1. Introduction
In recent years, the performance of target-tracking algorithms has been greatly improved with the development of artificial feature-based trackers and deep learning-based trackers. Target-tracking technology has found widespread applications in computer vision fields such as smart cities, autonomous driving, and video surveillance [
1,
2,
3,
4]. However, challenges such as target appearance changes during tracking, complex backgrounds, and the presence of similar objects can lead to tracking drift. Therefore, it is still crucial to design a robust tracking algorithm that can effectively handle the target’s abrupt motion.
Siamese network-based tracking has drawn extensive attention due to its appropriate balance between accuracy and efficiency. SiamFC [
5] maps the search patch into multiple scales and selects the scale with the highest classification score as the target scale for the current frame to predict the bounding box (Bbox). Zhang et al. [
6] leveraged deeper and wider convolutional neural networks to further improve the tracking robustness and accuracy. However, the multiple-scale strategy is not well adapted to targets undergoing deformation while increasing the model parameters. Li et al. [
7] combined the Siamese network and the region proposal network to predict the scale variation of the target, which improved the model speed and enhanced the adaptability to the deformed targets. To further simplify the model and reduce the computational complexity, some studies [
8,
9] introduced the anchor-free mechanism into the tracking field, easing the tuning of complex parameters in anchor-based methods. The above studies are devoted to optimizing the feature extraction network or regression function to improve the accuracy of the Bbox and tracking efficiency. However, such methods still have some limitations.
In real tracking scenarios, a complex background can lead to deviations or even drifting of the tracking prediction box from the ground truth or toward other distractors, especially when the target undergoes drastic appearance changes or moves suddenly over long distances. To address these challenges, existing Siamese network-based trackers [
10,
11] introduce the centeredness or quality estimation branch independent of the classification branch to suppress excessive displacement, which solves the problem of performance degradation caused by using classification confidence for bounding box selection directly. Chen et al. [
12] further proposed the Siamese center prediction network. This model predicts an object’s location by correcting the target position appropriately through the offset branch. Some recent methods [
13,
14] build links between classification and regression, optimizing them in a synchronized manner for consistent inference. Most of these methods add extra branches or networks to improve the accuracy of target localization. In addition, in order to improve the confidence of the response map, some researchers introduced a series of fixed-window penalty functions [
15,
16,
17] into the tracking model to alleviate the boundary effect, and these methods suppress the interference response to a certain extent. However, a pretrained deep network is not enough to model arbitrary forms of target features when the target state changes significantly, and the extracted target depth features may be redundant. Therefore, it is crucial to adaptively adjust the target features based on different target poses. Additionally, when the target undergoes sudden long-distance movements, the incorrect spatial penalty term can result in the response value of the distractor being higher than that of the target, significantly increasing the probability of tracking drift. Moreover, the absence of a robust target template update mechanism can lead to model degradation during the tracking process.
This work presents a Siamese-based method that addresses the aforementioned limitations. A Siamese network is a symmetric network with two input branches that share the same network structure and weight and is widely used in tracking algorithms. Our method contains a spatial-semantic-aware attention model, a flexible spatiotemporal constraint strategy, and an adaptive weight template update model. The proposed algorithm combines the response results of low-level feature maps and high-level feature maps to determine the target. While multilayer features contain richer target information, the contributions of pretrained target’s deep features for visual tracking are different. We establish a spatial-semantic-aware attention model that focuses on the most informative region of the target feature map. This model strengthens feature channels with rich target semantic information by assigning them higher weights. Secondly, we observe that the fixed-window penalty function may decrease the confidence value of the correct target on the score map. To overcome this issue, we designed a flexible spatiotemporal constraint strategy which adaptively adjusts the penalty weights on the confidence map to reduce the probability of tracking failure. In order to further adapt to the target deformation, we designed an adaptive weight template updating strategy to enhance the robustness of the tracking model. The contributions of this work can be summarized as follows:
(1) A spatial-semantic-aware attention model is proposed for visual tracking. We employ a single convolutional spatially aware attention model to adaptively adjust the significance of various feature regions, thereby emphasizing the most informative location on the target feature map. Additionally, the single convolutional channel attention network is used to strengthen target-specific channels that have more target semantic information, which is achieved by increasing their weights. This approach facilitates the learning of effective feature representations for high-tracking performance.
