
Constant-Stress Modeling of Log-Normal Data under Progressive Type-I Interval Censoring: Maximum Likelihood and Bayesian Estimation Approaches

Abstract
:1. Introduction
2. Model and Underlying Assumptions
2.1. Model Description
2.2. Basic Assumptions
- The lifetime of test units follows a log-normal distribution at stress level , with PDF given by
- For the log-normal location parameter , the life-stress model is assumed to be log-linear, i.e., it is described as
3. Maximum Likelihood Estimation
3.1. EM Algorithm
3.2. Midpoint Approximation Method
3.3. Asymptotic Standard Errors
4. Bayesian Estimation
4.1. MCMC Method
| Algorithm 1: M-H algorithm |
|
4.2. Tierney–Kadane Method
5. Simulation Study and Data Analysis
5.1. Monte Carlo Simulation Study
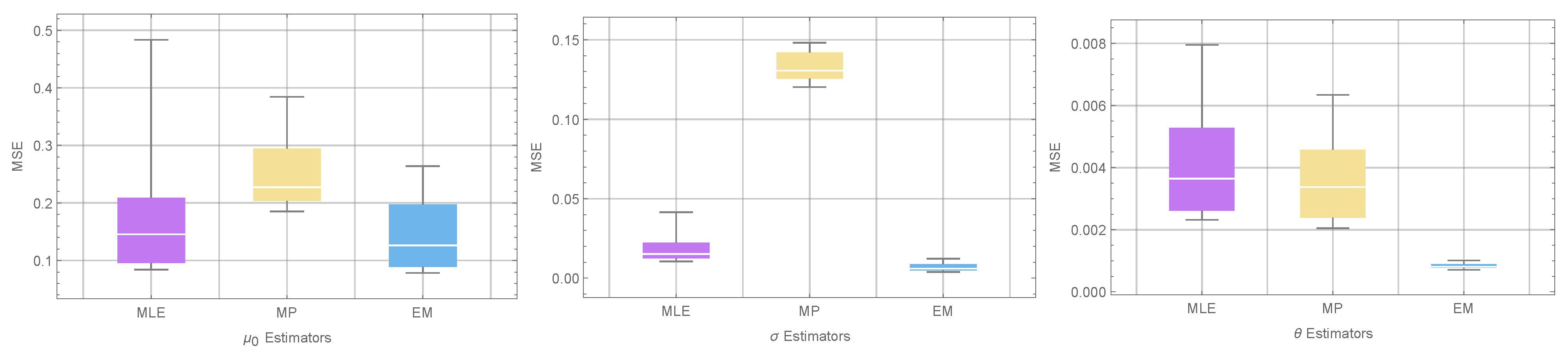
- For a fixed censoring scheme, the trend observed in the tabulated results indicates that as the sample size n increases, the MSE and RAB values of all estimates decrease. This trend aligns with the statistical theory, which suggests that larger sample sizes tend to result in more accurate parameter estimates.
- The Bayesian estimators consistently outperform the MLEs, EM estimators, and MP estimators in terms of MSE and RAB values. This highlights the superior performance of the Bayesian approach in estimation tasks.
- Among the different progressive censoring schemes , and , all the estimates obtained under scheme (traditional type-I interval censoring) exhibit the smallest MSE and RAB values compared to schemes and . This result is in line with expectations, as longer testing duration and lower censoring rates generally lead to more accurate parameter estimation.
- The BEs of the parameters under the LINEX loss function display higher accuracy compared to the estimators under the SE and GE loss functions.
