1. Introduction
Today artificial intelligence is a powerful tool for solving problems in various fields. Artificial Neural Networks (ANN) are one of the most promising areas for the development of artificial intelligence. They are used in the field of cybernetics, pattern recognition [
1], prediction and forecasting [
2], decision making [
3], etc. Despite the fact that neural networks are used in a wide range of tasks, the task of increasing an ANN productivity increase is still urgent. One of the approaches to improve productivity is the optimal selection of the neural network hyperparameters, i.e., parameters that do not change during the neural network training (the number of hidden layers and neurons in each; the speed of the neural network training; the batch size for training; layer type; activation function; regularization parameters, etc.) [
4].
The complexity of the neural networks hyperparameters settings is due to the fact that it is necessary to find a compromise between the high accuracy of solving the problem and the speed of the neural network training. When setting ANN models for solving specific problems and improving their quality during experiments, expert estimates and manual hyperparameters settings are used [
5,
6]. In the manual setting method, the researcher sets hyperparameters based on his own experience and, after training, evaluates the productivity.
Another approach to ANN hyperparameters settings is based on the use of automatic methods. One of the methods of automatic setting is based on the use of evolutionary algorithms [
7,
8].
Additionally, there are some approaches to solve the problem of adjusting the weights in the ANN model. One of these is to improve the quality of the designed ANN models considered in this work based on the development of new approaches to adjusting the weight coefficients based on the use of global optimization algorithms [
9].
Currently, ANN are trained using various gradient algorithms and their modifications [
10,
11]. The algorithms have advantages, such as the purposefulness of the search and proven convergence, which make it possible to successfully apply them in solving the problems of ANN training. The algorithm converges to global (for the case of convex functions) or local minima (for the case of non-convex functions) [
12]. However, gradient algorithms also have a number of disadvantages that make their application in specific tasks either problematic or completely impossible. As a rule, this is due to the fact that these algorithms are unable to get out of the local minima for the case of non-convex optimized functions [
13,
14]. Modern approaches to the problem of ANN parameter updating, as discussed in this paper, are based on the use of metaheuristic optimization algorithms [
15] and do not require knowledge of the structure of the optimized function and calculation of the gradient. Another class is the non-iterative approach to learning neural networks [
16,
17,
18].
Although metaheuristic algorithms vary widely, they do not always provide the required accuracy when setting neural network weights. This is due to the fact that optimization algorithms often focus on a certain class of problems, that is “there is no universal optimizer that could solve all classes of problems”. Thus, the problem of adjusting neural network weights using optimization techniques involves the problem of choosing the most efficient algorithm, which involves experimenting with existing metaheuristic algorithms, improving them, as well as developing new approaches.
The main contributions of this article are as follows. First, the paper proposes a new algorithm for solving the global optimization problem based on the behavior of orb-weave spiders [
19]. Second, the applicability of the developed algorithm is studied for solving the problem of setting the weights of neural networks.
To study the proposed algorithm, the task of setting the weights of the recurrent neural network used to predict the values of the time series was chosen, since it represents a complex multi-parameter optimization problem with many local optima.
The development and research of optimization algorithms are relevant, both for solving various applied problems, and for the science of artificial intelligence in general. The practical value of the presented work for other researchers lies in the possibility of using proposed algorithm to solve a wide range of applied problems in various fields: industry, medicine, urban economy, etc.
In addition, the results are compared with the results obtained by other metaheuristic algorithms of global optimization [
20,
21,
22]: particle swarm optimization [
23], bats [
24], and differential evolution [
25,
26,
27,
28]. The results obtained by applying the global optimization algorithm under consideration are also compared with the results of the classical algorithm of back error propagation [
29]. Therefore, the rest of the article is organized as follows.
Section 2 presents the task of time series forecasting and the literature review of metaheuristic algorithms.
Section 3 describes the parameters of the studied optimization algorithms, the initial data, as well as the obtained results of adjustment of the neural network weights with the help of the studied algorithms. The program is available at
https://github.com/digger32/Spider-Algorithm.git (accessed on 14 July 2022).
2. Materials and Methods
2.1. Problem Statement of the Time Series Forecasting
Recurrent neural networks are used to process time series events or sequential spatial circuits. The present study focuses on the time series forecasting problem, respectively; all the conclusions and results of experiments are valid for this application of recurrent ANN. The test of the effectiveness of the proposed approach in solving the problem of analysis of successive spatial chains is the subject of future research.
The problem of a time series forecasting has the following formulation. Let the values of the time series be given in discrete moments of time
[
30,
31]:
where
x(
t) is the value of the analyzed indicator registered at the
t-th moment of time.
It is necessary, on the basis of the values of the analyzed indicator at the previous points in time
x(
t),
x(
t − 1),
x(
t − 2), …,
x(
t −
k + 1),
k ≤
N, to predict (most accurately evaluate) the values of the analyzed indicator at moments
t + 1,
t + 2, …,
t +
l, i.e., and build a sequence of predicted values:
To calculate the values of the time series at future points in time, it is required to determine a functional relationship
that reflects the relationship between the past and future values of this time:
The presented functional dependence (3) is called the forecasting model.
Thus, the solution to the problem of a time series forecasting is to create a forecasting model that will meet the relevant criteria for the forecasting quality evaluation.
In this paper, we will consider the case of short-term forecasting, i.e., at τ = 1.
