
Study of the Influence of Non-Deposit Locations in Data-Driven Mineral Prospectivity Mapping: A Case Study on the Iskut Project in Northwestern British Columbia, Canada


Abstract
:1. Introduction
2. RF Algorithm
3. Study Area: Iskut Project
3.1. Geological Setting
3.2. Au Mineralization
3.3. Conceptual Exploration Model
- Proximity to mineralized porphyritic intrusions;
- Proximity to faults;
- Presence of hydrothermal alteration zones;
- Geochemical enrichment in gold and associated pathfinder elements;
- Viability of host rock.
4. Methods
4.1. Spatial Data Input
4.1.1. Target Variable
4.1.2. Predictor Maps
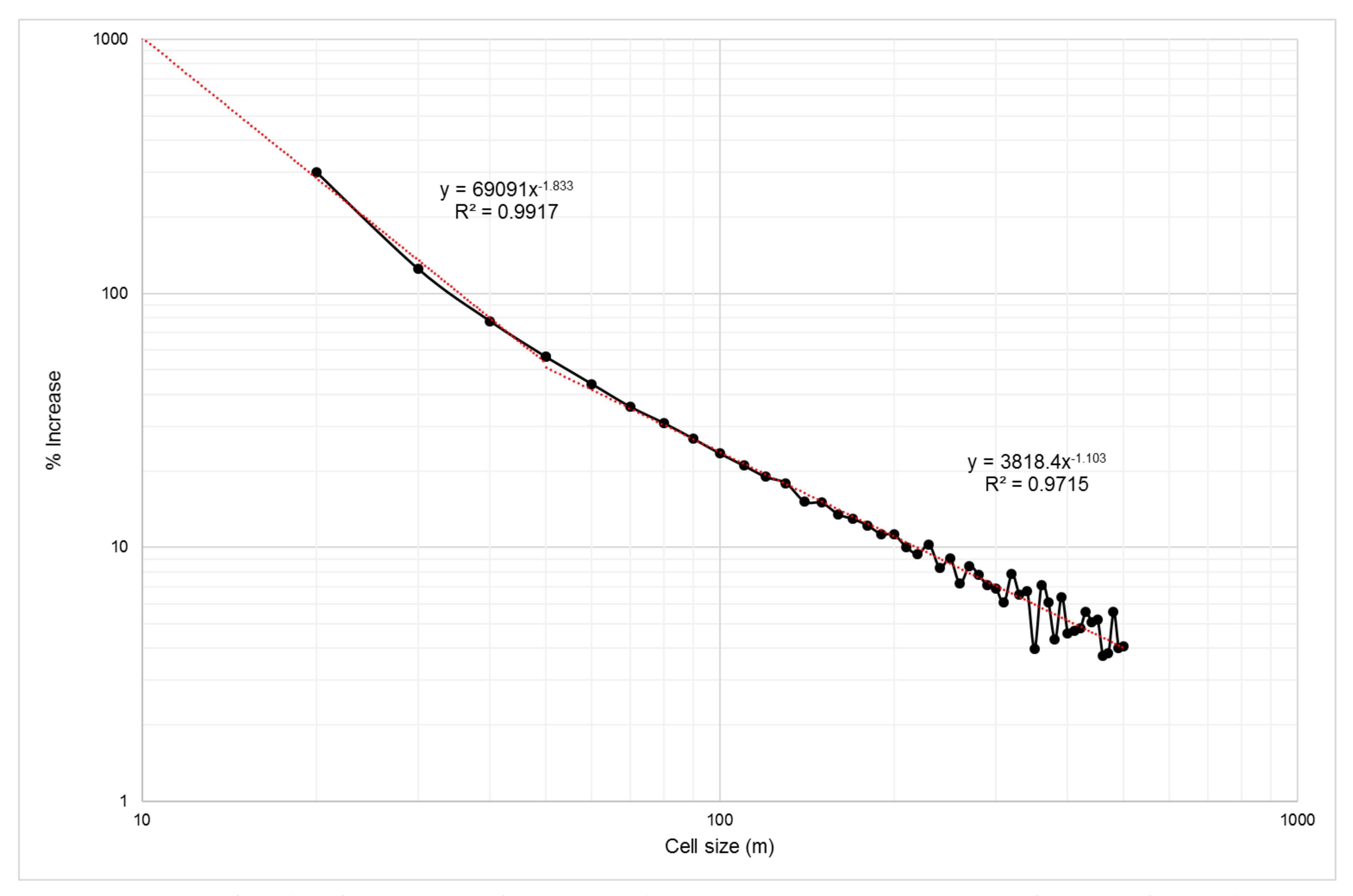
4.1.3. Cell Size
4.2. RF Algorithm Parameters
4.3. Model Evaluation
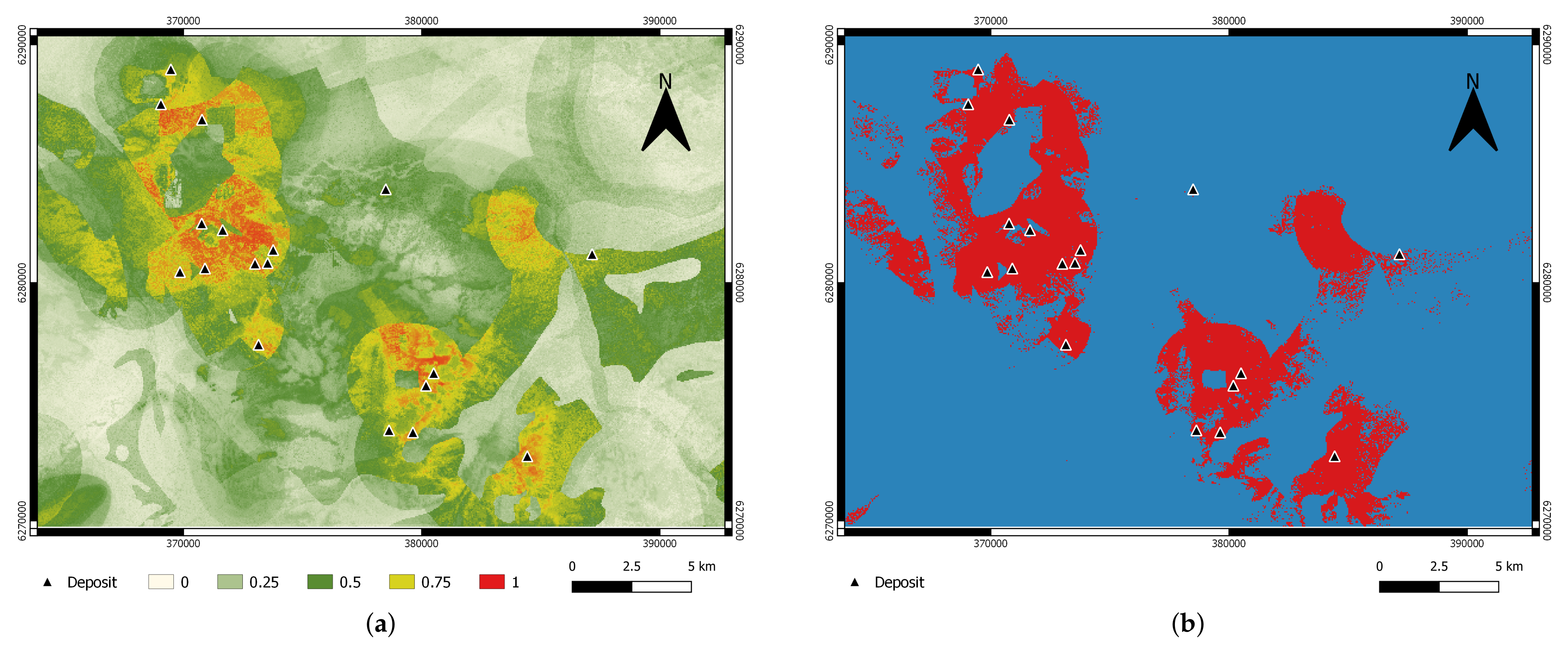
5. Results
5.1. Relative Importance of Predictor Maps
5.2. Predictive Accuracy of the Model
5.3. Performance of RF Modelling
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MINFILE # | NAME | STATUS | DEPOSIT TYPE | UTM NORTH | UTM EAST |
|---|---|---|---|---|---|
| 104B 077 | BRONSON SLOPE | Developed Prospect | High-sulfidation epithermal | 6,282,211 | 371,642 |
| 104B 089 | SNIP NORTH - EAST ZONE | Prospect | Massive sulphide Cu-Pb-Zn | 6,286,850 | 370,775 |
| 104B 107 | JOHNNY MOUNTAIN | Past Producer | Subaqueous hot spring Ag-Au | 6,277,401 | 373,149 |
| 104B 113 | INEL | Developed Prospect | Massive sulphide Cu-Zn | 6,275,679 | 380,178 |
| 104B 116 | TAMI (BLUE RIBBON) | Prospect | Alkalic porphyry Cu-Au | 6,272,714 | 384,430 |
| 104B 138 | KHYBER PASS | Prospect | Massive sulphide Cu-Zn | 6,273,715 | 379,627 |
| 104B 204 | WARATAH 6 | Prospect | Au pyrrhotite veins | 6,283,926 | 378,489 |
| 104B 250 | SNIP | Past Producer | Au pyrrhotite veins | 6,282,486 | 370,764 |
| 104B 264 | C3 (REG) | Prospect | Au pyrrhotite veins | 6,280,600 | 370,900 |
| 104B 300 | BRONSON | Prospect | Au pyrrhotite veins | 6,281,374 | 373,763 |
| 104B 356 | GORGE | Prospect | Vein | 6,287,500 | 369,050 |
| 104B 357 | GREGOR | Prospect | Unspecified | 6,288,962 | 369,467 |
| 104B 537 | MYSTERY | Prospect | Au pyrrhotite veins | 6,281,200 | 387,150 |
| 104B 557 | AK | Prospect | Subaqueous hot spring Ag-Au | 6,276,200 | 380,500 |
| 104B 563 | CE CONTACT | Prospect | Au pyrrhotite veins | 6,280,800 | 373,000 |
