
A Novel Twin Support Vector Machine with Generalized Pinball Loss Function for Pattern Classification


Abstract
:1. Introduction
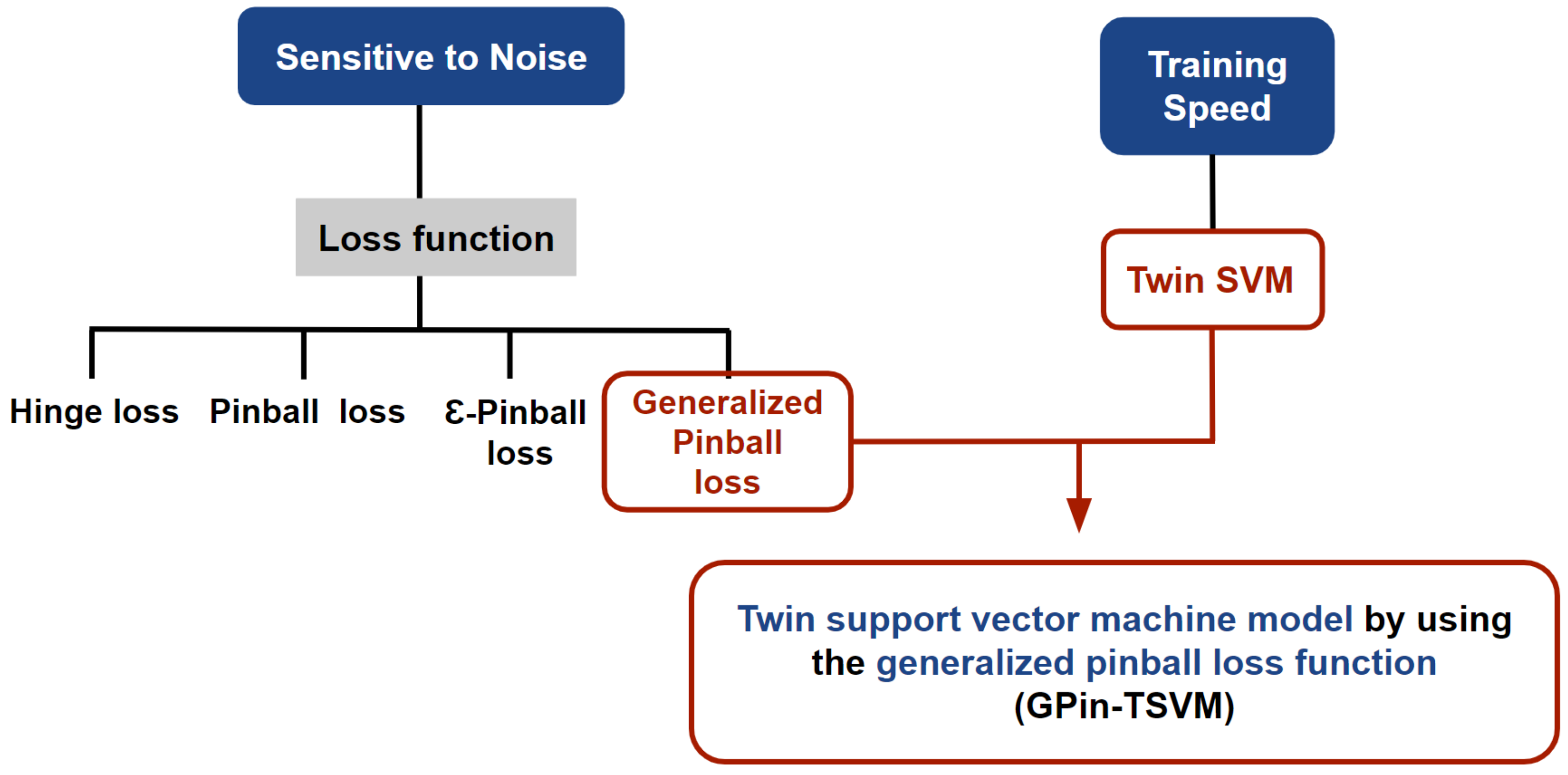
- For pattern classification, we add a generalized pinball loss function to the standard TSVM, resulting in a better classifier model that is called a generalized pinball loss function-based TSVM (GPin-TSVM);
- We demonstrate that the proposed algorithm GPin-TSVM surpasses existing classifiers in terms of accuracy in numerical experiments. We also examine its characteristics, such as noise sensitivity and within-class scatter;
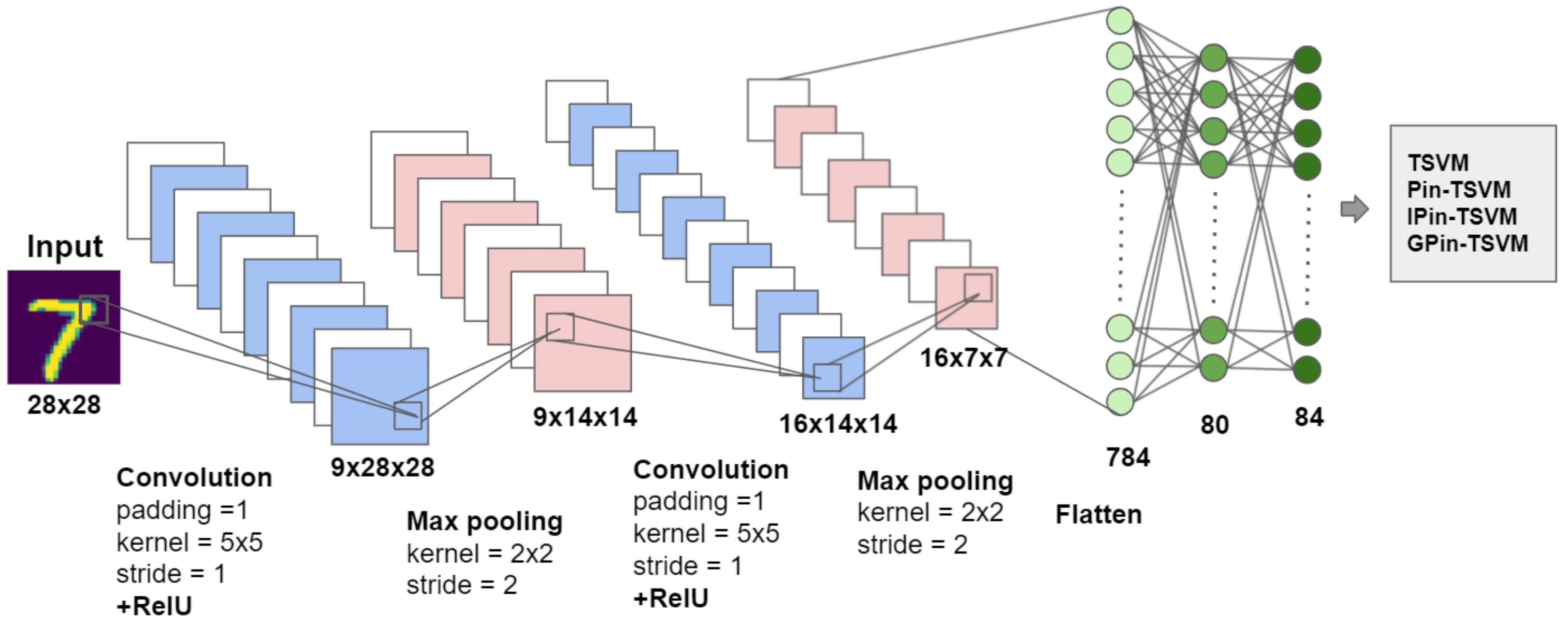
- We examine the applicability of the main techniques of GPin-TSVM toward handwritten digit recognition problems compared with the standard TSVM, Pin-TSVM, and -insensitive zone TSVM (IPin-TSVM). Moreover, we use the automatic feature extractor by the convolutional neural network (CNN) and TSVM, Pin-TSVM, IPin-SVM, and GPin-TSVM, which work as a binary classifier by replacing the softmax layer of CNN;
- We perform numerical testing on a synthetic dataset and datasets from numerous UCI benchmarks with noise of various variances to illustrate the validity of our proposed GPin-TSVM. The results also show the robustness of the proposed approach, which is less sensitive to noise and retains the sparsity of the solution.
