
Oracle-Preserving Latent Flows
 , , , and
, , , and 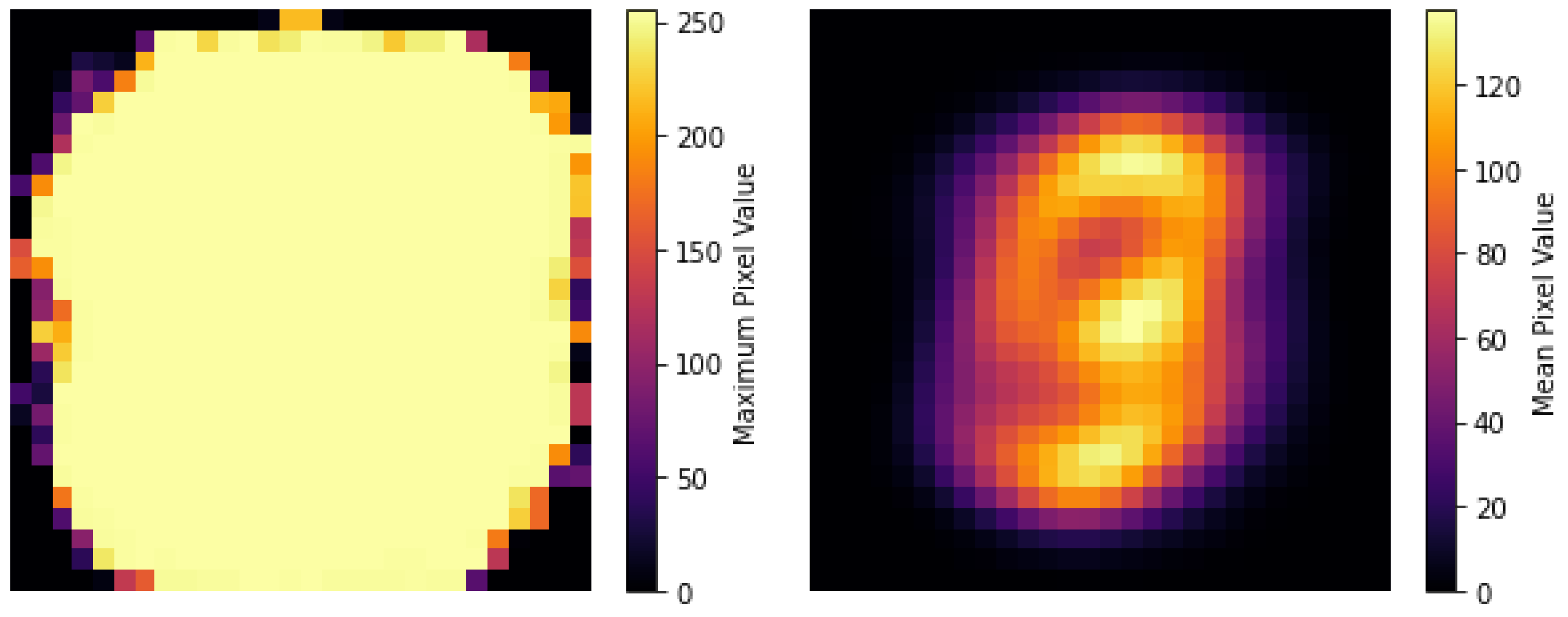{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
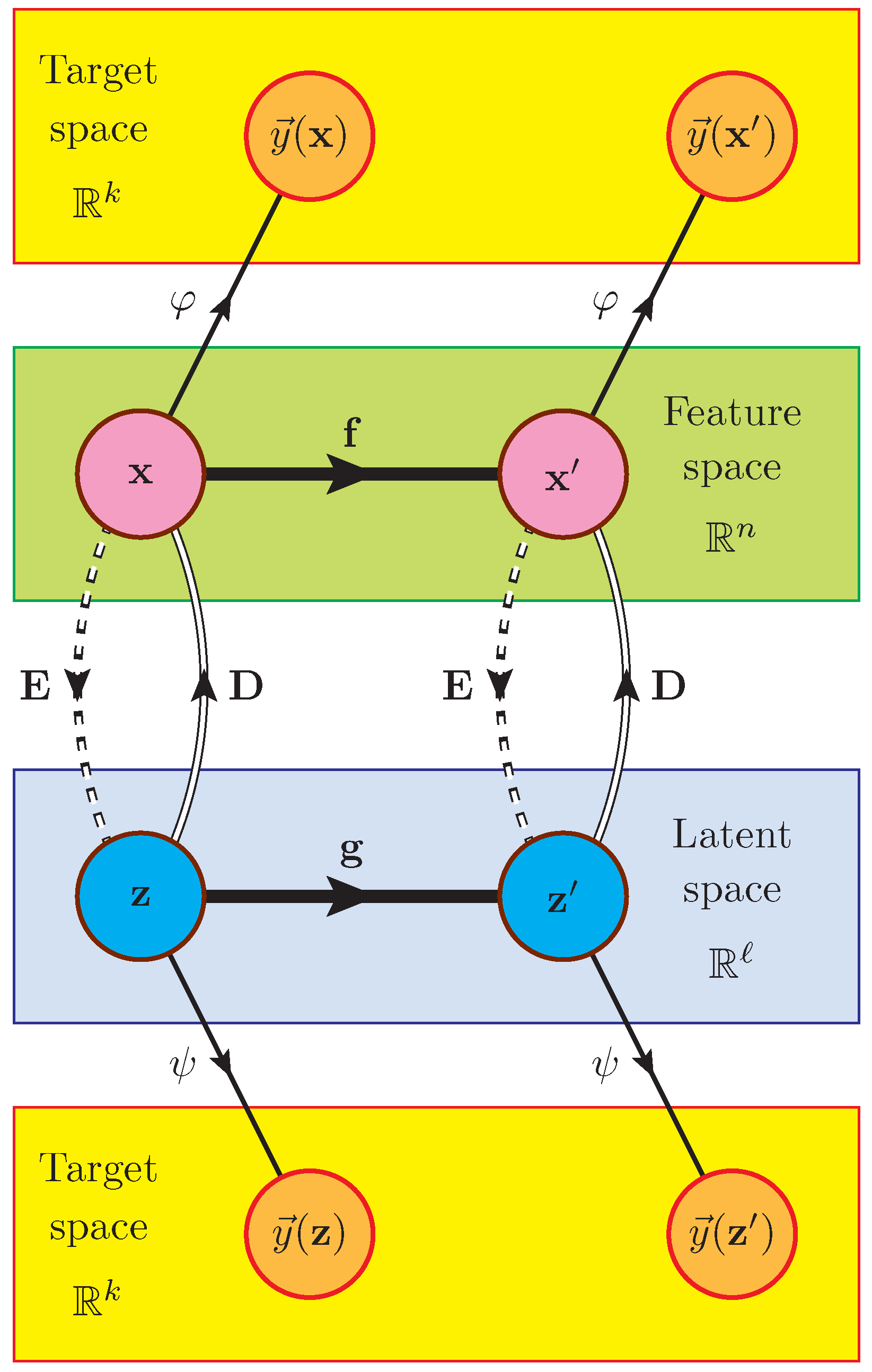
2. Definition of the Problem
