4.1. Analysis of Weathered and Fresh Bed Rock Observations
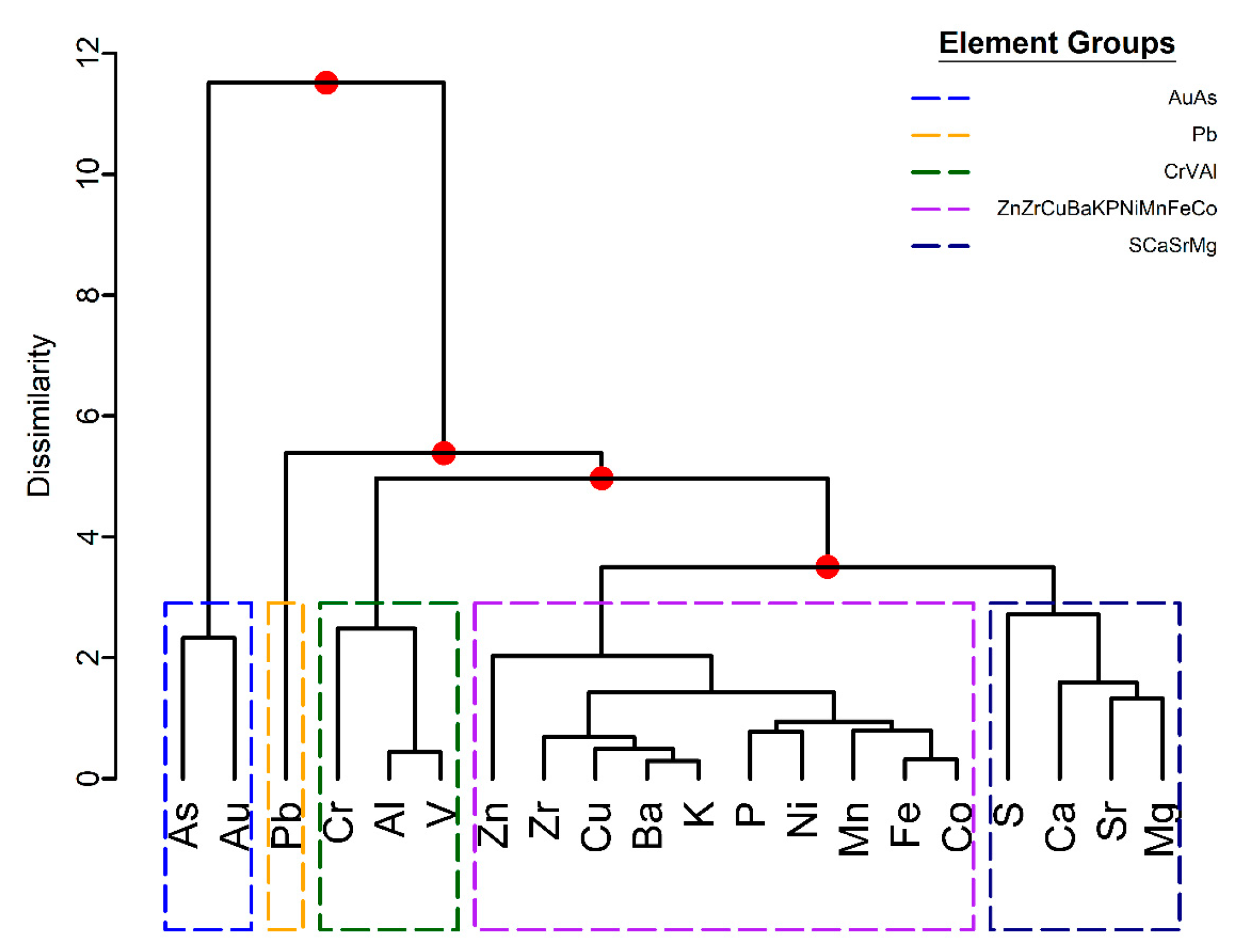
The hierarchical cluster analysis of the geochemical variables shows clusters of elements that can be linked to the Paracatu geochemical attributes,
Figure 7. The greatest dissimilarity occurs between the Au-As cluster and the large cluster of the remaining geochemical elements. The Au-As co-dependency is explained by the association of arsenopyrite and gold mineralization at Paracatu [
28]. The dissimilarity of Au-As to the other elements indicates that the most evident geochemical variability at Paracatu is related to gold mineralization. The remaining geochemical elements define four clusters whose ratios are affected by a combination of geochemical processes including mineralization, hydrothermal alteration and weathering. For example, Pb has the least co-dependence to the other elements and it is considered its own cluster. Pb is a low field strength element that can be mobilized during weathering processes. The Cr–V–Al cluster represents a group of immobile elements in the phyllite [
26,
30]. Similarly, the other two clusters can be explained by mineralization and hydrothermal alteration at Paracatu [
26]. Accordingly, the groupings suggested by the cluster dendrogram capture geochemical processes expected for the Paracatu deposit and can be used to reduce the 20-part geochemical data to a 5-part subcomposition of dissimilar variables.
Five composite geochemical variables are created from the hierarchical dendrogram clusters. The joint matrix of compositional data, composite geochemical variables and non-compositional data, BWI, PLSI_AX, RQD and MAGSUSC is used in PCA following the approach of [
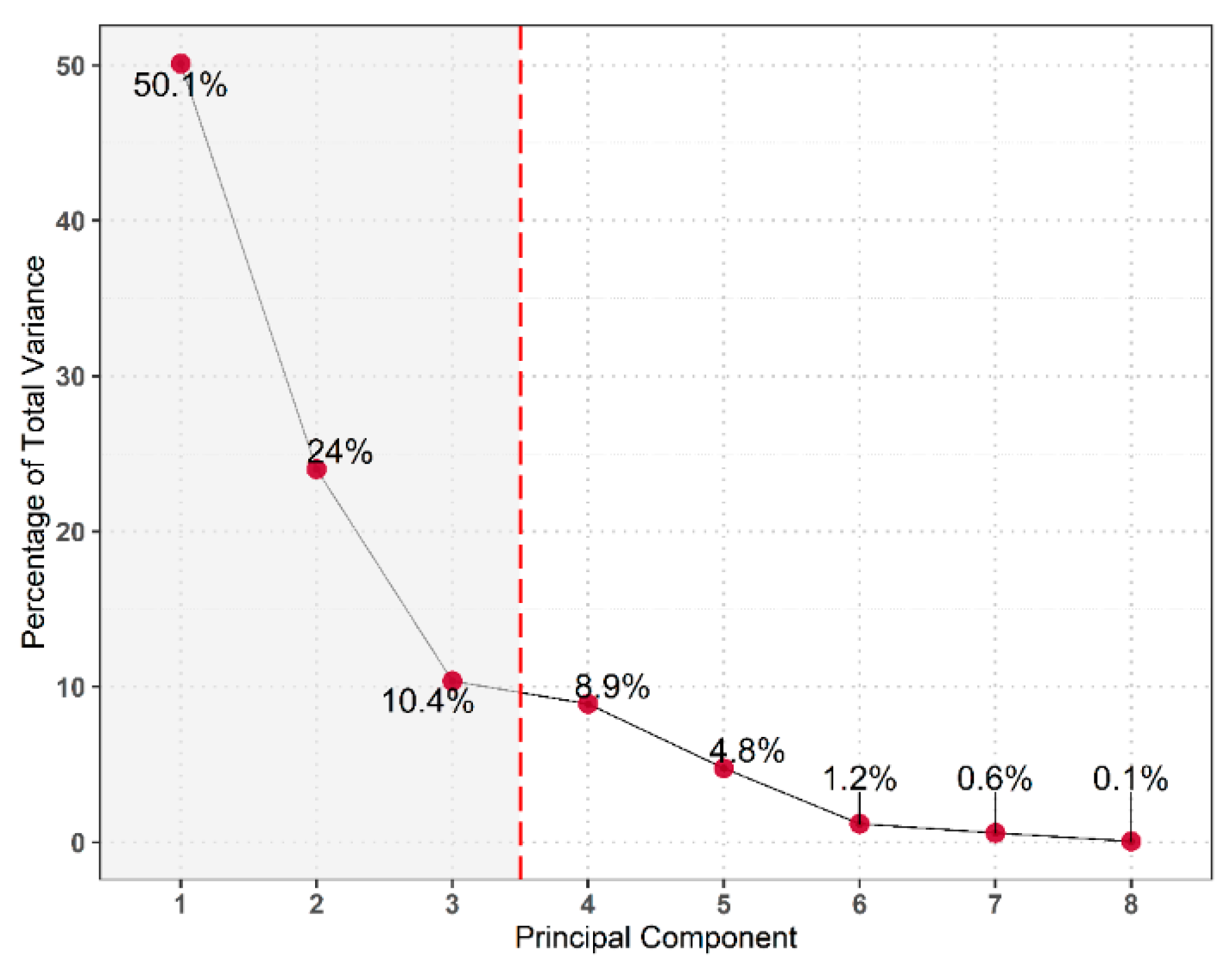
47] (Section 3.3.1). The first three principal components capture approximately 85% of the sample variance for weathered and fresh rock observations,
Figure 8; the inflection point occurs at PC3. Approximately 50% and 24% of the variance is explained by PC1 and PC2, respectively.