2.2. Problem Statement of the Adjusting the Weight Coefficients of a Neural Network
The optimization approach to the problem of adjusting the neural network weights is to present this problem as a problem of minimizing the error function of the neural network. In general, this optimization problem is formulated as follows:
where
L—weighting error function,
W is a matrix of neural network weights,
—elements of the training sample, and
—the value of the output signal of the neural network.
As a result of solving this problem, values of the weighting coefficients of the neural network should be found, where the neural network provides the minimum work error on the training sample.
2.3. Literature Review
The class of heuristic algorithms using patterns and principles borrowed from nature has proven itself especially well for solving global optimization problems. These include algorithms for evolutionary optimization [
7] and swarm intelligence algorithms [
32,
33]. These algorithms belong to the class of population algorithms, which are based on modeling the collective behavior of self-organizing systems, the interacting elements which are called agents. Despite the lack of evidence on the convergence of these algorithms, they are often used in practice to solve complex optimization problems.
Evolutionary algorithms are based on a collective training process within an agent’s population. The population is randomly initialized and then, at each step, the algorithm simulates the process of natural selection, when the stronger agents from the population outlive the weaker ones and produce the next generation [
7].
A prominent representative of the evolutionary algorithm is the genetic algorithm (GA). It is a heuristic optimization algorithm originally based on the Darwinian principle of evolution through genetic selection. GA uses a very abstract version of evolutionary processes to develop solutions to given problems. Each GA handles a population of artificial chromosomes—these are strings in a finite alphabet (usually binary). Each chromosome represents a solution to a problem and has a fitness parameter—a real number, which is a measure of how well the solution fits a particular problem [
34].
There is also an imperialist competition algorithm based on human social evolution modeling. However, unlike the traditionally used evolutionary algorithms, it is based on the social evolution of a person in society, and not on the biological evolution of species in nature [
35].
Swarm intelligence optimization algorithms originate from nature. Unlike evolutionary algorithms, it is no longer required to create a new population at each step of the algorithm. Typical representatives of swarm intelligence algorithms are the ant algorithm (ACO) [
36] and the particle swarm optimization algorithm (PSO) [
23].
The use of metaheuristic algorithms in various applications is used in the scientific literature to adjust the weights of recurrent neural networks. The article [
37,
38] deals with the problem of adjusting neural network weights with long-term short-term memory for the task of predicting the vibration of the aircraft engine using the ant colony algorithm. Articles [
39,
40] discuss the application of the ant-lion algorithm for health and energy management problems. To solve practical problems in various applied fields (healthcare, ecology, mechanical engineering, energy, and stock market), the use of metaheuristic optimization algorithms are also found in the literature, such as: the gray wolf flock algorithm [
40,
41,
42], whale optimization algorithm [
43,
44], cuckoo algorithm [
45], etc. These articles show that that the application of metaheuristic optimization algorithms to adjust the weights of recurrent neural networks for each specific task leads to better performance and accurate results. In this regard, further study of the applicability of other metaheuristic optimization algorithms for adjusting the weights of recurrent neural networks remains relevant.
The algorithm proposed by the authors of the article is completely different from these algorithms in its biological roots, motivations, implementations, and search behavior. It is based on the peculiarities of the construction of the web and the competitive behavior of the orb weaving spiders. In this case, many spiders cannot be considered in the context of a “swarm”, since each spider acts in its own interests. This, in turn, eases the rigidity of specimen selection, which is very difficult for other swarm algorithms.
For a comparative analysis, the following will be considered:
2.4. Description of Algorithms
2.4.1. Backpropagation Algorithm
Error backpropagation algorithm (BP) is a widely used neural network training algorithm for supervised training [
29]. This algorithm is iterative and uses the principle of training “step by step” when the weights of the neurons of the network are corrected after submitting one training example to its input.
There are two network passes at each iteration—forward and backward. With a forward pass, the input vector propagates from the inputs of the network to its outputs and forms some output vector corresponding to the current (actual) state of the weight coefficients. The neural network error is then calculated as the difference between the actual and objective values. On the backward pass, this error propagates from the network output to its inputs, and the neuron weight coefficients are corrected.
The task of training a neural network is the task of minimizing the loss function in the space of weight coefficients. To solve this problem, gradient optimization algorithms are usually used; usually gradient descent or its modifications are used, for example, stochastic gradient descent.
2.4.2. Metaheuristic Algorithms
The differential evolution algorithm (DE) is a modification of the evolutionary optimization algorithm [
25]. DE works by improving the collection of N possible solutions, which are being evaluated using the objective function
f through the iterative process. At the first stage, a set of random vectors, called a generation, are initialized, which represent possible solutions to the optimization problem. Further, at each iteration, a new generation of vectors is generated randomly combining the vectors of the previous generation. After crossing, a selection operation is performed. If the resulting vector turns out to be better than the base vector (the value of the objective function has improved), then, in the new generation, the base vector is replaced with a trial one, otherwise the base vector remains in the new generation. In every era of the evolutionary process or at a given frequency, the best generation vector is determined in order to control the speed of finding the optimal solution.
The described stages of the differential evolution algorithm are repeated upon reaching a given number of iterations .
The particle swarm optimization algorithm (PSO) is based on the movement of particles-agents in the search space and the evaluation of the attractiveness of the solutions found [
23]. Each agent at some point in time is characterized by a vector of parameter values from the solution domain and the value of the function being optimized.
