1. Introduction
Modern production is subject to a great deal of uncertainty since new items are being introduced at an increasingly rapid rate, particularly those with multiple varieties and a limited lifespan. Therefore, the ability to create flexible and reconfigurable production systems is highly desired. When it comes to flexible tasks, human abilities such as quick perception and the processing of different types of information or adaptability and improvisation can be crucial success factors [
1,
2,
3]. The most sensitive jobs, including operating chemical experiments, still rely entirely on physical labor, despite automated robots playing a large role in modern manufacturing lines. These lines require significant labor, and a human worker may have to spend hours drilling in screws or wheels without stopping. Modern business needs collaborative robots that can effectively aid human employees because labor is becoming more expensive due to an aging population. Therefore, giving full play to the advantages of robots and using them to complete some cumbersome and high-risk experiments will become the main direction of the intelligent development of chemical laboratories. In the same process, the use of intelligent devices such as robots and robotic arms requires the mastery of complex programming and control techniques, which is still difficult for chemical experimenters. This raises the question of how to control robots, robotic arms and other intelligent devices to complete chemical experiments in a simpler and faster way.
Chemical experiment is an indispensable link in the process of research, study and production in the chemical industry [
4]. At present, the intelligence of chemical engineering procedures is not very high; the experimental process that can be completed by using intelligent mechanical equipment such as manipulators to carry out chemical experiments is relatively simple, and the programming is relatively complex. In addition, various chemical reagents are used in chemical experiments. These reagents interact with each other during the experiment to produce various harmful substances, and unpredictable dangers may occur as a result of experimental errors. Therefore, it is necessary to use more intelligent manipulators and other equipment to replace the operator to complete the relevant complex tasks.
Today’s technologies enable us to send a robot to land on Mars, but not to properly control a robot shaking hands with us. The performance of most advanced robot control systems at present still cannot match that of humans’ adaptability, flexibility and cooperative ability, which are urgently required by the flexible manufacturing systems used to facilitate mass customization in the context of Industry 4.0 [
5,
6]. Modelling human skills from a robot control view is still challenging, especially for high level versatile and collaborative skills. Robots have recently been finding their way into human industrial and daily life, an example of which is by learning motor skills from human tutors through demonstration, and then generating these learned skills [
7]. Obviously, a skilled robot would be more efficient in interacting with humans and industrial productions. It is increasingly expected that robots should be capable of flexible skills in order to adapt to more complex situations. Teaching by demonstration is seen as one of the most effective ways for a robot to learn motion and manipulation skills from humans [
8]. In this paper, inspired by human mechanical intelligence adaptivity to variations of tasks, both position trajectory and oral interaction are achieved for robot motion control to realize a more completed skill transfer process.
With the development of machine learning and machine vision technology, the deductive programming of the manipulator provides a new solution for human-computer interaction, which is an important way to reduce the difficulty of acquiring skills for the manipulator [
9,
10,
11]. The teaching programming of the manipulator is a process of automatically learning the motion trajectory by watching and learning the teaching actions of people; teaching robots by visual signals such as motion tracking-based teleoperation, or by audio inputs such as oral command interface, plays an increasingly important role. Researchers such as Haage of Lund University used an RGB-D camera-based sensing module to track human movements when implementing robot teaching. The robot is mainly used to install industrial parts and inspection equipment [
12]. Li C et al. designed a LeapMotion sensor-based controller for tracking the operator’s hand movements to achieve the real-time robot teaching. The end-effector of the robot is actually held for demonstration to teach the robot action. Meanwhile, a neural network (NN)-based adaptive controller has successfully been developed for the remote manipulation of the DLR-HIT II robot hand [
13]. In [
14], the authors developed a robot learning method by modelling the motor skills of a human operator using dynamic motor primitives (DMP) and integrating the speech recognition, wherein people could easily teach the robot by speaking. However, only a few works [
15,
16] take advantage of the visual signals- and audio inputs-based robot teaching by combining them, which results in a negative effect on the data transmission latency and the diversity of motor skills.
