
Enhanced Lot Acceptance Testing Based on Defect Counts and Posterior Odds Ratios
Departamento de Matemáticas, Estadística e Investigación Operativa and Instituto de Matemáticas y Aplicaciones (IMAULL), Universidad de La Laguna (ULL), 38071 Tenerife, Canary Islands, Spain
Axioms 2022, 11(11), 604; https://doi.org/10.3390/axioms11110604
Submission received: 21 September 2022
/
Revised: 26 October 2022
/
Accepted: 27 October 2022
/
Published: 29 October 2022
(This article belongs to the Special Issue Computational Statistics & Data Analysis)
Abstract
:Optimal defects-per-unit test plans based on posterior odds ratios are developed for the disposition of product lots. The number of nonconformities per unit is modeled by the Conway–Maxwell–Poisson distribution rather than the typical Poisson model. In essence, a submitted batch is conforming if its posterior acceptability is sufficiently large. First, a useful approximation of the optimal test plan is derived in closed form using the asymptotic normality of the log ratio. A mixed-integer nonlinear programming problem is then solved via Monte Carlo simulation to find the smallest number of inspected items per lot and the maximum tolerable posterior odds ratio. The methodology is applied to the manufacturing of paper and glass. The suggested sampling plan for lot sentencing provides the specified protections to both manufacturers and customers and minimizes the needed sample size. In terms of inspection effort and accuracy, the proposed approach is virtually an advantageous extension of the classical frequentist perspective. In many practical cases, it yields more precise assessments of the current consumer and producer risks, as well as more realistic decision rules.
Keywords:
industrial quality control; acceptance sampling; Bayesian statistics; mixed-integer nonlinear programming; Conway–Maxwell–Poisson distribution; Monte Carlo simulationMSC:
62F03; 62F15; 62K05; 62P30; 65C05; 90C111. Introduction
Sampling inspection plans for lot acceptance are often designed in industry to suitably discriminate between satisfactory and unsatisfactory batches. In essence, the construction of the best decision rule for lot disposition can be stated as a constrained optimization problem. Generally, proper acceptance test plans must provide the desired protections to both customers and manufacturers, and the required number of items to be sampled should be as small as possible. Many test plans are available in the literature for sentencing lots of incoming or outgoing goods. Papers [1,2,3,4,5,6,7,8,9,10,11,12,13,14] are just a sample of recent references.
The number of minor defects (or nonconformities) per unit is sometimes the quality characteristic of interest; for example, when the inspected units are metal, linoleum, glass, paper or plastic. In such cases, the Poisson model is commonly used for analyzing the observed sample. For instance, Fernández [15] adopted Poisson models to describe the number of blemishes per sheet in inspecting paper. In these situations, the Poisson parameter, is precisely the defect rate per sampled unit. Moreover, the number of events in a specific time period is often modeled by a Poisson distribution. In particular, many studies assume that the stochastic demands follow that distribution; see, e.g., [16,17,18,19,20].
The mean and variance of a Poisson distributed variable are both equal to which could be too restrictive in practice. Evidently, the Poisson distribution is not suitable for fitting dispersed data. Due to this reason, Fernández [21] considers the Conway–Maxwell–Poisson (CMP) distribution with centering parameter and dispersion parameter d for modeling the defect count data. The CMP law with parameter is a generalization of the Poisson distribution, where d can reflect under- equi- and over-dispersion Conway and Maxwell [22] introduced this distribution for modeling queuing systems with state-dependent service rates. Samuel et al. [23] studied some statistical and probabilistic properties of the CMP law. An extensive survey of procedures and applications of this model in a wide diversity of areas, including numerous references, can be found in Sellers et al. [24]. Other interesting papers are Francis et al. [25], Zhu [26] and Santarelli et al. [27].
In many practical situations, the combination of available empirical information with a previous objective and subjective knowledge appreciably improves the efficiency of the inferential methods; see, e.g., [28,29,30,31,32,33,34,35,36,37,38]. The presence of prior information is common in most manufacturing processes. In such cases, the incorporation of earlier inspection results and subjective expert opinions is frequently advantageous in acceptance sampling. Fernández [21] studied the construction of acceptance test plans for CMP models using exclusively sample information. In contrast, this paper deals with the determination of optimal lot inspection schemes based on dispersed defect count data and prior knowledge. A constrained minimization problem is solved via Monte Carlo simulation to determine the optimal inspection scheme. The proposed sampling plan provides the demanded protections to both consumers and producers and minimizes the needed sample size. Essentially, a submitted lot is accepted whenever its posterior lot acceptability is large enough. The suggested Bayesian approach is an appealing alternative to the typical frequency-based perspective in terms of accuracy and inspection effort. Controlling the Bayesian risks allows the practitioners to ensure that the rejected and accepted lots are, in fact, rejectable and acceptable at the required confidence levels.
The rest of this paper is structured as follows. Section 2 presents the posterior odds ratio criterion for lot sentencing based on dispersed defect count data and prior information. The design of sampling plans with controlled Bayesian consumer and producer risks and minimum sample size is developed in Section 3. A mixed-integer nonlinear programming problem is formulated in order to find the best inspection scheme. Then, explicit approximations of the Bayesian risks and the optimal plan are deduced in Section 4 by using the asymptotic normality of the test statistic. Next, Section 5 introduces a Monte Carlo simulation approach to calculate the optimal scheme, which is applied in Section 6 to the manufacturing of paper and glass. Finally, Section 7 offers some concluding remarks.
2. Posterior Odds Ratio Testing
A random variable X is said to follow the CMP probability model with parameter which is denoted by if its probability mass function is given by
where denotes the set of nonnegative integers,
and is the parameter space.
Clearly, the i-th moment of the random variable is given by
where represents the set of natural numbers. Hence, the mean and variance of X can be expressed as
Consider that in a certain production process, the number X of minor defects or nonconformities detected in a given item follows the distribution and also that a large batch of products has been submitted to determine its acceptability. In addition, the experimental information is contained in a simple random sample of size n from the variable where represents the number of imperfections observed in the i-th inspected item from the lot for
The manufacturer assumes that the distribution is an acceptable model for whereas the customer supposes that the distribution is rejectable, where is less than In other words, the manufacturer considers that the null hypothesis is admissible, while the customer specifies the alternative hypothesis In short, is the acceptable parameter and is the unacceptable one.
