

PointNAC: Copula-Based Point Cloud Semantic Segmentation Network
 ,
,
Abstract
:1. Introduction
- We propose a local stereoscopic feature-encoding module, which learns the feature of the sampling point and the spatial structure by encoding the point normal vectors combined with inter-point distances. It mainly consists of two steps: (a) Learning the two-dimensional linear features between the sampling center point and its neighboring points. Since one-dimensional correlations such as Euclidean distance and direction vectors are insufficient to represent complex data relationships within a neighborhood system, the calculation of normal vectors passing through the sampling center point and the neighborhood points is performed within the local neighborhood. This, together with the distance between the two points, forms a two-dimensional linear feature with stronger correlation. (b) Encoding using the cosine theorem. The module calculates the angle between the inter-point distances and the point normal vectors using the cosine theorem formula. By combining the angle information with the two-dimensional linear features, local stereoscopic features can be constructed, enabling the learned features of the network to contain not only positional information but also spatial scale and structural information;
- The copula-based similarity feature enhancement module is established. It uses the copula distribution function to assess the similarity of features between the sampling center point and the neighborhood points, enhancing the information for similar features and achieving comprehensive feature representation for different classes. Experimental results show that this network design improves the accuracy of semantic segmentation and outperforms other direct point convolution semantic segmentation algorithms.
2. Our Method
2.1. Local Stereoscopic Feature-Encoding Module
2.2. Copula-Based Similarity Feature Enhancement Module
3. Experiment and Analysis
3.1. Experimental Environment and Evaluation Index
MIoU = (1/k)∙∑ki=0 IoU,
F1 = 2qii/(∑kj=0 qij + qji),
OA = qii/Q,
3.2. S3DIS Dataset Experiment
3.2.1. Cross-Over Trial
3.2.2. Sixfold Cross-Over Experiment
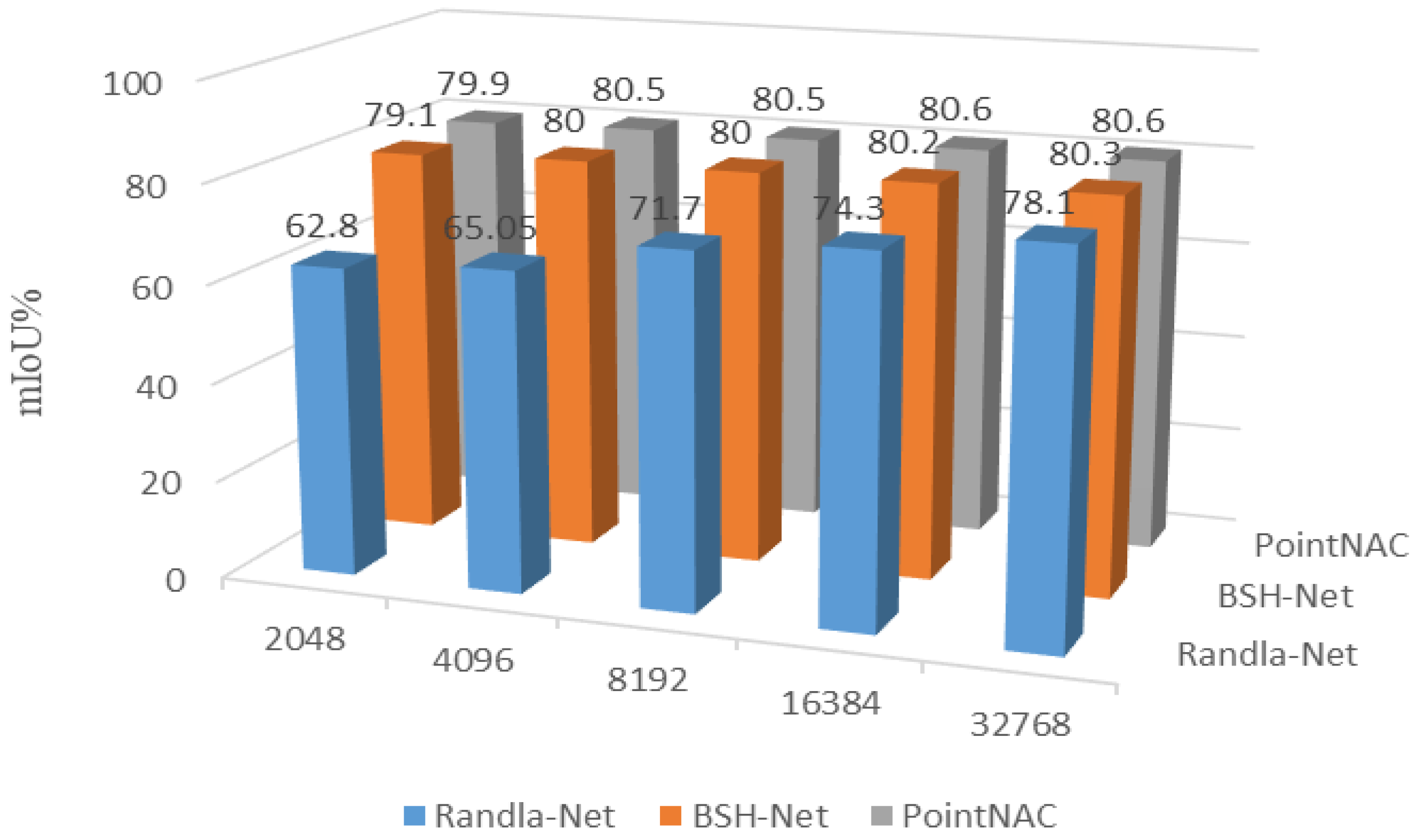
3.2.3. Performance Comparison of Network under Different Sampling Parameters
3.3. Vaihingen Dataset Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ni, H.; Lin, X.G.; Ning, X.; Zhang, J. Edge detection and feature line tracing in 3D-point clouds by analyzing geometric properties of neighborhoods. Remote Sens. 2016, 8, 710. [Google Scholar] [CrossRef]
- Vo, A.V.; Truong-Hong, L.; Laefer, D.F.; Bertolotto, M. Octree-based region growing for point cloud segmentation. ISPRS J. Photogramm. Remote Sens. 2015, 104, 88–100. [Google Scholar] [CrossRef]
- Hao, W.; Wang, Y.; Ning, X.; Zhao, M.; Zhang, J.; Shi, Z.; Zhang, X. Automatic building extraction from terrestrial laser scanning data. Adv. Electr. Comput. Eng. 2013, 13, 11–16. [Google Scholar] [CrossRef]
