
Pulmonary Nodule Detection and Classification Using All-Optical Deep Diffractive Neural Network
 , and
, and
Abstract
:1. Introduction
2. Methods
2.1. Dataset
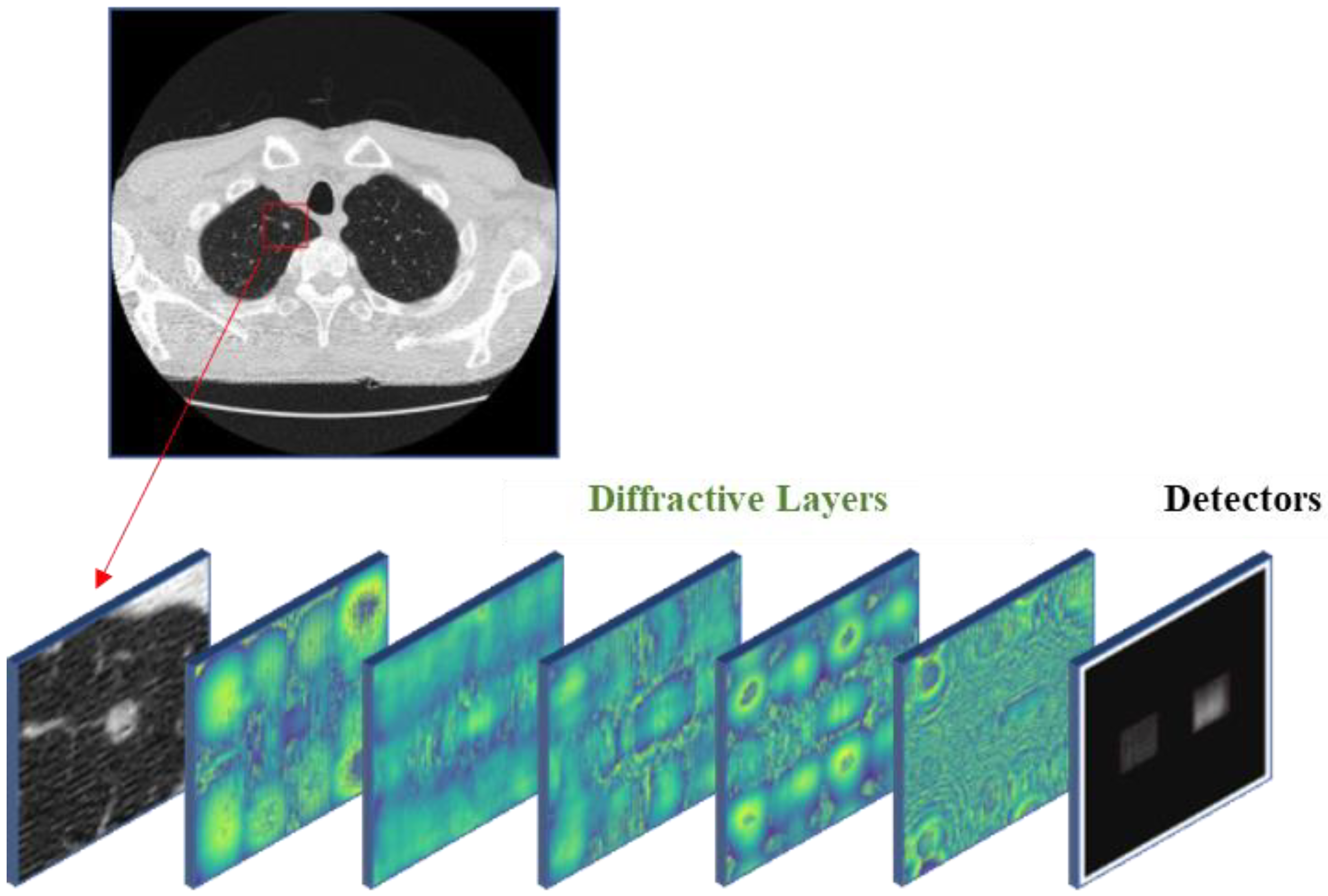
2.2. All-Optical Diffractive Deep Neural Network

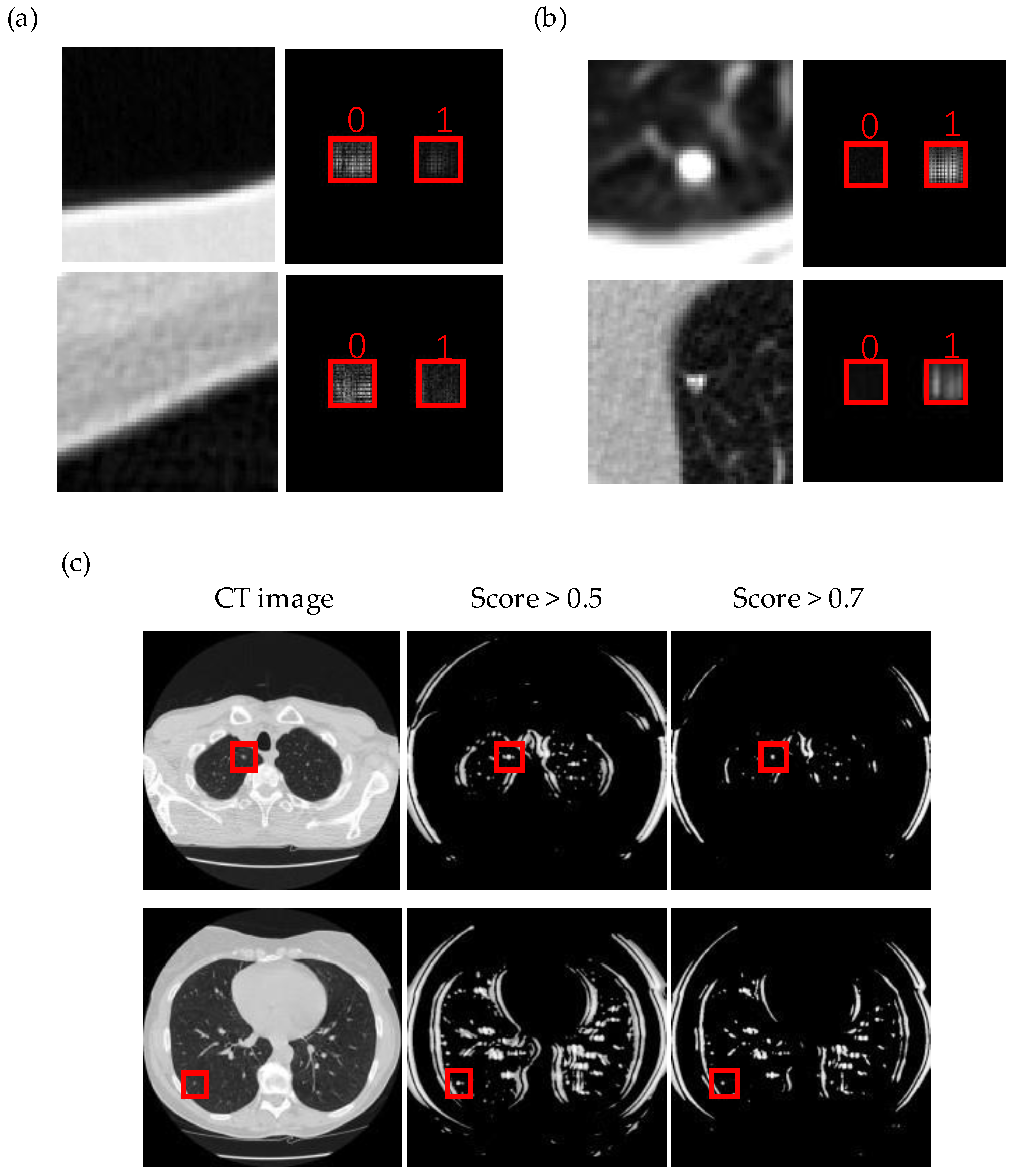
2.3. Pulmonary Nodule Detection
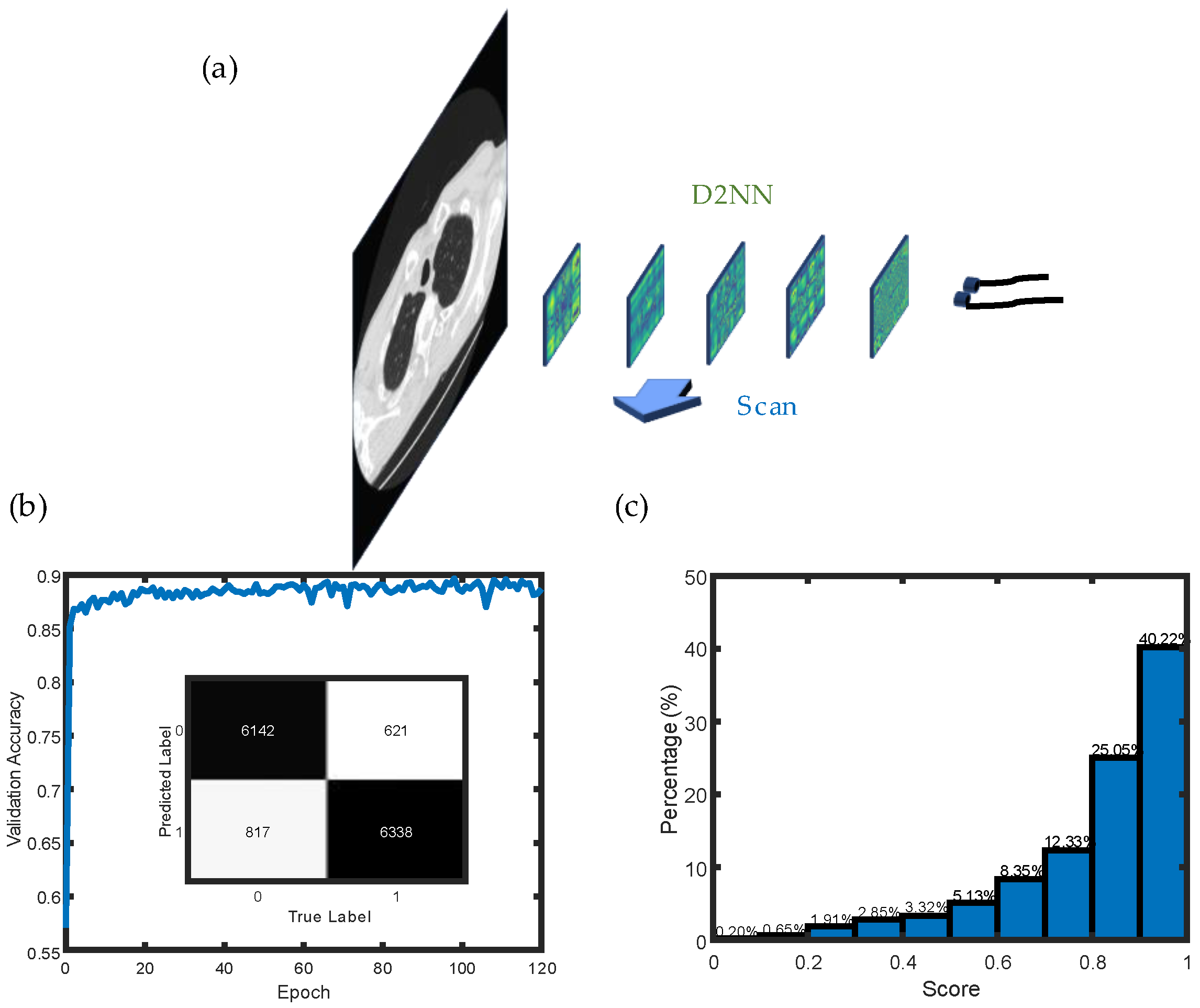
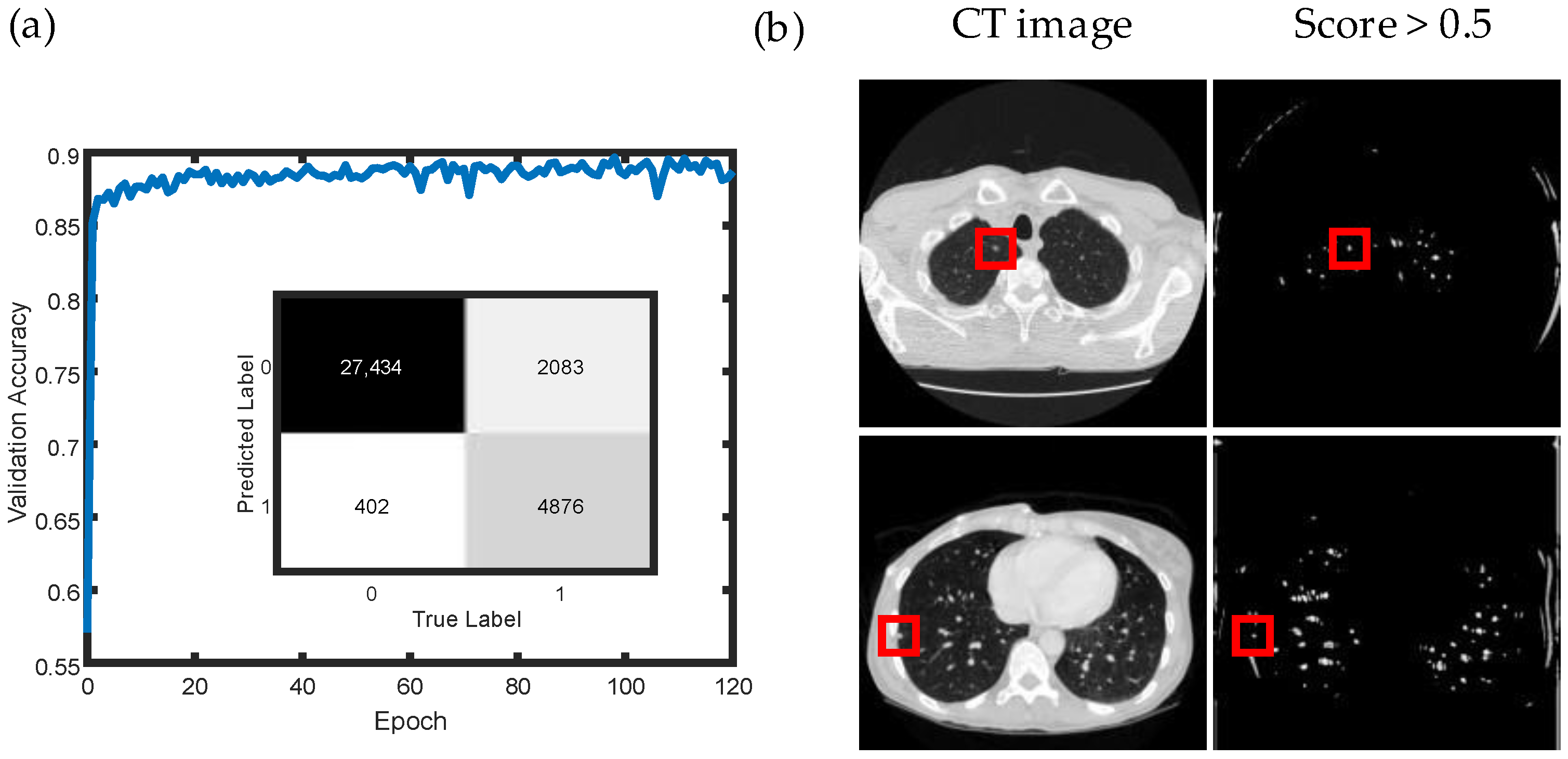
2.4. Pulmonary Nodule Classification
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process Syst. 2017, 30. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process Syst. 2017, 27. [Google Scholar]
- Zhang, T.; Ye, W.; Yang, B.; Zhang, L.; Ren, X.; Liu, D.; Sun, J.; Zhang, S.; Zhang, H.; Zhao, W. Frequency-Aware Contrastive Learning for Neural Machine Translation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February 2022. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6 July 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 20 June 2021. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7 June 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Borse, S.; Wang, Y.; Zhang, Y.; Porikli, F. InverseForm: A Loss Function for Structured Boundary-Aware Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19 June 2021. [Google Scholar]
- Choi, J.; Chun, D.; Kim, H.; Lee, H.J. Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019. [Google Scholar]
- Aghdam, H.H.; Heravi, E.J.; Demilew, S.S.; Laganiere, R. RAD: Realtime and Accurate 3D Object Detection on Embedded Systems. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 20 June 2021. [Google Scholar]