5.2. Data Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nelson, W.B. Accelerated Testing: Statistical Models, Test Plans, and Data Analysis; John Wiley & Sons: New York, NY, USA, 2009; Volume 344. [Google Scholar]
- Meeker, W.Q.; Escobar, L.A. Statistical Methods for Reliability Data; John Wiley & Sons: New York, NY, USA, 2014. [Google Scholar]
- Bagdonavicius, V.; Nikulin, M. Accelerated Life Models: Modeling and Statistical Analysis; Chapman and Hall: Boca Raton, FL, USA, 2001. [Google Scholar]
- Limon, S.; Yadav, O.P.; Liao, H. A literature review on planning and analysis of accelerated testing for reliability assessment. Qual. Reliab. Eng. Int. 2017, 33, 2361–2383. [Google Scholar] [CrossRef]
- Zheng, G. A characterization of the factorization of hazard function by the Fisher information under type-II censoring with application to the Weibull family. Stat. Probab. Lett. 2001, 52, 249–253. [Google Scholar] [CrossRef]
- Xu, H.; Fei, H. Approximated optimal designs for a simple step-stress model with type-II censoring, and Weibull distribution. In Proceedings of the 2009 8th International Conference on Reliability, Maintainability and Safety, Chengdu, China, 20–24 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1203–1207. [Google Scholar]
- Wu, W.; Wang, B.X.; Chen, J.; Miao, J.; Guan, Q. Interval estimation of the two-parameter exponential constant stress accelerated life test model under type-II censoring. Qual. Technol. Quant. Manag. 2022, 1–12. [Google Scholar] [CrossRef]
- Nelson, W.; Kielpinski, T.J. Theory for optimum censored accelerated life tests for normal and lognormal life distributions. Technometrics 1976, 18, 105–114. [Google Scholar] [CrossRef]
- Bai, D.S.; Kim, M.S. Optimum simple step-stress accelerated life tests for Weibull distribution and type I censoring. Nav. Res. Logist. (NRL) 1993, 40, 193–210. [Google Scholar] [CrossRef]
- Tang, L.; Goh, T.; Sun, Y.; Ong, H. Planning accelerated life tests for censored two-parameter exponential distributions. Nav. Res. Logist. (NRL) 1999, 46, 169–186. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications, 1st ed.; Statistics for Industry and Technology; Birkhäuser: Basel, Switzerland, 2000. [Google Scholar]
- Aggarwala, R. Progressive interval censoring: Some mathematical results with applications to inference. Commun. Stat. Theory Methods 2001, 30, 1921–1935. [Google Scholar] [CrossRef]
- Lodhi, C.; Tripathi, Y.M. Inference on a progressive type-I interval censored truncated normal distribution. J. Appl. Stat. 2020, 47, 1402–1422. [Google Scholar] [CrossRef]
- Singh, S.; Tripathi, Y.M. Estimating the parameters of an inverse Weibull distribution under progressive type-I interval censoring. Stat. Pap. 2018, 59, 21–56. [Google Scholar] [CrossRef]
- Chen, D.G.; Lio, Y.; Jiang, N. Lower confidence limits on the generalized exponential distribution percentiles under progressive type-I interval censoring. Commun. Stat.-Simul. Comput. 2013, 42, 2106–2117. [Google Scholar] [CrossRef]
