
Overview of Multi-Robot Collaborative SLAM from the Perspective of Data Fusion
 , , , , , , and
, , , , , , and 
Abstract
:1. Introduction
- The theoretical era (1986–2010): The SLAM problem was first proposed by Smith, Self, and Cheeseman [1] in 1986. It involves converting several problems into a state estimation problem. The extended Kalman filter [7], particle filter [8], maximum likelihood method, and other methods can be used to solve such problems. In fact, in an unknown location and environment, the robot needs to determine its position by repeatedly observing environmental characteristics during its movement [9], consequently building an incremental map of the surrounding environment according to its position, allowing it to achieve the goal of simultaneous positioning and map construction. In this era, a large number of SLAM algorithm theories were proposed. In these three decades of development, researchers roughly divided relevant algorithms into two categories: optimization-based and filtering-based. In 2010, Strasdat [10] summarized and compared filtering and optimization methods, which marked the end of the theoretical era and laid a theoretical foundation for the later single-sensor SLAM, multi-sensor SLAM, and distributed SLAM.
- The single-sensor era (1990–2015): During this period, the theory of SLAM was put into practice, and many problems were identified and solved. Many scholars studied the basic characteristics of SLAM problems, including observability, convergence, and consistency. The researchers came to understand the sparsity of the SLAM problem (i.e., the sparsity of the H-matrix structure in the incremental equation), which plays a key role in improving the efficiency of SLAM. In 1990, Moutarlier [11] took the lead in applying the EKF (extended Kalman filter) to run SLAM on a mobile robot equipped with a horizontal scanning laser rangefinder and odometer. This also marked the beginning of the single-sensor era. Lu [12] first proposed a 2D SLAM algorithm based on graph optimization in 1997. In 1999, Gutmann [13] formally proposed the graph optimization framework. In the single-sensor period, 2D laser SLAM methods emerged, such as Fast SLAM [14], Karto SLAM [15], G mapping [16], and other classic models. In the 1990s, visual SLAM began to emerge, and feature methods such as SUSAN [17] and SIFT (scale-invariant feature transform) [18] were proposed. During the rapid development of VSLAM, many classic VSLAM algorithms emerged, including the well-known ORB-SLAM [19], Mono SLAM [20], and PTAM [21]. In addition, some major open-source SLAM frameworks and data sets were put forward at this stage. After 2015, the single-sensor SLAM blowout period ended, and many classic single-sensor SLAM algorithms had reached maturity in terms of application, thus marking the end of the single-sensor era. In this era, a large number of SLAM techniques based on one sensor emerged, laying a solid foundation for the subsequent development of multi-source data fusion SLAM.
- The fusion era (2003–present): During this period, the limitations of single-sensor SLAM were gradually exposed, leading SLAM researchers to pay more attention to multi-source information fusion technology. Information fusion technology originated in the early 1980s and, with the continuous development of technology, information fusion in the context of SLAM also began to develop. Multi-sensor fusion technology has vigorously developed, among which the multi-sensor VIO-SLAM, VL-SLAM, and LIO-SLAM techniques have developed rapidly. In addition, classical multi-sensor fusion frameworks, such as LOAM [22], LeGO-LOAM [23], LVI-SAM [24], and DS-VIO [25], were also proposed and put into practice in this period. Swarm robots first appeared in 1988 [26], but they did not start to grow significantly until 2003. At first, researchers experimentally applied the algorithms designed for single-robot systems to the multi-robot systems and obtained many successful cases, such as the multi-robot EKF algorithm [27] and multi-robot CL (cooperative localization) algorithm [28]. In addition, many classical distributed SLAM frameworks have been proposed, such as CCM-SLAM [29], CVI-SLAM [30], Co SLAM [31], DDF-SAM [32], and so on. In the fusion era, SLAM researchers have begun to pay attention to the collection of multi-source information and, at the same time, have continued to integrate SLAM technology with the emerging disciplines of machine learning and deep learning, making SLAM more and more intelligent and adaptable to multi-source data. At the same time, the use of diverse and rich information enables SLAM systems to adapt to changes in the environment well, allowing the system to operate for a long time with a low failure rate.
- From the perspective of, and method used for multi-modal data fusion, data fusion technology is divided into homogeneous and heterogeneous data fusion. Then, these two data fusion approaches are classified and distinguished according to the algorithm. The literature focused on the system structure of SLAM is combed, and the papers on distributed SLAM published in recent years are summarized. At the same time, Citespace is used to conduct an overall analysis of the SLAM and distributed SLAM fields, in order to analyze and predict the development of distributed robot SLAM in the future.
- The common sensor types in SLAM are reviewed, carefully dividing several common single-sensor types in SLAM and introducing them along with examples. In addition, multi-sensor fusion SLAM and multi-robot SLAM approaches are sorted and classified based on these sensor types.
- Semantic SLAM is combined with distributed robot SLAM and the content of semantic SLAM is integrated into multi-robot SLAM. From the perspective of generating semantic labels, multi-robot semantic SLAM is divided into three categories: supervised learning methods, unsupervised learning methods, and semi-supervised learning algorithms.
2. Related Work
2.1. SLAM Sensors
2.1.1. Laser Sensors
2.1.2. Visual Sensors
2.1.3. IMU Sensors
2.1.4. Sonar Sensors
2.2. SLAM Data Sets
2.3. Analysis of SLAM Development Based on Literature Data
2.4. Data Fusion Methods
Early Fusion
- (a)
- Same sensor data fusion
- (b)
- Different sensor data fusion methods
2.5. Mid-Term Fusion
2.5.1. Late Fusion
2.5.2. Classification of Multi-Source Data Fusion Algorithms
- (a)
- Traditional Methods
- (b)
- Cutting-Edge Methods
3. Single-Robot SLAM
3.1. Single-Robot Single-Sensor SLAM
3.1.1. SLAM Framework
- (a)
- Sensor information reading
- (b)
- Foreground thread
- (c)
- Background thread
- (d)
- Loop detection
- (e)
- Mapping
3.1.2. Laser SLAM
3.1.3. Visual SLAM
3.1.4. Sonar SLAM
3.1.5. Summary of SLAM Algorithms
3.2. Single-Robot Multi-Sensor SLAM
- Ambiguity in data associations, which is reflected in the fact that each obtained data type has obvious differences in terms of attributes, expression, and quality. The difference in data attributes mainly derives from in the difference in data structure.
- A basic theoretical framework and generalized fusion algorithm have not yet been formed. The difficulty lies in the determination of fusion criteria under a large number of random and uncertain problems, as well as how to effectively fuse under these uncertain reactions considering the premise of imprecise, incomplete, unreliable, and fuzzy measurements.
3.2.1. IMU–Visual Fusion
3.2.2. Visual–LiDAR Fusion
3.2.3. Laser–IMU Fusion
3.2.4. LiDAR-Visual-IMU Sensor Fusion
3.2.5. Other Sensor Fusion
3.3. Summary
4. SLAM with Multi-Robot Data Fusion
- Strong adaptability to the environment: Compared with a single-robot operation, a multi-robot operation has strong flexibility, with better functional and spatial distribution than that in the single-robot scenario.
- Strong robustness: In multi-robot systems, the completion of a task requires the participation of multiple robots as a whole, rather than depending on a single robot. If one robot in the system makes a mistake or is damaged, the deployment system can transfer the task to another robot. At the same time, if the working environment of the robot changes or the multi-robot system fails, the multi-robot system can coordinate each robot through its controller to re-assign tasks to adapt to the new environment.
- Cheaper to manufacture: Single-robot SLAM requires the robot’s functionality to be able to cope with everything possible, whereas multi-robot SLAM tends to use multiple low-cost robots in collaboration to complete a task. Therefore, multi-robot systems have lower requirements regarding the performance and hardware of a single robot.
- High work efficiency: Multiple robots can complete each part of the task at the same time through mutual coordination and cooperation, with a clear division of labor and high efficiency.
4.1. The Components of Multi-Robot SLAM
4.1.1. Front-End Data Acquisition
4.1.2. Collaborative Pose Estimation
4.1.3. Map Positioning
- (a)
- Map positioning
- (b)
- Classification of algorithms
4.1.4. Collaborative Map Building
- (a)
- Fusion types
- (b)
- Map fusion algorithm
4.1.5. Loopback Detection
4.2. Multi-Robot SLAM Architecture
4.2.1. Centralized
4.2.2. Distributed
4.2.3. Hybrid
- (1)
- How to perform distributed posterior estimation based on the available data collected by different robots.
- (2)
- Stable and efficient communication techniques in diverse environments.
- (3)
- Application of deep learning in multi-robot SLAM.
- (4)
- The need for teamwork and shared global maps.
- (5)
- Flexible transformation of cooperative technology according to the number of robots.
4.3. Multi-Robot Semantic SLAM
4.3.1. Neural Networks in Semantic VSLAM
4.3.2. Multi-Robot Semantic VSLAM
- (a)
- Supervised learning algorithms
- (b)
- Unsupervised learning algorithms

- (c)
- Semi-supervised learning algorithms
5. Conclusions and Prospects
- (1)
- Small and numerous swarm robot systems. Swarm robot SLAM has begun to develop in the direction of large robot swarm SLAM, with a large number of robots of small size. Researchers are increasingly inclined to combine thousands of small and cheap robots to achieve distributed robot SLAM, which is also the expected development trend of swarm robots in the future. At the same time, how to transform the simple behavior generated by a single individual into the collective behavior generated by a large number of robot interactions, then give full play to the advantages of thousands of swarm robots, is also very challenging.
- (2)
- Self-learning ability of individual robots. Through deep learning, swarm robots can self-learn and process massive information data. In recent years, the environment of swarm robots has become more complex and changeable. A UAV formation may have several or dozens of visual sensors collecting information at the same time and, in future development, there may easily be thousands of UAVs to cluster. Therefore, how to fully process and utilize the information and control the whole system in real-time has become the development goal for robot swarms. How to combine deep learning and swarm robot SLAM is another associated direction of future efforts.
- (3)
- Human–computer collaborative interaction. By embedding some user-driven robots in the cluster, the robot cluster can be directly controlled and manipulated by the user; for example, a human may control the swarm robots as a whole through the use of gestures and/or brain waves, such that the swarm can complete the specified task more efficiently.
- (4)
- Association of swarm robot SLAM with semantic maps. By using the SLAM framework of deep learning, an accurate semantic map of the environment can be constructed. Distributed semantic SLAM systems have stronger robustness and accuracy in complex dynamic environments. Multi-robot systems bring multi-view semantic information to semantic VSLAM, which also reduces the ambiguity of object associations. At the same time, the fusion of semantic information will help the multi-robot system to achieve more stable and accurate global map localization.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AUV | Autonomous underwater vehicle |
| BA | Bundle adjustment |
| C3I | Command, control, communication, and intelligence |
| CL | Cooperative localization |
| CML | Concurrent mapping and localization |
| CNN | Convolutional neural network |
| DARPA | Defense Advanced Research Projects Agency |
| DDF | Decentralized data fusion |
| D-RPGO | Distributed Riemann pose graph optimization |
| D-S | Dempster–Shafer |
| EKF | Extensible Kalman filter |
| EM | Expectation maximization |
| ESKF | Error state Kalman filter |
| FLS | Forward-looking sonar |
| GNSS | Global navigation satellite system |
| GPS | Global position system |
| GPU | Graphics processing unit |
| ICP | Iterative closest point |
| IEKF | Iterated extended Kalman filter |
| IMU | Inertial measurement unit |
| INS | Inertial navigation system |
| KF | Kalman filtering |
| LIO | Laser inertial odometry |
| MAV | Micro aerial vehicles |
| MCL | Monte Carlo method |
| MEMS | Micro-electro-mechanical system |
| MF | Map fusion |
| MHT | Multiple hypothesis tracking |
| ML | Markov localization |
| MLE | Maximum likelihood estimation |
| MSCKF | Multi-state constraint Kalman filter |
| PL-ICP | Point-to-line iterative closest point |
| RFID | Radio frequency identification |
| ROI | Region of interest |
| SAM | Smooth and mapping |
| SFM | Structure from motion |
| SIFT | Scale invariant feature transform |
| SLAM | Simultaneous localization and mapping |
| TSDF | Truncation sign distance function |
| UAV | Unmanned aerial vehicle |
| UGV | Unmanned ground vehicle |
| UKF | Unscented Kalman filter |
| UUV | Unmanned underwater vehicle |
| UWB | Ultra wide band |
| VINS | Visual-inertial navigation system |
| VIO | Visual-inertial odometry |
| VSLAM | Visual simultaneous localization and mapping |
References
- Smith, R.C.; Cheeseman, P. On the Representation and Estimation of Spatial Uncertainty. Int. J. Robot. Res. 1986, 5, 56–68. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, F.; Chang, S.; Liu, Y.; Wu, H.; Feng, Z. MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review. Sensors 2022, 22, 2542. [Google Scholar] [CrossRef]
- Zhou, X.; Wen, X.; Wang, Z.; Gao, Y.; Li, H.; Wang, Q.; Yang, T.; Lu, H.; Cao, Y.; Xu, C.; et al. Swarm of Micro Flying Robots in the Wild. Sci. Robot. 2022, 7, eabm5954. [Google Scholar] [CrossRef]
- Qin, T.; Shen, S. Robust initialization of monocular visual-inertial estimation on aerial robots. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4225–4232. [Google Scholar]
- Debeunne, C.; Vivet, D. A Review of Visual-LiDAR Fusion Based Simultaneous Localization and Mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef] [Green Version]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2006, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Se, S.; Lowe, D.; Little, J. Mobile Robot Localization and Mapping with Uncertainty Using Scale-Invariant Visual Landmarks. Int. J. Robot. Res. 2002, 21, 735–758. [Google Scholar] [CrossRef]
- Gordon, N.J.; Salmond, D.J.; Smith, A.F.M. Novel Approach to Nonlinear/Non-Gaussian Bayesian State Estimation. IEEE Proc. F Radar Signal Process 1993, 140, 107. [Google Scholar] [CrossRef] [Green Version]
- Thrun, S. Bayesian Landmark Learning for Mobile Robot Localization. Mach. Learn. 1998, 33, 41–76. [Google Scholar] [CrossRef]
- Strasdat, H.; Montiel, J.M.M.; Davison, A.J. Real-Time Monocular SLAM: Why Filter? In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 2657–2664. [Google Scholar]
- Moutarlier, P.; Chatila, R. An Experimental System for Incremental Environment Modelling by an Autonomous Mobile Robot. In Experimental Robotics I; Hayward, V., Khatib, O., Eds.; Springer: Heidelberg/Berlin, Germany, 1990; Volume 139, pp. 327–346. [Google Scholar]
- Lu, F.; Milios, E. Globally Consistent Range Scan Alignment for Environment Mapping. Auton. Robot. 1997, 4, 333–349. [Google Scholar] [CrossRef]
- Gutmann, J.-S.; Konolige, K. Incremental Mapping of Large Cyclic Environments. In Proceedings of the 1999 IEEE International Symposium on Computational Intelligence in Robotics and Automation.CIRA’99 (Cat. No.99EX375), Monterey, CA, USA, 8–9 November 1999; pp. 318–325. [Google Scholar]
- Montemerlo, M.; Thrun, S.; Koller, D.; Wegbreit, B. FastSLAM: A Factored Solution to the Simultaneous Localization and Mapping Problem. In Proceedings of the American Association for Artificial Intelligence, Edmonton, AB, Canada, 28 July 2002; Volume 50, pp. 240–248. [Google Scholar]
- Konolige, K.; Grisetti, G.; Kümmerle, R.; Burgard, W.; Limketkai, B.; Vincent, R. Efficient Sparse Pose Adjustment for 2D Mapping. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 22–29. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters. IEEE Trans. Robot 2007, 23, 34–46. [Google Scholar] [CrossRef] [Green Version]
- Smith, S.M.; Brady, J.M. SUSAN—A New Approach to Low Level Image Processing. Int. J. Comput. Vis. 1997, 23, 45–78. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints(SIFT). Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Davison, A.J.; Reid, I.; Molton, N.D.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [Green Version]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 1–10. [Google Scholar]
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-Time. In Proceedings of the Robotics: Science and Systems Conference (RSS), Computer Science, Berkeley, CA, USA, 12–16 July 2014; pp. 109–111. [Google Scholar]
- Shan, T.; Englot, B. LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Shan, T.; Englot, B.; Ratti, C.; Rus, D. LVI-SAM: Tightly-Coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 5692–5698. [Google Scholar]
- Xiong, X.; Chen, W.; Liu, Z.; Shen, Q. DS-VIO: Robust and Efficient Stereo Visual Inertial Odometry Based on Dual Stage EKF. arXiv 2019, arXiv:1905.00684. [Google Scholar] [CrossRef]
- Fukuda, T.; Nakagawa, S.; Kawauchi, Y.; Buss, M. Self Organizing Robots Based on Cell Structures—CKBOT. In Proceedings of the IEEE International Workshop on Intelligent Robots, Tokyo, Japan, 31 October–2 November 1988; pp. 145–150. [Google Scholar]
- Rodriguez-Losada, D.; Matia, F.; Jimenez, A. Local Maps Fusion for Real Time Multirobot Indoor Simultaneous Localization and Mapping. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004; Volume 2, pp. 1308–1313. [Google Scholar]
- Nerurkar, E.D.; Roumeliotis, S.I.; Martinelli, A. Distributed Maximum a Posteriori Estimation for Multi-Robot Cooperative Localization. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 1402–1409. [Google Scholar]
- Schmuck, P.; Chli, M. CCM-SLAM: Robust and Efficient Centralized Collaborative Monocular Simultaneous Localization and Mapping for Robotic Teams. J. Field Robot. 2019, 36, 763–781. [Google Scholar] [CrossRef] [Green Version]
- Karrer, M.; Schmuck, P.; Chli, M. CVI-SLAM—Collaborative Visual-Inertial SLAM. IEEE Robot. Autom. Lett. 2018, 3, 2762–2769. [Google Scholar] [CrossRef] [Green Version]
- Zou, D.; Tan, P. CoSLAM: Collaborative Visual SLAM in Dynamic Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 354–366. [Google Scholar] [CrossRef] [PubMed]
- Cunningham, A.; Paluri, M.; Dellaert, F. DDF-SAM: Fully Distributed SLAM Using Constrained Factor Graphs. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 3025–3030. [Google Scholar]
- Durrant-Whyte, H.; Bailey, T. Simultaneous Localization and Mapping: Part I. IEEE Robot. Automat. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef] [Green Version]
- Bailey, T.; Durrant-Whyte, H. Simultaneous Localization and Mapping (SLAM): Part II. IEEE Robot. Automat. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef] [Green Version]
- Aulinas, J.; Petillot, Y.R.; Salvi, J.; Lladó, X. The SLAM Problem: A Survey. In Proceedings of the 11th International Conference of the Catalan Association for Artificial Intelligence, Amsterdam, The Netherlands, 3 July 2008; pp. 363–371. [Google Scholar]
- Strasdat, H.; Montiel, J.M.M.; Davison, A.J. Visual SLAM: Why Filter? Image Vis. Comput. 2012, 30, 65–77. [Google Scholar] [CrossRef]
- Dissanayake, G.; Huang, S.; Wang, Z.; Ranasinghe, R. A Review of Recent Developments in Simultaneous Localization and Mapping. In Proceedings of the 2011 6th International Conference on Industrial and Information Systems, Kandy, Sri Lanka, 16–19 August 2011; pp. 477–482. [Google Scholar]
- Huang, S.; Dissanayake, G. A Critique of Current Developments in Simultaneous Localization and Mapping. Int. J. Adv. Robot. Syst. 2016, 13, 172988141666948. [Google Scholar] [CrossRef]
- Saeedi, S.; Trentini, M.; Seto, M.; Li, H. Multiple-Robot Simultaneous Localization and Mapping: A Review: Multiple-Robot Simultaneous Localization and Mapping. J. Field Robot. 2016, 33, 3–46. [Google Scholar] [CrossRef]
- Dorigo, M.; Theraulaz, G.; Trianni, V. Swarm Robotics: Past, Present, and Future [Point of View]. Proc. IEEE 2021, 109, 1152–1165. [Google Scholar] [CrossRef]
- Marques, L.; Nunes, U.; de Almeida, A.T. Olfaction-Based Mobile Robot Navigation. Thin Solid Film. 2002, 418, 51–58. [Google Scholar] [CrossRef] [Green Version]
- Magnabosco, M.; Breckon, T.P. Cross-Spectral Visual Simultaneous Localization and Mapping (SLAM) with Sensor Handover. Robot. Auton. Syst. 2013, 61, 195–208. [Google Scholar] [CrossRef]
- Robertson, P.; Frassl, M.; Angermann, M.; Doniec, M.; Julian, B.J.; Garcia Puyol, M.; Khider, M.; Lichtenstern, M.; Bruno, L. Simultaneous Localization and Mapping for Pedestrians Using Distortions of the Local Magnetic Field Intensity in Large Indoor Environments. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation, Montbeliard, France, 28–31 October 2013; pp. 1–10. [Google Scholar]
- Montemerlo, M.; Becker, J.; Bhat, S.; Dahlkamp, H.; Dolgov, D.; Ettinger, S.; Haehnel, D.; Hilden, T.; Hoffmann, G.; Huhnke, B.; et al. Junior: The Stanford Entry in the Urban Challenge. In The Darpa Urban Challenge: Autonomous Vehicles in City Traffic; Buehler, M., Iagnemma, K., Singh, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 91–123. [Google Scholar]
- Levinson, J.; Askeland, J.; Becker, J.; Dolson, J.; Held, D.; Kammel, S.; Kolter, J.Z.; Langer, D.; Pink, O.; Pratt, V.; et al. Towards Fully Autonomous Driving: Systems and Algorithms. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 163–168. [Google Scholar]
- Shan, T.; Englot, B.; Meyers, D.; Wang, W.; Ratti, C.; Rus, D. LIO-SAM: Tightly-Coupled Lidar Inertial Odometry via Smoothing and Mapping. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–19 October 2020; pp. 5135–5142. [Google Scholar]
- Kohlbrecher, S.; von Stryk, O.; Meyer, J.; Klingauf, U. A Flexible and Scalable SLAM System with Full 3D Motion Estimation. In Proceedings of the 2011 IEEE International Symposium on Safety, Security, and Rescue Robotics, Kyoto, Japan, 1–5 November 2011; pp. 155–160. [Google Scholar]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-Time Loop Closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Monica, J.; Campbell, M. Vision Only 3-D Shape Estimation for Autonomous Driving. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 1676–1683. [Google Scholar]
- Rueckauer, B.; Delbruck, T. Evaluation of Event-Based Algorithms for Optical Flow with Ground-Truth from Inertial Measurement Sensor. Front. Neurosci. 2016, 10, 176. [Google Scholar] [CrossRef] [Green Version]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-Time Dense Surface Mapping and Tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Dansereau, D.G.; Williams, S.B.; Corke, P.I. Simple Change Detection from Mobile Light Field Cameras. Comput. Vis. Image Underst. 2016, 145, 160–171. [Google Scholar] [CrossRef]
- UTIAS. Available online: http://asrl.utias.utoronto.ca/datasets/mrclam/ (accessed on 11 February 2023).
- KITTI. Available online: https://www.cvlibs.net/datasets/kitti/ (accessed on 16 November 2022).
- TUM RGB-D. Available online: https://cvg.cit.tum.de/data/datasets/rgbd-dataset/download (accessed on 16 November 2022).
- NYUDv2. Available online: https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html (accessed on 16 November 2022).
- ICL-NUIM. Available online: https://www.doc.ic.ac.uk/~ahanda/VaFRIC/iclnuim.html (accessed on 16 November 2022).
- EuRoC. Available online: https://projects.asl.ethz.ch/datasets/doku.php?id=kmavvisualinertialdatasets#the_euroc_mav_dataset (accessed on 16 November 2022).
- Oxford Robotcar. Available online: https://robotcar-dataset.robots.ox.ac.uk/ (accessed on 16 November 2022).
- ScanNet. Available online: http://www.scan-net.org/ (accessed on 16 November 2022).
- Re Fusion. Available online: https://github.com/PRBonn/refusion (accessed on 16 November 2022).
- Cityscapes. Available online: https://www.cityscapes-dataset.com/ (accessed on 16 November 2022).
- Air Museum. Available online: https://github.com/AirMuseumDataset (accessed on 16 November 2022).
- S3E. Available online: https://github.com/PengYu-Team/S3E (accessed on 16 November 2022).
