
A Particle Swarm Optimization Method for AI Stream Scheduling in Edge Environments

Abstract
:1. Introduction
2. Related Works
3. Task Scheduling Model for Edge Computing
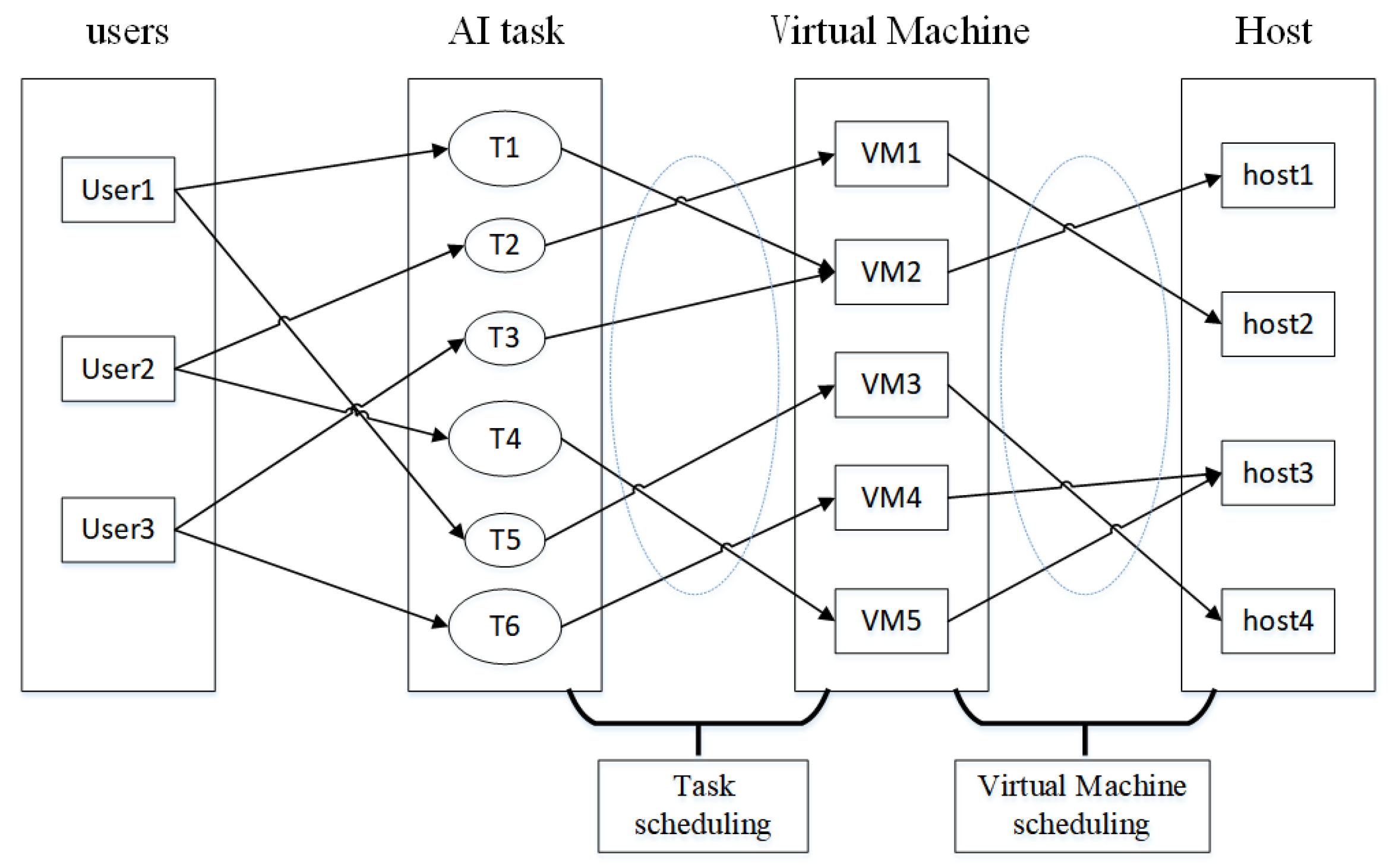
3.1. Problem Description
3.2. Task Scheduling Mathematical Model
- (1)
- Optimal total task execution time.
- (2)
- Maximum completion time optimal.