2. Related Work and Background
2.1. Support Vector Machine
2.2. Twin Support Vector Machine
2.3. Support Vector Machine with Generalized Pinball Loss
3. Proposed Twin Support Vector Machine with Generalized Pinball Loss (GPin-TSVM)
3.1. Linear Case
3.2. Nonlinear Case
4. Properties of the GPin-TSVM
4.1. Noise Insensitivity
4.2. Scatter Minimization
5. Numerical Experiments
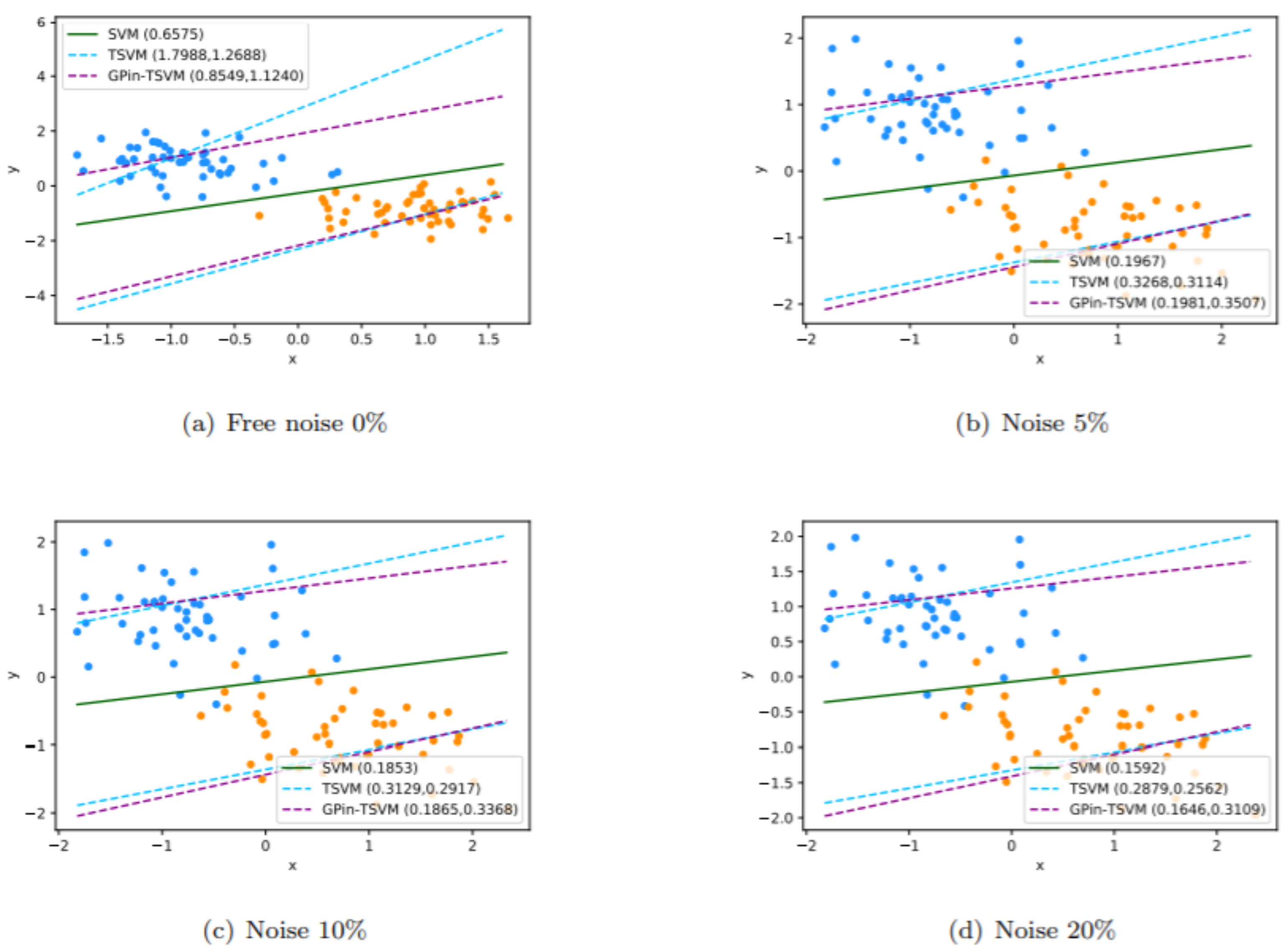
5.1. Synthetic Dataset
5.2. UCI Datasets
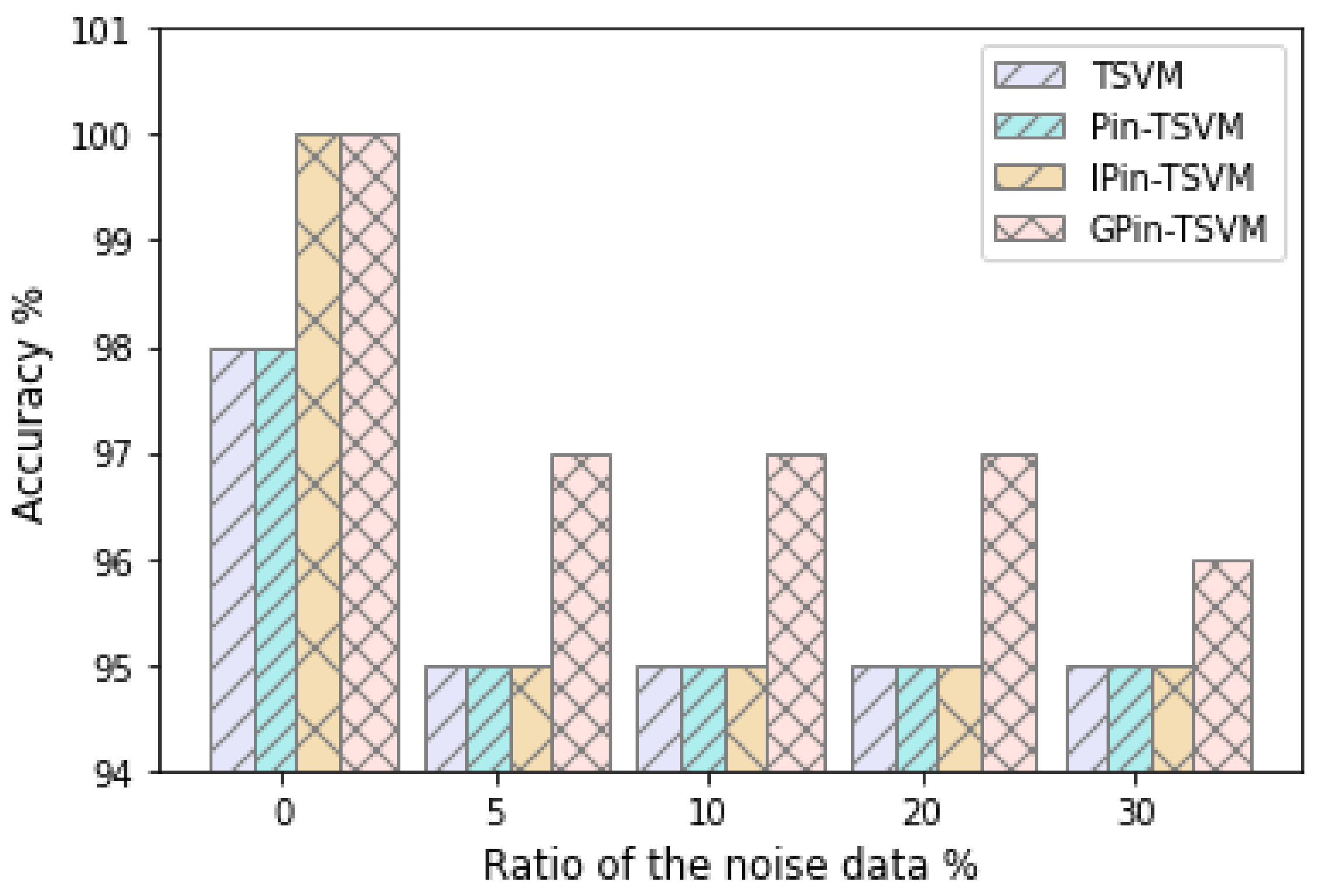
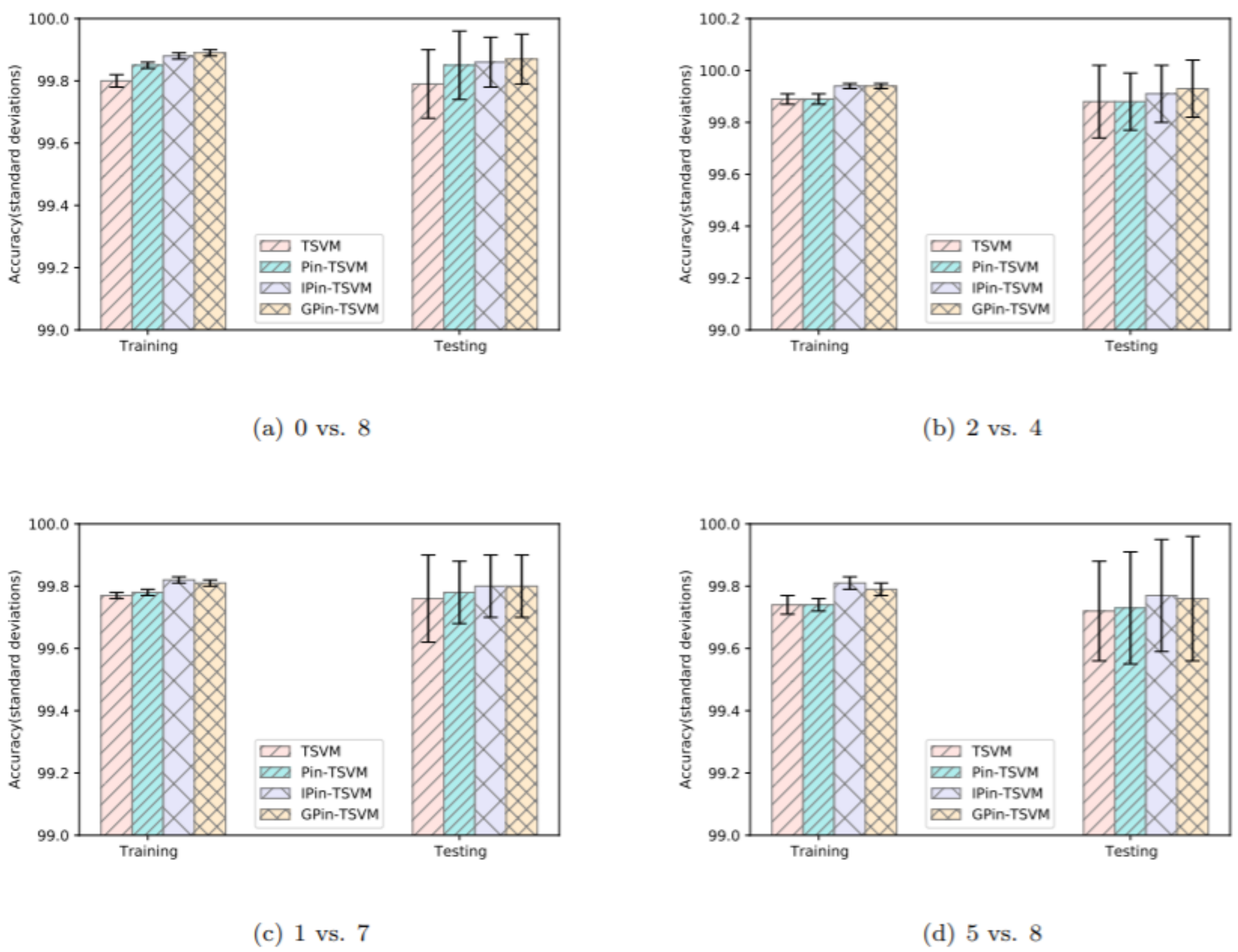
5.3. Hybrid CNN-GPin-TSVM Classifier for Handwritten Digit Recognition
5.4. Statistical Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balasundaram, S.; Tanveer, M. On proximal bilateral-weighted fuzzy support vector machine classifiers. Int. J. Adv. Intell. Paradig. 2012, 4, 199–210. [Google Scholar] [CrossRef]
- Chang, F.; Guo, C.Y.; Lin, X.R.; Lu, C.J. Tree decomposition for large-scale SVM problems. J. Mach. Learn. Res. 2010, 11, 2935–2972. [Google Scholar]
- Zhang, C.; Tian, Y.; Deng, N. The new interpretation of support vector machines on statistical learning theory. Sci. China 2010, 53, 151–164. [Google Scholar] [CrossRef]
- Smola, A.J.; Scholkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Tang, L.; Tian, Y.; Pardalos, P.M. A novel perspective on multiclass classification: Regular simplex support vector machine. Inf. Sci. 2019, 480, 324–338. [Google Scholar] [CrossRef]
