1. Introduction
In the mining industry, the economic value of a mineral deposit is estimated using a resource model that is built from the existing direct measurements of the resource of interest. These models are greatly influenced by the quantity, quality, and spatial distribution of the existing direct measurements for the properties of interest (e.g., grades). In general, ore deposit models are built based exclusively on the existing primary data that has been collected from rock core samples and/or logging tools with great precision and accuracy, which are less prone to measurement errors and, therefore, low uncertainty. During the determination of the spatial distribution of this resource, the kinds of data used are generally high quality and provide reliable measurements of the property of interest. Therefore, the data are considered to be reliable hard data with no uncertainty.
Later, during quasi-mining operations, more samples of the property of interest become available. These samples are normally used to fill in the informational gaps that were left over from previous rock core samples, and are often collected along several distinct campaigns from blast holes during the production years, prepared using different protocols, sampled with different equipment, and/or analyzed at different laboratories. Ideally, as the spacing between samples decreases, the uncertainty about the spatial distribution of the mineral deposit is also reduced. However, due to the abovementioned reasons, this information does not have the same quality throughout the entire dataset or within the existing rock core samples. Therefore, it is common to observe different statistical populations formed by readings of the same geological attribute when sampled, prepared, and/or assayed by distinct protocols. These analyses often produce different results when compared with the high quality measurements from the core analysis. From a modeling point of view, lower quality data is frequently considered to be secondary variables (i.e., soft data).
In the mining industry, it is still a common practice to exclude these uncertain measurements from the long-term and auditable resource models due to their imprecision and the bias they may introduce during the geo-modeling workflow and the final ore deposit model. Whether the soft measurement data should be included or not during the modeling procedure is still an open and relevant scientific question, e.g., [
1,
2,
3,
4,
5,
6,
7].
Emery et al. [
1] discussed the impact of the lack of accuracy within the available set of measurements for resource and reserve evaluation. This work showed that the quantity of data prevailed over its quality (i.e., the more experimental samples that were analyzed, the more accurate the resource and/or reserve models were, independent of the data quality). Therefore, the characterization of a given ore deposit would be improved if all the data available, even with different degrees of uncertainty, are considered during resource modeling.
An alternative approach to integrate secondary data was proposed by Babak and Deutsch [
2]. Their methodology consisted of merging all secondary data into a single super secondary variable, which is then used in the geo-modeling workflow through collocated co-kriging. Leuangthong and Deutsch [
8] transformed multiple variables into univariate and multivariate Gaussian variables with no cross-correlation. The transformed variables were then submitted to independent stochastic Gaussian simulation and back transformed to the original variables.
Ribeiro et al. [
3] proposed the use of mixed support data (i.e., samples obtained using diamond drill holes, and samples collected using a reverse circulation drilling method) in an iron ore deposit evaluation. Although the results showed a small global bias and high spatial correlation between some variables, in general, the differences in volumetric sample support between the two drilling methods generated a conditional bias and low or no correlation on a local scale. Reuwsaat [
4] also discussed the effect of sampling using different supports on the precision and accuracy of iron ore deposit models, demonstrating the importance of the correlation between the variables in the quality of the models.
Minnitt and Deutsch [
5] showed the importance of using simultaneously primary, accurate, and precise data together with a more abundant, imprecise, and biased secondary dataset, using cokriging as the estimation technique and a linear model of coregionalization to control the use of the secondary data in the estimation of recoverable reserves of mineral deposit grades. Cornah and Machaka [
6], and Donovan [
7], using a number of specialized geostatistical tools, most of all cokriging-based techniques, also demonstrated that the use of imprecise or biased (or both) secondary data in mineral resource estimations is recommended if the correlation between the data types can be properly estimated. The geostatistical tools used in these works allowed the use of secondary data without transmitting bias and error through to the final models [
7], but the uncertainty associated with the measurements was not properly assessed.
A usual way to integrate secondary information during the geo-modeling workflow of natural resources relies on stochastic sequential co-simulation algorithms [
9,
10,
11,
12]. Alternative procedures [
13] consider the integration of secondary information in the form of geophysical data through Sequential Gaussian Co-simulation (Co-SGS), but do not consider the physical (or geological) processes between variables (i.e., the secondary data is integrated exclusively considering the statistical criteria). Alternative approaches for joint simulation define a hierarchy of variables, in a process known by Collocated Co-simulation [
14].
