1. Introduction
Fault diagnosis of rotating machinery plays a vital role in the entire life cycle of machines, which monitors operation processes, analyzes operation data, and provides reasonable maintenance suggestions [
1,
2,
3]. For wind turbines, due to the particularity of the working scene, the uncertainty of working conditions, and the high cost of operation and maintenance, it is essential to monitor the different states during operations. Wind turbine farms are located in remote areas that have abundant wind energy resources but poor natural conditions. It is far among the turbines, and it is difficult to monitor each wind turbine in real time. Moreover, the problem of information exchange in the cluster is prominent when turbines are running, and the amount of data generated by wind turbines in actual operation is on a large scale, resulting in significance difficulties in data management, storage, calling, and transmission.
The key point of current research on wind turbine fault diagnosis is that it is difficult to extract and analyze fault knowledge under complex working conditions among various wind turbines in a wind turbine cluster [
4,
5]. In the actual industry, fault data from a single turbine are limited and cannot contain all fault information of various fault states, forms, and periods. There is still a sparsity problem of more normal data without fault but fewer fault data. When modeling only by a single turbine, obstacles such as low accuracy, weak generalization ability, and weak robustness caused by an insufficient amount of fault data make the model unsuitable for application. In contrast, in a wind turbine cluster, different turbines are in various states. Through local modeling of each turbine in a cluster, transmitting model information, and fusing the model, the fault knowledge of each wind turbine is stored with collaborative intelligence [
6,
7] so that it can be better applied to operation state monitoring and the operation data analysis of each turbine. Collaborative intelligence or swarm intelligence are used to solve the problems that hinder the model training and optimizating in the mode of single machine intelligence.
For the fault diagnosis of wind turbine clusters, there are some limitations and obstacles in modeling and fault diagnosis owing to complex structures, working conditions, and other practical factors.
First, for the problem of data sparsity, commonly used methods are mostly from the perspective of sample expansion [
8,
9]. The research content is mainly the difference between the original samples and the newly generated samples and how to reduce this difference. However, such a difference varies in different states of turbines in a cluster and is difficult to determine, which hinders the modeling and training process.
Second, for complex working conditions in clusters, existing solutions mainly focus on transfer learning (TL) [
10,
11]. The concept of the domain in transfer learning corresponds to the different working conditions in the fault diagnosis problem. It typically uses the knowledge learned in one data domain by the fault diagnosis model to solve the problem in another data domain. Commonly applied transfer learning is mostly used for the data processing and mining of a single wind turbine, but it involves fewer wind turbine individuals.
Third, for the model fusion process, most existing methods focus on more traditional ensemble learning (EL) [
12,
13] and federated learning (FL) [
14,
15]. Voting, in which the minority obeys the majority, is the most widely used in EL. FL is a distributed model-training instance that sets up multiple federated participants and has a central server for model fusion. Such methods are usually set under ideal conditions and seldom consider external interference in the actual process of model training. The performance of the model corresponding to the average weight did not reach its best state.