At each iteration of the algorithm, the agents change their position and speed depending on the previously found best solutions. Thus, as the study progresses, all agents begin to pull together in the area of the global solution. If an agent finds the best solution, then the values of the best positions for each agent of the entire system are updated. Further iterations are repeated until a certain stopping criterion is reached.
The bats algorithm (BI) is based on imitating the echolocation properties of bats [
24]. As an agent approaches the local (or global) optimum, the volume of the emitted signal decreases, and its intensity increases. The approximation is determined by the current change in the value of the objective function.
At the first stage, a population of bats is initialized, each of which is characterized by position, speed, frequency, wavelength of the emitted pulse, and volume for searching of prey. The search of a solution is carried out taking into account the average loudness value of all bats at a certain time step. If the obtained solution is less than the best solution at the current step, then the volume is lowered, and the pulse propagation speed is increased.
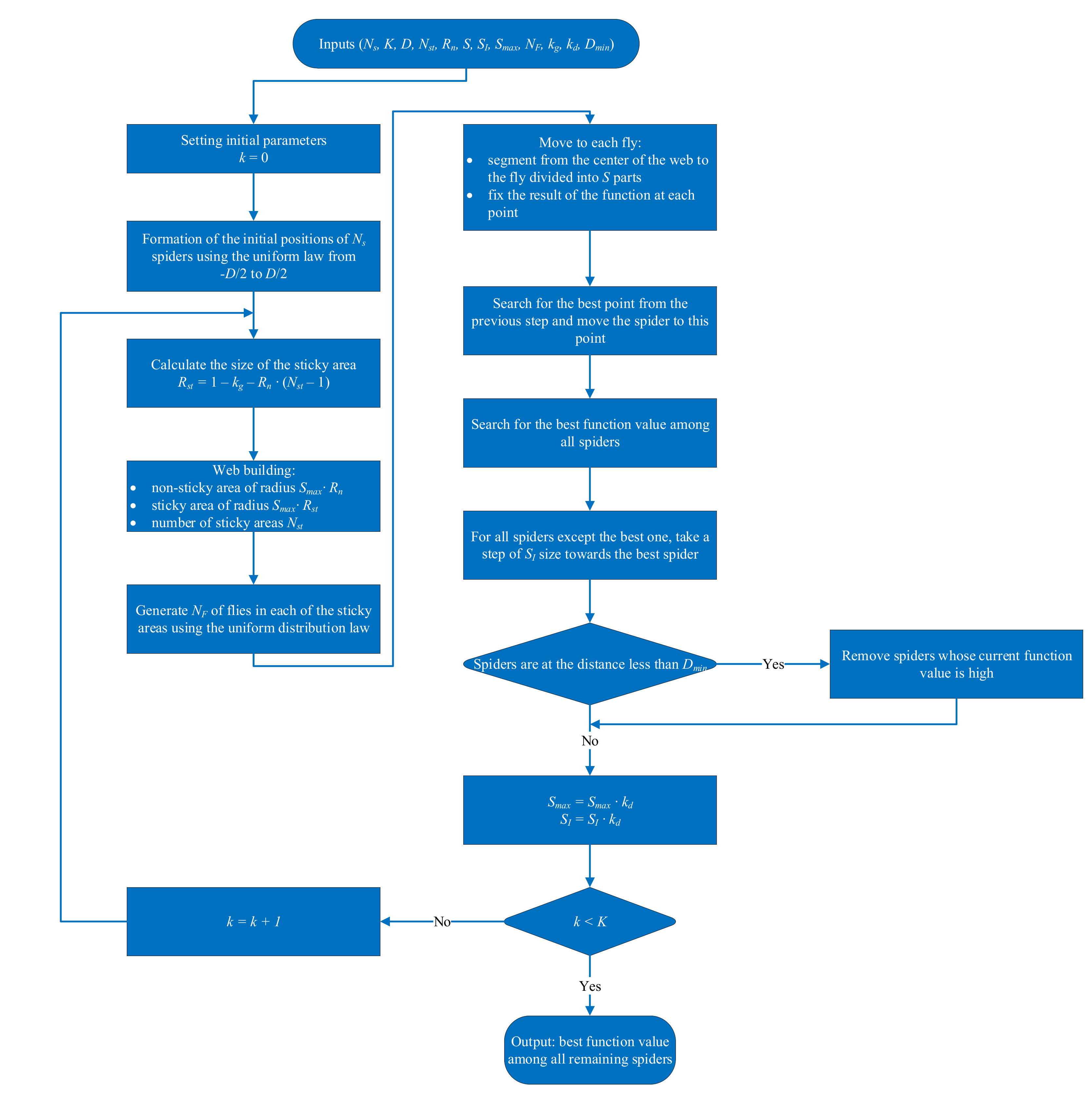
2.4.3. Orb-Weaving Spider Algorithm
The orb-weaving spider algorithm is a heuristic competitive iterative random search algorithm, the main idea of which is to simulate the behavior of a diadem spider from the orb-weaving spider family [
19].
Each iteration represents a day. During the day, the spider hunts, exploring the search area. At the end of the day, the spider looks for a new good place to build a web and destroys the old one, moving in the direction of the spider with the lowest (largest) function value.
If a spider enters the territory of another spider while moving, competition occurs. The stronger spider with the smallest (largest) function value at a given iteration wins and eats the spider with a greater (lower) function value.
