
Short-Term Energy Forecasting Using Machine-Learning-Based Ensemble Voting Regression




Abstract
:1. Introduction
1.1. Contribution
- 1.
- A forecasting performance comparison of seventeen ML algorithms on a training set using error metrics was conducted during the training process.
- 2.
- The top five ML algorithms, namely ETR, RFR, LGBM, GBR, and KNN, that had minimum errors were selected and combined to build the proposed VR algorithm.
- 3.
- To conduct final predictions and improve accuracy, our ensemble VR model performed a majority voting and selected the best predictions among the five ML algorithms.
- 4.
- The performance evaluation was finally conducted by comparing the proposed model and the five standalone ML and ARIMA models.
1.2. Paper Structure
2. Prior Works
3. Proposed System
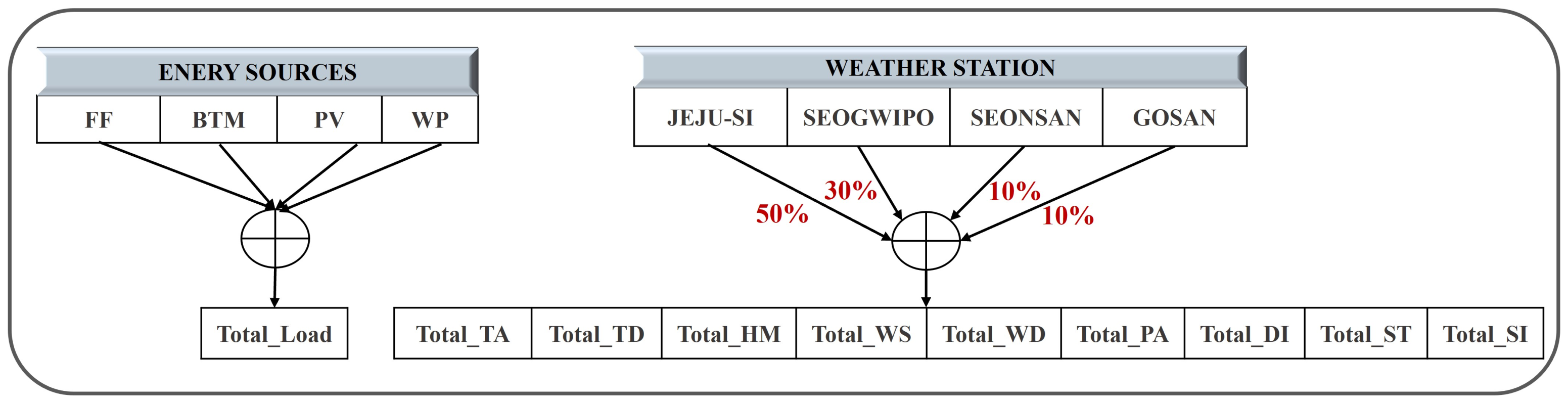
3.1. Data Collection
