1. Introduction
Unmanned aerial vehicles (UAVs), commonly known as drones, have been around since the First World War and were initially used in the military field [
1]. However, they are currently used for both civilian and commercial purposes as well [
2]. Search and rescue operations [
3], remote sensing [
4], last-mile deliveries [
5], and aerial spray and disinfection [
6] are just a few practical applications.
Quadrotors are a type of six-degree-of-freedom (6-DOF) UAV with four rotors, which produce lift through difference in the thrust of the rotation of its propellers. Due to their vertical takeoff and landing (VTOL) capability, omnidirectional flight, and mobility in constrained spaces, UAV quadrotors can perform outdoor and indoor tasks. Furthermore, the lightweight, small size, versatility, easy handling, and low cost of quadrotors make them more suitable compared to the fixed-wing UAVs for short-term missions [
7].
Disturbances such as wind, temperature, air pressure, reference changes, aerodynamic effects (ground effect, drag, and downwash), or uncertainties can cause the UAV to become unstable and get damaged, as the applications are designed for specific operating conditions [
8]. To achieve the variety of intended applications, controllers must ensure stability, correct execution of movements in a short time with a small margin error, robustness, and efficient energy consumption [
9]. However, the design of attitude and position controllers for quadrotors is challenging due to their unstable and under-acted nature and coupled and multi-variable nonlinear dynamics.
Several approaches have been developed to overcome the challenge of controlling quadrotor UAVs under different operating conditions. These approaches can be broadly categorized into model-based and model-free controllers. Model-based controllers require a precise understanding of the system and depend on a model. PID controller plus Linear-Quadratic Regulator (PID+LQR) [
10] or robust Sliding Mode Control (SMC) [
11] are examples of model-based controllers. However, these types of control approaches can be sensitive to modeling errors, and it is important to count on accurate modeling and system identification for effective control design [
12].
A linear model for a nonlinear system can be obtained by using a small-signal approximation around an operating point [
13]. These models allow the development of classical linear [
14] and optimal [
10] control systems, demonstrating stability even in environments with wind speed fluctuation [
15]. In contrast, linear control algorithms fail to control the UAV in states other than the operating point.
More complex control systems have been proposed to improve the performance of UAVs under specific operation points and to enhance the stability of these vehicles in the presence of external disturbances, such as those considering the dependency between movement and attitude in our plant to offer a robust control in the presence of loads [
16], un-modeled high-frequency dynamics [
17], an adaptive control for multi-quadrotor cooperation under load uncertainties [
18], Robust adaptive control for heterogeneous multi-quadrotor cooperation [
19], and Adaptive Backstepping Control to deal with uncertainties and non-linear dynamics from the UAV model [
20]. However, these models often require an accurate high-order mathematical model with sophisticated coefficient computations. Finally, although these approaches propose to solve specific points of operation un-modeled dynamic factors can lead to system instability, low convergence rate, chattering effect, or transient and steady-state problems.
Model-free controllers such as PD Hybrid Artificial Neural Network (PD-ANN) [
21], Fuzzy Based Backstepping Control [
22], and Nonlinear Integral Backstepping Model-free Control (NIB-MFC) [
23] have been proposed to control under system uncertainties and modeling errors, resulting in a significant improvement in low-level control for UAVs compared to classical controllers [
24]. Furthermore, intelligent models based on neural networks can generalize experience from provided data for different operating points, making them suitable for controlling and modeling complex dynamic systems such as UAV low-level control [
25].
Model-free controllers can be further divided into online and offline approaches. Online methods such as Reinforcement Learning [
26] build the data simultaneously as it is experienced but requires a lot of time and a high computational cost. Offline approaches [
27] learn from a specified dataset and are faster and more efficient than online methods. Still, model performance depends on the quality and quantity of the available data. Combining both strategies, as proposed by Ashvin Nair and co. [
28], can accelerate model learning by offline learning on a prior dataset and then fine-tuning with online interaction.
This paper is organized as follows: In
Section 2, we describe the recent research effort in flight control systems toward intelligent control, robust control, hybrid approaches, and the paper’s contribution. Then,
Section 3 explains the applied software and techniques proposed with definitions from the literature. Next, the results of the experiments used to evaluate our trained controllers and their evaluation compared to our base PID controller are explained in
Section 4 and commented on in
Section 5. Finally, the conclusions and recommendations for future works are commented on in
Section 6 and
Section 7.
3. Materials and Methods
The implementation of the proposed models was developed at the simulation level based on the commercial drone model and is highly used in the UAV research area, such as the Crazyflie. This section includes information on the simulation environment, implemented models, and the developed methodology.
3.1. Simulation Environment
Pybullet [
52] is an open-source Python interface that provides a link with the Bullet Physics SDK library [
53], specialized in robotics physics.
3.1.1. Drone Model
We chose a drone model for conducting our tests based on the open source development platform Bitcraze’s Crazyflie 2.0 [
54]. Our model is a nanoquad, which is lightweight and small, allowing for better indoor flight and the ability to perform aggressive trajectories. The drone can be simulated in either a cross (reference body frame aligned with the drone arms) or equis (body axis at a 45-degree angle to the drone arms) configuration, and its features are listed in
Table 1 and depicted in
Figure 1.
As defined by Sabatino [
13], the dynamics of the UAV in space, by assuming that
, which is true for small angle motions, and
, would be defined by (
1).
Additionally, a vector of disturbances is defined in (
2), mainly caused by changes in wind direction and magnitude, which alter the force and torque in each of the aircraft dimensions.
3.1.2. DSLPID Controller
We have chosen Utia’s DSLPID controller as our baseline for training the Neural Networks. Our aim is to replicate the controller behavior using Deep Learning techniques. The DSLPID controller was developed initially by Jacopo Panerati et al. [
55] at the University of Toronto Institute for Aerospace Studies (Utia) in their laboratory of dynamic systems (DSL).
Table 2 shows the PID parameters obtained from the Mellinger controller [
56] and designed for the model Bitcraze’s Crazyflie
Cf2x/Cf2p [
54]. The code for the Crazyflie controller is available on the
GitHub of
gym-pybullet-drones [
57].
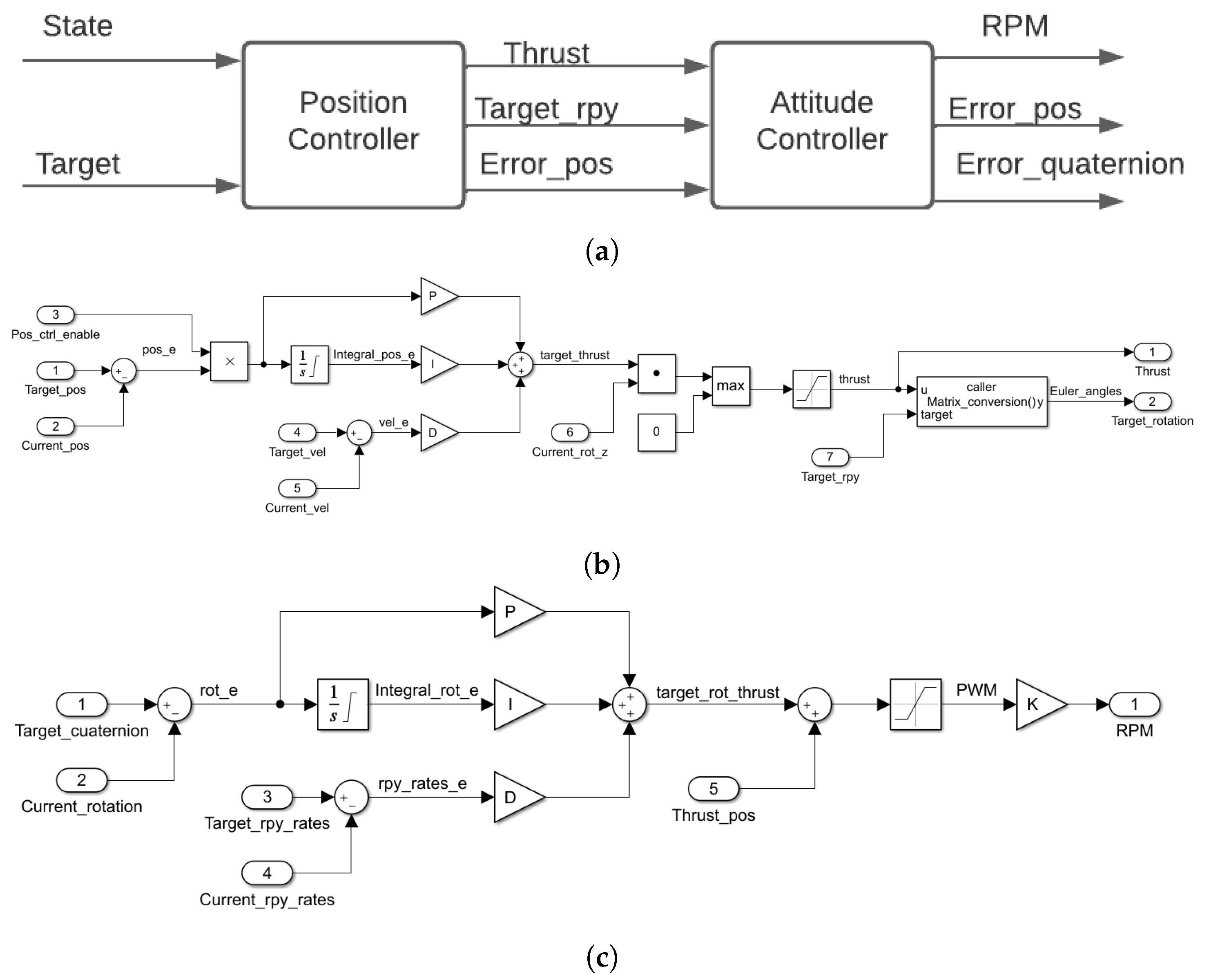
Figure 2a shows the general scheme of the controller. Due to a drone being an under-acted system, it is not possible to implement a straightforward controller for the
x and
y axis. It is necessary for a double loop controller to manipulate the mentioned axis by fixing the values of the
and
axis. Then the controller will calculate a thrust value (which will act over the
z-axis) to obtain a desired rotation that will move our drone in the
plane.
Inside, this controller is composed of PID controllers in the way that is displayed in
Figure 2b,c for the position and attitude control, respectively.
3.1.3. Pybullet Set-Up
Along with the
Pybullet framework, we use the
gym-pybullet-drones project [
58] and the
OpenAI Gym library [
59] to perform the Drone simulation.
Open AI Gym: It is a tool kit developed to perform deep learning tasks. It allows one to design a simulation environment and works with several numeric calculation libraries such as
TensorFlow [
60].
Gym-pybullet-drones: This open-source project is an environment from the Open AI Gym based on Pybullet, which has simulation tools for simulations with one and multiple agents. Furthermore, it allows the low-level control of aerial vehicles and emulation of aerodynamic effects such as friction, ground effect, and wind direction change.
To easily perform our simulations, we developed three classes:
BaseControl,
Drone, and
PybulletSimDrone (you can find the developed software and a deeper explanation of these classes to implement it as well in
our Git-Hub repository [
61]).
BaseControl defines the properties and methods of our drone controller according to its kind (for this project DSLPIDControl, SimplePIDControl, and NNControl). If we want to implement a PID controller (DSLPIDControl and SimplePIDControl), it will be necessary to define the , , and coefficients for this controller. If we want to implement a Deep Neural Controller (NNControl), it will be necessary to define the file from Tensorflow (.h5) where our Neural Network is saved. This class contains methods to calculate the control signal and process the current states.
Drone defines the drone properties, such as model, controller, initial position, and orientation. This class has methods to gather the current states from the environment and apply the control action.
PybulletSimDrone defines the properties of our simulation environment required by Pybullet (such as physics engine, simulation frequency, control frequency, environment, and obstacles), debug options (such as graphic interface, video recording, console output, data graphics, and data storage); further, we define the trajectories to perform and whether we want to simulate with disturbances or not. The methods for this class allow one to initialize the environment, define drones and trajectories, debug the simulation, run one simulation step, and save state data).
Table 3 summarizes the environment parameters defined for this project.
3.2. Technical Specifications
The machine used for developing this investigation has an processor, a NVIDIA GeForce RTX-2080Ti graphic card and 64 GB RAM. In terms of software to develop the experiments shown within this project. It is recommendable to use Python version 3.8.10, 0.6.0, Pybullet 3.1.6 simulator, Gym 0.20.0, and the libraries for Python: 1.19.5, 3.3.4, 0.12.2, Tensoflow-gpu 2.5.0, 2.5.0rc0, and 1.0.3.
