
Sub-Health Identification of Reciprocating Machinery Based on Sound Feature and OOD Detection

Abstract
:1. Introduction
- (1)
- A kind of mechanical running state is defined, which is called a mechanical sub-health state, and it has a positive effect on maintaining machining accuracy and preventing mechanical damage in real work;
- (2)
- We prove that the working sound of heavy machinery can identify the state of a machine, as well as the enhancement effect of OOD detection on the adaptability and recognition accuracy of our model. Since there are no similar public data, a planer sound dataset was collected and collated by us;
- (3)
- A baseline model for identifying mechanical sub-health states is proposed. Then, the performance of the basic model is improved by adding an auxiliary decision module and using Mahalanobis distance to represent the distances between samples.
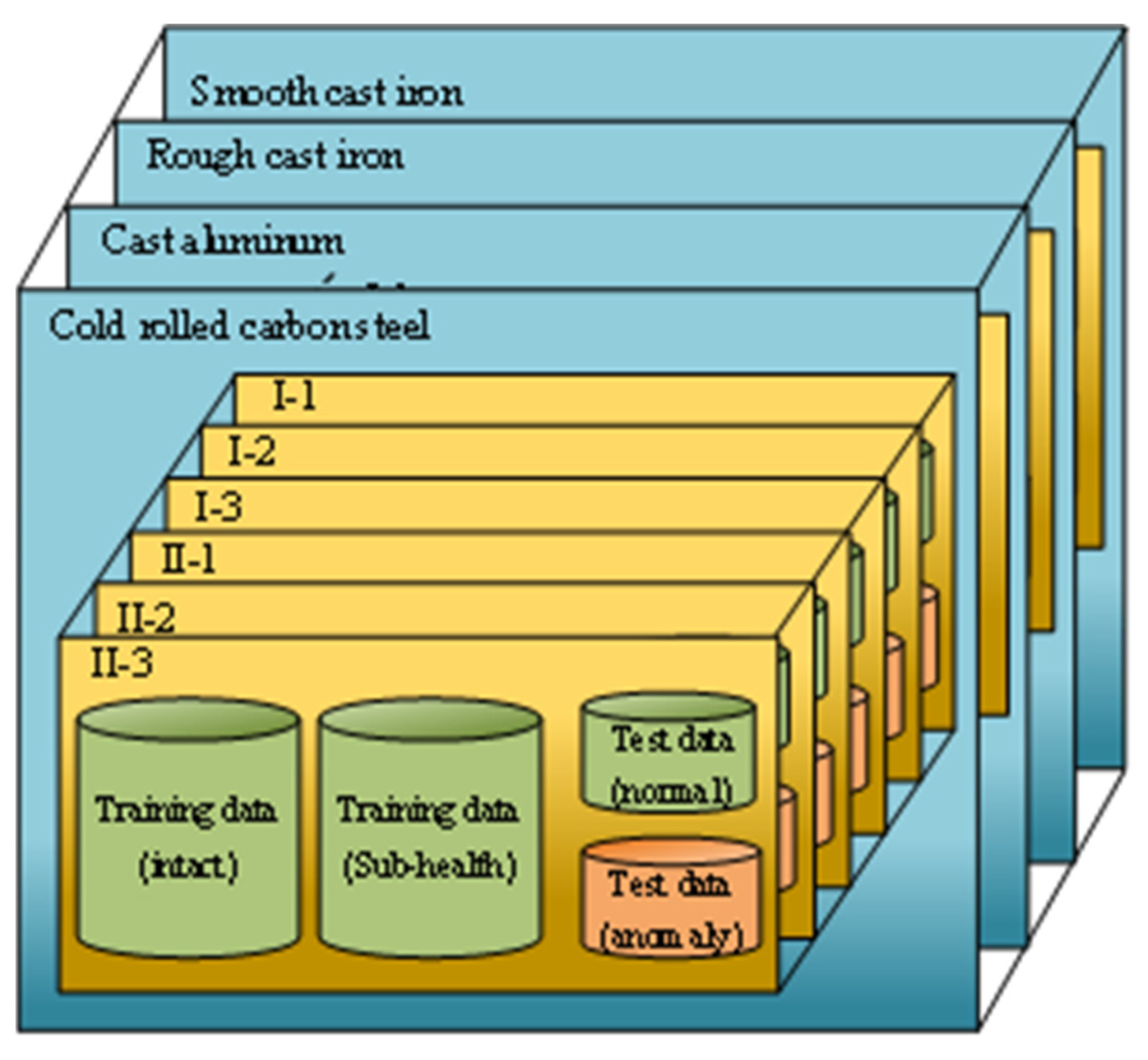
2. Dataset
- Smooth cast iron;
- Rough cast iron;
- Cast aluminum;
- Cold-rolled carbon steel.
