1. Introduction
Processing, storage, transfer, and analysis of multidimensional (MD) images, mathematically represented as MD tensors, recently became a question of particular focus studied in numerous research works. In the last years, various tensor decomposition methods have been developed [
1,
2,
3,
4], among which are the multilinear extensions of the matrix SVD, and the generalizations of the SVD matrix for higher-order tensors, called higher-order SVD (HOSVD). This includes several well-known methods: canonical polyadic decomposition (CPD) also known as parallel factor analysis (PARAFAC), where the tensor is represented as a sum of rank-one tensors; the hierarchical Tucker decomposition (H-Tucker), which is a higher-order form of the principal component analysis (PCA); the multilinear PCA (MPCA) [
5]; the non-negative tensor factorization (NTF) [
6]; the tensor-train decomposition (TTD) [
7], etc. For the tensor decomposition components calculation, different iterative methods are used: the alternating least square (ALS) [
8]; the tensor power iteration; the higher-order eigenvalue decomposition; the Jacobi algorithm; the QR factorization [
9], etc.
Additionally, for object detection in tensor multispectral images, mathematical models of stochastic random fields for the background description are suggested [
10]. In this work, the existing contemporary approaches for object detection is based on convolutional neural network (CNN) deep learning with structures of the kind region-based CNN (R-CNN), fast R-CNN, YOLO (You Only Live Once), EfficientDet (efficient object detection), SSD (single-shot detector), etc., which are compared with the introduced new approach, and it is indicated that neural networks ensure high efficiency of object detection, but unlike the approach based on the stochastic random fields models, they demand significant computational resources and a huge amount of priori visual information about the objects.
Tensors play, nowadays, the leading part in modern deep learning architectures. As is known, deep neural networks sometimes perform in an extremely complicated regime, manipulating tens of millions of parameters—much larger than the training data amount. Unlike this, the use of tensor decompositions in deep learning architectures results in a significant reduction in the number of unknown parameters [
11].
To achieve computational complexity reduction, a new non-iterative approach for MD tensor image representation based on the multilayer tensor spectrum pyramid (MLTSP) [
12] with embedded 3D orthogonal transforms (3D OTs) and hierarchical tensor SVD (HTSVD) [
13] is proposed in this work. This approach is illustrated by an example representation of a tensor of the size 8 × 8 × 8 through two-layer tensor spectrum pyramid (2LTSP), with embedded 3D frequency-ordered fast Walsh–Hadamard transform (3D FO-FWHT) [
14] and HTSVD for a tensor of the size 2 × 2 × 2 (HTSVD
2×2×2) [
13]. Furthermore, one application of the presented pyramidal structure aimed at the accelerated search of 3D objects represented through MLTSP and 3D modified Mellin–Fourier Transform (3D MMFT), which is an upgrade from the previous research of the authors [
15], is given in this work.
In the next sections of the paper, more details are given about the new approach; i.e.,
Section 2 contains the basic relations, which represent the two-layer tensor spectrum pyramid implementation for a tensor of the size 8 × 8 × 8; in
Section 3, the HTSVD decomposition algorithm for a spectrum tensor of the size 2 × 2 × 2 (which is the building element in the introduced pyramidal structure) is given; in
Section 4, the fast algorithm for 3D FO-FWHT calculation is explained;
Section 5 evaluates the computational complexity of 3D-FWHT; in
Section 6, the general algorithm for 3D object search in a database of 3D objects represented through MLTSP is given; in
Section 7, the invariant 3D object representation based on the 3D MMFT is given; and
Section 8 contains the Conclusion.