- van de Wolfshaar, J.; Karaaba, M.F.; Wiering, M.A. Deep Convolutional Neural Networks and Support Vector Machines for Gender Recognition. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015; pp. 188–195. [Google Scholar]
- Lilleberg, J.; Zhu, Y.; Zhang, Y. Support vector machines and Word2vec for text classification with semantic features. In Proceedings of the IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Beijing, China, 6–8 July 2015; pp. 136–140. [Google Scholar]
- Mohammad, A.H.; Alwada’n, T.; Al-Momani, O. Arabic Text Categorization Using Support vector machine, Naïve Bayes and Neural Network. GSTF J. Comput. 2016, 5, 108–115. [Google Scholar] [CrossRef]
- Mehmood, Z.; Mahmood, T.; Javid, M.A. Content-based image retrieval and semantic automatic image annotation based on the weighted average of triangular histograms using support vector machine. Appl. Intell. 2018, 48, 166–181. [Google Scholar] [CrossRef]
- Richhariya, B.; Tanveer, M. EEG signal classification using universum support vector machine. Expert Syst. Appl. 2018, 106, 169–182. [Google Scholar] [CrossRef]
- Soula, A.; Tbarki, K.; Ksantini, R.; Saida, S.B.; Lachiri, Z. A novel incremental Kernel Nonparametric SVM model (iKN-SVM) for data classification: An application to face detection. Eng. Appl. Artif. Intell. 2020, 89, 103468. [Google Scholar] [CrossRef]
