1. Introduction
Recently, some attempts have been made to introduce new families of distributions or generalize some of the presented distributions to provide high flexibility in the modeling of real phenomena based on data. They can involve special transformations that are possibly modulated by one or several parameters.
For example, Marshall and Olkin [
1] proposed a method of adding an extra shape parameter to a given baseline distribution; the resulting distribution is known as the “expanded Marshall-Olkin (MO) distribution”. In order to fix the idea, let us present the mathematical foundations of the MO family. Consider an absolutely continuous baseline distribution depending on a generic parameter vector denoted by
and with support denoted by
, and the corresponding cumulative distribution function (cdf) and probability density function (pdf) denoted by
and
, respectively. Then the survival function (sf) and pdf of the MO distribution are, respectively,
and
where
is a shape parameter and
. The MO family has inspired numerous studies for the modeling of various physical phenomena and has been extended in numerous ways. For more information, we refer the reader to the overview [
2].
On the other hand, Eugene et al. [
3] introduced a new family, which is generated from the beta distribution, called the beta-generated family. Its corresponding cdf takes the following form:
where
and
are two additional parameters whose rule is to increase the skewness and to vary tail weights, and
is the standard beta function. The pdf corresponding to Equation (
3) is
For further developments on the beta family, we redirect the reader to [
4]. As a remark, by taking
, the beta-generated family is reduced to the exponentiated-generated (ExG) family initiated in [
5] and further discussed in detail in [
6]. This special family plays a secondary role in our study.
Kumaraswamy’s work was also very inspiring in terms of proposing new modeling alternatives, starting with Reference [
7]. The Kumaraswamy (K) distribution is a two-parameter distribution with support
that has proven useful in many hydrological applications. Its cdf is defined by
where
and
are two additional shape parameters. The corresponding pdf is
Based on the K distribution, Cordeiro and de Castro [
8] introduced the K generated family. Its cdf takes the following form:
where
and
are two shape parameters. The corresponding pdf is
By taking
, the K generated family is reduced to the type 2 exponentiated-generated (T2ExG) family, which will also play a secondary role in our study.
All the previous families and many other families in the statistical literature depend on adding one or more shape parameters to a baseline distribution in order to provide greater flexibility. This reason led the researchers to suggest alternative options that unify certain current families based on straightforward functional transformations (power, logarithmic, exponential, trigonometric, etc.). See, for example, the family based on a special poly-exponential transformation in [
9] and the sine-generated family introduced in [
10]. With this knowledge in mind, the findings of this paper are based on the following new theoretical approach: Let
be an sf of an absolutely continuous distribution with support
, and
be a decreasing continuous function such that
and
. Then, the following function is a valid cdf:
It is important to note that
is not necessarily a valid sf because we can have
, which allows for a wide range of functions. With the mathematical structure of Equation (
9), various families can be created, but one interesting way is to choose
and
of different nature to enrich the functionalities of
. In this paper, we follow this line by adopting an original power-exponential transformation approach: we chose
as the sf of the T2ExG family defined with a certain generic baseline distribution, and
as a decreasing exponential function compounds with a possible other baseline distribution. This created “unified family” is called the
modified generalized-G (MGG) family. The new MGG family has the following significant and desirable ambitions in addition to its innovative construction:
Thanks to its power-exponential transformation approach, the MGG family is capable of modifying the standard baseline distributions by changing their functional forms without adding any additional shape parameter.
It can also provide more flexible generalized forms by adding one or two shape parameters.
It can be considered as a compounding family. The MGG family can provide new generalized distributions by compounding two different baseline distributions.
The special sub-distributions of the MGG family accommodates all important hazard rate (hr) shapes including bathtub, constant, upside down bathtub, increasing, decreasing–increasing–decreasing, and decreasing shapes. Hence, its special distributions can model different types of real-life data in many applied sciences.
The MGG family is not generated based on the well-known baseline distributions similar to the MO, beta-generated, ExG, and K families.
The special sub-distributions of the MGG family provide consistently better fits than its competing and baseline distributions.
All of these claims are supported in the paper with thorough investigations of theory and practice, as well as with the aid of graphics and quantitative information.
To be more specific, the paper is structured as follows: In
Section 2, we define the MGG family and its important sub-families. In
Section 3, we provide three special sub-distributions of the MGG family. In
Section 4, the modified uniform (MU) distribution is studied with its analytical shapes.