| 104B 567 | SMC | Prospect | Massive sulphide Cu-Pb-Zn | 6,280,450 | 369,850 |
| 104B 571 | CE | Prospect | Au pyrrhotite veins | 6,280,829 | 373,529 |
| 104B 685 | KHYBER WEST | Prospect | Unspecified | 6,273,802 | 378,627 |
| MINFILE # | NAME | STATUS | DEPOSIT TYPE | UTM NORTH | UTM EAST |
|---|---|---|---|---|---|
| 104B 005 | CRAIG RIVER | Showing | Cu skarn | 6,2761,77 | 366,697 |
| 104B 205 | HANDEL | Showing | Polymetallic veins | 6,281,905 | 376,693 |
| 104B 206 | WOLVERINE | Showing | Polymetallic veins Ag-Pb-Zn | 6,277,250 | 377,150 |
| 104B 256 | WOLVERINE (INEL) | Showing | Cu skarn | 6,277,063 | 383,766 |
| 104B 268 | HANGOVER TRENCH | Showing | Polymetallic veins Ag-Pb-Zn | 6,275,185 | 369738 |
| 104B 272 | DAN 2 | Showing | Polymetallic veins Ag-Pb-Zn | 6,271,824 | 375,475 |
| 104B 292 | GIM (ZONE 1) | Showing | Polymetallic veins Ag-Pb-Zn | 6,281,770 | 383,605 |
| 104B 305 | MILL | Showing | Porphyry Cu-Mo-Au | 6,272,879 | 363,417 |
| 104B 306 | NORTH CREEK | Showing | Polymetallic veins Ag-Pb-Zn | 6,275,031 | 368,709 |
| 104B 324 | IAN 4 | Showing | Cu-Ag quartz veins | 6,286,725 | 379,485 |
| 104B 326 | CAM 9 | Showing | Cu skarn | 6,279,635 | 391,709 |
| 104B 327 | CAM SOUTH | Showing | Polymetallic veins Ag-Pb-Zn | 6,279,579 | 392,696 |
| 104B 331 | IAN 8 | Showing | Cu skarn | 6,286,038 | 383,655 |
| 104B 362 | KIRK MAGNETITE | Showing | Fe skarn | 6,276,565 | 389,635 |
| 104B 368 | ELMER | Showing | Fe skarn | 6,275,780 | 391,286 |
| 104B 377 | ROCK AND ROLL | Developed Prospect | Massive sulphide Cu-Zn | 6,288,261 | 363,286 |
| 104B 416 | IAN 6 SOUTH | Showing | Massive sulphide Cu-Pb-Zn | 6,286,900 | 382,200 |
| 104B 500 | KRL-FORREST | Showing | Vein | 6,288,950 | 393,400 |
| 104B 536 | ANDY | Showing | Pb-Zn skarn | 6,278,300 | 385,825 |
References
- Bonham-Carter, G.F. Geographic Information Systems for Geoscientists: Modelling with GIS; Pergamon (Elsevier Science Ltd.): Oxford, UK, 1994. [Google Scholar]
- Carranza, E.J.M. Geochemical Anomaly and Mineral Prospectivity Mapping in GIS. In Handbook of Exploration and Environmental Geochemistry, 2009th ed.; Elsevier Science: Amsterdam, The Netherlands, 2008; Volume 11. [Google Scholar]
- Harris, J.; Grunsky, E.; Behnia, P.; Corrigan, D. Data- and knowledge-driven mineral prospectivity maps for Canada’s North. Ore Geol. Rev. 2015, 71, 788–803. [Google Scholar] [CrossRef]