- Krishna, G.; Prakash, N. A new training approach based on ECOC-SVM for SAR image retrieval. Int. J. Intell. Enterp. 2021, 8, 492–517. [Google Scholar] [CrossRef]
- Jayadeva; Khemchandani, R.; Chandra, S. Twin Support Vector Machines: Models; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Xu, J.; Xu, C.; Zou, B.; Tang, Y.Y.; Peng, J.; You, X. New Incremental Learning Algorithm With Support Vector Machines. IEEE Trans. Syst. 2018, 49, 2230–2241. [Google Scholar] [CrossRef]
- Catak, F.Ö. Classification with boosting of extreme learning machine over arbitrarily partitioned data. Soft Comput. 2017, 21, 2269–2281. [Google Scholar] [CrossRef] [Green Version]
- Jayadeva; Khemchandani, R.; Chandra, S. Twin support vector machines for pattern classification. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 905–910. [Google Scholar] [CrossRef] [PubMed]
- Kumar, M.; Gopal, M. Least squares twin support vector machines for text categorization. In Proceedings of the 39th National Systems Conference (NSC), Greater Noida, India, 14–16 December 2015. [Google Scholar]
- Francis, L.M.; Sreenath, N. Robust Scene Text Recognition: Using Manifold Regularized Twin-SupportVector Machine. J. King Saud Univ. Comput. Inf. Sci. 2007. Available online: https://www.sciencedirect.com/science/article/pii/S1319157818309509 (accessed on 2 February 2019).
