
Development of Network Analysis and Visualization System for KEGG Pathways


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Studies
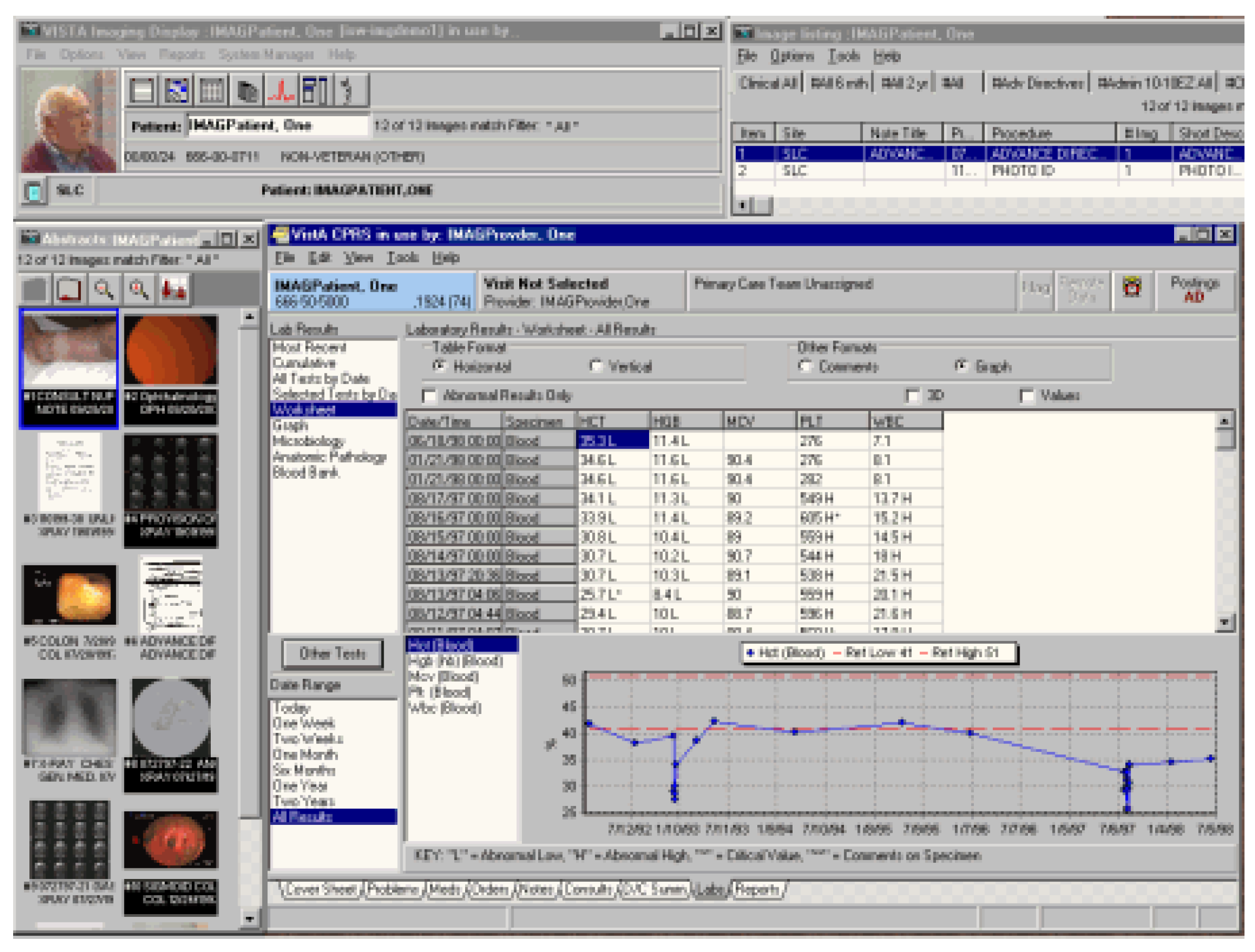
2.1. Bioinformatics Data Based Big Data Services


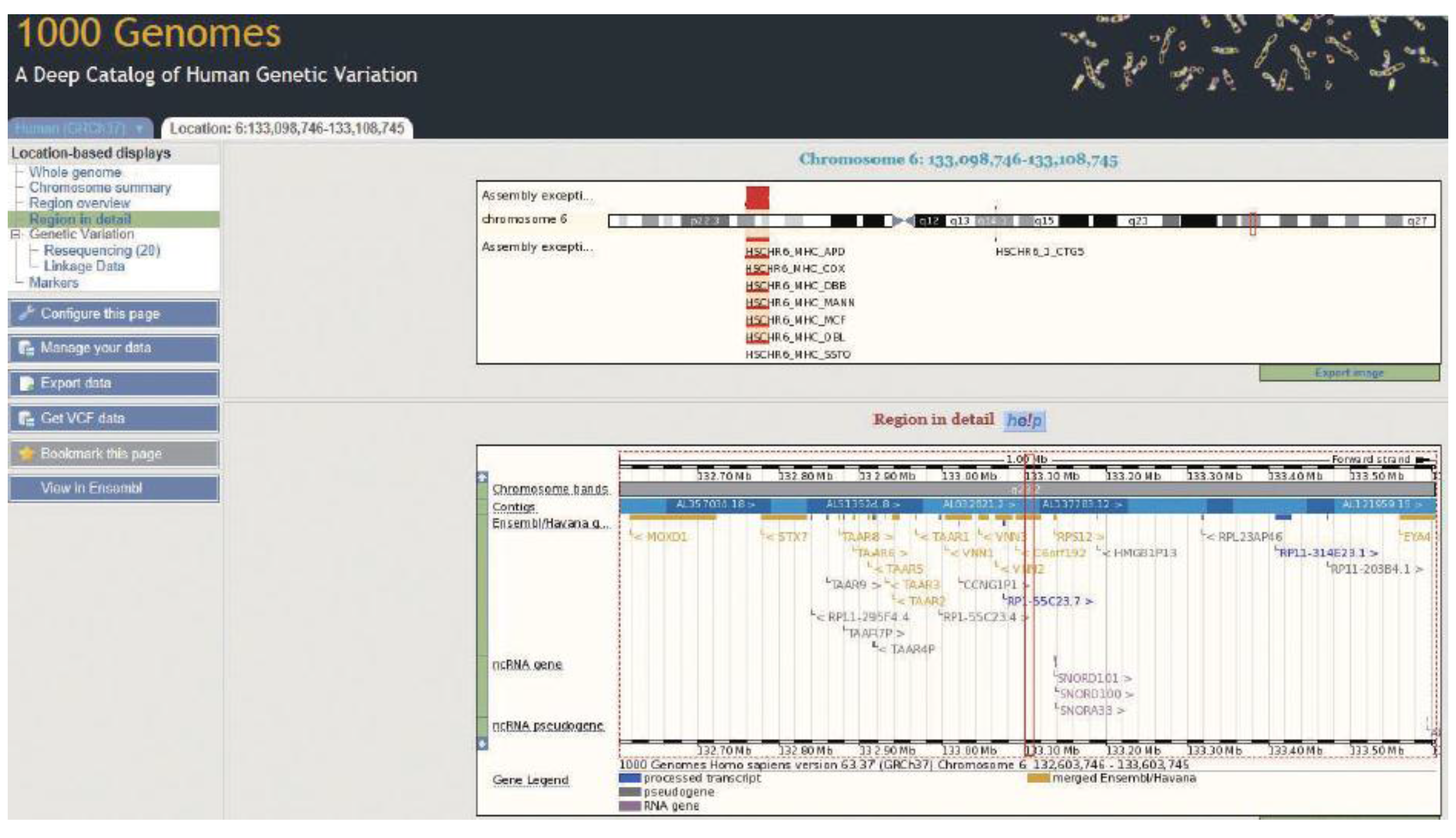
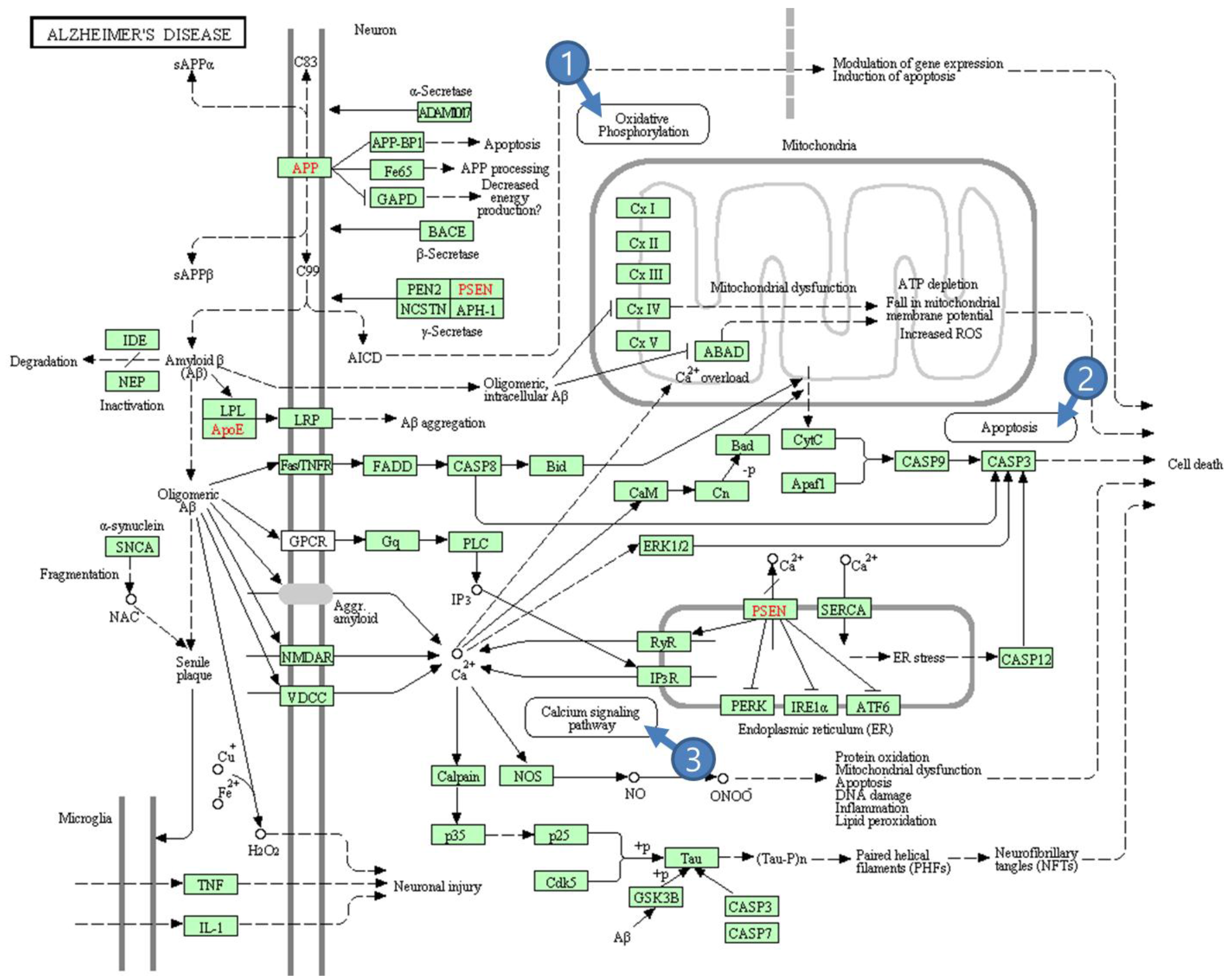
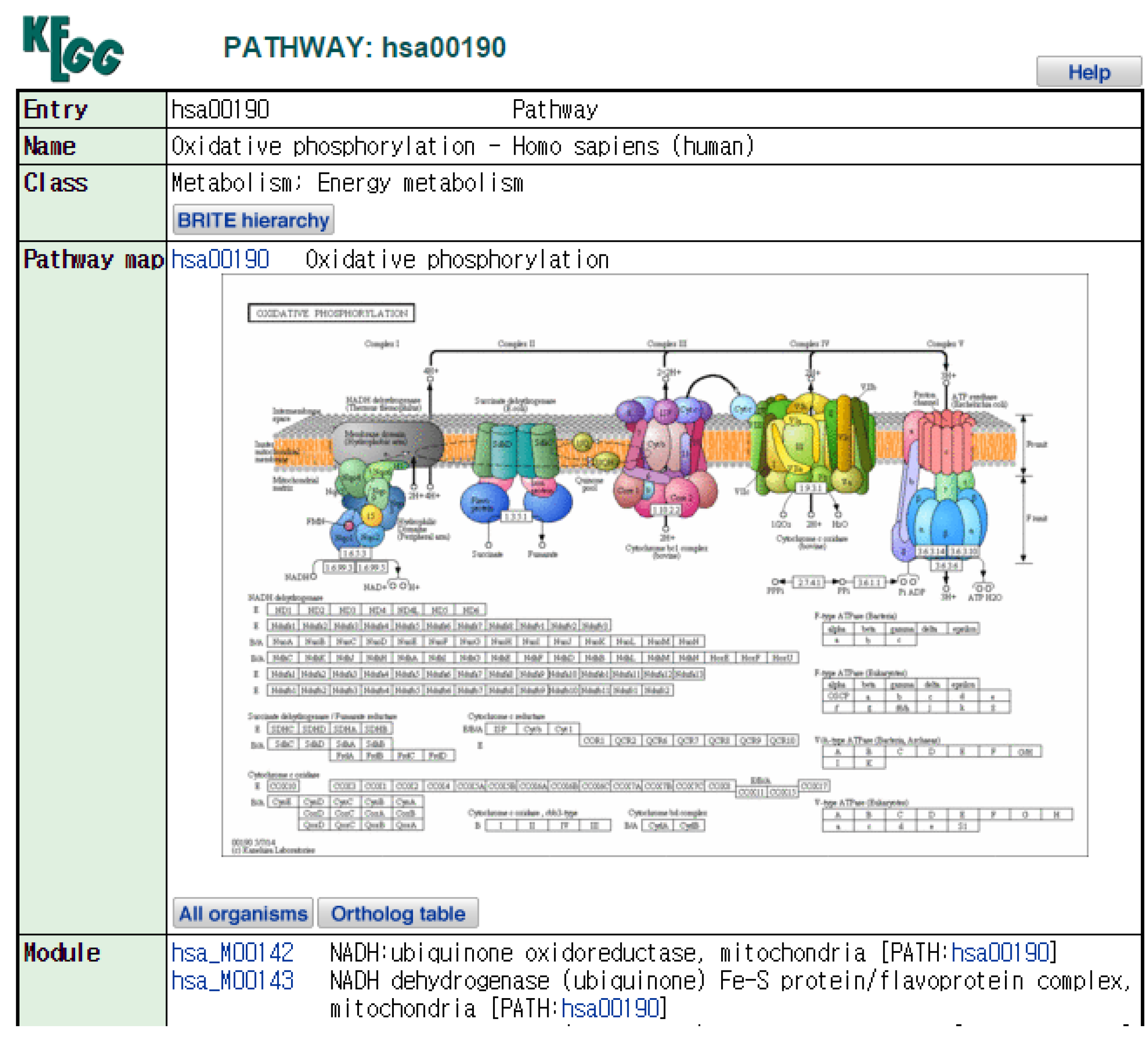
2.2. KEGG Pathway Database

3. Proposed Multidimensional Pathway Analysis System
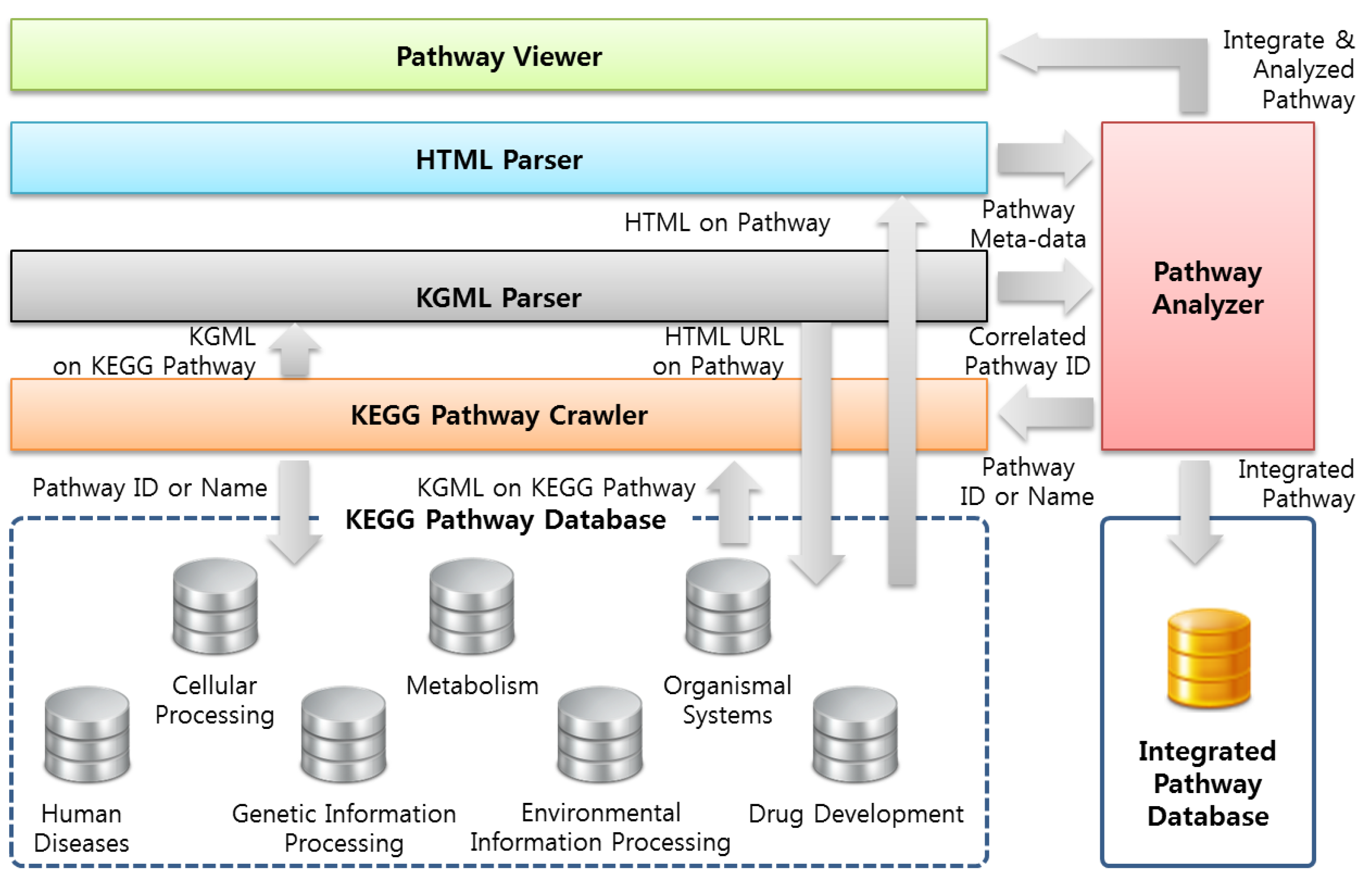
3.1. System Structure Diagram

| Algorithm 1. Multiple pathways crawling. |
| H = The number of hops inputted by a user |
| PU = A pathway ID inputted by a user |
| NC = 0 // Count variable |
| NC = 0 |
| MultiplePathwayCrawler(H, PU, NC++) |
| Function MultiplePathwayCrawler(H, PID, NC) |