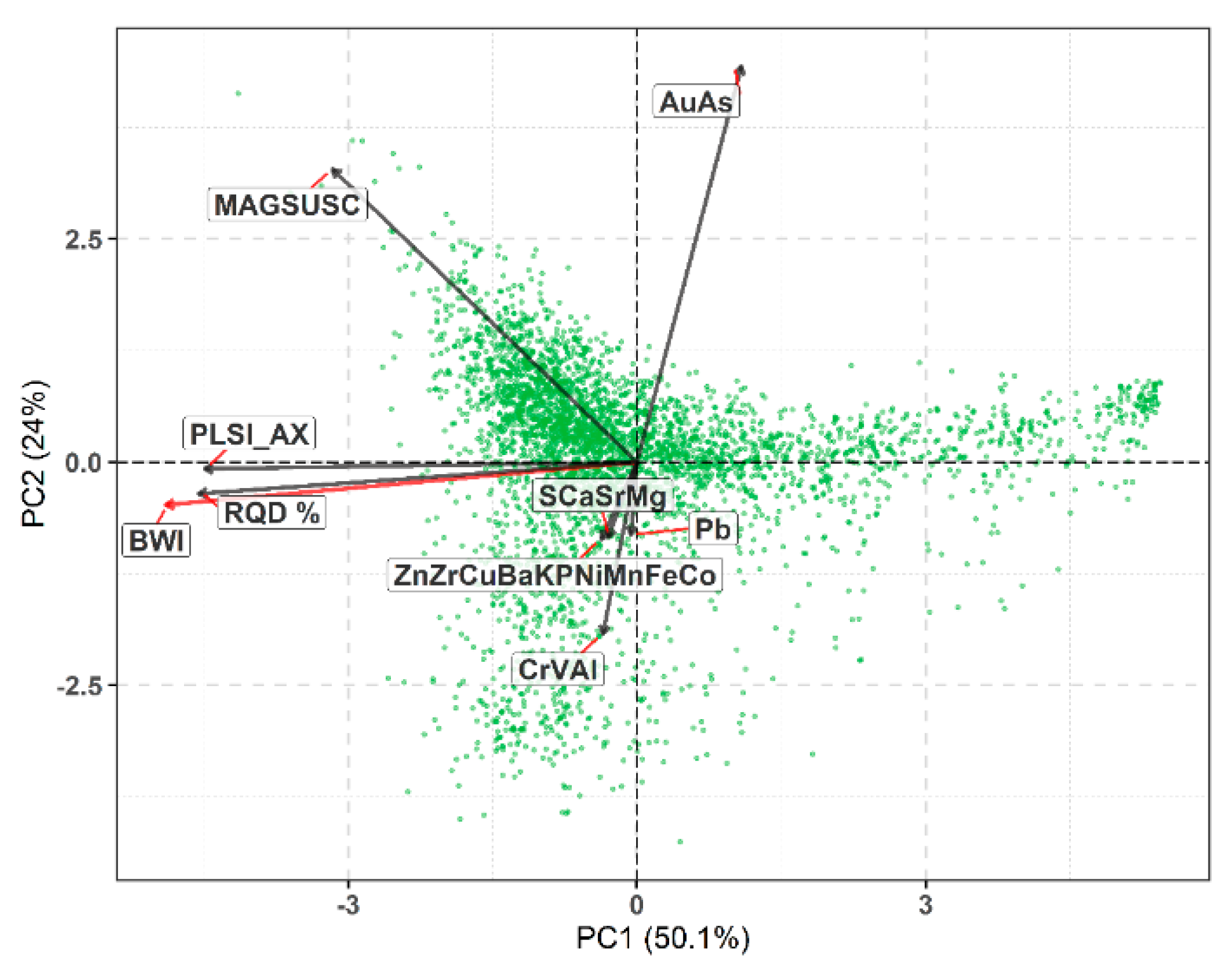
Figure 9 presents the biplot for PC1 and PC2. Both geomechanical variable vectors, PLSI_AX and RQD, have small angles to BWI, which signifies a strong geometallurgical association between rock competency (rock strength and fracturing) and grindability. In contrast, the BWI is less associated with the geochemical variables and MAGSUSC, which is shown by the larger angles between BWI and the respective vectors. MAGSUSC has approximately equal loading from both. The BWI, PLSI_AX and RQD vectors have high loadings on PC1, while the geochemical variables have larger loadings on PC2. Thus, PC1 represents a high degree of variability in the data related to the geomechanical and grindability characteristics at Paracatu. PC1 segregates the data into domains with a large difference in rock competency. The scores representing observations with higher grindability and lower rock strength and competency extend along the positive PC1 axis and fall opposite the direction of BWI, PLSI_AX and RQD vectors. The geometallurgical relationship between BWI and rock competency can be best applied to these observations. PC2 is predominantly a function of geochemical variation represented by relative gold mineralization content at Paracatu. Scores that extend away from AuAs are observations with depleted gold content; observations with a negative PC2 score have a median Au grade of 0.01 ppm compared to a median Au grade of 0.34 ppm for observations with a positive PC2 score. A third grouping of observations occur in the negative PC1-positive PC2 quadrant along the MAGSUSC vector. These scores represent observations with a stronger magnetic signature. Overall, the association of BWI to PLSI and RQD is the relevant geometallurgical relationship found from this PCA.
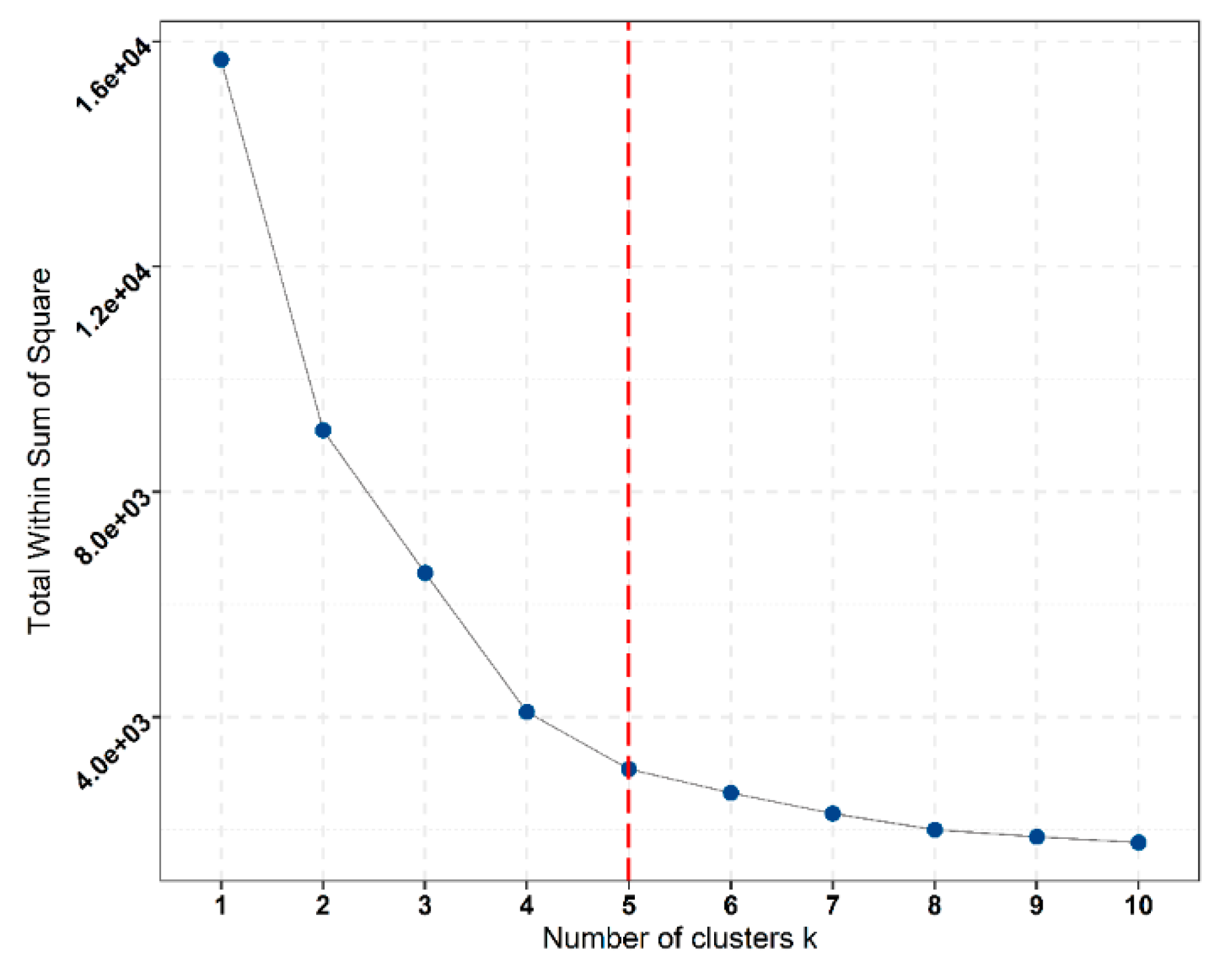
The scores of the first three PCs are clustered using the
K-means clustering algorithm to partition the data structure captured by PCA. Changes of the within-cluster sum of squares with the number of
K-clusters suggests 4 to 5 significant clusters,
Figure 10.
