

Direct Training via Backpropagation for Ultra-Low-Latency Spiking Neural Networks with Multi-Threshold


Abstract
:1. Introduction
- (1)
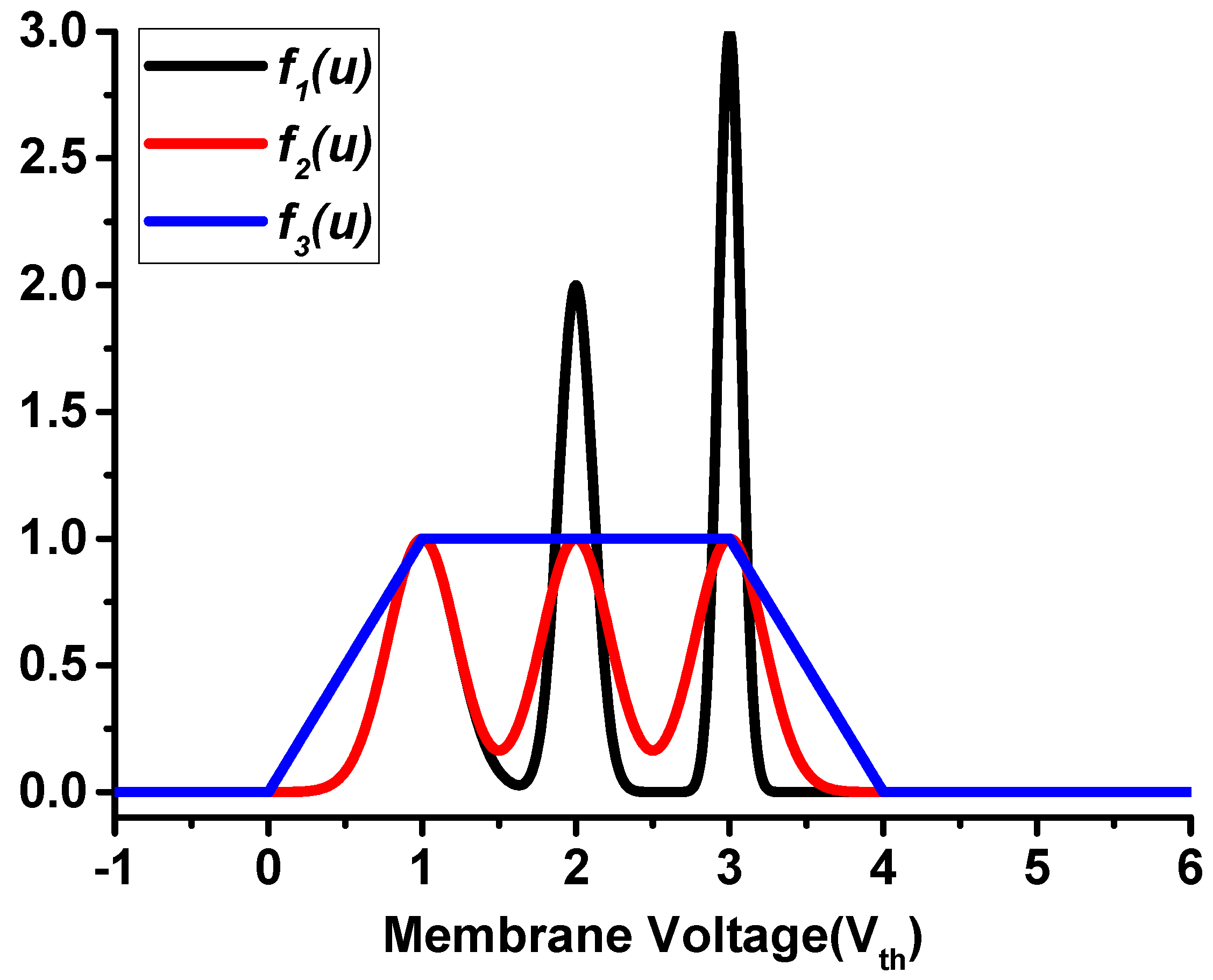
- To address the issue of non-differentiability, we propose two axisymmetric surrogate functions and a non-axisymmetric surrogate function to approximate the derivative of spike activity of multi-threshold LIF models.
