
ConvLSTM Coupled Economics Indicators Quantitative Trading Decision Model



Abstract
:1. Introduction
2. Related Work
2.1. Stochastic Regression Model
2.2. Deep Learning Model
3. Materials and Methods
3.1. Data Processing and Hypothesis
3.1.1. Data Pre-Processing
3.1.2. Hurst Index Test
3.2. CONVLSTM Integrated Economic Forecasting Model
3.2.1. LSTM
3.2.2. CONVLSTM
3.3. Machine Learning Simulation Decision Model Combining Economics
3.3.1. Evaluation Model of Economic Indicators Based on Decision Trees
- Introduction of economics indicators.
- Construction of quantitative evaluation model of decision tree.
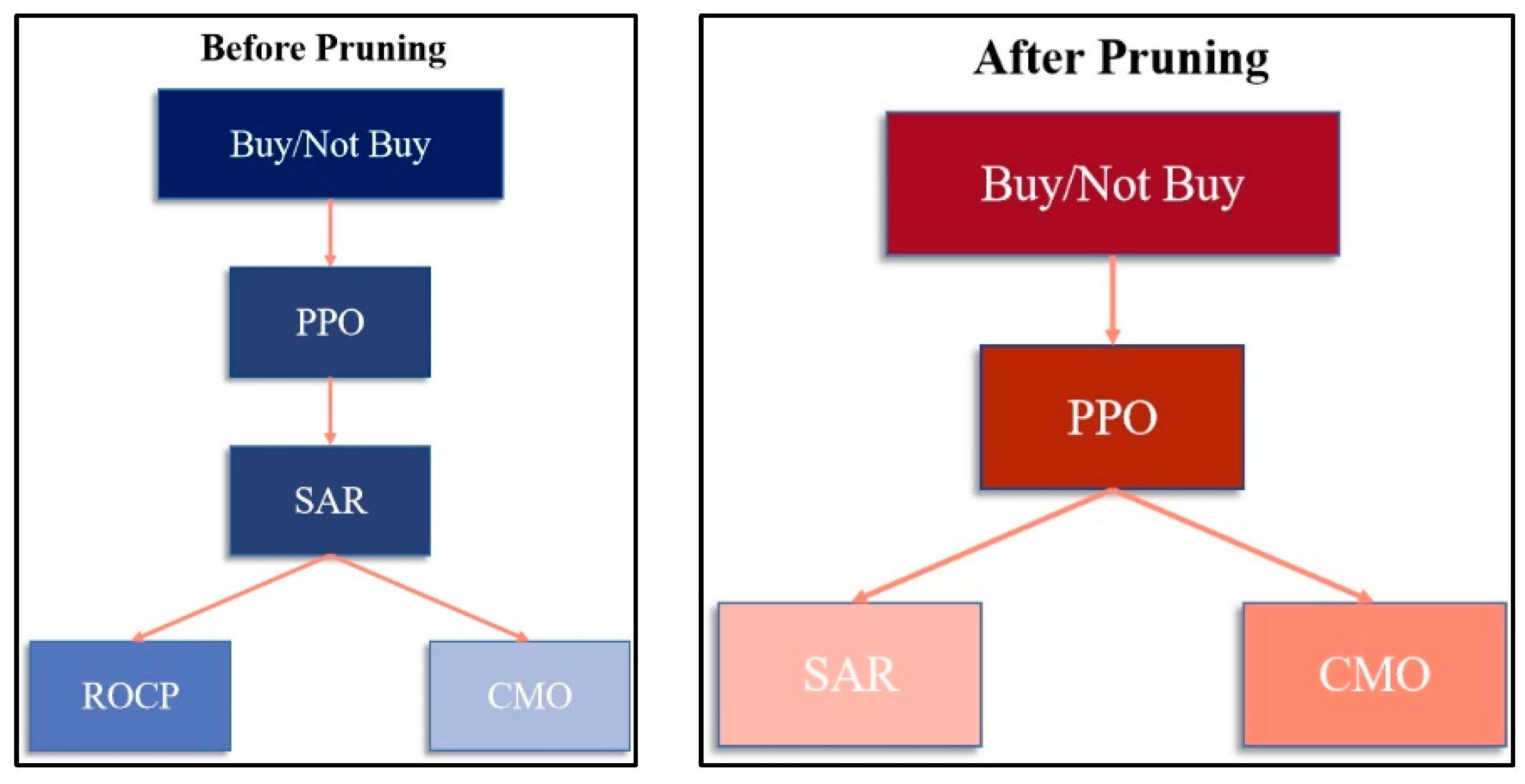
3.3.2. Decision Modeling
4. Results
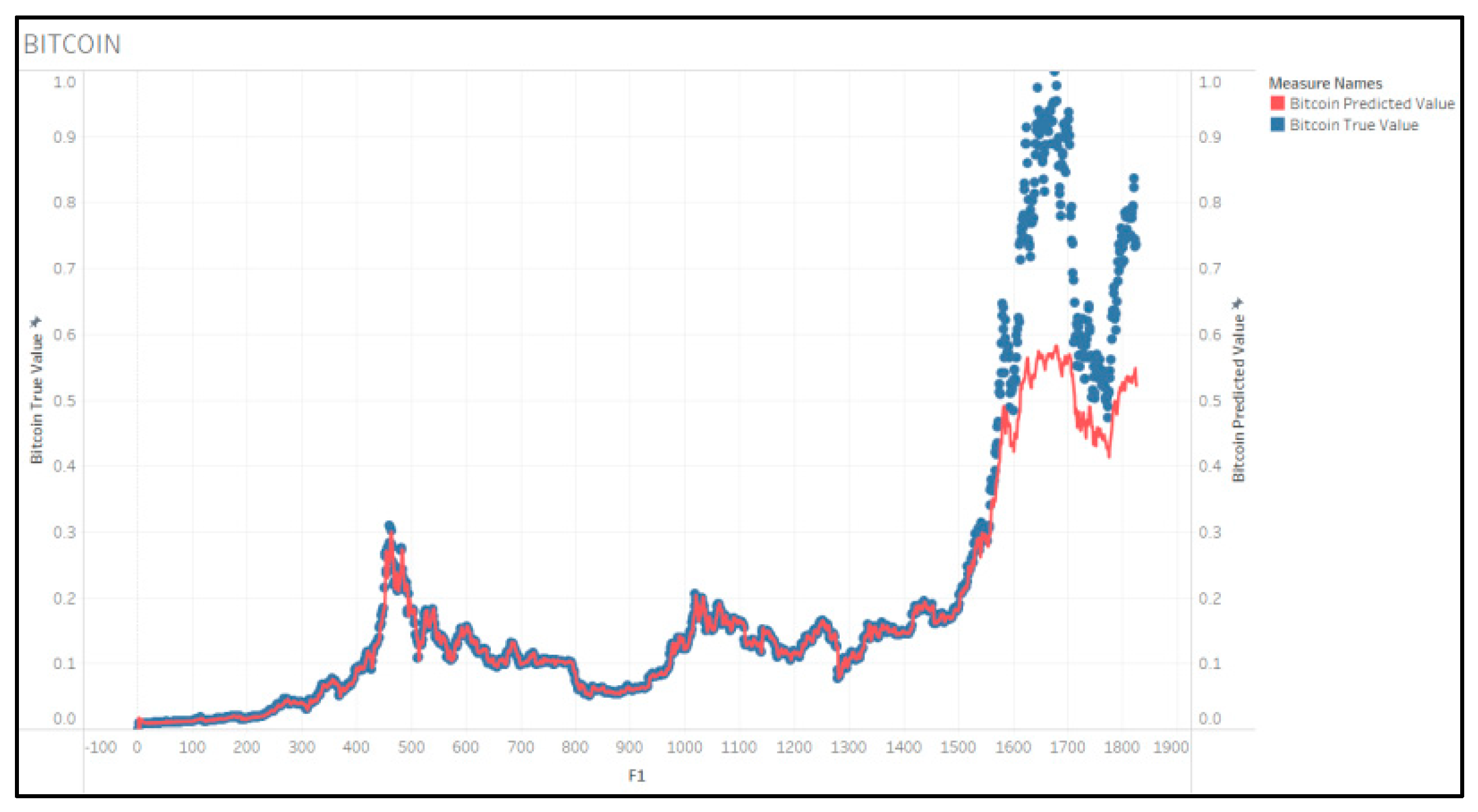
4.1. CONVLSTM Model Results Analysis
4.2. Analysis of the Results of the Control Model
4.3. Analysis of Decision Model Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviations | Full Name |
| ConvLSTM | convolution Long Short Term Memory |
| LSTM | Long Short Term Memory |
| RNN | recurrent neural networks |
| CMO | Chande Momentum Oscillator |
| PPO | Percentage price oscillator |
| SAR | Stop And Reverse |
| CART | Classification and Regression Tree |
| MLP | Multilayer Perceptron |
| CNN | Convolution neural networks |
| ARIMA | Auto regressive Integrated Moving Average |
| ARMA | Auto regressive moving average |
| HONN | higher order neural networks |
| CIAC | Comprehensive Investment Appraisal Coefficient |
References
- Nelson, B.K. Time series analysis using autoregressive integrated moving average (ARIMA) models. Acad. Emerg. Med. 1998, 5, 739–744. [Google Scholar] [CrossRef] [PubMed]
- Ullrich, T. On the Autoregressive Time Series Model Using Real and Complex Analysis. Forecasting 2021, 3, 716–728. [Google Scholar] [CrossRef]
