

Rapid Detection of Tannin Content in Wine Grapes Using Hyperspectral Technology

Abstract
:1. Introduction
2. Materials and Methods
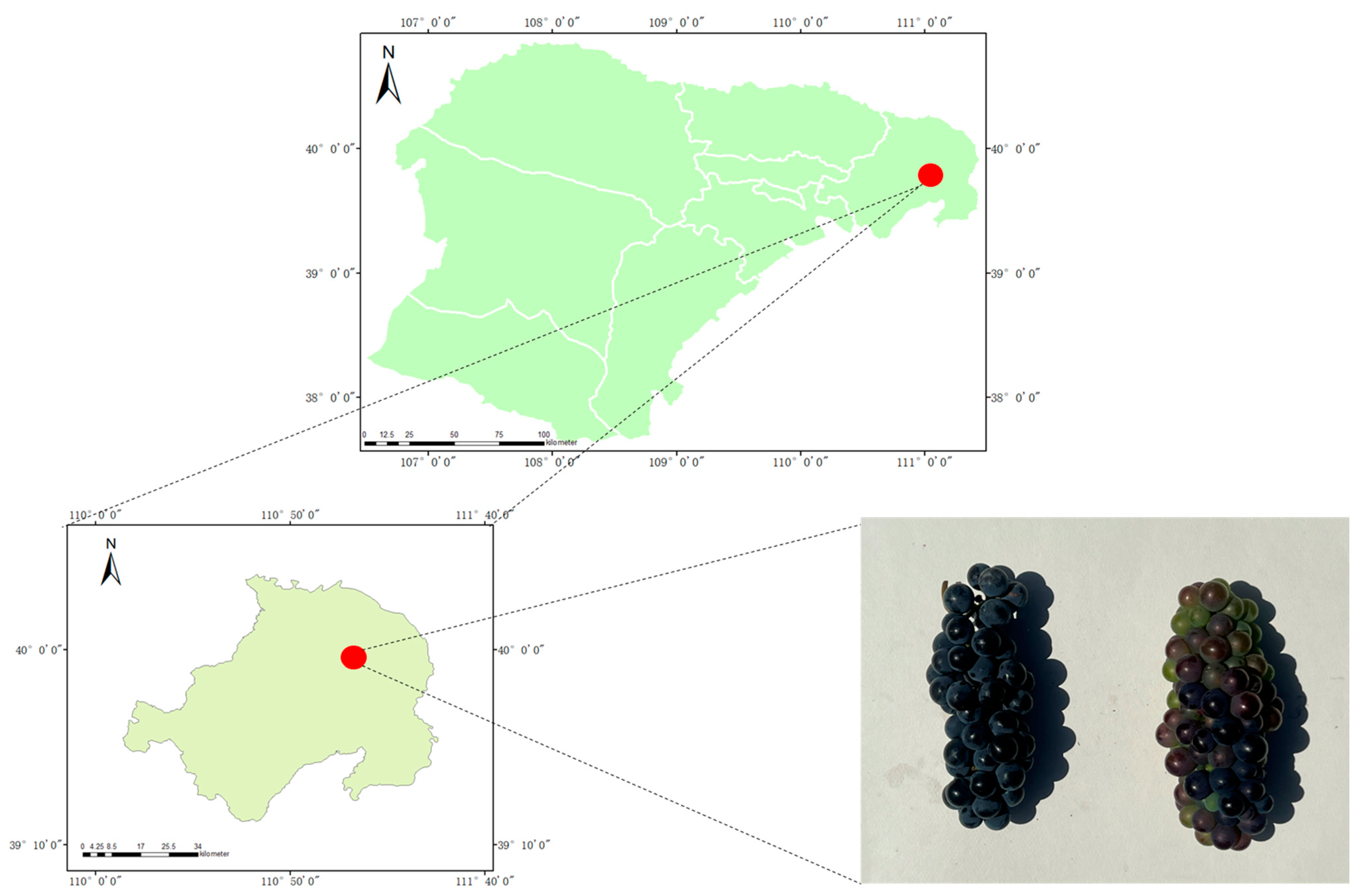
2.1. Sample Preparation
2.2. Spectral Acquisition
2.3. Software and Model Evaluation
2.4. Measurements of Tannin Content
2.5. Data Analysis Methods
2.5.1. Hyperspectral Preprocessing
2.5.2. Data Dimensionality
2.5.3. Model Establishment
2.5.4. Model Performance
3. Results
3.1. Analysis of the Tannin Content of Grapes
3.2. Hyperspectral Data Preprocessing Analysis
3.3. Data Dimension Reduction
3.4. Performance of Models for Tannin Content Estimation
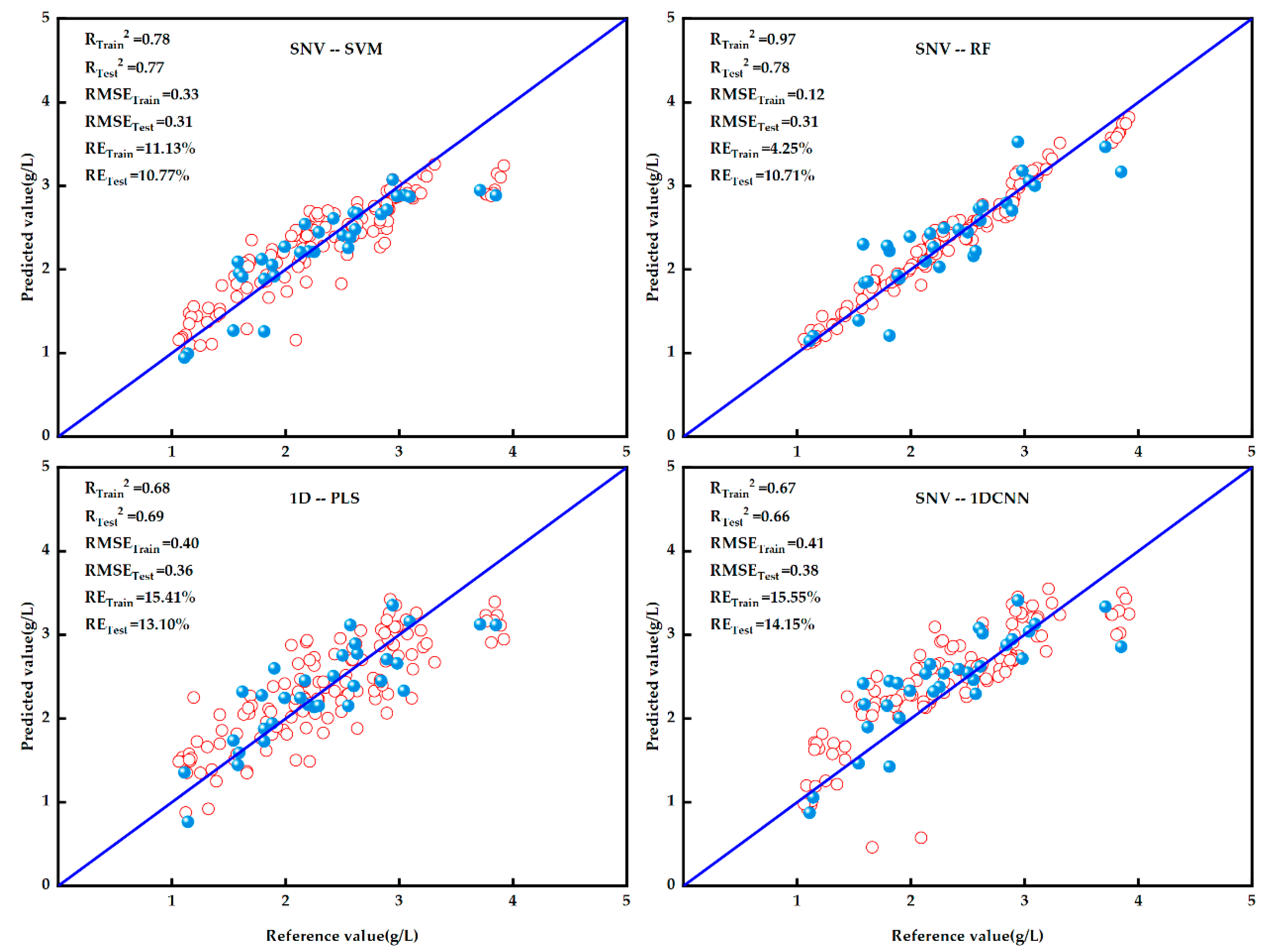
3.4.1. SVM Model Prediction Results
3.4.2. RF Model Prediction Results
3.4.3. PLS Model Prediction Results
3.4.4. 1DCNN Model Prediction Results
3.4.5. Selection of Optimal Model for Tannin Content Estimation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Todorov, S.D.; Alves, V.F.; Popov, I.; Weeks, R.; Pinto, U.M.; Petrov, N.; Ivanova, I.V.; Chikindas, M.L. Antimicrobial compounds in wine. Probiotics Antimicrob. Proteins 2023, ahead of print. [Google Scholar] [CrossRef]
- Gabrielli, M.; Ounaissi, D.; Lançon-Verdier, V.; Julien, S.; Le Meurlay, D.; Maury, C. Hyperspectral imaging to assess wine grape quality. JSFA Rep. 2023, 3, 452–462. [Google Scholar] [CrossRef]