3.3. Dataset
In our proposed dataset, we want to collect data describing the behavior of our baseline controller in different states. To do so, we must first identify the information to be gathered from the environment. As a result, we read the input state vector (which was sent to the controller in Pybullet by the state estimator), which is shown in (
3).
where
u,
v, and
w are the linear speeds of the
x,
y, and
z axes, respectively.
p,
q, and
r are the angular speeds of the
,
, and
axes, respectively. Moreover, we derive the speed state vector provided by the estimator to get the acceleration vector. The derived variables are directly related to the input variables and may provide additional information that can potentially improve the accuracy of the model’s predictions. Reading in this way, all the variables of the current state. The reference position and orientation are depicted in (
4). Finally, the Neural Network outputs are gathered in (
5), and we read the four control signals for the actuator calculated by the reference controller.
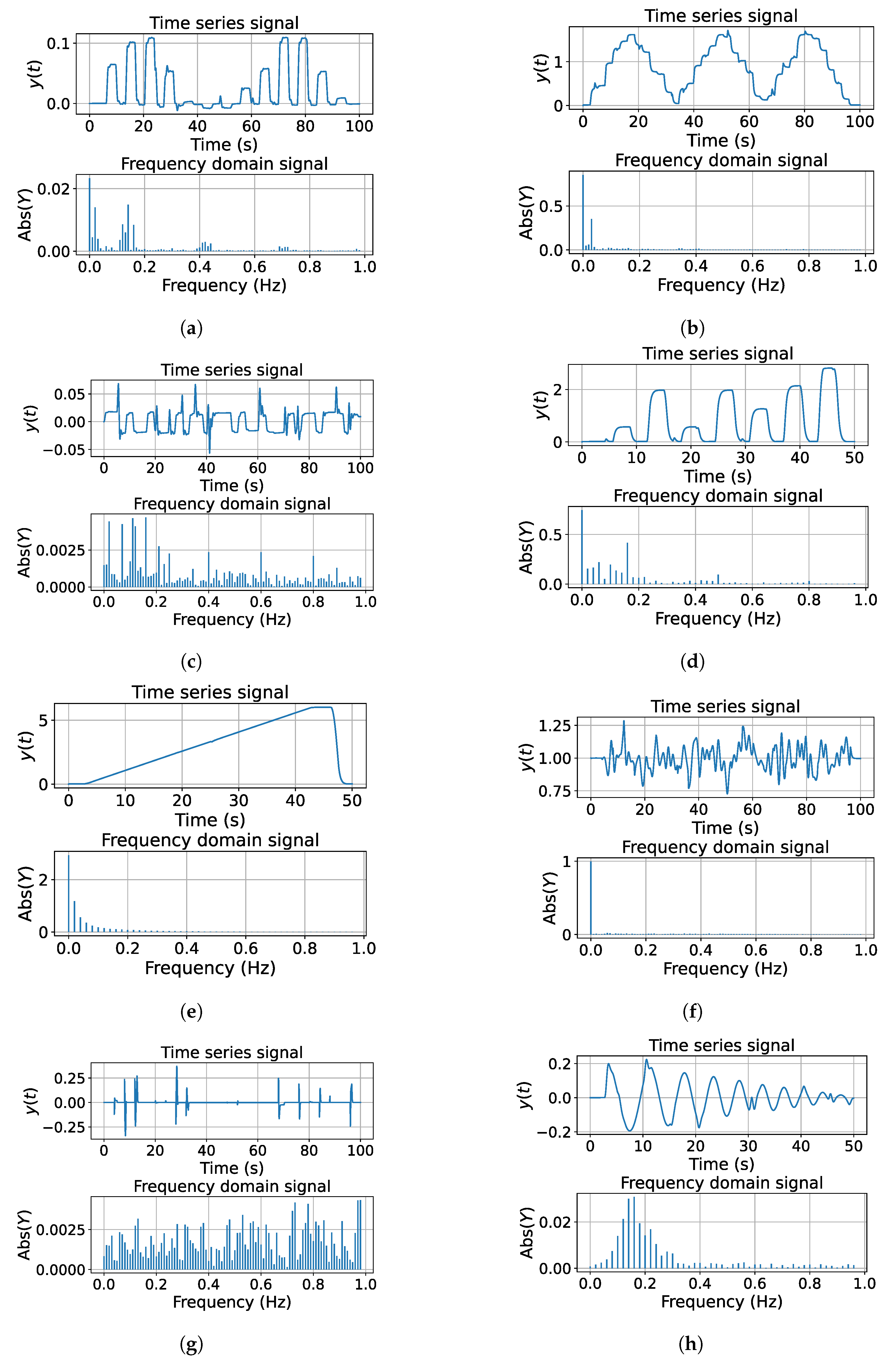
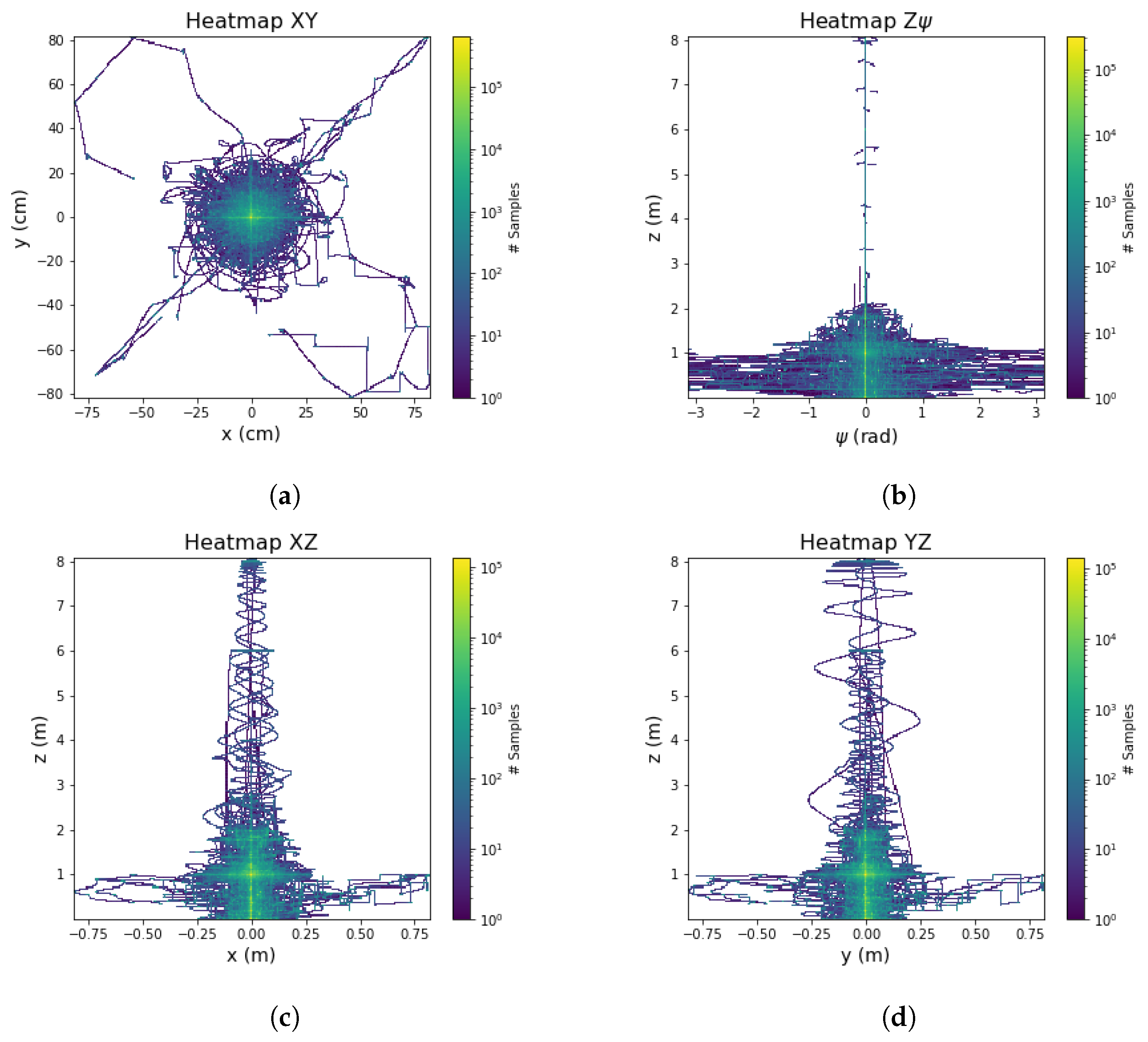
Once one defines all the variables to read from our environment, we proceeded to define the trajectories to save. We propose the trajectories presented in
Figure 3.
The aim of these signals is to prioritize the number of harmonics, the normal distribution of data, and the balance between information at the transitory state and steady state. Moreover, some trajectories contain disturbances, where it will be possible to observe how the controller recovers in these scenarios. The process to generate this dataset is automatic; the trajectories for each axis and the parameters of these were chosen randomly. We dismissed the signals when the drone fell or was not possible to track the trajectory.
3.4. Time Window
Due to the signals of the system being a time series, it is important to feed previous states to our Neural Networks so that it is possible for the network to calculate the control signal for each motor. We will define a number of previous states where we find a balance between inference time, memory size, and performance of our models.
3.4.1. Partial Autocorrelation Function
This function is defined in (
6).
where
x is our signal, composed of the current state and the previous states, and
is the average of our data, defined as
.
This function calculates the autocorrelation between the current state and the previous states. A positive correlation value means a strong association between the values of the current state and previous states [
62].
For our case, we calculate the autocorrelation taking signals from our dataset for each axis. Getting the autocorrelation value for several quantities of states in a range of 1 to 100.
Table 4 shows in descending order the quantity of states per axis where we found the highest autocorrelation.
Taking the median per axis, we find that the highest autocorrelation value is obtained with the two previous states. However, taking into account the simulation frequency and the rise times per axis of our baseline controller, this is a small amount of information for our Neural Network. Hence we take a number of the previous states between the third and second highest value of autocorrelation (58 and 75).
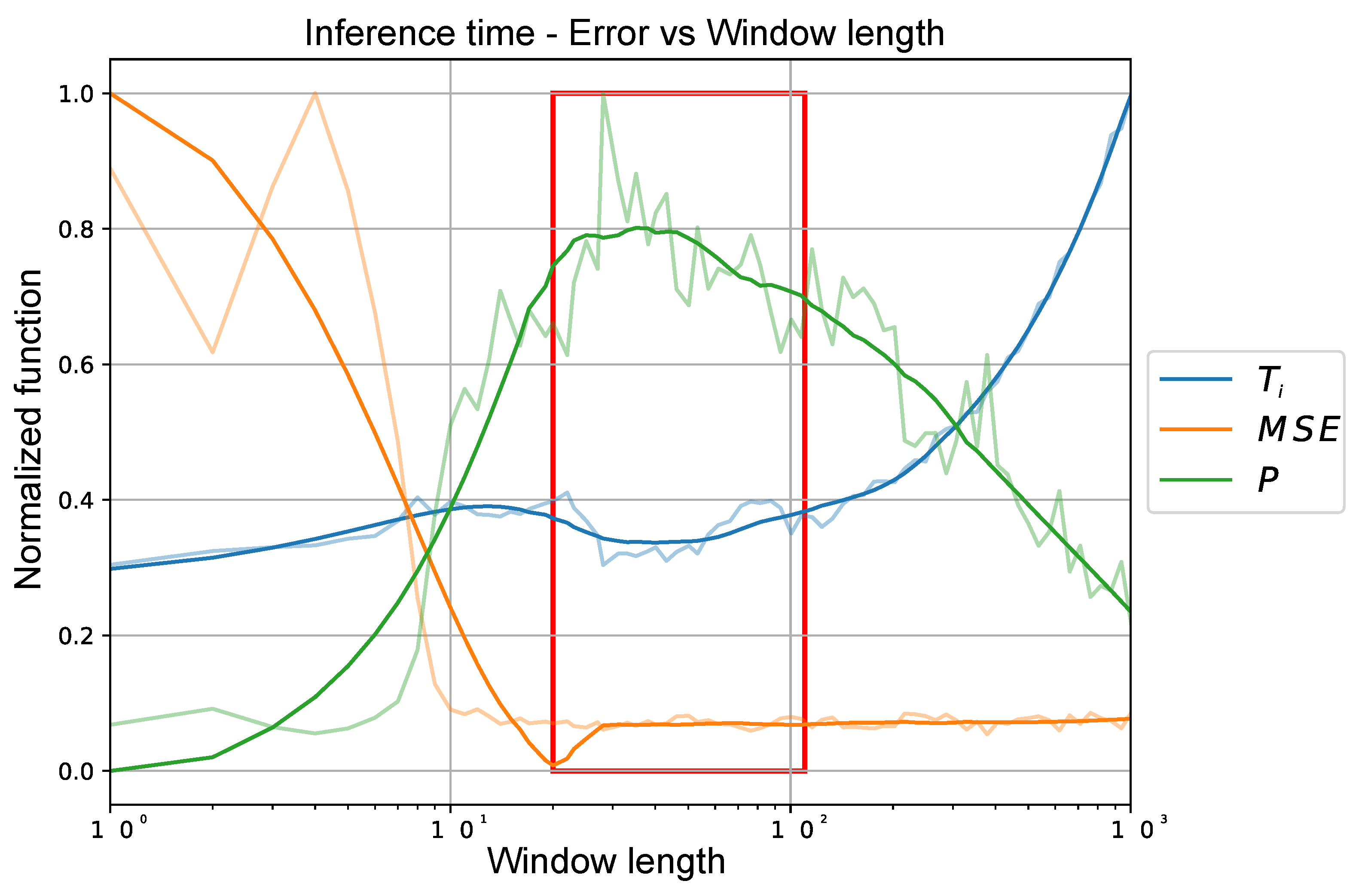
3.4.2. Empirical Method
This method relies on taking into account the Average Inference Time (
) and Mean Square Error (
). We sweep the Time Window sizes between a range of 1 to 1000, taking 100 window sizes that are separated logarithmically along the defined range. To evaluate the performance of our model, we use a dataset size of 4096 samples obtained from our dataset and measure
as well as
for the samples passed to our model. Finally, we calculate the performance (
P) with the function defined in (
7).