- Zhong, S.; Qi, Y.; Chen, Z.; Wu, J.; Chen, H.; Liu, M. DCL-SLAM: A Distributed Collaborative LiDAR SLAM Framework for a Robotic Swarm. arXiv 2022, arXiv:2210.11978. [Google Scholar]
- Xie, Y.; Zhang, Y.; Chen, L.; Cheng, H.; Tu, W.; Cao, D.; Li, Q. RDC-SLAM: A Real-Time Distributed Cooperative SLAM System Based on 3D LiDAR. IEEE Trans. Intell. Transport. Syst. 2022, 23, 14721–14730. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Visual-Lidar Odometry and Mapping: Low-Drift, Robust, and Fast. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2174–2181. [Google Scholar]
- Sehgal, A.; Singandhupe, A.; La, H.M.; Tavakkoli, A.; Louis, S.J. Lidar-Monocular Visual Odometry with Genetic Algorithm for Parameter Optimization. In Advances in Visual Computing; Lecture Notes in Computer Science; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Ushizima, D., Chai, S., Sueda, S., Lin, X., Lu, A., Thalmann, D., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11845, pp. 358–370. [Google Scholar]
- Lynen, S.; Achtelik, M.W.; Weiss, S.; Chli, M.; Siegwart, R. A Robust and Modular Multi-Sensor Fusion Approach Applied to MAV Navigation. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 1–5 November 2013; pp. 3923–3929. [Google Scholar]
- Leutenegger, S.; Furgale, P.; Rabaud, V.; Chli, M.; Konolige, K.; Siegwart, R. Keyframe-Based Visual-Inertial SLAM Using Nonlinear Optimization. In Proceedings of the Robotis Science and Systems (RSS), Berlin, Germany, 24–28 June 2013. [Google Scholar]
- von Stumberg, L.; Cremers, D. Cremers DM-VIO: Delayed Marginalization Visual-Inertial Odometry. IEEE Robot. Autom. Lett. 2022, 7, 1408–1415. [Google Scholar] [CrossRef]
- Riazuelo, L.; Civera, J.; Montiel, J.M.M. C2TAM: A Cloud Framework for Cooperative Tracking and Mapping. Robot. Auton. Syst. 2014, 62, 401–413. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Xu, L.; Sun, H.; Xin, J.; Zheng, N. Bionic Vision Inspired On-Road Obstacle Detection and Tracking Using Radar and Visual Information. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 39–44. [Google Scholar]
- Knuth, J.; Barooah, P. Collaborative 3D Localization of Robots from Relative Pose Measurements Using Gradient Descent on Manifolds. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 1101–1106. [Google Scholar]
- Knuth, J.; Barooah, P. Collaborative Localization with Heterogeneous Inter-Robot Measurements by Riemannian Optimization. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1534–1539. [Google Scholar]
- Zhang, J.; Kaess, M.; Singh, S. Real-Time Depth Enhanced Monocular Odometry. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 4973–4980. [Google Scholar]
- Forster, C.; Lynen, S.; Kneip, L.; Scaramuzza, D. Collaborative Monocular SLAM with Multiple Micro Aerial Vehicles. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 3962–3970. [Google Scholar]
- Zhang, T.; Zhang, L.; Chen, Y.; Zhou, Y. CVIDS: A Collaborative Localization and Dense Mapping Framework for Multi-Agent Based Visual-Inertial SLAM. IEEE Trans. Image Process 2022, 31, 6562–6576. [Google Scholar] [CrossRef]
- Gao, J.; Weng, L.; Xia, M.; Lin, H. MLNet: Multichannel Feature Fusion Lozenge Network for Land Segmentation. J. Appl. Remote Sens. 2022, 16, 016513. [Google Scholar] [CrossRef]
- Miao, S.; Xia, M.; Qian, M.; Zhang, Y.; Liu, J.; Lin, H. Cloud/Shadow Segmentation Based on Multi-Level Feature Enhanced Network for Remote Sensing Imagery. Int. J. Remote Sens. 2022, 43, 5940–5960. [Google Scholar] [CrossRef]
- Deng, W.; Huang, K.; Chen, X.; Zhou, Z.; Shi, C.; Guo, R.; Zhang, H. Semantic RGB-D SLAM for Rescue Robot Navigation. IEEE Access 2022, 8, 221320–221329. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial Cross Attention Meets CNN: Bibranch Fusion Network for Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 32–43. [Google Scholar] [CrossRef]
- Bahr, A.; Walter, M.R.; Leonard, J.J. Consistent Cooperative Localization. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3415–3422. [Google Scholar]
- Lázaro, M.T.; Paz, L.M.; Piniés, P.; Castellanos, J.A.; Grisetti, G. Multi-Robot SLAM Using Condensed Measurements. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1069–1076. [Google Scholar]
- Zhao, B.; Zhong, Y.; Zhang, L. Hybrid Generative/Discriminative Scene Classification Strategy Based on Latent Dirichlet Allocation for High Spatial Resolution Remote Sensing Imagery. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium—IGARSS, Melbourne, VIC, Australia, 21–26 July 2013; pp. 196–199. [Google Scholar]
- Fischer, R.; Dinklage, A. Integrated Data Analysis of Fusion Diagnostics by Means of the Bayesian Probability Theory. Rev. Sci. Instrum. 2004, 75, 4237–4239. [Google Scholar] [CrossRef]
- LeBlanc, K.; Saffiotti, A. Multirobot Object Localization: A Fuzzy Fusion Approach. IEEE Trans. Syst. Man Cybern. B 2009, 39, 1259–1276. [Google Scholar] [CrossRef]
- Dan, Y.; Hongbing, J.; Yongchan, G. A Robust D–S Fusion Algorithm for Multi-Target Multi-Sensor with Higher Reliability. Inf. Fusion 2019, 47, 32–44. [Google Scholar] [CrossRef]
- Shao, W.; Vijayarangan, S.; Li, C.; Kantor, G. Stereo Visual Inertial LiDAR Simultaneous Localization and Mapping. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 370–377. [Google Scholar]
- Zhao, S.; Fang, Z.; Li, H.; Scherer, S. A Robust Laser-Inertial Odometry and Mapping Method for Large-Scale Highway Environments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 370–377. [Google Scholar]
- Qin, C.; Ye, H.; Pranata, C.E.; Han, J.; Zhang, S.; Liu, M. LINS: A Lidar-Inertial State Estimator for Robust and Efficient Navigation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May 2020–31 August 2020; pp. 8899–8906. [Google Scholar]
- Castle, R.; Klein, G.; Murray, D.W. Video-Rate Localization in Multiple Maps for Wearable Augmented Reality. In Proceedings of the 2008 12th IEEE International Symposium on Wearable Computers, Pittsburgh, PA, USA, 28 September–1 October 2008; pp. 15–22. [Google Scholar]
- Cao, Y.; Beltrame, G. VIR-SLAM: Visual, Inertial, and Ranging SLAM for Single and Multi-Robot Systems. Auton. Robot. 2021, 45, 905–917. [Google Scholar] [CrossRef]
- Bigdeli, B.; Samadzadegan, F.; Reinartz, P. A Decision Fusion Method Based on Multiple Support Vector Machine System for Fusion of Hyperspectral and LIDAR Data. Int. J. Image Data Fusion 2014, 5, 196–209. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Hu, N.; Cheng, Z.; Zhang, L.; Zhang, Y. A Deep Convolutional Neural Network Based Fusion Method of Two-Direction Vibration Signal Data for Health State Identification of Planetary Gearboxes. Measurement 2019, 146, 268–278. [Google Scholar] [CrossRef]
- Lajoie, P.-Y.; Ramtoula, B.; Chang, Y.; Carlone, L.; Beltrame, G. DOOR-SLAM: Distributed, Online, and Outlier Resilient SLAM for Robotic Teams. IEEE Robot. Autom. Lett. 2020, 5, 1656–1663. [Google Scholar] [CrossRef] [Green Version]
- Ran, C.; Deng, Z. Self-Tuning Weighted Measurement Fusion Kalman Filtering Algorithm. IEEE Comput. Stat. Data Anal. 2012, 56, 2112–2128. [Google Scholar] [CrossRef]
- Zheng, M.M.; Krishnan, S.M.; Tjoa, M.P. A Fusion-Based Clinical Decision Support for Disease Diagnosis from Endoscopic Images. IEEE Comput. Biol. Med. 2005, 35, 259–274. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Chowdhury, S.S.; Niloy, N.; Zohra Aurin, F.T.; Ahmed, T. Sonar-Based SLAM Using Occupancy Grid Mapping and Dead Reckoning. In Proceedings of the TENCON 2018—2018 IEEE Region 10 Conference, Jeju, Republic of Korea, 28–31 October 2018; pp. 1707–1712. [Google Scholar]
- Jang, J.; Kim, J. Dynamic Grid Adaptation for Panel-Based Bathymetric SLAM. In Proceedings of the 2019 IEEE Underwater Technology (UT), Kaohsiung, Taiwan, 16–19 April 2019; pp. 1–4. [Google Scholar]
- Howard, A. Multi-Robot Simultaneous Localization and Mapping Using Particle Filters. Int. J. Robot. Res. 2006, 25, 1243–1256. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.; Yoon, S.; Kim, S.; Kim, A. Unsupervised Balanced Covariance Learning for Visual-Inertial Sensor Fusion. IEEE Robot. Autom. Lett. 2021, 6, 819–826. [Google Scholar] [CrossRef]
- Vo, A.-V.; Truong-Hong, L.; Laefer, D.F.; Tiede, D.; dOleire-Oltmanns, S.; Baraldi, A.; Shimoni, M.; Moser, G.; Tuia, D. In Proceedings of the Extremely High Resolution LiDAR and RGB Data: Outcome of the 2015 IEEE GRSS Data Fusion Contest—Part B: 3-D Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5560–5575. [Google Scholar] [CrossRef]
- Ma, Z.; Xia, M.; Weng, L.; Lin, H. Local Feature Search Network for Building and Water Segmentation of Remote Sensing Image. Sustainability 2023, 15, 3034. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Lin, H. Multi-Scale Strip Pooling Feature Aggregation Network for Cloud and Cloud Shadow Segmentation. Neural. Comput. Applic. 2022, 34, 6149–6162. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip Pooling Channel Spatial Attention Network for the Segmentation of Cloud and Cloud Shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. CNN-SLAM: Real-Time Dense Monocular SLAM with Learned Depth Prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6565–6574. [Google Scholar]
- Ma, R.; Wang, R.; Zhang, Y.; Pizer, S.; McGill, S.K.; Rosenman, J.; Frahm, J.-M. RNNSLAM: Reconstructing the 3D Colon to Visualize Missing Regions during a Colonoscopy. Med. Image Anal. 2021, 72, 102100. [Google Scholar] [CrossRef]
- Zhou, F.; Wang, T.; Zhong, T.; Trajcevski, G. Identifying User Geolocation with Hierarchical Graph Neural Networks and Explainable Fusion. Inf. Fusion 2022, 81, 1–13. [Google Scholar] [CrossRef]
- Wang, Z.; Xia, M.; Lu, M.; Pan, L.; Liu, J. Parameter Identification in Power Transmission Systems Based on Graph Convolution Network. IEEE Trans. Power Deliv. 2022, 37, 3155–3163. [Google Scholar] [CrossRef]
- Moravec, H.P. Obstacle Avoidance and Navigation in the Real World by a Seeing Robot Rover. In Proceedings of the International Joint Conference on Artificial Intelligence, San Francisco, CA, USA, 24–28 August 1980; pp. 584–588. [Google Scholar]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference 1988, Manchester, UK, 1 January 1988. [Google Scholar]
- Shi, J.; Tomasi. Good Features to Track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Lowe, D. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Wu, Y.; Zhang, Y.; Zhu, D.; Feng, Y.; Coleman, S.; Kerr, D. EAO-SLAM: Monocular Semi-Dense Object SLAM Based on Ensemble Data Association. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 January 2021; pp. 4966–4973. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Baker, S.; Matthews, I. Lucas-Kanade 20 Years On: A Unifying Framework. Int. J. Comput. Vis. 2004, 56, 221–255. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunck, B.G. Determining Optical Flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense Tracking and Mapping in Real-Time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast Semi-Direct Monocular Visual Odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An Accurate O(n) Solution to the PnP Problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Manolis, I.A.; Argyros, A.A. SBA: A Software Package for Generic Sparse Bundle Adjustment. ACM Trans. Math. Softw. 2009, 36, 1–30. [Google Scholar]
- Hahnel, D.; Burgard, W.; Fox, D.; Thrun, S. An Efficient Fastslam Algorithm for Generating Maps of Large-Scale Cyclic Environments from Raw Laser Range Measurements. In Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003) (Cat. No.03CH37453), Las Vegas, NV, USA, 27–31 October 2003; Volume 1, pp. 206–211. [Google Scholar]
- Cadena, C.; Neira, J. SLAM in O(Log n) with the Combined Kalman—Information Filter. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 2069–2076. [Google Scholar]
- Carlone, L.; Aragues, R.; Castellanos, J.A.; Bona, B. A Linear Approximation for Graph-Based Simultaneous Localization and Mapping. In Robotics: Science and Systems; Robotics and Control Systems; Durrant-Whyte, H., Nicholas, R., Pieter, A., Eds.; MIT Press: Cambridge, MA, USA, 2012; Volume 7, pp. 41–48. [Google Scholar]
- Reinke, A.; Palieri, M.; Morrell, B.; Chang, Y.; Ebadi, K.; Carlone, L.; Agha-Mohammadi, A.-A. LOCUS 2.0: Robust and Computationally Efficient Lidar Odometry for Real-Time 3D Mapping. IEEE Robot. Autom. Lett. 2022, 7, 9043–9050. [Google Scholar] [CrossRef]
- Pire, T.; Fischer, T.; Castro, G.; De Cristóforis, P.; Civera, J.; Jacobo Berlles, J. S-PTAM: Stereo Parallel Tracking and Mapping. Robot. Auton. Syst. 2017, 93, 27–42. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Kerl, C.; Sturm, J.; Cremers, D. Dense Visual SLAM for RGB-D Cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar]
- Wang, R.; Schworer, M.; Cremers, D. Stereo DSO: Large-Scale Direct Sparse Visual Odometry with Stereo Cameras. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3923–3931. [Google Scholar]
- Izadi, S.; Davison, A.; Fitzgibbon, A.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; et al. KinectFusion: Real-Time 3D Reconstruction and Interaction Using a Moving Depth Camera. In Proceedings of the 24th annual ACM symposium on User interface software and technology—UIST ’11, Santa Barbara, CA, USA, 16 October 2011; p. 559. [Google Scholar]
- Whelan, T.; McDonald, J.; Kaess, M.; Fallon, M.; Johannsson, H.; Leonard, J.J. Kintinuous: Spatially Extended KinectFusion. MIT-CSAIL-TR 2012, 20, 8–16. [Google Scholar]
- Whelan, T.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J.; Leutenegger, S. ElasticFusion: Real-Time Dense SLAM and Light Source Estimation. Int. J. Robot. Res. 2016, 35, 1697–1716. [Google Scholar] [CrossRef] [Green Version]
- Mono SLAM. Available online: https://github.com/hanmekim/SceneLib2 (accessed on 17 November 2022).
- PTAM. Available online: https://github.com/Oxford-PTAM/PTAM-GPL (accessed on 17 November 2022).
- DTAM. Available online: https://github.com/anuranbaka/OpenDTAM/tree/2.4.9_experimental/Cpp (accessed on 17 November 2022).
- Kinect Fusion. Available online: https://github.com/chrdiller/KinectFusionApp (accessed on 17 November 2022).
- Kintinuous. Available online: https://github.com/mp3guy/Kintinuous (accessed on 17 November 2022).
- DVO-SLAM. Available online: https://github.com/songuke/dvo_slam (accessed on 17 November 2022).
- LSD-SLAM. Available online: https://github.com/tum-vision/lsd_slam (accessed on 17 November 2022).
- SVO. Available online: https://github.com/uzh-rpg/rpg_svo (accessed on 17 November 2022).
- ORB-SLAM. Available online: http://webdiis.unizar.es/~raulmur/orbslam/ (accessed on 17 November 2022).
- ORB-SLAM2. Available online: https://github.com/raulmur/ORB_SLAM2 (accessed on 17 November 2022).
- Elastic Fusion. Available online: https://github.com/mp3guy/ElasticFusion (accessed on 17 November 2022).
- S-PTAM. Available online: https://github.com/lrse/sptam (accessed on 17 November 2022).
- Binocular DSO. Available online: https://github.com/HorizonAD/stereo_dso (accessed on 17 November 2022).
- DSO. Available online: https://github.com/JakobEngel/dso (accessed on 17 November 2022).
- Koestler, L.; Yang, N.; Zeller, N.; Cremers, D. Tandem: Tracking and Dense Mapping in Real-Time Using Deep Multi-View Stereo. Robot. Learn. 2022, 164, 34–45. [Google Scholar]
- Wimbauer, F.; Yang, N.; von Stumberg, L.; Zeller, N.; Cremers, D. Monorec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6108–6118. [Google Scholar]
- Mallios, A.; Ridao, P.; Ribas, D.; Carreras, M.; Camilli, R. Toward Autonomous Exploration in Confined Underwater Environments. J. Field Robot. 2016, 33, 994–1012. [Google Scholar] [CrossRef] [Green Version]
- Walter, M.; Hover, F.; Leonard, J. SLAM for Ship Hull Inspection Using Exactly Sparse Extended Information Filters. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 1463–1470. [Google Scholar]
- Johnson-Roberson, M.; Pizarro, O.; Williams, S.B.; Mahon, I. Generation and Visualization of Large-Scale Three-Dimensional Reconstructions from Underwater Robotic Surveys. J. Field Robot. 2010, 27, 21–51. [Google Scholar] [CrossRef]
- Fallon, M.F.; Folkesson, J.; McClelland, H.; Leonard, J.J. Relocating Underwater Features Autonomously Using Sonar-Based SLAM. IEEE J. Ocean. Eng. 2013, 38, 500–513. [Google Scholar] [CrossRef] [Green Version]
- Matsebe, O.; Mpofu, K.; Agee, J.T.; Ayodeji, S.P. Corner Features Extraction: Underwater SLAM in Structured Environments. J. Eng. Des. Technol. 2015, 13, 556–569. [Google Scholar] [CrossRef]
- Rahman, S.; Li, A.Q.; Rekleitis, I. Contour Based Reconstruction of Underwater Structures Using Sonar, Visual, Inertial, and Depth Sensor. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 8054–8059. [Google Scholar]
- Hu, K.; Wang, T.; Shen, C.; Weng, C.; Zhou, F.; Xia, M.; Weng, L. Overview of Underwater 3D Reconstruction Technology Based on Optical Images. J. Mar. Sci. Eng. 2023, 11, 949. [Google Scholar] [CrossRef]
- Chen, W.; Zhou, C.; Shang, G.; Wang, X.; Li, Z.; Xu, C.; Hu, K. SLAM Overview: From Single Sensor to Heterogeneous Fusion. Remote Sens. 2022, 14, 6033. [Google Scholar] [CrossRef]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-Based Visual–Inertial Odometry Using Nonlinear Optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef] [Green Version]
- Qin, T.; Shen, S. Online Temporal Calibration for Monocular Visual-Inertial Systems. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3662–3669. [Google Scholar]
- Li, P.; Qin, T.; Hu, B.; Zhu, F.; Shen, S. Monocular Visual-Inertial State Estimation for Mobile Augmented Reality. In Proceedings of the 2017 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Nantes, France, 9–13 October 2017; pp. 11–21. [Google Scholar]
- Shamwell, E.J.; Lindgren, K.; Leung, S.; Nothwang, W.D. Unsupervised Deep Visual-Inertial Odometry with Online Error Correction for RGB-D Imagery. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2478–2493. [Google Scholar] [CrossRef]
- Mourikis, A.I.; Roumeliotis, S.I. A Multi-State Constraint Kalman Filter for Vision-Aided Inertial Navigation. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Rome, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar]
- Weiss, S. Vision Based Navigation for Micro Helicopters. Ph.D. Thesis, ETH Zurich, Zurich, Switzerland, 2012. [Google Scholar]
- Bloesch, M.; Burri, M.; Omari, S.; Hutter, M.; Siegwart, R. Iterated Extended Kalman Filter Based Visual-Inertial Odometry Using Direct Photometric Feedback. Int. J. Robot. Res. 2017, 36, 1053–1072. [Google Scholar] [CrossRef] [Green Version]
- MSCKF. Available online: https://github.com/daniilidis-group/msckf_mono (accessed on 19 February 2023).
- SSF. Available online: https://github.com/ethz-asl/ethzasl_sensor_fusion (accessed on 19 February 2023).
- MSF. Available online: https://github.com/Ewenwan/ethzasl_msf (accessed on 19 February 2023).
- OKVIS. Available online: https://github.com/Ewenwan/okvis (accessed on 19 February 2023).
- VINS-Mono. Available online: https://github.com/Ewenwan/VINS-Mono (accessed on 19 February 2023).
- VINS-Mobile. Available online: https://github.com/HKUST-Aerial-Robotics/VINS-Mobile (accessed on 19 February 2023).
- ROVIO. Available online: https://github.com/Ewenwan/rovio (accessed on 19 February 2023).
- DM-VIO. Available online: https://cvg.cit.tum.de/research/vslam/dm-vio?redirect=1 (accessed on 19 February 2023).
- López, E.; García, S.; Barea, R.; Bergasa, L.; Molinos, E.; Arroyo, R.; Romera, E.; Pardo, S. A Multi-Sensorial Simultaneous Localization and Mapping (Slam) System for Low-Cost Micro Aerial Vehicles in Gps-Denied Environments. Sensors 2017, 17, 802. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Ou, Y.; Xu, T.; Roumeliotis, S.I. SLAM of Robot Based on the Fusion of Vision and LIDAR. In Proceedings of the 2018 IEEE International Conference on Cyborg and Bionic Systems (CBS), Shenzhen, China, 25–27 October 2007; pp. 3565–3572. [Google Scholar]
- Shin, Y.-S.; Park, Y.S.; Kim, A. Direct Visual SLAM Using Sparse Depth for Camera-LiDAR System. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 5144–5151. [Google Scholar]
- Wisth, D.; Camurri, M.; Fallon, M. VILENS: Visual, Inertial, Lidar, and Leg Odometry for All-Terrain Legged Robots. IEEE Trans. Robot. 2023, 39, 309–326. [Google Scholar] [CrossRef]
- DEMO. Available online: https://github.com/Jinqiang/demo_lidar (accessed on 18 November 2022).
- LIMO. Available online: https://github.com/agilexrobotics/limo-doc (accessed on 18 November 2022).
- VIL-SLAM. Available online: https://github.com/laboshinl/loam_velodyne (accessed on 18 November 2022).
- LVI-SAM. Available online: https://github.com/TixiaoShan/LVI-SAM (accessed on 18 November 2022).
- Tang, J.; Chen, Y.; Niu, X.; Wang, L.; Chen, L.; Liu, J.; Shi, C.; Hyyppä, J. LiDAR Scan Matching Aided Inertial Navigation System in GNSS-Denied Environments. Environ. Sci. Sens. 2015, 15, 16710–16728. [Google Scholar] [CrossRef]
- Chen, B.; Zhao, H.; Zhu, R.; Hu, Y. Marked-LIEO: Visual Marker-Aided LiDAR/IMU/Encoder Integrated Odometry. Comput. Sci. Sens. 2022, 22, 4749. [Google Scholar] [CrossRef]
- Soloviev, A.; Bates, D.; Van Graas, F. Tight Coupling of Laser Scanner and Inertial Measurements for a Fully Autonomous Relative Navigation Solution. Navigation 2007, 54, 189–205. [Google Scholar] [CrossRef]
- Hemann, G.; Singh, S.; Kaess, M. Long-Range GPS-Denied Aerial Inertial Navigation with LIDAR Localization. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 1659–1666. [Google Scholar]
- Geneva, P.; Eckenhoff, K.; Yang, Y.; Huang, G. LIPS: LiDAR-Inertial 3D Plane SLAM. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 123–130. [Google Scholar]
- Ye, H.; Chen, Y.; Liu, M. Tightly Coupled 3D Lidar Inertial Odometry and Mapping. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3144–3150. [Google Scholar]
- LOAM. Available online: https://github.com/HKUST-Aerial-Robotics/A-LOAM (accessed on 18 November 2022).
- LIPS. Available online: https://lips.js.org/ (accessed on 18 November 2022).
- LeGo-LOAM. Available online: https://github.com/RobustFieldAutonomyLab/LeGO-LOAM (accessed on 18 November 2022).
- LIO-Mapping. Available online: https://github.com/hyye/lio-mapping (accessed on 18 November 2022).
- LIOM. Available online: https://github.com/liom17/liom (accessed on 18 November 2022).
- LIO-SAM. Available online: https://github.com/TixiaoShan/LIO-SAM (accessed on 18 November 2022).