(2) We propose a flexible spatiotemporal constraint which adaptively adjusts the constraint weights on the response map by evaluating the tracking result features. This constraint addresses the issue of the fixed-window function incorrectly penalizing the target confidence when tracking fails. By incorporating the flexible spatiotemporal constraint, we can obtain a more reliable confidence score for the target location and avoid low-quality but high-scoring tracking results.
(3) We designed an adaptive weight template-updating strategy to mitigate model degradation caused by target appearance changes. This update mechanism evaluates the correlation between the target templates and tracking results using the depth-correlation assessment criteria and thus adaptively assigns weights to both the templates and tracking results to gather reliable template samples. Our update mechanism prevents template contamination while enriching template information.
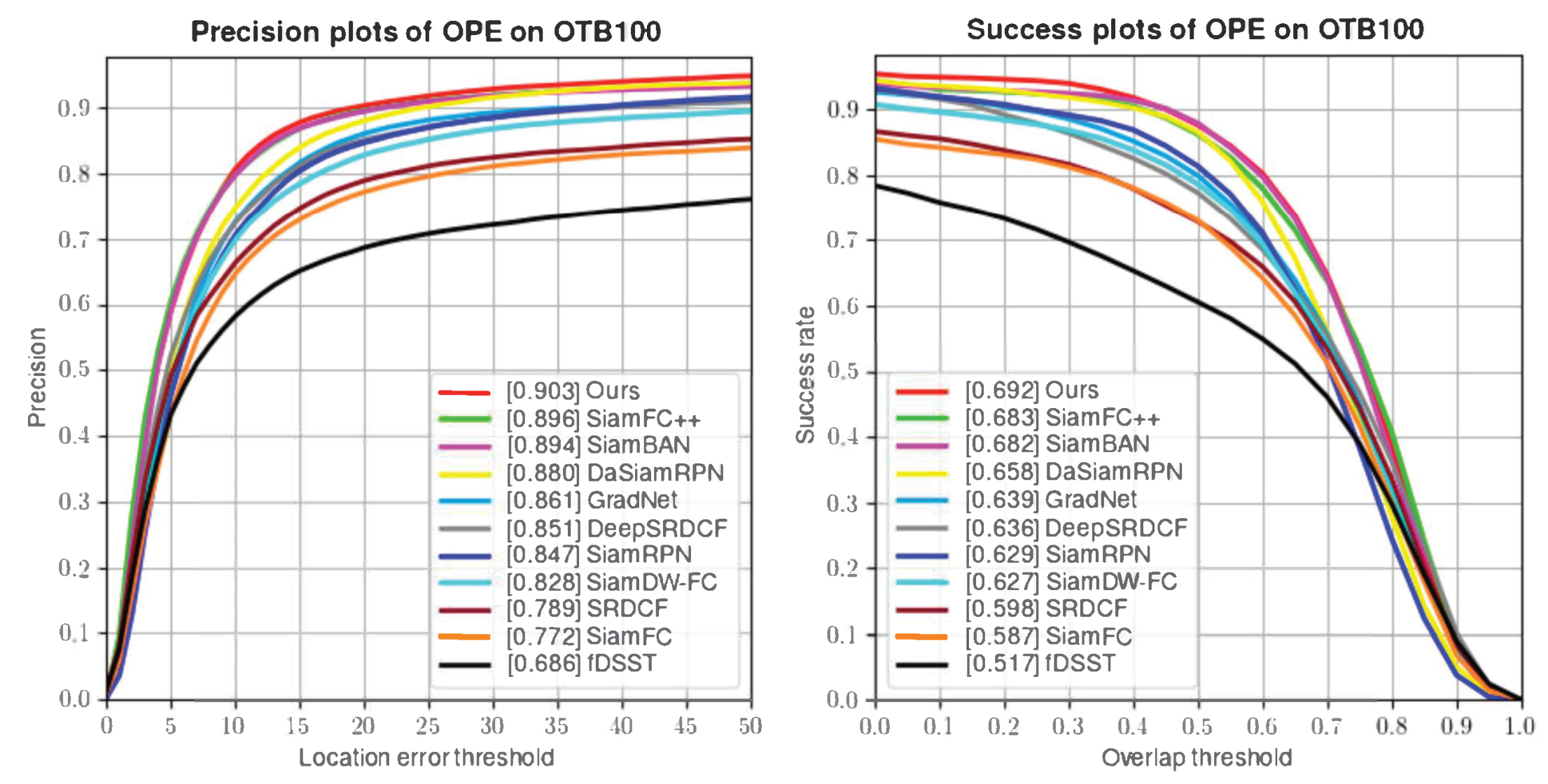
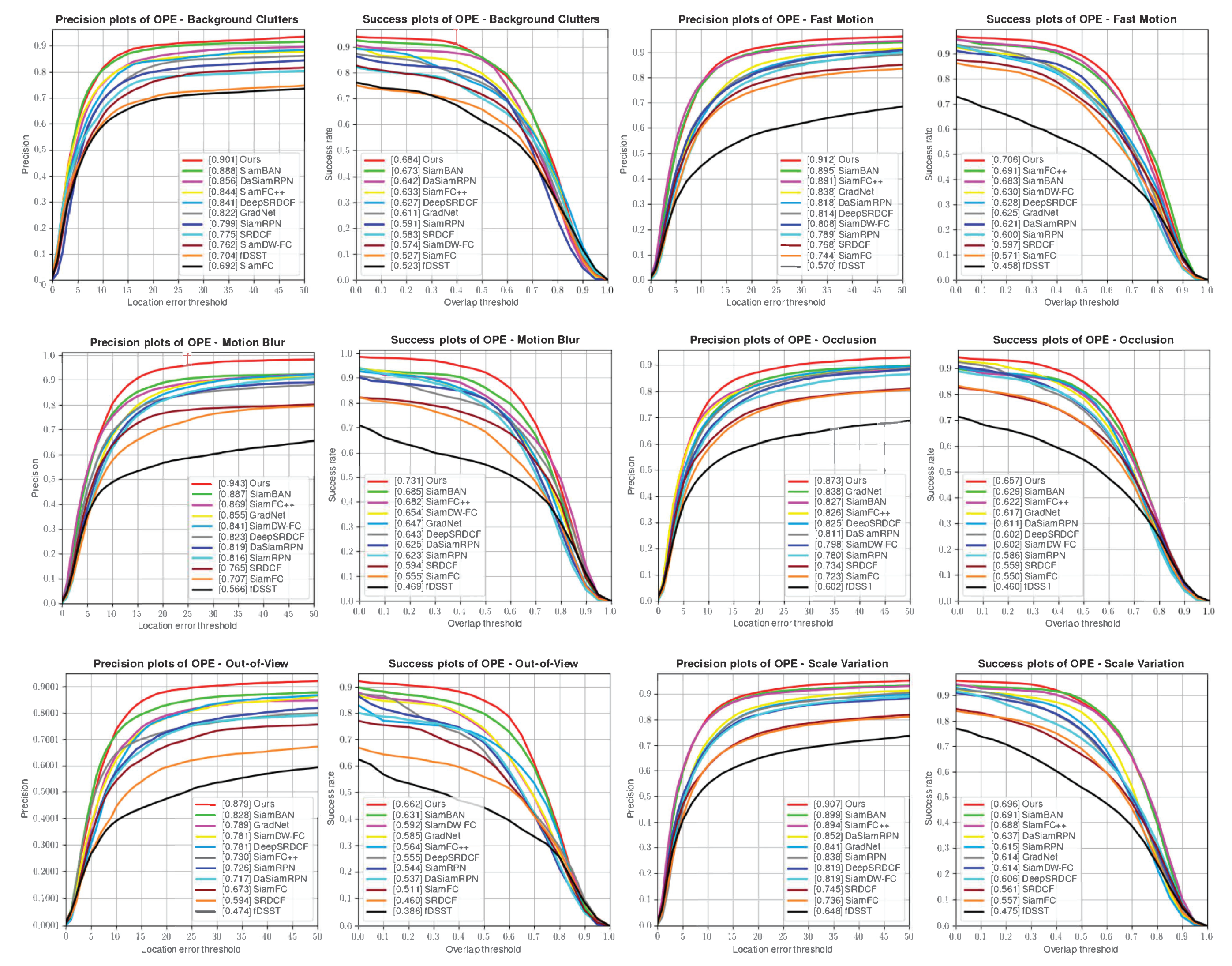
In this paper, we first briefly review some classical tracking algorithms in recent years, especially those involving attention mechanisms and spatiotemporal constraints, and discuss some disadvantages of the current approaches. Next, we describe in detail our proposed spatial-semantic-aware attention Siamese tracking with a flexible spatiotemporal constraint. Extensive experiments on the OTB100, NFS, UAV123 VOT2016, and TC128 datasets demonstrate the superiority of our approach. Finally, the advances of the proposed methods are summarized, and its limitations are discussed.
