
Application of Feature Selection Based on Multilayer GA in Stock Prediction

Abstract
:1. Introduction
- (1)
- A multilayer GA-based feature selection model is proposed to eliminate features that are still relatively redundant after dimensionality reduction;
- (2)
- Improving the GA fitness function based on an ensemble learning model with TSCV;
- (3)
- To cope with the change in data dimensionality during the two-dimensionality reduction processes and the HSD dataset’s imbalance, set corresponding adaptation functions in each layer;
- (4)
- Introduce TSCV for the HSD dataset;
- (5)
- Use adversarial validation to analyze the impact of the inconsistent distribution of the HSD dataset.
2. Related Work
2.1. The High-Stock Dividend Forecast
2.2. Genetic Algorithm for Feature Selection
3. Methods and Data
3.1. Multilayer GA Feature Selection Model
- Layer 1: Determining the fitness function
| Algorithm 1: GA determines the fitness function combination form at the first layer |
| Input: training set, population number P, current iteration numbert, maximum iteration number T, crossover rate c, mutation rate a, fitness function F, model set M{M1, M2, M3, M4, M5, M6}, fitness function set TSCV_X{ TSCV_AUC, TSCV_ACC } Output: fitness function combination: Mi:F 1 Initialize the population and encode the features of the training set 2 for Mi in M do 3 while t ≤ T do 4 for F in TSCV_X do 5 if F = TSCV_ACC, the fitness value of each chromosome in the current population is calculated using the fitness function shown in Equation (1). else if F = TSCV_AUC, the fitness function as shown in Equation (2) is used to calculate the fitness value of each chromosome in the current population. 6 end for 7 Random probability sampling of chromosomes in the population, crossover operation with crossover rate c, and mutation operation with mutation rate a, generate a new population and calculate the fitness value of each chromosome in the current population. 8 end while 9 Record the current model name Mi, fitness function F, and optimal fitness value 10 end for 11 From the records, the model Mi and F corresponding to the optimal fitness value is selected according to the ranking of the optimal fitness value 12 Print Mi:F and return |
- Layer 2: solving the optimal solution
- Layer 3: determine the optimal solution convergence range
| Algorithm 2: GA third layer to determine the convergence range of the optimal solution |
| Input: DR1-DATA, DR1-DATA feature dimension N, chromosome number Ci (1 ≤ i ≤ N), population number P, current iteration times t, maximum iteration times T, crossover rate c, mutation rate a, fitness function F Output: convergence range of optimal solution: Ci 1 Initialize the population and encode the DR1-DATA features 2 while Ci ≤ N do 3 while t ≤ T do 4 F is used as fitness function as shown in Equation (3) to calculate the fitness value of each chromosome in the current population. 5 The chromosomes in the population are sampled with random probability, the crossover rate is c, and the mutation operation is performed with the mutation rate a to generate a new population, and the fitness value of each chromosome in the current population is calculated. 6 end while 7 Record the current chromosome number Ci of the current chromosome number and its corresponding optimal fitness value 8 end while 9 From the records, the Ci of the convergence of the optimal fitness value is determined 10 Output Ci and return |
- Layer 4: Dimensionality reduction of the optimal solution
3.2. Data
3.2.1. Data Sources
3.2.2. Data Pre-Processing
- Basic data processing:
- 2.
- Annual data processing:
- 3.
- Daily data processing:
- 4.
- Missing values handling:
- 5.
