
Technology Opportunity Analysis Based on Machine Learning

Abstract
:1. Introduction
2. Background
2.1. Importance of Patent in Technology Management
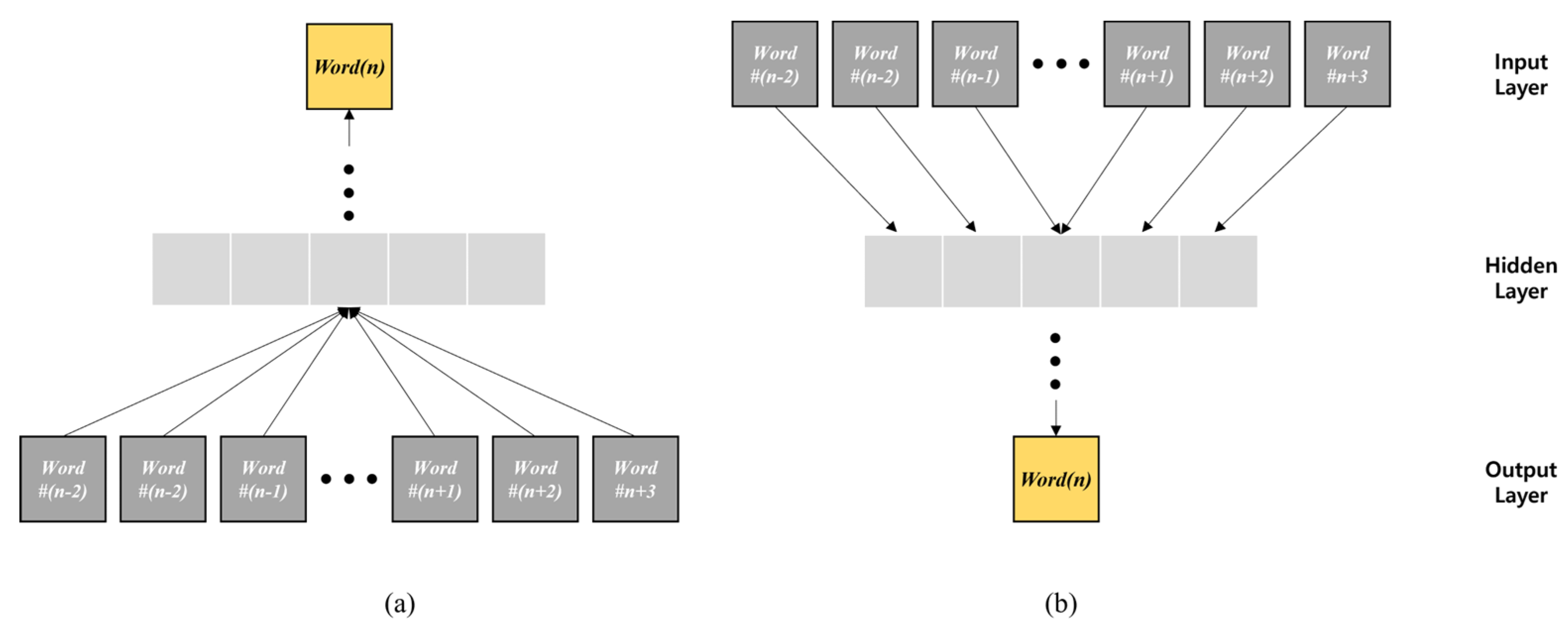
2.2. Word2Vec
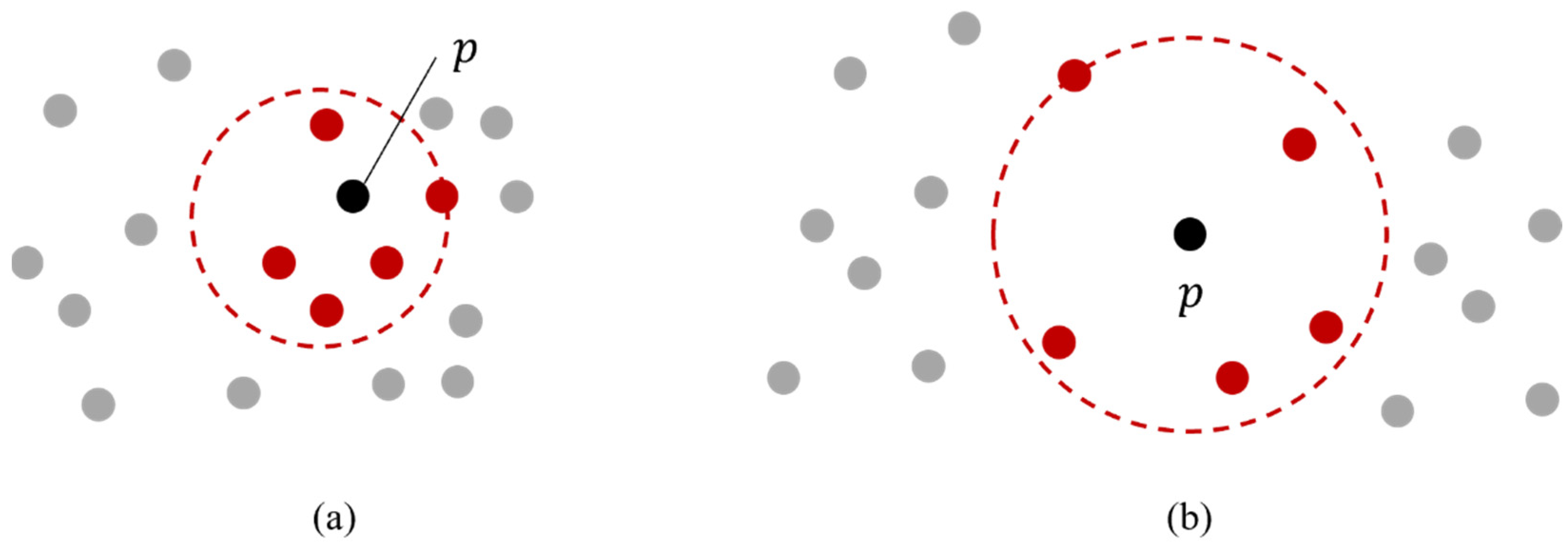
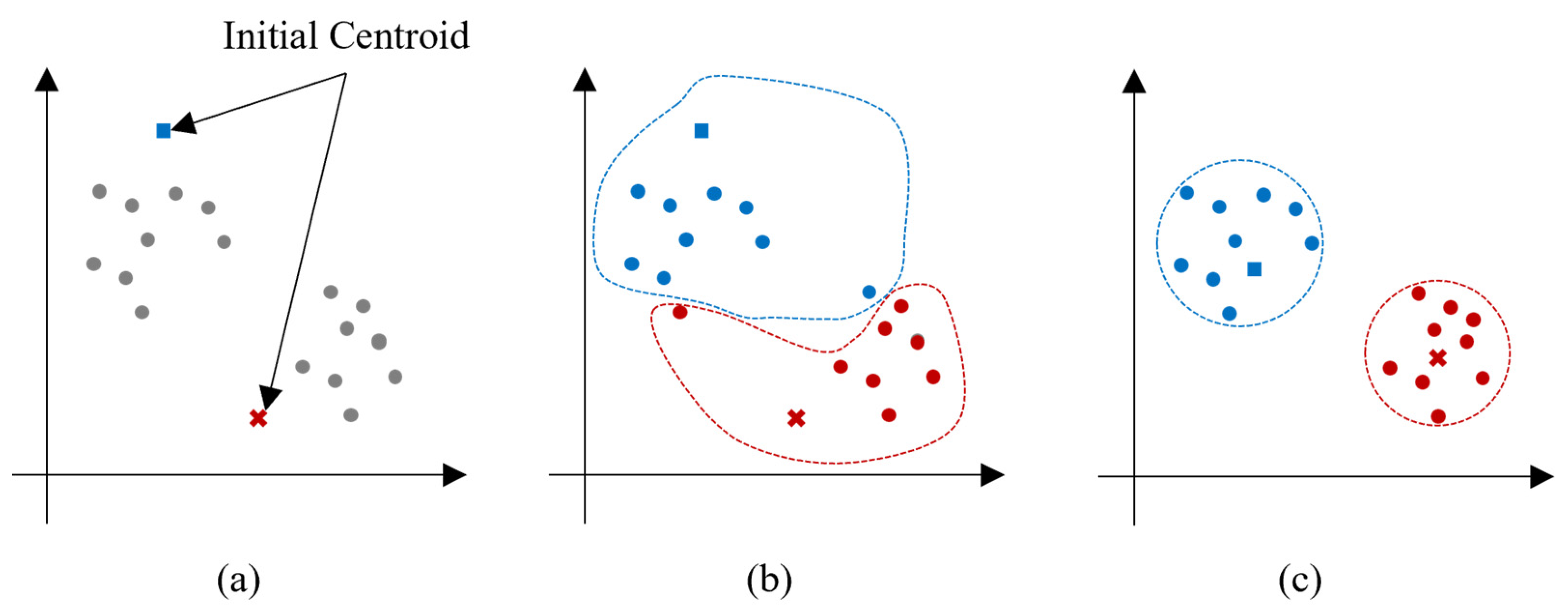