- Xu, X.Y.; Tan, M.X.; Corcoran, B.; Wu, J.Y.; Boes, A.; Nguyen, T.G.; Chu, S.T.; Little, B.E.; Hicks, D.G.; Morandotti, R.; et al. 11 TOPS photonic convolutional accelerator for optical neural networks. Nature 2021, 589, 44–51. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhang, W.J.; Yang, F.; He, Z.Y. Photonic convolution neural network based on interleaved time-wavelength modulation. J. Light. Technol. 2021, 39, 4592–4600. [Google Scholar] [CrossRef]
- Shen, Y.C.; Harris, N.C.; Skirlo, S.; Prabhu, M.; Baehr-Jones, T.; Hochberg, M.; Sun, X.; Zhao, S.J.; Larochelle, H.; Englund, D.; et al. Deep learning with coherent nanophotonic circuits. Nat. Photonics 2017, 11, 441–446. [Google Scholar] [CrossRef]
- Hughes, T.W.; Minkov, M.; Shi, Y.; Fan, S.H. Training of photonic neural networks through in situ backpropagation and gradient measurement. Optica 2018, 5, 864–871. [Google Scholar] [CrossRef]
- Fang, M.Y.S.; Manipatruni, S.; Wierzynski, C.; Khosrowshahi, A.; DeWeese, M.R. Design of optical neural networks with component imprecisions. Opt. Express 2019, 27, 14009–14029. [Google Scholar] [CrossRef]
- Feldmann, J.; Youngblood, N.; Wright, C.D.; Bhaskaran, H.; Pernice, W.H.P. All-optical spiking neurosynaptic networks with self-learning capabilities. Nature 2019, 569, 208–214. [Google Scholar] [CrossRef] [PubMed]