- Cheynier, V.; Duenas-Paton, M.; Salas, E.; Maury, C.; Souquet, J.M.; Sarni-Manchado, P.; Fulcrand, H. Structure and properties of wine pigments and tannins. Am. J. Enol. Vitic. 2006, 57, 298–305. [Google Scholar] [CrossRef]
- Molino, S.; Francino, M.P.; Henares, J.Á.R. Why is it important to understand the nature and chemistry of tannins to exploit their potential as nutraceuticals? Food Res. Int. 2023, 173, 113329. [Google Scholar] [CrossRef]
- Wimalasiri, P.M.; Harrison, R.; Hider, R.; Donaldson, I.; Kemp, B.; Tian, B. Development of Tannins and Methoxypyrazines in Grape Skins, Seeds, and Stems of Two Pinot Noir Clones during Ripening. J. Agric. Food Chem. 2023, 71, 15754–15765. [Google Scholar] [CrossRef]
- Zhao, Q.; Du, G.; Zhao, P.; Guo, A.; Cao, X.; Cheng, C.; Liu, H.; Wang, F.; Zhao, Y.; Liu, Y.; et al. Investigating wine astringency profiles by characterizing tannin fractions in Cabernet Sauvignon wines and model wines. Food Chem. 2023, 414, 135673. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Gil, M.; Pérez-Lamela, C.; Falqué-López, E. Comparison of Chromatic and Spectrophotometric Properties of White and Red Wines Produced in Galicia (Northwest Spain) by Applying PCA. Molecules 2022, 27, 7000. [Google Scholar] [CrossRef]
