
A Symmetrical Fuzzy Neural Network Regression Method Coordinating Structure and Parameter Identifications for Regression

Abstract
:1. Introduction
- A new structure and training mode of the FNN is designed for regression problems, and thus the numbers of fuzzy rules and fuzzy partitions can be learned automatically by the gradient descent method, thereby eliminating the implicit relationship between the number of rules and the number of features and fuzzy partitions, meanwhile effectively alleviating the problem of rule explosion.
- The structure and parameter identifications of the FNN are considered as a whole, which means that the number of fuzzy partitions, the number of fuzzy rules, the MF parameters of antecedents, and the parameters of the consequent are adjusted and tuned at the same time. On this basis, an alternate training strategy is designed to help with the algorithm convergence and find the optimal solution in the whole parameter space without any pre-processing or post-processing.
- The interpretability of the model is measured from both the fuzzy rule level and fuzzy partition level, and the measurement is introduced to the training process in terms of regularization. Therefore, the trained model has high precision with a simple structure and clear semantics.
2. Preliminaries
2.1. The TSK Fuzzy Rules
- (1)
- Calculate the firing strength. The firing strength of the feature vector on shown in Equation (1) is calculated as follows:where represents the fuzzy intersection operator (T-norm operator). If the connective is “or”, you just need to change the fuzzy intersection operator of Equation (2) to the fuzzy union operator (S-norm operator), which is expressed by .
- (2)
- Calculate the normalized firing strength. The normalized firing strength of the feature vector on is calculated as follows:
- (3)
- Calculate the output. The output of the feature vector on K fuzzy rules is calculated as follows:
2.2. The FNNC
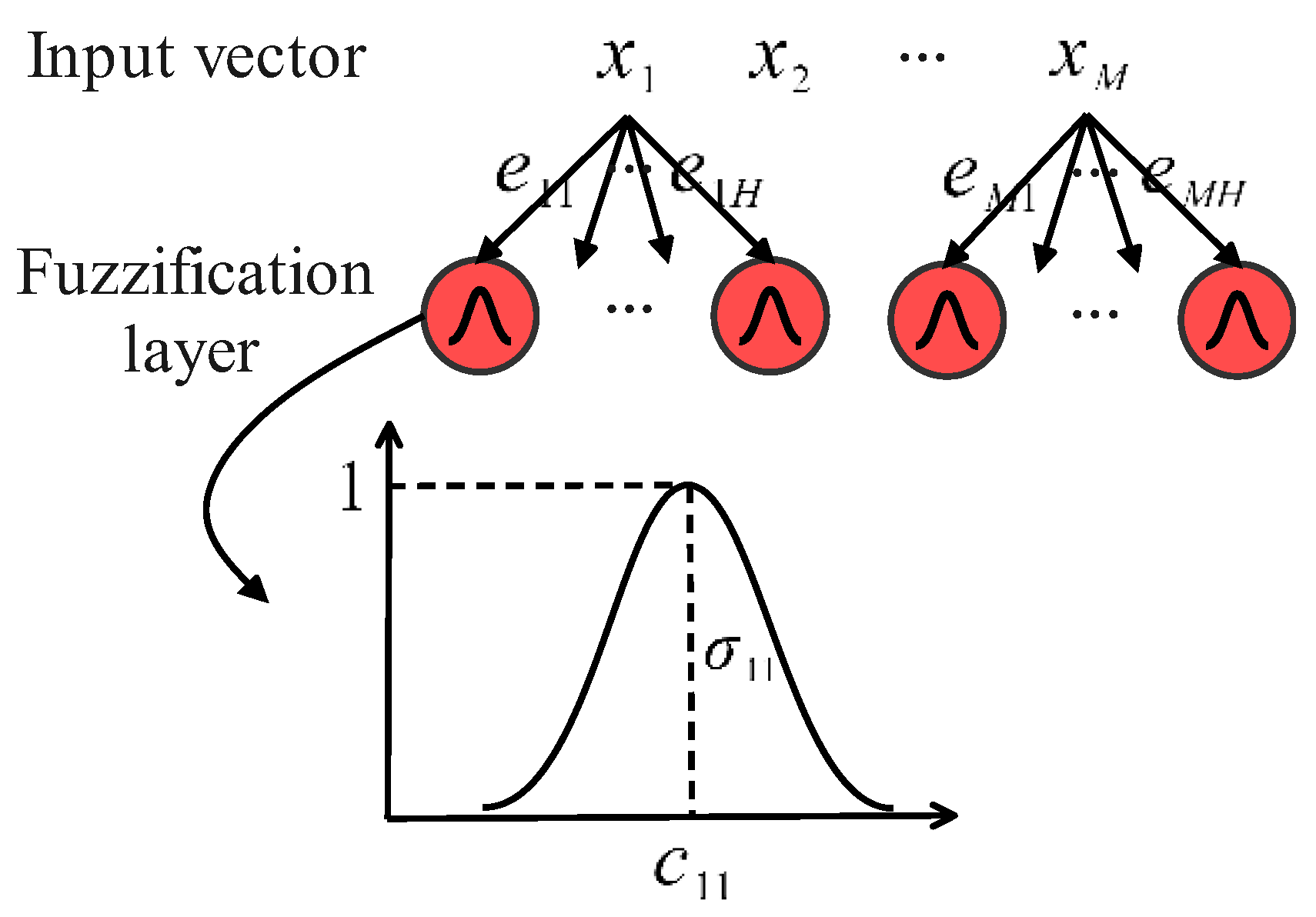
- The fuzzification layer is utilized to translate crisp input features into fuzzy variables. Gaussian MFs are utilized. The parameters of Gaussian MFs are determined based on experience before the training and remain unchanged during the training.
- The fuzzy logic layers are used to represent fuzzy rules. Let denote the parameter of fuzzy logic layers, where j is the jth node of the fuzzy logic layer, and i is the ith node of the previous layer (the same below). The nodes of fuzzy logic layers represent “and” and “or” connectives in fuzzy rules through fuzzy intersection operators and fuzzy union operators. Through the connecting and stacking of multiple fuzzy logic layers, complex fuzzy rules can be represented.
- The classification layer is for integrating the outputs of fuzzy logic layers and giving the final classification. The number of nodes in the classification layer is the same as the number of class labels.