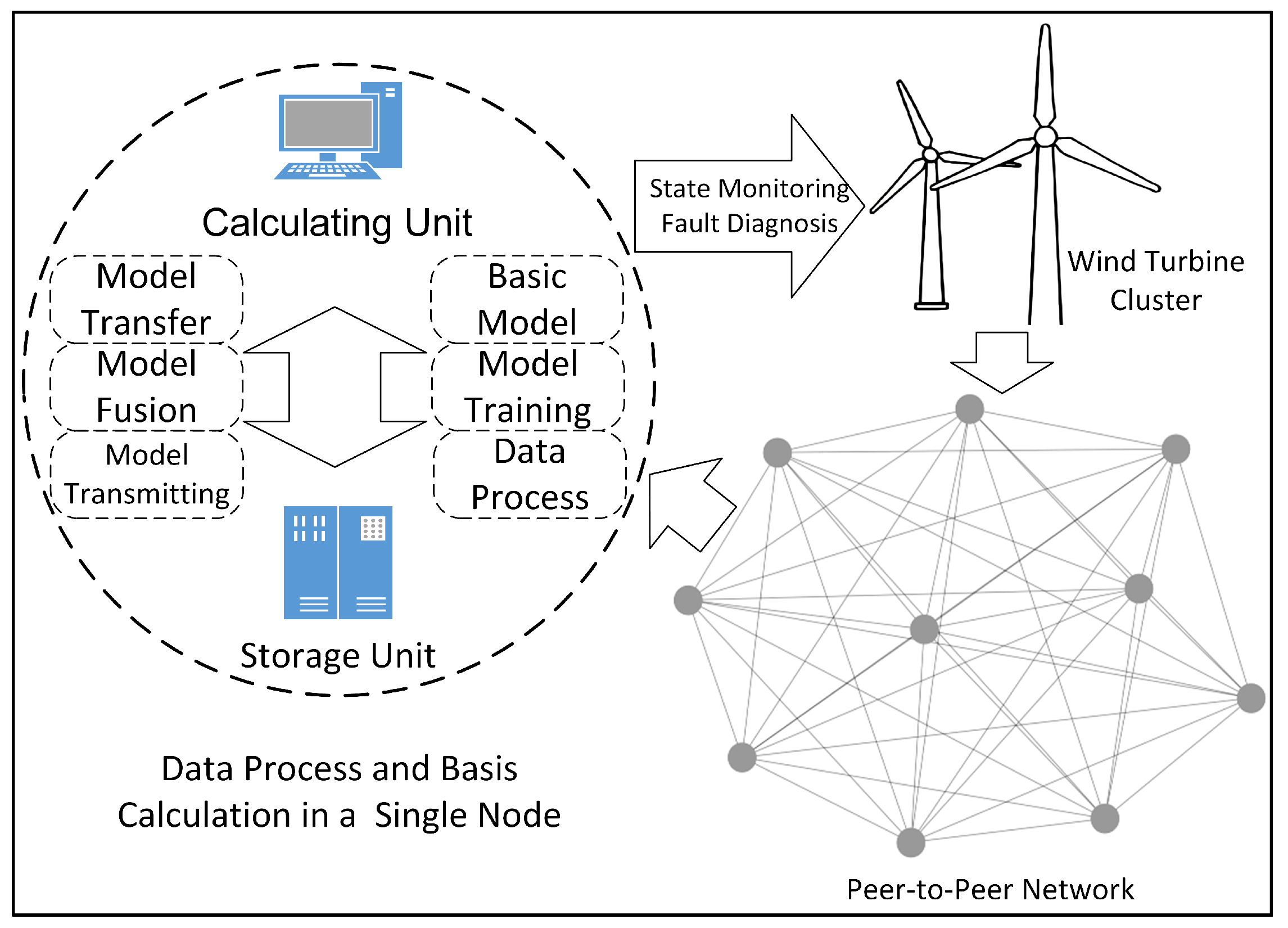
To solve such problems, a peer-to-peer network (P2PNet) [
16] is constructed for the wind turbine cluster, where each node corresponds to a wind turbine. A P2PNet is a computer network that assigns tasks, data, and work among peers in the entire network. The network consists of peers and the information transmission channels among peers. Each participant is equal and has the ability to communicate with other peers.
In the P2PNet, a fault diagnosis framework for a wind turbine cluster is proposed as shown in
Figure 1, where raw data are saved locally in distributed storage. A calculating unit for computing and storage unit for data storage are configured in each node. Each node is equivalent and has functional replicability, including data preprocessing, model configuration, training, transferring, fusion, and transmission. In addition, multi-task learning (MTL) is introduced, and a dynamic adaptive outlier monitoring process and weight adjustment method is proposed in this process. The final results of fault diagnosis models are to configured for state monitoring and fault diagnosis of the wind turbine cluster.
The core contributions and highlights of this paper can be listed as follows.