In Bayesian hypothesis testing, the null hypothesis is accepted whenever its posterior probability is large enough. Obviously, it is needed to estimate prior probabilities for and before applying Bayes’ theorem. Suppose that is a numerical value in the interval representing the decision-maker’s prior level of credibility in the acceptability of the submitted batch based on available expert opinions and previous data. Hence, and is the prior odds ratio in favor of versus
The submitted lot would be accepted by the Bayesian test whenever the posterior odds ratio of against given which is defined as is small enough. In our situation, the posterior odds ratio based on the available data is given by
where and Since the log ratio is given by
where it is clear that the posterior odds ratio test would accept if and only if the test statistic is at most the so-called acceptance constant i.e., the batch is accepted whenever The test statistic is based on the sufficient statistic which captures all relevant information in the data.
The acceptance sampling plan based on the posterior odds ratio criterion can be summarized as follows: Step 1: At random, select n items from the submitted batch. Step 2: Count the number of minor defects in n items, and calculate and Step 3: Compute the value of the test statistic Step 4: Accept the batch if and reject it otherwise.
Assuming that with it is derived from the central limit theorem that converges in law to a standard normal random variable as where and are the mean and variance of respectively. Consequently, the test statistic is approximately normally distributed when n is large enough.
It should be noted that the posterior lot acceptability which represents the conditional degree of belief in given the observed sample and the posterior odds ratio may be revised in light of additional subjective and objective information.
3. Design of Lot Acceptance Sampling Plans
Sampling inspection schemes for lot acceptance purposes are usually designed in industrial quality control to minimize the needed sample size for lot judgment while ensuring that the so-called producer and consumer risks are sufficiently small; say, at most, and respectively, where An agreement between the manufacturer and the customer is commonly assumed on the choices of the prior probabilities of the hypotheses, and the acceptable and unacceptable CMP parameters, and and the maximum allowable Bayesian producer and consumer risks, and respectively.
Essentially, the Bayesian consumer risk is the probability that an accepted batch has an unacceptable quality level, whereas the Bayesian producer risk is the probability that a rejected batch has an acceptable quality level. These risks provide the assurance that practitioners typically require. The manufacturer wants a small maximum probability that is true when the lot is rejected, while the consumer desires a small maximum probability that is false when the batch is accepted.
In our situation, the Bayesian producer and consumer risks associated with the inspection scheme can be expressed as
respectively. Based on Bayes’ theorem, the Bayesian producer risk is defined as
where
whereas the Bayesian consumer risk is given by
Equivalently, in terms of the prior odds ratio the Bayesian risks can be expressed as
and
A suitable Bayesian inspection scheme must satisfy the requirements
It is assumed that and because it is natural to consider that and That is, biased tests are not admissible. The optimal inspection scheme would then be the test plan with a minimal sample size that simultaneously satisfies the conditions (1). The constrained minimization problem to determine the required number of items to test, and the optimal acceptance constant, is a mixed-integer nonlinear programming problem, which can be stated as
where is the set of real numbers. More compactly, the optimization problem (2) may be formulated as
where
denotes the feasible region.
Since is non-increasing in c and is non-decreasing in it is deduced that the required sample size is
where
and
It should be noted that the optimal sample size, is finite because, as ,
which is less than That is, is less than if n is sufficiently large. In addition, any value in the nonempty interval is a feasible value of the acceptance constant. The midpoint of the above interval is a neutral choice for It is assumed in the present paper that
is the optimal acceptance constant. Generally, and cannot be explicitly expressed. Nevertheless, accurate estimates can be computed by Monte Carlo simulation.
4. Explicit Approximate Risks and Plans
Closed-form approximations of the Bayesian risks and the optimal inspection scheme can be deduced by using the asymptotic normality of under the null and alternative hypotheses. For later use, denotes the standard normal cumulative distribution function and for
Assuming that n is large enough, it follows that the distribution of the test statistic is approximately when where and In such a case, an approximation of the Bayesian producer risk is given by
Similarly, the Bayesian consumer risk is approximately
Equating the above approximate risks to and respectively, it is derived that
where
Consequently, it is derived from (3) that
which imply that It is then deduced that
is an approximation of the smallest sample size where stands for the least integer upper bound. Moreover,
are approximate estimates of the optimal acceptance constant. A balanced estimation of would be which is given by
In general, the acceptance plan is often a satisfactory approximation of the best scheme if is sufficiently large. Evidently, the approximation is not excellent when is small. Anyway, is always a convenient initial point in order to find via iterative procedures.
5. Computation of Optimal Inspection Schemes
Monte Carlo methods are widely used in optimization, especially when it is difficult or impossible to apply other approaches. Essentially, their key idea is using randomness to solve complex deterministic problems.
In our situation, it is needed to use Monte Carlo simulation to find the best inspection scheme because the Bayesian risks cannot be assessed in closed forms. The global solution of the minimization program (2) can be practically determined by using repeated random sampling.
Assume that is a simple random sample of a large size m of the test statistic when for Suppose also that represents the empirical cumulative distribution function of based on the corresponding sample for That is,
for and where I denotes the indicator function.
Strongly consistent estimations of the Bayesian producer and consumer risks associated with the sampling plan are then given by
and
An accurate approximation of the best inspection scheme can be obtained by simulation. If m is large enough, the optimal sample size would be precisely
where
and
are the natural sample estimates of and respectively. In terms of the prior odds ratio the estimations and can alternatively be expressed as
and
Computationally, it is convenient to use starting values for and . The approximate plan can serve as the initial point in the iterative process to find the best scheme which is of vital importance to decrease calculation costs. The size m of the simulated samples is assumed here to be with the intention of obtaining accurate results.
6. Illustrative Examples
An application to glass manufacturing presented in Fernández [39] is first considered in this section to illustrate the methodology developed for the CMP distribution. In this case, an analyst wants to find the optimal inspection scheme to accept or reject large lots of 0.64 m2 sheets of glass. The number X of blemishes per sheet of glass is the quality characteristic of interest, and the decision rule to determine the lot acceptability is based on a simple random sample from the variable Fernández [39] assumes that X has a Poisson model with parameter However, in many cases, the defect count data are under- or over-dispersed with respect to the Poisson distribution. Due to this reason, the number of imperfections occurring on each sheet is assumed here to follow the distribution.