3. The Proposed Method
Aiming at the problem that most tracking methods easily fail during abrupt motion and target appearance changes, a tracking framework is proposed that can handle this problem. In specific tasks, the depth features acquired by the pretrained network have different importance to the target representation, resulting in a worse discrimination ability for the tracker regarding the target and background information. Immediately after, we find that the fixed-window function unreasonably weights the confidence values on the response map to produce lower-quality but higher-scoring tracking results. Finally, we develop a flexible template-updating strategy to mitigate model degradation.
Figure 1 shows the overall scheme of our proposed algorithm. It is a tracker based on classification and regression that uses ResNet-50 as the feature extraction network. In our work, Conv3, Conv4, and Conv5 from the ResNet-50 [
33] network were selected to extract image features. Since the shallow features contain more spatial structure information while the deep features contain rich semantic information [
34], we introduced spatial attention in Conv3 and channel attention in Conv4 and Conv5 to highlight the information that was valuable for target representation. Then, the classification (Cls) map and regression (Reg) map were obtained by correlation matching between the target template feature and the search area feature. The Cls map estimated the probability that each position in the search area was the target, and the Reg map performed bounding box prediction. Next, the multilayer depth features of each frame-tracking result were compared with the template based on the Euclidean distance to determine whether the flexible spatiotemporal constraint strategy was activated. The flexible spatiotemporal constraint strategy was activated, which gradually increased the weight of the edge of the confidence map with the time of target loss to help the tracking recover. Finally, the adaptive weight template-updating strategy was used to generate a new template for the next frame tracking.
3.1. Spatial-Semantic-Aware Attention Model
Human visual perception usually does not need to focus on the whole environment but rather on the part of the target to perceive comprehensive information about and thus understand the corresponding visual patterns [
35]. The coordinate attention [
36] enables mobile networks to focus on a larger area by embedding positional information into the channel domain. Yang et al. [
23] proposed that dual wavelet attention can coordinate spatial and structural attention for different channels to prevent the loss of feature information and structural features. Since single-target tracking is similar to focusing on the most salient features, it is advantageous to focus on the critical regions of the target feature map. Unlike other trackers with attention mechanisms, we propose a spatial-semantic-aware attention model where the spatial-aware attention model focuses on prominent target regions in the shallow feature map, while the semantic-aware attention model distinguishes the importance of different channels of deeper features for target representation.
3.1.1. Spatial-Aware Attention Model
For the tracking target, the depth features are constructed by multiple two-dimensional feature maps. However, the contribution of all regions of the depth features obtained by the pretrained network to the tracking task is not equally important, and only the location related to the task needs to be focused upon.
Spatial attention focuses on ‘where’ an informative part is and enhances the informative features of the target in the image to facilitate target localization. To program this attention, we performed global max pooling and average pooling on the Conv3 feature map and fused the resulting pooling features and in the channel domain. This kind of local convolution operation can focus on the desired information on the feature map.
After fusing the doubly pooled features, we used a convolution layer
to downsample the number of feature channels to one to obtain a single-channel feature map (the
convolution filter was selected as the best result through experimentation). Then, the obtained single-channel convolution feature map was broadcasted with a sigmoid operation, and the single-channel convolutional feature map was multiplied by the previous Conv3 feature map
to obtain the spatial attention feature map
, with the ultimate effect shown in
Figure 2. The computation of the attention feature map can be described as follows:
and
where
represents the concatenation operation,
is the convolution operation with the
kernel, the padding and stride are one, and
represents the usual sigmoid function
.
In addition, to make our aware attention mechanism more compatible with different targets, we adjusted the feature weights online utilizing a single convolutional. The specific method involved convolving all the samples
acquired by the attention mechanism into one-dimensional features and regressing them to a Gaussian label map
, where
is the offset against the target and
is the kernel width. Then, the new aware attention weight
was obtained by minimizing the following objective function:
where ⊙ denotes the convolution operation and
W is the regression weight, while
is a regularization parameter which can inhibit the overfitting of the training process.