An overview of the spider method is presented in
Figure 1.
3. Experimental Study and Discussion
3.1. Algorithm Parameters
The efficiency of the algorithms in the search for the global minimum is caused by the setting of their respective parameters. Within the framework of this work, the selection of effective values of the parameters was carried out. The correct choice of such parameters has the greatest influence on the result of solving the optimization problem, namely, on achieving the minimum of the standard deviation function [
48,
49,
50]. The results are shown in
Table 1,
Table 2,
Table 3 and
Table 4.
3.2. Data Description
To study the training algorithms, three datasets were taken from the Kaggle data science community website:
Daily climate: Average daily temperature data from Delhi, India recorded over 3 years—from 1 January 2013 to 24 April 2017 [
51,
52].
Advance retail sales: US Census Bureau dataset hosted on the Federal Reserve Economic Database [
53].
Solar radiation: Solar radiation dataset. Contains columns such as “wind direction”, “wind speed”, “humidity”, and “temperature”. Parameter “wind direction” is predicted [
54].
Time series parameters are shown in
Table 5.
For time series forecasting, neural networks with long short-term memory (LSTM) have been designed and built.
The architecture of neural networks for solving each subtask was chosen individually. The number of LSTM layers varied from one to three, the number of neurons in each layer—from 50 to 100 with a step of 10. The setting up of other model hyperparameters was carried out using the random search technique with cross validation.
A description of the architectures of the obtained neural networks is presented in
Table 6.
3.3. Analysis and Comparison
To train the model, the sample was divided into training and test in a 3:1 ratio. For each of the algorithms, the following parameters were calculated:
MAE and
MSE [
55]. To calculate the descriptive statistics for metrics of the estimation of quality of predictive models during the analysis, each algorithm was used to configure neural networks and was run
m times:
Let us look at the results for each dataset. In order to compare metrics that indicate forecast errors, you need to know the maximum, minimum and average values for each dataset.
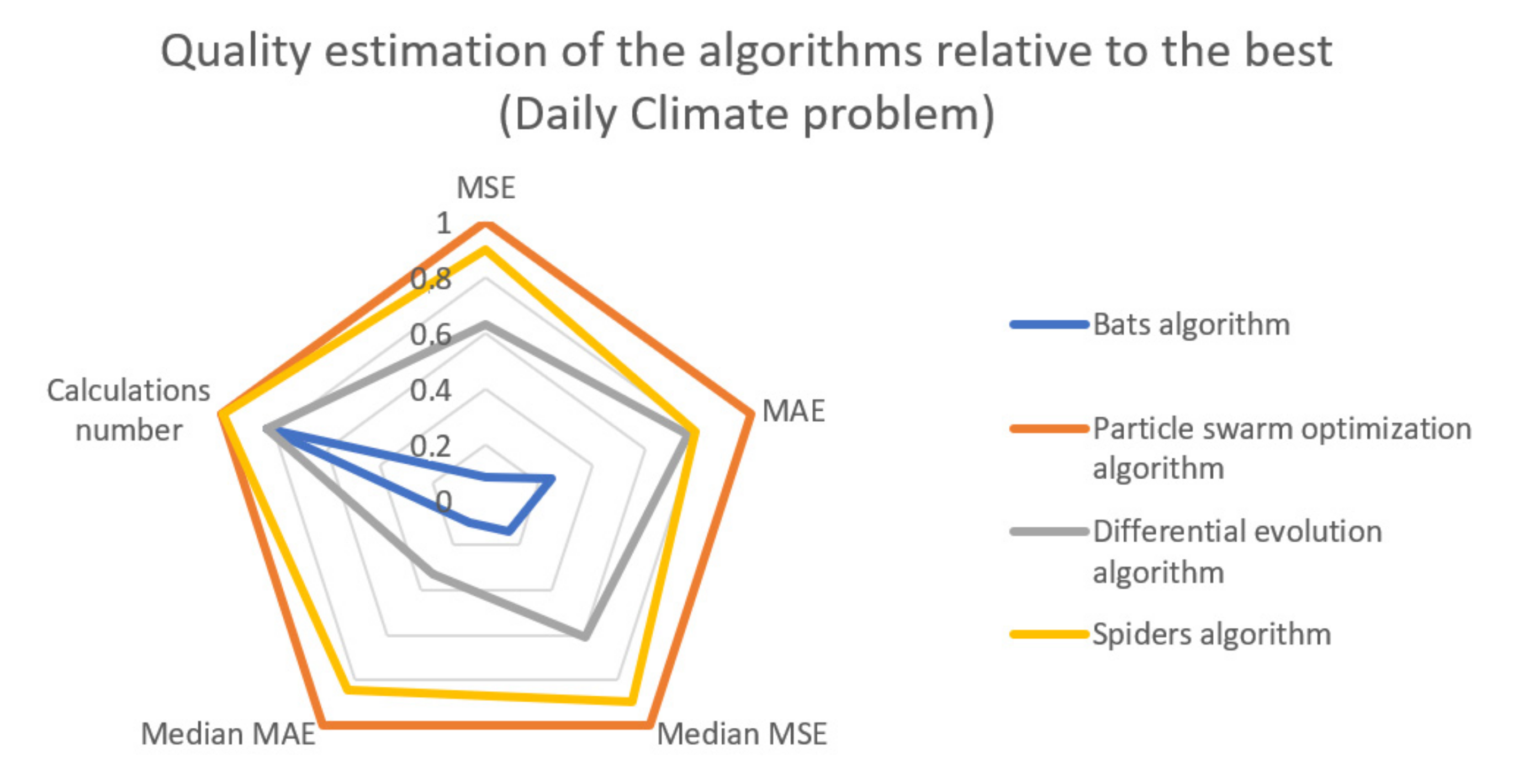
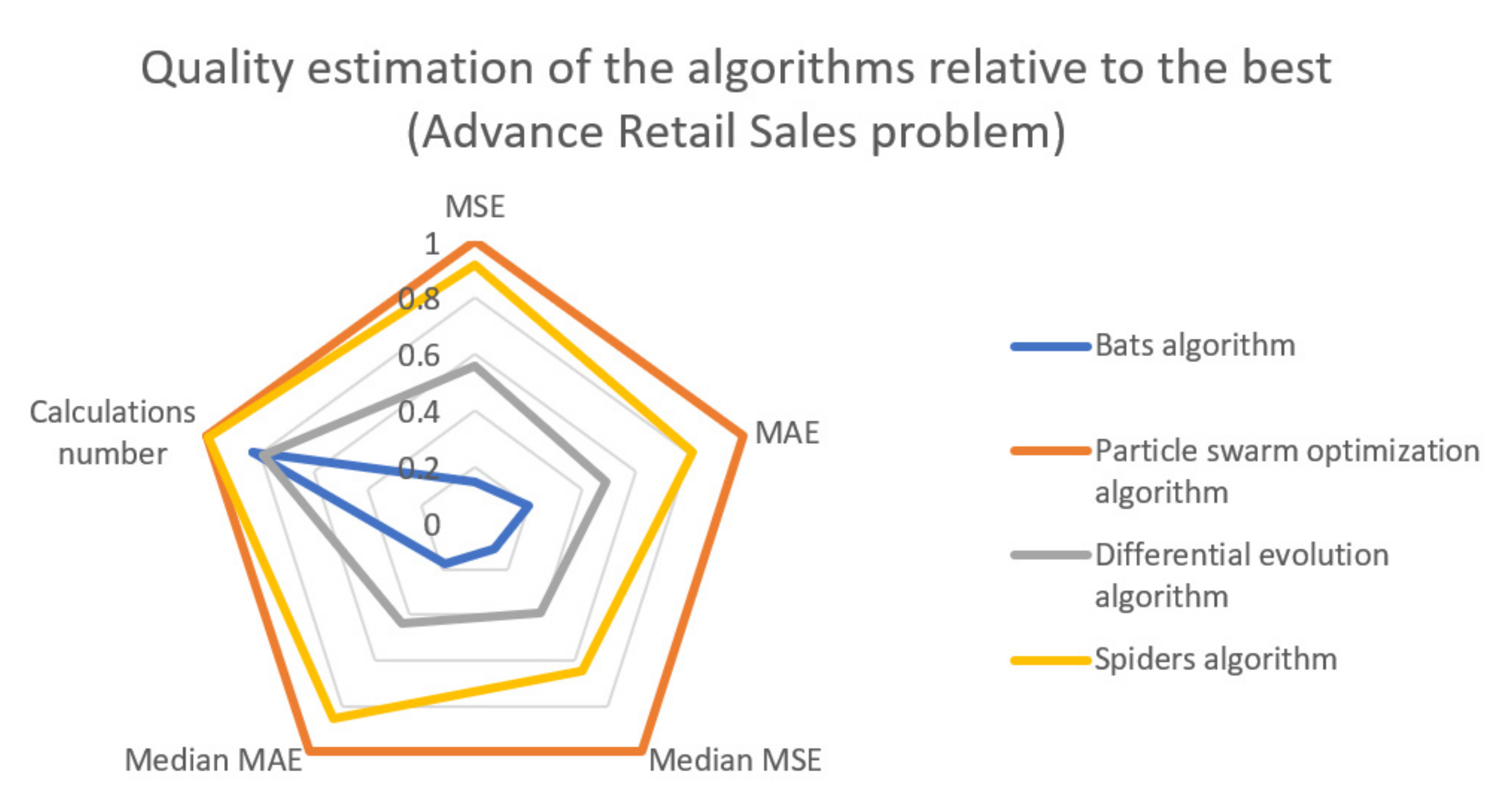
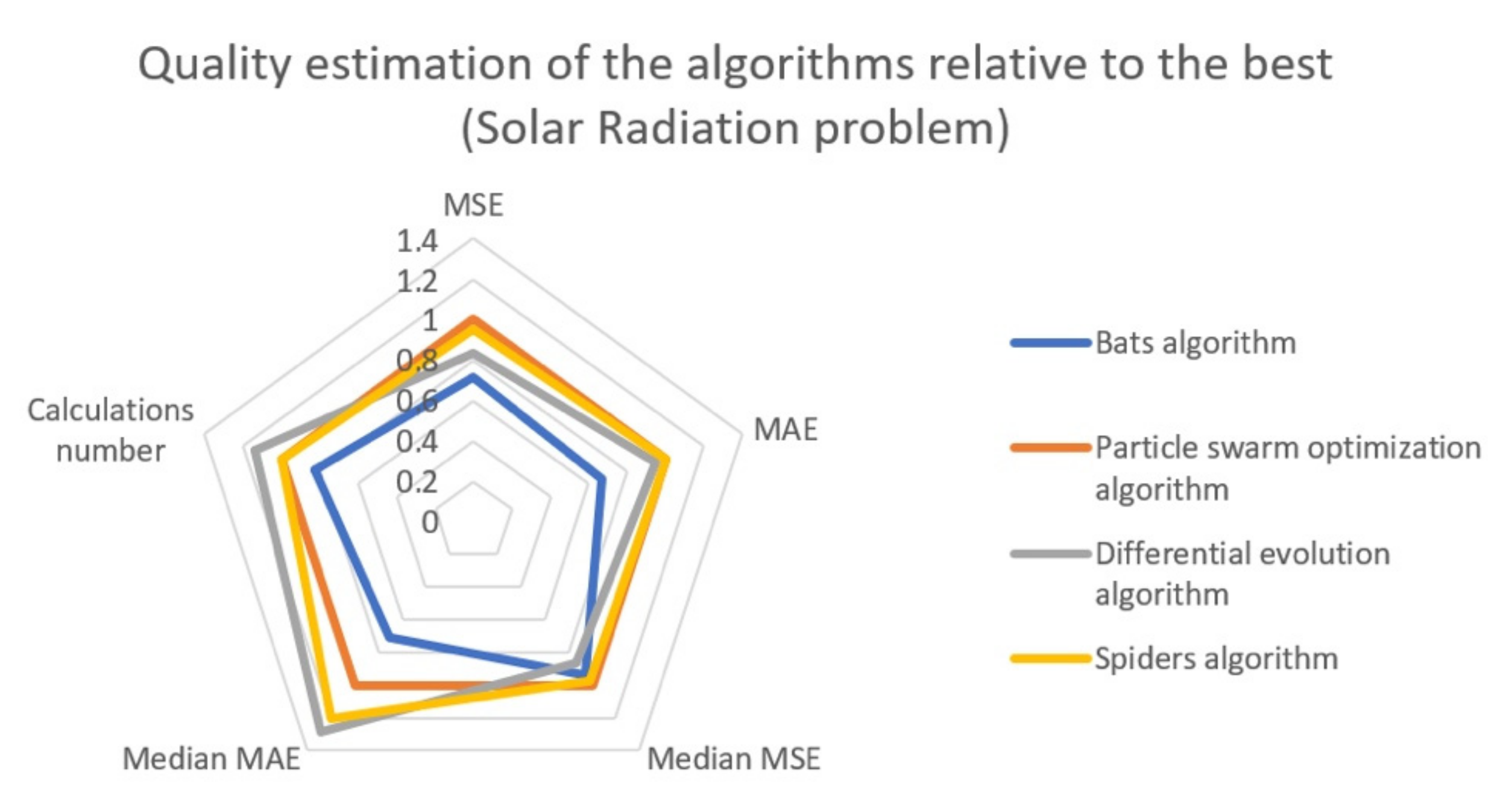
Based on the calculated data, we can conclude that the bats algorithm showed the worst results both in terms of the quality metrics of the obtained solution MSE and MAE, and in terms of the complexity of the computational process. On average for the three tasks, the MSE metric was 6.9 times higher, and the number of calculations was 20% higher compared to the best PSO algorithm.
The spider algorithm lags slightly behind the particle swarm optimization algorithm in terms of performance and has the same number of calculations, but is significantly ahead of the bats and differential evolution algorithms both in the number of calculations and in their quality:
According to the MSE metric, the spider algorithm outperforms the:
Bats algorithm in the daily climate, advance retail sales and solar radiation problems by 11.22, 6.26, and 1.25 times, respectively.
Differential evolution algorithm in the daily climate, advance retail sales, and solar radiation problems by 1.43, 1.64, and 1.15 times, respectively.
According to the MAE metric, the spider algorithm outperforms the:
Bats algorithm in the daily climate, advance retail sales, and solar radiation problems by 3.17, 4.03, and 1.49 times, respectively.
Differential evolution algorithm daily climate, advance retail sales, and solar radiation problems by 1.04, 1.67, and 1.05 times, respectively.
It can be seen that when solving the daily climate problem, the spider’s algorithm showed significantly better results for all considered criteria compared to BI and DE, while being slightly inferior to PSO. When solving the advance retail sales problem, AA is even more superior to BI and DE, but also more inferior to PSO in terms of the median MSE criterion. In the solar radiation problem, all algorithms showed similar results, with AA outperforming PSO in the median MAE criterion.