- Data merging:
3.3. Division of Time-Series Data Set
3.4. Parameter Setting
3.4.1. Parameter Setting of Multilayer GA Feature Selection Model
3.4.2. Parameter Setting of HSD Prediction Experiment
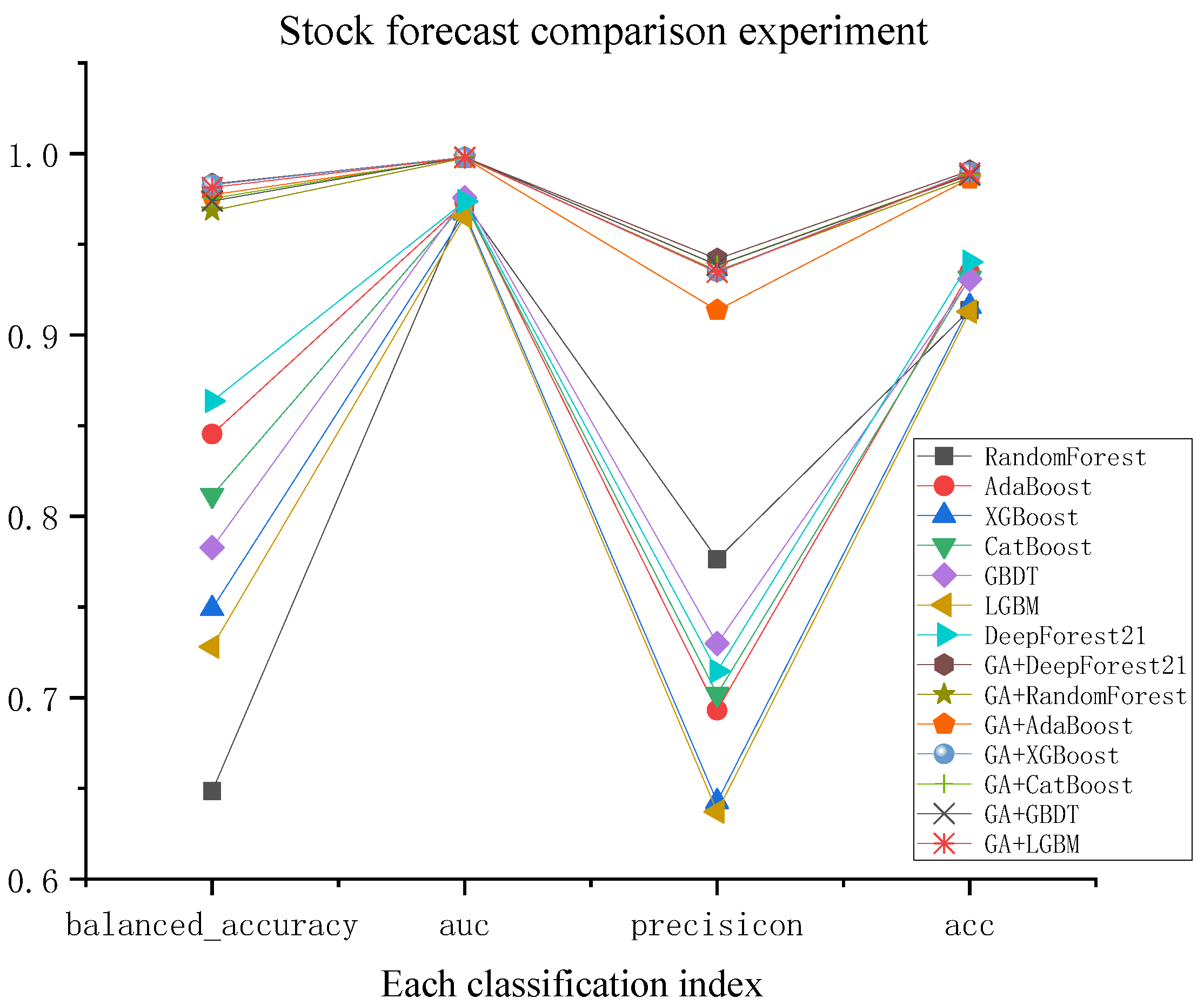
4. Results
4.1. HSD after Multi-Layer GA Feature Selection Results
4.2. HSD Forecast Results
5. Discussion
6. Conclusions and Prospects
- (1)
- When using the ensemble learning model and TSCV metrics as the fitness function, the ensemble model’s excellent performance enables the genetic algorithm’s fitness value to reach convergence with a small number of iterations. For data sets with large data dimensions, this approach can save time by setting a smaller number of iterations to reach convergence quickly, but how to determine the exact number of iterations is something worth exploring further.