2. Basic Relations, Which Represent the Two-Layer Tensor Spectrum Pyramid with 3D OT and HTSVD
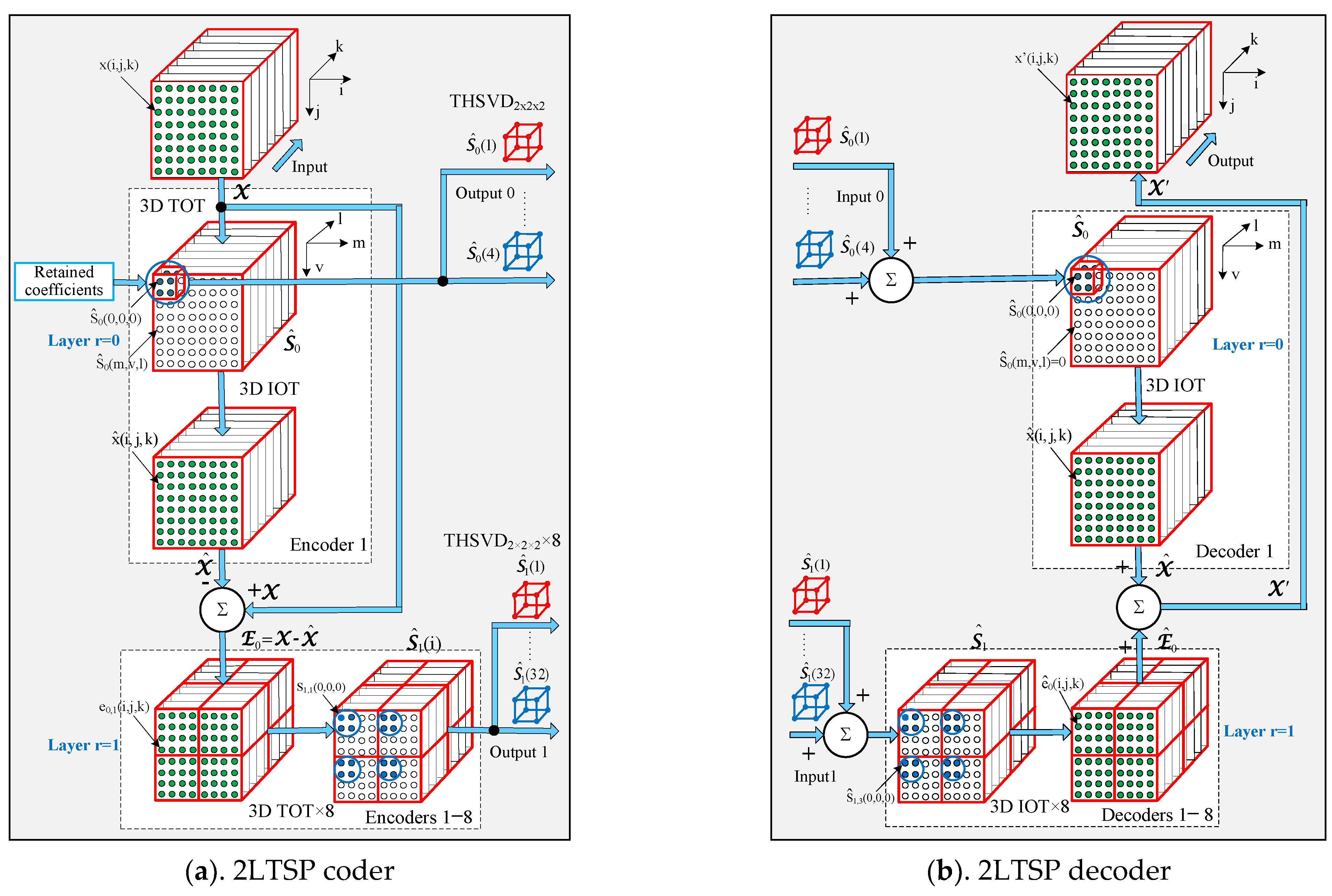
To explain the structure of the multilayer TSP, we use, as an example, the 2LTSP, which comprises a coder and decoder. The structure of the decoder is mirror-symmetrical to that of the coder. The corresponding block diagrams are shown in
Figure 1a,b.
The following symbols are used:
X—cubical tensor of size N = 2
n for N = 8; r = 0, 1—the 2LTSP layer number;
S—cubical spectrum tensor of size N = 2
n; F(.)—operator for direct 3D orthogonal transform (3D OT) (for example, one of the following: 3D FFT [
16], 3D FO-AHKLT [
17], 3D FO-FWHT [
14], etc.); F
T(.)—operator for direct truncated orthogonal transform (3D TOT); F
−1(.)—operator for 3D inverse orthogonal transform (3D IOT); HTSVD
2×2×2—hierarchical tensor singular value decomposition for a 2 × 2 × 2 elementary tensor [
13].
2.1. Description of the 2LTSP Coder Performance
The performance of the coder (
Figure 1a) is presented through the following operations:
In the first layer, for r = 0:
Here, denotes the spectrum tensor, which is the approximation of X in the layer r = 0; —the difference tensor in the layer r = 0; —the spectrum sub-tensor of the size 2 × 2 × 2 in the layer r = 0, which comprises eight low-frequency spectrum coefficients of the selected 3D truncated orthogonal transform (3D TOT); —the approximation of tensor X; —the SVD component t for the sub-tensor .
In the second layer, for r = 1:
where
denotes the u
th difference sub-tensor of the size 4 × 4 × 4;
—the u
th spectrum sub-tensor of the size 4 × 4 × 4, which is the approximation of the sub-tensor
in the layer r = 1;
—the u
th spectrum sub-tensor of the size 2 × 2 × 2 in the layer r = 1, which comprises eight low-frequency spectrum coefficients of the selected 3D TOT;
—the SVD component
t of the sub-tensor
. At the coder output in the layer r = 0 and in correspondence with Equation (2), four HTSVD
2×2×2 components are obtained, arranged following the decreasing values of their dispersions. At the coder output in the layer r = 1, 32 components of HTSVD
2×2×2 are obtained, calculated in correspondence with Equation (5) for the sub-tensors u = 1, 2, …, 8, and arranged following the decreasing values of their dispersions.
2.2. Description of the 2LTSP Decoder Performance
Because of the mirror symmetry existing in the coder/decoder structures (
Figure 1), the performance of the decoder is presented through operations, inverse to these in the coder.
In the first layer, for r = 0:
In accordance with Equation (6), the tensor
is restored by uniting the sub-tensors
in correspondence with
Figure 1b, and the values of the remaining spectrum coefficients (
voxels) are replaced by zeros.
In the second layer, for r = 1:
In accordance with Equation (9), the tensor
is restored through uniting the sub-tensors
in correspondence with
Figure 1b, and the values of the remaining spectrum coefficients (voxels of
) are replaced by zeros. In cases that in the process of 2LTSP coder performance is used, 3D OT instead of 3D TOT, at the output of the decoder 2LTSP, the restored tensor
X is obtained, i.e., the transform of the input tensor
X through 2LTSP is reversible.
The difference between the original and restored tensors defines the error tensor, Δ
X:
The restoration accuracy of the tensor depends on:
- (1)
The number of retained low-frequency spectrum coefficients, which compose the cubical spectrum tensors and for u = 1, 2, …, 8 (in the last case, each spectrum tensor comprises eight coefficients);
- (2)
The number of retained components of each HTSVD2×2×2, applied on the spectrum tensors and .
The restoration accuracy of tensor increases together with the number of retained HTSVD spectrum coefficients, and the use of 3D FO-AHKLT as a basis for 2LTSP. The presented approach could be easily generalized for MTSP of more than two layers. The increase in the number of layers results in a lower power of the error tensor, ΔX.
