
TranSegNet: Hybrid CNN-Vision Transformers Encoder for Retina Segmentation of Optical Coherence Tomography
Abstract
:1. Introduction
2. Methods
2.1. Problem Statement
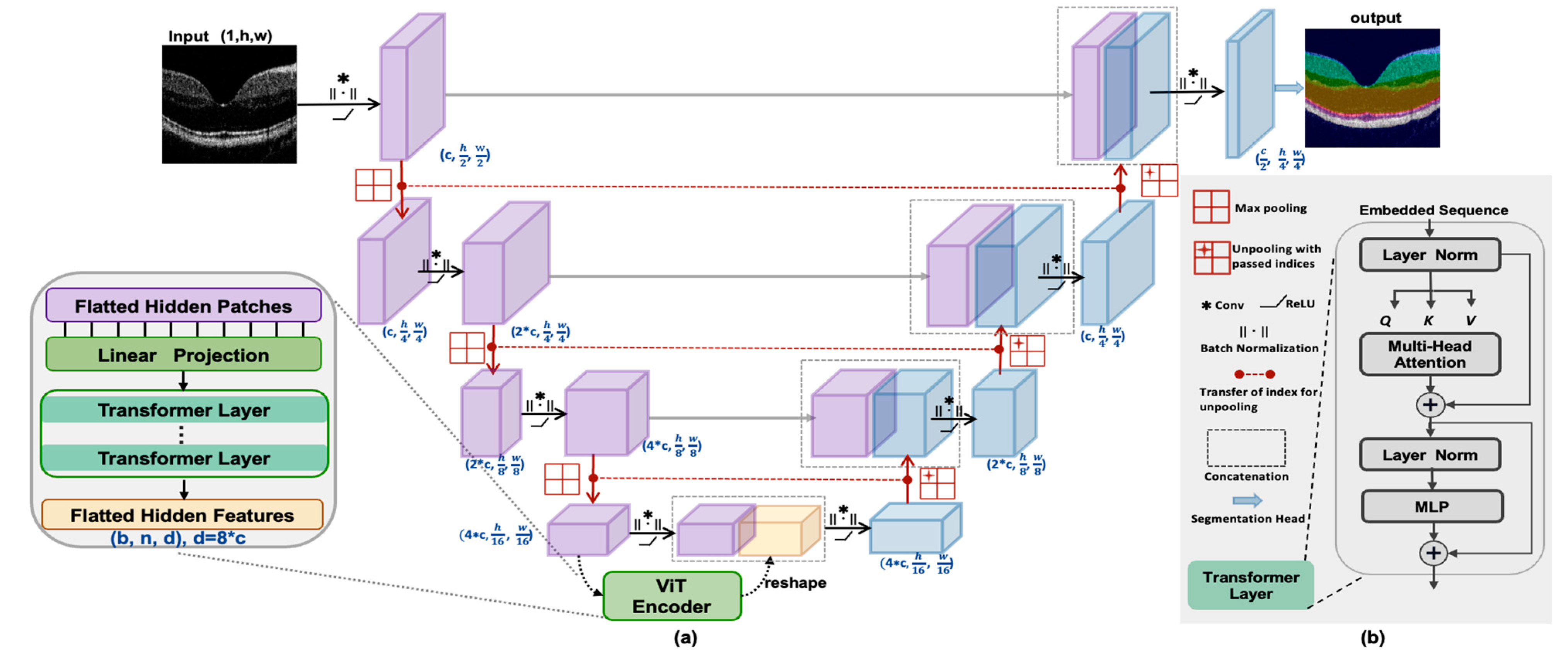
2.2. Network Architecture
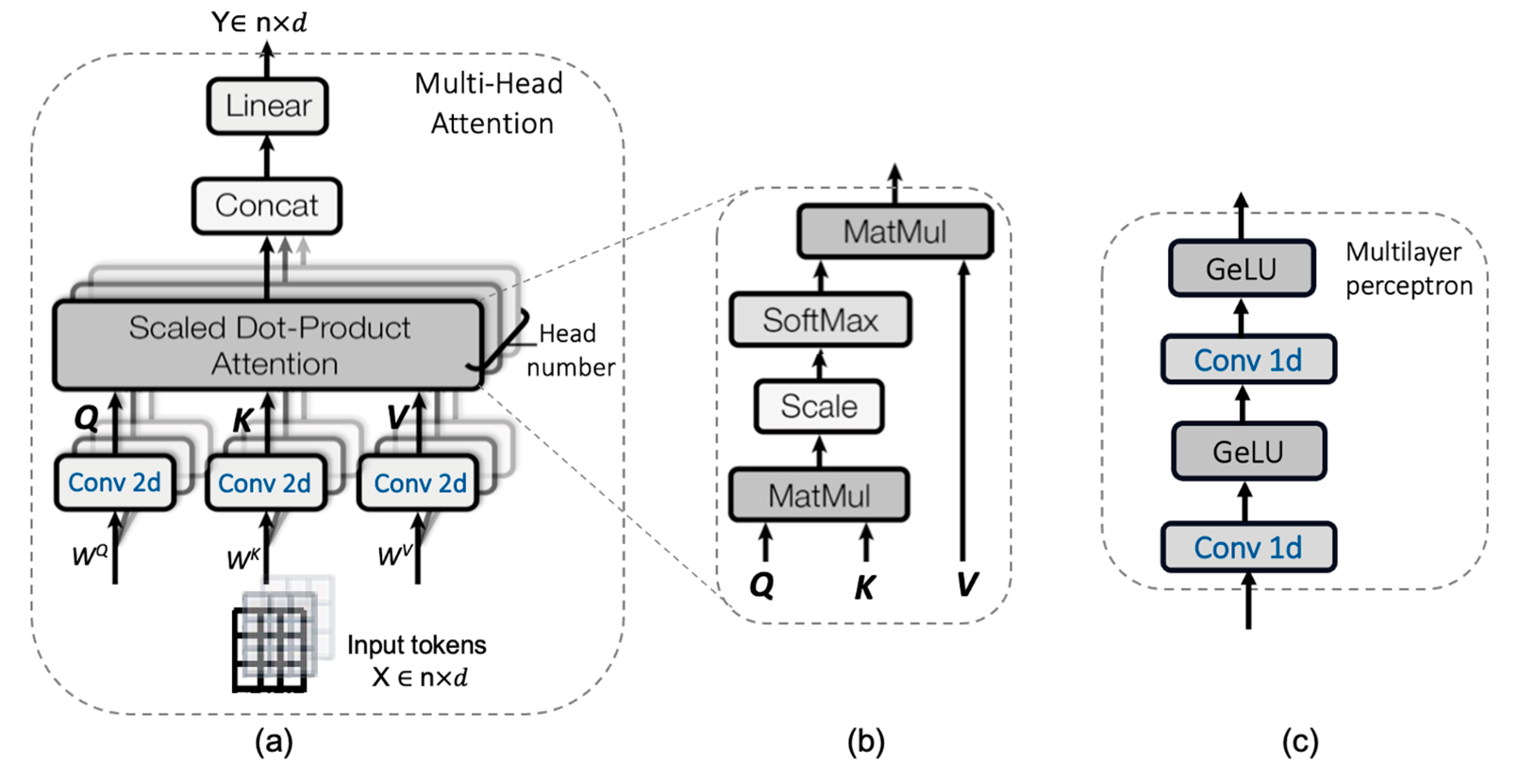
2.2.1. CNN-Transformer Hybrid as an Encoder
2.2.2. Decoder
2.3. Loss Function
3. Experimental Setup
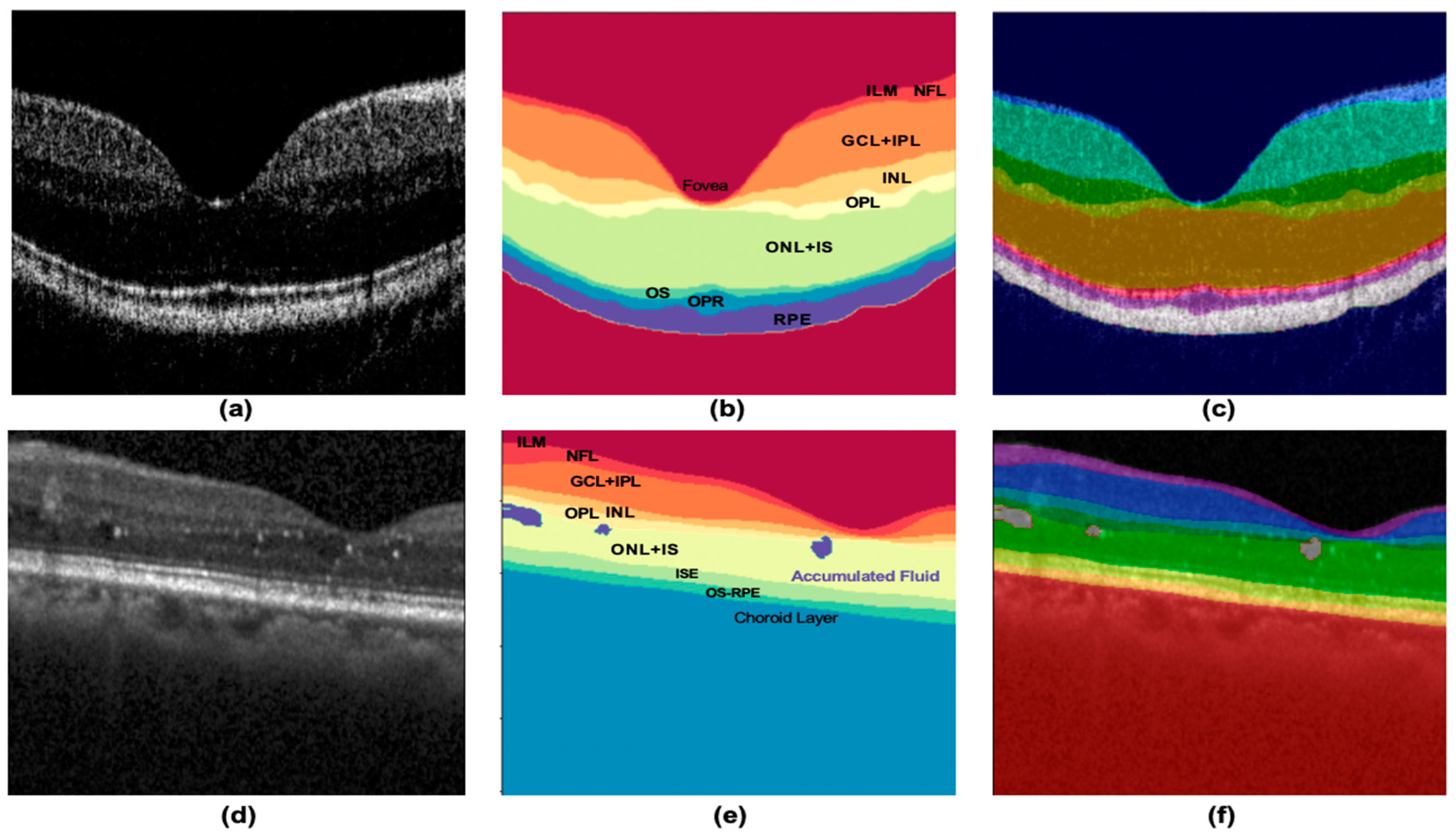
3.1. Dataset
3.2. Experimental Settings
3.3. Evaluation Metrics
4. Experimental
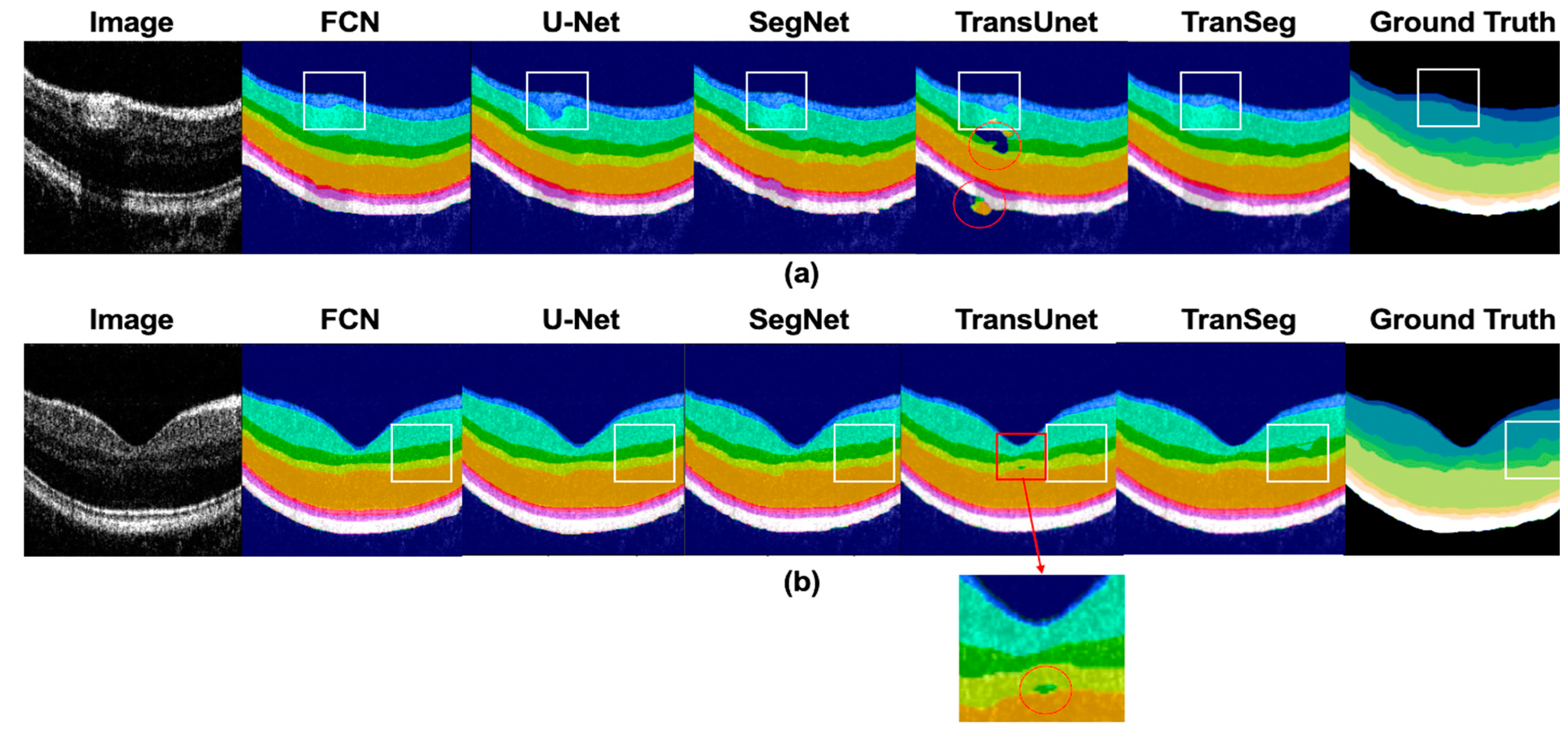
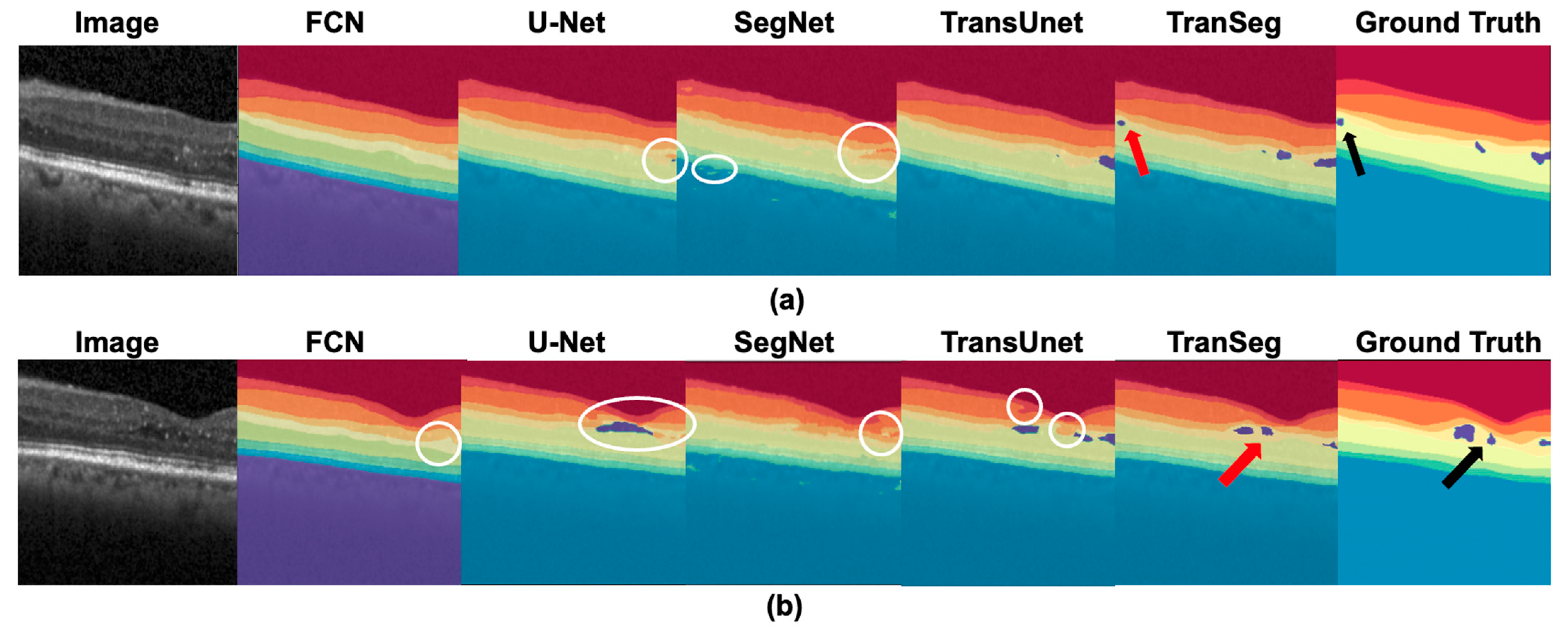
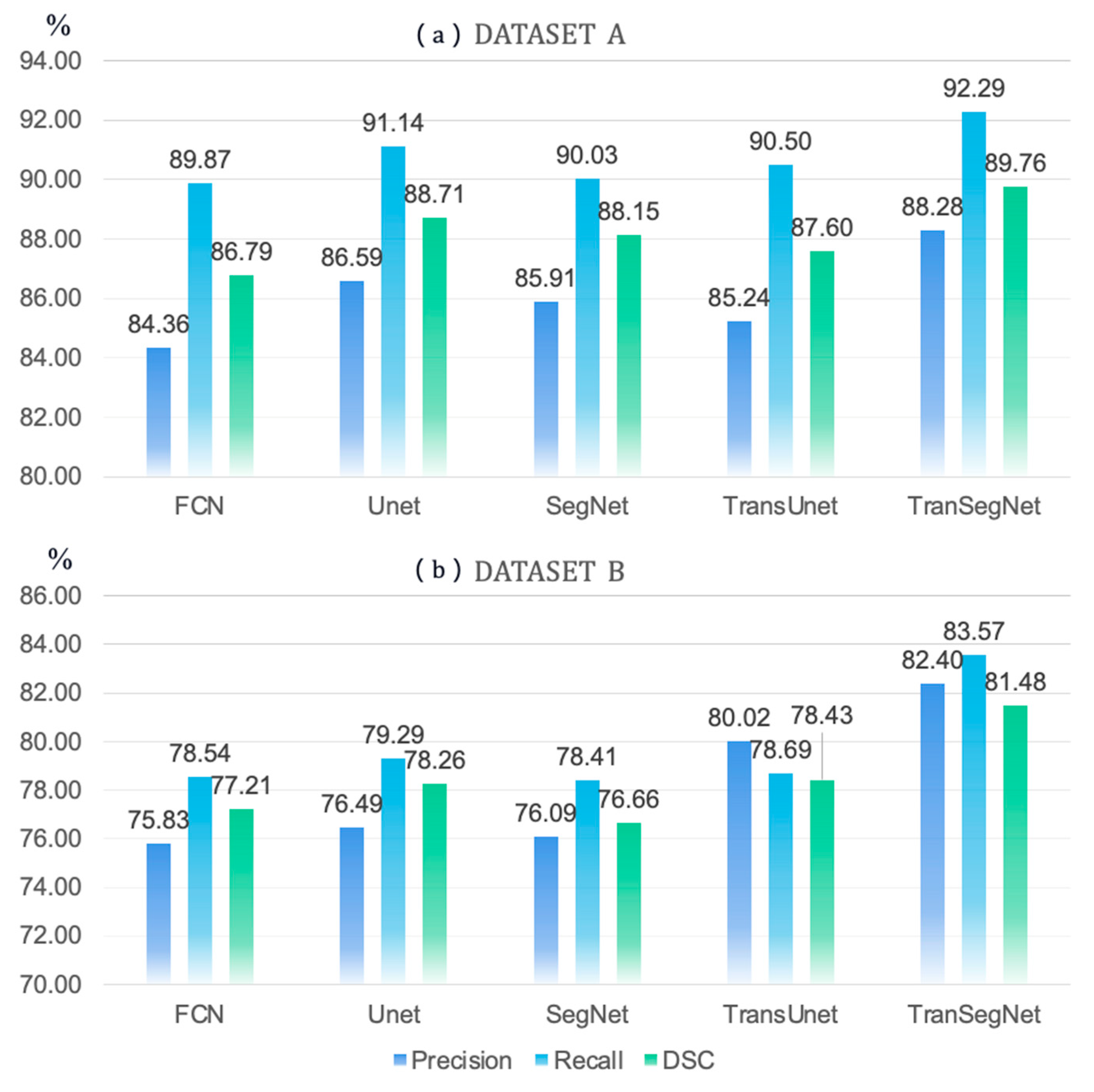
4.1. Comparison of TranSegNet with Comparative Methods
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Drexler, W.; Fujimoto, J.G. (Eds.) Optical Coherence Tomography; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, K.; Tsunoda, K.; Mizuno, Y.; Akiyama, K.; Noda, T. Outer Retinal Morphology and Visual Function in Patients With Idiopathic Epiretinal Membrane. JAMA Ophthalmol. 2013, 131, 172–177. