
Output Layer Structure Optimization for Weighted Regularized Extreme Learning Machine Based on Binary Method

Abstract
:1. Introduction
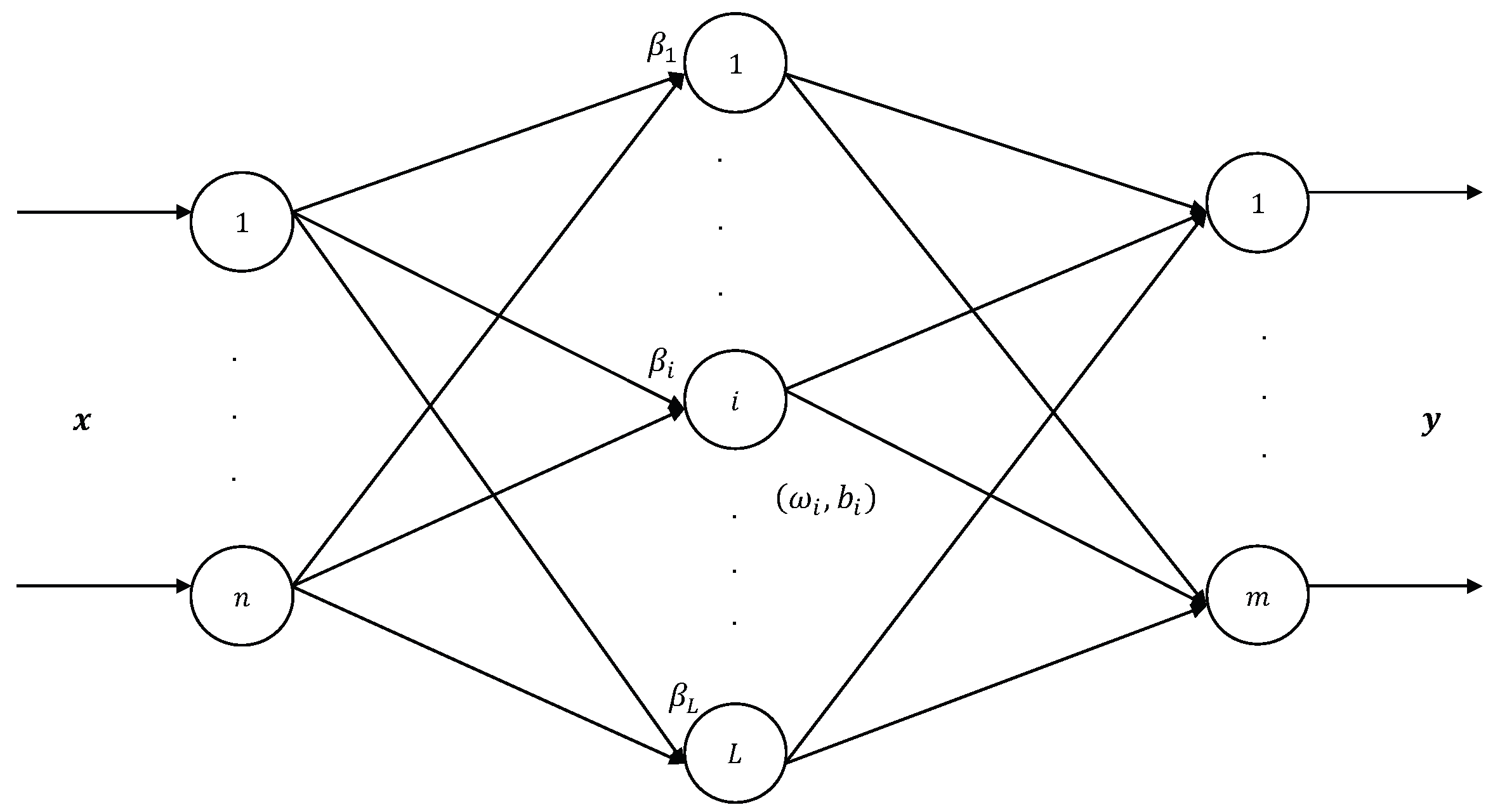
2. Brief Review of WRELM
3. Output Layer Settings
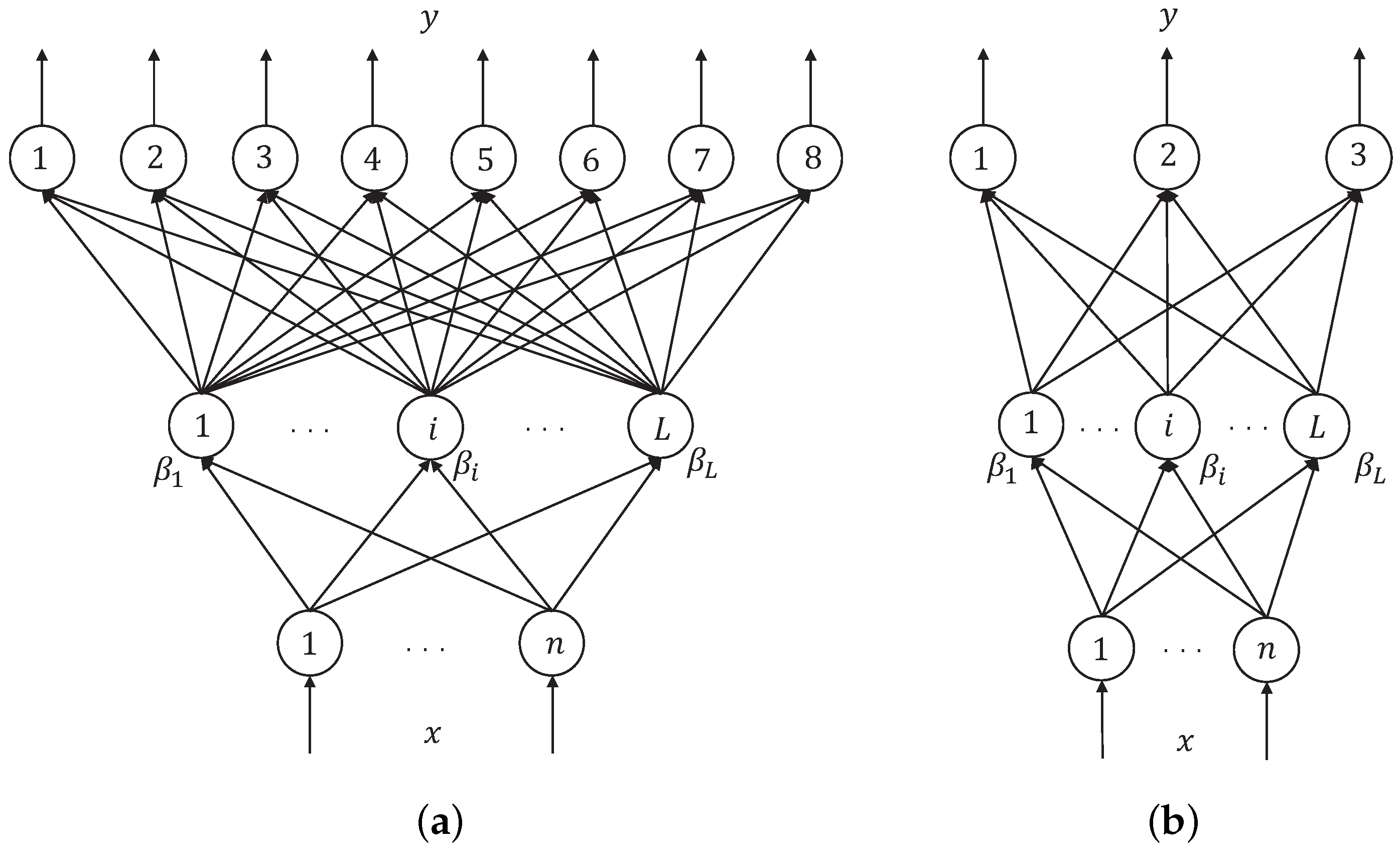
3.1. One-Hot Method
3.2. Binary Method
4. Numerical Experiments
4.1. Experiment Settings
| Algorithm 1 Experiment process |
|
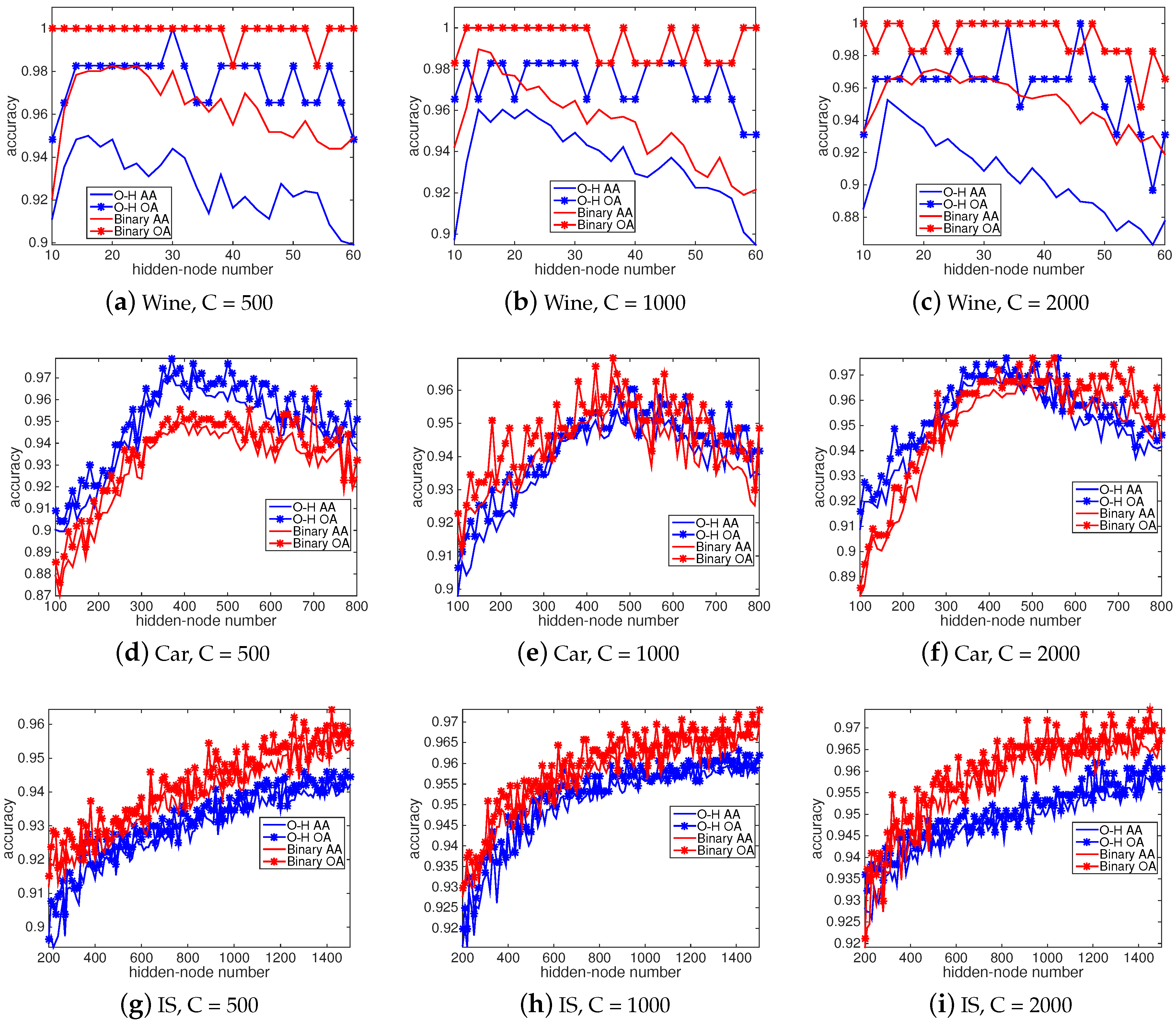
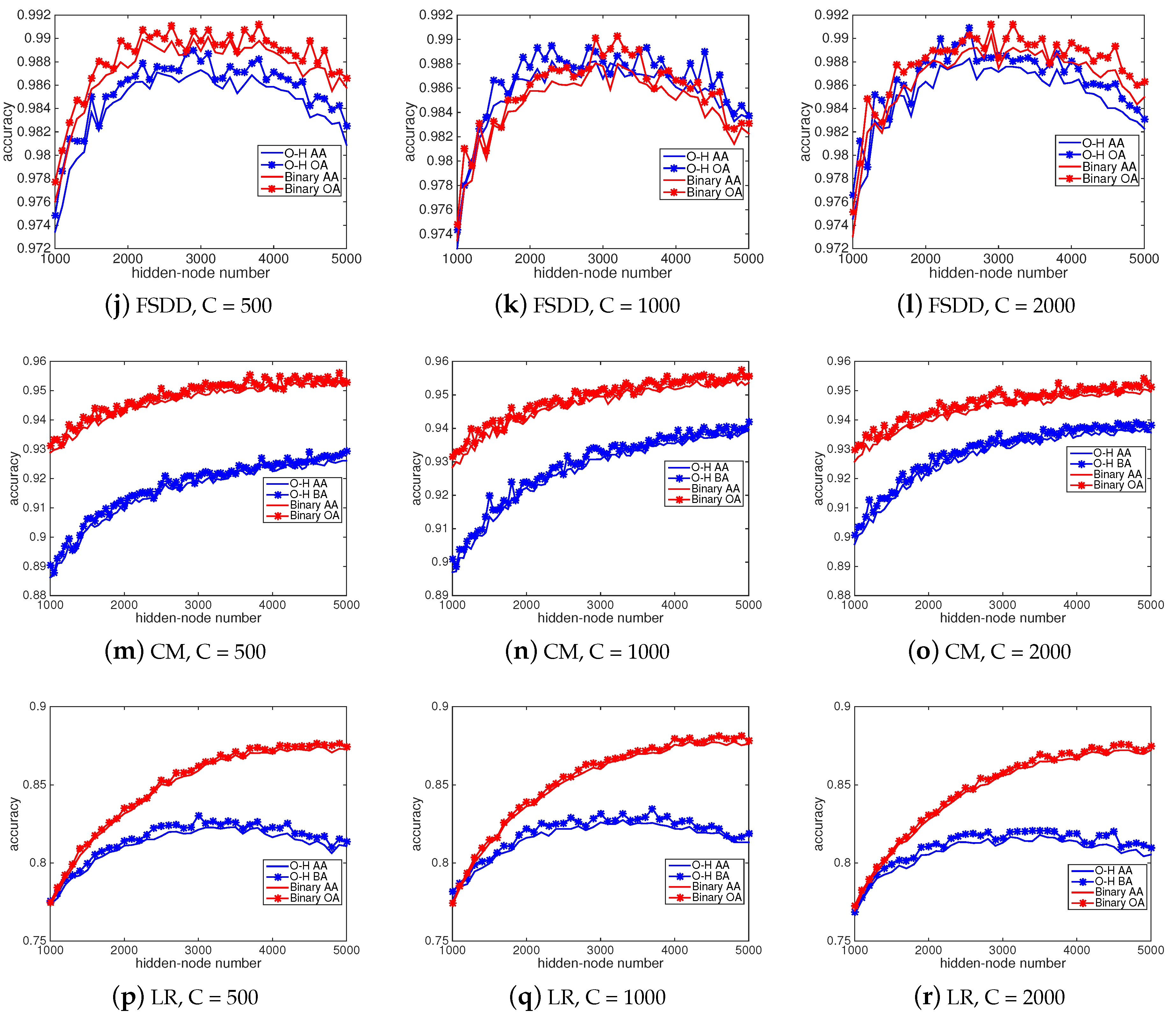
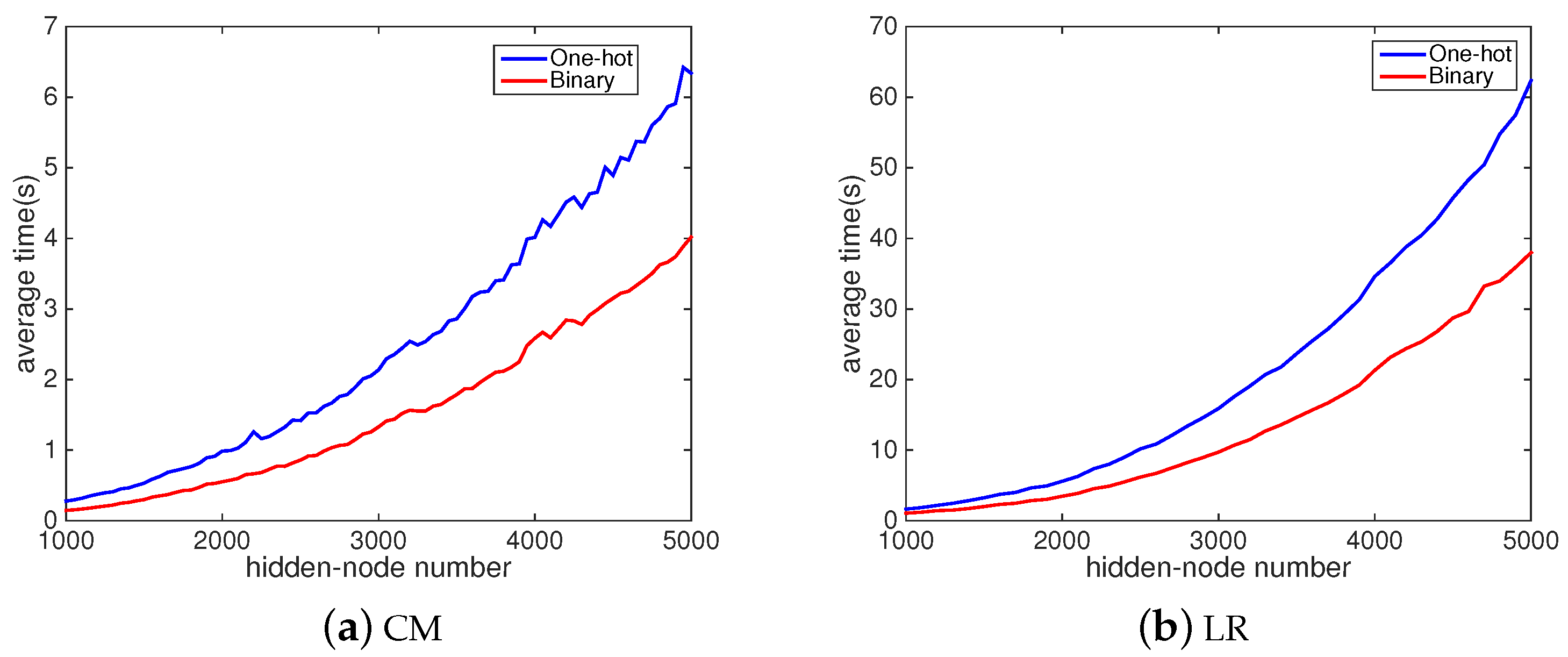
4.2. Classification Accuracies and Computational Time
4.3. Comparison on Several Evaluation Criteria
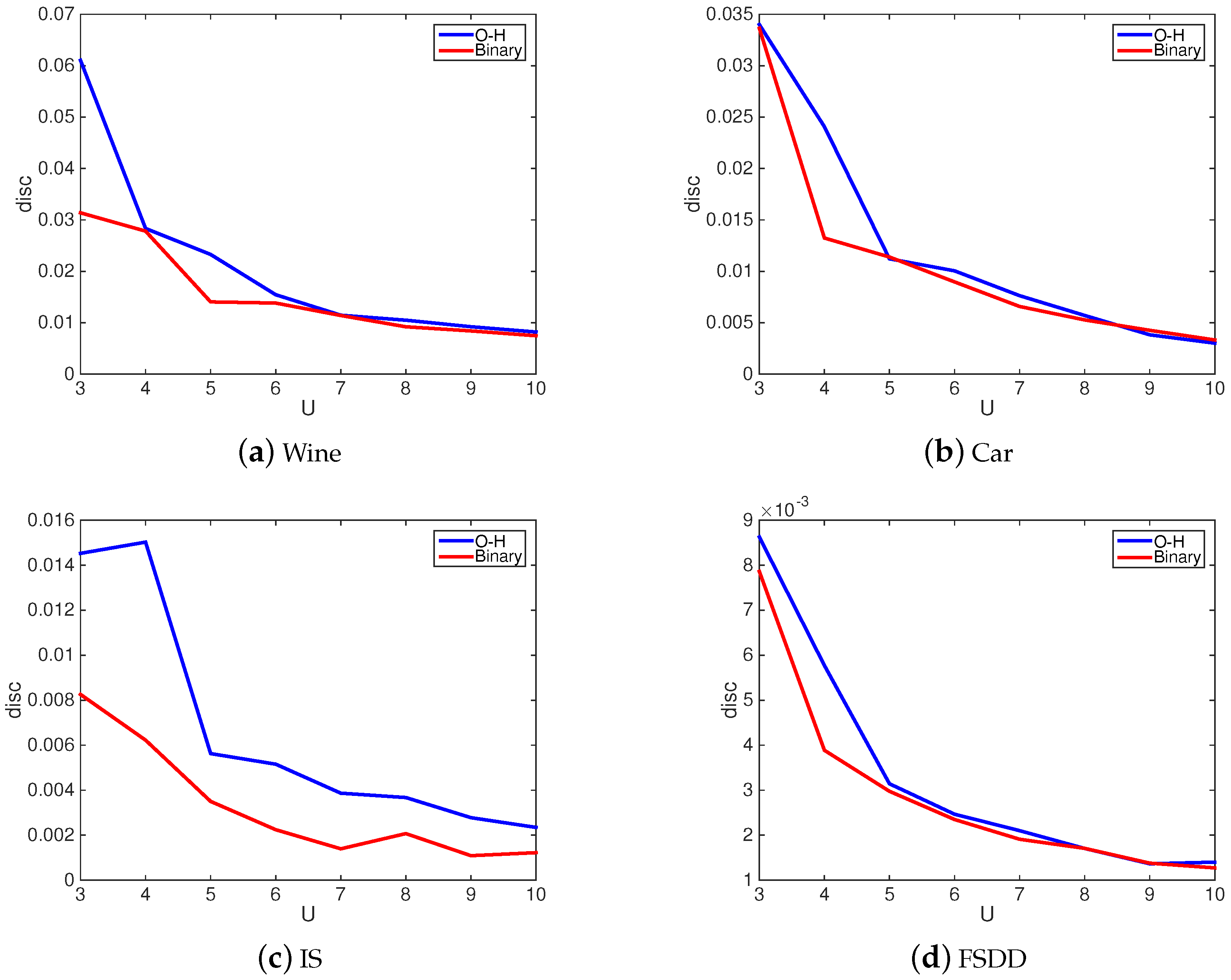
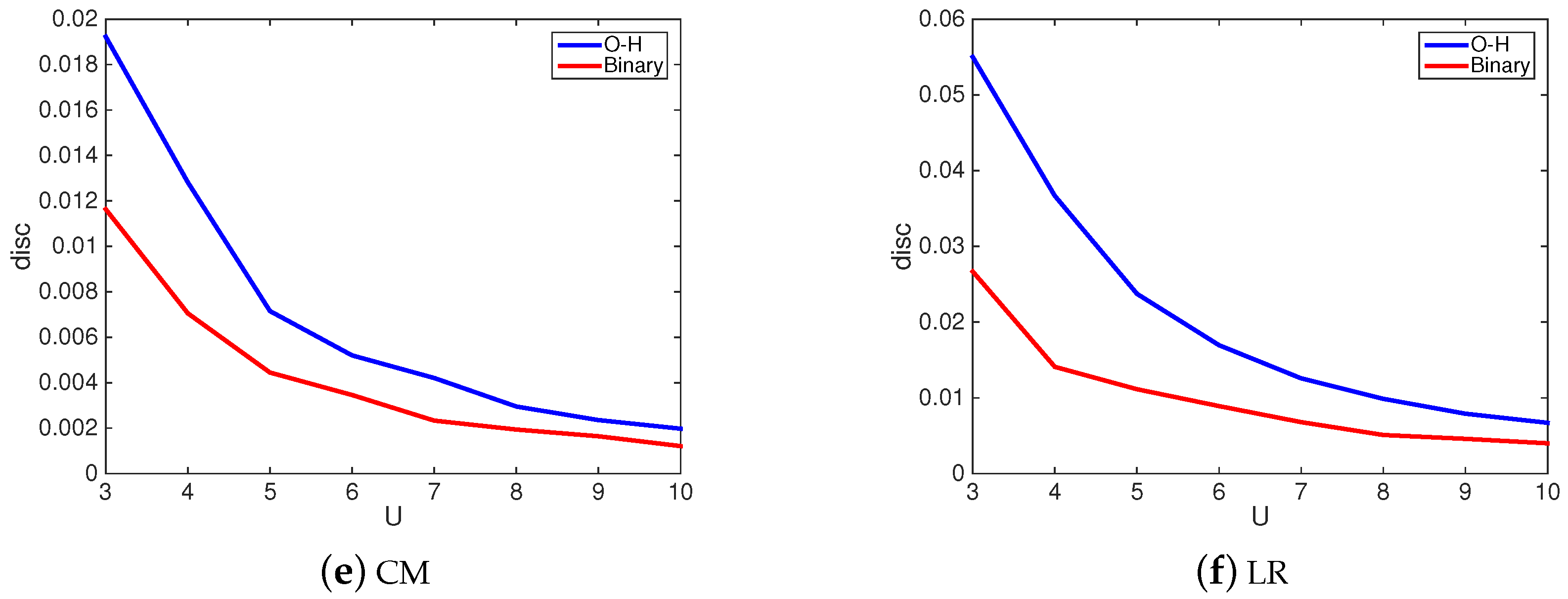
4.4. Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Faris, H.; Aljarah, I.; Mirjalili, S. Training feedforward neural networks using multi-verse optimizer for binary classification problems. Appl. Intell. 2016, 45, 322–332. [Google Scholar] [CrossRef]
- Eldan, R.; Shamir, O. The power of depth for feedforward neural networks. In Proceedings of the Conference on Learning Theory, New York, NY, USA, 23–26 June 2016; pp. 907–940. [Google Scholar]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B 2011, 42, 513–529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sattar, A.M.; Ertuğrul, Ö.F.; Gharabaghi, B.; McBean, E.A.; Cao, J. Extreme learning machine model for water network management. Neural Comput. Appl. 2019, 31, 157–169. [Google Scholar] [CrossRef]
- Dai, H.; Cao, J.; Wang, T.; Deng, M.; Yang, Z. Multilayer one-class extreme learning machine. Neural Netw. 2019, 115, 11–22. [Google Scholar] [CrossRef] [PubMed]
- Yaseen, Z.M.; Sulaiman, S.O.; Deo, R.C.; Chau, K.W. An enhanced extreme learning machine model for river flow forecasting: State-of-the-art, practical applications in water resource engineering area and future research direction. J. Hydrol. 2019, 569, 387–408. [Google Scholar] [CrossRef]
