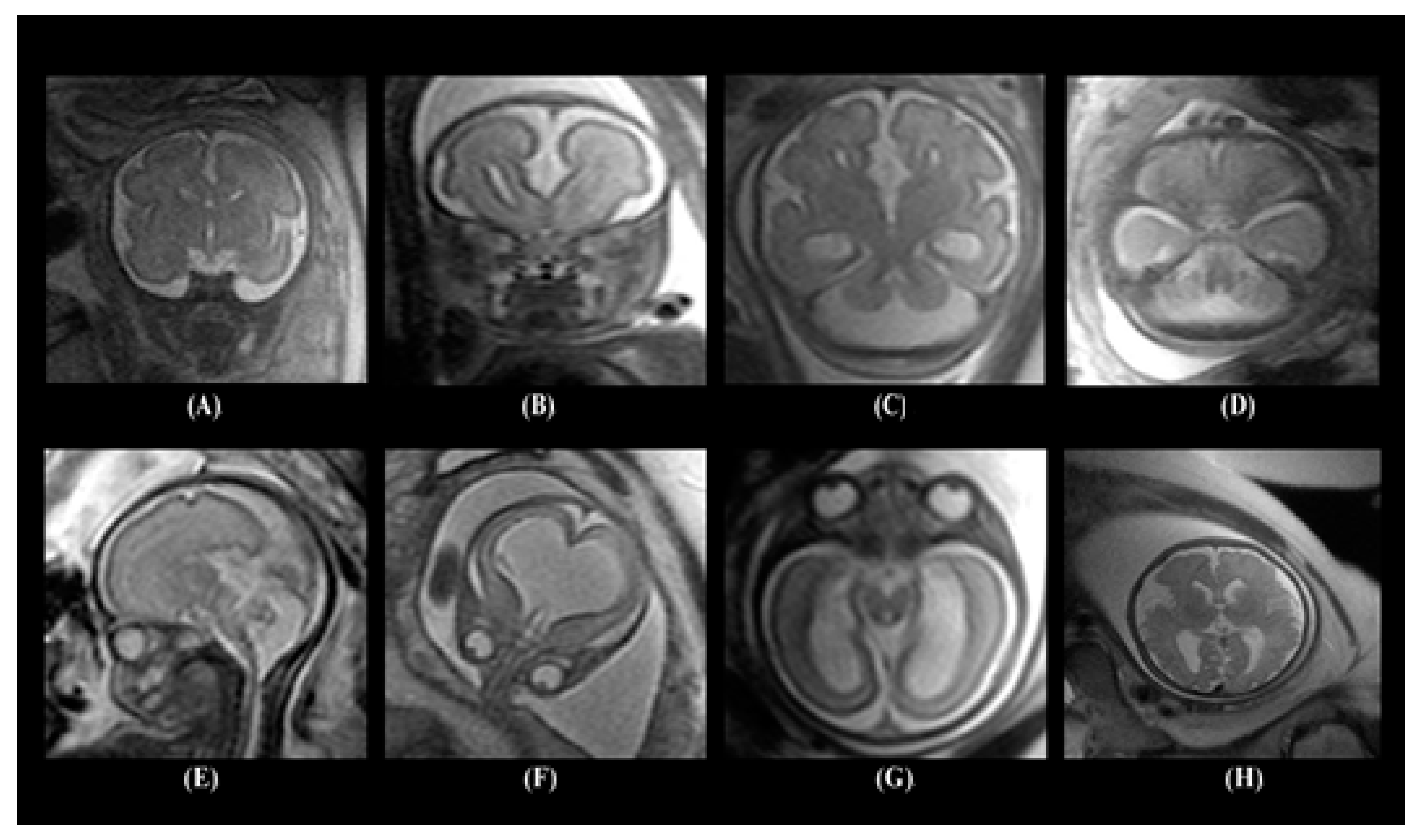
2.1. Dataset
2.2. Deep Learning Techniques
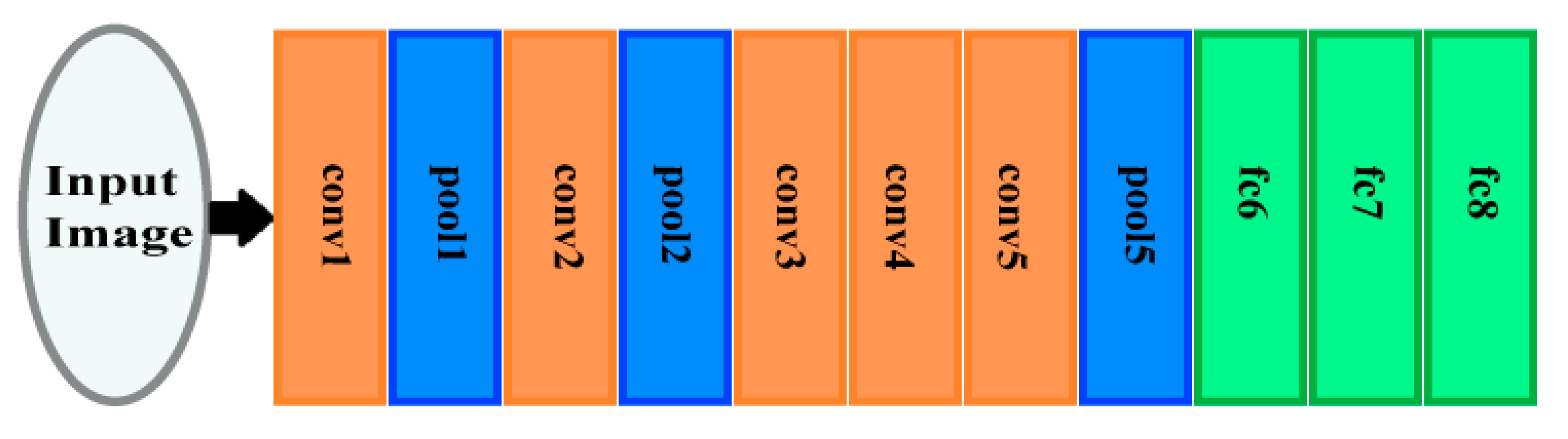
2.2.1. AlexNet DCNN Architecture
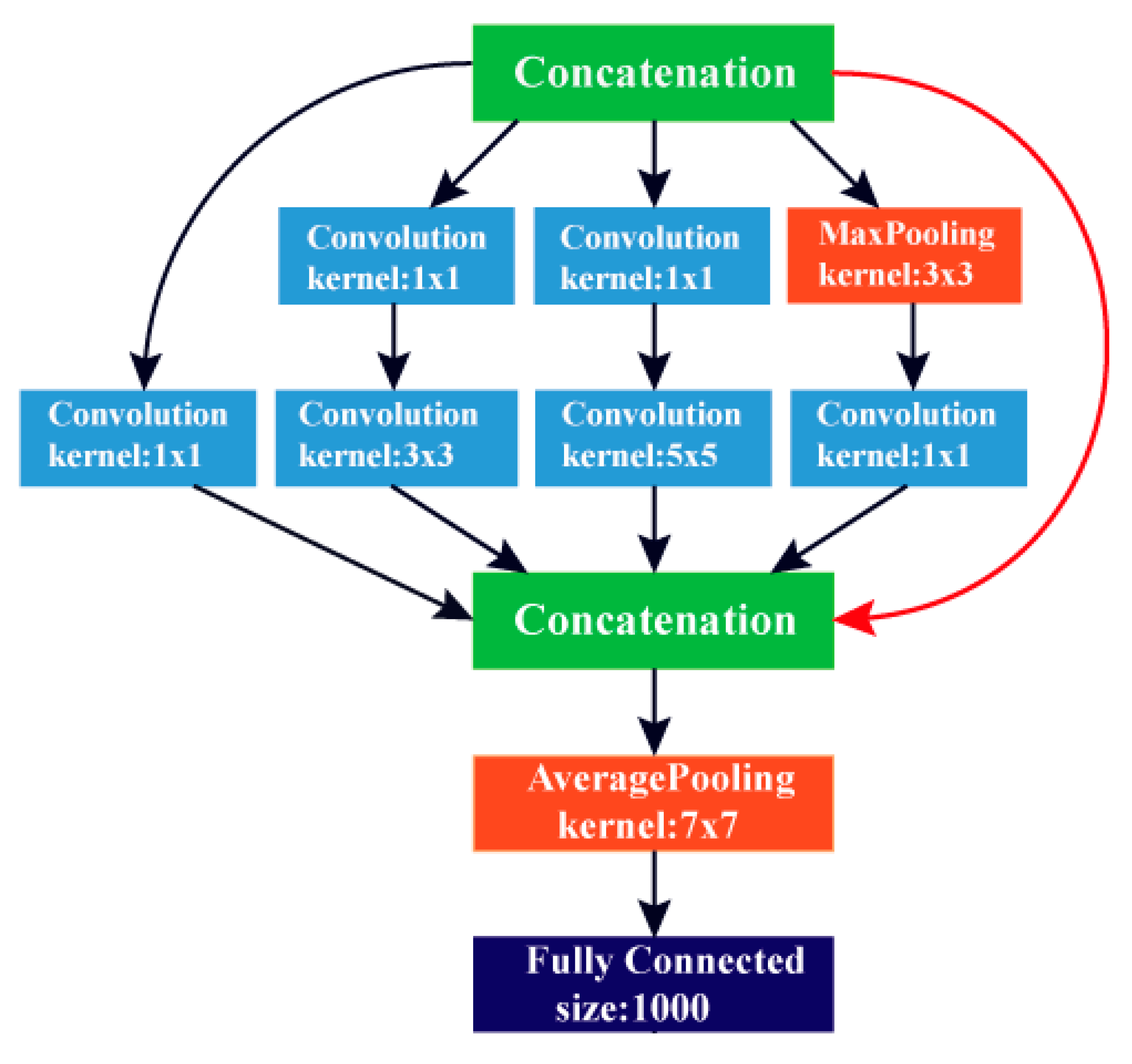
2.2.2. GoogleNet DCNN Architecture
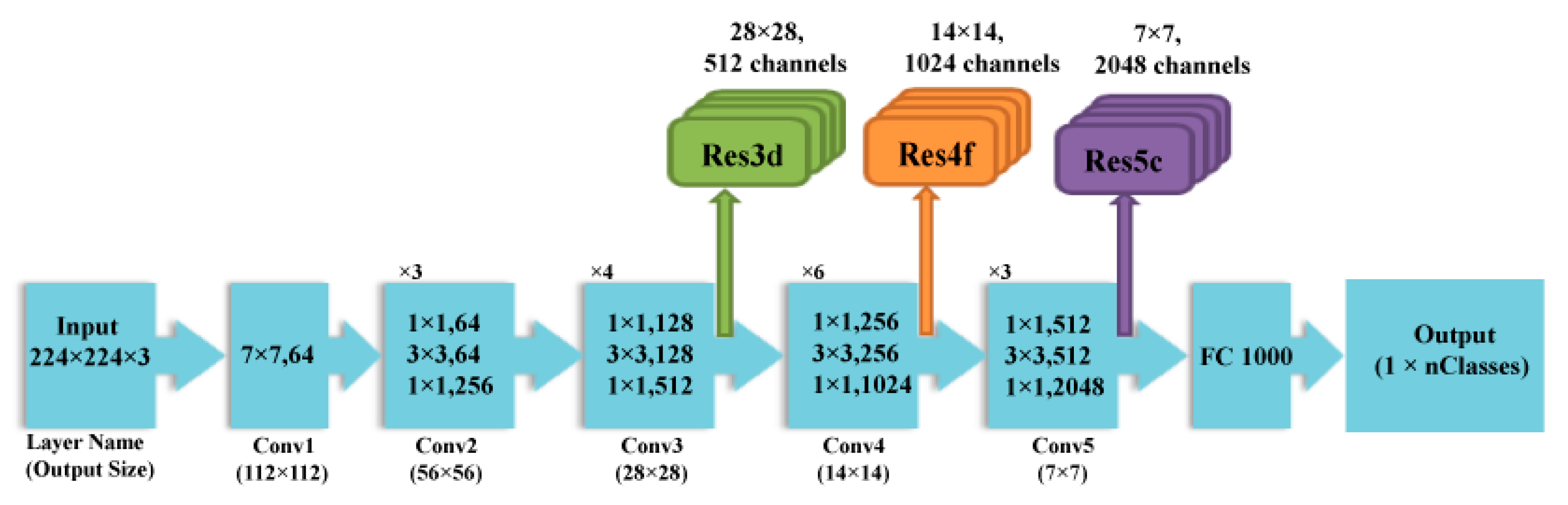
2.2.3. ResNet 50 DCNN Architecture
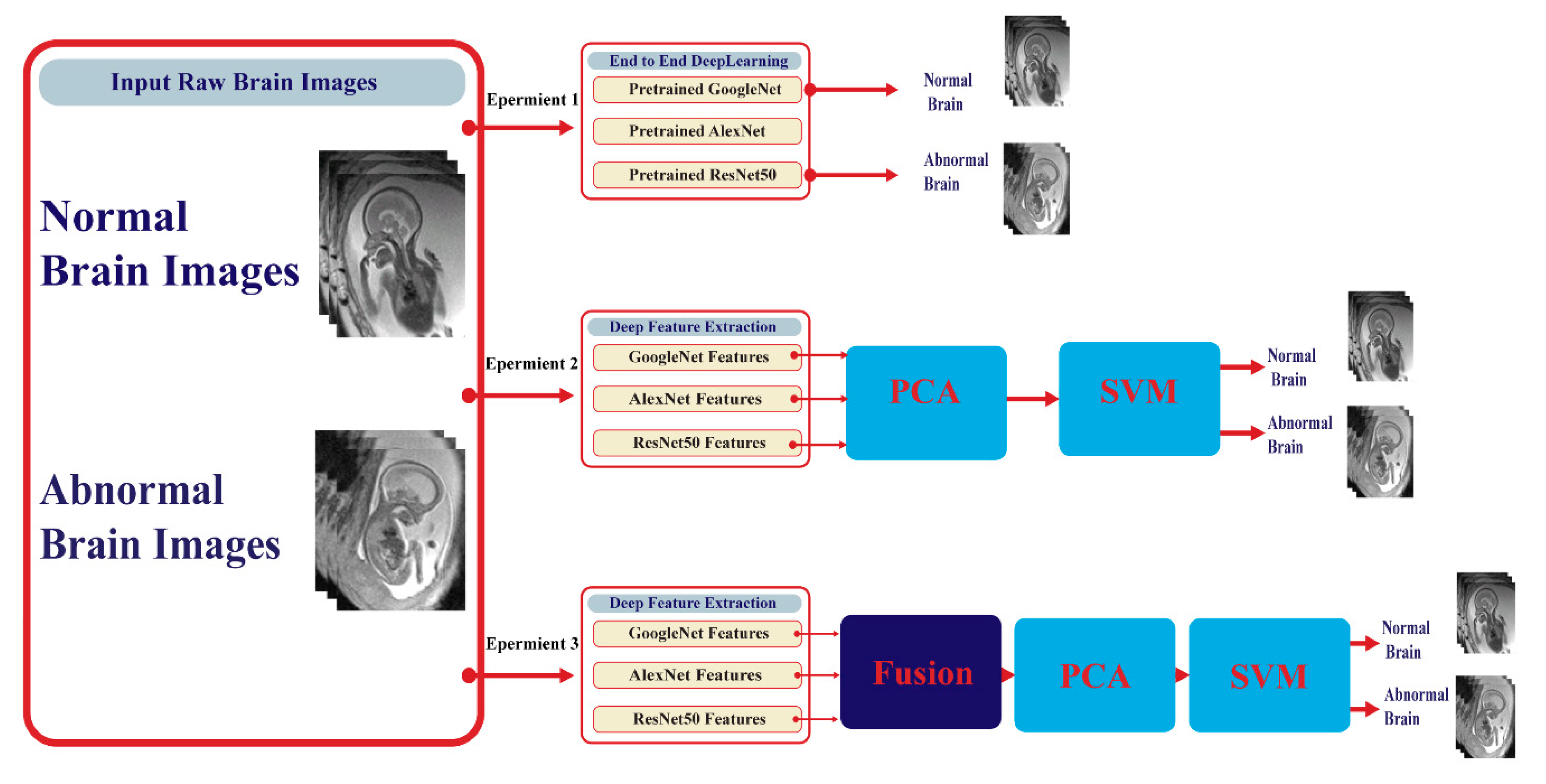
2.3. Proposed Framework
2.3.1. Transfer Learning Stage
2.3.2. Deep Feature Extraction Stage
2.3.3. Feature Reduction Stage
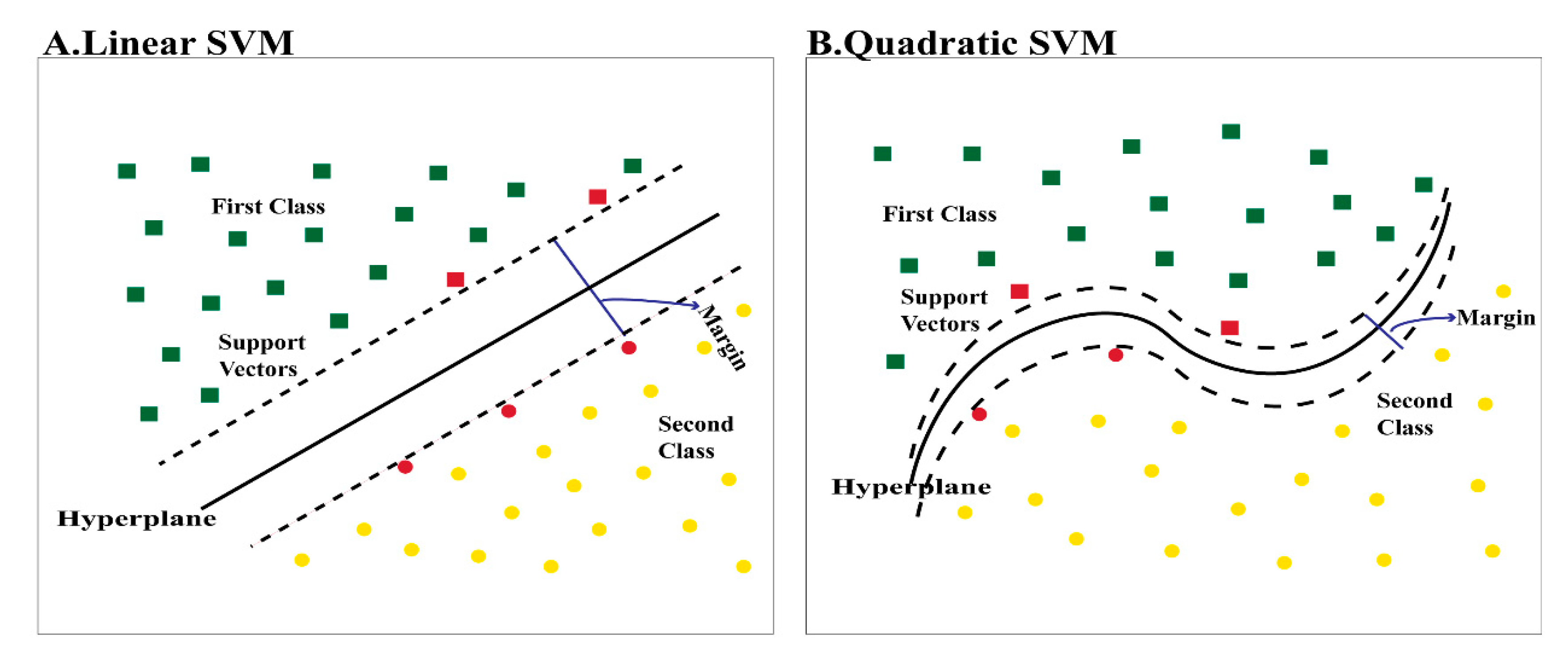
2.3.4. Classification Stage
3. Experimental Set-Up
3.1. Data Augmentation
3.2. Parameter Setting
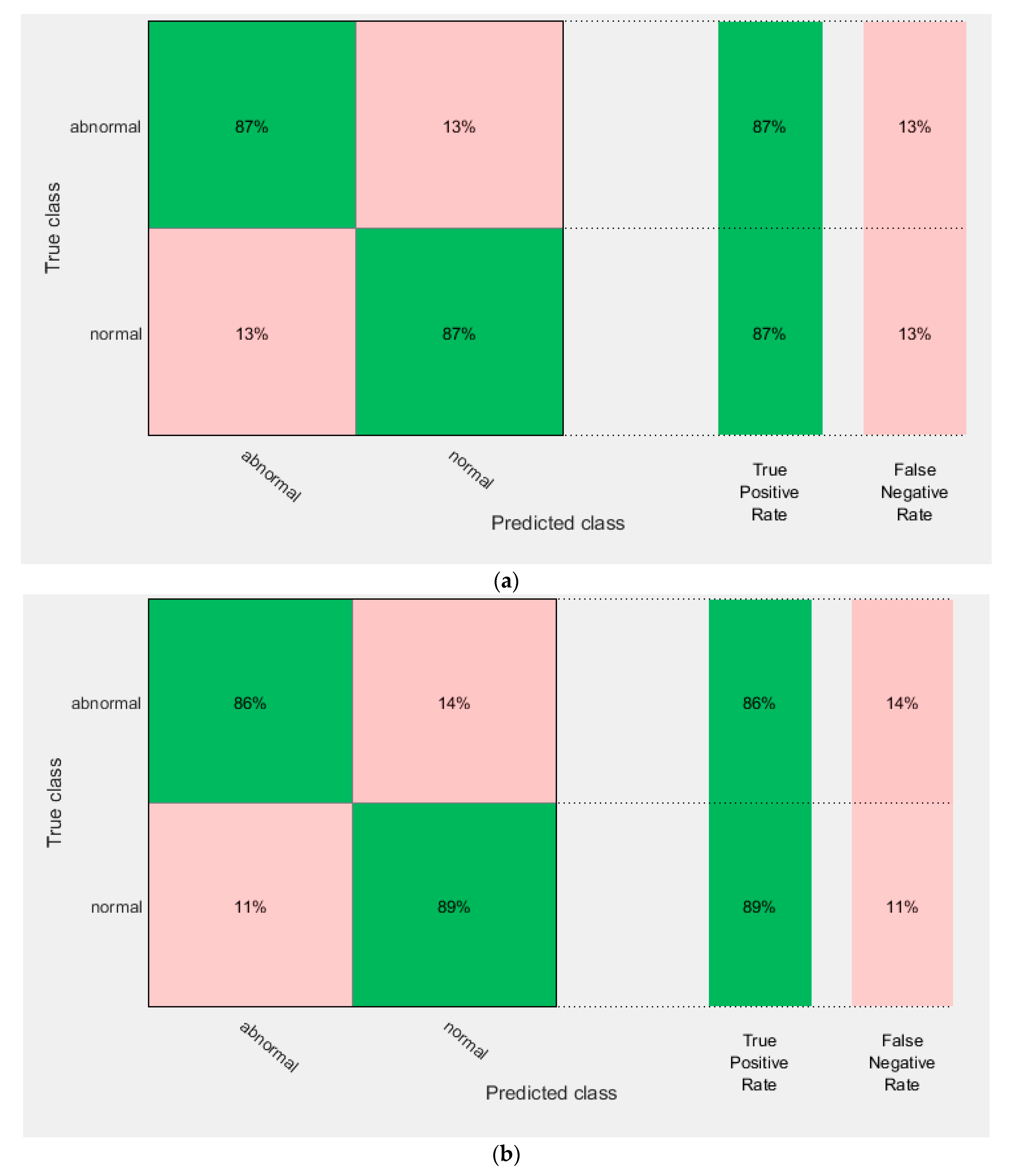
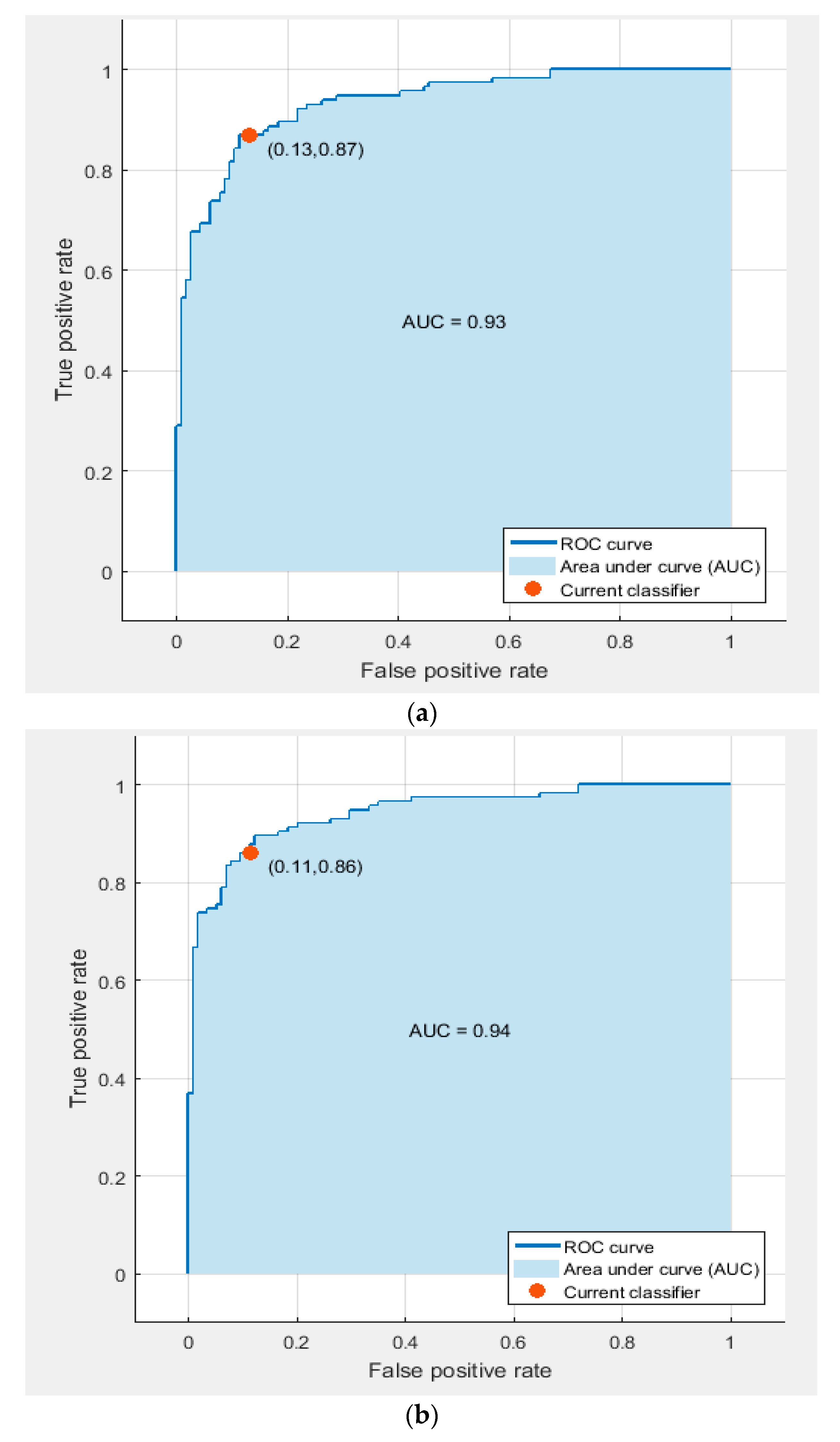
4. Evaluation Metrics
5. Results
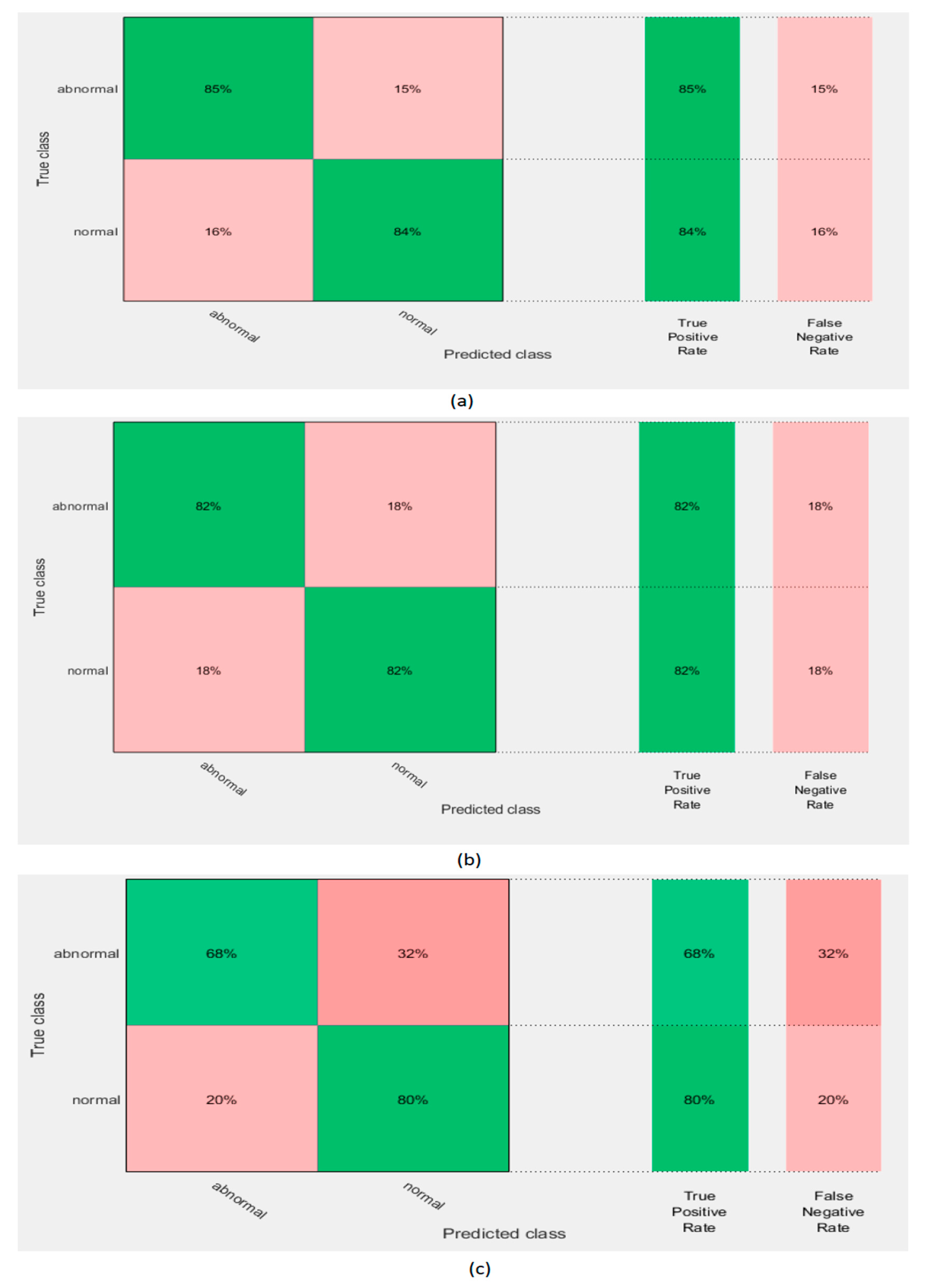
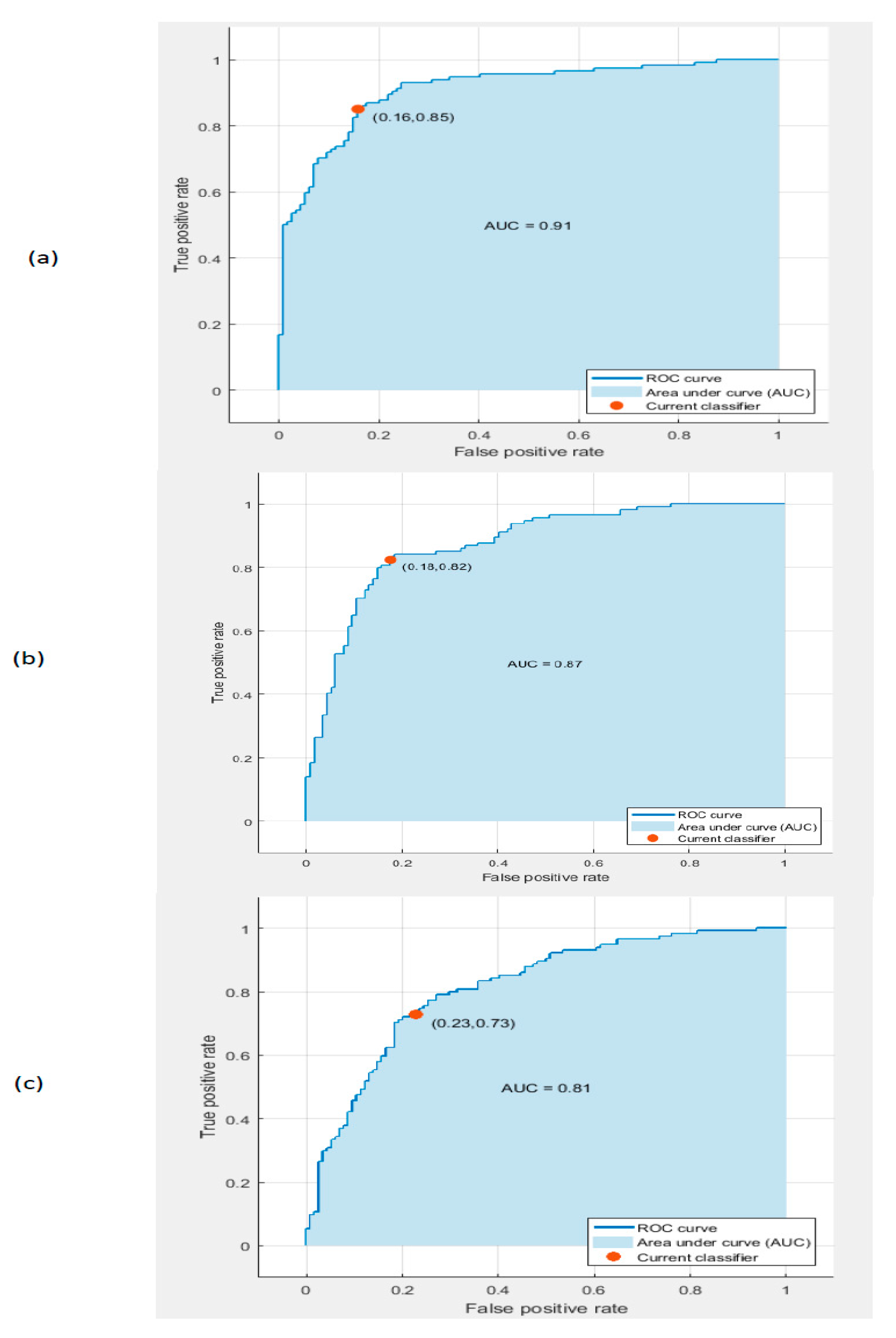
5.1. Experiment I Results
5.2. Experiment II Results
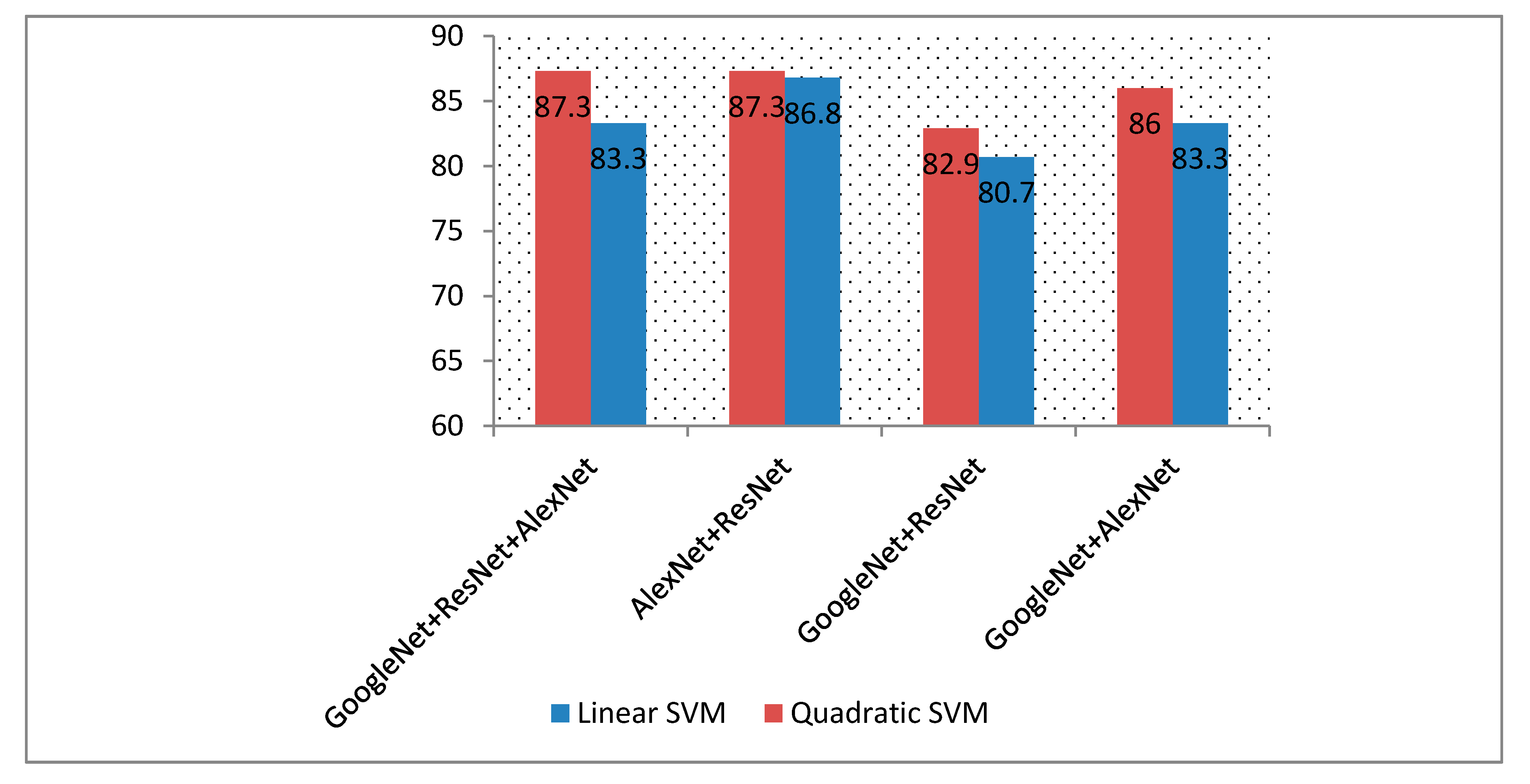
