
Corn Disease Recognition Based on Attention Mechanism Network


Abstract
:1. Introduction
Related Work and Motivation
- Different types of diseases have little difference in appearance at the initial stage of growth. The diseases may overlap with light intensity changes, noise, background interference, etc. The convolutional neural network can automatically extract image features and overcome the defects of traditional methods, while the convolution kernel performs feature fusion on the local area when extracting the feature map and captures the local spatial relationship, resulting in classification errors;
- The attention mechanism is still in the exploratory stages of improving the image feature extraction ability of CNN models. At present, the typical attention modules in convolutional neural networks mainly include the SE attention mechanism [38] and the CBAM attention mechanism [39], which use global pooling to extract high-level features of disease images, decouple the channel correlation and spatial correlation of features, and improve the ability of detailed disease-feature extraction to a certain extent. However, these cannot capture the nonlinear relationship between channels, and the use of global pooling compresses the dimension of features, resulting in the loss of detailed information.
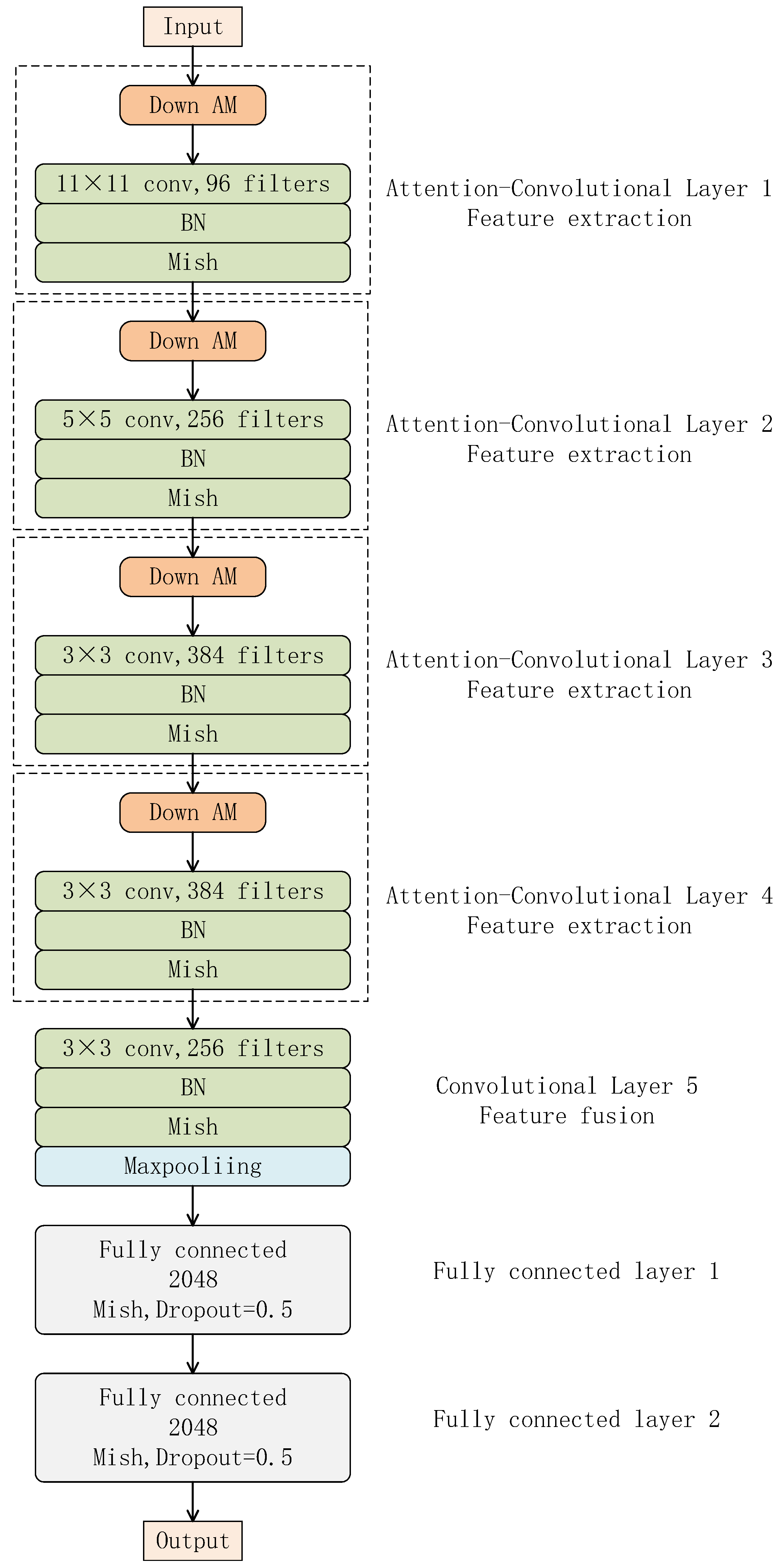
- In the field of crop diseases, the attention mechanism is introduced, and the down-sampling attention module is designed and embedded into the AlexNet network to reduce the loss of detailed disease-feature information and improve the network’s ability to extract disease features;
- By using group convolution in the network, the recognition accuracy of the model is improved while the parameters are reduced;
- The Mish function is used to improve the traditional ReLu activation function in the convolutional neural network to enhance the non-linear expression ability of the network;
- A new fully connected layer is constructed to reduce the model’s parameters. Finally, the corn disease identification and the detection algorithm AT-AlexNet of attention neural network are formed, which are trained and tested on the datasets of six corn diseases and verify the feasibility and accuracy of the model proposed in this paper.