- Arabi Belaghi, R.; Noori Asl, M.; Singh, S. On estimating the parameters of the BurrXII model under progressive type-I interval censoring. J. Stat. Comput. Simul. 2017, 87, 3132–3151. [Google Scholar] [CrossRef]
- Abd El-Raheem, A.M. Optimal design of multiple constant-stress accelerated life testing for the extension of the exponential distribution under type-II censoring. J. Comput. Appl. Math. 2021, 382, 113094. [Google Scholar] [CrossRef]
- Abd El-Raheem, A.M. Optimal design of multiple accelerated life testing for generalized half-normal distribution under type-I censoring. J. Comput. Appl. Math. 2020, 368, 112539. [Google Scholar] [CrossRef]
- Abd El-Raheem, A.M. Optimal plans of constant-stress accelerated life tests for extension of the exponential distribution. J. Test. Eval. 2018, 47, 1586–1605. [Google Scholar] [CrossRef]
- Sief, M.; Liu, X.; Abd El-Raheem, A.M. Inference for a constant-stress model under progressive type-I interval censored data from the generalized half-normal distribution. J. Stat. Comput. Simul. 2021, 91, 3228–3253. [Google Scholar] [CrossRef]
- Feng, X.; Tang, J.; Tan, Q.; Yin, Z. Reliability model for dual constant-stress accelerated life test with Weibull distribution under Type-I censoring scheme. Commun. Stat. Theory Methods 2022, 51, 8579–8597. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Castilla, E.; Ling, M.H. Optimal designs of constant-stress accelerated life-tests for one-shot devices with model misspecification analysis. Qual. Reliab. Eng. Int. 2022, 38, 989–1012. [Google Scholar] [CrossRef]
- Nassar, M.; Dey, S.; Wang, L.; Elshahhat, A. Estimation of Lindley constant-stress model via product of spacing with Type-II censored accelerated life data. Commun. Stat. Simul. Comput. 2021, 1–27. [Google Scholar] [CrossRef]
- Serfling, R. Efficient and robust fitting of lognormal distributions. N. Am. Actuar. J. 2002, 6, 95–109. [Google Scholar] [CrossRef] [Green Version]
- Punzo, A.; Bagnato, L.; Maruotti, A. Compound unimodal distributions for insurance losses. Insur. Math. Econ. 2018, 81, 95–107. [Google Scholar] [CrossRef]
- Limpert, E.; Stahel, W.A.; Abbt, M. Log-normal distributions across the sciences: Keys and clues: On the charms of statistics, and how mechanical models resembling gambling machines offer a link to a handy way to characterize log-normal distributions, which can provide deeper insight into variability and probability-normal or log-normal: That is the question. BioScience 2001, 51, 341–352. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar]
- McLachlan, G.J.; Krishnan, T. The EM Algorithm and Extensions, 2nd ed.; Wiley: New York, NY, USA, 2008; pp. 159–218. [Google Scholar]
- Little, R.J.A.; Rubin, D.B. Incomplete data. In Encyclopedia of Statistical Sciences; Kotz, S., Johnson, N.L., Eds.; Wiley: New York, NY, USA, 1983; Volume 4, pp. 46–53. [Google Scholar]