In this paper, the arm motion detection and speech recognition are combined, and at the same time, with the help of information fusion and pose recognition, a teaching control system for the manipulator is designed [
17] so that the manipulator can understand the skills taught by the experimental staff. It can complete the human-robot interaction more accurately and quickly, and then replace the operator to complete the experimental work. Compared with other robot learning methods, our proposed system possesses the following features:
The teaching process is simple and does not require operators to have programming skills, which is suitable for direct use by chemical operators.
The self-developed desktop manipulator is small in size and suitable for simple desktop chemical experiments.
Chemical experimental actions are decomposed into a combination of multiple basic actions, and a combination of visual action recognition and speech recognition is used to improve the accuracy of teaching.
Compared with the manipulator used in traditional research, our proposed method employs a low-cost manipulator with lower power consumption but embeds advanced robot learning algorithms.
4. Skill Acquisition Module Design
4.1. Motion Detection
At the beginning, we selected the action detection of the skeleton network, but the effect was not obvious, and the earliest dual-stream network also had a very good accuracy in action detection. Based on the dual-stream network, we performed the feature extraction part and the fusion classification algorithm. The next step is to improve and expand the behavioral action recognition data set and apply it in the chemical analysis experiment business scenario.
The action detection part of this paper is mainly based on an improved two-stream convolutional network. This part inputs the preprocessed image information into the network, uses the EfficientNetv2 [
20] algorithm to calculate the RGB image and optical flow image features, and then uses the extracted feature information to use linear classification. The SVM [
21,
22,
23,
24] is used to classify the behavior and obtain the identification information of the action.
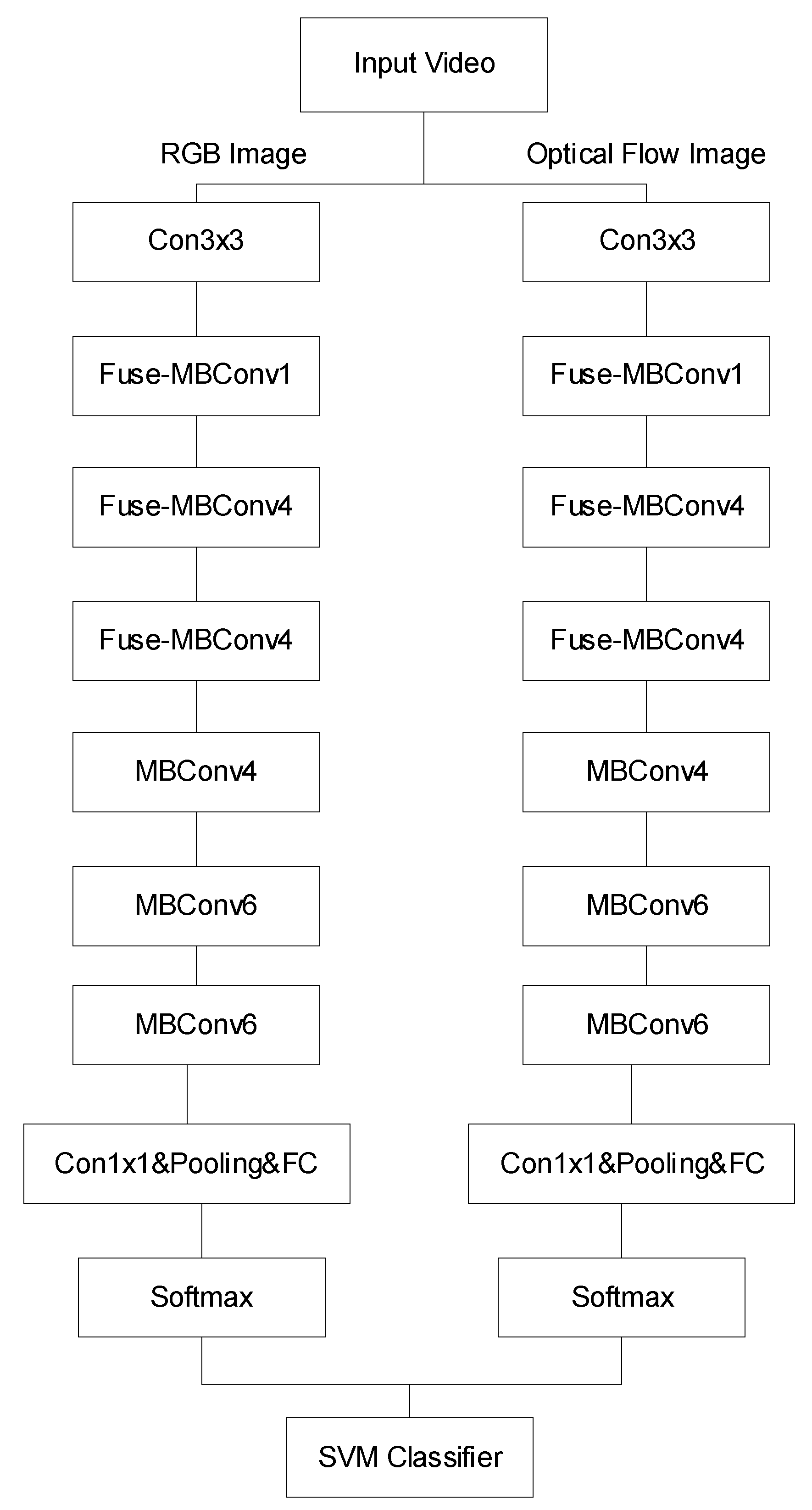
As shown in
Figure 5, the two-stream convolutional network divides the input video into two channels for processing, one of which is to extract the task arm and scene-related information in the RGB image by the convolutional neural network, and the other is to process the optical flow image information, which is finally normalized and fused by the Softmax function.
The extraction of optical flow images in the network (action video preprocessing) is obtained by gradient-based operations. The key principles of the algorithm (1) are as follows: first, set the image sequence
I(x, y, t); the vector
X =
[x, y]. The sequence is extracted from the previous and subsequent frames in a demo video, that is, when the local optical flow image of the video is basically constant. For any