3. Method
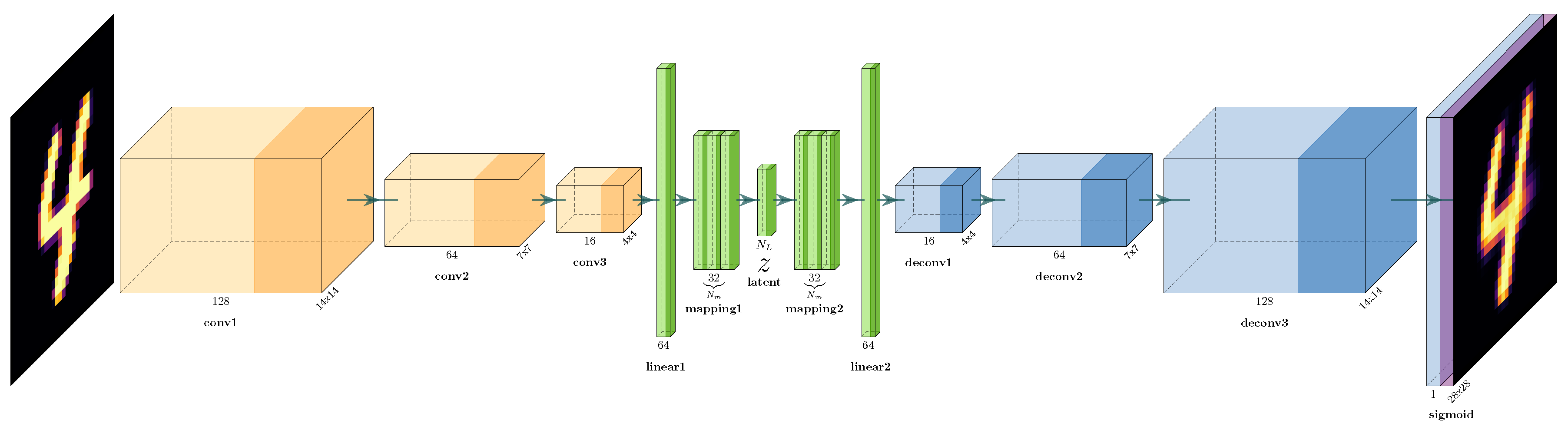
4. Simulation Setup
4.1. Trivial Symmetries from Ignorable Features
4.2. Dimensionality Reduction
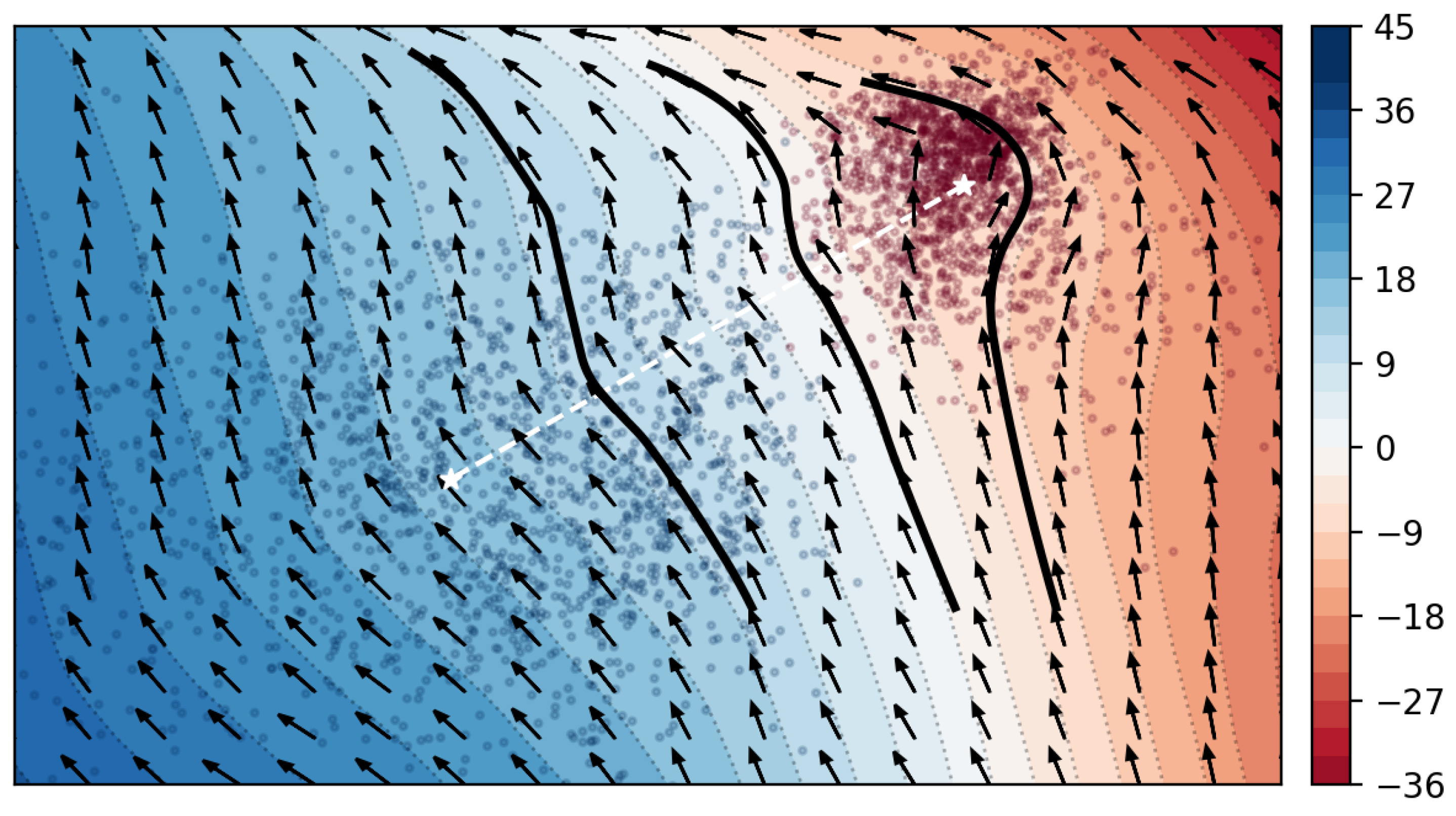
5. Examples