- Camurri, M.; Ramezani, M.; Nobili, S.; Maurice, F. Pronto: A Multi-Sensor State Estimator for Legged Robots in Real-World Scenarios. Front. Robot. AI 2020, 7, 68. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Zhang, H.; Wang, P.; Nogueira, L.; Scherer, S. Super Odometry: Imu-Centric Lidar-Visual-Inertial Estimator for Challenging Environments. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 8729–8736. [Google Scholar]
- Zheng, C.; Zhu, Q.; Xu, W.; Liu, X.; Guo, Q.; Zhang, F. Fast-Livo: Fast and Tightly-Coupled Sparse-Direct Lidar-Inertial-Visual Odometry. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 4003–4009. [Google Scholar]
- Hu, K.; Jin, J.; Shen, C.; Xia, M.; Weng, L. Attentional Weighting Strategy-Based Dynamic Gcn for Skeleton-Based Action Recognition. Multimed. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- Almalioglu, Y.; Turan, M.; Lu, C.X.; Trigoni, N.; Markham, A. Milli-RIO: Ego-Motion Estimation with Low-Cost Millimetre-Wave Radar. IEEE Sensors J. 2021, 21, 3314–3323. [Google Scholar] [CrossRef]
- Rahman, S.; Li, A.Q.; Rekleitis, I. Sonar Visual Inertial Slam of Underwater Structures. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 5190–5196. [Google Scholar]
- Rahman, S.; Li, A.Q.; Rekleitis, I. Svin2: An Underwater Slam System Using Sonar, Visual, Inertial, and Depth Sensor. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1861–1868. [Google Scholar]
- Zou, H.; Chen, C.-L.; Li, M.; Yang, J.; Zhou, Y.; Xie, L.; Spanos, C.J. Adversarial Learning-Enabled Automatic WiFi Indoor Radio Map Construction and Adaptation with Mobile Robot. IEEE Internet Things J. 2020, 7, 6946–6954. [Google Scholar] [CrossRef]
- Ocaña, M.; Bergasa, L.M.; Sotelo, M.A.; Flores, R. Indoor Robot Navigation Using a Pomdp Based on Wifi and Ultrasound Observations. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 2592–2597. [Google Scholar]
- Kim, H.D.; Seo, S.W.; Jang, I.H.; Sim, K.B. Slam of Mobile Robot in the Indoor Environment with Digital Magnetic Compass and Ultrasonic Sensors. In Proceedings of the 2007 International Conference on Control, Automation and Systems, Seoul, Republic of Korea, 17–20 October 2007; pp. 87–90. [Google Scholar]
- Shkurti, F.; Rekleitis, I.; Scaccia, M.; Dudek, G. State Estimation of an Underwater Robot Using Visual and Inertial Information. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 5054–5060. [Google Scholar]
- Mirowski, P.; Ho, T.K.; Yi, S.; MacDonald, M. Signalslam: Simultaneous Localization and Mapping with Mixed Wifi, Bluetooth, Lte and Magnetic Signals. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation, Montbeliard, France, 28–31 October 2013; pp. 1–10. [Google Scholar]
- Joshi, B.; Modasshir, M.; Manderson, T.; Damron, H.; Xanthidis, M.; Li, A.Q.; Rekleitis, I.; Dudek, G. Deepurl: Deep Pose Estimation Framework for Underwater Relative Localization. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 1777–1784. [Google Scholar]
- Gautam, A.; Mohan, S. A Review of Research in Multi-Robot Systems. In Proceedings of the 2012 IEEE 7th International Conference on Industrial and Information Systems (ICIIS), Chennai, India, 6–9 August 2012; pp. 1–5. [Google Scholar]
- Karapetyan, N.; Benson, K.; McKinney, C.; Taslakian, P.; Rekleitis, I. Efficient Multi-Robot Coverage of a Known Environment. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1846–1852. [Google Scholar]
- Coppola, M.; McGuire, K.N.; De Wagter, C.; De Croon, G.C. A Survey on Swarming with Micro Air Vehicles: Fundamental Challenges and Constraints. Front. Robot. AI 2020, 7, 18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, S.; Yin, D.; Niu, Y. A Survey of Robot Swarms’ Relative Localization Method. Sensors 2022, 22, 4424. [Google Scholar] [CrossRef]
- Kshirsagar, J.; Shue, S.; Conrad, J.M. A Survey of Implementation of Multi-Robot Simultaneous Localization and Mapping. In Proceedings of the SoutheastCon 2018, Petersburg, FL, USA, 19–22 April 2018; pp. 1–7. [Google Scholar]
- Schmuck, P.; Chli, M. Multi-UAV Collaborative Monocular SLAM. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3863–3870. [Google Scholar]
- Chang, Y.; Tian, Y.; How, J.P.; Carlone, L. Kimera-Multi: A System for Distributed Multi-Robot Metric-Semantic Simultaneous Localization and Mapping. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11210–11218. [Google Scholar]
- Sumikura, S.; Shibuya, M.; Sakurada, K. OpenVSLAM: A Versatile Visual SLAM Framework. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 15 October 2019; pp. 2292–2295. [Google Scholar]
- Pollefeys, M.; Koch, R.; Gool, L.V. Self-Calibration and Metric Reconstruction Inspite of Varying and Unknown Intrinsic Camera Parameters. Int. J. Comput. Vis. 1999, 32, 7–25. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision: N-View Geometry. Comput. Sci. KüNstliche Intell 2001, 15, 41. [Google Scholar]
- Royer, E.; Lhuillier, M.; Dhome, M.; Chateau, T. Localization in Urban Environments: Monocular Vision Compared to a Differential GPS Sensor. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 114–121. [Google Scholar]
- Wolf, W. Key Frame Selection by Motion Analysis. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, GA, USA, 9 May 1996; Volume 2, pp. 1228–1231. [Google Scholar]
- Mouragnon, E.; Lhuillier, M.; Dhome, M.; Dekeyser, F.; Sayd, P. Real Time Localization and 3D Reconstruction. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 363–370. [Google Scholar]
- Fenwick, J.W.; Newman, P.M.; Leonard, J.J. Cooperative Concurrent Mapping and Localization. In Proceedings of the 2002 IEEE International Conference on Robotics and Automation (Cat. No.02CH37292), Washington, DC, USA, 11–15 May 2002; Volume 2, pp. 1810–1817. [Google Scholar]
- Nister, D. An Efficient Solution to the Five-Point Relative Pose Problem. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 26, 756–770. [Google Scholar] [CrossRef]
- Sun, K.; Heß, R.; Xu, Z.; Schilling, K. Real-Time Robust Six Degrees of Freedom Object Pose Estimation with a Time-of-Flight Camera and a Color Camera: Real-Time Robust 6DOF Object Pose Estimation. J. Field Robot. 2015, 32, 61–84. [Google Scholar] [CrossRef]
- Martinelli, A.; Pont, F.; Siegwart, R. Multi-Robot Localization Using Relative Observations. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 2797–2802. [Google Scholar]
- Eliazar, A.; Parr, R. DP-SLAM: Fast, Robust Simultaneous Localization and Mapping without Predetermined Landmarks. In Proceedings of the International Joint Conference on Artificial Intelligence, Acapulco, Mexico, 9–15 August 2003; pp. 1135–1142. [Google Scholar]
- Ziparo, V.; Kleiner, A.; Marchetti, L.; Farinelli, A.; Nardi, D. Cooperative Exploration for USAR Robots with Indirect Communication. IFAC Proc. Vol. 2007, 40, 554–559. [Google Scholar] [CrossRef] [Green Version]
- Paull, L.; Huang, G.; Seto, M.; Leonard, J.J. Communication-Constrained Multi-AUV Cooperative SLAM. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 509–516. [Google Scholar]
- Liu, R.; Deng, Z.; Cao, Z.; Shalihan, M.; Lau, B.P.L.; Chen, K.; Bhowmik, K.; Yuen, C.; Tan, U.-X. Distributed Ranging SLAM for Multiple Robots with Ultra-WideBand and Odometry Measurements. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 13684–13691. [Google Scholar]
- Nguyen, T.; Nguyen, T.; Xie, L. Flexible and Resource-Efficient Multi-Robot Collaborative Visual-Inertial-Range Localization. IEEE Robot. Autom. Lett. 2022, 7, 928–935. [Google Scholar] [CrossRef]
- Penumarthi, P.K.; Li, A.Q.; Banfi, J.; Basilico, N.; Amigoni, F.; O’ Kane, J.; Rekleitis, I.; Nelakuditi, S. Multirobot Exploration for Building Communication Maps with Prior from Communication Models. In Proceedings of the 2017 International Symposium on Multi-Robot and Multi-Agent Systems (MRS), Los Angeles, CA, USA, 4–5 December 2017; pp. 90–96. [Google Scholar]
- Feng, D.; Wang, C.; He, C.; Zhuang, Y.; Xia, X.-G. Kalman-Filter-Based Integration of IMU and UWB for High-Accuracy Indoor Positioning and Navigation. IEEE Internet Things J. 2020, 7, 3133–3146. [Google Scholar] [CrossRef]
- Thrun, S.; Burgard, W.; Fox, D. A Real-Time Algorithm for Mobile Robot Mapping with Applications to Multi-Robot and 3D Mapping. In Proceedings of the 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation, Symposia Proceedings (Cat. No.00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 1, pp. 321–328. [Google Scholar]
- Thrun, S. A Probabilistic On-Line Mapping Algorithm for Teams of Mobile Robots. Int. J. Robot. Res. 2001, 20, 335–363. [Google Scholar] [CrossRef]
- Rekleitis, I.M.; Dudek, G.; Milios, E.E. Multi-Robot Collaboration for Robust Exploration. In Proceedings of the 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No.00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 4, pp. 3164–3169. [Google Scholar]
- Kurazume, R.; Nagata, S.; Hirose, S. Cooperative Positioning with Multiple Robots. In Proceedings of the 1994 IEEE International Conference on Robotics and Automation, San Diego, CA, USA, 8–13 May 1994; pp. 1250–1257. [Google Scholar]
- Fox, D.; Burgard, W.; Kruppa, H.; Thrun, S. A Probabilistic Approach to Collaborative Multi-Robot Localization. Int. J. Robot. Res. 2000, 8, 335–363. [Google Scholar]
- Bekey, G.A.; Roumeliotis, S.I. Robust Mobile Robot Localization: From Single-Robot Uncertainties to Multi-Robot Interdependencies. Ph.D. Thesis, University of Southern California, Los Angeles, CA, USA, 2000. [Google Scholar]
- Howard, A.; Matark, M.J.; Sukhatme, G.S. Localization for Mobile Robot Teams Using Maximum Likelihood Estimation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Lausanne, Switzerland, 30 September–4 October 2002; Volume 1, pp. 434–439. [Google Scholar]
- Howard, A.; Matarić, M.J.; Sukhatme, G.S. Localization for Mobile Robot Teams: A Distributed MLE Approach. In Experimental Robotics VIII; Springer Tracts in Advanced Robotics; Siciliano, B., Dario, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 5, pp. 146–155. [Google Scholar]
- Elfes, A. Sonar-Based Real-World Mapping and Navigation. IEEE J. Robot. Automat. 1987, 3, 249–265. [Google Scholar] [CrossRef]
- Olson, C.F. Probabilistic Self-Localization for Mobile Robots. IEEE Trans. Robot. Automat. 2000, 16, 55–66. [Google Scholar] [CrossRef] [Green Version]
- Ju-Long, D. Control Problems of Grey Systems. Syst. Control Lett. 1982, 1, 288–294. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy Sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Oriolo, G.; Ulivi, G.; Vendittelli, M. Fuzzy Maps: A New Tool for Mobile Robot Perception and Planning. J. Robot. Syst. 1997, 14, 179–197. [Google Scholar] [CrossRef]
- Gasós, J.; Rosetti, A. Uncertainty Representation for Mobile Robots: Perception, Modeling and Navigation in Unknown Environments. Fuzzy Sets Syst. 1999, 107, 1–24. [Google Scholar] [CrossRef]
- Rulong, X.; Qiang, W.; Lei, S.; Lei, C. Design of Multi-Robot Path Planning System Based on Hierarchical Fuzzy Control. Procedia Eng. 2011, 15, 235–239. [Google Scholar] [CrossRef]
- Benedettelli, D.; Garulli, A.; Giannitrapani, A. Cooperative SLAM Using -Space Representation of Linear Features. Robot. Auton. Syst. 2012, 60, 1267–1278. [Google Scholar] [CrossRef]
- Thrun, S.; Liu, Y. Multi-Robot SLAM with Sparse Extended Information Filers. In Robotics Research. The Eleventh International Symposium; Springer Tracts in Advanced Robotics; Dario, P., Chatila, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 15, pp. 254–266. [Google Scholar]
- Birk, A.; Carpin, S. Merging Occupancy Grid Maps From Multiple Robots. Proc. IEEE 2006, 94, 1384–1397. [Google Scholar] [CrossRef]
- Romero, V.A.; Costa, O.L.V. Map Merging Strategies for Multi-Robot FastSLAM: A Comparative Survey. In Proceedings of the 2010 Latin American Robotics Symposium and Intelligent Robotics Meeting, Sao Bernardo do Campo, Brazil, 23–28 October 2010; pp. 61–66. [Google Scholar]
- Huang, W.H.; Beevers, K.R. Topological Map Merging. Int. J. Robot. Res. 2005, 24, 601–613. [Google Scholar] [CrossRef]
- Andersson, L.A.A.; Nygards, J. C-SAM: Multi-Robot SLAM Using Square Root Information Smoothing. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 2798–2805. [Google Scholar]
- Zhou, X.; Roumeliotis, S. Multi-Robot SLAM with Unknown Initial Correspondence: The Robot Rendezvous Case. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 1785–1792. [Google Scholar]
- Gil, A.; Reinoso, Ó.; Ballesta, M.; Juliá, M. Multi-Robot Visual SLAM Using a Rao-Blackwellized Particle Filter. Robot. Auton. Syst. 2010, 58, 68–80. [Google Scholar] [CrossRef]
- Thrun, S.; Burgard, W.; Fox, D. A Probabilistic Approach to Concurrent Mapping and Localization for Mobile Robots. Mach. Learn. 2004, 31, 29–53. [Google Scholar] [CrossRef] [Green Version]
- Denniston, C.E.; Chang, Y.; Reinke, A.; Ebadi, K.; Sukhatme, G.S.; Carlone, L.; Morrell, B.; Agha-mohammadi, A. Loop Closure Prioritization for Efficient and Scalable Multi-Robot SLAM. IEEE Robot. Autom. Lett. 2022, 7, 9651–9658. [Google Scholar] [CrossRef]
- Cohen, W.W. Adaptive Mapping and Navigation by Teams of Simple Robots. Robot. Auton. Syst. 1996, 18, 411–434. [Google Scholar] [CrossRef]
- Khoshnevis, B.; Bekey, G. Centralized Sensing and Control of Multiple Mobile Robots. Comput. Ind. Eng. 1998, 35, 503–506. [Google Scholar] [CrossRef]
- Tong, T.; Yalou, H.; Jing, Y.; Fengchi, S. Multi-Robot Cooperative Map Building in Unknown Environment Considering Estimation Uncertainty. In Proceedings of the 2008 Chinese Control and Decision Conference, Yantai, China, 2–4 July 2008; pp. 2896–2901. [Google Scholar]
- Mohanarajah, G.; Usenko, V.; Singh, M.; D’Andrea, R.; Waibel, M. Cloud-Based Collaborative 3D Mapping in Real-Time with Low-Cost Robots. IEEE Trans. Automat. Sci. Eng. 2015, 12, 423–431. [Google Scholar] [CrossRef] [Green Version]
- Jang, Y.; Oh, C.; Lee, Y.; Kim, H.J. Multirobot Collaborative Monocular SLAM Utilizing Rendezvous. IEEE Trans. Robot. 2021, 37, 1469–1486. [Google Scholar] [CrossRef]
- Malebary, S.; Moulton, J.; Li, A.Q.; Rekleitis, I. Experimental Analysis of Radio Communication Capabilities of Multiple Autonomous Surface Vehicles. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–6. [Google Scholar]
- Hao, Y.; Laxton, B.; Benson, E.R.; Agrawal, S.K. Robotic Simulation of the Docking and Path Following of an Autonomous Small Grain Harvesting System. In Proceedings of the 2003 ASAE Annual International Meeting Sponsored by ASAE, Las Vegas, NV, USA, 27–30 July 2003; pp. 14–27. [Google Scholar]
- Hao, Y.; Laxton, B.; Agrawal, S.; Benson, E. Differential Flatness-Based Formation Following of a Simulated Autonomous Small Grain Harvesting System. Trans. ASABE 2004, 47, 933–941. [Google Scholar] [CrossRef]
- Hu, K.; Li, Y.; Xia, M.; Wu, J.; Lu, M.; Zhang, S.; Weng, L. Federated Learning: A Distributed Shared Machine Learning Method. Complexity 2021, 2021, 8261663. [Google Scholar] [CrossRef]
- Smith, R.C.; Self, M.; Cheeseman, P.C. Estimating Uncertain Spatial Relationships in Robotics. In Proceedings of the 1987 IEEE International Conference on Robotics and Automation, Raleigh, NC, USA, 31 March–3 April 1987; p. 850. [Google Scholar]
- Cunningham, A.; Indelman, V.; Dellaert, F. DDF-SAM 2.0: Consistent Distributed Smoothing and Mapping. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 5220–5227. [Google Scholar]
- Huang, Y.; Shan, T.; Chen, F.; Englot, B. DiSCo-SLAM: Distributed Scan Context-Enabled Multi-Robot LiDAR SLAM with Two-Stage Global-Local Graph Optimization. IEEE Robot. Autom. Lett. 2022, 7, 1150–1157. [Google Scholar] [CrossRef]
- Chen, W.; Shang, G.; Ji, A.; Zhou, C.; Wang, X.; Xu, C.; Li, Z.; Hu, K. An Overview on Visual SLAM: From Tradition to Semantic. Remote Sens. 2022, 14, 3010. [Google Scholar] [CrossRef]
- Hu, K.; Weng, C.; Shen, C.; Wang, T.; Weng, L.; Xia, M. A Multi-Stage Underwater Image Aesthetic Enhancement Algorithm Based on a Generative Adversarial Network. Eng. Appl. Artif. Intell. 2023, 123, 106196. [Google Scholar] [CrossRef]
- Hu, K.; Ding, Y.; Jin, J.; Weng, L.; Xia, M. Skeleton Motion Recognition Based on Multi-Scale Deep Spatio-Temporal Features. Appl. Sci. 2022, 12, 1028. [Google Scholar] [CrossRef]
- Hu, K.; Li, M.; Xia, M.; Lin, H. Multi-Scale Feature Aggregation Network for Water Area Segmentation. Remote Sens. 2022, 14, 206. [Google Scholar] [CrossRef]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar]
- Li, X.; Ao, H.; Belaroussi, R.; Gruyer, D. Fast Semi-Dense 3D Semantic Mapping with Monocular Visual SLAM. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 385–390. [Google Scholar]
- Li, G.; Chou, W.; Yin, F. Multi-Robot Coordinated Exploration of Indoor Environments Using Semantic Information. Sci. China Inf. Sci. 2018, 61, 1–3. [Google Scholar] [CrossRef] [Green Version]
- Yue, Y.; Zhao, C.; Wu, Z.; Yang, C.; Wang, Y.; Wang, D. Collaborative Semantic Understanding and Mapping Framework for Autonomous Systems. IEEE/ASME Trans. Mechatron 2021, 26, 978–989. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Qian, M.; Huang, J. MANet: A Multi-Level Aggregation Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Int. J. Remote Sens. 2022, 43, 5874–5894. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Dai, X.; Xia, M.; Zhou, F.; Weng, L.; Lin, H. MCSGNet: A Encoder–Decoder Architecture Network for Land Cover Classification. Remote Sens. 2023, 15, 2810. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. MCANet: A Multi-Branch Network for Cloud/Snow Segmentation in High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Rosinol, A.; Abate, M.; Chang, Y.; Carlone, L. Kimera: An Open-Source Library for Real-Time Metric-Semantic Localization and Mapping. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1689–1696. [Google Scholar]
- Rosinol, A.; Violette, A.; Abate, M.; Hughes, N.; Chang, Y.; Shi, J.; Gupta, A.; Carlone, L. Kimera: From SLAM to Spatial Perception with 3D Dynamic Scene Graphs. Int. J. Robot. Res. 2021, 40, 1510–1546. [Google Scholar] [CrossRef]
- Tian, Y.; Chang, Y.; Arias, F.H.; Nieto-Granda, C.; How, J.P.; Carlone, L. Carlone Kimera-Multi: Robust, Distributed, Dense Metric-Semantic SLAM for Multi-Robot Systems. IEEE Trans. Robot. 2022, 38, 2022–2038. [Google Scholar] [CrossRef]
- Majcherczyk, N.; Nallathambi, D.J.; Antonelli, T.; Pinciroli, C. Distributed Data Storage and Fusion for Collective Perception in Resource-Limited Mobile Robot Swarms. IEEE Robot. Autom. Lett. 2021, 6, 5549–5556. [Google Scholar] [CrossRef]
- Zobeidi, E.; Koppel, A.; Atanasov, N. Dense Incremental Metric-Semantic Mapping for Multiagent Systems via Sparse Gaussian Process Regression. IEEE Trans. Robot. 2022, 38, 3133–3153. [Google Scholar] [CrossRef]
- Ma, J.W.; Leite, F. Performance Boosting of Conventional Deep Learning-Based Semantic Segmentation Leveraging Unsupervised Clustering. Autom. Constr. 2022, 136, 104167. [Google Scholar] [CrossRef]
- Wu, Z.; Xiong, Y.; Yu, S.; Lin, D. Unsupervised Feature Learning via Non-Parametric Instance-Level Discrimination. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- Van Gansbeke, W.; Vandenhende, S.; Georgoulis, S.; Van Gool, L. Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10032–10042. [Google Scholar]
- Gao, S.; Li, Z.-Y.; Yang, M.-H.; Cheng, M.-M.; Han, J.; Torr, P. Large-Scale Unsupervised Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7457–7476. [Google Scholar] [CrossRef] [PubMed]
- Jamieson, S.; Fathian, K.; Khosoussi, K.; How, J.P.; Girdhar, Y. Multi-Robot Distributed Semantic Mapping in Unfamiliar Environments through Online Matching of Learned Representations. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 8587–8593. [Google Scholar]
- Fralick, S. Learning to Recognize Patterns without a Teacher. IEEE Trans. Inf. Theory 1967, 13, 57–64. [Google Scholar] [CrossRef]
- Zhou, Z.-H. A Brief Introduction to Weakly Supervised Learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Modasshir, M.; Rekleitis, I. Enhancing Coral Reef Monitoring Utilizing a Deep Semi-Supervised Learning Approach. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1874–1880. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C. Mixmatch: A Holistic Approach to Semi-Supervised Learning. arXiv 2019, arXiv:1905.02249. [Google Scholar]
- Lei, X.; Guan, H.; Ma, L.; Yu, Y.; Dong, Z.; Gao, K.; Reza Delavar, M.; Li, J. Wspointnet: A Multi-Branch Weakly Supervised Learning Network for Semantic Segmentation of Large-Scale Mobile Laser Scanning Point Clouds. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103129. [Google Scholar] [CrossRef]
- Badea, M.; Florea, C.; Racoviţeanu, A.; Florea, L.; Vertan, C. Timid Semi–Supervised Learning for Face Expression Analysis. Pattern Recognit. 2023, 138, 109417. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything. Segm. Anything, 2023, in press.
