

Salient Preprocessing: Robotic ICP Pose Estimation Based on SIFT Features


Abstract
:1. Introduction
- (1)
- Our method proposes reducing the SIFT feature points’ extraction and matching based on salient preprocessing, which saves the calculation of solving R, t based on all the matching feature points and with less processing time.
- (2)
- The interference from the background’s feature points can be eliminated, and the matching quality of feature points can be improved after salient preprocessing.
- (3)
- Our algorithm uses a coarse-to-fine method to eliminate the wrong matching feature points, simultaneously improving the quality of the matching point pairs and reducing the number of point sets.
- (4)
- We propose a salient object’s feature point selection method to improve the real-time performance of ICP pose estimation while achieving good robustness. Moreover, we analyze the main influencing factors that affect its related performance.
2. Related Work
3. Methodology
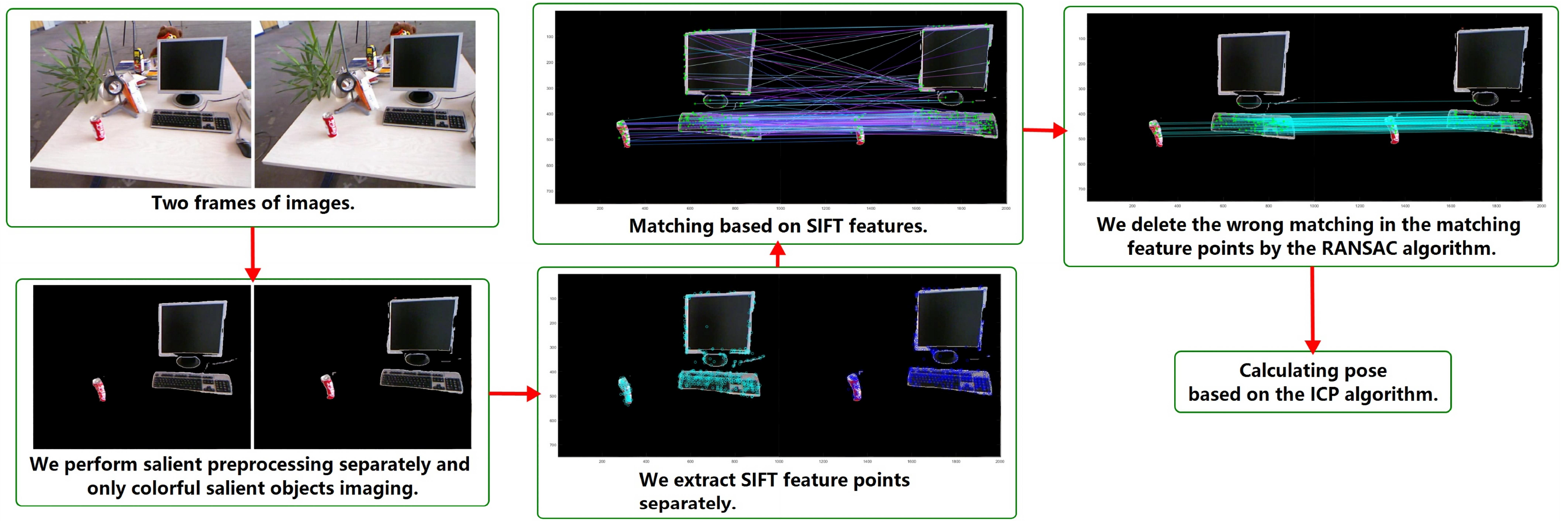
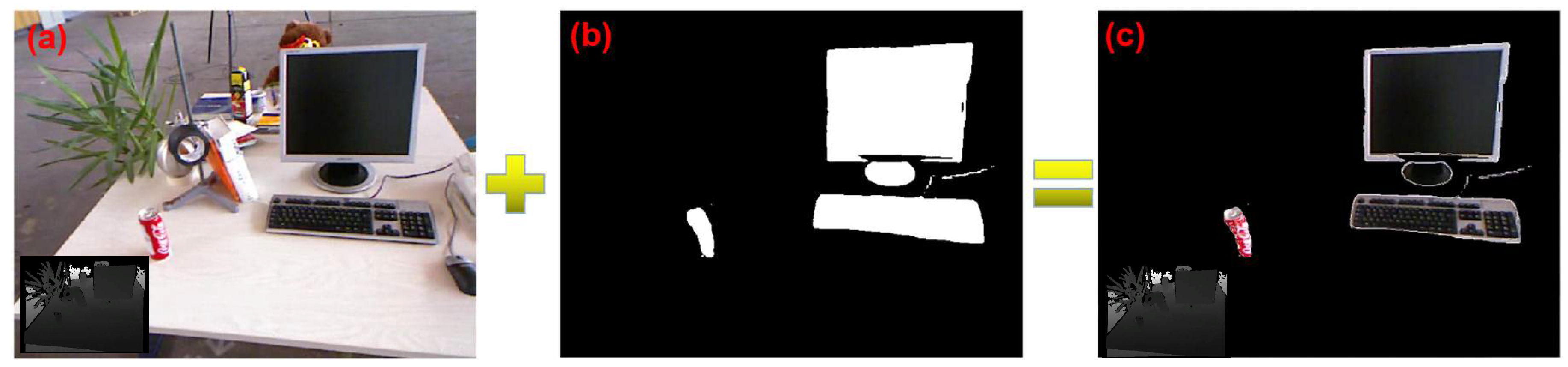
3.1. Salient Preprocessing
3.2. RANSAC Removes Incorrectly Matching Salient SIFT Feature Points
3.3. Pose Estimation Based on Matching Salient Feature Points
4. Experiments
4.1. Salient Preprocessing Experiment
- (1)
- (2)
- We set the alpha channel of the salient object part where the pixel value is greater than 200 to transparent in the gray value image. That is, its alpha value is set to 0 at the place where the pixel value is greater than 200.
- (3)
4.2. The Advantages of Salient Preprocessing
4.3. Main Influencing Factors
4.3.1. The Large Difference between Image Frames
4.3.2. Object Contour and Texture Information
4.3.3. Salient Imaging Differences
4.4. Comparison Test Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mo, J.; Islam, J.; Sattar, J. Fast Direct Stereo Visual SLAM. IEEE Robot. Autom. Lett. 2022, 7, 778–785. [Google Scholar] [CrossRef]
- Zeng, Y.; Jiang, Y. Weight Algorithm Based Depth Camera Point-to-Plane ICP Algorithm. In Proceedings of the 2021 IEEE 11th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems, CYBER 2021, Jiaxing, China, 27–31 July 2021. [Google Scholar]
- Li, J.; Hu, Q.; Zhang, Y.; Ai, M. Robust symmetric iterative closest point. ISPRS J. Photogramm. Remote Sens. 2022, 185, 219–231. [Google Scholar] [CrossRef]
- Wang, J.; Xu, M.; Foroughi, F.; Dai, D.; Chen, Z. FasterGICP: Acceptance-Rejection Sampling Based 3D Lidar Odometry. IEEE Robot. Autom. Lett. 2022, 7, 255–262. [Google Scholar] [CrossRef]
- Pavan, N.L.; dos Santos, D.R.; Khoshelham, K. Global Registration of Terrestrial Laser Scanner Point Clouds Using Plane-to-Plane Correspondences. Remote Sens. 2020, 12, 1127. [Google Scholar] [CrossRef] [Green Version]