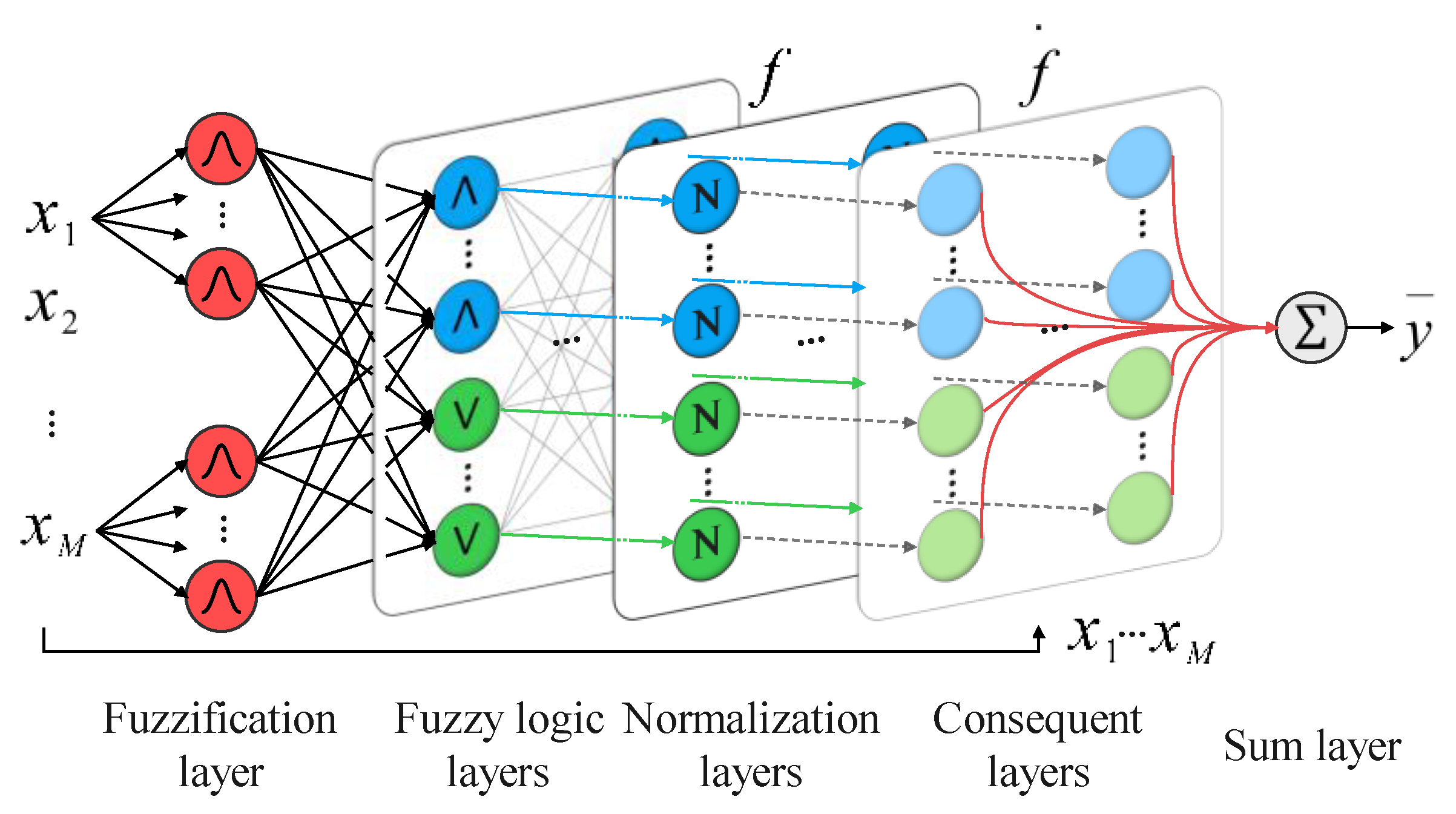
3. The FNNR
3.1. The Structure of the FNNR
3.1.1. The Fuzzification Layer
3.1.2. The Output Layers
3.2. Training
3.2.1. The Design of the Loss Function
3.2.2. The Alternate Training Strategy
| Algorithm 1: Alternate Training Strategy. |
| input: The dataset, ; the number of epoches for joint training, ; the number of epoches for fixing fuzzy logic layers, ; the number of epoches for fixing fuzzy partitifon parameters, . |
| output: A trained FNNR model, FNNR |
| begin |
| initialize the parameters of model |
| for do |
| training and updating all the parameters with for epoches\; |
| training and updating all the parameters except for with for epochs; |
| training and updating all the parameters except for with for epochs; |
| ; |
| end |
| return FNNR |
| end |
4. Experiments
4.1. Experimental Design
- (1)
- How does the FNNR perform when compared with other state-of-the-art regression methods?
- (2)
- What roles do the training modes of the fuzzification layer, the design of the output layers, and the strategy of alternate training play in the FNNR?
- (3)
- How much do different regularization coefficients affect the final prediction of the FNNR?
- (4)
- How explainable is the FNNR?
4.1.1. Datasets
4.1.2. Parameter Settings for the FNNR
4.1.3. Experimental Settings
- Benchmark Methods
- The decision tree (DT) [40];
- The training algorithm for the TSK fuzzy system based on mini-batch gradient descent with regularization, droprule, and adabound (MBGD-RDA) [14];
- The learning algorithm of TSK fuzzy rules based on evolutionary learning (FRULER) [41];
- The learning algorithm of the TSK fuzzy system based on multi-objective evolutionary algorithms (METSK-HD) [35];
- The learning algorithm of the zero-order TSK fuzzy system based on Apriori and local search methods (Freq-SD-LSLS) [42];
- The learning algorithm of Mamdani fuzzy rules based on multi-objective evolutionary learning algorithms (MOKBL + MOMs) [36];