- Luo, X.; Jiang, C.; Wang, W.; Xu, Y.; Wang, J.H.; Zhao, W. User behavior prediction in social networks using weighted extreme learning machine with distribution optimization. Future Gener. Comput. Syst. 2019, 93, 1023–1035. [Google Scholar] [CrossRef]
- Zhang, D.; Peng, X.; Pan, K.; Liu, Y. A novel wind speed forecasting based on hybrid decomposition and online sequential outlier robust extreme learning machine. Energy Convers. Manag. 2019, 180, 338–357. [Google Scholar] [CrossRef]
- Cao, F.; Yang, Z.; Ren, J.; Chen, W.; Han, G.; Shen, Y. Local block multilayer sparse extreme learning machine for effective feature extraction and classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5580–5594. [Google Scholar] [CrossRef] [Green Version]
- Ding, S.; Ma, G.; Shi, Z. A rough RBF neural network based on weighted regularized extreme learning machine. Neural Process. Lett. 2014, 40, 245–260. [Google Scholar] [CrossRef]
- Huang, N.; Yuan, C.; Cai, G.; Xing, E. Hybrid short term wind speed forecasting using variational mode decomposition and a weighted regularized extreme learning machine. Energies 2016, 9, 989. [Google Scholar] [CrossRef]
- Belghit, A.; Lazri, M.; Ouallouche, F.; Labadi, K.; Ameur, S. Optimization of One versus All-SVM using AdaBoost algorithm for rainfall classification and estimation from multispectral MSG data. Adv. Space Res. 2023, 71, 946–963. [Google Scholar] [CrossRef]
- Pawara, P.; Okafor, E.; Groefsema, M.; He, S.; Schomaker, L.R.; Wiering, M.A. One-vs-One classification for deep neural networks. Pattern Recognit. 2020, 108, 107528. [Google Scholar] [CrossRef]
- Liu, K.H.; Gao, J.; Xu, Y.; Feng, K.J.; Ye, X.N.; Liong, S.T.; Chen, L.Y. A novel soft-coded error-correcting output codes algorithm. Pattern Recognit. 2023, 134, 109122. [Google Scholar] [CrossRef]
- Nie, Q.; Jin, L.; Fei, S.; Ma, J. Neural network for multi-class classification by boosting composite stumps. Neurocomputing 2015, 149, 949–956. [Google Scholar] [CrossRef]