The manufacturer deems that the model is acceptable when the defect rate per unit is and whereas the customer supposes that the distribution is rejectable if and Table 1 shows the best inspection scheme, and the approximately optimal plan, for and The Bayesian producer and consumer risks (BPR and BCR) of the schemes and are also reported. In light of Table 1, the required sample size tends to reduce when and/or increase. Likewise, the reduction in sampling inspection effort is clear when is high.
Assume that the maximum permissible producer and consumer risks are and respectively. In the non-informative case, i.e., when or the optimal plan is obtained to be Thus, the best decision rule consists of taking 17 sheets of glass at random from the submitted lot and then accepting the whole lot if is at most otherwise, the lot is rejected. The proposed approximate plan is given by The optimal plan and the Bayesian risks of and have been obtained by simulating random samples of size 17 from the and distributions. In this balanced situation, the approximate plan is nearly optimal because the BCR is lower than 10%, and the BPR is only slightly higher than 5%.
Suppose now that the producer and the consumer agreed to assign a prior probability to the lot acceptability, which implies that the prior odds ratio r is 1/4. Thus, there is a strong prior belief that the lot is acceptable. In this case, the approximate plan is quite different from the optimal scheme Similarly, is not a good approximation of the best inspection scheme when Evidently, the normality of is not reasonable when n is small. In all events, however, is a useful initial estimate of
