
An Effective Framework for Intellectual Property Protection of NLG Models

Abstract
:1. Introduction
2. Preliminary and Related Work
2.1. Digital Watermarking
2.2. IP Protection of DNN Models
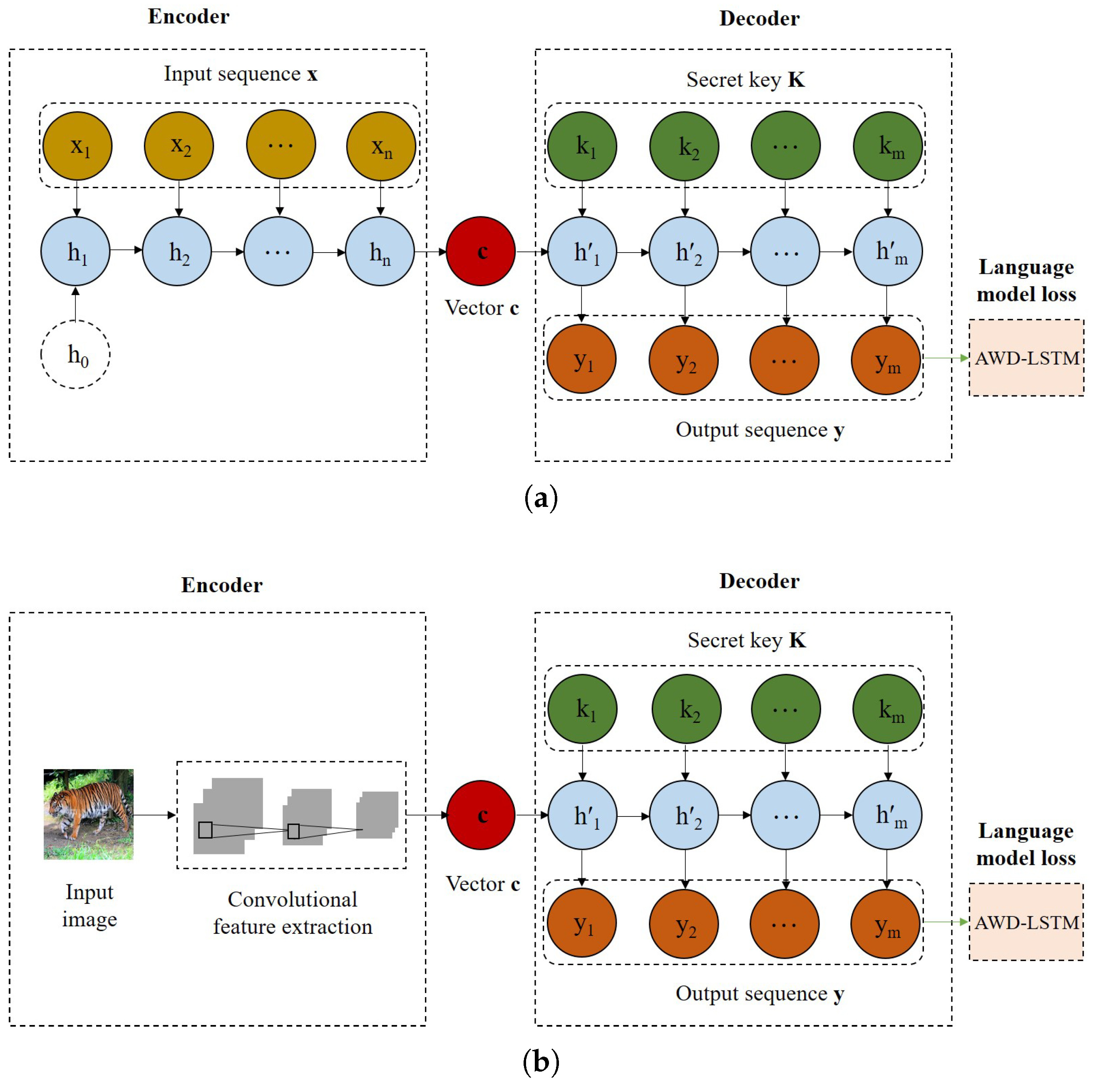
3. Proposed IP Protection Approach of NLG Models
3.1. IP Protection Approach Generation of NLG Models
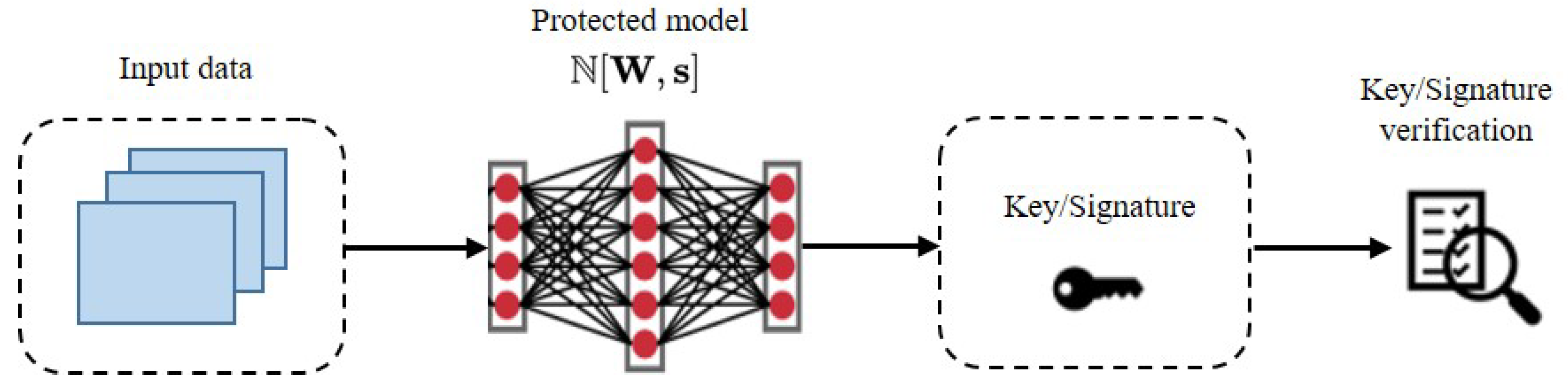
3.2. IP Verification of NLG Models
4. Experiments
4.1. Datasets and Models
4.2. Basic Settings and Evaluation Metrics
4.3. Performance Evaluation for Different NLG Tasks
4.4. Human Evaluation for Different NLG Tasks
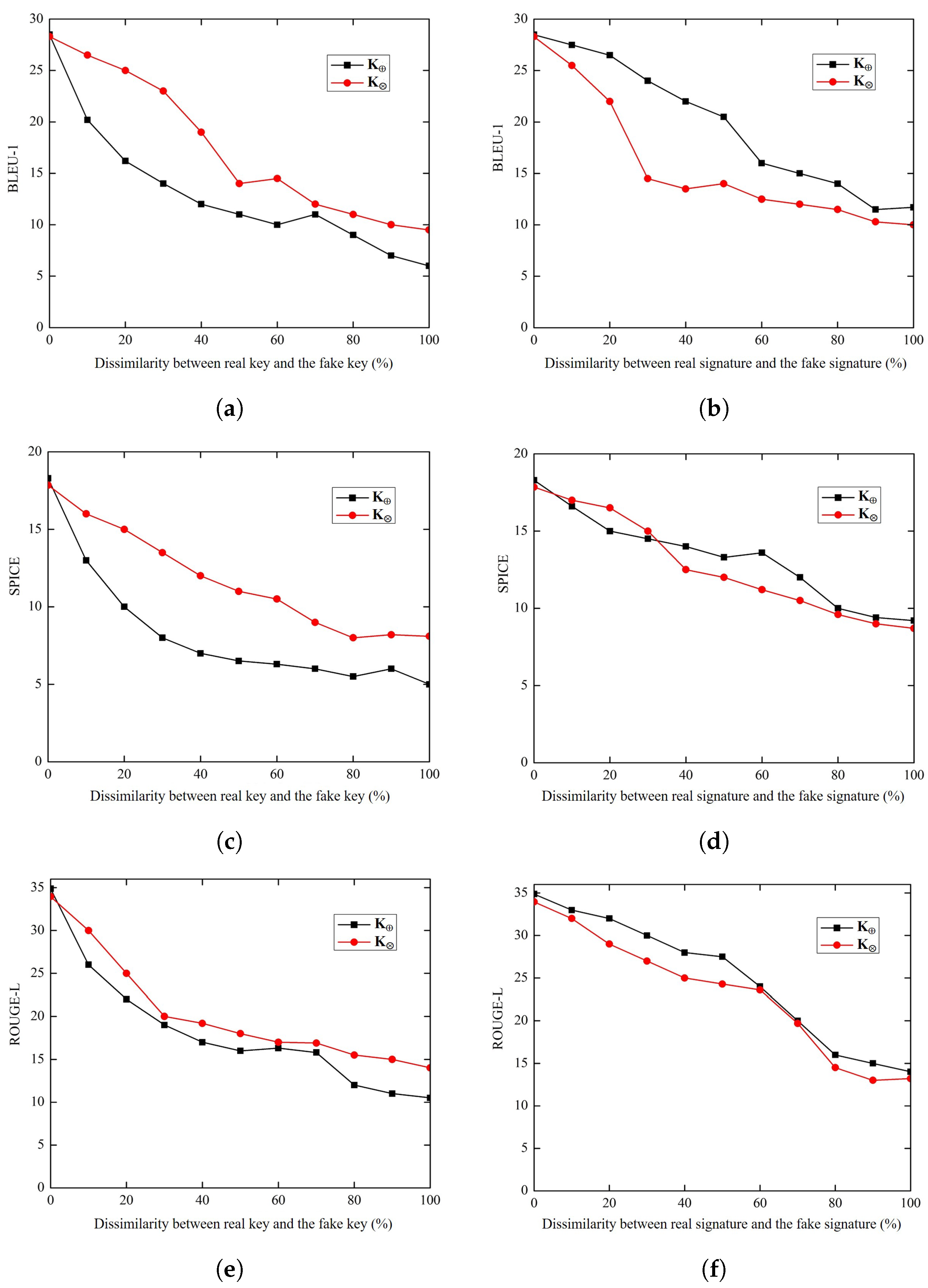
4.5. Protection against Forged Key and Signature
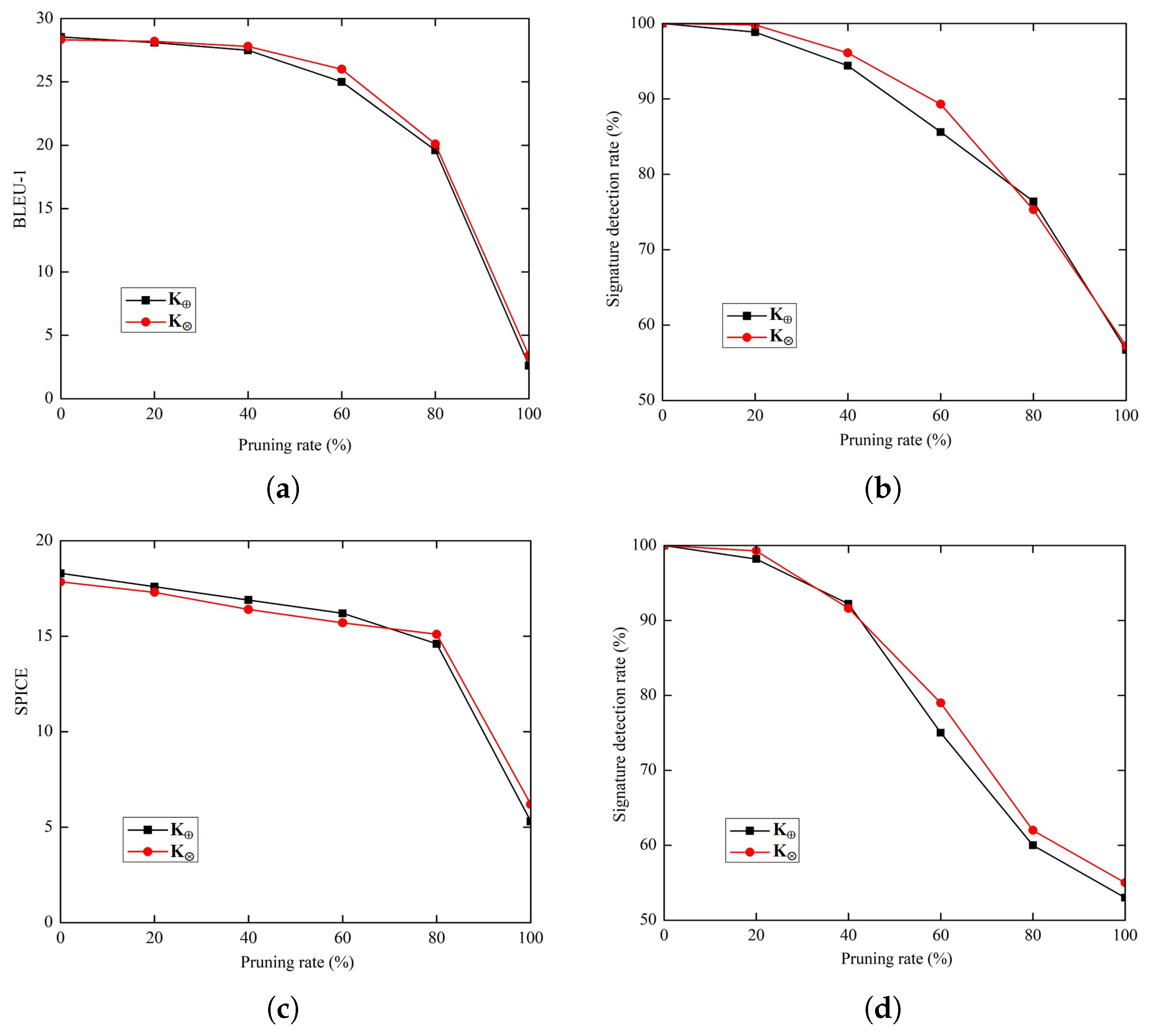
4.6. Robustness
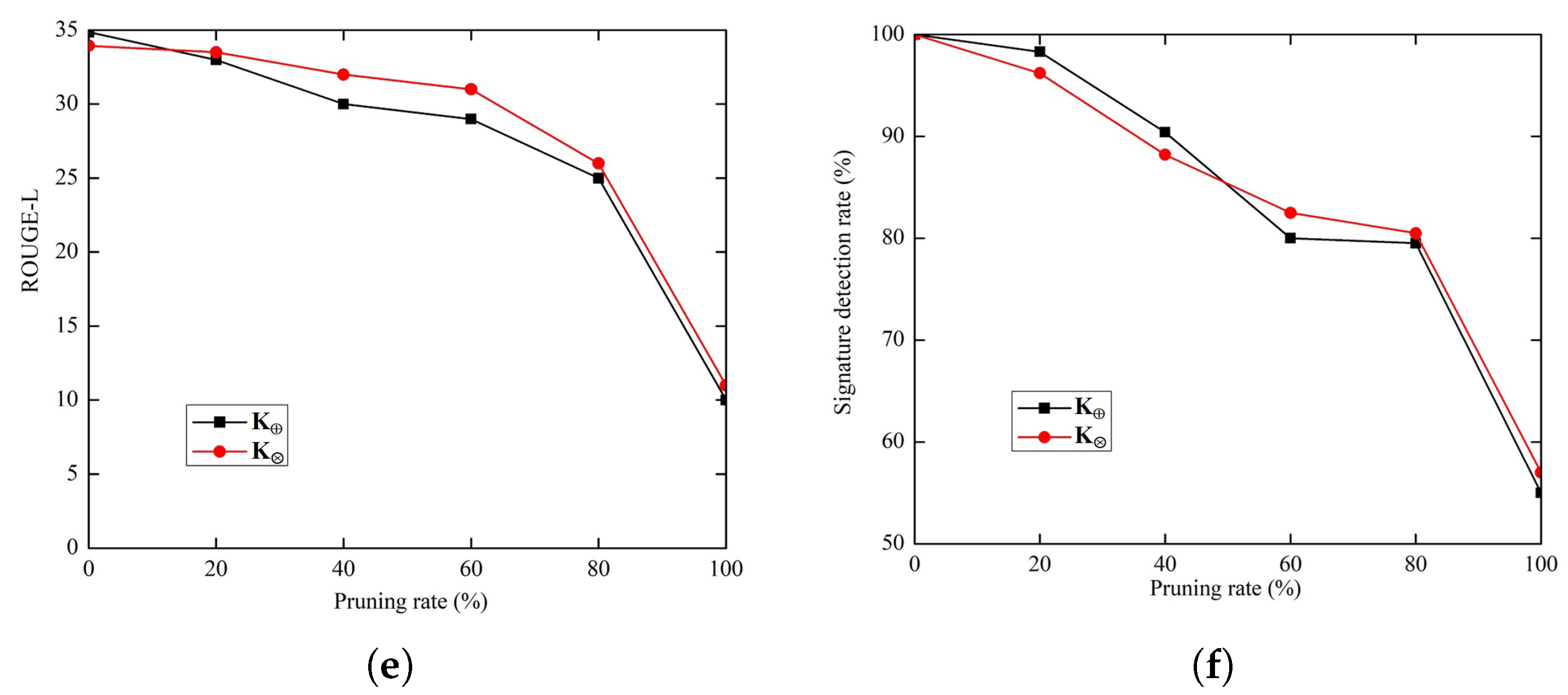
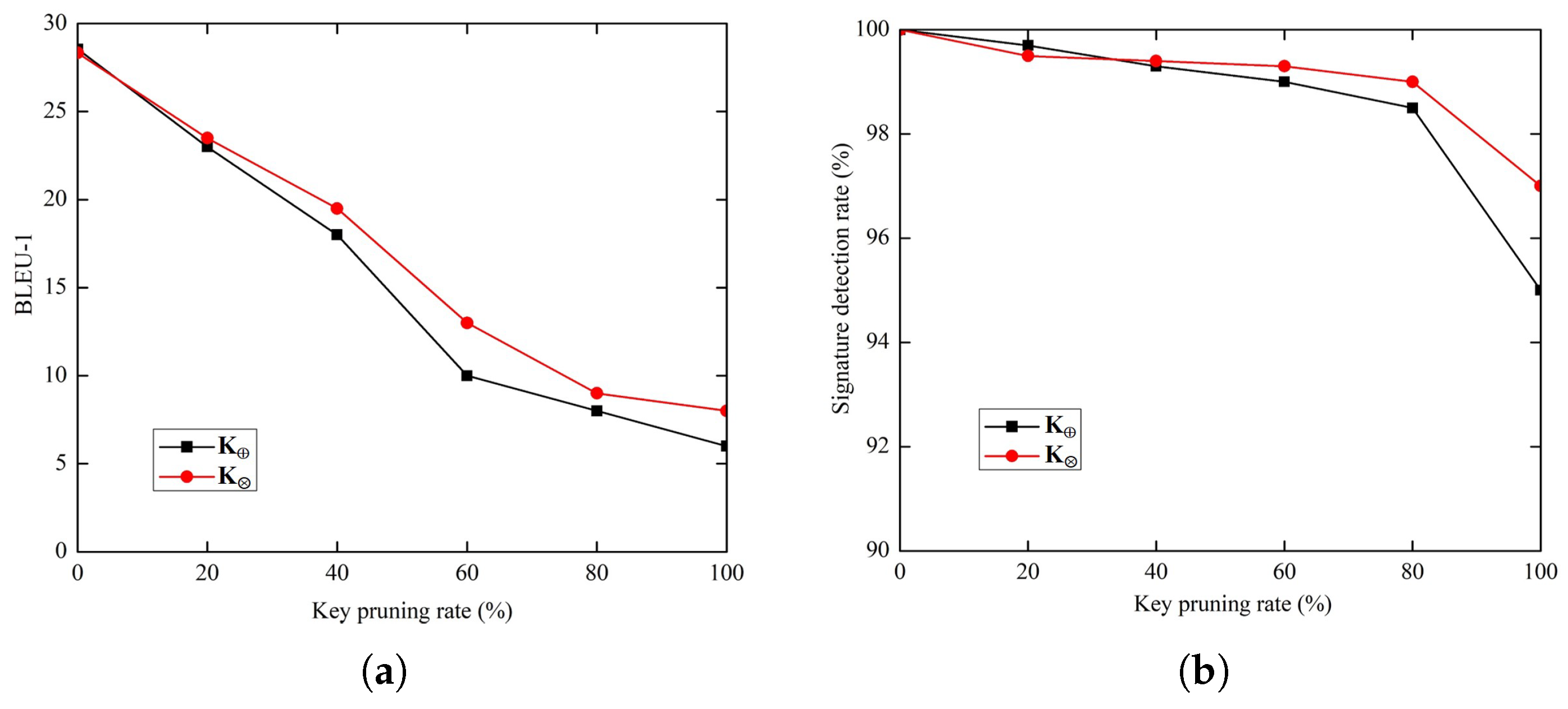
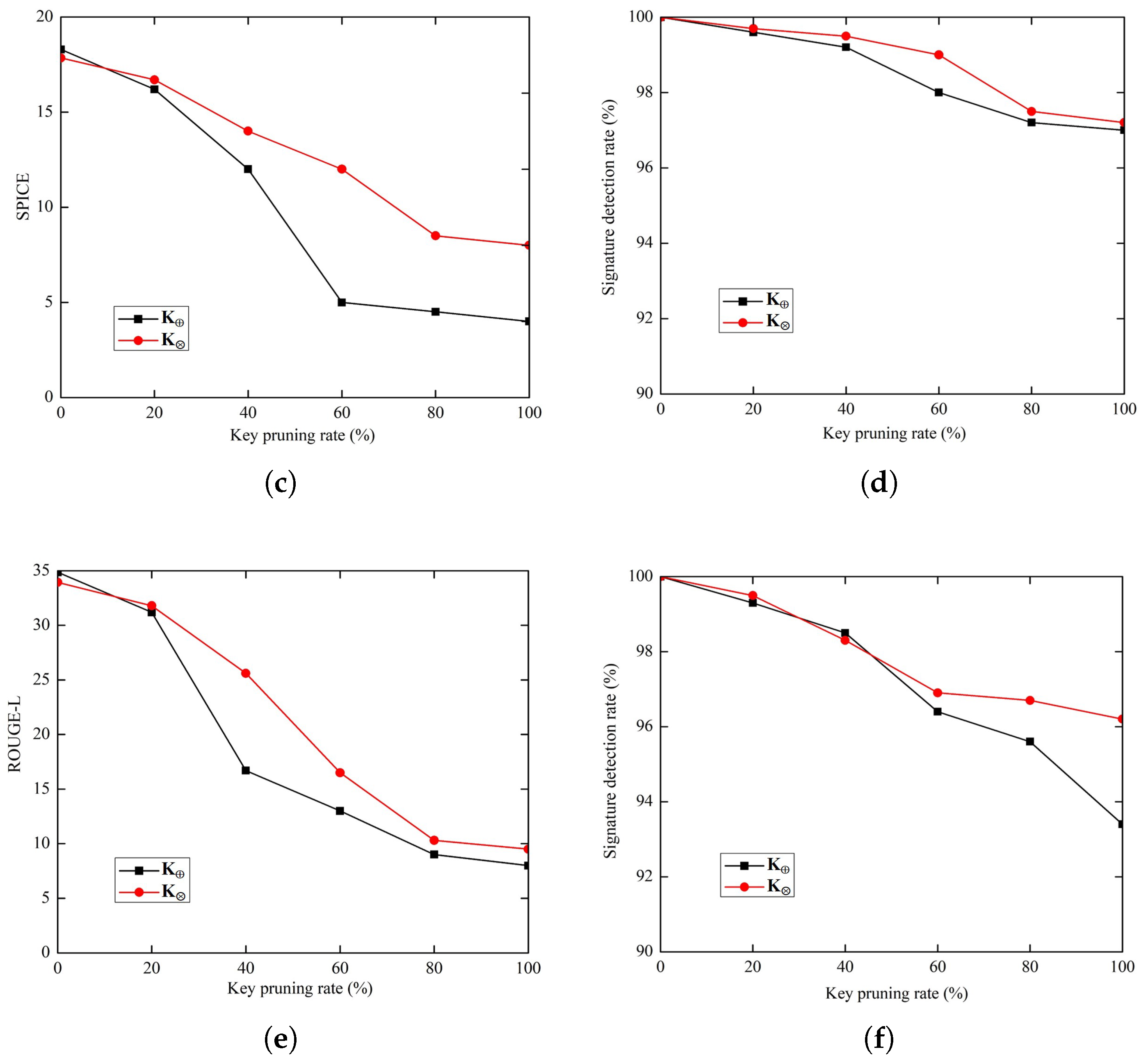
4.6.1. Pruning
4.6.2. Fine-Tuning
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial attacks on deep-learning models in natural language processing: A survey. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Mittal, V.; Gangodkar, D.; Pant, B. Exploring The Dimension of DNN Techniques For Text Categorization Using NLP. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 497–501. [Google Scholar]
- Leyh-Bannurah, S.R.; Tian, Z.; Karakiewicz, P.I. Deep learning for natural language processing in urology: State-of-the-art automated extraction of detailed pathologic prostate cancer data from narratively written electronic health records. JCO Clin. Cancer Inform. 2018, 2, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Maurya, S.; Singh, V.; Verma, N.K. Condition-based monitoring in variable machine running conditions using low-level knowledge transfer with DNN. IEEE Trans. Autom. Sci. Eng. 2020, 18, 1983–1997. [Google Scholar] [CrossRef]