| // PID = KEGGs Pathway ID |
| DK = Obtain a KGML on PID from the KEGGs pathway database |
| while (EM = Obtain entry elements with type = “map”) |
| // The name of a pathway connected with a pathway of PID |
| PN = Obtain a value of the name attribute of EM |
| // The URL of HTML of a pathway connected with a pathway of PID |
| PL = Obtain a value of the link attribute of EM |
| Integrated Pathway Database.Insert(PN, PL) |
| if (NC + 1 ≤ H) |
| MultiplePathwayCrawler(H, PN, NC++) |
| END if |
| END while |
| END Function |


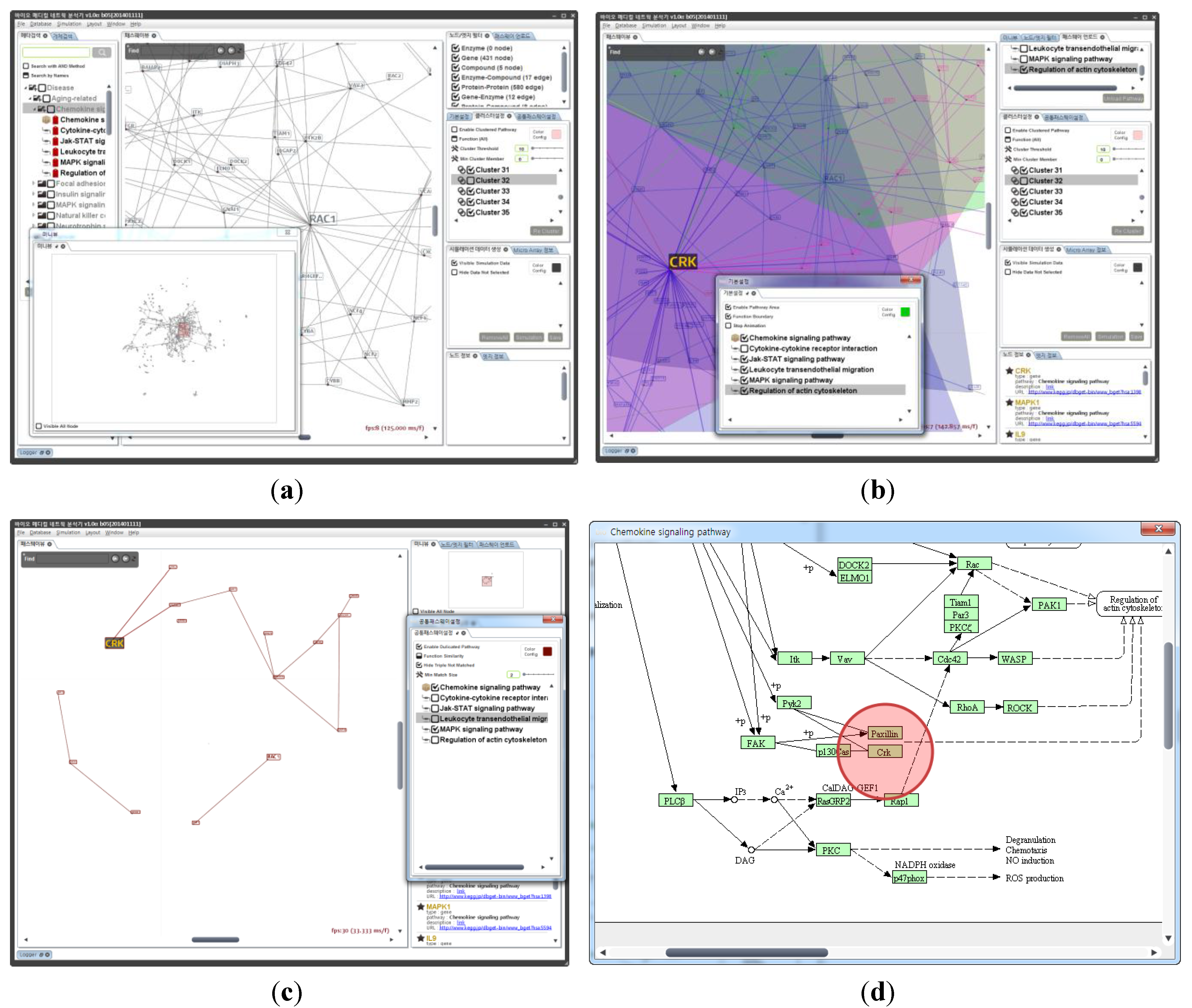
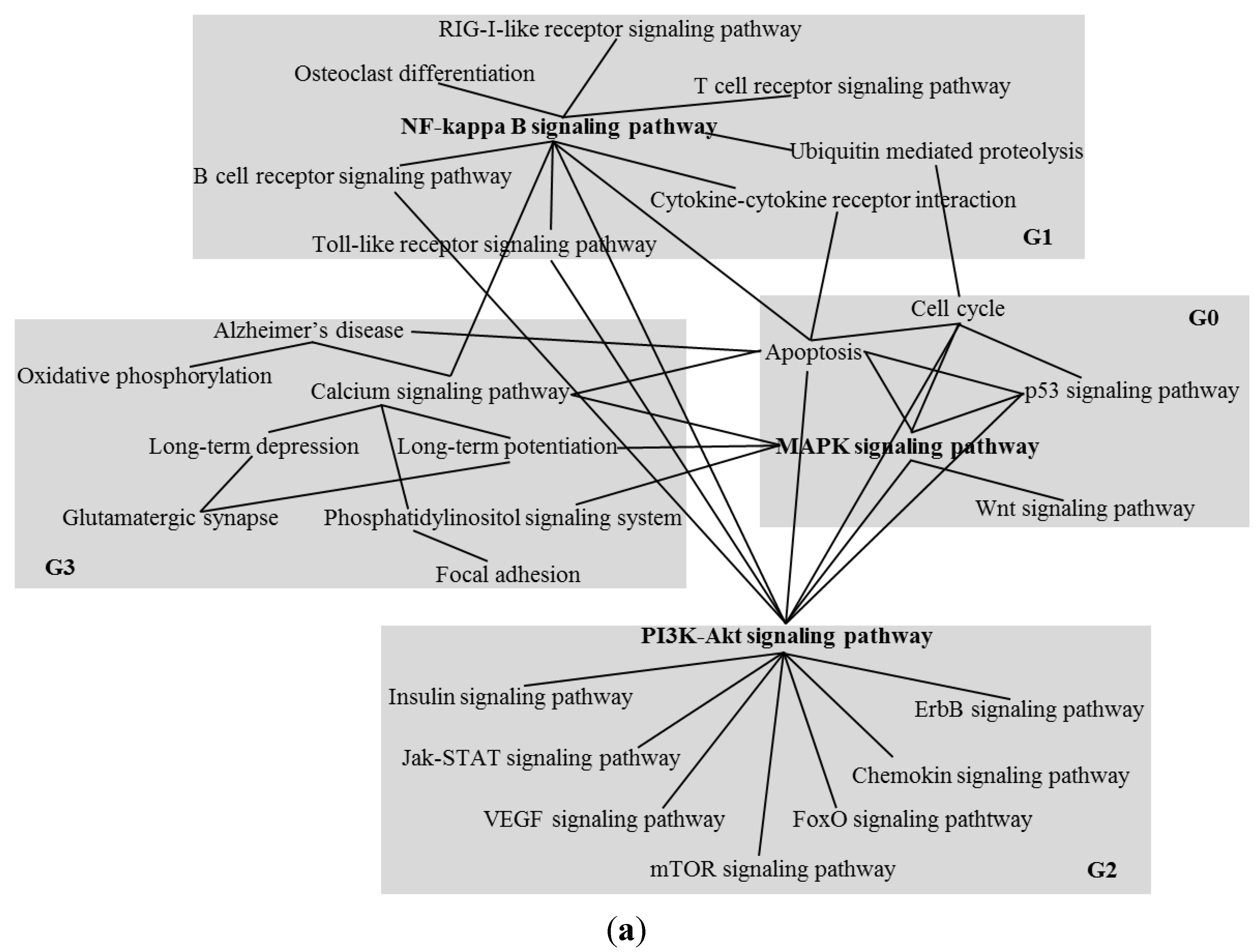
3.2. Pathway Analyzer for Pathway Analysis
| Algorithm 2. Key pathway selection standards within cluster groups. |