- (3)
- Optimal total task scheduling cost:
4. Task Scheduling Algorithm Based on Goal Ordering
4.1. Standard Particle Swarm Algorithm
4.2. Adaptive Inertia Weights
4.3. Contraction Factor Update Mechanism
4.4. Adaptability Function
4.5. Particle Swarm Algorithm Based on Target Ranking
| Algorithm 1: Particle swarm optimization algorithm based on objective ranking |
| Input: number of iterations of the algorithm K, task T, virtual machine VM Output: the best scheduling solution pbest of tasks to VMs 1. while termination criterion not met do 2. Calculate the three optimization objective values→Texe, Makespan, Tcost//Using Equations (9)–(11) 3. Initial Population (Particle Swarm, vi, xi, pbest) 4. for Particle Swarm ∈ T do //iterate all particles 5. for vm ∈ VMs do 6. Initial (Objective ranking) //Initialize sort list 7. Sort the execution time in ascending order→vm1 8. Sort the maximum completion time in ascending order→vm2 9. Sort the scheduling cost in ascending order→vm3 10. for vm ∈ VMs do 11. Objective ranking(vm) = vm1 + vm2 + vm3//Sum the ranking of each optimization goal 12. end for 13. Sum of the three objectives in ascending order→vmbest 14. Return vmbest (0) //Returns particles with index 0 15. pbest(i) = Evaluate Particle Swarm(i) //Evaluation of particles 16. Update (vi, xi) // Update the velocity and position of the particles, suing Equations (13) and (17) 17. end for 18. end for 19. return pbest 20. end while |
5. Simulation Experiment Results and Analysis
5.1. Task Scheduling Environment Configuration
- (1)
- Cloudlet: The task of building the environment; this paper studies AI data-intensive computing tasks.
- (2)
- DataCenter: Data center that provides virtualized grid resources and contains the allocation policy of virtual machines to resources.
- (3)
- Host: Extends the machine to virtual machine parameters allocation policy, such as bandwidth, memory, etc. A host can correspond to multiple virtual machines.
- (4)
- VMScheduler: Virtual machine scheduling policy that manages the execution of tasks.
5.2. Results and Analysis
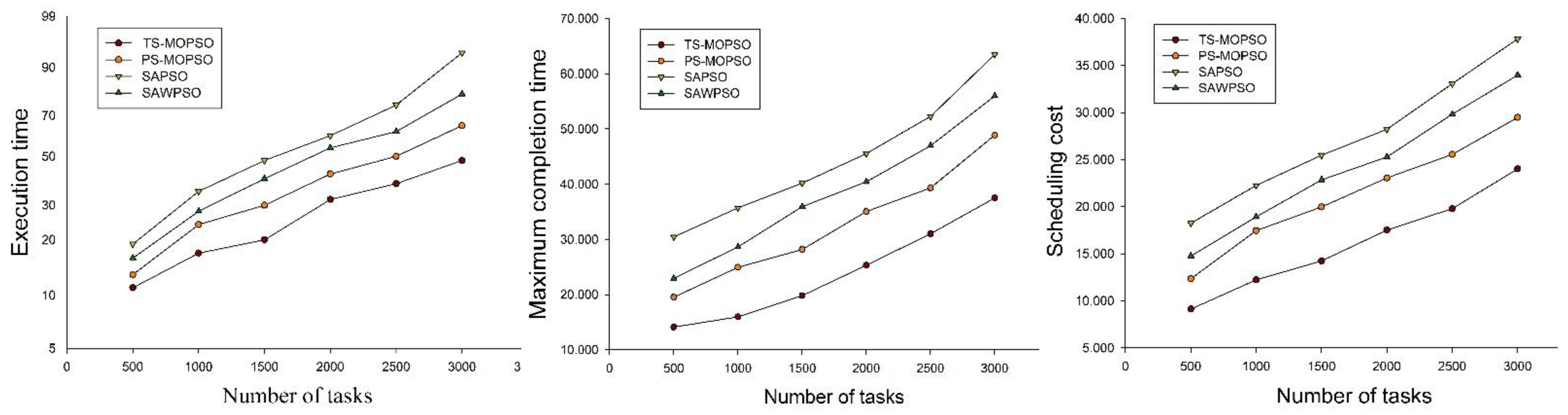
5.2.1. Algorithm Performance Analysis
5.2.2. Simulation Experiment Comparison Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abouzaid, L.; Sabir, E.; Elbiaze, H.; Errami, A. The meshing of the sky: Delivering ubiquitous connnectivity to ground internet of things. IEEE Internet Things J. 2020, 8, 3743–3757. [Google Scholar] [CrossRef]
- Din, I.U.; Bano, A.; Awan, K.A. LightTrust: Lightweight Trust Management for EdgeDevices in Industrial Internet of Things. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Kim, Y.; Song, C.; Han, H.; Jung, H. Collaborative Task Scheduling for IoT-Assisted Edge Computing. IEEE Access 2020, 8, 216593–216606. [Google Scholar] [CrossRef]
- Zhang, N.; Li, W.; Liu, Z.; Li, Z.; Liu, Y. A New Task Scheduling Scheme Based on Genetic Algorithm for Edge Computing. CMC-Comput. Mater. Contin. 2022, 71, 843–854. [Google Scholar]
- Kang, L.; Chen, R.S.; Cao, W. Mechanism analysis of non-inertial particle swarm optimization for Internet of Things in edge computing. Eng. Appl. Artif. Intell. 2020, 94, 103803. [Google Scholar] [CrossRef]
- Zhou, E.; Zhang, J.; Dai, K. Research on Task and Resource Matching Mechanism in the Edge Computing Network. Int. Core J. Eng. 2020, 6, 94–104. [Google Scholar]
- Kh, A.; Iud, B.; Aa, C. Intelligent and Secure Edge-enabled Computing Model for Sustainable Cities using Green Internet of Things. Sustain. Cities Soc. 2021, 68, 102779. [Google Scholar]
