
Isokinetic Rehabilitation Trajectory Planning of an Upper Extremity Exoskeleton Rehabilitation Robot Based on a Multistrategy Improved Whale Optimization Algorithm
Abstract
:1. Introduction
- A preliminary trajectory was first generated based on a piecewise polynomial;
- To more closely resemble a human-like motion, a bounded jerk trajectory was constructed using the WOA, with a minimal running time as the optimization objective;
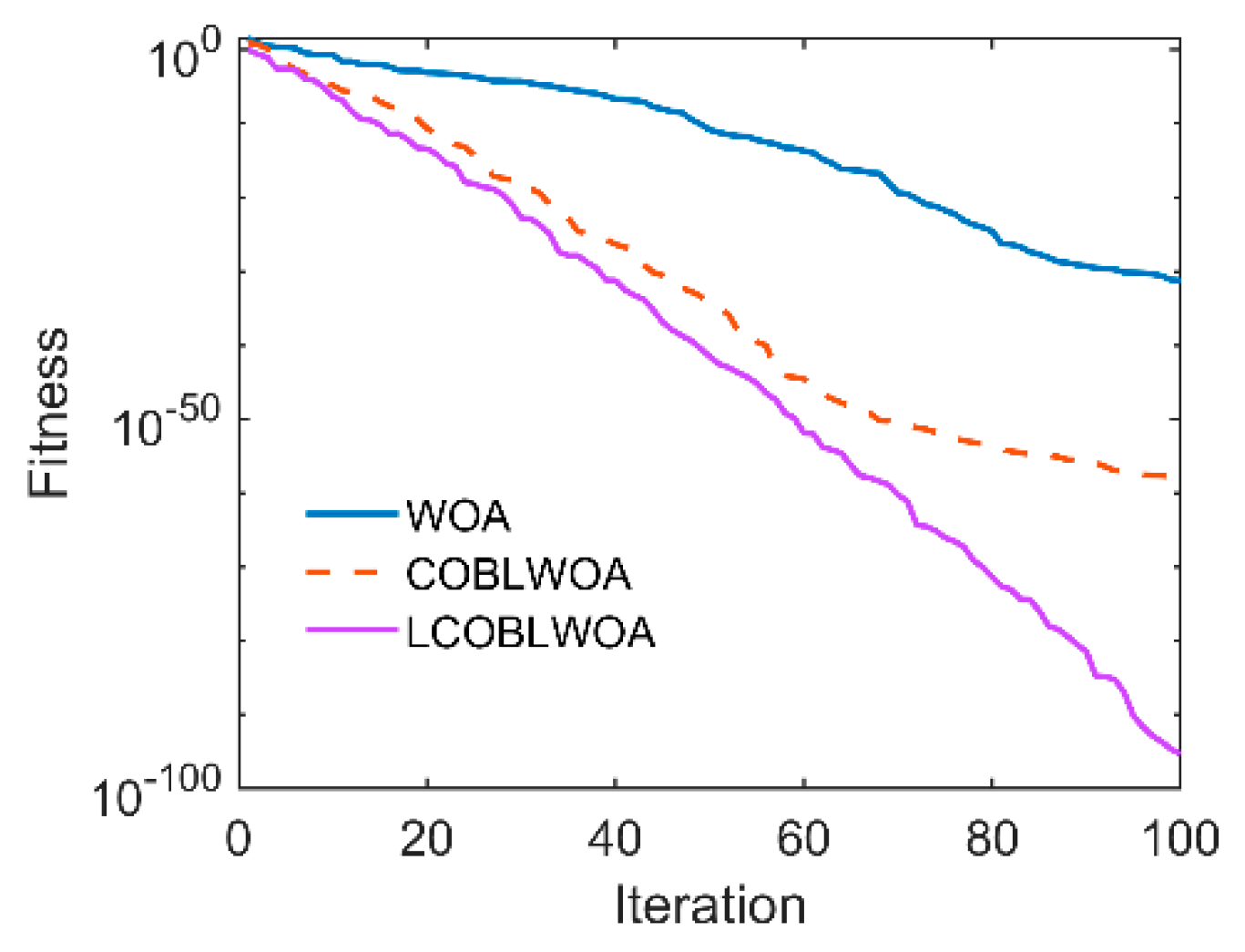
- To tackle the WOA’s shortage in search ability under complex constraints, three strategies were integrated into the proposed MWOA, and the resulting trajectories were compared to those obtained by the original WOA. A dual-population search with a novel communication mechanism to bypass local optimum was used. Mutation centroid opposition-based learning was used to improve the diversity of the population. An adaptive inertia weight mechanism was used to balance the WOA’s exploration and exploitation abilities;
- Finally, a 4-DOF upper extremity exoskeleton rehabilitation (4-DOF UEER) robot was tested by simulation analysis and then validated on a healthy volunteer to mimic isokinetic rehabilitation training along the trajectory planned by the MWOA.
2. Piecewise Polynomial Trajectory Planning
2.1. Generation of a Preliminary Rehabilitation Trajectory by Piecewise Polynomial
2.2. Description of the Trajectory Optimization Problem
3. Optimization Algorithm
3.1. Whale Optimization Algorithm
3.1.1. Encircling Prey
3.1.2. Bubble-Net Attacking Method (Exploitation Phase)
3.1.3. Search for Prey (Exploration Phase)
3.2. Multistrategy Improved Whale Optimization Algorithm (MWOA)
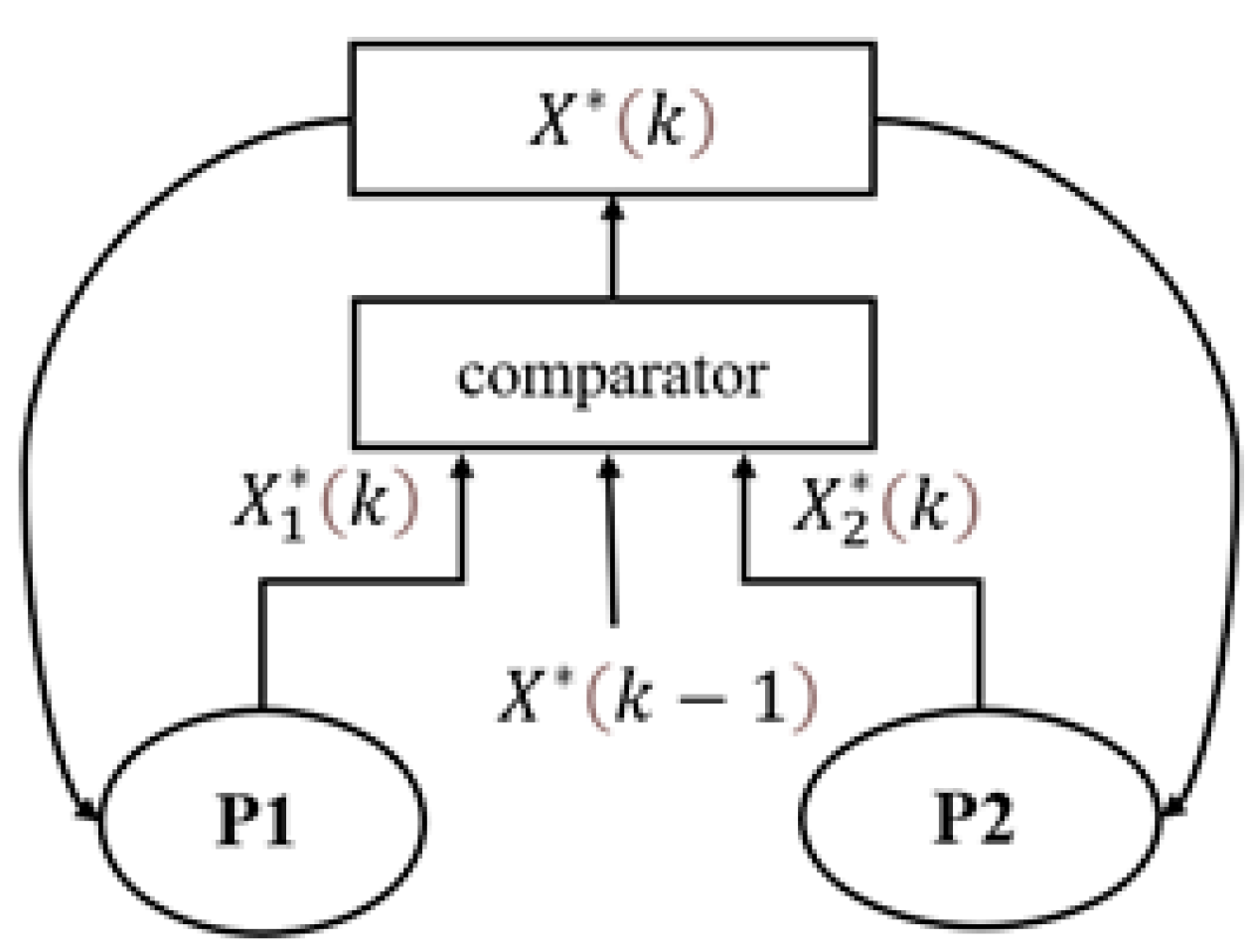
3.2.1. Dual-Population Search
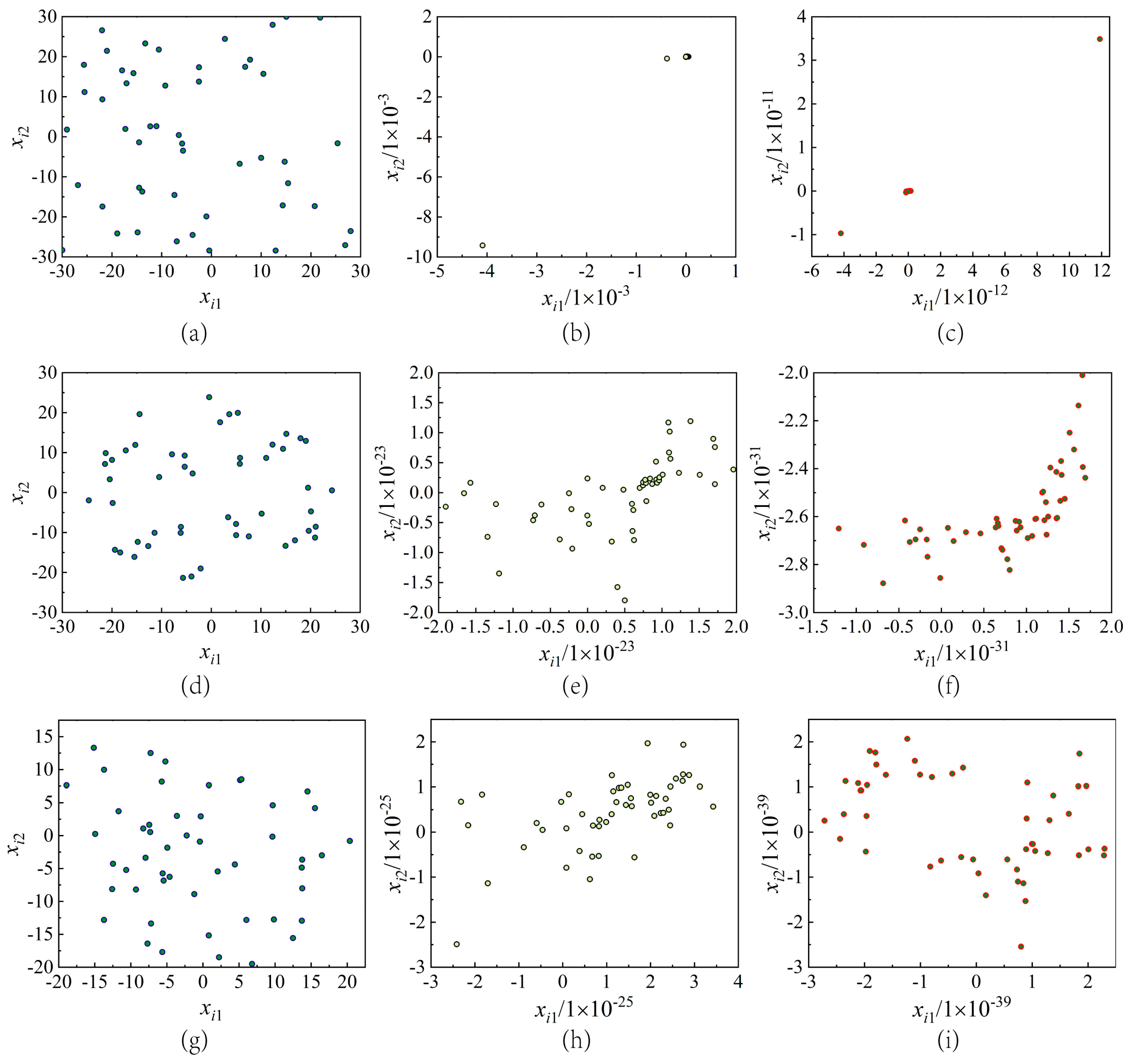
3.2.2. Mutation Centroid Opposition-Based Learning