Figure 4 shows the values of this function for the described range, where the optimal value is between the values of 20 to 90 previous states as shown in
Figure 4 by the red square.
Due to both tests of the previous states, it is defined as a quantity in the middle of the found ranges. Hence the size of our time window will be 63 previous states plus the current state because it is a multiplot of 2 and could be advantageous in the implementation.
3.5. Data Pre-Processing
First, we apply average normalization to the data. We normalize each signal presented in the state vector (
Section 3.3) according to the function presented in (
8).
where
is the average value of the signal;
and
are maximum and minimum values, respectively; and
is the signal’s sample to normalize.
Later, we sort our data into three batches (train, validation, and test), of which the portions are shown in
Table 5.
Finally, we define a Data Generator Class from Tensorflow per batch [
63]. This helps us to select the data while training. To create one sample, our generator takes a current random state from our normalized dataset and appends it to the previous states; subsequently, the data are sorted according to the input sizes required for each net architecture. In this way, the generator creates samples until it fulfills the defined batch size. Once this process is done, the batch is provided to perform one episode of our Neural Network training. The previous process is performed iteratively by the generator until it finishes the training.
3.6. Proposed Architectures
To model the behavior of the controller, we propose analyzing several types of Neural Network architectures:
- (i)
Fully Connected Artificial Neural Networks (ANN): These networks are also known as Multi-Layer Perceptrons (MLPs) or Feedforward Neural Networks (FNN). This architecture is the simplest and also the architecture that consumes the least resources. They consist of multiple layers of nodes (neurons) connected in a feedforward manner, where each neuron in a layer is connected to all the neurons in the previous layer. ANNs are suitable for modeling nonlinear relationships between inputs and outputs, which makes them suitable for modeling the behavior of a position PID controller.
- (ii)
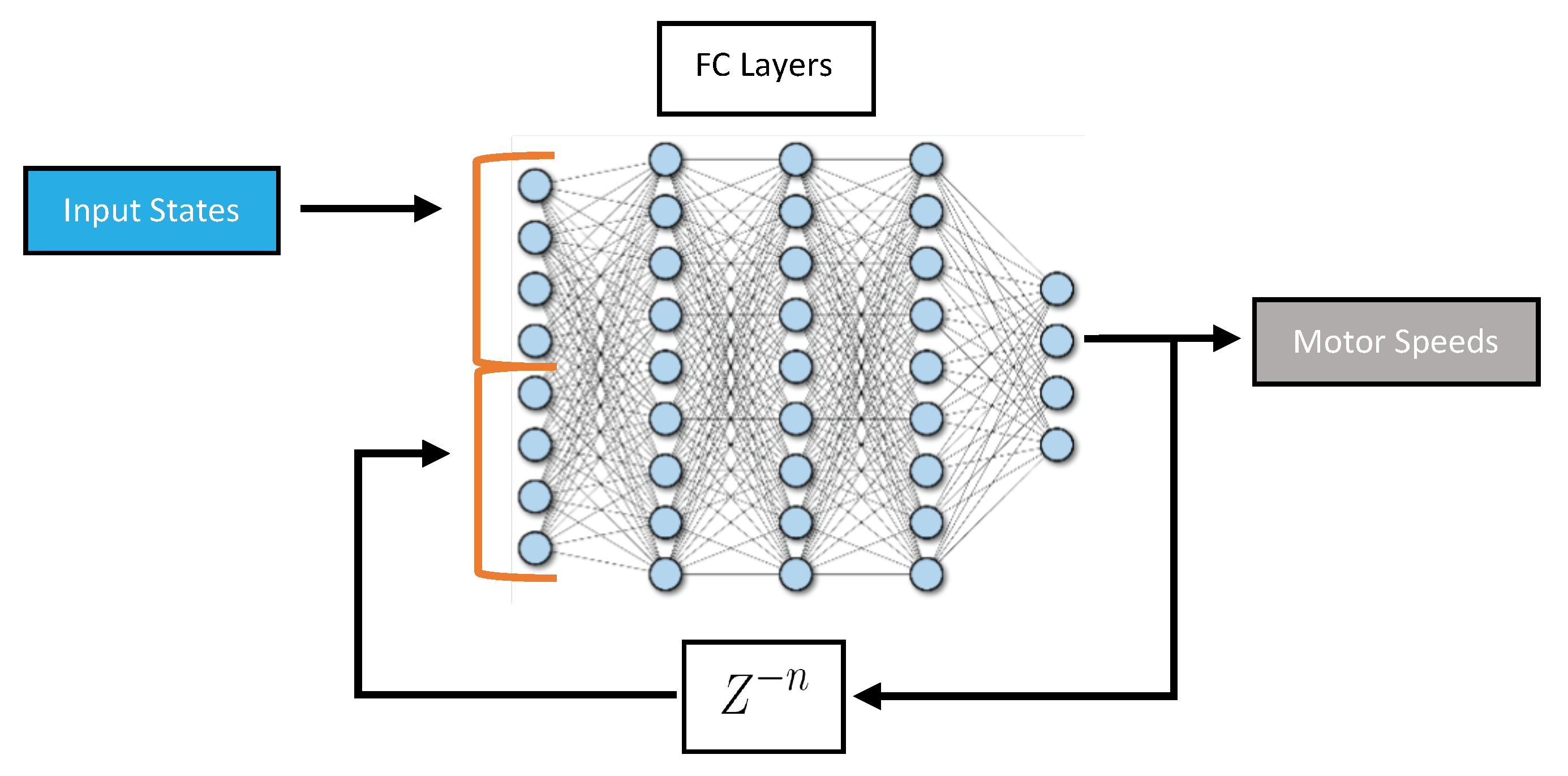
Fully Connected Artificial Neural Networks with Feedback (ANN Feedback): This architecture is sometimes referred to as an autoregressive model or iterative prediction. It is based on ANN, but the input states include the previous output of the network as illustrated in
Figure 5. It can allow the network to incorporate information about past predictions into future predictions. This could be particularly useful in applications where the system being controlled is dynamic and subject to rapid changes.
- (iii)
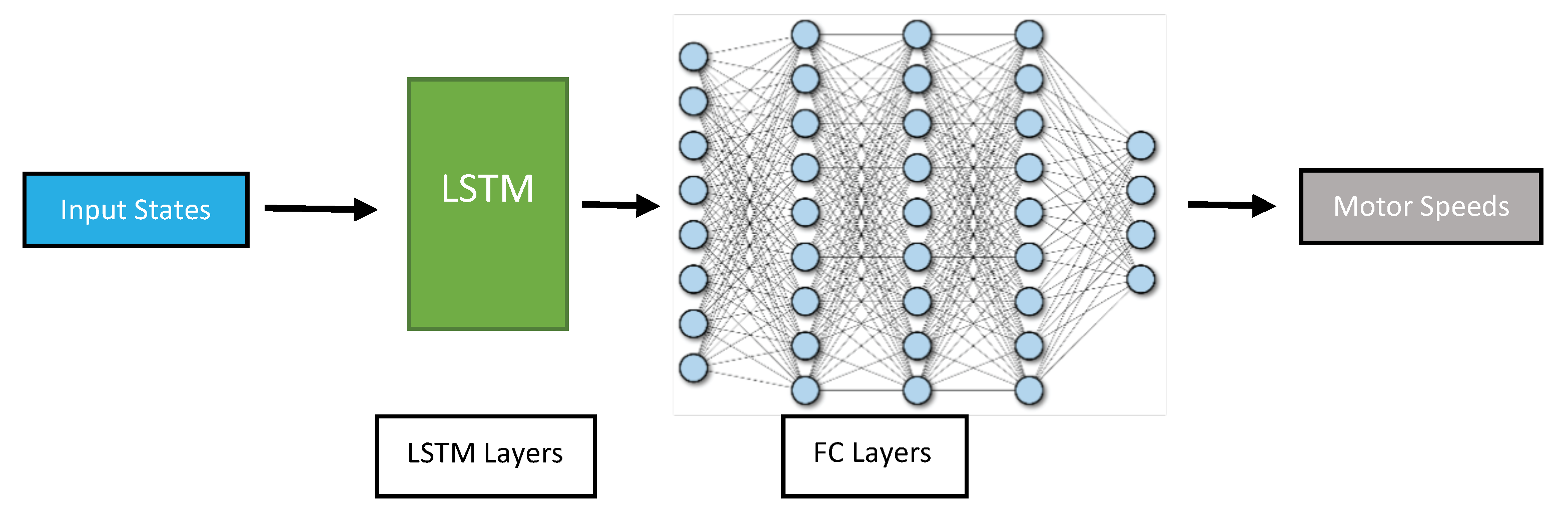
Long-Short Term Memory (LSTM): These networks are a type of Recurrent Neural Network (RNN) that are designed to handle long-term dependencies in sequential data such as time series data. They use a memory cell to store information over time, which allows them to maintain a long-term memory of past observations. It can be used to learn the patterns and dynamics of the drone’s movements over time. One potential advantage of using an LSTM for drone position control is its ability to handle variable-length input sequences. This can be particularly useful in situations where the drone’s movements are not perfectly regular or predictable: the input sequence could be longer or shorter depending on the complexity of the environment and the level of variability in the conditions. The proposed architecture is shown in
Figure 6.