- Xiang, S.Y.; Ren, Z.X.; Song, Z.W.; Zhang, Y.H.; Guo, X.X.; Han, G.Q.; Hao, Y. Computing primitive of fully VCSEL-based all-optical spiking neural network for supervised learning and pattern classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2494–2505. [Google Scholar] [CrossRef] [PubMed]
- Lin, X.; Rivenson, Y.; Yardimei, N.T.; Veli, M.; Luo, Y.; Jarrahi, M.; Ozcan, A. All-optical machine learning using diffractive deep neural networks. Science 2018, 361, 1004–1008. [Google Scholar] [CrossRef] [PubMed]
- Li, J.X.; Mengu, D.; Luo, Y.; Rivenson, Y.; Ozcan, A. Class-specific differential detection in diffractive optical neural networks improves inference accuracy. Adv. Photonics 2019, 1, 046001. [Google Scholar] [CrossRef]
- Yan, T.; Wu, J.M.; Zhou, T.K.; Xie, H.; Xu, F.; Fan, J.T.; Fang, L.; Lin, X.; Dai, Q.H. Fourier-space diffractive deep neural network. Phys. Rev. Lett. 2019, 123, 023901. [Google Scholar] [CrossRef]
- Zhou, T.K.; Lin, X.; Wu, J.M.; Chen, Y.T.; Xie, H.; Li, Y.P.; Fan, J.T.; Wu, H.Q.; Fang, L.; Dai, Q.H. Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit. Nat. Photonics 2021, 15, 367–373. [Google Scholar] [CrossRef]
- Rahman, M.S.S.; Li, J.X.; Mengu, D.; Rivenson, Y.; Ozcan, A. Ensemble learning of diffractive optical networks. Light Sci. Appl. 2021, 10, 14. [Google Scholar] [CrossRef]
- Fang, T.; Li, J.W.; Zhang, X.; Dong, X.W. Classification accuracy improvement of the optical diffractive deep neural network by employing a knowledge distillation and stochastic gradient descent beta-Lasso joint training framework. Opt. Express 2021, 29, 44264–44274. [Google Scholar] [CrossRef]