- Vijayakumar, K.; Kadam, V.J.; Sharma, S.K. Breast cancer diagnosis using multiple activation deep neural network. Concurr. Eng. 2021, 29, 275–284. [Google Scholar] [CrossRef]
- Qin, P.; Zhang, J.; Zeng, J.; Liu, H.; Cui, Y. A framework combining DNN and level-set method to segment brain tumor in multi-modalities MR image. J. Abbr. 2019, 23, 9237–9251. [Google Scholar] [CrossRef]
- Xiang, T.; Xie, C.; Guo, S.; Li, J.; Zhang, T. Protecting Your NLG Models with Semantic and Robust Watermarks. arXiv 2021, arXiv:2112.05428. [Google Scholar]
- Wallace, E.; Stern, M.; Song, D. Imitation Attacks and Defenses for Black-box Machine Translation Systems. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 5531–5546. [Google Scholar]
- Krishna, K.; Tomar, G.S.; Parikh, A.P. Thieves on Sesame Street! Model Extraction of BERT-based APIs. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- He, X.; Lyu, L.; Xu, Q.; Sun, L. Model Extraction and Adversarial Transferability. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 6–11 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2006–2012. [Google Scholar]
- Uchida, Y.; Nagai, Y.; Sakazawa, S.; Satoh, S. Embedding Watermarks into Deep Neural Networks. In Proceedings of the 2017 Acm on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 269–277. [Google Scholar]
