
Assessment of Dynamic Bayesian Models for Gas Turbine Diagnostics, Part 1: Prior Probability Analysis


Abstract
:1. Introduction
2. Methods
2.1. Bayesian Network
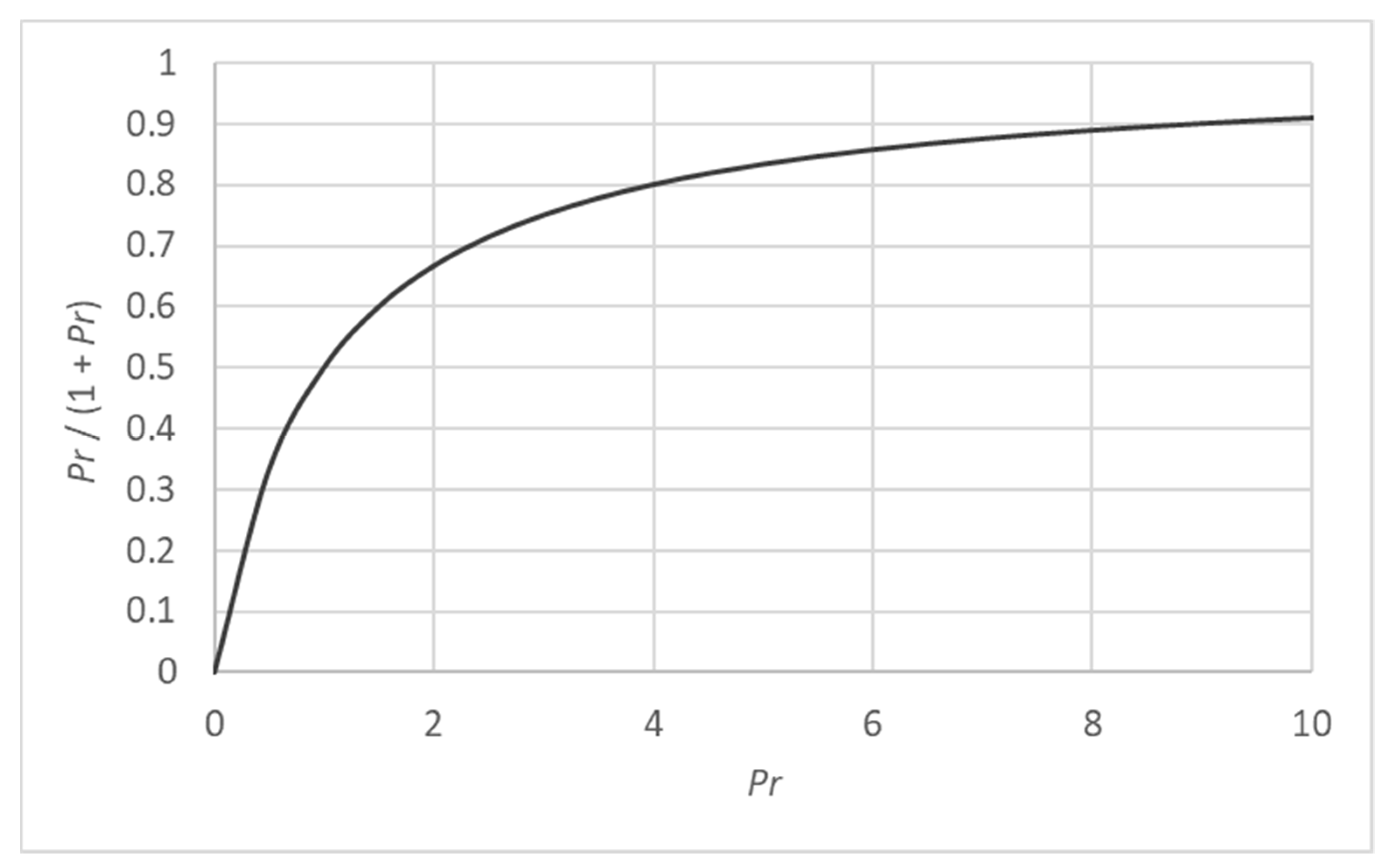
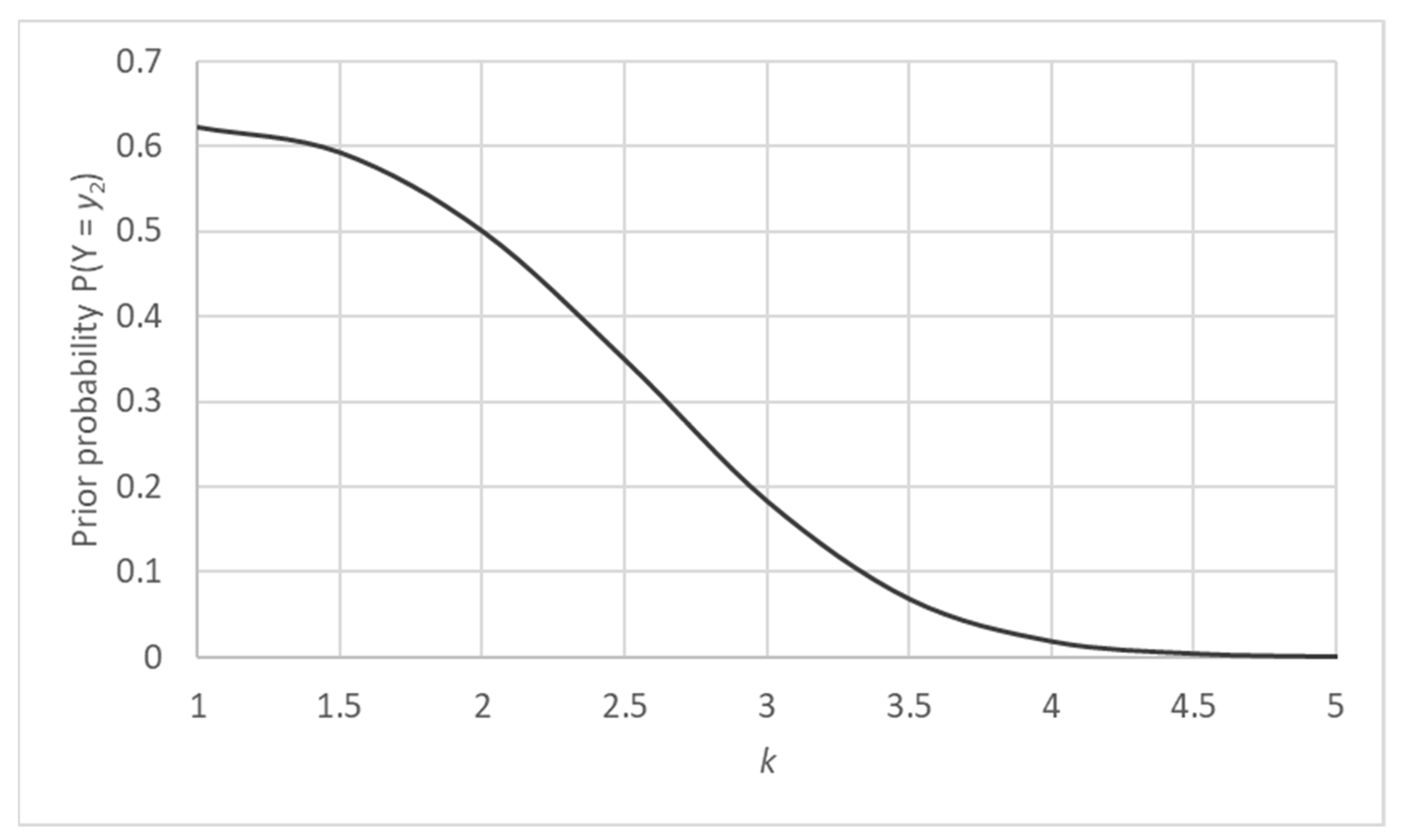