- Abdullahi, M.; Ngadi, M.A.; Dishing, S.I. An efficient symbiotic organisms search algorithm with chaotic optimization strategy for multi-objective task scheduling problems in cloud computing environment. J. Netw. Comput. Appl. 2019, 133, 60–74. [Google Scholar] [CrossRef]
- Li, E.; Zeng, L.; Zhou, Z.; Chen, X. Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing. IEEE Trans. Wirel. Commun. 2020, 19, 447–457. [Google Scholar] [CrossRef] [Green Version]
- Guang, P. Multi-objective Optimization Research and Applied in Cloud Computing. In Proceedings of the 2019 IEEE International Symposium on Software Reliability Engineering Workshops, Berlin, Germany, 27–30 October 2019; pp. 97–99. [Google Scholar]
- SI, G. Towards Application-Driven Task Offloading in Edge Computing Based on Deep Reinforcement Learning. Micromachines 2021, 12, 1011. [Google Scholar]
- Shang, J.; Tian, Y.; Liu, Y. Production Scheduling Optimization Method Based on Hybrid Particle Swarm Optimization Algorithm. J. Intell. Fuzzy Syst. 2018, 34, 955–964. [Google Scholar] [CrossRef]
- Fang, J.; Ma, A. IoT Application Modules Placement and Dynamic Task Processing in Edge-Cloud Computing. IEEE Internet Things J. 2021, 8, 12771–12781. [Google Scholar] [CrossRef]
- Milan, S.T.; Rajabion, L.; Darwesh, A.; Hosseinzadeh, M. Priority-based task scheduling method over cloudlet using a swarm intelligence algorithm. Clust. Comput. 2020, 23, 663–671. [Google Scholar] [CrossRef]
- Bi, J.; Yuan, H.; Duanmu, S. Energy-Optimized Partial Computation Offloading in Mobile-Edge Computing with Genetic Simulated-Annealing-Based Particle Swarm Optimization. IEEE Internet Things J. 2020, 8, 3774–3785. [Google Scholar] [CrossRef]
- Steenkamp, C.; Engelbrecht, A.P. A Scalability Study of the Multi-Guide Particle Swarm Optimization Algorithm to Many-objectives. Swarm Evol. Comput. 2021, 66, 100943. [Google Scholar] [CrossRef]
- Verma, A.; Kaushal, R. A hybrid multi-objective particle swarm optimization for scientific workflow scheduling. Parallel Comput. 2017, 62, 1–19. [Google Scholar] [CrossRef]
- Saeedi, S.; Khorsand, R. Improved many-objective particle swarm optimization algorithm for scientific workflow scheduling in cloud computing. Comput. Ind. Eng. 2020, 147, 106649. [Google Scholar] [CrossRef]
- Paweł, J.; Beatrice, M.; Ombuki, B.; Andries, P. Multi-guide particle swarm optimisation archive management strategies for dynamic optimisation problems. Swarm Intell. 2022, 16, 143–168. [Google Scholar]
- Kalka, D.; Sharma, S.C. A novel multi-objective CR-PSO task scheduling algorithm with deadline constraint in cloud computing. Sustain. Comput. Inform. Syst. 2021, 32, 100605. [Google Scholar]
- Huang, X.; Li, C.; Chen, H.; An, D. Task scheduling in cloud computing using particle swarm optimization with time varying inertia weight strategies. Clust. Comput. 2020, 23, 1137–1147. [Google Scholar] [CrossRef]
- Fakhouri, H.N.; Hudaib, A.; Sleit, A. Multivector particle swarm optimization algorithm. Soft Comput. 2019, 24, 11695–11713. [Google Scholar] [CrossRef]
- Wang, B.; Cheng, J.; Cao, J. Integer particle swarm optimization based task scheduling for device-edge-cloud cooperative computing to improve SLA satisfaction. PeerJ Comput. Sci. 2022, 8, e893. [Google Scholar] [CrossRef]
- Vindigni, C.R.; Orlando, C.; Milazzo, A. Computational Analysis of the Active Control of Incompressible Airfoil Flutter Vibration Using a Piezoelectric V-Stack Actuator. Vibration 2021, 4, 369–396. [Google Scholar] [CrossRef]
- Bellendorf, J.; Dám, M. Classification of optimization problems in fog computing. Future Gener. Comput. Syst. 2020, 107, 158–176. [Google Scholar] [CrossRef]