- Shi, J.S.; Chen, Y.S.; Zhang, X.Y. Broad-spectrum diffractive network via ensemble learning. Opt. Lett. 2022, 47, 605–608. [Google Scholar] [CrossRef]
- Mengu, D.; Zhao, Y.F.; Yardimci, N.T.; Rivenson, Y.; Jarrahi, M.; Ozcan, A. Misalignment resilient diffractive optical networks. Nanophotonics 2020, 9, 4207–4219. [Google Scholar] [CrossRef]
- Mengu, D.; Rivenson, Y.; Ozcan, A. Scale-, shift-, and rotation-invariant diffractive optical networks. ACS Photonics 2021, 8, 324–334. [Google Scholar] [CrossRef]
- Shi, J.S.; Chen, M.C.; Wei, D.; Hu, C.; Luo, J.; Wang, H.W.; Zhang, X.Y.; Xie, C.S. Anti-noise diffractive neural network for constructing an intelligent imaging detector array. Opt. Express 2020, 28, 37686–37699. [Google Scholar] [CrossRef] [PubMed]
- Mengu, D.; Luo, Y.; Rivenson, Y.; Ozcan, A. Analysis of diffractive optical neural networks and their integration with electronic neural networks. IEEE J. Sel. Top. Quantum Electron. 2020, 26, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Mengu, D.; Yardimci, N.T.; Rivenson, Y.; Veli, M.; Jarrahi, M.; Ozcan, A. Design of task-specific optical systems using broadband diffractive neural networks. Light Sci. Appl. 2019, 8, 112. [Google Scholar] [CrossRef]
- Veli, M.; Mengu, D.; Yardimci, N.T.; Luo, Y.; Li, J.X.; Rivenson, Y.; Jarrahi, M.; Ozcan, A. Terahertz pulse shaping using diffractive surfaces. Nat. Commun. 2021, 12, 37. [Google Scholar] [CrossRef]
- Qian, C.; Lin, X.; Lin, X.B.; Xu, J.; Sun, Y.; Li, E.R.; Zhang, B.L.; Chen, H.S. Performing optical logic operations by a diffractive neural network. Light Sci. Appl. 2020, 9, 59. [Google Scholar] [CrossRef]