- Ng, H.; Chan, P.; Balakrishnan, N. Estimation of parameters from progressively censored data using EM algorithm. Comput. Stat. Data Anal. 2002, 39, 371–386. [Google Scholar] [CrossRef]
- Ng, H.K.T.; Wang, Z. Statistical estimation for the parameters of Weibull distribution based on progressively type-I interval censored sample. J. Stat. Comput. Simul. 2009, 79, 145–159. [Google Scholar] [CrossRef]
- Louis, T.A. Finding the observed information matrix when using the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1982, 44, 226–233. [Google Scholar]
- Arnold, B.C.; Press, S. Bayesian inference for Pareto populations. J. Econom. 1983, 21, 287–306. [Google Scholar] [CrossRef]
- Smith, A.F.; Roberts, G.O. Bayesian computation via the Gibbs sampler and related Markov chain Monte Carlo methods. J. R. Stat. Soc. Ser. B (Methodol.) 1993, 55, 3–23. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of State Calculations by Fast Computing Machines. J. Chem. Phys. 1953, 21, 1087. [Google Scholar] [CrossRef] [Green Version]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Tierney, L.; Kadane, J.B. Accurate approximations for posterior moments and marginal densities. J. Am. Stat. Assoc. 1986, 81, 82–86. [Google Scholar] [CrossRef]
- Kimber, A. Exploratory data analysis for possibly censored data from skewed distributions. J. R. Stat. Soc. Ser. C Appl. Stat. 1990, 39, 21–30. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data, 2nd ed.; Wiley Series in Probability and Statistics; Wiley-Interscience: Hoboken, NJ, USA, 2002. [Google Scholar]
- Cui, W.; Yan, Z.Z.; Peng, X.Y.; Zhang, G.M. Reliability analysis of log-normal distribution with nonconstant parameters under constant-stress model. Int. J. Syst. Assur. Eng. Manag. 2022, 13, 818–831. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| n | CS | MLE | MP | EM | MLE | MP | EM | MLE | MP | EM |
|---|---|---|---|---|---|---|---|---|---|---|
| 40 | 0.48345 | 0.38437 | 0.26390 | 0.04159 | 0.14822 | 0.01222 | 0.00795 | 0.00634 | 0.00101 | |
| (0.18292) | (0.27032) | (0.17876) | (0.13258) | (0.37055) | (0.08386) | (0.06153) | (0.05826) | (0.02718) | ||
| 0.27676 | 0.32929 | 0.21991 | 0.02434 | 0.13226 | 0.01140 | 0.00694 | 0.00585 | 0.00100 | ||
| (0.18075) | (0.25572) | (0.16967) | (0.12104) | (0.35167) | (0.08338) | (0.06065) | (0.05550) | (0.02732) | ||
| 0.19653 | 0.30132 | 0.20288 | 0.02351 | 0.12777 | 0.01030 | 0.00510 | 0.00430 | 0.00093 | ||
| (0.16592) | (0.24502) | (0.16894) | (0.12087) | (0.34676) | (0.07970) | (0.05530) | (0.05445) | (0.02637) | ||
| 60 | 0.22157 | 0.28766 | 0.19152 | 0.02118 | 0.14385 | 0.00718 | 0.00546 | 0.00485 | 0.00085 | |
| (0.15658) | (0.24018) | (0.15182) | (0.11214) | (0.37033) | (0.06819) | (0.05385) | (0.05231) | (0.02601) | ||
| 0.16201 | 0.23724 | 0.12269 | 0.01723 | 0.13064 | 0.00662 | 0.00327 | 0.00403 | 0.00083 | ||
| (0.14385) | (0.21936) | (0.13442) | (0.10188) | (0.35426) | (0.06392) | (0.04689) | (0.04914) | (0.02549) | ||
| 0.13278 | 0.19047 | 0.11819 | 0.01449 | 0.12324 | 0.00673 | 0.00399 | 0.00290 | 0.00081 | ||