In this paper, we propose an alternative way to integrate uncertain soft data into the natural resource modeling procedure through stochastic sequential simulation with local probability distribution functions [
15]. This approach uses the soft data as a probabilistic model by transforming the existing soft data into local probability distribution functions that represent the existing local uncertainty. These local probability functions may be derived exclusively from the existing secondary data, inferred from analogue geological scenarios, provided by expert knowledge, or a combination of all these options. The distribution types should be directly related to the degree of uncertainty expected for the secondary data in order to reproduce the real conditions of the natural resource and its uncertainty measurements.
In order to evaluate the advantages of integrating uncertainty experimental data in stochastic simulation methods, we compare the results between models resulting from conventional stochastic simulation algorithms (i.e., direct sequential simulation (DSS) and co-simulation (co-DSS)) and from stochastic sequential simulation with local probability distribution, as a way to integrate uncertain experimental data (soft data). We base our comparisons exclusively on the methods related to DSS to ensure that all scenarios are based on the same type of assumptions.
2. Methodology
This study proposed direct sequential simulation with local probability distributions [
15] as a modeling technique to include uncertain experimental data consistently during the geo-modeling workflow.
DSS with local probability distribution functions can be considered to be a natural extension of the DSS with joint probability distributions [
16]. This geostatistical simulation algorithm was designed to integrate data measurements that have variable degrees of uncertainty in the stochastic sequential simulation workflow. This uncertainty can result from the lack of accuracy and precision in the measurements at each location, and can be expressed by a local probability distribution function.
As with any stochastic sequential simulation technique, the main idea of this simulation algorithm was to generate spatially-correlated data values in a sequential approach. DSS with local probability distribution functions is based on two main steps. In the first step, locations associated with uncertain samples,
, were visited following a random path, generating
values from the collocated local distributions
. Following the guidelines of direct sequential simulation [
12], at each location,
the local mean and variance were computed using simple kriging conditioned to the existing hard data values,
, and to the previously simulated samples from other locations associated with uncertain distributions,
, around a given neighborhood. From the local distribution
centered at the local simple kriging estimate:
where the kriging weights,
and
, are associated with the hard data and the previously simulated uncertain experimental data, respectively, and the local variance is represented by the simple kriging variance. From this auxiliary distribution, a value,
is drawn at the location of the uncertain experimental data [
15].
In the second step, after all uncertain locations were visited and a set of
values was generated from the local distributions, the stochastic sequential procedure visits the remaining locations of the model using the conventional direct sequential simulation methodology. The resulting models reproduced the spatial covariances, and the global and local distributions [