2.3. Local Outlier Factor
3. Methodology
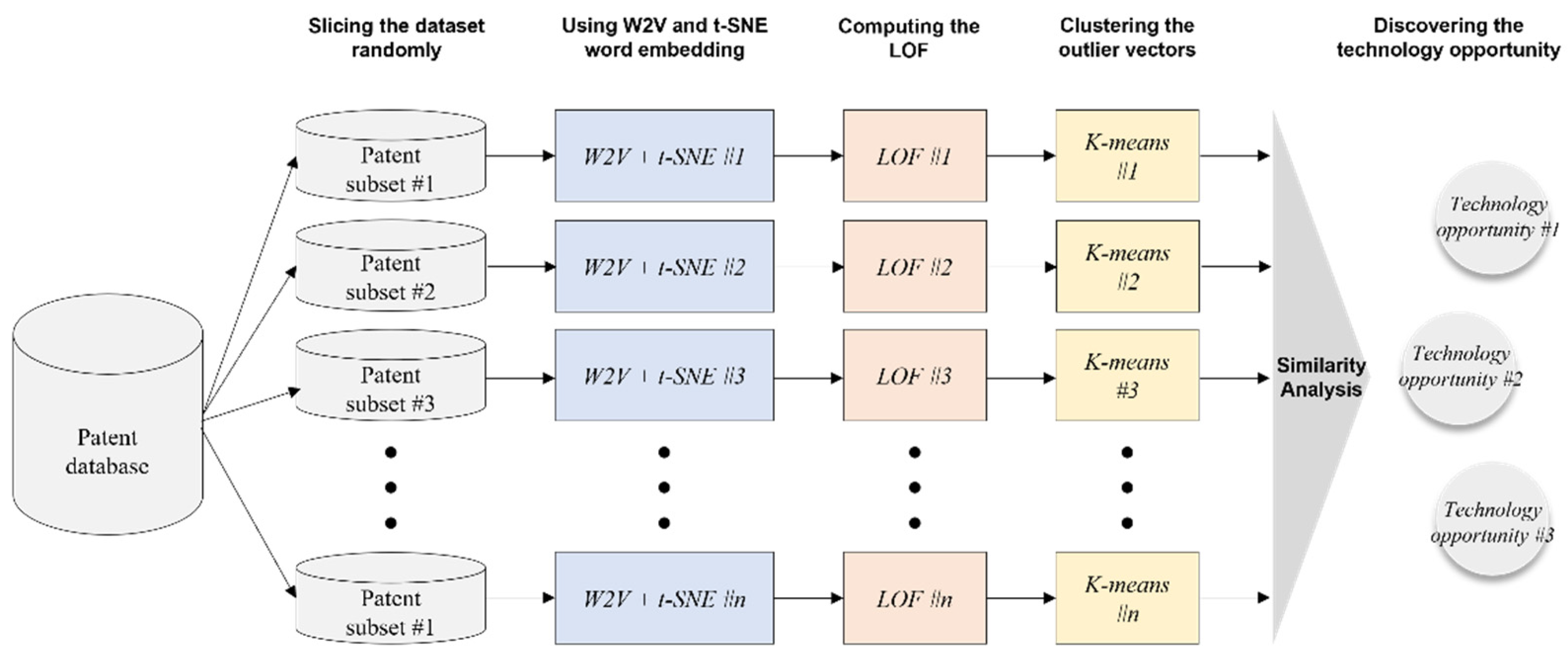
3.1. Introduce to Methodology
- -
- Collecting the data of the drone technology field from the patent database;
- -
- Randomly splitting the patent dataset into subsets.