- Song, X.; Yang, W.; Qian, X.; Zhang, X.; Ling, M.; Yang, L.; Shi, Y.; Duan, C.; Lan, Y. Comparison of Chemical and Sensory Profiles between Cabernet Sauvignon and Marselan Dry Red Wines in China. Foods 2023, 12, 1110. [Google Scholar] [CrossRef]
- Morgani, M.B.; Fanzone, M.; Peña, J.E.P.; Sari, S.; Gallo, A.E.; Tournier, M.G.; Prieto, J.A. Late pruning modifies leaf to fruit ratio and shifts maturity period, affecting berry and wine composition in Vitis vinífera L. cv. ‘Malbec’ in Mendoza, Argentina. Sci. Hortic. 2023, 313, 111861. [Google Scholar] [CrossRef]
- Stavrakaki, M.; Doudoumi, T.; Daskalakis, I.; Bouza, D.; Biniari, K. Effect of different viticultural techniques on the qualitative and quantitative characters of cv. Xinomavro under vineyard conditions in Naoussa. In BIO Web of Conferences; EDP Sciences: Les Ulis, France, 2023; Volume 56, p. 01023. [Google Scholar] [CrossRef]
- Van Truong, N.; Khanh, T.Q. The Impact of Technology and Automation in Enhancing Efficiency, Quality, and Control in Modern Vineyards and Wineries. J. Comput. Soc. Dyn. 2023, 8, 1–14. Available online: https://vectoral.org/index.php/JCSD/article/view/40 (accessed on 17 December 2023).