2.2. Prior Probability Distribution
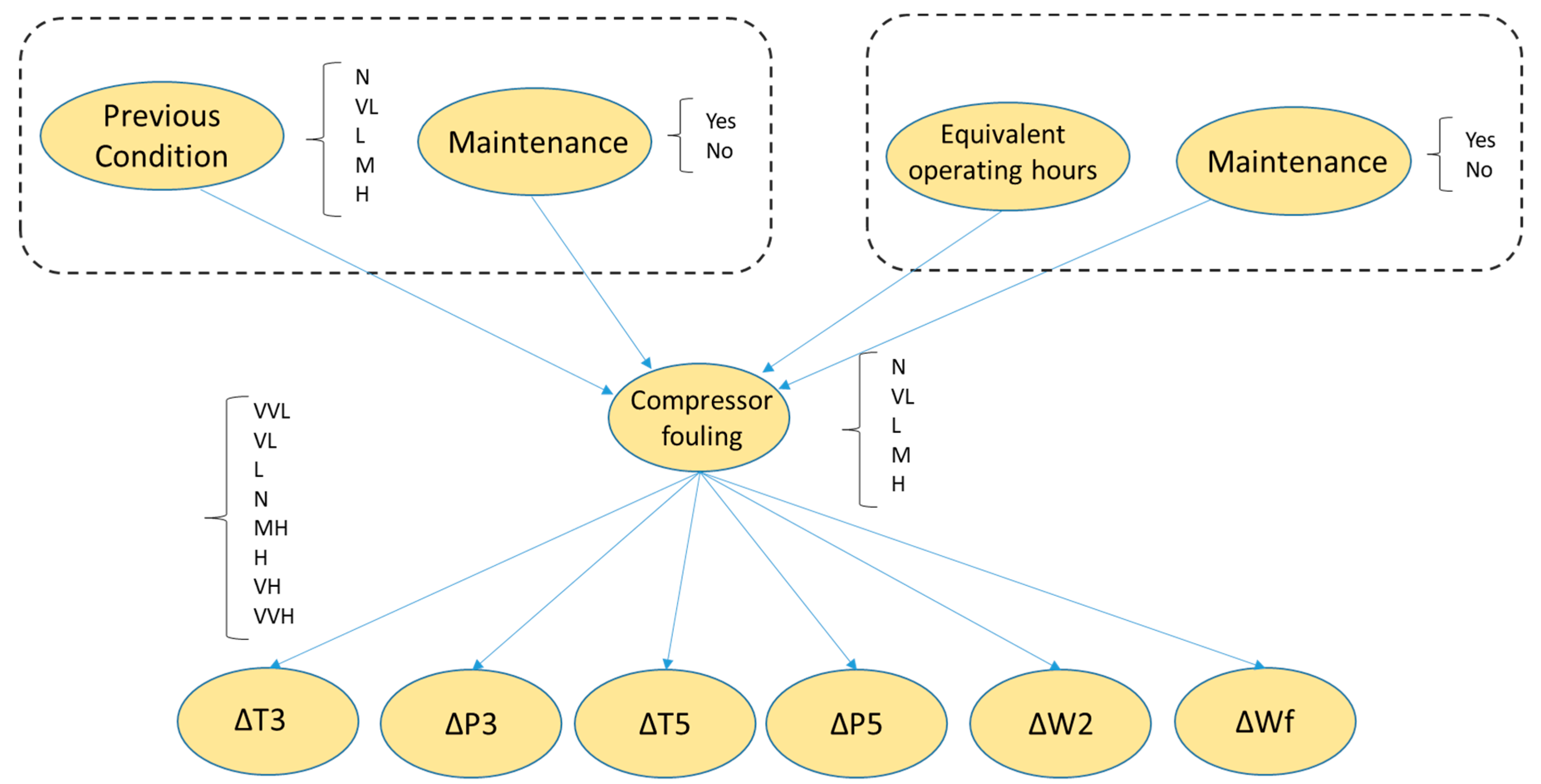
2.3. Dynamic Bayesian Network
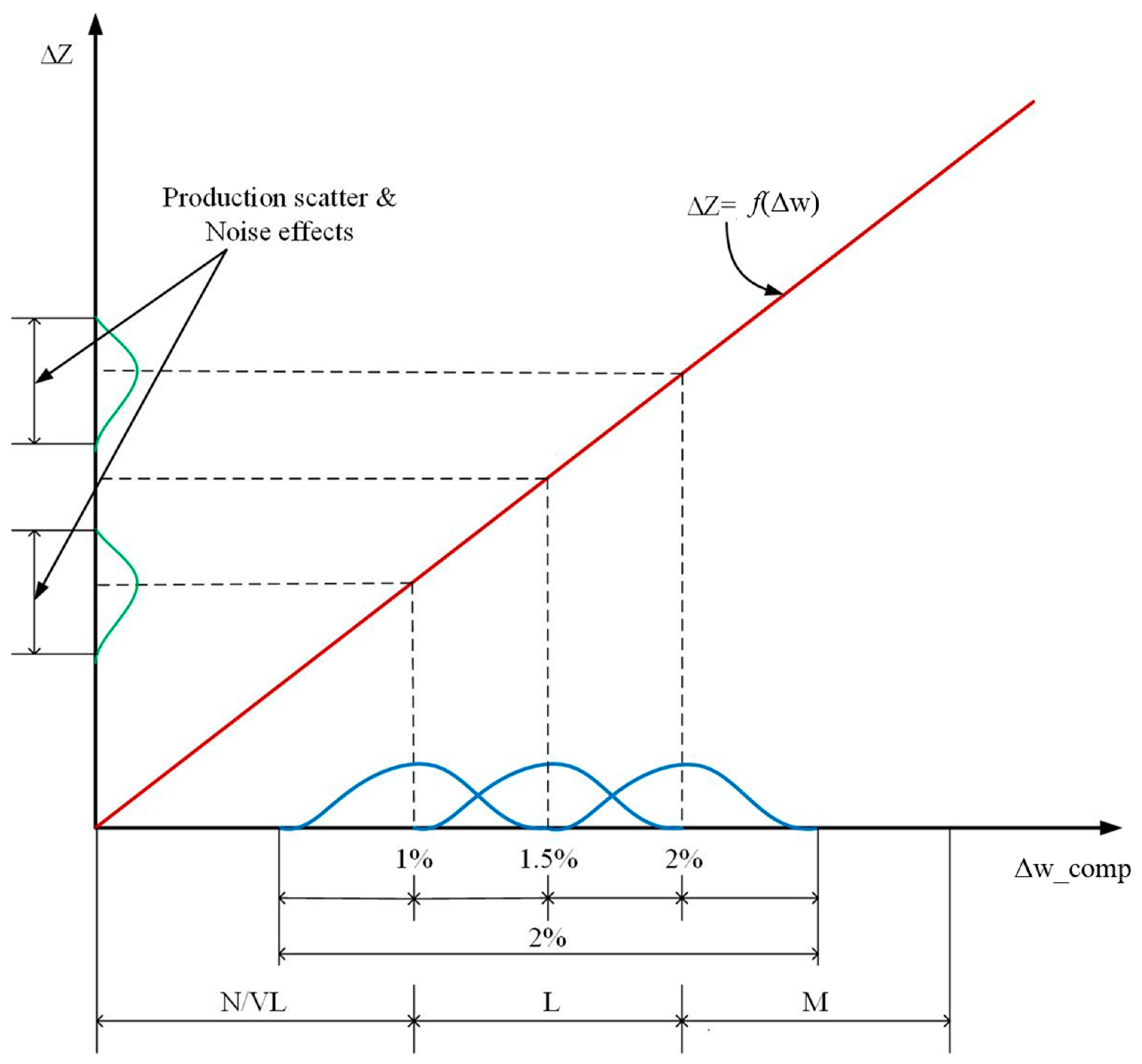
- Normal conditions (N)—fault severity equal to zero.
- Very low degradation (VL)—fault severity lower than 1%, which together with N represents healthy conditions.
- Low degradation (L)—fault severity between 1% and 2%.
- Medium degradation (M)—fault severity between 2% and 3%.
- High degradation (H)—fault severity higher than 3%.
