
Review and Evaluation of Belief Propagation Decoders for Polar Codes


Abstract
:1. Introduction
2. Polar Codes
2.1. The Concept and Encoding
2.2. Decoding Methods
2.2.1. Successive Cancellation Decoding
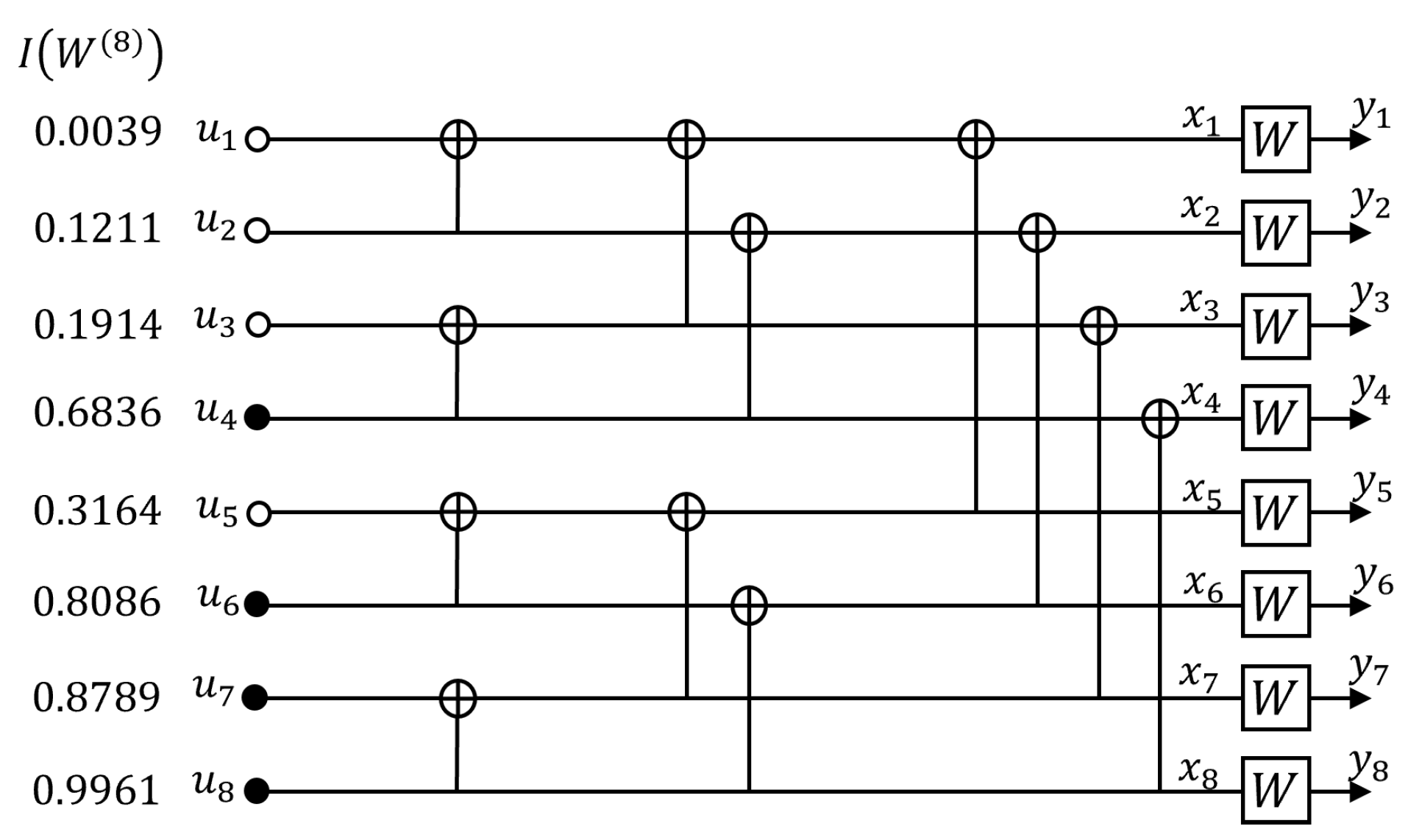
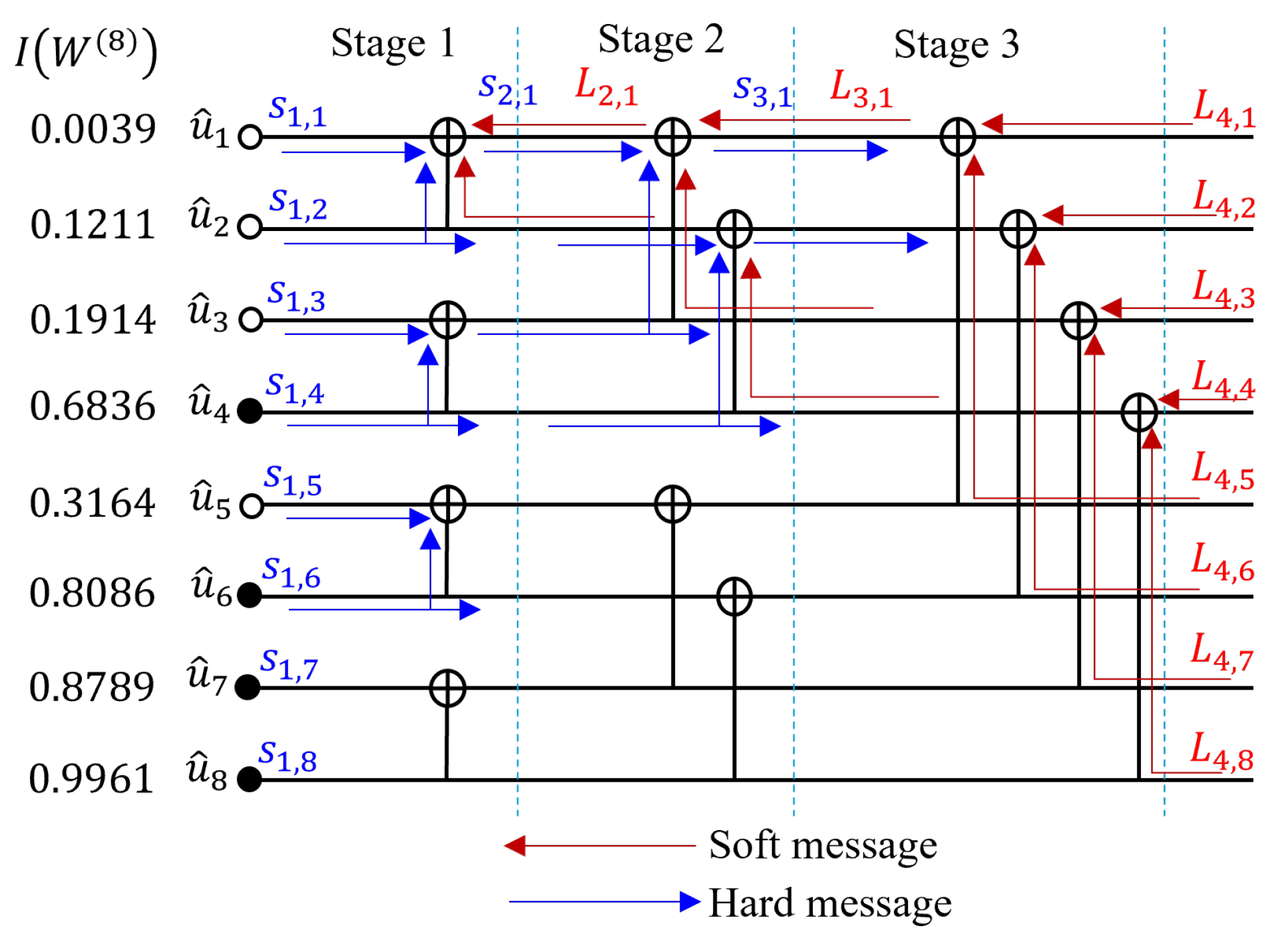
2.2.2. Belief Propagation Decoding
3. Variations of Belief Propagation Decoders and Implementation Issues
3.1. Belief Propagation Decoding with List, BPDL
3.1.1. Review of the Previous Works on BPDL
