
Double-Attention YOLO: Vision Transformer Model Based on Image Processing Technology in Complex Environment of Transmission Line Connection Fittings and Rust Detection


Abstract
:1. Introduction
2. The Proposed Theory
2.1. Hardware System and Model Deployment
2.2. Fog Removal Algorithm for Complex Scenes Based on Improved Dark Channel Prior
2.3. Model Structure of Double-Attention YOLO
2.3.1. The Architecture of Vision Transformer
2.3.2. Attention Mechanism Unit
2.3.3. The Principle of the YOLOv5 Algorithm and BiFPN Feature Fusion
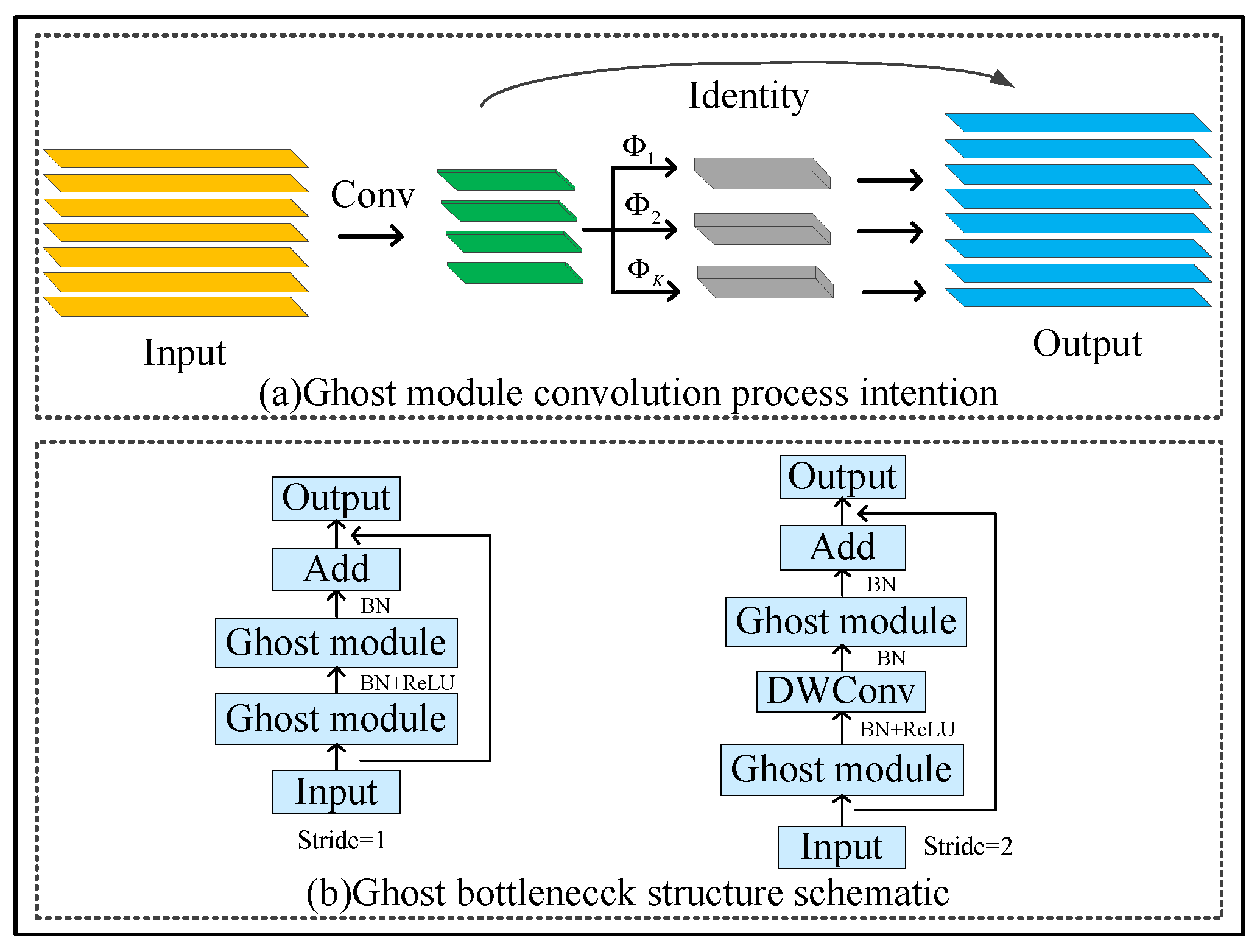
2.3.4. Ghost Net Model Compression
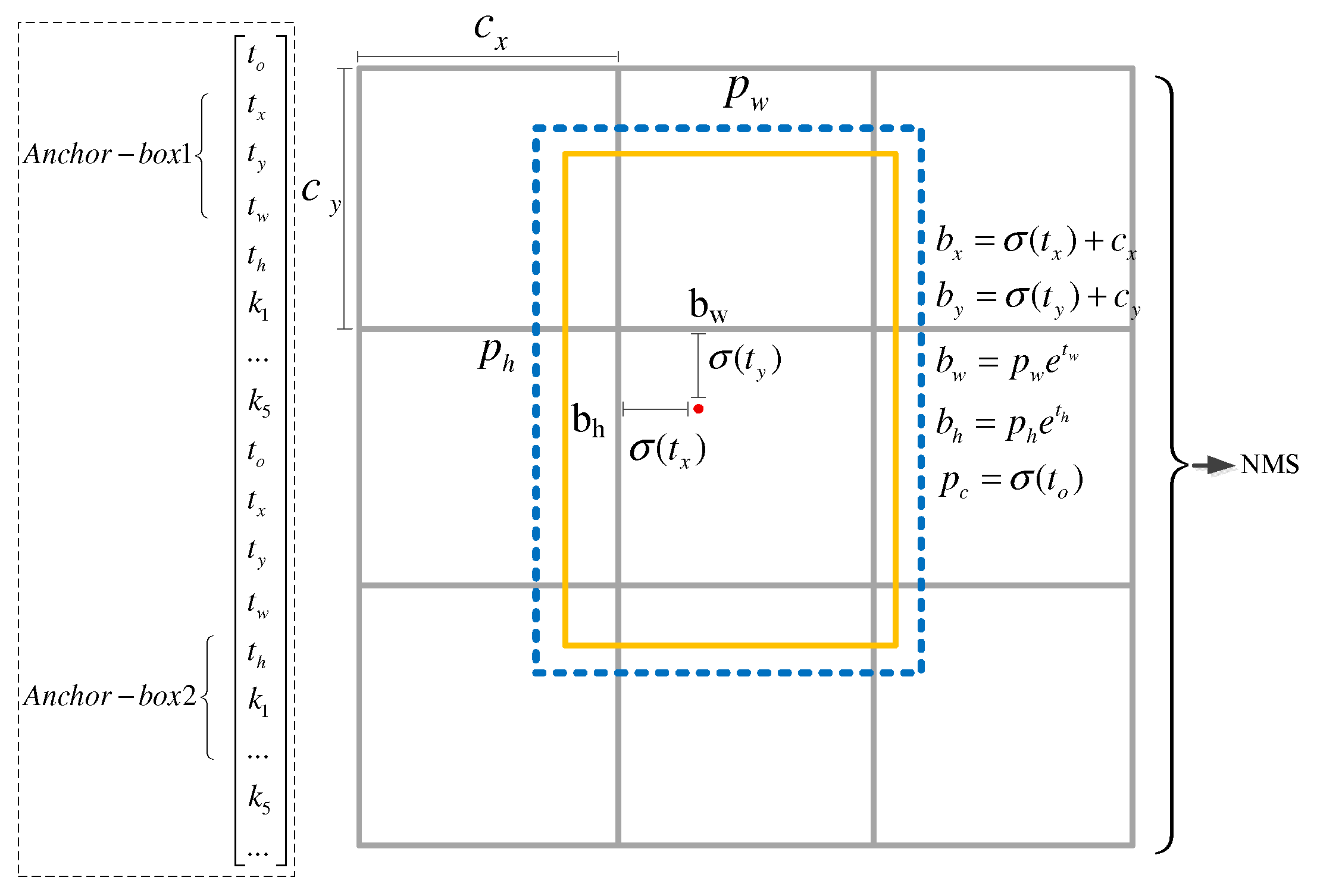
2.4. Improved K-Means Anchors Clustering
3. Experimental Results
3.1. The Application of the Improved Dark Channel Prior Defogging Algorithm in this Study
3.2. The Anchors Clustering Based on Improved K-Means and Genetic Algorithm Optimization
3.3. Model Performance Verification Experiment
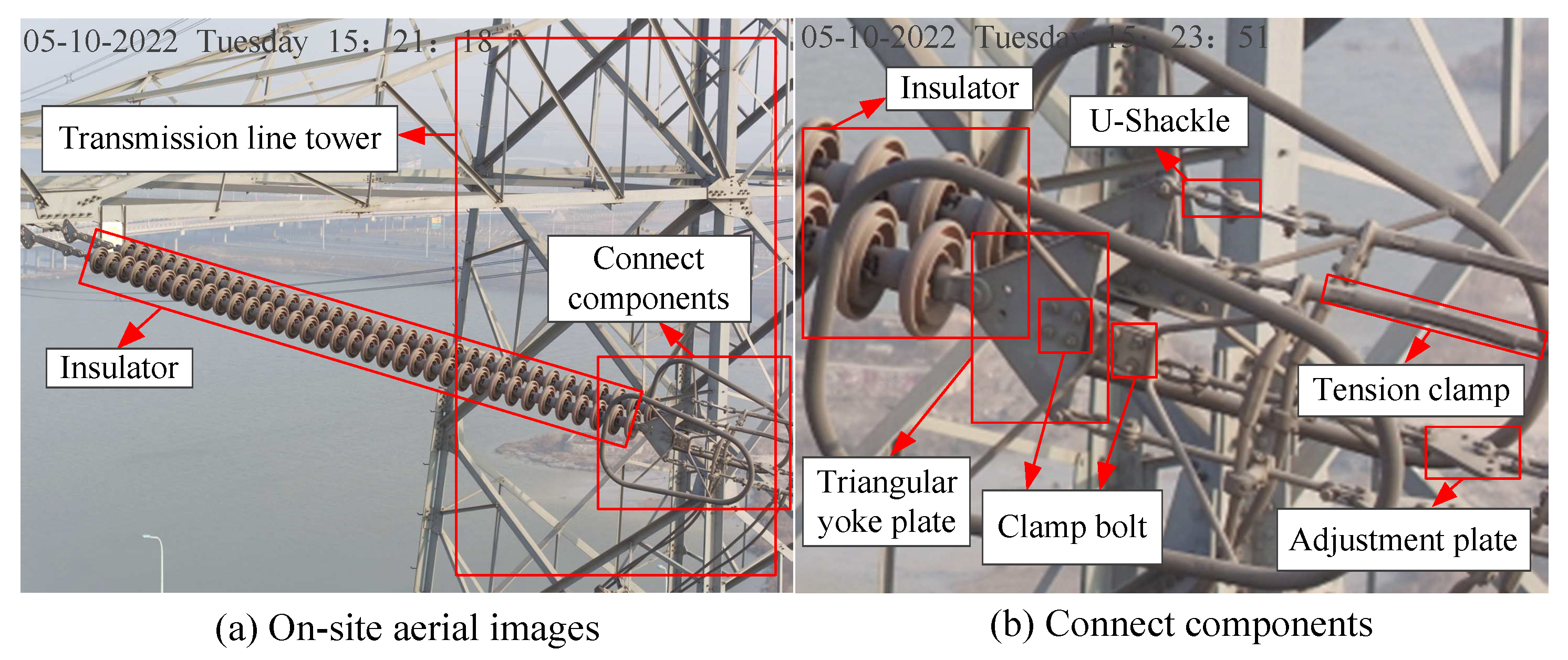
3.3.1. Data Preprocessing
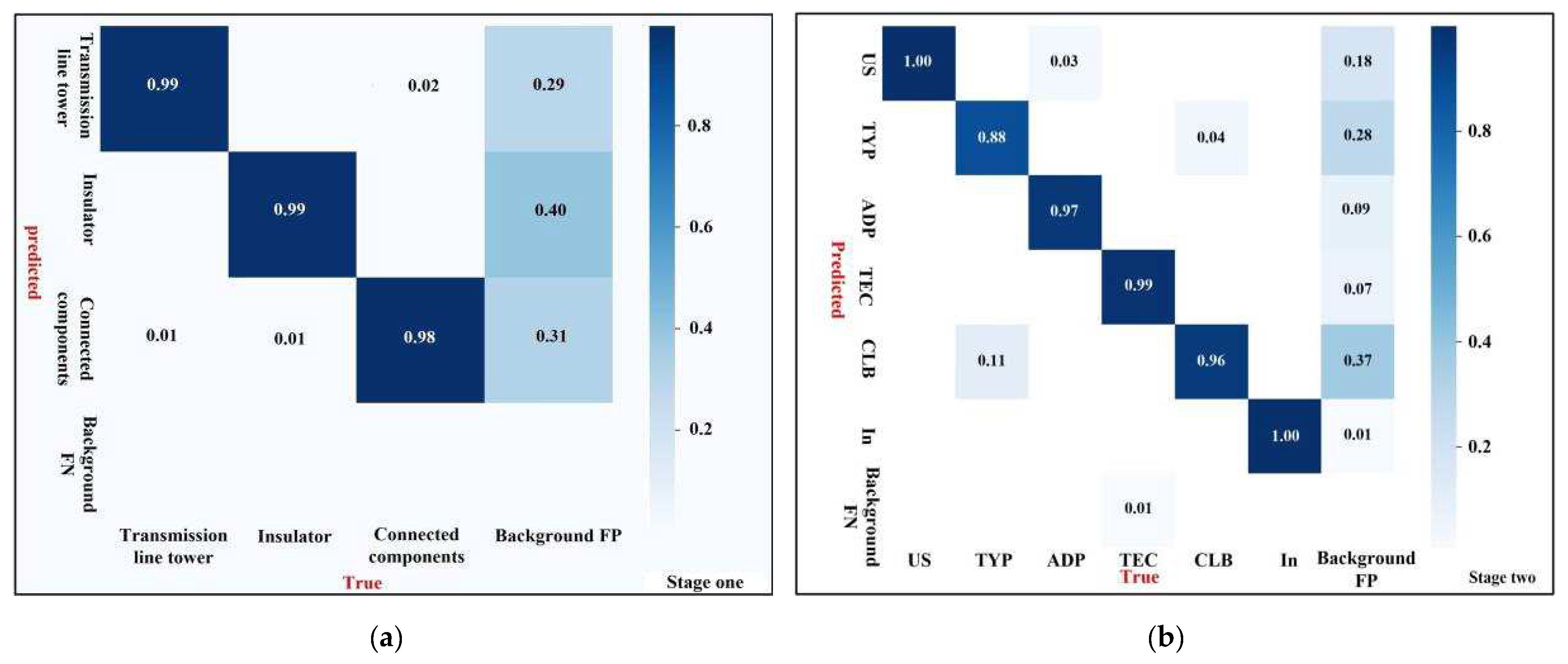
3.3.2. Two Stage Training and Testing Results
3.3.3. Design of Condition Monitoring System for Transmission Line Connection Fittings
4. Conclusions
- An improved dark channel prior defogging algorithm is proposed to solve the preprocessing problem of transmission line fittings in complex environments.
- The potential advantages and application value of the multi-head self-attention mechanism in Vision Transformer for dense target prediction tasks are verified.