- Cauchy Mutation
- 2.
- Levy mutation
3.2.3. Adaptive Inertia Weight
| Algorithm 1: Pseudo-code of MWOA algorithm. |
| 1: and , respectively. |
| 2: < ) do |
| 3: , |
| 4: Levy |
| 5: is fitness function |
| 6: after mutating |
| 7: else |
| 8: |
| 9: end if |
| 10: In |
| 11: . |
| 12: |
| 13: 14: Cauchy |
| 15: |
| 16: |
| 17: |
| 18: |
| 19: |
| 20: by the new communication mechanism |
| 21: 2) do |
| 22: |
| 23: end while 2 |
| 24: ; |
| 25: |
| 26: |
| 27: |
| 28: using Equations (26)–(28), calculate the fitness of each particle |
| 29: end for |
| 30: |
| 31: |
| 32: using Equations (26)–(28), calculate the fitness of each particle |
| 33: end for |
| 34: if there is a better solution |
| 35: = + 1 |
| 36: end while 1 |
| 37: return |
3.2.4. Trajectory Planning Process Based on the MWOA
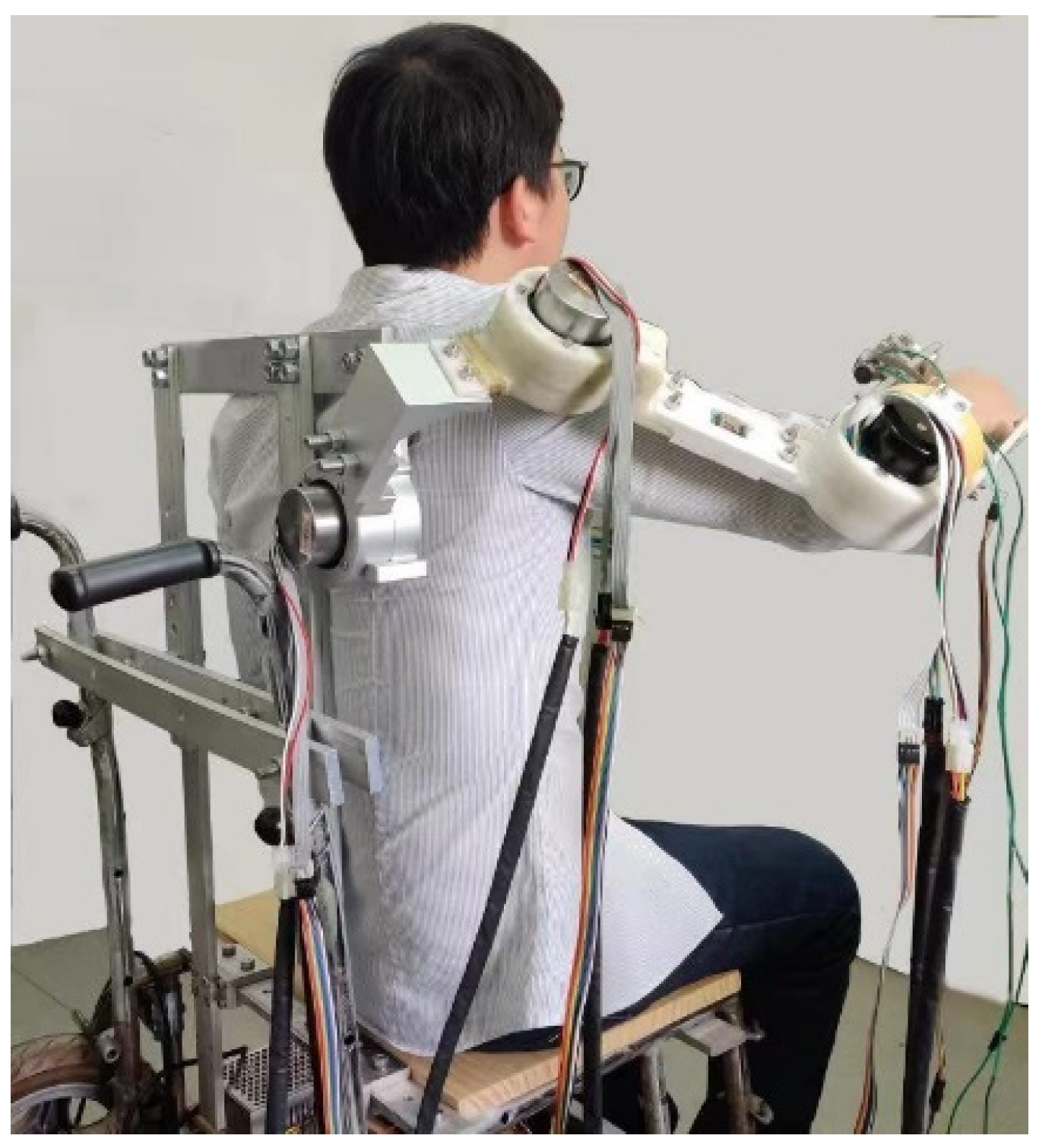
4. Simulation Analysis and Pilot Experiment
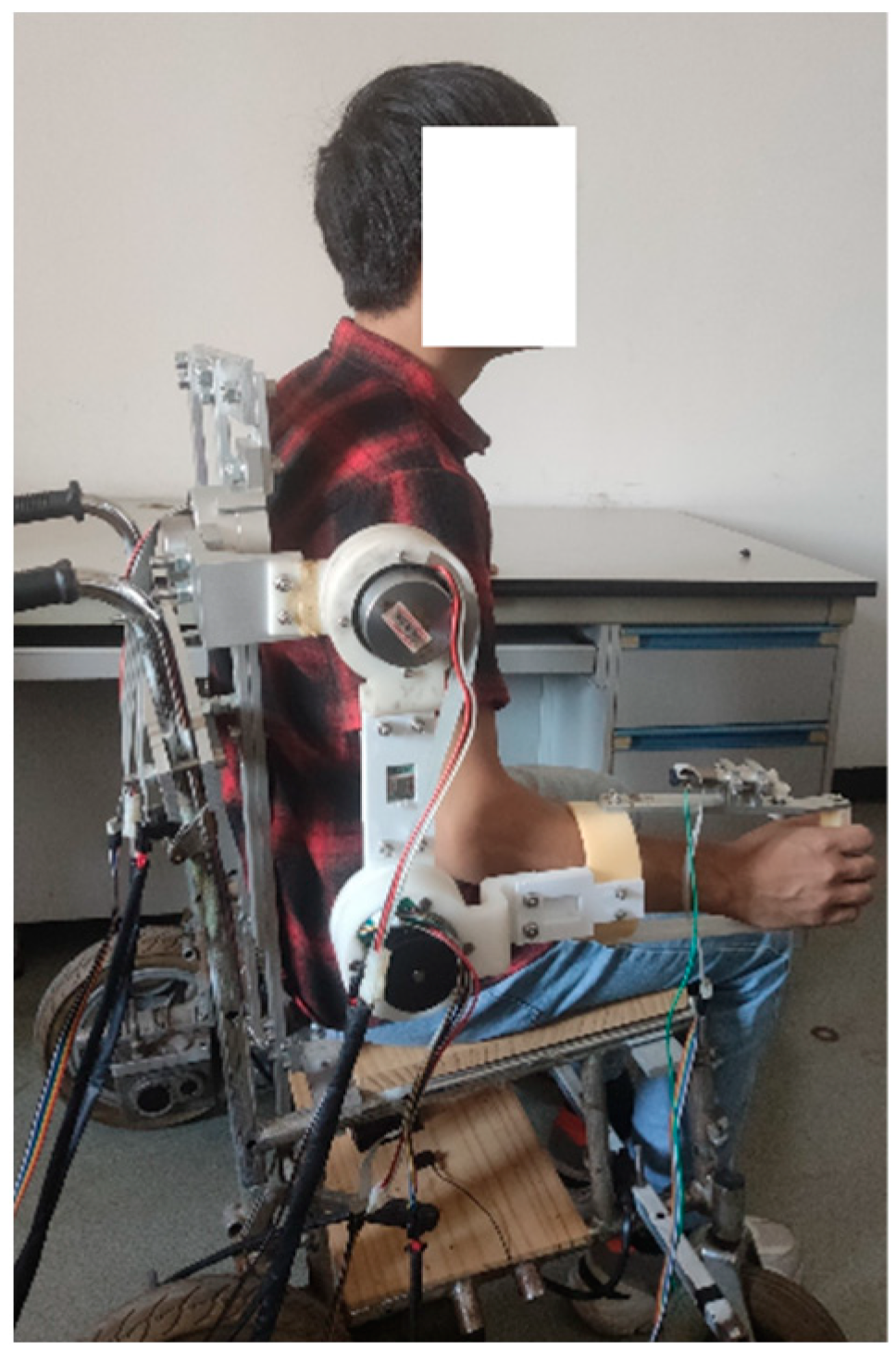
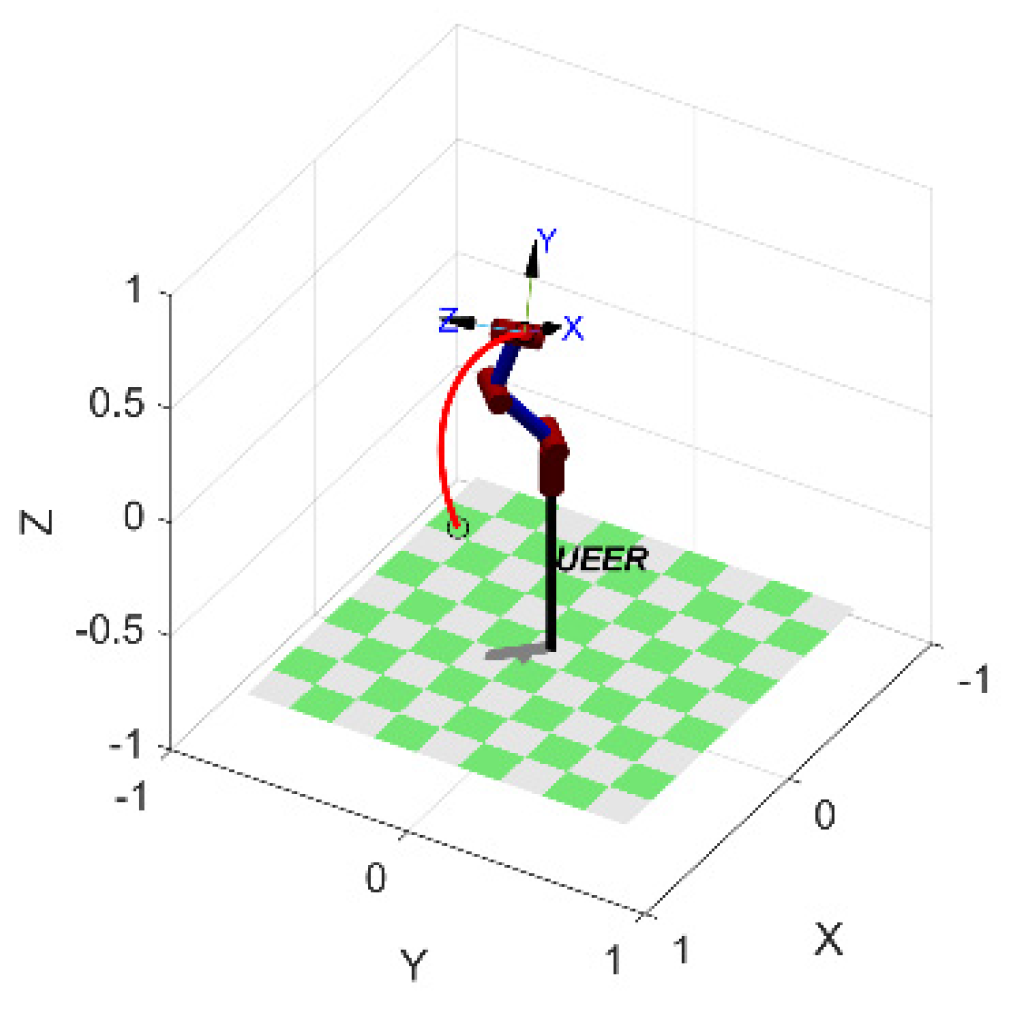
4.1. 4-DOF Upper Extremity Exoskeleton Rehabilitation Robot
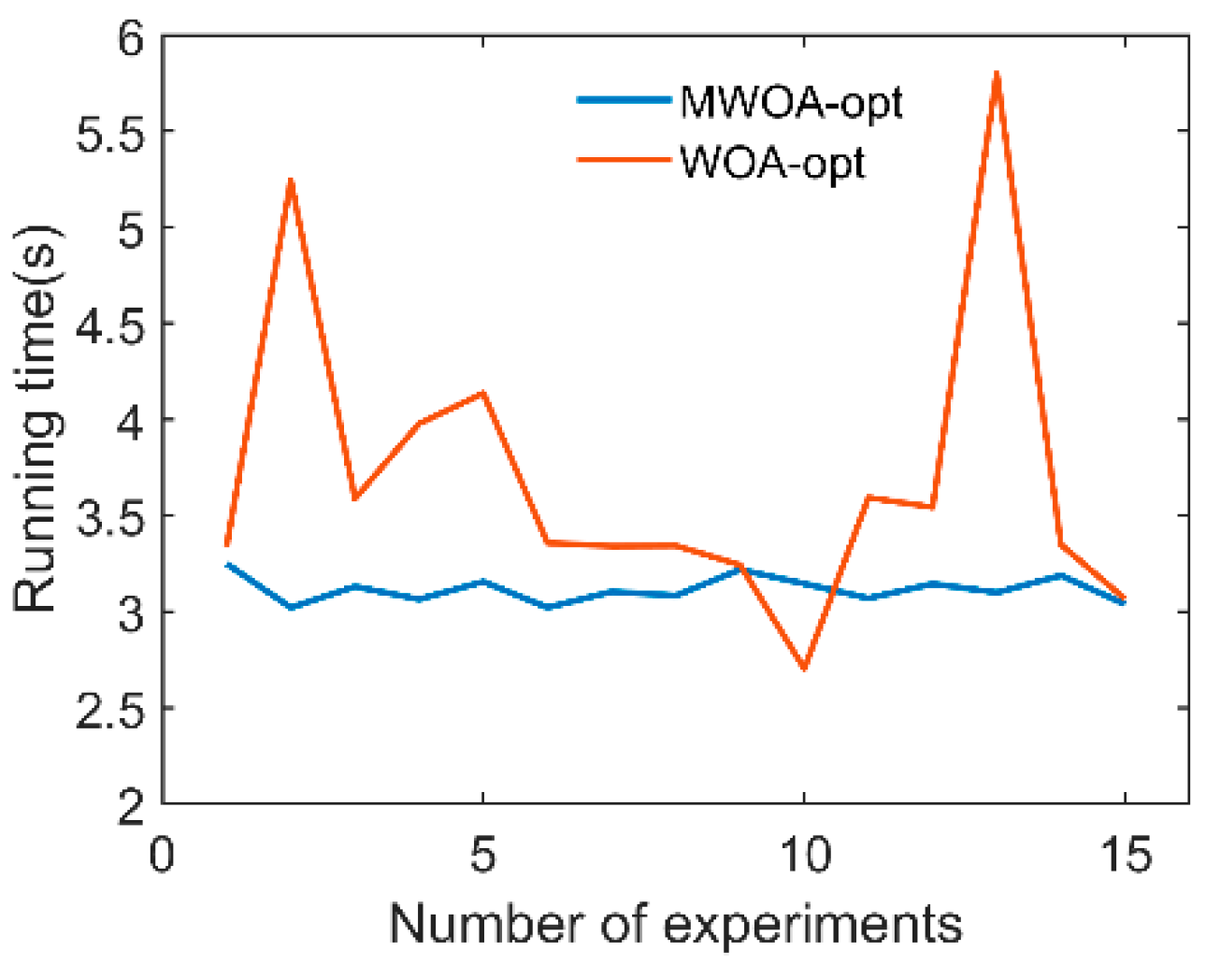
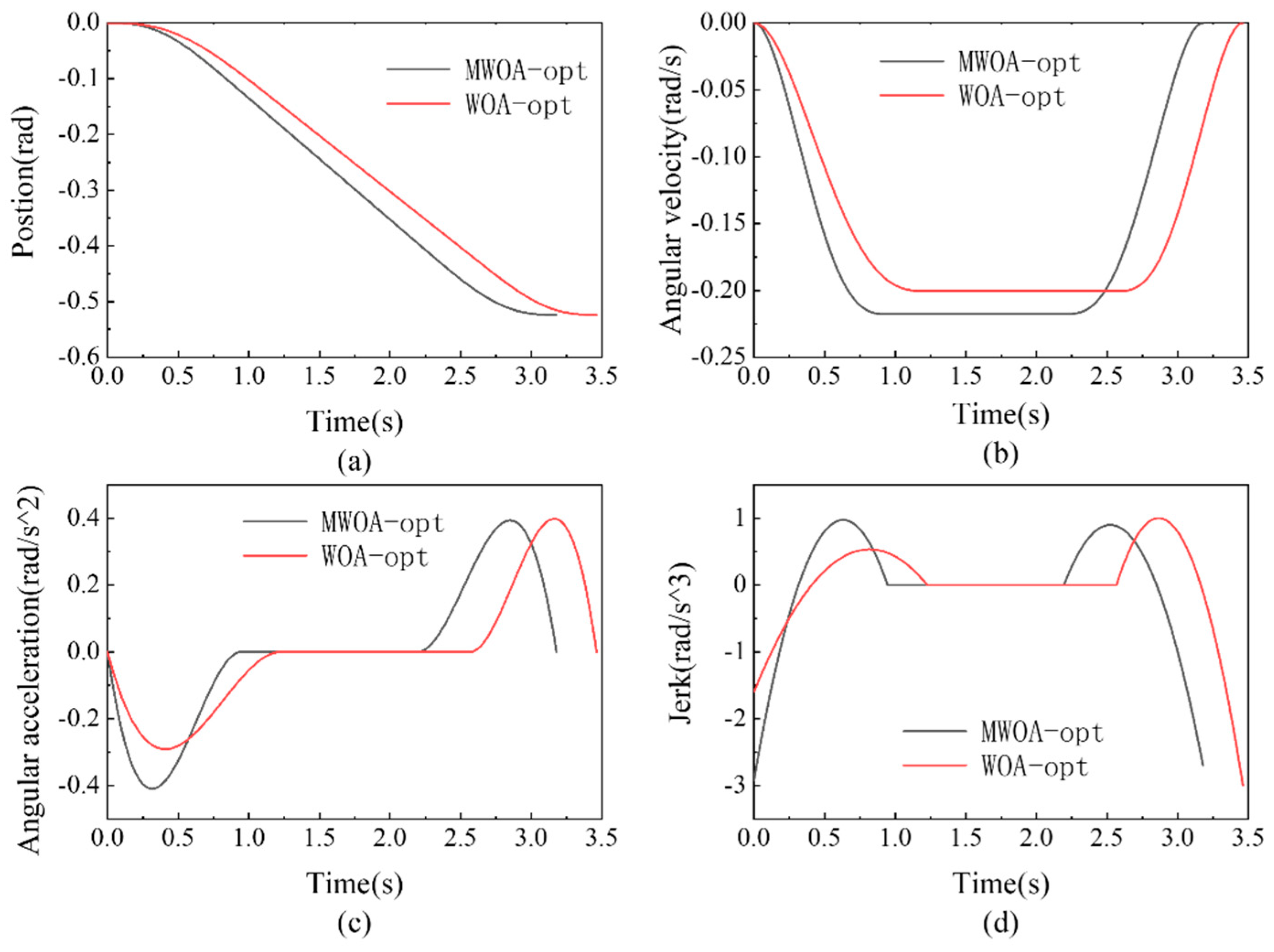
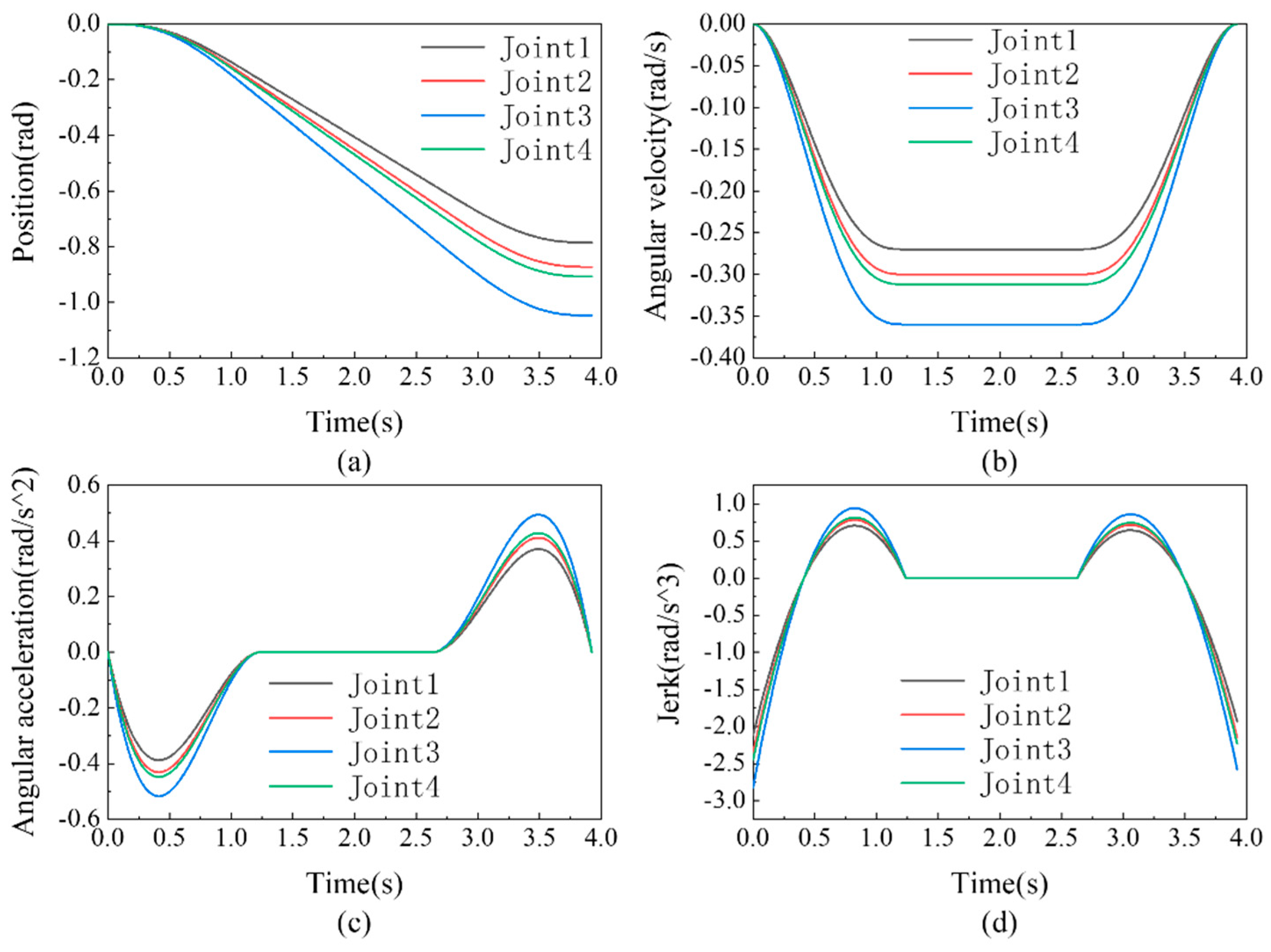
4.2. Single Joint Trajectory Planning Experiment
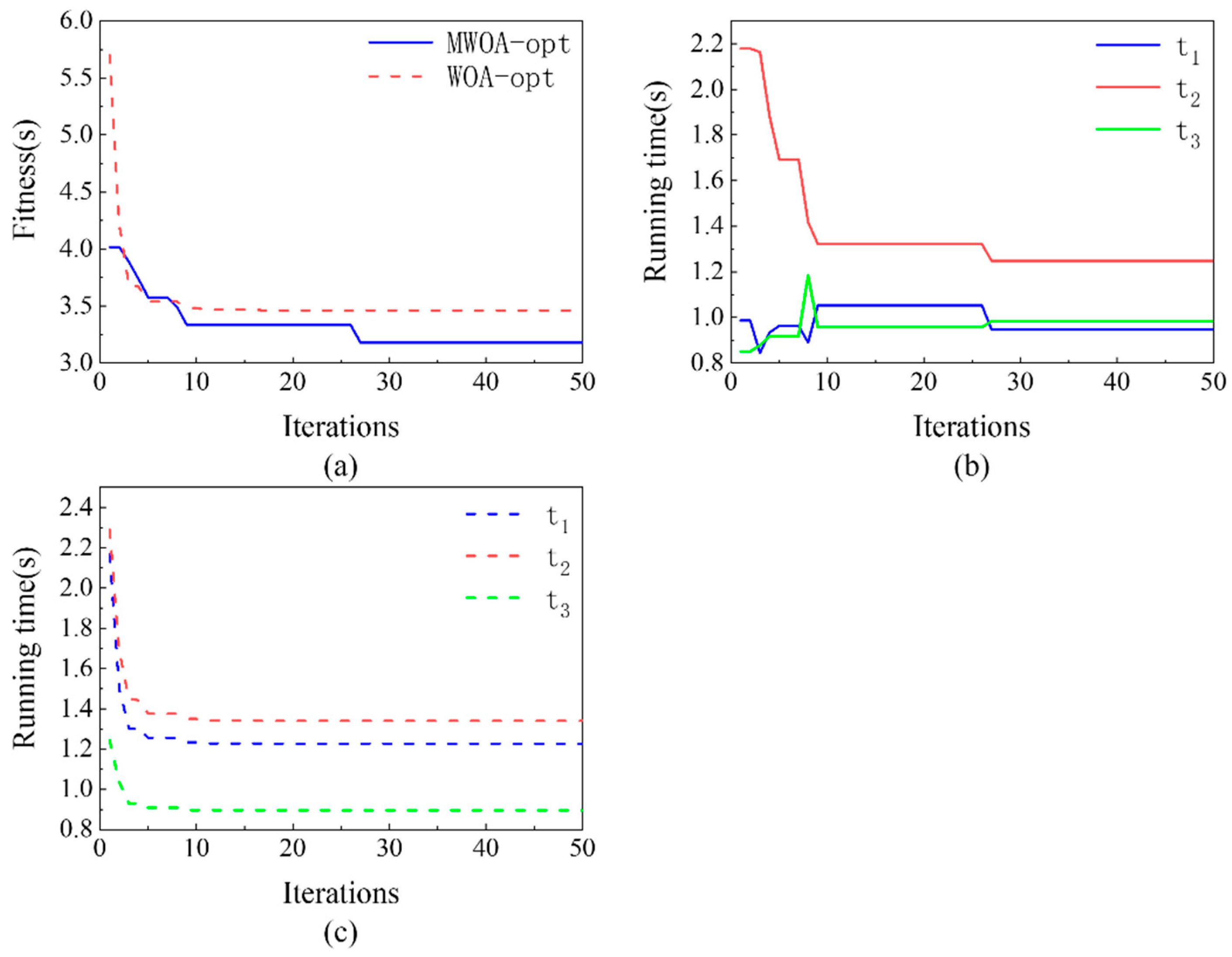
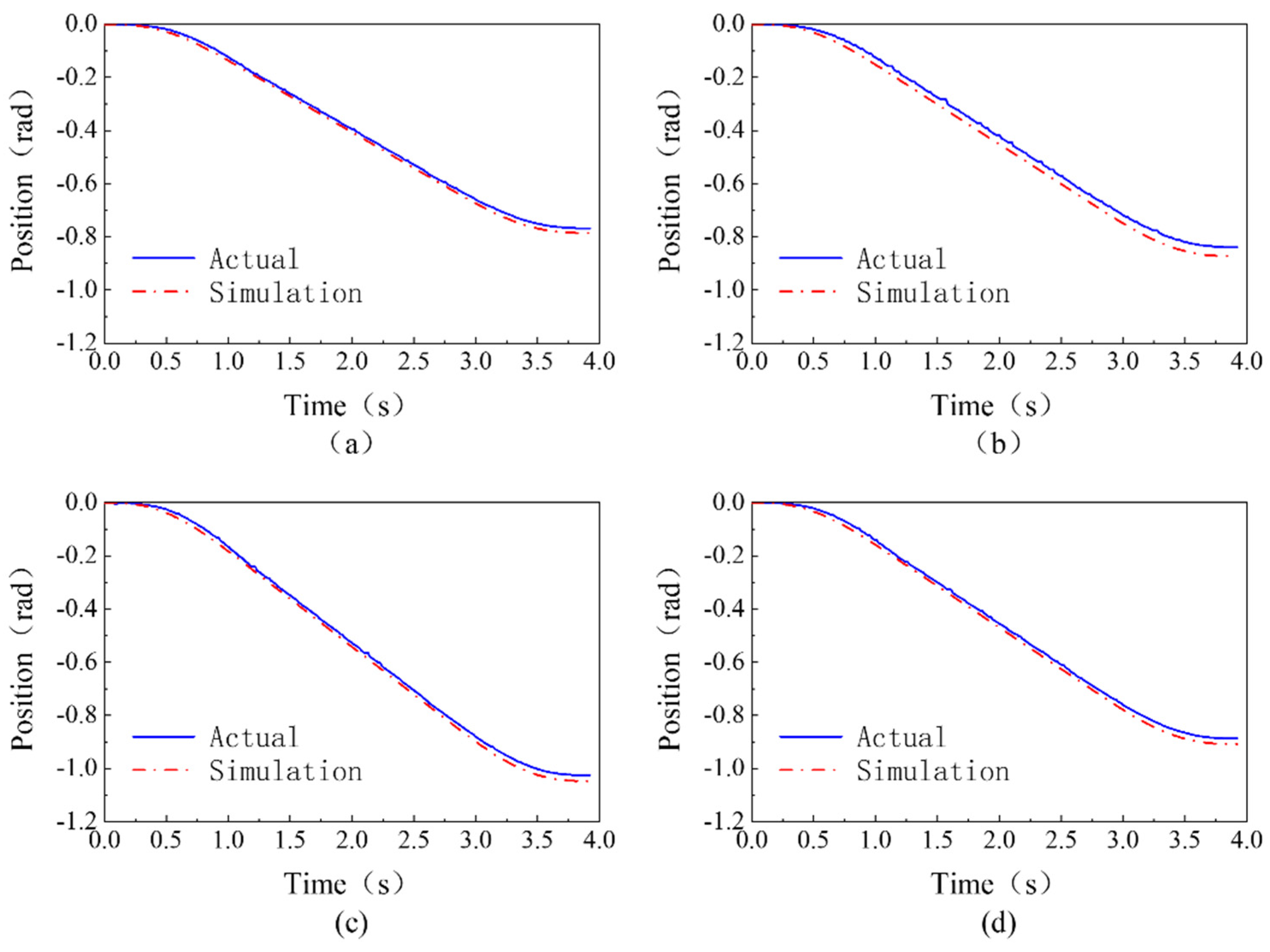
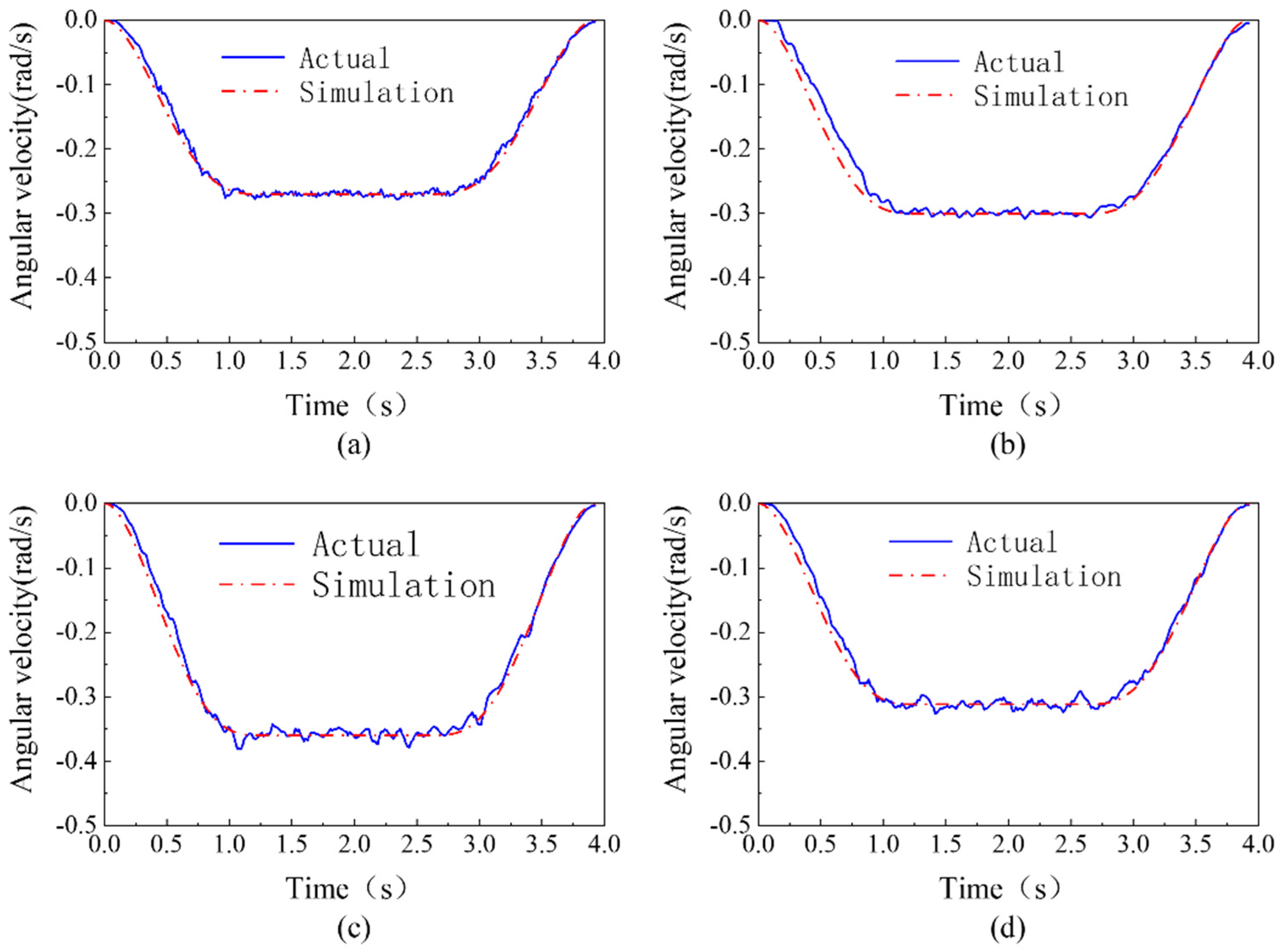
4.3. Multi-Joint Trajectory Planning Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Ethical Approval
Abbreviations
| ACO | Ant colony optimization |
| COBL | Centroid opposition-based learning |
| COBLWOA | Centroid opposition-based learning whale optimization algorithm |
| DE | Differential evolution algorithm |
| DOF | Degree of freedom |
| FA | Firefly algorithm |
| GA | Genetic algorithm |
| GOA | Grasshopper optimization algorithm |
| HHO | Harris hawks optimization |
| IWOA | Improved whale optimization algorithm |