- Agarwal, S.; Tomar, D. Siddhant Prediction of software defects using Twin Support Vector Machine. In Proceedings of the International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 1–2 March 2014. [Google Scholar]
- Cao, Y.; Ding, Z.; Xue, F.; Rong, X. An improved twin support vector machine based on multi-objective cuckoo search for software defect prediction. Int. J. Bio-Inspired Comput. 2018, 11, 282–291. [Google Scholar] [CrossRef]
- Tomar, D.; Agarwal, S. A Multilabel Approach Using Binary Relevance and One-versus-Rest Least Squares Twin Support Vector Machine for Scene Classification. In Proceedings of the Second International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, 12–13 February 2016. [Google Scholar]
- Gu, Z.; Zhang, Z.; Sun, J.; Li, B. Robust image recognition by L1-norm twin-projection support vector machine. Neurocomputing 2017, 223, 1–11. [Google Scholar] [CrossRef]
- Cong, H.; Yang, C.; Pu, X. Efficient Speaker Recognition based on Multi-class Twin Support Vector Machines and GMMs. In Proceedings of the IEEE Conference on Robotics, Automation and Mechatronics, Chengdu, China, 21–24 September 2008. [Google Scholar]
- Cumani, S.; Laface, P. Large-Scale Training of Pairwise Support Vector Machines for Speaker Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1590–1600. [Google Scholar] [CrossRef] [Green Version]
- Nasiri, J.A.; Charkari, N.M.; Mozafari, K. Energy-based model of least squares twin Support Vector Machines for human action recognition. Signal Process. 2014, 104, 248–257. [Google Scholar] [CrossRef]
- Sadewo, W.; Rustam, Z.; Hamidah, H.; Chusmarsyah, A.R. Pancreatic Cancer Early Detection Using Twin Support Vector Machine Based on Kernel. Symmetry 2020, 12, 667. [Google Scholar] [CrossRef] [Green Version]
- Peng, X. TPMSVM: A novel twin parametric-margin support vector machine for pattern recognition. Pattern Recognit. 2011, 44, 2678–2692. [Google Scholar] [CrossRef]
- Shao, Y.; Zhang, C.; Wang, X.; Deng, N. Improvements on twin support vector machines. IEEE Trans. Neural Netw. 2011, 22, 962–968. [Google Scholar] [CrossRef]
- Shao, Y.; Chen, W.; Zhang, C.; Wang, X.; Deng, N. An efficient weighted lagrangian twin support vector machine for imbalanced data classification. Pattern Recognit. 2014, 47, 3158–3167. [Google Scholar] [CrossRef]
- Kumar, M.A.; Gopal, M. Application of smoothing technique on twin support vector machines. Pattern Recognit. Lett. 2008, 29, 1842–1848. [Google Scholar] [CrossRef]
- Kumar, M.A.; Khemchandani, R.; Gopal, M.; Chandra, S. Knowledge based least squares twin support vector machines. Inform. Sci. 2010, 180, 4606–4618. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Tanveer, M. LSTSVM classifier with enhanced features from pre-trained functional link network. Appl. Soft Comput. J. 2020, 93, 106305. [Google Scholar] [CrossRef]
- Tian, Y.; Ping, Y. Large-scale linear nonparallel support vector machine solver. Neural Netw. 2014, 50, 166–174. [Google Scholar] [CrossRef]
- Tanveer, M.; Tiwari, A.; Choudhary, R.; Jalan, S. Sparse pinball twin support vector machines. Appl. Soft Comput. J. 2019, 78, 164–175. [Google Scholar] [CrossRef]
- Lee, Y.J.; Mangasarian, O.L. SSVM: A Smooth Support Vector Machine for Classification. Comput. Optim. Appl. 2001, 20, 5–22. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, Y. Robust truncated hinge loss support vector machines. J. Am. Stat. Assoc. 2007, 102, 974–983. [Google Scholar] [CrossRef] [Green Version]
- Cao, L.; Shen, H. Imbalanced data classification based on hybrid resampling and twin support vector machine. Comput. Sci. Inf. Syst. 2017, 16, 1–7. [Google Scholar] [CrossRef]
- Tomar, D.; Agarwal, S. An effective Weighted Multi-class Least Squares Twin Support Vector Machine for Imbalanced data classification. Int. J. Comput. Intell. Syst. 2015, 8, 761–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Shi, L.; Suykens, J.A.K. Support vector machine classifier with pinball loss. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 984–997. [Google Scholar] [CrossRef]
- Rastogi, R.; Pal, A.; Chandra, S. Generalized pinball loss SVMs. Neurocomputing 2018, 322, 151–165. [Google Scholar] [CrossRef]
- Mangasarian, O.L. Nonlinear Programming; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1994. [Google Scholar]
- Xu, Y.; Yang, Z.; Pan, X. A novel twin support-vector machine with pinball loss. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 359–370. [Google Scholar] [CrossRef] [PubMed]