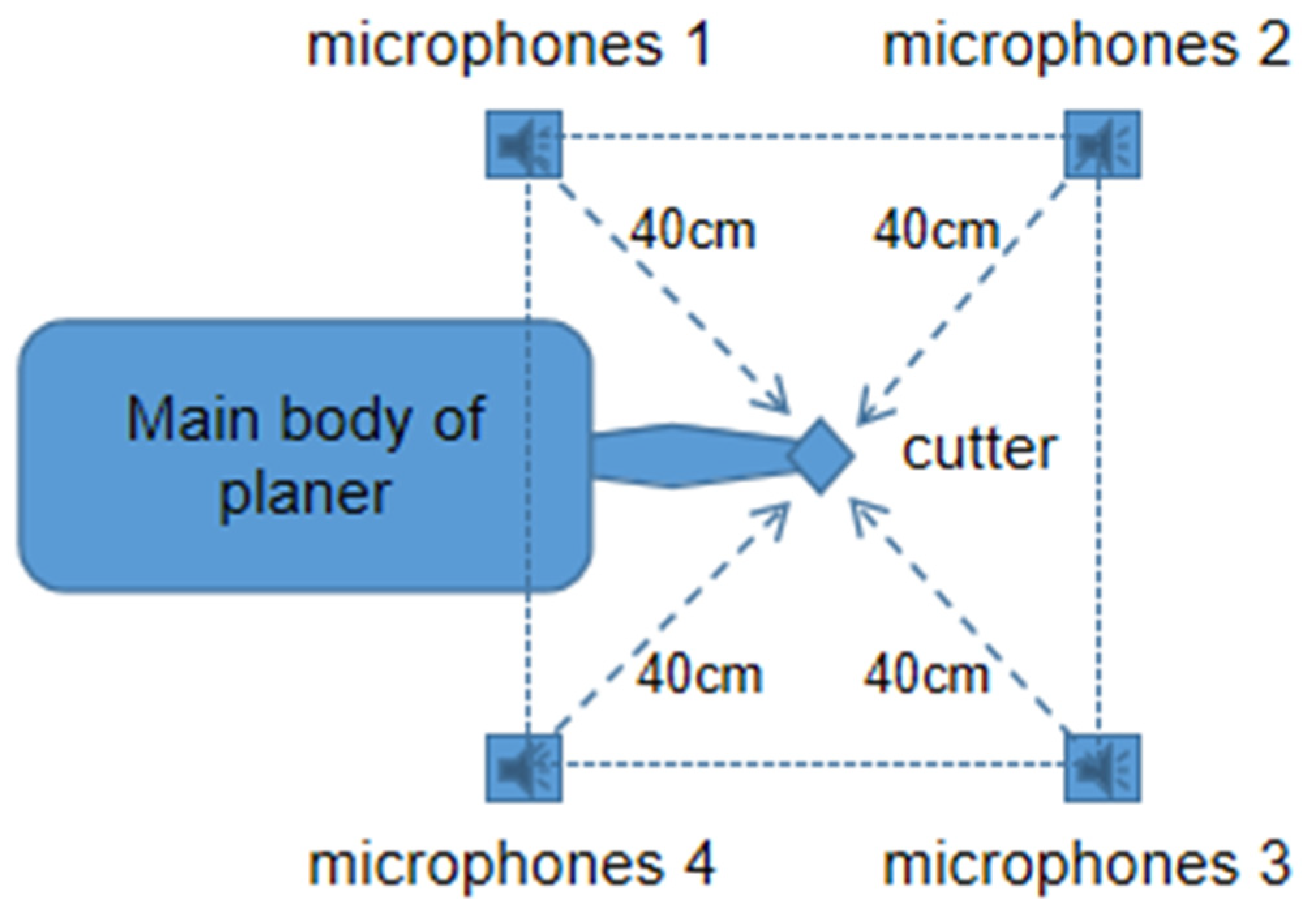
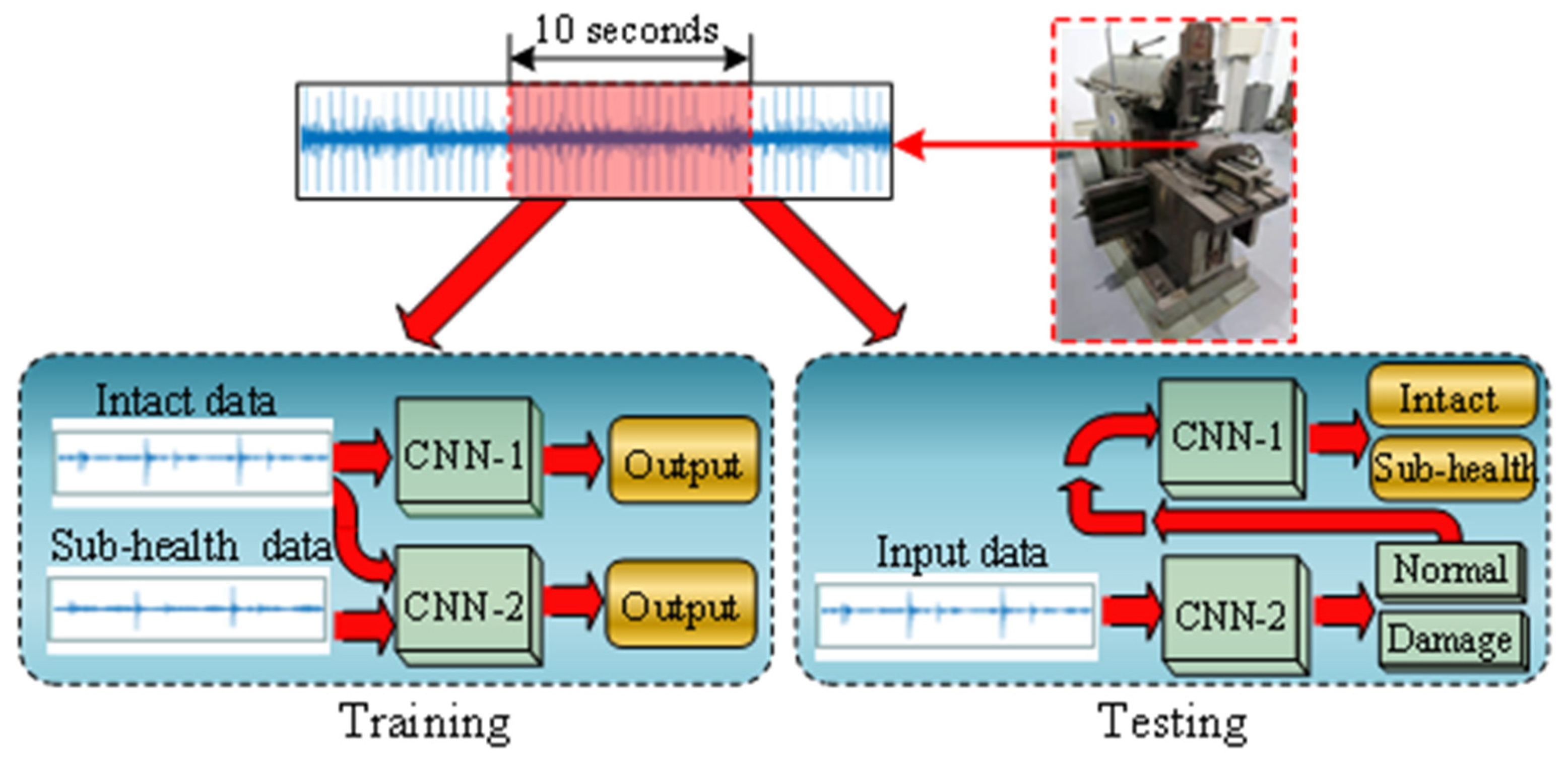
2.1. Recording Process
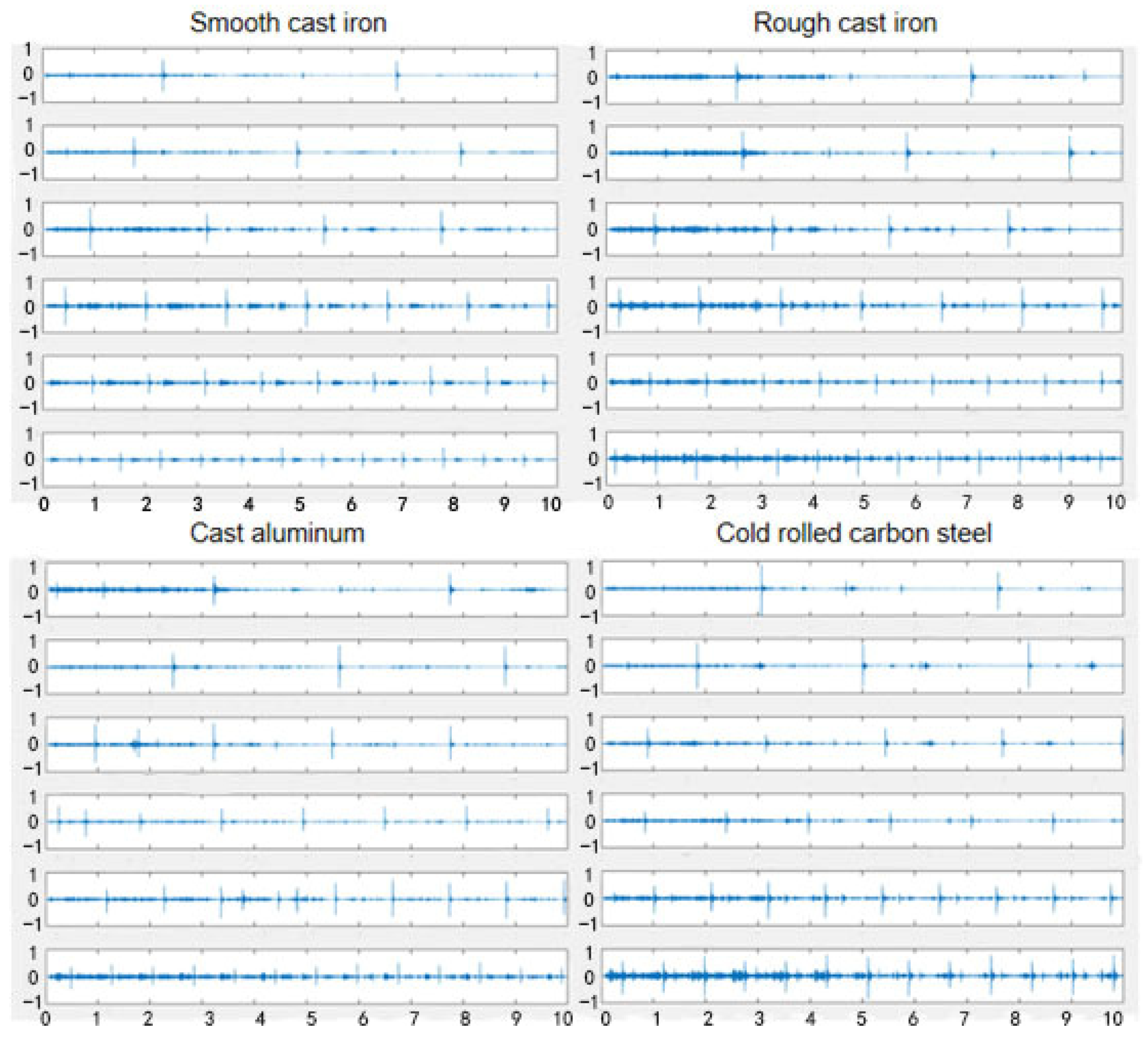
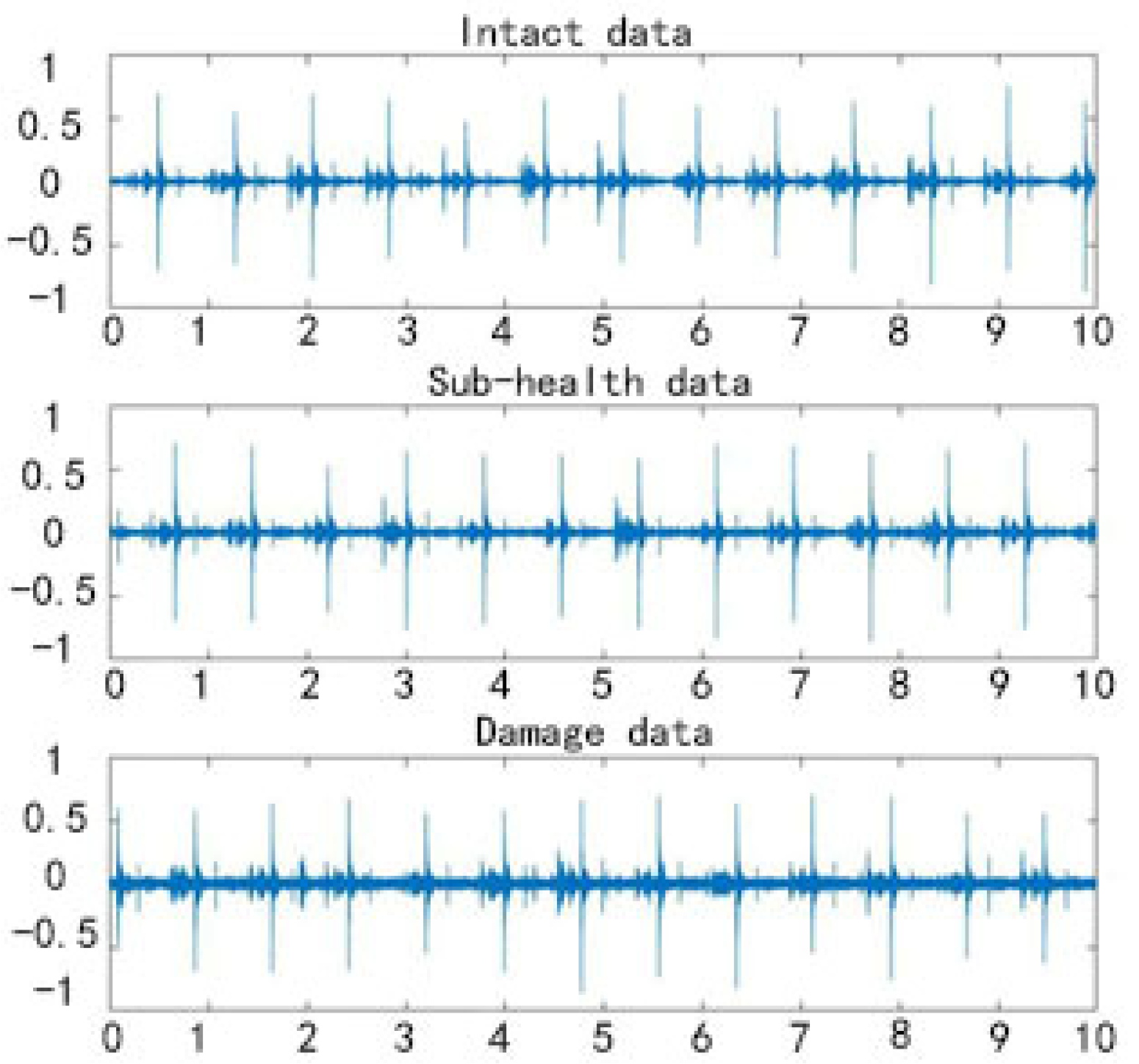