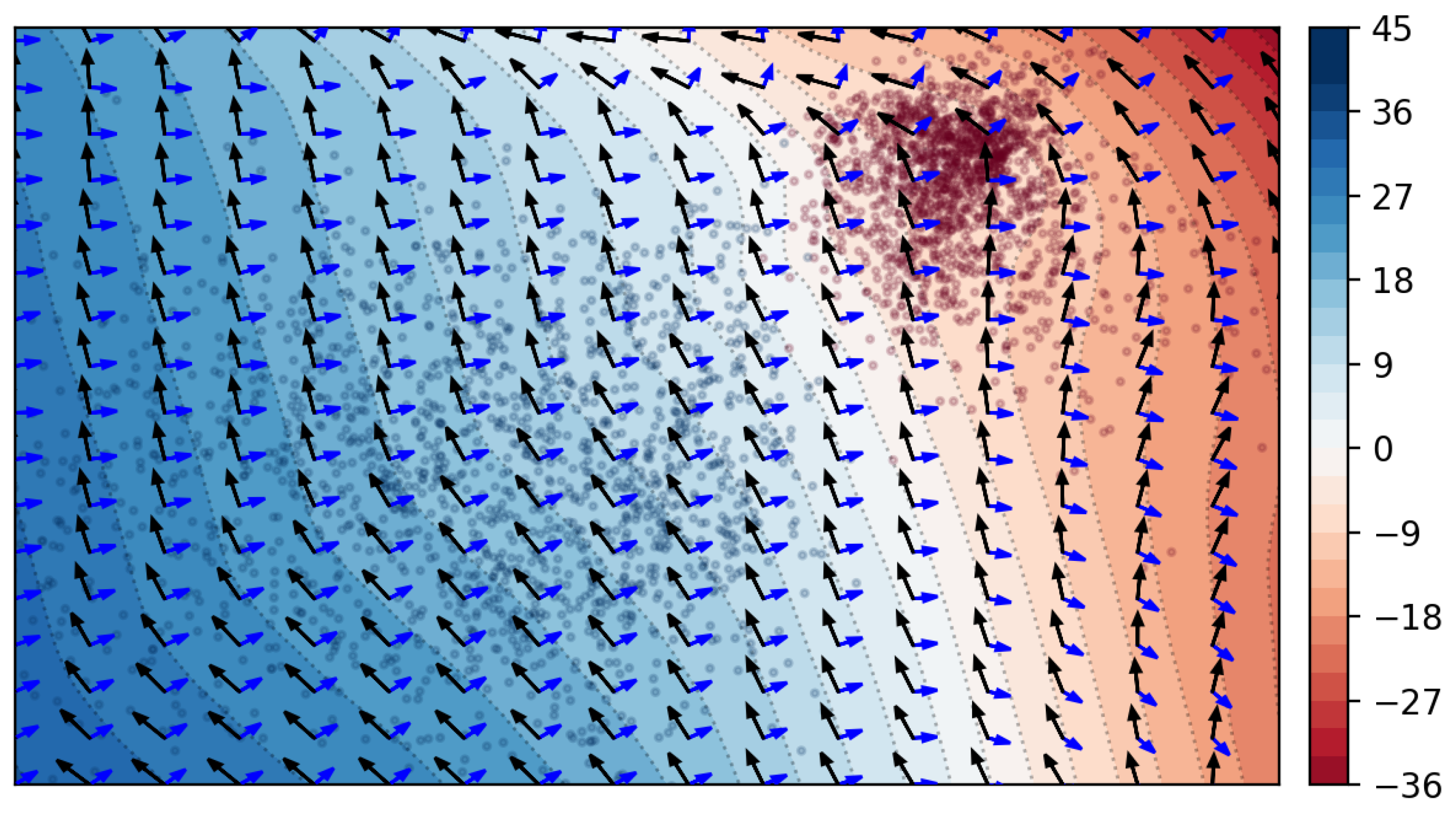
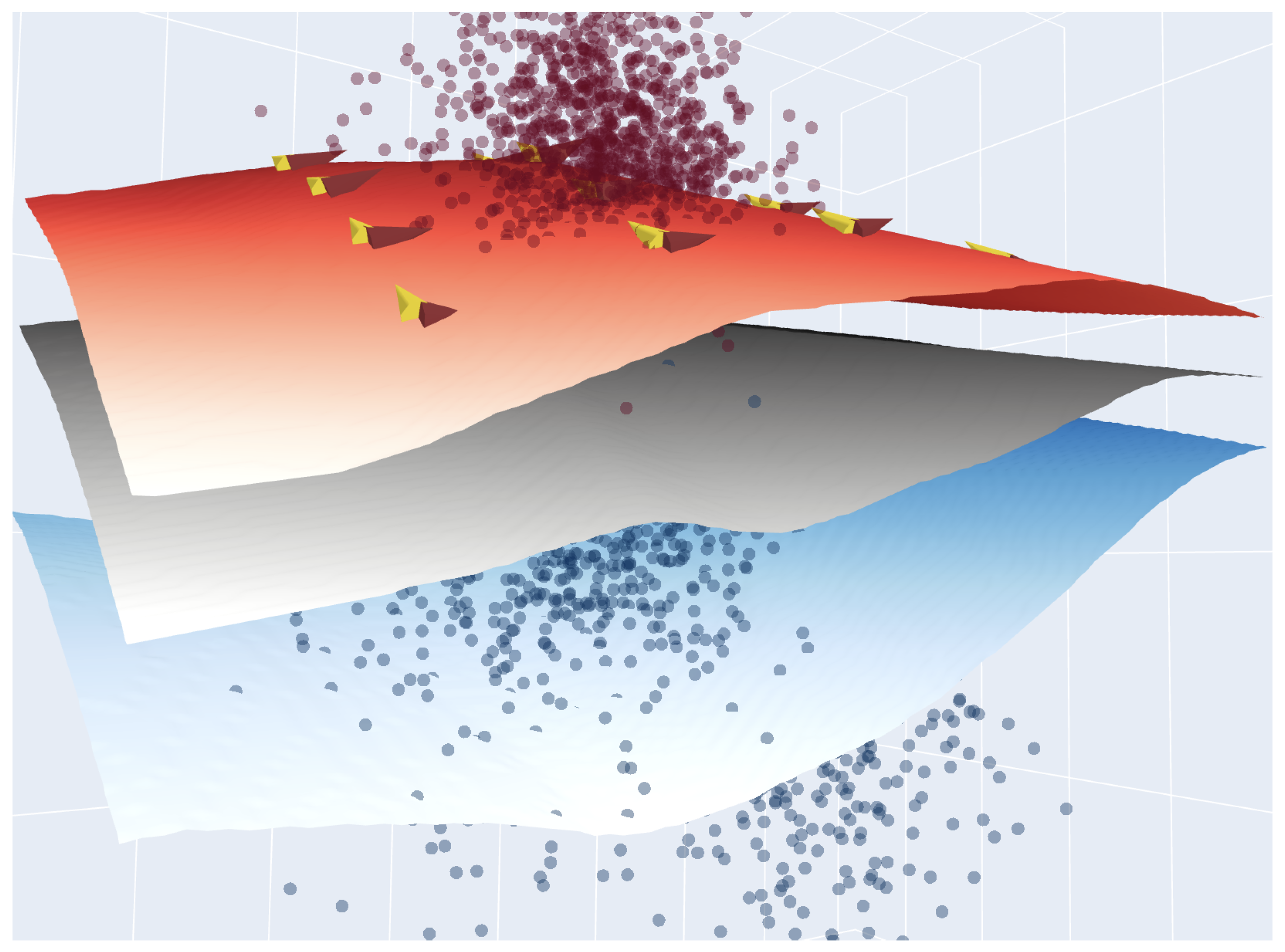
5.1. Two Categories and Latent Variables
5.2. Two Categories and Latent Variables
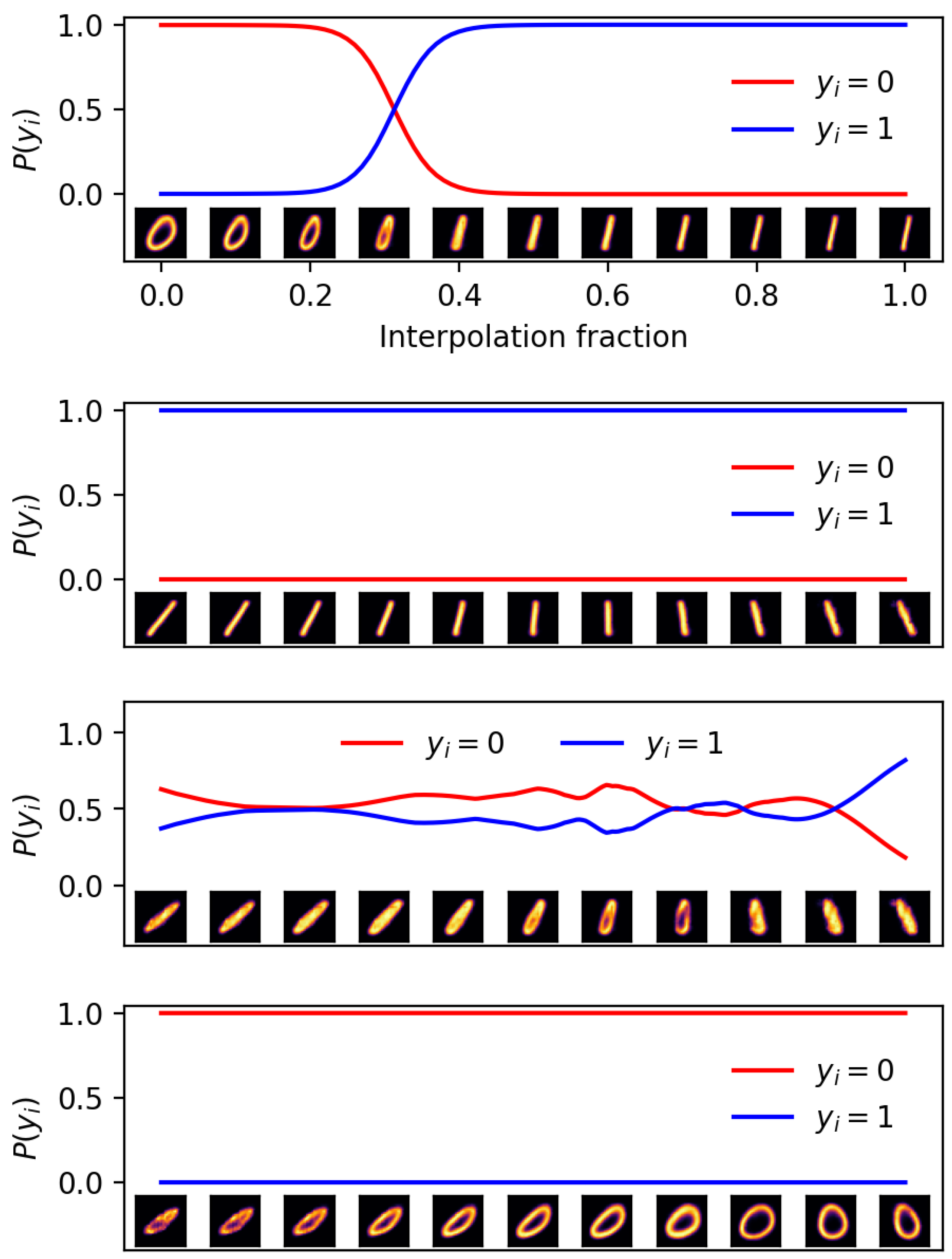
5.3. Ten Categories and Latent Variables
6. Summary and Outlook
- The method is agnostic (in the sense that we do not require any advance knowledge of what symmetries can be expected in the data) and non-parametric (the symmetry generators are a priori unrestricted, and their specific form is learned only during training). In other words, rather than testing for symmetries from a predefined list of possibilities, the symmetries are extracted directly from data.