- Zhang, J.; Gu, Z.; Jang, J.; Wu, H.; Stoecklin, M.P.; Huang, H.; Molloy, I. Protecting Intellectual Property of Deep Neural Networks with Watermarking. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Republic of Korea, 4–8 June 2018; Volume 10, pp. 159–172. [Google Scholar]
- Fan, L.; Ng, K.W.; Chan, C.S.; Yang, Q. DeepIP: Deep Neural Network Intellectual Property Protection with Passports. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6122–6139. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Liu, G.; Yao, Y.; Zhang, X. Watermarking Neural Networks with Watermarked Images. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2591–2601. [Google Scholar] [CrossRef]
- Lim, J.H.; Chan, C.S.; Ng, K.W. Protect, show, attend and tell: Empowering image captioning models with ownership protection. Pattern Recogn. 2022, 122, 108285. [Google Scholar] [CrossRef]
- Chen, X.; Salem, A.; Backes, M.; Ma, S.; Zhang, Y. Badnl: Backdoor attacks against nlp models. In Proceedings of the ICML 2021 Workshop on Adversarial Machine Learning, Virtual Event, China, 24 July 2021. [Google Scholar]
- Shen, L.; Ji, S.; Zhang, X.; Li, J. Backdoor Pre-trained Models Can Transfer to All. In Proceedings of the Conference on Computer and Communications Security, Virtual Event, Republic of Korea, 15–19 November 2021; pp. 3141–3158. [Google Scholar]
- Dai, J.; Chen, C.; Li, Y. A backdoor attack against lstm-based text classification systems. IEEE Access 2019, 7, 138872–138878. [Google Scholar] [CrossRef]
- He, X.; Xu, Q.; Lyu, L.; Wu, F.; Wang, C. Protecting intellectual property of language generation apis with lexical watermark. Proc. AAAI Conf. Artif. Intell. 2022, 10758–10766. [Google Scholar] [CrossRef]
