
CLHF-Net: A Channel-Level Hierarchical Feature Fusion Network for Remote Sensing Image Change Detection


Abstract
:1. Introduction
- We propose a novel CD network with symmetric structure, called the channel-level hierarchical feature fusion network (CLHF-Net). It aims to solve the problems of insufficient communication between bi-temporal feature pairs and inadequate feature fusion in channel groups.
- A channel-split feature fusion module (CSFM) with symmetric structure is proposed, which consists of three parts, namely the channel splitting branch (CSB), interaction fusion unit (IFU), and feature aggregation branch (FAB). The CSB splits the feature map into multiple channel-group features. The IFU is designed to enable effective communication and adequate fusion of channel multi-group feature pairs. The FAB integrates the input feature pairs and the fused features, resulting in a higher quality change feature map.
- To fuse the semantic features of different levels more effectively, an interaction guidance fusion module (IGFM) is proposed. First, the IGFM introduces high-level semantic information into low-level features, which can eliminate the redundant semantic information in shallow features. The low-level detailed feature information is introduced into the high-level features, which can compensate the detailed semantic information in the deep features. Then, convolution and attention operations are implemented to further fuse the two updated features.
2. Related Work
2.1. Traditional Methods
2.2. Deep-Learning-Based Methods
3. Proposed Method
3.1. The Proposed CLHF-Net Network
3.2. Channel-Split Feature Fusion Module
3.3. Interaction Guidance Fusion Module
3.4. Convs-N and Pixelwise Classifier
4. Experiments and Results
4.1. Datasets
4.2. Implementation Details
4.2.1. Loss Function
4.2.2. Evaluation Metrics
4.3. Comparison Methods
4.4. Experiment Results
4.4.1. Evaluation for the Season-Varying Dataset
4.4.2. Evaluation for the WHU-CD Dataset
4.4.3. Evaluation for the LEVIR-CD Dataset
5. Discussion
5.1. Ablation Study
5.2. Effectiveness of CSFM
5.2.1. Analysis of Channel Splitting Branch (CSB)
5.2.2. Analysis of IFU
5.3. Effectiveness of IGFM
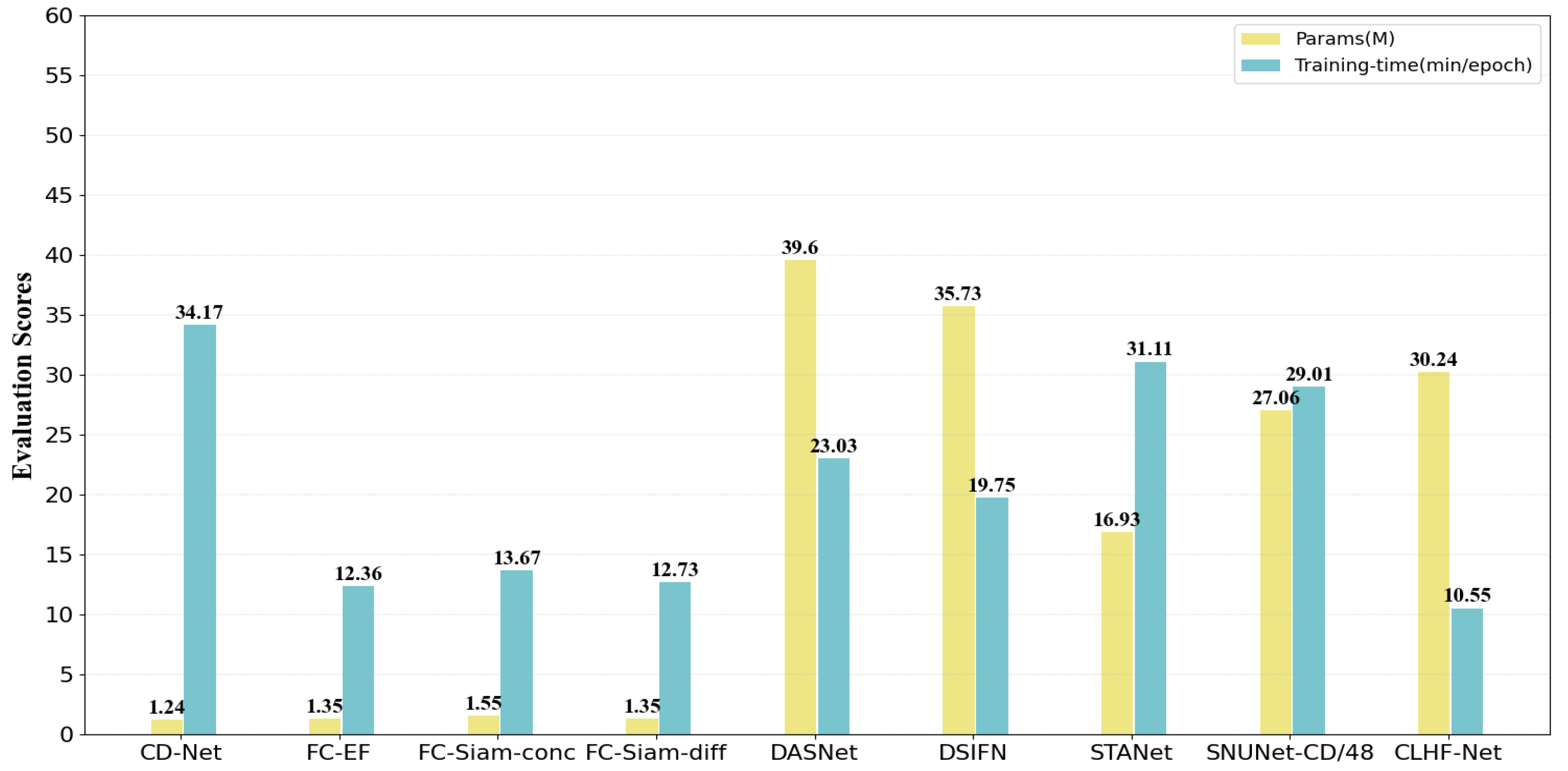
5.4. Efficiency Analysis of the Proposed Network
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CD | Change Detection |
| RS | Remote Sensing |
| CLHF-Net | Channel-Level Hierarchical Feature Fusion Network |
| CSFM | Channel-Split Feature Fusion Module |
| IGFM | Interaction Guidance Fusion Module |
| CNN | Convolutional Neural Network |
| FCN | Fully Convolutional Neural Network |
| CSB | Channel Splitting Branch |
| IFU | Interaction Fusion Unit |
| FAB | Feature Aggregation Branch |
| DL | Deep Learning |
| ICA | Independent Component Analysis |
| MAD | Multivariate Alteration Detection |
| CVA | Change Vector Analysis |
| Compressed Change Vector Analysis | |
| HSCVA | Hierarchical Spectral Change Vector Analysis |
| Sequential Spectral Change Vector Analysis | |
| SVD | Singular Value Decomposition |
| PCA | Principal Component Analysis |