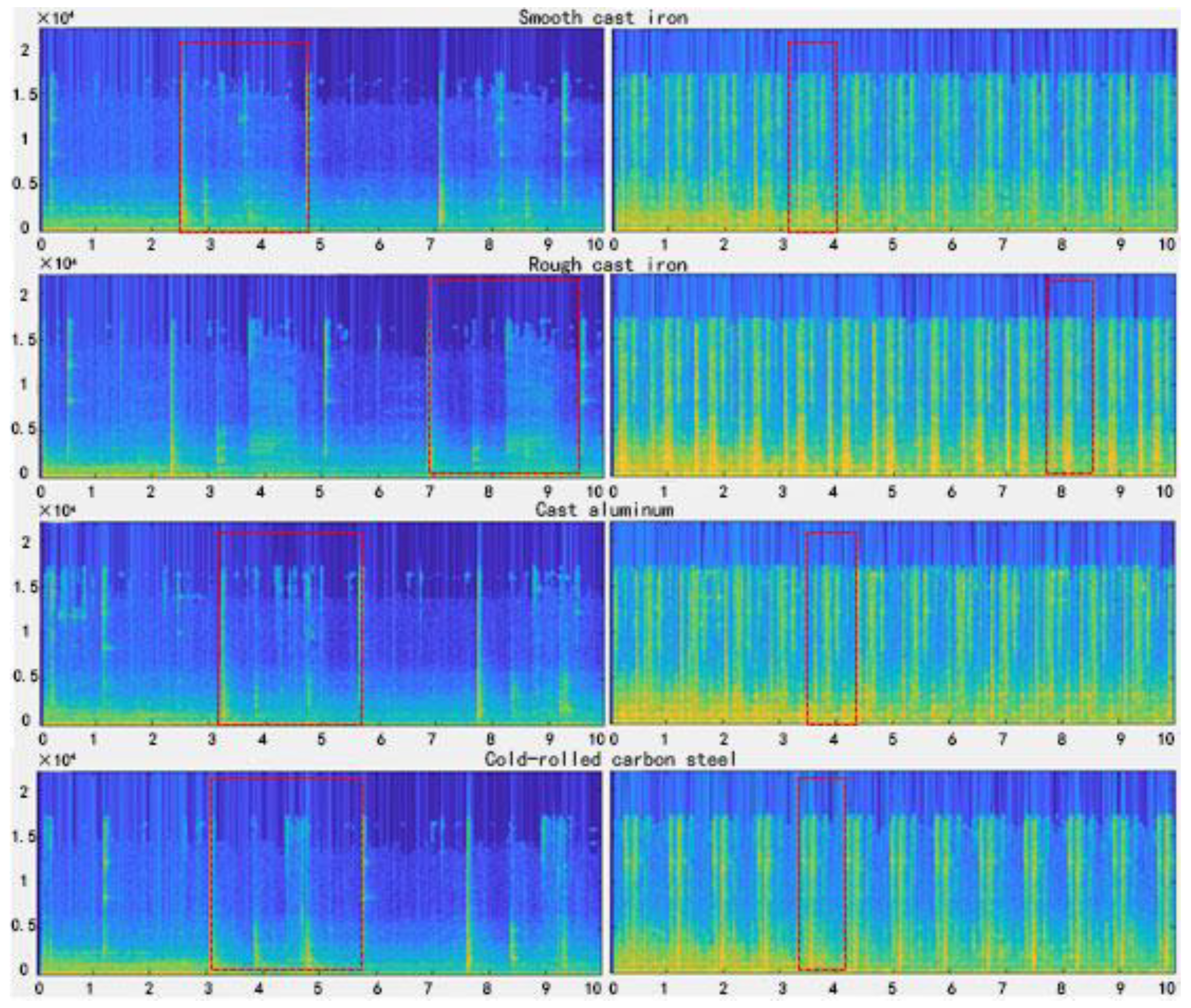
2.2. Introduction to Datasets
3. Materials and Methods
3.1. Pre-Process and Feature Extration
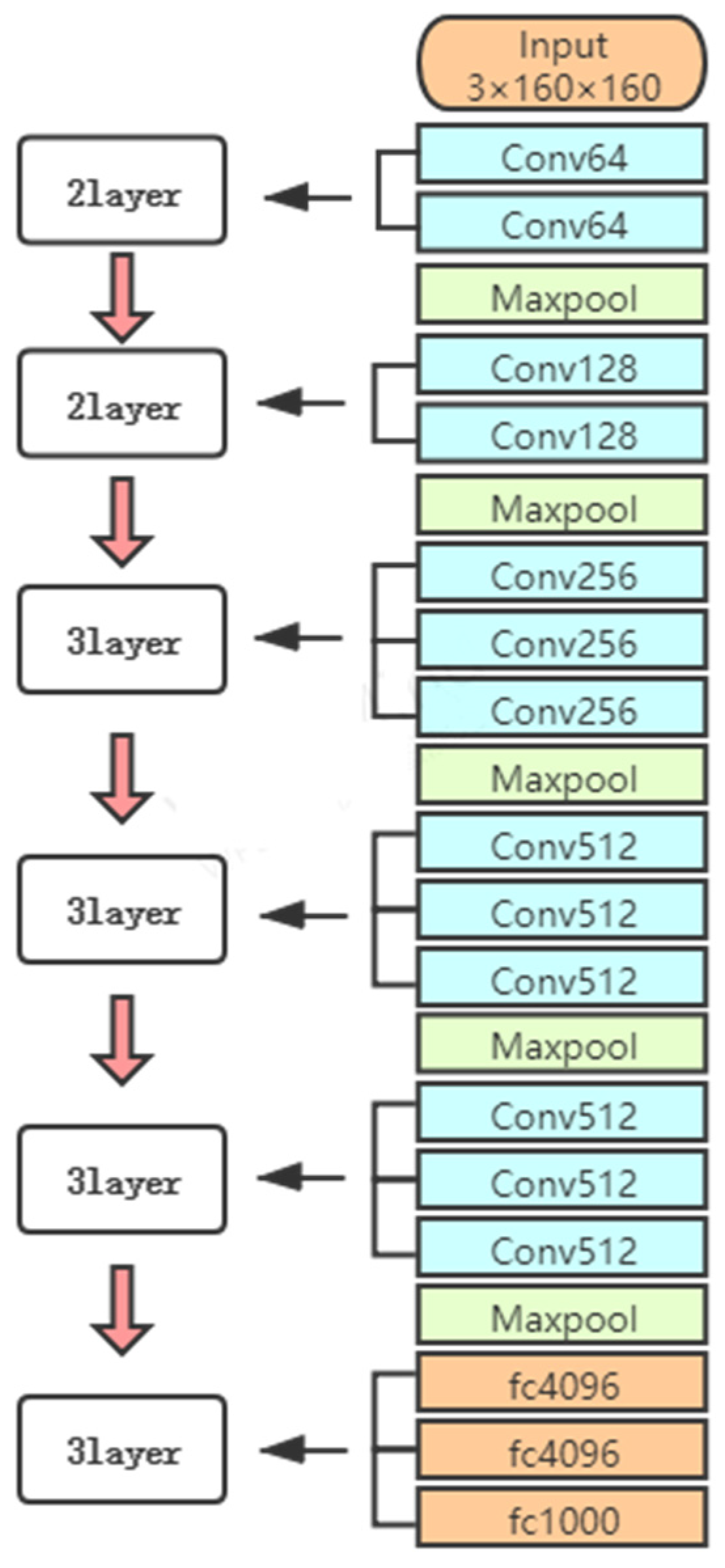
3.2. The Proposed Model
3.3. OOD Detection Principle and Fusion
- (1)
- The model can provide a high softmax probability in the OOD samples, and it also has some misclassified samples; in addition, probability cannot directly represent confidence;
- (2)
- Currently classified samples have a higher softmax probability than misclassified samples and OOD samples.