- (iv)
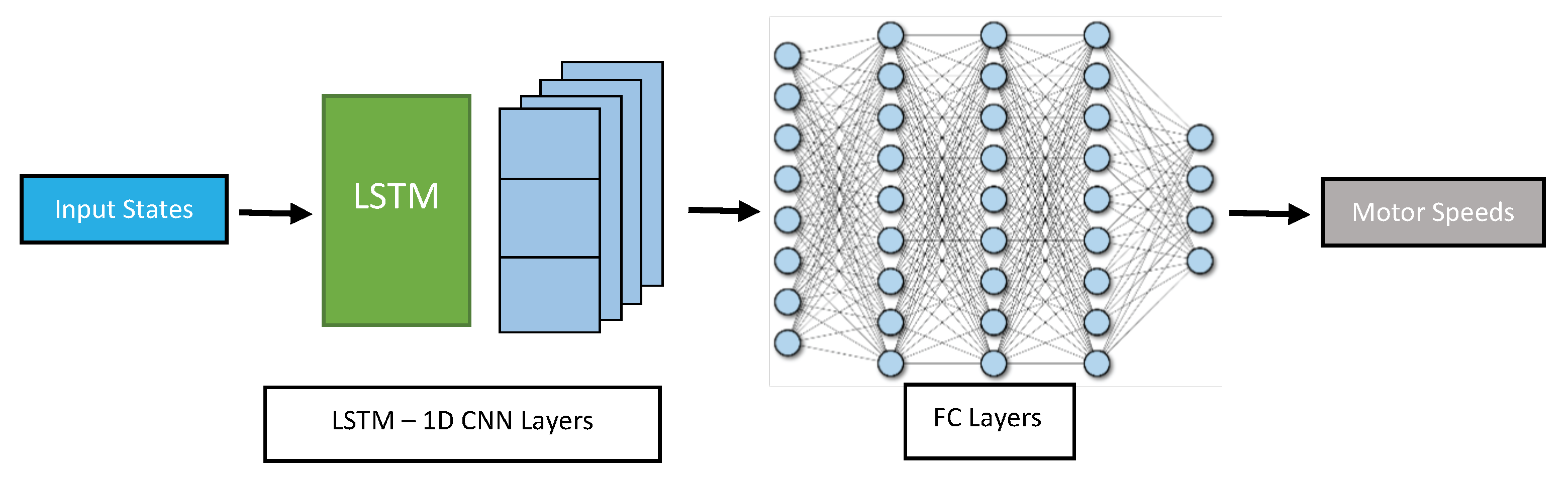
LSTM Layers interleaved with convolutional 1D layers (LSTMCNN): This architecture consists of connected blocks in a cascade at the beginning of the network, where each block is composed of LSTM layers followed by convolution layers in one dimension (CNN-1D) as shown in
Figure 7. The CNN-1D can capture local patterns and features in the sequential data, while the LSTM can capture long-term dependencies and context. The output of each block can be fed into the next block, allowing for a hierarchical feature extraction process in both time and frequency domains. The fully connected layers can further process the extracted features and generate the final output. Both CNN-1D and LSTM can handle variable length sequences of data. CNN-1D is also robust to noise and variability in the input data.
- (v)
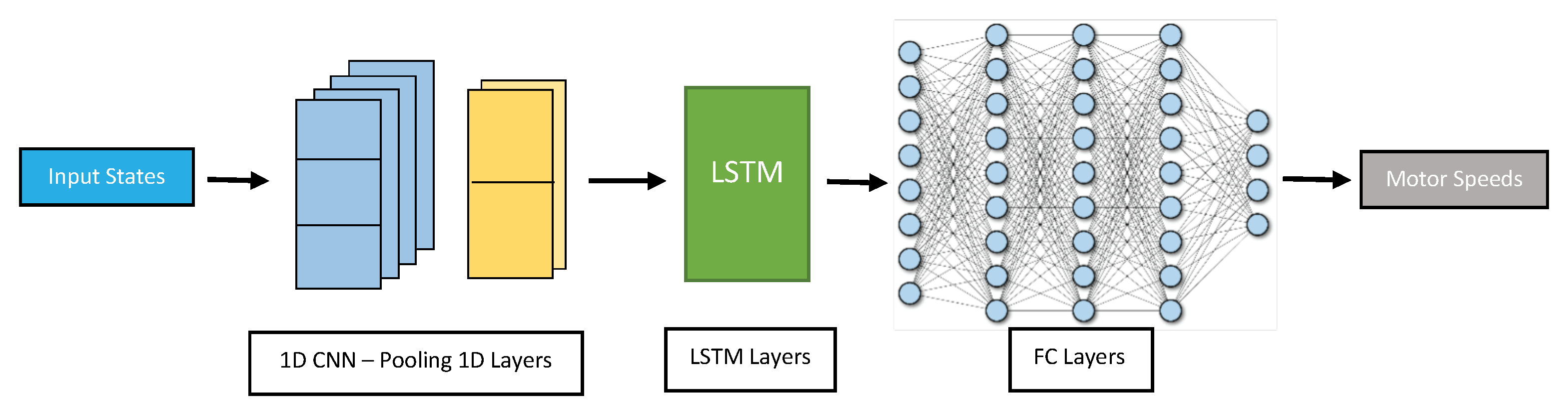
Convolutional 1D Layers in cascade with LSTM layers (CLSTM): This proposed architecture consists of connected blocks in a cascade at the beginning of the network, where each block is composed of convolutional 1D layers followed by max pooling layers to identify the most salient features in the data by taking the maximum value within a pooling window. The output of each block can be fed into LSTM layers, which can capture the long-term dependencies in the drone’s flight path based on the most important features extracted from the convolutional layers. The output of the LSTM layers can then be fed into several fully connected layers in a cascade to process the extracted features further and generate the final output as shown in
Figure 8.
Model Compilation and Hyper-Parameter Tuning
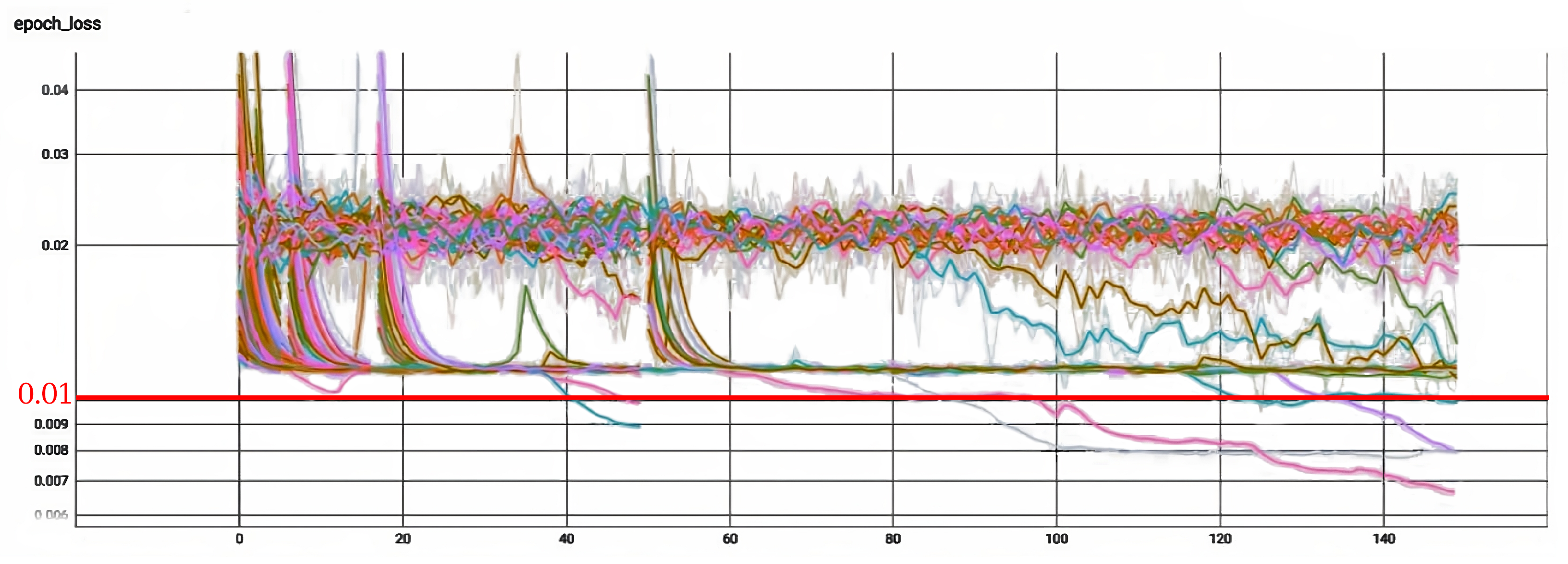
For this stage, the Neural Network model is defined according to the desired architecture to train. It is defined as an optimizer, a loss function, activation functions, a gradient clipping value to avoid gradient exploding (specifically for the most complex architectures, which include LSTM and Convolutional layers), and some other hyper-parameters. These values were obtained from the evaluation of the final error in numerous randomly combined hyper-parameter training carried out experimentally. The values of the previously mentioned Hyper-parameters are summarized in
Table 6.
For each of the architectures, hyper-parameters such as the number of neurons per layer, the number of layers, and the activation function of each neuron were obtained using the Hyperband algorithm [
51], as shown in
Table 7. Hyperband is designed to efficiently allocate resources, such as computation time or hardware resources, to explore the hyper-parameter space and find the best set of hyper-parameters for a given machine learning model.
Once these values are defined, the training starts. Subsequently, we briefly evaluate the trained model according to its mean square error value with the test data batch.
3.7. Evaluation Functions
The evaluation of the proposed system focuses on reducing energy consumption and error in trajectory tracking, as shown below.
3.7.1. Control Effort
To evaluate the control effort for our controllers, we apply (
9) by comparing the output signal
with
, which is the magnitude from the controller output to counteract gravity (this value is 14,468.429).
where
T is the integration time from the total duration of the simulation.
3.7.2. F1 Custom Function
This function rates the performance in terms of Settling Time (Ts), Overshoot (Os), and Steady State Error (sse) with the ITSE function as indicated in (
10)–(
13).
where
is the series of position values in the evaluated axis and
is the final value in the evaluated axis. Moreover,
a,
b, and
c are the weights of function F1 whose aim is to compare each value in each function for the proposed controllers compared with our reference PID. Those weights are defined as the multiplicative inverse of the scores assigned by each function to our PID baseline as depicted by (
14).
5. Discussion
According to the results presented in
Table 12, the LSTMCNN model stands out as the best-performing network architecture. It demonstrates superior flight performance in terms of the F1 and Q functions. The F1 function measures the desired time response, considering parameters such as settling time (Ts), overshoot (Os), and steady-state error (sse). The Q function evaluates the actuator control effort.
In terms of network architecture, our proposed LSTMCNN model combines the strengths of long short-term memory (LSTM) networks and Convolutional Neural Networks (CNNs). This hybrid architecture allows the model to capture both temporal dependencies and spatial patterns, enhancing its ability to learn and predict complex drone dynamics. This integration of LSTM and CNN architectures is a unique approach that sets our methodology apart from existing studies.
Our evaluation process encompasses a comprehensive set of experiments and analyses to assess the performance of the controller in various scenarios. These include step response, big step response, disturbance rejection, aggressive trajectories, noise sensitivity, and the consideration of aerodynamic effects such as the downwash effect. By examining the controller’s behavior under different conditions and evaluating key metrics such as settling time, overshoot, steady-state error, and control effort, we provide a thorough and multifaceted assessment of its capabilities.