3. HTSVD Algorithm for Spectrum Tensor Decomposition
In this case, on each tensor
S2×2×2, obtained at the outputs 0 and 1 of the 2LTSP coder shown in
Figure 1a, HTSVD
2×2×2 is applied. As a result, a sum of four components is obtained, for which the energy of each tensor is concentrated mainly in the first and second components. This permits us to reduce (cut off) the number of low-energy components without lessening the quality of the restored tensor, in correspondence with
Figure 1b.
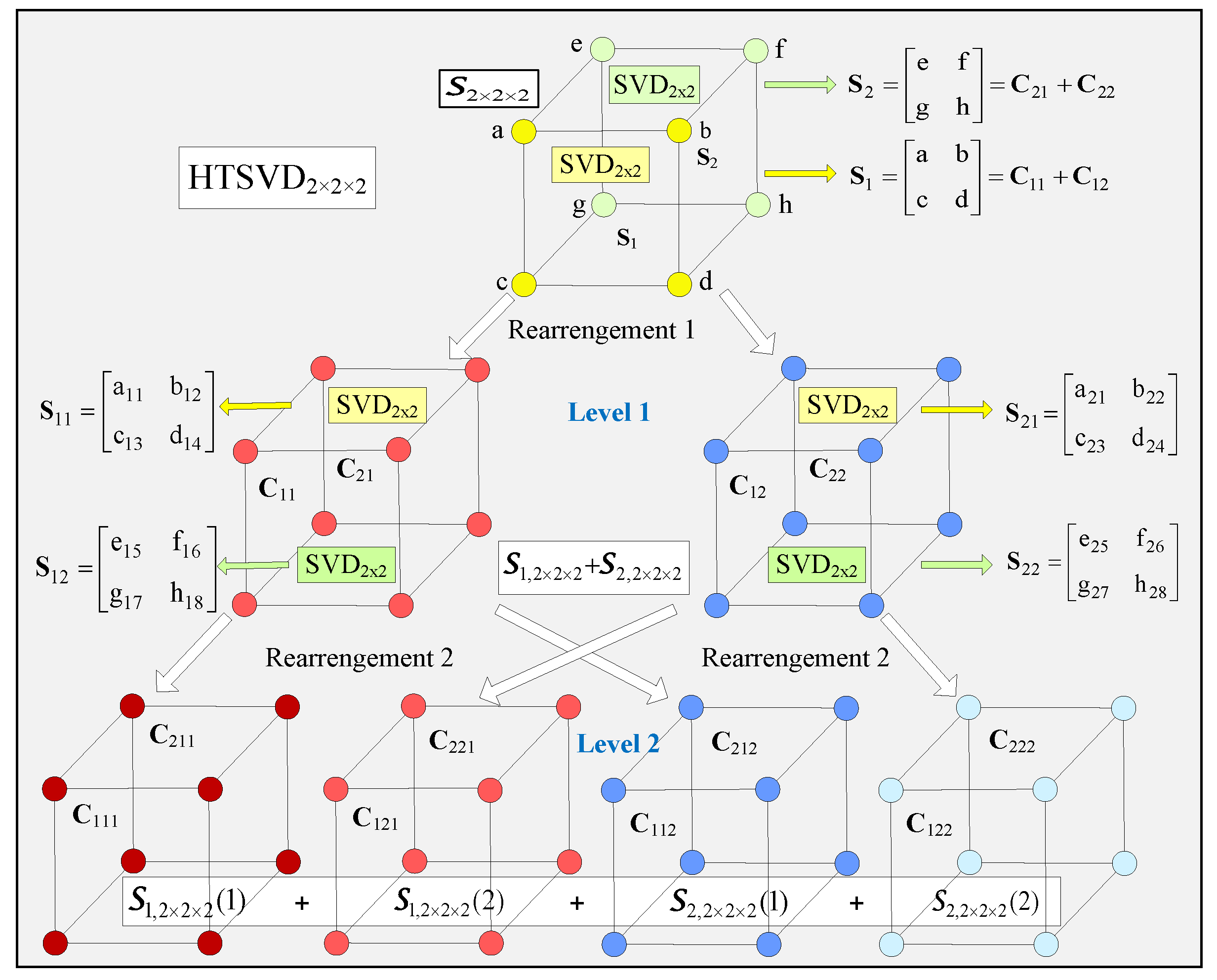
The block diagram of the computational graph of the two-level HTSVD
2×2×2 algorithm for decomposition of the elementary tensor
S2×2×2 is shown in
Figure 2. The decomposition is based on SVD for the matrix
X of size 2 × 2, denoted as SVD
2×2, and described by the relation below [
13]:
where a, b, c, and d are the elements of the matrix
X,
,
,
,
,
,
,
,
. Since
, the energy of the first decomposition component in (12) is much larger than that of the second. The number of parameters which define SVD
2×2 is four (
), i.e., the decomposition is not “over-complete”.
After mode1 unfolding (matricization) of the elementary tensor
S2×2×2, the following is obtained:
In the first level of the algorithm HTSVD for the tensor
S2×2×2 (HTSVD
2×2×2), for each matrix
S1 and
S2, an SVD of the size 2 × 2 (SVD
2×2) is executed, and as a result we obtain:
The matrices
Ci,j of the size 2 × 2 for i, j = 1, 2, calculated in accordance with Equation (12), are rearranged into new couples in correspondence with their singular values. After this, the first couple of matrices,
C11 and
C21, which have high singular values, define the tensor
S1(2×2×2) by inverse matricization, and for the second couple,
C12 and
C22, which have lower singular values, the corresponding tensor is
S2(2×2×2). Then:
After mode-3 unfolding of both tensors, the following is obtained:
In the second HTSVD
2×2×2 level, SVD
2×2 is applied for each matrix
Si,j of the size 2 × 2, and this result is obtained:
The matrices Ci,j,k of the size 2 × 2 for i, j, k = 1, 2 are rearranged into four new couples, following the decrease in their singular values. After inverse matricization, each of these four couples of matrices defines a corresponding tensor of size 2 × 2 × 2.