- Lei, Y.; Dogan, Ü.; Zhou, D.X.; Kloft, M. Data-dependent generalization bounds for multi-class classification. IEEE Trans. Inf. Theory 2019, 65, 2995–3021. [Google Scholar] [CrossRef] [Green Version]
- Tang, L.; Tian, Y.; Pardalos, P.M. A novel perspective on multiclass classification: Regular simplex support vector machine. Inf. Sci. 2019, 480, 324–338. [Google Scholar] [CrossRef]
- Dong, Q.; Zhu, X.; Gong, S. Single-label multi-class image classification by deep logistic regression. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3486–3493. [Google Scholar]
- Ruivo, E.L.; de Oliveira, P.P. A perfect solution to the parity problem with elementary cellular automaton 150 under asynchronous update. Inf. Sci. 2019, 493, 138–151. [Google Scholar] [CrossRef]
- Saberi-Movahed, F.; Rostami, M.; Berahmand, K.; Karami, S.; Tiwari, P.; Oussalah, M.; Band, S.S. Dual regularized unsupervised feature selection based on matrix factorization and minimum redundancy with application in gene selection. Knowl.-Based Syst. 2022, 256, 109884. [Google Scholar] [CrossRef]
- Rostami, M.; Berahmand, K.; Nasiri, E.; Forouzandeh, S. Review of swarm intelligence-based feature selection methods. Eng. Appl. Artif. Intell. 2021, 100, 104210. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, H.; Chen, H.; Wang, Y.; Zhang, Y. Structure-Guided L1/2 Minimization for Stable Multichannel Seismic Attenuation Compensation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–9. [Google Scholar] [CrossRef]
- Heydari, E.; Abadi, M.S.E.; Khademiyan, S.M. Improved multiband structured subband adaptive filter algorithm with L0-norm regularization for sparse system identification. Digit. Signal Process. 2022, 122, 103348. [Google Scholar] [CrossRef]