- In the data preprocessing stage, the advanced MixUp data enhancement strategy is adopted, and the feature fusion of multi-scale targets is realized through the BiFPN structure. The optimal anchors are generated by improved the K-Means clustering algorithm and the genetic algorithm to match the diversity of target information in the datasets.
- In YOLOv5, Vision Transformer, channel and spatial attention mechanism, and the GhostNet model compression unit are integrated. Compared with the original baseline model and the improved baseline model, the performance of YOLOv5 is greatly improved, and it is better than several current advanced target detection algorithms.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; Volume 28. [Google Scholar]
- Wu, W.; Yin, Y.; Wang, X.; Xu, D. Face Detection with Different Scales Based on Faster R-CNN. IEEE Trans. Cybern. 2015, 49, 4017–4028. [Google Scholar] [CrossRef] [PubMed]
- Mai, X.; Zhang, H.; Jia, X.; Meng, M.Q. Faster R-CNN With Classifier Fusion for Automatic Detection of Small Fruits. IEEE Trans. Autom. Sci. Eng. 2021, 17, 1555–1569. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lu, X.; Ji, J.; Xing, Z.; Miao, Q. Attention and Feature Fusion SSD for Remote Sensing Object Detection. IEEE Trans. Instrum. Meas. 2021, 70, 5501309. [Google Scholar] [CrossRef]
- Ge, H.; Dai, Y.; Zhu, Z.; Liu, R. A Deep Learning Model Applied to Optical Image Target Detection and Recognition for the Identification of Underwater Biostructures. Machines 2022, 10, 809. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- He, J.; Zhao, L.; Yang, H.; Zhang, M.; Li, W. HSI-BERT: Hyperspectral image classification using the bidirectional encoder representation from transformers. IEEE Trans. Geosci. Remote Sens. 2019, 58, 165–178. [Google Scholar] [CrossRef]
