
Diabetic Retinopathy Classification Using CNN and Hybrid Deep Convolutional Neural Networks

Abstract
:1. Introduction
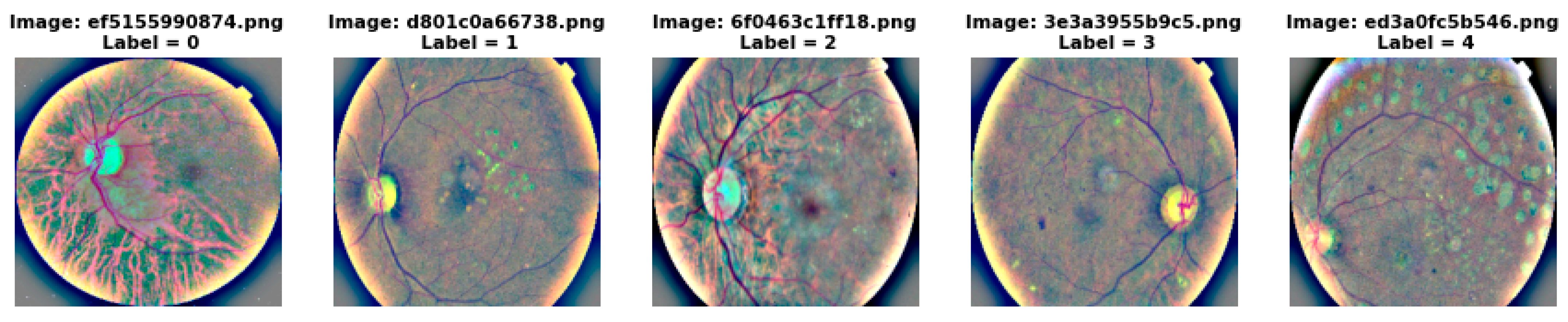
1.1. Non-Proliferate Diabetic Retinopathy
- Mild NPDR—a few micro aneurysms.
- Moderate NPDR—Presence of cotton-wool spots and hemorrhages.
- Severe NPDR—Presence of intra retinal hemorrhaging in four quadrants of the eye–two with venous beading or one with intra retinal micro vascular abnormality.
1.2. Proliferative Diabetic Retinopathy
- i.
- The automated model for diabetic retinopathy detection have proven to be time saving and also efficient as compared to the manual method. Hence a custom CNN model and transfer learning are analysed to automate the process of predicting DR.
- ii.
- An enhanced hybrid CNN with DenseNet is developed to detect blood vessels and to efficiently identify the hemorrhages and exudates.
- iii.
- The proposed model performed image augmentation to solve the problem of class imbalance inorder to attain a high accuracy.
2. Related Work
2.1. Convolutional Neural Network
2.2. Transfer Learning
- Higher start: The skill present initially on the source model is higher as compared to the model where transfer learning isn’t used.
- Higher slope: The skill improves at a faster rate while training the model which means that the performance is better.
- Higher asymptote: The convergence of skill is better than the one that doesn’t make use of transfer learning.