| QN = (Num of nodes connected with a node/Num of all nodes in a cluster) × 100 |
| QU = User threshold |
| ArrayList Results |
| for (CN = Num of all clusters; CN > 0; CN = CN-1) |
| for (V = 1; V ≤ Num of all nodes in a cluster; V++) |
| if (QN ≥ QU && VC == CN) Results.add(V) // VC = Num of connections on other clusters |
| else if (QN ≥ QU) Results.add(V) |
| else if (VC == CN) Results.add(V) |
| END for |
| if (Results.size() > 0) return Results |
| END for |
3.3. Pathway Viewer for Pathway Visualization


4. Performance Evaluation


5. Conclusions and Future Research
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Seo, D.M.; Jung, H.M. Intelligent Web Crawler for Supporting Big Data Analysis Services. J. Korea Contents Assoc. 2013, 13, 575–584. [Google Scholar] [CrossRef]
- Sung, W.K.; Lee, S.H.; Jung, H.M.; Park, K.S.; Lee, S.W.; Kim, S.T.; Hwang, M.N.; Jo, M.H. Planning Research for Digging Promotion Works on Scientific Technology Big-Data and Maximizing Utilization; Ministry of Education and Science Technology: Seoul, Korea, 2013. [Google Scholar]
- Hsieh, J.C.; Li, A.H.; Yang, C.C. Mobile, Cloud, and Big Data Computing: Contributions, Challenges, and New Directions in Telecardiology. Int. J. Environ. Res. Public Health 2013, 10, 6131–6153. [Google Scholar] [CrossRef] [PubMed]
- Yun, M.Y. Global Advanced Cases on Big-Data; National Information Society Agency: Seoul, Korea, 2012. [Google Scholar]