In result of the mode1, unfolding is obtained:
After execution of the two HTSVD
2×2×2 levels, the tensor
is represented as:
After the execution of the
decomposition, the tensors in the resulting sum are arranged following the decrease in the dispersion values for the sub-matrices obtained after the unfolding. The voxels of higher values in the decomposition (19) are colored in dark red in
Figure 2, and those of lower values are in light blue. The decomposition of tensor
is a basic structure unit of HTSVD, when 3D tensors of size N × N × N for N = 2
n are decomposed [
13].
4. Algorithm for Calculation of the 3D Frequency-Ordered Fast Walsh–Hadamard Transform
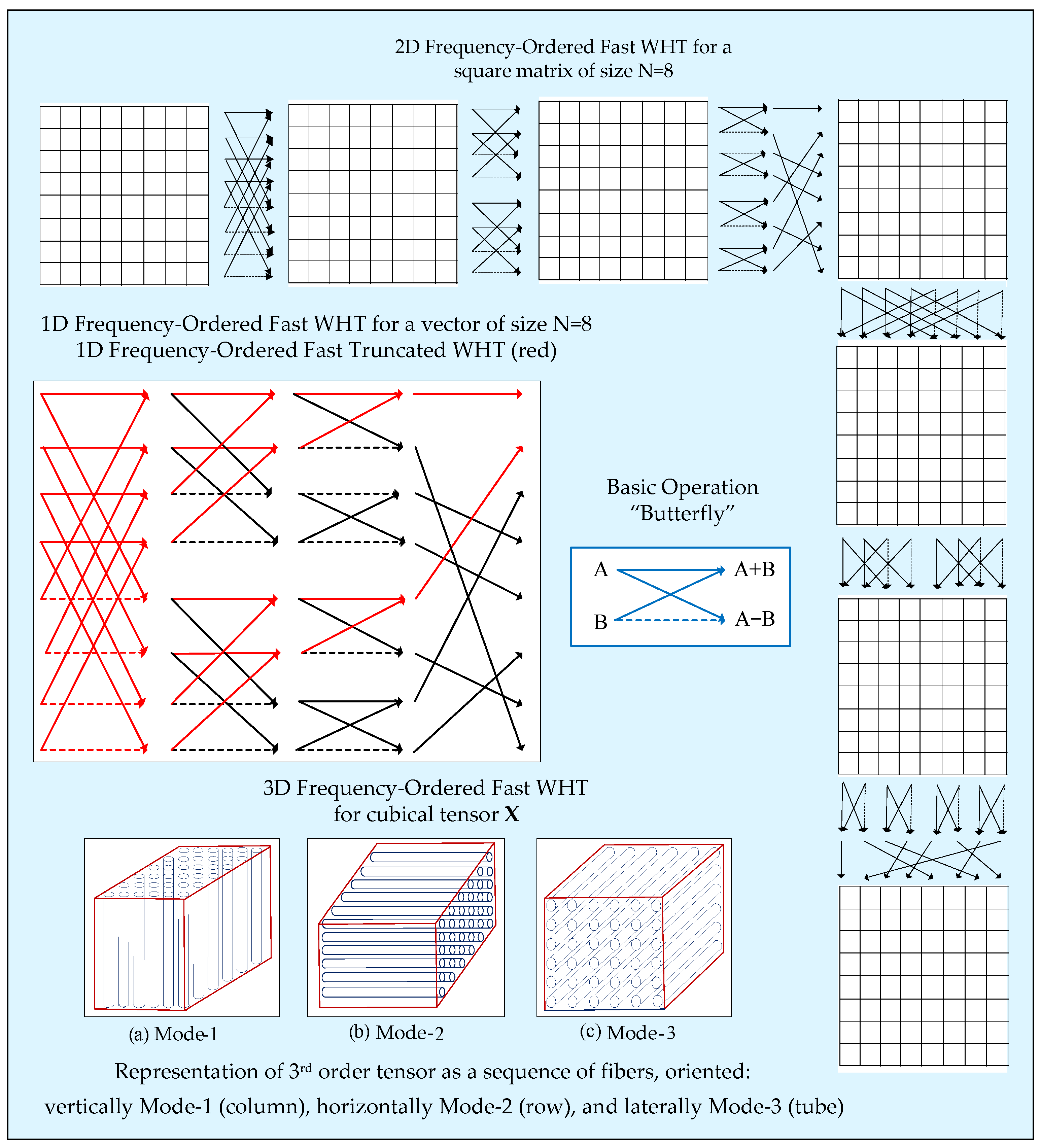
The embedding of the 3D frequency-ordered fast Walsh–Hadamard Transform (3D FO-FWHT) in the 2LTSP coder/decoder ensures maximum acceleration of the tensor restoration. This approach is suitable for applications where high execution speed is requested, as, for example, the efficient compression of multidimensional images, etc.