- Harris, J.; Wilkinson, L.; Heather, K.; Fumerton, S.; Bernier, M.A.; Ayer, J.; Dahn, R. Application of GIS Processing Techniques for Producing Mineral Prospectivity Maps—A Case Study: Mesothermal Au in the Swayze Greenstone Belt, Ontario, Canada. Nat. Resour. Res. 2001, 34, 91–124. [Google Scholar] [CrossRef]
- Yousefi, M.; Carranza, E.J.M. Geometric average of spatial evidence data layers: A GIS-based multi-criteria decision-making approach to mineral prospectivity mapping. Comput. Geosci. 2015, 83, 72–79. [Google Scholar] [CrossRef]
- Abedi, M.; Mostafavi Kashani, S.B.; Norouzi, G.H.; Yousefi, M. A deposit scale mineral prospectivity analysis: A comparison of various knowledge-driven approaches for porphyry copper targeting in Seridune, Iran. J. Afr. Earth Sci. 2017, 128, 127–146. [Google Scholar] [CrossRef]
- Joly, A.; Porwal, A.; McCuaig, T.C. Exploration targeting for orogenic gold deposits in the Granites-Tanami Orogen: Mineral system analysis, targeting model and prospectivity analysis. Ore Geol. Rev. 2012, 48, 349–383. [Google Scholar] [CrossRef]
- Porwal, A.; Das, R.D.; Chaudhary, B.; Gonzalez-Alvarez, I.; Kreuzer, O. Fuzzy inference systems for prospectivity modeling of mineral systems and a case-study for prospectivity mapping of surficial Uranium in Yeelirrie Area, Western Australia. Ore Geol. Rev. 2015, 71, 839–852. [Google Scholar] [CrossRef]
- Yousefi, M.; Carranza, E.J.M. Fuzzification of continuous-value spatial evidence for mineral prospectivity mapping. Comput. Geosci. 2015, 74, 97–109. [Google Scholar] [CrossRef]
- Yousefi, M.; Nykänen, V. Data-driven logistic-based weighting of geochemical and geological evidence layers in mineral prospectivity mapping. J. Geochem. Explor. 2016, 164, 94–106. [Google Scholar] [CrossRef]
- Harris, D.; Zurcher, L.; Stanley, M.; Marlow, J.; Pan, G. A Comparative Analysis of Favorability Mappings by Weights of Evidence, Probabilistic Neural Networks, Discriminant Analysis, and Logistic Regression. Nat. Resour. Res. 2003, 12, 241–255. [Google Scholar] [CrossRef]
- Porwal, A.; González-Álvarez, I.; Markwitz, V.; McCuaig, T.; Mamuse, A. Weights-of-evidence and logistic regression modeling of magmatic nickel sulfide prospectivity in the Yilgarn Craton, Western Australia. Ore Geol. Rev. 2010, 38, 184–196. [Google Scholar] [CrossRef]