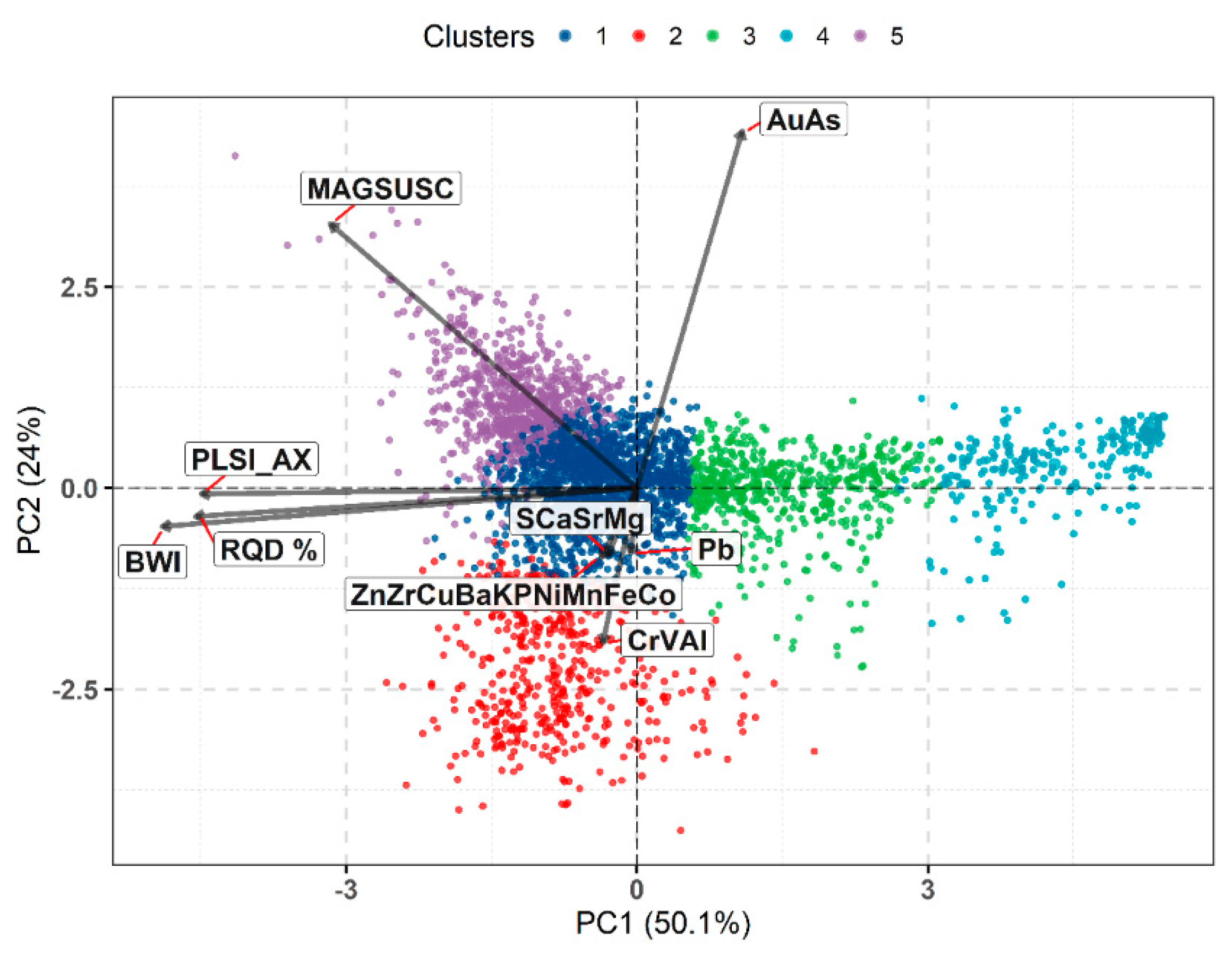
Five clusters are chosen to investigate the possibility of a segmentation in the PC scores that is meaningful for capturing variability in orebody characteristics for geometallurgical domaining. The resulting PCA clusters are well-delineated data driven representations of the score groupings observed on the biplot, cf.
Figure 9 and
Figure 11.
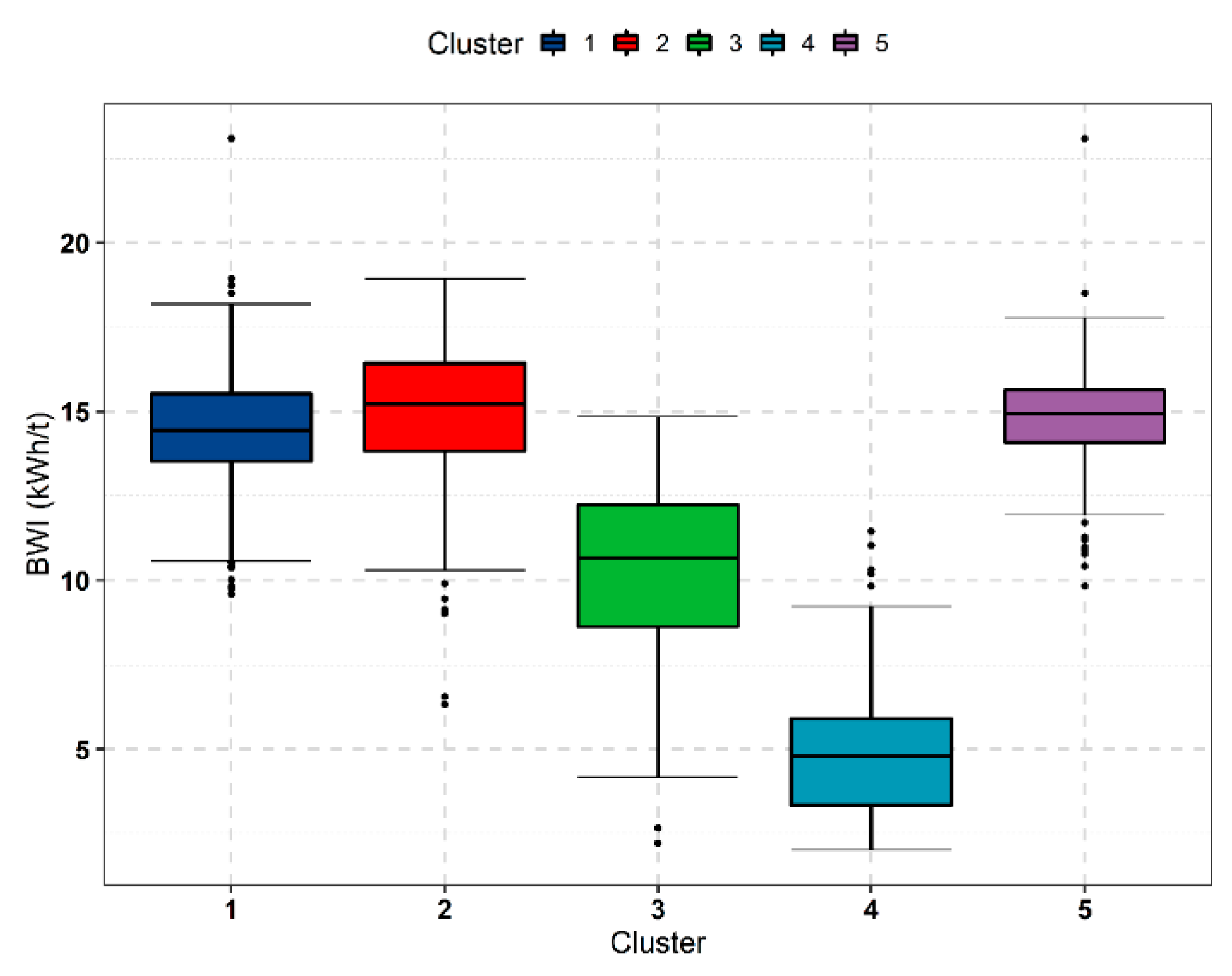
Clusters 3 and 4 represent the observations with the lowest BWI (
Figure 12) and therefore lower rock competency and higher grindability. The strong alignment of the two clusters along the PC1 axis indicates that these observations have variability that is best explained by PC1, whose linear combination is dominated by BWI, PLSI_AX and RQD. Therefore, the geometallurgical relationship of BWI to the geomechanical variables is most relevant to clusters 3 and 4. In addition, the median BWI of cluster 4 (c.a. 5 kWh/t) is lower than that of cluster 3 (c.a. 10 kWh/t). The median BWI of the remaining clusters is consistently between 14 and 15 kWh/t. The dispersion of each PCA cluster along the PC1 axis somewhat describes the spread of observations in its corresponding boxplot. For example, cluster 1 and 5 have relatively tight dispersions which are reflected in the boxplots. While clusters 1, 2 and 5 are not distinguished by BWI differences, their dissimilarities arise from other orebody characteristics. Cluster 2 represents observations in phyllite with a low ratio of Au and As to the immobile Cr, V and Al. Cluster 5 observations cluster around the MAGSUSC vector and have a median MAGSUSC value of 1.98 compared to a value 0.72 for the other clusters. It is likely that cluster 5 observations represent the magnetic pyrrhotite of the Paracatu ore. Cluster 1 is generally equidistant along PC2 but has higher PC2 scores than cluster 2. Cluster 1 also extends into the negative PC1 axis, which signifies an increase in rock strength. However, the nounced as those for clusters 3 and 4. This reasoning, combined with the appreciable difference intrend of BWI, PLSI_AX and RQD vectors in comparison to the cluster axes of 1, 2 and 5 is not as pro BWI between the two sets of clusters, signifies a geometallurgical control for observations in clusters 3 and 4 that enables rock strength and fracturing to be related to BWI but which does not affect observations in clusters 1, 2 and 5.