- Courbariaux, M.; Bengio, Y. BinaryConnect: Training Deep Neural Networks with Binary Weights during Propagations; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Chitrakar, P.; Zhang, C.; Warner, G.; Liao, X. Social Media Image Retrieval Using Distilled Convolutional Neural Network for Suspicious e-Crime and Terrorist Account Detection. In Proceedings of the 2016 IEEE International Symposium on Multimedia (ISM), San Jose, CA, USA, 11–13 December 2016. [Google Scholar]
- Lu, H.; Yao, Q.; Kwok, J.T. Loss-aware Binarization of Deep Networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Hartmann, M.; Farooq, H.; Imran, A. Distilled Deep Learning based Classification of Abnormal Heartbeat Using ECG Data through a Low Cost Edge Device. In Proceedings of the 2019 IEEE Symposium on Computers and Communications (ISCC), Barcelona, Spain, 29 June–3 July 2019. [Google Scholar]
- Darabi, S.; Belbahri, M.; Courbariaux, M.; Nia, V.P. BNN+: Improved Binary Network Training. arXiv 2018, arXiv:1812.11800. [Google Scholar]
- Liu, C.; Ding, W.; Xia, X.; Zhang, B.; Gu, J.; Liu, J.; Ji, R.; Doermann, D. Circulant Binary Convolutional Networks: Enhancing the Performance of 1-bit DCNNs with Circulant Back Propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Kung, J.; Zhang, D.; Gooitzen, V.; Chai, S.; Mukhopadhyay, S. Efficient Object Detection Using Embedded Binarized Neural Networks. J. Signal Process. Syst. 2017, 90, 877–890. [Google Scholar] [CrossRef]
- Leng, C.; Li, H.; Zhu, S.; Jin, R. Extremely Low Bit Neural Network: Squeeze the Last Bit Out with ADMM. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Li, R.; Wang, Y.; Liang, F.; Qin, H.; Fan, R. Fully Quantized Network for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. Neural Netw. 2004, 2, 985–990. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.B.; Wang, D.H.; Lan, Y. Extreme learning machines: A survey. Int. J. Mach. Learn. Cybern. 2011, 2, 107–122. [Google Scholar] [CrossRef]
- Fill, J.A.; Fishkind, D.E. The Moore–Penrose Generalized Inverse for Sums of Matrices. SIAM J. Matrix Anal. Appl. 2000, 21, 629–635. [Google Scholar] [CrossRef] [Green Version]