| TMF | Triple Markov Field |
| FC-EF | Fully Convolutional Early Fusion |
| FC-Siam-conc | Fully Convolutional Siamese Concatenation |
| FC-Siam-diff | Fully Convolutional Siamese Difference |
| DSIFN | Deeply Supervised Image Fusion Network |
| ADS-Net | Attention Mechanism-based Deep Supervision Network |
| HDFNet | Hierarchical Dynamic Fusion Network |
| CLNet | U-Net based Cross-Layer Convolutional Neural Network |
| STANet | Spatial–Temporal Attention Neural Network |
| AGCDetNet | Attention-based End-to-End Change Detection Network |
| GT | Ground Truth |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
References
- Bruzzone, L.; Bovolo, F. A Novel Framework for the Design of Change-Detection Systems for Very-High-Resolution Remote Sensing Images. Proc. IEEE 2013, 101, 609–630. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Khelififi, L.; Mignotte, M. Deep Learning for Change Detection in Remote Sensing Images: Comprehensive Review and Meta-Analysis. IEEE Access. 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change Detection Based on Artificial Intelligence: State-of-the-Art and Challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Ma, B.; Ban, X.; Huang, H.; Chen, Y.; Liu, W.; Zhi, Y. Deep Learning-Based Image Segmentation for Al-La Alloy Microscopic Images. Symmetry 2018, 10, 107. [Google Scholar] [CrossRef] [Green Version]
- Fu, H.; Song, G.; Wang, Y. Improved YOLOv4 Marine Target Detection Combined with CBAM. Symmetry 2021, 13, 623. [Google Scholar] [CrossRef]
- Sun, Y.; Bi, F.; Gao, Y.; Chen, L.; Feng, S. A Multi-Attention UNet for Semantic Segmentation in Remote Sensing Images. Symmetry 2022, 14, 906. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved unet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef] [Green Version]
- Daudt, R.C.; Saux, B.L.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, S.; Ji, S.; Lu, M. Detecting large-scale urban land cover changes from very high-resolution remote sensing images using CNN-based classification. ISPRS Int. J. Geo-Inf. 2019, 8, 89. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Gong, M.; Zhang, P.; Su, L.; Shi, J. Feature-level change detection using deep representation and feature change analysis for multispectral imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1666–1670. [Google Scholar] [CrossRef]
- Zhao, Q.; Ma, J.; Gong, M.; Li, H.; Zhan, T. Three-class change detection in synthetic aperture radar images based on deep belief network. J. Comput. Theor. Nanosci. 2016, 13, 3757–3762. [Google Scholar] [CrossRef]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A general end-to-end 2-D CNN framework for hyperspectral image change detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Quarmby, N.A.; Cushnie, J.L. Monitoring urban land cover changes at the urban fringe from SPOT HRV imagery in south-east England. Int. J. Remote Sens. 1989, 10, 953–963. [Google Scholar] [CrossRef]
- Howarth, P.J.; Wickwareg, M. Procedures for change detection using Landsat digital data. Int. J. Remote Sens. 1981, 2, 277–291. [Google Scholar] [CrossRef]