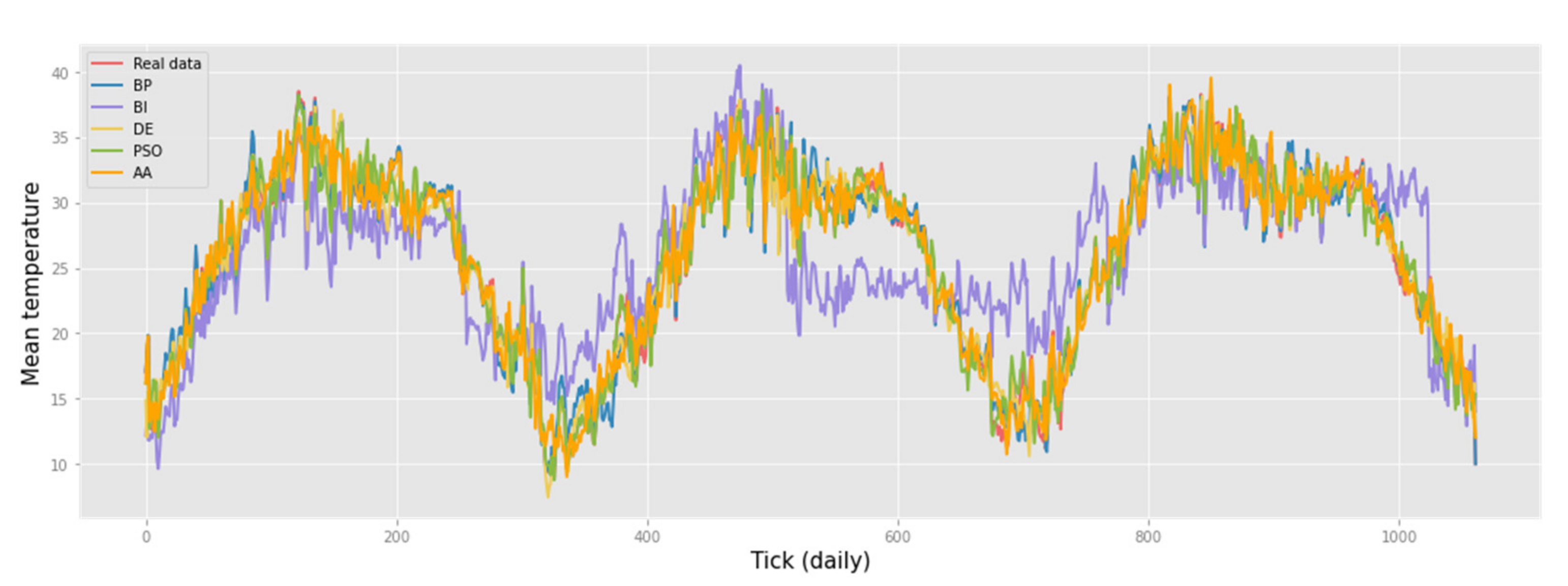
Figure 5 shows that AA allows a good approximation of the seasonal fluctuations of the mean temperature, both in the annual cycle and in the seasonal warming at the end of each year.
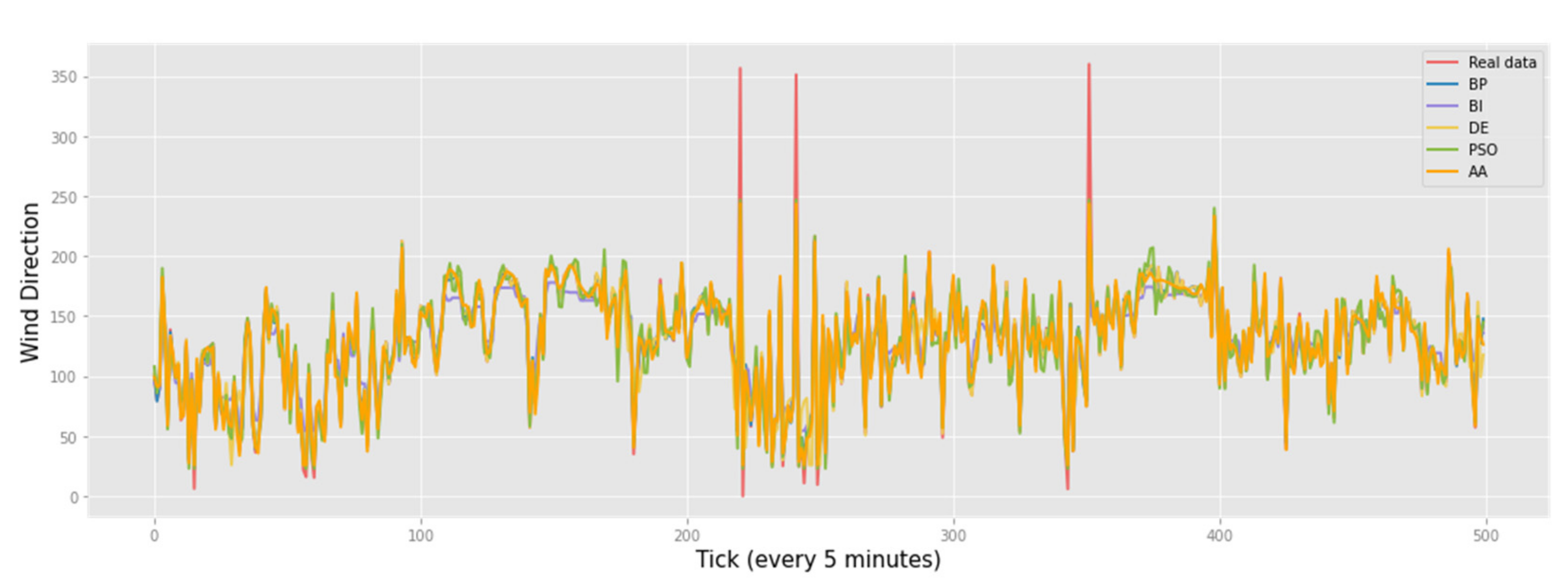
In the solar radiation problem (
Figure 6), the AA algorithm made it possible, not only to approximate the real data, but also to take into account the peaks of the wind direction on 218, 243, and 352 ticks.