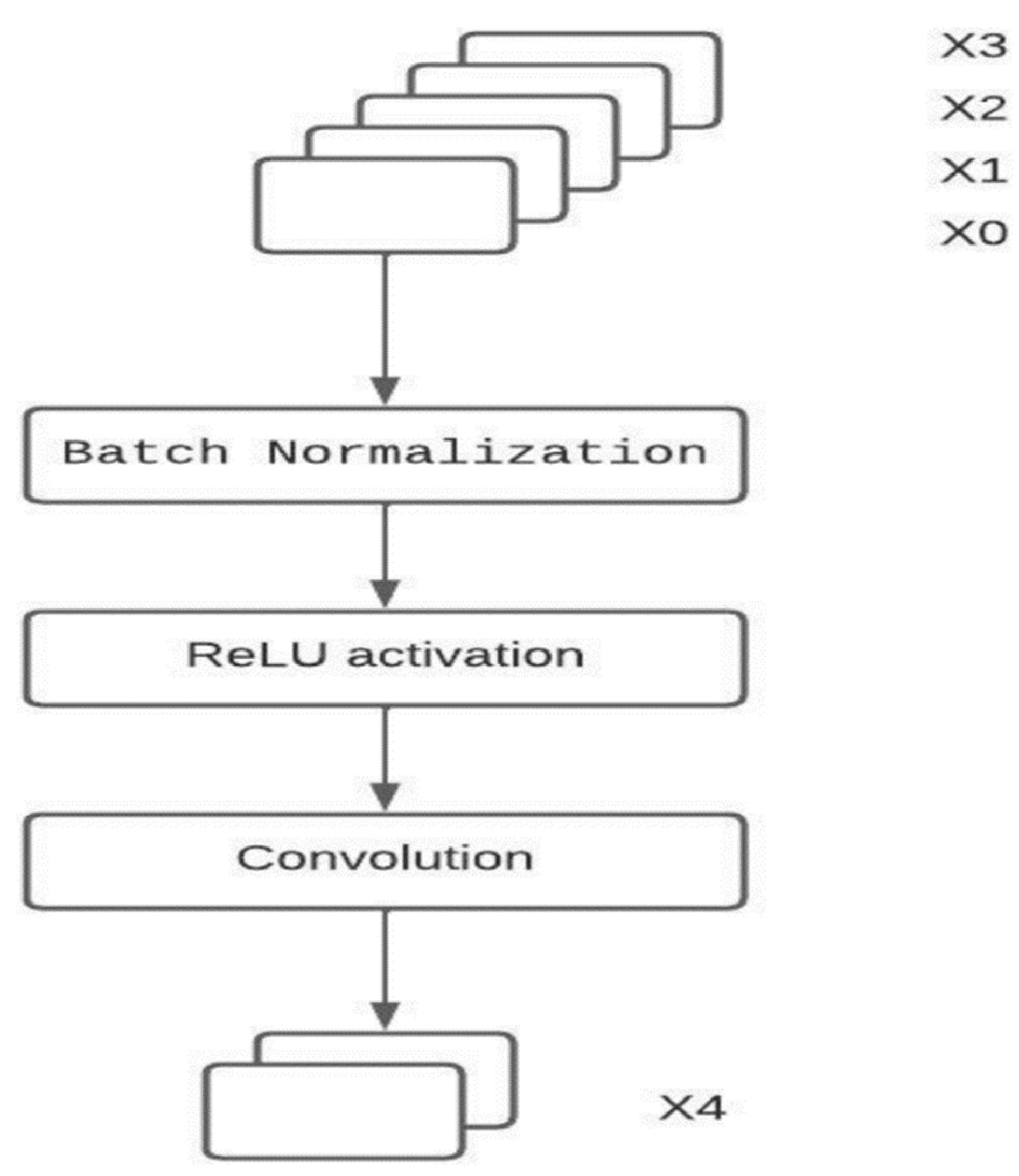
DenseNet
- Strong Gradient flow: The propagation of error is easier down the lane of the DenseNet neural network. This is because the earlier layers are directly connected to the final classification layer.
- Parameters: Number of parameters in DenseNet is directly proportional to l × k × k where k is the growth rate. The size of a DenseNet is smaller than ResNet.
- Low complexity features: In DenseNet, features of all complexity levels are used. This gives smooth decision boundaries. This is the reason for DenseNet performing well even when training data is insufficient.