After online training of the target in the first frame, we could find better attention weights
. Lastly, the features which reinforced the target area were obtained by the spatial-aware attention module as follows:
3.1.2. Semantic-Aware Attention Model
Some feature channels have a more prominent contribution to modeling the visual pattern of an object; that is, different channels contain different semantic information about the target. Therefore, each channel should not be treated equally when using these depth features for tracking.
For Conv4 and Conv5 obtained from the backbone network, the global average pooling operation was performed on them (the squeeze process), the detailed operations of which were as follows:
where
represents the squeeze process,
represents the Conv4 or Conv5 features, and
are the width and height of the feature map, respectively.
We obtained two feature vectors
and
through two levels of full connection (the excitation process). The first full connection
compressed
C channels into
channels to reduce computation, and the second full connection
reverted to
C channels. The excitation process can be expressed as follows:
where
represents the usual sigmoid function
and
is a rectified linear unit layer.
Then, the
and
, as feature weights, are multiplied by the corresponding channels of the features of Conv4 and Conv5 to acquire the output features for the channel attention model:
Similar to
Section 3.1.1, we assigned different weights to each channel utilizing a single convolutional. We convolved all the multi-channel
values acquired by the channel attention mechanism into one-dimensional features and regressed them to a Gaussian label map. The better aware attention weight
was obtained by minimizing the following objective function:
Lastly, the target semantic features obtained by the semantic-aware attention module were as follows:
Figure 2 and
Figure 3 show our spatial-aware attention model and semantic-aware attention model frameworks, respectively. The method enhances the effective features online and weakens those that are redundant or even interfering with the tracking.
3.2. Flexible Spatiotemporal Constraint
Most of the existing trackers were proposed under the assumption of smoothness; that is, researchers assume that the target displacement between two frames will not be too large, and thus various window functions were proposed to punish the final response graph (assign a value [0,1] according to the distance between the sample center and the target in the previous frame). This can improve the confidence of the target response to a certain extent. But in the actual tracking scene, there will always be some similar targets or other interference information that leads to tracker drift. Once the tracking fails, the response of the correct target location will be continuously suppressed under the action of the fixed-window function, resulting in low-quality but high-scoring tracking results. The fixed-window function (Hanning window) fails to correct the tracker when the target deviates too far from the center of the search area, as shown in
Figure 4. Therefore, to reduce the continuous negative impact of fixed spatio-temporal constraints on the target when the tracker fails, we developed a flexible spatiotemporal constraint strategy.
Generally speaking, due to the smoothness assumption, the depth features of the target will not change greatly between adjacent frames. Therefore, when the tracker produces low-quality tracking results, the depth features of the tracking result will be significantly different from the template features. Based on this, we can consider whether to switch the spatiotemporal constraint by evaluating the depth features of both the tracking result and the target template. We expanded the tracking results to the same size as the target template and used the backbone network ResNet-50 to obtain the three-layer depth features of the tracking results. For the tracking result and target template, we compared the depth features of their corresponding layers based on the Euclidean distance. We will switch the spatiotemporal constraints when Equation (
12) is met:
where
is the initial template feature,
is the tracking result feature (
t is the sequence number of frames, while
L is the layer of the features index), and
and
are the feature pixel values of the template and tracking result, respectively (
l is the channel ordinal number, while
x and
y represent the pixel position index).
We observed that when the tracking error was caused by a change in target appearance, although the confidence score of the correct target was higher on the response graph without applying the window penalty function, due to the fixed spacetime constraints, the response of the target far away from the center of the search area would be suppressed, and thus the tracker could not recover to the correct target. However, in most cases, the window function could reduce the likelihood that the tracker would track similar objects far from the center point of the search area. Based on this, we established a flexible spatiotemporal constraint to penalize the target confidence score
on the response map. More details are shown in
Figure 4. Our strategy is defined as follows:
where
is a predefined hyperparameter and determines the degree to which the flexible spatiotemporal constraint affects the original response map. If
is set to a large value, then the flexible spatiotemporal constraint has minimal impact on the original response map, which may cause the response value far from the center of the response map to be too large, resulting in the boundary effect. On the other hand, if
is set to a small value, then the final response map is primarily determined by the flexible spatiotemporal constraint, and the initial response map output by the tracker is largely disregarded. This will greatly reduce the confidence of the response map, where
is the expansion rate indicating the distance penalty,
represents the amount of translation to the left, which allows the value to continue expanding from any position without having to start from
(
is one),
,
n, and
represent the initial value, the expansion time length, and the final value, respectively, and each
represents the spatiotemporal constraint weight of the original position, in which different
values form different expansion curves.