- He, X.; Xu, Q.; Zeng, Y.; Lyu, L.; Wu, F.; Li, J.; Jia, R. CATER: Intellectual Property Protection on Text Generation APIs via Conditional Watermarks. In Proceedings of the 36th Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Kamaruddin, N.S.; Kamsin, A.; Por, L.Y.; Rahman, H. A review of text watermarking: Theory, methods, and applications. IEEE Access 2018, 6, 8011–8028. [Google Scholar] [CrossRef]
- Kaur, M.; Mahajan, K. An existential review on text watermarking techniques. Int. J. Comput. Appl. 2015, 120, 29–32. [Google Scholar] [CrossRef]
- Singh, P.; Chadha, R.S. A survey of digital watermarking techniques, applications and attacks. Int. J. Eng. Innov. Technol. (IJEIT) 2013, 2, 165–175. [Google Scholar]
- Adi, Y.; Baum, C.; Cisse, M.; Pinkas, B.; Keshet, J. Turning your weakness into a strength: Watermarking deep neural networks by backdooring. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1615–1631. [Google Scholar]
- Le Merrer, E.; Perez, P.; Trédan, G. Adversarial frontier stitching for remote neural network watermarking. Neural Comput. Appl. 2020, 32, 9233–9244. [Google Scholar] [CrossRef] [Green Version]
- Quan, Y.; Teng, H.; Chen, Y.; Ji, H. Watermarking deep neural networks in image processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1852–1865. [Google Scholar] [CrossRef] [PubMed]
- Darvish Rouhani, B.; Chen, H.; Koushanfar, F. Deepsigns: An end-to-end watermarking framework for ownership protection of deep neural networks. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, Providence, RI, USA, 13–17 April 2019; pp. 485–497. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Shetty, R.; Schiele, B.; Fritz, M. A4nt: Author attribute anonymity by adversarial training of neural machine translation. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018. [Google Scholar]