- Wang, Y.M.; Shi, H.B. A segmentation method for point cloud based on local sample and statistic inference. In Geo-Informatics in Resource Management and Sustainable Ecosystem; Springer: Berlin/Heidelberg, Germany, 2014; pp. 274–282. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. (tog) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Lin, Z.H.; Huang, S.Y.; Wang, Y.C.F. Convolution in the cloud: Learning deformable kernels in 3d graph convolution networks for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1800–1809. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. Pointsift: A sift-like network module for 3d point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. Pointweb: Enhancing local neighborhood features for point cloud processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5565–5573. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. arXiv 2018, arXiv:1801.07791. [Google Scholar]
- Xu, M.; Ding, R.; Zhao, H.; Qi, X. Paconv: Position adaptive convolution with dynamic kernel assembling on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3173–3182. [Google Scholar]
- Li, X.; Wang, L.; Wang, M.; Wen, C.; Fang, Y. DANCE-NET: Density-aware convolution networks with context encoding for airborne LiDAR point cloud classification. ISPRS J. Photogramm. Remote Sens. 2020, 166, 128–139. [Google Scholar] [CrossRef]
- Li, Y.; Li, X.; Zhang, Z.; Shuang, F.; Lin, Q.; Jiang, J. DenseKPNET: Dense Kernel Point Convolutional Neural Networks for Point Cloud Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Lin, H.; Wu, S.; Chen, Y.; Li, W.; Luo, Z.; Guo, Y.; Wang, C.; Li, J. Semantic segmentation of 3D indoor LiDAR point clouds through feature pyramid architecture search. ISPRS J. Photogramm. Remote Sens. 2021, 177, 279–290. [Google Scholar] [CrossRef]
- Yin, C.; Yang, B.; Cheng, J.C.; Gan, V.J.; Wang, B.; Yang, J. Label-efficient semantic segmentation of large-scale industrial point clouds using weakly supervised learning. Autom. Constr. 2023, 148, 104757. [Google Scholar] [CrossRef]
- Zhang, T.; Ma, M.; Yan, F.; Li, H.; Chen, Y. PIDS: Joint point interaction-dimension search for 3D point cloud. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 1298–1307. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Deng, C.; Peng, Z.; Chen, Z.; Chen, R. Point Cloud Deep Learning Network Based on Balanced Sampling and Hybrid Pooling. Sensors 2023, 23, 981. [Google Scholar] [CrossRef] [PubMed]
- Deng, H.; Birdal, T.; Ilic, S. PPF-FoldNet: Unsupervised Learning of Rotation Invariant 3D Local Descriptors. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Chang, L.; Zhang, L.; Xu, X. Correlation-oriented Complex System Structural Risk Assessment using Copula and Belief Rule Base. Inf. Sci. 2021, 564, 220–236. [Google Scholar] [CrossRef]
- Hoppe, H.; DeRose, T.; Duchamp, T.; McDonald, J.; Stuetzle, W. Surface reconstruction from unorganized points. In SIGGRAPH ′92: Proceedings of the 19th Annual Conference on Computer Graphics and Interactive Techniques; Association for Computing Machinery: New York, NY, USA, 1992; Volume 26, pp. 71–78. [Google Scholar]