- Rakha, M.A. On the Moore–Penrose generalized inverse matrix. Appl. Math. Comput. 2004, 158, 185–200. [Google Scholar] [CrossRef]
- Cosmo, D.L.; Salles, E.O.T. Multiple Sequential Regularized Extreme Learning Machines for Single Image Super Resolution. IEEE Signal Process. Lett. 2019, 26, 440–444. [Google Scholar] [CrossRef]
- Yu, Q.; Miche, Y.; Eirola, E.; Van Heeswijk, M.; SéVerin, E.; Lendasse, A. Regularized extreme learning machine for regression with missing data. Neurocomputing 2013, 102, 45–51. [Google Scholar] [CrossRef]
- Lang, K.; Zhang, M.; Yuan, Y.; Yue, X. Short-term load forecasting based on multivariate time series prediction and weighted neural network with random weights and kernels. Clust. Comput. 2019, 22, 12589–12597. [Google Scholar] [CrossRef]
- Seferbekov, S.S.; Iglovikov, V.; Buslaev, A.; Shvets, A. Feature Pyramid Network for Multi-Class Land Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 272–275. [Google Scholar]
- Gupta, Y. Selection of important features and predicting wine quality using machine learning techniques. Procedia Comput. Sci. 2018, 125, 305–312. [Google Scholar] [CrossRef]
- Yang, L.; Luo, P.; Change Loy, C.; Tang, X. A large-scale car dataset for fine-grained categorization and verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3973–3981. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ameid, T.; Menacer, A.; Talhaoui, H.; Harzelli, I. Rotor resistance estimation using Extended Kalman filter and spectral analysis for rotor bar fault diagnosis of sensorless vector control induction motor. Measurement 2017, 111, 243–259. [Google Scholar] [CrossRef]
- Yu, Y.; Shi, W.; Chen, R.; Chen, L.; Bao, S.; Chen, P. Map-Assisted Seamless Localization Using Crowdsourced Trajectories Data and Bi-LSTM Based Quality Control Criteria. IEEE Sens. J. 2022, 22, 16481–16491. [Google Scholar] [CrossRef]