The calculation of 3D FO-FWHT for tensors of the size 8 × 8 × 8 could be executed in accordance with the diagrams, shown in
Figure 3. The transform is separable and is executed through consecutive 1D FO-WHT calculations for the columns, rows, and tubes of the tensor
X of the size N × N × N, for N = 2
n. To speed up the 1D FO-WHT calculations, the famous “fast” algorithm is used [
16]. The number of basic operations “addition” (A
R) needed for the execution of the “fast” 1D FO-WHT (1D FO-FWHT) in correspondence with the computational graph from
Figure 3 is
. For the case when the “fast“ truncated 1D FO-TWHT (i.e., 1D FO-FTWHT) is used with a reduction (truncation) in some of the output coefficients from N down to 2, the number of “additions”
is defined by the relation:
The corresponding graph from
Figure 3 is colored in red. In this case, the number of calculations needed for the 1D FO-FWHT compared to 1D FO-FTWHT is defined by the relation below:
Hence, for ,
In accordance with
Figure 3, for the 3D WHT transform of the tensor
X, it is first divided into N frontal slices (2D matrices). Then, for each column of the sequence of 2D matrices, 1D FWHT is executed, followed by a similar operation for each row of the corresponding transformed matrices. The calculated tensor
X comprises all matrices transformed this way. Then, the tensor is divided again, but into N horizontal slices (2D matrices), which are transformed column-by-column through 1D FWHT. After that, on each row of the obtained 2D matrices, 1D TFWHT is applied again (for unfolding mode3 only), which, in correspondence with Equation (20), needs 2(N-1) additions only. Hence, the total number of additions needed to transform the tensor
X of the size N × N × N (N = 2
n) through 3D FO-FWHT is correspondingly:
The total number of additions needed to transform the tensor
X of the size N × N × N through 3D WHT is:
Hence, the acceleration of the calculations when the modified “fast” 3D FO-WHT (i.e., 3D FO-FWHT) is used, compared to the 3D FO-TFWHT, is:
For the case when n = 3, from Equation (24) it follows that , i.e., the acceleration of the calculations based on the 3D FO-FWHT compared to 3D FO-TFWHT for a tensor X of the size 8 × 8 × 8, is 2.6 times.
5. Comparative Evaluation of 3D-FWHT Computational Complexity
Here, a comparative evaluation of the computational complexity (CC) of the 3D-FWHT is given with respect to the known hierarchical tensor decompositions 3D discrete wavelet transform (3D-DWT) and H-Tucker. For the evaluation, the number of needed basic operations is used. In the general case, the number of additions (A
3H) for the hierarchical 3D-FWHT [
14] when N = 2
n (n denotes the number of decomposition levels) is:
The needed number of multiplications for the execution of the direct 3D FWHT is
. Then, the CC of the 3D FWHT evaluated through the total number of operations
is defined by the relation:
The global number of additions and multiplications needed to transform the tensor of a size N × N × N through n-level 3D-DWT with orthogonal filters (3, 5) is correspondingly [
14]:
Then, the CC of the 3D-DWT is:
The H-Tucker decomposition [
2] of the cubical tensor of minimum rank R = 2
n, size N = 2
n, and order d = 3 requires
operations. For the TT decomposition [
7], the needed operations for the same tensor are
, i.e., the CC is approximately 1.5 times higher than that of the H-Tucker. This is why the H-Tucker transform was selected for the CC comparison with the analyzed 3D deterministic orthogonal transforms.
The relative CC (denoted as
) for the execution of the 3D FWHT compared to that of the 3D-DWT and H-Tucker is given below:
The relative CC of the 3D FWHT decreases in inverse proportion to n towards the 3D DWT, while compared to H-Tucker, it grows proportionally to . The CC of the 3D FWHT is lower when compared to that of the 3D DWT for levels n < 16, while compared to H-Tucker, it starts to decrease for levels n ≥ 4. In this case, the value of the function . The comparison results permit the choosing of the number of hierarchical decomposition levels n, for which the algorithm 3D FWHT is more efficient than 3D DWT and H-Tucker.