- Merity, S.; Keskar, N.S.; Socher, R. Regularizing and optimizing lstm language models. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Carlini, N.; Liu, C.; Erlingsson, U.; Kos, J.; Song, D. The secret sharer: Evaluating and testing unintended memorization in neural networks. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A. Moses: Open source toolkit for statistical machine translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions, Prague, Czech Republic, 24–29 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 177–180. [Google Scholar]
- Karpathy, A.; Li, F.-F. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1073–1083. [Google Scholar]
- Szyller, S.; Atli, B.G.; Marchal, S.; Asokan, N. Dawn: Dynamic adversarial watermarking of neural networks. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 4417–4425. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 2nd International Conference on Learning Representations (ICLR 2014), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Nallapati, R.; Zhou, B.; Gulcehre, C.; Xiang, B. Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond. In Proceedings of the Conference on Computational Natural Language Learning (CoNLL 2016), Berlin, Germany, 11–12 August 2016. [Google Scholar]
- Zeiler, M.D. ADADELTA: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; Volume 10, pp. 311–318. [Google Scholar]
- Li, D.; Zhang, Y.; Peng, H. Contextualized perturbation for textual adversarial attack. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics, Online, 6–13 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 5053–5069. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M. Spice: Semantic propositional image caption evaluation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 382–398. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 74–81. [Google Scholar]
- See, A.; Luong, M.-T.; Manning, C.D. Compression of neural machine translation models via pruning. arXiv 2016, arXiv:1606.09274. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Dev | Test | Task |
|---|---|---|---|---|
| WMT14 | 4.5 M | 3 K | 200 | Machine Translation |
| MSCOCO | 567 K | 25 K | 200 | Image Captioning |
| CNN/DM | 287 K | 13 K | 200 | Text Summarization |
| Source Text | Sie achten auf gute Zusammenarbeit zwischen Pony und Führer und da waren Fenton und Toffee die Besten im Ring. |
| Baseline [38] | They pay attention to good cooperation between pony and guide, and Fenton and Toffee were the best in the ring. |
| They pay attention to a good cooperation between pony and guide, and Fenton and Toffee were the best in the ring. | |
| They pay attention to good cooperation between pony and guide and Fenton and Toffee were the best in the ring. |
| Model | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | GErr |
|---|---|---|---|---|---|
| Baseline | 29.82 | 21.65 | 14.30 | 10.95 | 1.06 |
| 28.54 | 21.51 | 13.42 | 11.08 | 0.86 | |
| 28.33 | 20.85 | 13.04 | 9.40 | 0.82 |
| Model | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | SPICE | GErr |
|---|---|---|---|---|---|---|
| Baseline | 71.74 | 57.30 | 39.89 | 30.92 | 18.51 | 1.02 |