- Sankara Babu, B.; Nalajala, S.; Sarada, K.; Muniraju Naidu, V.; Yamsani, N.; Saikumar, K. Machine Learning Based Online Handwritten Telugu Letters Recognition for Different Domains. In A Fusion of Artificial Intelligence and Internet of Things for Emerging Cyber Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 227–241. [Google Scholar]
- Wong, T.T.; Yang, N.Y. Dependency analysis of accuracy estimates in k-fold cross validation. IEEE Trans. Knowl. Data Eng. 2017, 29, 2417–2427. [Google Scholar] [CrossRef]
- Jiang, P.; Chen, J. Displacement prediction of landslide based on generalized regression neural networks with K-fold cross-validation. Neurocomputing 2016, 198, 40–47. [Google Scholar] [CrossRef]
- He, J.; Fan, X. Evaluating the Performance of the K-fold Cross-Validation Approach for Model Selection in Growth Mixture Modeling. Struct. Equ. Model. A Multidiscip. J. 2019, 26, 66–79. [Google Scholar] [CrossRef]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- DuBois, J.; Boylan, L.; Shiyko, M.; Barr, W.; Devinsky, O. Seizure prediction and recall. Epilepsy Behav. 2010, 18, 106–109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, R.; Li, J. Bayes Test of Precision, Recall, and F1 Measure for Comparison of Two Natural Language Processing Models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4135–4145. [Google Scholar]
- Azami, H.; Fernández, A.; Escudero, J. Refined multiscale fuzzy entropy based on standard deviation for biomedical signal analysis. Med. Biol. Eng. Comput. 2017, 55, 2037–2052. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sign | Meaning | Sign | Meaning |
|---|---|---|---|
| n-dimensional vector space | data set | ||
| output matrix of hidden layer | transpose of matrix | ||
| generalized inverse of matrix | inverse of matrix | ||
| identity matrix | C | regularization parameter | |
| 2-norm | g | sigmoid function |
| Dataset | Class | Attribute | Case | O-H | Binary | ||