| LMCOBL | Levy mutation centroid opposition-based learning |
| LMCOBLWOA | Levy mutation centroid opposition-based learning whale optimization algorithm |
| MCDE | Multi-population covariance learning differential evolution |
| MPSO | Multi-population particle swarm optimization |
| MWOA | Multi-strategy improved whale optimization algorithm |
| NURBS | Non-uniform rational B-spline |
| OBL | Opposition-based learning |
| PSO | Particle swarm optimization algorithm |
| STD | Standard deviation |
| SSA | Salp swarm algorithm |
| UEER | Upper extremity exoskeleton rehabilitation |
| WOA | Whale optimization algorithm |
References
- Rodgers, H.; Bosomworth, H.; Krebs, H.I.; van Wijck, F.; Howel, D.; Wilson, N.; Aird, L.; Alvarado, N.; Andole, S.; Cohen, D.L.; et al. Robot assisted training for the upper limb after stroke (RATULS): A multicentre randomised controlled trial. Lancet 2019, 394, 51–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taveggia, G.; BorboNi, A.; SalVi, L.; MulÉ, C.; FoGliarEsi, S.; VillafaÑE, J.H.; CasalE, R. Efficacy of robot-assisted re-habilitation for the functional recovery of the upper limb in post-stroke patients: A randomized controlled study. Eur. J. Phys. Rehabil. Med. 2016, 52, 767–773. [Google Scholar] [PubMed]
- Al-Quraishi, M.S.; Elamvazuthi, I.; Daud, S.A.; Parasuraman, S.; Borboni, A. EEG-Based Control for Upper and Lower Limb Exoskeletons and Prostheses: A Systematic Review. Sensors 2018, 18, 3342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stinear, C.M.; Lang, C.E.; Zeiler, S.; Byblow, W.D. Advances and challenges in stroke rehabilitation. Lancet Neurol. 2020, 19, 348–360. [Google Scholar] [CrossRef]
- Borboni, A.; Mor, M.; Faglia, R. Gloreha—Hand Robotic Rehabilitation: Design, Mechanical Model, and Experiments. J. Dyn. Syst. Meas. Control Trans. ASME 2016, 138, 111003. [Google Scholar] [CrossRef]