According to Fernández [21], the optimal plan under the frequentist perspective is which is quite similar to when the prior odds ratio is In general, the Bayesian viewpoint produces a significant reduction in sample size when r is small. For example, is only 12 when However, in the non-informative case, the optimal Bayesian and frequentist test plans are often nearly equivalent.
With the aim of studying the effect of the dispersion parameter d on the optimal test plan, Table 2 presents the approximate and optimal inspection schemes, and and their corresponding Bayesian risks when and for and In view of Table 2, it is clear that is a non-decreasing function of d when and are fixed. Therefore, the required sample size in the Poisson case is an upper bound of when the dispersion parameter is less than 1, and a lower bound of when d is greater than 1.
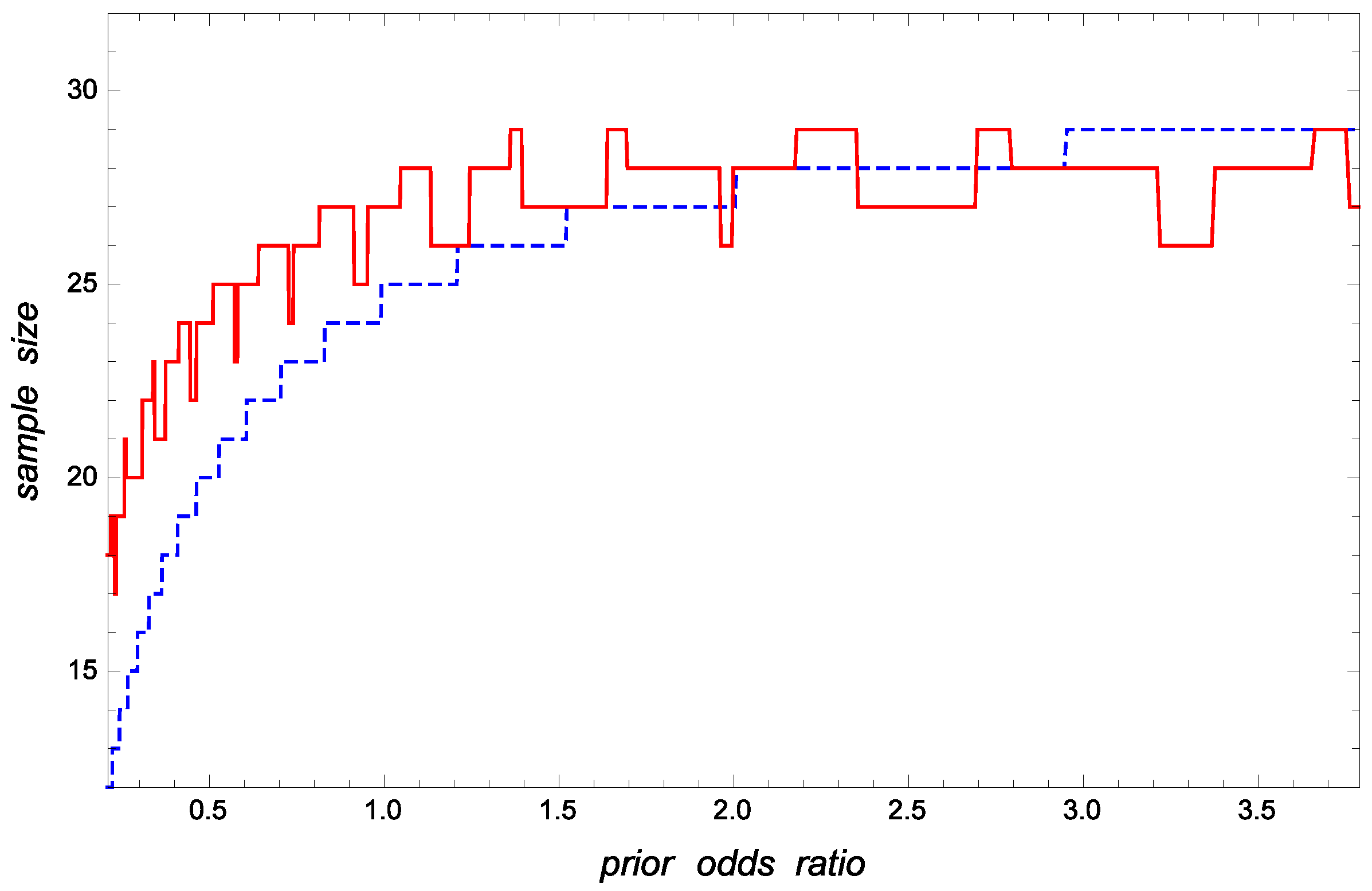
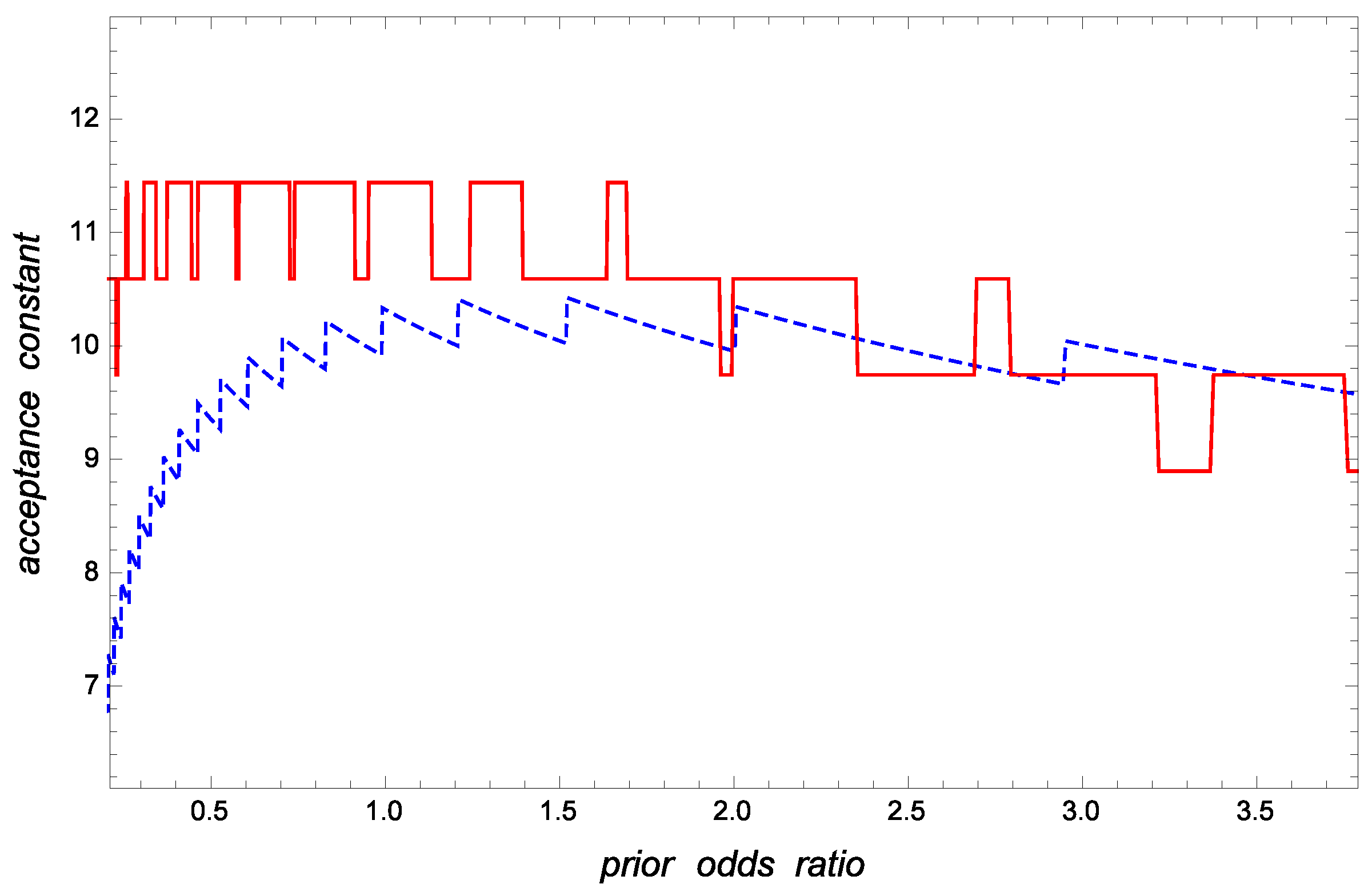
As graphical illustrations of the influence of r on the optimal and approximate sampling inspection schemes, Figure 1 and Figure 2 show the values of the approximate and optimal sample sizes and acceptance constants, respectively, versus r when and Clearly, and are smaller than and respectively, when r is small. Otherwise, is a practical estimate of
An application to the production of paper is now discussed to exemplify the determination of optimal sampling plans based on prior odds ratio tests. The number of impurities discovered per inspection unit is typically the most important quality characteristic in paper manufacturing. In our case, a practitioner wishes to determine the best decision rule to reject or accept large lots of 0.49 m2 sheets of paper, assuming that the number X of imperfections per sheet follows a distribution with mean