3.3. Adaptive Weight Template Updating
In practical tracking tasks, most tracker models continuously degrade due to the constant change in target appearance, resulting in tracker drift. Some Siamese trackers utilize the target state given in the first frame to obtain an initial template and do not update it again [
5,
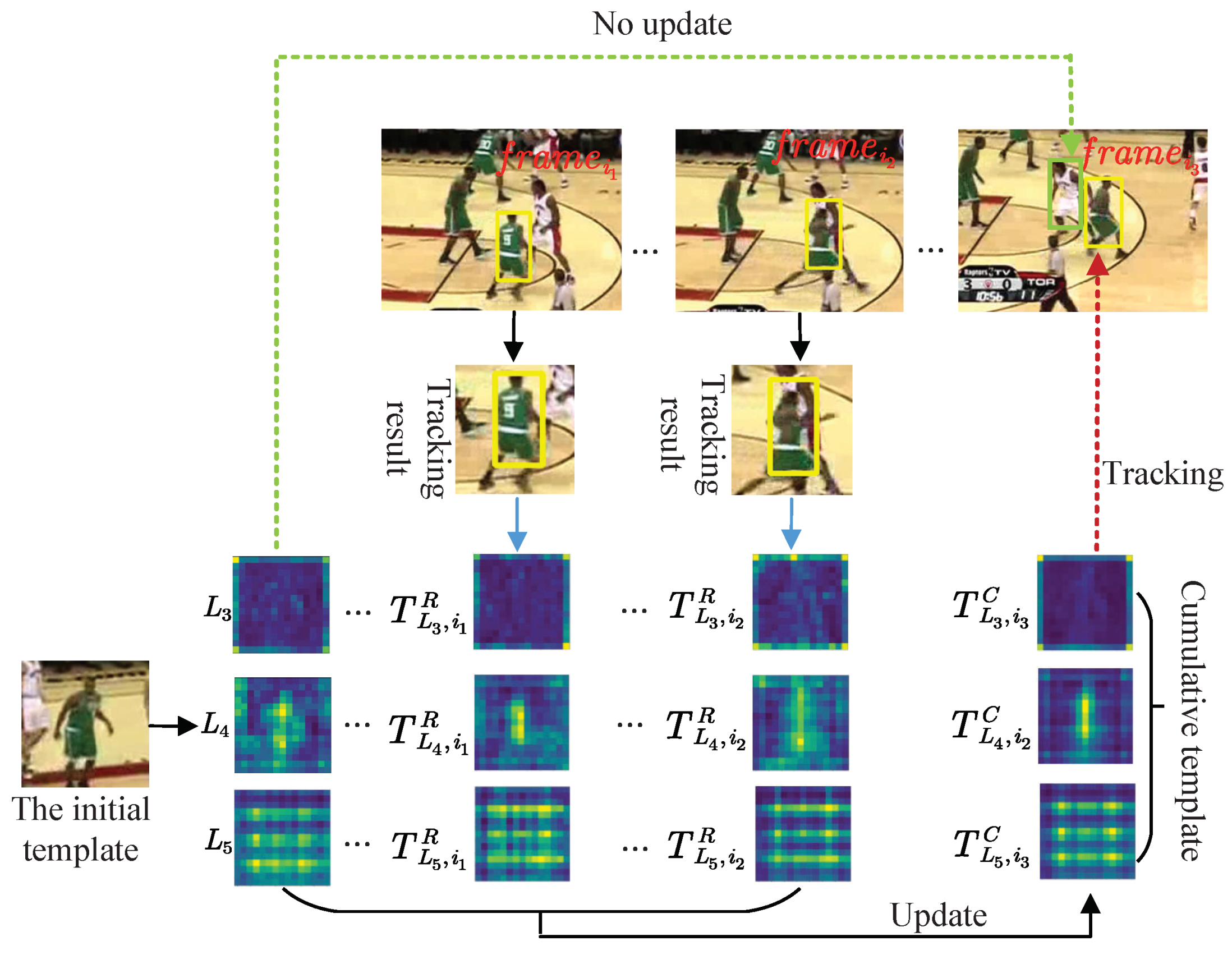
7]. Most update functions are limited to linear combinations with previous templates, and fixed combination weights severely limit the universality of the update mechanism. In order to make the template dynamically update to reduce model degradation and prevent contamination of the template from undifferentiated updates, we developed an adaptive weight template-updating strategy which can dynamically fuse the tracking results to generate the cumulative template for subsequent frame tracking.