- Shwartz, S.; Ben-David, S. Understanding Machine Learning Theory Algorithms; Cambridge University Press: Cambridge, UK, 2014; p. 207. [Google Scholar]
- Tikhonov, A.N.; Arsenin, V.Y. Solution of Ill Posed Problems; John Wiley and Sons: Hoboken, NJ, USA, 1977. [Google Scholar]
- Khemchandani, R.; Jayadeva; Chandra, S. Optimal kernel selection in twin support vector machines. Optim. Lett. 2009, 3, 77–88. [Google Scholar] [CrossRef]
- Dua, D.; Taniskidou, E.K. UCI Machine Learning Repository; University of California, School ofInformation and Computer Science: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 24 September 2018).
- Garcı, V.; Sanche, J.S.; Mollineda, R.A. On the effectiveness of preprocessing methods when dealing with different levels of class imbalance. Knowl. Based Syst. 2012, 25, 13–21. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Chang, C.-C.; Lina, C.-J. A Practical Guide to Support Vector Classification. Nat. Taiwan Univ. Taipei Taiwa 2012, 25, 1–12. [Google Scholar]
- Hamid, N.A.; Sjarif, N.N.A. Handwritten Recognition Using SVM, KNN and Neural Network. arXiv 2017, arXiv:1702.00723. [Google Scholar]
- Agarap, A.F.M. An Architecture Combining Convolutional Neural Network (CNN) and Support Vector Machine (SVM) for Image Classification. arXiv 2019, arXiv:1712.03541v2. [Google Scholar]
- Ahlawata, S.; Choudhary, A. Hybrid CNN-SVM Classifier for Handwritten Digit Recognition. Procedia Comput. Sci. 2020, 167, 2554–2560. [Google Scholar] [CrossRef]
- Aliab, A.A.A.; Mallaiah, S. Intelligent handwritten recognition using hybrid CNN architectures based-SVM classifier with dropout. Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Remaida, A.; Moumen, A.; Idrissi, Y.; El, B.; Sabri, Z. Handwriting Recognition with Artificial Neural Networks a Decade Literature Review. In Proceedings of the 3rd International Conference on Networking, Information Systems & Security, Marrakech, Morocco, 31 March–2 April 2020; pp. 1–5. [Google Scholar]
- Aqab, S.; Tariq, M.U. Handwriting Recognition using Artificial Intelligence Neural Network and Image Processing. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 137–146. [Google Scholar] [CrossRef]
- Mawaddah, A.H.; Sari, C.A.; Setiadi, D.R.I.M.; Rachmawanto, E.H. Handwriting Recognition of Hiragana Characters using Convolutional Neural Network. In Proceedings of the International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, 19–20 September 2020. [Google Scholar]
- Altwaijry, N.; Al-Turaiki, I. Arabic handwriting recognition system using convolutional neural network. Neural Comput. Appl. 2021, 33, 2249–2261. [Google Scholar] [CrossRef]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Handcrafted versus CNN Features for Ear Recognition. Symmetry 2019, 11, 1493. [Google Scholar] [CrossRef] [Green Version]
- Xin, Q.; Hu, S.; Liu, S.; Ma, X.; Lv, H.; Zhang, Y.D. Epilepsy EEG classification based on convolution support vector machine. J. Med. Imaging Health Inf. 2021, 11, 25–32. [Google Scholar] [CrossRef]
- Garcia, S.; Fernandez, A.; Luengo, J.; Herrera, F. Advanced non-parametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining experimental analysis of power. Inf. Sci. 2010, 180, 2044–2064. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | #Features | #Samples | IR |
|---|---|---|---|
| Breast | 10 | 116 | 1.23 |
| Planning relax | 12 | 182 | 2.5 |
| Ionosphere | 33 | 351 | 1.79 |
| Heart-Statlog | 13 | 270 | 1.25 |
| Heart-C | 13 | 303 | 1.19 |
| Spect | 22 | 267 | 3.85 |
| Saheart | 9 | 462 | 1.89 |
| WDBC | 30 | 569 | 1.68 |
| Pima-Indian | 8 | 768 | 1.86 |
| Australian | 14 | 690 | 1.25 |
| Datasets | r | Existing Algorithm | Proposed Algorithm | ||
|---|---|---|---|---|---|
| TSVM | Pin-TSVM | IPin-TSVM | GPin-TSVM | ||
| Breast | 0 | 69.02 ± 8.61 | 69.85 ± 7.92 | 72.73 ± 16.79 | 71.67 ± 15.53 |
| 0.05 | 69.02 ± 8.46 | 69.02 ± 8.61 | 72.73 ± 16.79 | 71.74 ± 15.45 | |
| 0.1 | 68.03 ± 8.09 | 68.26 ± 11.86 | 73.56 ± 14.44 | 73.41 ± 14.32 | |
| 0.2 | 69.85 ± 10.08 | 70.08 ± 13.15 | 71.82 ± 15.82 | 71.82 ± 14.56 | |
| Planning relax | 0 | 71.61 ± 13.78 | 71.61 ± 13.78 | 71.61 ± 13.78 | 71.61 ± 13.78 |
| 0.05 | 71.61 ± 13.78 | 71.61 ± 13.78 | 71.61 ± 13.78 | 71.61 ± 13.78 | |
| 0.1 | 71.61 ± 13.78 | 71.05 ± 13.41 | 71.61 ± 13.78 | 72.16 ± 13.68 | |
| 0.2 | 71.61 ± 13.78 | 72.69 ± 13.95 | 71.61 ± 13.78 | 71.61 ± 13.78 | |