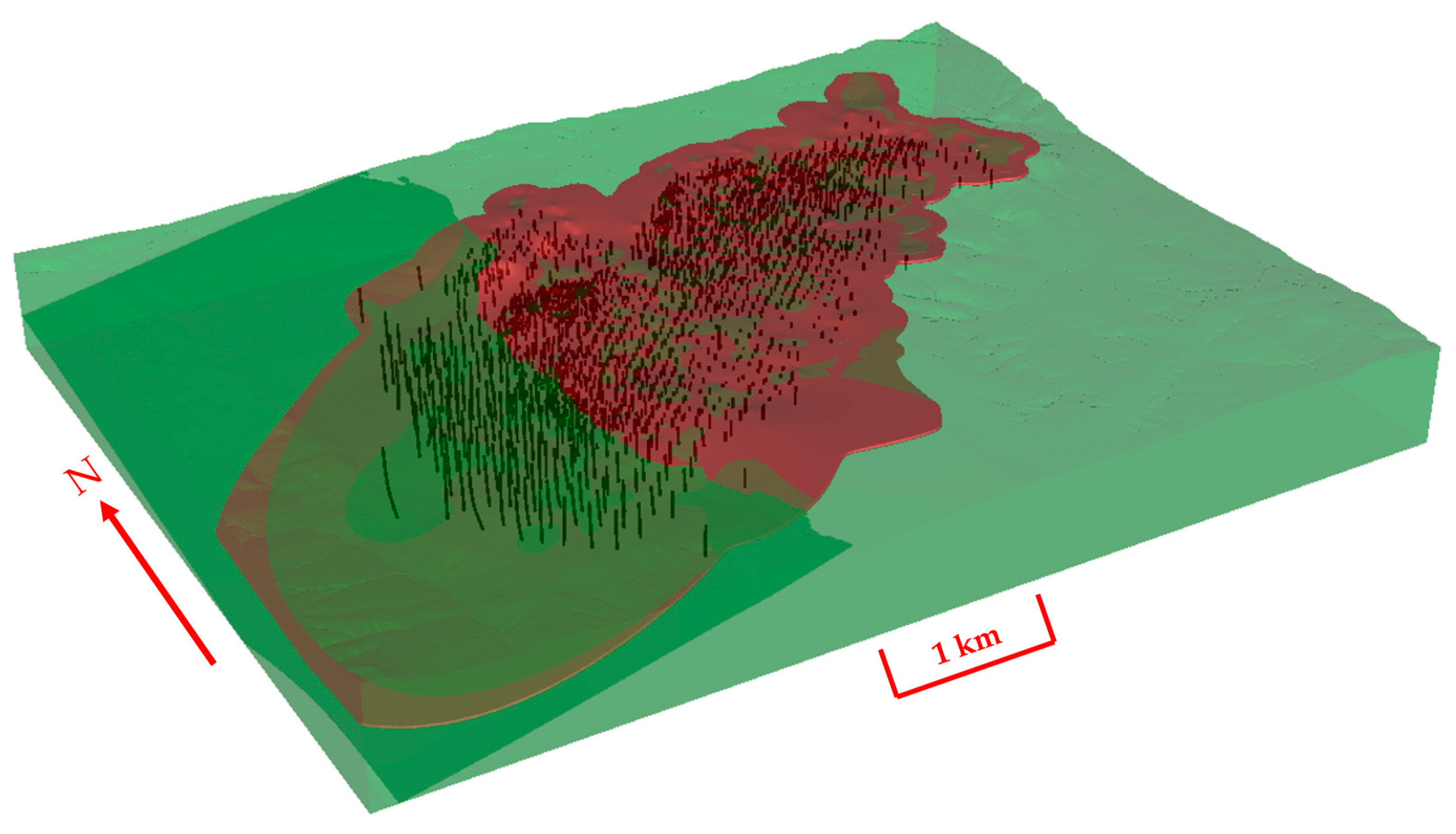
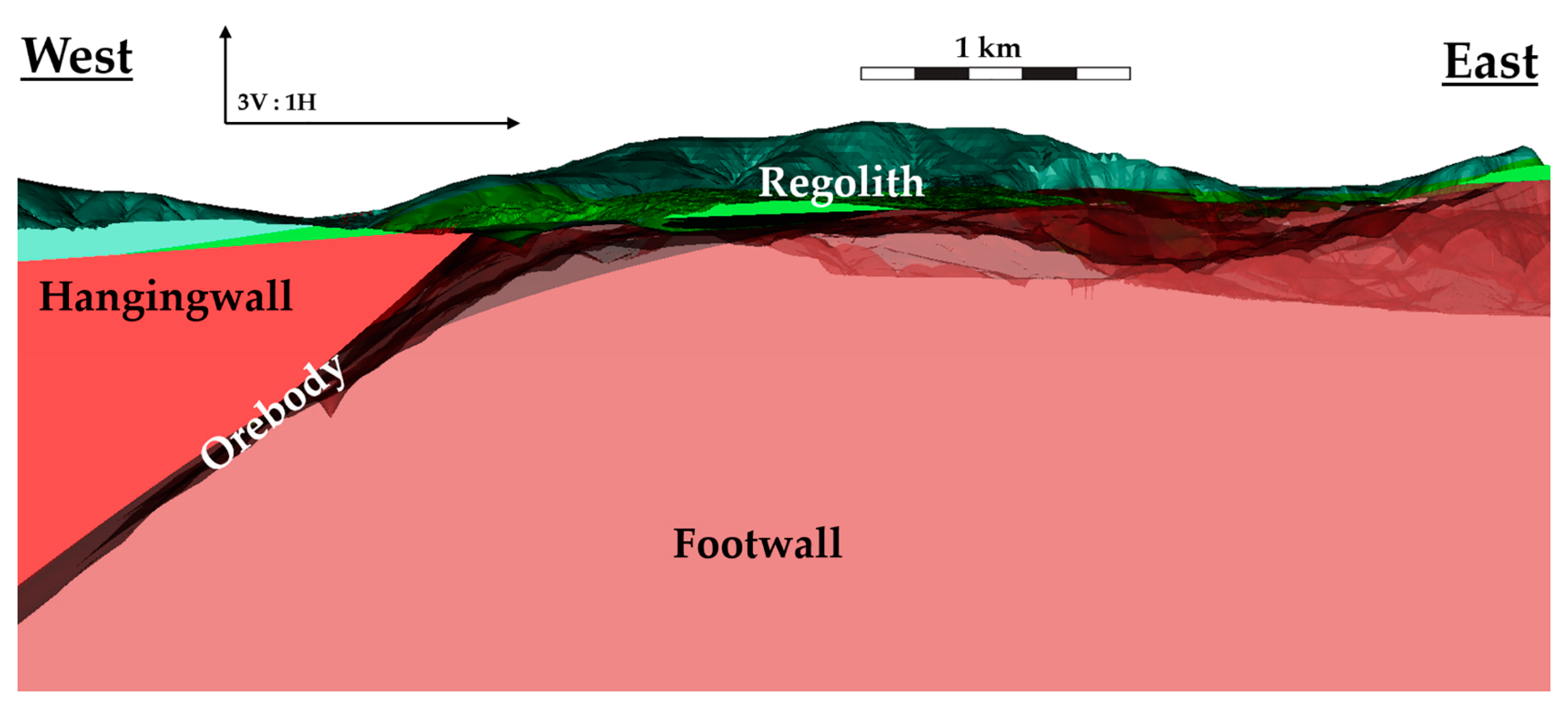
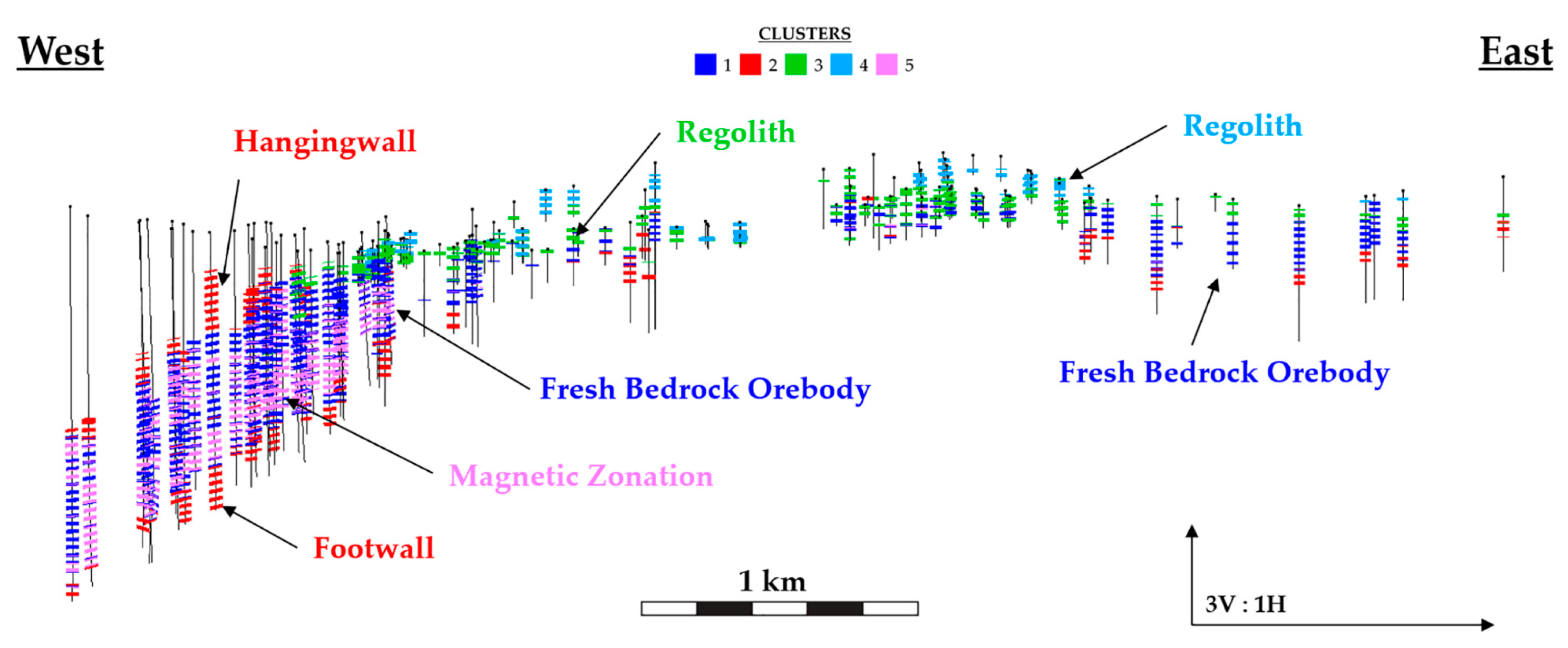
Figure 13 presents a cross-section of the clusters at the Paracatu deposit. The spatial relation of the clusters follows the structure and weathering profile of the Paracatu orebody, c.f.
Figure 3. Clusters 3 and 4 represents the upper part of the orebody; which is located in the lateric saprolith, (
Figure 5 and
Figure 6). Clusters 1, 2 and 5 manifest within the fresh rock of the orebody underlying the saprolith. The significant difference in BWI between the two sets of clusters is caused by extensive lateritic weathering of the deposit (
Figure 5). The regolith clusters capture BWI variation between regolith zones of the orebody. Cluster 4 represents the near surface saprolite layer in the regolith given its higher elevation and lower BWI relative to cluster 3. Similarly, the saprock and transition material of lower regolith is defined by cluster 3. The degree of weathering influence on the geomechanical characteristics in the regolith clusters is comparable to its influence on BWI. This results in the large variability captured by PC1 and the considerable contrast in rock competency between the regolith clusters and fresh rock clusters. Thus, the relationship between BWI and PLSI_AX and RQD in the geometallurgical orebody domain identified by the regolith clusters 3 and 4 is attributed to the weathering process. The fresh rock clusters also show distinct spatial patterns that corroborate well with the geological attributes of the orebody. Cluster 2 represents the non-mineralized hanging wall and footwall phyllite characterized by the relatively high content of immobile Cr, V and Al. Clusters 1 and 5 represent the fresh rock observations of the orebody. Cluster 1 has a significant lateral variation in thickness from east to west that follows the dip of the hypogene B2 mineralization domain in the Paracatu orebody. This area of the orebody shows zonations with magnetic cluster 5 mapping the presence of pyrrhotite in the mineralized zone.