- Min, Z.; Wang, J.; Pan, J.; Meng, M.Q.-H. Generalized 3-D Point Set Registration with Hybrid Mixture Models for Computer-Assisted Orthopedic Surgery: From Isotropic to Anisotropic Positional Error. IEEE Trans. Autom. Sci. Eng. 2021, 18, 1679–1691. [Google Scholar] [CrossRef]
- Makovetskii, A.; Voronin, S.; Kober, V.; Voronin, A. A regularized point cloud registration approach for orthogonal transformations. J. Glob. Optim. 2022, 83, 497–519. [Google Scholar] [CrossRef]
- Gao, X.; Zhang, T.; Liu, Y.; Yan, Q. 14 Lectures on Visual SLAM: From Theory to Practice; Publishing House of Electronics Industry: Beijing, China, 2017. [Google Scholar]
- Serafin, J.; Grisetti, G. NICP: Dense Normal Based Point Cloud Registration. In Proceedings of the IEEE International Con-ference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; Volume 2015. [Google Scholar]
- Jia, S.; Ding, M.; Zhang, G.; Li, X. Improved Normal Iterative Closest Point Algorithm with Multi-Information. In Proceedings of the 2016 IEEE International Conference on Information and Automation, IEEE ICIA 2016, Ningbo, China, 1–3 August 2016. [Google Scholar]
- Pomerleau, F.; Colas, F.; Siegwart, R.; Magnenat, S. Comparing ICP variants on real-world data sets. Auton. Robots 2013, 34, 133–148. [Google Scholar] [CrossRef]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the Third International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001. [Google Scholar] [CrossRef] [Green Version]
- Rodolà, E.; Albarelli, A.; Cremers, D.; Torsello, A. A simple and effective relevance-based point sampling for 3D shapes. Pattern Recognit. Lett. 2015, 59, 41–47. [Google Scholar] [CrossRef] [Green Version]
- Servos, J.; Waslander, S.L. Multi-Channel Generalized-ICP: A robust framework for multi-channel scan registration. Robot. Auton. Syst. 2017, 87, 247–257. [Google Scholar] [CrossRef]
- Zhu, Z.; Xiang, W.; Huo, J.; Yang, M.; Zhang, G.; Wei, L. Non-Cooperative Target Pose Estimation based on Improved Iterative Closest Point Algorithm. J. Syst. Eng. Electron. 2022, 33, 1–10. [Google Scholar] [CrossRef]
- Yue, X.; Liu, Z.; Zhu, J.; Gao, X.; Yang, B.; Tian, Y. Coarse-fine point cloud registration based on local point-pair features and the iterative closest point algorithm. Appl. Intell. 2022, 12569–12583. [Google Scholar] [CrossRef]
- Yu, J.; Yu, C.; Lin, C.; Wei, F. Improved Iterative Closest Point (ICP) Point Cloud Registration Algorithm based on Matching Point Pair Quadratic Filtering. In Proceedings of the 2021 International Conference on Computer, Internet of Things and Control Engineering, CITCE, Guangzhou, China, 12–14 November 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Ran, Y.; Xu, X. Point cloud registration method based on SIFT and geometry feature. Optik 2020, 203, 163902. [Google Scholar] [CrossRef]