- Yue, M.; Fu, G.; Wu, M.; Wang, H. Semi-Supervised Monocular Depth Estimation Based on Semantic Supervision. J. Intell. Robot. Syst. 2020, 100, 455–463. [Google Scholar] [CrossRef]
- Rosu, R.A.; Quenzel, J.; Behnke, S. Semi-Supervised Semantic Mapping through Label Propagation with Semantic Texture Meshes. Int. J. Comput. Vis. 2020, 128, 1220–1238. [Google Scholar] [CrossRef] [Green Version]
- Cramariuc, A.; Bernreiter, L.; Tschopp, F.; Fehr, M.; Reijgwart, V.; Nieto, J.; Siegwart, R.; Cadena, C. Maplab 2.0—A Modular and Multi-Modal Mapping Framework. IEEE Robot. Autom. Lett. 2023, 8, 520–527. [Google Scholar] [CrossRef]































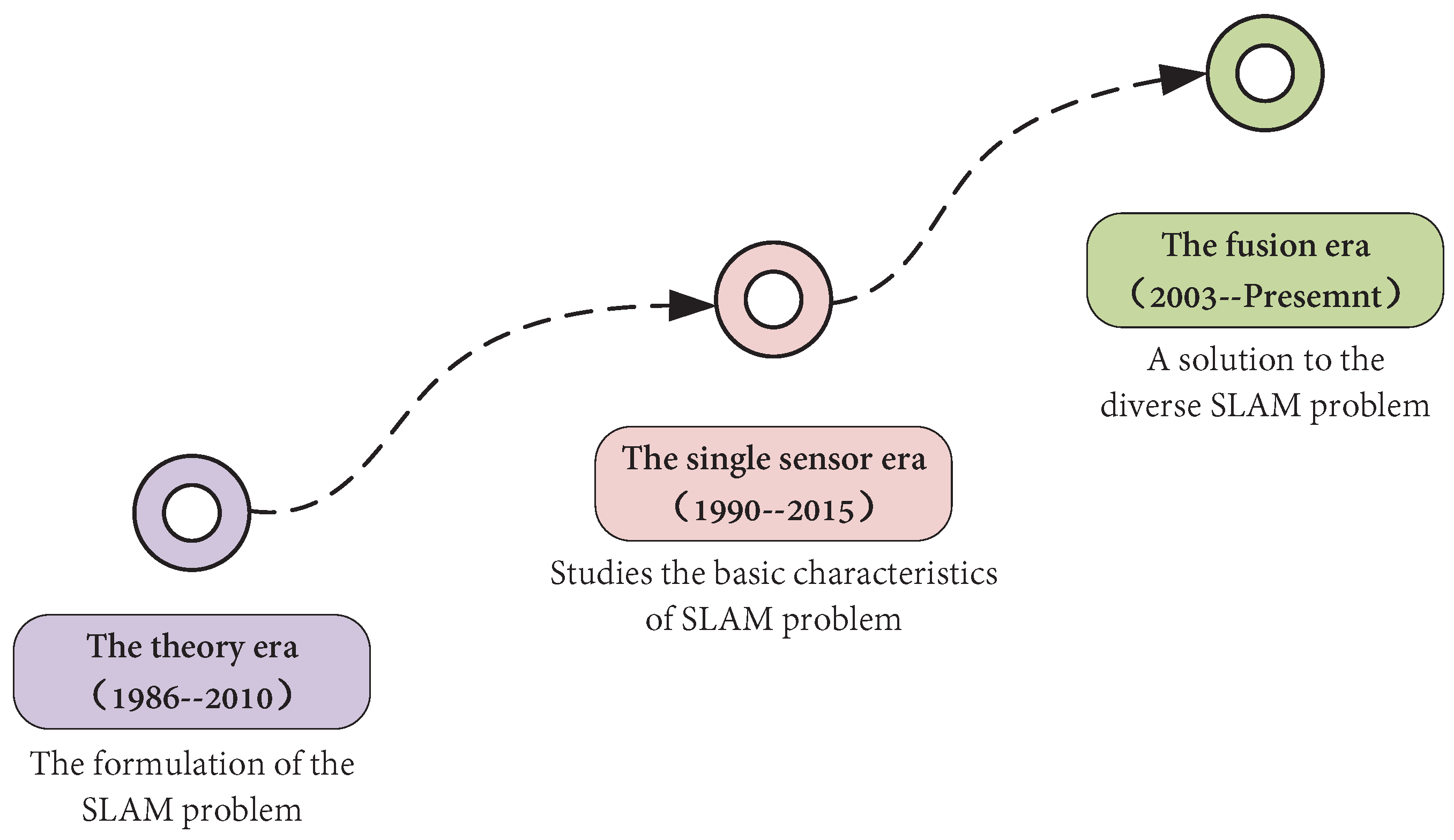{kind=link}
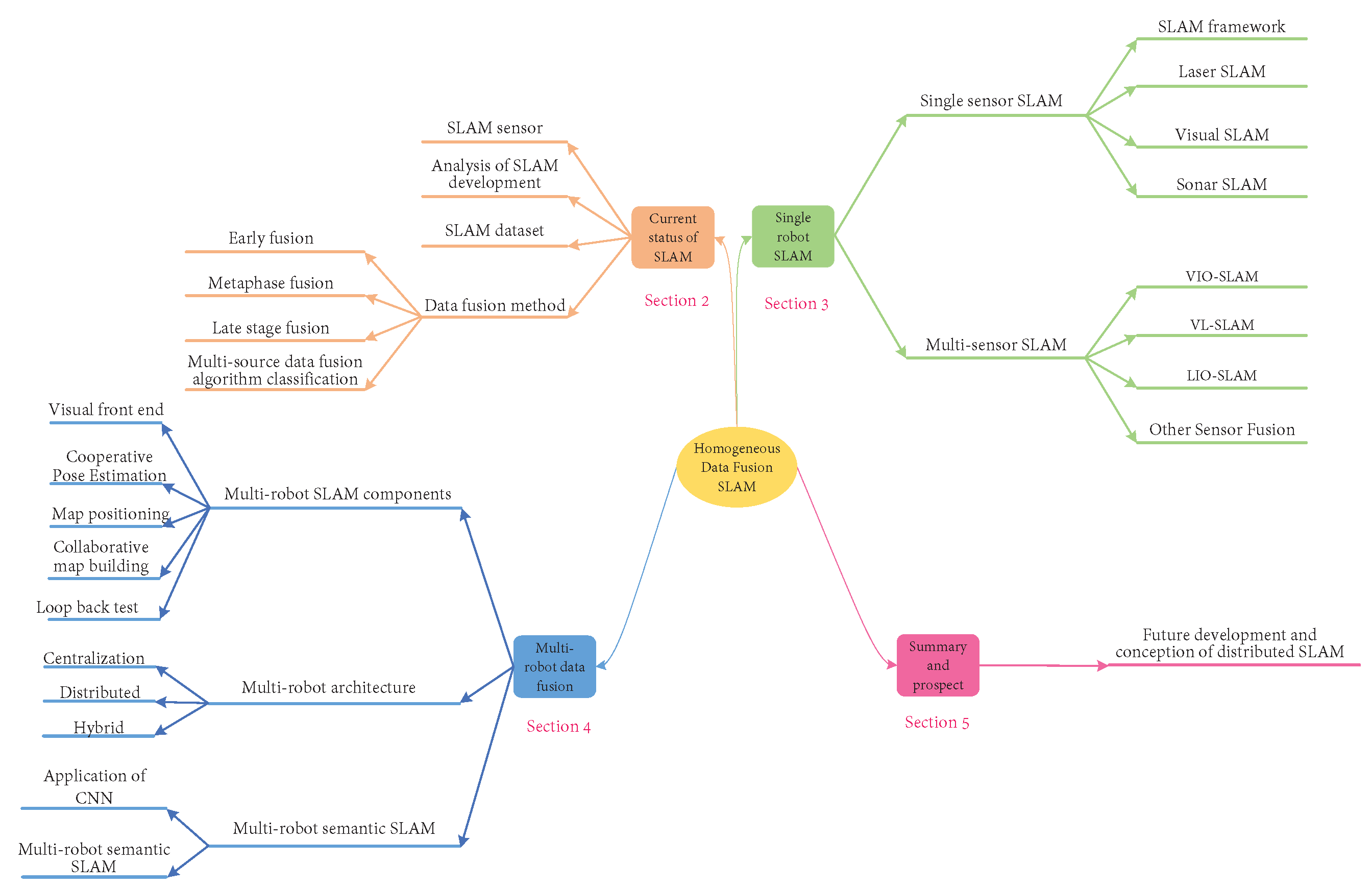{kind=link}
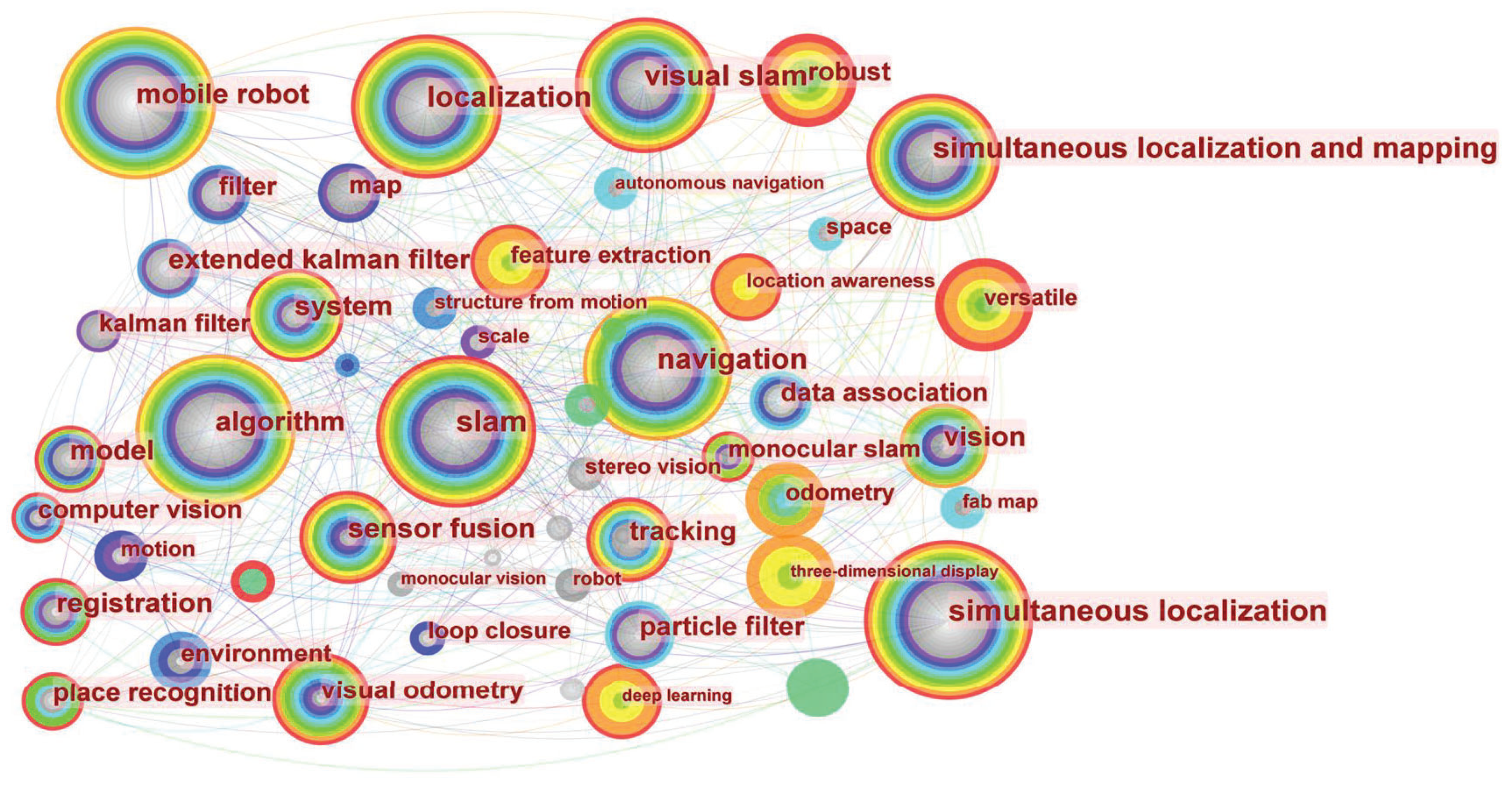{kind=link}
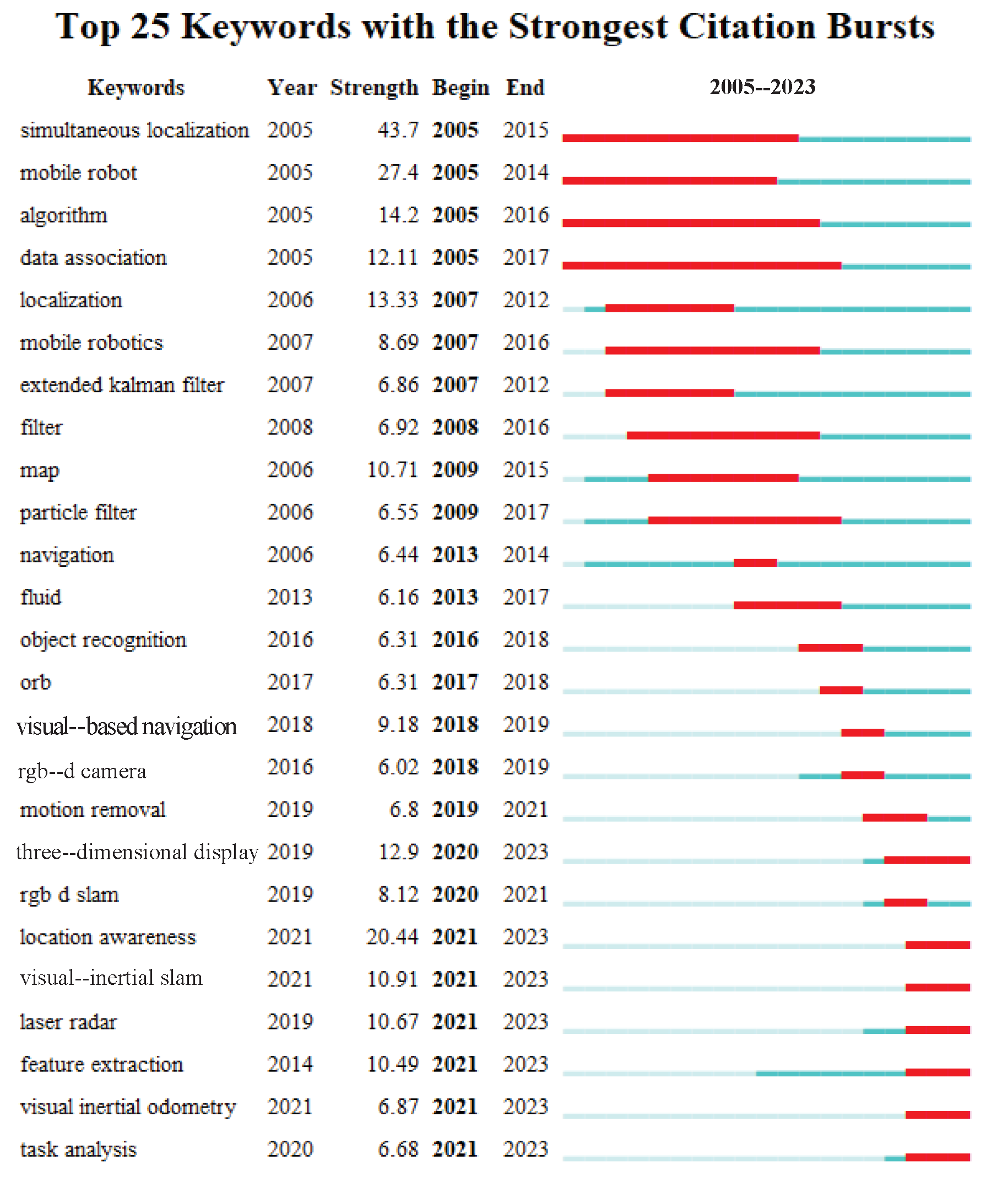{kind=link}
{kind=link}
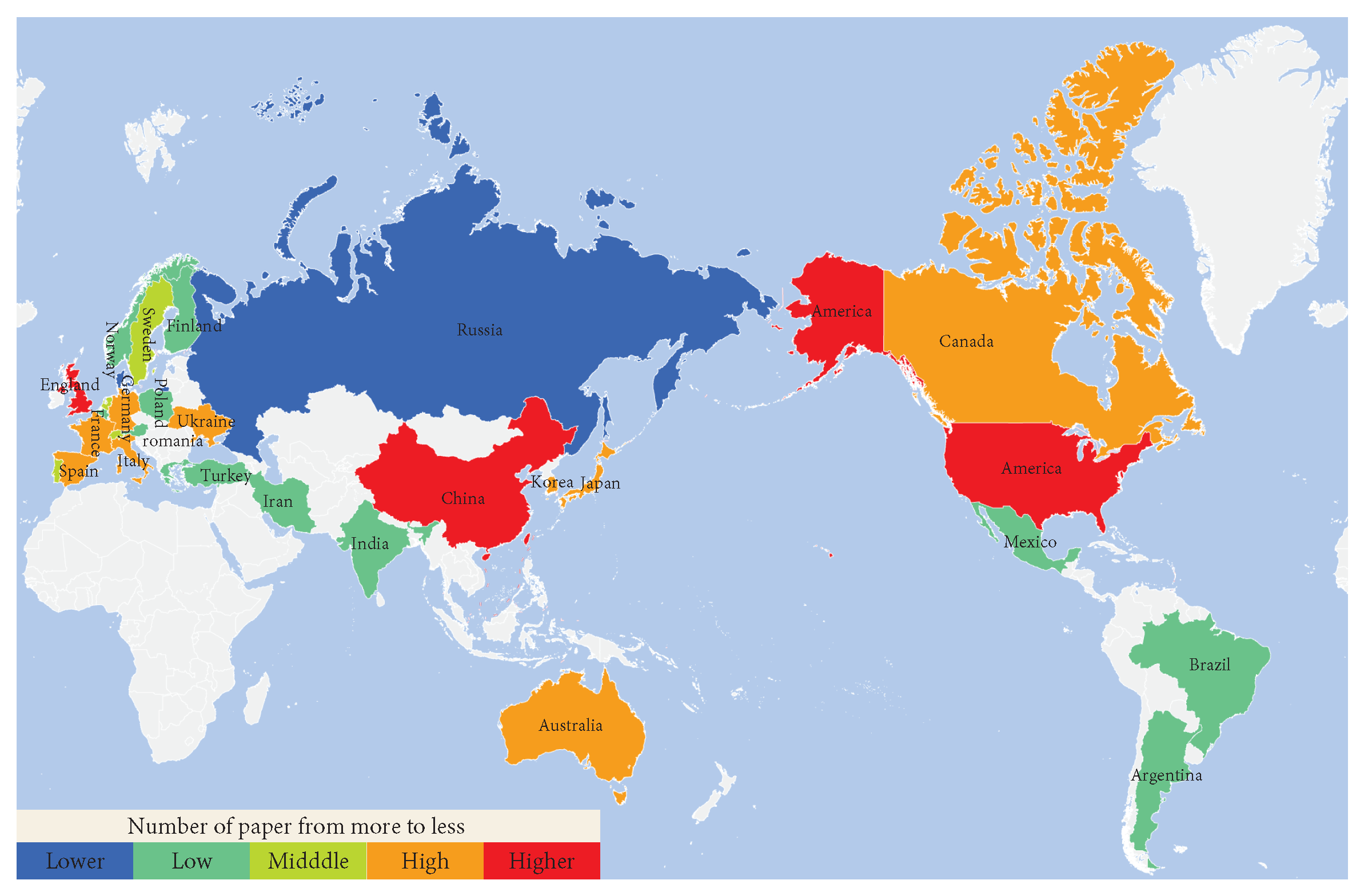{kind=link}
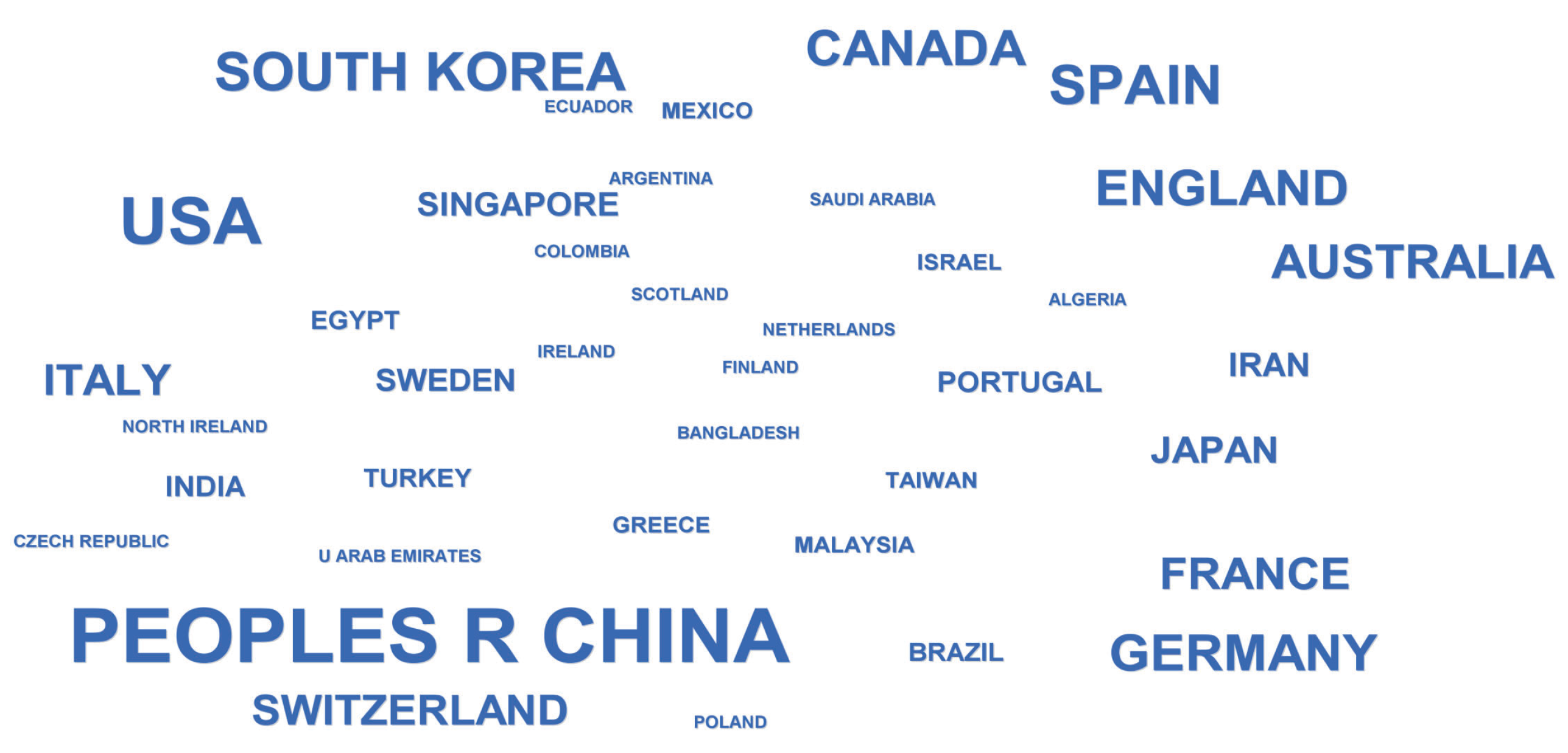{kind=link}
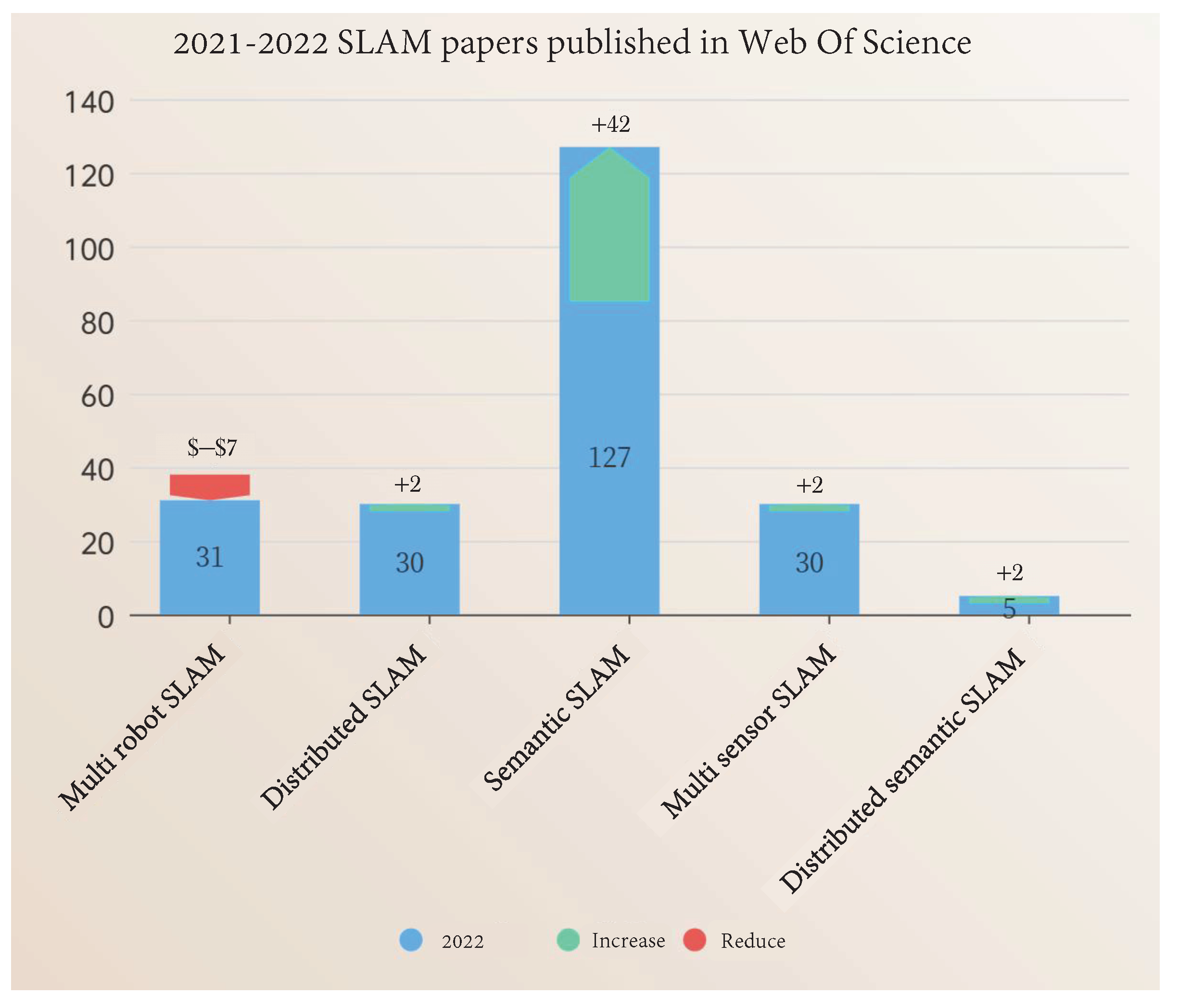{kind=link}
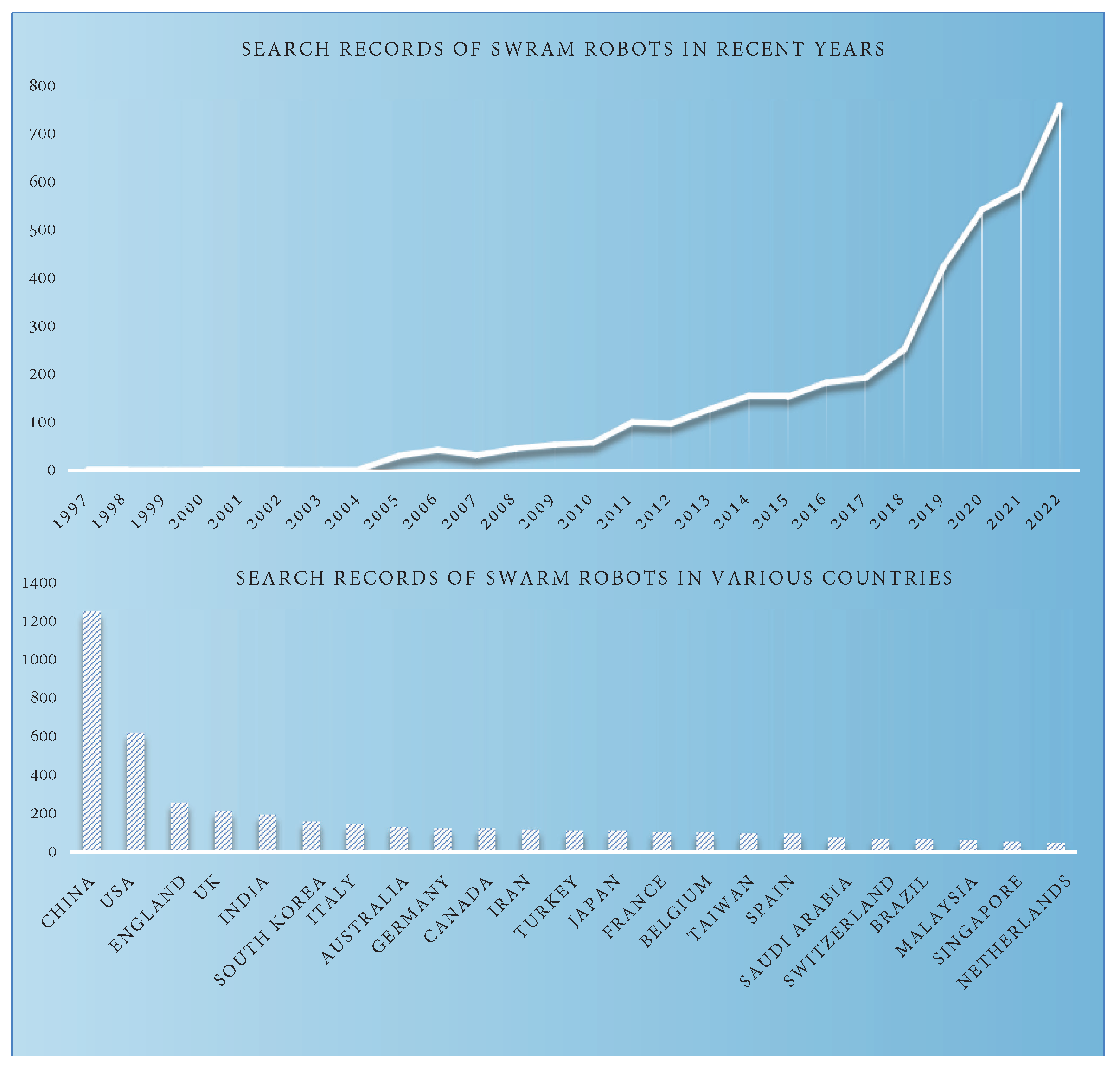{kind=link}
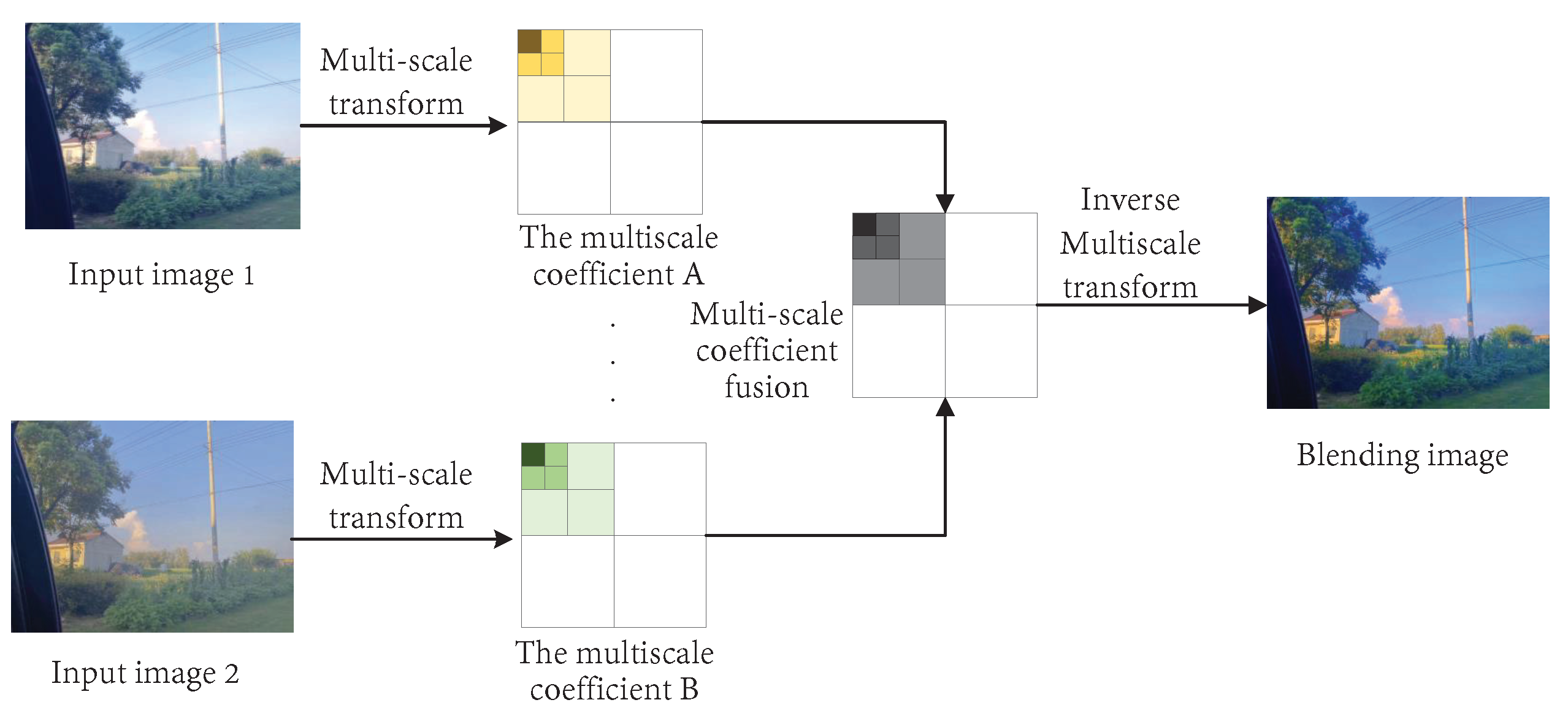{kind=link}
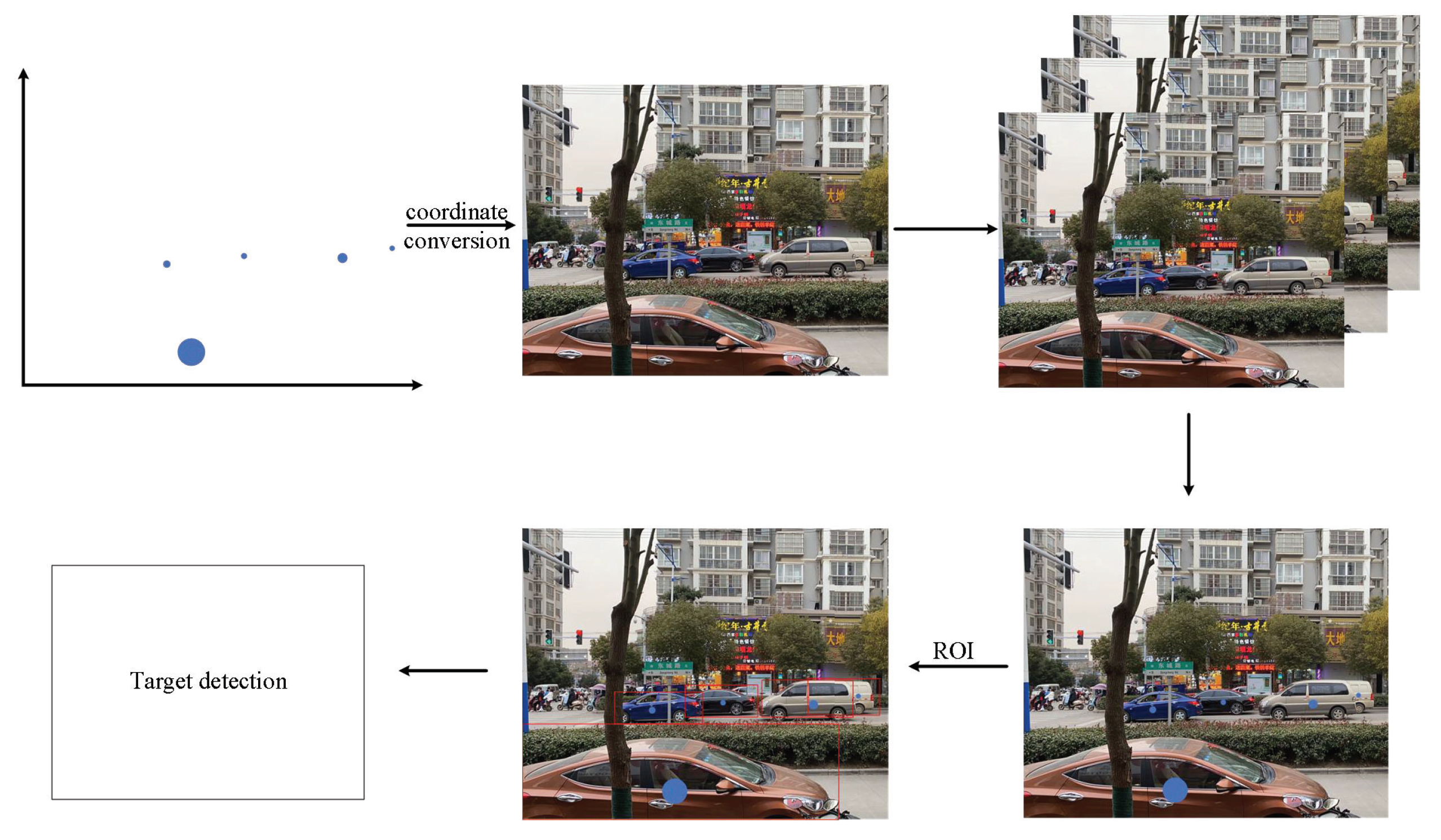{kind=link}
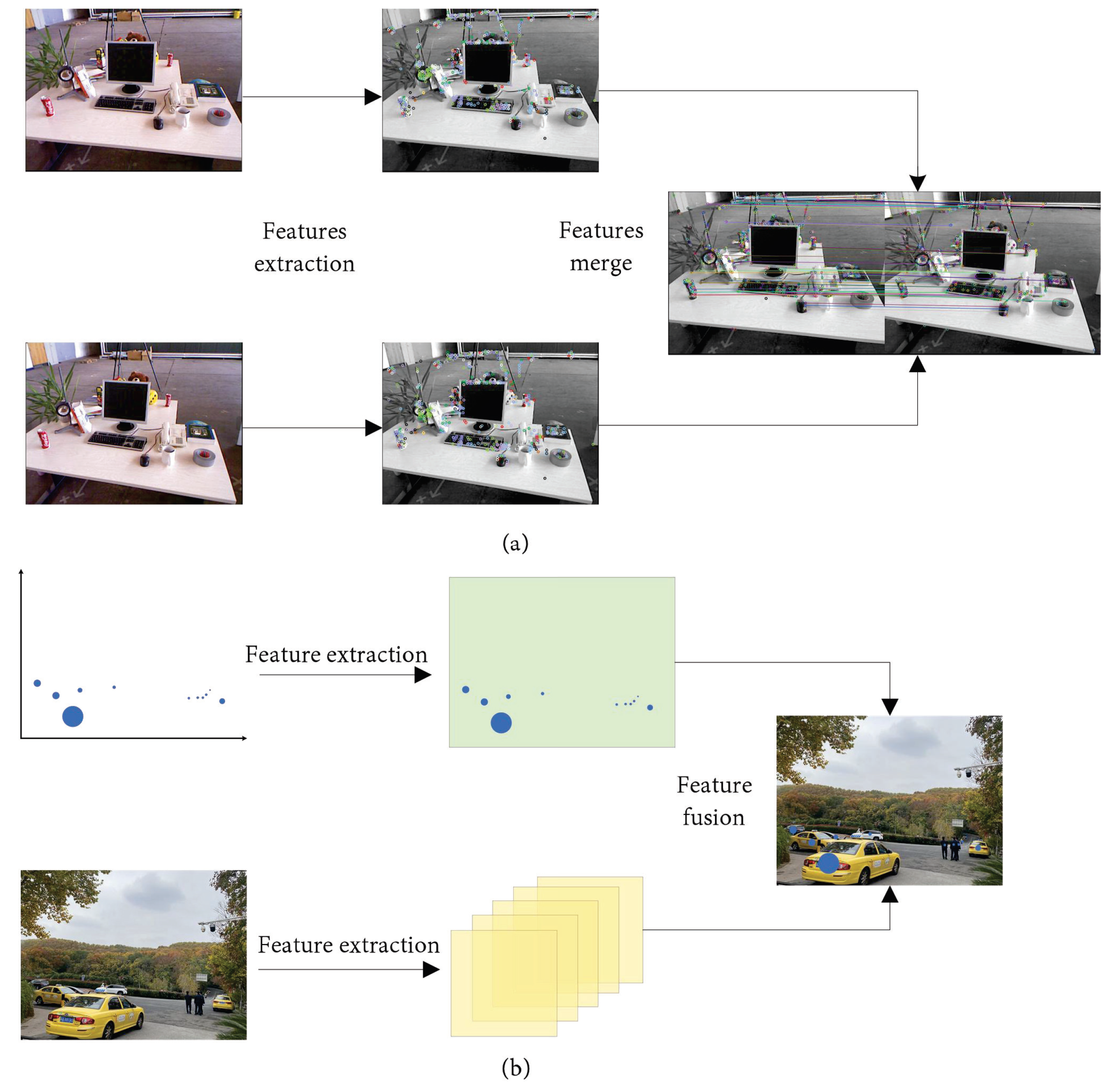{kind=link}
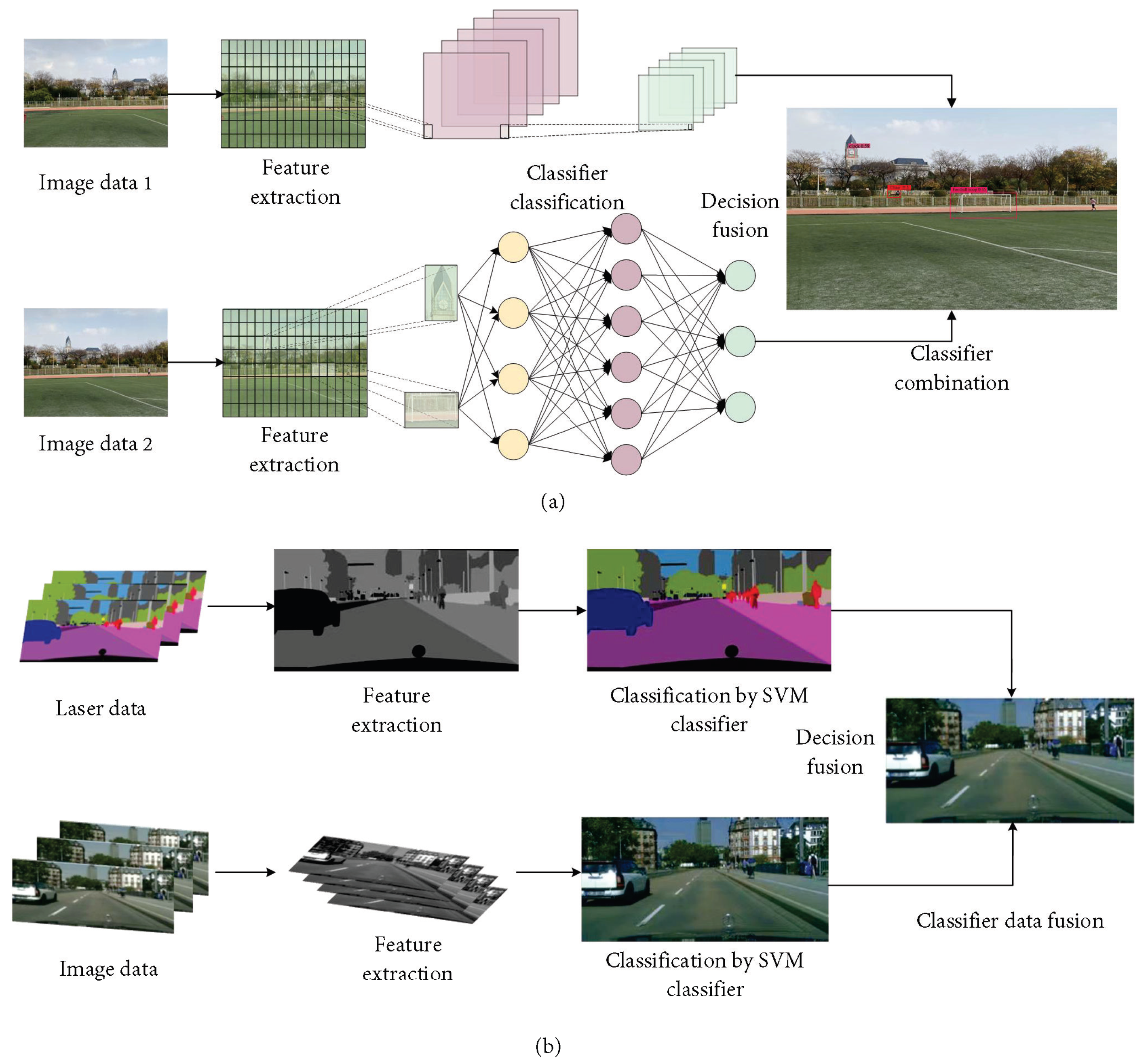{kind=link}
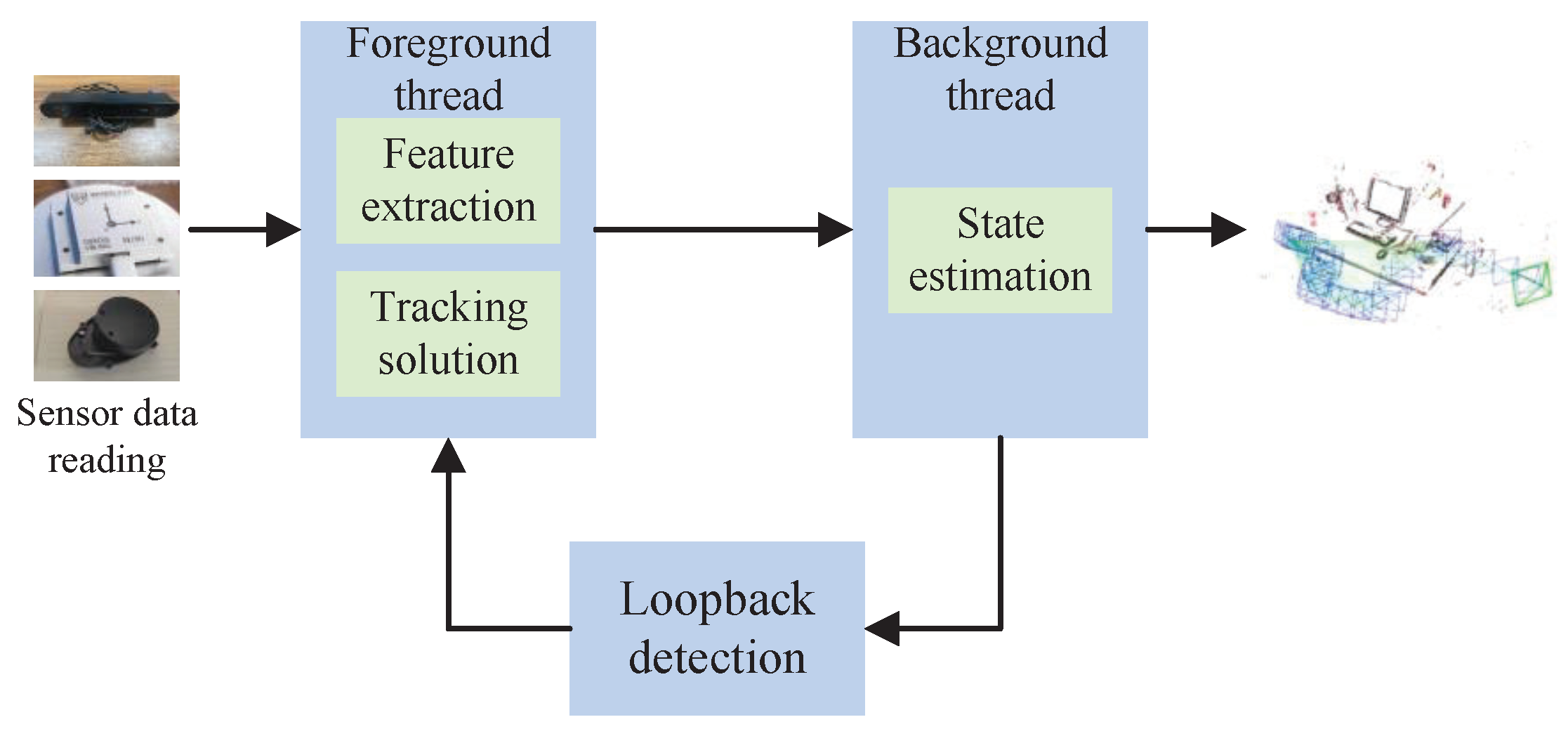{kind=link}
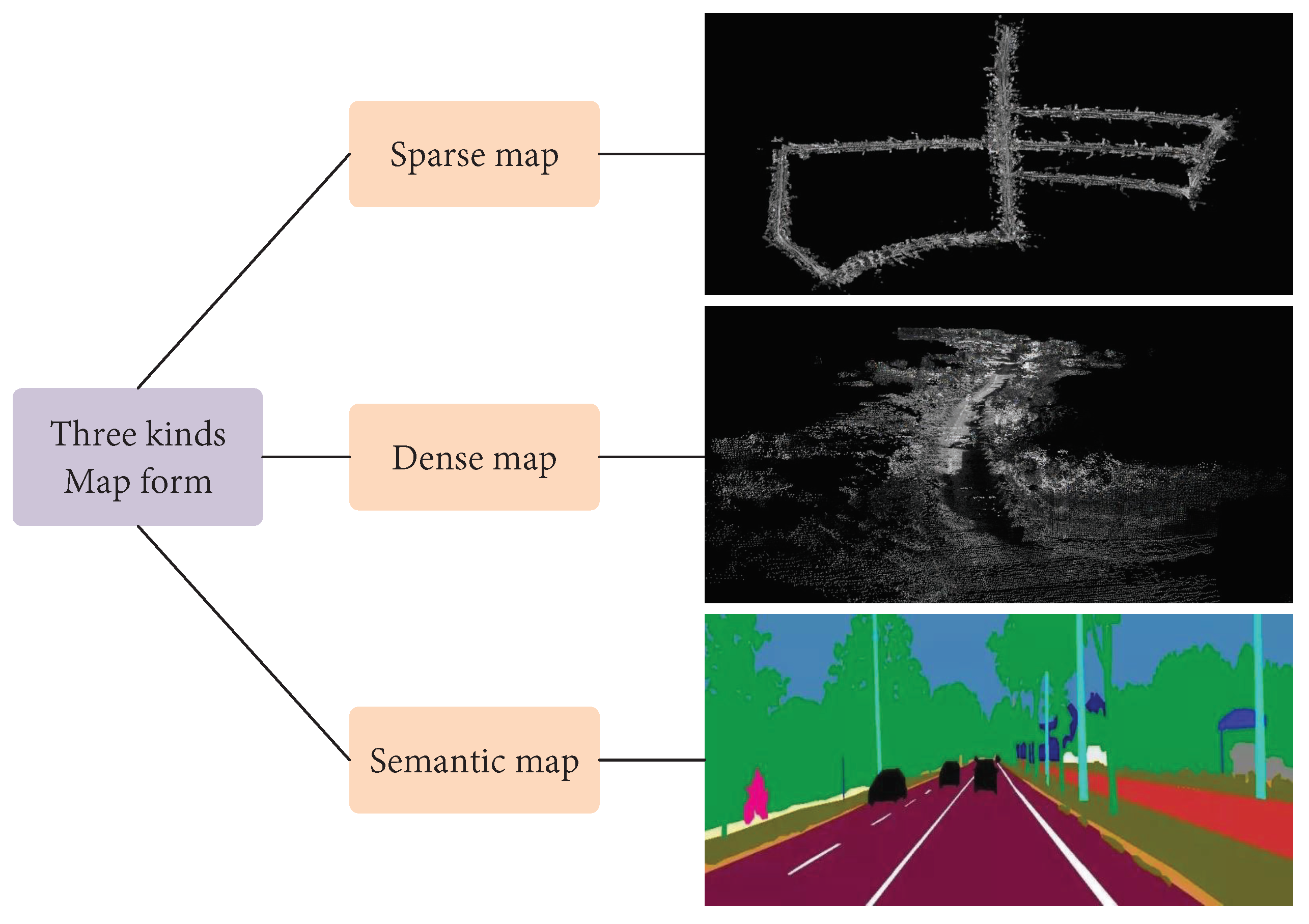{kind=link}
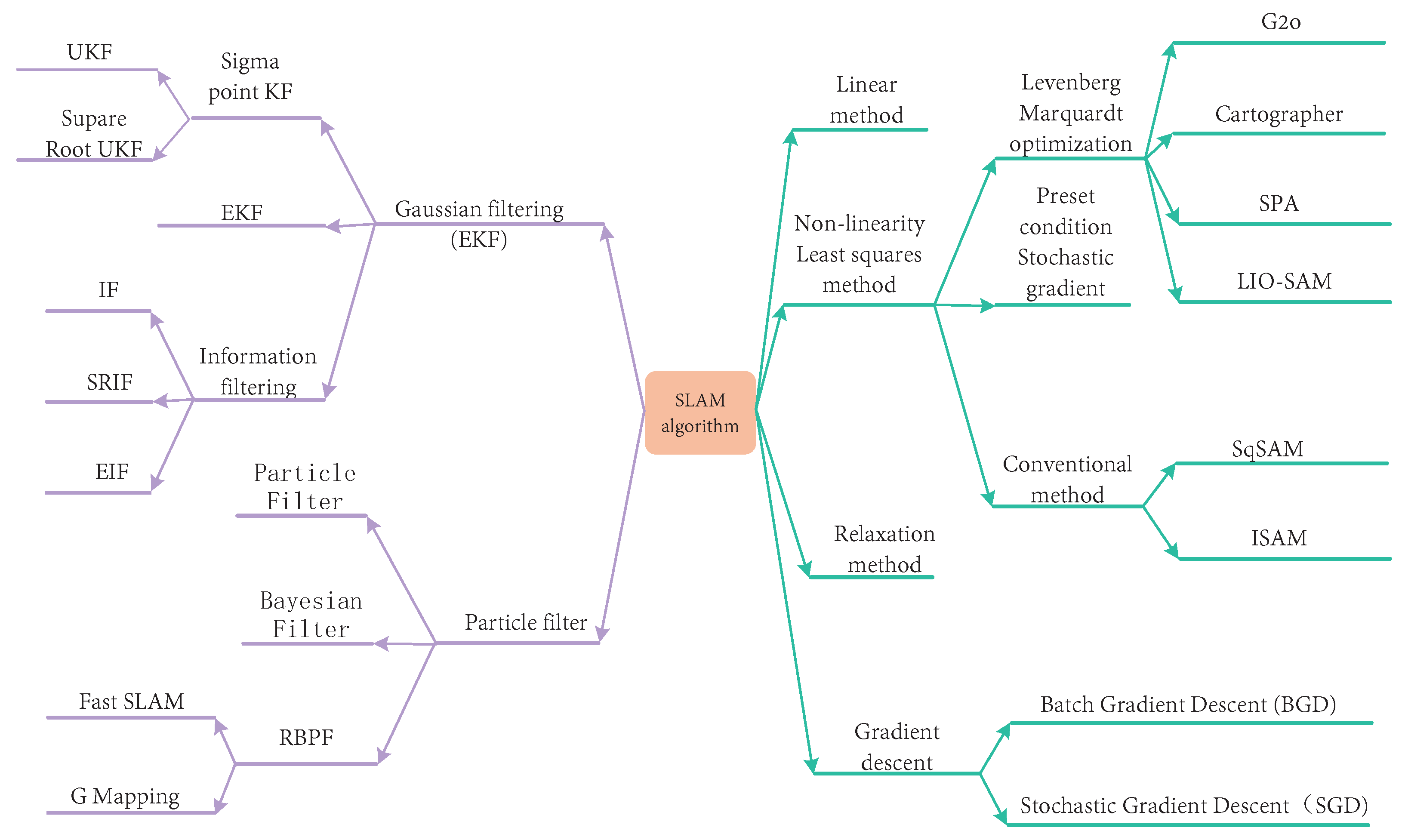{kind=link}
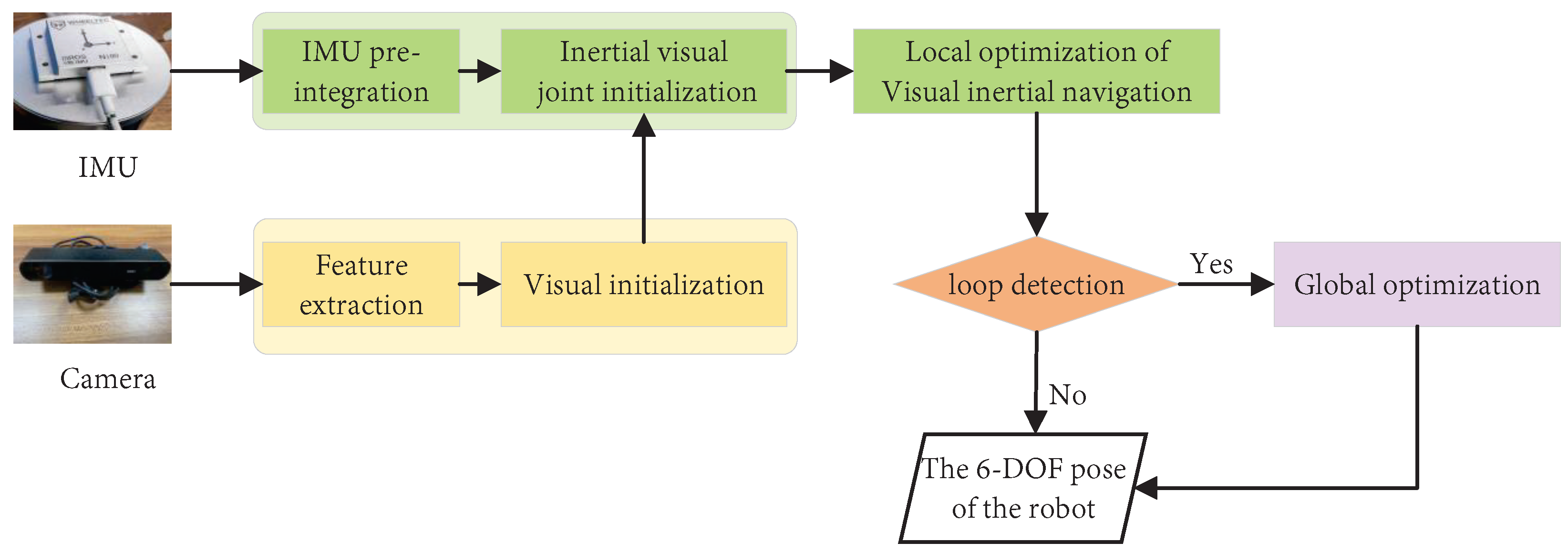{kind=link}
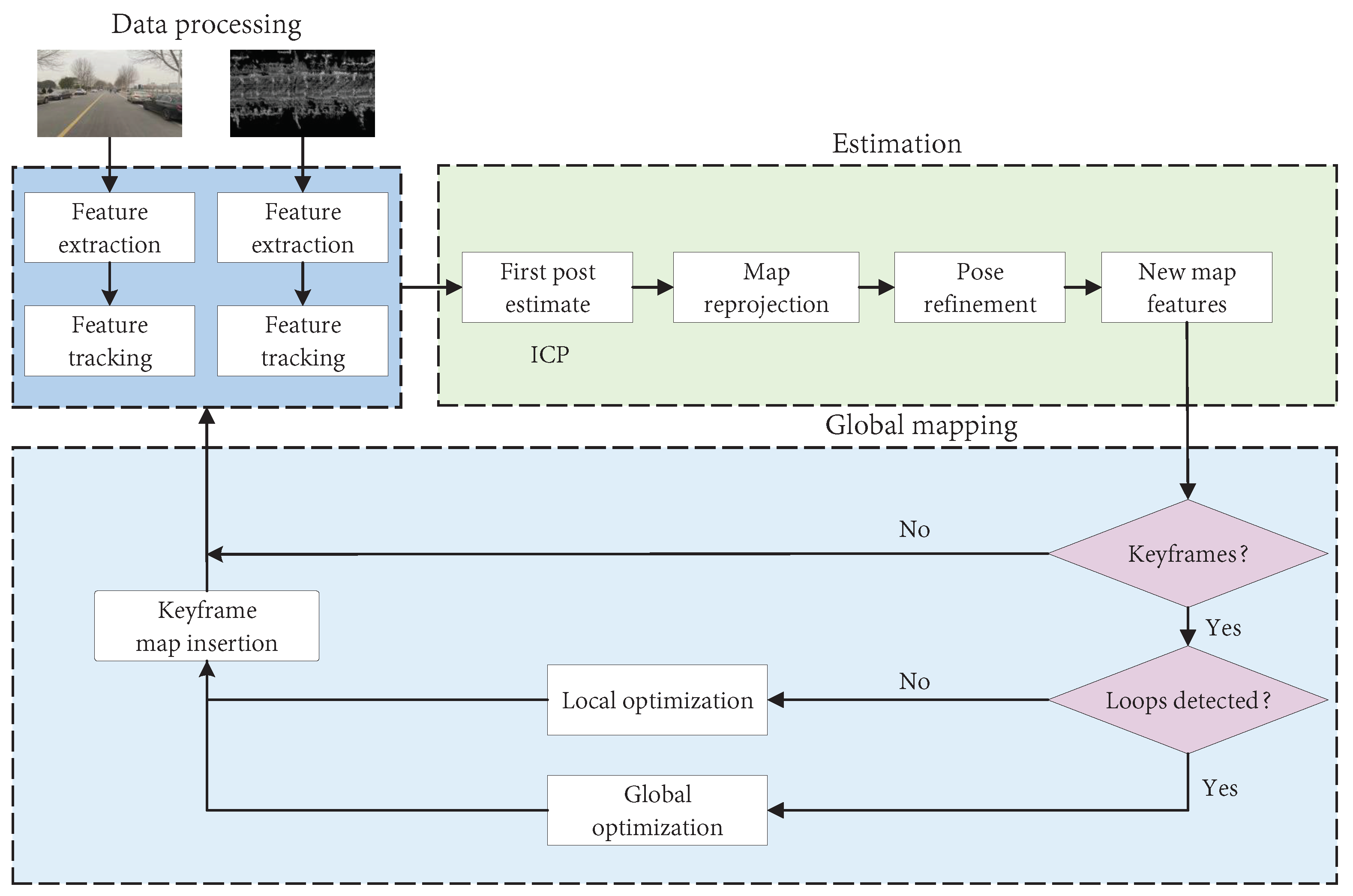{kind=link}
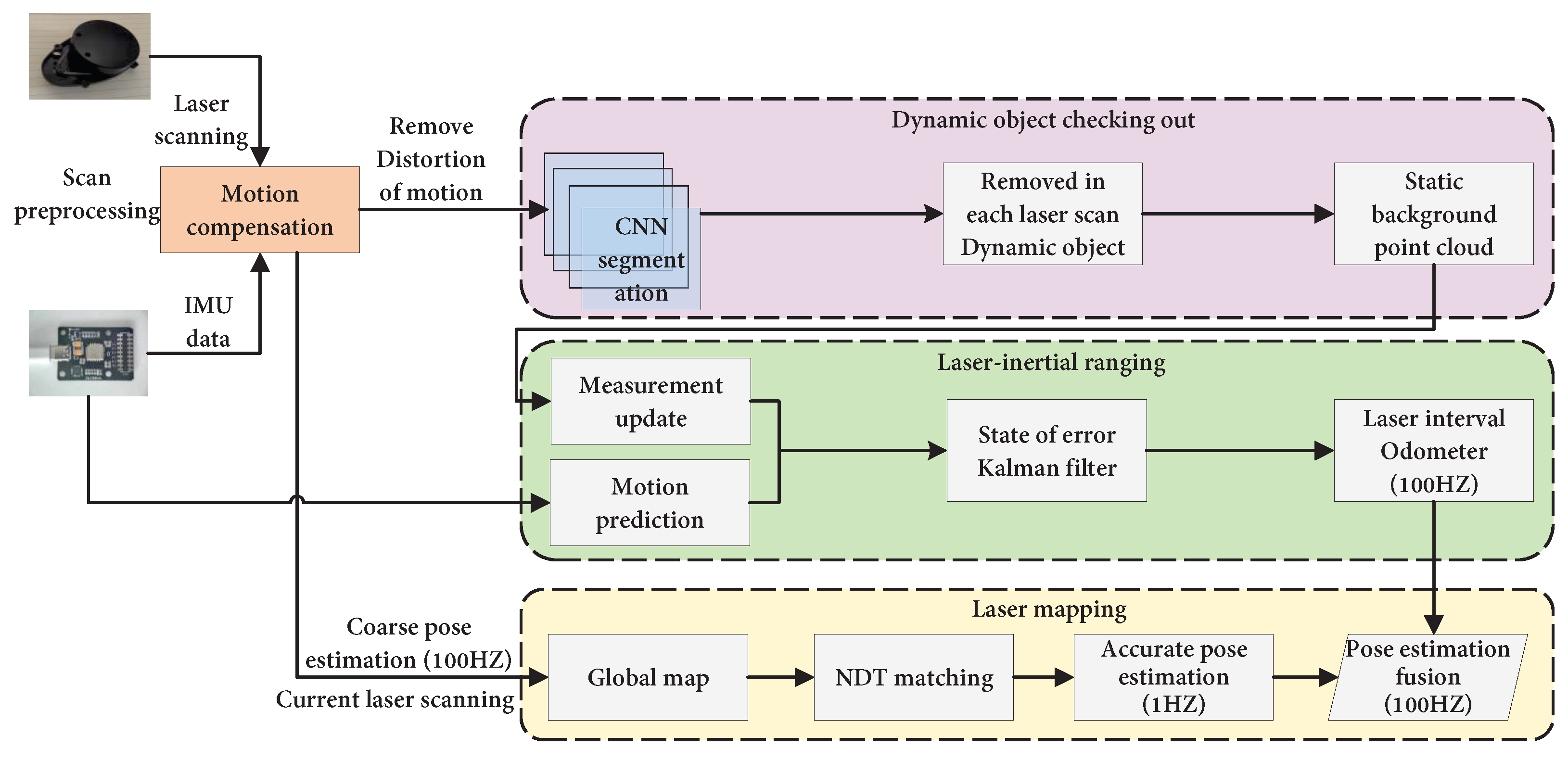{kind=link}
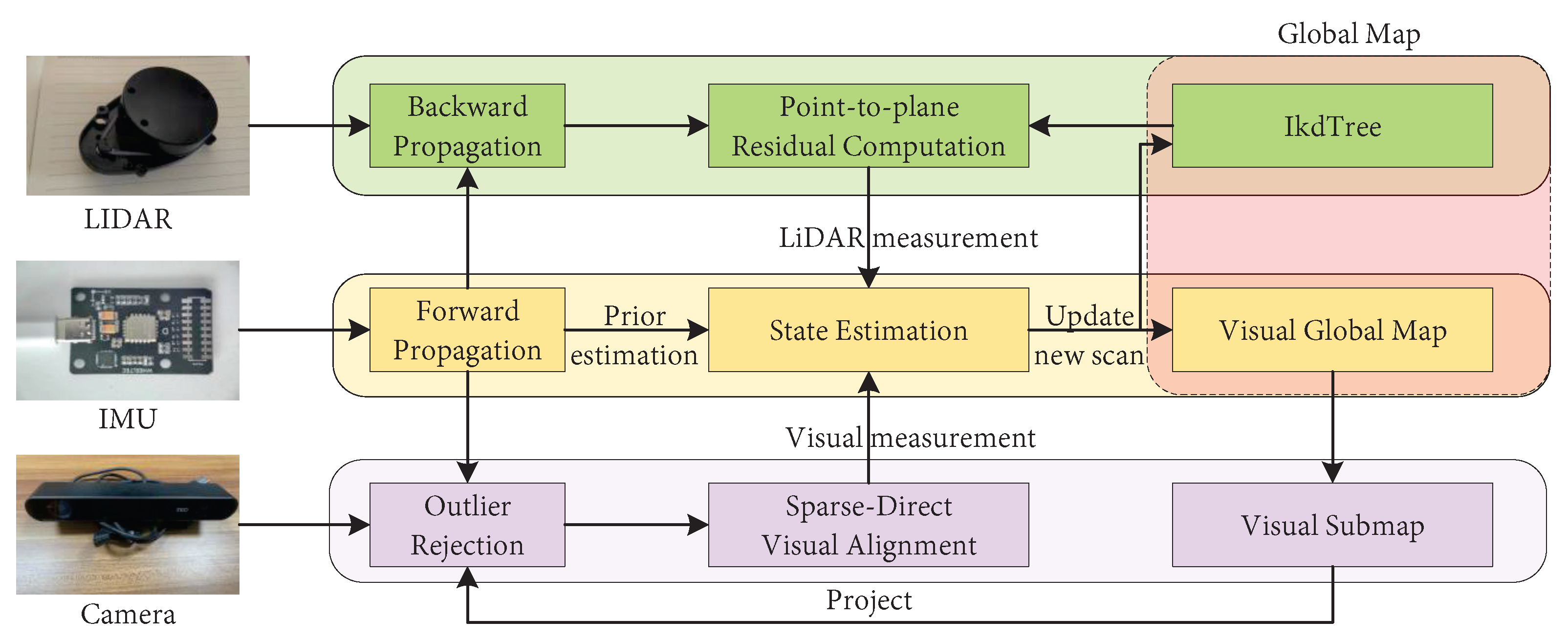{kind=link}
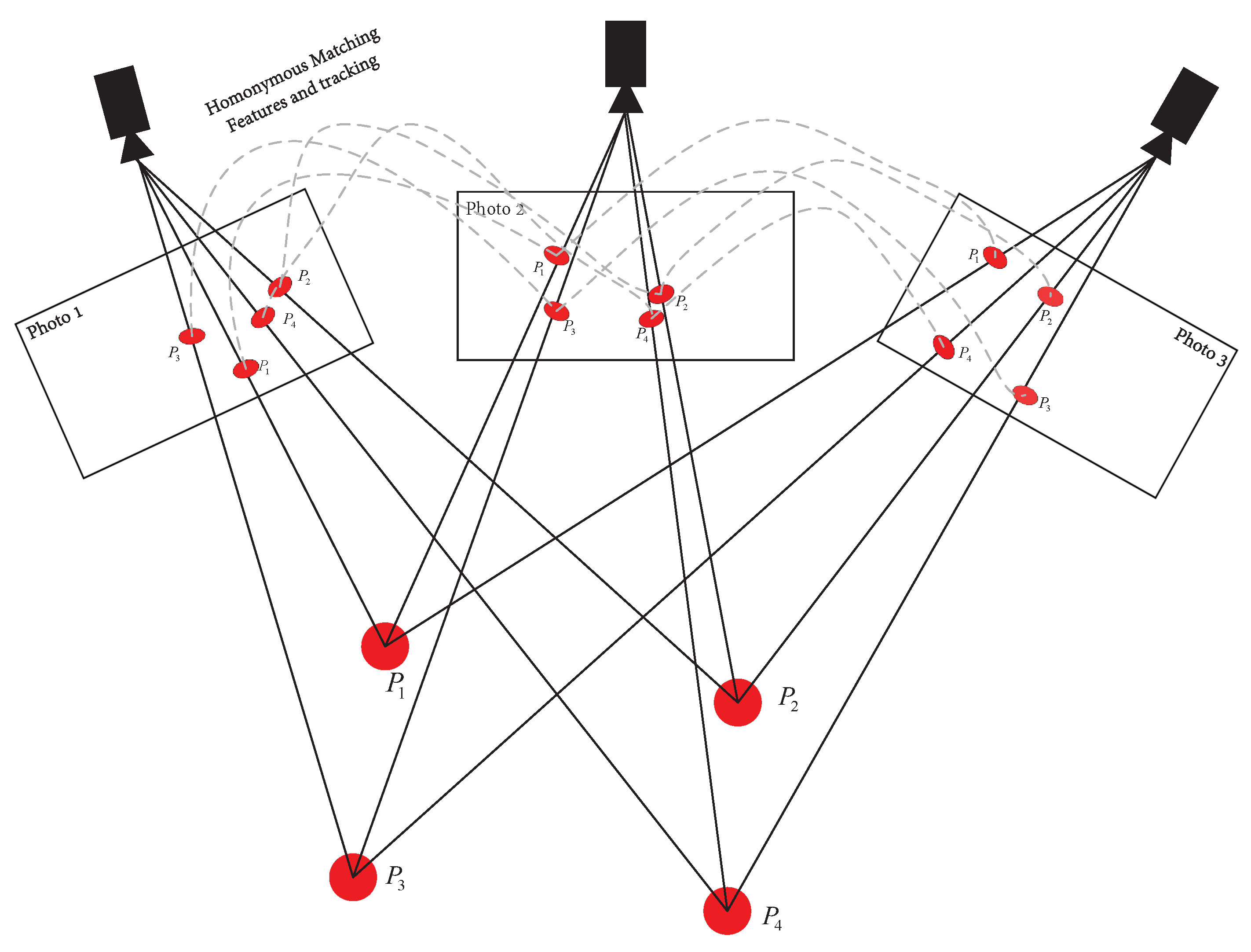{kind=link}
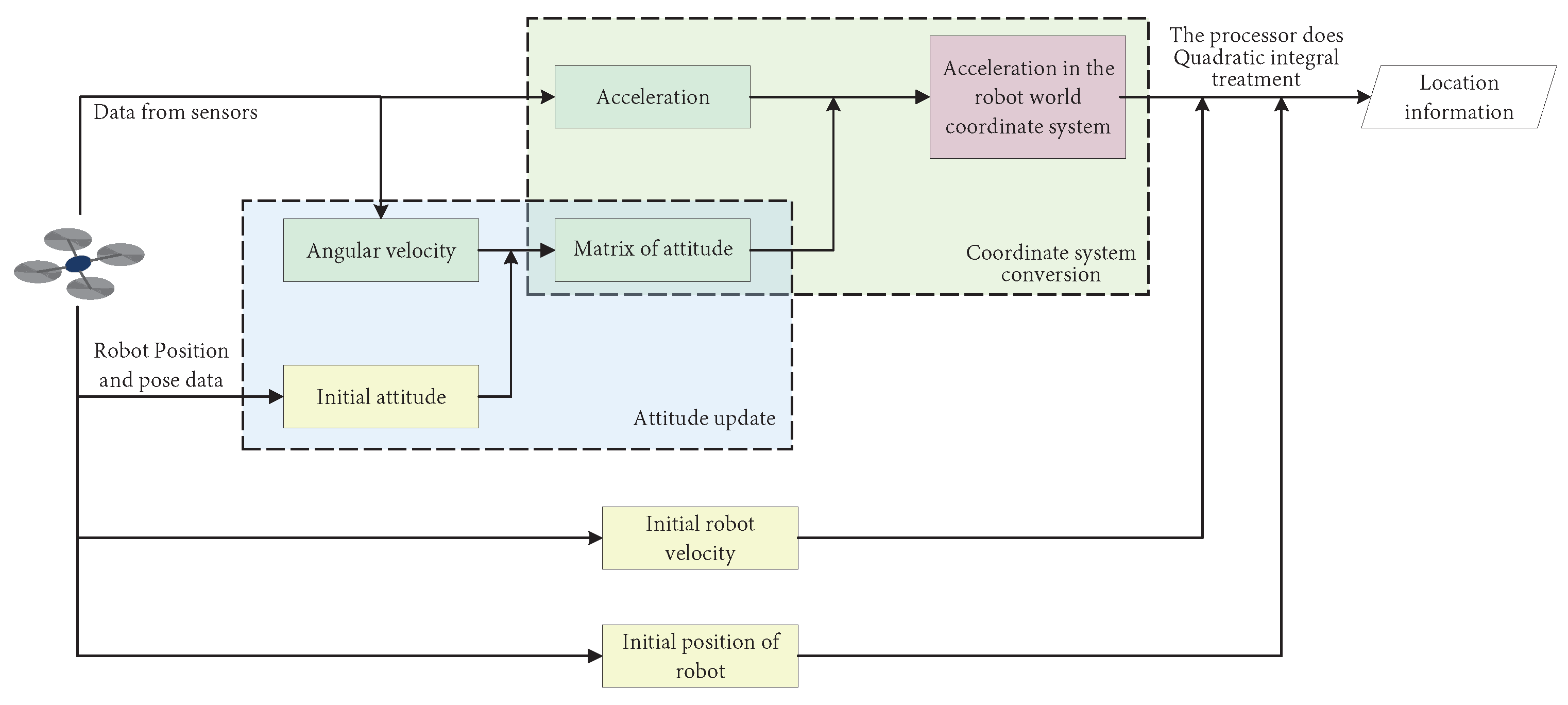{kind=link}
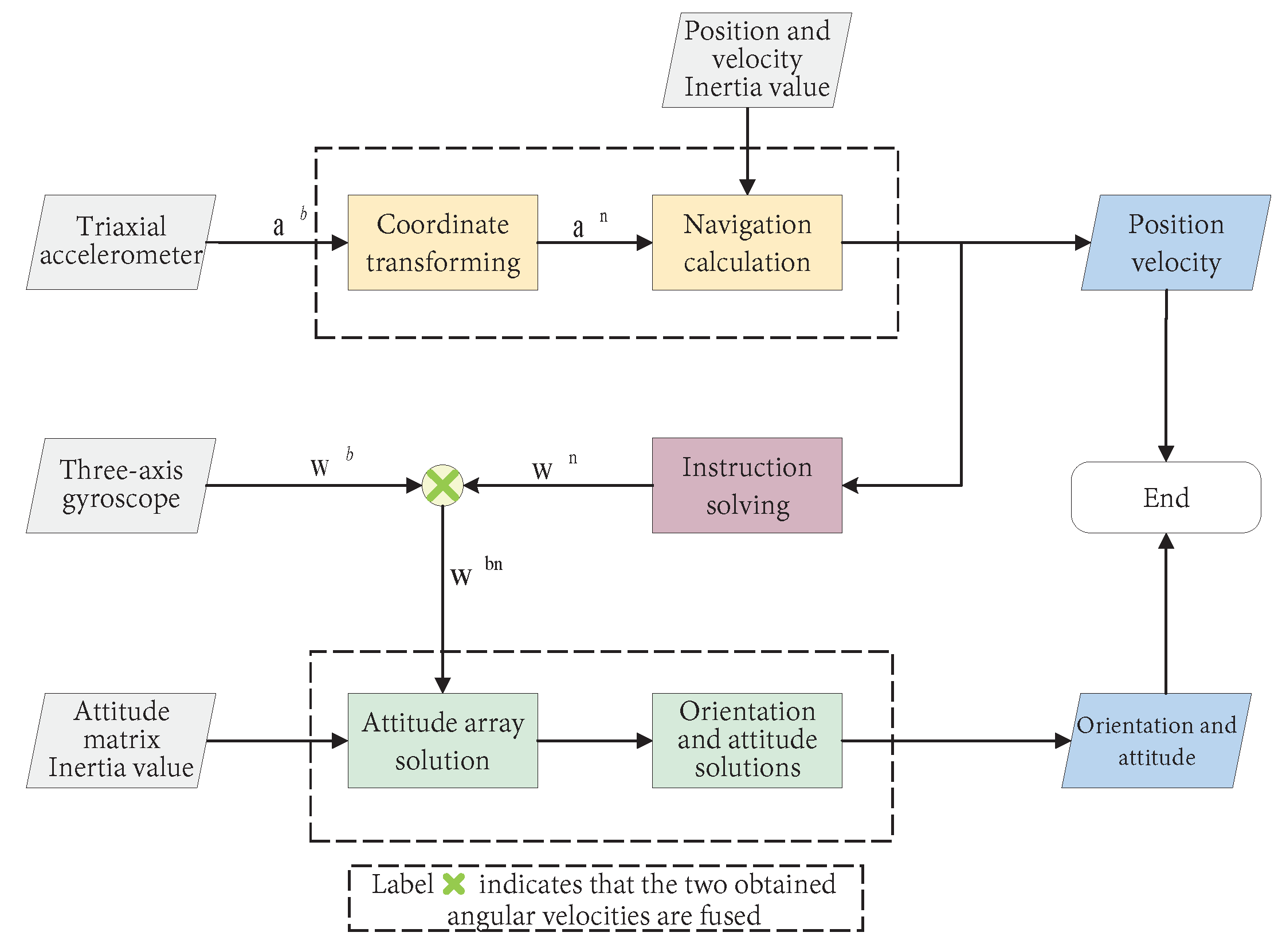{kind=link}
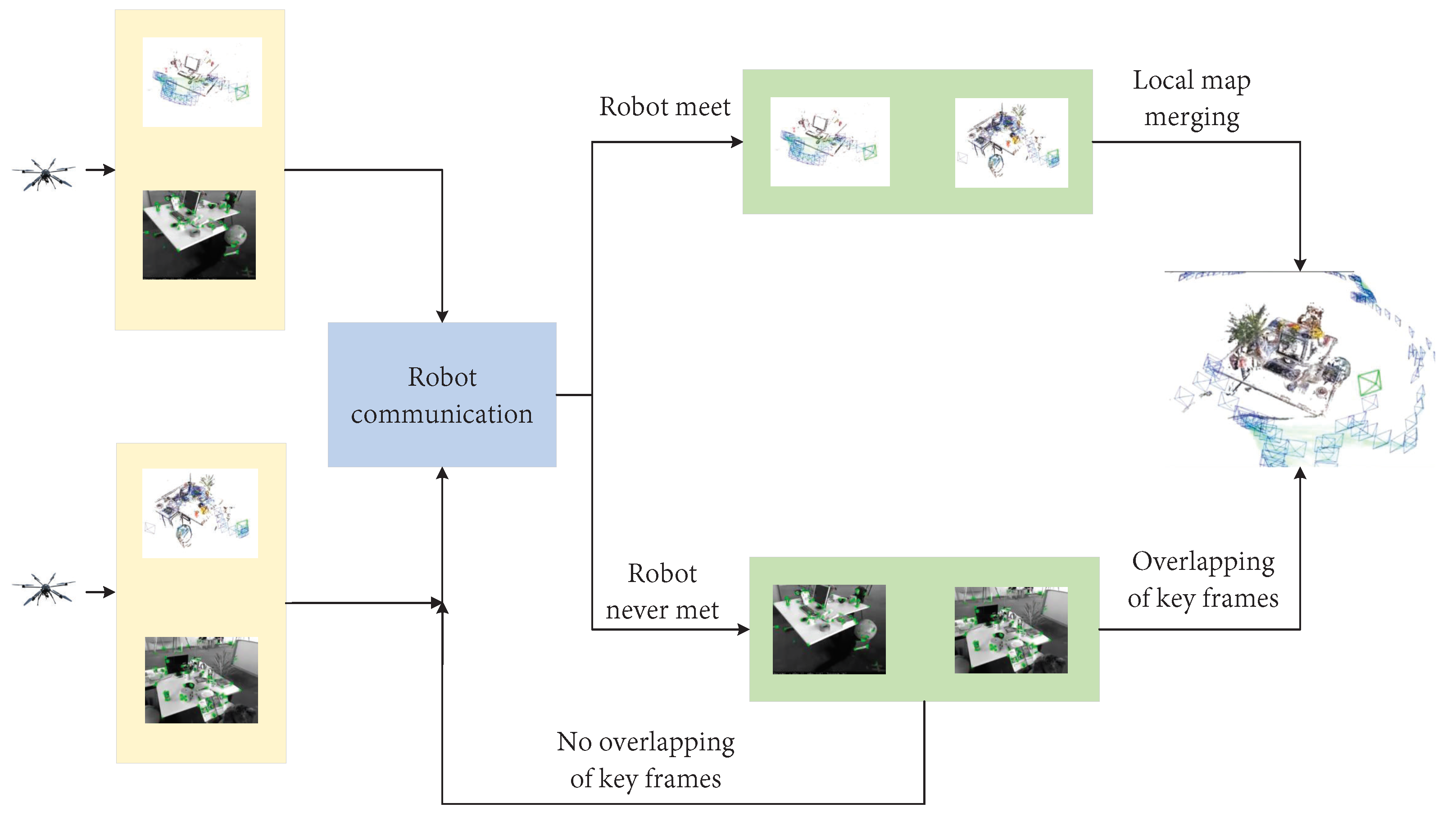{kind=link}
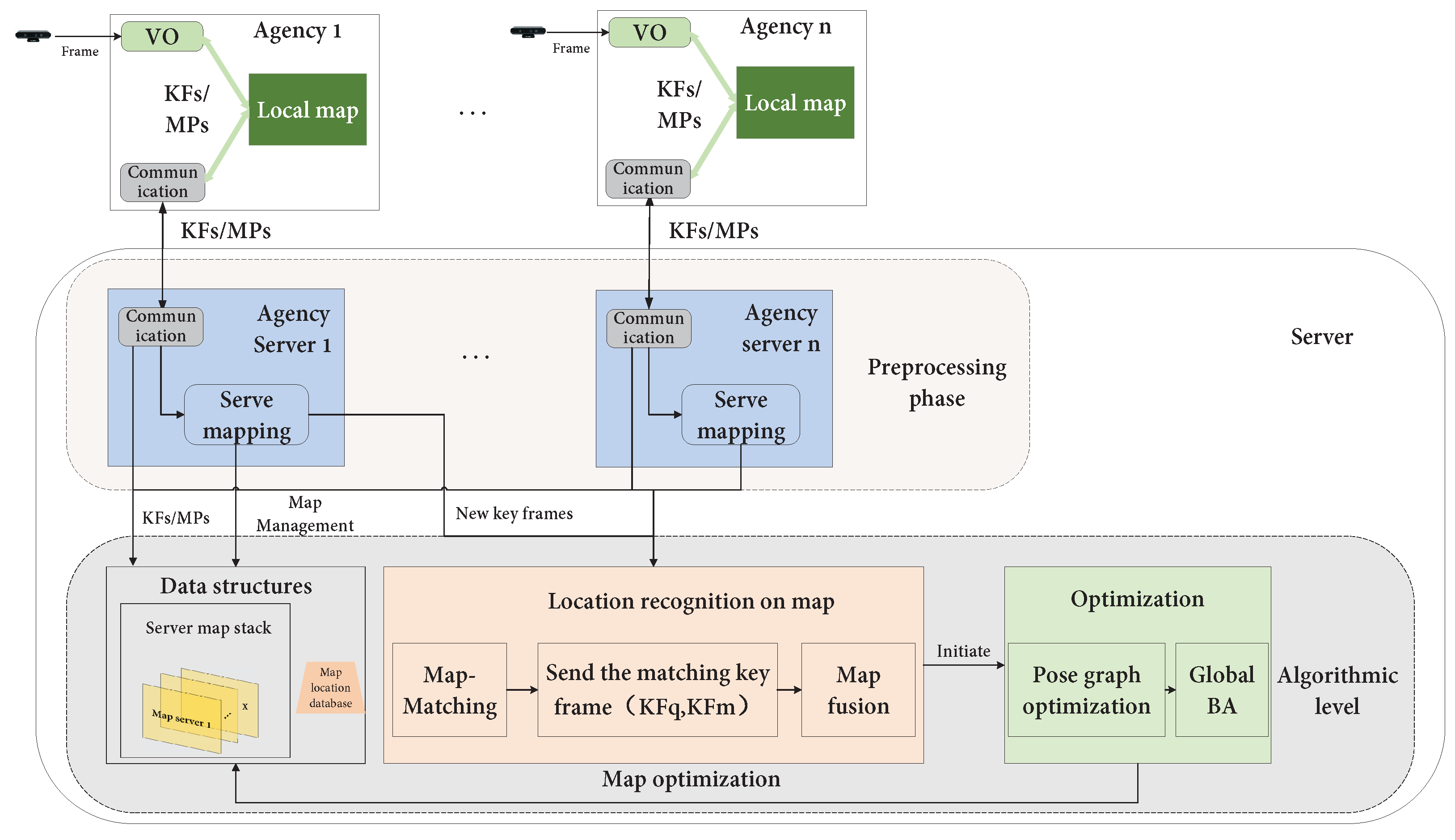{kind=link}
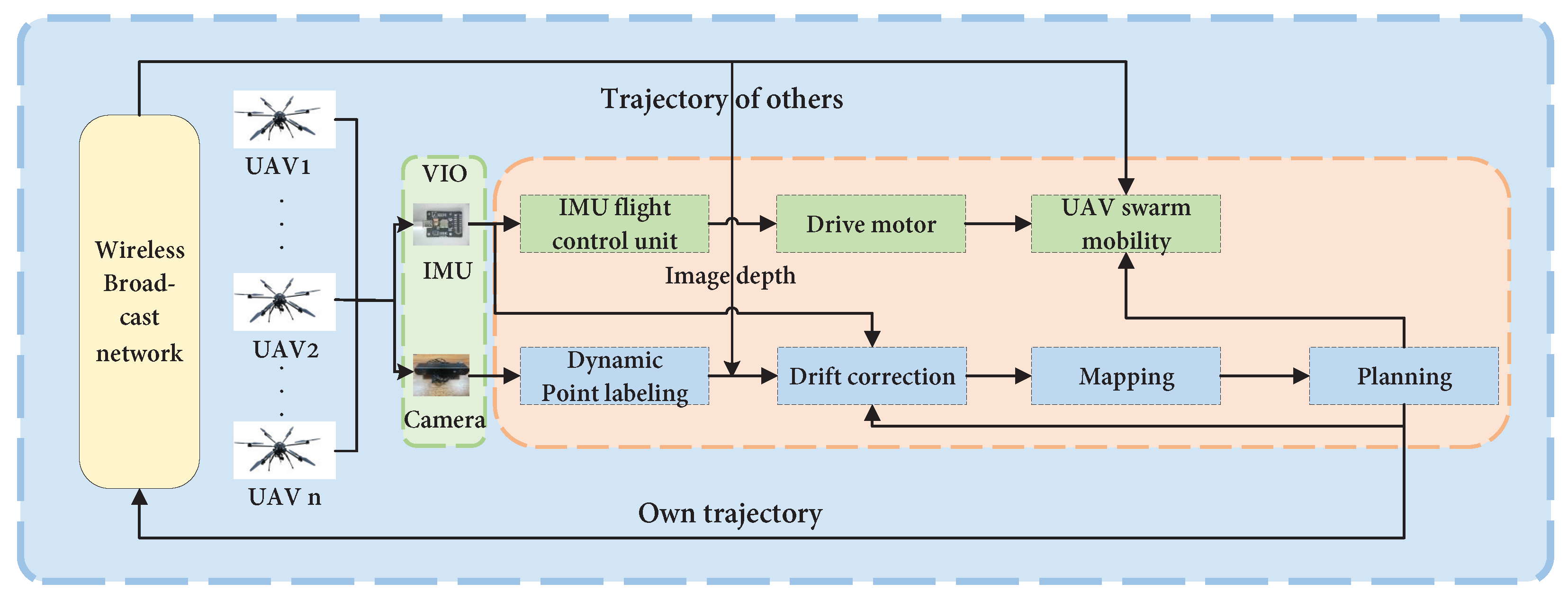{kind=link}
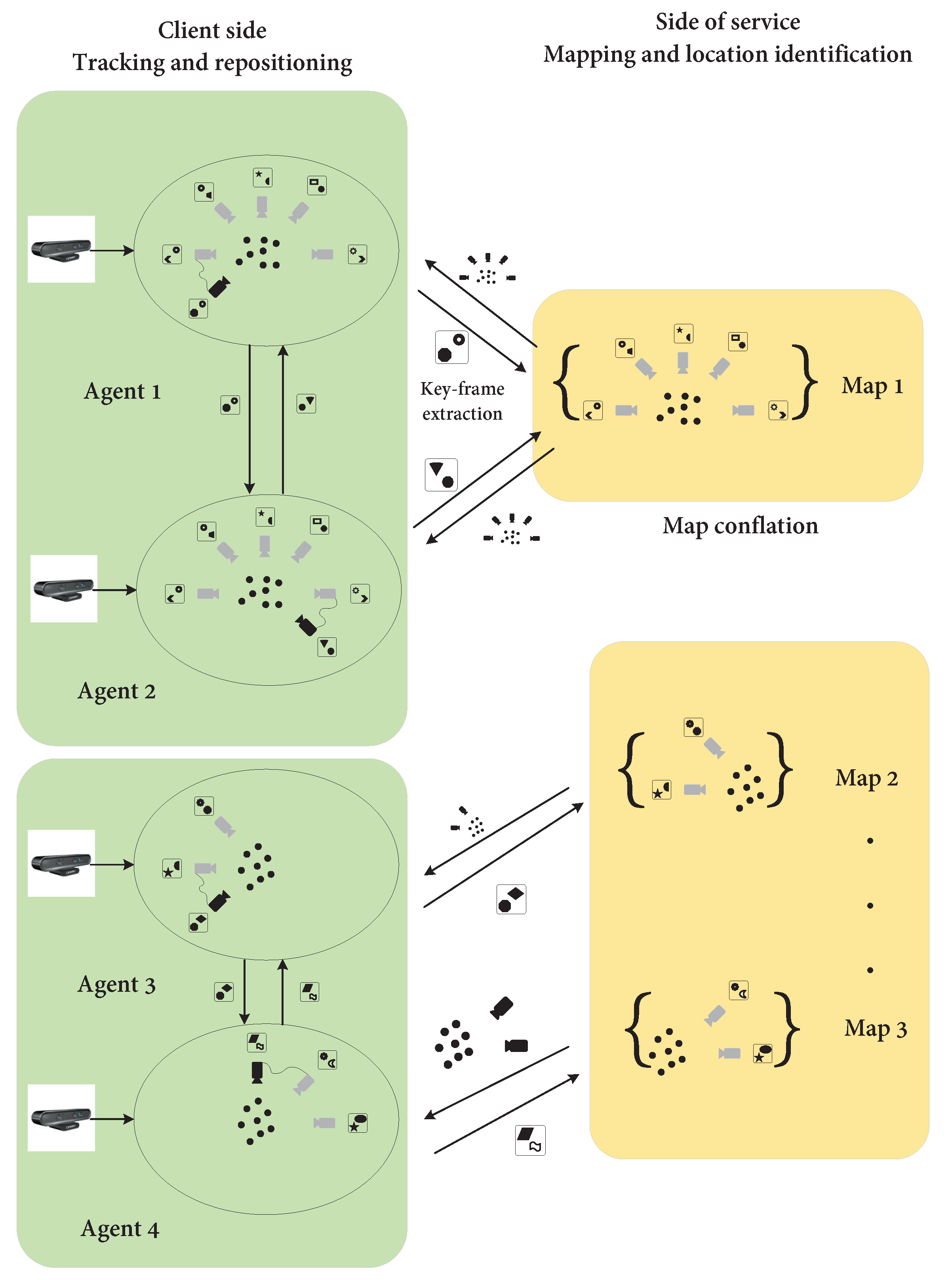{kind=link}
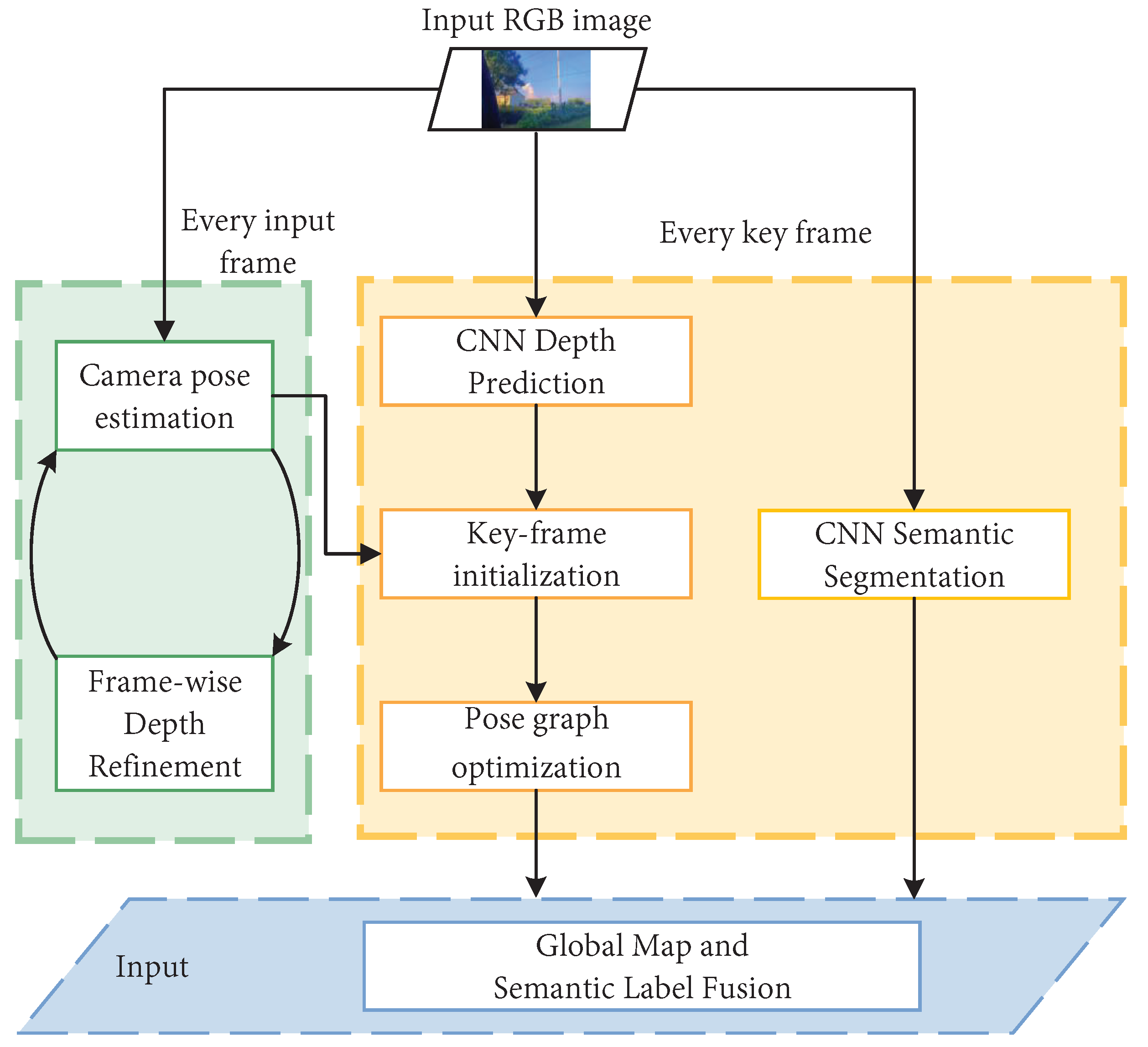{kind=link}
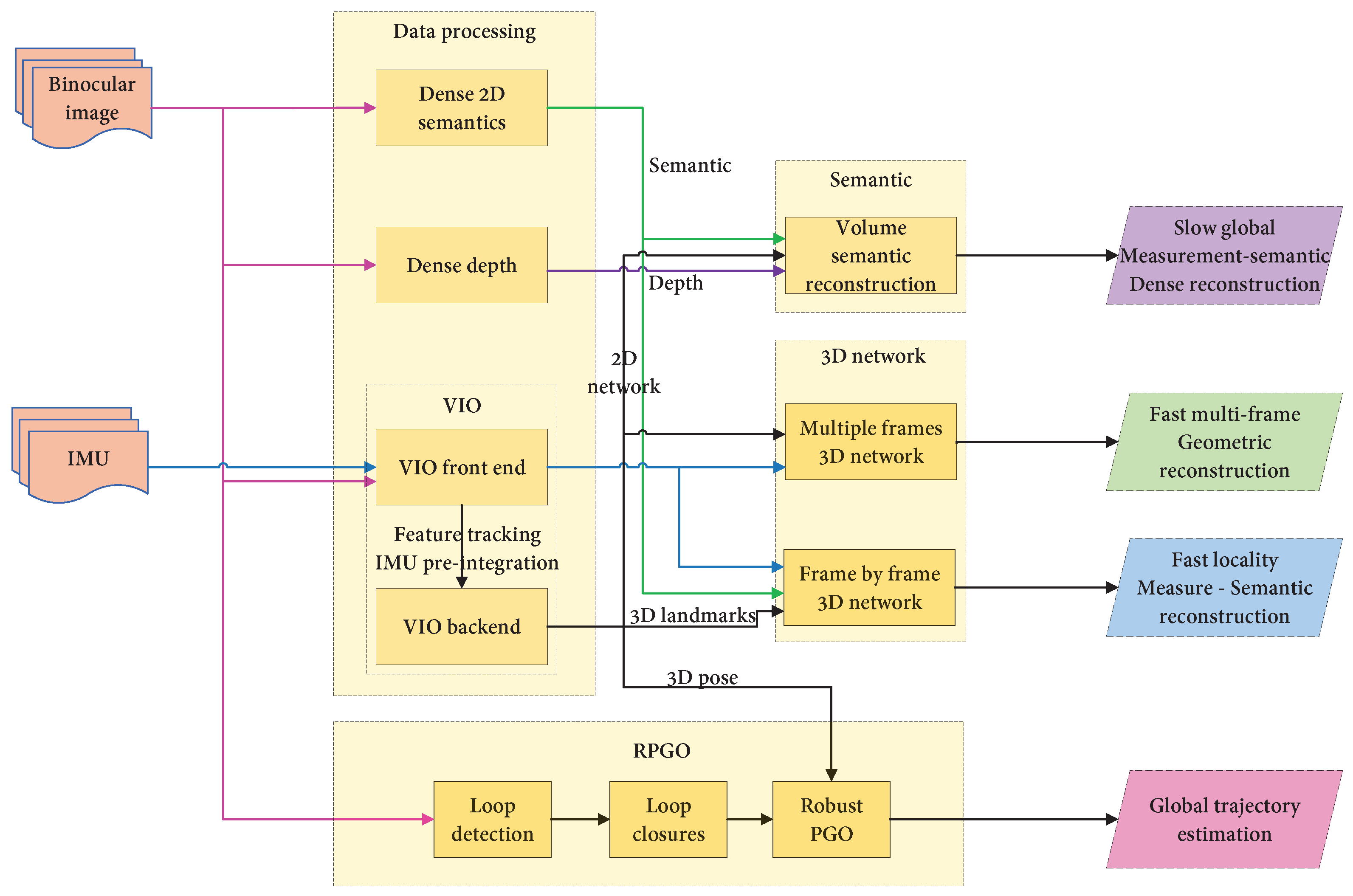{kind=link}
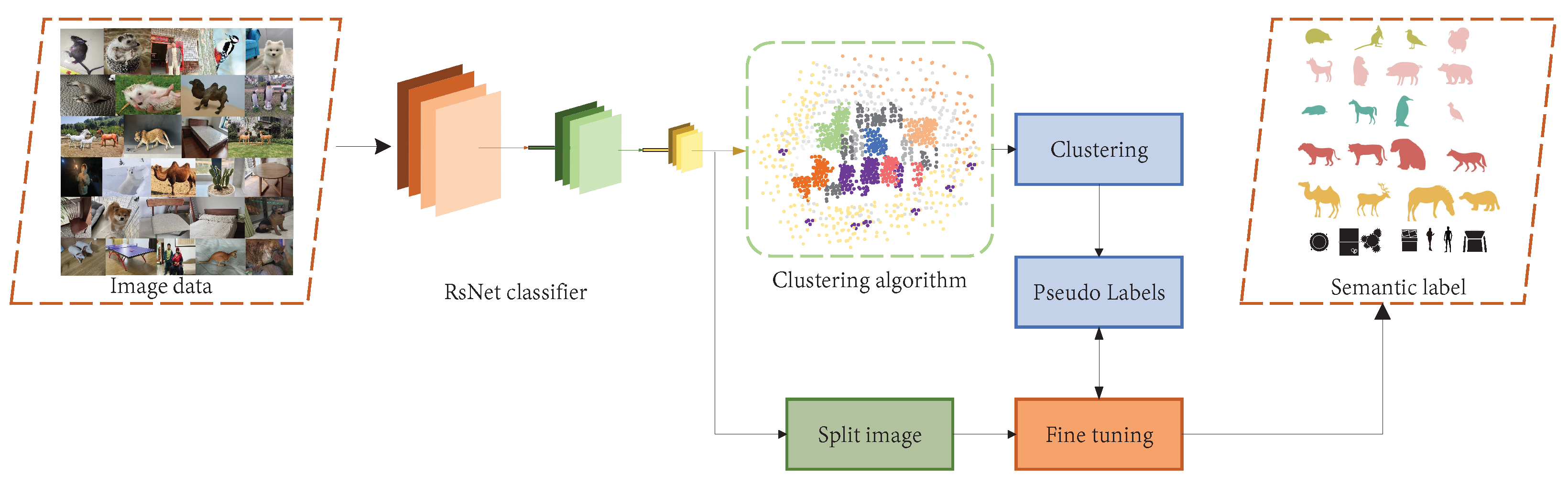{kind=link}
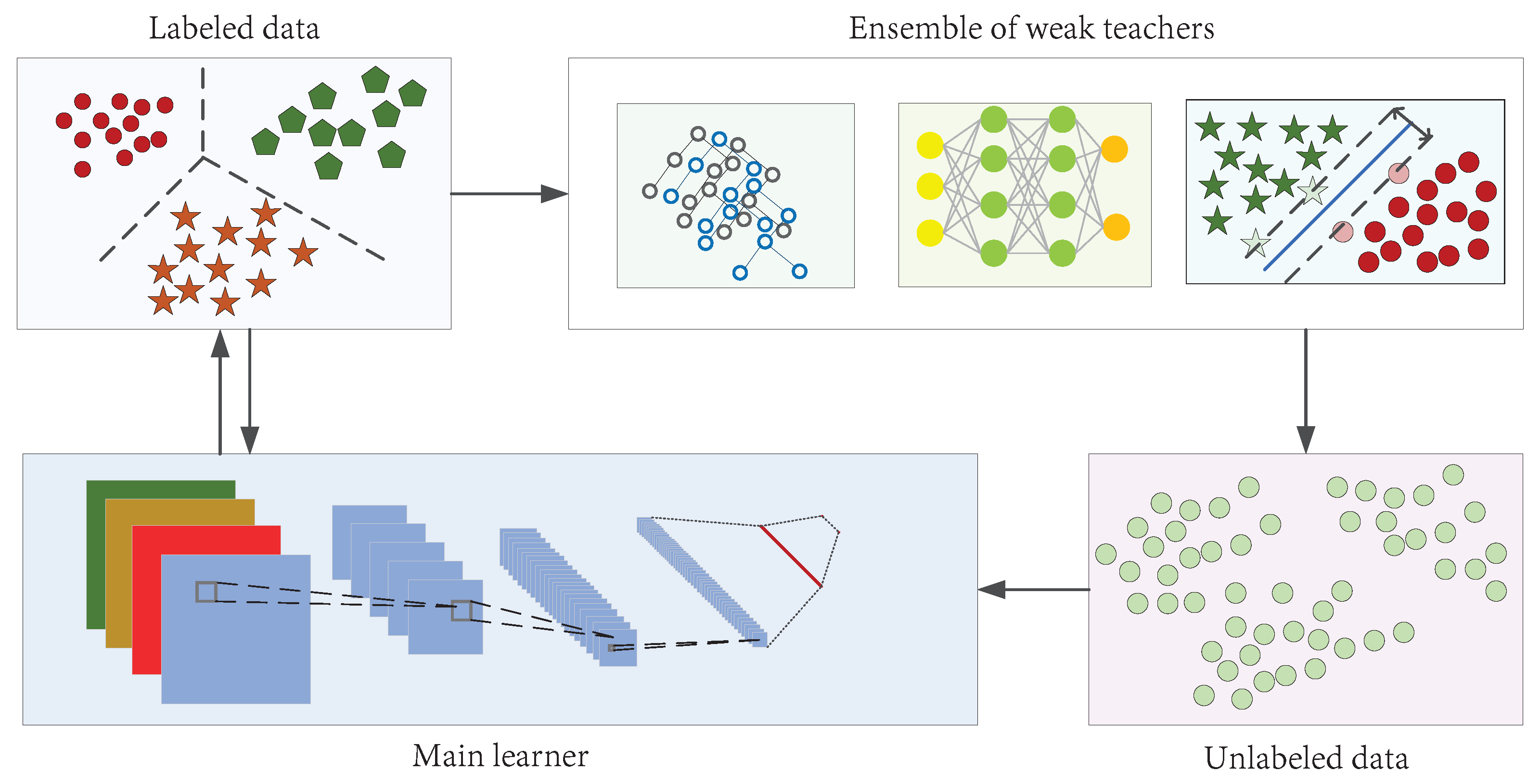{kind=link}
| Type | 2D Laser Radar | 3D Laser Radar |
|---|---|---|
| Characteristic | It can scan and identify the obstacles in the plane and can update the status in real-time, small in size and lightweight. | It can scan and identify obstacles in the three-dimensional plane, has high measurement accuracy, wide measurement range, strong anti-interference ability, strong penetration ability, and can respond quickly in dynamic and static states. |
| Principal manufacturer | Sure Star, Robo Sense, Innoviz, LeddarTech | SLAMTEC, Hensai Technology, Velodyne, Quanergy |
| Representative products | XD–TOF–10HM, XD–TOF–10H | ULTRA Puck VLP–32C, Leddar M16,VLS–128 |
| Chief application | Obstacle monitoring, unmanned ranging | Unmanned driving, terrain mapping |
| Company | Type of Car | Number of Cameras | Number of Radar Sensors | Number of Ultrasonic Sensors |
|---|---|---|---|---|
| Zhiji | Zhi ji L7 | 12 | 5 | 12 |
| Tesla | Model 3 | 8 | 1 | 12 |
| LynkCo | Mobileye | 12 | 5 | 12 |
| Xpeng | Xpeng P7 | 14 | 5 | 12 |
| Ideal | Ideal ONE | 5 | 5 | 12 |
| BMW | BMW iX | 5 | 5 | 12 |
| Mercedes Benz | EQS | 5 | 6 | 12 |
| Honda | Honda Flagship Legend | 5 | 10 | 12 |
| Camera Type | Manufacturer | Configuration | Measuring Range | Applicable Scene |
|---|---|---|---|---|
| D435I | Intel | Binocular + TR active infrared | 0.1–10 m | Indoor/Outdoor |
| Kinect2 | Microsoft | TOF | 0.5–4.5 m | Indoor |
| ZED | Stereolabs | Binocular | 0.3–25 m | Outdoor |
| FS830-BD | Percipio | Structured light | 0.5–5.5 m | Indoor |
| D1000-IR-120 | MYNT | Binocular + IR active infrared | 0.37–7 m | Indoor |
| Data Set | Year | Unit of Supply | Camera | Rada | IMU | Moving Object | Surroundings |
|---|---|---|---|---|---|---|---|
| UTIAS [53] | 2011 | University of Toronto Institute of Aeronautics and Astronautics | 1 × Monocular camera | N | N | UGVs (5) | Nine individual data sets |