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sakata, L.M.; DeLeon-Ortega, J.; Sakata, V.; A Girkin, C. Optical coherence tomography of the retina and optic nerve—A review. Clin. Exp. Ophthalmol. 2009, 37, 90–99. [Google Scholar] [CrossRef]
- Wan, M.; Liang, S.; Li, X.; Duan, Z.; Zou, J.; Chen, J.; Yuan, J.; Zhang, J. Dual-beam delay-encoded all fiber Doppler optical coherence tomography for in vivo measurement of retinal blood flow. Chin. Opt. Lett. 2022, 20, 011701. [Google Scholar] [CrossRef]
- Chen, C.; Shi, W.; Qiu, Z.; Yang, V.X.D.; Gao, W. B-scan-sectioned dynamic micro-optical coherence tomography for bulk-motion suppression. Chin. Opt. Lett. 2022, 20, 021102. [Google Scholar] [CrossRef]
- Pekala, M.; Joshi, N.; Liu, T.Y.A.; Bressler, N.M.; DeBuc, D.C.; Burlina, P. OCT Segmentation via Deep Learning: A Review of Recent Work. In Computer Vision—ACCV 2018 Workshops; Carneiro, G., You, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11367, pp. 316–322. [Google Scholar] [CrossRef]
- Ishikawa, H.; Stein, D.M.; Wollstein, G.; Beaton, S.; Fujimoto, J.G.; Schuman, J.S. Macular Segmentation with Optical Coherence Tomography. Investig. Opthalmol. Vis. Sci. 2005, 46, 2012–2017. [Google Scholar] [CrossRef] [Green Version]
- Tan, O.; Li, G.; Lu, A.T.-H.; Varma, R.; Huang, D. Mapping of Macular Substructures with Optical Coherence Tomography for Glaucoma Diagnosis. Ophthalmology 2008, 115, 949–956. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, X.; Yousefi, S.; An, L.; Wang, R.K. Automated segmentation of intramacular layers in Fourier domain optical coherence tomography structural images from normal subjects. J. Biomed. Opt. 2012, 17, 0460111–0460117. [Google Scholar] [CrossRef]
- Luo, S.; Yang, J.; Gao, Q.; Zhou, S.; Zhan, C.A. The Edge Detectors Suitable for Retinal OCT Image Segmentation. J. Health Eng. 2017, 2017, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fernández, D.C.; Villate, N.; Puliafito, C.A.; Rosenfeld, P.J. Comparing total macular volume changes measured by Optical Coherence Tomography with retinal lesion volume estimated by active contours. Investig. Ophthalmol. Vis. Sci. 2004, 45, 3072. [Google Scholar]