- Hossein-Nejad, Z.; Nasri, M. An adaptive image registration method based on SIFT features and RANSAC transform. Comput. Electr. Eng. 2017, 62, 524–537. [Google Scholar] [CrossRef]
- Stanković, I.; Brajović, M.; Lerga, J.; Daković, M.; Stanković, L. Image denoising using RANSAC and compressive sensing. Multimed. Tools Appl. 2022, 81, 44311–44333. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. Point Cloud Registration Based on One-Point RANSAC and Scale-Annealing Biweight Estimation. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9716–9729. [Google Scholar] [CrossRef]
- Borji, A.; Cheng, M.-M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2019, 5, 117–150. [Google Scholar] [CrossRef] [Green Version]
- Zhuge, M.; Fan, D.P.; Liu, N.; Zhang, D.; Xu, D.; Shao, L. Salient object detection via integrity learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1. [Google Scholar] [CrossRef]
- Hu, L.; Zhang, Y.; Wang, Y.; Jiang, Q.; Ge, G.; Wang, W. A simple information fusion method provides the obstacle with saliency labeling as a landmark in robotic mapping. Alex. Eng. J. 2022, 61, 12061–12074. [Google Scholar] [CrossRef]
- Wang, R.; Su, C.; Yu, H.; Wang, S. Six-dimensional Target Pose Estimation for Robot Autonomous Manipulation: Methodology and Verification. IEEE Trans. Cogn. Dev. Syst. 2022, 1. [Google Scholar] [CrossRef]
- Du, T.; Shi, S.; Zeng, Y.; Yang, J.; Guo, L. An Integrated INS/Lidar Odometry/Polarized Camera Pose Estimation via Factor Graph Optimization for Sparse Environment. IEEE Trans. Instrum. Meas. 2022, 71, 1–11. [Google Scholar] [CrossRef]
- Anderson, J.D.; Raettig, R.M.; Larson, J.; Nykl, S.L.; Taylor, C.N.; Wischgoll, T. Delaunay walk for fast nearest neighbor: Accelerating correspondence matching for ICP. Mach. Vis. Appl. 2022, 33, 31. [Google Scholar] [CrossRef]
- Reyes-Aviles, F.; Fleck, P.; Schmalstieg, D.; Arth, C. Compact World Anchors: Registration Using Parametric Primitives as Scene Description. IEEE Trans. Vis. Comput. Graph. 2022, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Li, W.; Yan, M. 3D scene reconstruction based on improved ICP algorithm. Microprocess. Microsystems 2020, 75. [Google Scholar] [CrossRef]
- Wan, T.; Du, S.; Cui, W.; Yao, R.; Ge, Y.; Li, C.; Gao, Y.; Zheng, N. RGB-D Point Cloud Registration Based on Salient Object Detection. IEEE Trans. Neural Networks Learn. Syst. 2022, 33, 21621947. [Google Scholar] [CrossRef] [PubMed]