- Alsurdeh, R.; Calheiros, R.N.; Matawie, K.M. Hybrid Workflow Scheduling on Edge Cloud Computing Systems. IEEE Access 2021, 9, 134783–134799. [Google Scholar] [CrossRef]
- Pishgoo, B.; Azirani, A.A.; Raahemi, B. A hybrid distributed batch stream processing approach for anomaly detection. Inf. Sci. 2021, 543, 309–327. [Google Scholar] [CrossRef]
- Shi, Z.; Shi, Z.G. Multi-node Task Scheduling Algorithm for Edge Computing Based on Multi-Objective Optimization. J. Phys. Conf. Ser. 2020, 1607, 012017. [Google Scholar] [CrossRef]
- Sahkhar, L.; Balabantaray, B.K. Scheduling Cloudlets to Improve Response Time Using CloudSim Simulator. Lect. Notes Netw. Syst. 2021, 170, 483–493. [Google Scholar]
- Xie, Y.; Zhu, Y.; Wang, Y. A novel directional and non-local-convergent particle swarm optimization based workflow scheduling in cloud-edge environment. Future Gener. Comput. Syst. 2019, 97, 361–378. [Google Scholar] [CrossRef]
- Yang, L.; Hu, X.; Li, K. A vector angles-based many-objective particle swarm optimization algorithm using archive. Appl. Soft Comput. 2021, 106, 107299. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| m | number of tasks |
| n | number of Virtual Machines |
| k | number of physical hosts |
| T | task sequence T = {T1, T2,…, Ti} |
| VM | virtual machine nodes VM = {vm1, vm2,…, vmn} |
| length of task i | |
| processing speed of VMj | |
| bandwith of VMj | |
| VTij | the size of the data transfer assigned to VMj by task i |
| Xij | the assignment matrix, aij, represents the task i assigned to VMj |
| Hardware Configuration | configuration information | CPU | RAM | HD | OS |
| parameters | Intel(R) Core(TM)i7-3930K | 16.0 GB | 1 TB | Windows 10 | |
| Mainframe Features | configuration information | CPU MIPS | RAM Size | Bandwidth | PE |
| parameter | {2000, 2500, 3000, 3500} | {4096, 4096, 4096, 4096} | 1,000,000 | 2 | |
| Virtual Machine Configuration | virtual machine number | 1 | 2 | 3 | 4 |
| memory | 256 | 512 | 256 | 512 | |
| processing power | 150 | 200 | 180 | 300 | |
| CPU cores | 1 | 1 | 1 | 1 | |
| bandwidth | 1500 | 2000 | 1000 | 3000 | |
| Mission Properties | task properties | task size | data transfer volume | number of tasks | |
| fetch value | 45–14,500 | 200–800 | 200–1000 | ||
| Algorithm | Worst Value | Best Value | Mean | Variance | |
|---|---|---|---|---|---|
| Execution time | SAPSO | 94 | 19 | 55.2 | 615 |
| SAWPSO | 80 | 16 | 46.6 | 456.4 | |
| PS-MOPSO | 65 | 13 | 37.3 | 295.3 | |
| TS-MOPSO | 48 | 11 | 27.7 | 165.3 | |
| Maximum completion time | SAPSO | 634 | 304 | 446 | 109 |
| SAWPSO | 559 | 228 | 384 | 113 | |
| PS-MOPSO | 488 | 195 | 326 | 97.3 | |
| TS-MOPSO | 375 | 141 | 239 | 83 | |
| Scheduling cost | SAPSO | 378 | 182 | 55.2 | 65 |
| SAWPSO | 339 | 147 | 46.6 | 64.2 | |
| PS-MOPSO | 294 | 125 | 37.3 | 55 | |
| TS-MOPSO | 240 | 91 | 27.7 | 49 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Liu, L.; Li, C.; Wang, H.; Li, M. A Particle Swarm Optimization Method for AI Stream Scheduling in Edge Environments. Symmetry 2022, 14, 2565. https://doi.org/10.3390/sym14122565
Zhang M, Liu L, Li C, Wang H, Li M. A Particle Swarm Optimization Method for AI Stream Scheduling in Edge Environments. Symmetry. 2022; 14(12):2565. https://doi.org/10.3390/sym14122565
Chicago/Turabian StyleZhang, Ming, Luanqi Liu, Changzhen Li, Haifeng Wang, and Ming Li. 2022. "A Particle Swarm Optimization Method for AI Stream Scheduling in Edge Environments" Symmetry 14, no. 12: 2565. https://doi.org/10.3390/sym14122565