- Yazdanpanah, A.; Hamarneh, G.; Smith, B.; Sarunic, M. Intra-retinal Layer Segmentation in Optical Coherence Tomography Using an Active Contour Approach. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2009, London, UK, 20–24 September 2009; pp. 649–656. [Google Scholar] [CrossRef] [Green Version]
- Ghorbel, I.; Rossant, F.; Bloch, I.; Tick, S.; Paques, M. Automated segmentation of macular layers in OCT images and quantitative evaluation of performances. Pattern Recognit. 2011, 44, 1590–1603. [Google Scholar] [CrossRef]
- Garvin, M.K.; Abramoff, M.D.; Wu, X.; Russell, S.R.; Burns, T.L.; Sonka, M. Automated 3-D Intraretinal Layer Segmentation of Macular Spectral-Domain Optical Coherence Tomography Images. IEEE Trans. Med Imaging 2009, 28, 1436–1447. [Google Scholar] [CrossRef] [Green Version]
- Haeker, M.; Abràmoff, M.; Kardon, R.; Sonka, M. Segmentation of the surfaces of the retinal layer from OCT images. Med. Image Comput. Comput. Assist. Interv. 2006, 9 Pt 1, 800–807. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chiu, S.J.; Li, X.T.; Nicholas, P.; Toth, C.A.; Izatt, J.A.; Farsiu, S. Automatic segmentation of seven retinal layers in SDOCT images congruent with expert manual segmentation. Opt. Express 2010, 18, 19413–19428. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mohandass, G.; Natarajan, R.A.; Sendilvelan, S. Retinal Layer Segmentation in Pathological SD-OCT Images Using Boisterous Obscure Ratio Approach and its Limitation. Biomed. Pharmacol. J. 2017, 10, 1585–1591. [Google Scholar] [CrossRef]
- Ma, Y.; Gao, Y.; Li, Z.; Li, A.; Wang, Y.; Liu, J.; Yu, Y.; Shi, W.; Ma, Z. Automated retinal layer segmentation on optical coherence tomography image by combination of structure interpolation and lateral mean filtering. J. Innov. Opt. Heal. Sci. 2021, 14, 2140011. [Google Scholar] [CrossRef]
- Shirokanev, A.; Ilyasova, N.; Andriyanov, N.; Zamytskiy, E.; Zolotarev, A.; Kirsh, D. Modeling of Fundus Laser Exposure for Estimating Safe Laser Coagulation Parameters in the Treatment of Diabetic Retinopathy. Mathematics 2021, 9, 967. [Google Scholar] [CrossRef]
- Liu, J.; Yan, S.; Lu, N.; Yang, D.; Lv, H.; Wang, S.; Zhu, X.; Zhao, Y.; Wang, Y.; Ma, Z.; et al. Automated retinal boundary segmentation of optical coherence tomography images using an improved Canny operator. Sci. Rep. 2022, 12, 1–16. [Google Scholar] [CrossRef]
- Zawadzki, R.J.; Fuller, A.R.; Wiley, D.F.; Hamann, B.; Choi, S.S.; Werner, J.S. Adaptation of a support vector machine algorithm for segmentation and visualization of retinal structures in volumetric optical coherence tomography data sets. J. Biomed. Opt. 2007, 12, 041206. [Google Scholar] [CrossRef]
- Vermeer, K.A.; Van Der Schoot, J.; Lemij, H.G.; de Boer, J. Automated segmentation by pixel classification of retinal layers in ophthalmic OCT images. Biomed. Opt. Express 2011, 2, 1743–1756. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015. Available online: http://arxiv.org/abs/1505.04597 (accessed on 15 December 2022).