- Yao, R.; Du, S.; Wan, T.; Cui, W. A robust registration algorithm based on salient object detection. Multimed. Tools Appl. 2022, 81, 34387–34400. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Xie, J.; Cheng, M.-M.; Ling, H.; Borji, A. Revisiting Video Saliency Prediction in the Deep Learning Era. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 220–237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Volume 1. [Google Scholar]
- Li, J.; Pei, L.; Zou, D.; Xia, S.; Wu, Q.; Li, T.; Sun, Z.; Yu, W. Attention-SLAM: A Visual Monocular SLAM Learning From Human Gaze. IEEE Sens. J. 2021, 21, 6408–6420. [Google Scholar] [CrossRef]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M. Dynamic Feature Integration for Simultaneous Detection of Salient Object, Edge, and Skeleton. IEEE Trans. Image Process. 2020, 29, 8652–8667. [Google Scholar] [CrossRef]
- Bansal, M.; Kumar, M. 2D object recognition: A comparative analysis of SIFT, SURF and ORB feature descriptors. Multimedia Tools Appl. 2021, 80, 18839–18857. [Google Scholar] [CrossRef]
- Yang, J.; Huang, Z.; Quan, S.; Zhang, Q.; Zhang, Y.; Cao, Z. Toward Efficient and Robust Metrics for RANSAC Hypotheses and 3D Rigid Registration. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 893–906. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, L.; Yang, J.; Liu, C.; Xiong, Y.; Luo, M.; Tan, Z.; Liu, B. LiDAR–camera calibration method based on ranging statistical characteristics and improved RANSAC algorithm. Robot. Auton. Syst. 2021, 141, 103776. [Google Scholar] [CrossRef]
- Maken, F.A.; Ramos, F.; Ott, L. Stein ICP for Uncertainty Estimation in Point Cloud Matching. IEEE Robot. Autom. Lett. 2021, 7, 1063–1070. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Whelan, T.; Johannsson, H.; Kaess, M.; Leonard, J.J.; McDonald, J. Robust Real-Time Visual Odometry for Dense RGB-D Mapping. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Zhang, H.; Zheng, G.; Fu, H. Research on image feature point matching based on ORB and RANSAC algorithm. J. Phys. Conf. Ser. IOP Publ. 2020, 1651, 012187. [Google Scholar] [CrossRef]
- Zhang, J.; Yin, X.; Luan, J.; Liu, T. An improved vehicle panoramic image generation algorithm. Multimedia Tools Appl. 2019, 78, 27663–27682. [Google Scholar] [CrossRef]
- Abu Bakar, S.; Jiang, X.; Gui, X.; Li, G.; Li, Z. Image Stitching for Chest Digital Radiography Using the SIFT and SURF Feature Extraction by RANSAC Algorithm. J. Phys. Conf. Ser. 2020, 1624. [Google Scholar] [CrossRef]
- Michael Grupp. Python package for the evaluation of odometry and SLAM. Available online: https://github.com/MichaelGrupp/evo (accessed on 1 October 2022).