15], as inferred from the existing certain and uncertain data.
The main question about the usability of this stochastic sequential simulation technique relied on how the local probability distribution functions,
, were built to properly describe the uncertainty of the existing measurements. These distribution functions can be derived from expert guesses or from auxiliary variables, at another
experimental sample locations associated with uncertain measurements of the same property in the framework of the stochastic sequential simulation [
15].
In this study, we proposed alternative strategies to build local probability distributions. The impacts of the different strategies in the resulting models were then compared against each other and contrasted against models resulting from a conventional stochastic sequential simulation algorithm. These different scenarios were applied to a mineral deposit from where a reference model was built from the existing data [
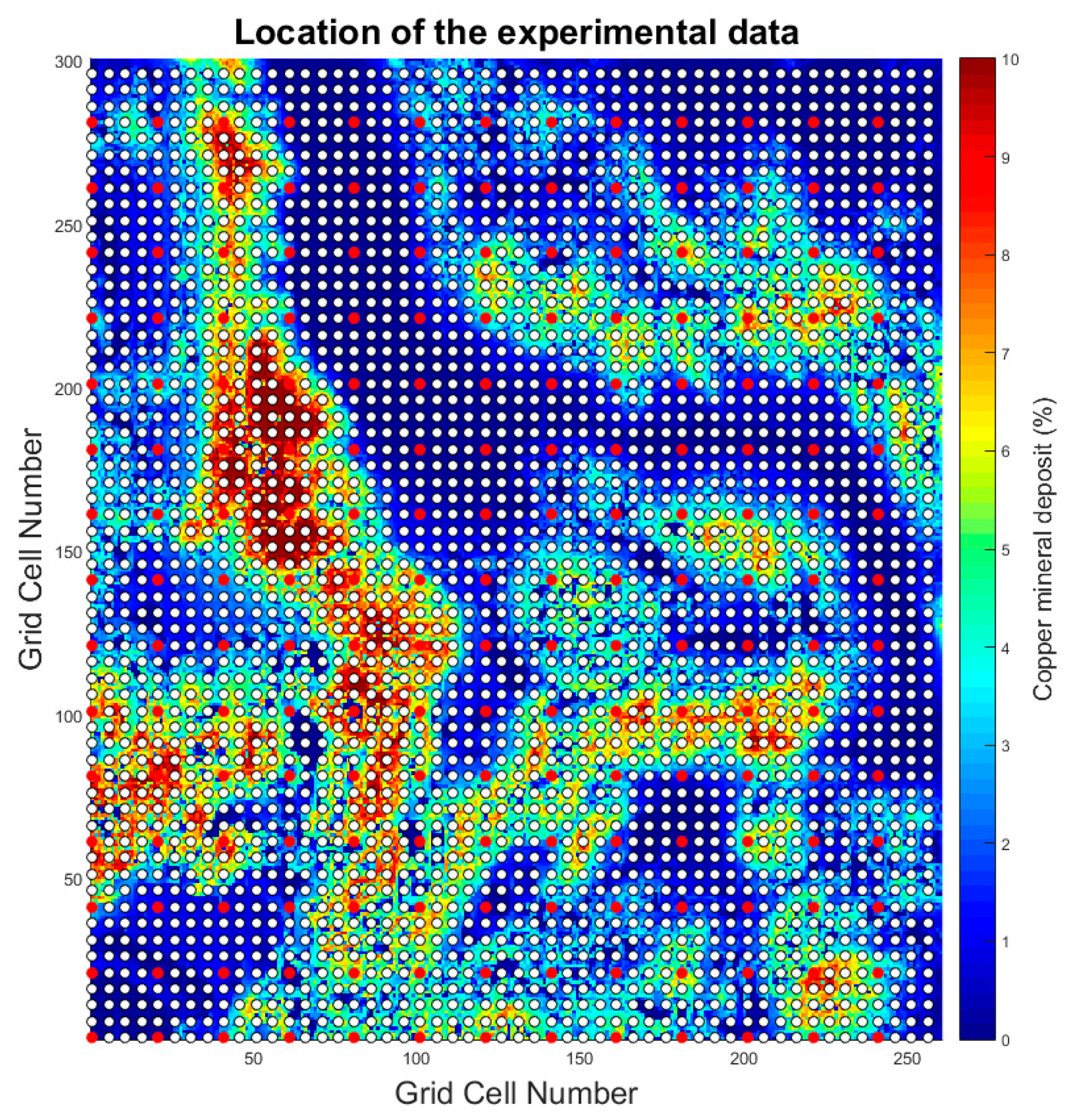
17]. This dataset is described in the section below.
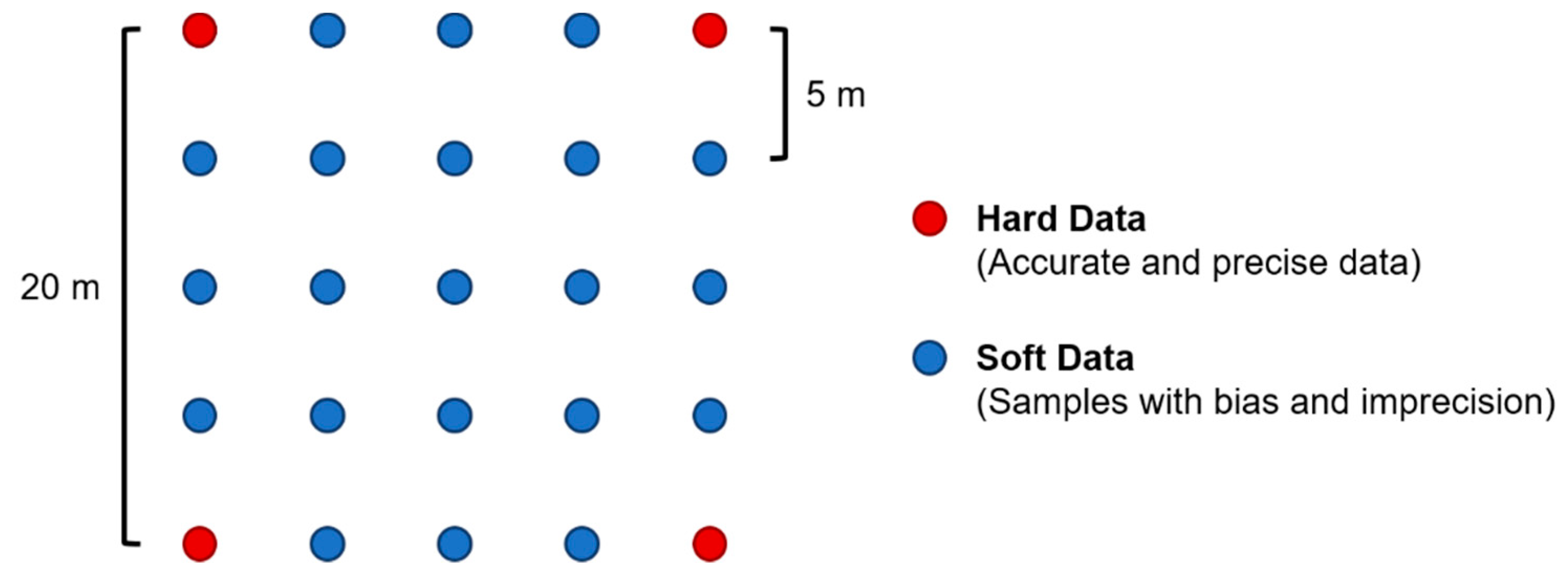
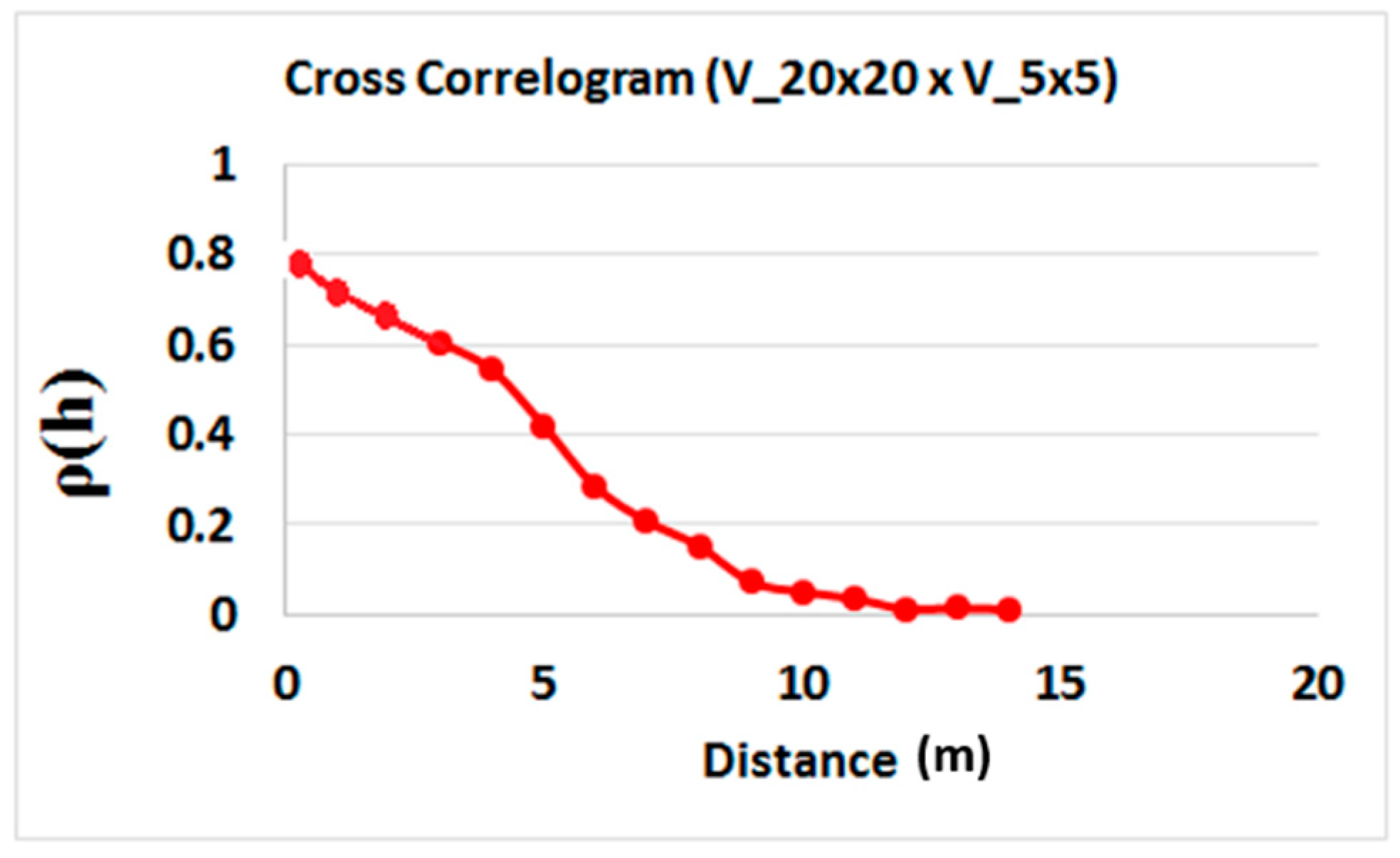
In order to assess the impact of the local probability distribution functions, two different approaches were created:
Experimental local probability distribution functions: the local probability distribution functions were built from 15 soft data samples that were the nearest to the location of the uncertain measurement; and
Parametric local probability distribution functions: the local probability distribution functions were built using Gaussian distributions with the means and standard deviations inferred from the 15 samples closest to the uncertain location.