- Luo, Y.; Mengu, D.; Ozcan, A. Cascadable all-optical NAND gates using diffractive networks. Sci. Rep. 2022, 12, 7121. [Google Scholar] [CrossRef]
- Ali, I.; Hart, G.R.; Gunabushanam, G.; Liang, Y.; Muhammad, W.; Nartowt, B.; Kane, M.; Ma, X.M.; Deng, J. Lung nodule detection via deep reinforcement learning. Front. Oncol. 2018, 8, 108. [Google Scholar] [CrossRef]
- Harsono, I.W.; Liawatimena, S.; Cenggoro, T.W. Lung nodule detection and classification from Thorax CT-scan using RetinaNet with transfer learning. J. King Saud Univ.-Comput. Inf. Sci. 2020, 34, 567–577. [Google Scholar] [CrossRef]
- Cao, H.C.; Liu, H.; Song, E.M.; Ma, G.Z.; Xu, X.Y.; Jin, R.C.; Liu, T.Y.; Hung, C.C. A two-stage convolutional neural networks for lung Nodule Detection. IEEE J. Biomed. Health Inform. 2020, 24, 2006–2015. [Google Scholar] [CrossRef]
- Song, Q.Z.; Zhao, L.; Luo, X.K.; Dou, X.C. Using deep learning for classification of lung nodules on computed tomography images. J. Healthc. Eng. 2017, 2017, 8314740. [Google Scholar] [CrossRef] [PubMed]
- Apostolopoulos, I.D.; Papathanasiou, N.D.; Panayiotakis, G.S. Classification of lung nodule malignancy in computed tomography imaging utilising generative adversarial networks and semi-supervised transfer learning. Biocybern. Biomed. Eng. 2021, 41, 1243–1257. [Google Scholar] [CrossRef]
- Chen, H.; Feng, J.A.; Jiang, M.W.; Wang, Y.Q.; Lin, J.; Tan, J.B.; Jin, P. Diffractive deep neural networks at visible wavelengths. Engineering 2021, 7, 1483–1491. [Google Scholar] [CrossRef]