- Ludeke, A.K.; Maggio, R.; Reid, L.M. An Analysis of Anthropogenic Deforestation Using Logistic Regression and GIS. J. Environ. Manag. 1990, 31, 247–259. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, R. Multi-temporal remote sensing change detection based on independent component analysis. Int. J. Remote Sens. 2006, 27, 2055–2061. [Google Scholar] [CrossRef]
- Nielsen, A.A. The Regularized Iteratively Reweighted MAD Method for Change Detection in Multi- and Hyperspectral Data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bovolo, F.; Bruzzone, L. A theoretical framework for unsupervised change detection based on change vector analysis in the polar domain. IEEE Trans. Geosci. Remote Sens. 2007, 45, 218–236. [Google Scholar] [CrossRef] [Green Version]
- Bovolo, F.; Marchesi, S.; Member, S. A framework for automatic and unsupervised detection of multiple changes in multitemporal images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2196–2212. [Google Scholar] [CrossRef]
- Liu, S.; Bruzzone, L.; Bovolo, F.; Du, P. Hierarchical unsupervised change detection in multi-temporal hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 244–260. [Google Scholar]
- Liu, S.; Bruzzone, L.; Bovolo, F.; Zanetti, M.; Du, P. Sequential spectral change vector analysis for iteratively discovering and detecting multiple changes in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4363–4378. [Google Scholar] [CrossRef]
- Zanetti, M.; Bruzzone, L. A theoretical framework for change detection based on a compound multiclass statistical model of the difference image. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1129–1143. [Google Scholar] [CrossRef]
- Ghaderpour, E.; Vujadinovic, T. Change Detection within Remotely Sensed Satellite Image Time Series via Spectral Analysis. Remote Sens. 2020, 12, 4001. [Google Scholar] [CrossRef]
- Ghaderpour, E. JUST: MATLAB and python software for change detection and time series analysis. GPS Solut. 2021, 25, 85. [Google Scholar] [CrossRef]
- Masiliūnas, D.; Tsendbazar, N.-E.; Herold, M.; Verbesselt, J. BFAST Lite: A Lightweight Break Detection Method for Time Series Analysis. Remote Sens. 2021, 13, 3308. [Google Scholar] [CrossRef]
- Su, J.; Wang, G.; Lin, X.; Liu, D. A Change Detection Algorithm for Man-made Objects Based on Multi-temporal Remote Sensing Images. Acta Autom. Sin. 2008, 34, 13–19. [Google Scholar]
- Wang, L.; Li, H. PCA based unsupervised change detection for color satellite images under the quaternion model. In Proceedings of the 2010 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS 2010), Chengdu, China, 6–8 December 2010; pp. 782–786. [Google Scholar]
- Benedek, C.; Sziranyi, T. Change Detection in Optical Aerial Images by a Multilayer Conditional Mixed Markov Model. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3416–3430. [Google Scholar] [CrossRef] [Green Version]