| (0.13819) | (0.12115) | (0.11269) | (0.09458) | (0.34376) | (0.06484) | (0.05024) | (0.04505) | (0.02521) | ||
| 80 | 0.15822 | 0.24515 | 0.13522 | 0.01580 | 0.14225 | 0.00544 | 0.00401 | 0.00338 | 0.00079 | |
| (0.13113) | (0.22474) | (0.12670) | (0.09824) | (0.37088) | (0.05839) | (0.04583) | (0.04441) | (0.02553) | ||
| 0.12900 | 0.20886 | 0.12976 | 0.01305 | 0.13066 | 0.00523 | 0.00330 | 0.00337 | 0.00081 | ||
| (0.12442) | (0.20909) | (0.12596) | (0.08884) | (0.35602) | (0.05533) | (0.04412) | (0.04229) | (0.02565) | ||
| 0.09420 | 0.21711 | 0.09083 | 0.01235 | 0.12027 | 0.00510 | 0.00251 | 0.00232 | 0.00079 | ||
| (0.12033) | (0.21439) | (0.11865) | (0.08875) | (0.34112) | (0.05743) | (0.04272) | (0.04124) | (0.02501) | ||
| 100 | 0.09723 | 0.21292 | 0.08704 | 0.01275 | 0.14167 | 0.00471 | 0.00273 | 0.00245 | 0.00077 | |
| (0.12076) | (0.21116) | (0.11555) | (0.08828) | (0.37121) | (0.05429) | (0.04357) | (0.04163) | (0.02500) | ||
| 0.08692 | 0.19848 | 0.07887 | 0.01062 | 0.12906 | 0.00432 | 0.00237 | 0.00207 | 0.00075 | ||
| (0.11444) | (0.20703) | (0.11012) | (0.08211) | (0.35498) | (0.05233) | (0.04050) | (0.03829) | (0.02471) | ||
| 0.08407 | 0.18521 | 0.07826 | 0.01055 | 0.12062 | 0.00391 | 0.00232 | 0.00205 | 0.00071 | ||
| (0.11034) | (0.19890) | (0.10737) | (0.08157) | (0.34267) | (0.04979) | (0.03967) | (0.03762) | (0.02363) | ||
| n | CS | T-K | MCMC | T-K | MCMC | T-K | MCMC |
|---|---|---|---|---|---|---|---|
| 40 | 0.00096 | 0.00098 | 0.00287 | 0.00286 | 0.00430 | 0.00130 | |
| (0.01220) | (0.01233) | (0.04270) | (0.04257) | (0.05445) | (0.03025) | ||
| 0.00092 | 0.00095 | 0.00263 | 0.00263 | 0.00128 | 0.00130 | ||
| (0.01218) | (0.01225) | (0.04125) | (0.04125) | (0.03001) | (0.02917) | ||
| 0.00083 | 0.00084 | 0.00244 | 0.00244 | 0.00127 | 0.00103 | ||
| (0.01152) | (0.01161) | (0.03925) | (0.03933) | (0.02888) | (0.02729) | ||
| 60 | 0.00076 | 0.00077 | 0.00269 | 0.00270 | 0.00088 | 0.00089 | |
| (0.01104) | (0.01106) | (0.04187) | (0.04198) | (0.02477) | (0.02489) | ||
| 0.00072 | 0.00073 | 0.00240 | 0.00240 | 0.00074 | 0.00075 | ||
| (0.01062) | (0.01072) | (0.03883) | (0.03890) | (0.02272) | (0.02290) | ||
| 0.00063 | 0.00064 | 0.00234 | 0.00235 | 0.00070 | 0.00071 | ||
| (0.00999) | (0.01008) | (0.03861) | (0.03861) | (0.02210) | (0.02219) | ||
| 80 | 0.00059 | 0.00060 | 0.00241 | 0.00242 | 0.00073 | 0.00074 | |
| (0.00968) | (0.00972) | (0.03861) | (0.03876) | (0.02237) | (0.02247) | ||
| 0.00055 | 0.00057 | 0.00236 | 0.00236 | 0.00063 | 0.00063 | ||
| (0.00930) | (0.00938) | (0.03897) | (0.03894) | (0.02099) | (0.02105) | ||
| 0.00053 | 0.00054 | 0.00209 | 0.00209 | 0.00060 | 0.00060 | ||
| (0.00908) | (0.00914) | (0.03675) | (0.03679) | (0.02030) | (0.02036) | ||
| 100 | 0.00042 | 0.00046 | 0.00231 | 0.00231 | 0.00056 | 0.00056 | |
| (0.00802) | (0.00900) | (0.03885) | (0.03889) | (0.01983) | (0.01985) | ||
| 0.00039 | 0.00043 | 0.00212 | 0.00216 | 0.00050 | 0.00050 | ||
| (0.00798) | (0.00816) | (0.03672) | (0.03689) | (0.01886) | (0.01888) | ||