- (2)
- Combining the SNN with multi-threshold LIF models and our proposed training algorithm, we can successfully train SNNs at a very short latency, e.g., two time steps.
- (3)
- (4)
- In addition, we also explore the impact of the symmetry of derivative approximation curves, the number of time steps, etc. This work may help researchers to choose the proper parameters for the method and achieve higher-performance SNNs.
2. Approach
2.1. Multi-Threshold Spiking Neuron Model
2.2. Proposed Methods
2.2.1. Forward Pass
| Algorithm 1: State update for an explicitly iterative multi-threshold LIF neuron at time step t in the l-th layer. |
 |
2.2.2. Backforward Pass
3. Experiments and Results
3.1. Experimental Settings
3.2. Parameter Initialization
3.3. Dataset Experiments
3.3.1. MNIST
3.3.2. FashionMNIST
3.3.3. CIFAR10
3.4. Performance Analysis
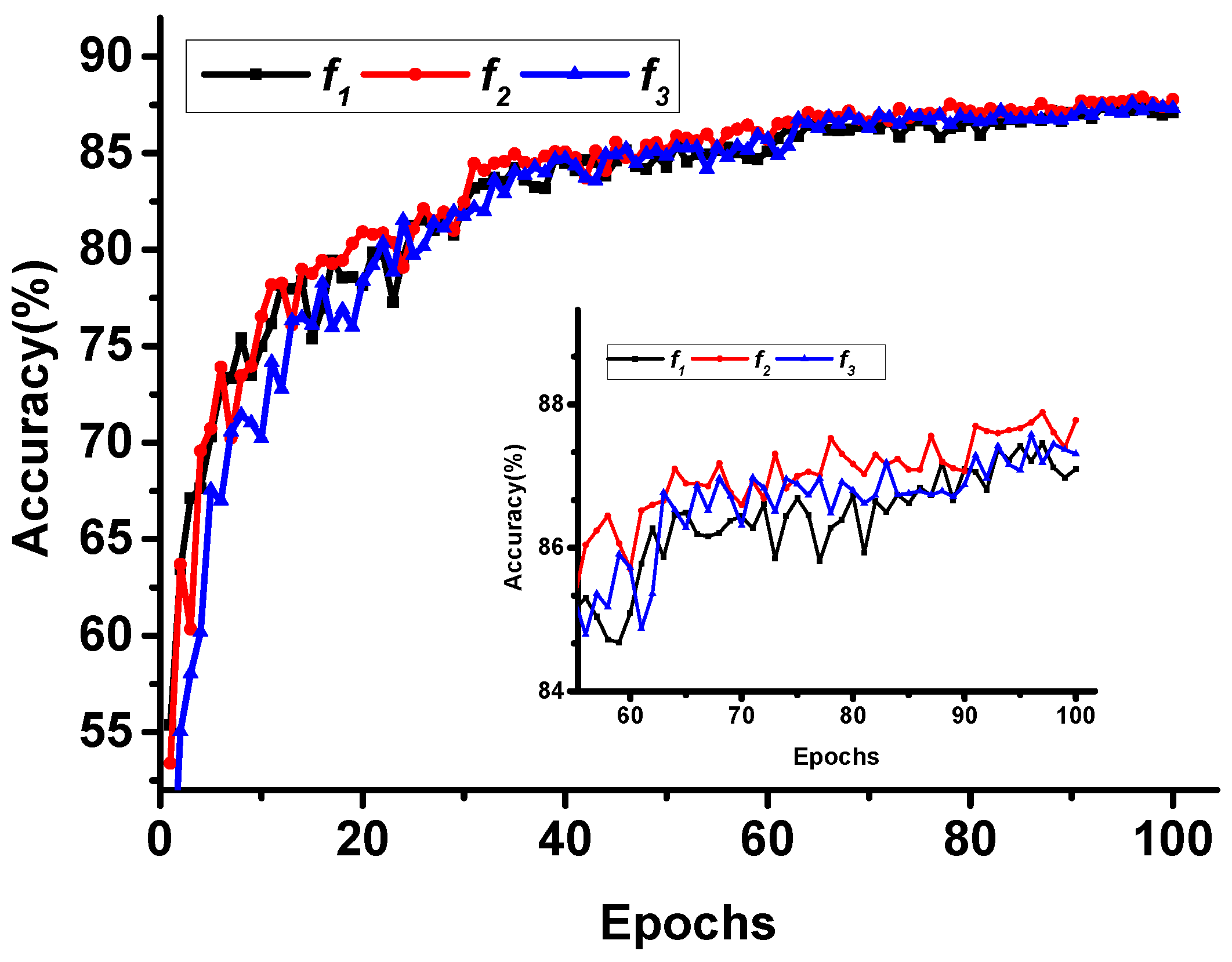
3.4.1. The Impact of Derivative Approximation Curves
3.4.2. The Impact of SMax
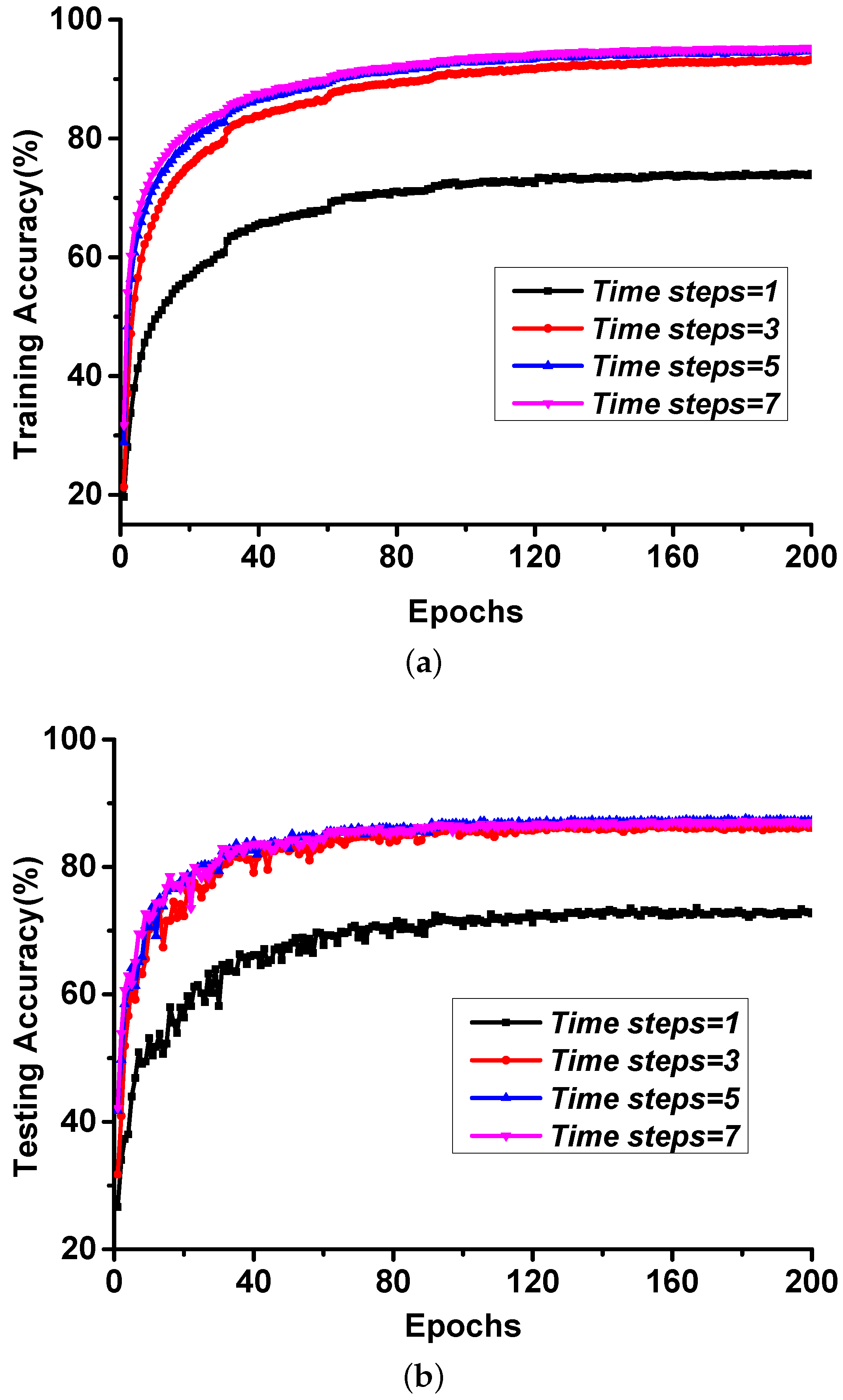
3.4.3. The Impact of Length of Spike Train
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gerstner, W.; Kistler, W.M. Spiking Neuron Models: Single Neurons, Populations, Plasticity; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Xiang, S.; Jiang, S.; Liu, X.; Zhang, T.; Yu, L. Spiking vgg7: Deep convolutional spiking neural network with direct training for object recognition. Electronics 2022, 11, 2097. [Google Scholar] [CrossRef]