- Disjunctive fuzzy neural network (DJFNN), a new splitting-based approach to designing a TS fuzzy model [10].
- Evaluation Metrics
- The Significance Testing
4.2. Result Analysis
- 1.
- The proposed FNNR achieves the minimum average MSEs on seven of eleven datasets among the models involved. On three of the remaining four datasets, FNNR still exhibits the second-best performance. It proves that the proposed FNNR method has a significant performance advantage on low-dimensional and simple tasks. Considering that parameters of MFs and fuzzy partitions in the fuzzification layer are not adjusted during the training process on low-dimensional datasets, there is still a lot of room for performance improvement of the FNNR.
- 2.
- The FNNR shows great improvement over the other four approaches in terms of regression performance. On some datasets, such as ELE1, FRIE, and MPG8, the FNNR reduces the MSEs by over 20% compared with the recently proposed DJFNN. Moreover, the average MSEs are more than 4% lower than the DJFNN on datasets ELE2 and MPG6.
- 3.
- The significance tests are conducted on the results shown in Table 2. The Friedman test suggests rejecting the hypothesis () for a significance level of 0.1 with (4, 40) degrees of freedom. This suggests that on low-dimensional datasets, there are significant differences between at least two methods across the benchmark. The Bonferroni–Dunn post hoc test suggests that the regression performance of the FNNR is significantly different from that of DT, MBGD-RDA, and FRULER, while the performance of the FNNR and the DJFNN are equivalent.
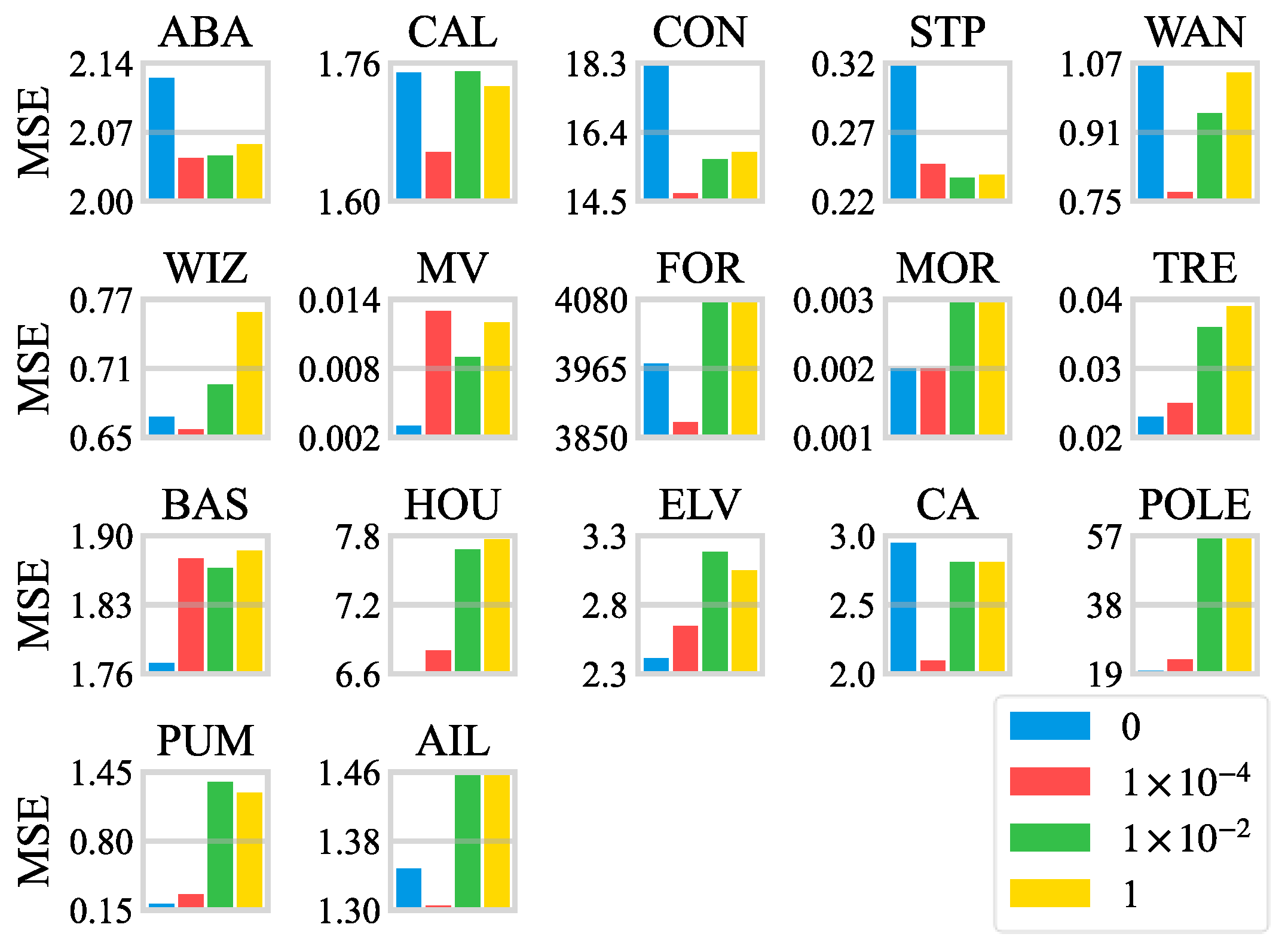
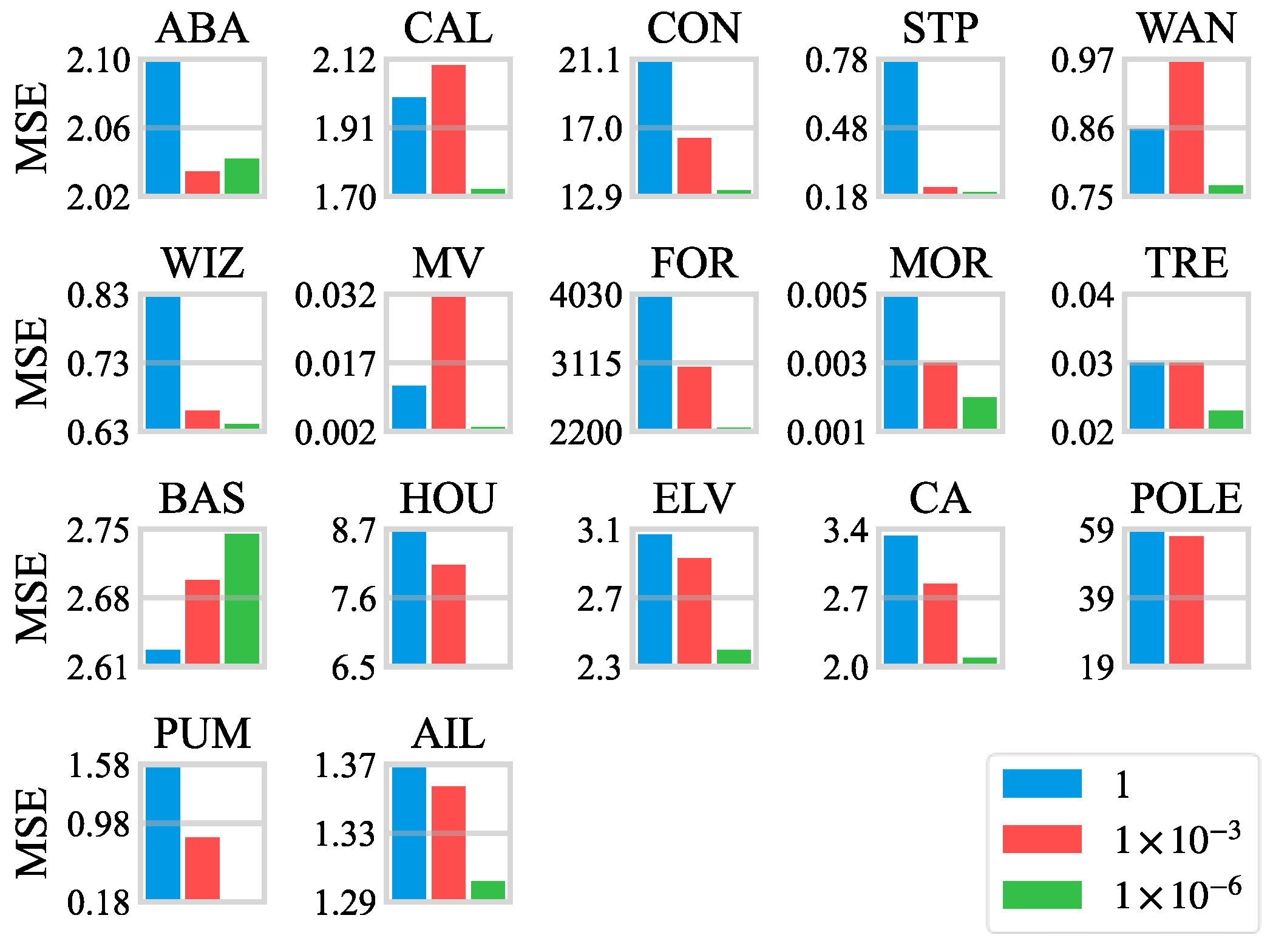
- 1.
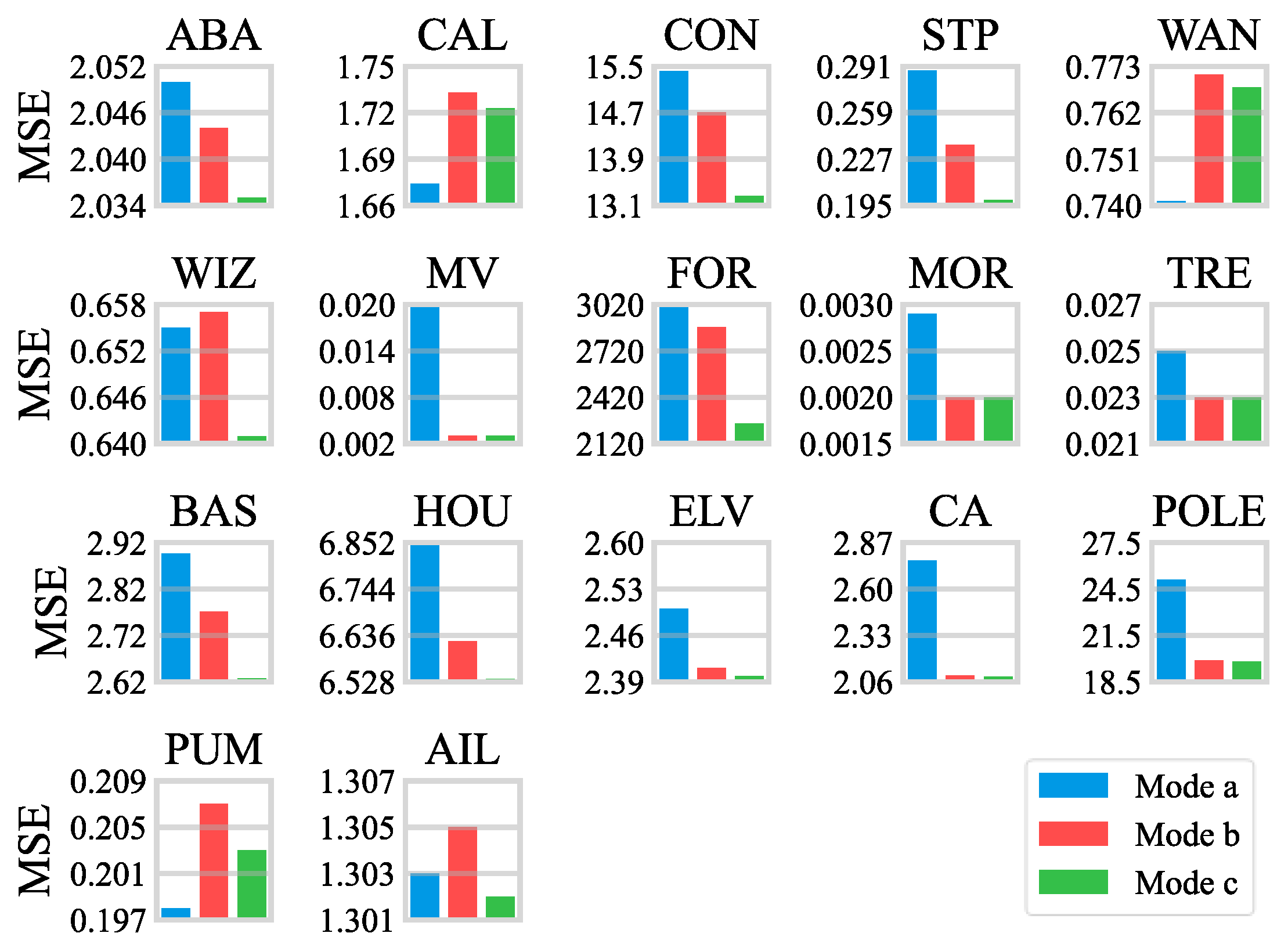
- The FNNR also shows great improvement over other approaches in terms of regression performance on high-dimensional tasks. On some datasets, such as STP, MV, and POLE, the FNNR reduces the errors by about 50% compared with the DJFNN. Moreover, the average MSEs are more than 20% lower than the DJFNN on datasets CON, MOR, and CA.