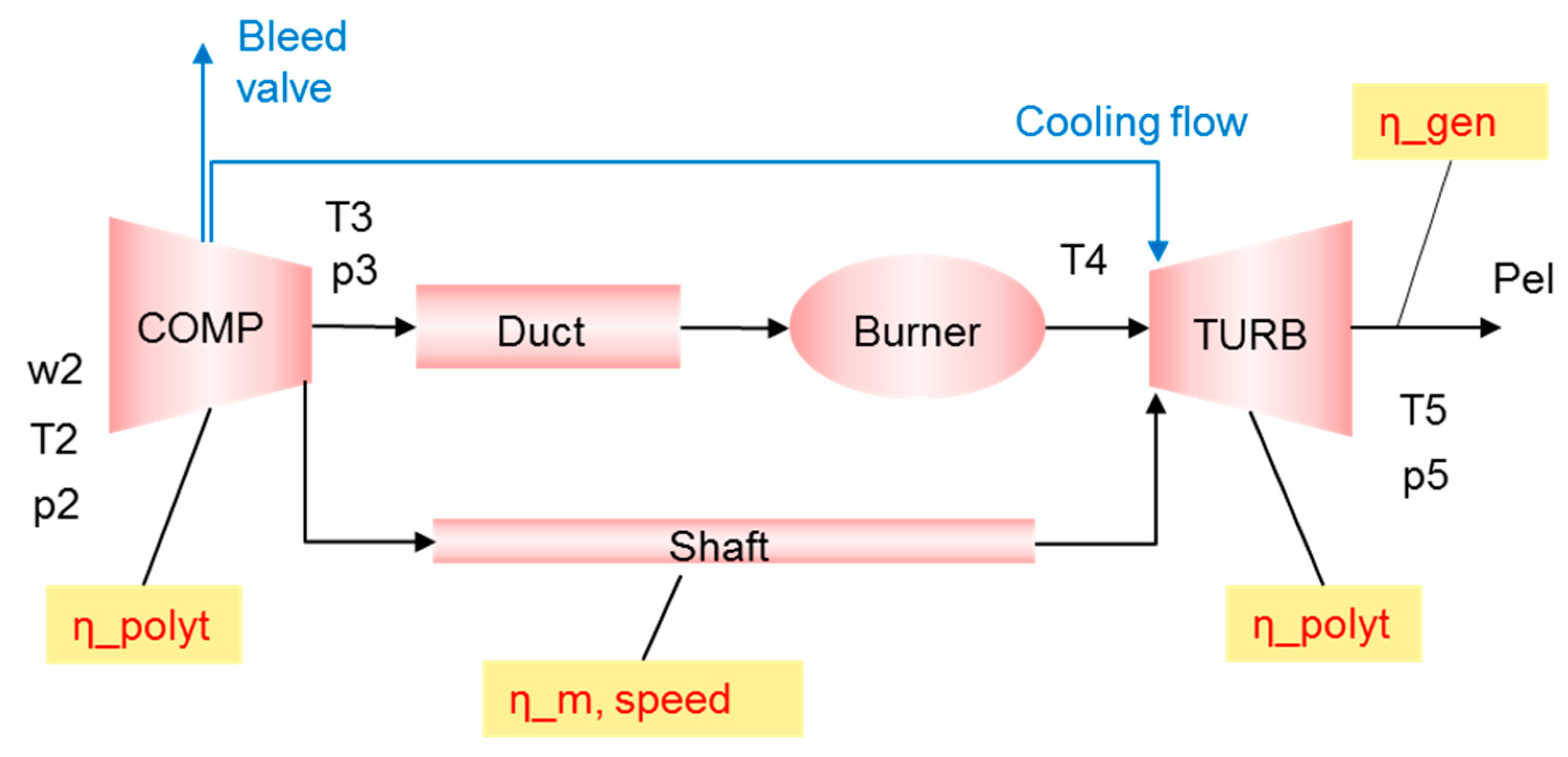
2.4. Gas Turbine Model
3. Results and Discussion
3.1. Constant Prior Distribution
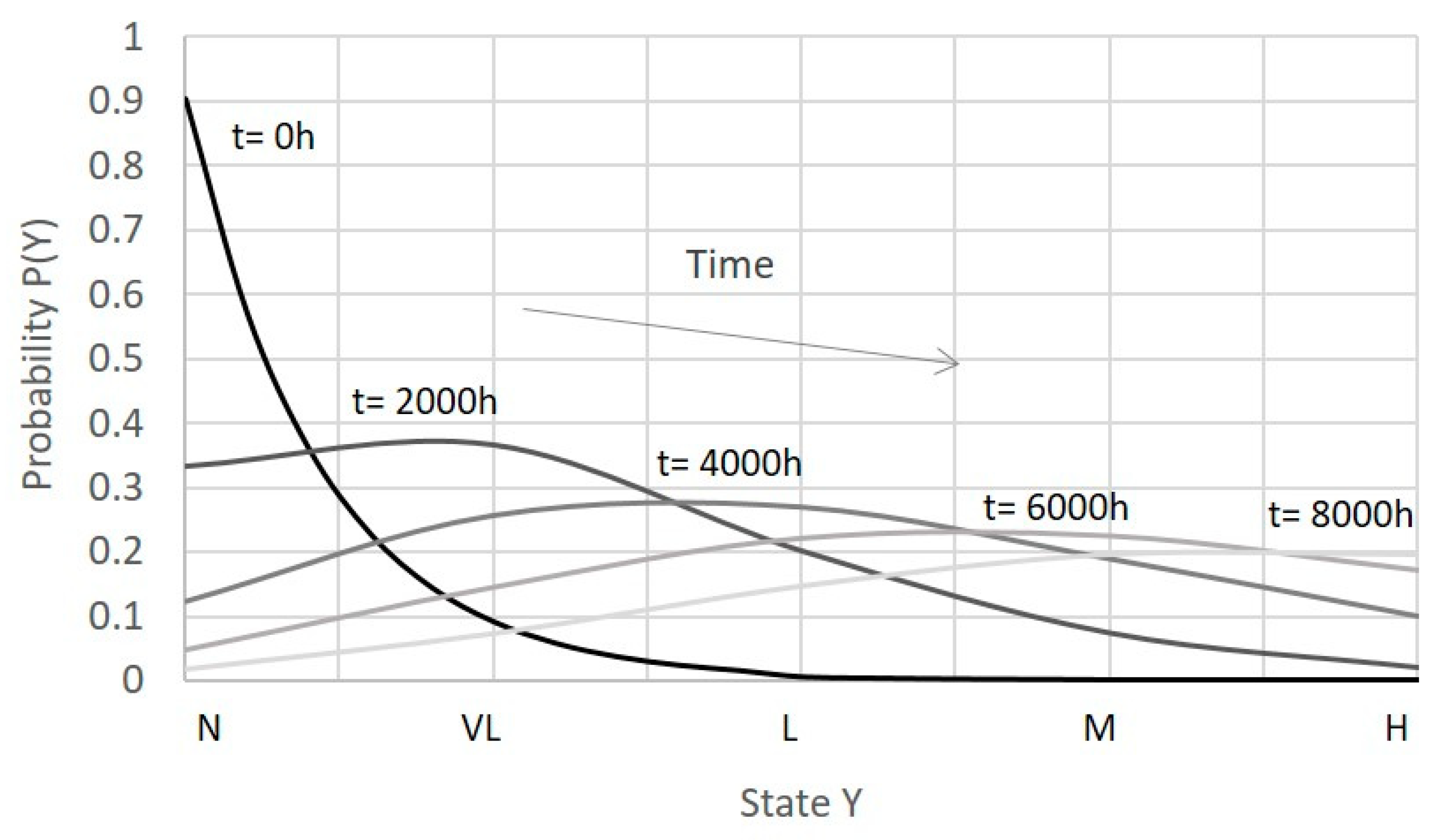
3.2. Time-Dependent Prior Distribution
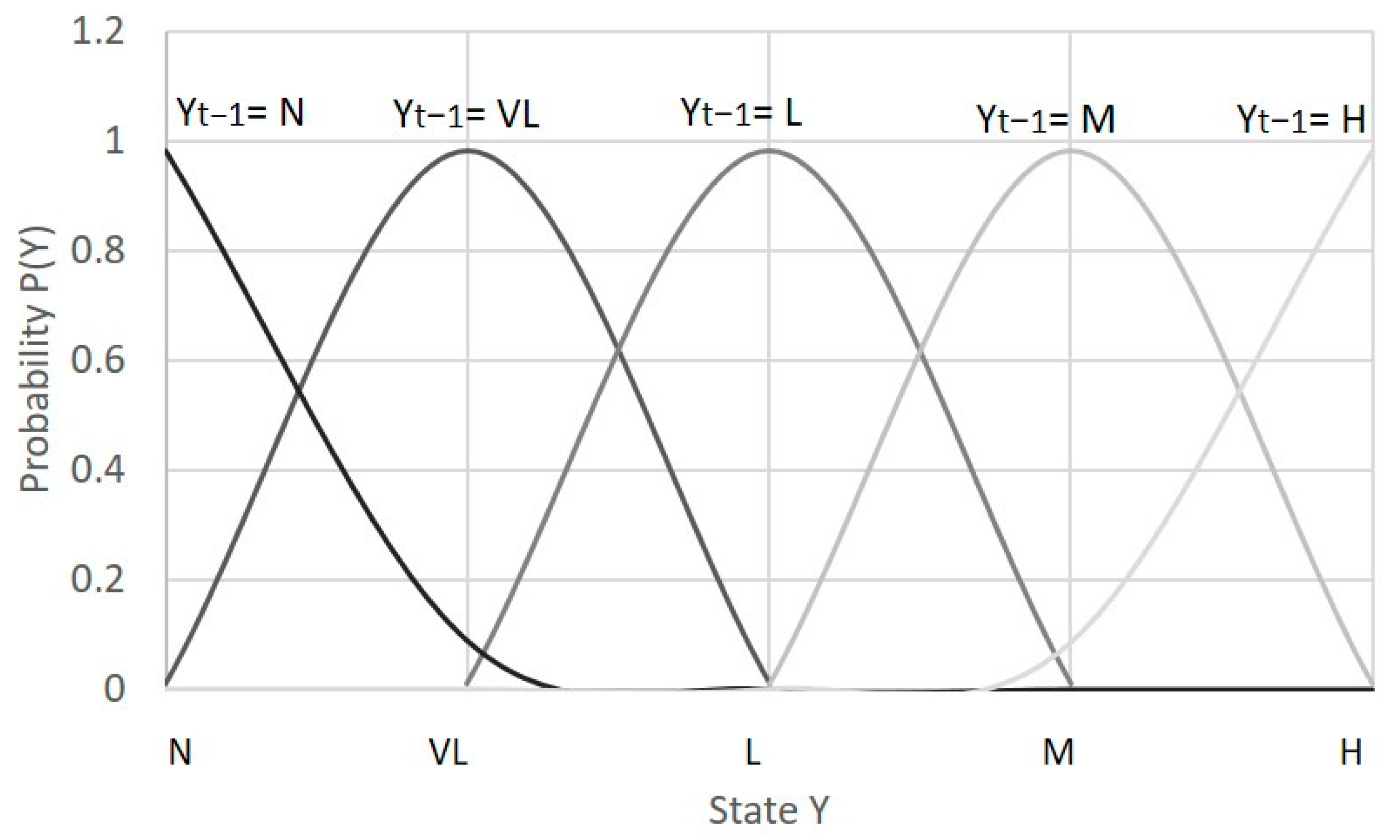
3.3. Condition-Based Prior Distribution
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Acronyms | |
| BN | Bayesian Network |
| CF | Compressor Fouling |
| CPT | Conditional Probability Table |
| DBN | Dynamic Bayesian Network |
| H | High |
| IGV | Inlet Guide Vane |
| L | Low |
| M | Medium |
| N | Normal |
| TE | Turbine Erosion |
| VH | Very High |
| VL | Very Low |
| Symbols and Greek letters | |
| P | Probability distribution |
| Pr | Conditional probability ratio |
| r | Residual |
| S | Fault severity |
| Flow capacity | |
| z | Measurement |
| Δ | Deviation from healthy conditions |
| η | Efficiency |
| λ | Poisson coefficient |
| σ | Standard deviation |
| φ | Hyperparameter |
| Subscripts | |
| ref | Reference conditions |
| t | Time |
References
- Fentaye, A.; Zaccaria, V.; Kyprianidis, K. Discrimination of rapid and gradual deterioration for an enhanced gas turbine life-cycle monitoring and diagnostics. Int. J. Progn. Health Manag. 2021, 12. [Google Scholar] [CrossRef]
- Zhou, D.; Zhang, H.; Weng, S. A new gas path fault diagnostic method of gas turbine based on support vector machine. J. Eng. Gas Turbines Power 2015, 137, 102605. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; Liu, J.; Li, M.; Geng, J.; Wu, Y.; Song, Z. An improved hybrid modeling method based on extreme learning machine for gas turbine engine. Aerosp. Sci. Technol. 2020, 107, 106333. [Google Scholar] [CrossRef]
- Fentaye, A.D.; Baheta, A.T.; Gilani, S.I.; Kyprianidis, K.G. A review of gas turbine gas-path diagnostics: State-of-the-Art methods, challenges and opportunities. Aerospace 2019, 6, 83. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Lin, W.; Ji, Y. An integrated ensemble learning model for imbalanced fault diagnostics and prognostics. IEEE Access 2018, 6, 8394–8402. [Google Scholar] [CrossRef]
- Romessis, C.; Mathioudakis, K. Bayesian network approach for gas path fault diagnosis. J. Eng. Gas Turbines Power 2004, 128, 64–72. [Google Scholar] [CrossRef]
- Loboda, I.; Robles, M.A.O. Gas turbine fault diagnosis using probabilistic neural networks. Int. J. Turbo Jet-Engines 2015, 32, 175–191. [Google Scholar] [CrossRef]
- Mohammadi, E.; Montazeri-Gh, M. A fuzzy-based gas turbine fault detection and identification system for full and part-load performance deterioration. Aerosp. Sci. Technol. 2015, 46, 82–93. [Google Scholar] [CrossRef]
- Kestner, B.K.; Lee, Y.K.; Voleti, G.; Mavris, D.N.; Kumar, V.; Lin, T. Diagnostics of highly degraded industrial gas turbines using Bayesian networks. In Proceedings of the ASME 2011 Turbo Expo: Turbine Technical Conference and Exposition, Vancouver, BC, Canada, 6–10 June 2011. [Google Scholar]