2. Materials and Methods
2.1. Data Sources
2.2. Data Preprocessing
2.2.1. Data Augmentation
2.2.2. Sample Normalization
2.3. Experiment Method
2.3.1. Basic Network
2.3.2. Down-Sampling Attention Module
2.3.3. Mish Activation Function
2.3.4. Group Convolution
2.3.5. Batch Normalization
2.3.6. Dropout Strategy
2.3.7. Softmax Classification
2.3.8. Model Computation Flow
2.3.9. Model Evaluation Index
3. Results
3.1. Experimental Environment
3.2. Training Parameter Settings
3.3. Experimental Design
3.4. Analysis and Comparison of Training Results
3.4.1. Analysis of the Impact of Data Enhancement
3.4.2. Analysis of the Impact of Batch-Size
3.4.3. Analysis of the Impact of Learning Rate
3.5. Network Structure Ablation Test
3.6. Model Effect Test
3.7. Model Performance Comparison Test
4. Discussion
Model Application Guide
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Parraga-Alava, J.; Cusme, K.; Loor, A.; Santander, E. RoCoLe: A robusta coffee leaf images dataset for evaluation of machine learning based methods in plant diseases recognition. Data Brief 2019, 25, 104414. [Google Scholar] [CrossRef] [PubMed]
- Tan, L.; Lu, J.; Jiang, H. Tomato Leaf Diseases Classification Based on Leaf Images: A Comparison between Classical Machine Learning and Deep Learning Methods. AgriEngineering 2021, 3, 542–558. [Google Scholar] [CrossRef]
- Zou, J.Z.; Ya, J.X.; Li, H.; Shuai, C.; Huang, D. Bridge apparent damage detection based on the improved YOLO v3 in complex background. J. Railw. Sci. Eng. 2021, 18, 3257–3266. [Google Scholar]
- Hou, J.X.; Li, R.; Deng, H.X.; Li, H.F. Leaf disease identification of fusion channel information attention network. Comput. Eng. Appl. 2020, 56, 124–129. [Google Scholar]
- Xie, C.Y.; Wu, D.; Wang, C.; Li, Y. Insect Pest Leaf Detection System Based on Information Fusion of Image and Spectrum. Trans. Chin. Soc. Agric. Mach. 2013, 44, 269–272. [Google Scholar]
- Arnal Barbedo, J.G. Digital image processing techniques for detecting, quantifying and classifying plant diseases. SpringerPlus 2013, 2, 660. [Google Scholar] [CrossRef]
- Prasad, S.; Peddoju, S.K.; Ghosh, D. Multi-resolution mobile vision system for plant leaf disease diagnosis. Signal Image Signal Image Video Processing 2016, 10, 379–388. [Google Scholar] [CrossRef]
- Chaudhary, P.; Chaudhari, A.K.; Godara, S. Color transform based approach for disease spot detection on plant leaf. Int. J. Comput. Sci. Telecommun. 2012, 3, 65–70. [Google Scholar]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef]
- Yang, G.F.; Yang, Y.; He, Z.K.; Zhang, X.Y.; He, Y. A rapid, low-cost deep learning system to classify strawberry disease based on cloud service. Integr. Agric. 2022, 21, 460–473. [Google Scholar]
- Too, E.C.; Yujian, L.; Njuki, S.; Yingchun, L. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Anitescu, C.; Atroshchenko, E.; Alajlan, N.; Rabczuk, T. Artificial neural network methods for the solution of second order boundary value problems. Comput. Mater. Contin. 2019, 59, 345–359. [Google Scholar] [CrossRef]
- Guo, H.; Zhuang, X.; Chen, P.; Alajlan, N.; Rabczuk, T. Stochastic deep collocation method based on neural architecture search and transfer learning for heterogene.ous porous media. Eng. Comput. 2022, 26, 1–26. [Google Scholar]