- -
- Creating the corpus;
- -
- Cleaning the text data using text preprocessing technique, for example, removing punctuation, stopwords, and numbers;
- -
- Constructing the document-term matrix (DTM);
- -
- Applying DTM to W2V words represented in vector space;
- -
- Reducing the dimensionality from high-dimensional to two-dimensional using t-SNE algorithm.
- -
- Estimating the anomaly score using the LOF technique;
- -
- Extracting the outlier keywords using IQR for each subset.
- -
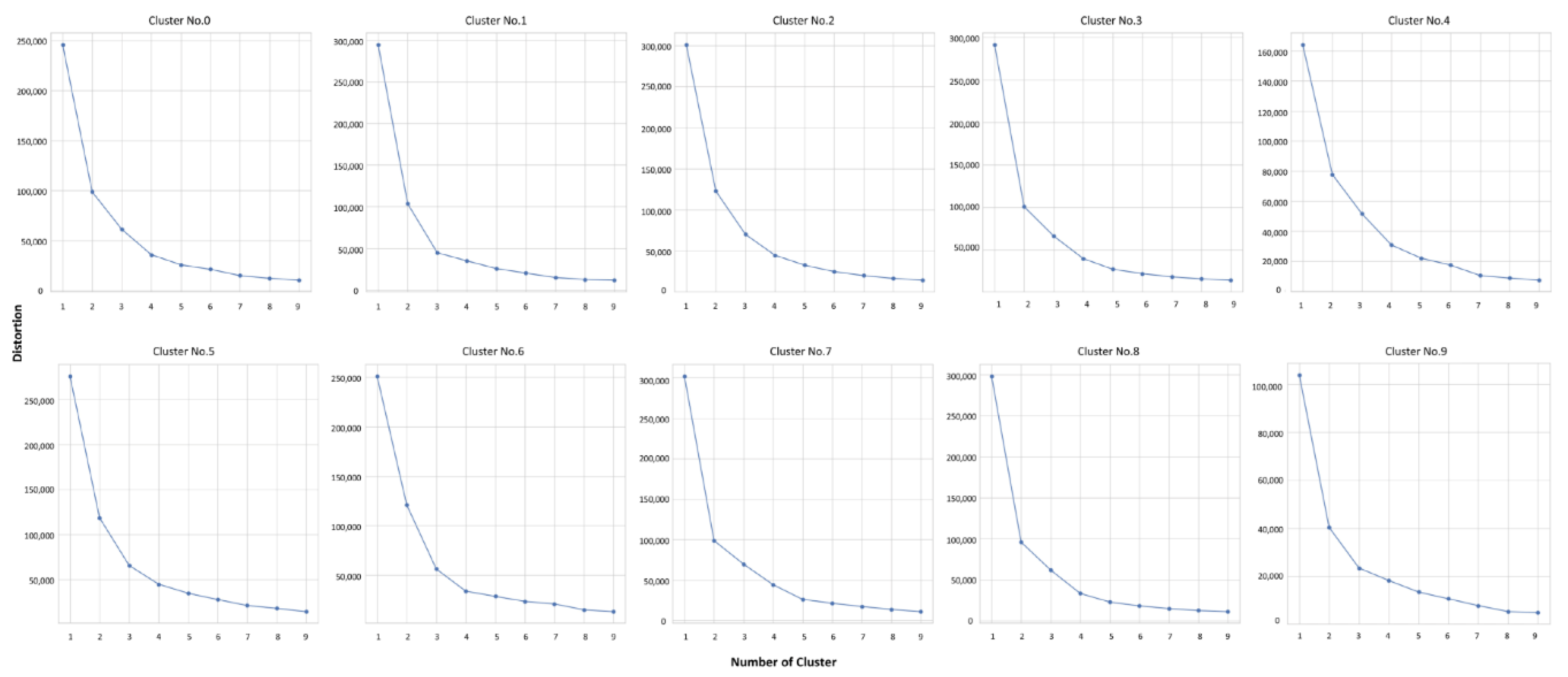
- Checking the elbow point from 1 to 10 and selecting the optimal k for each subset;
- -
- Clustering outlier keywords for each subset.