Section 5 provides some of its statistical properties. In
Section 6, the parameters of the MU model are estimated using some classical estimation methods. A simulation study to compare the behavior of different estimates is presented in
Section 7. In
Section 8, the MU distribution is fitted to two real data sets. Finally,
Section 9 offers some concluding remarks.
4. The Modified Uniform Distribution
In this section, we introduce a new double bounded distribution called the modified-uniform (MU) distribution, as a special case of the MGG family, with support and derive some of its properties.
Let
for
be a common baseline uniform distribution with a scale parameter
. By virtue of Equation (
11), the cdf of the MU distribution takes the form
Its pdf has the form
The parameters of the MU distribution can be reduced by setting
, making it suitable to model phenomena with values in
(such as rescaled data, proportions, percentages, etc.). It thus belongs to the family of the unit distributions. In this case, the cdf of the MU distribution is given by
Since, for , , the functional limit that corresponds to the cdf of the type 2 power distribution, the MU distribution can be viewed as an extension of the type 2 power distribution.
The corresponding pdf and hrf of the MU distribution have the forms
and
The limits of the pdf of the MU distribution as
and as
are presented below. We have
and
We observe that the values of
are discriminating for the limit
, whereas the values of
are discriminating for the limit
. This is a preliminary theoretical result demonstrating the significance of these parameters in the possible shapes of the pdf.
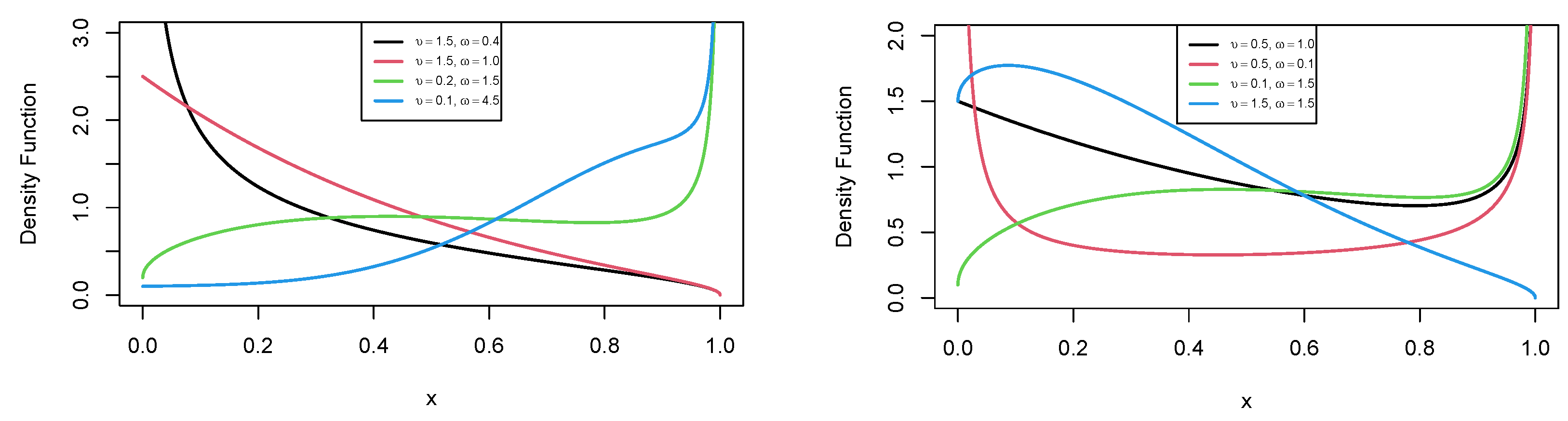
Indeed, an important characteristic of the MU distribution is that its pdf can be monotonically decreasing, increasing, unimodal, bathtub, and N-shaped, i.e., strictly increasing, and then followed by a bathtub shape. The plots of this pdf for different parameter values are given in
Figure 2.