- 2.
- The proposed FNNR obtained the minimum MSEs on the last four datasets with high feature dimensions, which indicates that the selection of features and antecedents is completed flexibly through trainable parameters of fuzzy partitions and fuzzy logic layers in the FNNR. For datasets BAS and FOR, which are easy to overfit, although the FNNR does not get the optimal performance among all the methods, there is no significant difference between the average error of the FNNR and the best one, with increases of 2% and 10.8%, respectively. It indicates that the proposed method can avoid overfitting to a certain extent. On datasets with large sample sizes like MV, CAL, and HOU, the FNNR achieves the minimum MSEs, showing that the FNNR also has good performance in handling regression tasks with large samples.
4.3. Ablation Study
4.3.1. The Ablation of Training Modes of the Fuzzification Layer
- The parameters of the fuzzification layer are fixed during the training.
- Only the parameters of Gaussian MFs in the fuzzification layer are trained.
- The parameters of Gaussian MFs and fuzzy partitions in the fuzzification layer are trained together.
4.3.2. The Ablation of the Rule Type Represented by the Output Layers
- (1)
- The FNNR model with Mamdani fuzzy rules
- (2)
- The FNNR model with rules whose consequents use nonlinear calculations
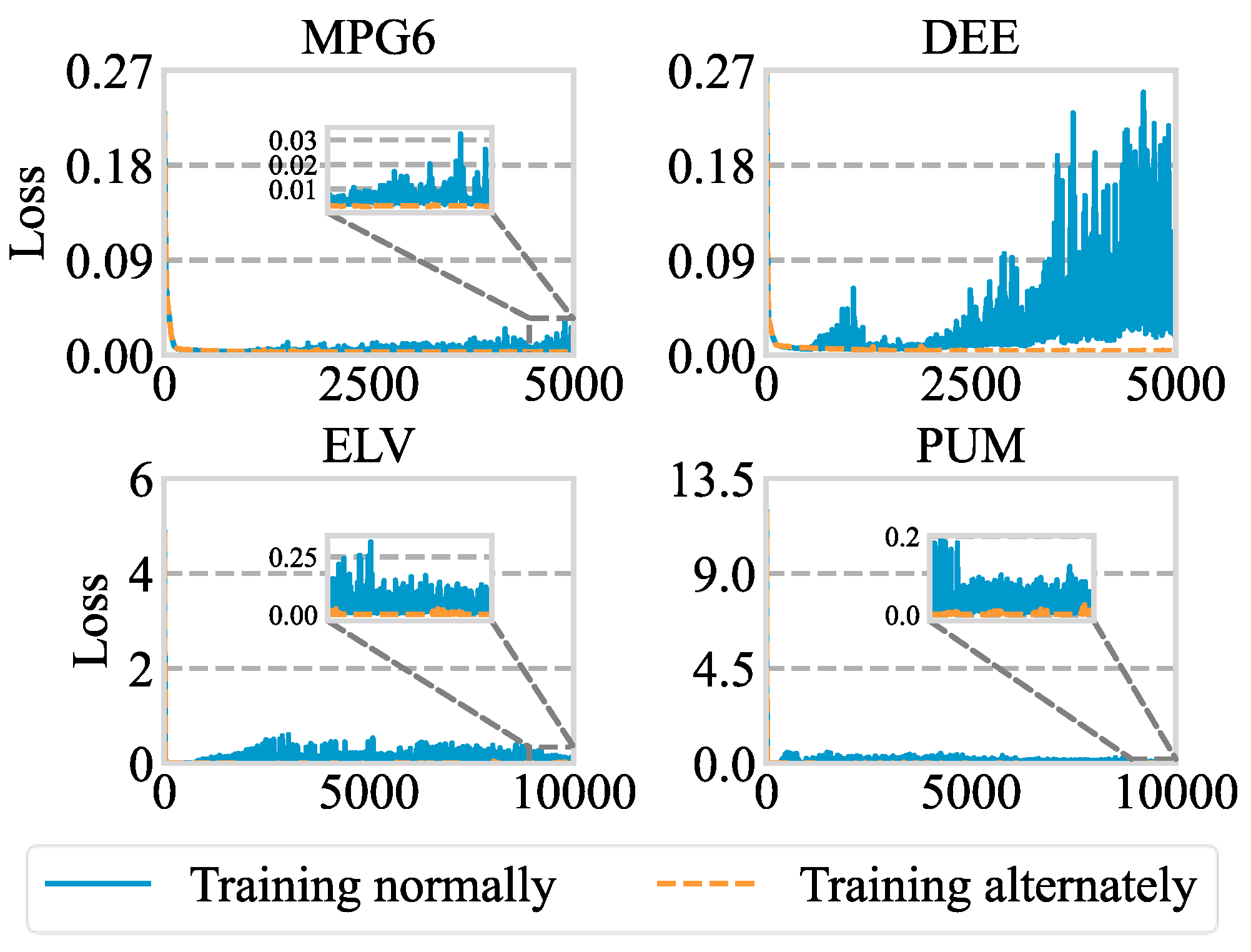
4.3.3. The Ablation of Alternate Training Strategy
4.4. Parameter Analysis
4.4.1. The Parameter Analysis on the Regularization Coefficient
4.4.2. The Parameter Analysis on the Regularization Coefficient
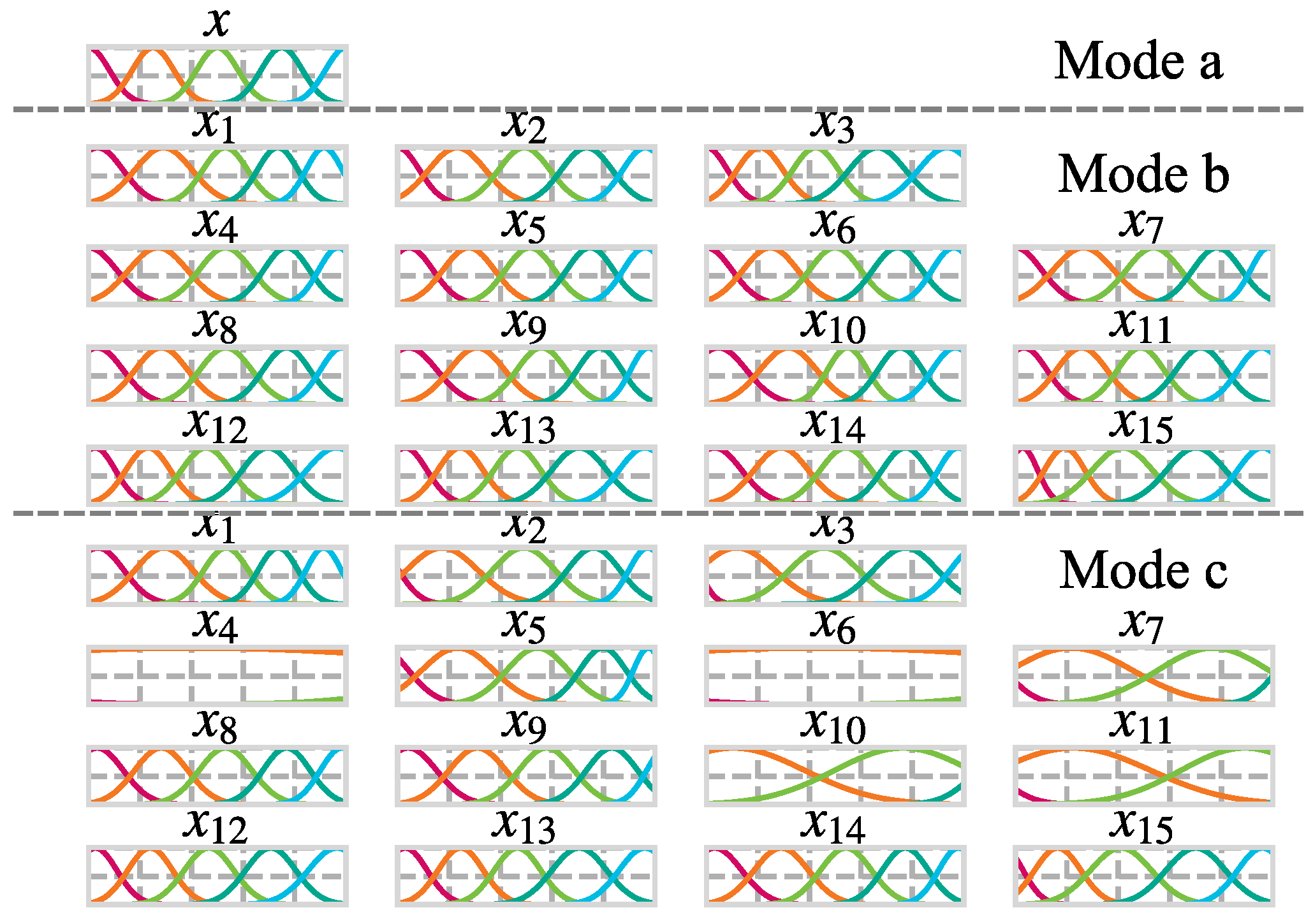
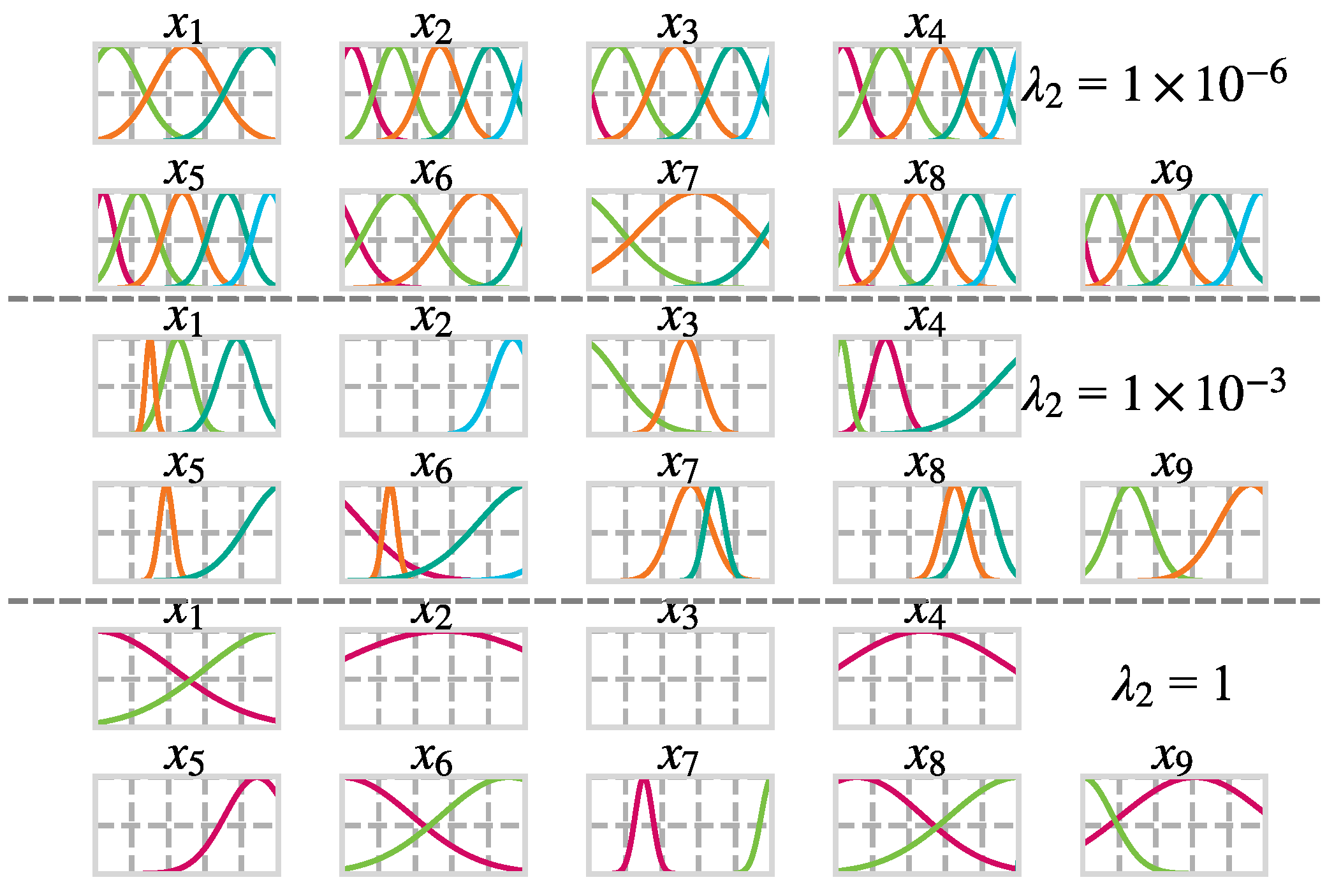
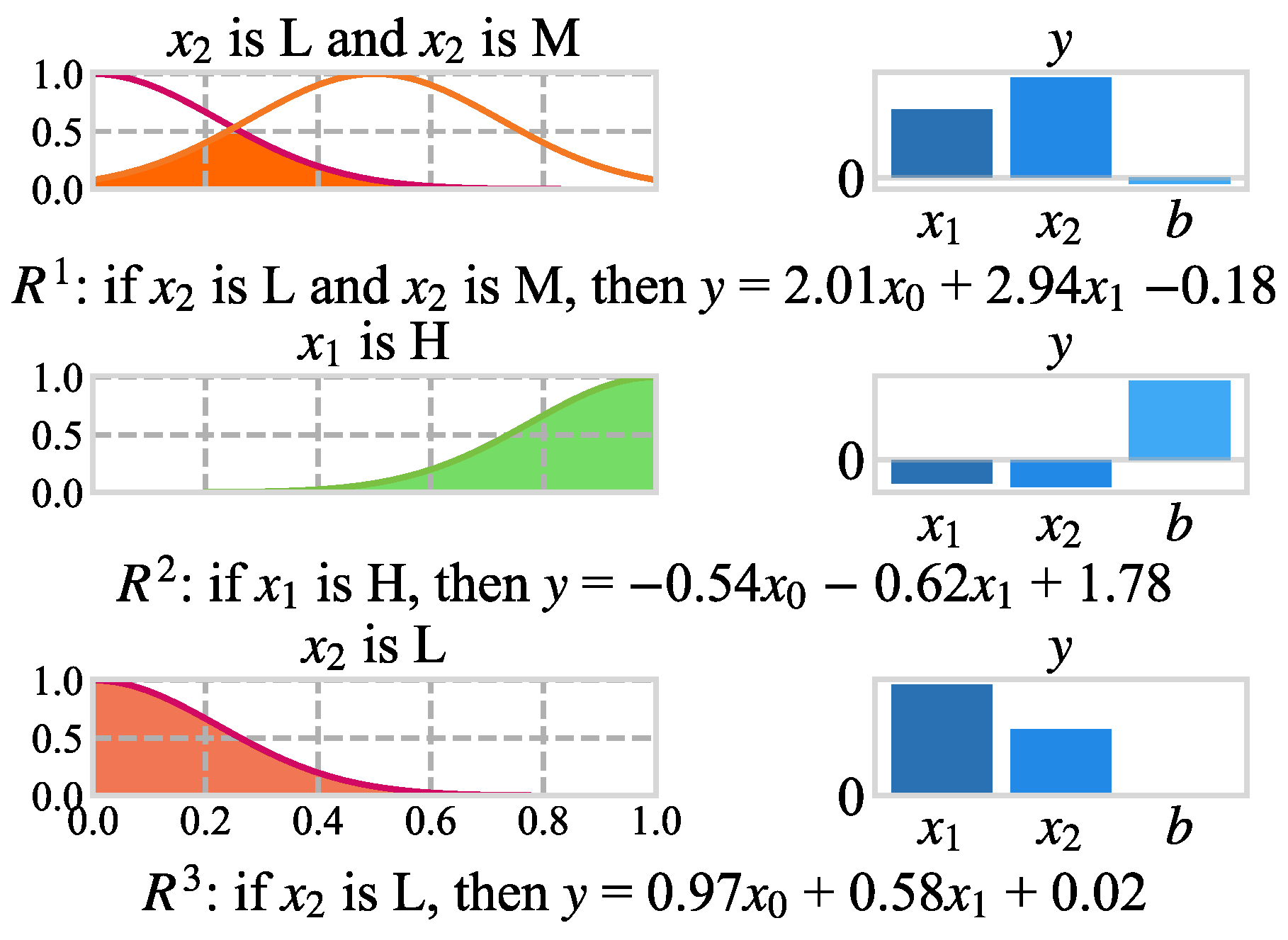
4.5. The Interpretability of the FNNR
5. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Das, R.; Sen, S.; Maulik, U. A survey on fuzzy deep neural networks. ACM Comput. Surv. 2020, 53, 1–25. [Google Scholar] [CrossRef]
- Kerk, Y.W.; Tay, K.M.; Lim, C.P. Monotone Fuzzy Rule Interpolation for Practical Modeling of the Zero-Order TSK Fuzzy Inference System. IEEE Trans. Fuzzy Syst. 2022, 30, 1248–1259. [Google Scholar] [CrossRef]
- Li, G.; Peng, C.; Xie, X.; Xie, S. On Stability and Stabilization of T–S Fuzzy Systems with Time-Varying Delays via Quadratic Fuzzy Lyapunov Matrix. IEEE Trans. Fuzzy Syst. 2022, 30, 3762–3773. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- De Campos Souza, P.V. Fuzzy neural networks and neuro-fuzzy networks: A review the main techniques and applications used in the literature. Appl. Soft Comput. 2020, 92, 106275. [Google Scholar] [CrossRef]
- Škrjanc, I.; Iglesias, J.A.; Sanchis, A.; Leite, D.; Lughofer, E.; Gomide, F. Evolving fuzzy and neuro-fuzzy approaches in clustering, regression, identification, and classification: A survey. Inf. Sci. 2019, 490, 344–368. [Google Scholar] [CrossRef]
- Deng, Y.; Ren, Z.; Kong, Y.; Bao, F.; Dai, Q. A hierarchical fused fuzzy deep neural network for data classification. IEEE Trans. Fuzzy Syst. 2017, 25, 1006–1012. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Li, Q.; Tiwari, P.; Wang, B.; Li, Y.; Pandey, H.M.; Zhang, P.; Song, D. CFN: A complex-valued fuzzy network for sarcasm detection in conversations. IEEE Trans. Fuzzy Syst. 2021, 29, 3696–3710. [Google Scholar] [CrossRef]
- Yang, C.H.; Moi, S.H.; Hou, M.F.; Chuang, L.Y.; Lin, Y.D. Applications of deep learning and fuzzy systems to detect cancer mortality in next-generation genomic data. IEEE Trans. Fuzzy Syst. 2021, 29, 3833–3844. [Google Scholar] [CrossRef]
- Wang, N.; Pedrycz, W.; Yao, W.; Chen, X.; Zhao, Y. Disjunctive Fuzzy Neural Networks: A New Splitting-Based Approach to Designing a T–S Fuzzy Model. IEEE Trans. Fuzzy Syst. 2022, 30, 370–381. [Google Scholar] [CrossRef]