6. Global Algorithm for 3D Object Search in a Database of 3D Objects Represented through MLTSP
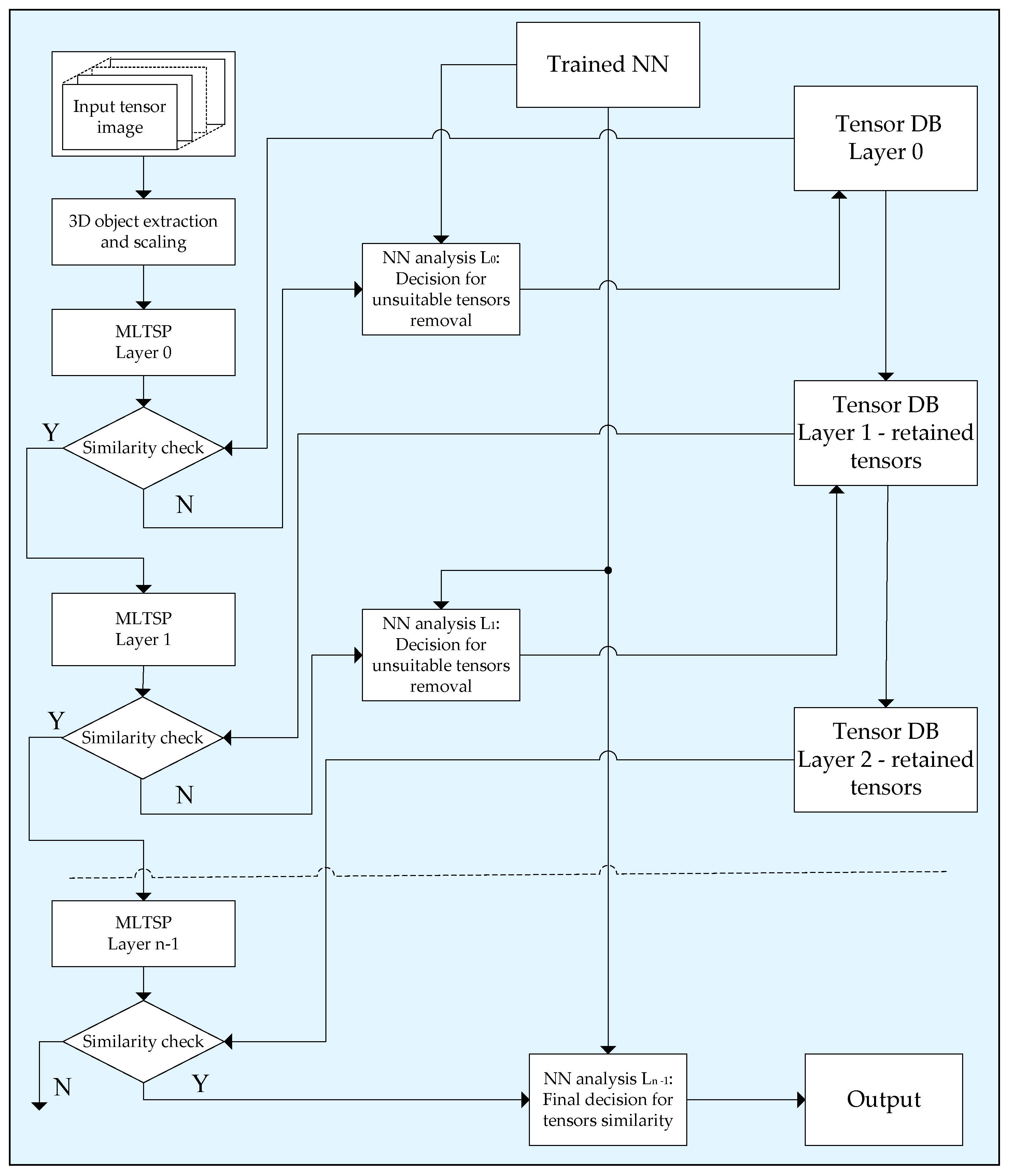
We give here one possible application of the tensor representation based on the n-layer MLTSP, aimed at the accelerated 3D object search in a related database (DB). Such visual information is usually represented by image sequences obtained from various sources: video cameras, multispectral scanners, computer tomography, etc. The authentication degree of the 3D object search is increased significantly compared to the case when 2D image representation only is used. The main problems, which arise when such 3D image systems are created, are related to the high computational complexity of the operations needed for the full search in the DB and the huge number of data needed for the 3D object representation. To overcome these problems, we propose here the global algorithm for accelerated 3D object search, shown in
Figure 4.
We suppose that the 3D object DB is already created and contains normalized tensor object representations, each of size N × N × N (for N = 2
n), calculated through the n-layer MLTSP. For the query, the 3D object used is a deep neural network [
18]. The segmented object image is scaled so as to match the size of the objects in the DB, and its tensor is represented through the n-layer MLTSP. The basic principle which we used to search for the unknown 3D object is to detect the closest similar objects in the DB through sequential multilayer selection. In the first MLTSP layer (r = 0), the search is full, and, as a result, a group of closest similar objects is selected. The selection is based on the similarity degree between homonymous HTSVD components of the spectrum tensors of the size 2 × 2 × 2 in layers r = 0 of the corresponding MLTSPs. The small size of the compared THSVD components does not demand the use of significant computational resources for similarity evaluations. The search in the next MLTSP layer (r = 1) is also based on the similarity evaluation of the HTSVD components, but for the already selected group in the layer r = 0 only. As a result, the total number of computational operations needed for the similarity evaluation of the query tensor is reduced compared to the group from the previous layer. The search continues in the next MLTSP layers and stops when a 3D object is detected in the DB, whose similarity is higher than a predefined threshold. The thresholds used to select the groups of similar tensors in each layer of MLTSP are defined through training the corresponding neural network (NN).
The similarity degree for a couple of P-dimensional vectors
and
is calculated by using the squared cosine similarity (SCSim) criterion [
15], defined by the relation:
To use this criterion for similarity evaluation between a couple of tensors of the same size, first of all, unfolding of the same kind (mode 1, 2, or 3) for each tensor,
X and
Y, must be executed. In cases that the total number of vectors obtained after the unfolding is Q, for the similarity evaluation, the mean value of SCSim could be used for each couple of vectors
xq and
yq of the same sequential number q = 1, 2, …, Q, which belongs to
X and
Y, correspondingly:
7. Invariant 3D Object Representation, Based on MLTSP with 3D Modified Mellin–Fourier Transform
The description of the 3D object should be invariant to 3D rotations (R) on angles α
r, β
r, γ
r, 3D translation shift (T) in directions x
s, y
s, z
s, 3D scaling (S), and contrast (C) changes. To obtain the invariant representation of a 3D object through MLTSP, the spectrum coefficients at the outputs of the decomposition layers r = 0, 1, …, n−1 must be calculated by using the 3D modified Mellin–Fourier transform (3D MMFT), which is an upgrade from the previous work of the authors, introduced in [
15].