5.3. Experiment III Results
5.4. Comparison with Related Work
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- He, L.; Li, H.; Holland, S.K.; Yuan, W.; Altaye, M.; Parikh, N.A. Early prediction of cognitive deficits in very preterm infants using functional connectome data in an artificial neural network framework. NeuroImage Clin. 2018, 18, 290–297. [Google Scholar] [CrossRef] [PubMed]
- Thapar, A.; Cooper, M.; Rutter, M. Neurodevelopmental disorders. Lancet Psychiatry 2017, 4, 339–346. [Google Scholar] [CrossRef] [Green Version]
- Connors, S.L.; Levitt, P.; Matthews, S.G.; Slotkin, T.A.; Johnston, M.V.; Kinney, H.C.; Johnson, W.G.; Dailey, R.M.; Zimmerman, A.W. Fetal mechanisms in neurodevelopmental disorders. Pediatr. Neurol. 2008, 38, 163–176. [Google Scholar] [CrossRef] [PubMed]
- Griffiths, P.D.; Bradburn, M.; Campbell, M.J.; Cooper, C.L.; Graham, R.; Jarvis, D.; Kilby, M.D.; Mason, G.; Mooney, C.; Robson, S.C.; et al. Use of MRI in the diagnosis of fetal brain abnormalities in utero (MERIDIAN): A multicentre, prospective cohort study. Lancet 2017, 389, 538–546. [Google Scholar] [CrossRef] [Green Version]
- Levine, D.; Barnewolt, C.E.; Mehta, T.S.; Trop, I.; Estroff, J.; Wong, G. Fetal thoracic abnormalities: MR imaging. Radiology 2003, 228, 379–388. [Google Scholar] [CrossRef] [PubMed]
- Khalili, N.; Lessmann, N.; Turk, E.; Claessens, N.; de Heus, R.; Kolk, T.; Viergever, M.A.; Benders, M.; Išgum, I. Automatic brain tissue segmentation in fetal MRI using convolutional neural networks. Magn. Reson. Imaging 2019, 64, 77–89. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rathore, S.; Habes, M.; Iftikhar, M.A.; Shacklett, A.; Davatzikos, C. A review on neuroimaging-based classification studies and associated feature extraction methods for Alzheimer’s disease and its prodromal stages. NeuroImage 2017, 155, 530–548. [Google Scholar] [CrossRef]