The maximal Bayesian risks that the consumer and the producer are willing to incur in the development of a test plan for lot acceptance are and respectively. Furthermore, the presence of sixty-five impurities is considered rejectable by the customer, whereas thirty-five blemishes per hundred sheets is deemed acceptable by the manufacturer. Thus, and the acceptable and rejectable means are and Table 3 reports the optimal and approximate inspection schemes, and and their corresponding Bayesian risks when and for and
According to Table 3, if the acceptable and rejectable means, and are fixed, the optimal sample size is reduced when the dispersion parameter d assumed by the manufacturer and customer increases. Therefore, the required sample size in the Poisson case is a lower bound of when the dispersion parameter is and an upper bound of when For example, if the minimal sample size when is a lower/upper bound of the value of when the dispersion parameter d is less/greater than Clearly, the needed sample size increases when the observed random sample is over-dispersed compared to the Poisson distribution. For instance, if the optimal sample size is when whereas if
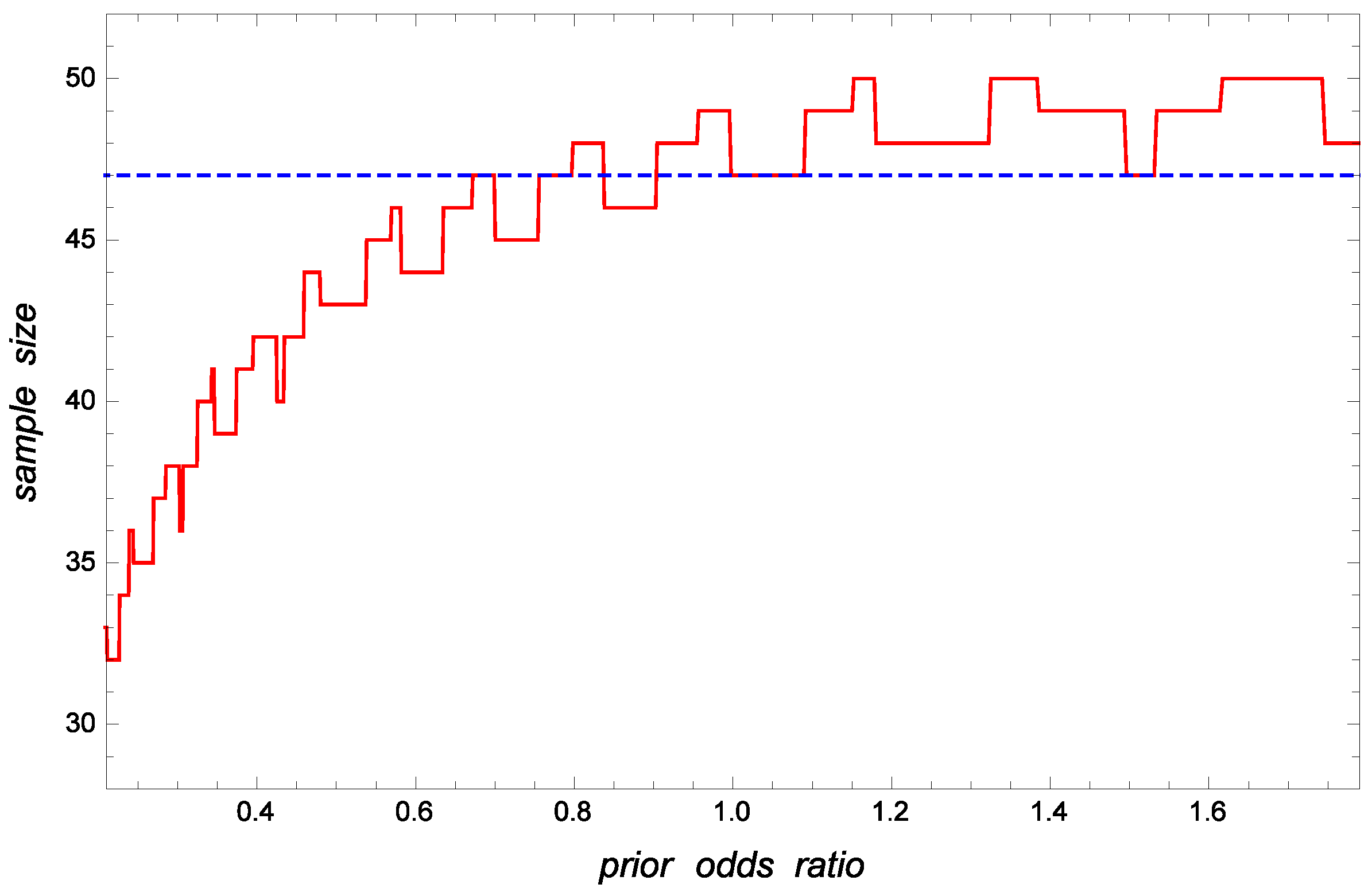
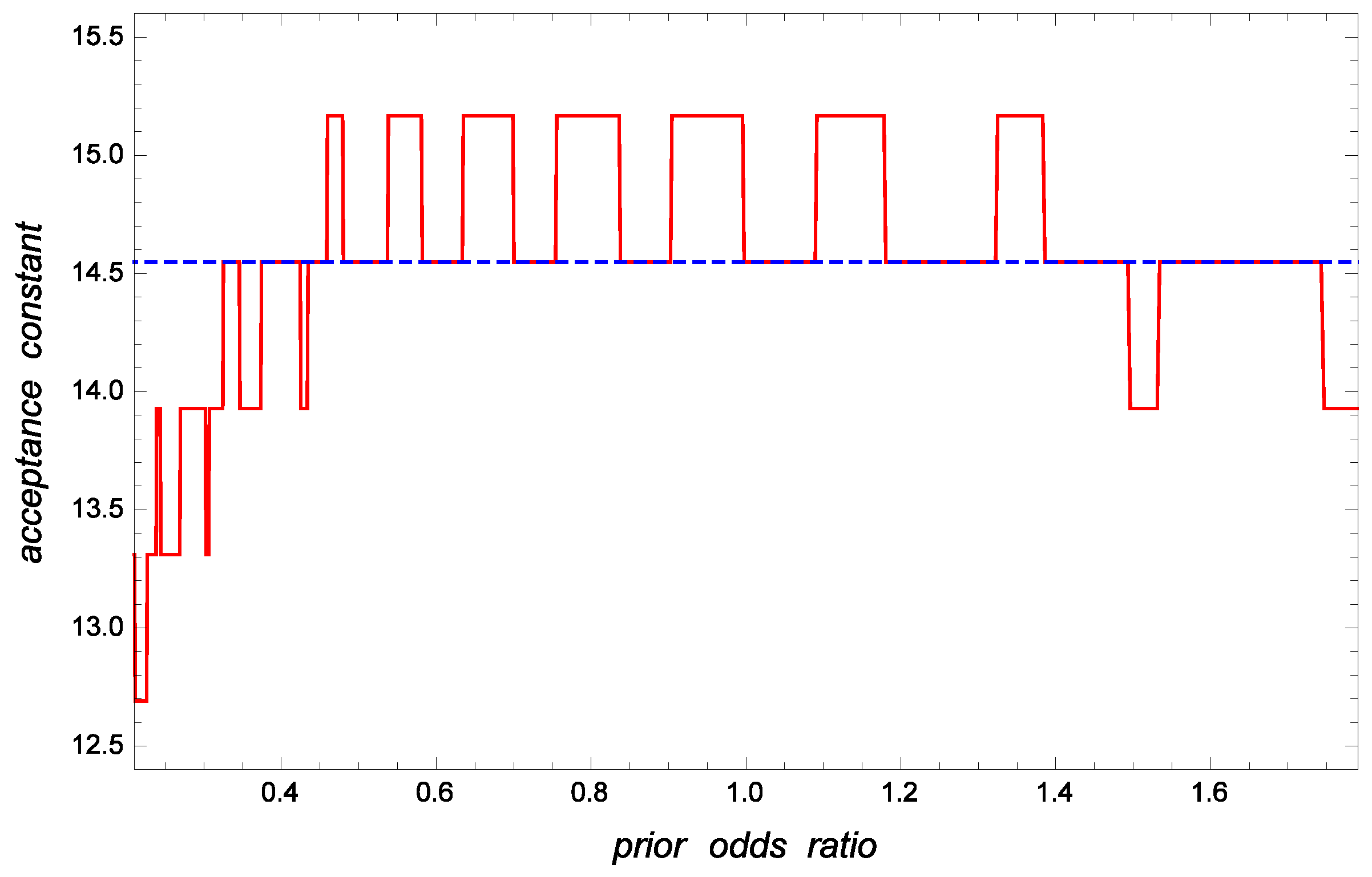
For illustrative and comparative purposes, Figure 3 displays the optimal sample size under the frequentist perspective and the optimal Bayesian sample size as a function of the prior odds ratio when and The corresponding acceptance constants and are shown in Figure 4. In view of these figures, it is evident that the Bayesian approach greatly decreases the required sample size and acceptance constant when the prior lot acceptability, , is high; i.e., when the prior odds ratio r is low. In the non-informative case, the best frequentist and Bayesian plans are quite similar.