- Luo, X.H.; Hu, Y.Q.; Ou, X.N.; Li, X.; Lai, J.J.; Liu, N.; Cheng, X.B.; Pan, A.L.; Duan, H.G. Metasurface-enabled on-chip multiplexed diffractive neural networks in the visible. Light Sci. Appl. 2022, 11, 158. [Google Scholar] [CrossRef]
- Hu, Y.; Fu, S.; Wang, S.; Zhang, W.; Kwok, H.S. Flatness and Diffractive Wavefront Measurement of Liquid Crystal Computer-Generated Hologram Based on Photoalignment Technology. In Proceedings of the 9th International Symposium on Advanced Optical Manufacturing and Testing Technologies: Meta-Surface-Wave and Planar Optics, Chengdu, China, 26 June 2018. [Google Scholar]
- Goodman, J.W. Introduction to Fourier Optics; Roberts and Company Publishers: Greenwood Village, CO, USA, 2005. [Google Scholar]
- Nibali, A.; He, Z.; Wollershhheim, D. Pulmonary nodule classification with deep residual networks. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 1799–1808. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, L.; Qi, S.; Teng, Y.; Li, J.; Qian, W. Agile convolutional neural network for pulmonary nodule classification using CT images. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 585–595. [Google Scholar] [CrossRef]
- Kulce, O.; Mengu, D.; Rivenson, Y.; Ozcan, A. All-optical information-processing capacity of diffractive surfaces. Light Sci. Appl. 2021, 10, 25. [Google Scholar] [CrossRef]