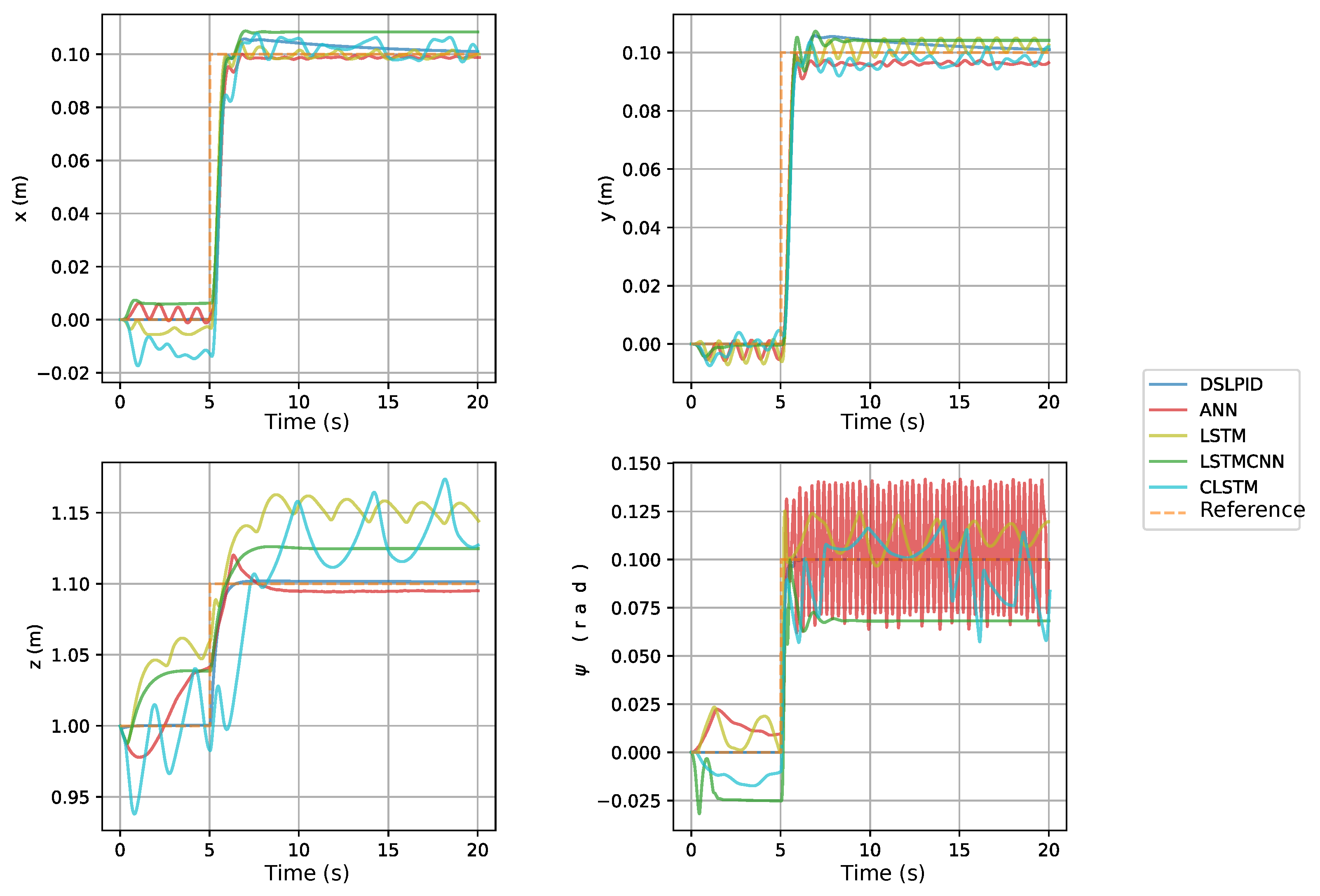
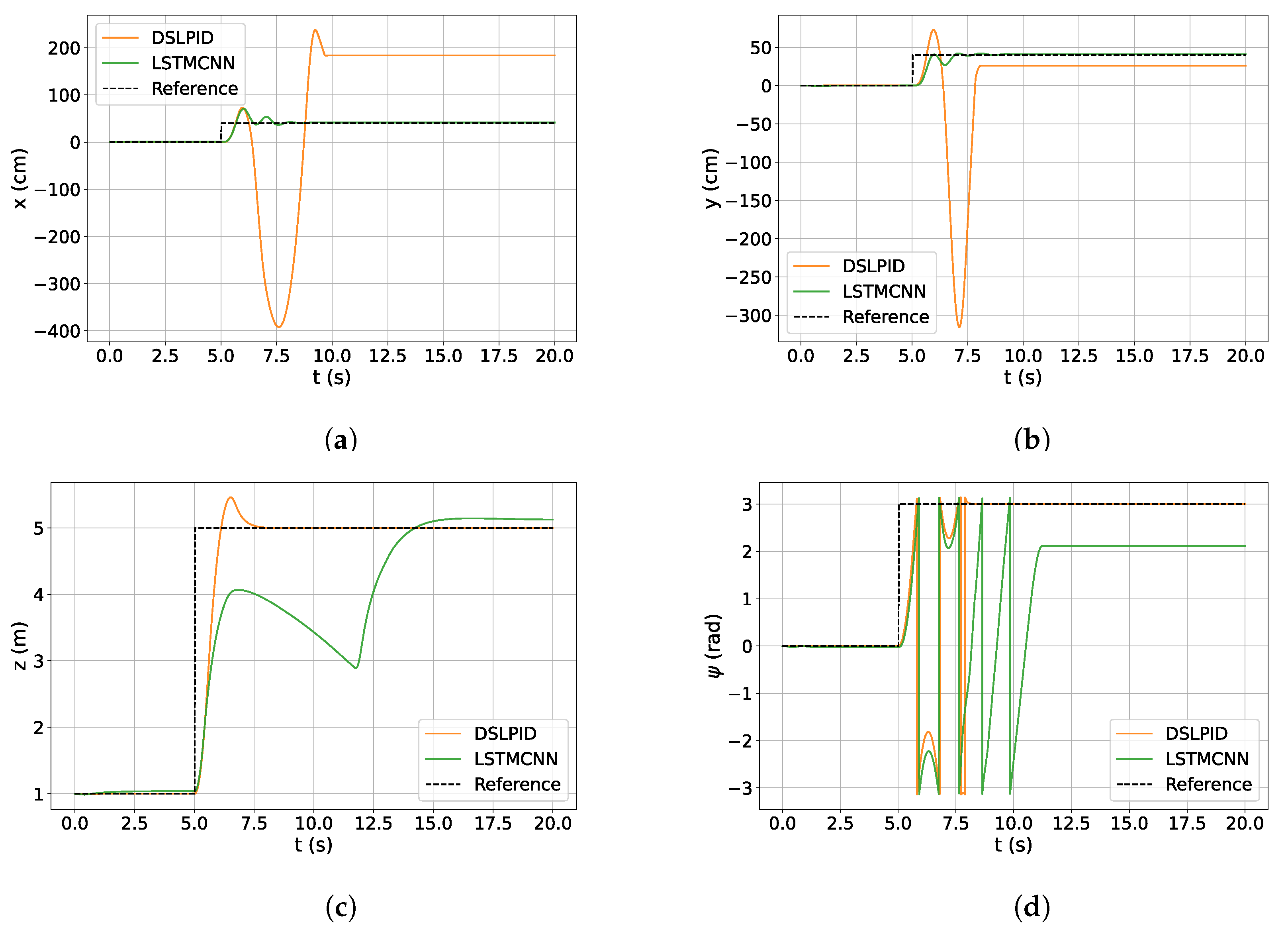
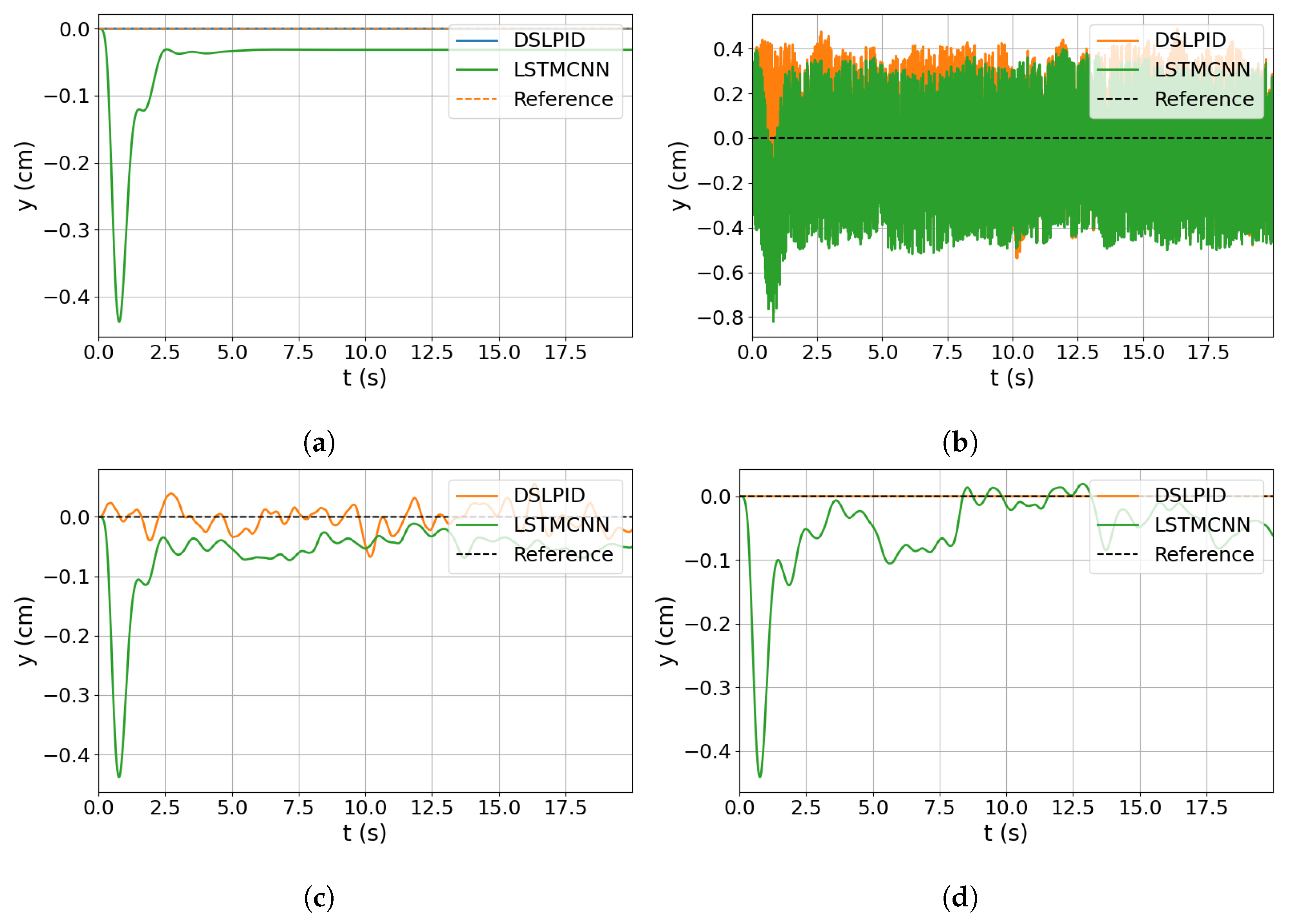
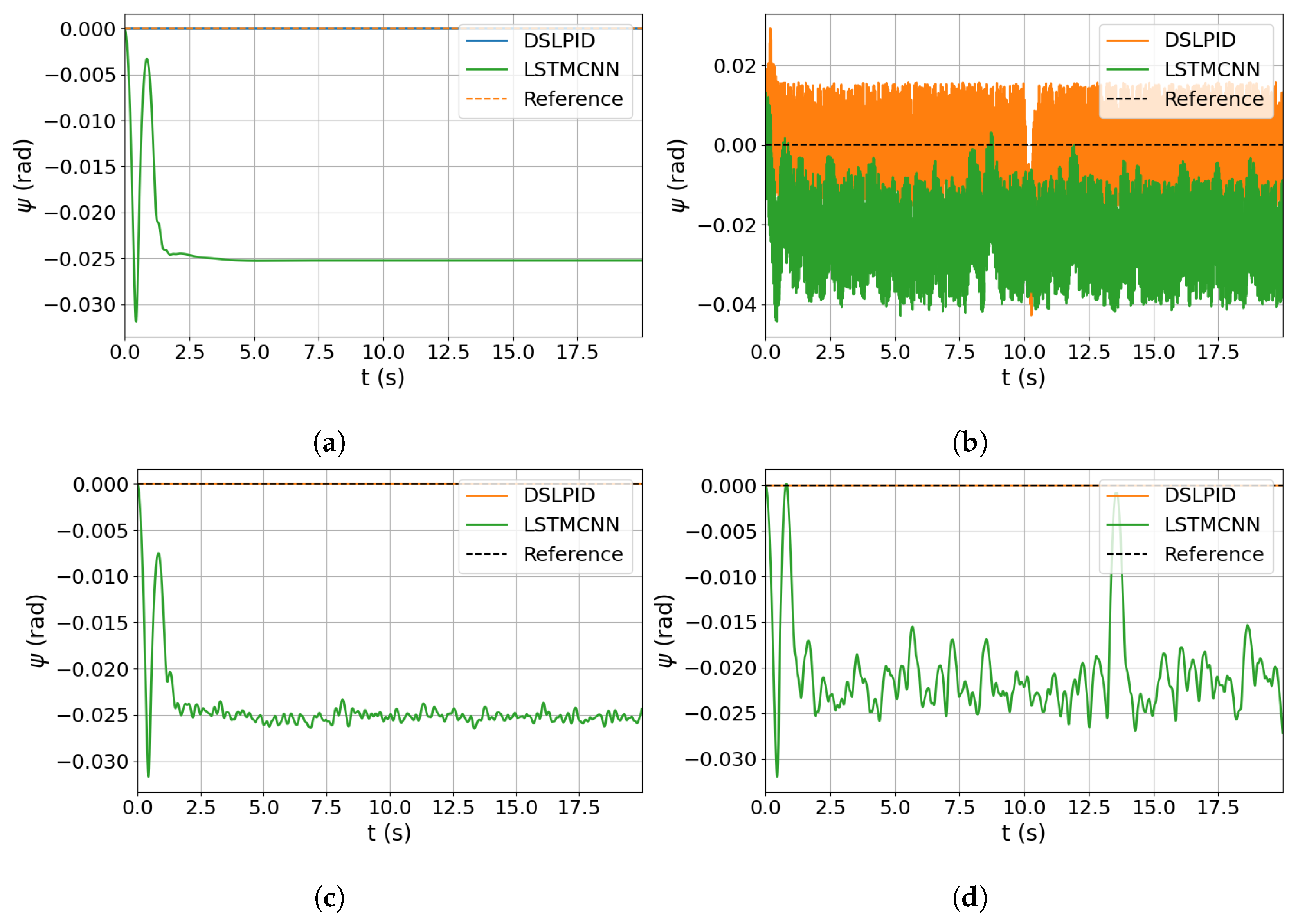
Regarding the step response experiment (
Section 4.3.1), our controller exhibited similar responses to the baseline controller in the X and Y axes, accurately following the set point and maintaining stability. However, it showed higher steady-state error compared to the baseline controller in the
and Z axes. The
axis was particularly challenging due to the discontinuity of the state bounded between [
;
].