7. Concluding Remarks
Lot acceptance sampling is widely used in industrial quality control to develop inspection schemes for defects per unit. The CMP model is a plausible generalization of the Poisson law that adds a parameter to represent the dispersion level. Assuming the presence of prior information on the production process, this paper has determined the best test plans for lot acceptance purposes when the number of minor defects per unit has a CMP distribution.
The proposed test plan for screening lots protects the consumer and the producer at the requested confidence levels and minimizes the sampling inspection effort. Mixed-integer nonlinear programming problems were solved through Monte Carlo simulation to determine the best inspection schemes based on posterior odds ratio tests. An explicit asymptotic approximation of the best plan was used as a starting point for iteratively searching the optimal scheme, which is of exceeding importance because the calculation of the optimal plan can be very computer intensive. The presented results were applied to the production of paper and glass.
The suggested approach is practically an extension of the classical frequentist perspective because both are quite similar in the non-informative case. Nonetheless, note that a classical statistician considers a probability is a frequency, whereas a Bayesian views a probability as a degree of belief. Our setting offers some advantages to the decision-maker. In particular, the producer and the consumer may assign different probabilities to the lot acceptability, even if they have identical background knowledge. A convenient way of combining new sample evidence with prior beliefs is also provided. Bayes’ rule can be used to continually update the posterior odds ratio as new subjective or objective information is acquired. In general, the inclusion of the dispersion parameter in the underlying probability distribution leads to improved decision rules for lot disposition based on under- or over-dispersed samples. Moreover, the incorporation of prior knowledge provides more precise assessments of the actual consumer and producer risks, as well as substantial savings in sample size when the prior lot acceptability is high.
Funding
This research was partially supported by MCIN/AEI/10.13039/501100011033 under grant PID2019-110442GB-I00.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The author thanks the Editor and Reviewers for providing valuable comments and suggestions.
Conflicts of Interest
The author declares no conflict of interest.
References
- Baklizi, A.; El Masri, A.E.Q. Acceptance sampling based on truncated life tests in the Birnbaum Saunders model. Risk Anal. 2004, 24, 1453–1457. [Google Scholar] [CrossRef] [PubMed]
- Balamurali, S.; Jun, C.-H. Multiple dependent state sampling plans for lot acceptance based on measurement data. Eur. J. Oper. Res. 2007, 180, 1221–1230. [Google Scholar] [CrossRef]
- Tsai, T.-R.; Lu, Y.-T.; Wu, S.-J. Reliability sampling plans for Weibull distribution with limited capacity of test facility. Comput. Ind. Eng. 2008, 55, 721–728. [Google Scholar] [CrossRef]
- Lee, W.-C.; Wu, J.-W.; Hong, C.-W. Assessing the lifetime performance index of products with the exponential distribution under progressively type II right censored samples. J. Comput. Appl. Math. 2009, 231, 648–656. [Google Scholar] [CrossRef] [Green Version]
- Lu, W.; Tsai, T.-R. Interval censored sampling plans for the gamma lifetime model. Eur. J. Oper. Res. 2009, 192, 116–124. [Google Scholar] [CrossRef]
- Aslam, M.; Azam, M.; Jun, C.-H. A mixed repetitive sampling plan based on process capability index. Appl. Math. Model. 2013, 37, 10027–10035. [Google Scholar] [CrossRef]
- Fernández, A.J. Optimum attributes component test plans for k-out-of-n:F Weibull systems using prior information. Eur. J. Oper. Res. 2015, 240, 688–696. [Google Scholar] [CrossRef]
- Wu, C.-W.; Shu, M.-H.; Nugroho, A.A.; Kurniati, N. A flexible process-capability-qualified resubmission-allowed acceptance sampling scheme. Comput. Ind. Eng. 2015, 80, 62–71. [Google Scholar] [CrossRef]
- Wu, C.-W.; Lee, A.H.I.; Liu, S.-W.; Shih, M.-H. Capability-based quick switching sampling system for lot disposition. Appl. Math. Model. 2017, 52, 131–144. [Google Scholar] [CrossRef]
- Qin, R.; Cudney, E.A.; Hamzic, Z. An optimal plan of zero-defect single-sampling by attributes for incoming inspections in assembly lines. Eur. J. Oper. Res. 2015, 246, 907–915. [Google Scholar] [CrossRef]
- Lee, A.H.I.; Wu, C.-W.; Wang, Z.-H. The construction of a modified sampling scheme by variables inspection based on the one-sided capability index. Comput. Ind. Eng. 2018, 122, 87–94. [Google Scholar] [CrossRef]
- Roy, S. Bayesian accelerated life test plans for series systems with Weibull component lifetimes. Appl. Math. Model. 2018, 62, 383–403. [Google Scholar] [CrossRef]
- Algarni, A. Group Acceptance Sampling Plan Based on New Compounded Three-Parameter Weibull Model. Axioms 2022, 11, 438. [Google Scholar] [CrossRef]
- Alyami, S.A.; Elgarhy, M.; Elbatal, I.; Almetwally, E.M.; Alotaibi, N.; El-Saeed, A.R. Fréchet Binomial Distribution: Statistical Properties, Acceptance Sampling Plan, Statistical Inference and Applications to Lifetime Data. Axioms 2022, 11, 389. [Google Scholar] [CrossRef]