- Jang, J.-S.R. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Eyoh, I.; John, R.; De Maere, G. Interval type-2 A-intuitionistic fuzzy logic for regression problems. IEEE Trans. Fuzzy Syst. 2018, 26, 2396–2408. [Google Scholar] [CrossRef]
- Park, S.; Lee, S.J.; Weiss, E.; Motai, Y. Intra- and inter-fractional variation prediction of lung tumors using fuzzy deep learning. IEEE J. Transl. Eng. Health Med. 2016, 4, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Xue, G.; Wang, J.; Yuan, B.; Dai, C. DG-ALETSK: A High-Dimensional Fuzzy Approach with Simultaneous Feature Selection and Rule Extraction. In IEEE Transactions on Fuzzy Systems; IEEE: New York, NY, USA, 2023. [Google Scholar] [CrossRef]
- Wu, D.; Yuan, Y.; Huang, J.; Tan, Y. Optimize TSK fuzzy systems for big data regression problems: Mini-batch gradient descent with regularization, droprule and adabound (MBGD-RDA). IEEE Trans. Fuzzy Syst. 2020, 28, 1003–1015. [Google Scholar] [CrossRef]
- Fidan, S.; Karasulu, B. Clustering Methods Comparison for Optimization of Adaptive Neural Fuzzy Inference System. In Proceedings of the 2022 30th Signal Processing and Communications Applications Conference (SIU), Safranbolu, Turkey, 15–18 May 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Souza PV, D.C.; Guimares, A.J.; Rezende, T.S.; Araujo, V.S.; Araujo VJ, S.; Batista, L.O. Bayesian fuzzy clustering neural network for regression problems. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 1492–1499. [Google Scholar] [CrossRef]
- Huang, W.; Oh, S.-K.; Pedrycz, W. Fuzzy wavelet polynomial neural networks: Analysis and design. IEEE Trans. Fuzzy Syst. 2017, 25, 1329–1341. [Google Scholar] [CrossRef]
- Palconit MG, B.; Conception, R.S., II; Alejandrino, J.D.; Nuñez, W.A.; Bandala, A.A.; Dadios, E.P. Comparative ANFIS Models for Stochastic On-road Vehicle CO2 Emission using Grid Partitioning, Subtractive, and Fuzzy C-means Clustering. In Proceedings of the 2021 IEEE 9th Region 10 Humanitarian Technology Conference (R10-HTC), Bangalore, India, 30 September–2 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Ouyang, C.S.; Kao, T.C.; Cheng, Y.Y.; Wu, C.H.; Tsai, C.H.; Wu, M.W. An improved fuzzy extreme learning machine for classification and regression. In Proceedings of the International Conference on Cybernetics, Robotics and Control (CRC), Hong Kong, China, 19–21 August 2016; pp. 91–94. [Google Scholar]
- Zhao, K.; Dai, Y.; Jia, Z.; Ji, Y. General Fuzzy C-Means Clustering Strategy: Using Objective Function to Control Fuzziness of Clustering Results. IEEE Trans. Fuzzy Syst. 2022, 30, 3601–3616. [Google Scholar] [CrossRef]
- Dey, S.; Dam, T. Rainfall-runoff prediction using a Gustafson-Kessel clustering based Takagi-Sugeno Fuzzy model. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 5–7 December 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Deng, Z.H.; Choi, K.S.; Wang, S.T. Scalable TSK fuzzy modeling for very large datasets using minimal-enclosing-ball approximation. IEEE Trans. Fuzzy Syst. 2011, 19, 210–226. [Google Scholar] [CrossRef]
- Leski, J.M. SparseFIS: Data-driven learning of fuzzy systems with sparsity constraints. IEEE Trans. Fuzzy Syst. 2010, 18, 396–411. [Google Scholar]
- Yi-Zhang, J.; Zhao-Hong, D.; Shi-Tong, W. Mamdani-Larsen type transfer learning fuzzy system. Acta Autom. Sin. 2012, 38, 1393–1409. [Google Scholar]
- Pal, N.R.; Mudi, R.; Pal, K. Rule extraction through exploratory data analysis for self-tuning fuzzy controllers. Int. J. Fuzzy Syst. 2004, 6, 71–80. [Google Scholar]
- Zhang, Y.; Ishibuchi, H.; Wang, S. Deep Takagi–Sugeno–Kang fuzzy classifier with shared linguistic fuzzy rules. IEEE Trans. Fuzzy Syst. 2018, 26, 1535–1549. [Google Scholar] [CrossRef]
- de Jesus Rubio, J. SOFMLS: Online self-organizing fuzzy modified least-squares network. IEEE Trans. Fuzzy Syst. 2009, 17, 1296–1309. [Google Scholar] [CrossRef]