- (1)
In a situation of insufficient labeled samples and complex working conditions, a fault diagnosis framework and method with a peer-to-peer network for a wind turbine cluster has been proposed based on multiple model transfer and dynamic adaptive weight adjustment fusion (MMT-DAWA).
- (2)
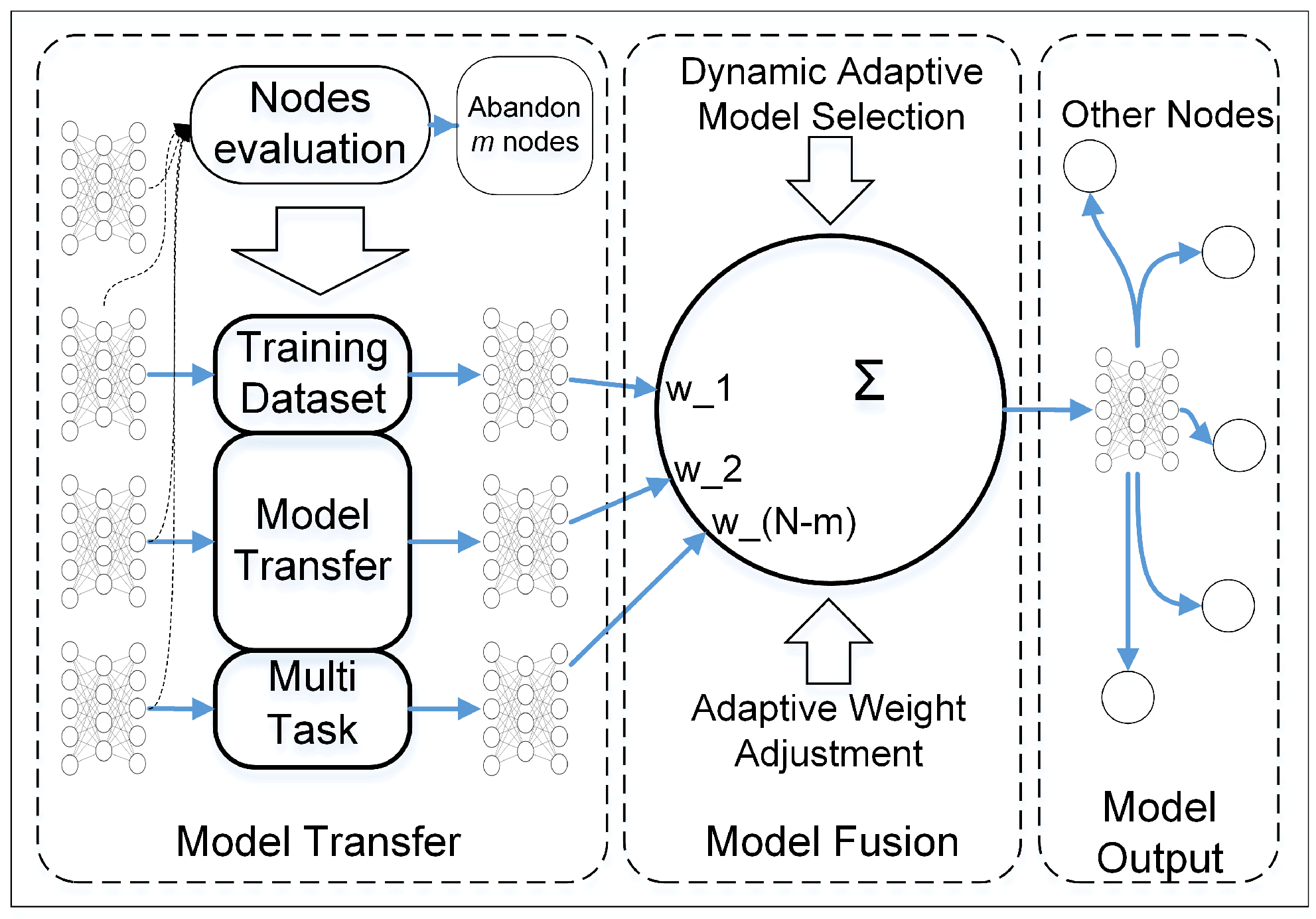
Considering the different data distributions between wind turbines in a cluster resulting from various working conditions and environments, multi-task transfer-based elastic weighted consolidation with a fisher information matrix constricting model parameters has been introduced to reduce the impact of domain drift.