- Ratta, G.A.; Figueras Retuerta, F.; Bonet Carné, E.; Padilla Gomes, N.; Arranz Betegón, Á.; Bargalló Alabart, N.; Gratacós Solsona, E. Automatic quantitative MRI texture analysis in small-for-gestational-age fetuses discriminates abnormal neonatal neurobehavior. PLoS ONE 2013, 8, e69595. [Google Scholar]
- Sanz-Cortes, M.; Figueras, F.; Bonet-Carne, E.; Padilla, N.; Tenorio, V.; Bargallo, N.; Amat-Roldan, I.; Gratacós, E. Fetal brain MRI texture analysis identifies different microstructural patterns in adequate and small for gestational age fetuses at term. Fetal Diagn. Ther. 2013, 33, 122–129. [Google Scholar] [CrossRef]
- Attallah, O.; Gadelkarim, H.; Sharkas, M.A. Detecting and Classifying Fetal Brain Abnormalities Using Machine Learning Techniques. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1371–1376. [Google Scholar]
- Attallah, O.; Sharkas, M.A.; Gadelkarim, H. Fetal Brain Abnormality Classification from MRI Images of Different Gestational Age. Brain Sci. 2019, 9, 231. [Google Scholar] [CrossRef] [Green Version]
- Basaia, S.; Agosta, F.; Wagner, L.; Canu, E.; Magnani, G.; Santangelo, R.; Filippi, M.; Initiative, A.D.N. Automated classification of Alzheimer’s disease and mild cognitive impairment using a single MRI and deep neural networks. NeuroImage Clin. 2019, 21, 101645. [Google Scholar] [CrossRef] [PubMed]
- Hssayeni, M.D.; Saxena, S.; Ptucha, R.; Savakis, A. Distracted driver detection: Deep learning vs handcrafted features. Electron. Imaging 2017, 2017, 20–26. [Google Scholar] [CrossRef]
- Kong, Y.; Gao, J.; Xu, Y.; Pan, Y.; Wang, J.; Liu, J. Classification of autism spectrum disorder by combining brain connectivity and deep neural network classifier. Neurocomputing 2019, 324, 63–68. [Google Scholar] [CrossRef]
- Vieira, S.; Pinaya, W.H.; Mechelli, A. Using deep learning to investigate the neuroimaging correlates of psychiatric and neurological disorders: Methods and applications. Neurosci. Biobehav. Rev. 2017, 74, 58–75. [Google Scholar] [CrossRef] [Green Version]
- Makropoulos, A.; Counsell, S.J.; Rueckert, D. A review on automatic fetal and neonatal brain MRI segmentation. NeuroImage 2017, 170, 231–248. [Google Scholar] [CrossRef] [Green Version]
- Somasundaram, K.; Gayathri, S.P.; Shankar, R.S.; Rajeswaran, R. Fetal head localization and fetal brain segmentation from MRI using the center of gravity. In Proceedings of the 2016 International Computer Science and Engineering Conference (ICSEC), Chiang Mai, Thailand, 14–17 December 2016; pp. 1–6. [Google Scholar]
- Fetal MRI: Brain. Available online: http://radnet.bidmc.harvard.edu/fetalatlas/brain/brain.html (accessed on 13 February 2018).