Overall, the PCA clusters delineate two orebody domains significant for geometallurgical relationships to BWI: the regolith and the fresh rock. In addition, the PCA clusters are validated by the spatial variability in the orebody physical characteristics.
4.2. Analysis of Fresh Bedrock Observations Subset
The PCA and K-means cluster analysis is effective in capturing variations in the orebody weathering profile related to the upper saprolite, transitional saprock and fresh rock. However, a significant part of the orebody is hosted in the fresh rock, within which weathering is not present as the geometallurgical control. Therefore, to investigate geometallurgical relationships in the fresh rock domain, the analytical workflow is repeated for only the observations in fresh rock clusters. Accordingly, the regolith clusters 3 and 4 are removed from the dataset. This results in the retention of n = 2750 observations for 762 BWI samples located in the fresh rock clusters 1, 2 and 5.
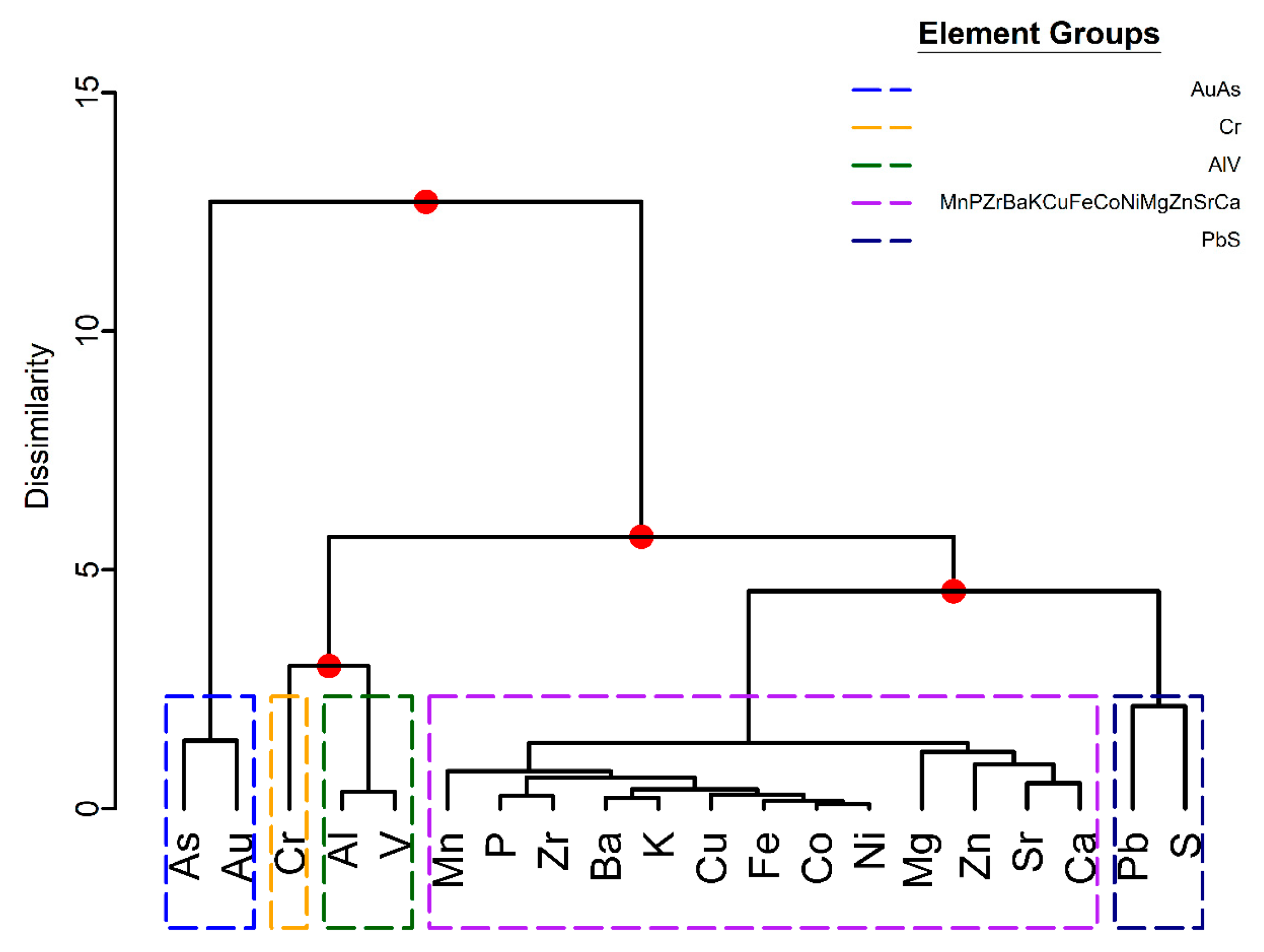
Hierarchical clustering was applied to a variation matrix created for fresh rock observations,
Figure 14 and
Table A2. In the fresh bedrock, most of the element associations are similar to the associations obtained from clustering weathered and fresh rocks,
Section 4.1. The Au-As cluster is retained. Some differences, at a 2.5 level of dissimilarity, include the separation of Cr from Al and V to form its own cluster and the production of a single cluster from the combination of Ca, Sr and Mg with the ZnZrCuBaKPNiMnFeCo cluster determined from the clustering of weathered and fresh rocks, as shown in
Figure 6. In addition, Pb and S show more similarity in the fresh rocks, relative to the weathered and fresh counterparts. These differences in Pb may well be explained by mobility of Pb and S in the weathering profile, which results in dissimilar relationships when the entire dataset is considered. Five compositional geochemical variables are created based on the cluster dendrogram: AuAs; Cr; AlV; MnPZrBakCuFeCoNiMgZnSrCa; and PbS.