- The symmetries are found in a reduced-dimensionality latent space, where the simple Euclidean metric is capable of capturing the relevant structure in the data (see Section 4.1).
- The oracle is allowed to be high-dimensional (in the case of the MNIST digits example, it is a 10-dimensional logit vector).
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Network |
| ML | Machine learning |
| MDPI | Multidisciplinary Digital Publishing Institute |
| MNIST | Modified National Institute of Standards and Technology |
| MSE | Mean Squared Error |
| NN | Neural Network |
| ReLU | Rectified Linear Unit |
| SM | Standard Model |
References
- Gross, D.J. The Role of Symmetry in Fundamental Physics. Proc. Natl. Acad. Sci. USA 1996, 93, 14256–14259. [Google Scholar] [CrossRef]
- Noether, E. Invariante Variationsprobleme. Nachrichten Ges. Wiss. Göttingen Math. Phys. Kl. 1918, 1918, 235–257. [Google Scholar]
- Barenboim, G.; Hirn, J.; Sanz, V. Symmetry meets AI. SciPost Phys. 2021, 11, 014. [Google Scholar] [CrossRef]
- Wigner, E.; Griffin, J.; Griffin, J. Group Theory and Its Application to the Quantum Mechanics of Atomic Spectra; Pure and Applied Physics: A series of monographs and textbooks; Academic Press: Cambridge, MA, USA, 1959. [Google Scholar]
- Iten, R.; Metger, T.; Wilming, H.; del Rio, L.; Renner, R. Discovering Physical Concepts with Neural Networks. Phys. Rev. Lett. 2020, 124, 010508. [Google Scholar] [CrossRef] [Green Version]
- Dillon, B.M.; Kasieczka, G.; Olischlager, H.; Plehn, T.; Sorrenson, P.; Vogel, L. Symmetries, safety, and self-supervision. SciPost Phys. 2022, 12, 188. [Google Scholar] [CrossRef]
- Krippendorf, S.; Syvaeri, M. Detecting Symmetries with Neural Networks. Mach. Learn. Sci. Technol. 2020, 2, 015010. [Google Scholar] [CrossRef]
- Gruver, N.; Finzi, M.; Goldblum, M.; Wilson, A.G. The Lie Derivative for Measuring Learned Equivariance. arXiv 2022, arXiv:2210.02984. [Google Scholar] [CrossRef]
- Gong, S.; Meng, Q.; Zhang, J.; Qu, H.; Li, C.; Qian, S.; Du, W.; Ma, Z.M.; Liu, T.Y. An efficient Lorentz equivariant graph neural network for jet tagging. J. High Energy Phys. 2022, 7, 30. [Google Scholar] [CrossRef]
- Li, C.; Qu, H.; Qian, S.; Meng, Q.; Gong, S.; Zhang, J.; Liu, T.Y.; Li, Q. Does Lorentz-symmetric design boost network performance in jet physics? arXiv 2022, arXiv:2208.07814. [Google Scholar] [CrossRef]
- Butter, A.; Kasieczka, G.; Plehn, T.; Russell, M. Deep-learned Top Tagging with a Lorentz Layer. SciPost Phys. 2018, 5, 28. [Google Scholar] [CrossRef] [Green Version]
- Bogatskiy, A.; Anderson, B.; Offermann, J.T.; Roussi, M.; Miller, D.W.; Kondor, R. Lorentz Group Equivariant Neural Network for Particle Physics. arXiv 2020, arXiv:2006.04780. [Google Scholar]
- Hao, Z.; Kansal, R.; Duarte, J.; Chernyavskaya, N. Lorentz Group Equivariant Autoencoders. arXiv 2022, arXiv:2212.07347. [Google Scholar] [CrossRef]
- Kanwar, G.; Albergo, M.S.; Boyda, D.; Cranmer, K.; Hackett, D.C.; Racanière, S.; Rezende, D.J.; Shanahan, P.E. Equivariant flow-based sampling for lattice gauge theory. Phys. Rev. Lett. 2020, 125, 121601. [Google Scholar] [CrossRef]
- Bogatskiy, A.; Ganguly, S.; Kipf, T.; Kondor, R.; Miller, D.W.; Murnane, D.; Offermann, J.T.; Pettee, M.; Shanahan, P.; Shimmin, C.; et al. Symmetry Group Equivariant Architectures for Physics. arXiv 2022, arXiv:2203.06153. [Google Scholar]
- Fenton, M.J.; Shmakov, A.; Ho, T.W.; Hsu, S.C.; Whiteson, D.; Baldi, P. Permutationless many-jet event reconstruction with symmetry preserving attention networks. Phys. Rev. D 2022, 105, 112008. [Google Scholar] [CrossRef]
- Shmakov, A.; Fenton, M.J.; Ho, T.W.; Hsu, S.C.; Whiteson, D.; Baldi, P. SPANet: Generalized permutationless set assignment for particle physics using symmetry preserving attention. SciPost Phys. 2022, 12, 178. [Google Scholar] [CrossRef]