- Cao, C.; Liu, F.; Tan, H.; Song, D.; Shu, W.; Li, W.; Zhou, Y.; Bo, X.; Xie, Z. Deep Learning and Its Applications in Biomedicine. Genom. Proteom. Bioinform. 2018, 16, 17–32. [Google Scholar] [CrossRef]
- Mahmud, M.; Kaiser, M.S.; Hussain, A.; Vassanelli, S. Applications of deep learning and reinforcement learning to biological data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2063–2079. [Google Scholar] [CrossRef] [Green Version]
- Angermueller, C.; Pärnamaa, T.; Parts, L.; Stegle, O. Deep learning for computational biology. Mol. Syst. Biol. 2016, 12, 878. [Google Scholar] [CrossRef]
- Ceschin, R.; Zahner, A.; Reynolds, W.; Gaesser, J.; Zuccoli, G.; Lo, C.W.; Gopalakrishnan, V.; Panigrahy, A. A computational framework for the detection of subcortical brain dysmaturation in neonatal MRI using 3D Convolutional Neural Networks. NeuroImage 2018, 178, 183–197. [Google Scholar] [CrossRef]
- Ravì, D.; Wong, C.; Deligianni, F.; Berthelot, M.; Andreu-Perez, J.; Lo, B.; Yang, G.-Z. Deep learning for health informatics. IEEE J. Biomed. Health Inform. 2016, 21, 4–21. [Google Scholar] [CrossRef] [Green Version]
- Zemouri, R.; Zerhouni, N.; Racoceanu, D. Deep Learning in the Biomedical Applications: Recent and Future Status. Appl. Sci. 2019, 9, 1526. [Google Scholar] [CrossRef] [Green Version]
- Kawahara, J.; Brown, C.J.; Miller, S.P.; Booth, B.G.; Chau, V.; Grunau, R.E.; Zwicker, J.G.; Hamarneh, G. BrainNetCNN: Convolutional neural networks for brain networks; towards predicting neurodevelopment. NeuroImage 2017, 146, 1038–1049. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Suzuki, S.; Zhang, X.; Homma, N.; Ichiji, K.; Sugita, N.; Kawasumi, Y.; Ishibashi, T.; Yoshizawa, M. Mass Detection Using Deep Convolutional Neural Network for Mammographic Computer-Aided Diagnosis. In Proceedings of the SICE Annual Conference, Tsukuba, Japan, 20–23 September 2016; pp. 1382–1386. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. Available online: https://www.researchgate.net/profile/Li_Jia_Li/publication/221361415_ImageNet_a_Large-Scale_Hierarchical_Image_Database/links/00b495388120dbc339000000/ImageNet-a-Large-Scale-Hierarchical-Image-Database.pdf (accessed on 7 January 2020).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2015, 7, 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Talo, M.; Baloglu, U.B.; Yıldırım, Ö.; Acharya, U.R. Application of deep transfer learning for automated brain abnormality classification using MR images. Cogn. Syst. Res. 2019, 54, 176–188. [Google Scholar] [CrossRef]
- Lei, H.; Han, T.; Zhou, F.; Yu, Z.; Qin, J.; Elazab, A.; Lei, B. A deeply supervised residual network for HEp-2 cell classification via cross modal transfer learning. Pattern Recognit. 2018, 79, 290–302. [Google Scholar] [CrossRef]
- Greenspan, H.; Van Ginneken, B.; Summers, R.M. Guest editorial deep learning in medical imaging: Overview and future promise of an exciting new technique. IEEE Trans. Med. Imaging 2016, 35, 1153–1159. [Google Scholar] [CrossRef]
- Smith, L.I. A tutorial on Principal Components Analysis Introduction. Available online: https://ourarchive.otago.ac.nz/bitstream/handle/10523/7534/OUCS-2002-12.pdf (accessed on 4 January 2020).
- Islam, J.; Zhang, Y. Brain MRI analysis for Alzheimer’s disease diagnosis using an ensemble system of deep convolutional neural networks. Brain Inform. 2018, 5, 2. [Google Scholar] [CrossRef]
- Schmidt-Erfurth, U.; Sadeghipour, A.; Gerendas, B.S.; Waldstein, S.M.; Bogunović, H. Artificial intelligence in retina. Prog. Retin. Eye Res. 2018, 67, 1–29. [Google Scholar] [CrossRef]
- D’Agaro, E. Artificial intelligence used in genome analysis studies. Euro. Biotech J. 2018, 2, 78–88. [Google Scholar] [CrossRef]
- Zhang, Y.-D.; Wu, L. An MR brain images classifier via principal component analysis and kernel support vector machine. Prog. Electromagn. Res. 2012, 130, 369–388. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Li, L.; Zheng, L.; Hu, J.; Li, W.; Jiang, Y.; Yan, C. Image Classification base on PCA of Multi-view Deep Representation. J. Vis. Commun. Image Represent. 2019, 62, 253–258. [Google Scholar] [CrossRef] [Green Version]
- Shen, Y.; Abubakar, M.; Liu, H.; Hussain, F. Power Quality Disturbance Monitoring and Classification Based on Improved PCA and Convolution Neural Network for Wind-Grid Distribution Systems. Energies 2019, 12, 1280. [Google Scholar] [CrossRef] [Green Version]
- Mateen, M.; Wen, J.; Song, S.; Huang, Z. Fundus Image Classification Using VGG-19 Architecture with PCA and SVD. Symmetry 2019, 11, 1. [Google Scholar] [CrossRef] [Green Version]
- Ragab, D.A.; Sharkas, M.; Marshall, S.; Ren, J. Breast cancer detection using deep convolutional neural networks and support vector machines. PeerJ. 2019, 7, e6201. [Google Scholar] [CrossRef] [PubMed]
- Ming, J.T.C.; Noor, N.M.; Rijal, O.M.; Kassim, R.M.; Yunus, A. Lung disease classification using GLCM and deep features from different deep learning architectures with principal component analysis. Int. J. Integr. Eng. 2018, 10. [Google Scholar]
- Kumar, M.D.; Babaie, M.; Tizhoosh, H.R. Deep Barcodes for Fast Retrieval of Histopathology Scans. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway Township, NS, USA, 2018; pp. 1–8. [Google Scholar]