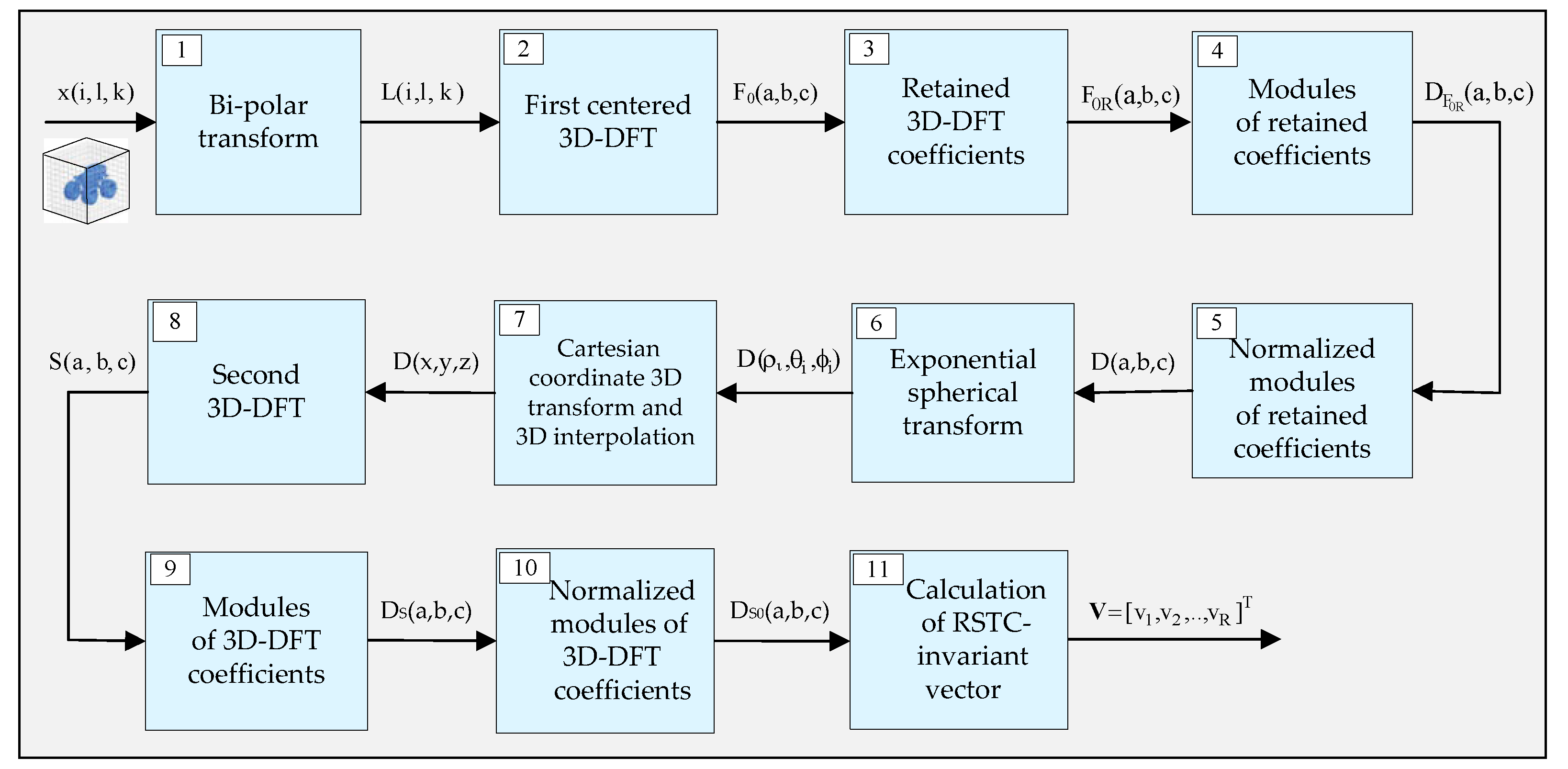
The block diagram of the algorithm for calculation of the direct 3D MMFT spectrum coefficients is shown in
Figure 5. The main operations for the 3D MMFT execution are:
- (1)
Bi-polar transform of the voxels x(i, l, k) of the input tensor image
X:
where x
max is the maximum value in the voxel quantization scale.
- (2)
First direct 3D discrete Fourier transform (3D DFT):
followed by centering of the Fourier coefficients F(a,b,c):
- (3)
Retaining the centered low-frequency spectrum Fourier coefficients:
The retained coefficients’ region is a cube with a side H ≤ N, which envelopes the center (0,0,0) of the 3D Fourier spectrum (H—even number). For H < N and ; this cube contains low-frequency coefficients only.
- (4)
Calculation of modules and phases of the retained coefficients
:
where
and
are the real and the imaginary components of
, correspondingly.
- (5)
Calculation of the retained coefficients’ normalized modules:
- (6)
Replacement of the orthogonal 3D discretization grid, which contains the voxels
, by a new grid, defined through 3D logarithmic spherical polar transform (3D LSPT), using the relations below:
After discretization of
, the voxels
are obtained where:
Here, instead of the 3D LSPT given in Equation (32), we used the 3D exponential polar transform (3D EPT) from Equation (33), which gives a higher density of the retained voxels around the origin (0,0,0) of the discretization grid .