- Oh, D.H. Copulas for High Dimensions: Models, Estimation, Inference, and Applications. Ph.D. Thesis, Duke University, Durham, NC, USA, 2014. [Google Scholar]
- Gao, J.; Barzel, B.; Barabási, A.L. Universal resilience patterns in complex networks. Nature 2016, 530, 307–312. [Google Scholar] [CrossRef] [PubMed]
- Sklar, M. Fonctions de Repartition an Dimensions et Leurs Marges; Publications de l’Institut de Statistique de l’Université de Paris: Paris, France, 1959; Volume 8, pp. 229–231. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D Semantic Parsing of Large-Scale Indoor Spaces. In Proceedings of the Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Cramer, M. The DGPF-test on digital airborne camera evaluation overview and test design. Photogramm.-Fernerkund.-Geoinf. 2010, 73–82. [Google Scholar] [CrossRef]
- Ye, X.; Li, J.; Huang, H.; Du, L.; Zhang, X. 3D Recurrent Neural Networks with Context Fusion for Point Cloud Semantic Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 415–430. [Google Scholar]
- Hyeon, J.; Lee, W.; Kim, J.H.; Doh, N. NormNet: Point-wise normal estimation network for three-dimensional point cloud data. Int. J. Adv. Robot. Syst. 2019, 16, 1729881419857532. [Google Scholar] [CrossRef]
- Chen, L.Z.; Li, X.Y.; Fan, D.P.; Wang, K.; Lu, S.P.; Cheng, M.M. LSANet: Feature Learning on Point Sets by Local Spatial Attention. arXiv 2019, arXiv:1905.05442. [Google Scholar]
- Lin, Y.; Yan, Z.; Huang, H.; Du, D.; Liu, L.; Cui, S.; Han, X. Fpconv: Learning local flattening for point convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4293–4302. [Google Scholar]
- Guo, F.; Ren, Q.; Tang, J.; Li, Z. Dilated Multi-scale Fusion for Point Cloud Classification and Segmentation. Multimed. Tools Appl. 2022, 81, 6069–6090. [Google Scholar] [CrossRef]
- Huang, R.; Xu, Y.; Hong, D.; Yao, W.; Ghamisi, P.; Stilla, U. Deep point embedding for urban classification using ALS point clouds: A new perspective from local to global. ISPRS J. Photogramm. Remote Sens. 2020, 163, 62–81. [Google Scholar] [CrossRef]
- Yang, Z.; Tan, B.; Pei, H.; Jiang, W. Segmentation and Multi-Scale Convolutional Neural Network-Based Classification of Airborne Laser Scanner Data. Sensors 2018, 18, 3347. [Google Scholar] [CrossRef]
- Zhao, R.; Pang, M.; Wang, J. Classifying airborne LiDAR point clouds via deep features learned by a multi-scale convolutional neural network. Int. J. Geogr. Inf. Sci. 2018, 32, 960–979. [Google Scholar] [CrossRef]
- Wen, C.; Yang, L.; Li, X.; Peng, L.; Chi, T. Directionally Constrained Fully Convolutional Neural Network For Airborne Lidar Point Cloud Classification. ISPRS J. Photogramm. Remote Sens. 2020, 162, 50–62. [Google Scholar] [CrossRef]
- Li, W.; Wang, F.D.; Xia, G.S. A geometry-attentional network for ALS point cloud classification. ISPRS J. Photogramm. Remote Sens. 2020, 164, 26–40. [Google Scholar] [CrossRef]
- Huang, R.; Xu, Y.; Stilla, U. GraNet: Global relation-aware attentional network for semantic segmentation of ALS point clouds. ISPRS J. Photogramm. Remote Sens. 2021, 177, 1–20. [Google Scholar] [CrossRef]