- Fernández, A.J. Optimal defects-per-unit acceptance sampling plans using truncated prior distributions. IEEE Trans. Reliab. 2014, 63, 634–645. [Google Scholar] [CrossRef]
- Anbazhagan, N.; Wang, J.; Gomathi, D. Base stock policy with retrial demands. Appl. Math. Model. 2013, 37, 4464–4473. [Google Scholar] [CrossRef]
- Alizadeh, M.; Eskandari, H.; Sajadifar, S.M. A modified (S-1,S) inventory system for deteriorating items with Poisson demand and non-zero lead time. Appl. Math. Model. 2014, 38, 699–711. [Google Scholar] [CrossRef]
- Chen, K.-S.; Yang, C.-M. Developing a performance index with a Poisson process and an exponential distribution for operations management and continuous improvement. J. Comput. Appl. Math. 2018, 343, 737–747. [Google Scholar] [CrossRef]
- Chuang, H.H.-C. Fixing shelf out-of-stock with signals in point-of-sale data. Eur. J. Oper. Res. 2018, 270, 862–872. [Google Scholar] [CrossRef]
- Wan, Q.; Liu, C.; Wu, Y.; Zhou, W. A TBE control chart-based maintenance policy for a service facility. Comput. Ind. Eng. 2018, 126, 136–148. [Google Scholar] [CrossRef]
- Fernández, A.J. Most powerful lot acceptance test plans from dispersed nonconformity counts. Int. J. Adv. Manuf. Technol. 2017, 90, 233–240. [Google Scholar] [CrossRef]
- Conway, R.W.; Maxwell, W.L. A queuing model with state dependent service rates. J. Ind. Eng. 1962, 12, 132–136. [Google Scholar]
- Shmueli, G.; Minka, T.; Kadane, J.B.; Borle, S.; Boatwright, P.B. A useful distribution for fitting discrete data: Revival of the Conway-Maxwell-Poisson distribution. Appl. Stat. 2005, 54, 127–142. [Google Scholar] [CrossRef]
- Sellers, K.F.; Borle, S.; Shmueli, G. The COM-Poisson model for count data: A survey of methods and applications. Appl. Stoch. Model. Bus. Ind. 2012, 28, 104–116. [Google Scholar] [CrossRef]
- Francis, R.A.; Geedipally, S.R.; Guikema, S.D.; Dhavala, S.S.; Lord, D.; LaRocca, S. Characterizing the performance of the Conway-Maxwell-Poisson generalized linear model. Risk Anal. 2012, 32, 167–183. [Google Scholar] [CrossRef] [Green Version]
- Zhu, F. Modeling time series of counts with COM-Poisson INGARCH models. Math. Comput. Model. 2012, 56, 191–203. [Google Scholar] [CrossRef]
- Santarelli, M.F.; Della Latta, D.; Scipioni, M.; Positano, V.; Landini, L. A Conway-Maxwell-Poisson (CMP) model to address data dispersion on positron emission tomography. Comput. Biol. Med. 2016, 77, 90–101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Torney, D.C. Bayesian analysis of binary sequences. J. Comput. Appl. Math. 2005, 175, 231–243. [Google Scholar] [CrossRef] [Green Version]
- Fernández, A.J. Bayesian estimation based on trimmed samples from Pareto populations. Comput. Stat. Data Anal. 2006, 51, 1119–1130. [Google Scholar] [CrossRef]
- Fernández, A.J. Weibull inference using trimmed samples and prior information. Stat. Pap. 2009, 50, 119–136. [Google Scholar] [CrossRef]
- Fernández, A.J. Computing tolerance limits for the lifetime of a k-out-of-n:F system based on prior information and censored data. Appl. Math. Model. 2014, 38, 548–561. [Google Scholar] [CrossRef]
- Yan, L.; Yang, F.; Fu, C. A Bayesian inference approach to identify a Robin coefficient in one-dimensional parabolic problems. J. Comput. Appl. Math. 2009, 231, 840–850. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.-C.; Wu, J.-W.; Hong, M.-L.; Lin, L.-S.; Chan, R.-L. Assessing the lifetime performance index of Rayleigh products based on the Bayesian estimation under progressive type II right censored samples. J. Comput. Appl. Math. 2011, 235, 1676–1688. [Google Scholar] [CrossRef]
- Jaheen, Z.F.; Okasha, H.M. E-Bayesian estimation for the Burr type XII model based on type-2 censoring. Appl. Math. Model. 2011, 35, 4730–4737. [Google Scholar] [CrossRef]
- Asl, M.N.; Belaghi, R.A.; Bevrani, H. Classical and Bayesian inferential approaches using Lomax model under progressively type-I hybrid censoring. J. Comput. Appl. Math. 2018, 343, 397–412. [Google Scholar] [CrossRef]
- He, D.; Wang, Y.; Chang, G. Objective Bayesian analysis for the accelerated degradation model based on the inverse Gaussian process. Appl. Math. Model. 2018, 61, 341–350. [Google Scholar] [CrossRef]
- Alotaibi, R.; Nassar, M.; Ghosh, I.; Rezk, H.; Elshahhat, A. Inferences of a Mixture Bivariate Alpha Power Exponential Model with Engineering Application. Axioms 2022, 11, 459. [Google Scholar] [CrossRef]
- Yousef, M.M.; Hassan, A.S.; Alshanbari, H.M.; El-Bagoury, A.-A.H.; Almetwally, E.M. Bayesian and Non-Bayesian Analysis of Exponentiated Exponential Stress–Strength Model Based on Generalized Progressive Hybrid Censoring Process. Axioms 2022, 11, 455. [Google Scholar] [CrossRef]
- Fernández, A.J. Optimal schemes for resubmitted lot acceptance using previous defect count data. Comput. Ind. Eng. 2015, 87, 66–73. [Google Scholar] [CrossRef]
Figure 1.
Optimal (solid line) and approximate (dashed line) sample sizes, and versus the prior odds ratio when and
Figure 1.
Optimal (solid line) and approximate (dashed line) sample sizes, and versus the prior odds ratio when and

Figure 2.
Optimal (solid line) and approximate (dashed line) acceptance constants, and versus the prior odds ratio when and
Figure 2.
Optimal (solid line) and approximate (dashed line) acceptance constants, and versus the prior odds ratio when and

Figure 3.