- Mirhosseini, A.M.; Nazari, S.A.; Pour, A.M.; Haghighi, S.E.; Zareh, M. Probabilistic failure analysis of hot gas path in a heavy-duty gas turbine using Bayesian networks. Int. J. Syst. Assur. Eng. Manag. 2019, 10, 1173–1185. [Google Scholar] [CrossRef]
- Zaccaria, V.; Fentaye, A.D.; Stenfelt, M.; Kyprianidis, K.G. Probabilistic model for aero-engines fleet condition monitoring. Aerospace 2020, 7, 66. [Google Scholar] [CrossRef]
- Weber, P.; Simon, C. Benefits of Bayesian Network Models; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2016. [Google Scholar]
- Losi, E.; Venturini, M.; Manservigi, L.; Ceschini, G.F.; Bechini, G. Anomaly detection in gas turbine time series by means of bayesian hierarchical models. J. Eng. Gas Turbines Power 2019, 141, 111019. [Google Scholar] [CrossRef]
- Lee, Y.K.; Mavris, D.N.; Volovoi, V.V.; Yuan, M.; Fisher, T. A fault diagnosis method for industrial gas turbines using bayesian data analysis. J. Eng. Gas Turbines Power 2010, 132, 041602. [Google Scholar] [CrossRef]
- Liu, Y.; Su, M. Nonlinear model based diagnostic of gas turbine faults: A case study. Turbo Expo Power Land Sea Air 2011, 54631, 1–8. [Google Scholar] [CrossRef]
- Lu, F.; Gao, T.; Huang, J.; Qiu, X. A novel distributed extended Kalman filter for aircraft engine gas-path health estimation with sensor fusion uncertainty. Aerosp. Sci. Technol. 2018, 84, 90–106. [Google Scholar] [CrossRef]
- Lu, F.; Wang, Y.; Huang, J.; Huang, Y. Gas turbine transient performance tracking using data fusion based on an adaptive particle filter. Energies 2015, 8, 13911–13927. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Zhang, L.; Ma, L.; Liang, W. An integrated safety prognosis model for complex system based on dynamic Bayesian network and ant colony algorithm. Expert Syst. Appl. 2011, 38, 1431–1446. [Google Scholar] [CrossRef]
- Zhou, J.; Wei, S.; Chai, Y. Using improved dynamic Bayesian networks in reliability evaluation for flexible test system of aerospace pyromechanical device products. Reliab. Eng. Syst. Saf. 2021, 210, 107508. [Google Scholar] [CrossRef]
- Cai, B.; Huang, L.; Xie, M. Bayesian networks in fault diagnosis. IEEE Trans. Ind. Inform. 2017, 13, 2227–2240. [Google Scholar] [CrossRef]
- Amin, T.; Khan, F.; Imtiaz, S. Dynamic availability assessment of safety critical systems using a dynamic Bayesian network. Reliab. Eng. Syst. Saf. 2018, 178, 108–117. [Google Scholar] [CrossRef]
- Lewis, A.D.; Groth, K.M. A Dynamic bayesian network structure for joint diagnostics and prognostics of complex engineering systems. Algorithms 2020, 13, 64. [Google Scholar] [CrossRef] [Green Version]
- Kurz, R.; Brun, K. Degradation in gas turbine systems. J. Eng. Gas Turbines Power 2000, 123, 70–77. [Google Scholar] [CrossRef] [Green Version]