- Tiboni, M.; Borboni, A.; Faglia, R.; Pellegrini, N. Robotics rehabilitation of the elbow based on surface electromyography signals. Adv. Mech. Eng. 2018, 10, 1687814018754590. [Google Scholar] [CrossRef]
- Hong, C.; Rui, H.; Qiu, J.; Wang, Y.; Chaobin, Z.; Kecheng, S. A Survey of Rehabilitation Robot and Its Clinical Applications. Robot 2021, 43, 606–619. [Google Scholar]
- Kim, B.; Ahn, K.-H.; Nam, S.; Hyun, D.J. Upper extremity exoskeleton system to generate customized therapy motions for stroke survivors. Robot. Auton. Syst. 2022, 154, 104128. [Google Scholar] [CrossRef]
- Li, G.; Fang, Q.; Xu, T.; Zhao, J.; Cai, H.; Zhu, Y. Inverse kinematic analysis and trajectory planning of a modular upper limb rehabilitation exoskeleton. Technol. Health Care 2019, 27, 123–132. [Google Scholar] [CrossRef] [Green Version]
- Yu, X.; Meng, W.; Liu, Z.; Ai, Q.; Liu, Q. Multi-objective Trajectory Optimization of Redundant Manipulator for Patient Assistance. In Proceedings of the 2021 27th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Shanghai, China, 26–28 November 2021; pp. 66–71. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Y.; Shuai, K.; Zhu, W.; Chen, B.; Chen, K. Multi-objective Trajectory Planning Method based on the Improved Elitist Non-dominated Sorting Genetic Algorithm. Chin. J. Mech. Eng. 2022, 35, 7. [Google Scholar] [CrossRef]
- Parikh, P.A.; Trivedi, R.R.; Joshi, K.D. Trajectory planning of a 5 DOF feeding serial manipulator using 6th order polynomial method. J. Physics. Conf. Ser. 2021, 1921, 012088. [Google Scholar] [CrossRef]
- Xu, J. Application of isokinetic exercise in rehabilitation evaluation and treatment. Chin. J. Phys. Med. Rehabil. 2006, 8, 570–573. [Google Scholar]