| 0.00034 | 0.00041 | 0.00196 | 0.00214 | 0.00047 | 0.00047 | ||
| (0.00735) | (0.00806) | (0.03522) | (0.03564) | (0.01806) | (0.01815) | ||
| n | CS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 40 | 0.00126 | 0.00098 | 0.00085 | 0.00293 | 0.00286 | 0.00284 | 0.00126 | 0.00130 | 0.00134 | |
| (0.01422) | (0.01233) | (0.01150) | (0.04296) | (0.04257) | (0.04248) | (0.02983) | (0.03025) | (0.03073) | ||
| 0.00119 | 0.00095 | 0.00086 | 0.00277 | 0.00263 | 0.00255 | 0.00125 | 0.00130 | 0.00136 | ||
| (0.01376) | (0.01225) | (0.01179) | (0.04233) | (0.04125) | (0.04061) | (0.02866) | (0.02917) | (0.02973) | ||
| 0.00106 | 0.00084 | 0.00078 | 0.00253 | 0.00244 | 0.00241 | 0.00101 | 0.00106 | 0.00111 | ||
| (0.01314) | (0.01161) | (0.01121) | (0.04012) | (0.03933) | (0.03902) | (0.02705) | (0.02761) | (0.02821) | ||
| 60 | 0.00105 | 0.00077 | 0.00065 | 0.00282 | 0.00270 | 0.00265 | 0.00086 | 0.00089 | 0.00092 | |
| (0.01306) | (0.01105) | (0.01018) | (0.04273) | (0.04198) | (0.04161) | (0.02455) | (0.02489) | (0.02527) | ||
| 0.00099 | 0.00073 | 0.00064 | 0.00254 | 0.00240 | 0.00233 | 0.00073 | 0.00075 | 0.00078 | ||
| (0.01267) | (0.01072) | (0.01004) | (0.03977) | (0.03890) | (0.03822) | (0.02254) | (0.02290) | (0.02330) | ||
| 0.00087 | 0.00064 | 0.00057 | 0.00249 | 0.00235 | 0.00229 | 0.00069 | 0.00071 | 0.00073 | ||
| (0.01177) | (0.01008) | (0.00962) | (0.03974) | (0.03861) | (0.03857) | (0.02185) | (0.02219) | (0.02257) | ||
| 80 | 0.00088 | 0.00060 | 0.00049 | 0.00246 | 0.00236 | 0.00233 | 0.00072 | 0.00074 | 0.00076 | |
| (0.01198) | (0.00972) | (0.00884) | (0.03993) | (0.03894) | (0.03862) | (0.02224) | (0.02247) | (0.02273) | ||
| 0.00081 | 0.00057 | 0.00049 | 0.00256 | 0.00242 | 0.00236 | 0.00061 | 0.00063 | 0.00065 | ||
| (0.01142) | (0.00938) | (0.00883) | (0.039810 | (0.03876) | (0.03847) | (0.02080) | (0.02105) | (0.02132) | ||
| 0.00078 | 0.00054 | 0.00048 | 0.00222 | 0.00209 | 0.00205 | 0.00059 | 0.00060 | 0.00062 | ||
| (0.01113) | (0.00914) | (0.00871) | (0.03772) | (0.03679) | (0.03656) | (0.02010) | (0.02036) | (0.02065) | ||
| 100 | 0.00073 | 0.00050 | 0.00045 | 0.00231 | 0.00216 | 0.00214 | 0.00055 | 0.00056 | 0.00057 | |
| (0.01096) | (0.00901) | (0.00867) | (0.03677) | (0.03564) | (0.03557) | (0.01964) | (0.01985) | (0.02008) | ||
| 0.00070 | 0.00043 | 0.00035 | 0.00243 | 0.00231 | 0.00229 | 0.00049 | 0.00050 | 0.00051 | ||
| (0.01055) | (0.00816) | (0.00761) | (0.03972) | (0.03889) | (0.03885) | (0.01865) | (0.01888) | (0.01913) | ||
| 0.00066 | 0.00041 | 0.00034 | 0.00227 | 0.00214 | 0.00212 | 0.00046 | 0.00047 | 0.00049 | ||
| (0.01040) | (0.00806) | (0.00746) | (0.03813) | (0.03689) | (0.03663) | (0.01797) | (0.01815) | (0.01834) | ||
| n | CS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 40 | 0.00194 | 0.00187 | 0.00185 | 0.00288 | 0.00286 | 0.00288 | 0.00127 | 0.00133 | 0.00141 | |
| (0.01338) | (0.01307) | (0.01211) | (0.04262) | (0.04260) | (0.04285) | (0.02999) | (0.03053) | (0.03114) | ||