- Guo, H.; Zhuang, X.; Chen, P.; Alajlan, N.; Rabczuk, T. Analysis of three-dimensersional potential problems in non-homogeneous media with physics-informed deep collocation method using material transfer learning and sensitivity analysis. Eng. Comput. 2022, in press. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound. Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Wang, K.; Wang, T.; Liu, L.; Yuan, C. Human behaviour recognition and monitoring based on deep convolutional neural networks. Behav. Inform. Technol. 2019, 40, 1–12. [Google Scholar] [CrossRef]
- Arefan, D.; Mohamed, A.A.; Berg, W.A.; Zuley, M.L.; Sumkin, J.H.; Wu, S. Deep learning modeling using normal mammograms for predicting breast cancer risk. Med. Phys. 2020, 47, 110–118. [Google Scholar] [CrossRef]
- Brahimi, M.; Boukhalfa, K.; Moussaoui, A. Deep Learning for Tomato Diseases: Classification and Symptoms Visualization. Appl. Artif. Intell. 2017, 31, 1–17. [Google Scholar] [CrossRef]
- Wang, D.F.; Wang, J. Crop disease classification with transfer learning and residual networks. Trans. Chin. Soc. Agric. Eng. 2021, 37, 199–207. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. Eur. Conf. Comput. Vision. 2014, 8689, 818–833. [Google Scholar]
- Lei, F.Y.; Liu, X.; Dai, Q.Y.; Ling, W.K. Shallow convolutional neural network for image classification. SN Appl. Sci. 2020, 2, 1–8. [Google Scholar] [CrossRef]
- Tian, J.; Zhang, J.; Xue, M.A.; Xu, X.; Wen, C. A Convolutional Neural Network Based Method for ECG Signal Recognition. J. Hangzhou Dianzi Univ. (Nat. Sci.) 2018, 38, 62–66. [Google Scholar]
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep Neural Networks Based Recognition of Plant Diseases by Leaf Image Classification. Comput. Intel. Neurosc. 2016, 2016, 3289801. [Google Scholar] [CrossRef]
- Sun, J.; Tan, W.J.; Mao, H.P.; Wu, X.H.; Chen, Y.; Wang, L. Recognition of multiple plant leaf diseases based on improved convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2017, 33, 209–215. [Google Scholar]
- Lv, M.; Zhou, G.; He, M.; Chen, A.; Zhang, W.; Hu, Y. Maize leaf disease identification based on feature enhancement and DMS-robust alexnet. IEEE Access 2020, 8, 57952–57966. [Google Scholar] [CrossRef]
- Waheeda, A.; Goyala, M.; Guptaa, D.; Khannaa, A.; Hassanienb, A.E.; Pandeyc, H.M. An optimized dense convolutional neural network model for disease recognition and classification in corn leaf. Comput. Electron. Agric. 2020, 175, 105456. [Google Scholar] [CrossRef]
- Bao, W.; Huang, X.; Hu, G.; Liang, D. Identification of maize leaf diseases using improved convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2021, 37, 160–167. [Google Scholar]
- Fan, X.P.; Zhou, J.P.; Xu, Y.; Peng, X. Corn disease recognition under complicated background based on improved convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2021, 52, 210–217. [Google Scholar]
- Priyadharshini1, R.A.; Arivazhagan, S.; Arun, M.; Mirnalini, A. Maize leaf disease classification using deep convolutional neural networks. Neural Comput. Appl. 2019, 31, 8887–8895. [Google Scholar] [CrossRef]