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. In Proceedings of the Robotics: Science and System XIV, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Data Type | Number | Sampling Premise |
|---|---|---|---|
| TUM [42] | RGB-D image | 600 pairs | Salient imaging is clear, and the Raw RGB image pairs are the same scene. |
| Category | Extracted Key Points | Feature Point Matching Pairs | Number of Matching Pairs after RANSAC Processing |
|---|---|---|---|
| Without salient preprocessing | Left IMG 611, Right IMG 666 | 202 | 30 |
| Salient preprocessing | Left IMG 627, Right IMG 535 | 172 | 12 |
| Category | Unable to Estimate the Pose by Our Method (Relative Pose Error t > 0.1 m/s, R > 2 deg/s) | The Pose Estimation Becomes Better after Salient Preprocessing (without RANSAC) | The Pose Estimation Becomes Better after Salient Preprocessing (with RANSAC) | Improved Real-Time Performance |
|---|---|---|---|---|
| Our method | 7.9% | 92.5% | 85.6% | 96.5% |
| Category | Extracted Key Points | Feature Point Matching Pairs | Number of Matching Pairs after RANSAC Processing |
|---|---|---|---|
| Without salient preprocessing | Left IMG 549, Right IMG 626 | 42 | 4 |
| Salient preprocessing | Left IMG 350, Right IMG 615 | 30 | 4 |
| Category | Extracted Key Points | Feature Point Matching Pairs | Number of Matching Pairs after RANSAC Processing |
|---|---|---|---|
| Without salient preprocessing | Left IMG 70, Right IMG 40 | 17 | 4 |
| Salient preprocessing | Left IMG 197, Right IMG 79 | 20 | 4 |
| Category | Extracted Key Points | Feature Point Matching Pairs | Number of Matching Pairs after RANSAC Processing |
|---|---|---|---|
| Before salient preprocessing | Left IMG 1629, Right IMG 1602 | 591 | 321 |
| Salient preprocessing | Left IMG 885, Right IMG 592 | 164 | 29 |
| Category | The Incorrectly Matching Logarithm of Figure 3 (before RANSAC Processing) | The Incorrectly Matching Logarithm of Figure 3 (after RANSAC Processing) | 600 Pairs of Images |
|---|---|---|---|
| Without salient preprocessing | 172 | The incorrect matching pairs difference is not apparent before and after salient preprocessing. | Over 95% of image pairs reduce the incorrectly matching feature point pairs containing the process from salient preprocessing to RANSAC processing. |
| Salient preprocessing | 160 |
| Category | The Average Number of Extracted Feature Points (One Image). | Average Matching Feature Point Pairs (One Pair of Images). | Match Logarithms after RANSAC Processing (One Pair of Images). | Average Pose Estimation Time (One Pair of Images). |
|---|---|---|---|---|
| Without salient preprocessing | 522.8 | 181.1 | 69.4 | 1.92s |
| Salient preprocessing | 351.5 | 123.7 | 43.3 | 1.49 s |
| Percentage of saved time | 22.40% |
| Method | The Average Number of Extracted Feature Points (One Image). | Average Matching Feature Point Pairs (One Pair of Images). | Match Logarithms after RANSAC Processing (One Pair of Images). | Average Pose Estimation Time (One Pair of Images) | Relative Pose Error (RPE) |
|---|---|---|---|---|---|
| Ous | 351.5 | 123.7 | 43.3 | 1.49 s | 0.057 m/s, 1.512 deg/s |
| SIFT+RANSAC [19,40,41] | 522.8 | 181.1 | 69.4 | 1.92s | 0.054 m/s, 1.467 deg/s |
| ORB+RANSAC [40,41,43] | 494 | 177 | 59 | 0.36s | 0.076 m/s, 1.791 deg/s |
| SURF+RANSAC [40,41,44,45] | 353 | 159 | 62 | 0.84 s | 0.062 m/s, 1.619 deg/s |
| Method | Average Pose Estimation Time (One Pair of Images, TUM) | Relative Pose Error (RPE) (TUM [42]) | Average Pose Estimation Time (One Pair of Images, YCB-Video) | Relative Pose Error (RPE) (YCB-Video [47]) |
|---|---|---|---|---|
| Ous | 1.49 s | 0.057 m/s, 1.512 deg/s | 1.32 s | 0.033 m/s 1.023 deg/s |
| SIFT+RANSAC [19,40,41] | 1.92 s | 0.054 m/s, 1.467 deg/s | 1.97 s | 0.032 m/s 0.987 deg/s |
| ORB+RANSAC [40,41,43] | 0.36 s | 0.076 m/s, 1.791 deg/s | 0.24 s | 0.062 m/s 1.545 deg/s |
| SURF+RANSAC [40,41,44,45] | 0.84 s | 0.062 m/s, 1.619 deg/s | 0.67 s | 0.041 m/s 1.203 deg/s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, L.; Zhang, Y.; Wang, Y.; Ge, G.; Wang, W. Salient Preprocessing: Robotic ICP Pose Estimation Based on SIFT Features. Machines 2023, 11, 157. https://doi.org/10.3390/machines11020157
Hu L, Zhang Y, Wang Y, Ge G, Wang W. Salient Preprocessing: Robotic ICP Pose Estimation Based on SIFT Features. Machines. 2023; 11(2):157. https://doi.org/10.3390/machines11020157
Chicago/Turabian StyleHu, Lihe, Yi Zhang, Yang Wang, Gengyu Ge, and Wei Wang. 2023. "Salient Preprocessing: Robotic ICP Pose Estimation Based on SIFT Features" Machines 11, no. 2: 157. https://doi.org/10.3390/machines11020157