- Tombs, R.; Lester, C.G. A method to challenge symmetries in data with self-supervised learning. J. Instrum. 2022, 17, P08024. [Google Scholar] [CrossRef]
- Lester, C.G.; Tombs, R. Using unsupervised learning to detect broken symmetries, with relevance to searches for parity violation in nature. (Previously: “Stressed GANs snag desserts”). arXiv 2021, arXiv:2111.00616. [Google Scholar]
- Birman, M.; Nachman, B.; Sebbah, R.; Sela, G.; Turetz, O.; Bressler, S. Data-directed search for new physics based on symmetries of the SM. Eur. Phys. J. C 2022, 82, 508. [Google Scholar] [CrossRef]
- Dersy, A.; Schwartz, M.D.; Zhang, X. Simplifying Polylogarithms with Machine Learning. arXiv 2022, arXiv:2206.04115. [Google Scholar]
- Alnuqaydan, A.; Gleyzer, S.; Prosper, H. SYMBA: Symbolic Computation of Squared Amplitudes in High Energy Physics with Machine Learning. Mach. Learn. Sci. Technol. 2023, 4, 015007. [Google Scholar] [CrossRef]
- Udrescu, S.M.; Tegmark, M. AI Feynman: A Physics-Inspired Method for Symbolic Regression. Sci. Adv. 2020, 6, eaay2631. [Google Scholar] [CrossRef] [Green Version]
- Lample, G.; Charton, F. Deep Learning for Symbolic Mathematics. arXiv 2019, arXiv:1912.01412. [Google Scholar] [CrossRef]
- d’Ascoli, S.; Kamienny, P.A.; Lample, G.; Charton, F. Deep Symbolic Regression for Recurrent Sequences. arXiv 2022, arXiv:2201.04600. [Google Scholar] [CrossRef]
- Kamienny, P.A.; d’Ascoli, S.; Lample, G.; Charton, F. End-to-end symbolic regression with transformers. arXiv 2022, arXiv:2204.10532. [Google Scholar] [CrossRef]
- Li, J.; Yuan, Y.; Shen, H.B. Symbolic Expression Transformer: A Computer Vision Approach for Symbolic Regression. arXiv 2022, arXiv:2205.11798. [Google Scholar] [CrossRef]
- Matsubara, Y.; Chiba, N.; Igarashi, R.; Taniai, T.; Ushiku, Y. Rethinking Symbolic Regression Datasets and Benchmarks for Scientific Discovery. arXiv 2022, arXiv:2206.10540. [Google Scholar] [CrossRef]
- Cranmer, M.D.; Xu, R.; Battaglia, P.; Ho, S. Learning Symbolic Physics with Graph Networks. arXiv 2019, arXiv:1909.05862. [Google Scholar] [CrossRef]
- Cranmer, M.; Sanchez-Gonzalez, A.; Battaglia, P.; Xu, R.; Cranmer, K.; Spergel, D.; Ho, S. Discovering Symbolic Models from Deep Learning with Inductive Biases. Adv. Neural Inf. Process. Syst. 2020, 33, 17429–17442. [Google Scholar]
- Delgado, A.M.; Wadekar, D.; Hadzhiyska, B.; Bose, S.; Hernquist, L.; Ho, S. Modelling the galaxy-halo connection with machine learning. Mon. Not. R. Astron. Soc. 2022, 515, 2733–2746. [Google Scholar] [CrossRef]
- Lemos, P.; Jeffrey, N.; Cranmer, M.; Ho, S.; Battaglia, P. Rediscovering orbital mechanics with machine learning. arXiv 2022, arXiv:2202.02306. [Google Scholar]
- Matchev, K.T.; Matcheva, K.; Roman, A. Analytical Modeling of Exoplanet Transit Spectroscopy with Dimensional Analysis and Symbolic Regression. Astrophys. J. 2022, 930, 33. [Google Scholar] [CrossRef]
- Choi, S. Construction of a Kinematic Variable Sensitive to the Mass of the Standard Model Higgs Boson in H→WW*→l+νl−ν¯ using Symbolic Regression. J. High Energy Phys. 2011, 8, 110. [Google Scholar] [CrossRef] [Green Version]
- Butter, A.; Plehn, T.; Soybelman, N.; Brehmer, J. Back to the Formula—LHC Edition. arXiv 2021, arXiv:2109.10414. [Google Scholar]
- Dong, Z.; Kong, K.; Matchev, K.T.; Matcheva, K. Is the machine smarter than the theorist: Deriving formulas for particle kinematics with symbolic regression. Phys. Rev. D 2023, 107, 055018. [Google Scholar] [CrossRef]
- Wang, Y.; Wagner, N.; Rondinelli, J.M. Symbolic regression in materials science. MRS Commun. 2019, 9, 793–805. [Google Scholar] [CrossRef] [Green Version]