- Chen, J.; Wang, W.; Zhang, D.; Zeb, A.; Nanehkaran, Y.A. Attention embedded lightweight network for maize disease recognition. Plant Pathol. 2021, 70, 630–642. [Google Scholar] [CrossRef]
- Xu, J.H.; Shao, M.Y.; Wang, Y.C.; Han, W.T. Recognition of Corn Leaf Spot and Rust Based on Transfer Learning with Convolutional Neural Network. Trans. Chin. Soc. Agric. Mach. 2020, 51, 230–236. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Houlsby, N. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv Prepr. 2020, arXiv:2010.11929. [Google Scholar]
- Jia, Z.H.; Zhang, Y.Y.; Wang, H.T.; Liang, D. Identification Method of Tomato Disease Period Based on Res2Net and Bilinear Attention Mechanism. Trans. Chin. Soc. Agric. Mach. 2022, 1–10. [Google Scholar]
- Huang, L.S.; Luo, Y.W.; Yang, X.D.; Yang, G.J.; Wang, D.Y. Crop Disease Recognition Based on Attention Mechanism and Multi-scale Residual Network. Trans. Chin. Soc. Agric. Mach. 2021, 52, 264–271. [Google Scholar]
- Sun, W.B.; Wang, R.; Gao, R.H.; Li, Q.F.; Wu, H.R.; Feng, L. Crop Disease Recognition Based on Visible Spectrum and Improved Attention Module. Spectrosc. Spect. Anal. 2022, 42, 1572–1580. [Google Scholar]
- Liu, B.; Xu, H.W.; Li, C.Z.; Song, H.L.; He, D.J.; Zhang, H.X. Apple Leaf Disease Identification Method Based on Snapshot Ensemble CNN. Trans. Chin. Soc. Agric. Mach. 2022, 53, 286–294. [Google Scholar]
- Jie, H.; Li, S.; Gang, S.; Albanie, S. Squeeze-and-excitation networks. IEEE. Trans. Pattern. Amal. Mach. Intell. 2017, 42, 2011–2023. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland; pp. 3–19. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Du, L.Q.; Yu, Y.W. Deterioration Prediction of Machine Tools’ motion accuracy Combining Attention Mechanism under the Framework of Deep Learning. Trans. Chin. Soc. Agric. Mach. 2022. accepted. [Google Scholar]
- Mo, R.P.; Si, X.S.; Li, T.M.; Zhu, X. Bearing life prediction based on multi-scale features and attention mechanism. J. Zhejiang Univ. Eng. Sci. 2022, 56, 1447–1456. [Google Scholar]
- Zhang, W.; Li, P. Facial Expression Recognition Network Based on Attention Mechanism. J. Tianjin Univ. Sci. Technol. 2022, 55, 706–713. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Su, S.F.; Qiao, Y.; Rao, Y. Recognition of grape leaf diseases and mobile application based on transfer learning. Trans. Chin. Soc. Agric. Eng. 2021, 37, 127–134. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. CoAtNet: Marrying Convolution and Attention for All Data Sizes. Comput. Vis. Pattern Recognit. 2021, 34, 3965–3977. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease Name | Number of Original Samples/Piece | Number of Enhanced Samples/Piece | Sample Label |
|---|---|---|---|
| Common rust | 470 | 1880 | 1 |
| Bipolaris maydis | 645 | 1835 | 2 |
| Own spot | 260 | 1660 | 3 |
| Northern leaf blight | 356 | 1780 | 4 |
| Sheath blight | 448 | 1792 | 5 |
| Curvularia lunata (wakker) Boed spot | 546 | 1838 | 6 |
| Total | 2725 | 10,785 | 6 |
| Hyperparameters | Setting |
|---|---|
| Optimizer types | SGD |
| Momentum | 0.9 |
| Weight decay | 0.0008 |
| Learning rate | 0.01 |
| Batch size | 32 |
| Epoch | 60 |