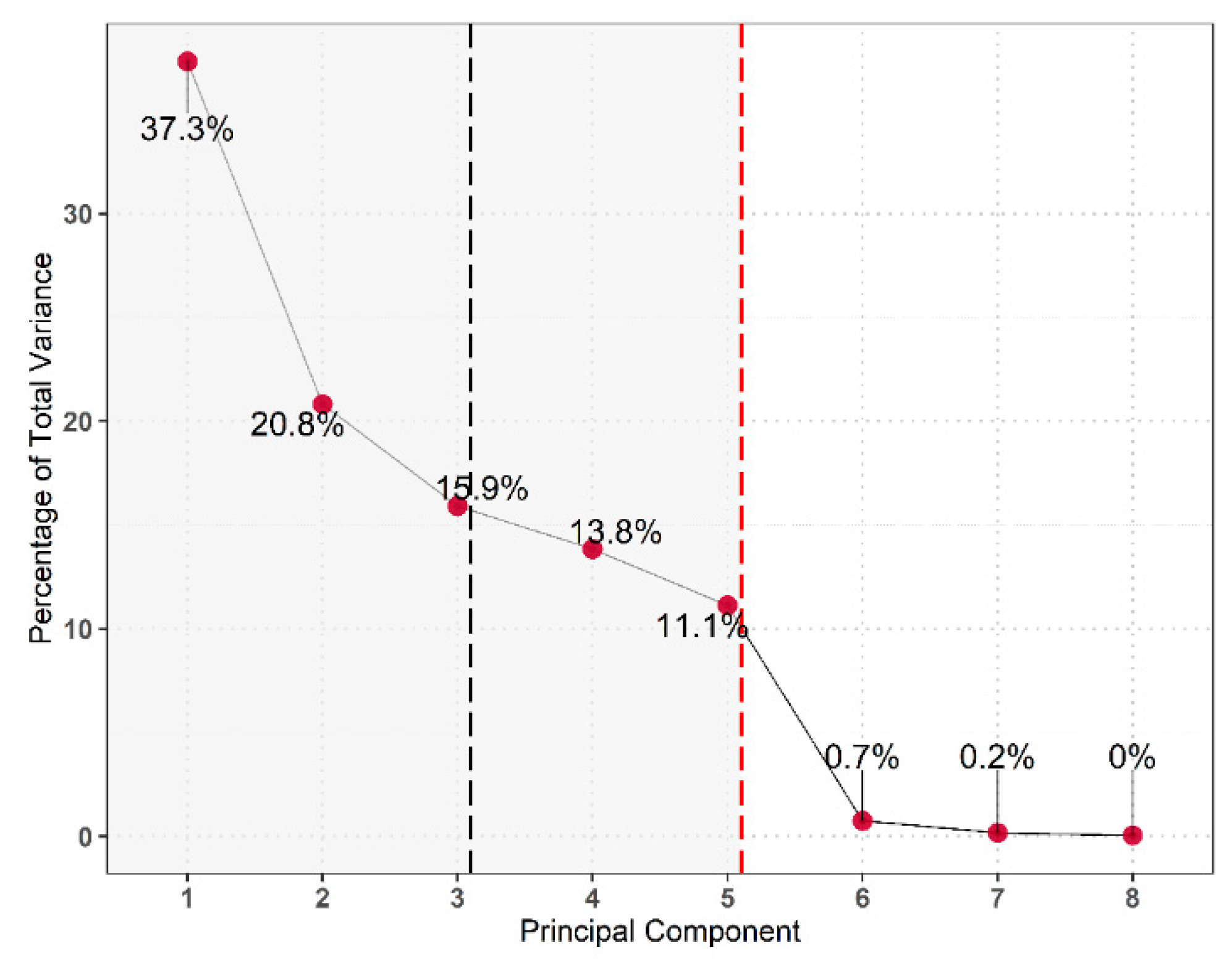
PCA is applied to a joint data matrix of the five compositional geochemical variables and the aforementioned non-compositional variables. The first three and five PCs capture 74% and 99%, respectively, of the total variability,
Figure 15. Two plot inflections occur at PC2 and PC5. PC3, PC4 and PC5 have comparable variance. The lack of a drop-off in variance captured between these three means that it is difficult to retain a number of PCs without resorting to higher dimensions (>3). The first three PCs of the fresh rock analysis equate to the same amount of variance explained by the first two PCs from analysis of the entire dataset. Retaining the first two would only capture ~57% of the sample variance.
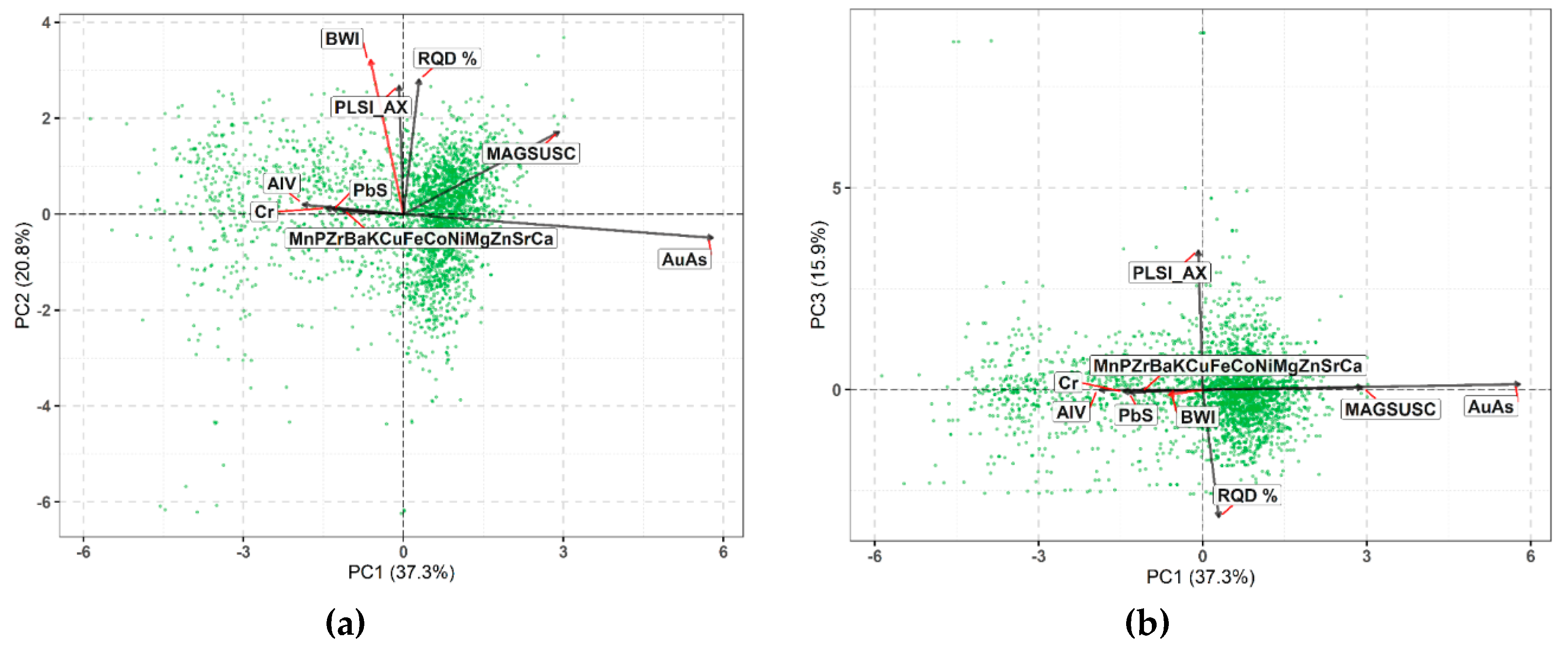
Examining the PC space of the first three components also reveals changes in BWI association,
Figure 16. In the PC1-PC2 plane, BWI maintains the relationship with the geomechanical variables found from the PCA of the entire dataset but this association is represented on the lesser PC2 direction,
Figure 16a. The BWI-PLSI_AX-RQD relationship is weaker than the first PCA as seen by an increase in the angles between the BWI vector and PLSI_AX and RQD, c.f.