- Sung, C.; Dhamecha, T.I.; Mukhi, N. Improving short answer grading using transformer-based pre-training. In Proceedings of the International Conference on Artificial Intelligence in Education, Chicago, IL, USA, 25–29 June 2019; Springer: Cham, Switzerland, 2019; pp. 469–481. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. J. Softw. Eng. Appl. 2018, 12, 11. [Google Scholar]
- Chen, Y.; Zhang, X.; Chen, W.; Li, Y.; Wang, J. Research on Recognition of Fly Species Based on Improved RetinaNet and CBAM. IEEE Access 2020, 8, 102907–102919. [Google Scholar] [CrossRef]
- Wei, S.; Qu, Q.; Su, H.; Shi, J.; Zeng, X.; Hao, X. Intra-pulse modulation radar signal recognition based on Squeeze-and-Excitation networks. Signal Image Video Process. 2020, 14, 1133–1141. [Google Scholar] [CrossRef]
- Jiang, G.; Jiang, X.; Fang, Z.; Chen, S. An efficient attention module for 3d convolutional neural networks in action recognition. Appl. Intell. 2021, 51, 7043–7057. [Google Scholar] [CrossRef]
- Xie, J.; Miao, Q.; Liu, R.; Xin, W.; Tang, L.; Zhong, S.; Gao, X. Attention adjacency matrix based graph convolutional networks for skeleton-based action recognition. Neurocomputing 2021, 440, 230–239. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Pereira, N.S.; Plaza, J.; Plaza, A. Ghostnet for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10378–10393. [Google Scholar] [CrossRef]