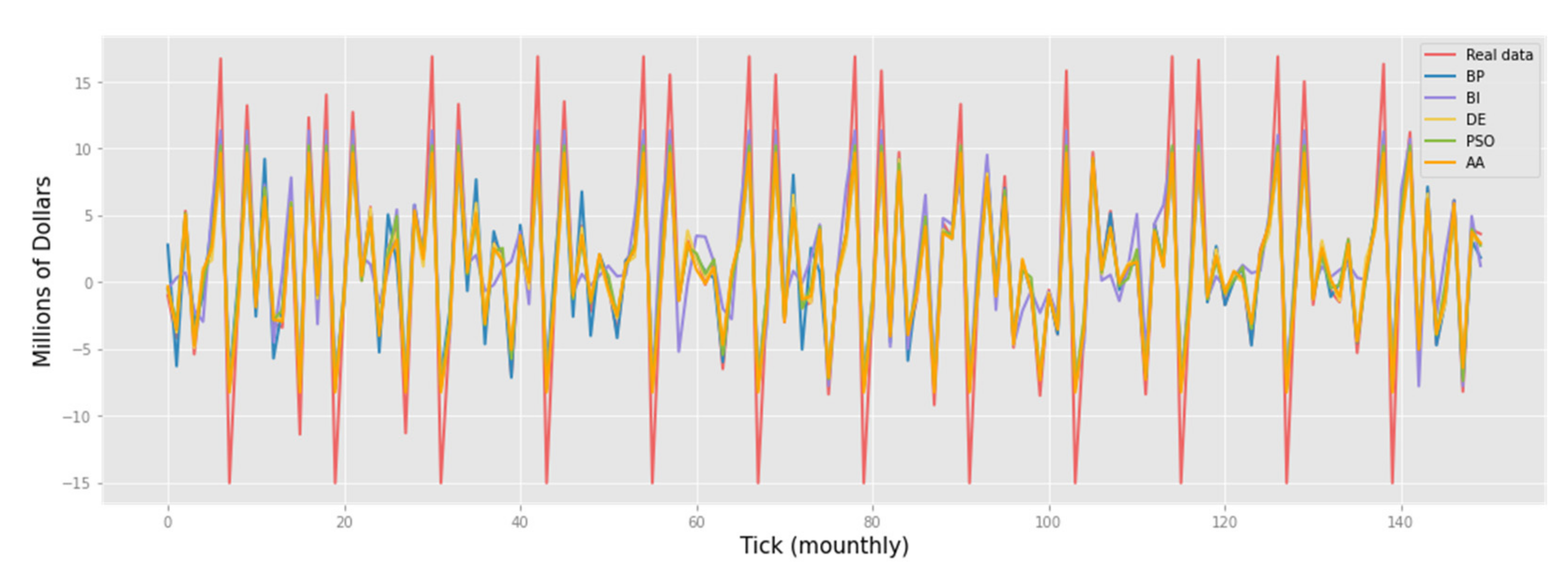
In the advance retail sales task (
Figure 7), the AA algorithm was allowed to train the recurrent neural network, which takes into account better negative peaks rather than positive.
Based on the presented fragments of forecasting results, we can conclude that the best results were shown by the PSO, AA, and BP algorithms. On datasets like daily climate and Advance Retail Sales, the PSO algorithm performed better than on datasets like solar radiation—AA. It is also worth noting that AA predicts the amplitude of the time series with a high percentage of probability.
4. Conclusions
This paper compares metaheuristic optimization algorithms using the example of setting up the weights of a recurrent neural network. The main attention is paid to the study of the properties of the new optimization algorithm for orb-weaving spiders.
In order to assess the effectiveness of AA, three datasets of different directions were selected and forecasting was performed. The comparison was happening with three classical optimization algorithms. The results showed the high efficiency of the proposed approach to solve the problem of recurrent neural networks training.
To date, there are many new metaheuristic optimization algorithms that are also applicable to the problem of tuning the weights of neural networks and, at the same time, can outperform the classical global optimization algorithms selected in this article. However, the comparison with classical algorithms, taking into account their existing standard software implementation, allows us to make an adequate comparative analysis. At the same time, as part of further research, it is planned to compare the effectiveness of the algorithm proposed in the article with other state-of-the-art metaheuristic algorithms on a wider and more representative set of tasks.
In addition, when solving machine learning problems using neural networks, it is important to tune, not only the weights of connections between neurons, but also the hyperparameters of neural networks, such as the number of layers, the number of neurons within each layer, and the type of activation function. In this article, to solve the problems under consideration, specific structures of neural networks that have become widespread have been chosen. However, a number of modern global optimization algorithms allow us to simultaneously adjust the weights and choose an optimal architecture of neural networks, which is a limitation of the presented study and a topic for future developments within the proposed approach.
Thus, from the point of view of expanding the capabilities of the proposed algorithm, the potential value lies in modifying this algorithm to solve, not only the problem of neural network training, but also architecture synthesis problems by extending the orb-weaving spider algorithm to solve discrete and mixed optimization problems [
56,
57,
58].
In addition, one more future research question will be to study and improve the presented algorithm for setting up other types of neural networks, as well as to implement a multi-threaded version of the algorithm, which will significantly increase the speed of calculations.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}