3.1.2. A New Proposed BPDL
3.2. Belief Propagation Decoding with Reduced Factor Graph
- code:
- All the leaf nodes of this constituent code are frozen bits, whose LLR, is set to ∞, this leads to:
- code:
- This is the opposite case of ; all leaf nodes are information bits, so is set to 0, and during the decoding process, it is always maintained as 0. This leads to:
- code:
- This constituent code has a single information bit on the last leaf node. Since each node is a duplication of others, they share the belief messages with others in the factor graph. This leads to:
- code:
- This has a single frozen bit on the first leaf node. In this case, R update can be simplified as follows:
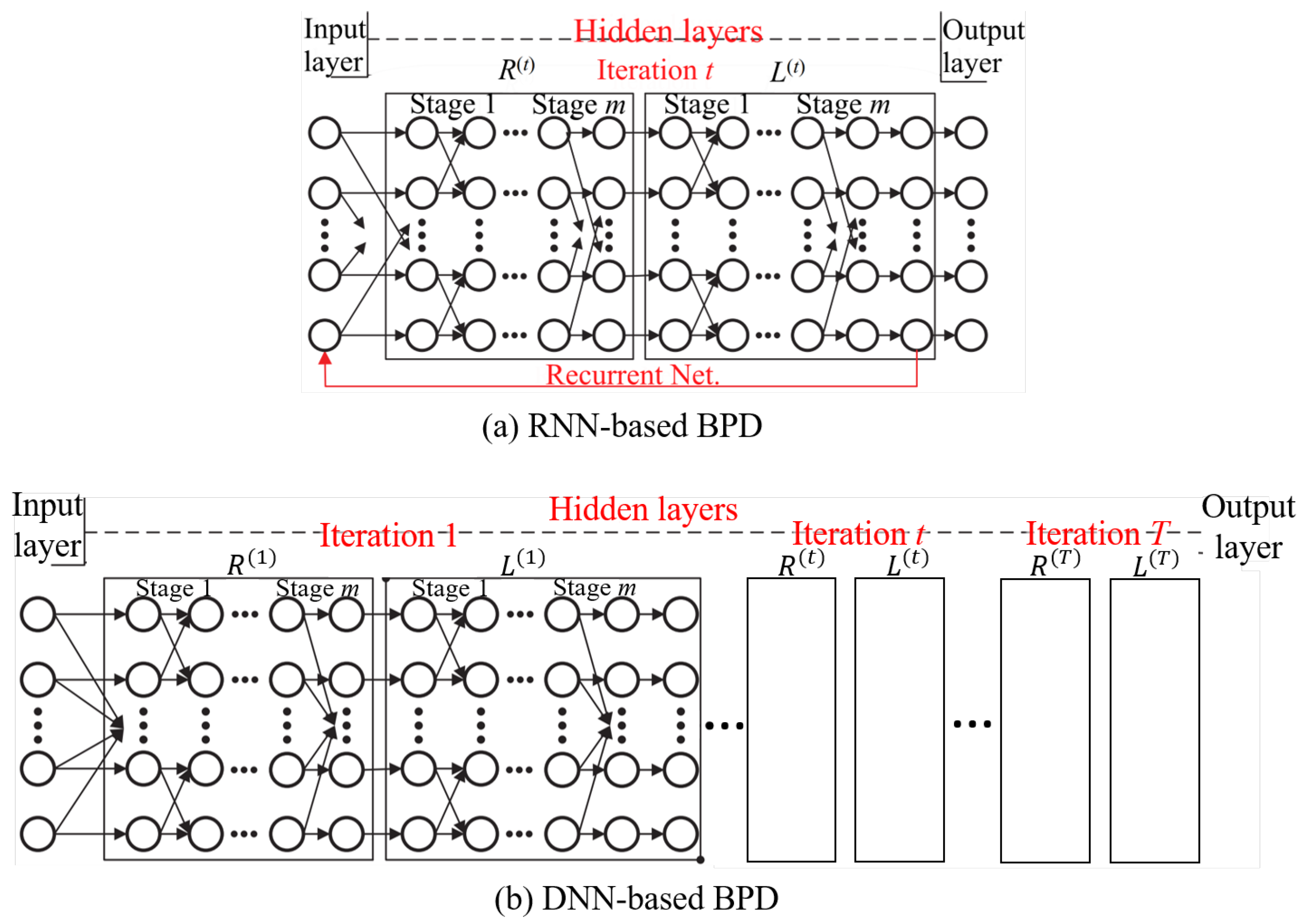
3.3. Belief Propagation Decoding with Neural Network
3.3.1. Review of the Previous Works on BPD with Neural Network
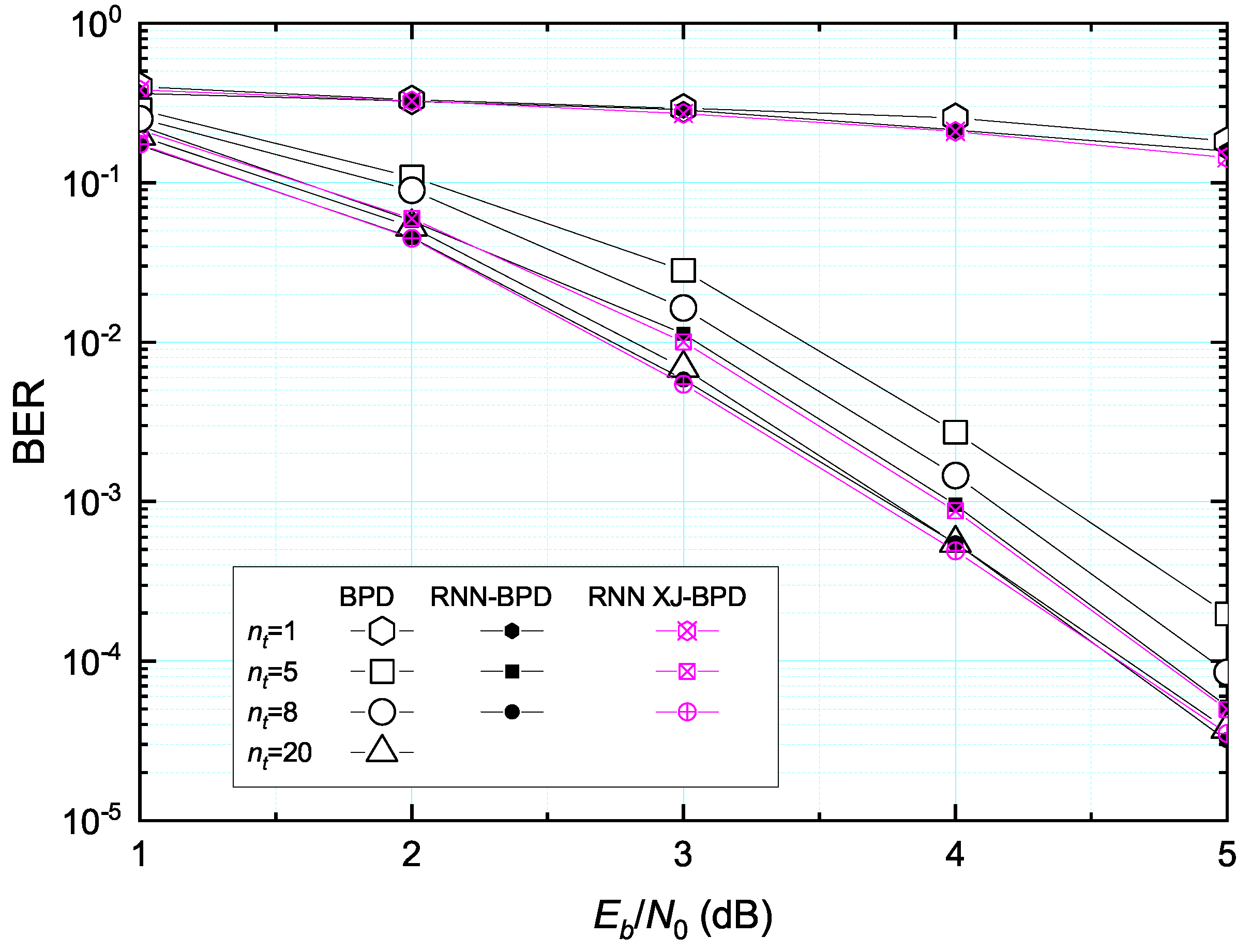
3.3.2. The Proposed Complexity Reduced BPD with a Neural Network; RNN XJ-BPD
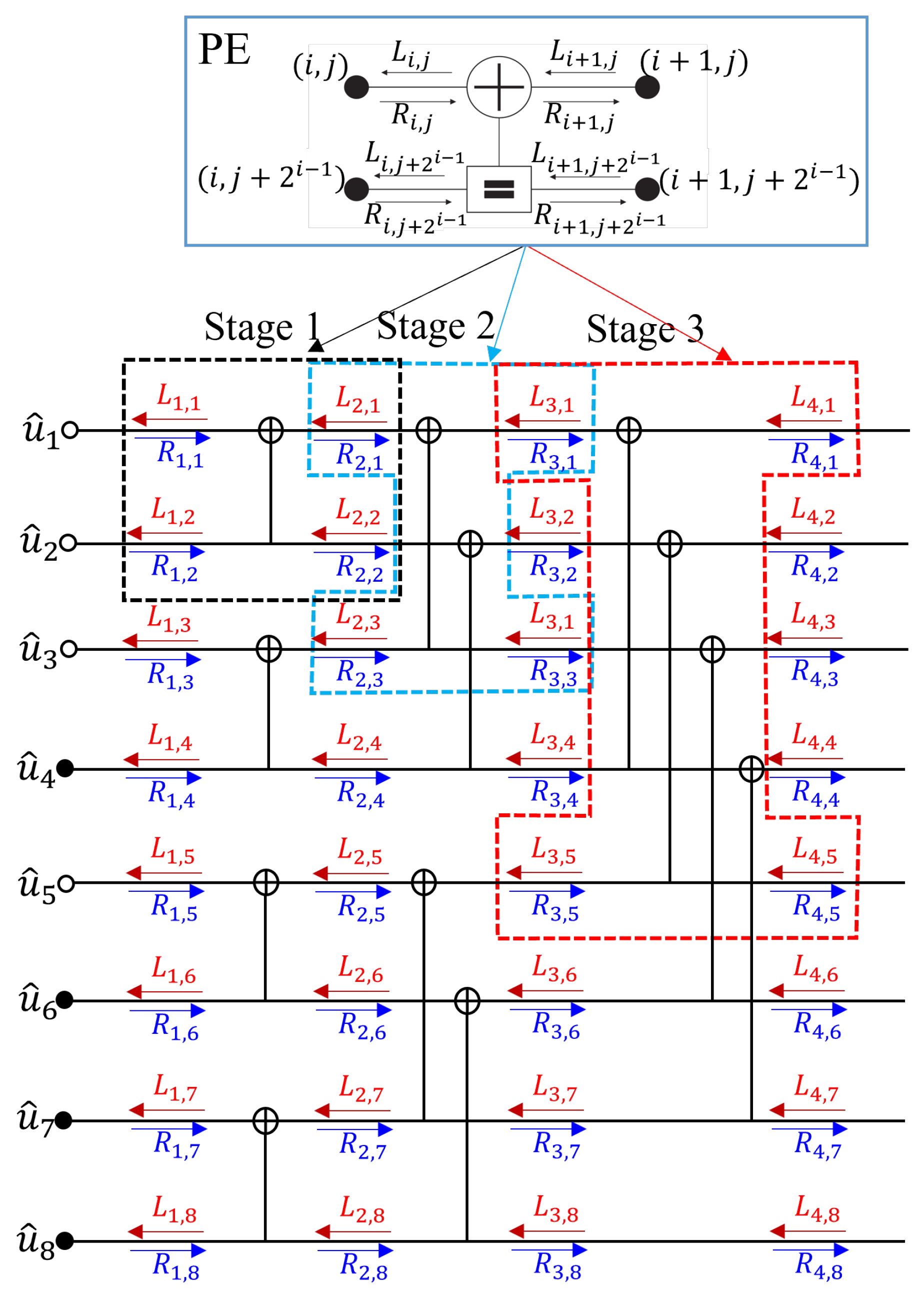