- -
- (Step 5) Similarity analysis and discovering the technology opportunity:
- -
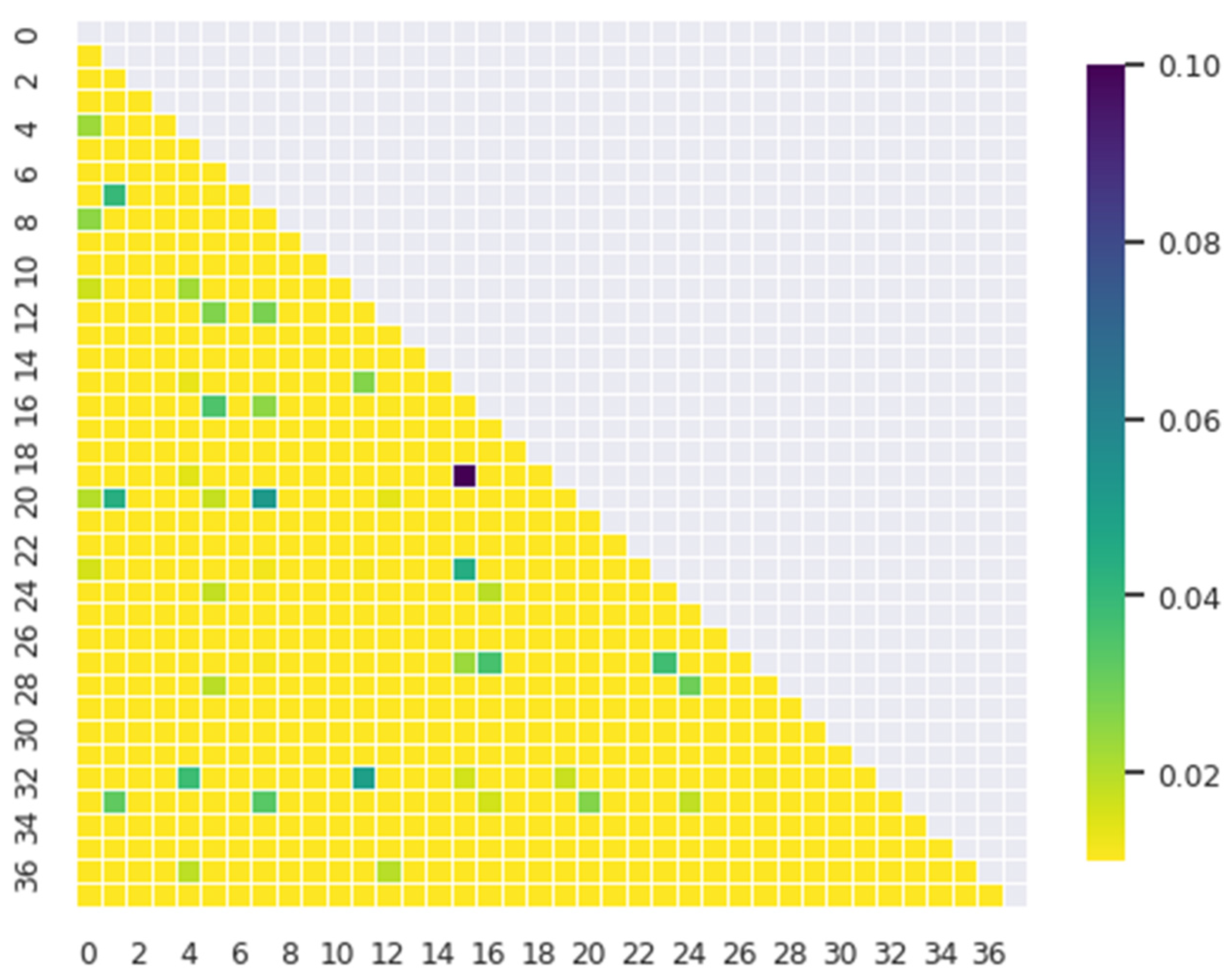
- Analyzing the similarity between clusters;
- -
- Identifying the technology opportunity through results of similarity analysis and establishing the R&D strategy.
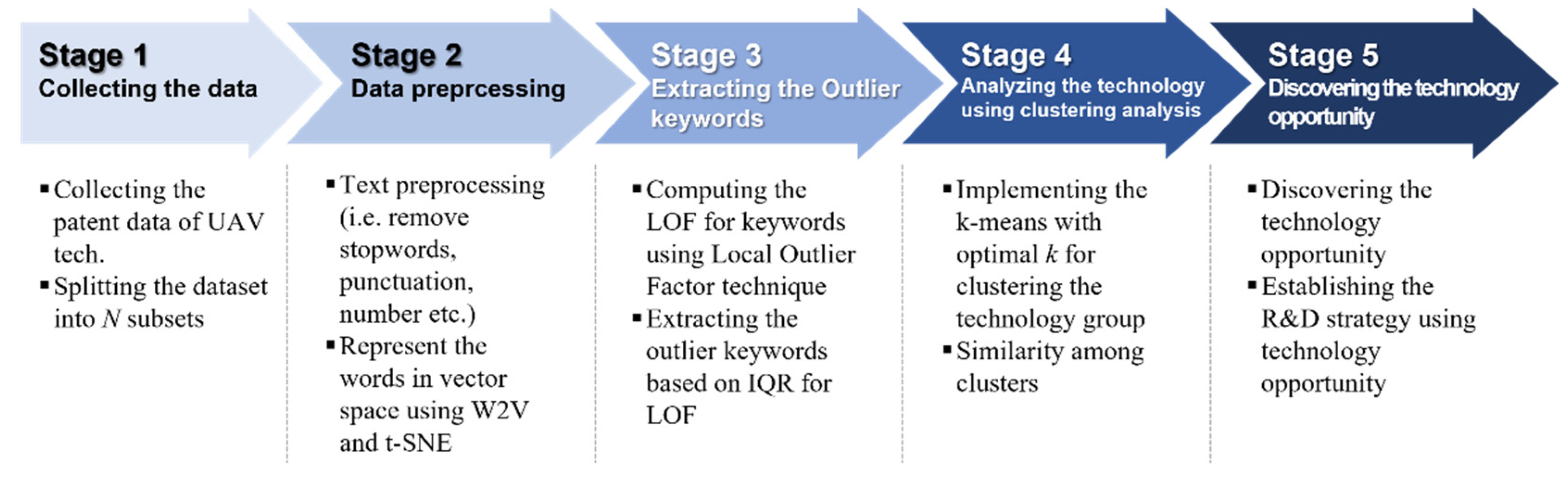
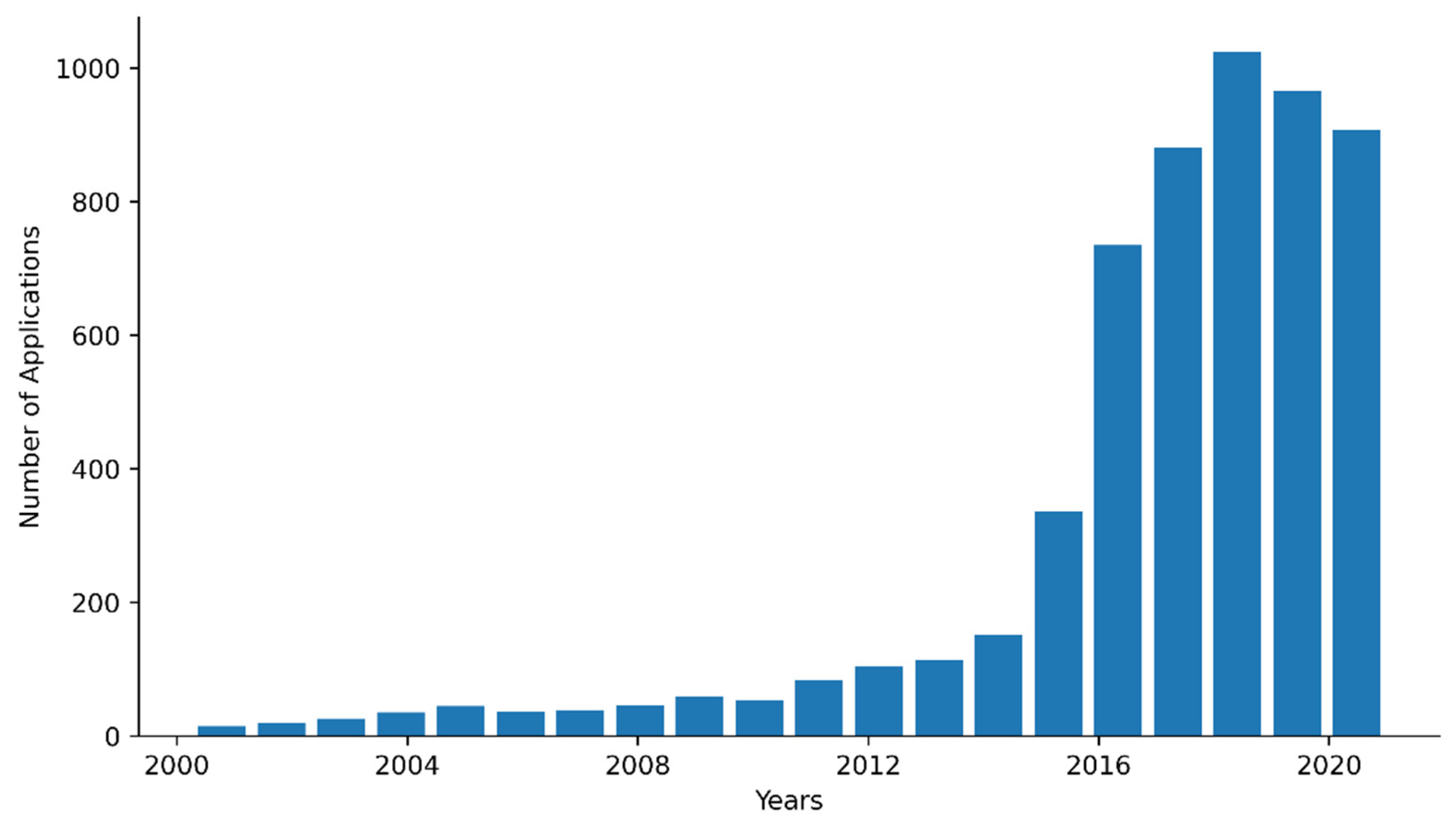
3.2. Collecting the Data—Patent Data Related to UAV
3.3. Data Preprcessing
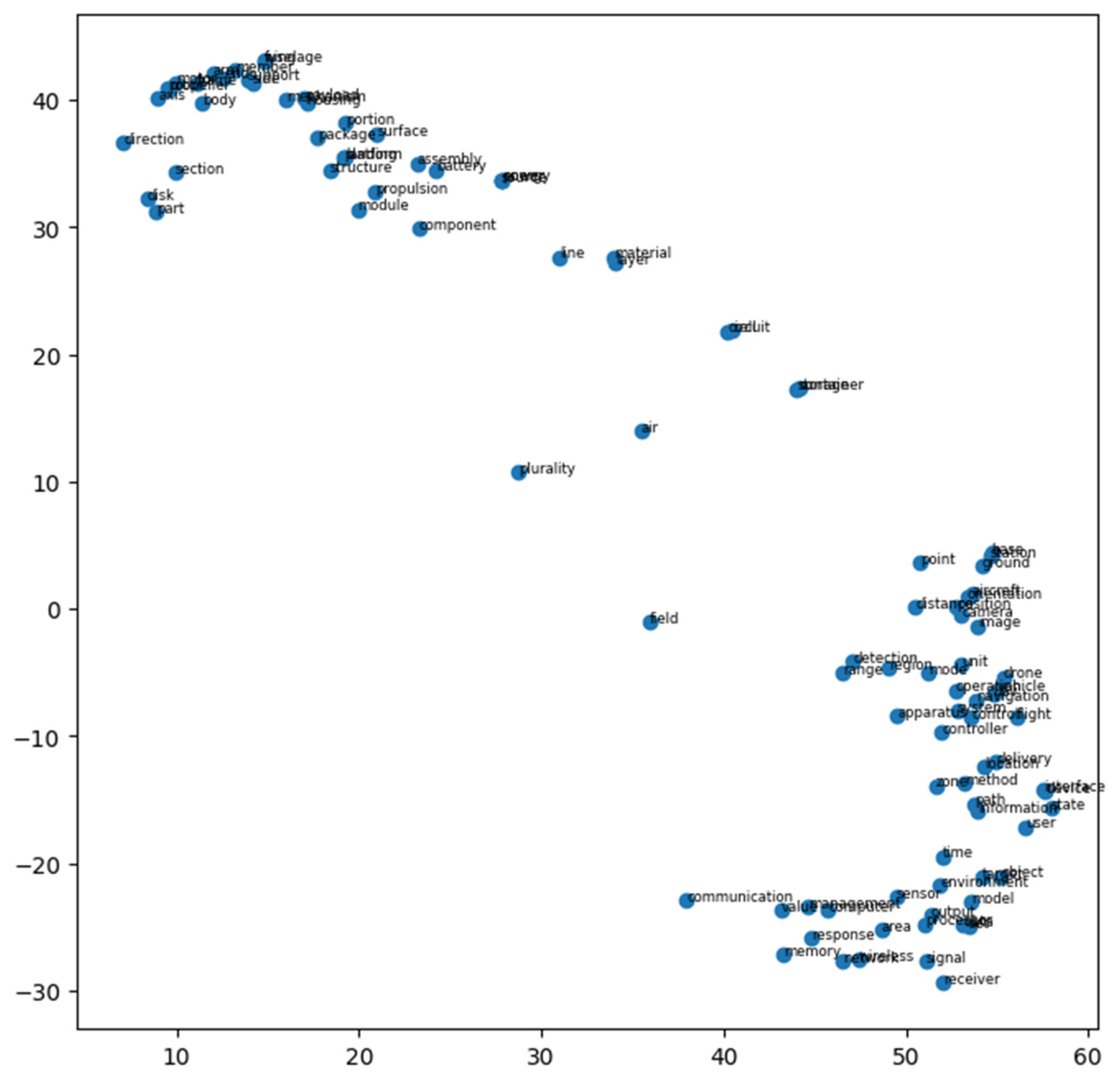
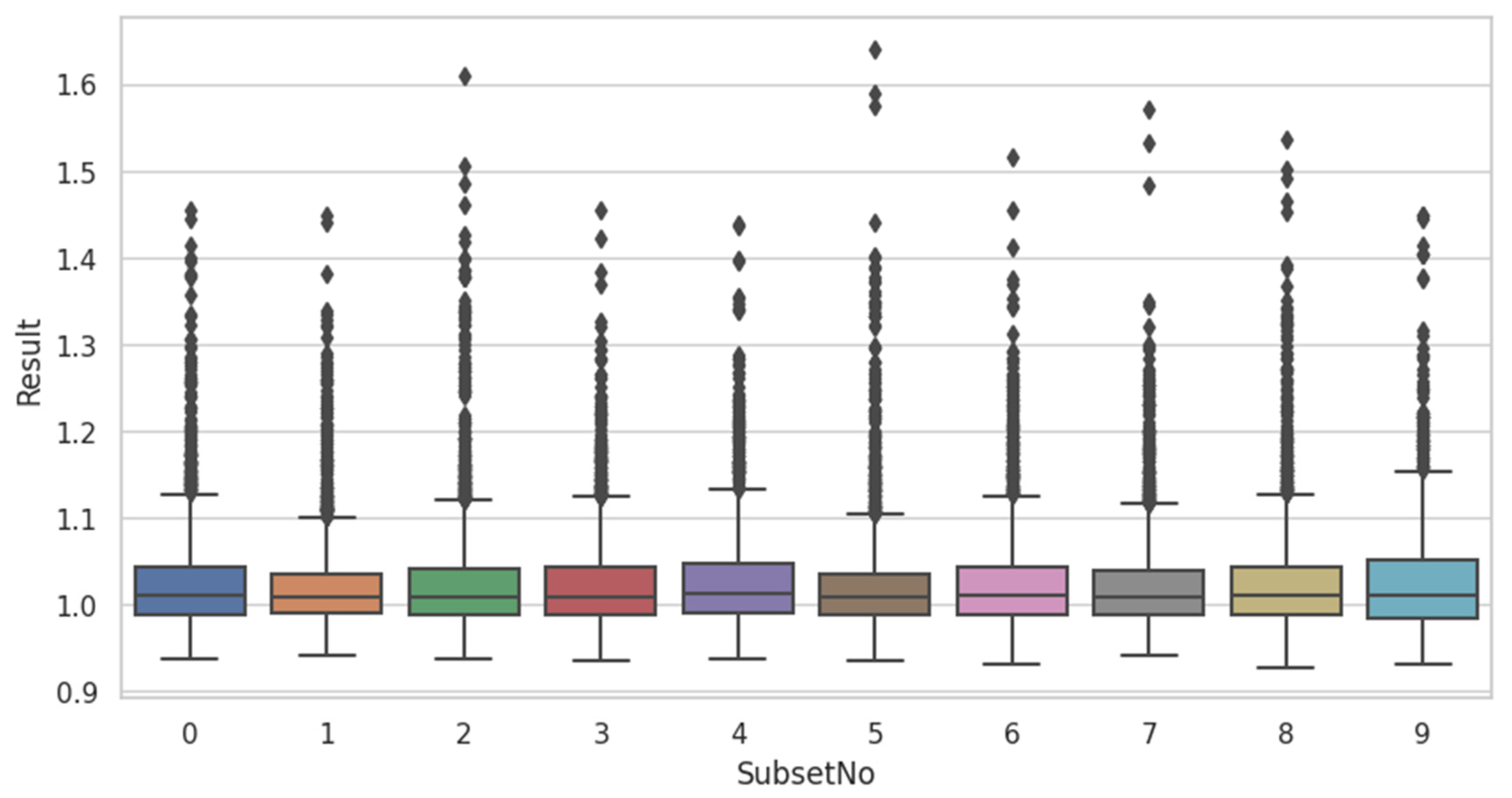
3.4. Extracting the Outlier Keywords Using Local Outlier Factor
3.5. Analyzing the Technology Using Clustering Technique
3.6. Discovering the Technology Opportunity
4. Experiments and Results
5. Conclusions and Future Works
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronyms | Explanation |
|---|---|
| W2V | Word2Vec |
| LOF | Local outlier factor |
| UAV | Unmanned aerial vehicle |
| R&D | Research and Development |
| TOA | Technology opportunity analysis |
| GTM | Generative topology mapping |
| IQR | Interquartile range |
| IPA | Intellectual property analytics |
| TF-IDF | Term frequency-Inverse document frequency |
| CBOW | Continuous bag-of-words |
| DTM | Document-Term matrix |
| t-SNE | t-distributed stochastic neighbor embedding |
| PCA | Principal component analysis |
| POS | Part-of-speech |
References
- Porter, A.L.; Detampel, M.J. Technology Opportunities Analysis. Technol. Forecast. Soc. Chang. 1995, 49, 237–255. [Google Scholar] [CrossRef]
- Olsson, O. Technological Opportunity and Growth. J. Econ. Growth 2005, 10, 31–53. [Google Scholar] [CrossRef]
- Yoon, B.; Park, Y. A Systematic Approach for Identifying Technology Opportunities: Keyword-Based Morphology Analysis. Technol. Forecast. Soc. Chang. 2005, 72, 145–160. [Google Scholar] [CrossRef]
- Ma, T.; Porter, A.L.; Guo, Y.; Ready, J.; Xu, C.; Gao, L. A Technology Opportunities Analysis Model: Applied to Dye-Sensitised Solar Cells for China. Technol. Anal. Strateg. Manag. 2014, 26, 87–104. [Google Scholar] [CrossRef]