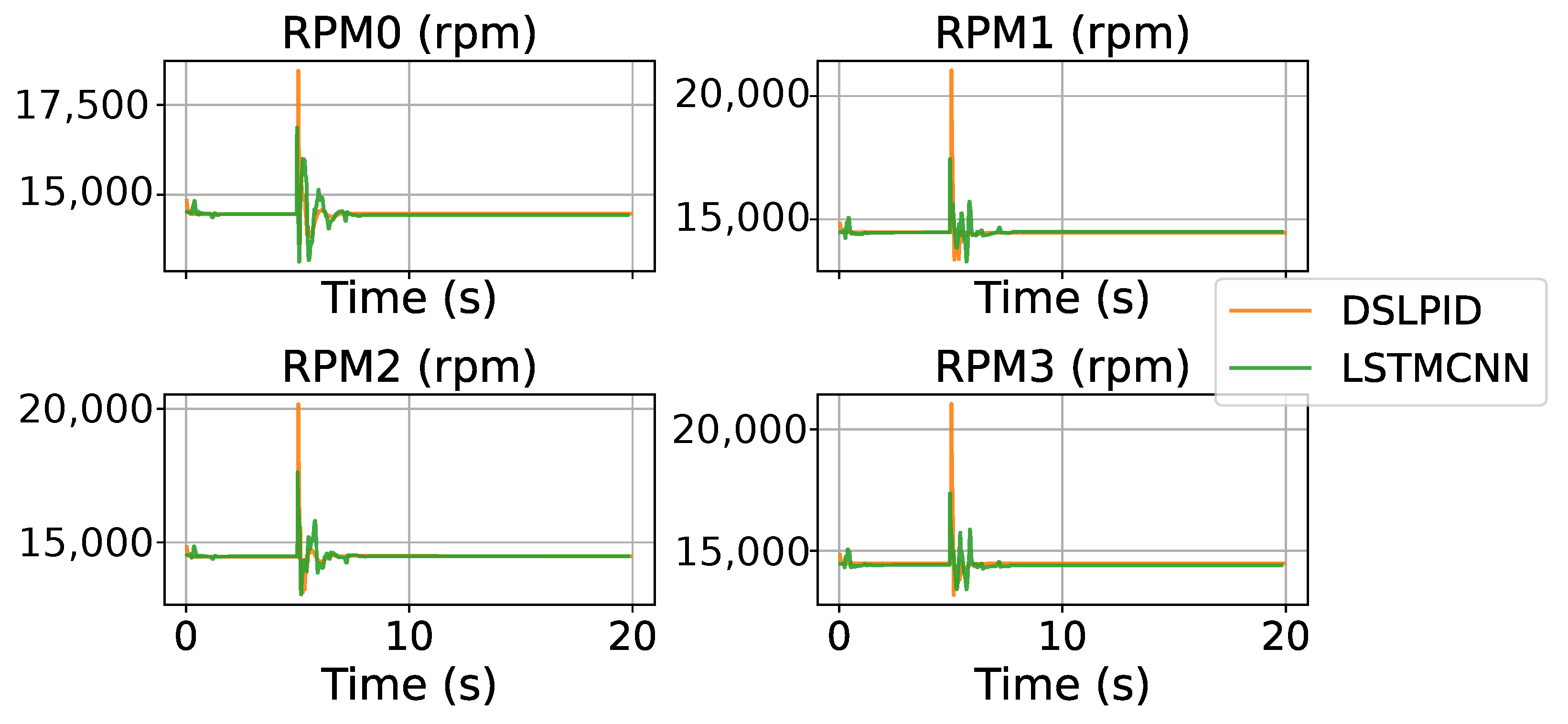
Figure 13 depicts the control effort related to the stepping trajectory. The experiments indicate that our controller reduces the control effort required compared to the baseline controller.
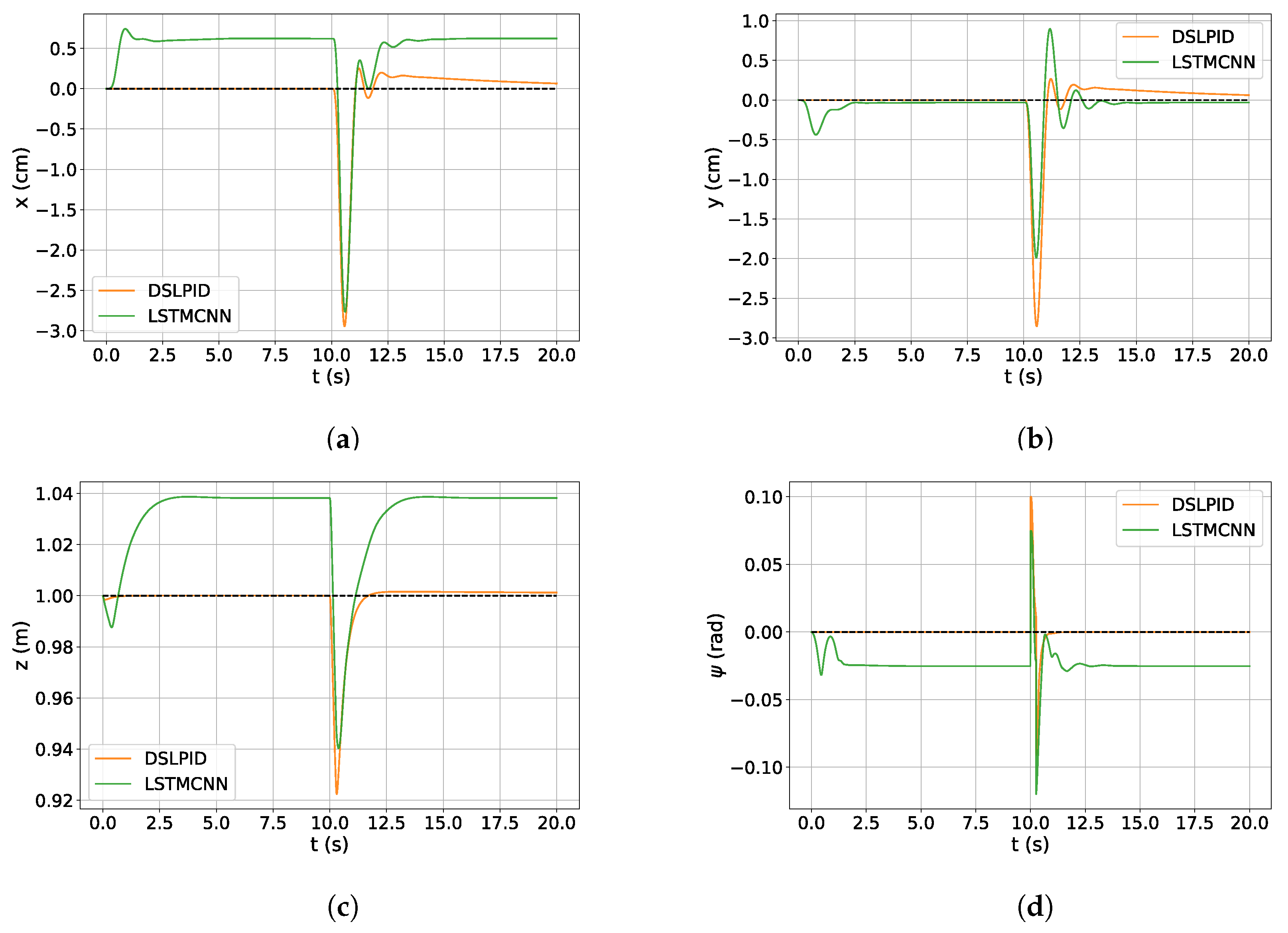
The results of the big-step experiment (
Section 4.3.2) demonstrated that the LSTMCNN controller exhibited stability over a wider range of control beyond the nominal operating point in the
x and
y axes. This indicates its capability to accurately track and control the drone’s position even when subjected to larger step inputs. However, improvements are needed in the
z axis and especially in the
axis, where the LSTMCNN controller showed instability. Fine-tuning of controller parameters or architecture may be necessary to enhance performance in these specific axes.
In the disturbance rejection experiment (
Section 4.3.3), both controllers maintained stability in the presence of sudden disturbances. However, the DSLPID controller outperformed the LSTMCNN controller based on metrics such as settling time, overshoot, and steady-state error.