- Kerimov, K.; Benlidayi, I.C.; Ozdemir, C.; Gunasti, O. The Effects of Upper Extremity Isokinetic Strengthening in Post-Stroke Hemiplegia: A Randomized Controlled Trial. J. Stroke Cerebrovasc. Dis. 2021, 30, 105729. [Google Scholar] [CrossRef] [PubMed]
- Hammami, N.; Coroian, F.; Julia, M.; Amri, M.; Mottet, D.; Hérisson, C.; Laffont, I. Isokinetic muscle strengthening after acquired cerebral damage: A literature review. Ann. Phys. Rehabil. Med. 2012, 55, 279–291. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maharum, S.M.M.; Ishak, N.I.I.; Hussain, R.; Mansor, Z.; Rahim, S.Z.B.A.; Abdullah, M.M.A.B. Upper limb rehabilitation equipment with performance animation for isotonic and isokinetic exercises. AIP Conf. Proc. 2019, 2129, 020103. [Google Scholar]
- Meng, X.; Zhu, X. Autonomous Obstacle Avoidance Path Planning for Grasping Manipulator Based on Elite Smoothing Ant Colony Algorithm. Symmetry 2022, 14, 1843. [Google Scholar] [CrossRef]
- Patle, B.; Pandey, A.; Jagadeesh, A.; Parhi, D. Path planning in uncertain environment by using firefly algorithm. Def. Technol. 2018, 14, 691–701. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Zhao, J.; Zhu, X.; Meng, X.; Wu, X. Application of Improved Whale Optimization Algorithm in Time-optimal Trajectory Planning of Manipulator. Mech. Sci. Technol. Aerosp. Eng. 2021, 1–10. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Gholizadeh, H. A comprehensive survey: Whale Optimization Algorithm and its applications. Swarm Evol. Comput. 2019, 48, 1–24. [Google Scholar] [CrossRef]
- Li, M.; Xu, G.; Lai, Q.; Chen, J. A chaotic strategy-based quadratic Opposition-Based Learning adaptive variable-speed whale optimization algorithm. Math. Comput. Simul. 2021, 193, 71–99. [Google Scholar] [CrossRef]
- Tong, W. A new whale optimisation algorithm based on self-adapting parameter adjustment and mix mutation strategy. Int. J. Comput. Integr. Manuf. 2020, 33, 949–961. [Google Scholar] [CrossRef]