| KITTI [54] | 2012 | Karlsruhe Institute of Technology, Germany, Toyota | 2 × Color camera, 2 × Grayscale camera | Y | Y | Car | Outdoor 39.2 km |
| TUM RGB-D [55] | 2012 | Munich Industrial University | 1 × RGB-D | N | N | Handheld and wheeled robots | 39 indoor sequences |
| NYUDv2 [56] | 2012 | New York University | 1 × Color camera, 1 × RGB-D | N | N | Handheld and wheeled robots | 1449 annotated RGB images and depth maps, 407,024 unlabeled images |
| ICL-NUIM [57] | 2014 | Royal Academy of London | 1 × RGB-D | N | N | Handheld and wheeled robots | 8 sets of outdoor sequences |
| EuRoC [58] | 2016 | ETH Zurich | 1 × Binocular grayscale camera | N | Y | UAV | 11 sets of indoor/outdoor sequences |
| Oxford Robotcar [59] | 2017 | Oxford university | 6 × Color camera | Y | N | Car | 100 sets of outdoor/urban sequences |
| Scan Net [60] | 2018 | Stanford University | 1 × RGB-D | N | N | Handheld camera | 21 sets of indoor sequences |
| Re Fusion [61] | 2019 | University of Bonn | 1 × RGB-D | N | N | Handheld robot | 26 sets of outdoor sequences |
| Cityscapes [62] | 2019 | Darmstadt University of Technology | Stereo camera | N | N | Car | 19 sets of outdoor sequences |
| Air Museum [63] | 2020 | French aerospace laboratory | 2 × Stereo monochrome camera | N | Y | 3 × Wheeled robot, 1 × UAV | Five interior scenes |
| S3E [64] | 2022 | Sun Yat-sen University | 1 × Stereo camera | Y | Y | UGVs (3) | Seven outdoor scenes, five interior scenes |
| Laboratory | Research Direction | Website Link |
|---|---|---|
| ETH Zurich | Create robots and intelligent systems that can operate autonomously in complex environments. | https://asl.ethz.ch/ (accessed on 14 June 2023) |
| University of Minnesota | Vision-/laser-assisted inertial navigation systems, multi-robot/-sensor positioning, optimal information selection and fusion, mobile operation, human–machine cooperation, and so on. | http://mars.cs.umn.edu/ (accessed on 14 June 2023) |
| Munich Industrial University | Image-based 3D reconstruction, optical flow estimation, robot vision, visual SLAM, and so on. | https://cvg.cit.tum.de/research (accessed on 14 June 2023) |
| Hong Kong University of Science and Technology | Tightly coupled algorithm for visual–inertial navigation based on UAV. Representative work: VINS-Mono. | https://uav.hkust.edu.hk/ (accessed on 14 June 2023) |
| Zhejiang University | SLAM, AR, 3D reconstruction. Representative achievements: RKSLAM, ACTS, swarm drones. | http://www.cad.zju.edu.cn/english.html (accessed on 14 June 2023) |
| Wuhan University | Computer vision, remote sensing imaging, SLAM, image and video processing and analysis, robot vision navigation and positioning, multi-sensor integration. | https://cvrs.whu.edu.cn/ (accessed on 14 June 2023) |
| Institute of Automation, Chinese Academy of Sciences | 3D computer vision, including camera calibration as well as 3D reconstruction, pose estimation, vision-based robot navigation, and vision services. | http://vision.ia.ac.cn/index.html (accessed on 14 June 2023) |
| Tsinghua University | Computational photography, brain science and international frontiers of artificial intelligence, biological intelligence, computational imaging. | http://media.au.tsinghua.edu.cn/english/index/index.html (accessed on 14 June 2023) |
| Carnegie Mellon University | Robot perception, structure, service type, field machines. | https://www.ri.cmu.edu/ (accessed on 14 June 2023) |
| University of California, San Diego | Multi-modal environment understanding, semantic navigation, autonomous information acquisition. | https://existentialrobotics.org/index.html (accessed on 14 June 2023) |
| TU Munich | 3D reconstruction, robot vision, deep learning, visual SLAM, and so on. | https://cvg.cit.tum.de/research/vslam (accessed on 14 June 2023) |
| Fusion Type | Early Fusion | Mid-Term Fusion | Late Fusion |
|---|---|---|---|
| Fusion level | Data level | Feature level | Decision level |