- Zhang, Z.; Zuo, R.; Xiong, Y. A comparative study of fuzzy weights of evidence and random forests for mapping mineral prospectivity for skarn-type Fe deposits in the southwestern Fujian metallogenic belt, China. Sci. China Earth Sci. 2016, 59, 556–572. [Google Scholar] [CrossRef]
- Brown, W.M.; Gedeon, T.D.; Groves, D.I.; Barnes, R.G. Artificial neural networks: A new method for mineral prospectivity mapping. Aust. J. Earth Sci. 2000, 47, 757–770. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Abedi, M.; Norouzi, G.H.; Bahroudi, A. Support vector machine for multi-classification of mineral prospectivity areas. Comput. Geosci. 2012, 46, 272–283. [Google Scholar] [CrossRef]
- Geranian, H.; Tabatabaei, S.H.; Asadi, H.H.; Carranza, E.J.M. Application of Discriminant Analysis and Support Vector Machine in Mapping Gold Potential Areas for Further Drilling in the Sari-Gunay Gold Deposit, NW Iran. Nat. Resour. Res. 2016, 25, 145–159. [Google Scholar] [CrossRef]
- Shabankareh, M.; Hezarkhani, A. Application of support vector machines for copper potential mapping in Kerman region, Iran. J. Afr. Earth Sci. 2017, 128, 116–126. [Google Scholar] [CrossRef]
- Carranza, E.J.M.; Laborte, A.G. Data-driven predictive mapping of gold prospectivity, Baguio district, Philippines: Application of Random Forests algorithm. Ore Geol. Rev. 2015, 71, 777–787. [Google Scholar] [CrossRef]
- Carranza, E.J.M.; Laborte, A.G. Data-Driven Predictive Modeling of Mineral Prospectivity Using Random Forests: A Case Study in Catanduanes Island (Philippines). Nat. Resour. Res. 2016, 25, 35–50. [Google Scholar] [CrossRef]
- Hariharan, S.; Tirodkar, S.; Porwal, A.; Bhattacharya, A.; Joly, A. Random Forest-Based Prospectivity Modelling of Greenfield Terrains Using Sparse Deposit Data: An Example from the Tanami Region, Western Australia. Nat. Resour. Res. 2017, 26, 489–507. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Chica-Olmo, M.; Chica-Rivas, M. Predictive modelling of gold potential with the integration of multisource information based on random forest: A case study on the Rodalquilar area, Southern Spain. Int. J. Geogr. Inf. Sci. 2014, 28, 1336–1354. [Google Scholar] [CrossRef]