- Guaita, M.; Bosso, A. Polyphenolic characterization of grape skins and seeds of four Italian red cultivars at harvest and after fermentative maceration. Foods 2019, 8, 395. [Google Scholar] [CrossRef]
- Gomes, V.; Mendes-Ferreira, A.; Melo-Pinto, P. Application of hyperspectral imaging and deep learning for robust prediction of sugar and pH levels in wine grape berries. Sensors 2021, 21, 3459. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Cao, W.; Zhang, F.; Li, Z.; Xu, S.; Wu, X. A review of deep learning in multiscale agricultural sensing. Remote Sens. 2022, 14, 559. [Google Scholar] [CrossRef]
- Zhang, N.; Liu, X.; Jin, X.; Li, C.; Wu, X.; Yang, S.; Ning, J.; Yanne, P. Determination of total iron-reactive phenolics, anthocyanins and tannins in wine grapes of skins and seeds based on near-infrared hyperspectral imaging. Food Chem. 2017, 237, 811–817. [Google Scholar] [CrossRef] [PubMed]
- Gao, S.; Xu, J.H. Hyperspectral image information fusion-based detection of soluble solids content in red globe grapes. Comput. Electron. Agric. 2022, 196, 106822. [Google Scholar] [CrossRef]
- Benelli, A.; Cevoli, C.; Ragni, L.; Fabbri, A. In-field and non-destructive monitoring of grapes maturity by hyperspectral imaging. Biosyst. Eng. 2021, 207, 59–67. [Google Scholar] [CrossRef]
- Zhang, J.; Lei, Y.; He, L.; Hu, X.; Tian, J.; Chen, M.; Huang, D.; Luo, H. The rapid detection of the tannin content of grains based on hyperspectral imaging technology and chemometrics. J. Food Compos. Anal. 2023, 123, 105604. [Google Scholar] [CrossRef]
- Rouxinol, M.I.; Martins, M.R.; Murta, G.C.; Mota Barroso, J.; Rato, A.E. Quality Assessment of Red Wine Grapes through NIR Spectroscopy. Agronomy 2022, 12, 637. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, Y.; Liu, B.; Chao, W.; Duan, X.; Yue, T. Using hyperspectral imaging technology for assessing internal quality parameters of persimmon fruits during the drying process. Food Chem. 2022, 386, 132774. [Google Scholar] [CrossRef] [PubMed]
- Gao, S.; Wang, Q.; Fu, D.; Li, Q. Nondestructive detection of red grape sugar content and hardness by hyperspectral imaging. J. Opt. 2019, 10, 355–364. [Google Scholar]
- Nogales-Bueno, J.; Baca-Bocanegra, B.; Rodríguez-Pulido, F.J.; Heredia, F.J.; Hernández-Hierro, J.M. Use of near infrared hyperspectral tools for the screening of extractable polyphenols in red grape skins. Food Chem. 2015, 172, 559–564. [Google Scholar] [CrossRef] [PubMed]
- Vines, L.L.; Kays, S.E.; Koehler, P.E. Near-infrared reflectance model for the rapid prediction of total fat in cereal foods. J. Agric. Food Chem. 2005, 53, 1550–1555. [Google Scholar] [CrossRef] [PubMed]
- Yue, J.; Yang, G.; Feng, H. Comparative of remote sensing estimation models of winter wheat biomass based on random forest algorithm. Trans. Chin. Soc. Agric. Eng. 2016, 32, 175–182. [Google Scholar]
- Li, Z.; Song, J.; Ma, Y.; Yu, Y.; He, X.; Guo, Y.; Dou, J.; Dong, H. Identification of aged-rice adulteration based on near-infrared spectroscopy combined with partial least squares regression and characteristic wavelength variables. Food Chem. 2023, 17, 100539. [Google Scholar] [CrossRef] [PubMed]
- Zheng, C.; Abd-Elrahman, A.; Whitaker, V.M.; Dalid, C. Deep learning for strawberry canopy delineation and biomass prediction from high-resolution images. Plant Phenomics 2022, 2022, 9850486. [Google Scholar] [CrossRef]
- Matteoli, S.; Diani, M.; Massai, R.; Corsini, G.; Remorini, D. A spectroscopy-based approach for automated nondestructive maturity grading of peach fruits. IEEE Sens. J. 2015, 15, 5455–5464. [Google Scholar] [CrossRef]