- (3)
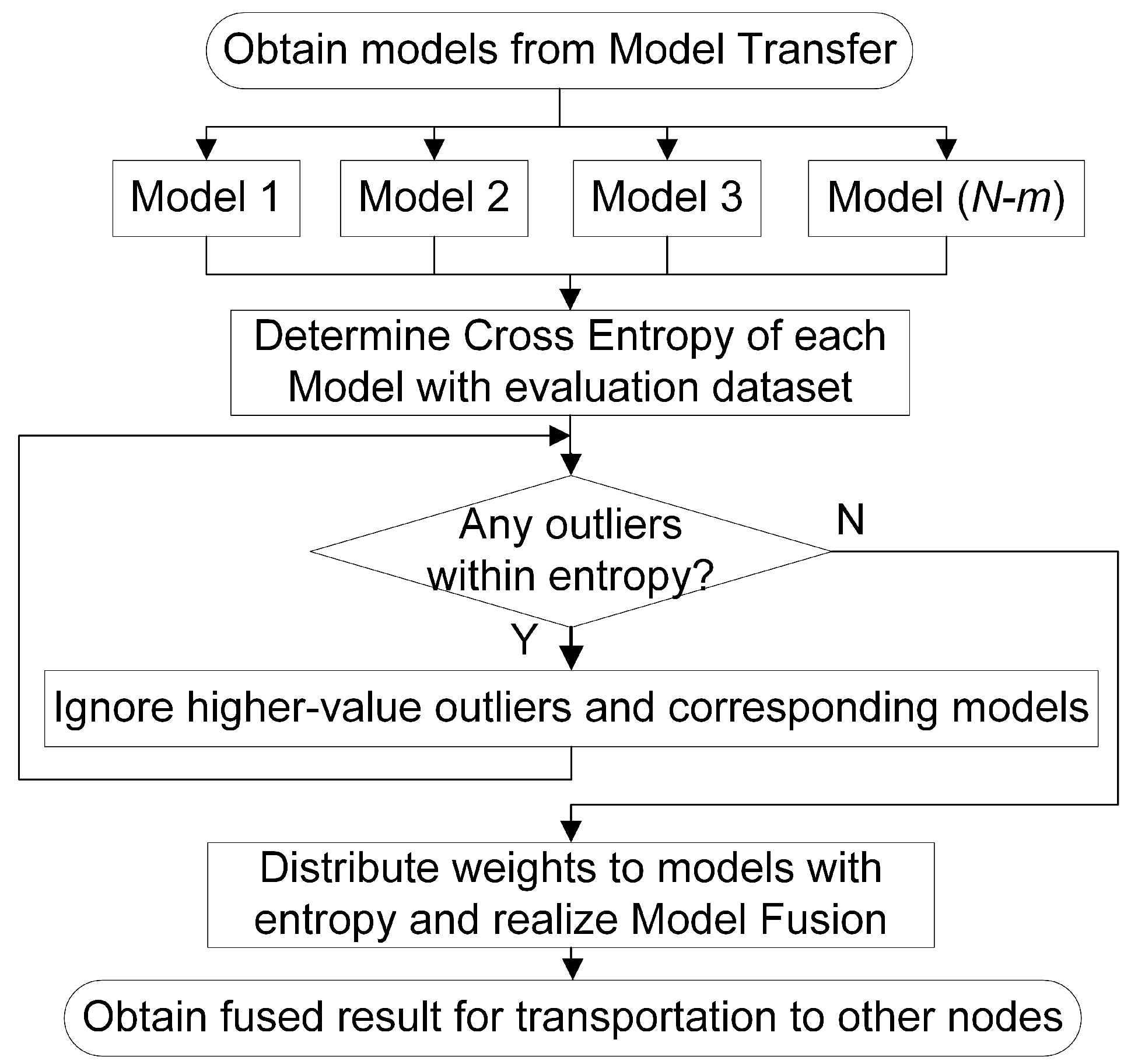
To decrease the influence of noise on the model training process at each turbine in a cluster, a modified dynamic adaptive weight adjustment model fusion method based on a federated average algorithm has been proposed, with model processes of outlier monitoring, determination of evaluation criteria for outliers, and weight distribution.