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv 2016. [Google Scholar] [CrossRef]
- Roy, A.G.; Conjeti, S.; Karri, S.P.K.; Sheet, D.; Katouzian, A.; Wachinger, C.; Navab, N. ReLayNet: Retinal Layer and Fluid Segmentation of Macular Optical Coherence Tomography using Fully Convolutional Network. arXiv 2017. [Google Scholar] [CrossRef] [Green Version]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. arXiv 2015. [Google Scholar] [CrossRef]
- Li, Q.; Li, S.; He, Z.; Guan, H.; Chen, R.; Xu, Y.; Wang, T.; Qi, S.; Mei, J.; Wang, W. DeepRetina: Layer Segmentation of Retina in OCT Images Using Deep Learning. Transl. Vis. Sci. Technol. 2020, 9, 61. [Google Scholar] [CrossRef]
- Yadav, S.K.; Kafieh, R.; Zimmermann, H.G.; Kauer-Bonin, J.; Nouri-Mahdavi, K.; Mohammadzadeh, V.; Shi, L.; Kadas, E.M.; Paul, F.; Motamedi, S.; et al. Deep Learning based Intraretinal Layer Segmentation using Cascaded Compressed U-Net. Neurology 2021, preprint. [Google Scholar] [CrossRef]
- Fazekas, B.; Aresta, G.; Lachinov, D.; Riedl, S.; Mai, J.; Schmidt-Erfurth, U.; Bogunovic, H. SD-LayerNet: Semi-supervised retinal layer segmentation in OCT using disentangled representation with anatomical priors. arXiv 2022. Available online: http://arxiv.org/abs/2207.00458 (accessed on 15 December 2022).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021. [Google Scholar] [CrossRef]
- Chiu, S.J.; Allingham, M.J.; Mettu, P.S.; Cousins, S.W.; Izatt, J.A.; Farsiu, S. Kernel regression based segmentation of optical coherence tomography images with diabetic macular edema. Biomed. Opt. Express 2015, 6, 1172–1194. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Srinivasan, P.P.; Kim, L.A.; Mettu, P.S.; Cousins, S.W.; Comer, G.M.; Izatt, J.A.; Farsiu, S. Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images. Biomed. Opt. Express BOE 2014, 5, 3568–3577. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. arXiv 2021. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017. [Google Scholar] [CrossRef]
- Aydin, O.U.; Taha, A.A.; Hilbert, A.; Khalil, A.A.; Galinovic, I.; Fiebach, J.B.; Frey, D.; Madai, V.I. On the usage of average Hausdorff distance for segmentation performance assessment: Hidden error when used for ranking. Eur. Radiol. Exp. 2021, 5, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Powers, D. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation. Mach. Learn. Technol. 2008, 2, 37–63. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acc (%) | HD (μm) | FLOPs (G) | Para (M) | Training Time (s) | |
|---|---|---|---|---|---|
| FCN (2014) | 92.53 ± 1.30 | 6.92 ± 0.98 | 194.71 | 31.90 | 219.30 |
| U-Net (2015) | 93.18 ± 0.65 | 7.53 ± 2.49 | 516.46 | 16.42 | 406.60 |
| SegNet (2015) | 93.45 ± 0.21 | 5.63 ± 1.12 | 255.14 | 19.41 | 280.82 |
| TransUnet (2021) | 93.36 ± 0.40 | 9.30 ± 1.10 | 383.96 | 42.66 | 352.03 |
| TranSegNet | 94.64 ± 0.06 | 5.29 ± 0.77 | 195.48 | 18.58 | 218.11 |
| % | BG | NFL | GCL+IPL | INL | OPL | ONL+IS | OS | OPR | RPE | |
|---|---|---|---|---|---|---|---|---|---|---|
| FCN | Precision | 99.73 | 80.04 | 97.51 | 75.87 | 69.13 | 98.24 | 75.88 | 87.19 | 75.61 |
| Recall | 97.09 | 93.52 | 90.12 | 93.15 | 80.97 | 92.86 | 86.76 | 81.59 | 92.78 | |
| DSC | 98.42 | 86.26 | 94.13 | 83.63 | 74.58 | 95.48 | 80.96 | 84.30 | 83.32 | |