First, the object defined by the ground truth in the initial frame has its most reliable original information, and thus we used the appearance features of the initial template as a baseline for the tracking results of the subsequent frames to generate cumulative templates by using a convolutional neural network to learn the target information that the initial template had. A new cumulative template was updated for each frame during the tracking process. For each frame to be tracked, its corresponding template
was generated from three components: the initial template, the cumulative template
, and the tracking result
for the previous frame. This would give the template richer temporal information. The generation process can be formalized as follows:
where
represents the convolutional operation and
t is the sequence index of the frame.
Furthermore, as can be seen in
Figure 5, the tracking result features of different frames differed significantly from the initial template features due to the constant changes in the target appearance. Even for the same object, updates to the target template needed to change dynamically based on the tracking state. If all tracking results were utilized indiscriminately to update the template, then this may have led to redundancy or contamination of the template.
Therefore, we estimated the correlation between the cumulative template and the initial template and assigned weights to both by means of depth correlation assessment criteria. Since the depth features of different layers had different contributions to the final response map, we conducted depth cross-correlation between the three depth features of the initial template and the corresponding layers of the cumulative template. Then, we found the ratio with the autocorrelation of the initial template features to generate the weights of the corresponding layers. According to the weight of the corresponding layer, the feature of the tracking result and the feature of the cumulative template were fused to generate a new cumulative template for the tracking of the next frame. Note that the target from the first frame provided the most reliable information, and therefore we set the shrink parameter so that the template retained more of the initial information of the target. The following is thte recursive formula for the template update:
where
L is the layer of the features index and
t is the sequence index of the frame. The operator ⊛ denotes the cross-correlation operation (i.e., the former is used as a convolution kernel to perform convolution operations on the latter).
It can be seen in
Figure 5 that our model can improve the template degradation caused by target deformation or target background changes.
5. Conclusions
This paper proposes Siamese tracking with spatial-semantic-aware attention and adaptive template updating to suppress irrelevant information about an object’s appearance and reduce model degradation. We used the spatial-semantic-aware attention model to enhance the feature representation ability and improve the tracking performance. The proposed spatial-aware attention module is responsible for highlighting the location of the target, and the semantic-aware attention module focuses on important feature channels. Then, the flexible spatiotemporal constraint strategy was proposed to remove the incorrect penalty of the fixed spatiotemporal constraint strategy on the correct target response in case of tracking failure. Finally, we proposed an adaptive weight template-updating strategy to adapt to changes in target appearance during tracking. It can adaptively generate new reliable templates using the tracking results of each frame. We conducted extensive experiments on several challenging datasets such as OTB100, VOT2016, NFS, UAV123, and TC128 to validate the effectiveness of the proposed method.
In this work, our primary focus was on addressing the challenges associated with target tracking in scenarios involving abrupt motion. While our spatial-semantic-aware attention model improved the tracking accuracy, it is important to note that the global average pooling and convolutional network utilized in the model may result in the loss of certain feature information. Additionally, the increased number of model parameters can lead to a decrease in tracking speed. In future works, we will explore alternative attention mechanisms and consider developing lightweight models to reduce the overall number of model parameters. Furthermore, tracking models trained and tested on specific datasets have limitations in their generalization ability, and our study is no exception. Although the dataset samples used for training of the proposed method are sufficiently varied, the capturing device acquires video sequences under unbalanced illumination, a certain viewing angle, etc., which may lead to capture bias. Ambiguous definitions of visual semantic facts can also lead to labeling and category bias. The limited nature of the dataset when confronted with new, unseen samples may lead to erroneous conclusions. Studying the differences between existing datasets and debiasing methods to improve the generalization ability of tracking algorithms will be our future research direction.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