The remainder of this paper is organized as follows.
Section 2 presents related works with some research and applications related to the topic.
Section 3 describes the proposed algorithm and model training process.
Section 4 presents the experiment, discussing the model performance and analysis of the proposed method.
Section 5 concludes the study and proposes the future research directions.
2. Related Works
Artificial intelligence has greatly improved the model performance and diagnostic accuracy in condition monitoring and fault diagnosis [
17]. A great number of studies on intelligent fault diagnosis adapting to a single machine [
18,
19] instead of multiple machines in a cluster have been carried out. Several methods of traditional machine learning (ML) have been applied [
20,
21,
22] to solve the problems of fault diagnosis such as the hidden Markov model, support vector machine, gray neural network, and artificial neural network. With the development of ML and the computing ability of modern computers in the big data era, the idea of deep learning (DL) [
23] has been applied. Common DL networks include convolutional neural networks [
24], recurrent neural networks [
25], sparse auto encoders [
26], and generative adversarial networks [
27]. When considering the situation of non-independent and identically distributed (Non-IID) data under various working conditions, TL with knowledge transfer is introduced to the process of fault diagnosis [
28].
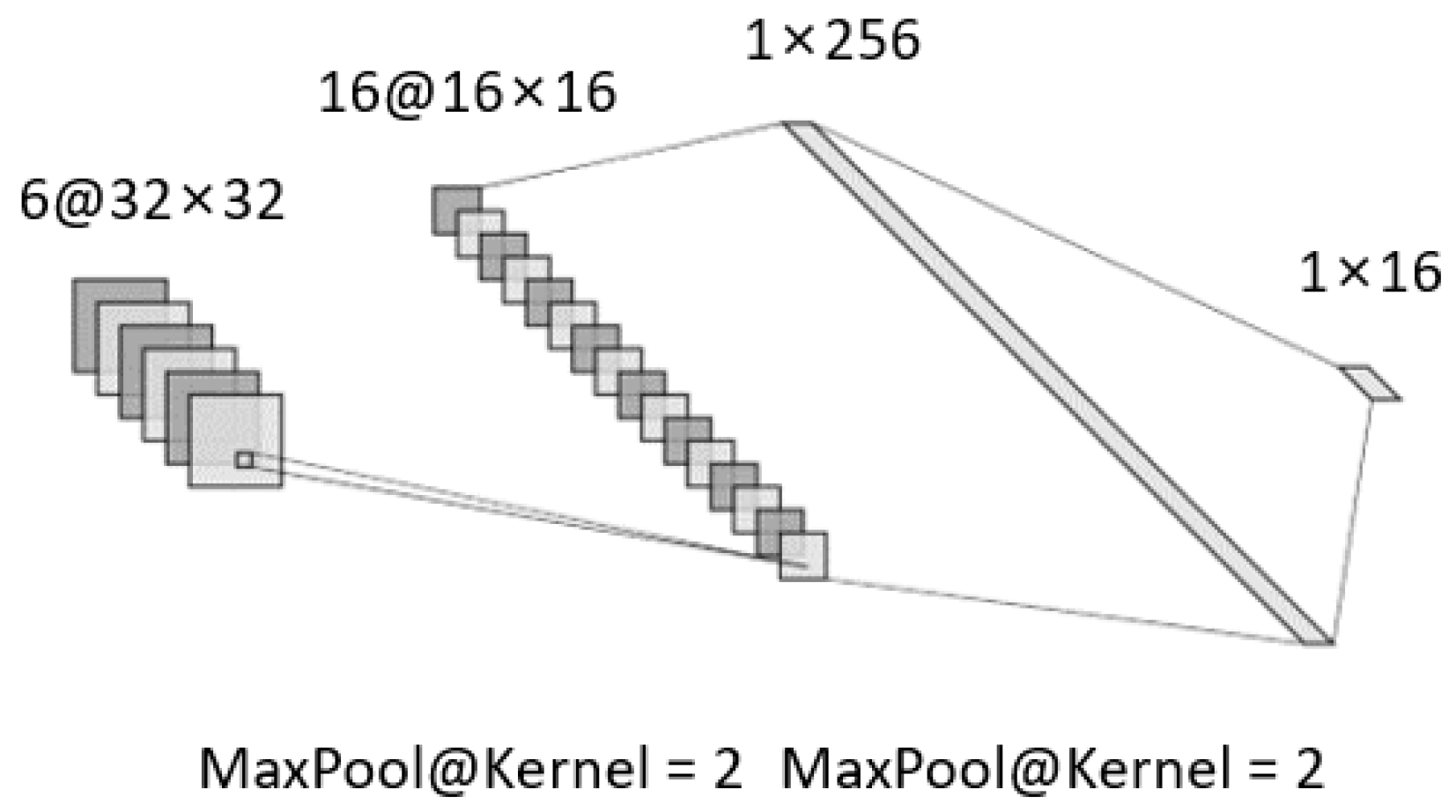
Among them, convolutional neural network (CNN) [
29] is broadly used in the pattern recognization and fault diagnosis, which contains a convolution layer, a pooling layer, and a fully connected layer. Combined with the convolution calculation, the number of model parameters is reduced compared with that of the fully connected layer. In the network training process, the cross-entropy loss is often selected for backpropagation. During model training, the updating form of the model parameters often adopts the stochastic gradient descent (SGD) algorithm with momentum, which introduces a momentum accumulating historical gradient information based on traditional SGD to speed up the processing of gradient descent. It accumulates the average moving value of the current gradient and all previous gradient exponential attenuation and continues to move in this direction.