| Australian | 0 | 86.09 ± 3.56 | 86.38 ± 4.45 | 86.96 ± 3.72 | 86.81 ± 3.69 |
| 0.05 | 85.36 ± 4.02 | 86.23 ± 4.50 | 85.80 ± 4.57 | 87.39 ± 3.43 | |
| 0.1 | 85.22 ± 3.71 | 85.51 ± 3.67 | 85.36 ± 5.16 | 88.26 ± 4.02 | |
| 0.2 | 83.91 ± 4.91 | 85.22 ± 4.04 | 84.93 ± 4.55 | 86.81 ± 3.69 | |
| Heart-Statlog | 0 | 84.07 ± 8.12 | 83.33 ± 7.45 | 83.70 ± 9.40 | 83.33 ± 6.47 |
| 0.05 | 83.33 ± 8.32 | 83.70 ± 8.15 | 83.33 ± 9.69 | 84.44 ± 6.99 | |
| 0.1 | 83.70 ± 8.15 | 82.59 ± 7.95 | 83.70 ± 9.54 | 84.07 ± 7.04 | |
| 0.2 | 84.44 ± 8.08 | 83.33 ± 7.08 | 81.11 ± 9.86 | 83.70 ± 8.80 | |
| Saheart | 0 | 71.64 ± 5.01 | 71.01 ± 7.40 | 72.08 ± 5.34 | 72.93 ± 6.37 |
| 0.05 | 71.63 ± 5.50 | 70.58 ± 7.51 | 71.86 ± 4.43 | 72.71 ± 6.59 | |
| 0.1 | 72.51 ± 5.84 | 70.37 ± 7.25 | 71.86 ± 5.90 | 72.06 ± 5.94 | |
| 0.2 | 71.21 ± 5.58 | 69.93 ± 6.00 | 71.00 ± 5.28 | 71.64 ± 5.39 | |
| WDBC | 0 | 95.43 ± 1.61 | 95.96 ± 1.37 | 96.31 ± 2.54 | 97.19 ± 1.61 |
| 0.05 | 94.20 ± 3.34 | 94.03 ± 3.16 | 95.08 ± 3.02 | 96.13 ± 2.04 | |
| 0.1 | 93.32 ± 2.19 | 92.97 ± 3.68 | 93.50 ± 3.05 | 95.60 ± 1.97 | |
| 0.2 | 93.32 ± 2.19 | 92.44 ± 1.93 | 93.32 ± 2.57 | 94.55 ± 1.46 | |
| Pima | 0 | 76.83 ± 3.71 | 76.70 ± 3.36 | 76.57 ± 4.12 | 77.22 ± 4.07 |
| 0.05 | 76.70 ± 3.74 | 76.31 ± 3.53 | 76.44 ± 3.66 | 76.96 ± 3.81 | |
| 0.1 | 76.44 ± 4.29 | 77.22 ± 3.30 | 77.09 ± 3.96 | 76.44 ± 3.87 | |
| 0.2 | 76.18 ± 3.62 | 76.83 ± 3.23 | 77.22 ± 4.03 | 76.18 ± 3.73 | |
| Ionosphere | 0 | 90.60 ± 3.61 | 91.46 ± 3.10 | 90.90 ± 5.20 | 92.31 ± 2.87 |
| 0.05 | 87.47 ± 6.28 | 90.31 ± 2.92 | 88.89 ± 4.51 | 90.88 ± 3.34 | |
| 0.1 | 87.44 ± 5.90 | 86.88 ± 5.90 | 86.62 ± 5.83 | 89.18 ± 5.05 | |
| 0.2 | 84.34 ± 5.85 | 85.47 ± 5.64 | 84.91 ± 4.38 | 87.16 ± 5.17 | |
| Datasets | r | Existing Algorithm | Proposed Algorithm | ||
|---|---|---|---|---|---|
| TSVM | Pin-TSVM | IPin-TSVM | GPin-TSVM | ||
| Breat | 0 | 74.24 ± 11.23 | 74.24 ± 11.23 | 78.71 ± 12.47 | 74.24 ± 12.16 |
| 0.05 | 74.24 ± 11.23 | 74.24 ± 11.23 | 80.38 ± 10.61 | 74.32 ± 13.35 | |
| 0.1 | 73.33 ± 12.36 | 74.32 ± 10.34 | 80.38 ± 11.25 | 73.41 ± 11.79 | |
| 0.2 | 73.41 ± 13.15 | 73.33 ± 12.36 | 77.80 ± 12.09 | 75.15 ± 13.63 | |
| Spect | 0 | 83.50 ± 6.15 | 84.25 ± 6.31 | 84.23 ± 7.00 | 84.63 ± 7.05 |
| 0.05 | 83.12 ± 5.69 | 83.49 ± 6.60 | 84.62 ± 6.46 | 84.63 ± 6.43 | |
| 0.1 | 82.75 ± 5.69 | 83.15 ± 7.32 | 83.87 ± 6.97 | 84.64 ± 7.72 | |
| 0.2 | 82.02 ± 5.22 | 82.01 ± 6.96 | 83.12 ± 7.05 | 83.29 ± 7.43 | |
| Australian | 0 | 86.81 ± 2.93 | 86.67 ± 3.60 | 86.96 ± 3.94 | 86.67 ± 4.19 |
| 0.05 | 82.46 ± 4.02 | 84.78 ± 3.90 | 86.81 ± 4.27 | 87.39 ± 3.11 | |
| 0.1 | 82.61 ± 2.59 | 82.90 ± 4.93 | 86.38 ± 3.32 | 86.52 ± 3.61 | |
| 0.2 | 82.32 ± 3.42 | 82.46 ± 4.74 | 85.51 ± 2.67 | 85.65 ± 3.63 | |
| Heart-Statlog | 0 | 84.44 ± 7.73 | 84.81 ± 7.49 | 83.33 ± 8.32 | 84.81 ± 7.49 |
| 0.05 | 84.07 ± 7.60 | 84.44 ± 8.08 | 84.81 ± 8.36 | 84.81 ± 7.49 | |
| 0.1 | 84.07 ± 7.95 | 84.44 ± 6.99 | 83.70 ± 8.31 | 84.44 ± 7.91 | |
| 0.2 | 84.07 ± 7.23 | 82.59 ± 7.60 | 84.07 ± 7.42 | 84.07 ± 6.84 | |
| Heart-C | 0 | 82.85 ± 4.52 | 82.23 ± 8.94 | 82.85 ± 4.79 | 82.90 ± 8.36 |
| 0.05 | 82.19 ± 5.04 | 81.25 ± 8.30 | 81.87 ± 4.08 | 82.54 ± 7.08 | |
| 0.1 | 81.56 ± 7.04 | 80.89 ± 6.77 | 81.89 ± 6.09 | 82.53 ± 4.59 | |
| 0.2 | 80.23 ± 5.95 | 80.81 ± 5.79 | 80.23 ± 4.55 | 82.18 ± 5.46 | |
| WDBC | 0 | 97.54 ± 1.17 | 97.71 ± 1.58 | 97.89 ± 1.32 | 97.89 ± 1.32 |
| 0.05 | 95.61 ± 2.51 | 95.79 ± 2.24 | 95.61 ± 1.96 | 95.60 ± 2.26 | |
| 0.1 | 95.08 ± 3.12 | 95.08 ± 2.91 | 95.78 ± 2.74 | 95.08 ± 2.58 | |
| 0.2 | 93.49 ± 2.75 | 93.85 ± 1.79 | 94.03 ± 2.24 | 94.20 ± 2.72 | |
| Ionosphere | 0 | 96.02 ± 2.58 | 95.17 ± 3.60 | 95.16 ± 2.23 | 95.15 ± 4.05 |
| 0.05 | 95.17 ± 3.12 | 94.60 ± 3.91 | 94.87 ± 2.49 | 94.59 ± 3.24 | |
| 0.1 | 94.60 ± 3.22 | 94.60 ± 2.67 | 94.87 ± 3.07 | 94.31 ± 3.36 | |
| 0.2 | 93.46 ± 3.09 | 92.60 ± 2.91 | 92.59 ± 4.09 | 93.48 ± 4.44 | |
| Pima | 0 | 77.09 ± 3.31 | 76.96 ± 3.20 | 77.35 ± 3.71 | 77.48 ± 3.33 |
| 0.05 | 76.96 ± 3.45 | 76.83 ± 3.34 | 76.70 ± 3.01 | 76.96 ± 3.83 | |
| 0.1 | 76.57 ± 2.51 | 75.66 ± 3.14 | 75.92 ± 3.42 | 76.43 ± 2.68 | |
| 0.2 | 75.53 ± 1.65 | 76.18 ± 3.51 | 76.05 ± 2.82 | 76.57 ± 3.16 | |
| Datasets | TSVM | Pin-TSVM | IPin-TSVM | GPin-TSVM |
|---|---|---|---|---|
| Breast | 0.01, 0.01 | 0.01, 0.01, 1 | 10, 0.01, 1, 1 | 0.01, 0.01, 0.75, 0.5, 0.1, 0.1 |
| Planning relax | 0.1, 1 | 0.1, 1, 0.1 | 0.1, 1, 0.1, 0.1 | 0.1, 0.1, 1, 0.1, 0.1, 0.1 |