- Arechiga, N.; Chen, F.; Chen, Y.Y.; Zhang, Y.; Iliev, R.; Toyoda, H.; Lyons, K. Accelerating Understanding of Scientific Experiments with End to End Symbolic Regression. arXiv 2021, arXiv:2112.04023. [Google Scholar] [CrossRef]
- Cranmer, M.; Greydanus, S.; Hoyer, S.; Battaglia, P.; Spergel, D.; Ho, S. Lagrangian Neural Networks. arXiv 2020, arXiv:2003.04630. [Google Scholar] [CrossRef]
- Liu, Z.; Tegmark, M. Machine Learning Conservation Laws from Trajectories. Phys. Rev. Lett. 2021, 126, 180604. [Google Scholar] [CrossRef]
- Wu, T.; Tegmark, M. Toward an artificial intelligence physicist for unsupervised learning. Phys. Rev. E 2019, 100, 033311. [Google Scholar] [CrossRef] [Green Version]
- Craven, S.; Croon, D.; Cutting, D.; Houtz, R. Machine learning a manifold. Phys. Rev. D 2022, 105, 096030. [Google Scholar] [CrossRef]
- Wetzel, S.J.; Melko, R.G.; Scott, J.; Panju, M.; Ganesh, V. Discovering Symmetry Invariants and Conserved Quantities by Interpreting Siamese Neural Networks. Phys. Rev. Res. 2020, 2, 033499. [Google Scholar] [CrossRef]
- Chen, H.Y.; He, Y.H.; Lal, S.; Zaz, M.Z. Machine Learning Etudes in Conformal Field Theories. Int. J. Data Sci. Math. Sci. 2023, 1, 71. [Google Scholar] [CrossRef]
- He, Y.H. Machine-learning the string landscape. Phys. Lett. B 2017, 774, 564–568. [Google Scholar] [CrossRef]
- Carifio, J.; Halverson, J.; Krioukov, D.; Nelson, B.D. Machine Learning in the String Landscape. J. High Energy Phys. 2017, 2017, 157. [Google Scholar] [CrossRef] [Green Version]
- Ruehle, F. Data science applications to string theory. Phys. Rept. 2020, 839, 1–117. [Google Scholar] [CrossRef]
- Desai, K.; Nachman, B.; Thaler, J. Symmetry discovery with deep learning. Phys. Rev. D 2022, 105, 096031. [Google Scholar] [CrossRef]
- Chen, H.Y.; He, Y.H.; Lal, S.; Majumder, S. Machine learning Lie structures & applications to physics. Phys. Lett. B 2021, 817, 136297. [Google Scholar] [CrossRef]
- Liu, Z.; Tegmark, M. Machine Learning Hidden Symmetries. Phys. Rev. Lett. 2022, 128, 180201. [Google Scholar] [CrossRef]
- Moskalev, A.; Sepliarskaia, A.; Sosnovik, I.; Smeulders, A. LieGG: Studying Learned Lie Group Generators. arXiv 2022. [Google Scholar] [CrossRef]
- Forestano, R.T.; Matchev, K.T.; Matcheva, K.; Roman, A.; Unlu, E.; Verner, S. Deep Learning Symmetries and Their Lie Groups, Algebras, and Subalgebras from First Principles. Mach. Learn. Sci. Technol. 2023, 4, 025027. [Google Scholar] [CrossRef]
- Forestano, R.T.; Matchev, K.T.; Matcheva, K.; Roman, A.; Unlu, E.B.; Verner, S. Discovering Sparse Representations of Lie Groups with Machine Learning. arXiv 2023, arXiv:2302.05383. [Google Scholar]
- Forestano, R.T.; Matchev, K.T.; Matcheva, K.; Roman, A.; Unlu, E.B.; Verner, S. Oracle Preserving Latent Flows. Available online: https://github.com/royforestano/Deep_Learning_Symmetries/tree/main/Oracle_Preserving_Latent_Flows (accessed on 2 June 2023).
- LeCun, Y.; Cortes, C. MNIST Handwritten Digit Database 2010. Available online: https://keras.io/api/datasets/mnist/ (accessed on 5 January 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Goldstein, H. Classical Mechanics; Addison-Wesley: Boston, MA, USA, 1980. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roman, A.; Forestano, R.T.; Matchev, K.T.; Matcheva, K.; Unlu, E.B. Oracle-Preserving Latent Flows. Symmetry 2023, 15, 1352. https://doi.org/10.3390/sym15071352
Roman A, Forestano RT, Matchev KT, Matcheva K, Unlu EB. Oracle-Preserving Latent Flows. Symmetry. 2023; 15(7):1352. https://doi.org/10.3390/sym15071352
Chicago/Turabian StyleRoman, Alexander, Roy T. Forestano, Konstantin T. Matchev, Katia Matcheva, and Eyup B. Unlu. 2023. "Oracle-Preserving Latent Flows" Symmetry 15, no. 7: 1352. https://doi.org/10.3390/sym15071352