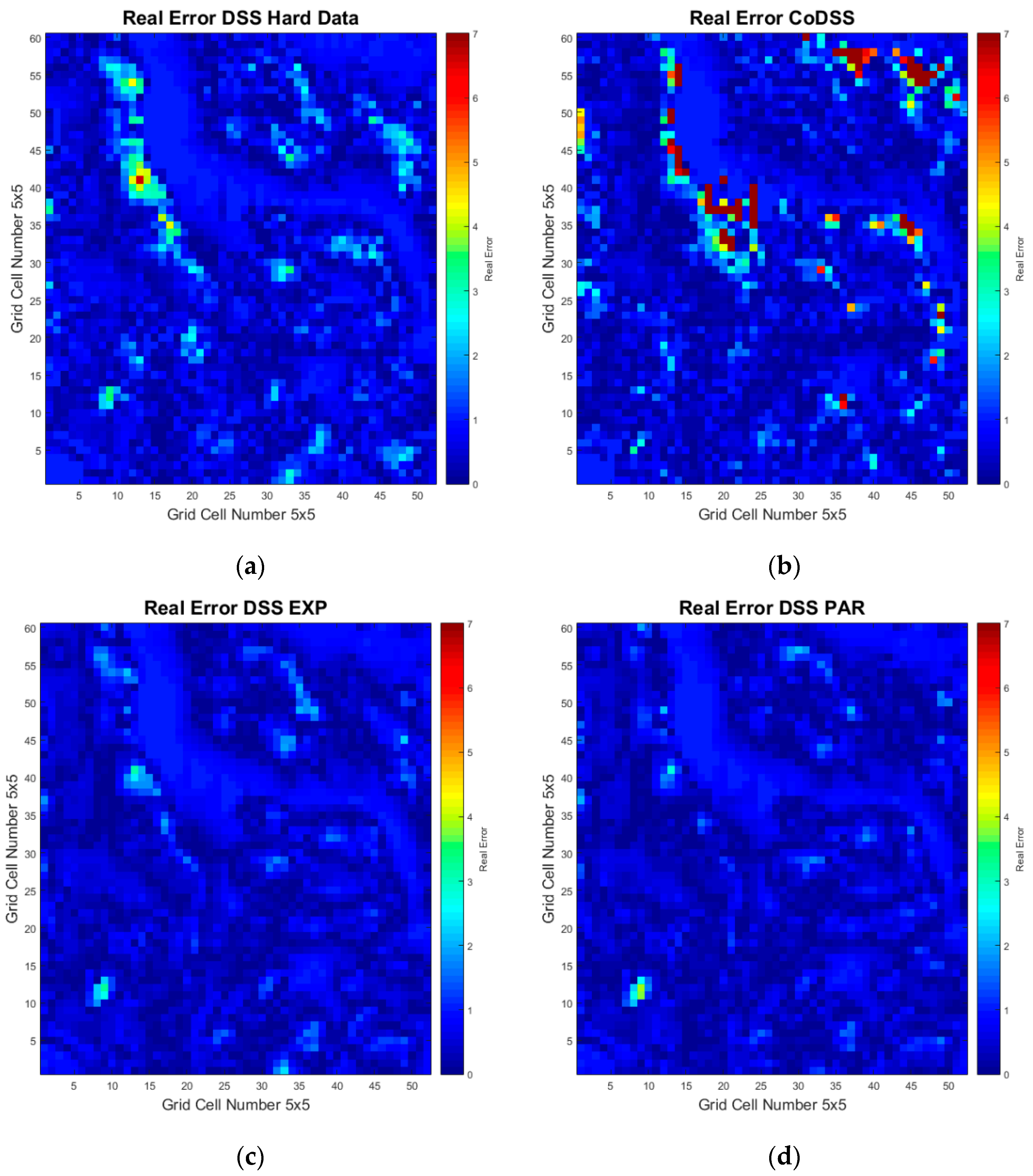
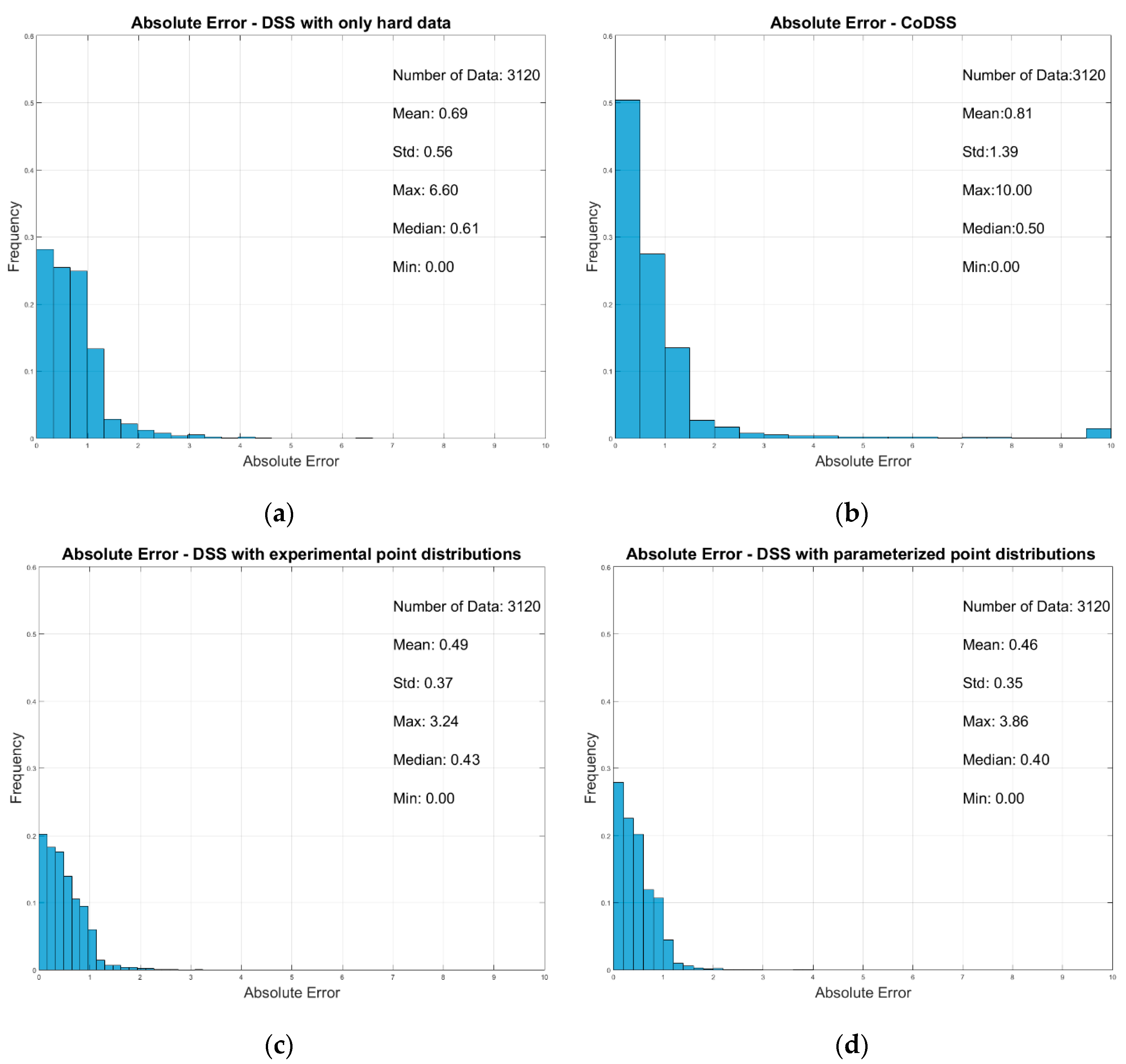
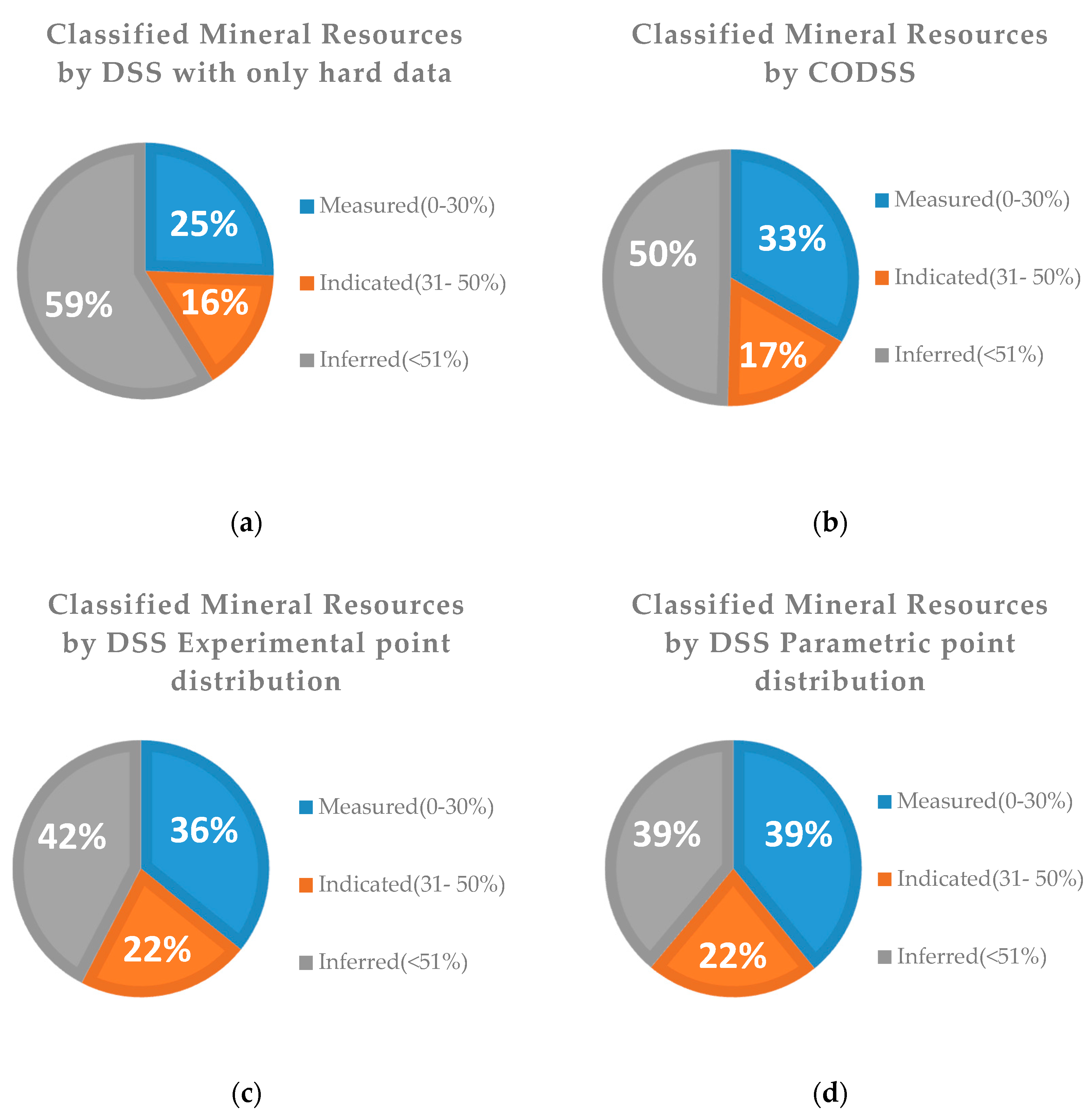
The results of each simulation strategy were compared quantitatively by calculating the error by re-blocking each realization along the reference model, and by computing the proportions of the classified mineral resources as a function of the calculated error.