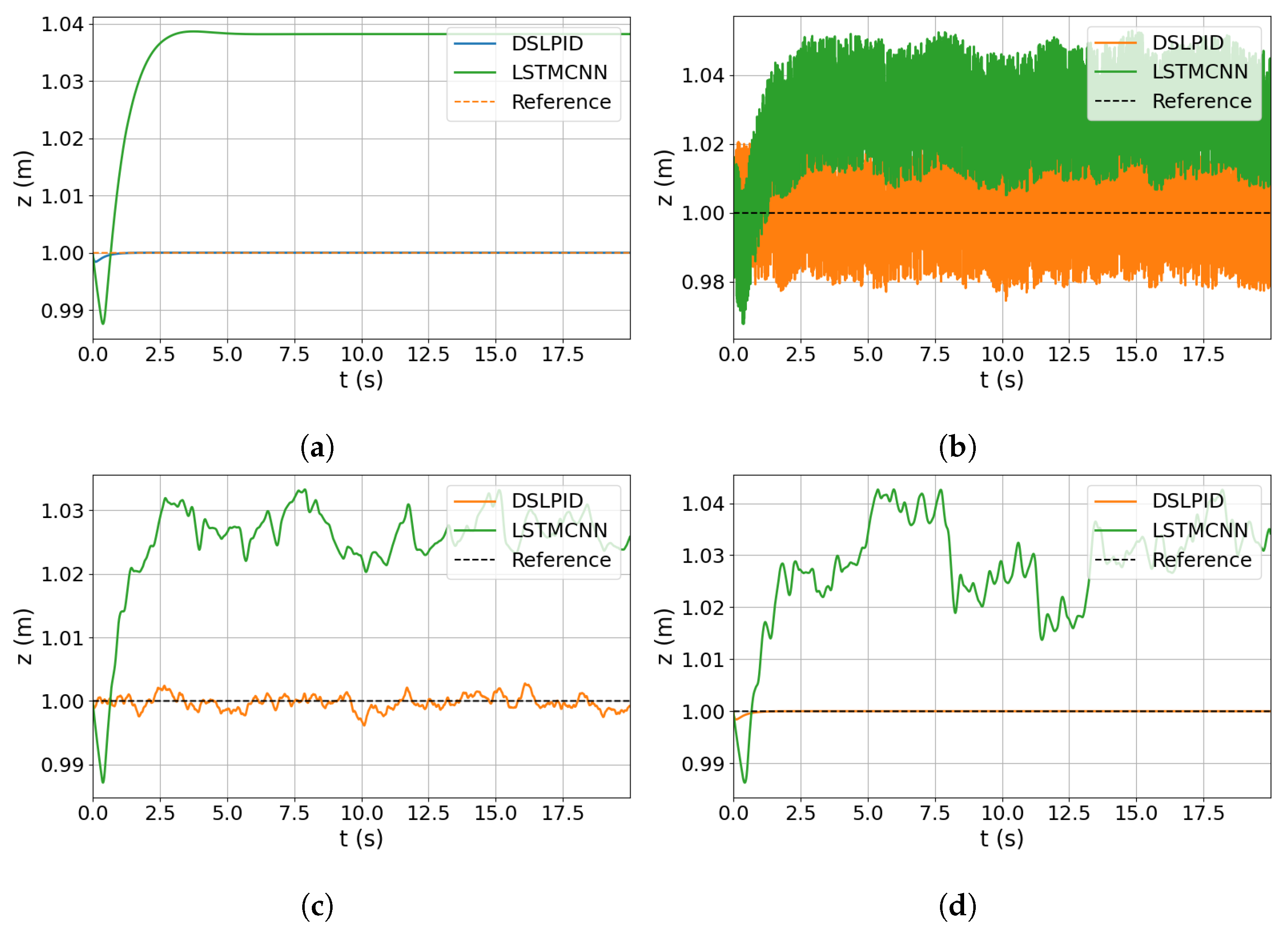
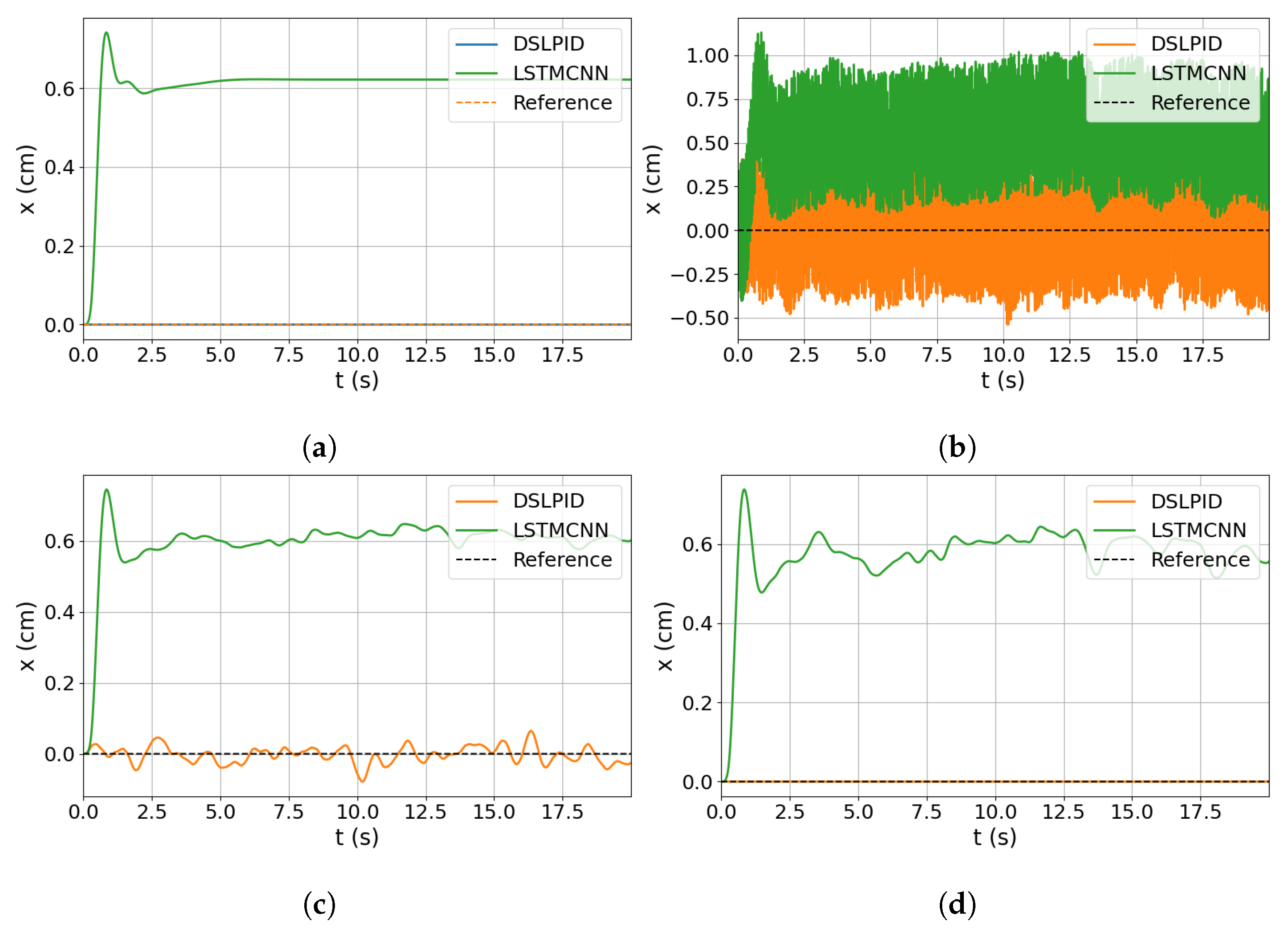
Contrary to our initial expectations, the noise degradation experiment (
Section 4.3.4) revealed that the LSTMCNN Neural Network Controller exhibited increased sensitivity to noise, particularly when it affected the position variable. This highlights the challenges associated with noise in Neural Network Controllers and suggests the need for further investigation and improvements in architecture and training strategies to enhance noise robustness. The inclusion of acceleration information in the neural network’s predictions offers better generalization capabilities but also increases sensitivity to noise due to additional variables.
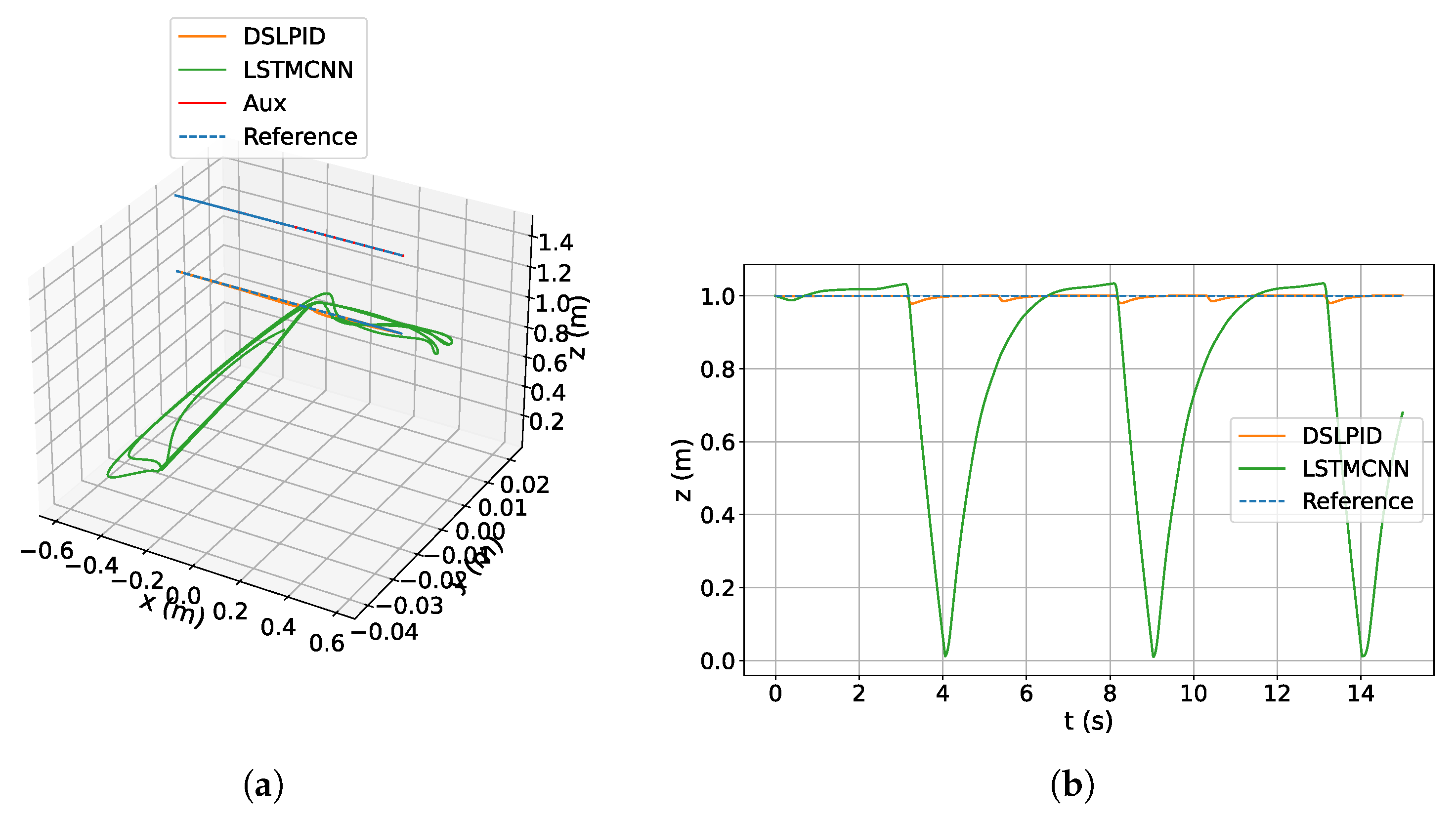
In the Lemniscate experiment (
Section 4.3.5), the LSTMCNN Neural Network Controller successfully tracked the intricate shape of the Lemniscate function, showcasing its ability to handle demanding trajectories. Conversely, the baseline DSLPID controller struggled to follow the desired trajectory, leading to eventual instability accurately. These findings underscore the superior performance and robustness of the LSTMCNN controller in challenging scenarios involving aggressive set-points with high accelerations or large attitude angles.
When subjected to the downwash effect (
Section 4.3.6), an aerodynamic phenomenon absent in the initial dataset, our model demonstrated limited adaptability. Although it maintained stability, the controller’s performance declined. To address this issue, retraining the controller with a more comprehensive dataset incorporating a wider range of aerodynamic scenarios could enhance its ability to handle the downwash effect and related factors. Alternatively, integrating online learning techniques into the controller’s architecture could enable continuous adaptation to real-time feedback and varying aerodynamic conditions. Further research and experimentation are necessary to determine the most suitable approach, considering factors such as resource availability, performance requirements, and feasibility within the specific problem context.