- Inglada, J.; Mercier, G. A New Statistical Similarity Measure for Change Detection in Multitemporal SAR Images and Its Extension to Multiscale Change Analysis. IEEE Trans. Geosci. Remote Sens. 2011, 45, 1432–1445. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Wu, Y.; Zhang, Q.; Zhang, P.; Li, M.; Lu, Y. Unsupervised Change Detection on SAR Images Using Triplet Markov Field Mode. IEEE Geosci. Remote Sens. Lett. 2013, 10, 697–701. [Google Scholar] [CrossRef]
- Wang, X.; Liu, S.; Du, P.; Liang, H.; Xia, J.; Li, Y. Object-Based Change Detection in Urban Areas from High Spatial Resolution Images Based on Multiple Features and Ensemble Learning. Remote Sens. 2018, 10, 276. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Peng, D.; Huang, X. Object-based change detection for VHR images based on multiscale uncertainty analysis. IEEE Geosci. Remote Sens. Lett. 2017, 15, 13–17. [Google Scholar] [CrossRef]
- Tan, K.; Zhang, Y.; Wang, X.; Chen, Y. Object-Based Change Detection Using Multiple Classifiers and Multi-Scale Uncertainty Analysis. Remote Sens. 2019, 11, 359. [Google Scholar] [CrossRef] [Green Version]
- Wiratama, W.; Sim, D. Fusion network for change detection of high-resolution panchromatic imagery. Appl. Sci. 2019, 9, 1441. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lei, Y.; Peng, D.; Zhang, P.; Ke, Q.; Li, H. Hierarchical paired channel fusion network for street scene change detection. IEEE Trans. Image Process. 2020, 30, 55–67. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, D.; Chen, X.; Jiang, M.; Du, S.; Xu, B.; Wang, J. ADS-Net: An Attention-Based deeply supervised network for remote sensing image change detection. Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102348. [Google Scholar]
- Zhang, Y.; Fu, L.; Li, Y.; Zhang, Y. HDFNet: Hierarchical Dynamic Fusion Network for Change Detection in Optical Aerial Images. Int. J. Remote Sens. 2021, 13, 1440. [Google Scholar] [CrossRef]
- Hou, X.; Bai, Y.; Li, Y.; Shang, C.; Shen, Q. High-resolution triplet network with dynamic multiscale feature for change detection on satellite images. ISPRS J. Photogramm. Remote Sens. 2021, 177, 103–115. [Google Scholar] [CrossRef]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Yang, K.; Xia, G.-S.; Liu, Z.; Du, B.; Yang, W.; Pelillo, M.; Zhang, L. Asymmetric Siamese Networks for Semantic Change Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional siamese networks for change detection of high-resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1194–1206. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Song, K.; Jiang, J. AGCDetNet:An Attention-Guided Network for Building Change Detection in High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4816–4831. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Chen, M.; Bai, Z.; Lin, W.; Ling, H. Hierarchical Alternate Interaction Network for RGB-D Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 3528–3542. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, X.; Wang, L. A Lightweight Convolutional Neural Network Based on Channel Multi-Group Fusion for Remote Sensing Scene Classification. Remote Sens. 2022, 14, 9. [Google Scholar] [CrossRef]