- Yue, X.; Li, H.; Shimizu, M.; Kawamura, S.; Meng, L. YOLO-GD: A Deep Learning-Based Object Detection Algorithm for Empty-Dish Recycling Robots. Machines 2022, 10, 294. [Google Scholar] [CrossRef]
- Du, F.; Jiao, S.; Chu, K. Research on Safety Detection of Transmission Line Disaster Prevention Based on Improved Lightweight Convolutional Neural Network. Machines 2022, 10, 588. [Google Scholar] [CrossRef]
- Yan, S.; Chen, P.; Liang, S.; Zhang, L.; Li, X. Target Detection in Infrared Image of Transmission Line Based on Faster-RCNN. In Proceedings of the International Conference on Advanced Data Mining and Applications, Sydney, NSW, Australia, 2–4 February 2022; Springer: Cham, Switzerland, 2022; pp. 276–287. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Wang, B.; Chen, S.; Wang, J.; Hu, X. Residual feature pyramid networks for salient object detection. Vis. Comput. 2020, 36, 1897–1908. [Google Scholar] [CrossRef]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Ding, X.; Paisley, J. PanNet: A deep network architecture for pan-sharpening. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5449–5457. [Google Scholar]
- Chen, J.; Mai, H.; Luo, L.; Chen, X.; Wu, K. Effective feature fusion network in BIFPN for small object detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 699–703. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, C.Y.; Liao HY, M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ottakath, N.; Al-Ali, A.; Al Maadeed, S. Vehicle identification using optimised ALPR. In Proceedings of the Qatar University Annual Research Forum and Exhibition (QUARFE 2021), Doha, Qatar, 20 October 2021. [Google Scholar]