- Fadock, M.; Brown, R.B.; Reynolds, A.G. Visible-near infrared reflectance spectroscopy for nondestructive analysis of red wine grapes. Am. J. Enol. Vitic. 2016, 67, 38–46. [Google Scholar] [CrossRef]
- Zhou, X.; Liu, W.; Li, K.; Lu, D.; Su, Y.; Ju, Y.; Fang, Y.; Yang, J. Discrimination of Maturity Stages of Cabernet Sauvignon Wine Grapes Using Visible–Near-Infrared Spectroscopy. Foods 2023, 12, 4371. [Google Scholar] [CrossRef]
- Saad, A.; Azam, M.M.; Amer, B.M. Quality analysis prediction and discriminating strawberry maturity with a hand-held Vis–NIR spectrometer. Food Anal. Methods 2022, 15, 689–699. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Variety | Measuring Time | Sample Size | Minimum (g/L) | Maximum (g/L) | Mean (g/L) | Standard Deviation (g/L) |
|---|---|---|---|---|---|---|
| Chardonnay | 2021 | 40 | 1.12 | 3.19 | 2.01 | 0.46 |
| 2022 | 40 | 1.09 | 3.85 | 2.32 | 0.59 | |
| Pinot Noir | 2021 | 40 | 1.06 | 3.31 | 2.35 | 0.70 |
| 2022 | 40 | 1.08 | 3.92 | 2.66 | 0.86 |
| Preprocessing Method | Number of Feature Bands | Maximum Correlation Coefficient |
|---|---|---|
| 1D | 19 | 0.63 |
| SG | 20 | 0.72 |
| SNV | 20 | 0.86 |
| SG1D | 19 | 0.60 |
| SG1DSNV | 20 | 0.62 |
| RAW | 20 | 0.73 |
| Preprocessing Method | Train | Test | ||||
|---|---|---|---|---|---|---|
| R2 | RMSE | RE (%) | R2 | RMSE | RE (%) | |
| Raw | 0.78 | 0.33 | 11.56 | 0.71 | 0.35 | 12.07 |
| 1D | 0.80 | 0.31 | 9.63 | 0.66 | 0.38 | 13.61 |
| SG | 0.78 | 0.33 | 11.56 | 0.71 | 0.35 | 12.07 |
| SNV | 0.78 | 0.33 | 11.13 | 0.77 | 0.31 | 10.77 |
| SG1D | 0.64 | 0.43 | 13.90 | 0.43 | 0.49 | 18.39 |
| SG1DSNV | 0.59 | 0.45 | 13.86 | 0.37 | 0.52 | 19.53 |
| Preprocessing Method | Train | Test | ||||
|---|---|---|---|---|---|---|
| R2 | RMSE | RE (%) | R2 | RMSE | RE (%) | |
| Raw | 0.96 | 0.14 | 4.72 | 0.80 | 0.29 | 9.64 |
| 1D | 0.95 | 0.16 | 5.63 | 0.56 | 0.43 | 16.16 |
| SG | 0.96 | 0.14 | 4.77 | 0.81 | 0.28 | 9.29 |
| SNV | 0.97 | 0.12 | 4.25 | 0.78 | 0.31 | 10.71 |
| SG1D | 0.92 | 0.20 | 7.19 | 0.40 | 0.51 | 20.92 |
| SG1DSNV | 0.92 | 0.20 | 7.17 | 0.39 | 0.51 | 19.97 |
| Preprocessing Method | Train | Test | ||||
|---|---|---|---|---|---|---|
| R2 | RMSE | RE (%) | R2 | RMSE | RE (%) | |
| Raw | 0.67 | 0.41 | 15.07 | 0.57 | 0.43 | 16.66 |
| 1D | 0.68 | 0.40 | 15.41 | 0.69 | 0.36 | 13.10 |
| SG | 0.67 | 0.41 | 15.07 | 0.57 | 0.43 | 16.66 |
| SNV | 0.78 | 0.33 | 11.13 | 0.77 | 0.31 | 10.77 |
| SG1D | 0.55 | 0.48 | 17.94 | 0.59 | 0.42 | 16.51 |
| SG1DSNV | 0.53 | 0.49 | 17.62 | 0.47 | 0.47 | 18.75 |
| Preprocessing Method | Train | Test | ||||
|---|---|---|---|---|---|---|
| R2 | RMSE | RE (%) | R2 | RMSE | RE (%) | |
| Raw | 0.31 | 1.60 | 27.82 | 0.23 | 1.53 | 24.12 |
| 1D | 0.76 | 0.35 | 10.84 | 0.31 | 0.54 | 21.34 |
| SG | 0.43 | 1.03 | 23.53 | 0.27 | 0.81 | 17.03 |
| SNV | 0.67 | 0.41 | 15.55 | 0.66 | 0.38 | 14.15 |
| SG1D | 0.66 | 0.41 | 14.56 | 0.50 | 0.46 | 19.12 |
| SG1DSNV | 0.87 | 0.26 | 8.84 | 0.21 | 0.58 | 23.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Wu, Q.; Wang, Y.; Huang, Y.; Xie, M.; Fan, L. Rapid Detection of Tannin Content in Wine Grapes Using Hyperspectral Technology. Life 2024, 14, 416. https://doi.org/10.3390/life14030416
Zhang P, Wu Q, Wang Y, Huang Y, Xie M, Fan L. Rapid Detection of Tannin Content in Wine Grapes Using Hyperspectral Technology. Life. 2024; 14(3):416. https://doi.org/10.3390/life14030416
Chicago/Turabian StyleZhang, Peng, Qiang Wu, Yanhan Wang, Yun Huang, Min Xie, and Li Fan. 2024. "Rapid Detection of Tannin Content in Wine Grapes Using Hyperspectral Technology" Life 14, no. 3: 416. https://doi.org/10.3390/life14030416