Figure 9. The BWI vector shifts slightly towards the geochemical variable vectors. The variance captured by PC2 in this analysis, 20.8%, is much lower than the c.a. 50 % of PC1 which represented the BWI-PLSI_AX-RQD relationship from the first PCA. The PC1 of this analysis shows that the greatest variability in fresh rock, 37.3%, occurs from geochemical and magnetic variations related to gold mineralization. In the PC1-PC3 plane, PC3 is largely controlled by variability in PLSI_AX and RQD (15.9%;
Figure 16b); however, this variability does not correlate to variability in BWI or geochemical and magnetic susceptibility.
Overall, the PCA results of the fresh rock observations indicate that variability in this data subset is primarily controlled by geochemical characteristics and is less related to BWI and the other orebody variables. It is likely that PCA, as an unsupervised linear dimensionality reduction technique, may not detect potential associations between BWI and the geochemical characteristics in the fresh rock [
3,
7] given that BWI associations from PCA at Paracatu are not robust and translate poorly for practical purposes. Therefore, potential non-linear relationships between BWI, geochemical characteristics and the other orebody variables in the fresh rock are investigated using supervised RF classification.
RF variable importance is used to identify orebody variables most significant to BWI for the fresh rock data subset. The PCA cluster membership is added to the dataset as a categorical variable to include geologically validated information about the Paracatu orebody which could improve RF prediction. The ilr variables are defined by using the sequential binary partition of balances between groups of parts established from the fresh rock cluster dendrogram. This results in 19 ilr variables which describe balances between groups of the 20-element subcomposition (
Appendix B Table A3). The ilr variables replace the 5-part composite variables as geochemical variables in the fresh rock data subset.
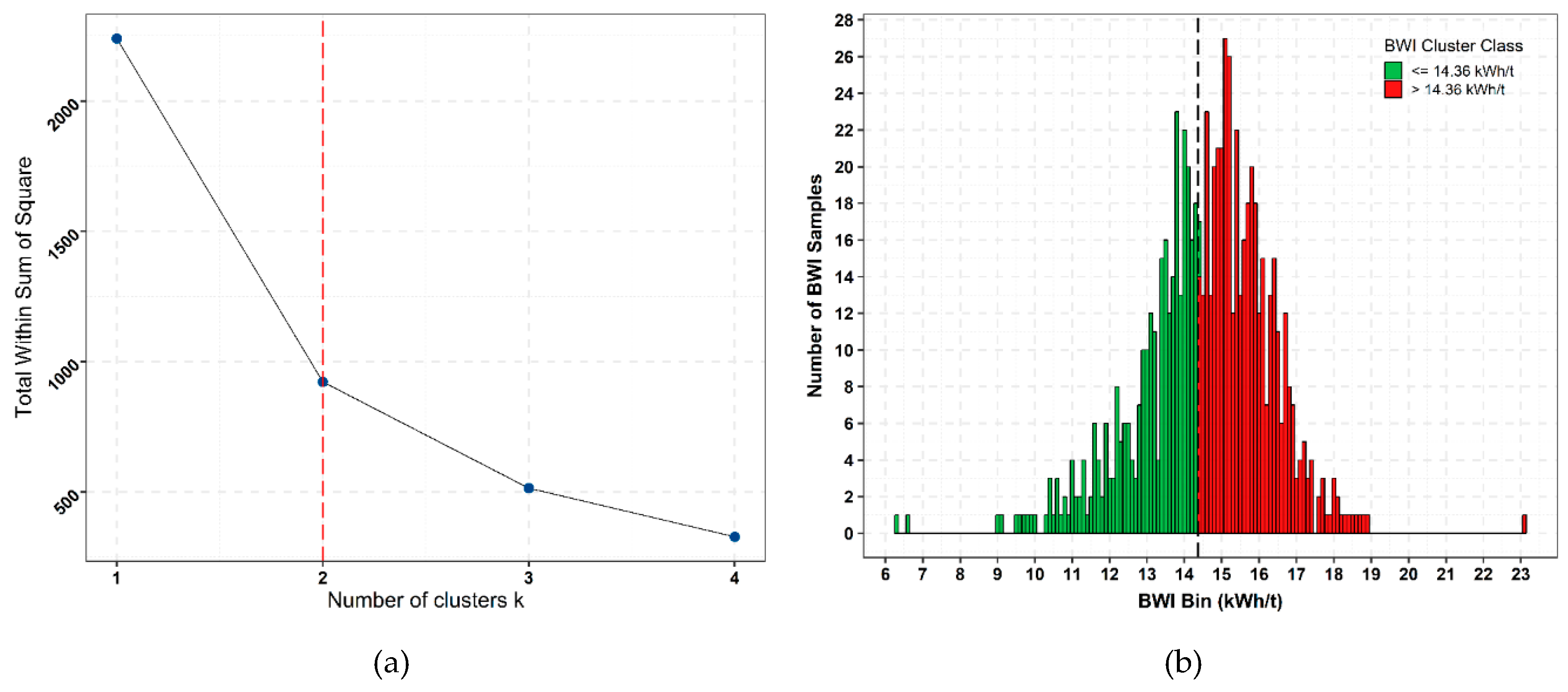
Clustering of BWI sample data from fresh rock indicates that that 2 or 3 classes are suitable for RF classification,
Figure 17a. The percentage share of observations in
K = 2 clusters is 60–40, which is a better balance than a 52–35–13 percentage share of observations for
K = 3 clusters.
K = 2 results in two BWI classes, <= 14.36 kWh/t and >14.36 kWh/t,
Figure 17b. A BWI operational boundary of 14 kWh/t is suitable for the Paracatu processing circuits (Kinross Gold, personal communication), which is close to the clustered BWI boundary for
K = 2. Accordingly, the clustered boundary of 14.36 kWh/t is selected for the reasonable proximity to the operational boundary and improved class balance.
The partitioning of observations into two classes yields n = 1103 observations, corresponding to n = 319 BWI samples, of BWI <= 14.36 kWh/t and n = 1647 observations, corresponding to n = 443 BWI samples, of BWI > 14.36 kWh/t, respectively. The 10-fold CV split of the dataset results in 2484 training observations and 276 test observations for each fold. The first stage of RF hyper-parameter tuning yields a ntree of 800 with the lowest MER over the set of ntree values. In the second tuning stage, an mtry of 14 is selected from a set of mtry values ranging from 3 to 18.
The tuned RF model yields an overall CV classification accuracy of 70%,
Table 3. The similar precisions of the two classes, 67% and 72%, suggests that the model is capturing meaningful structure in the orebody variable predictor space for BWI to the same degree for each class, rather than arbitrarily classifying observations. However, the class sensitivities are disproportionate, which suggests an influence of class imbalance. The <= 14.36 kWh/t class, which represents 40% of the dataset, has a much lower sensitivity of 52% than the sensitivity of 83% for the >14.36 kWh/t class. This indicates the RF model is less effective in detecting the minority class.