| Common algorithm | Weighted mean; optimization methods; artificial neural networks [95]; color space fusion | Principal component analysis; linear discriminant analysis; neural networks | Majority voting [85]; average value fusion; Bayesian rule fusion [86]; ensemble learning; Dempster–Shafer (D-S) [88]; fuzzy set theory [96] |
| Algorithm | Filtering Method | Non-Linear Optimization Method |
|---|---|---|
| Advantage | Simple method. In the case of limited computing resources and simple estimation, the filtering method represented by EKF is more effective and is commonly used in laser SLAM. | It can be globally optimized and works well. |
| Disadvantage | Not suitable for large scenarios. In the vision-based SLAM scheme, the efficiency is very low due to the high data volume. | With the accumulation of time, there is more and more data and the solution scale becomes larger. |
| Representative algorithms | KF, EKF, UKF, PF | BA (bundle adjustment) [124] |
| Stand for SLAM | Karto SLAM [15] | LSD-SLAM [117] |
| Type | Year | Sensor | Algorithm | Innovation |
|---|---|---|---|---|
| EKF-SLAM [11] | 1990 | 2D laser | Filtering | The EKF was applied to 2D laser SLAM for the first time; the feature map can be well-constructed. |
| Fast SLAM [14] | 2002 | 2D laser | Filtering | The particle filter was applied to robot SLAM for the first time; the matching speed is very fast. |
| CF SLAM [126] | 2009 | 2D laser | Filtering | EKF and EIF were combined for the first time. |
| Karto SLAM [15] | 2010 | 2D laser | Optimization | Back-end optimization with loop-back detection was introduced for the first time in laser SLAM. |
| Hector SLAM [47] | 2011 | 2D laser | Filtering | The 2D SLAM system was combined with 3D scan-matching technology and an inertial sensing system. |
| Lago SLAM [127] | 2012 | 2D laser | Optimization | 2D Laser SLAM with linear approximation graph optimization. |
| LOAM [22] | 2014 | 3D laser | Optimization | Good real-time performance, constant velocity motion assumption, no closed-loop detection. |
| V-LOAM [67] | 2015 | 3D laser, monocular camera | Optimization | High precision and good robustness of the algorithm, uniform drift assumption, no closed loop detection. |
| Cartographer [48] | 2016 | 2D laser | Optimization | Using a sub-map and closed loop, it provides a solution for indoor real-time mapping. |
| LeGO-LOAM [23] | 2018 | 3D laser, IMU | Optimization | Compared to LOAM, back-end optimization is added to make the diagram more complete. |
| LIO-SAM [46] | 2020 | 3D laser, IMU, GPS | Optimization | A variety of sensors are tightly coupled, and the robustness is strong. |
| LOCUS 2.0 [128] | 2022 | 3D laser | Filtering | Other sensor data can be robustly fused in a loosely coupled scheme. |
| Project | Year | Sensor | Front-End | Back-End | Mapping | Introduce | Code Link |
|---|---|---|---|---|---|---|---|
| Mono SLAM [20] | 2007 | M | F | F | S | The first real-time monocular SLAM system based on EKF. | [137] |
| PTAM [21] | 2007 | M | F | O | S | The first monocular SLAM based on non-linear optimization. | [138] |
| DTAM [120] | 2011 | M | D | O | D | Works well in the case of missing features and blurred images. | [139] |
| Kinect Fusion [134] | 2011 | R | D | O | D | Inexpensive and works in real-time. | [140] |
| Kintinuous [135] | 2012 | R | D | O | D | Works in a wide range of environments in real-time with strong robustness and small drift. | [141] |
| DVO-SLAM [132] | 2013 | R | D | O | D | The trajectory error is small. | [142] |
| LSD-SLAM [117] | 2014 | M | D | O | S-D | It can run in real-time and build large-scale, consistent maps of the environment. | [143] |
| SVO [122] | 2014 | M | SD | O | S | The combination of a feature method and a direct method eliminates the problems associated to the feature extraction technique and the robust matching technique. | [144] |
| ORB-SLAM [19] | 2015 | M/S/R | F | O | S | Has strong robustness and can run both indoors and outdoors. | [145] |
| ORB-SLAM2 [130] | 2016 | M/S/R | F | O | S | Extending ORB-SLAM to binocular cameras, also a model framework for many SLAM methods. | [146] |