- Yuan, X.; Huang, B.; Wang, Y.; Yang, C.; Gui, W. Deep learning-based feature representation and its application for soft sensor modeling with variable-wise weighted SAE. IEEE Trans. Ind. Inform. 2018, 14, 3235–3243. [Google Scholar] [CrossRef]
- Zhong, G.; Yan, S.; Huang, K.; Cai, Y.; Dong, J. Reducing and stretching deep convolutional activation features for accurate image classification. Cogn. Comput. 2018, 10, 179–186. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Label | Specifications | Output Dimension | |
|---|---|---|---|
| Input layer | 227 × 227 × 3 | ||
| Convolution layer 1 | Filter size | 11 × 11 | 55 × 55 × 96 |
| Stride | 4 | ||
| Padding | 0 | ||
| Pooling layer 1 | Pooling size | 3 × 3 | 27 × 27 × 96 |
| Stride | 2 | ||
| Convolution layer 2 | Filter size | 5 × 5 | 27 × 27 × 256 |
| Stride | 1 | ||
| Pooling layer 2 | Pooling size | 3 × 3 | 13 × 13 × 256 |
| Stride | 2 | ||
| Convolution layer 3 | Filter size | 3 × 3 | 13 × 13 × 384 |
| Stride | 1 | ||
| Convolution 4 | Filter Size | 3 × 3 | 13 × 13 × 384 |
| Stride | 1 | ||
| Convolution layer5 | Filter size | 3 × 3 | 13 × 13 × 256 |
| Stride | 1 | ||
| Pooling layer 5 | Pooling size | 3 × 3 | 6 × 6 × 256 |
| Stride | 2 | ||
| FC6 layer | 4096 × 2 | ||
| FC7 layer | 4096 × 2 | ||
| FC8 layer | 1000 × 2 | ||
| Layer Label | Filter Dimension | Stride | Output Dimension |
|---|---|---|---|
| Input layers | 224 × 224 × 3 | ||
| Convolution layer 1 | 7 × 7 | 2 | 112 × 112 × 64 |
| Pooling layer 1 | 3 × 3 | 2 | 56 × 56 × 64 |
| Convolution layer 2 | 3 × 3 | 1 | 56 × 56 × 192 |
| Pooling layer 2 | 3 × 3 | 2 | 28 × 28 × 192 |
| Inception layer (3a) | - | - | 28 × 28 × 256 |
| Inception layer (3b) | - | - | 28 × 28 × 480 |
| Pooling layer 3 | 3 × 3 | 2 | 14 × 14 × 480 |
| Inception layer (4a) | - | - | 14 × 14 × 512 |
| Inception layer (4b) | - | - | 14 × 14 × 512 |
| Inception layer (4c) | - | - | 14 × 14 × 512 |
| Inception layer (4d) | - | - | 14 × 14 × 528 |
| Inception layer (4e) | - | - | 14 × 14 × 832 |
| Pooling layer 4 | 3 × 3 | 2 | 7 × 7 × 832 |
| Inception layer (5a) | - | - | 7 × 7 × 832 |
| Inception layer (5b) | - | - | 7 × 7 × 1024 |
| Average pooling layer | 7 × 7 | 1 | 1 × 1 × 1024 |
| FC layer | 1024 × 2 | ||
| Layer Label | Input Layer Dimension | Output Dimension |
|---|---|---|
| Input Layer | 227 × 227 × 3 | |
| Conv1 | 112 × 112 × 64 | Filter size = 7 × 7 Number of filters = 64 Stride = 2 Padding = 3 |
| pool1 | 56 × 56 × 64 | Pooling size = 3 × 3 Stride = 2 |
| Conv2_x | 56 × 56 × 64 | |
| Conv3_x | 28 × 28 × 128 | |
| Conv4_x | 14 × 14 × 256 | |
| Conv5_x | 7 × 7 × 512 | |
| Average pooling | Pool size = 7 × 7 Stride = 7 | |
| 1 × 1 × 2048 | ||
| FC layer | 2 (2048 × 2) | |
| DCNN | Accuracy (%) | Sensitivity (%) | Specificity (%) |
|---|---|---|---|
| GoogleNet | 77.9 | 79.4 | 76.5 |
| AlexNet | 73.5 | 85.3 | 61.8 |
| ResNet 50 | 76.5 | 82.4 | 70.6 |
| SVM Trained with Deep Features | Accuracy (%) of Deep Features without PCA | Accuracy (%) of Deep Features with PCA |
|---|---|---|
| Linear SVM | ||
| GoogleNet | 83.8 | 84.6 |
| AlexNet | 81.1 | 82.0 |
| ResNet 50 | 75.0 | 75.0 |
| Quadratic SVM | ||
| GoogleNet | 79.4 | 78.9 |
| AlexNet | 84.6 | 85.5 |
| ResNet 50 | 79.8 | 79.8 |
| DCNN | Accuracy (%) of Deep Features without PCA | Accuracy (%) of Deep Features with PCA |
|---|---|---|
| Linear SVM | ||
| Google + ResNet 50 | 80.7 | 86 |
| Google + AlexNet | 83.3 | 82.0 |
| AlexNet + ResNet 50 | 86.3 | 87.2 |
| The three DCNNs | 83.3 | 84.2 |
| Quadratic SVM | ||
| Google + ResNet 50 | 82.9 | 83.8 |
| Google + AlexNet | 86 | 86.8 |
| AlexNet + ResNet 50 | 87.3 | 88.6 |
| The three DCNNs | 87.3 | 87.7 |
| Article | Feature Extraction | Classifier | Accuracy (ACC) |
|---|---|---|---|
| [10] | Discrete wavelet transform + statistical features | Linear Discriminant Analysis (LDA) | 79% |
| SVM | 79% | ||
| K Nearest Neighbor (KNN) | 73% | ||
| Ensemble Subspace Discriminates | 80% | ||
| [11] | Gabor filter + Gray Level Co-occurrence Matrix (GLCM) + PCA | Diagonal Quadratic Discriminant Analysis (DQDA) | 92% |
| Neural networks | 93% | ||
| Naïve Bayes | 91.63% | ||
| Random forest | 90.3% | ||
| The proposed framework | Deep features: | Linear SVM | 84.2% |
| GoogleNet + AlexNet + ResNet 50 | Quadratic SVM | 87.7% | |
| Deep features: | Linear SVM | 87.2% | |
| AlexNet + ResNet 50 | Quadratic SVM | 88.6% | |
| Deep features: | Linear SVM | 86% | |
| GoogleNet + ResNet 50 | Quadratic SVM | 83.8% | |
| Deep features: | Linear SVM | 82% | |
| GoogleNet + AlexNet | Quadratic SVM | 86.8% |
| DCNN | Training Time |
|---|---|
| AlexNet | 5 min 57 s |
| GoogleNet | 10mins 29 s |
| ResNet 50 | 6 min 25 s |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Attallah, O.; Sharkas, M.A.; Gadelkarim, H. Deep Learning Techniques for Automatic Detection of Embryonic Neurodevelopmental Disorders. Diagnostics 2020, 10, 27. https://doi.org/10.3390/diagnostics10010027
Attallah O, Sharkas MA, Gadelkarim H. Deep Learning Techniques for Automatic Detection of Embryonic Neurodevelopmental Disorders. Diagnostics. 2020; 10(1):27. https://doi.org/10.3390/diagnostics10010027
Chicago/Turabian StyleAttallah, Omneya, Maha A. Sharkas, and Heba Gadelkarim. 2020. "Deep Learning Techniques for Automatic Detection of Embryonic Neurodevelopmental Disorders" Diagnostics 10, no. 1: 27. https://doi.org/10.3390/diagnostics10010027