- (2)
- For the two-dimensionality reduction processes of the model, corresponding adaptation functions are set in each layer according to the changes in data dimensionality and the unbalanced characteristics of the HSD data set.
- (3)
- According to the HSD data set’s time-series characteristics, the HSD’s TSCV is introduced.
- (4)
- The TSCV indicator in the ensemble model is used as the fitness function, which not only takes into account the time-series characteristics of the HSD data set but also avoids overfitting while evaluating the model effect of the data in the feature contained in the selected populations in GA.
- (1)
- Given the excellent performance of the ensemble learning model, when combined with the GA, only a small number of iterations are required for the fitness to reach convergence, and how to determine the appropriate number of iterations is worth exploring further.
- (2)
- The genetic algorithm’s crossover rate and mutation rate can be set too large to enhance the searchability of the algorithm, making the chromosomes in the population more diverse. The combination of features is more abundant but leads to an optimal solution in the combination of features that cannot be fixed. Too low a crossover and mutation rate can easily make the genetic algorithm fall into local optimum and reduce the searchability of the algorithm. The focus of the subsequent research is how to set the appropriate crossover and mutation rate.
- (3)
- There is a serious imbalance problem in the HSD data set. However, it also has very distinctive time-series characteristics, and the eight-year data limit further study of the HSD phenomenon, so the traditional methods of dealing with imbalance, such as SMOTE, cannot cope with this problem well. The focus of the subsequent work is on how to better solve the imbalance problem of data sets with time-series characteristics or collect more data on HSDs.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, X.D.; Yu, H.H.; Lu, R.; Xu, L.B. Research on the Phenomenon of “highly dividend” in Chinese Stock Market. Manag. World 2014, 11, 133–145. [Google Scholar]
- Wang, Y. Analysis on the influencing factors of highly dividend of listed companies. Chin. Foreign Entrep. 2019, 29, 1. [Google Scholar]
- Feng, X.X. Listed companies “highly dividend” is high return or interest delivery? J. Financ. Account. 2018, 17, 74–78. [Google Scholar]
- Chen, X.; Chen, X.Y.; Ni, F. An empirical study on the signaling effect of initial dividends of listed companies in China. Econ. Sci. 1998, 5, 34–44. [Google Scholar] [CrossRef]
- Gong, H.Y. A study on the behavior of dividend conversions of listed companies in China based on dividend catering theory. Shanghai Financ. 2010, 11, 67–72. [Google Scholar]
- Yan, J.X. Research on “Highly Dividend” Excess Returns of Gem Listed Companies and Its Influencing Factors. Master’s Thesis, Soochow University, Jiangsu, China, 2017. [Google Scholar]
- Ling, S.Q.; Xie, C. High dividend to an investment strategy based on the Logit model. J. Time Financ. 2017, 20, 277–281. [Google Scholar]
- Yan, M.C. Investment Strategy Analysis Based on the Effect of “Highly Dividend and Transfer” Announcement. Master’s Thesis, Nanjing Agricultural University, Nanjing, China, 2017. [Google Scholar]
- Jiang, C.; Xia, X.L.; Wu, W.; Cui, H.B.; Ma, C.X. Research on highly dividend prediction of listed companies based on Data Mining. J. Hubei Univ. 2021, 43, 698–705. [Google Scholar]
- Mai, J.F.; Zhao, H.Q. Research on the prediction of “highly dividend” of Chinese listed companies: Based on the mixed analysis of Grey Prediction and Support Vector Regression Model. J. Shaoguan Univ. 2001, 42, 5–10. [Google Scholar]