- Li, J.; Hung, Y.C.; Kulce, O.; Mengu, D.; Ozcan, A. Polarization multiplexed diffractive computing: All-optical implementation of a group of linear transformations through a polarization-encoded diffractive network. Light Sci. Appl. 2022, 11, 153. [Google Scholar] [CrossRef]
- Bai, B.; Li, Y.; Luo, Y.; Li, X.; Cetintas, E.; Jarrahi, M.; Ozcan, A. All-optical image classification through unknown random diffusers using a single-pixel diffractive network. Light Sci. Appl. 2023, 12, 69. [Google Scholar] [CrossRef]
- Zuo, Y.; Li, B.H.; Zhao, Y.J.; Jiang, Y.; Chen, Y.C.; Chen, P.; Jo, G.B.; Liu, J.W.; Du, S.W. All-optical neural network with nonlinear activation functions. Optica 2019, 6, 1132–1137. [Google Scholar] [CrossRef]
- Li, Y.M.; Zheng, Z.X.; Li, R.; Chen, Q.; Luan, H.T.; Yang, H.; Zhang, Q.M.; Gu, M. Multiscale diffractive U-Net: A robust all-optical deep learning framework modeled with sampling and skip connections. Opt. Express 2022, 30, 36700–36710. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Accuracy (%) | Recall (Sensitivity) (%) | Precision (%) | F1 Score | MMC |
|---|---|---|---|---|---|
| Trained with 1:1 ratio (validation set) | 89.54 | 90.96 | 88.44 | 0.8968 | 0.7911 |
| Trained with 1:1 ratio (test set) | 89.67 | 91.08 | 88.58 | 0.8981 | 0.7937 |
| Trained with 1:4 ratio (validation set) | 92.67 | 69.66 | 91.68 | 0.7917 | 0.7586 |
| Trained with 1:4 ratio (test set) | 92.86 | 70.07 | 79.68 | 0.7218 | 0.8585 |
| Work | Accuracy (%) | Recall (Sensitivity) (%) | Precision (%) | F1 Score | MMC |
|---|---|---|---|---|---|
| Validation set | 67.13 | 51.35 | 77.08 | 0.6164 | 0.3706 |