- Xue, G.; Chang, Q.; Wang, J.; Zhang, K.; Pal, N.R. An Adaptive Neuro-Fuzzy System with Integrated Feature Selection and Rule Extraction for High-Dimensional Classification Problems. IEEE Trans. Fuzzy Syst. 2023, 31, 2167–2181. [Google Scholar] [CrossRef]
- Wang, D.; Zeng, X.-J.; Keane, J.A. Hierarchical hybrid fuzzy neural networks for approximation with mixed input variables. Neurocomputing 2007, 70, 3019–3033. [Google Scholar] [CrossRef]
- Trillo, J.R.; Fernandez, A.; Herrera, F. HFER: Promoting Explainability in Fuzzy Systems via Hierarchical Fuzzy Exception Rules. In Proceedings of the 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Chen, J. Adaptive Fuzzy Neural Network Control Based on Genetic Algorithm. In Proceedings of the 2021 13th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Beihai, China, 16–17 January 2021; pp. 393–396. [Google Scholar] [CrossRef]
- Kumari, N.; Gill, A.; Singh, M. Two-Area Power System Load Frequency Regulation Using ANFIS and Genetic Algorithm. In Proceedings of the 2023 4th International Conference for Emerging Technology (INCET), Belgaum, India, 26–28 May 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Tung, S.; Quek, C.; Guan, C. eT2fifis: An evolving type-2 neural fuzzy inference system. Inf. Sci. 2013, 220, 124–148. [Google Scholar] [CrossRef]
- Gacto, M.J.; Galende, M.; Alcalá, R.; Herrera, F. METSK-HDe: A multiobjective evolutionary algorithm to learn accurate TSK-fuzzy systems in high-dimensional and large-scale regression problems. Inf. Sci. 2014, 276, 63–79. [Google Scholar] [CrossRef]
- Aghaeipoor, F.; Javidi, M.M. MOKBL+MOMs: An interpretable multi-objective evolutionary fuzzy system for learning high-dimensional regression data. Inf. Sci. 2019, 496, 1–24. [Google Scholar] [CrossRef]
- Zhang, K.; Hao, W.N.; Yu, X.H.; Chen, G.; Yu, K. A fuzzy neural network classifier and its dual network for adaptive learning of structure and parameters. Int. J. Fuzzy Syst. 2023, 25, 1034–1054. [Google Scholar] [CrossRef]
- Gacto, M.J.; Alcalá, R.; Herrera, F. Interpretability of linguistic fuzzy rule-based systems: An overview of interpretability measures. Inf. Sci. 2011, 181, 4340–4360. [Google Scholar] [CrossRef]
- Alcal-Fdez, J.; Fernndez, A.; Luengo, J.; Derrac, J.; Garca, S.; Snchez, L.; Herrera, F. Keel data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. J. Mult.-Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Rodrıguez-Fdez, I.; Mucientes, M.; Bugarın, A. FRULER: Fuzzy rule learning through evolution for regression. Inf. Sci. 2016, 354, 1–18. [Google Scholar] [CrossRef]
- Cozar, J.; delaOssa, L.; Gamez, J.A. Learning compact zero-order TSK fuzzy rule-based systems for high-dimensional problems using an Apriori + local search approach. Inf. Sci. 2018, 433, 1–16. [Google Scholar] [CrossRef]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1939, 11, 86–92. [Google Scholar] [CrossRef]
- Dunn, O.J. Multiple comparisons among means. J. Am. Stat. Assoc. 1961, 56, 52–64. [Google Scholar] [CrossRef]
- Zheng, X.-J.; Singh, M.G. Approximation accuracy analysis of fuzzy systems with the center-average defuzzifier. In Proceedings of the 1995 IEEE International Conference on Fuzzy Systems, Yokohama, Japan, 20–24 March 1995; Volume 1, pp. 109–116. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning about Data; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 9. [Google Scholar]
- Mendel, J.M. Uncertain Rule-Based Fuzzy Systems: Introduction and New Directions, 2nd ed.; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Wu, D. On the fundamental differences between interval type-2 and type-1 fuzzy logic controllers. IEEE Trans. Fuzzy Syst. 2012, 20, 832–848. [Google Scholar] [CrossRef]
- Feng, S.; Chen, C.L.P. Fuzzy broad learning system: A novel neuro-fuzzy model for regression and classification. IEEE Trans. Cybern. 2020, 50, 414–424. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fuzzy Rule Level | Fuzzy Partition Level |
|---|---|