- Wei, H.; Chen, R.; Yu, C.; Yang, H.; An, S. BASNet: A Boundary-Aware Siamese Network for Accurate Remote Sensing Change Detection. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Xu, J.; Luo, C.; Chen, X.; Wei, S.; Luo, Y. Remote Sensing Change Detection Based on Multidirectional Adaptive Feature Fusion and Perceptual Similarity. Remote Sens. 2021, 13, 3053. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lebedev, M.; Vizilter, Y.V.; Vygolov, O.; Knyaz, V.; Rubis, A.Y. Change Detection in Remote Sensing Images Using Conditional Adversarial Networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 565–571. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Simon, S.; Germán, R.; Roberto, A.; Riccardo, G. Street-view change detection with deconvolutional networks. Auton. Robot. 2018, 42, 1301–1322. [Google Scholar] [CrossRef]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Vadera, M.P.; Marlin, B.M. Challenges and Opportunities in Approximate Bayesian Deep Learning for Intelligent IoT Systems. arXiv 2021, arXiv:2112.01675. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Spatial Resolution | Number of Samples | Size of Samples | ||
|---|---|---|---|---|---|
| Training Set | Validation Set | Test Set | |||
| Season-Varying | 3–100 cm/pixel | 10,000 | 3000 | 3000 | 256 × 256 |
| WHU-CD | 0.2 m/pixel | 7918 | 987 | 955 | 224 × 224 |
| LEVIR-CD | 0.5 m/pixel | 7120 | 1024 | 2048 | 256 × 256 |
| True Value | Predicted Value | |
|---|---|---|
| Positive | Negative | |
| Positive | TP | FN |
| Negative | FP | TN |
| Methods | Architecture | Loss Function | Published Year |
|---|---|---|---|
| CD-Net [59] | FCN | Weighted cross-entropy loss | 2018 |
| FC-EF [10] | FCN | Weighted negative log likelihood loss | 2018 |
| FC-Siam-Conc [10] | Siamese, FCN | Weighted negative log likelihood loss | 2018 |
| FC-Siam-Diff [10] | Siamese, FCN | Weighted negative log likelihood loss | 2018 |
| DASNet [48] | Siamese, VGG16/ResNet50 | Weighted double-margin contrastive loss | 2021 |
| DSIFN [8] | Siamese, VGG16 | Sigmoid binary cross-entropy, dice loss | 2020 |
| STANet [49] | Siamese, ResNet18 | Batch-balanced contrastive loss | 2020 |
| SNUNet-CD/48 [42] | Siamese, UNet++ | Weighted cross-entropy loss, dice loss | 2021 |
| Method | OA (%) | P (%) | R (%) | F1 (%) | Kappa (%) |
|---|---|---|---|---|---|
| CD-Net | 95.85 | 94.04 | 72.51 | 81.89 | 79.59 |
| FC-EF | 96.02 | 92.31 | 75.50 | 83.07 | 80.84 |
| FC-Siam-Conc | 96.25 | 94.05 | 75.84 | 83.96 | 81.87 |
| FC-Siam-Diff | 96.39 | 93.11 | 77.86 | 84.80 | 82.78 |
| DASNet | 97.50 | 92.26 | 88.09 | 90.12 | 88.69 |
| DSIFN | 97.69 | 94.96 | 86.08 | 90.30 | 89.21 |
| STANet | 97.95 | 88.97 | 94.31 | 91.56 | 90.40 |
| SNUNet-CD/48 | 99.09 | 96.33 | 95.99 | 96.16 | 95.65 |
| CLHF-Net | 99.33 | 95.54 | 98.90 | 97.19 | 96.80 |
| Method | OA (%) | P (%) | R (%) | F1 (%) | Kappa (%) |
|---|---|---|---|---|---|
| CD-Net | 98.02 | 77.18 | 84.00 | 80.45 | 79.40 |
| FC-EF | 98.24 | 80.34 | 84.39 | 82.31 | 81.38 |
| FC-Siam-Conc | 98.17 | 79.16 | 87.08 | 82.93 | 81.97 |
| FC-Siam-Diff | 98.37 | 82.77 | 83.93 | 83.35 | 82.49 |
| DASNet | 97.50 | 92.26 | 88.09 | 90.12 | 88.69 |