The hrf limits of the MU distribution as
and
are determined below. We have
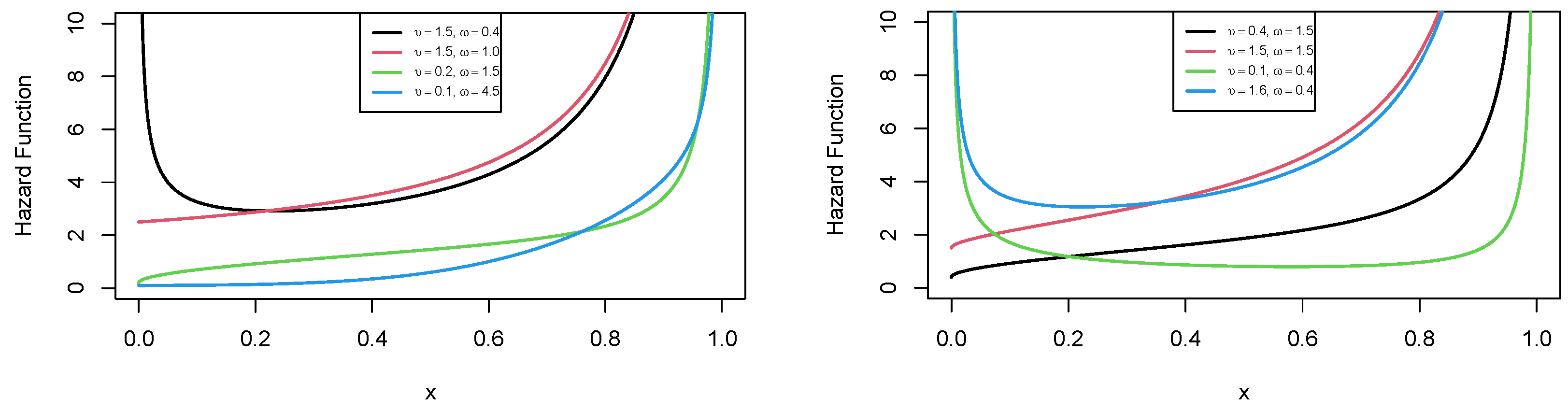
The following theorem shows mathematically that the hrf of the MU distribution can be increasing- or bathtub-shaped.
Theorem 1. The hrf of the MU distribution is increasing-shaped for and is bathtub-shaped for for all values of υ.
Proof. From Equation (
25), we have
For
,
, as a result, the hrf is increasing-shaped. On the other hand, the roots of
exist and are unique for
; then, the hrf is bathtub-shaped since
. This ends the proof. □
Additionally, it is noted that the hrf of the MU distribution cannot be decreasing-shaped.
The shape of the hrf, which can be monotonically increasing- or bathtub-shaped, depends only on the value of
. The plots of the hrf of the MU distribution for different parameter values are given in
Figure 3, supporting the findings of Theorem 1.
8. Real Data Applications
In this part, we analyze two real data sets to demonstrate the performance of the MU model in practice by fitting two real-life data sets. The proposed MU model is compared to models based on the following distributions: the K distribution, which is defined by the pdf in Equation (
6) and other four known competitors such as
Size-biased Kumaraswamy (SK) distribution [
20] with pdf indicated as
Exponentiated Kumaraswamy (EK) distribution [
21] with pdf given as
Transmuted Kumaraswamy (TK) distribution [
22] with pdf specified by
McDonald (M) distribution [
23] with pdf given as
The first data set is reported by Murthy et al. [
24]. It represents censored data (failure times) for thirty items tested, with testing stopping after the 20
th failure. The second data set represents observations on the stress resistance shear (MPa) of a joint joined in a particular way. It is taken from Stoop and Ouden [
25]. To determine the interval parameter (
, sometimes called the product maximum life), Wang [
26] used the following formula:
where
n is the sample size,
is the value of
time of the sample, and
k is the number of
in the sample. By applying the above formula to two data sets, the summary of their statistical measures is listed in
Table 6.
Table 6.
Summary measures of the two data sets.
Table 6.
Summary measures of the two data sets.
| Data | Min | Q1 | Median | Mean | Q3 | SD | Skewness | Kurtosis | Max |
|---|
| First | 0.1813 | 0.5419 | 0.6150 | 0.6480 | 0.8457 | 0.2413 | −0.3187 | −1.0937 | 0.9990 |
| Second | 0.0390 | 0.2320 | 0.3254 | 0.4161 | 0.6241 | 0.2846 | 0.5328 | −1.0472 | 0.9770 |
The MLEs of the parameters for the compared models are computed. In addition, the values of various discrimination measures are evaluated to provide model efficiency. These are the Akaike information criterion (AIC), defined as AIC
); Bayesian information criterion (BIC), defined as BIC
); consistent-AIC (CAIC), defined as CAIC
); and Hannan–Quinn information criterion (HQIC), defined as HQIC
), where
k is the number of estimated parameters,
n is the sample size, and
is the maximum value of the corresponding likelihood function. Furthermore, the goodness of fit for the compared models is checked by various test statistics, such as the Cramér–von Mises
, Anderson–Darling
, Watson
, Liao–Shimokawa
, and sum of squares (SS). We also calculate the Kolmogorov–Smirnov (KS) statistics and their corresponding
p-values. To check the fitting performance of the models (
p-value > 0.05), these test statistics demonstrate the differences between the proposed cdf and the empirical cdf for each data set. For more details about the goodness-of-fit test statistics, the reader can see Shama et al. [
27].