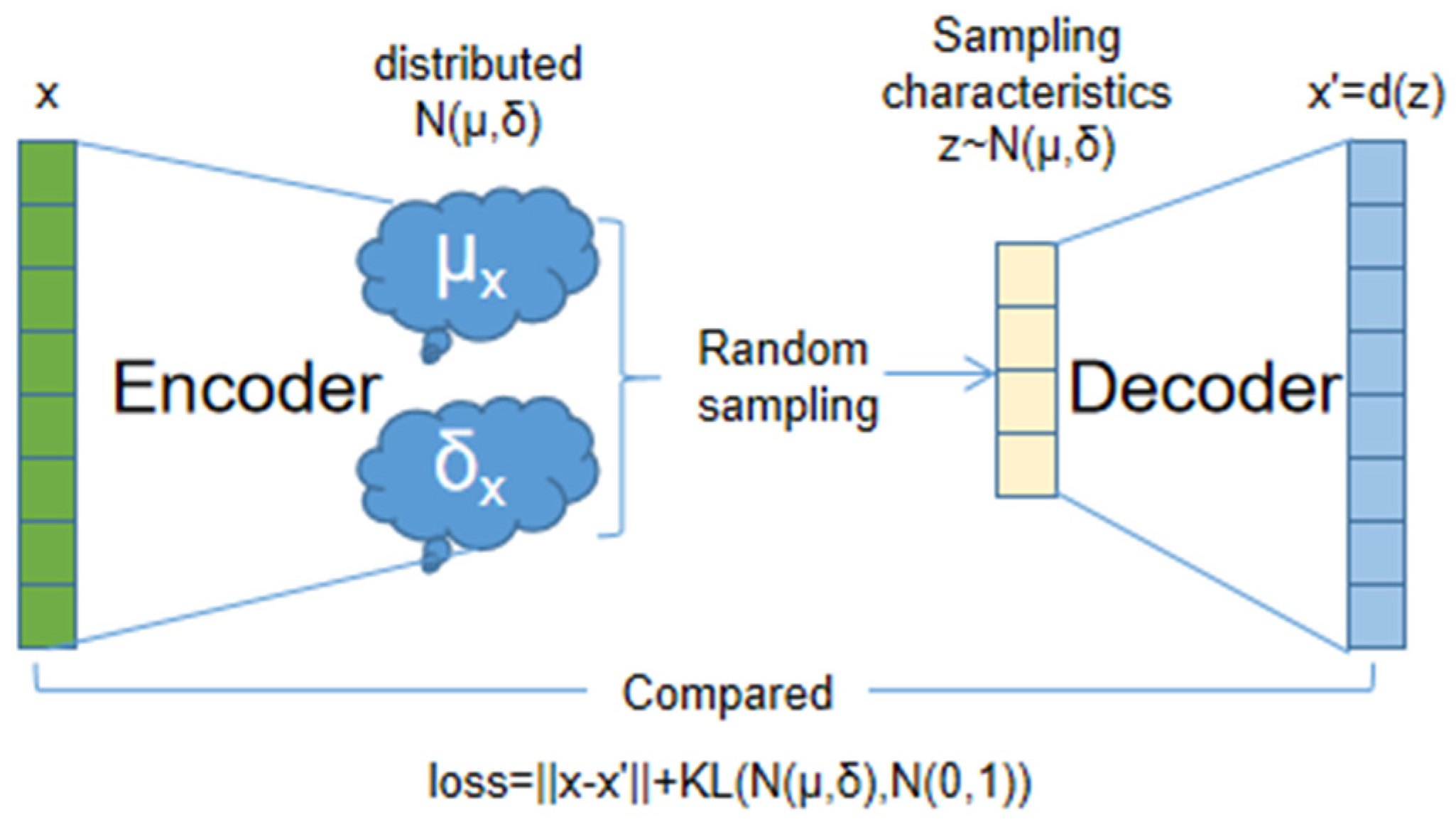
3.4. Further Improvements to the Model
4. Experiment and Discussion
4.1. Parameter Introduction
4.2. Results and Discussion
4.3. Comparison of Effects under Different Conditions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, A.; Li, S.; Cui, Y.; Yang, W. Limited Data Rolling Bearing Fault Diagnosis with Few-Shot Learning. IEEE Access 2019, 7, 110895–110904. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef]
- Hang, Q.; Yang, J.; Xing, L. Diagnosis of rolling bearing based on classification for high dimensional unbalanced data. IEEE Access 2019, 7, 79159–79172. [Google Scholar] [CrossRef]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Yiallourides, C.; Naylor, P.A. Time-Frequency Analysis and Parameterisation of Knee Sounds for Non-invasive Detection of Osteoarthritis. IEEE. Trans. Biomed. Eng. 2021, 68, 1250–1261. [Google Scholar] [CrossRef]
- Das, S.; Pal, S.; Mitra, M. Acoustic feature based unsupervised approach of heart sound event detection. Comput. Biol. Med. 2020, 126, 103990–104000. [Google Scholar] [CrossRef] [PubMed]
- Bayram, B.; Duman, T.B.; Ince, G. Real time detection of acoustic anomalies in industrial processes using sequential autoencoders. Expert Syst. J. Knowl. Eng. 2020, 38, e12564. [Google Scholar] [CrossRef]
- Liu, L.; Li, B.; Zhao, R.; Yao, W.; Shen, M.; Yang, J. A Novel Method for Broiler Abnormal Sound Detection Using WMFCC and HMM. J. Sens. 2020, 2020, 2985478. [Google Scholar] [CrossRef] [Green Version]
- Tran, T.; Lundgren, J. Drill Fault Diagnosis Based on the Scalogram and Mel Spectrogram of Sound Signals Using Artificial Intelligence. IEEE Access 2020, 8, 203655–203666. [Google Scholar] [CrossRef]
- Wang, F.; Lin, W.; Liu, Z.; Qiu, X. Pipeline Leak Detection and Location Based on Model-Free Isolation of Abnormal Acoustic Signals. Energies 2019, 12, 3172. [Google Scholar] [CrossRef] [Green Version]
- Volkmann, N.; Kulig, B.; Kemper, N. Using the Footfall Sound of Dairy Cows for Detecting Claw Lesions. Animals 2019, 9, 78. [Google Scholar] [CrossRef] [Green Version]
- Hou, C.; Qiao, T.; Qiao, M.; Xiong, X.; Yang, Y. Research on Audio-Visual Detection Method for Conveyor Belt Longitudinal Tear. IEEE Access 2019, 7, 120202–120213. [Google Scholar] [CrossRef]
- Ramteke, S.M.; Chelladurai, H.; Amarnath, M. Diagnosis of Liner Scuffing Fault of a Diesel Engine via Vibration and Acoustic Emission Analysis. J. Vib. Eng. Technol. 2019, 8, 815–833. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimple, K. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. arXiv 2017, arXiv:1610.02136. [Google Scholar]
- Liang, S.; Li, Y.; Srikant, R. Principled Detection of Out-of-Distribution Examples in Neural Networks. arXiv 2017, arXiv:1706.02690. [Google Scholar]
- Devries, T.; Taylor, G.W. Learning Confidence for Out-of-Distribution Detection in Neural Networks. arXiv 2018, arXiv:1802.04865. [Google Scholar]
- Shalev, G.; Adi, Y.; Keshet, J. Out-of-Distribution Detection using Multiple Semantic Label Representations. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018; Volume 31, pp. 1–11. [Google Scholar]
- Denouden, T.; Salay, R.; Czarnecki, K.; Abdelzad, V. Improving Reconstruction Autoencoder Out-of-distribution Detection with Mahalanobis Distance. arXiv 2018, arXiv:1812.02765. [Google Scholar]