- Fan, Q.; Chen, Z.; Li, Z.; Xia, Z.; Yu, J.; Wang, D. A new improved whale optimization algorithm with joint search mecha-nisms for high-dimensional global optimization problems. Eng. Comput. 2021, 37, 1851–1878. [Google Scholar] [CrossRef]
- Jiang, F.; Wang, L.; Bai, L. An Improved Whale Algorithm and Its Application in Truss Optimization. J. Bionic Eng. 2021, 18, 721–732. [Google Scholar] [CrossRef]
- Elaziz, M.A.; Lu, S.; He, S. A multi-leader whale optimization algorithm for global optimization and image segmentation. Expert Syst. Appl. 2021, 175, 114841. [Google Scholar] [CrossRef]
- Tizhoosh, H.R. Opposition-Based Learning: A New Scheme for Machine Intelligence. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06), Vienna, Austria, 28–30 November 2005. [Google Scholar]
- Rahnamayan, S.; Jesuthasan, J.; Bourennani, F.; Salehinejad, H.; Naterer, G.F. Computing opposition by involving entire population. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014. [Google Scholar]
- Yuan, W.; You, X.; Liu, S. Dual-Population Ant Colony Algorithm on Dynamic Learning Mechanism. J. Front. Comput. Sci. Technol. 2019, 13, 1239–1250. [Google Scholar]
- Kılıç, F.; Kaya, Y.; Yildirim, S. A novel multi population based particle swarm optimization for feature selection. Knowledge-Based Syst. 2021, 219, 106894. [Google Scholar] [CrossRef]
- Du, Y.; Fan, Y.; Liu, P.; Tang, J.; Luo, Y. Multi-populations Covariance Learning Differential Evolution Algorithm. J. Electron. Inf. Technol. 2019, 41, 1488–1495. [Google Scholar]
- Liu, X. Whale Optimization Algorithm for Multi-group with Information Exchange and Vertical and Horizontal Bidirectional Learning. J. Electron. Inf. Technol. 2021, 43, 3247–3256. [Google Scholar]