From
Table 7 and
Table 8, we note that the MU model gives the lowest values for all the discrimination measures. These results indicate that the MU model could be chosen as the best model against all the competitors.
Table 9 and
Table 10 show that all models fit two data sets (
p-value > 0.05) and the proposed model displays the lowest test statistics with the highest
p-values. As a result, the MU model offers excellent competition against other models and fits the two data sets quite well.
Furthermore, seven estimation methods are used to estimate the parameters of the MU model from real data.
Table 11 and
Table 12 display the estimates, the values of
and
with their
p-values, and the rank of estimation methods for the two data sets. We can draw the conclusion that, for the first data set, the ML estimation method is advised for estimating the unknown parameters of the proposed model, whereas the LS estimation method is advised for estimating the unknown parameters of the MU model.
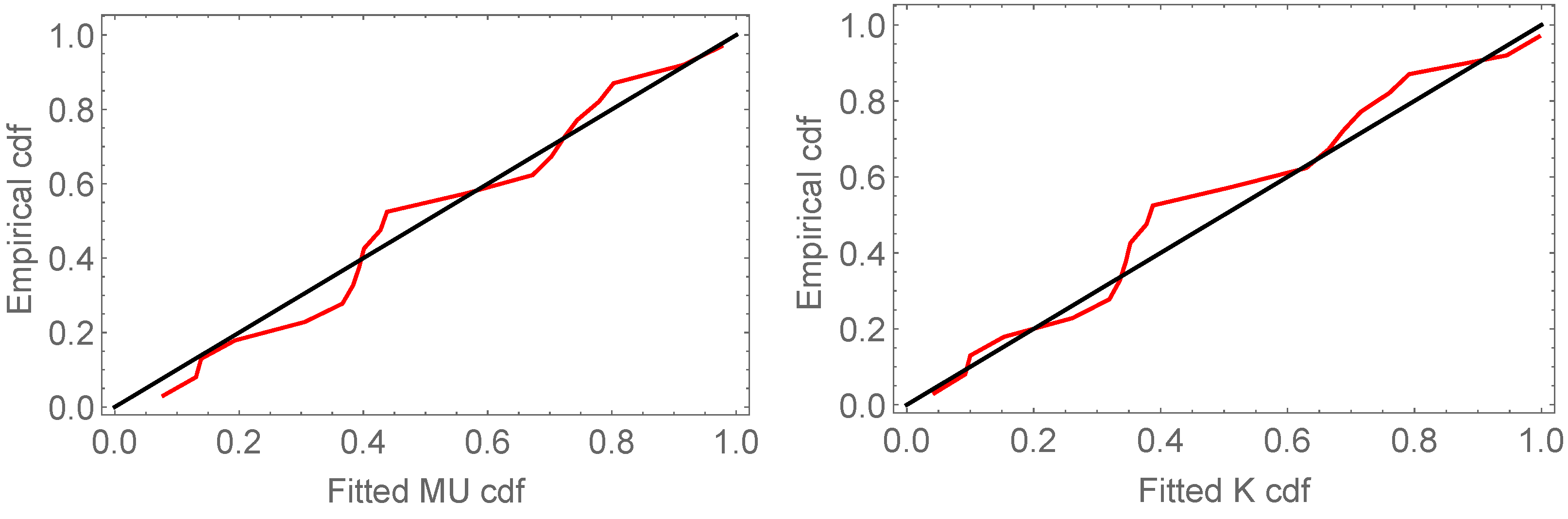
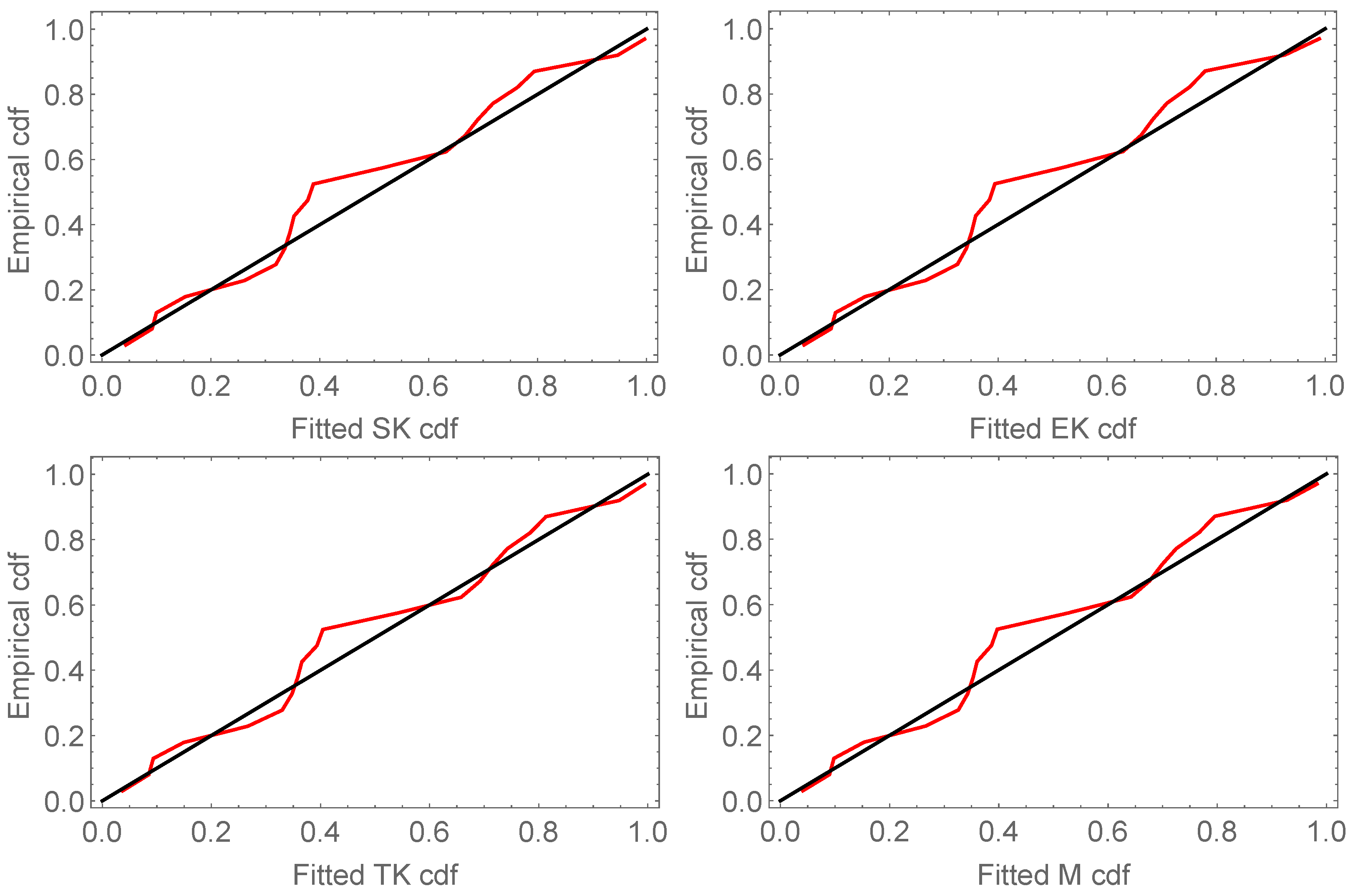
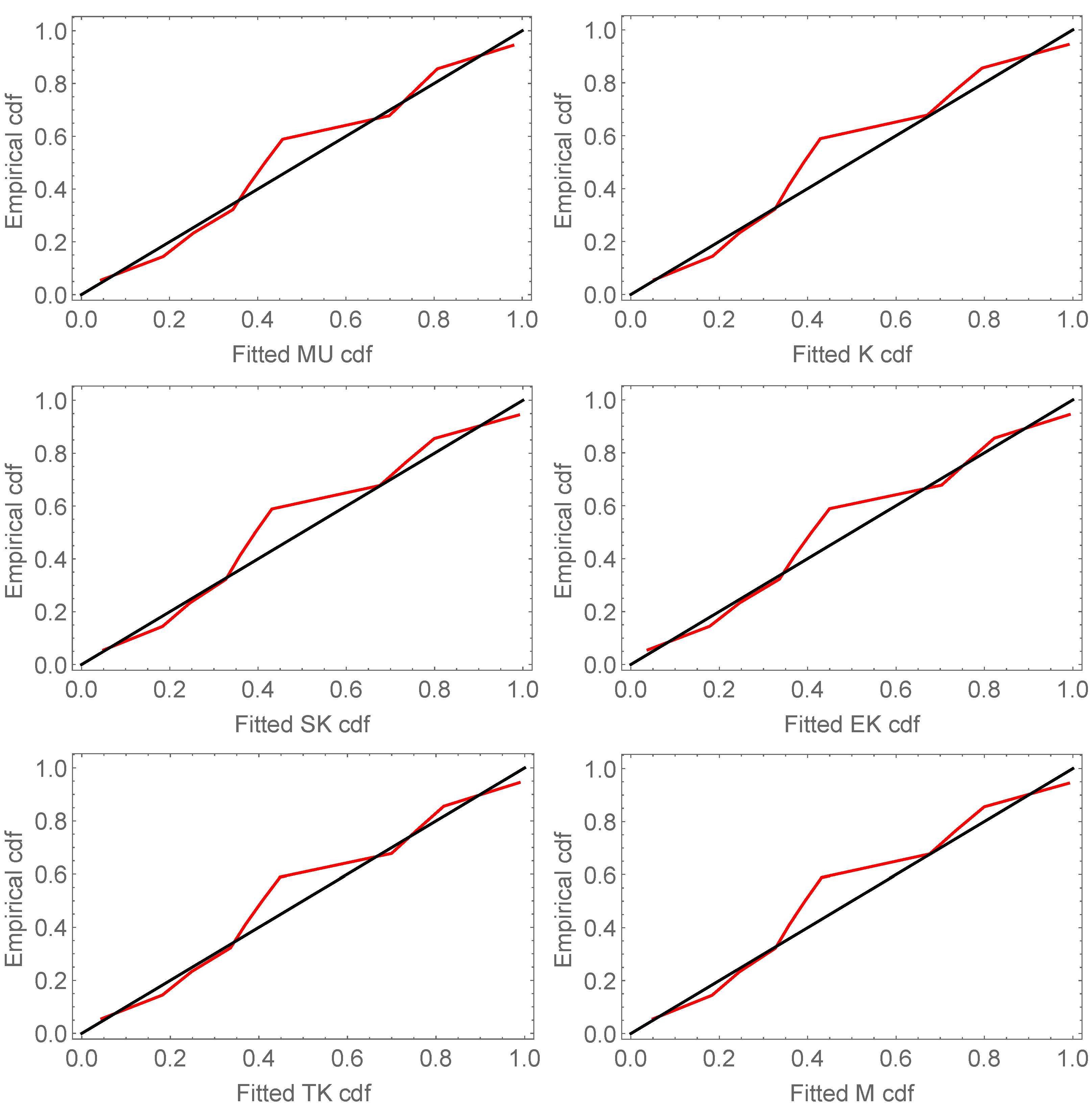
The probability–probability (P-P) plots of the fitted models for the two data sets are shown in
Figure 4 and
Figure 5. It can be observed that the MU model achieves a better approximation between the empirical and theoretical curves and provides a better fit than other models.
9. Conclusions and Perspectives
In this article, a new family of distributions, called the “modified GG” (MGG) family, is proposed. It provides some generated families and new flexible modified distributions whose probability density and hazard function shapes are desirable for numerous modeling purposes. The proposed MGG family has some interesting characteristics, such as providing more flexible models without adding any additional parameters. We study a special model, namely the modified uniform (MU) distribution, in detail. Various estimation methods of the MU model are studied and assessed using a simulation study. An analysis of two real data sets indicates that the MU distribution can be efficiently used for modeling data arising from different real-life situations. The MU distribution may attract wider applications in many applied areas such as engineering, quality control, medicine, and agriculture, among others, to model different real-life data sets.
The perspectives of this study are numerous, including more developments based on the novel power-exponential transformation approach (with the bivariate case being of particular interest), the applications of introduced lifetime sub-distributions of the MGG family, and the construction of quantile regression models by exploiting the flexibility of the MU distribution.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