- Zhang, T.H.; Luo, K.X. An empirical study on highly dividend prediction of listed companies based on ensemble learning. J. Comput. Eng. Appl. 2022, 58, 255–262. [Google Scholar]
- Yu, Q.D.; Dai, J.J. Prediction of highly dividend of listed companies based on Combination Model. Math. Theory Appl. 2020, 40, 101. [Google Scholar]
- Cao, L.; Li, J.; Zhou, Y.; Liu, Y.; Liu, H. Automatic feature group combination selection method based on GA for the functional regions clustering in DBS. Comput. Methods Programs Biomed. 2020, 183, 105091. [Google Scholar] [CrossRef] [PubMed]
- Saibene, A.; Gasparini, F. GA for feature selection of EEG heterogeneous data. arXiv 2021, arXiv:2103.07117, 2021. [Google Scholar]
- Li, X.H.; Jia, H.D.; Cheng, X.; Li, T. Prediction of Stock market volatility based on Improved Genetic Algorithm and Graph Neural Network. J. Comput. Appl. 2022, 42, 1624–1633. [Google Scholar]
- Elsawy, A.; Selim, M.M.; Sobhy, M. A hybridised feature selection approach in molecular classification using CSO and GA. Int. J. Comput. Appl. Technol. 2019, 59, 165–174. [Google Scholar] [CrossRef]
- Omidvar, M.; Zahedi, A.; Bakhshi, H. EEG signal processing for epilepsy seizure detection using 5-level Db4 discrete wavelet transform, GA-based feature selection and ANN/SVM classifiers. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 10395–10403. [Google Scholar] [CrossRef]
- Mandal, R.; Azam, B.; Verma, B.; Zhang, M. Deep Learning Model with GA-based Visual Feature Selection and Context Integration. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Kraków, Poland, 28 June–1 July 2021; pp. 288–295. [Google Scholar]
- Zhang, Y.; Wang, X.N. Text Feature Selection Method based on Word2Vec Word Embedding and Genetic Algorithm for High-dimensional Biological Gene Selection. Comput. Appl. 2021, 41, 3151–3155. [Google Scholar]
- Chen, Q.R.; Li, Y.L.; Xu, K.Q.; Liu, X.L.; Wang, S.Q. WKNN Feature Selection Method based on Self-tuning adaptive Genetic Algorithm. Comput. Eng. Appl. 2021, 57, 164–171. [Google Scholar]
- Xie, L.R.; Yang, H.; Li, J.W. Bearing Fault Diagnosis of Doubly-Fed Wind Turbine Based on Ga-ENN Feature Selection and Parameter Optimization. J. Sol. Energy 2021, 42, 149–156. [Google Scholar]
- Zhou, Z.H.; Feng, J. Deep forest. Natl. Sci. Rev. 2019, 6, 74–86. [Google Scholar] [CrossRef] [PubMed]
- Bühlmann, P. Bagging, boosting and ensemble methods. In Handbook of Computational Statistics; Springer: Berlin/Heidelberg, Germany, 2012; pp. 985–1022. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Categories | Number of Features | Number of Rows | Notes |
|---|---|---|---|
| Basic Data | 4 | 3466 | |
| Training set Yearly data | 362 | 24,262 | First seven years of data |
| Test set Yearly data | 362 | 3466 | 8th year data |
| Training set Daily data | 61 | 5,899,132 | First seven years of data |
| Test set Daily data | 61 | 842,238 | 8th year data |
| Model | Data Set | Fitness Function | Number of Populations | Number of Iterations | Crossover Rate | Mutation Rate |
|---|---|---|---|---|---|---|
| First layer | Training sets | Model: TSCV_ACC, AUC | 200 | 5 | 0.7 | 0.5 |
| Second layer | Training sets | Model: TSCV_AUC | 500 | 20 | 0.3 | 0.1 |
| Third layer | Optimal solution data set | Model: TSCV_balanced accuracy | 200 | 5 | 0.3 | 0.1 |
| Fourth layer | Optimal solution data set | Model: TSCV_balanced accuracy | 500 | 20 | 0.3 | 0.1 |
| Model | Parameter Setting |
|---|---|
| RandomForest | n_estimators = 400, max_depth = 13, min_samples_leaf = 10, min_samples_split = 30 |