- Eshati, S.; Abu, A.; Laskaridis, P.; Haslam, A. Investigation into the effects of operating conditions and design parameters on the creep life of high pressure turbine blades in a stationary gas turbine engine. Mech. Mech. Eng. 2011, 15, 237–247. [Google Scholar]
- Kelly, D.L.; Smith, C. Bayesian inference in probabilistic risk assessment—The current state of the art. Reliab. Eng. Syst. Saf. 2009, 94, 628–643. [Google Scholar] [CrossRef]
- Pulkkinen, U.; Simola, K. Bayesian models and ageing indicators for analysing random changes in failure occurrence. Reliab. Eng. Syst. Saf. 2000, 68, 255–268. [Google Scholar] [CrossRef]
- Zaccaria, V.; Fentaye, A.D.; Kyprianidis, K. Assessment of dynamic Bayesian models for gas turbine diagnostics, Part 2: Discrimination of gradual degradation and rapid faults. Machines 2021. under review. [Google Scholar]
- Pgmpy Documentation. Available online: pgmpy.org (accessed on 6 July 2021).
- Simon, D.L. Propulsion Diagnostic Method Evaluation Strategy (ProDiMES) User’s Guide. NASA/TM—2010-215840. June 2010. Available online: https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20100005639.pdf (accessed on 30 March 2021).
- Saatlou, E.N.; Kyprianidis, K.; Sethi, V.; Abu, A.O.; Pilidis, P. On the trade-off between minimum fuel burn and maximum time between overhaul for an intercooled aeroengine. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2014, 228, 2424–2438. [Google Scholar] [CrossRef]
- Rahman, M.; Zaccaria, V.; Zhao, X.; Kyprianidis, K. Diagnostics-Oriented modelling of micro gas turbines for fleet monitoring and maintenance optimization. Processes 2018, 6, 216. [Google Scholar] [CrossRef] [Green Version]
- Zaccaria, V.; Stenfelt, M.; Sjunnesson, A.; Hansson, A.; Kyprianidis, K.G. A model-based solution for gas turbine diagnostics: Simulations and experimental verification. In Proceedings of the ASME TURBO EXPO 2019: Power for Land, Sea and Air, Phoenix, AZ, USA, 11–15 June 2019; p. GT2019-90858. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Typical Implementation | Benefits | Disadvantages |
|---|---|---|---|
| Physics-based models | Degradation tracking [1] Abrupt faults [15] | Full understanding of physical, thermal, and aerodynamic nature of the engine behavior. Qualitative and quantitative assessment of the health status of gas path component(s) is possible using measurement deviations. Multiple faults diagnosis. | Knowledge about component characteristic changes due to different faults required. The reliability is dependent on the fault magnitude. Large number of sensors required. Sensitive to measurement uncertainty. |