- Lee, C.; Kang, B.; Shin, J. Novelty-Focused Patent Mapping for Technology Opportunity Analysis. Technol. Forecast. Soc. Chang. 2015, 90, 355–365. [Google Scholar] [CrossRef]
- Song, K.; Kim, K.S.; Lee, S. Discovering New Technology Opportunities Based on Patents: Text-Mining and F-Term Analysis. Technovation 2017, 60–61, 1–14. [Google Scholar] [CrossRef]
- Yoon, B.; Magee, C.L. Exploring Technology Opportunities by Visualizing Patent Information Based on Generative Topographic Mapping and Link Prediction. Technol. Forecast. Soc. Chang. 2018, 132, 105–117. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.J. A Novelty Detection Patent Mining Approach for Analyzing Technological Opportunities. Adv. Eng. Inform. 2019, 42, 100941. [Google Scholar] [CrossRef]
- Choi, J.; Jeong, B.; Yoon, J. Identification of Emerging Business Areas for Business Opportunity Analysis: An Approach Based on Language Model and Local Outlier Factor. Comput. Ind. 2022, 140, 103677. [Google Scholar] [CrossRef]
- Park, H.; Yoon, J.; Kim, K. Using Function-Based Patent Analysis to Identify Potential Application Areas of Technology for Technology Transfer. Expert. Syst. Appl. 2013, 40, 5260–5265. [Google Scholar] [CrossRef]
- Aristodemou, L.; Tietze, F. The State-of-the-Art on Intellectual Property Analytics (IPA): A Literature Review on Artificial Intelligence, Machine Learning and Deep Learning Methods for Analysing Intellectual Property (IP) Data. World Patent Inf. 2018, 55, 37–51. [Google Scholar] [CrossRef]
- Ernst, H. Patent Information for Strategic Technology Management. World Patent Inf. 2003, 25, 233–242. [Google Scholar] [CrossRef]
- Abbas, A.; Zhang, L.; Khan, S.U. A Literature Review on the State-of-the-Art in Patent Analysis. World Patent Inf. 2014, 37, 3–13. [Google Scholar] [CrossRef]
- Lee, C. A Review of Data Analytics in Technological Forecasting. Technol. Forecast. Soc. Chang. 2021, 166, 120646. [Google Scholar] [CrossRef]
- Grzegorczyk, T.; Głowiński, R. Patent Management Strategies: A Review. J. Econ. Manag. 2020, 40, 36–51. [Google Scholar] [CrossRef]