|---|---|---|---|---|---|---|---|
| AA | OA | AA | OA | ||||
| SVM | 94.16% | 97.42% | 95.53% | 98.28% | |||
| APNN | 94.30% | 98.28% | 96.06% | 100.00% | |||
| ELM | 94.71% | 100.00% | 96.19% | 100.00% | |||
| Wine | 4 | 13 | WELM, C = 0 | 95.04% | 98.28% | 97.16% | 100.00% |
| WRELM, C = 500 | 95.00% | 100.00% | 98.28% | 100.00% | |||
| WRELM, C = 1000 | 96.03% | 98.28% | 97.16% | 100.00% | |||
| WRELM, C = 2000 | 95.26% | 100.00% | 97.16% | 100.00% | |||
| SVM | 93.59% | 94.07% | 93.46% | 94.05% | |||
| APNN | 94.27% | 95.62% | 94.78% | 96.11% | |||
| ELM | 96.54% | 97.90% | 94.86% | 96.73% | |||
| Car | 4 | 6 | WELM, C = 0 | 97.03% | 98.11% | 97.12% | 98.04% |
| WRELM, C = 500 | 97.27% | 97.90% | 94.94% | 96.50% | |||
| WRELM, C = 1000 | 95.56% | 96.03% | 96.34% | 96.96% | |||
| WRELM, C = 2000 | 97.12% | 97.66% | 96.94% | 97.66% | |||
| SVM | 93.54% | 93.91% | 94.70% | 95.26% | |||
| APNN | 94.02% | 94.35% | 95.39% | 96.71% | |||
| ELM | 94.69% | 95.43% | 96.12% | 97.04% | |||
| IS | 7 | 18 | WELM, C = 0 | 95.37% | 95.91% | 96.49% | 97.17% |
| WRELM, C = 500 | 94.38% | 94.59% | 95.70% | 96.44% | |||
| WRELM, C = 1000 | 96.11% | 96.31% | 96.93% | 97.30% | |||
| WRELM, C = 2000 | 95.90% | 96.34% | 96.89% | 97.43% | |||
| SVM | 96.78% | 97.51% | 97.03% | 97.84% | |||
| APNN | 97.28% | 97.90% | 97.50% | 98.21% | |||
| ELM | 98.80% | 99.03% | 98.91% | 99.09% | |||
| FSDD | 4 | 48 | WELM, C = 0 | 98.80% | 99.01% | 98.82% | 99.06% |
| WRELM, C = 500 | 98.73% | 98.90% | 99.01% | 99.12% | |||
| WRELM, C = 1000 | 98.82% | 98.95% | 98.80% | 99.03% | |||
| WRELM, C = 2000 | 98.83% | 99.09% | 99.02% | 99.12% | |||
| SVM | 91.04% | 91.60% | 92.86% | 93.37% | |||
| APNN | 91.90% | 92.35% | 93.67% | 94.02% | |||
| ELM | 92.67% | 93.18% | 94.58% | 95.15% | |||
| CM | 6 | 28 | WELM, C = 0 | 92.81% | 93.76% | 94.97% | 95.28% |
| WRELM, C = 500 | 92.66% | 92.93% | 95.35% | 95.61% | |||