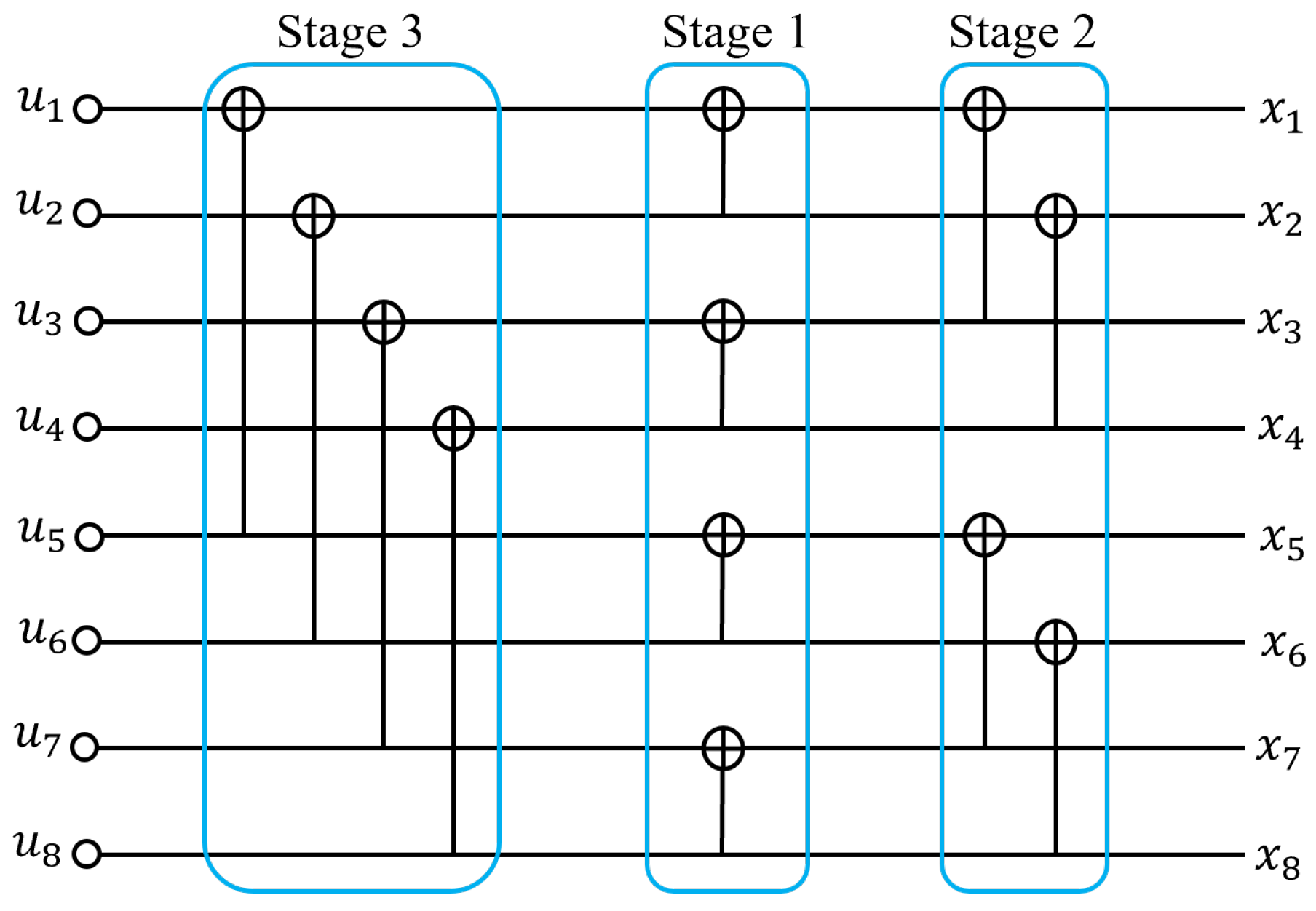
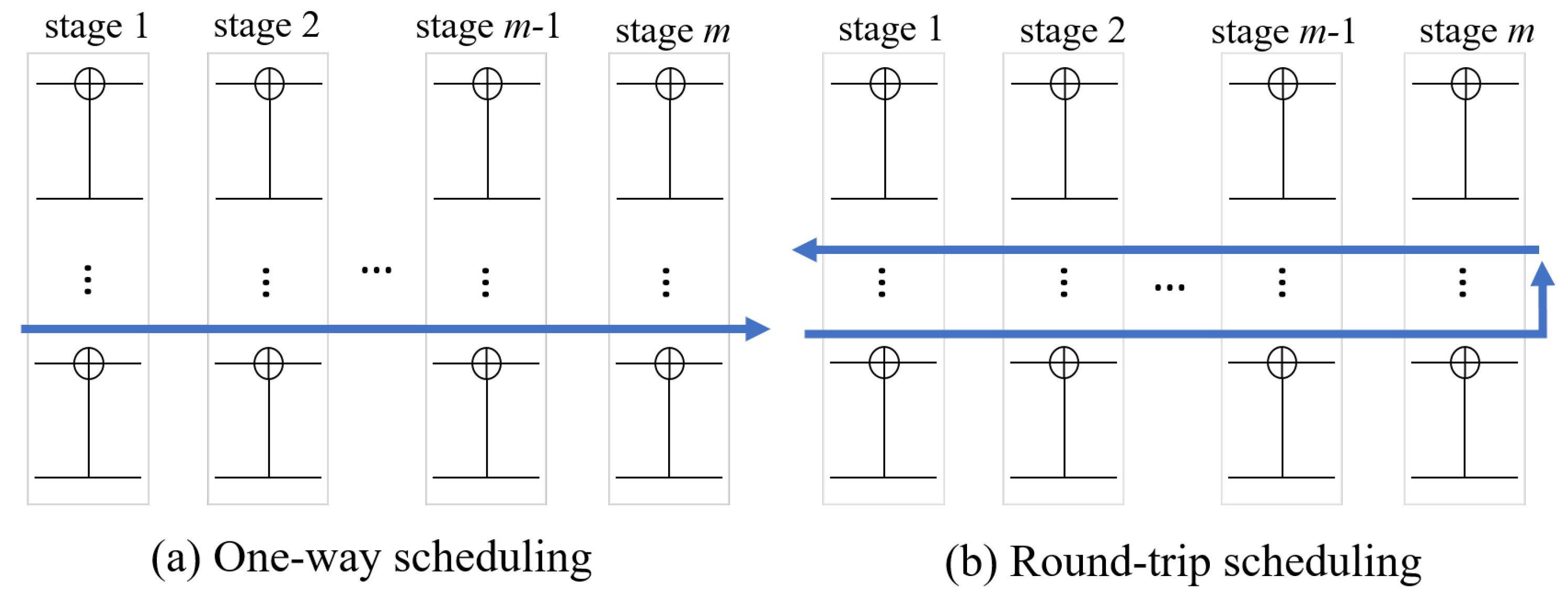
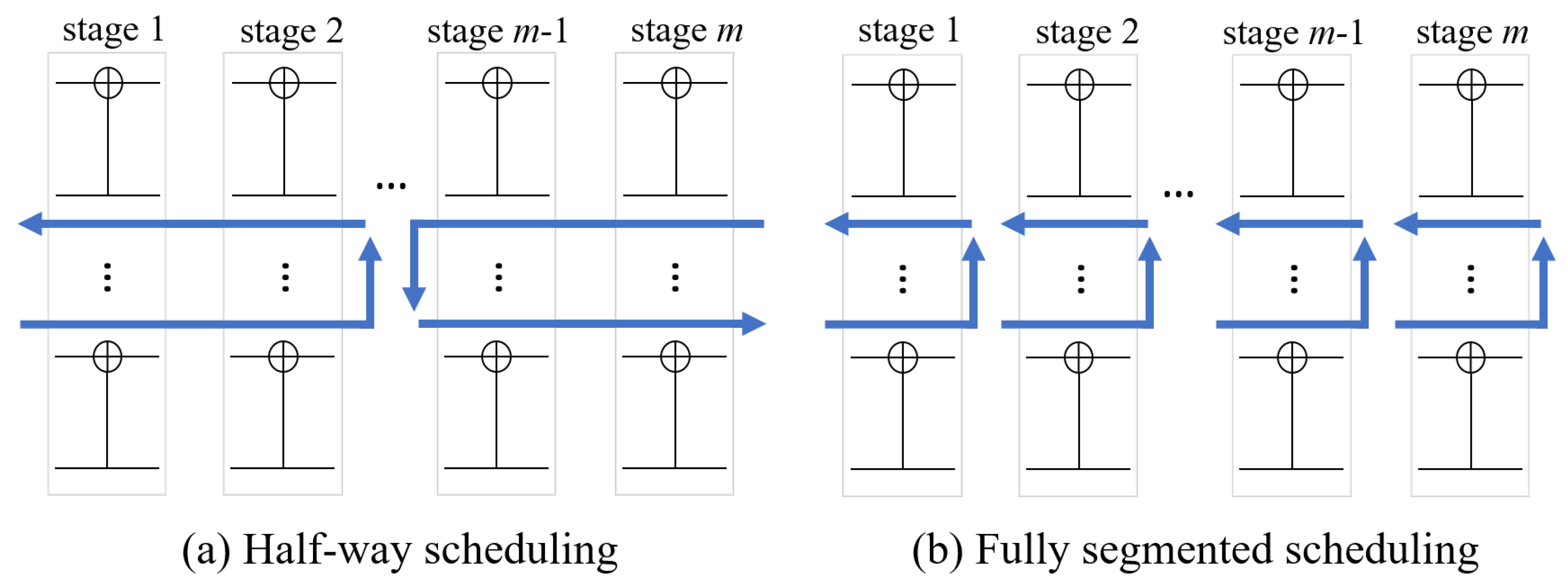
3.4. Implementation of Belief Propagation Decoding with Segmented Scheduling
3.4.1. Review of the Previous Works on Scheduling for BPD
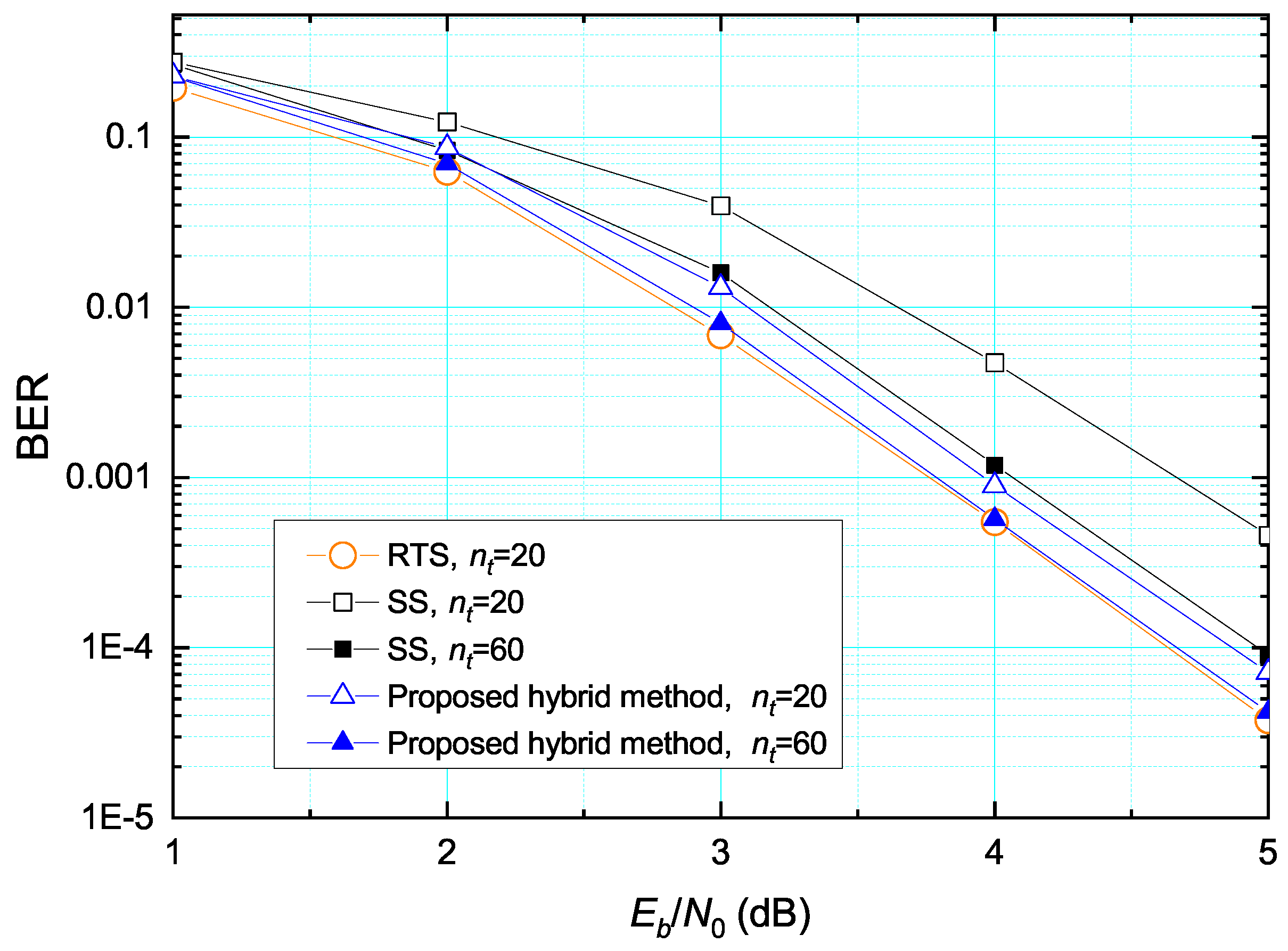
3.4.2. The Proposed Hybrid Scheduling Scheme
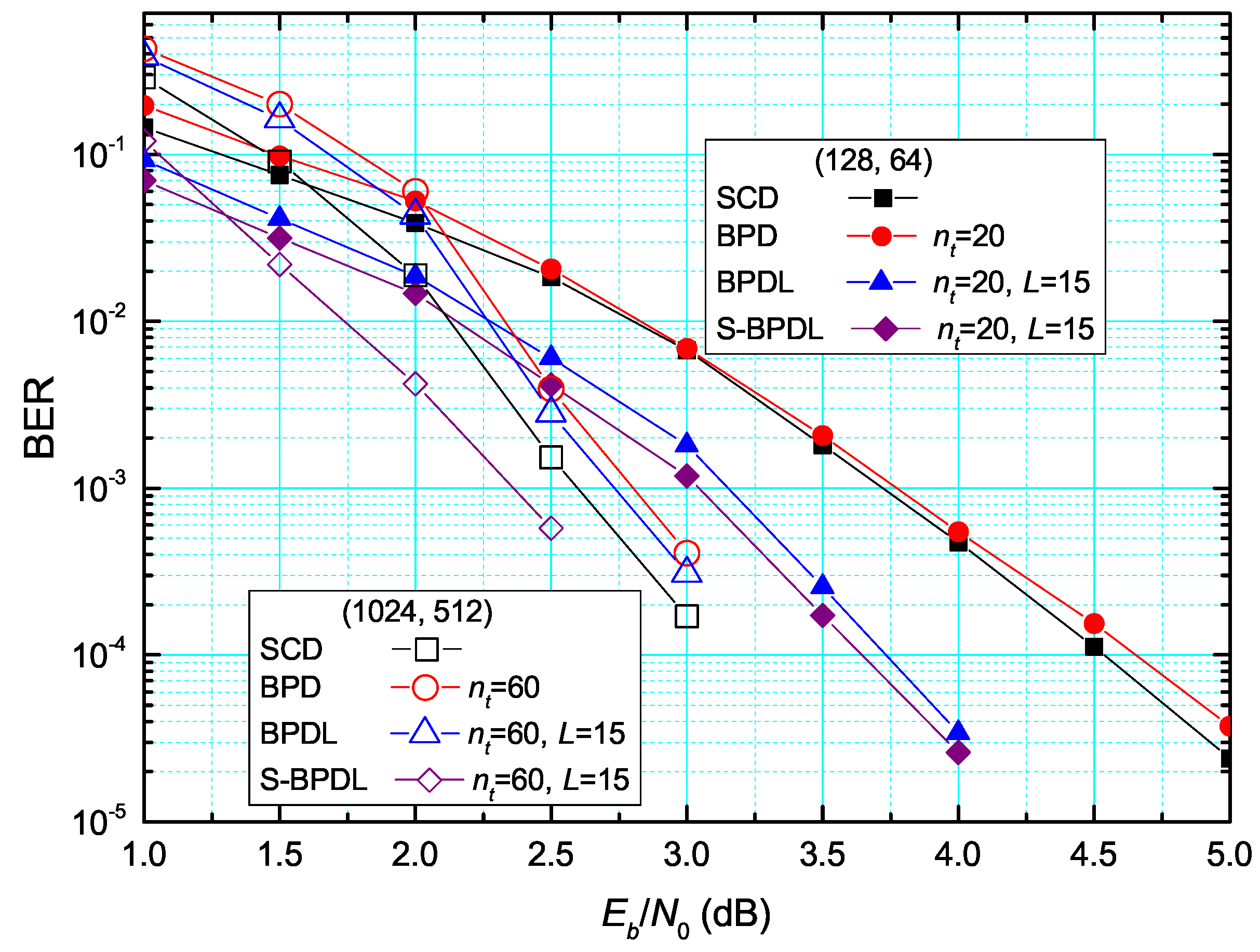
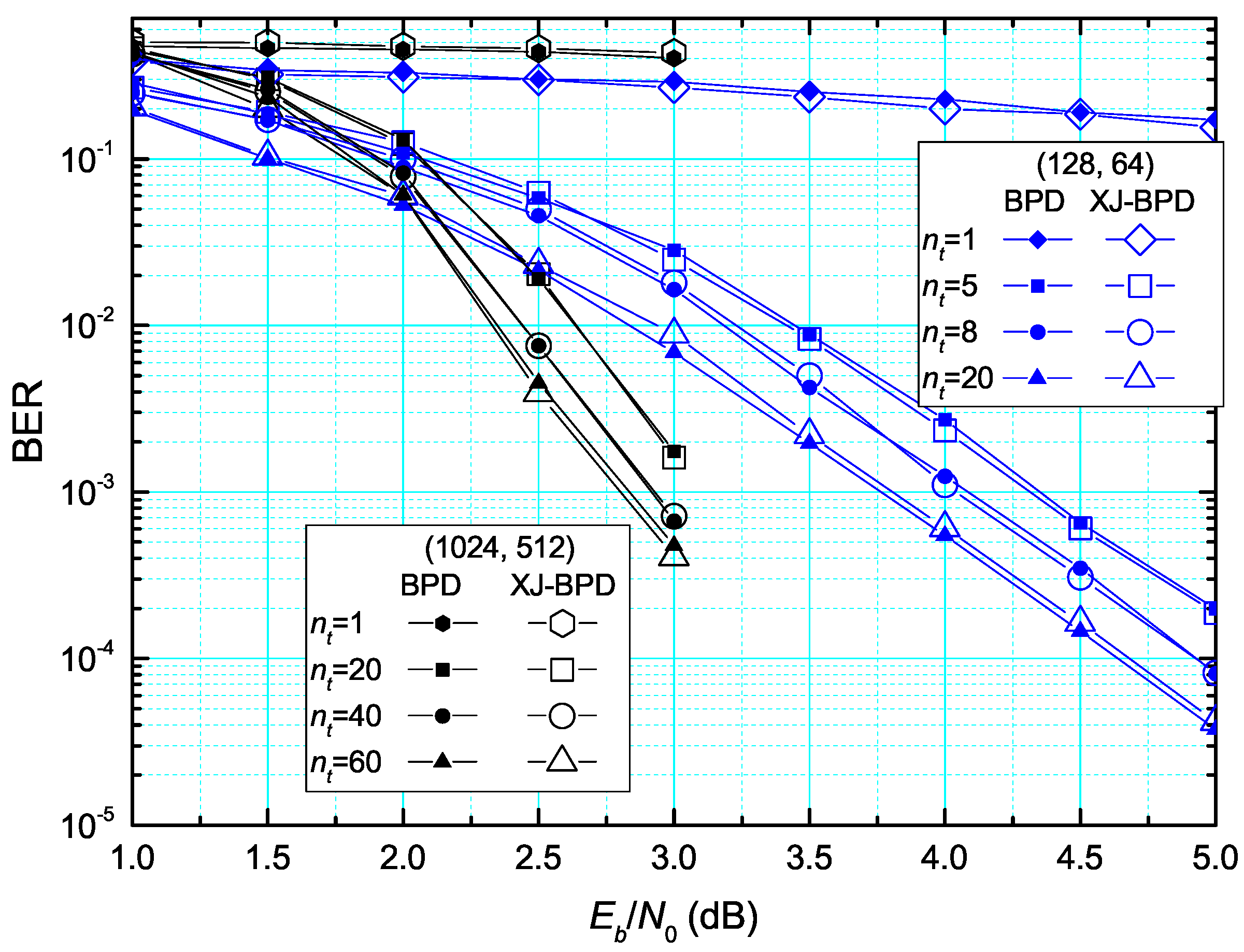
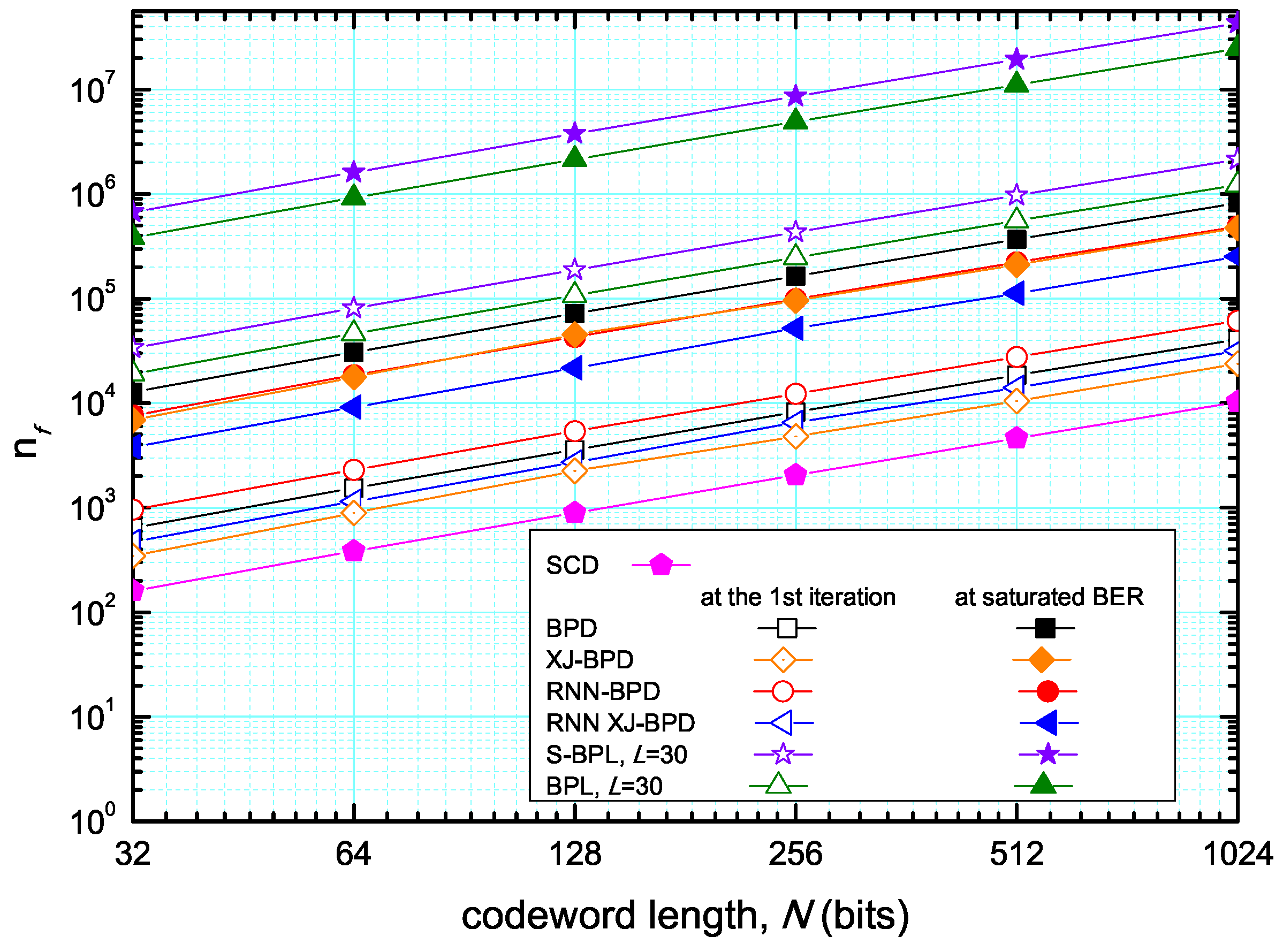
4. Performance Evaluation