| DSIFN | 98.86 | 88.94 | 87.29 | 88.11 | 87.51 |
| STANet | 99.05 | 93.37 | 86.50 | 89.80 | 89.30 |
| SNUNet-CD/48 | 99.13 | 88.42 | 90.39 | 89.39 | 88.94 |
| CLHF-Net | 99.41 | 92.56 | 92.63 | 92.62 | 92.21 |
| Method | OA (%) | P (%) | R (%) | F1 (%) | Kappa (%) |
|---|---|---|---|---|---|
| CD-Net | 97.80 | 79.59 | 76.53 | 78.03 | 76.88 |
| FC-EF | 98.03 | 80.46 | 81.03 | 80.74 | 79.70 |
| FC-Siam-Conc | 98.08 | 78.00 | 86.79 | 82.17 | 81.15 |
| FC-Siam-Diff | 98.33 | 83.31 | 84.15 | 83.73 | 82.85 |
| DASNet | 98.37 | 81.49 | 87.95 | 84.60 | 83.74 |
| DSIFN | 98.65 | 91.73 | 80.82 | 85.93 | 85.22 |
| STANet | 98.91 | 89.96 | 82.62 | 86.54 | 85.97 |
| SNUNet-CD/48 | 99.03 | 89.46 | 86.36 | 87.88 | 87.38 |
| CLHF-Net | 99.25 | 89.15 | 92.75 | 90.91 | 90.52 |
| Model | Season-Varying | WHU-CD | LEVIR-CD | |||||
|---|---|---|---|---|---|---|---|---|
| Baseline | CSFM | IGFM | F1 (%) | OA (%) | F1 (%) | OA (%) | F1 (%) | OA (%) |
| √ | × | × | 95.11 | 98.93 | 88.64 | 98.92 | 87.42 | 98.79 |
| √ | √ | × | 96.09 | 99.08 | 92.06 | 99.24 | 88.95 | 98.81 |
| √ | × | √ | 96.50 | 99.16 | 91.47 | 99.16 | 89.37 | 98.87 |
| √ | √ | √ | 97.19 | 99.33 | 92.62 | 99.41 | 90.91 | 99.25 |
| Method/c | Season-Varying | WHU-CD | LEVIR-CD | |||
|---|---|---|---|---|---|---|
| F1 (%) | OA (%) | F1 (%) | OA (%) | F1 (%) | OA (%) | |
| CLHF-Net /16 | 97.19 | 99.33 | 92.62 | 99.41 | 90.91 | 99.25 |
| CLHF-Net /32 | 96.39 | 99.15 | 91.27 | 99.29 | 89.43 | 99.11 |
| CLHF-Net /64 | 95.87 | 99.02 | 90.69 | 99.18 | 88.97 | 99.03 |
| CLHF-Net | Season-Varying | WHU-CD | LEVIR-CD | |||
|---|---|---|---|---|---|---|
| F1 (%) | OA (%) | F1 (%) | OA (%) | F1 (%) | OA (%) | |
| CLHF-Net -w-CSB | 97.19 | 99.33 | 92.62 | 99.41 | 90.91 | 99.25 |
| CLHF-Net -w/o-CSB | 96.26 | 99.12 | 91.22 | 99.22 | 89.16 | 99.01 |
| CLHF-Net | Season-Varying | WHU-CD | LEVIR-CD | |||
|---|---|---|---|---|---|---|
| F1 (%) | OA (%) | F1 (%) | OA (%) | F1 (%) | OA (%) | |
| CLHF-Net -w-IFU | 97.19 | 99.33 | 92.62 | 99.41 | 90.91 | 99.25 |
| CLHF-Net -w-NIFU | 96.23 | 99.12 | 91.43 | 99.30 | 89.38 | 99.11 |
| CLHF-Net | Season-Varying | WHU-CD | LEVIR-CD | |||
|---|---|---|---|---|---|---|
| F1 (%) | OA (%) | F1 (%) | OA (%) | F1 (%) | OA (%) | |
| CLHF-Net -w-IGFM | 97.19 | 99.33 | 92.62 | 99.41 | 90.91 | 99.25 |
| CLHF-Net -w-FFM | 96.46 | 99.17 | 91.35 | 99.29 | 89.26 | 99.08 |
Publisher′s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Lu, D.; Li, Y.; Shi, G. CLHF-Net: A Channel-Level Hierarchical Feature Fusion Network for Remote Sensing Image Change Detection. Symmetry 2022, 14, 1138. https://doi.org/10.3390/sym14061138
Ma J, Lu D, Li Y, Shi G. CLHF-Net: A Channel-Level Hierarchical Feature Fusion Network for Remote Sensing Image Change Detection. Symmetry. 2022; 14(6):1138. https://doi.org/10.3390/sym14061138
Chicago/Turabian StyleMa, Jinming, Di Lu, Yanxiang Li, and Gang Shi. 2022. "CLHF-Net: A Channel-Level Hierarchical Feature Fusion Network for Remote Sensing Image Change Detection" Symmetry 14, no. 6: 1138. https://doi.org/10.3390/sym14061138