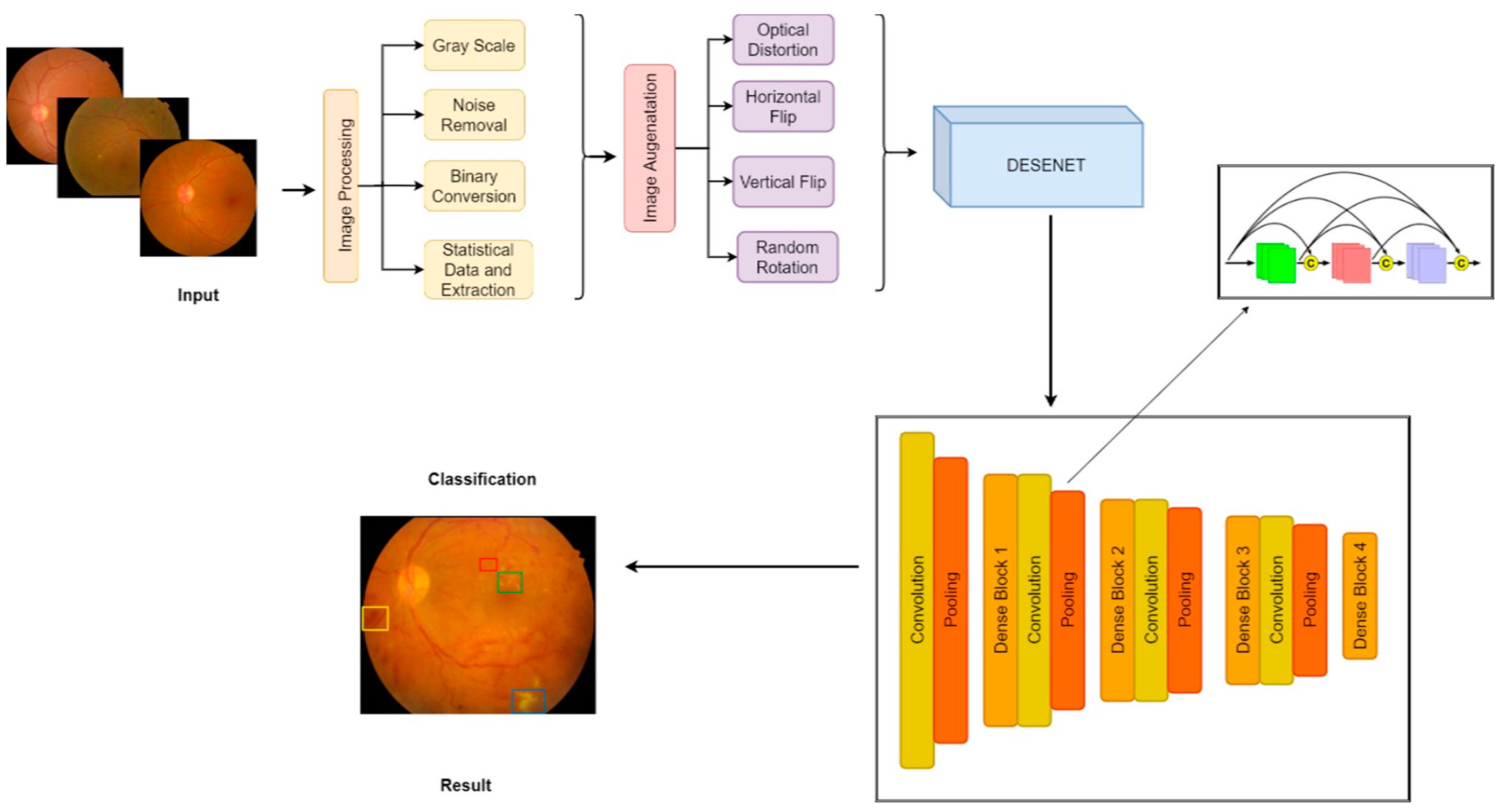
3. Proposed System
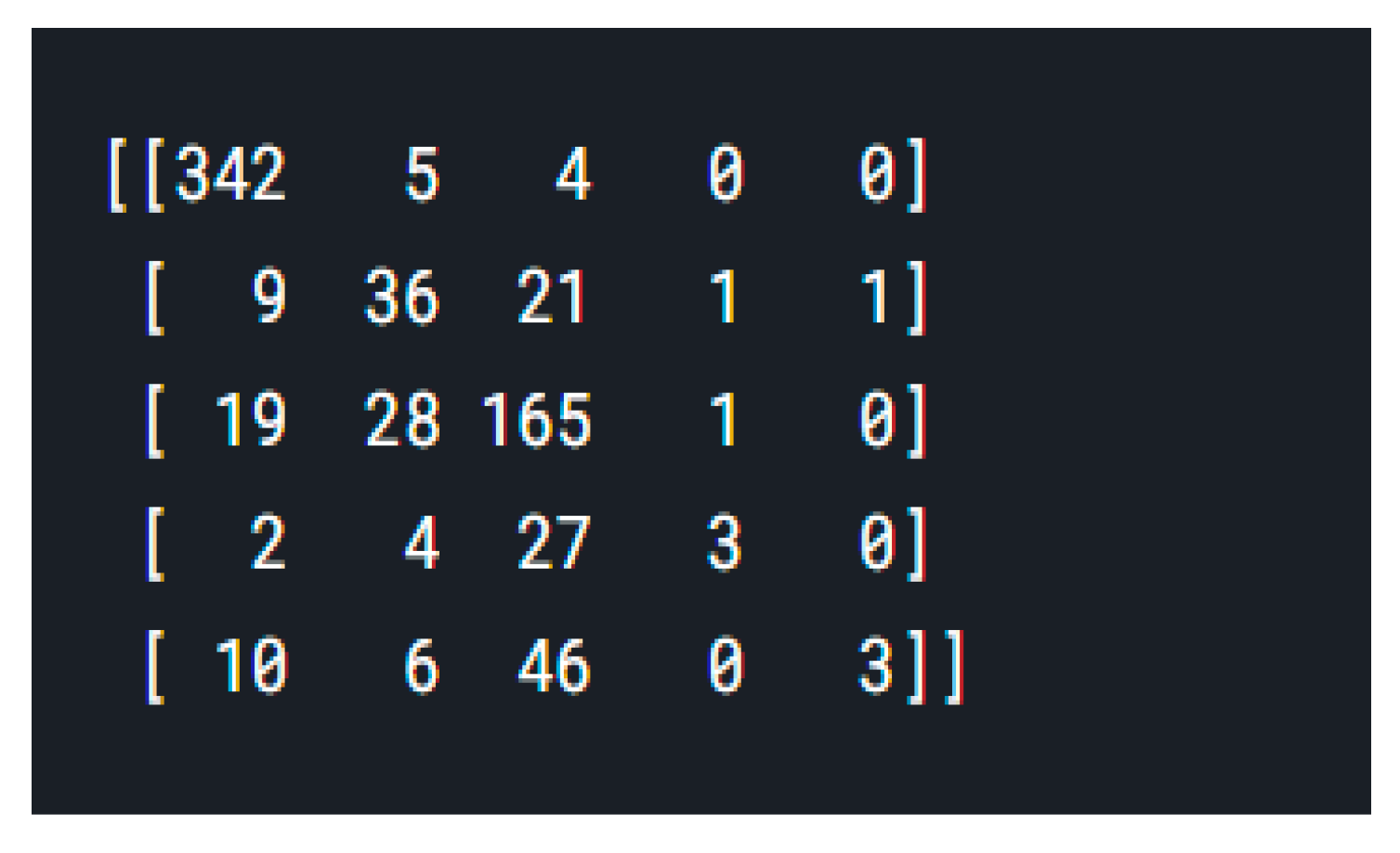
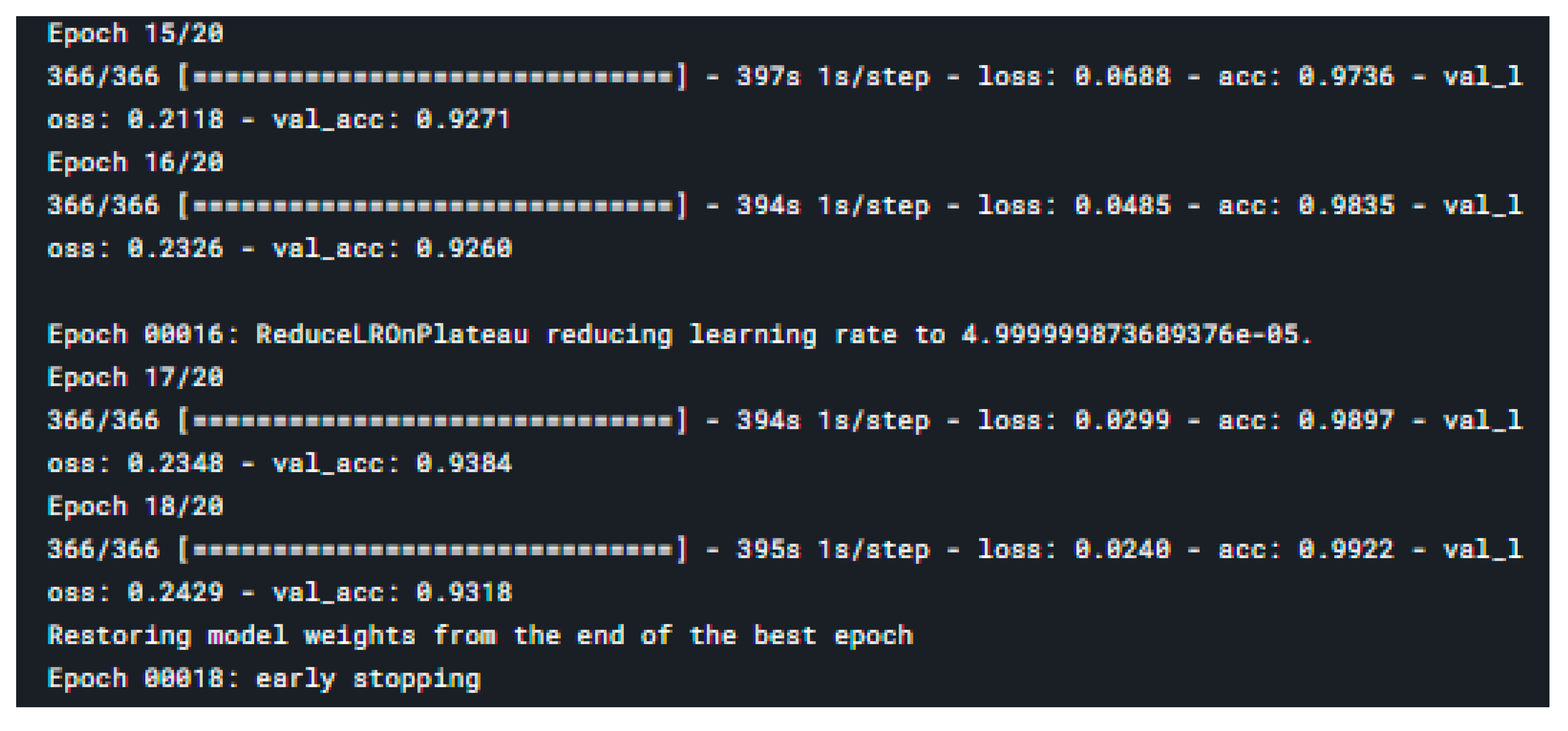
4. Results and Discussion
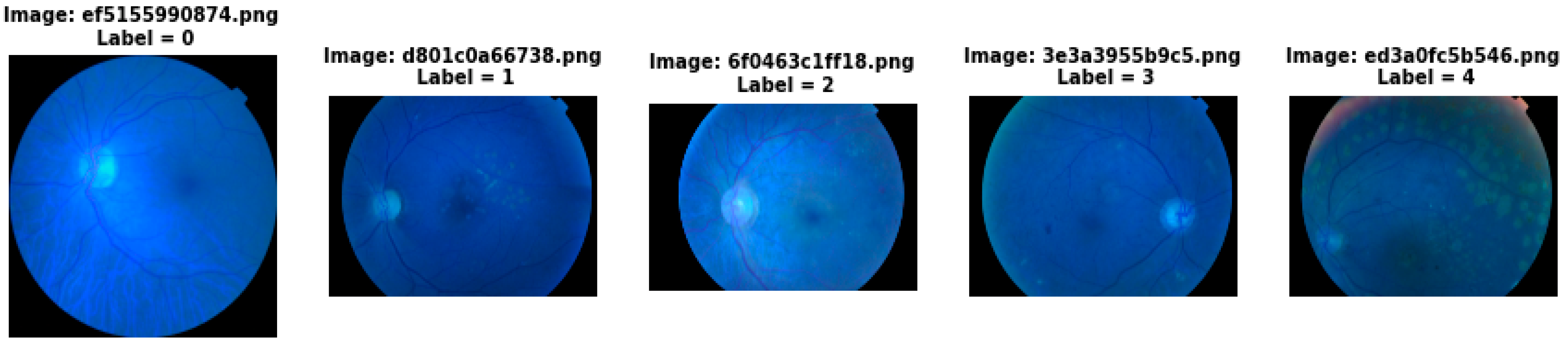
4.1. Image Pre Processing
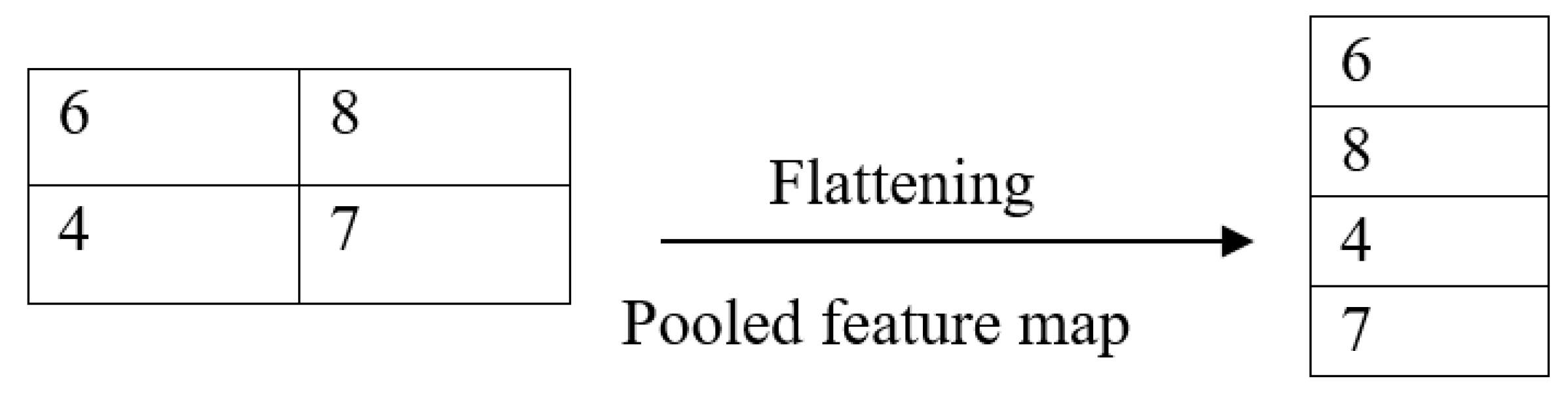
4.2. Convolutional Nueral Network Model
4.3. CNN with ResNet Model
4.4. CNN with DenseNet Model
5. Comparison of Performance
6. Conclusions
7. Future Enhancement
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chazhoor, A.; Sarobin, V.R. Intelligent automation of invoice parsing using computer vision techniques. Multimed. Tools Appl. 2022, 81, 29383–29403. [Google Scholar] [CrossRef]
- Sanket, S.; Vergin Raja Sarobin, M.; Jani Anbarasi, L.; Thakor, J.; Singh, U. Narayanan, S. Detection of novel coronavirus from chest X-rays using deep convolutional neural networks. Multimed. Tools Appl. 2022, 81, 22263–22288. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.L. Predictive Analytics of COVID-19 Pandemic: Statistical Modelling Perspective. Walailak J. Sci. Technol. (WJST) 2021, 18, 15583. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/competitions/aptos2019-blindness-detection/data?select=test_images (accessed on 13 June 2022).