- Carranza, E.J.M. Natural Resources Research Publications on Geochemical Anomaly and Mineral Potential Mapping, and Introduction to the Special Issue of Papers in These Fields. Nat. Resour. Res. 2017, 26, 379–410. [Google Scholar] [CrossRef]
- Parsa, M.; Maghsoudi, A.; Yousefi, M. Spatial analyses of exploration evidence data to model skarn-type copper prospectivity in the Varzaghan district, NW Iran. Ore Geol. Rev. 2018, 92, 97–112. [Google Scholar] [CrossRef]
- Sun, T.; Chen, F.; Zhong, L.; Liu, W.; Wang, Y. GIS-based mineral prospectivity mapping using machine learning methods: A case study from Tongling ore district, eastern China. Ore Geol. Rev. 2019, 109, 26–49. [Google Scholar] [CrossRef]
- McKay, G.; Harris, J. Comparison of the Data-Driven Random Forests Model and a Knowledge-Driven Method for Mineral Prospectivity Mapping: A Case Study for Gold Deposits Around the Huritz Group and Nueltin Suite, Nunavut, Canada. Nat. Resour. Res. 2016, 25, 125–143. [Google Scholar] [CrossRef]
- Zhang, S.; Xiao, K.; Carranza, E.J.M.; Yang, F. Maximum Entropy and Random Forest Modeling of Mineral Potential: Analysis of Gold Prospectivity in the Hezuo–Meiwu District, West Qinling Orogen, China. Nat. Resour. Res. 2019, 28, 645–664. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification And Regression Trees; Taylor & Francis Group: Boca Raton, FL, USA, 1984. [Google Scholar]
- Macdonald, A.J.; Lewis, P.D.; Thompson, J.F.H.; Nadaraju, G.; Bartsch, R.; Bridge, D.J.; Rhys, D.A.; Roth, T.; Kaip, A.; Godwin, C.I.; et al. Metallogeny of an Early to Middle Jurassic arc, Iskut River area, northwestern British Columbia. Econ. Geol. 1996, 91, 1098–1114. [Google Scholar] [CrossRef]
- Nelson, J.; Kyba, J. Structural and stratigraphic control of porphyry and related mineralization in the Treaty Glacier KSM Brucejack Stewart trend of western Stikinia. Br. Columbia Geol. Surv. Pap. 2014, 2013, 111–140. [Google Scholar]
- Logan, J.M.; Mihalynuk, M.G. Tectonic Controls on Early Mesozoic Paired Alkaline Porphyry Deposit Belts (Cu-Au Ag-Pt-Pd-Mo) Within the Canadian Cordillera. Econ. Geol. 2014, 109, 827–858. [Google Scholar] [CrossRef]
- Rhys, D.A. Geology of the Snip Mine and Its Relationship to the Magmatic and Deformational History of the Johnny Mountain Area, Northwestern British Columbia. Master’s Thesis, University of British Columbia, Vancouver, BC, Canada, 1993. [Google Scholar]