| Elastic Fusion [136] | 2016 | R | D | O | D | Makes full use of depth information to solve the problem of indoor mapping. | [147] |
| S-PTAM [129] | 2017 | S | F | O | S | Has good robustness and accuracy in indoor, outdoor, dynamic objects, and other conditions. | [148] |
| Binocular DSO [133] | 2017 | S | D | O | S | Can achieve more accurate dense 3D reconstruction. | [149] |
| DSO [121] | 2018 | M | D | O | S | Has good accuracy and robustness. | [150] |
| Algorithm Name | Year | Submitting Unit | Algorithm Type | Fusion Type | Code Link |
|---|---|---|---|---|---|
| MSCKF [165] | 2007 | University of Minnesota | F | T | [168] |
| SSF [166] | 2012 | ETH Zurich | F | L | [169] |
| MSF [69] | 2013 | University of Edinburgh | F | L | [170] |
| OKVIS [70] | 2013 | Imperial College London | O | T | [171] |
| VINS-Mono [163] | 2017 | Hong Kong University of Science and Technology | O | T | [172] |
| VINS-Mobile [4] | 2017 | Hong Kong University of Science and Technology | O | T | [173] |
| ROVIO [167] | 2017 | ETH Zurich | F | T | [174] |
| DM-VIO [71] | 2022 | Munich Industrial University | O | L | [175] |
| Algorithm Name | Year | Algorithm Type | Fusion Type | Features | Code Link |
|---|---|---|---|---|---|
| DEMO [76] | 2014 | B | L | IMU independent module fusion with vision state estimator | [180] |
| V-LOAM [67] | 2015 | B | T | Not open-source | |
| LIMO [68] | 2019 | B | T | Take advantage of minimizing residuals to achieve better accuracy and robustness at a higher computational cost | [181] |
| VIL-SLAM [89] | 2019 | B | T | [182] | |
| LVI-SAM [24] | 2021 | F | T | [183] |
| Algorithm Name | Year | Submitting Unit | Algorithm Type | Fusion Type | Code Link |
|---|---|---|---|---|---|
| LOAM [22] | 2014 | Hong Kong University of Science and Technology | O | L | [190] |
| LIPS [188] | 2018 | University of Delaware | O | T | [191] |
| LeGo-LOAM [23] | 2018 | Stevens Institute of Technology | O | L | [192] |
| LIO-Mapping [189] | 2019 | Hong Kong University of Science and Technology | O | T | [193] |
| LIOM [90] | 2019 | Northeastern University | F | T | [194] |
| LIO-SAM [46] | 2020 | Massachusetts Institute of Technology | O | T | [195] |
| Marked-LIEO [185] | 2022 | Central South University | O | L | Not open-source |
| Algorithm Name | Year | Performance and Contribution | Fusion Algorithm |
|---|---|---|---|
| Khan et al. [99] | 2018 | Uses KF to combine multiple ultrasonic distance sensors, IMUs, and wheel encoders for localization and occupancy grid maps. | KF |
| Jang and Kim [100] | 2019 | A robust measurement update method for a panel-based SLAM algorithm. | Constrained extended Kalman filter |
| Zou et al. [203] | 2020 | WiFi signals are used to achieve high-precision positioning of mobile robot platforms in complex indoor environments. | Adversarial learning |
| Almalioglu et al. [200] | 2021 | UKF is used to fuse IMU and millimeter-wave radar to complete low-cost pose estimation for indoor SLAM. | UKF |
| Kim et al. [102] | 2021 | The limitation of single-sensor uncertainty is overcome. | Unsupervised learning |
| VILENS [179] | 2022 | Sensor information such as inertial, mechanical leg, and LiDAR data can be seamlessly fused. | Factor graph optimization |
| Algorithm Name | Bayesian Filtering Theory | Grey System Theory | Fuzzy Theory | Rough Boundary Theory |
|---|---|---|---|---|
| Research object | Random uncertain | Poor information uncertain | Cognitive uncertainty | Uncertain boundaries |
| Method basis | Mapping | Information coverage | Mapping | To divide |
| Data request | Typical distribution | Arbitrary distribution | Membership is known | Equivalence relationship |
| Features | Large sample data | Small sample data | Experience data | Information sheet |
| Method | Direct Fusion | Indirect Fusion |
|---|---|---|
| Map format | Multiple coordinate systems for conversion. | There is only one common format to expose maps. |
| Mode of integration | Through rendezvous and coordinate transformation of specific landmarks, the maps are fused. | Map merging is performed according to the overlapping areas in the maps. |