- Ding, L.; Goshtasby, A. On the Canny edge detector. Pattern Recognit. 2001, 34, 721–725. [Google Scholar] [CrossRef]
- Al-Rahlawee AT, H.; Rahebi, J. Multilevel thresholding of images with improved Otsu thresholding by black widow optimization algorithm. Multimed. Tools Appl. 2021, 80, 28217–28243. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Tufail, Z.; Khurshid, K.; Salman, A.; Nizami, I.F.; Khurshid, K.; Jeon, B. Improved Dark Channel Prior for Image Defogging Using RGB and YCbCr Color Space. IEEE Access 2018, 6, 32576–32587. [Google Scholar] [CrossRef]
- Fan, T.; Li, C.; Ma, X.; Chen, Z.; Zhang, X.; Chen, L. An improved single image defogging method based on Retinex. In Proceedings of the International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 410–413. [Google Scholar] [CrossRef]
- Koley, S.; Sadhu, A.; Roy, H.; Dhar, S. Single Image Visibility Restoration Using Dark Channel Prior and Fuzzy Logic. In Proceedings of the International Conference on Electronics, Materials Engineering & Nano-Technology (IEMENTech), Kolkata, India, 4–5 May 2018; pp. 1–7. [Google Scholar]
- Kapoor, R.; Gupta, R.; Son, L.H.; Kumar, R.; Jha, S. Fog removal in images using improved dark channel prior and contrast limited adaptive histogram equalization. Multimed. Tools Appl. 2019, 78, 23281–23307. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