Y ∈
N(x), there are:
where
X is the
x vector,
H(I) is the Hesse matrix of the image sequence
I, and the relationship between
X and the offset
d is introduced in (2):
Setting the derivative equal to 0 yields (3):
The above process can be summarized as analyzing the changes of the pixels in the video image on the timeline and the correlation between adjacent frame images, finding the corresponding relationship between the previous frame and the current frame, and calculating the motion information (the offset is a kind of motion information), followed by drawing the optical flow image.
In the calculation feature part, as shown in
Figure 6, compared to the previous EfficientNet [
25] algorithm, EfficientNetv2 uses Fused-MBConv to replace the MBConv structure, that is, the conventional 3 × 3 convolution is used to replace the 3 × 3 depth convolution in MBConv and 1 × 1 convolution to improve the calculation speed of the network.
To obtain the feature information of the RGB image and optical flow image, it needs to be classified and verified. Support vector machine (SVM) is a binary classification model used to solve the separating hyperplane that can correctly divide the training data set. It also has the largest geometric interval. As shown in
Figure 7,
w ×
x +
b = 0 is the separation hyperplane. There are generally many such hyperplanes, but the separation hyperplane with the largest interval is indeed the only one. For the optimal value among them, Formula (4) can be used to select, which is as follows:
The overall structure is shown in
Figure 8. The RGB and optical flow feature extraction parts in the dual-stream convolutional network use lightweight Efficientnetv2 to perform convolution and pooling, respectively, and then combine the actions given by the SVM classifier for the two branches. The information is classified and, finally, identified action information is given. The data in the experiment are a self-made data set for chemical analysis. In the laboratory environment, a fixed camera is used to record the behaviors of stirring, picking up the experiment, putting down the experiment, taking liquid, and mixing liquid. This behavior was recorded 50 times. The video duration of the dataset is controlled within 10 s, and the recorded video changes in lighting, background, and occlusion, forming 10,000 chemical analysis action videos, with an average of 10 clip videos per video. The video format is 320 × 240, 25 fps and the audio is saved as a wav format file. The data set has a huge number of video frames, and there are data redundancy, interference, etc., which have a great impact on training and learning. Using the improved two-stream convolutional neural network, the recognition accuracy can reach 92%, which is improved in this experiment. Compared with other methods, the accuracy of the latter method is improved, but the training process still takes a significant amount of time.