4.1. Error Rate Performance
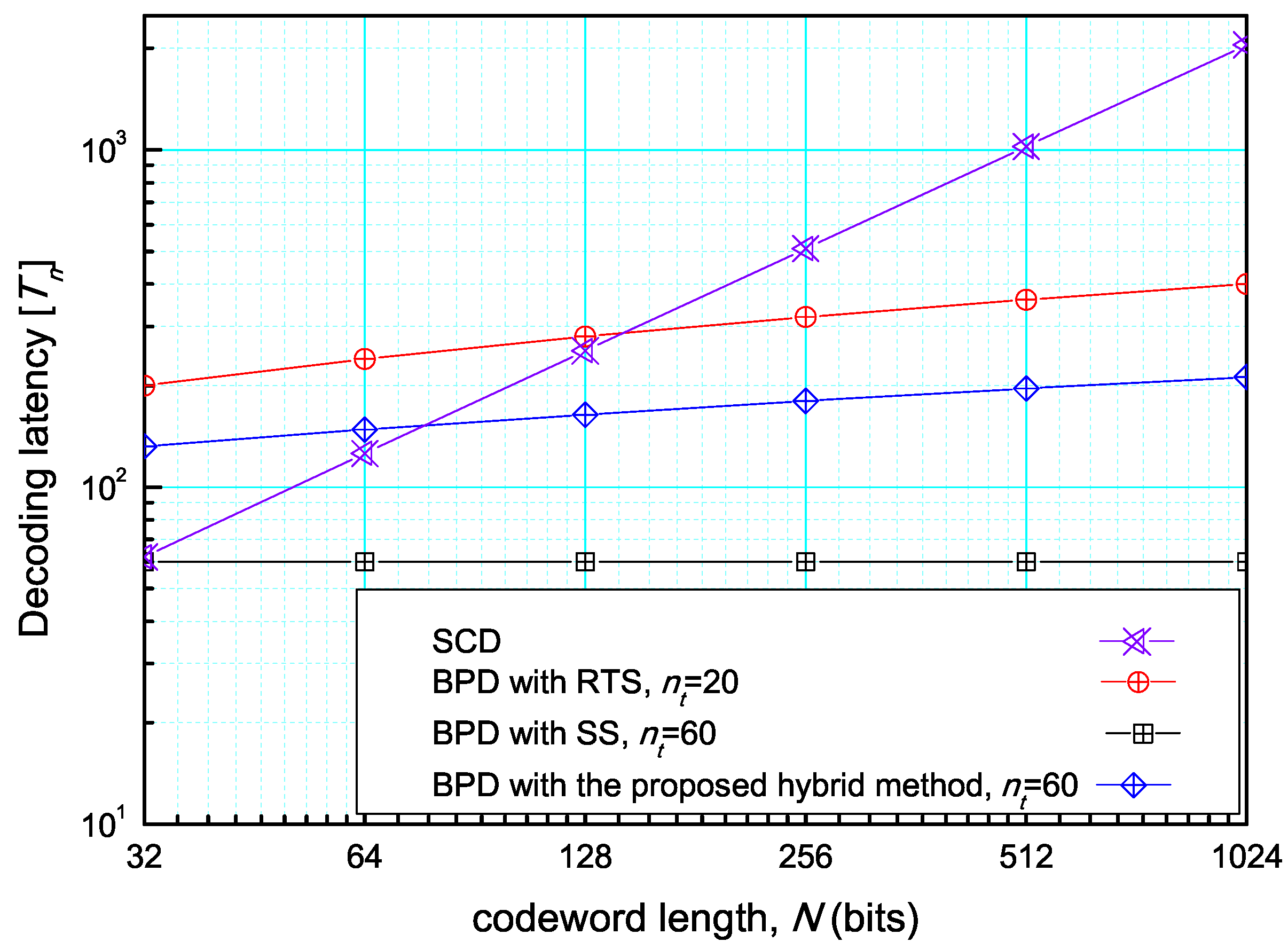
4.2. Complexity and Latency Performance
5. Conclusions and Discussion on Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AWGN | Additive white Gaussian noise |
| BER | Bit error rate |
| BPD | Belief propagation decoding |
| BPDL | Belief propagation decoding with list |
| BPSK | Binary phase shift keying |
| DNN | Deep neural network |
| FEC | Forward error correction |
| FLOP | Floating point operations |
| LDPC | Low-density parity-check |
| LLR | Log-likelihood ratio |
| PE | Processing element |
| ResNet-BP | Residual neural network-based belief propagation |
| RNN | Recurrent neural network |
| RNN-BPD | RNN-based belief propagation decoding |
| RNN XJ-BPD | RNN based express-journey belief propagation decoding |
| RTS | Round-trip scheduling |
| S-BPDL | Scalable belief propagation decoding with list |
| SC | Successive cancellation |
| SCD | Successive cancellation decoding |
| SS | Segmented scheduling |
| URLLC | Ultra reliable and low latency communications |
| XJ-BPD | Express-journey belief propagation decoding |
| XOR | Exclusive-or |
References
- Arıkan, E. A performance comparison of polar codes and Reed-Muller codes. IEEE Commun. Lett. 2008, 12, 447–449. [Google Scholar] [CrossRef]
- 3GPP. Multiplexing and Channel Coding (Release 10) 3gpp ts 21.101 v10.4.0. 2018. Available online: http://www.3gpp.org/ftp/Specs/2018-09/Rel-10/21-series/21101-a40.zip (accessed on 12 December 2022).