- Baragona, R.; Battaglia, F.; Cucina, D. Periodic autoregressive models for time series with integrated seasonality. J. Stat. Comput. Simul. 2021, 91, 694–712. [Google Scholar] [CrossRef]
- Andriyanov, N.; Korovin, D. Analysis of the Restrictive Measures Impact on the Disease Spread. In Proceedings of the 2021 International Conference on Information Technology and Nanotechnology (ITNT), Samara, Russia, 20–24 September 2021; pp. 1–6. [Google Scholar]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Dunis, C.L.; Nathani, A. Quantitative trading of gold and silver using nonlinear models. Neural Netw. World 2007, 17, 93. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In International Conference on Machine Learning; PMLR: 2013. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; PMLR: Cambridge, MA, USA, 2013. [Google Scholar]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lukáš, P.; Taisei, K. Volatility analysis of bitcoin price time series. Quant. Financ. Econ. 2017, 1, 474–485. [Google Scholar]
- McNally, S.; Roche, J.; Caton, S. Predicting the Price of Bitcoin Using Machine Learning. In Proceedings of the 2018 26th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Cambridge, UK, 21–23 March 2018; pp. 339–343. [Google Scholar]
- Siami-Namini, S.; Namin, A.S. Forecasting economics and financial time series: ARIMA vs. LSTM. arXiv 2018, arXiv:1803.06386. [Google Scholar]
- Wang, L.; Zeng, Y.; Chen, T. Back propagation neural network with adaptive differential evolution algorithm for time series forecasting. Expert Syst. Appl. 2015, 42, 855–863. [Google Scholar] [CrossRef]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative study of CNN and RNN for natural language processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | Full Name | Role | Buying and Selling Behavior |