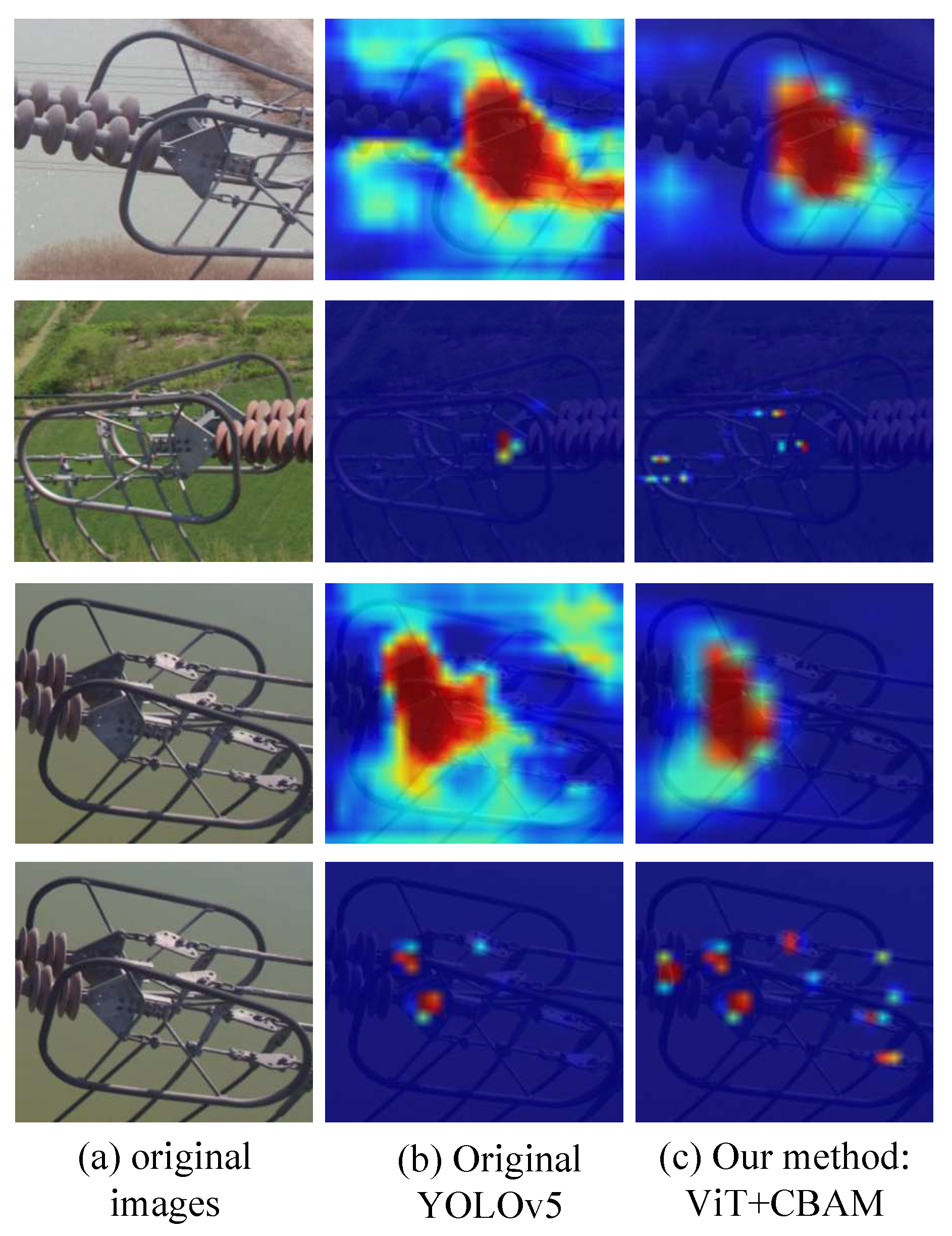{kind=link}
{kind=link}
{kind=link}
{kind=link}
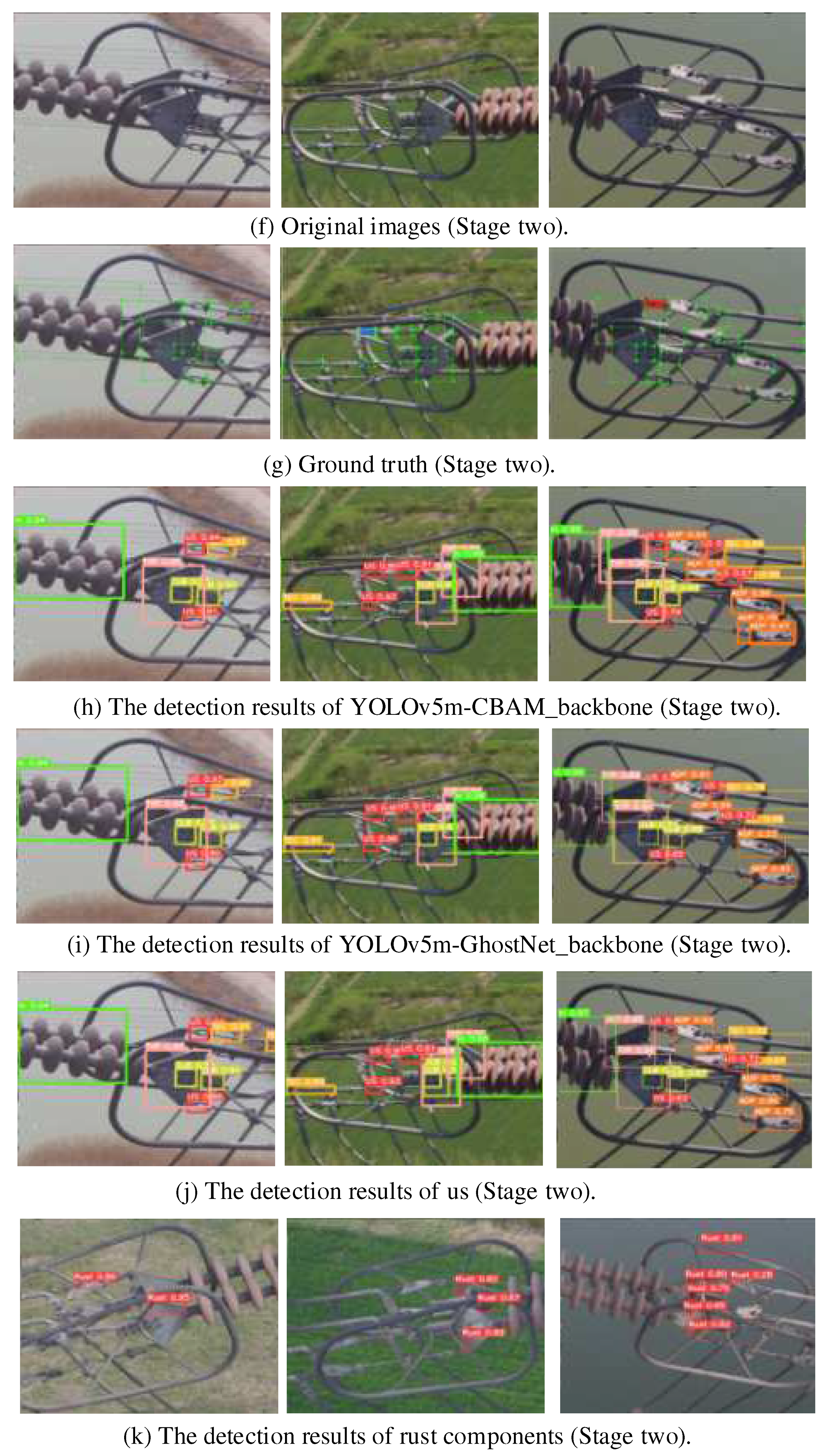{kind=link}
{kind=link}
{kind=link}
| Stage | Methods | Best Possible Recall (%) | Fitness | Anchors |
|---|---|---|---|---|
| Stage one | Original K-means | 0.99287 | 0.78492 | [27,10] [11,55] [9,11] [62,22] [19,31] [79,39] [53,150] [29,147] [24,101] |
| Our optimization | 1.00000 (+0.713) | 0.78575 (+0.083) | [25,11] [11,53] [10,11] [62,23] [19,30] [77,39] [51,151] [29,147] [22,100] | |
| Stage two | Original K-means | 0.99839 | 0.81036 | [[8,7] [14,12] [21,6] [20,41] [33,9] [18,28] [76,50] [34,54] [45,38] |
| Our optimization | 0.99951 (+0.112) | 0.81751 (+0.715) | [9,7] [15,13] [21,6] [21,41] [32,8] [18,29] [76,51] [34,55] [45,39] |
| Model | Backbone | Params | FLOPs | AR | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|---|
| YOLOv5s (Baseline) | CSP-Darknet53 | 7.0 M | 15.8 G | 0.991 | 0.9023 | 93 |
| YOLOv5s-SENet | CSPv5+SE block | 7.2 M | 16.6 G | 0.994 | 0.9406 | 96 |
| YOLOv5s-CA | CSPv5+Coordinate attention block | 7.13 M | 16.3 G | 0.992 | 0.9418 | 91 |
| YOLOv5s-ECA | CSPv5+Efficient channel attention | 7.08 M | 16.5 G | 0.990 | 0.9113 | 93 |
| YOLOv5s-CBAM_backbone | CSPv5+CBAM block | 7.1 M | 16.8 G | 0.995 | 0.9425 | 90 |
| YOLOv5m-Sufflenetv2_backbone | ShuffleNetv2 | 21.2 M | 40.4 G | 0.988 | 0.8812 | 61 |
| YOLOv5m-PP-LCNet_backbone | PP-LCNet | 21.6 M | 41.5 G | 0.988 | 0.8796 | 79 |
| YOLOv5m-Mobilenetv3Small_backbone | MobileNet_v3Small | 20.3 M | 38.2 G | 0.992 | 0.8909 | 67 |