| 0.00103 | 0.00093 | 0.00087 | 0.00268 | 0.00260 | 0.00257 | 0.00127 | 0.00132 | 0.00139 | ||
| (0.01269) | (0.01205) | (0.01164) | (0.04164) | (0.04097) | (0.04075) | (0.02886) | (0.02949) | (0.03020) | ||
| 0.00099 | 0.00091 | 0.00087 | 0.00220 | 0.00215 | 0.00221 | 0.00103 | 0.00108 | 0.00115 | ||
| (0.01252) | (0.01203) | (0.01184) | (0.03596) | (0.03566) | (0.03631) | (0.02728) | (0.02794) | (0.02868) | ||
| 60 | 0.00088 | 0.00081 | 0.00078 | 0.00274 | 0.00268 | 0.00268 | 0.00087 | 0.00091 | 0.00094 | |
| (0.01189) | (0.01141) | (0.01124) | (0.04219) | (0.04185) | (0.04189) | (0.02469) | (0.02511) | (0.02558) | ||
| 0.00078 | 0.00069 | 0.00065 | 0.00245 | 0.00237 | 0.00236 | 0.00074 | 0.00077 | 0.00080 | ||
| (0.01107) | (0.01044) | (0.01013) | (0.03915) | (0.03878) | (0.03890) | (0.02269) | (0.02313) | (0.02361) | ||
| 0.00068 | 0.00061 | 0.00058 | 0.00239 | 0.00232 | 0.00233 | 0.00070 | 0.00072 | 0.00075 | ||
| (0.01035) | (0.00988) | (0.00968) | (0.03895) | (0.03846) | (0.03860) | (0.02199) | (0.02240) | (0.02286) | ||
| 80 | 0.00082 | 0.00072 | 0.00067 | 0.00238 | 0.00235 | 0.00239 | 0.00073 | 0.00075 | 0.00077 | |
| (0.01145) | (0.01073) | (0.01033) | (0.03923) | (0.03881) | (0.03904) | (0.02233) | (0.02262) | (0.02294) | ||
| 0.00061 | 0.00053 | 0.00050 | 0.00246 | 0.00239 | 0.00240 | 0.00062 | 0.00064 | 0.00066 | ||
| (0.00976) | (0.00910) | (0.00884) | (0.03907) | (0.03865) | (0.03890) | (0.02126) | (0.02120) | (0.02153) | ||
| 0.00058 | 0.00051 | 0.00048 | 0.00212 | 0.00207 | 0.00211 | 0.00059 | 0.00061 | 0.00063 | ||
| (0.00949) | (0.00889) | (0.00869) | (0.03701) | (0.03672) | (0.03709) | (0.02090) | (0.02052) | (0.02086) | ||
| 100 | 0.00065 | 0.00055 | 0.00050 | 0.00246 | 0.00243 | 0.00246 | 0.00055 | 0.00057 | 0.00058 | |
| (0.01015) | (0.00937) | (0.00895) | (0.03955) | (0.03921) | (0.03942) | (0.01973) | (0.01998) | (0.02025) | ||
| 0.00048 | 0.00040 | 0.00036 | 0.00234 | 0.00231 | 0.00237 | 0.00049 | 0.00051 | 0.00052 | ||
| (0.00857) | (0.00788) | (0.00763) | (0.03907) | (0.03889) | (0.03950) | (0.01875) | (0.01902) | (0.01931) | ||
| 0.00045 | 0.00038 | 0.00034 | 0.00118 | 0.00113 | 0.00119 | 0.00047 | 0.00048 | 0.00050 | ||
| (0.00850) | (0.00772) | (0.00746) | (0.03723) | (0.03682) | (0.03718) | (0.01804) | (0.01825) | (0.01849) | ||
| n | CS | ACI | BCI | ACI | BCI | ACI | BCI |
|---|---|---|---|---|---|---|---|
| 40 | 2.3253 | 0.3819 | 0.7481 | 0.3416 | 0.3776 | 0.1604 | |
| 0.988 | 0.998 | 0.950 | 0.998 | 0.976 | 0.976 | ||
| 2.0258 | 0.3824 | 0.6322 | 0.3316 | 0.3303 | 0.1541 | ||
| 0.969 | 0.975 | 0.912 | 1.000 | 0.946 | 0.993 | ||
| 2.0878 | 0.3818 | 0.6215 | 0.3280 | 0.3574 | 0.1542 | ||
| 0.979 | 1.000 | 0.916 | 0.966 | 0.968 | 0.968 | ||
| 60 | 1.8085 | 0.3785 | 0.5848 | 0.3238 | 0.2948 | 0.1352 | |
| 0.972 | 0.949 | 0.948 | 0.978 | 0.962 | 0.977 | ||
| 1.5894 | 0.3773 | 0.5142 | 0.3117 | 0.2710 | 0.1304 | ||
| 0.976 | 0.977 | 0.940 | 0.994 | 0.963 | 0.982 | ||