| Kalman filter (KF) | Degradation tracking [16] | Accurate estimations for linear problems. Low computational complexity. Measurement uncertainty is considered during diagnosis. The actual sensor noise can be represented by white Gaussian distribution. | Even the extended KF based methods can only handle problems with a limited amount of non-linearity. The effectiveness is affected by the unknown performance deterioration and measurement noise covariance matrices. Choice of appropriate covariance matrix is challenging task. Smearing effect can be present. |
| Particle filter | Degradation tracking [17] | Can be used to model multivariate, dynamic processes. More accurate than KF variants for non-linear systems. Coping with measurement uncertainty. | A large number of samples is required; hence, the computation can be heavy. Large number of sensors required. |
| Neural networks | Degradation tracking Abrupt faults [1] | Suitable for non-linear problems. Training can be done by means of information extracted from performance data without detailed knowledge of the gas path system. Multiple faults diagnosis. Measurement uncertainty can be considered. Suitable for problems with limited number of sensors. | Great amount of data needed for training representing the full operating envelope. Sensitive to class imbalance problems (when sufficient faulty data are not available) Retraining required after overhaul. Full understanding of physical and thermodynamics behavior is not possible (black-box model). |
| Fuzzy logic | Abrupt faults [8] | Model-free, knowledge of the process not required. Capable of generalizing from examples. Coping with measurement uncertainty. Suitable for non-linear problems and multiple faults diagnostics. | Fuzzy rules depend on the knowledge of subject expert and diagnosis accuracy depends on the available rules. Large amounts of rules and training data sets are required. |
| Bayesian networks | Abrupt faults [6,9,11,12,13] | Simultaneous multiple faults diagnosis. Graphic model easy to visualize and understand physical relationships. Information from data can be fused with expert knowledge. Coping with measurement uncertainty. Coping with missing information. Confidence levels (probability) are given for diagnostics results. | As the numbers of nodes and edges increase, the model complexity and computational requirements increase. High expert knowledge required for setting up the model. Knowledge of prior probability required, which can be difficult to assess. |
| Dynamic Bayesian networks | Abrupt faults [18] | All advantages of BNs. The prior probability is a dynamic function and can vary over time, making the problem more realistic. Interaction between multiple faults can be taken into account. | Same disadvantages as BNs, but easier estimation of prior probability. |
| Sensor | Δ | σ | k = Δ/σ |
|---|---|---|---|
| T3 | 0.0022 | 0.0008 | 2.75 |
| P3 | 0.0054 | 0.0017 | 3.17 |
| T5 | 0.0089 | 0.002 | 4.4 |