After obtaining a complete set of identification information on the action, it is necessary to determine the execution sequence of the manipulator action of the module and obtain the executable action of the manipulator. First, design and name the motion primitives of the manipulator and store all the designed motion primitives in the library. The action information detected above is stored in a sequence, and the action primitives in the matching directory are used to determine the action primitive sequence in the current time. In each teaching process, the program matches the sequence combination composed of multiple action primitives, and then search for the associated actions in the manipulator action group library. The recognized action numbers are connected in series to obtain a sequence, and this sequence is used to find a complete match or the closest action group; these are identified as the recognized experimental actions and given a coverage. After the program finds the action group with the greatest match, it continues to match with the action group in the library and stores the relevant information that the action group coverage is higher than 50% in the matching process.
4.2. Speech Recognition and Keyword Extraction
Teaching is a process of speaking while doing. The operator dictates the current action during arm movement, which requires the addition of voice technology. The key to speech technology is to process natural language, recognize speech and generate text, so that machines can listen, speak, understand and think [
26]. This paper uses Baidu’s real-time speech recognition, which is based on Deep Peak2 end-to-end modeling, transforms the received audio stream into text characters in real time, and then uses regular expressions to extract action keywords. The flow chart is shown in
Figure 9.
In this process, since it is speech recognition in chemical experiments, it is necessary to supplement the training set text corpus for many terms in chemical experiments and the speech data required by the current experimental process. The corpus data include the format of the speech files, name and text information. The corpus data set summarizes about 55 min of relevant identification content, and its audio files are converted into a direct binary sequence PCM file format after analog-to-digital conversion, which realizes the digitization of the sound and deletes the file header and end marks that differ from other file formats, in order to facilitate the concatenation of files. After supplementing the corpus data set, the accuracy of speech recognition in experimental business scenarios can be effectively improved by 7–15%.
In the above speech recognition process, the program needs to read the action file keywords manually set earlier in the text in advance and write them into memory variables. In each teaching process, the keywords recognized by the speech are matched to the text. If the match is correct, the identifier number IdentNumber is recorded immediately and stored.
Summarize all the matched speech keyword numbers in the whole teaching process in order, similar to the action detection and matching part; search for the action group of the robot arm; and search for a complete match or the closest action group. This is the speech recognition to action group, which retains the coverage information and records other related action group information with a coverage higher than 50%.
4.3. Audio and Video Information Fusion
Since the manipulator teaching program in this paper is mainly run-in embedded devices, in some scenarios, mobile terminals and embedded devices are much inferior in configuration, computing power, and device performance compared to servers or PCs [
27]. Under such restrictive conditions, it is difficult to achieve high-speed and accurate recognition algorithms and teaching methods. Moreover, teaching is a dynamic process, which requires the continuous recognition of speech and actions. In this process, recognition failure will inevitably occur and affect the accuracy. Therefore, this paper draws on the information fusion of sensors [
15,
16,
28] and writes a highly targeted algorithm to combine the key information obtained by the two separate modules of action detection and speech recognition, so as to improve the accuracy of skill acquisition and save performance.
The video recognition Information and speech recognition information obtained during the teaching process of the manipulator are an action group and its coverage. In the case of the most ideal running effect, the length of the action group given by the video and the voice is equal, and the data are shown in
Table 2 as an example. The two modules in
Table 2 list the highest coverage information
ACT_G0 generated by the current teaching process and other action coverage information greater than 50% coverage.