| Unet | Precision | 99.82 | 81.89 | 98.11 | 84.61 | 72.43 | 98.30 | 78.40 | 86.26 | 79.52 |
| Recall | 97.47 | 95.37 | 93.64 | 88.87 | 85.44 | 94.04 | 84.73 | 87.44 | 93.25 | |
| DSC | 98.63 | 88.12 | 95.83 | 86.69 | 78.82 | 96.13 | 81.44 | 86.85 | 85.84 | |
| SegNet | Precision | 99.80 | 80.17 | 97.25 | 87.83 | 69.60 | 96.96 | 78.49 | 81.94 | 81.14 |
| Recall | 97.48 | 95.93 | 93.89 | 85.35 | 83.67 | 93.26 | 81.76 | 87.04 | 91.91 | |
| DSC | 98.63 | 87.76 | 96.04 | 86.57 | 76.80 | 95.08 | 81.12 | 84.41 | 86.90 | |
| TransUnet | Precision | 99.42 | 81.18 | 97.38 | 88.07 | 67.53 | 97.00 | 73.25 | 84.71 | 78.58 |
| Recall | 97.08 | 95.75 | 93.34 | 82.69 | 85.09 | 93.76 | 88.66 | 88.12 | 89.98 | |
| DSC | 98.23 | 88.45 | 95.32 | 85.29 | 75.30 | 95.35 | 80.22 | 86.38 | 83.90 | |
| TranSegNet | Precision | 99.75 | 82.18 | 97.91 | 89.29 | 77.40 | 98.21 | 77.98 | 91.30 | 80.46 |
| Recall | 97.99 | 96.36 | 94.33 | 91.29 | 85.37 | 94.56 | 89.83 | 85.32 | 95.56 | |
| DSC | 98.86 | 87.76 | 96.64 | 90.28 | 80.27 | 96.35 | 82.14 | 88.21 | 87.36 |
| % | BG | NFL | GCL +IPL | INL | OPL | ONL +IS | ISE | OS-RPE | Choroid | Fluid | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FCN | Precision | 99.74 | 68.9 | 93.15 | 66.48 | 57.48 | 90.92 | 89.14 | 82.5 | 99.9 | 10.05 |
| Recall | 96.6 | 92.29 | 83.9 | 68.7 | 78.9 | 83.83 | 88.17 | 88.6 | 99.03 | 5.37 | |
| DSC | 98.15 | 79.26 | 88.29 | 69.3 | 66.58 | 87.23 | 88.65 | 85.44 | 99.49 | 9.66 | |
| U-net | Precision | 99.59 | 70.3 | 93.19 | 62.37 | 51.43 | 91.70 | 91.71 | 80.96 | 99.96 | 23.64 |
| Recall | 96.77 | 91.4 | 83.27 | 67.22 | 78.79 | 81.85 | 89.12 | 91.21 | 99.04 | 14.23 | |
| DSC | 98.15 | 79.47 | 87.95 | 69.01 | 62.22 | 86.94 | 90.39 | 85.78 | 99.48 | 23.20 | |
| SegNet | Precision | 99.73 | 79.14 | 89.27 | 56.27 | 62.6 | 89.28 | 86.79 | 78.14 | 99.86 | 19.81 |
| Recall | 97.57 | 92.08 | 84.55 | 69.24 | 74.81 | 83.33 | 87.78 | 92.31 | 99.29 | 3.11 | |
| DSC | 98.69 | 85.12 | 86.85 | 62.08 | 68.16 | 87.58 | 87.28 | 85.95 | 99.52 | 5.38 | |
| TransUnet | Precision | 93.97 | 76.99 | 91.66 | 67.95 | 67.06 | 87.13 | 89.28 | 86.57 | 99.81 | 39.73 |
| Recall | 97.28 | 89.32 | 83.63 | 64.62 | 66.68 | 91.70 | 92.37 | 91.24 | 97.97 | 12.12 | |
| DSC | 95.6 | 82.7 | 87.46 | 66.24 | 66.87 | 89.36 | 90.36 | 86.84 | 98.88 | 19.95 | |
| TranSegNet | Precision | 99.47 | 81.53 | 92.88 | 68.73 | 67.69 | 91.45 | 88.17 | 86.57 | 99.96 | 47.56 |
| Recall | 98.24 | 93.05 | 86.99 | 70.35 | 79.10 | 92.78 | 93.55 | 92.20 | 99.26 | 30.17 | |
| DSC | 98.86 | 86.47 | 89.84 | 72.20 | 68.33 | 89.84 | 91.36 | 88.84 | 99.57 | 29.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Li, Z.; Nan, N.; Wang, X. TranSegNet: Hybrid CNN-Vision Transformers Encoder for Retina Segmentation of Optical Coherence Tomography. Life 2023, 13, 976. https://doi.org/10.3390/life13040976
Zhang Y, Li Z, Nan N, Wang X. TranSegNet: Hybrid CNN-Vision Transformers Encoder for Retina Segmentation of Optical Coherence Tomography. Life. 2023; 13(4):976. https://doi.org/10.3390/life13040976
Chicago/Turabian StyleZhang, Yiheng, Zhongliang Li, Nan Nan, and Xiangzhao Wang. 2023. "TranSegNet: Hybrid CNN-Vision Transformers Encoder for Retina Segmentation of Optical Coherence Tomography" Life 13, no. 4: 976. https://doi.org/10.3390/life13040976