| 1.5286 | 0.3771 | 0.4848 | 0.3061 | 0.2553 | 0.1290 | ||
| 0.969 | 0.998 | 0.928 | 0.999 | 0.948 | 0.988 | ||
| 80 | 1.5169 | 0.3752 | 0.5041 | 0.3088 | 0.2537 | 0.1207 | |
| 0.973 | 0.945 | 0.943 | 0.999 | 0.962 | 0.972 | ||
| 1.3455 | 0.3728 | 0.4456 | 0.2953 | 0.2266 | 0.1162 | ||
| 0.975 | 0.985 | 0.940 | 0.995 | 0.958 | 0.983 | ||
| 1.3270 | 0.3731 | 0.4201 | 0.2878 | 0.2284 | 0.1153 | ||
| 0.967 | 1.000 | 0.932 | 0.996 | 0.961 | 0.982 | ||
| 100 | 1.2512 | 0.3718 | 0.4443 | 0.2950 | 0.2159 | 0.1108 | |
| 0.972 | 0.954 | 0.938 | 0.997 | 0.953 | 0.982 | ||
| 1.1732 | 0.3689 | 0.4005 | 0.2810 | 0.2046 | 0.1069 | ||
| 0.969 | 0.950 | 0.942 | 0.995 | 0.957 | 0.984 | ||
| 1.1352 | 0.3681 | 0.3692 | 0.2720 | 0.1961 | 0.1057 | ||
| 0.960 | 0.994 | 0.905 | 0.988 | 0.948 | 0.985 | ||
| Stress (MPa) | Failure Times |
|---|---|
| 35 | 230, 169, 178, 271, 129, 568, 115, 280, 305, 326, 1101, 285, 734, 177, 493, 218, 342, 431, 143, 381 |
| 36 | 173, 218, 162, 288, 394, 585, 295, 262, 127, 151, 181, 209, 141, 186, 309, 192, 117, 203, 198, 255 |
| 37 | 141, 143, 98, 122, 110, 132, 194, 155, 104, 83, 125, 165, 146, 100, 318, 136, 200, 201, 251, 111 |
| 38 | 100, 90, 59, 80, 128, 117, 177, 98, 158, 107, 125, 118, 99, 186, 66, 132, 97, 87, 69, 109 |
| Stress Level | ||
|---|---|---|
| (0, 0, 3, 3, 1) | (0, 0, 0, 0, 13) | |
| (0, 0, 3, 7, 3) | (0, 0, 0, 0, 7) | |
| (0, 3, 10, 4, 1) | (0, 0, 0, 0, 2) | |
| (0, 10, 7, 3, 0) | (0, 0, 0, 0, 0) |
| MLE | MP | EM | MLE | MP | EM | MLE | MP | EM |
|---|---|---|---|---|---|---|---|---|
| 9.6536 × | 1.49323 × | 9.65582 × | 6.53758 | 6.55732 | 6.52934 | 1.8055 × | 2.11906 × | 1.8055 × |
| T-K | MCMC | T-K | MCMC | T-K | MCMC |
|---|---|---|---|---|---|
| 9.9638 × | 9.6536 × | 6.51924 | 6.59627 | 3.2541 × | 4.54567 × |
| 9.58256 × | 2.22045 × | 9.5825 × | 7.17327 | 6.59605 | 6.24409 | 4.53526 × | 1.0147 × | |
| 9.6536 × | 9.6536 × | 9.6536 × | 6.62828 | 6.56482 | 6.5037 | 5.33591 × | 3.36419 × | |
| ACI | BCI | ACI | BCI | ACI | BCI |
|---|---|---|---|---|---|
| (, 0.221022) | (, 0.201439) | (5.2699, 7.80526) | (5.48794, 8.04582) | (1.8055 × , 1.74424 × ) | (2.8756 × , 9.93455 × ) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sief, M.; Liu, X.; Hosny, M.; Abd El-Raheem, A.E.-R.M. Constant-Stress Modeling of Log-Normal Data under Progressive Type-I Interval Censoring: Maximum Likelihood and Bayesian Estimation Approaches. Axioms 2023, 12, 710. https://doi.org/10.3390/axioms12070710
Sief M, Liu X, Hosny M, Abd El-Raheem AE-RM. Constant-Stress Modeling of Log-Normal Data under Progressive Type-I Interval Censoring: Maximum Likelihood and Bayesian Estimation Approaches. Axioms. 2023; 12(7):710. https://doi.org/10.3390/axioms12070710
Chicago/Turabian StyleSief, Mohamed, Xinsheng Liu, Mona Hosny, and Abd El-Raheem M. Abd El-Raheem. 2023. "Constant-Stress Modeling of Log-Normal Data under Progressive Type-I Interval Censoring: Maximum Likelihood and Bayesian Estimation Approaches" Axioms 12, no. 7: 710. https://doi.org/10.3390/axioms12070710