If, in this teaching process, the two modules have the same maximum coverage action group—that is, the video and voice parts have selected the same action group with the highest matching degree—then the action can be regarded as a teaching action and does not need to follow the algorithmic process of fusion. The action can also be considered as being outside of this low-probability case.
After analyzing and testing the common fusion of confidence-based independent classifiers, this paper moves the fusion point to the action group category. The action group sequence given by the acquisition module is fused.
Algorithm idea: Define the
ACT_G0 of the video module part as
VG0, and then define it as
VGn in turn. Similarly, the audio module part is defined as
AG0,
AG1...
AGn. Compare
AG0 with 1–
n in the
VG part and find a
VGx that has a similarity of 100% with
AG0, according to the positive sequence—that is, if more than 50% of the
VG matches
AG0, then record and store the coverage product of
AG0 and
VGx (
AG0 ×
VGx, 0 <
x ≤
n). The same is true for the
AG part. The above two parts of the results are compared to the action group that outputs the optimal matching value (weights are equally divided), as shown in Formula (5):
Among them, Mag is the function of the action group to find the maximum value, and FG is the action group of the robot arm that obtains the maximum value after the coverage rate is multiplied.
When the action group whose similarity with
ACT_G0 is 100% in the above process is empty, enter the following search algorithm: there is a similarity (<100%) between any two sets of actions, and the product of the original coverage is used to equalize the two. The similarity between the two is obtained, the correlation value of the two is obtained, and all the correlation values are aggregated to output the maximum action, that is, the maximum value is obtained by the fusion of two actions with different coverage, and then the two actions. In the group, select the action group that is closest to the original set of action primitive sequences (with the largest coverage), which is the final teaching action. The above process is shown in Formulas (6) and (7).