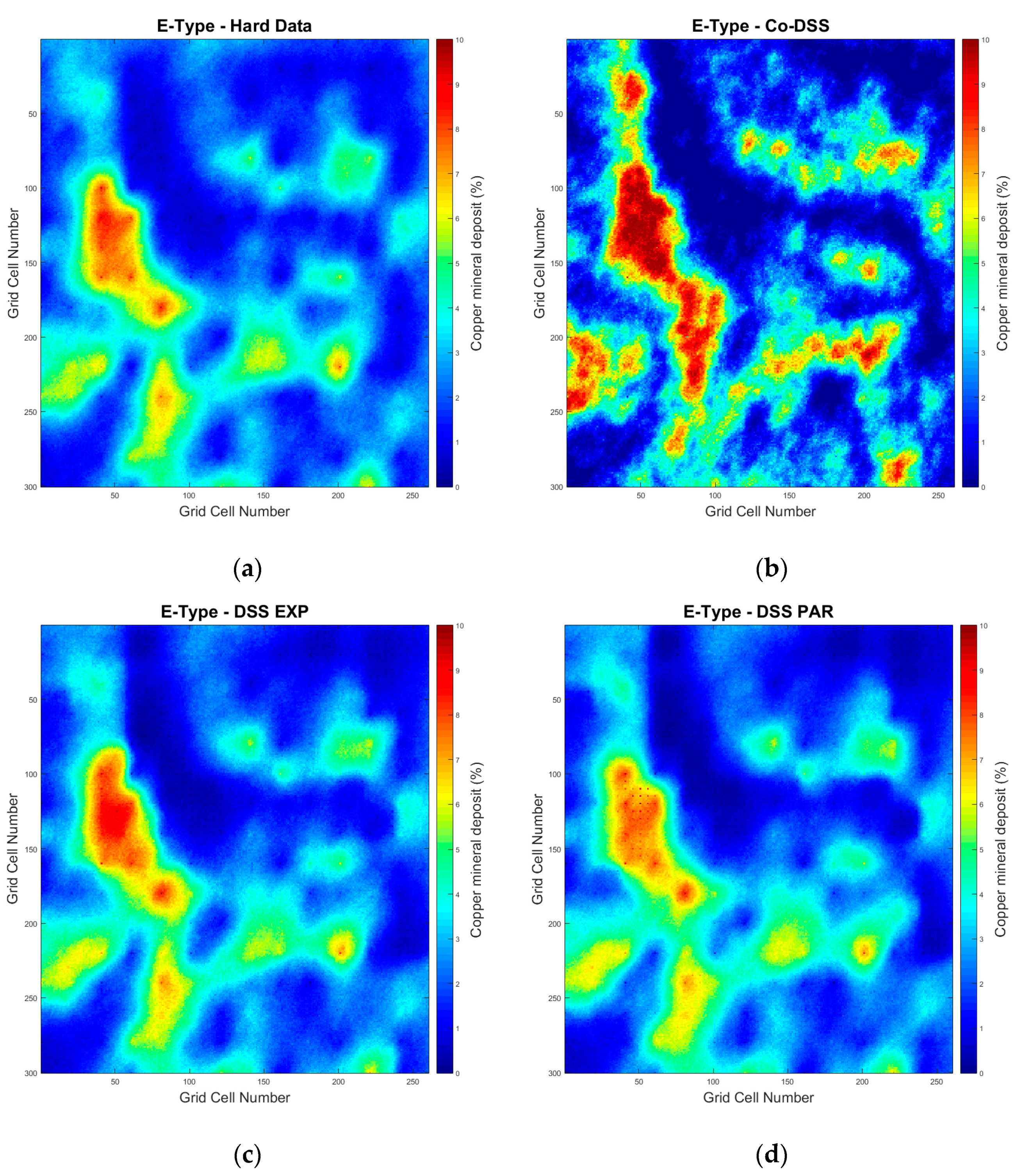
To properly assess the usefulness of the local probability distribution functions and the approaches proposed for a mineral deposit simulation strategy, we compared the following four simulation strategies, using an E-type model (i.e., the mean model of all simulations), the variance model, and the absolute relative errors for each simulation:
Direct sequential simulation only using the hard data to simulate the mineral deposit;
Direct sequential collocated co-simulation using the accurate and precise experimental data as the hard data and the uncertain experimental data as the secondary data to simulate the mineral deposit;
Direct sequential simulation with local probability distribution functions using the accurate and precise experimental data as the hard data and the uncertain experimental data to build experimental local probability distribution functions; and
Direct sequential simulation with local probability distribution functions using the accurate and precise experimental data as the hard data and the uncertain experimental data to build parametric local probability distribution functions.
4. Conclusions and Recommendations
We investigated the impact of integrating uncertain secondary data into the mineral resource modeling procedure using different DSS modeling strategies. In the example used here, the uncertain experimental data was contaminated by both bias and imprecision in order to mimic real mining conditions.
The results showed that, independent of the quality of the data, more data leads to more reliable models. However, traditional geostatistical modeling approaches, where secondary data are integrated through sequential co-simulation, are not able to properly incorporate the uncertainty present in the data within the resulting models, as these are affected by the bias presented in the secondary data. While the influence of the secondary data can be managed, for example by modifying the correlation coefficient between primary and secondary experimental data (i.e., user-defined correlation coefficients), it has an impact on the reserve calculation.
By using stochastic sequential simulation with local probability functions at the locations of the uncertain data, we were able to fully incorporate the uncertainty presented in the secondary data. The ability to integrate this uncertainty depends on the shape and size of the local probability distributions at the location of the secondary data samples. In this study, we considered two alternative options: using the uncertain data directly or building Gaussian distributions using the statistics retrieved from the uncertain data. The option selected should always be based on the type and quality of the existing data.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}