- Brahami, M.; Atmani, B.; Matta, N. Dynamic Knowledge Mapping Guided by Data Mining: Application on Healthcare. J. Inf. Process. Syst. 2013, 9, 1–30. [Google Scholar] [CrossRef]
- Silachan, K.; Tantatsanawong, P. Imputation of Medical Data Using Subspace Condition Order Degree Polynomials. J. Inf. Process. Syst. 2014, 10, 395–411. [Google Scholar] [CrossRef]
- Vanus, J.; Kucera, P.; Martinek, R.; Koziorek, J. Development and Testing of a Visualization Application Software, Iimplemented with Wireless Control System in Smart Home Care. J. Hum. Centric Comput. Inf. Sci. 2014, 4. [Google Scholar] [CrossRef]
- 1000 Genomes. Available online: http://1000genomes.org (accessed on 19 June 2015).
- U.S. Department of Veterans Affairs. Available online: http://www.va.gov/health/ (accessed on 19 June 2015).
- Baek, I.S.; Park, J.H. Data Era: Importance of Data Analysis; IT & Future Strategy: Seoul, Korea, 2013. [Google Scholar]
- KEGG PATHWAY Database. Available online: http://www.genome.jp/kegg/pathway.html (accessed on 19 June 2015).
- Gomez-Vela, F.; Diaz-Diaz, N. Gene Network Biological Validity Based on Gene-Gene Interaction Relevance. Sci. World J. 2014, 2014, 540679:1–540679:11. [Google Scholar] [CrossRef] [PubMed]
- Dehmer, M. Information Theory of Networks. Symmetry 2011, 3, 767–779. [Google Scholar] [CrossRef]
- Garlaschelli, D.; Ruzzenenti, F.; Basosi, R. Complex Networks and Symmetry I: A Review. Symmetry 2010, 2, 1683–1709. [Google Scholar] [CrossRef]
- Chambers, D.; Flapan, E. Topological Symmetry Groups of Small Complete Graphs. Symmetry 2014, 6, 189–209. [Google Scholar] [CrossRef]