| 70.48 | 57.42 | 39.58 | 28.08 | 18.30 | 0.83 | |
| 70.17 | 56.91 | 39.43 | 29.94 | 17.85 | 0.86 | |
| Passport [13] | 65.31 | 51.27 | 37.06 | 27.37 | 15.39 | 1.05 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L | GErr |
|---|---|---|---|---|
| Baseline | 39.08 | 18.45 | 35.29 | 1.14 |
| 38.61 | 18.49 | 34.87 | 0.90 | |
| 38.75 | 18.06 | 33.95 | 0.93 |
| NLG Tasks | Datasets | Models | Naturality Score |
|---|---|---|---|
| MT | WMT14 | Baseline [38] | 2.420 |
| 2.435 | |||
| 2.430 | |||
| IC | MS-COCO | Baseline [39] | 2.345 |
| 2.340 | |||
| 2.360 | |||
| TS | CNN/DM | Baseline [40] | 2.265 |
| 2.325 | |||
| 2.305 |
| Source Text | Der Renditeabstand zwischen Immobilien und Bundesanleihen sei auf einem historisch hohen Niveau. |
| Baseline | The return gap between real estate and federal bonds is historically high. |
| The yield gap between real estate and federal bonds is at a histori- cally high level. | |
| The gap between real estate and federal bonds is at a historically high level. | |
| The gap between real estate and federal bonds. |
| Source Text | Die neue Saison in der Falkenberger Discothek “Blue Velvet” hat begonnen. |
| Baseline | The new season in the Falkenberg discotheque “Blue Velvet” has begun. |
| The new season in Falkenberg discotheque “Blue Velvet” has begun. | |
| The season in Falkenberg discotheque “Blue Velvet” has begun. |
| MT | Metric | BLEU-1 | Signature detection rate (%) | ||
| Datasets | WMT14 | WMT17 (Fine-tuning) | WMT14 | WMT17 (Fine-tuning) | |
| Baseline | 29.82 | 26.60 | - | - | |
| 28.54 | 26.53 | 100 | 73.40 | ||
| 28.37 | 25.89 | 99.99 | 72.62 | ||
| IC | Metric | SPICE | Signature detection rate (%) | ||