Optimal Bayesian (solid line) and frequentist (dashed line) sample sizes, and versus the prior odds ratio when and
Figure 3.
Optimal Bayesian (solid line) and frequentist (dashed line) sample sizes, and versus the prior odds ratio when and

Figure 4.
Optimal Bayesian (solid line) and frequentist (dashed line) acceptance constants, and versus the prior odds ratio when and
Figure 4.
Optimal Bayesian (solid line) and frequentist (dashed line) acceptance constants, and versus the prior odds ratio when and


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Optimal and approximate plans, and and the corresponding Bayesian risks, BPR and BCR, when and .
Table 1.
Optimal and approximate plans, and and the corresponding Bayesian risks, BPR and BCR, when and .
| Optimal Test Plan | Approximate Test Plan | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BPR | BCR | BPR | BCR | |||||||
| 1% | 5% | 0.2 | 33 | 14.575 | 0.963% | 4.870% | 36 | 15.214 | 1.151% | 2.760% |
| 0.5 | 31 | 15.956 | 0.943% | 4.758% | 30 | 14.855 | 1.647% | 3.785% | ||
| 0.8 | 24 | 15.068 | 0.997% | 4.982% | 19 | 11.591 | 3.265% | 5.177% | ||
| 10% | 0.2 | 28 | 12.852 | 0.956% | 9.899% | 30 | 13.202 | 1.186% | 6.278% | |
| 0.5 | 25 | 13.769 | 0.900% | 9.487% | 22 | 11.710 | 1.693% | 9.667% | ||
| 0.8 | 17 | 12.443 | 0.839% | 9.475% | 11 | 8.1634 | 4.051% | 10.71% | ||
| 5% | 5% | 0.2 | 23 | 8.3266 | 4.720% | 4.228% | 28 | 9.9554 | 4.440% | 1.959% |
| 0.5 | 22 | 10.376 | 4.909% | 4.864% | 23 | 10.361 | 6.117% | 3.521% | ||
| 0.8 | 18 | 10.734 | 4.536% | 4.997% | 15 | 8.7219 | 10.19% | 4.742% | ||
| 10% | 0.2 | 18 | 6.8477 | 4.856% | 9.766% | 22 | 8.0255 | 4.361% | 5.688% | |
| 0.5 | 17 | 8.6809 | 4.622% | 9.919% | 17 | 8.2708 | 5.212% | 9.157% | ||
| 0.8 | 12 | 8.5751 | 4.270% | 9.459% | 8 | 5.8200 | 11.04% | 10.57% | ||
Table 2.
Optimal and approximate plans, and and the corresponding Bayesian risks, BPR and BCR, when and .
Table 2.
Optimal and approximate plans, and and the corresponding Bayesian risks, BPR and BCR, when and .
| Optimal Test Plan | Approximate Test Plan | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| d | BPR | BCR | BPR | BCR | |||||
| 0.5 | 0.2 | 20 | 8.0493 | 3.987% | 8.566% | 21 | 8.0642 | 4.713% | 5.862% |
| 0.5 | 19 | 9.7439 | 4.367% | 8.110% | 17 | 8.6257 | 4.632% | 10.05% | |
| 0.8 | 14 | 9.7439 | 3.886% | 8.359% | 8 | 5.9554 | 8.544% | 11.81% | |
| 1.0 | 0.2 | 27 | 8.8966 | 4.716% | 8.739% | 29 | 9.4692 | 4.124% | 8.143% |
| 0.5 | 27 | 11.439 | 3.982% | 9.600% | 25 | 10.320 | 4.583% | 10.44% | |
| 0.8 | 19 | 10.591 | 3.993% | 9.770% | 14 | 7.8529 | 7.929% | 10.89% | |
| 1.5 | 0.2 | 33 | 9.7439 | 4.939% | 8.821% | 35 | 10.328 | 4.220% | 8.793% |
| 0.5 | 33 | 12.286 | 4.296% | 9.908% | 31 | 11.315 | 5.144% | 10.11% | |
| 0.8 | 24 | 11.439 | 4.279% | 9.812% | 19 | 9.0881 | 9.565% | 9.628% | |
Table 3.
Optimal and approximate plans, and and the corresponding Bayesian risks, BPR and BCR, when and .
Table 3.
Optimal and approximate plans, and and the corresponding Bayesian risks, BPR and BCR, when and .
| Optimal Test Plan | Approximate Test Plan | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| d | BPR | BCR | BPR | BCR | |||||
| 0.5 | 0.2 | 56 | 12.412 | 4.857% | 9.455% | 60 | 13.231 | 4.273% | 8.455% |
| 0.5 | 55 | 14.524 | 4.749% | 9.674% | 53 | 13.881 | 5.114% | 9.976% | |
| 0.8 | 41 | 13.468 | 4.127% | 9.864% | 31 | 10.248 | 8.326% | 10.567% | |
| 1.0 | 0.2 | 48 | 12.690 | 4.421% | 9.735% | 50 | 12.987 | 5.517% | 6.300% |
| 0.5 | 47 | 14.547 | 4.985% | 9.248% | 45 | 13.894 | 5.361% | 9.721% | |
| 0.8 | 35 | 13.309 | 4.886% | 9.349% | 28 | 10.835 | 7.965% | 10.22% | |
| 1.5 | 0.2 | 43 | 12.956 | 4.255% | 9.445% | 43 | 12.677 | 4.259% | 9.528% |
| 0.5 | 43 | 15.057 | 4.844% | 8.594% | 40 | 14.040 | 4.365% | 11.08% | |
| 0.8 | 33 | 14.357 | 3.670% | 9.623% | 25 | 10.973 | 8.547% | 9.896% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Fernández, A.J. Enhanced Lot Acceptance Testing Based on Defect Counts and Posterior Odds Ratios. Axioms 2022, 11, 604. https://doi.org/10.3390/axioms11110604
AMA Style
Fernández AJ. Enhanced Lot Acceptance Testing Based on Defect Counts and Posterior Odds Ratios. Axioms. 2022; 11(11):604. https://doi.org/10.3390/axioms11110604
Chicago/Turabian StyleFernández, Arturo J. 2022. "Enhanced Lot Acceptance Testing Based on Defect Counts and Posterior Odds Ratios" Axioms 11, no. 11: 604. https://doi.org/10.3390/axioms11110604
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.