Traditional methods rely on single machines and simple conditions of a wind turbine, whereas fusion methods are required in multi-machines corresponding to various conditions of wind turbine clusters. A reasonable and effective approach to information exchange is essential for a wind turbine cluster. There are two mainstream methods of information exchange within clusters: data exchange and model exchange.
Data exchange indicates gathering all the local data of different machines as one dataset, modeling uniformly, and updating the parameters with model training. In such cases, TL is broadly used with excellent performance when there are different feature spaces or distributions between the source and target data [
30]. A popular explanation of TL is to transfer the knowledge learned through the training model in one data domain to another data domain to solve the corresponding problems. In TL, different domains are defined according to different feature spaces or edge probability distributions. In mechanical fault diagnosis, the data fields corresponding to different machine operating conditions, locations, and machine individuals can be regarded as different domains. Different tasks have different label spaces, corresponding to different fault types, states, and degrees. A large number of TL applications for fault diagnosis have been carried out, and excellent results have been obtained from model training and experiments [
31,
32,
33]. In addition to transfer fault diagnosis methods focusing on the adaptation of a single source domain, in an actual industrial scene, multiple labeled source domains can be obtained in a wind turbine cluster. Therefore, researchers have proposed methods of multi-source domain transfer learning fault diagnosis [
34], adversarial domain adaptation with classifier alignment [
35], and so on. Such a mode of data exchange makes the evaluation criteria more standardized and unified, and model training for fault diagnosis is more convenient to manage. However, considering multiple wind turbines in a cluster, the raw data of each turbine proportionally increase the amount of data, resulting in a high cost of data storage, low data transmission efficiency, and low quality and efficiency in data management.