|---|---|---|---|
| CMO | Chandler momentum oscillator | Measuring trend strength | >50 buy, <50 sell |
| APO | Absolute price oscillator | Difference of moving average | Buy above the 0 line, sell below the zero line |
| ROCP | Percentage change | The strength of supply and demand forces in buying and selling | Buy above the 0 line, sell below the zero line |
| SAR | Parabolic indicator | Stop loss turn action point indicator | Stocks break the SAR curve from below to buy and above to sell |
| PPO | Price oscillation percentage index | Difference between moving averages | >0 buy, <0 sell |
| CMO | APO | ROCP | SAR | PPO | B/NB | CMO | APO | ROCP | SAR | PPO | S/NS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| … | … | … | … | … | … | … | … | … | … | … | … |
| 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 |
| 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| Market Transactions | Viral Transmission |
|---|---|
| Buy | Illness |
| Sell out | Healing |
| Rating | Severity |
| Get profit | The cost of healing |
| Investment amount | Accumulation of toxins |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Y.; Jiang, H.; Li, S.; Cao, J. ConvLSTM Coupled Economics Indicators Quantitative Trading Decision Model. Symmetry 2022, 14, 1896. https://doi.org/10.3390/sym14091896
Qi Y, Jiang H, Li S, Cao J. ConvLSTM Coupled Economics Indicators Quantitative Trading Decision Model. Symmetry. 2022; 14(9):1896. https://doi.org/10.3390/sym14091896
Chicago/Turabian StyleQi, Yong, Hefeifei Jiang, Shaoxuan Li, and Junyu Cao. 2022. "ConvLSTM Coupled Economics Indicators Quantitative Trading Decision Model" Symmetry 14, no. 9: 1896. https://doi.org/10.3390/sym14091896