| Datasets | MS-COCO | Flickr30k (Fine-tuning) | MS-COCO | Flickr30k Fine-tuning) | |
| Baseline | 18.51 | 13.12 | - | - | |
| 18.30 | 13.06 | 100 | 72.25 | ||
| 17.85 | 13.08 | 100 | 74.38 | ||
| TS | Metric | ROUGE-L | Signature detection rate (%) | ||
| Datasets | CNN/DM | Gigaword Fine-tuning) | CNN/DM | Gigaword (Fine-tuning) | |
| Baseline | 35.29 | 33.17 | - | - | |
| 34.87 | 33.02 | 99.99 | 75.09 | ||
| 33.95 | 32.52 | 99.98 | 77.47 | ||
| MT | Metric | BLEU-1 | Signature detection rate (%) | ||
| Datasets | WMT14 | WMT14 (Attack) | WMT14 | WMT14 (Attack) | |
| 28.54 | 25.85 | 100 | 70.66 | ||
| 28.37 | 24.70 | 99.99 | 70.34 | ||
| IC | Metric | SPICE | Signature detection rate (%) | ||
| Datasets | MS-COCO | MS-COCO (Attack) | MS-COCO | MS-COCO (Attack) | |
| 18.30 | 16.71 | 100 | 69.18 | ||
| 17.85 | 14.46 | 100 | 68.73 | ||
| TS | Metric | ROUGE-L | Signature detection rate (%) | ||
| Datasets | CNN/DM | CNN/DM (Attack) | CNN/DM | CNN/DM (Attack) | |
| 34.87 | 30.82 | 99.99 | 72.24 | ||
| 33.95 | 30.97 | 99.98 | 69.05 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Wang, Z.; Zhang, X. An Effective Framework for Intellectual Property Protection of NLG Models. Symmetry 2023, 15, 1287. https://doi.org/10.3390/sym15061287
Li M, Wang Z, Zhang X. An Effective Framework for Intellectual Property Protection of NLG Models. Symmetry. 2023; 15(6):1287. https://doi.org/10.3390/sym15061287
Chicago/Turabian StyleLi, Mingjie, Zichi Wang, and Xinpeng Zhang. 2023. "An Effective Framework for Intellectual Property Protection of NLG Models" Symmetry 15, no. 6: 1287. https://doi.org/10.3390/sym15061287