- Al-Saqqa, S.; Awajan, A. The Use of Word2vec Model in Sentiment Analysis: A Survey. In Proceedings of the ACM International Conference Proceeding Series, Egypt, Cairo, 14–16 December 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 39–43. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv preprint 2013, arXiv:1301.3781. [Google Scholar]
- Breunig, M.M.; Kriegel, H.-P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data—SIGMOD ’00, Dallas, Texas, USA, 15–18 May 2000; ACM Press: New York, NY, USA, 2000; pp. 93–104. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Outlier Detection: A Survey. ACM Comput. Surv. 2007, 14, 15. [Google Scholar]
- Singh, K.; Upadhyaya, S. Outlier Detection: Applications and Techniques. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 307. [Google Scholar]
- Jeon, D.; Ahn, J.M.; Kim, J.; Lee, C. A Doc2vec and Local Outlier Factor Approach to Measuring the Novelty of Patents. Technol. Forecast. Soc. Chang. 2022, 174, 121294. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing Data Using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Lloyd, S.P. Least Squares Quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef] [Green Version]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An Efficient K-Means Clustering Algorithms: Analysis and Implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Jiawei, H.; Micheline, K.; Jian, P. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann Publishers: Waltham, MA, USA, 2011; ISBN 978-0-12-381479-1. [Google Scholar]











| Technology Field | Number of Documents | Patent DB |
|---|---|---|
| UAV | 5679 | WISDOMAIN |
| Hyperparameter | Candidates |
|---|---|
| Vector Size | 100 |
| Window | 3 |
| Algorithm | Skip-gram |
| Hyperparameter | Candidates |
|---|---|
| N_component | 2 |
| Initialization of embedding | PCA |
| Hyperparameter | Candidates |
|---|---|
| n_neighbors | 20 |
| metric | minkowski |
| Word | Subset No. | X | Y | LOF |
|---|---|---|---|---|
| vehicle | 0 | 55.023 | −6.405 | 1.088 |
| drone | 0 | 55.342 | −5.365 | 1.093 |
| system | 0 | 52.801 | −8.032 | 1.033 |