| P5 | 0.00004 | 0.00001 | 4.0 |
| W2 | 0.0082 | 0.002 | 4.1 |
| Sensor | Δ | σ | k = Δ/σ |
|---|---|---|---|
| T3 | 0.0014 | 0.00026 | 5.38 |
| P3 | 0.0055 | 0.00098 | 5.6 |
| T5 | 0.013 | 0.0021 | 6.26 |
| P5 | 0.000067 | 0.000011 | 6.0 |
| W2 | 0 | 0.0018 | 0 |
| N | VL | L | M | H |
|---|---|---|---|---|
| 90% | 7% | 1% | 1% | 1% |
| Predicted | N/VL | L | M | H | |
|---|---|---|---|---|---|
| Real | N/VL | 80% | 20% | 0% | 0% |
| L | 0% | 89.5% | 10.5% | 0% | |
| M | 0% | 0% | 89% | 11% | |
| H | 0% | 0% | 1% | 99% |
| Predicted | N/VL | L | M | H | |
|---|---|---|---|---|---|
| Real | N/VL | 99.5% | 0.5% | 0% | 0% |
| L | 12% | 73% | 14% | 0% | |
| M | 0% | 0% | 90% | 10% | |
| H | 0% | 0% | 0% | 100% |
| 0 h | 2000 h | 4000 h | 6000 h | 8000 h | |
|---|---|---|---|---|---|
| N | 90.5% | 33% | 12% | 5% | 1.8% |
| VL | 9% | 37% | 25% | 15% | 7% |
| L | 0.5% | 20% | 27% | 22% | 15% |
| M | 0% | 7% | 18% | 23% | 19% |
| H | 0% | 2% | 10% | 16% | 20% |
| Predicted | N/VL | L | M | H | |
|---|---|---|---|---|---|
| Real | N/VL | 74% | 26% | 0% | 0% |
| L | 0% | 90% | 10% | 0% | |
| M | 0% | 0% | 93.8% | 6.2% | |
| H | 0% | 0% | 0% | 100% |
| Predicted | N/VL | L | M | H | |
|---|---|---|---|---|---|
| Real | N/VL | 96% | 4% | 0% | 0% |
| L | 0% | 88% | 12% | 0% | |
| M | 0% | 0% | 90% | 10% | |
| H | 0% | 0% | 0% | 100% |
| Previous Condition | N | VL | L | M | H |
|---|---|---|---|---|---|
| N | 99% | 1% | 0% | 0% | 0% |
| VL | 1% | 98% | 1% | 0% | 0% |
| L | 0% | 1% | 98% | 1% | 0% |
| M | 0% | 0% | 1% | 98% | 1% |
| H | 0% | 0% | 0% | 1% | 99% |
| Predicted | N/VL | L | M | H | |
|---|---|---|---|---|---|
| Real | N/VL | 100% | 0% | 0% | 0% |
| L | 2.7% | 88% | 9.3% | 0% | |
| M | 0% | 0% | 100% | 0% | |
| H | 0% | 0% | 0% | 100% |
| Predicted | N/VL | L | M | H | |
|---|---|---|---|---|---|
| Real | N/VL | 95% | 5% | 0% | 0% |
| L | 0% | 94% | 6% | 0% | |
| M | 0% | 0% | 100% | 0% | |
| H | 0% | 0% | 0% | 100% |
| P(Y) = constant | P(Y) = f(t) | P(Y) = f(Yt−1) | |
|---|---|---|---|
| Compressor | 84% | 81% | 92% |
| Turbine | 90% | 93% | 95% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaccaria, V.; Fentaye, A.D.; Kyprianidis, K. Assessment of Dynamic Bayesian Models for Gas Turbine Diagnostics, Part 1: Prior Probability Analysis. Machines 2021, 9, 298. https://doi.org/10.3390/machines9110298
Zaccaria V, Fentaye AD, Kyprianidis K. Assessment of Dynamic Bayesian Models for Gas Turbine Diagnostics, Part 1: Prior Probability Analysis. Machines. 2021; 9(11):298. https://doi.org/10.3390/machines9110298
Chicago/Turabian StyleZaccaria, Valentina, Amare Desalegn Fentaye, and Konstantinos Kyprianidis. 2021. "Assessment of Dynamic Bayesian Models for Gas Turbine Diagnostics, Part 1: Prior Probability Analysis" Machines 9, no. 11: 298. https://doi.org/10.3390/machines9110298