| Advantage | High-precision transformation estimation can be provided. | Merging maps is more flexible and straightforward. |
| Shortcoming | It can only be used under certain conditions. | The merged maps are coarse, lack detail, and have a certain degree of drift. |
| Corresponding Architecture | Centralized | Distributed | Hybrid |
|---|---|---|---|
| Type of fusion | Centralized fusion | Distributed fusion | Hybrid fusion |
| Common fusion algorithms | Mid-term fusion, late fusion | Mid-term fusion, late fusion | Early fusion, mid-term fusion |
| Features | All measurements are sent to a center for fusion estimation. | First, the sensors are pre-processed to give local estimates, and then the track association and global fusion are carried out by the center node. | After collecting the data, the sensors are sent to the center for fusion directly, or can be sent to the center node for fusion after calculating a layout estimate. |
| Advantages | Little information loss, good coordination, optimal task allocation. | Simple operation, no storage requirements, no correlation estimation error, strong real-time performance, strong anti-interference ability, and low data redundancy. | Strong adaptability, taking into account the advantages of distributed and centralized approaches, strong stability. |
| Disadvantages | Difficult to realize, poor robustness, poor real-time and dynamic performance due to the high bandwidth demand and strong computing power required for the central processor. | The prior information is not well-utilized and the performance is poor. | The structure is more complex than the previous two, which increases the costs associated to communication and computation. |
| Relevant algorithms | KF fusion algorithm [260], neural network fusion algorithm. | Weighting method, statistical clustering method, classical assignment method [28], multiple hypothesis tracking methods, fuzzy function association method [96], fuzzy logic association method. | Factor graph fusion algorithm [77], interacting multiple model algorithm [72]. |
| SLAM System | Year | Number of Agents | Architecture | Front-End | Back-End | Map Style |
|---|---|---|---|---|---|---|
| PTAMM [92] | 2008 | 2 | C | VO, SFM, pose estimation | Triangulation, relocation, BA optimization. | G |
| CoSLAM [31] | 2012 | 3/4/12 | D | Monocular VO | Inter-camera pose estimation, mapping, BA optimization. | G |
| CSFM [77] | 2013 | 2 | C | Monocular VO | Location recognition, map fusion, pose optimization, BA optimization. | L |
| C2TAM [72] | 2013 | 2 | H | RGB-D VO, pose estimation | Triangulation, relocation, BA optimization. | L |
| CCM-SLAM [29] | 2018 | 3 | C | Monocular VO | Location recognition, map fusion, redundant keyframes are deleted. | L |
| CVI-SLAM [30] | 2018 | 4 | C | VO | Triangulation, global map optimization, loop closure, map fusion. | G |
| Door-SLAM [96] | 2020 | 2 | D | VO, point-to-point | Loop closure, map fusion. | L |
| VIR-SLAM [93] | 2021 | 2 | D | VO, UWB, pose estimation | Loop closure, direct map fusion, non-linear optimization. | L |
| DisCo-SLAM [269] | 2022 | 3 | D | LIO | Loop closure, feature matching, global and local optimization, and direct map fusion. | G |
| CVIDS [78] | 2022 | 3 | C | Monocular VO | Loop closure, map fusion. | L |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Wang, X.; Gao, S.; Shang, G.; Zhou, C.; Li, Z.; Xu, C.; Hu, K. Overview of Multi-Robot Collaborative SLAM from the Perspective of Data Fusion. Machines 2023, 11, 653. https://doi.org/10.3390/machines11060653
Chen W, Wang X, Gao S, Shang G, Zhou C, Li Z, Xu C, Hu K. Overview of Multi-Robot Collaborative SLAM from the Perspective of Data Fusion. Machines. 2023; 11(6):653. https://doi.org/10.3390/machines11060653
Chicago/Turabian StyleChen, Weifeng, Xiyang Wang, Shanping Gao, Guangtao Shang, Chengjun Zhou, Zhenxiong Li, Chonghui Xu, and Kai Hu. 2023. "Overview of Multi-Robot Collaborative SLAM from the Perspective of Data Fusion" Machines 11, no. 6: 653. https://doi.org/10.3390/machines11060653