Model exchange refers to fusing the models in different machines into a more comprehensive model through the relevant algorithms of model fusion, saving raw operation data locally and conducting model training at each turbine. Ensemble learning is an effective way to deal with voting, bagging and boosting. In addition, to improve the classification accuracy when the training data are insufficient, researchers have proposed an ensemble transfer learning (ETL) framework [
36], which combines the methods of TL and EL. A large number of applications of EL or ETL for machine fault diagnosis have been reported in recent years [
37,
38,
39,
40]. However, owing to data distribution differences, data volume differences, and fault data sample differences, there are still obstacles to the applications of fault diagnosis in wind turbine clusters such as efficiency in data management and calling, and the accuracy of the fused model of the ensemble. With technological progress in the era of big data, federated learning [
41], industrial Internet of Things [
42,
43], and cloud-edge collaborative computing [
44] have been applied to fault diagnosis research. FL is a branch of ML with the purpose of decentralization [
45], which focuses on building and optimizing diagnosis models in the situation of distributed datasets, constructing the corresponding federated network, and using the distributed data of each node in the network to improve the overall model performance.
Ideally, the intelligent fault diagnosis method for large-scale wind turbine clusters does not consider data communication problems, such as channel width and data flow. However, in industrial and practical applications, owing to the hardware structure and other factors, information transmission in fault diagnosis networks is limited. Therefore, researchers have proposed effective FL frameworks and algorithms to solve the problem of obstacles [
46,
47,
48]. These methods rely on simple working conditions and operating environments, and it is impossible to obtain excellent results in complex situations. In a wind turbine cluster, various turbines possess various distributions of data, so TL has been introduced to the methods in the cluster combined with FL frameworks, called federated transfer learning (FTL), where models perform excellently in fault diagnosis in clusters [
49,
50,
51].
However, the lack of constraining model parameters leads to an uncertain convergence rate, low recognition accuracy of the model, and weak generalization ability. Therefore, to accurately locate, identify, classify, and predict the fault development trend in the entire life cycle of a wind turbine gearbox, it is essential to deal with the balance between the management, calling of a huge dataset, and application of big data for gearbox fault diagnosis under complex working conditions in a wind turbine cluster.
5. Conclusions
In this study, a P2PNet for fault diagnosis in a large-scale wind turbine cluster and a method belonging to the network are proposed. Each node in P2PNet is equivalent and functional replicable, so a multiple model transfer and dynamic adaptive weight adjustment (MMT-DAWA) model fusion method for tasks in a single node corresponding to a wind turbine gearbox in the cluster is proposed. Each participant in P2PNet saves raw data locally, and only the model parameters are transmitted among nodes. Within a certain node, there are three main steps: model transfer, fusion, and transmission. When the node receives several models from other nodes, it adopts a model transfer based on MTL with EWC constraining model parameters. Then, based on the FL framework, several models are fused by DAWA model fusion with two stages of dynamic adaptive outlier monitoring-based model selection and adaptive weight adjustment-based model fusion. Finally, a better performing model is obtained not only for operation monitoring and fault diagnosis locally but also for transmission to other nodes for iteration and operation. After multi-round iteration and optimization, a state of collaborative intelligence is achieved, where the model performance is better than that of single machine intelligence.