| Test set | 76.77 | 65.97 | 79.68 | 0.7218 | 0.5323 |
| Study | Recall (Sensitivity) (%) | Runtime |
|---|---|---|
| Ali et al. [38] | 58.9 | DPPU |
| Harsono et al. [39] | 94.12 | DPPU |
| Cao et al. [40] | 92.5 | DPPU |
| Ours trained with 1:1 ratio | 91.08 | Real time |
| Ours trained with 1:4 ratio | 70.07 | Real time |
| Study | Accuracy (%) | Recall (Sensitivity) (%) | Specificity (%) | AUC | Runtime |
|---|---|---|---|---|---|
| Song et al. [41] | 82.59 | 83.96 | 81.35 | 0.884 | DPPU |
| Nibali et al. [47] | 89.90 | 91.07 | 88.64 | 0.9459 | DPPU |
| Zhao et al. [48] | 82.2 | NA | NA | 0.877 | DPPU |
| Apostolopoulos et al. [42] | 92.07 | 89.35 | 94.80 | 0.9208 | DPPU |
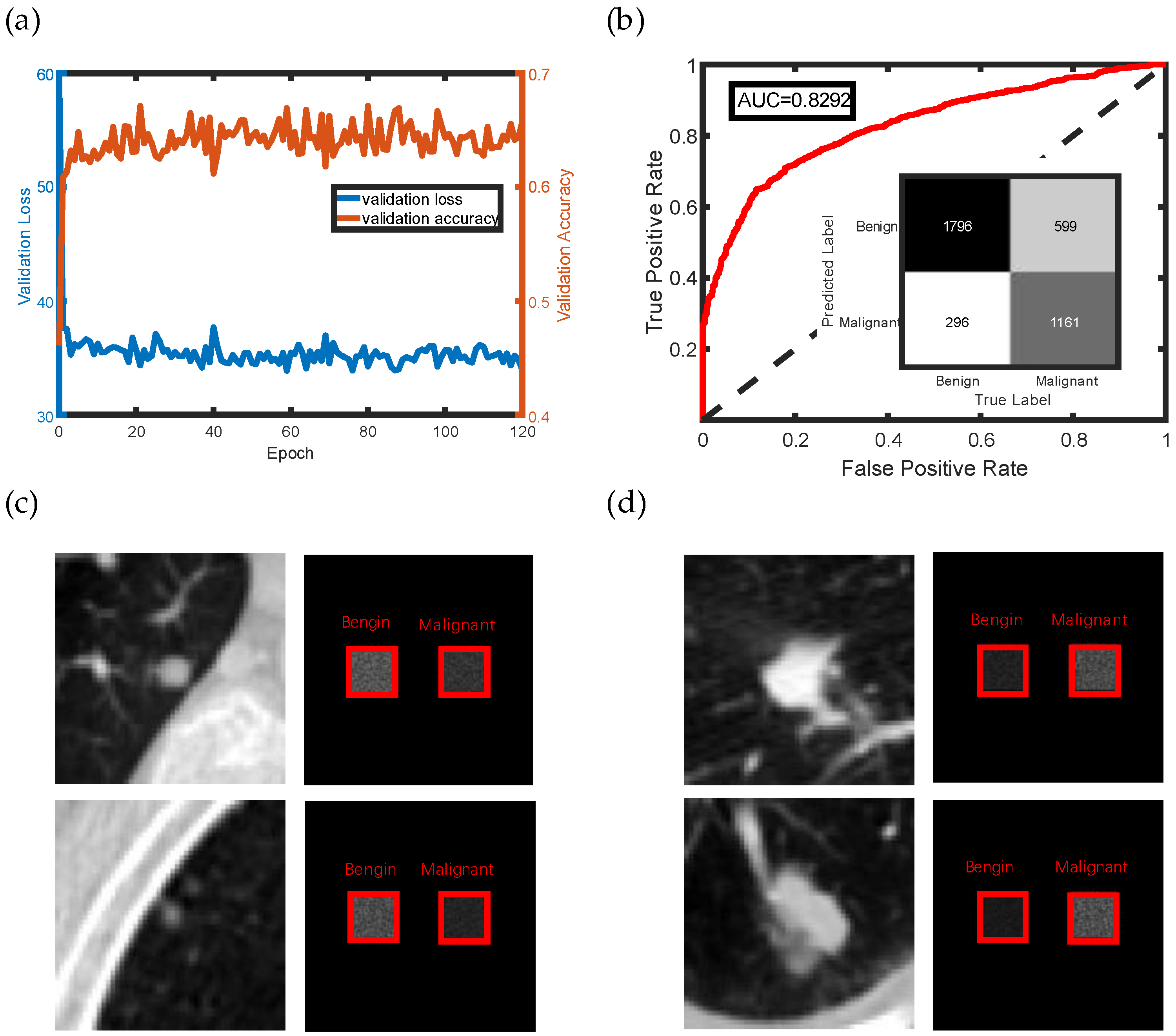
| Ours | 76.77 | 65.97 | 85.85 | 0.8292 | Real time |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, J.; Zhou, L.; Yeung, S.Y.F.; Lei, T.; Zhang, W.; Yuan, X. Pulmonary Nodule Detection and Classification Using All-Optical Deep Diffractive Neural Network. Life 2023, 13, 1148. https://doi.org/10.3390/life13051148
Shao J, Zhou L, Yeung SYF, Lei T, Zhang W, Yuan X. Pulmonary Nodule Detection and Classification Using All-Optical Deep Diffractive Neural Network. Life. 2023; 13(5):1148. https://doi.org/10.3390/life13051148
Chicago/Turabian StyleShao, Junjie, Lingxiao Zhou, Sze Yan Fion Yeung, Ting Lei, Wanlong Zhang, and Xiaocong Yuan. 2023. "Pulmonary Nodule Detection and Classification Using All-Optical Deep Diffractive Neural Network" Life 13, no. 5: 1148. https://doi.org/10.3390/life13051148