| Number of Rules | Number of MFs |
| Number of Antecedents | Number of Input Features |
| Complementarity |
| Datasets | DT | MBGD-RDA | FRULER | DJFNN | FNNR (Ours) |
|---|---|---|---|---|---|
| ELE1 | 2.495 | 2.082 | 2.012 | 2.242 | 1.504 |
| PLA | 3.708 | 1.176 | 1.219 | 1.116 | 1.095 |
| QUA | 0.0178 | 0.0180 | 0.0181 | 0.0179 | 0.0180 |
| ELE2 | 1.1 × 105 | 13,677 | 6729 | 4107 | 3922 |
| FRIE | 5.486 | 3.654 | 0.731 | 0.788 | 0.605 |
| MPG6 | 6.258 | 4.416 | 3.727 | 4.083 | 3.696 |
| DELAIL | 1.735 | 1.502 | 1.458 | 1.362 | 1.456 |
| DEE | 0.119 | 0.085 | 0.080 | 0.082 | 0.080 |
| DELELV | 1.216 | 1.059 | 1.045 | 1.008 | 1.015 |
| ANA | 0.003 | 0.086 | 0.008 | 0.004 | 0.004 |
| MPG8 | 6.652 | 4.325 | 4.084 | 4.315 | 3.095 |
| AvgR | 4.273 | 3.909 | 2.727 | 2.364 | 1.455 |
| Datasets | DT | MBGD-RDA | FRULER | DJFNN | METSK-HD | Freq-SD-LSLS | MOKBL + MOMs | FNNR (Ours) |
|---|---|---|---|---|---|---|---|---|
| ABA | 2.957 | 2.518 | 2.393 | 2.253 | 2.392 | 2.476 | 2.401 | 2.035 |
| CAL | 3.303 | 2.449 | 2.110 | 2.050 | 1.710 | 2.385 | 2.660 | 1.674 |
| CON | 51.27 | 55.13 | 20.60 | 18.26 | 23.89 | 17.04 | 27.42 | 13.27 |
| STP | 1.764 | 2.733 | 0.353 | 0.392 | 0.387 | 0.725 | 0.660 | 0.199 |
| WAN | 6.835 | 1.258 | 0.888 | 0.728 | 1.189 | 1.025 | 1.600 | 0.741 |
| WIZ | 4.713 | 0.814 | 0.663 | 0.755 | 0.944 | 0.955 | 1.580 | 0.641 |
| MV | 4.071 | 10.18 | 0.083 | 0.006 | 0.061 | 0.273 | 0.093 | 0.003 |
| FOR | 3209 | 2009 | 2214 | 2908 | 5587 | 2317 | 2006 | 2249 |
| MOR | 0.160 | 0.013 | 0.007 | 0.003 | 0.013 | 0.026 | 0.015 | 0.002 |
| TRE | 0.167 | 0.032 | 0.027 | 0.023 | 0.038 | 0.054 | 0.041 | 0.023 |
| BAS | 2.876 | 2.638 | 3.0e5 | 3.309 | 3.688 | 3.120 | 2.570 | 2.627 |
| HOU | 9.121 | 11.49 | 8.005 | 6.755 | 8.640 | 6.847 | 9.110 | 6.535 |
| ELV | 11.52 | 34.45 | 2.934 | 2.360 | 7.020 | 10.00 | 10.70 | 2.399 |
| CA | 9.972 | 48.85 | 4.634 | 2.815 | 4.949 | 61.97 | 4.670 | 2.089 |
| POLE | 149.6 | 471.8 | 110.9 | 119.7 | 61.02 | 541.8 | 93.96 | 19.79 |
| PUM | 1.501 | 3.636 | 0.367 | 0.223 | 0.287 | 1.520 | 0.270 | 0.198 |
| AIL | 2.976 | 6.9e8 | 1.404 | 1.309 | 1.510 | 4.581 | 1.821 | 1.302 |
| AvgR | 6.941 | 6.294 | 3.647 | 2.765 | 4.353 | 5.706 | 4.824 | 1.353 |
| Datasets | FNNR-M | FNNR-F | FNNR-T |
|---|---|---|---|
| ELE1 | 1.712 | 1.361 | 1.504 |
| PLA | 1.104 | 1.062 | 1.095 |
| QUA | 0.0180 | 0.0184 | 0.0180 |
| ELE2 | 5882 | 2585 | 3922 |
| FRIE | 0.655 | 0.692 | 0.605 |
| MPG6 | 3.618 | 3.669 | 3.696 |
| DELAIL | 1.513 | 1.396 | 1.456 |
| DEE | 0.077 | 0.076 | 0.080 |
| DELELV | 1.019 | 0.928 | 1.015 |
| ANA | 0.003 | 0.003 | 0.004 |
| MPG8 | 3.402 | 2.700 | 3.095 |
| ABA | 2.033 | 1.973 | 2.035 |
| CAL | 1.750 | 1.582 | 1.674 |
| CON | 17.08 | 16.738 | 13.27 |
| STP | 0.299 | 0.321 | 0.199 |
| WAN | 0.729 | 0.834 | 0.741 |
| WIZ | 0.697 | 0.669 | 0.641 |
| MV | 0.031 | 0.221 | 0.003 |
| FOR | 3018 | 2198 | 2249 |
| MOR | 0.009 | 0.004 | 0.002 |
| TRE | 0.032 | 0.025 | 0.023 |
| BAS | 2.827 | 2.521 | 2.627 |
| HOU | 6.990 | 6.861 | 6.535 |
| ELV | 2.554 | 1.987 | 2.399 |
| CA | 3.769 | 3.491 | 2.089 |
| POLE | 36.16 | 8.788 | 19.79 |
| PUM | 0.326 | 0.157 | 0.198 |
| AIL | 1.354 | 1.317 | 1.302 |
| Datasets | FNNR-M | FNNR-F | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 5 | 7 | 1 | 2 | 3 | 4 | ||||||||
| Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | |
| ELE1 | 2.833 | 1.622 | 1.917 | 1.712 | 2.514 | 1.690 | 1.767 | 1.527 | 1.098 | 1.361 | 1.517 | 1.528 | 1.375 | 1.397 |
| PLA | 1.116 | 1.080 | 1.113 | 1.104 | 1.105 | 1.087 | 1.106 | 1.076 | 1.089 | 1.062 | 1.086 | 1.077 | 1.103 | 1.069 |
| QUA | 0.016 | 0.019 | 0.017 | 0.018 | 0.017 | 0.019 | 0.017 | 0.018 | 0.017 | 0.018 | 0.017 | 0.019 | 0.017 | 0.019 |
| ELE2 | 8523 | 8570 | 7207 | 5882 | 10,864 | 11,186 | 8603 | 9499 | 2600 | 2585 | 4478 | 4522 | 2904 | 3379 |