- Zhong, X.; Pan, H. A spike neural network model for lateral suppression of spike-timing-dependent plasticity with adaptive threshold. Appl. Sci. 2022, 12, 5980. [Google Scholar] [CrossRef]
- Dora, S.; Kasabov, N. Spiking neural networks for computational intelligence: An overview. Big Data Cogn. Comput. 2021, 5, 67. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, W.; Liu, Y.; Li, P. Boosting throughput and efficiency of hardware spiking neural accelerators using time compression supporting multiple spike codes. Front. Neurosci. 2020, 14, 104. [Google Scholar] [CrossRef] [PubMed]
- Merolla, P.A.; Arthur, J.V.; Alvarez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Guo, C.; Nakamura, Y.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Joshi, P.; Lines, A.; Wild, A.; Wang, H. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro. 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Imec Builds World’s First Spiking Neural Network-Based Chip for Radar Signal Processing. Available online: https://www.imec-int.com/en/articles/imec-builds-world-s-first-spiking-neural-network-based-chip-for-radar-signal-processing (accessed on 31 October 2021).
- Thorpe, S.; Delorme, A.; Rullen, R.V. Spike-based strategies for rapid processing. Neural Netw. 2001, 14, 715–725. [Google Scholar] [CrossRef]
- Kayser, C.; Montemurro, M.A.; Logothetis, N.K.; Panzeri, S. Spike-phase coding boosts and stabilizes information carried by spatial and temporal spike patterns. Neuron 2009, 61, 597–608. [Google Scholar] [CrossRef]
- Magotra, A.; Kim, J. Neuromodulated dopamine plastic networks for heterogeneous transfer learning with hebbian principle. Symmetry 2021, 13, 1344. [Google Scholar] [CrossRef]
- Alhmoud, L.; Nawafleh, Q.; Merrji, W. Three-phase feeder load balancing based optimized neural network using smart meters. Symmetry 2021, 13, 2195. [Google Scholar] [CrossRef]
- Jaehyun, K.; Heesu, K.; Subin, H.; Jinho, L.; Kiyoung, C. Deep neural networks with weighted spikes. Neurocomputing 2018, 311, 373–386. [Google Scholar]
- Chowdhury, S.S.; Rathi, N.; Roy, K. One timestep is all you need: Training spiking neural networks with ultra low latency. arXiv 2021, arXiv:2110.05929. [Google Scholar]
- Yang, Y.; Zhang, W.; Li, P. Backpropagated neighborhood aggregation for accurate training of spiking neural networks. In Proceedings of the 38th International Conference on Machine Learning (ICML2021), Virtual, 18–24 July 2021. [Google Scholar]
- Zhang, W.; Li, P. Temporal spike sequence learning via backpropagation for deep spiking neural networks. arXiv 2020, arXiv:2002.10085. [Google Scholar]
- Lecun, Y.; Bottou, L. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Nair, V.; Hinton, G. The Cifar-10 Dataset. 2014. Available online: http://www.cs.toronto.edu/kriz/cifar.html (accessed on 1 September 2022).