| WRELM, C = 1000 | 93.96% | 94.20% | 95.48% | 95.75% | |||
| WRELM, C = 2000 | 93.71% | 93.92% | 95.05% | 95.43% | |||
| SVM | 81.36% | 82.13% | 81.71% | 82.64% | |||
| APNN | 82.72% | 83.41% | 82.94% | 83.79% | |||
| ELM | 81.57% | 82.60% | 87.60% | 87.96% | |||
| LR | 26 | 16 | WELM, C = 0 | 81.83% | 82.35% | 87.32% | 87.81% |
| WRELM, C = 500 | 82.30% | 83.04% | 87.44% | 87.68% | |||
| WRELM, C = 1000 | 82.75% | 83.46% | 87.78% | 88.14% | |||
| WRELM, C = 2000 | 81.79% | 82.08% | 87.24% | 87.60% | |||
| Dataset | O-H | Binary | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PR | RR | F1 | σ | RMSE | PR | RR | F1 | σ | RMSE | |
| Wine | 95.67% | 94.89% | 95.28% | 0.0238 | 0.0167 | 98.48% | 97.03% | 97.75% | 0.0202 | 0.0116 |
| Car | 93.97% | 93.15% | 93.56% | 0.0210 | 0.0152 | 92.45% | 91.40% | 91.92% | 0.0255 | 0.0171 |
| IS | 94.39% | 94.71% | 94.55% | 0.0169 | 0.0175 | 96.38% | 96.23% | 96.30% | 0.0108 | 0.0130 |
| FSDD | 98.56% | 99.04% | 98.80% | 0.0123 | 0.0047 | 99.09% | 98.60% | 98.84% | 0.0094 | 0.0037 |
| CM | 92.94% | 84.16% | 88.33% | 0.0153 | 0.0124 | 94.51% | 88.79% | 91.56% | 0.0105 | 0.0097 |
| LR | 84.72% | 70.04% | 76.68% | 0.0092 | 0.0021 | 89.94% | 72.61% | 80.35% | 0.0071 | 0.0015 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Wang, S.; Sun, L.; Luo, Z.; Bao, Y. Output Layer Structure Optimization for Weighted Regularized Extreme Learning Machine Based on Binary Method. Symmetry 2023, 15, 244. https://doi.org/10.3390/sym15010244
Yang S, Wang S, Sun L, Luo Z, Bao Y. Output Layer Structure Optimization for Weighted Regularized Extreme Learning Machine Based on Binary Method. Symmetry. 2023; 15(1):244. https://doi.org/10.3390/sym15010244
Chicago/Turabian StyleYang, Sibo, Shusheng Wang, Lanyin Sun, Zhongxuan Luo, and Yuan Bao. 2023. "Output Layer Structure Optimization for Weighted Regularized Extreme Learning Machine Based on Binary Method" Symmetry 15, no. 1: 244. https://doi.org/10.3390/sym15010244