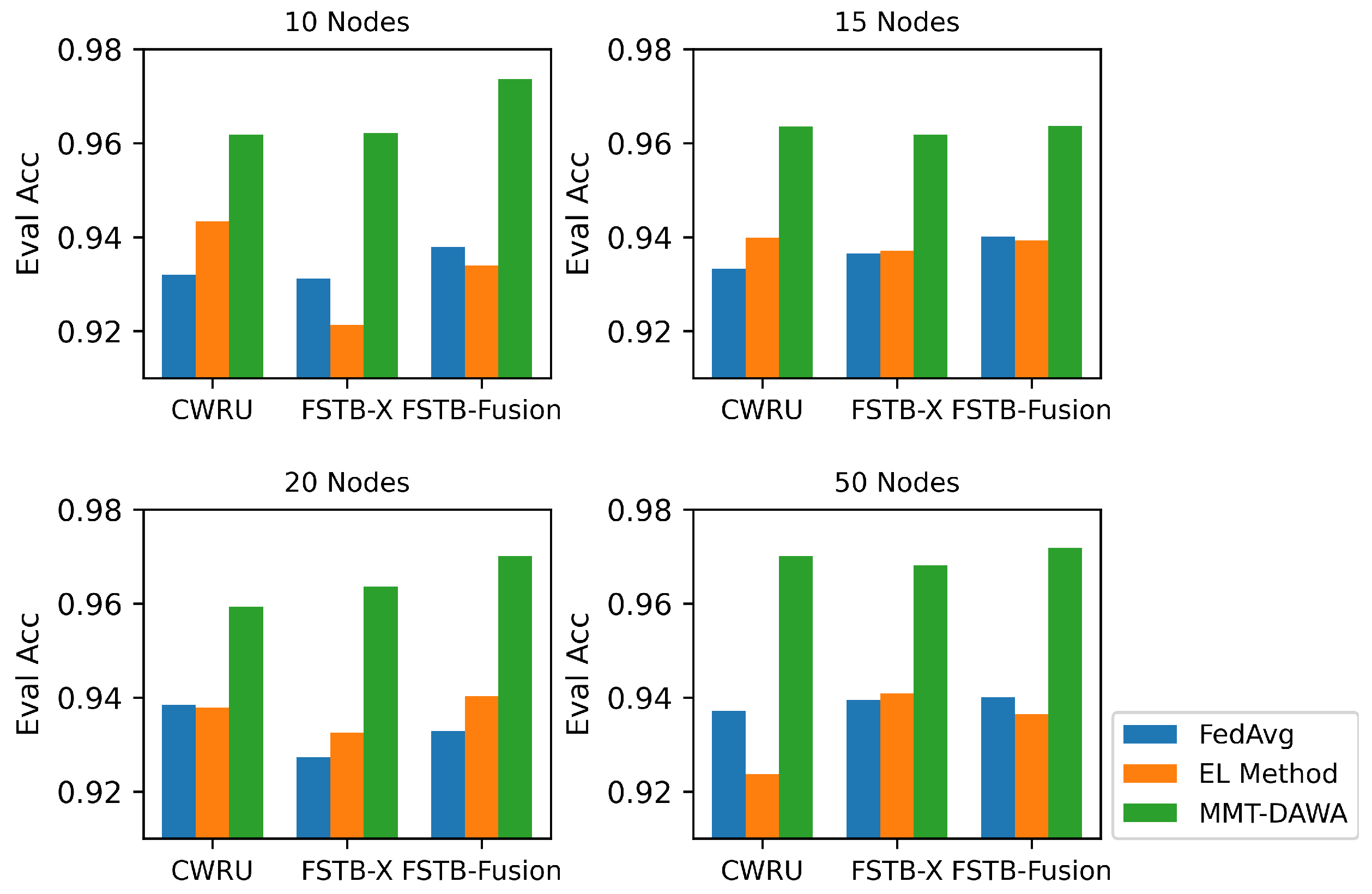
Experiments show the effectiveness and superiority of the methods proposed in this paper. Under any numbers of nodes, the performance of collaborative intelligence is always better than that of single machine intelligence. In any case of the experiment setting, the proposed method performs better than traditional federated average algorithm and ensemble learning-based voting methods for the corresponding tasks.
Therefore, the method proposed in this study is valid in terms of its effectiveness and superiority. This provides a specfic solution to the problems of poor performance of the fault diagnosis model when machine data are insufficient and the data management has obstacles in large-scale turbine clusters. Comparing with similar solutions, the proposed method performs better in terms of the information processing abilitity to deal with data management-based fault diagnosis in a wind turbine cluster. It is also a guidance for other types of machine clusters to implement fault diagnosis.
The future research direction is to combine the algorithm in this study with the comprehensive model transfer and model fusion of various kinds of multimodal signals, striving to understand the operation status of the wind turbines in an all-around way and providing reasonable fault diagnosis results and feasible maintenance schemes.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}