| Australian | 1, 0.1 | 0.1, 0.1, 0.5 | 1, 0.1, 0.1, 1 | 1, 0.1, 1, 0.5, 0.1, 0.1 |
| Heart-Statlog | 0.1, 0.1 | 1, 1, 1 | 1, 10, 0.5, 1 | 1, 10, 1, 0.5, 0.1, 0.5 |
| Saheart | 0.1, 0.1 | 1, 1, 1 | 1, 1, 1, 0.1 | 1, 1, 1.5, 0.5, 0.5, 0.1 |
| WDBC | 0.01, 0.01 | 0.1, 0.1, 0.1 | 1, 10, 0.1, 0.5 | 0.01, 0.01, 2, 1, 0.5, 0.1 |
| Pima | 0.1, 0.1 | 0.1, 0.1, 1.5 | 1, 1, 1, 0.1 | 1, 1, 1, 0.5, 0.1, 0.1 |
| Ionosphere | 0.01, 0.01 | 0.1, 0.1, 0.1 | 1, 10, 0.1, 0.5 | 1, 10, 1, 0.1, 0.5, 0.5 |
| Datasets | TSVM | Pin-TSVM | IPin-TSVM | GPin-TSVM |
|---|---|---|---|---|
| Breast | 0.01, 0.01, 0.1 | 0.01, 0.01, 0.1, 0.1 | 0.01, 0.01, 0.1, 1, 0.1 | 0.1, 0.1, 1, 1, 0.5, 0.5, 0.01 |
| Spect | 0.1, 0.1, 0.01 | 0.1, 0.1, 0.75, 0.01 | 0.1, 0.1, 1, 0.5, 0.01 | 0.1, 0.1, 1, 1, 0.75, 0.75, 0.01 |
| Australian | 10, 10, 0.01 | 10, 10, 1, 0.01 | 10, 10, 1, 0.1, 0.01 | 0.01, 0.01, 1, 1, 0.5, 0.5, 0.01 |
| Heart-Statlog | 0.1, 0.1, 0.01 | 1, 1, 1, 0.01 | 1, 10, 0.5, 1, 0.01 | 1, 10, 1, 0.5, 0.1, 0.5, 0.01 |
| Heart-C | 0.01, 0.01, 0.1 | 0.01, 0.01, 0.1, 0.1 | 0.01, 0.01, 0.5 0.1, 0.1 | 0.01, 0.01, 0.5, 0.5 0.1, 0.1, 0.1 |
| WDBC | 0.1, 0.1, 0.01 | 0.1, 0.1, 0.5, 0.01 | 1, 1, 1, 0.1, 0.01 | 0.01, 0.01, 2.5, 2.5, 0.1, 0.1, 0.01 |
| Ionosphere | 0.1, 1, 0.1 | 0.1, 1, 0.5, 0.1 | 1, 1, 0.5, 0.1, 0.1 | 0.1, 0.1, 1, 1, 0.5, 0.5, 0.01 |
| Pima | 0.1, 0.1, 0.01 | 0.1, 0.1, 1.5, 0.1 | 0.1, 0.1, 1, 0.5, 0.1 | 0.1, 0.1, 1, 1, 0.1, 0.1, 0.01 |
| Datasets | TSVM | GPTSVM | |||
|---|---|---|---|---|---|
| Heart-Statlog | 0 | 112 | 133 | 92 | 113 |
| 0.05 | 78 | 85 | |||
| 0.1 | 66 | 68 | |||
| 0.2 | 50 | 56 | |||
| 0.3 | 46 | 46 | |||
| 0.4 | 33 | 31 | |||
| Australian | 0 | 257 | 255 | 254 | 232 |
| 0.05 | 128 | 151 | |||
| 0.1 | 124 | 136 | |||
| 0.2 | 113 | 114 | |||
| 0.3 | 104 | 89 | |||
| 0.4 | 72 | 69 | |||
| Breast | 0 | 59 | 47 | 51 | 48 |
| 0.05 | 45 | 46 | |||
| 0.1 | 40 | 44 | |||
| 0.2 | 39 | 41 | |||
| 0.3 | 30 | 32 | |||
| 0.4 | 24 | 23 | |||
| WDBC | 0 | 339 | 196 | 234 | 150 |
| 0.05 | 136 | 125 | |||
| 0.1 | 93 | 103 | |||
| 0.2 | 69 | 66 | |||
| 0.3 | 51 | 42 | |||
| 0.4 | 30 | 26 | |||
| Ionosphere | 0 | 108 | 199 | 94 | 151 |
| 0.05 | 89 | 81 | |||
| 0.1 | 76 | 69 | |||
| 0.2 | 61 | 58 | |||
| 0.3 | 51 | 46 | |||
| 0.4 | 41 | 31 | |||
| Datasets | TSVM | GPTSVM | |||
|---|---|---|---|---|---|
| Heart-C | 0 | 138 | 165 | 138 | 165 |
| 0.05 | 113 | 115 | |||
| 0.1 | 78 | 83 | |||
| 0.2 | 62 | 65 | |||
| 0.3 | 53 | 52 | |||
| 0.4 | 38 | 38 | |||
| Spect | 0 | 55 | 212 | 55 | 212 |
| 0.05 | 55 | 121 | |||
| 0.1 | 55 | 90 | |||
| 0.2 | 54 | 64 | |||
| 0.3 | 50 | 56 | |||
| 0.4 | 36 | 47 | |||
| Australian | 0 | 383 | 307 | 383 | 307 |
| 0.05 | 134 | 155 | |||
| 0.1 | 121 | 138 | |||
| 0.2 | 114 | 117 | |||
| 0.3 | 100 | 95 | |||
| 0.4 | 71 | 67 | |||
| Ionosphere | 0 | 126 | 225 | 126 | 225 |
| 0.05 | 91 | 61 | |||
| 0.1 | 73 | 50 | |||
| 0.2 | 41 | 41 | |||
| 0.3 | 33 | 28 | |||
| 0.4 | 24 | 21 | |||
| Breast | 0 | 64 | 52 | 64 | 52 |
| 0.05 | 55 | 52 | |||
| 0.1 | 50 | 49 | |||
| 0.2 | 42 | 44 | |||
| 0.3 | 33 | 37 | |||
| 0.4 | 23 | 23 | |||
| Datasets | TSVM | Pin-TSVM | IPin-TSVM | GPin-TSVM |
|---|---|---|---|---|
| 0 vs. 8 | 0.1, 0.1 | 0.1, 0.1, 0.5 | 0.01, 0.01, 1, 1 | 0.01, 0.01, 1, 1, 0.1, 0.1 |
| 2 vs. 4 | 0.1, 0.1 | 0.1, 0.1, 0.5 | 0.1, 0.1, 1, 0.5 | 0.1, 0.1, 1, 1, 0.5, 0.5 |
| 1 vs. 7 | 1, 1 | 1, 1, 0.5 | 1, 1, 0.1, 1 | 1, 0.1, 1, 0.5, 0.1, 0.1 |
| 5 vs. 8 | 0.1, 0.1 | 1, 1, 1 | 1, 1, 0.5, 1 | 0.1, 0.1, 1, 0.5, 0.1, 0.5 |
| Datasets | TSVM | Pin-TSVM | IPin-TSVM | GPin-TSVM |
|---|---|---|---|---|
| 0 vs. 8 | 4 | 3 | 2 | 1 |
| 2 vs. 4 | 3.5 | 3.5 | 2 | 1 |
| 1 vs. 7 | 4 | 3 | 1.5 | 1.5 |
| 5 vs. 8 | 4 | 3 | 1 | 2 |
| Average Rank | 3.88 | 3.13 | 1.63 | 1.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panup, W.; Ratipapongton, W.; Wangkeeree, R. A Novel Twin Support Vector Machine with Generalized Pinball Loss Function for Pattern Classification. Symmetry 2022, 14, 289. https://doi.org/10.3390/sym14020289
Panup W, Ratipapongton W, Wangkeeree R. A Novel Twin Support Vector Machine with Generalized Pinball Loss Function for Pattern Classification. Symmetry. 2022; 14(2):289. https://doi.org/10.3390/sym14020289
Chicago/Turabian StylePanup, Wanida, Wachirapong Ratipapongton, and Rabian Wangkeeree. 2022. "A Novel Twin Support Vector Machine with Generalized Pinball Loss Function for Pattern Classification" Symmetry 14, no. 2: 289. https://doi.org/10.3390/sym14020289