Among them, in Formula (6), fit is the similarity between two sets of action groups, FQ is the product of a pair of coverage and multiplied by the action-related value of the similarity between the two. In Formula (7), all the two modules are action information fusion; output a pair of actions with the optimal correlation value, and then select the action group with the highest coverage with the original action primitive sequence, that is, FFG. In this way, the verification and fusion of the video module and the relevant action information of the audio module are completed, and the manipulator determines the final motor skills.
5. Manipulator Motion Control
The D-H method is usually used to build the model and analyze the motion of the mechanical arm. The D-H method is a common kinematic solution method in the field of robotics, which is beneficial to analyze and establish the kinematic model of the robotic arm and calculate the forward and inverse solutions. Through D-H modeling, the transformation matrix between each joint can be obtained, so as to obtain the transformation matrix from the base coordinate system to the claw coordinate system and the position and attitude of the end of the manipulator.
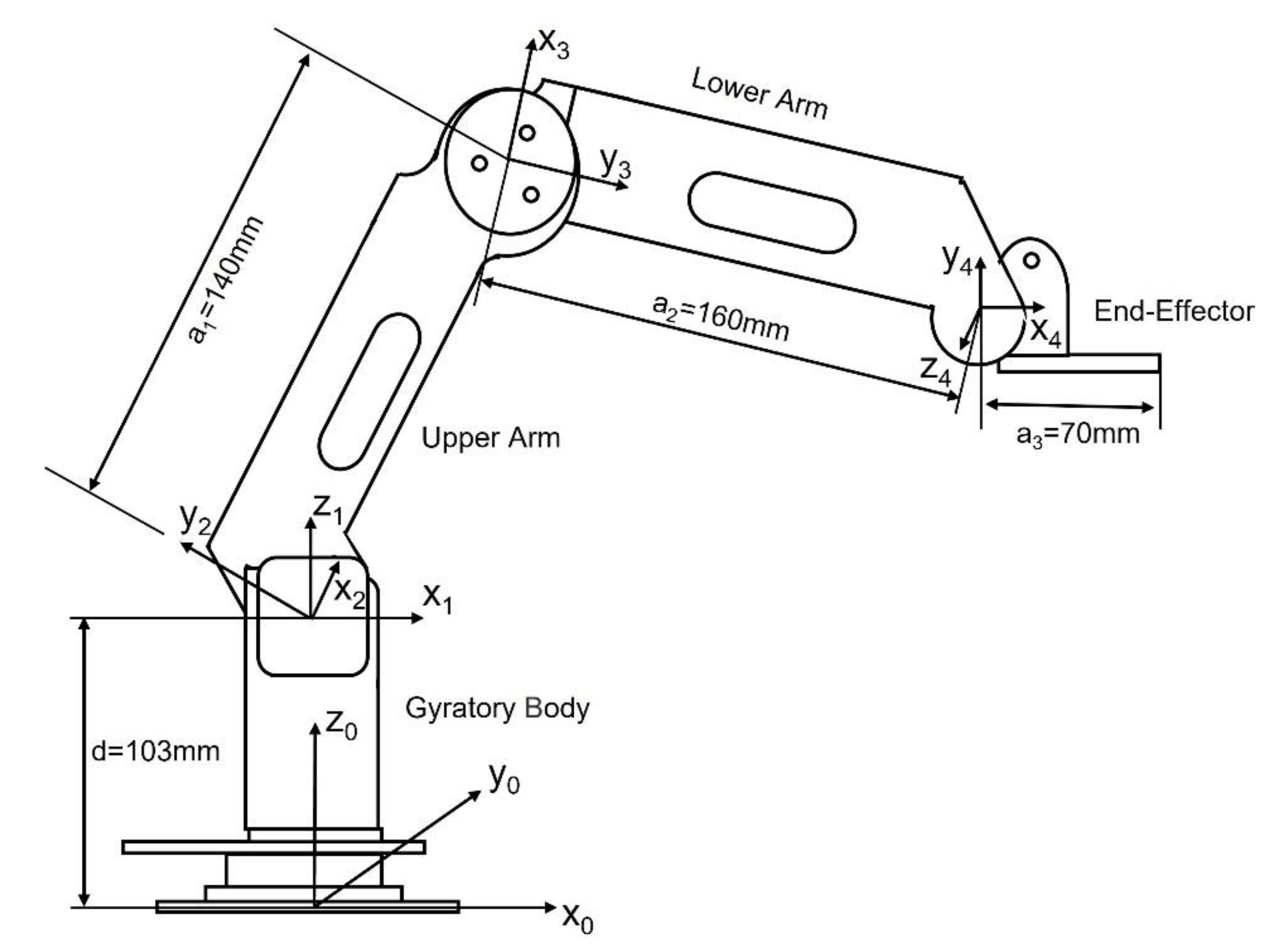
As shown in
Figure 10, the specific method of establishing the link structure coordinate system for the manipulator is as follows: where
j − 1 and
j represent two links,
j − 1,
j and
j + 1 represent three axis joints, and the axis joint coordinates. The
x-axis,
y-axis, and
z-axis of the system follow the right-hand rule. Among them,
a is used to indicate the length of the connecting rod,
α is used to indicate the rotation angle of the connecting rod,
d is used to indicate the offset distance of the connecting rod, and
θ is used to indicate the axis angle of the joint.
Table 3 is the attached connecting rod D-H parameters, in which the parameters of each connecting rod are d = 103 mm; a1 = 140 mm; b2 = 160 mm; a3 = 70 mm.
As shown in
Figure 11, the joint coordinate system of the three-degree-of-freedom experimental manipulator is established on the basis of the D-H parameter coordinate system, including the three rotating joints of the manipulator and the position of the end effector.
The analysis concluded that, for the demonstration function to be implemented in this paper and the designed three-degree-of-freedom robotic arm, it is more suitable to use the geometric solution method in the inverse kinematics solution because our network can get the position where the end actuator or the clamping jaws of the robotic arm are located very simply and precisely, and the robotic arm has only three motors responsible for the operation of
X,
Y and
Z.
Figure 12 shows the simplified spatial coordinate diagram of the drawn experimental manipulator.