| YOLOv5m-EfficientNetLite_backbone | EfficientNet_Lite | 22.9 M | 43.8 G | 0.990 | 0.9144 | 65 |
| YOLOv5m-GhostNet_backbone | GhostNet | 24.3 M | 42.3 G | 0.994 | 0.9187 | 63 |
| YOLOv5m-Swin_Transformer _backbone | CSPv5+Swin Transformer block | 102.3 M | 225.9 G | 0.989 | 0.9464 | 19 |
| Ours | CSPv5+ViT+CBAM block | 112.9 M | 270.1 G | 0.996 (0.3% ↑) | 0.9480 (4.6% ↑) | 20 |
| Model | Backbone | Params | FLOPs | AR | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|---|
| YOLOv5m (Baseline) | CSP-Darknet53 | 21.2 M | 49.2 G | 0.986 | 0.8241 | 79 |
| YOLOv5m-SENet | CSPv5+SE block | 21.3 M | 48.7 G | 0.986 | 0.8241 | 84 |
| YOLOv5m-CA | CSPv5+Coordinate attention block | 21.3 M | 48.5 G | 0.987 | 0.8246 | 83 |
| YOLOv5m-ECA | CSPv5+Efficient channel attention | 21.3 M | 48.6 G | 0.987 | 0.8239 | 84 |
| YOLOv5m-CBAM_backbone | CSPv5+CBAM block | 21.3 M | 48.7 G | 0.989 | 0.8264 | 79 |
| YOLOv5m-Sufflenetv2_backbone | ShuffleNetv2 | 21.2 M | 40.4 G | 0.987 | 0.8432 | 62 |
| YOLOv5m-PP-LCNet_backbone | PP-LCNet | 21.6 M | 41.5 G | 0.988 | 0.8346 | 80 |
| YOLOv5m-Mobilenetv3Small_backbone | MobileNet_v3Small | 20.3 M | 38.3 G | 0.993 | 0.8324 | 65 |
| YOLOv5m-EfficientNetLite_backbone | EfficientNet_Lite | 22.8 M | 43.8 G | 0.993 | 0.8432 | 58 |
| YOLOv5m-GhostNet_backbone | GhostNet | 24.2 M | 42.3 G | 0.992 | 0.8474 | 53 |
| YOLOv5m-Swin_Transformer _backbone | CSPv5+Swin Transformer block | 102.3 M | 225.2 G | 0.982 | 0.8337 | 15 |
| Ours | CSPv5+ViT+CBAM block | 112.9 M | 270.3 G | 0.994 (0.8% ↑) | 0.8674 (4.3% ↑) | 16 |