| Number | Datasets | Batch-Size | Learning Rate | Training Accuracy | Test Accuracy | Training Loss | Test Loss |
|---|---|---|---|---|---|---|---|
| 1 | A | 8 | 0.1 | 72.24 | 71.56 | 4.4540 | 4.5635 |
| 2 | 0.01 | 96.42 | 97.09 | 0.0863 | 0.0815 | ||
| 3 | 0.001 | 96.23 | 97.19 | 0.0971 | 0.0745 | ||
| 4 | 16 | 0.1 | 70.86 | 71.01 | 4.6724 | 4.6491 | |
| 5 | 0.01 | 98.84 | 98.17 | 0.0345 | 0.0536 | ||
| 6 | 0.001 | 96.66 | 97.31 | 0.0859 | 0.0664 | ||
| 7 | 32 | 0.1 | 91.97 | 91.47 | 0.2014 | 0.2222 | |
| 8 | 0.01 | 98.94 | 98.20 | 0.0287 | 0.9820 | ||
| 9 | 0.001 | 95.97 | 96.94 | 0.1012 | 0.0759 | ||
| 10 | B | 8 | 0.1 | 72.33 | 72.42 | 4.4386 | 4.4242 |
| 11 | 0.01 | 97.79 | 98.91 | 0.0575 | 0.0298 | ||
| 12 | 0.001 | 96.19 | 98.03 | 0.0993 | 0.0521 | ||
| 13 | 16 | 0.1 | 72.33 | 72.42 | 4.4598 | 4.4454 | |
| 14 | 0.01 | 99.31 | 99.30 | 0.0200 | 0.0210 | ||
| 15 | 0.001 | 97.41 | 98.63 | 0.0686 | 0.0386 | ||
| 16 | 32 | 0.1 | 97.55 | 97.75 | 0.0670 | 0.0653 | |
| 17 | 0.01 | 99.52 | 99.78 | 0.0138 | 0.0067 | ||
| 18 | 0.001 | 97.82 | 98.53 | 0.0587 | 0.0404 |
| Model | Common Rust | Bipolaris maydis | Curvularia lunata (Wakker) Boed Spot | Northern Leaf Blight | Sheath Blight | Own Spot |
|---|---|---|---|---|---|---|
| AT-AlexNet-A | 93.20% | 91.06% | 95.58% | 92.96% | 96.36% | 100% |
| AT-AlexNet-B | 99.46% | 98.39% | 99.18% | 100% | 99.06% | 100% |
| Network Model | Precision | Recall | F1 Score | Accuracy | Test Accuracy |
|---|---|---|---|---|---|
| AlexNet | 98.06% | 98.05% | 98.06% | 98.05% | 98.05% |
| AT-AlexNet | 99.35% | 99.35% | 99.35% | 99.35% | 99.78% |
| AT-AlexNet-R | 98.71% | 98.70% | 98.70% | 98.70% | 99.59% |
| AT-AlexNet-C | 99.14% | 99.12% | 99.13% | 99.12% | 99.12% |
| Disease Types | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| Common rust | 100% | 98% | 99% | 99% |
| Bipolaris maydis | 98% | 99% | 99% | 98% |
| Curvularia lunata (wakker) Boed spot | 98% | 99% | 99% | 99% |
| Northern leaf blight | 99% | 100% | 99% | 100% |
| Sheath blight | 99% | 98% | 98% | 99% |
| Own spot | 99% | 100% | 100% | 100% |
| Average | 99% | 99% | 99% | 99% |
| Network Structure | Precision | Recall | F1 Score | Training Accuracy | Test Accuracy |
|---|---|---|---|---|---|
| AT-AlexNet | 99.35% | 99.35% | 99.35% | 99.52% | 99.78% |
| LeNet | 95.99% | 95.97% | 95.98% | 97.58% | 95.97% |
| GoogLeNet | 99.73% | 99.72% | 99.72% | 99.52% | 99.72% |
| Network Model | Precision | Recall | F1 Score | Accuracy | Training Accuracy | Test Accuracy |
|---|---|---|---|---|---|---|
| AT-AlexNet | 99.35% | 99.35% | 99.35% | 99.35% | 99.52% | 99.78% |
| AT-AlexNet-D | 94.62% | 94.58% | 94.60% | 94.58% | 97.90% | 98.23% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Tao, J.; Gao, H. Corn Disease Recognition Based on Attention Mechanism Network. Axioms 2022, 11, 480. https://doi.org/10.3390/axioms11090480
Wang Y, Tao J, Gao H. Corn Disease Recognition Based on Attention Mechanism Network. Axioms. 2022; 11(9):480. https://doi.org/10.3390/axioms11090480
Chicago/Turabian StyleWang, Yingying, Jin Tao, and Haitao Gao. 2022. "Corn Disease Recognition Based on Attention Mechanism Network" Axioms 11, no. 9: 480. https://doi.org/10.3390/axioms11090480