- Wu, Y.; Lei, D.; Li, G.; Zhu, J.; Shi, L. Spatio-temporal backpropagation for training high-performance spiking neural networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Chintala, S. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.-C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Lee, J.H.; Delbruck, T.; Pfeiffer, M. Training deep spiking neural networks using backpropagation. Front. Neurosci. 2016, 10, 508. [Google Scholar] [CrossRef]
- Diehl, P.U.; Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going deeper in spiking neural networks: Vgg and residual architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, Y.; Zhang, W.; Li, P. Hybrid macro/micro level backpropagation for training deep spiking neural networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Zhang, W.; Li, P. Spike-train level backpropagation for training deep recurrent spiking neural networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Hunsberger, E.; Eliasmith, C. Training spiking deep networks for neuromorphic hardware. arXiv 2016, arXiv:1611.05141. [Google Scholar]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Direct training for spiking neural networks: Faster, larger, better. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1311–1318. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Value |
|---|---|---|
| Time constant of membrane voltage | 10 ms | |
| Threshold | 10 mV | |
| Derivative approximation parameters | 1 | |
| Derivative approximation parameters | 20 | |
| Upper limit of output spikes | 15 | |
| Batch size | 128 | |
| Learning rate (MNIST/FashionMNIST/CIFAR10) | 0.005, 0.005, 0.0005 | |
| Adam parameters | 0.9, 0.999, |
| Methods | Network | Time Steps | Accuracy |
|---|---|---|---|
| Converted SNN [23] * | 784-1200-1200-10 | 20 | 98.64% |
| STDP [25] | 784-6400-10 | 350 | 95.00% |
| BP [24] | 784-800-10 | 200-1000 | 98.71% |
| STBP [20] | 784-800-10 | 50-300 | 98.89% |
| Proposed Method | 784-800-10 | 2 | 99.15% |
| Methods | Network | Time Steps | Accuracy |
|---|---|---|---|
| SLAYER [26] | 12C5-P2-64C5-p2 1 | 300 | 99.36% |
| HM2BP [27] | 15C5-P2-40C5-P2-300 | 400 | 99.42% |
| ST-RSBP [28] | 15C5-P2-40C5-P2-300 | 400 | 99.57% |
| TSSL-BP [16] | 15C5-P2-40C5-P2-300 | 5 | 99.47% |
| Proposed Method | 15C5-P2-40C5-P2-300 | 2 | 99.56% |
| Methods | Network | Time Steps | Accuracy |
|---|---|---|---|
| ANN [28] * | 784-512-512-10 | 89.01% | |
| HM2BP [27] | 784-400-400-10 | 400 | 88.99% |
| ST-RSBP [28] | 784-400-400-10 | 400 | 90.13% |
| TSSL-BP [16] | 784-400-400-10 | 5 | 90.19% |
| Proposed Method | 784-400-400-10 | 2 | 91.08% |
| Methods | Network | Time Steps | Accuracy |
|---|---|---|---|
| ANN *1 | 32C5-P2-64C5-P2-1024 | 91.60% | |
| TSSL-BP [16] | 32C5-P2-64C5-P2-1024 | 5 | 92.45% |
| Converted SNN *2 | 16C5-P2-64C5-P2-1024 | 200 | 92.62% |
| Proposed Method | 32C5-P2-64C5-P2-1024 | 2 | 93.08% |
| Methods | Skills | Time Steps | Accuracy |
|---|---|---|---|
| ANN [29] *1 | Random cropping | 83.72% | |
| Converted SNN [29] *2 | Random cropping | 83.52% | |
| STBP [30] | Neuron normalization, dropout, and population decoding | 8 | 85.24% |
| TSSL-BP [16] | Random cropping and horizontal flipping | 5 | 86.78% |
| Proposed Method | Random cropping | 2 | 87.90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Liu, Y.; Chen, D.; Yang, Y. Direct Training via Backpropagation for Ultra-Low-Latency Spiking Neural Networks with Multi-Threshold. Symmetry 2022, 14, 1933. https://doi.org/10.3390/sym14091933
Xu C, Liu Y, Chen D, Yang Y. Direct Training via Backpropagation for Ultra-Low-Latency Spiking Neural Networks with Multi-Threshold. Symmetry. 2022; 14(9):1933. https://doi.org/10.3390/sym14091933
Chicago/Turabian StyleXu, Changqing, Yi Liu, Dongdong Chen, and Yintang Yang. 2022. "Direct Training via Backpropagation for Ultra-Low-Latency Spiking Neural Networks with Multi-Threshold" Symmetry 14, no. 9: 1933. https://doi.org/10.3390/sym14091933