| Framework | Backbone | mAP@0.5 | mAP@0.75 | mAP@0.5:0.95 |
|---|---|---|---|---|
| ATSS | ResNet50 | 0.988 | 0.945 | 0.846 |
| Faster RCNN+FPN | ResNet50 | 0.949 | 0.767 | 0.672 |
| FCOS | ResNet50 | 0.970 | 0.795 | 0.685 |
| SSD | VGG16 | 0.969 | 0.826 | 0.699 |
| RetinaNet | ResNet50 | 0.885 | 0.566 | 0.531 |
| Deformable DETR | ResNet50 | 0.976 | 0.767 | 0.661 |
| YOLOv5m-CBAM_backbone | CSPv5+CBAM block | 0.9941 | 0.904 | 0.8264 |
| YOLOv5m-GhostNet_backbone | GhostNet | 0.9937 | 0.9108 | 0.8374 |
| YOLOv5m-Swin Transformer _backbone | CSPv5+Swin Transformer block | 0.9940 | 0.9177 | 0.8337 |
| Ours | CSPv5+ViT +CBAM block | 0.9948 | 0.9302 | 0.8674 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Z.; Huang, X.; Ji, C.; Zhang, Y. Double-Attention YOLO: Vision Transformer Model Based on Image Processing Technology in Complex Environment of Transmission Line Connection Fittings and Rust Detection. Machines 2022, 10, 1002. https://doi.org/10.3390/machines10111002
Song Z, Huang X, Ji C, Zhang Y. Double-Attention YOLO: Vision Transformer Model Based on Image Processing Technology in Complex Environment of Transmission Line Connection Fittings and Rust Detection. Machines. 2022; 10(11):1002. https://doi.org/10.3390/machines10111002
Chicago/Turabian StyleSong, Zhiwei, Xinbo Huang, Chao Ji, and Ye Zhang. 2022. "Double-Attention YOLO: Vision Transformer Model Based on Image Processing Technology in Complex Environment of Transmission Line Connection Fittings and Rust Detection" Machines 10, no. 11: 1002. https://doi.org/10.3390/machines10111002