- (7)
Replacement of the discretization grid for voxels
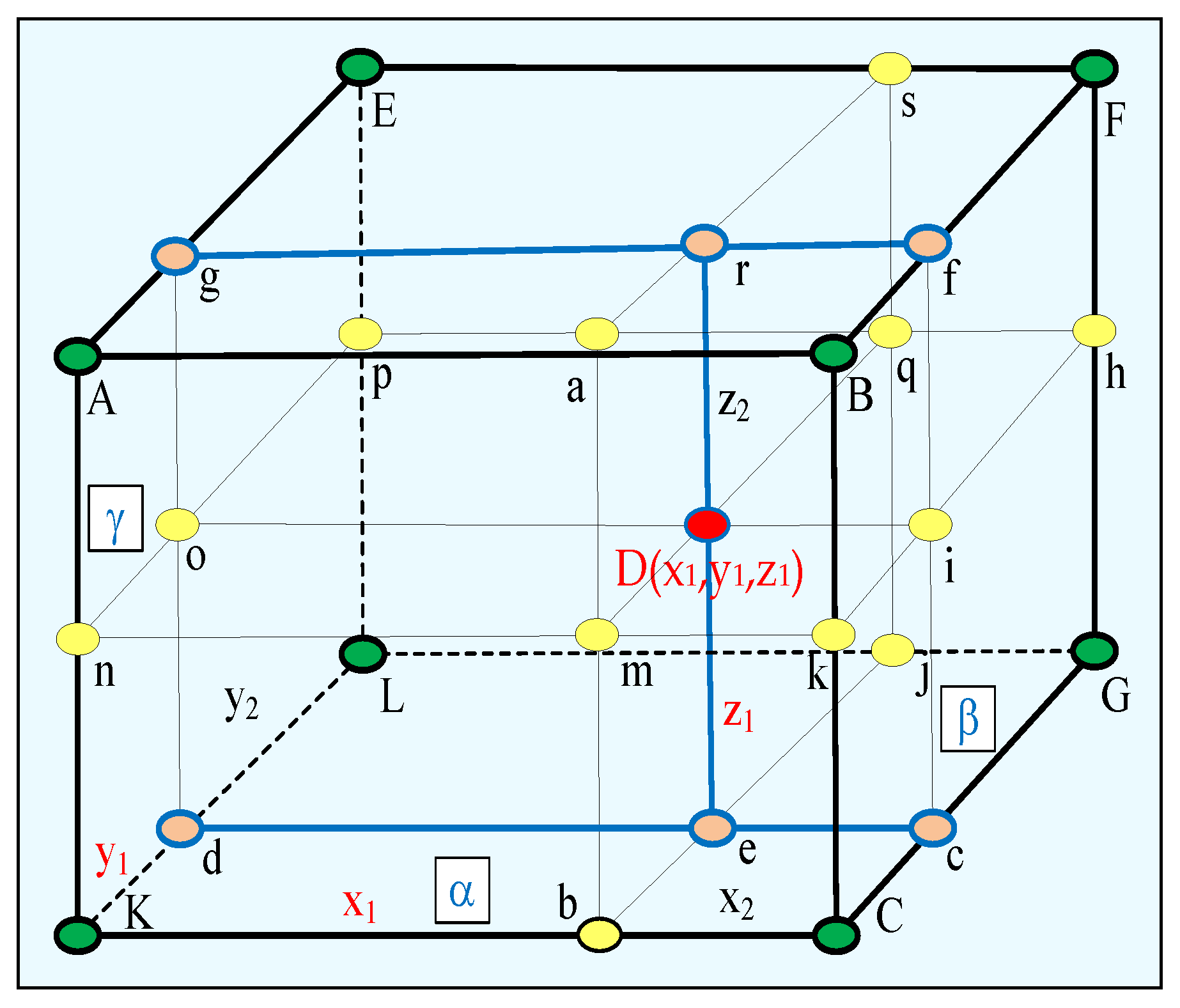
defined through 3D EPT, by the orthogonal discretization 3D grid for voxels D(x,y,z), calculated through trilinear interpolation (
Figure 6). In this case, each interpolated voxel D(x
1,y
1,z
1) is calculated taking into consideration the closest eight neighbor voxels on the grid:
where A, B, C, K, E, F, G, L—neighboring voxels from the discretization grid
;
α, β, γ—distances between the eight neighboring voxels in directions x, y, z;
D(x1,y1,z1)—linearly interpolated voxel for , , ;
The obtained results are the voxels D(x,y,z) of the interpolated output tensor D for x, y, z = 0, 1, 2, .., H − 1.
- (8)
Second direct 3D DFT for a tensor
D, with voxels D(x,y,z):
- (9)
Calculation of the complex coefficient
modules:
where
,
, and
are the real and the imaginary components of
, correspondingly.
- (10)
Calculation of the normalized modules
of the Fourier coefficients
:
where
is the module of the coefficient
with a maximum value for
.
- (11)
Calculation of the vector for RSTC-invariant 3D object representation based on the coefficients of highest energy in the amplitude spectrum 3D MMFT, for . The vm components for m = 1, 2, .., R of the corresponding RSTC-invariant vector are defined by coefficients , arranged as a 1D massif after scanning the 3D-MMFT spectrum in the frame of the 3D mask area with R < H3 voxels .
The main advantages of 3D MMFT compared to other famous spectrum 3D object descriptors [
19,
20,
21,
22] are that it is an RSTC invariant, and the features’ space dimensionality is reduced. This is why the approach based on MLTSP with embedded 3D MMFT accelerates the search of 3D objects in tensor DBs and ensures higher identification accuracy.
8. Conclusions
In this work, a new approach is proposed for 3D tensor representation through MLTSP with embedded 3D FO-FWHT and HTSVD, or 3D FO-FWHT and 3D-MMFT depending on the application, for example, information redundancy reduction in the input tensor, or an accelerated 3D object search in a tensor DB. In both cases, the main advantages of the MLTSP algorithms are the low computational complexity, the high flexibility regarding the choice of their parameters, and the ability for information redundancy reduction in the input tensor. These qualities have good potential for application in various areas where multidimensional signals and images are concerned.
Our future work will be focused on MLTSP modeling with various kinds of 3D OT and on the investigation of spectrum pyramid applications in different areas of tensor image processing, analysis, and computer vision. The future investigation of the MLTSP application in deep learning architectures is extremely promising.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