- Arıkan, E. Channel polarization: A method for constructing capacity achieving codes for symmetric binary-input memoryless channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef]
- Leroux, C.; Raymond, A.J.; Sarkis, G.; Gross, W.J. A semi-parallel successive-cancellation decoder for polar codes. IEEE Trans. Signal Process. 2013, 61, 289–299. [Google Scholar] [CrossRef]
- Elkelesh, A.; Ebada, M.; Cammerer, S.; Ten Brink, S. Belief propagation decoding of polar codes on permuted factor graphs. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Elkelesh, A.; Ebada, M.; Cammerer, S.; Ten Brink, S. Belief propagation list decoding of polar codes. IEEE Commun. Lett. 2018, 22, 1536–1539. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Bai, B.; Zhu, M.; Zhou, S. Improved Belief Propagation List Decoding for Polar Codes. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 1–6. [Google Scholar]
- Ranasinghe, V.; Rajatheva, N.; Latva-aho, M. Partially Permuted Multi-Trellis Belief Propagation for Polar Codes. In Proceedings of the 2020 IEEE International Conference on Communications (ICC 2020), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Wu, W.; Zhai, Z.; Siegel, P.H. Improved Hybrid RM-Polar Codes and Decoding on Stable Permuted Factor Graphs. In Proceedings of the 2021 11th International Symposium on Topics in Coding (ISTC), Montreal, QC, Canada, 30 August–3 September 2021; pp. 1–5. [Google Scholar]
- Dai, L.; Huang, L.; Bai, Y.; Liu, Y.; Liu, Z. CRC-Aided Belief Propagation with Permutated Graphs Decoding of Polar Codes. In Proceedings of the 2020 IEEE 3rd International Conference on Electronic Information and Communication Technology (ICEICT), Shenzhen, China, 13–15 November 2020; pp. 445–448. [Google Scholar]
- Li, L.; Liu, L. Belief Propagation with Permutated Graphs of Polar Codes. IEEE Access 2020, 8, 17632–17641. [Google Scholar] [CrossRef]
- Ren, Y.; Shen, Y.; Zhang, Z.; You, X.; Zhang, C. Efficient Belief Propagation Polar Decoder with Loop Simplification Based Factor Graphs. IEEE Trans. Veh. Technol. 2020, 69, 5657–5660. [Google Scholar] [CrossRef]
- Doan, N.; Hashemi, S.A.; Mondelli, M.; Gross, W.J. On the decoding of polar codes on permuted factor graphs. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Xu, J.; Che, T.; Choi, G. XJ-BP: Express Journey Belief Propagation Decoding for Polar Codes. In Proceedings of the 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]
- Nachmani, E.; Marciano, E.; Lugosch, L.; Gross, W.; Burshtein, D.; Be’ery, Y. Deep Learning Methods for Improved Decoding of Linear Codes. IEEE J. Sel. Top. Signal Process. 2018, 12, 119–131. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Wu, Z.; Ueng, Y.-L.; You, X.; Zhang, C. Improved polar decoder based on deep learning. In Proceedings of the IEEE International Workshop on Signal Processing Systems (SiPS), Lorient, France, 3–5 October 2017; pp. 1–6. [Google Scholar]
- Huang, Y.; Zhang, M.; Dou, Y. A Low-Complexity Residual Neural Network based BP Decoder for Polar Codes. In Proceedings of the 2020 International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 21–23 October 2020; pp. 889–893. [Google Scholar]
- Teng, C.-F.; Chen, C.-H.; Wu, A.-Y. An Ultra-Low Latency 7.8–13.6 pJ/b Reconfigurable Neural Network-Assisted Polar Decoder with Multi-Code Length Support. In Proceedings of the 2020 IEEE Symposium on VLSI Circuits, Honolulu, HI, USA, 16–19 June 2020; pp. 1–2. [Google Scholar]
- Teng, C.F.; Wu, C.H.D.; Ho, A.K.S.; Wu, A.Y.A. Low-complexity Recurrent Neural Network-based Polar Decoder with Weight Quantization Mechanism. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2019), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Yuan, B.; Parhi, K.K. Early stopping criteria for energy-efficient low-latency belief-propagation polar code decoders. IEEE Trans. Signal Process. 2014, 62, 6496–6506. [Google Scholar] [CrossRef]
- Park, Y.S.; Tao, Y.; Sun, S.; Zhang, Z. A 4.68 gb/s belief propagation polar decoder with bit-splitting register file. In Proceedings of the 2014 Symposium on VLSI Circuits Digest of Technical Papers, Honolulu, HI, USA, 10–13 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–2. [Google Scholar]
- Abbas, S.M.; Fan, Y.; Chen, J.; Tsui, C.-Y. High-throughput and energy-efficient belief propagation polar code decoder. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 1098–1111. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Addition | Multiplication | Comparison |
|---|---|---|---|
| BPD | - | ||
| RNN-BPD | |||
| SCD | - | ||
| BPDL | - | ||
| S-BPDL | |||
| XJ-BPD | << | - | << |
| RNN XJ-BPD | << | << | << |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Zhang, M.; Chan, S.; Kim, S. Review and Evaluation of Belief Propagation Decoders for Polar Codes. Symmetry 2022, 14, 2633. https://doi.org/10.3390/sym14122633
Zhou L, Zhang M, Chan S, Kim S. Review and Evaluation of Belief Propagation Decoders for Polar Codes. Symmetry. 2022; 14(12):2633. https://doi.org/10.3390/sym14122633
Chicago/Turabian StyleZhou, Lingxia, Meixiang Zhang, Satya Chan, and Sooyoung Kim. 2022. "Review and Evaluation of Belief Propagation Decoders for Polar Codes" Symmetry 14, no. 12: 2633. https://doi.org/10.3390/sym14122633