| device | 1 | 57.626 | −0.078 | 0.963 |
| localizing | 1 | −59.189 | −27.479 | 1.103 |
| … | … | … | … | … |
| traffic | 7 | 47.543 | 17.132 | 1.344 |
| part | 7 | 25.866 | 36.117 | 1.482 |
| station | 8 | 54.892 | −17.796 | 1.465 |
| receiving | 8 | 28.824 | 26.138 | 0.938 |
| tag | 9 | 35.094 | 7.839 | 1.448 |
| Subset No. | Mean | Std. | Min | Max | Q1 | Q3 | IQR |
|---|---|---|---|---|---|---|---|
| 0 | 1.02698 | 0.061575 | 0.936517 | 1.453869 | 0.987785 | 1.043947 | 0.056163 |
| 1 | 1.021218 | 0.053211 | 0.942201 | 1.448178 | 0.989804 | 1.034662 | 0.044858 |
| 2 | 1.028386 | 0.06783 | 0.936725 | 1.608826 | 0.989202 | 1.042044 | 0.052841 |
| 3 | 1.0243 | 0.055879 | 0.934708 | 1.45417 | 0.988664 | 1.043112 | 0.054447 |
| 4 | 1.026969 | 0.058455 | 0.937783 | 1.439178 | 0.990205 | 1.047507 | 0.057302 |
| 5 | 1.024395 | 0.063914 | 0.936138 | 1.640614 | 0.989406 | 1.035572 | 0.046166 |
| 6 | 1.026492 | 0.061354 | 0.931228 | 1.515098 | 0.987773 | 1.042835 | 0.055062 |
| 7 | 1.02419 | 0.058558 | 0.941442 | 1.570052 | 0.988169 | 1.039446 | 0.051278 |
| 8 | 1.028224 | 0.064822 | 0.927807 | 1.536986 | 0.988537 | 1.044326 | 0.055789 |
| 9 | 1.029998 | 0.068492 | 0.931828 | 1.448094 | 0.98459 | 1.052209 | 0.067619 |
| Subset 0. | Subset 1. | Subset 2. | Subset 3. | Subset 4. | Subset 5. | Subset 6. | Subset 7. | Subset 8. | Subset 9. |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 3 | 4 | 4 | 4 | 4 | 4 | 5 | 4 | 2 |
| Subset Index | Cluster Index | Representative Index | Similarity Average |
|---|---|---|---|
| 0 | 0 | 0 | 0.057 |
| 1 | 1 | 0.059 | |
| 2 | 2 | 0.034 | |
| 3 | 3 | 0.033 | |
| 1 | 0 | 4 | 0.065 |
| 1 | 5 | 0.058 | |
| 2 | 6 | 0.031 | |
| 2 | 0 | 7 | 0.079 |
| 1 | 8 | 0.045 | |
| 2 | 9 | 0.034 | |
| 3 | 10 | 0.029 | |
| 3 | 0 | 11 | 0.059 |
| 1 | 12 | 0.054 | |
| 2 | 13 | 0.034 | |
| 3 | 14 | 0.037 | |
| 4 | 0 | 15 | 0.057 |
| 1 | 16 | 0.066 | |
| 2 | 17 | 0.032 | |
| 3 | 18 | 0.031 | |
| 5 | 0 | 19 | 0.054 |
| 1 | 20 | 0.069 | |
| 2 | 21 | 0.035 | |
| 3 | 22 | 0.029 | |
| 6 | 0 | 23 | 0.061 |
| 1 | 24 | 0.058 | |
| 2 | 25 | 0.030 | |