- Chang, J.-J.; Tung, W.-L.; Wu, W.; Huang, M.-H.; Su, F.-C. Effects of Robot-Aided Bilateral Force-Induced Isokinetic Arm Training Combined with Conventional Rehabilitation on Arm Motor Function in Patients with Chronic Stroke. Arch. Phys. Med. Rehabil. 2007, 88, 1332–1338. [Google Scholar] [CrossRef]
- Nguiadem, C.; Raison, M.; Achiche, S. Motion Planning of Upper-Limb Exoskeleton Robots: A Review. Appl. Sci. 2020, 10, 7626. [Google Scholar] [CrossRef]
- Frisoli, A.; Loconsole, C.; Bartalucci, R.; Bergamasco, M. A new bounded jerk on-line trajectory planning for mimicking human movements in robot-aided neurorehabilitation. Robot. Auton. Syst. 2013, 61, 404–415. [Google Scholar] [CrossRef]
- Qie, X.; Kang, C.; Zong, G.; Chen, S. Trajectory Planning and Simulation Study of Redundant Robotic Arm for Upper Limb Rehabilitation Based on Back Propagation Neural Network and Genetic Algorithm. Sensors 2022, 22, 4071. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Dang, Q.; Xu, W.; Liu, L.; Luo, Y. Dynamic Penalty Function Method for Constrained Optimization Problem. Comput. Eng. Appl. 2022, 58, 83. [Google Scholar]
- Gharehchopogh, F.S. An Improved Tunicate Swarm Algorithm with Best-random Mutation Strategy for Global Optimization Problems. J. Bionic Eng. 2022, 19, 1177–1202. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, P.; Heidari, A.A.; Zhao, X.; Ma, C.; Chen, H. An enhanced Cauchy mutation grasshopper optimization with trigonometric substitution: Engineering design and feature selection. Eng. Comput. 2021, 38, 4583–4616. [Google Scholar] [CrossRef]
- Xu, L.; Cao, M.; Song, B. A new approach to smooth path planning of mobile robot based on quartic Bezier transition curve and improved PSO algorithm. Neurocomputing 2022, 473, 98–106. [Google Scholar] [CrossRef]