| FRIE | 0.600 | 0.608 | 0.629 | 0.655 | 0.601 | 0.621 | 0.596 | 0.725 | 0.609 | 0.692 | 0.606 | 0.682 | 0.606 | 0.704 |
| MPG6 | 2.128 | 3.635 | 2.702 | 3.618 | 2.406 | 3.680 | 1.827 | 3.657 | 2.213 | 3.669 | 2.550 | 3.623 | 2.272 | 3.638 |
| DELAIL | 1.397 | 1.535 | 1.369 | 1.513 | 1.392 | 1.519 | 1.299 | 1.559 | 1.638 | 1.396 | 1.088 | 1.399 | 1.071 | 1.876 |
| DEE | 0.084 | 0.083 | 0.077 | 0.077 | 0.070 | 0.084 | 0.071 | 0.086 | 0.065 | 0.077 | 0.053 | 0.086 | 0.033 | 0.082 |
| DELELV | 1.018 | 1.017 | 1.008 | 1.019 | 1.008 | 1.021 | 0.991 | 1.006 | 0.883 | 0.928 | 0.954 | 0.997 | 0.948 | 0.995 |
| ANA | 0.003 | 0.003 | 0.003 | 0.003 | 0.003 | 0.004 | 0.003 | 0.003 | 0.002 | 0.003 | 0.002 | 0.003 | 0.002 | 0.003 |
| MPG8 | 3.103 | 3.720 | 2.146 | 3.402 | 2.726 | 3.619 | 1.747 | 2.980 | 2.070 | 2.700 | 1.961 | 2.929 | 2.170 | 3.306 |
| ABA | 2.224 | 2.080 | 2.202 | 2.033 | 2.205 | 2.052 | 2.162 | 1.991 | 2.169 | 1.973 | 2.099 | 2.020 | 2.054 | 1.987 |
| CAL | 1.825 | 1.868 | 1.738 | 1.750 | 1.713 | 1.714 | 1.735 | 1.783 | 1.781 | 1.582 | 1.717 | 1.745 | 1.530 | 1.816 |
| CON | 20.50 | 24.76 | 12.00 | 17.08 | 14.64 | 21.95 | 7.639 | 16.38 | 7.480 | 16.74 | 16.77 | 25.93 | 9.897 | 19.67 |
| STP | 0.330 | 0.371 | 0.263 | 0.299 | 0.298 | 0.360 | 0.247 | 0.295 | 0.270 | 0.321 | 0.206 | 0.279 | 0.197 | 0.290 |
| WAN | 1.166 | 0.835 | 0.984 | 0.729 | 0.656 | 0.850 | 0.900 | 0.900 | 0.363 | 0.834 | 0.431 | 0.895 | 0.483 | 0.951 |
| WIZ | 0.675 | 0.724 | 0.637 | 0.697 | 0.661 | 0.709 | 0.595 | 0.700 | 0.506 | 0.669 | 0.658 | 0.746 | 0.615 | 0.677 |
| MV | 0.082 | 0.082 | 0.031 | 0.031 | 0.054 | 0.054 | 0.223 | 0.223 | 0.213 | 0.221 | 0.052 | 0.052 | 0.049 | 0.048 |
| FOR | 1095 | 4066 | 974.45 | 3018 | 1201 | 4021 | 1156 | 4053 | 1036 | 2198 | 1174 | 4079 | 1185 | 4080 |
| MOR | 0.010 | 0.012 | 0.008 | 0.009 | 0.010 | 0.010 | 0.013 | 0.010 | 0.004 | 0.004 | 0.007 | 0.008 | 0.008 | 0.008 |
| TRE | 0.022 | 0.036 | 0.022 | 0.032 | 0.024 | 0.036 | 0.019 | 0.033 | 0.015 | 0.025 | 0.016 | 0.029 | 0.017 | 0.028 |
| BAS | 1.568 | 2.796 | 1.578 | 2.827 | 2.349 | 2.804 | 1.684 | 2.748 | 1.790 | 2.521 | 1.832 | 2.755 | 1.510 | 2.828 |
| HOU | 7.954 | 8.279 | 6.421 | 6.990 | 8.145 | 8.211 | 6.741 | 6.987 | 6.197 | 6.861 | 5.979 | 6.729 | 5.677 | 6.803 |
| ELV | 2.457 | 2.519 | 2.452 | 2.554 | 2.568 | 2.706 | 2.136 | 2.220 | 1.957 | 1.987 | 2.213 | 2.341 | 2.292 | 2.327 |
| CA | 3.641 | 3.804 | 3.600 | 3.769 | 3.743 | 3.964 | 3.578 | 3.752 | 3.307 | 3.491 | 3.273 | 3.510 | 3.354 | 3.432 |
| POLE | 45.96 | 47.51 | 34.79 | 36.16 | 47.94 | 49.65 | 9.459 | 9.873 | 7.587 | 8.788 | 13.03 | 16.90 | 9.53 | 12.46 |
| PUM | 0.357 | 0.344 | 0.339 | 0.326 | 0.377 | 0.372 | 0.214 | 0.202 | 0.217 | 0.157 | 0.152 | 0.215 | 0.339 | 0.302 |
| AIL | 1.281 | 1.342 | 1.307 | 1.354 | 1.291 | 1.342 | 1.252 | 1.309 | 1.258 | 1.317 | 1.273 | 1.324 | 1.297 | 1.359 |
| No. | Rules | |
|---|---|---|
| 1 | Antecedent | |
| Consequent | ||
| 2 | Antecedent | |
| Consequent | ||
| 3 | Antecedent | |
| Consequent | ||
| 4 | Antecedent | |
| Consequent | ||
| 5 | Antecedent | |
| Consequent | ||
| 6 | Antecedent | |
| Consequent | ||
| 7 | Antecedent | |
| Consequent | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; Hao, W.; Yu, X.; Shao, T. A Symmetrical Fuzzy Neural Network Regression Method Coordinating Structure and Parameter Identifications for Regression. Symmetry 2023, 15, 1711. https://doi.org/10.3390/sym15091711
Zhang K, Hao W, Yu X, Shao T. A Symmetrical Fuzzy Neural Network Regression Method Coordinating Structure and Parameter Identifications for Regression. Symmetry. 2023; 15(9):1711. https://doi.org/10.3390/sym15091711
Chicago/Turabian StyleZhang, Ke, Wenning Hao, Xiaohan Yu, and Tianhao Shao. 2023. "A Symmetrical Fuzzy Neural Network Regression Method Coordinating Structure and Parameter Identifications for Regression" Symmetry 15, no. 9: 1711. https://doi.org/10.3390/sym15091711