- Rhys, D.A. Geology of the Stonehouse Gold Deposit (Johnny Mountain Gold Mine) and Exploration Implications; Technical Report; Spirit Bear Minerals Ltd.: Vancouver, BC, Canada, 1994. [Google Scholar]
- Cui, Y.; Miller, D.; Schiarizza, P.; Diakow, L.J. British Columbia Digital Geology. In Open File 2017-8, British Columbia Ministry of Energy, Mines and Petroleum Resources; British Columbia Geological Survey: Victoria, BC, Canada, 2017. [Google Scholar]
- Aitchison, J. The Statistical Analysis of Compositional Data; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Grunsky, E.C. The interpretation of geochemical survey data. Geochem. Explor. Environ. Anal. 2010, 10, 27–74. [Google Scholar] [CrossRef]
- Crósta, A.P.; De Souza Filho, C.R.; Azevedo, F.; Brodie, C. Targeting key alteration minerals in epithermal deposits in Patagonia, Argentina, using ASTER imagery and principal component analysis. Int. J. Remote Sens. 2003, 24, 4233–4240. [Google Scholar] [CrossRef]
- Di Tommaso, I.; Rubinstein, N. Hydrothermal alteration mapping using ASTER data in the Infiernillo porphyry deposit, Argentina. Ore Geol. Rev. 2007, 32, 275–290. [Google Scholar] [CrossRef]
- Moore, F.; Rastmanesh, F.; Asadi, H.; Modabberi, S. Mapping mineralogical alteration using principal-component analysis and matched filter processing in the Takab area, north-west Iran, from ASTER data. Int. J. Remote Sens. 2008, 29, 2851–2867. [Google Scholar] [CrossRef]
- Crowley, J.K.; Brickey, D.W.; Rowan, L.C. Airborne imaging spectrometer data of the Ruby Mountains, Montana: Mineral discrimination using relative absorption band-depth images. Remote Sens. Environ. 1989, 29, 121–134. [Google Scholar] [CrossRef]
- Rowan, L.C.; Mars, J.C. Lithologic mapping in the Mountain Pass, California area using Advanced Spaceborne Thermal Emission and Reflection Radiometer (ASTER) data. Remote Sens. Environ. 2003, 84, 350–366. [Google Scholar] [CrossRef]
- Pour, A.B.; Hashim, M. Identification of hydrothermal alteration minerals for exploring of porphyry copper deposit using ASTER data, SE Iran. J. Asian Earth Sci. 2011, 42, 1309–1323. [Google Scholar] [CrossRef]