| AdaBoost | n_estimators = 800, learning_rate = 0.1 |
| XGBoost | n_estimators = 400, learning_rate = 0.07, max_depth = 7, min_child_weight = 1 |
| CatBoost | learning_rate = 0.1, iterations = 400, max_depth = 5 |
| GBDT | learning_rate = 0.01, max_depth = 11, n_estimators = 850, subsample = 0.8, random_state = 5, min_samples_split = 100, min_samples_leaf = 20 |
| LGBM | n_estimators = 800, learning_rate = 0.03, max_depth = 13, num_leaves = 50, max_min = 225, min_data_in_leaf = 31 |
| DF21 | n_bins = 255, n_trees = 100, max_layers = 20 |
| Categories | Features |
|---|---|
| Basic features (12 in total) | Net interest expense, total equity attributable to owners of the parent company, highest price, lowest price, transaction amount, earnings before interest, taxes, depreciation and amortization, undistributed earnings, cash received from sales of goods and services, various taxes and fees paid, cash paid for investments, effect of exchange rate changes on cash and cash equivalents, ending balance of cash and cash equivalents |
| Statistical features (12 in total) | Return on net assets (diluted, %), Tangible net assets/total assets (%), Capital fixation rate (%), 120-day Sharpe ratio, Same necessary growth in total operating (%), Same necessary growth in return on net assets (diluted) (%), Total fixed assets turnover (times) Operating profit/total liabilities Money capital/Interest-bearing current liabilities Net non-financing cash flow/current liabilities Long-term amortization expense/total assets (%) P/E ratio |
| Individual stock features (7 in total) | Operating income per share (RMB/share), capital surplus per share (RMB/share), total operating income per share, net cash flow per share, basic earnings per share, and net cash flow from operating activities per share increased by the same amount (%), and net cash flow from operating activities per share increased by the same amount (%) Transfers per share |
| Evaluation | Models | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RF | GA- RF | AdaBoost | GA-AdaB | XGBoost | GA- XGB | CatBoost | GA- CatB | GBDT | GA- GBDT | LGBM | GA- LGBM | DF21 | GA- DF21 | |
| balanced_acc | 0.6485 | 0.9685 | 0.8454 | 0.9774 | 0.7491 | 0.9827 | 0.8116 | 0.9752 | 0.7827 | 0.9739 | 0.7281 | 0.9814 | 0.8635 | 0.9832 |
| auc | 0.9728 | 0.9976 | 0.9729 | 0.9974 | 0.9671 | 0.9979 | 0.9728 | 0.9981 | 0.9757 | 0.9981 | 0.9655 | 0.9978 | 0.9736 | 0.9980 |
| precisicon | 0.7763 | 0.9354 | 0.6931 | 0.9136 | 0.6426 | 0.9348 | 0.7020 | 0.9386 | 0.7299 | 0.9385 | 0.6372 | 0.9347 | 0.7145 | 0.9419 |
| recall | 0.3081 | 0.9452 | 0.7312 | 0.9661 | 0.5353 | 0.9739 | 0.6580 | 0.9582 | 0.5927 | 0.9556 | 0.4909 | 0.9713 | 0.7650 | 0.9739 |
| f1_score | 0.4411 | 0.9403 | 0.7116 | 0.9391 | 0.5841 | 0.9540 | 0.6792 | 0.9483 | 0.6542 | 0.9470 | 0.5545 | 0.9526 | 0.7390 | 0.9576 |
| acc | 0.9137 | 0.9867 | 0.9345 | 0.9852 | 0.9158 | 0.9896 | 0.9313 | 0.9885 | 0.9308 | 0.9882 | 0.9129 | 0.9893 | 0.9403 | 0.9905 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Yu, Q.; Tang, C.; Lu, Z.; Yang, Y. Application of Feature Selection Based on Multilayer GA in Stock Prediction. Symmetry 2022, 14, 1415. https://doi.org/10.3390/sym14071415
Li X, Yu Q, Tang C, Lu Z, Yang Y. Application of Feature Selection Based on Multilayer GA in Stock Prediction. Symmetry. 2022; 14(7):1415. https://doi.org/10.3390/sym14071415
Chicago/Turabian StyleLi, Xiaoning, Qiancheng Yu, Chen Tang, Zekun Lu, and Yufan Yang. 2022. "Application of Feature Selection Based on Multilayer GA in Stock Prediction" Symmetry 14, no. 7: 1415. https://doi.org/10.3390/sym14071415