- Jiang, H.; Yang, K.; Gao, M.; Zhang, D.; Ma, H.; Qian, W. An Interpretable Ensemble Deep Learning Model for Diabetic Retinopathy Disease Classification. In Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 2045–2048. [Google Scholar]
- Roy, A.; Dutta, D.; Bhattacharya, P.; Choudhury, S. Filter and fuzzy c means based feature extraction and classification of diabetic retinopathy using support vector machines. In Proceedings of the International Conference on Communication and Signal Processing (ICCSP), Tamil Nadu, India, 6–8 April 2017; pp. 1844–1848. [Google Scholar]
- Qian, Z.; Wu, C.; Chen, H.; Chen, M. Diabetic Retinopathy Grading Using Attention based Convolution Neural Network. In Proceedings of the IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; pp. 2652–2655. [Google Scholar]
- AbdelMaksoud, E.; Barakat, S.; Elmogy, M. Diabetic Retinopathy Grading Based on a Hybrid Deep Learning Model. In Proceedings of the International Conference on Data Analytics for Business and Industry: Way Towards a Sustainable Economy (ICDABI), Sakheer, Bahrain, 26–27 October 2020; pp. 1–6. [Google Scholar]
- Pires, R.; Jelinek, H.F.; Wainer, J.; Goldenstein, S.; Valle, E.; Rocha, A. Assessing the Need for Referral in Automatic Diabetic Retinopathy Detection. IEEE Trans. Biomed. Eng. 2013, 60, 3391–3398. [Google Scholar] [CrossRef] [PubMed]
- Dua, S.; Kandiraju, N.; Thompson, H. Design and implementation of a unique blood-vessel detection algorithm towards early diagnosis of diabetic retinopathy. In Proceedings of the International Conference on Information Technology: Coding and Computing (ITCC’05)-Volume II, Las Vegas, NV, USA, 4–6 April 2005; Volume 1, pp. 26–31. [Google Scholar] [CrossRef]
- Jelinek, H.F.; Pires, R.; Padilha, R.; Goldenstein, S.; Wainer, J.; Bossomaier, T.; Rocha, A. Data fusion for multi-lesion Diabetic Retinopathy detection. In Proceedings of the 25th IEEE International Symposium on Computer-Based Medical Systems (CBMS), Rome, Italy, 20–22 June 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Bourouis, S.; Zaguia, A.; Bouguila, N. Hybrid Statistical Framework for Diabetic Retinopathy Detection. In Proceedings of the International Conference Image Analysis and Recognition, Varzim, Portugal, 27–29 June 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 687–694. [Google Scholar]
- Lachure, J.; Deorankar, A.; Lachure, S.; Gupta, S.; Jadhav, R. Diabetic Retinopathy using morphological operations and machine learning. In Proceedings of the IEEE International Advance Computing Conference (IACC), Bangalore, India, 12–13 June 2015; pp. 617–622. [Google Scholar] [CrossRef]
- Bhatkar, A.P.; Kharat, G. Detection of Diabetic Retinopathy in Retinal Images Using MLP Classifier. In Proceedings of the IEEE International Symposium on Nanoelectronic and Information Systems, Indore, India, 21–23 December 2015; pp. 331–335. [Google Scholar] [CrossRef]
- Mishra, S.; Hanchate, S.; Saquib, Z. Diabetic Retinopathy Detection using Deep Learning. In Proceedings of the International Conference on Smart Technologies in Computing, Electrical and Electronics (ICSTCEE), Bangalore, India, 9–10 October 2020; pp. 515–520. [Google Scholar] [CrossRef]
- Palavalasa, K.K.; Sambaturu, B. Automatic Diabetic Retinopathy Detection Using Digital Image Processing. In Proceedings of the International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; pp. 72–76. [Google Scholar] [CrossRef]
- Prasad, D.K.; Vibha, L.; Venugopal, K. Early detection of diabetic retinopathy from digital retinal fundus images. In Proceedings of the IEEE Recent Advances in Intelligent Computational Systems (RAICS), Kerala, India, 10–12 December 2015; pp. 240–245. [Google Scholar] [CrossRef]