- Abdelzad, V.; Czarnecki, K.; Salay, R. Detecting Out-of-Distribution Inputs in Deep Neural Networks Using an Early-Layer Output. arXiv 2019, arXiv:1910.10307. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Asami, T.; Masumura, R.; Aono, Y.; Shinoda, K. Recurrent out-of-vocabulary word detection based on distribution of features. Comput. Speech Lang. 2019, 58, 247–259. [Google Scholar] [CrossRef]
- Berend, D.; Xie, X.; Ma, L.; Zhou, L.; Liu, Y.; Xu, C.; Zhao, J. Cats Are Not Fish: Deep Learning Testing Calls for Out-Of-Distribution Awareness. In Proceedings of the 2020 35th IEEE/ACM International Conference on Automated Software Engineering (ASE), Melbourne, VIC, Australia, 21–25 September 2020; pp. 1041–1052. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the 33rd International Conference on Machine Learning, ICML, New York, NY, USA, 19–24 June 2016; Volume 6, pp. 1651–1660. [Google Scholar]
- Henriksson, P.; Berger, C.; Borg, M.; Tornberg, L.; Raman, S. Performance Analysis of Out-of-Distribution Detection on Various Trained Neural Networks. In Proceedings of the 2019 45th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Kallithes, Greece, 28–30 August 2019; pp. 113–120. [Google Scholar]
- Kim, Y.; Cho, D.; Lee, J. Wafer Map Classifier using Deep Learning for Detecting Out-of-Distribution Failure Patterns. In Proceedings of the 2020 IEEE International Symposium on the Physical and Failure Analysis of Integrated Circuits (IPFA), Singapore, 20–23 July 2020; pp. 1–5. [Google Scholar]
- Jia, G.; Liu, G.; Yuan, Z.; Wu, J. An Anomaly Detection Framework Based on Autoencoder and Nearest Neighbor. In Proceedings of the 2018 15th International Conference on Service Systems and Service Management (ICSSSM), Hangzhou, China, 21–22 July 2018; pp. 1–6. [Google Scholar]
- McInnes, L.; Healy, J.; Saul, N.; Grossberger, L. Umap: Uniform manifold approximation and projection. J. Open Source Softw. 2018, 3, 861–923. [Google Scholar] [CrossRef]
- Chen, X.; Kingma, D.P.; Salimans, T.; Duan, Y.; Dhariwal, P.; Schulman, J.; Sutskever, I.; Abbeel, P. Variational Lossy Autoencoder. arXiv 2017, arXiv:1611.02731. [Google Scholar]
- Deng, J.; Zhang, Z.; Eyben, F.; Schuller, B. Autoencoder-based Unsupervised Domain Adaptation for Speech Emotion Recognition. IEEE Signal Process. Lett. 2014, 21, 1068–1072. [Google Scholar] [CrossRef]
- Hou, X.; Shen, L.; Ke, S.; Qiu, G.D. Deep Feature Consistent Variational Autoencoder. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1133–1141. [Google Scholar]
- Bando, Y.; Mimura, M.; Itoyama, K.; Yoshii, K.; Kawahara, T. Statistical Speech Enhancement Based on Probabilistic Integration of Variational Autoencoder and Non-Negative Matrix Factorization. In Proceedings of the 2018 IEEE Onternational Conference on Acoustice, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 716–720. [Google Scholar]
- Suh, S.; Chae, D.H.; Kang, H.-G.; Choi, S. Echo-state conditional variational autoencoder for anomaly detection. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1015–1022. [Google Scholar]
- Maesschalck, R.D.; Jouan-Rimbaud, D.; Massart, D.L. The Mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Vareldzhan, G.; Yurkov, K.; Ushenin, K. Anomaly Detection in Image Datasets Using Convolutional Neural Networks, Center Loss, and Mahalanobis Distance. arXiv 2021, arXiv:2104.06193. [Google Scholar]
- Sarmadi, H.; Karamodin, A. A novel anomaly detection method based on adaptive Mahalanobis-squared distance and one-class kNN rule for structural health monitoring under environmental effects. Mech. Syst. Signal Process. 2020, 140, 106495. [Google Scholar] [CrossRef]