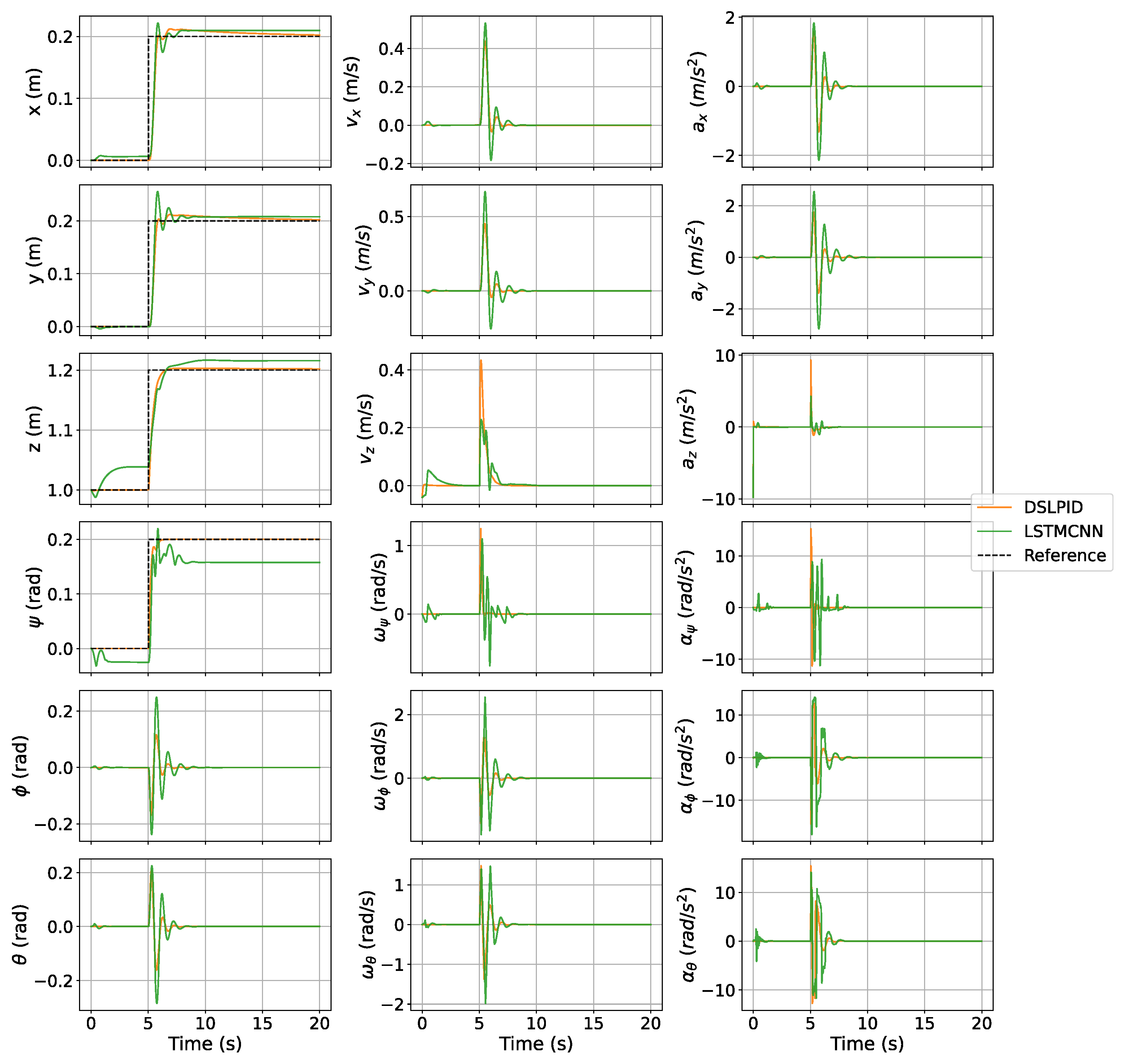
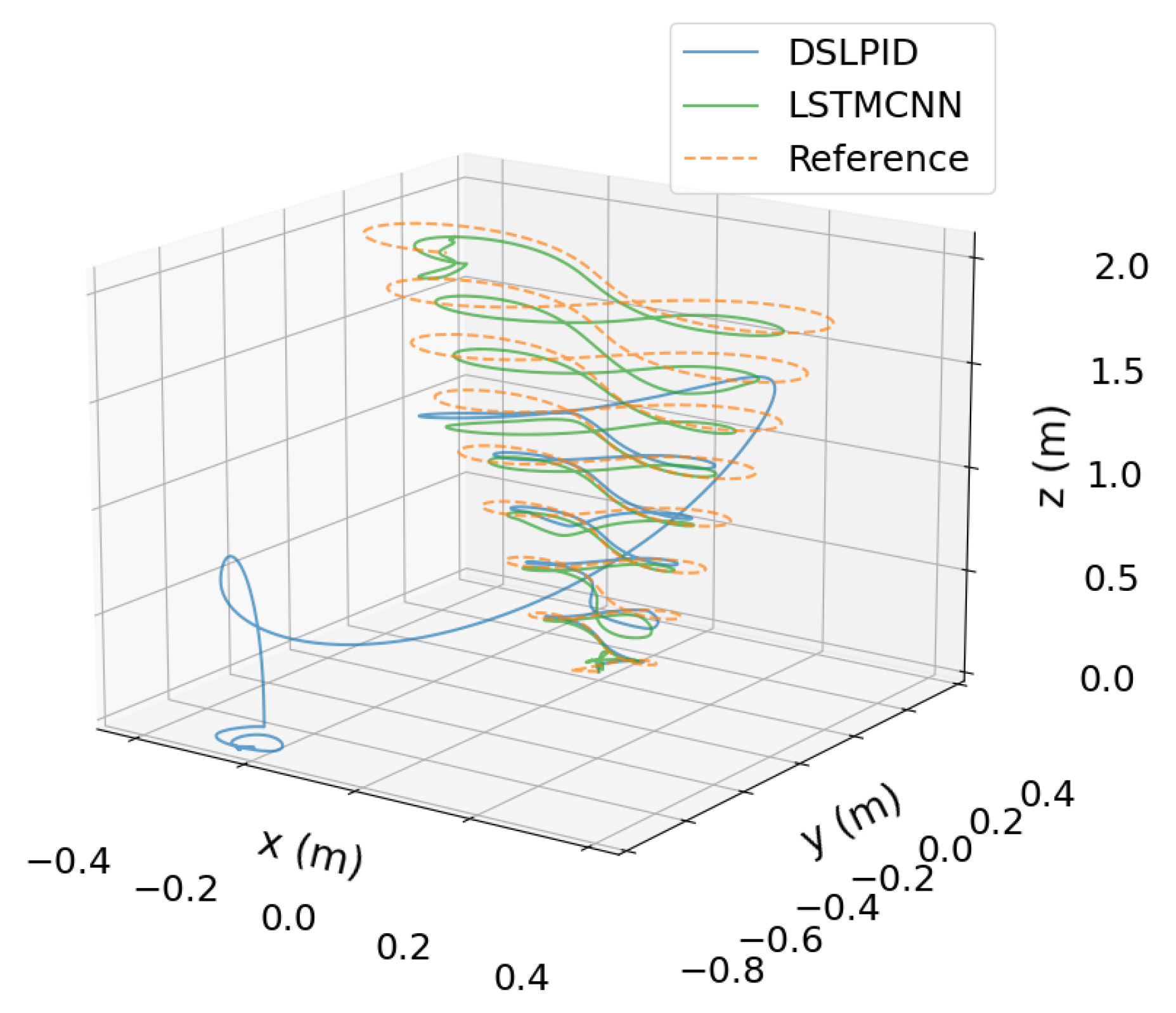
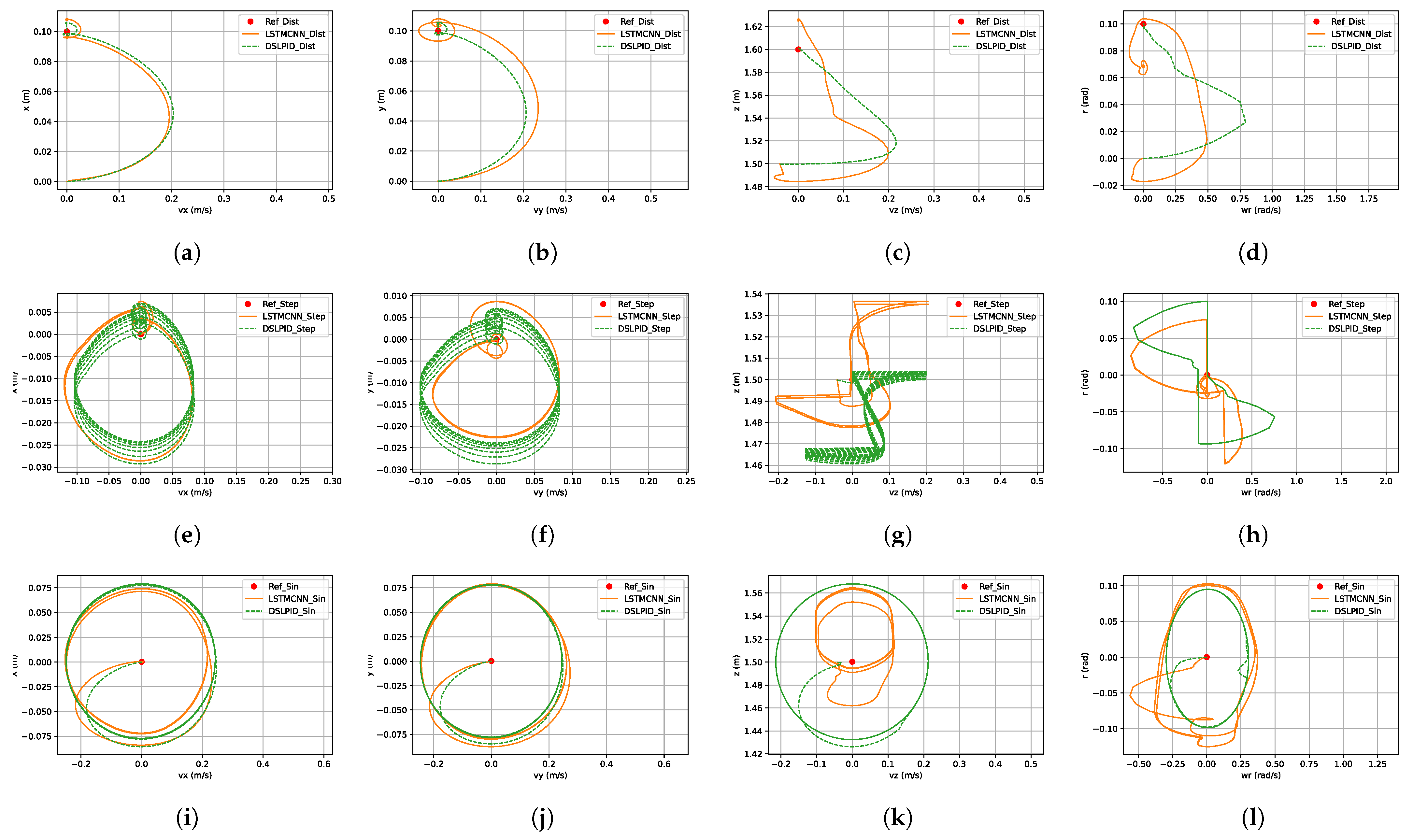
Lastly, the phase plane diagram in
Figure 22 illustrates the stability of our controller within and beyond the operating point of the baseline controller. This analysis provides valuable insights into the behavior of the system’s state variables and supports the assessment of controller performance.
Overall, our study contributes to the broader understanding of neural network-based controllers for drone position control by providing insights into the strengths, limitations, and areas for improvement of such approaches. We highlight the trade-offs between different architectures and the challenges associated with noise sensitivity, aggressive trajectories, and the impact of aerodynamic effects. These findings can guide future research and inform the development of more robust and adaptable control strategies.
6. Conclusions
In this paper, we proposed a new flight control system implemented with Pybullet and its model for the Craziflie quadrotor. Our controller was developed based on the training and building of several Neural Network architectures proposed in the literature. These architectures were trained with data gathered by flying with the controller offered by Pybullet. Finally, our controller was evaluated in comparison with the controller offered by Pybullet. From this, we can conclude:
From our experiments, we conclude that the LSTMCNN architecture offers the best performance for controlling the Craziflie quadrotor. The best way to obtain this architecture’s parameters was by using the Hyperband algorithm and its time window by applying the partial autocorrelation function in combination with our proposed empirical method, which involved gathering data from flying with the Pybullet controller. Our empirical stability evaluation of the proposed controller architecture, as shown in
Figure 22, demonstrates that it converges to the set-point in all axes for all evaluated trajectories.
From the proposed dataset, we found out that the signals that offer better information in terms of controller dynamics are the signals null with disturbances, low-frequency noise, and staggered random steps. These signals offer more information in terms of harmonic components.
Overall, this project provides a viable and reliable way to develop UAV flight neural controllers. The proposed Offline-Training approach enables the development of intelligent flight controllers in a more efficient manner than other proposals that might be implemented with Online-Training. We believe that these observations and conclusions offer important details for researchers and developers to take into account when gathering, training, and evaluating intelligent flight controllers.
7. Future Work
This work offers a broad landscape for future implementations of neural controllers for UAVs. For future offline training, we recommend training recurrent models for flight control by using the most realistic engine physics available to gather data, thereby providing more robustness. Our controller remained stable during testing, but we found that it was unsuitable for non-explored aerodynamic effects (
Section 4.3.6).
Moreover, we propose implementing our best model within an online training algorithm with Pybullet, such as deep Q-network (DQN), deep deterministic policy gradient (DDPG), or advantage actor–critic (A2C), utilizing our developed open-source library for simulating neural controllers. To enhance the main trouble for our controller, which is the steady-state error, we recommend implementing a loss function that considers the accumulated error with the set-point signal and the basic control evaluation parameters (such as the customized function F1 for evaluating controller performance).
It is important to acknowledge that relying solely on offline training is unlikely to address these details, as supervised learning theory suggests that the behavior of our neural controller will be limited to replicating the proficiency of the sample controller at best. By embracing our proposed future work and incorporating online training algorithms, we aim to optimize the neural controller to exhibit the best behavior based on the defined loss function rather than merely imitating the behavior of a sample controller.
This future work proposal, where we implement our model within an online training algorithm, is motivated by the potential to save time and computational resources in developing a proficient flight neural controller. Research suggests that achieving complex behaviors such as stable flight control in a UAV through online training alone can be a slow process. Therefore, leveraging the existing convergence capability of our neural controller towards set points during flight can facilitate a more efficient online training experience, enabling us to refine control details and further enhance the performance of the neural controller.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}