| 3 | 26 | 0.035 | |
| 7 | 0 | 27 | 0.066 |
| 1 | 28 | 0.051 | |
| 2 | 29 | 0.041 | |
| 3 | 30 | 0.029 | |
| 4 | 31 | 0.031 | |
| 8 | 0 | 32 | 0.061 |
| 1 | 33 | 0.057 | |
| 2 | 34 | 0.031 | |
| 3 | 35 | 0.031 | |
| 9 | 0 | 36 | 0.049 |
| 1 | 37 | 0.038 |
| Cluster No. | Keyword | Technology Definition |
|---|---|---|
| 7 (2-0) | phenomenon, drones, transformer, intent, oscillator, inhouse, lag, holding, rectifier, interdiction, concern, multi trigger, low rate, analyzing, sram, throttle, dc, diversity, nonoverlapping, disengagement, prevent, po, practice, dsl, constellation, system one, extremity, exporting, firefighting, multitab, display, derivatives | UAV defense technology |
| 20 (5-1) | power, air, surface, base, station, platform, frame, housing, ground, direction, axis, battery, center, source, material, channel, rotation, space, angle, layer, element, weight, plane, contact, block, prepreg, sensory, gate, ply, plate, synchronization, metal, cradle, cue, hanger, av, substrate, oblique, mobility, glide, vias, system | UAV charging station(platform) technology |
| 16 (4-1) | stack, ml, nonce, root, mask, magnetization, exhibition, interrogation, police, charging, dummy, provider, foam, redistribution, passivation, threat, heathing, reinforcement, operate, inhibitor, bounding, timestamp, dial, rearend, tracer, releasing, signaltonoise, cuav, spotlight, cone, metaloxide, molding, send, ingestion, pipeline, merkel, surrounding, higherlevel, fit, cap, metallization, blend | To improve the UAV measurement technology |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Park, S.; Lee, J. Technology Opportunity Analysis Based on Machine Learning. Axioms 2022, 11, 708. https://doi.org/10.3390/axioms11120708
Lee J, Park S, Lee J. Technology Opportunity Analysis Based on Machine Learning. Axioms. 2022; 11(12):708. https://doi.org/10.3390/axioms11120708
Chicago/Turabian StyleLee, Junseok, Sangsung Park, and Juhyun Lee. 2022. "Technology Opportunity Analysis Based on Machine Learning" Axioms 11, no. 12: 708. https://doi.org/10.3390/axioms11120708