There are mainly three constants in this manipulator: link length L1, link length L2 and link length L3; three rotation dependent variables: rotation angles Q1, Q2 and Q3; one variable: the general size of the gripper at the end of the manipulator; and a coordinate position (X, Y, Z).
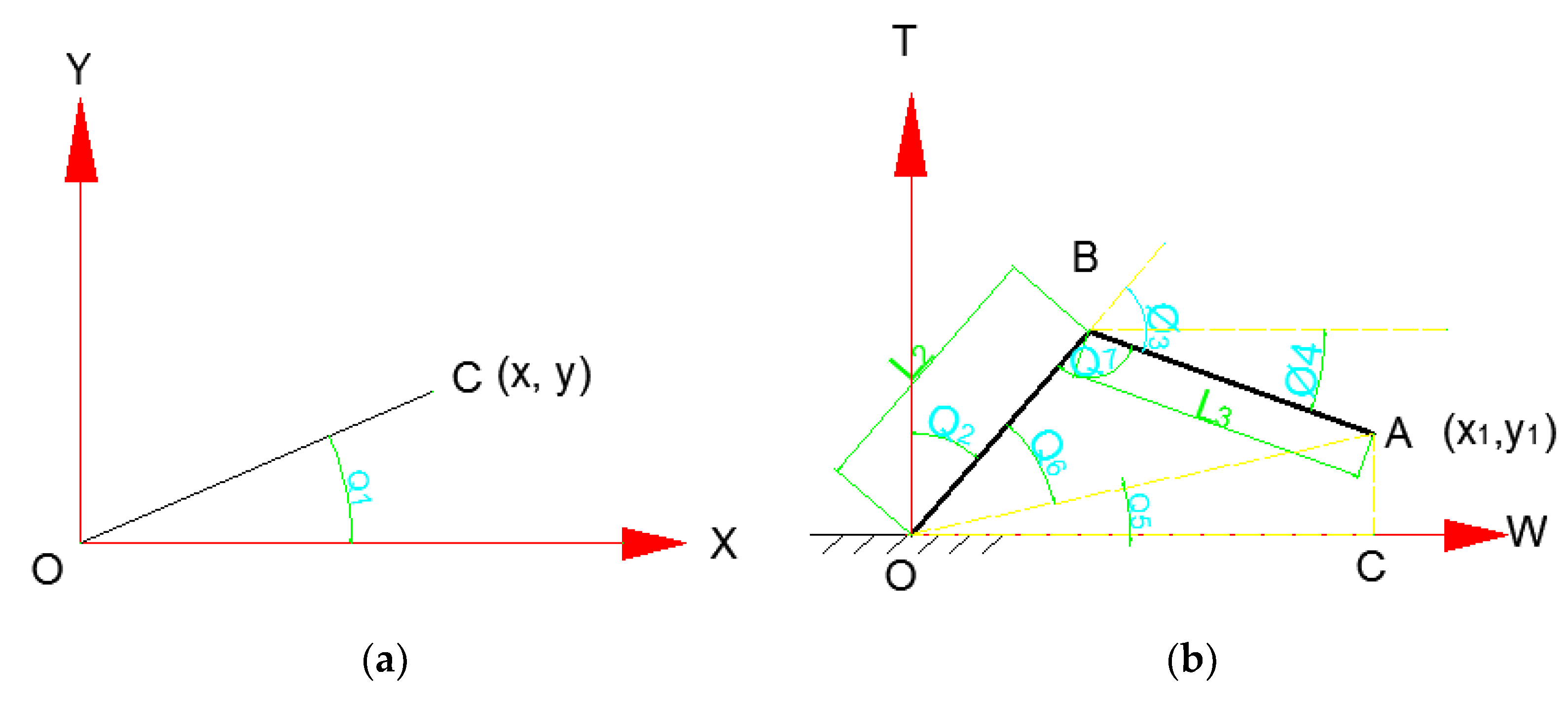
As shown in
Figure 13a, looking at it as a plane coordinate system with
x as the horizontal axis and
y as the vertical axis, the tangent of the connecting rod rotation angle
θcox is:
From the perspective of the XOZ plane of the space coordinate system of the manipulator, as shown in
Figure 13b, from the coordinates of point
A (
x1,
z1), we can know that
OC =
x1,
AC =
z1 and obtain:
Similarly, the cosine formula can be used to obtain:
Introduce this into formulas:
The corresponding rotation angle of the link L2, the corresponding rotation angle of the link L3, and the horizontal angle of the link L3 can be obtained.