- Kamoi, R.; Kobayashi, K. Why is the Mahalanobis Distance Effective for Anomaly Detection. arXiv 2020, arXiv:2003.00402. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
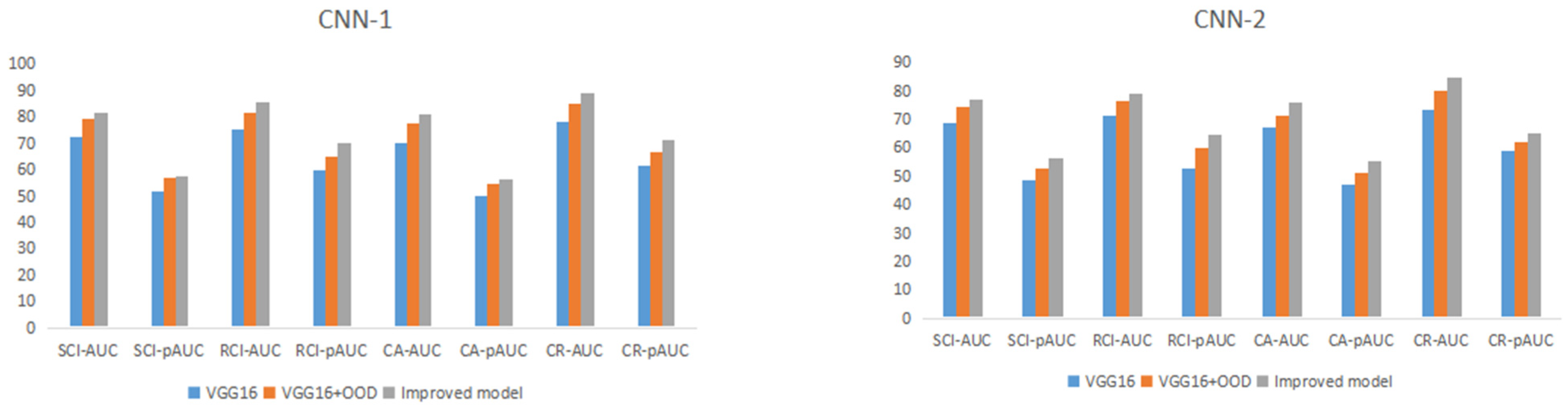{kind=link}
| CNN-1 | CNN-2 | ||
|---|---|---|---|
| AUPR Succ/base | AUPR Err/base | AUPR Succ/base | AUPR Err/base |
| 91/76 | 43/24 | 96/79 | 62/21 |
| Smooth Cast Iron | Rough Cast Iron | Cast Aluminum | Cold-Rolled Carbon Steel | |||||
|---|---|---|---|---|---|---|---|---|
| AUC | pAUC | AUC | pAUC | AUC | pAUC | AUC | pAUC | |
| CNN-1/ Damage | 72.31% | 51.52% | 75.01% | 59.77% | 69.82% | 50.13% | 78.29% | 61.75% |
| CNN-2/ Sub-health | 68.88% | 48.72% | 71.49% | 53.00% | 67.30% | 47.08% | 73.61% | 58.71% |
| Smooth Cast Iron | Rough Cast Iron | Cast Aluminum | Cold-Rolled Carbon Steel | |||||
|---|---|---|---|---|---|---|---|---|
| AUC | pAUC | AUC | pAUC | AUC | pAUC | AUC | pAUC | |
| CNN-1/ Damage | 79.31% | 56.87% | 81.70% | 64.70% | 77.62% | 54.89% | 85.16% | 66.75% |
| CNN-2/ Sub-health | 74.42% | 52.53% | 76.69% | 60.04% | 71.12% | 51.20% | 80.34% | 62.29% |
| Smooth Cast Iron | Rough Cast Iron | Cast Aluminum | Cold-Rolled Carbon Steel | |||||
|---|---|---|---|---|---|---|---|---|
| AUC | pAUC | AUC | pAUC | AUC | pAUC | AUC | pAUC | |
| CNN-1/ Damage | 81.74% | 57.47% | 85.46% | 70.10% | 80.74% | 56.47% | 88.92% | 71.30% |
| CNN-2/ Sub-health | 76.89% | 56.22% | 79.32% | 64.70% | 75.85% | 55.54% | 84.74% | 65.19% |
| Smooth Cast Iron | Rough Cast Iron | Cast Aluminum | Cold-Rolled Carbon Steel | Detection Time(s) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| TPR | FPR | TPR | FPR | TPR | FPR | TPR | FPR | |||
| 1 | CNN-1/ Damage | 70.4 | 9.5 | 71.0 | 9.6 | 69.2 | 8.7 | 75.5 | 7.1 | 323 |
| CNN-2/ Sub-health | 68.9 | 5.9 | 69.3 | 5.5 | 68.2 | 6.0 | 74.7 | 3.6 | ||
| 2 | CNN-1/ Damage | 74.5 | 7.4 | 74.2 | 7.4 | 72.9 | 8.2 | 77.3 | 6.2 | 384 |
| CNN-2/ Sub-health | 73.7 | 3.4 | 72.8 | 3.9 | 72.6 | 4.1 | 76.7 | 2.3 | ||
| 3 | CNN-1/ Damage | 75.8 | 6.6 | 76.0 | 6.5 | 73.3 | 8.0 | 78.1 | 5.8 | 571 |
| CNN-2/ Sub-health | 74.4 | 3.3 | 73.6 | 3.4 | 74.0 | 3.3 | 77.6 | 2.1 | ||
| AUC/pAUC | Fan | Pump | Slider | Valve | ToyCar | ToyConveyor |
|---|---|---|---|---|---|---|
| Baseline | 82.80/65.80 | 82.37/64.11 | 79.41/58.87 | 57.37/50.79 | 80.14/66.17 | 85.36/66.96 |
| Our model | 93.65/82.47 | 93.68/91.2 | 97.71/80.55 | 91.48/89.74 | 86.06/70.01 | 88.43/73.44 |
| Sub-Health Identification | Smooth Cast Iron | Rough Cast Iron | Cast Aluminum | Cold-Rolled Carbon Steel | ||||
|---|---|---|---|---|---|---|---|---|
| AUC | pAUC | AUC | pAUC | AUC | pAUC | AUC | pAUC | |
| AlexNet | 65.36% | 45.71% | 67.00% | 51.03% | 64.52% | 44.93% | 71.55% | 56.87% |
| ResNet | 70.57% | 50.76% | 71.33% | 53.19% | 69.21% | 50.01% | 77.65% | 60.14% |
| Our model | 76.89% | 56.22% | 79.32% | 64.70% | 75.85% | 55.54% | 84.74% | 65.19% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, P.; Wang, J.; Li, X.; Li, C. Sub-Health Identification of Reciprocating Machinery Based on Sound Feature and OOD Detection. Machines 2021, 9, 179. https://doi.org/10.3390/machines9080179
Cui P, Wang J, Li X, Li C. Sub-Health Identification of Reciprocating Machinery Based on Sound Feature and OOD Detection. Machines. 2021; 9(8):179. https://doi.org/10.3390/machines9080179
Chicago/Turabian StyleCui, Peng, Jinjia Wang, Xiaobang Li, and Chunfeng Li. 2021. "Sub-Health Identification of Reciprocating Machinery Based on Sound Feature and OOD Detection" Machines 9, no. 8: 179. https://doi.org/10.3390/machines9080179