- Lee, J.K.; Kang, T.H.; Yoo, J.S. Design and Implementation of Protein Pathway Analysis System. J. Korea Contents Assoc. 2005, 5, 31–40. [Google Scholar]
- Cytoscape. Available online: http://www.cytoscape.org (accessed on 19 June 2015).
- Nishida, K.; Ono, K.; Kanaya, S.; Takahashi, K. KEGGscape: A Cytoscape App for Pathway Data Integration. F1000Research 2014, 3. [Google Scholar] [CrossRef] [PubMed]
- KEGGscape. Available online: http://apps.cytoscape.org/apps/keggscape (accessed on 19 June 2015).
- KGMLReader. Available online: http://apps.cytoscape.org/apps/kgmlreader (accessed on 19 June 2015).
- PATHWAY: hsa00190. Available online: http://www.kegg.jp/dbget-bin/www_bget?hsa00190 (accessed on 14 July 2015).
- Noack, A.; Rotta, R. Multi-Level Algorithms for Modularity Clustering. Lect. Notes Comput. Sci. 2009, 5226, 257–268. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, D.; Lee, M.-H.; Yu, S.J. Development of Network Analysis and Visualization System for KEGG Pathways. Symmetry 2015, 7, 1275-1288. https://doi.org/10.3390/sym7031275
Seo D, Lee M-H, Yu SJ. Development of Network Analysis and Visualization System for KEGG Pathways. Symmetry. 2015; 7(3):1275-1288. https://doi.org/10.3390/sym7031275
Chicago/Turabian StyleSeo, Dongmin, Min-Ho Lee, and Seok Jong Yu. 2015. "Development of Network Analysis and Visualization System for KEGG Pathways" Symmetry 7, no. 3: 1275-1288. https://doi.org/10.3390/sym7031275