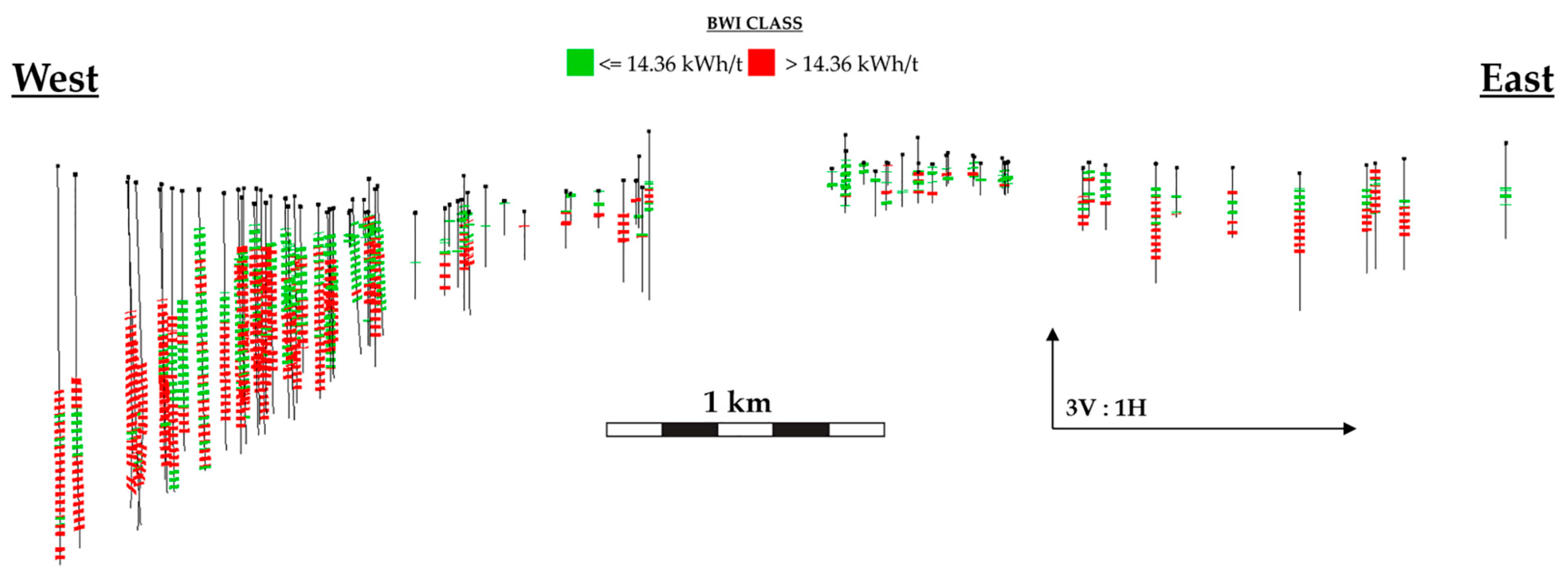
The distribution of each class’ misclassified observations (n = 531 for <=14.36 kWh/t and n = 284 for >14.36 kWh/t) was analyzed to check the BWI margins at which the bulk of misclassifications occur. The 25th, 50th and 75th percentiles are 12.95 kWh/t, 13.71 kWh/t and 14.04 kWh/t, respectively, for the <=14.35 kWh/t misclassified observations. The 25th, 50th and 75th percentiles are 14.75 kWh/t, 15.19 kWh/t and 15.73 kWh/t, respectively, for the > 14.35 kWh/t misclassified observations. Hence, most misclassifications occur for observations near the 14.36 kWh/t boundary, which is inadequate for predictive purposes since this region of BWI requires the greatest level of discrimination for operational decisions. The manifestation of the 14.36 kWh/t class boundary in the orebody,
Figure 18, is inconsistent with the geological interpretation of fresh rock clusters 1, 2 and 5 (orebody, hanging wall or footwall and magnetic ore; c.f.
Figure 13) and the orebody knowledge detailed in this study (
Section 2). The spatial profile of the class boundary shows a general increase in the BWI by depth in the east and an irregular sequence of BWI classes in the west, which is dominated by BWI >14.36 kWh/t. Knowledge of physical variability in the fresh phyllite domain, delineated by PCA clusters 1, 2 and 5.and understanding of BWI test variability at Paracatu should be improved to give a stronger geometallurgical basis for validating BWI classes.
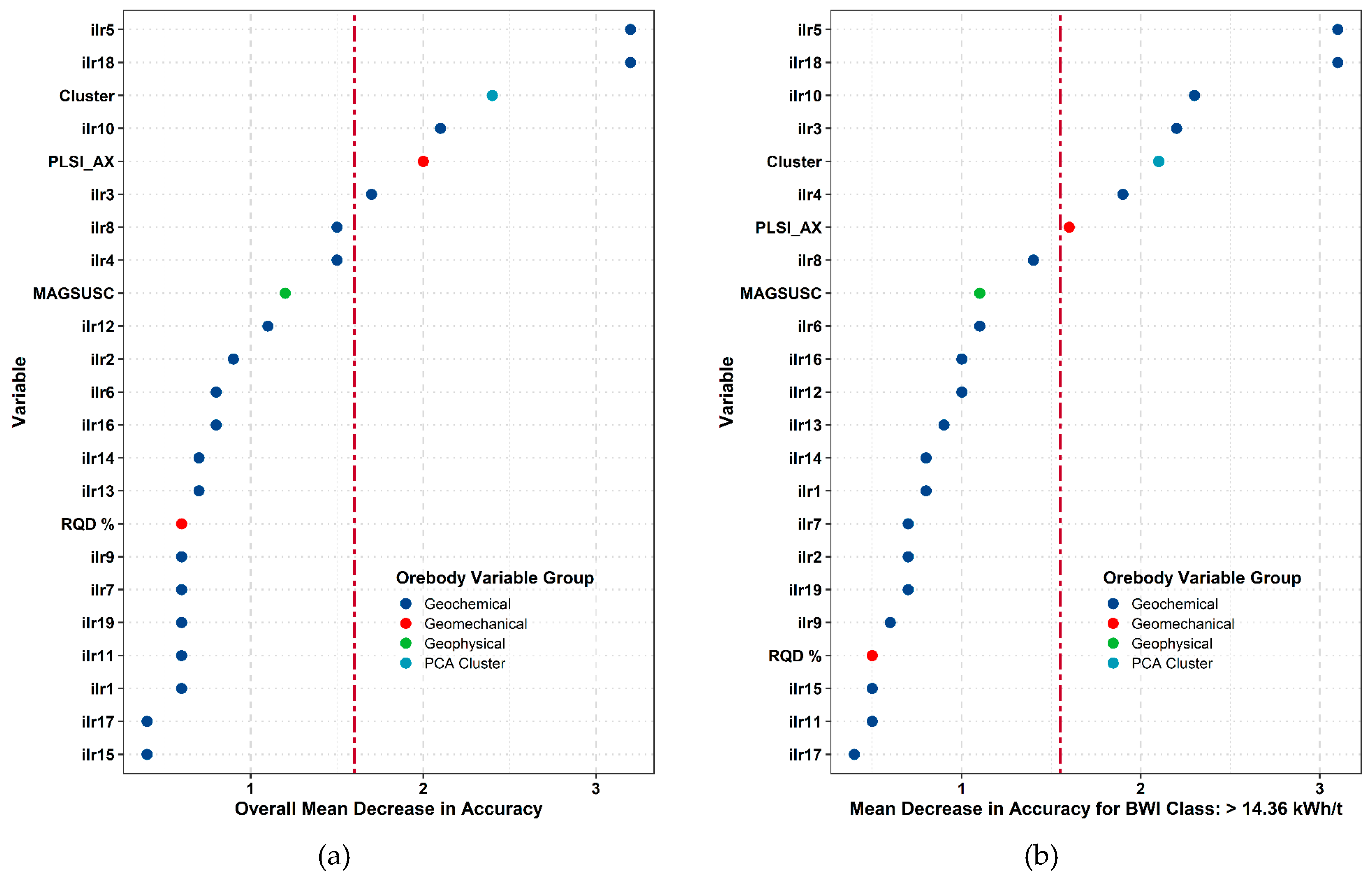
The overall variable importance integrates the importances of both BWI classes,
Figure 19. The variable importances of >14.36 kWht is also presented. The <= 14.36 kWh/t class is not considered given its borderline sensitivity of 52%; however, it still has an influence on the overall classification importance as evidenced by slight differences in importance ranking compared to the >14.36 kWh/t class. The PCA cluster and PLSI_AX rank higher in overall classification. In general, RQD is insignificant for BWI classification in fresh rock. Geochemical variables are the most important for classifying fresh phyllite BWI. The ilr 5 and ilr 18 are the two most important geochemical variables. The high importance rankings of ilr 3 and 10 are also consistent between both plots. The ilr 5 (
Table A3) is a balance between the immobile Al and immobile V. The ilr 18 is a balance between Sr and Ca. The ilr 10 is a balance between P and the immobile Zr The ilr 3 is a balance involving the immobile Cr and the remaining 19 elements. Accordingly. Therefore, it is likely that subtle variation, all balances important for BWI classification represent associations of immobile and mobile elements s in lithology, mineralization and hydrothermal alteration of the host phyllite exerts control on the BWI classes in the fresh rock.
The variable importances illustrates a shift in BWI association from the geomechanical variables to geochemical variables in the fresh rock domain. The phyllite becomes more intact as it transitions from the regolith into the fresh rock. The fresh phyllite’s grinding resistance is a function of intact strength dictated by mineralogical, textural and microstructural characteristics [
32,
74,
75], which manifest on a centimeter scale down to the micron scale. The ilr variables describe the geochemical variation related to phyllite mineralogy and alteration in the fresh rock. This information can be used to infer small-scale compositional heterogeneity in phyllite matrix characteristics that affect physiomechanical behavior on the micron scale of grinding.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


