- Amalia, R.; Bustamam, A.; Sarwinda, D. Detection and description generation of diabetic retinopathy using convolutional neural network and long short-term memory. J. Phys. Conf. Ser. 2021, 1722, 12010. [Google Scholar] [CrossRef]
- Nagi, A.T.; Awan, M.J.; Javed, R.; Ayesha, N. A Comparison of Two-Stage Classifier Algorithm with Ensemble Techniques On Detection of Diabetic Retinopathy In Proceedings of the 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA). Riyadh, Saudi Arabia, 6–7 April 2021; pp. 212–215. [Google Scholar] [CrossRef]
- Yadav, J.; Sharma, M.; Saxena, V. Diabetic retinopathy detection using feedforward neural network. In Proceedings of the Tenth International Conference on Contemporary Computing (IC3), Noida, India, 10–12 August 2017; pp. 1–3. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Khare, N.; Bhattacharya, S.; Singh, S.; Maddikunta, P.K.R.; Srivastava, G. Deep neural networks to predict diabetic retinopathy. J. Ambient. Intell. Humaniz.Comput. 2020, 1, 1–14. [Google Scholar] [CrossRef]
- Hemanth, D.J.; Anitha, J.; Son, L.H.; Mittal, M. Diabetic retinopathy diagnosis from retinal images using modified hopfield neural network. J. Med. Syst. 2018, 42, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Gayathri, S.; Gopi, V.P.; Palanisamy, P. Diabetic retinopathy classification based on multipath CNN and machine learning classifiers. Phys. Eng. Sci. Med. 2021, 44, 639–653. [Google Scholar] [CrossRef]
- Varghese, N.R.; Gopan, N.R. Performance analysis of automated detection of diabetic retinopathy using machine learning and deep learning techniques. In Proceedings of the International Conference on Innovative Data Communication Technologies and Application, Coimbatore, India, 17–18 October 2019; Springer: Cham, Switzerland, 2019; pp. 156–164. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Jawahar, M.; Babu, N.K.C.; Vani, K.; Anbarasi, L.J.; Geetha, S. Vision based inspection system for leather surface defect detection using fast convergence particle swarm optimization ensemble classifier approach. Multimed. Tools Appl. 2021, 80, 4203–4235. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Loss % | Accuracy % |
|---|---|---|
| CNN ACC: 75.61% |  |  |
| CNN with DenseNet ACC: 96.22% |  |  |
| CNN with ResNet ACC: 93.18% |  |  |
| Ref | Method | Validation Accuracy | Validation Loss |
|---|---|---|---|
| [1] | AdaBoost algorithm (combination of Inception V3, ResNet151, Inception-ResNet-V2) | 88.21% | |
| [14] | CNN with LSTM | 90% | |
| [4] | E-DenseNet | 91.6% | |
| Proposed | CNN | 75.61% | 0.5831 |
| Proposed | CNN with ResNet | 93.18% | 0.2429 |
| Proposed | CNN with DenseNet | 96.22% | 0.1142 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
R., Y.; Raja Sarobin M., V.; Panjanathan, R.; S., G.J.; L., J.A. Diabetic Retinopathy Classification Using CNN and Hybrid Deep Convolutional Neural Networks. Symmetry 2022, 14, 1932. https://doi.org/10.3390/sym14091932
R. Y, Raja Sarobin M. V, Panjanathan R, S. GJ, L. JA. Diabetic Retinopathy Classification Using CNN and Hybrid Deep Convolutional Neural Networks. Symmetry. 2022; 14(9):1932. https://doi.org/10.3390/sym14091932
Chicago/Turabian StyleR., Yasashvini, Vergin Raja Sarobin M., Rukmani Panjanathan, Graceline Jasmine S., and Jani Anbarasi L. 2022. "Diabetic Retinopathy Classification Using CNN and Hybrid Deep Convolutional Neural Networks" Symmetry 14, no. 9: 1932. https://doi.org/10.3390/sym14091932