- Yang, X. Firefly Algorithm, Stochastic Test Functions and Design Optimisation. Int. J. Bio-Inspired Comput. 2010, 2, 78–84. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Description |
|---|---|
| , th joint. | |
| The 1st, 2nd, and 3rd segment of the trajectory, respectively. | |
| th coefficient of the 1st, 2nd, and 3rd segment of the trajectory, respectively. | |
| Time corresponding to the 1st and 2nd transition points and the terminal point, respectively. |
| Algorithm | ||
|---|---|---|
| WOA | 30 | |
| MWOA | = 16 = 14 | = 0.9 = 0.3 |
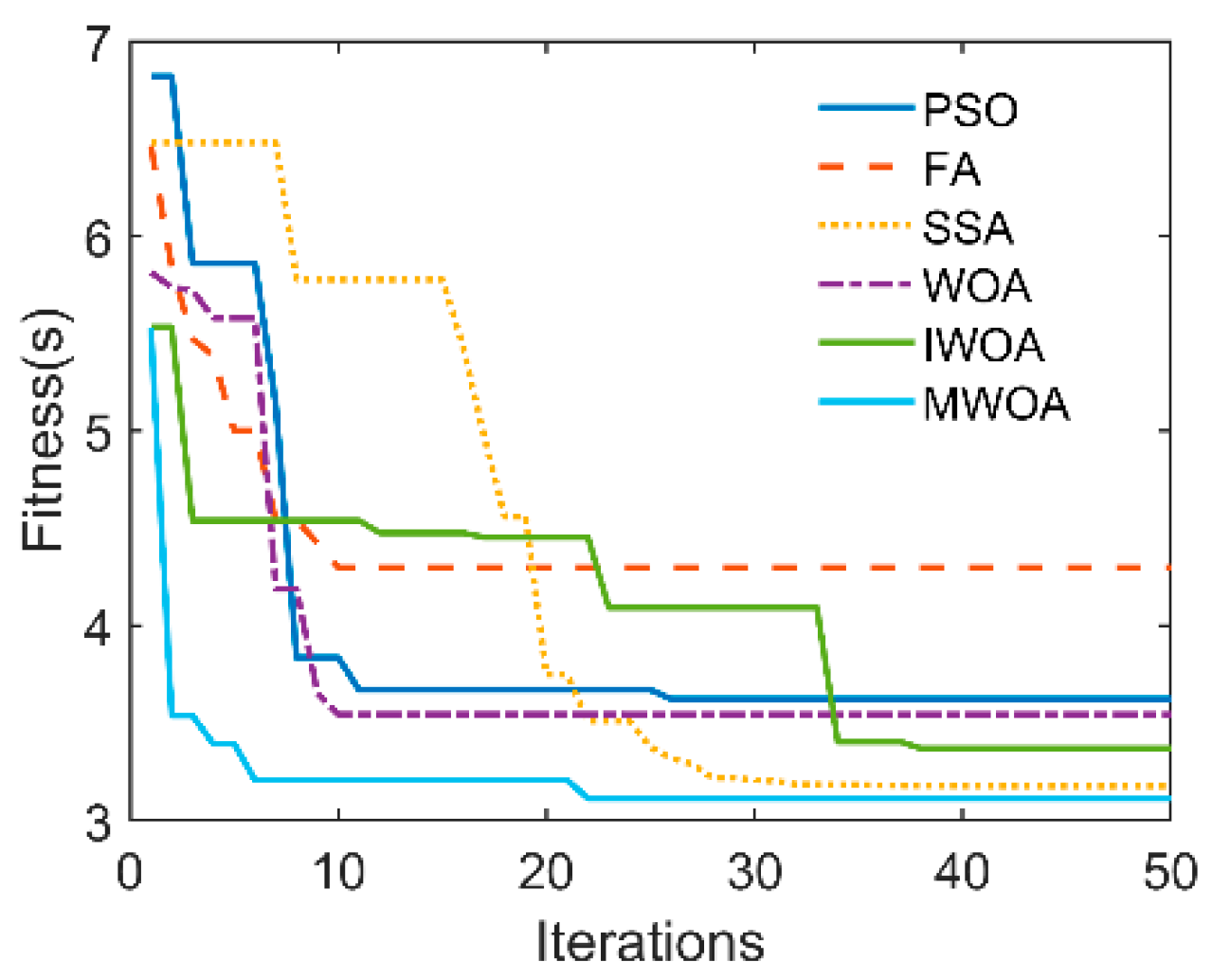
| Algorithm | STD | Failure Time | |
|---|---|---|---|
| PSO | 0.0467 | 0.1069 | 1 |
| FA | 0.2257 | 1.4820 | 0 |
| SSA | 0.0711 | 0.3466 | 0 |
| WOA | 0.2253 | 0.8870 | 2 |
| IWOA | 0.0764 | 0.2208 | 1 |
| MWOA | 0.0438 | 0.0824 | 0 |
| 1 | 1.1957 | 1.2527 | 1.1167 |
| 2 | 1.1572 | 1.2805 | 1.2361 |
| 3 | 1.2345 | 1.3914 | 1.2948 |
| 4 | 1.2368 | 1.3308 | 1.2344 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, F.; Zhang, H.; Xu, Y.; Xiong, G.; Zeng, C. Isokinetic Rehabilitation Trajectory Planning of an Upper Extremity Exoskeleton Rehabilitation Robot Based on a Multistrategy Improved Whale Optimization Algorithm. Symmetry 2023, 15, 232. https://doi.org/10.3390/sym15010232
Guo F, Zhang H, Xu Y, Xiong G, Zeng C. Isokinetic Rehabilitation Trajectory Planning of an Upper Extremity Exoskeleton Rehabilitation Robot Based on a Multistrategy Improved Whale Optimization Algorithm. Symmetry. 2023; 15(1):232. https://doi.org/10.3390/sym15010232
Chicago/Turabian StyleGuo, Fumin, Hua Zhang, Yilu Xu, Genliang Xiong, and Cheng Zeng. 2023. "Isokinetic Rehabilitation Trajectory Planning of an Upper Extremity Exoskeleton Rehabilitation Robot Based on a Multistrategy Improved Whale Optimization Algorithm" Symmetry 15, no. 1: 232. https://doi.org/10.3390/sym15010232