According to the above process, the inverse kinematics solution for the geometric solution of the three-degree-of-freedom experimental manipulator in this paper can be summarized as the flow chart shown in
Figure 14:
After the teaching is completed, the program loads the finalized XML action parameter file. The program reads the corresponding direction and step parameters of the X, Y and Z motors in sequence, executes them in sequence, and controls the high- and low-level outputs of the related pins of the Raspberry Pi to control the operation of the motor. Among them, the rotation angle of the robot arm corresponding to the step parameter 1024 is 18°, and the maximum is 10,240.
When the manipulator is in motion, the camera installed near the gripper at the front end of the manipulator can receive real-time image data and transmit them to the Raspberry Pi through the USB port. The system combines it with the grasping pose recognition algorithm [
29] for grasping. Five variables are used:
(x, y, θ, h, w) to describe the gripping position and direction of the gripper when the manipulator grips the object. As shown in the rectangular box in
Figure 15,
(x, y) is used to represent the center position of the rectangular box;
θ is used to represent the angle between the horizontal axis in the image and the current tilt position of the rectangular box;
h denotes height; and
w is used to represent width.
When the manipulator reaches the vicinity of the object, the position of the front end of the manipulator needs to be adjusted slightly, according to the position of the rectangular frame. That is, six basic adjustment actions are set: left and right, up and down, and clockwise/counterclockwise rotation. Use the above actions to adjust the mechanical arm to reach the preset position and achieve object grasping.
The grabbing pose algorithm is based on the Cornell Grasping Dataset, and on the basis of the data set, it continues to supplement and train the grabbing positions related to chemical equipment, which compensatively improves the accuracy of grabbing pose recognition.
7. Concluding Remarks
Operators need to perform various chemical experiments in chemical laboratories; these are cumbersome, and some of them are harmful to the human body. Therefore, it is necessary to use a manipulator instead of an operator to conduct experiments. However, the experimental manipulator that is currently used needs to be programmed by professional manipulator controllers, which is difficult for chemical operators. Therefore, in order to solve the above problems, this paper proposes a simple and efficient manipulator teaching system based on motion detection and speech recognition.
The operator dictates his movements during the experiment. The system uses motion detection to detect the movement of the operator’s arm, matches with voice recognition, and uses algorithms related to information fusion to teach the manipulator the motor skills that should be performed. The manipulator grasps objects in combination with pose recognition during the execution process, and completes a set of experimental tasks. The accuracy rate of the system in the acquisition of motor skills can reach more than 81%.
Based on the design and experimental results of this paper, the experimental manipulator is taught and programmed to acquire and execute experimental skills, and there is a certain applicability and feasibility to use the manipulator in chemical analysis experiments. However, some problems in the system were found during the experiment: the transparent material of the test tube and light affected the recognition accuracy, the response speed of the device had a delay, similar behaviors were easily misidentified, and the recognition accuracy needed to be further improved in the actual application process, etc. Since the manipulator is a self-developed manipulator in the laboratory, no model in the corresponding simulation environment has been established, and the subsequent research and development workload is heavy. In the future, we will focus on solving the above problems, create a suitable data production environment in the laboratory, minimize the interference such as light and noise, form models in the simulation environment which are open source for everyone to use, improve the efficiency of later research, and further improve the recognition accuracy and speed. The manipulator will be replaced if necessary to achieve the purpose, but it will still be researched in the direction of low cost and low power consumption.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}