- Rajendran, S.; Nasir, S. Characterization of ASTER spectral bands for mapping of alteration zones of volcanogenic massive sulphide deposits. Ore Geol. Rev. 2017, 88, 317–335. [Google Scholar] [CrossRef]
- Carranza, E.J.M. Objective selection of suitable unit cell size in data-driven modeling of mineral prospectivity. Comput. Geosci. 2009, 35, 2032–2046. [Google Scholar] [CrossRef]
- Hengl, T. Finding the right pixel size. Comput. Geosci. 2006, 32, 1283–1298. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159. [Google Scholar] [CrossRef] [PubMed] [Green Version]















| Ag | Au | As | Ba | Co | Cu | Fe | Mn | Mo | Pb | Sb | Zn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PC1 | −0.41 | −0.39 | 0.21 | 0.28 | 0.04 | 0.12 | −0.26 | 0.35 | −0.24 | 0.25 | −0.29 | 0.39 |
| PC2 | 0.09 | 0.28 | 0 | 0.21 | 0.1 | −0.38 | −0.38 | 0.40 | −0.15 | −0.46 | −0.29 | −0.30 |
| R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | R9 | R10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 88% | 67% | 72% | 78% | 75% | 81% | 83% | 83% | 81% | 72% |
| Kappa | 78% | 33% | 44% | 56% | 50% | 61% | 67% | 67% | 61% | 44% |
| Sensitivity | 94% | 61% | 67% | 78% | 78% | 78% | 89% | 83% | 78% | 67% |
| Specificity | 83% | 72% | 78% | 78% | 72% | 83% | 78% | 83% | 83% | 78% |
| Selected | Mean | Sd | |
|---|---|---|---|
| Accuracy | 84% | 78% | 6% |
| Kappa | 67% | 56% | 13% |
| Sensitivity | 79% | 77% | 10% |
| Specificity | 89% | 79% | 4% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lachaud, A.; Marcus, A.; Vučetić, S.; Mišković, I. Study of the Influence of Non-Deposit Locations in Data-Driven Mineral Prospectivity Mapping: A Case Study on the Iskut Project in Northwestern British Columbia, Canada. Minerals 2021, 11, 597. https://doi.org/10.3390/min11060597
Lachaud A, Marcus A, Vučetić S, Mišković I. Study of the Influence of Non-Deposit Locations in Data-Driven Mineral Prospectivity Mapping: A Case Study on the Iskut Project in Northwestern British Columbia, Canada. Minerals. 2021; 11(6):597. https://doi.org/10.3390/min11060597
Chicago/Turabian StyleLachaud, Alix, Adam Marcus, Slobodan Vučetić, and Ilija Mišković. 2021. "Study of the Influence of Non-Deposit Locations in Data-Driven Mineral Prospectivity Mapping: A Case Study on the Iskut Project in Northwestern British Columbia, Canada" Minerals 11, no. 6: 597. https://doi.org/10.3390/min11060597