- Wen, C.; Li, X.; Yao, X.; Peng, L.; Chi, T. Airborne LiDAR point cloud classification with global-local graph attention convolution neural network. ISPRS J. Photogramm. Remote Sens. 2021, 173, 181–194. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Module |
|---|---|
| BSH-Net | Baseline |
| +LSE | Local stereoscopic feature encoding |
| +CFE | Copula-based similarity feature enhancement |
| ALL | Our method |
| Module | SD | MIoU | OA | Ceiling | Floor | Wall | Beam | Column | Window | Door | Table | Chair | Sofa | Bookcase | Board | Clutter |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 33.4 | 54.7 | 89.2 | 95.4 | 97.7 | 79.2 | 0.0 | 1.2 | 61.9 | 54.2 | 72.6 | 83.9 | 12.9 | 63.9 | 35.8 | 53.0 |
| LSE | 30.0 | 59.0 | 89.4 | 95.5 | 97.3 | 79.8 | 0.0 | 6.4 | 70.2 | 62.5 | 74.3 | 79.3 | 40.1 | 59.4 | 45.1 | 56.1 |
| CFE | 30.8 | 56.1 | 89.6 | 96.0 | 97.3 | 80.9 | 0.0 | 1.7 | 64.5 | 55.9 | 70.3 | 63.2 | 28.4 | 69.4 | 46.7 | 54.9 |
| ALL | 30.0 | 60.4 | 90.0 | 95.5 | 98.1 | 80.6 | 0.2 | 26.3 | 57.5 | 58.8 | 78.9 | 84.0 | 18.9 | 75.3 | 49.5 | 61.5 |
| Method | OA | MIoU |
|---|---|---|
| 3DRCNN | 85.7 | 53.4 |
| DGCNN | 84.1 | 56.1 |
| NormNet | 84.5 | 57.1 |
| SPGrap | 85.5 | 62.1 |
| LSANet | 86.8 | 62.2 |
| PointCNN | 88.1 | 65.4 |
| PointWeb | 87.3 | 66.7 |
| Randla-Net | 88.0 | 70.0 |
| FPConv | 89.9 | 66.7 |
| DMSF | 87.9 | 67.2 |
| BSH-Net | 90.5 | 66.1 |
| PointNAC | 90.9 | 67.4 |
| Model | Power-Line | Car | Facade | Hedge | Impervious Surface | Low Vegetation | Roof | Shrub | Tree | OA | Average F1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DPE | 68.1 | 75.2 | 44.2 | 19.5 | 99.3 | 86.5 | 91.1 | 39.4 | 72.6 | 83.2 | 66.2 |
| WhuY4 | 42.5 | 74.7 | 53.1 | 53.7 | 91.4 | 82.7 | 94.3 | 47.9 | 82.8 | 84.9 | 69.2 |
| NANJ2 | 62.0 | 66.7 | 42.6 | 40.7 | 91.2 | 88.8 | 93.6 | 55.9 | 82.6 | 85.2 | 69.3 |
| D-FCN | 70.4 | 78.1 | 60.5 | 37.0 | 91.4 | 80.2 | 93.0 | 46.0 | 79.4 | 82.2 | 70.7 |
| Dance-Net | 68.4 | 77.2 | 60.2 | 38.6 | 92.8 | 81.6 | 93.9 | 47.2 | 81.4 | 83.9 | 71.2 |
| GACNN | 76.0 | 77.7 | 58.9 | 37.8 | 93.0 | 81.8 | 93.1 | 46.7 | 78.9 | 83.2 | 71.5 |
| GANet | 75.4 | 77.8 | 61.5 | 44.2 | 91.6 | 82.0 | 94.4 | 49.6 | 82.6 | 84.5 | 73.2 |
| GraNet | 67.7 | 80.9 | 62.0 | 51.1 | 91.7 | 82.7 | 94.5 | 49.9 | 82.0 | 84.5 | 73.6 |
| BSH-NET | 46.5 | 77.8 | 57.9 | 37.9 | 92.9 | 82.3 | 94.8 | 48.6 | 86.3 | 85.4 | 69.5 |
| PointNAC | 52.9 | 76.7 | 57.5 | 41.1 | 93.6 | 83.2 | 94.9 | 50.5 | 85.2 | 85.9 | 70.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, C.; Chen, R.; Tang, W.; Chu, H.; Xu, G.; Cui, Y.; Peng, Z. PointNAC: Copula-Based Point Cloud Semantic Segmentation Network. Symmetry 2023, 15, 2021. https://doi.org/10.3390/sym15112021
Deng C, Chen R, Tang W, Chu H, Xu G, Cui Y, Peng Z. PointNAC: Copula-Based Point Cloud Semantic Segmentation Network. Symmetry. 2023; 15(11):2021. https://doi.org/10.3390/sym15112021
Chicago/Turabian StyleDeng, Chunyuan, Ruixing Chen, Wuyang Tang, Hexuan Chu, Gang Xu, Yue Cui, and Zhenyun Peng. 2023. "PointNAC: Copula-Based Point Cloud Semantic Segmentation Network" Symmetry 15, no. 11: 2021. https://doi.org/10.3390/sym15112021