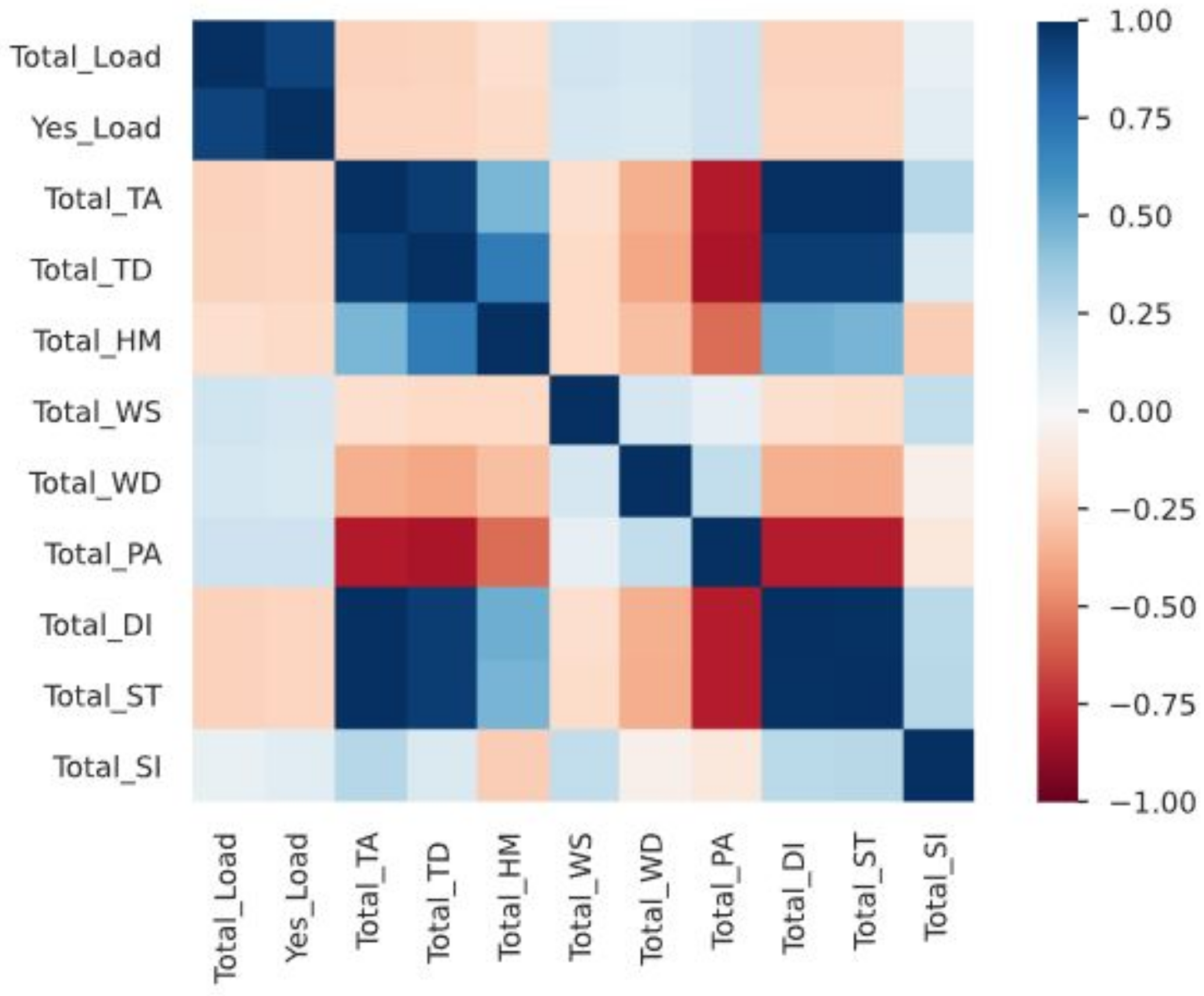
3.2. Data Analysis and Input Selection
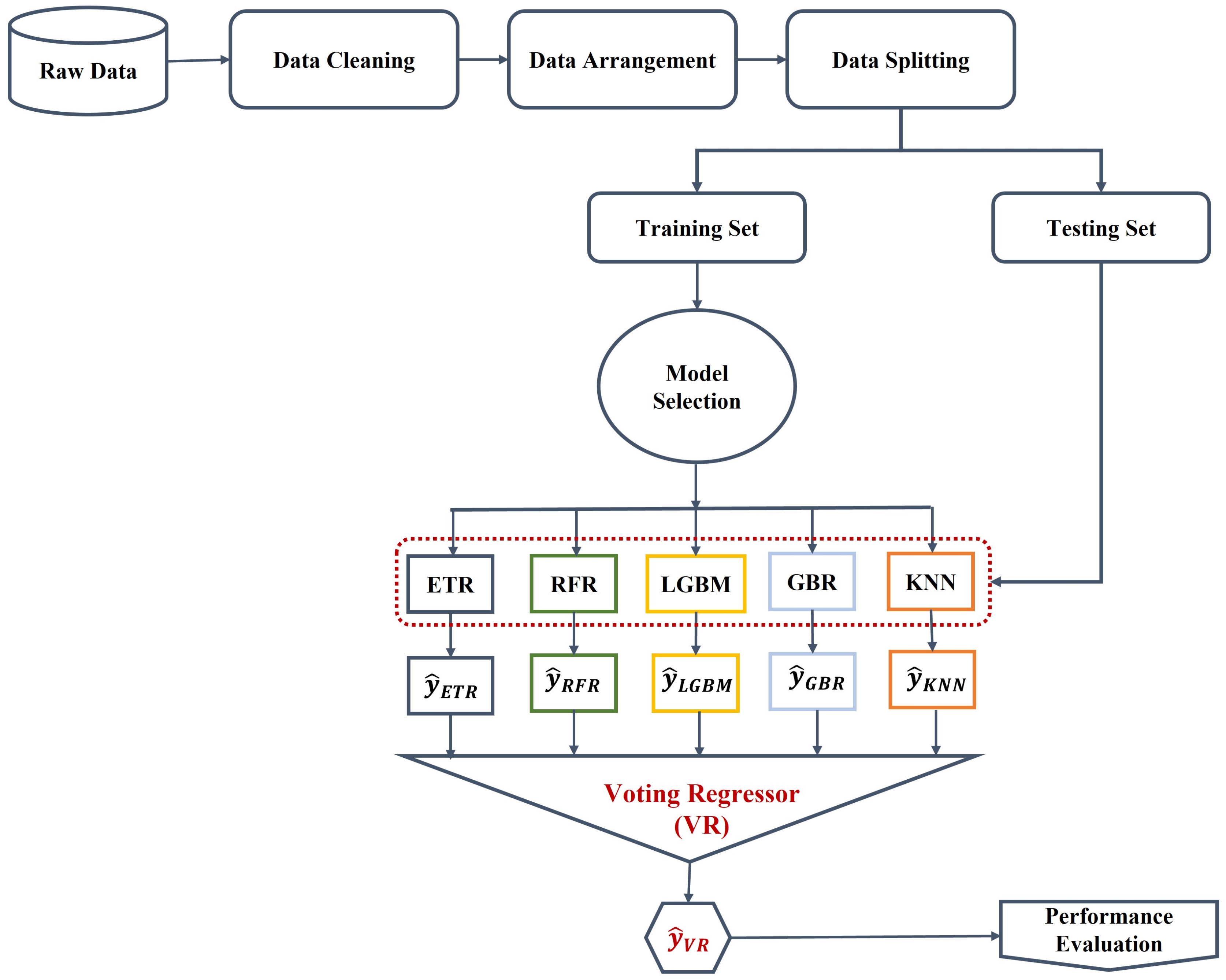
3.3. System Modeling
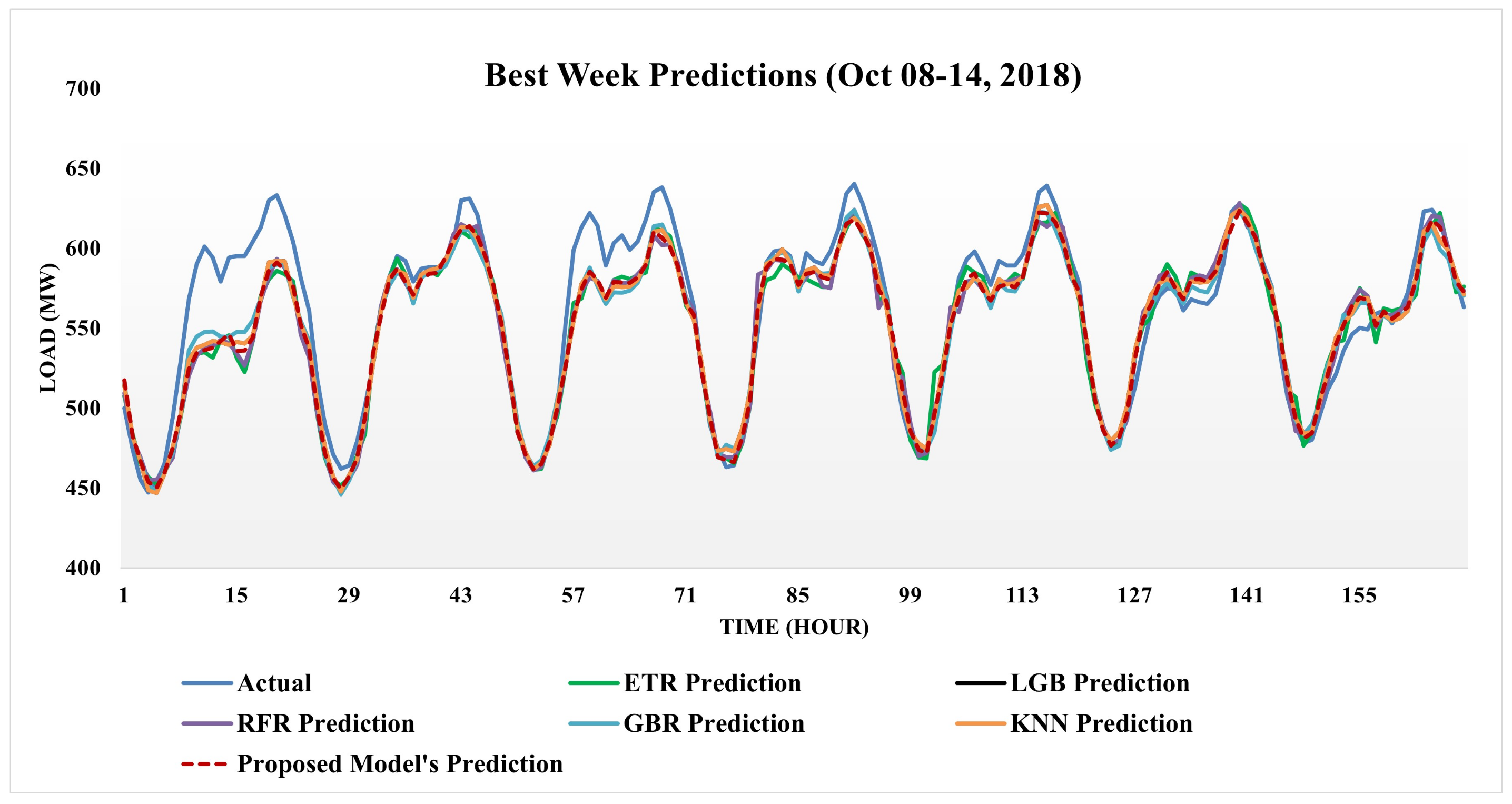
4. Result and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, P.W.; Byun, Y.C.; Lee, S.J.; Kang, D.H.; Kang, J.Y.; Park, H.S. Machine learning-based approach to predict energy consumption of renewable and nonrenewable power sources. Energies 2020, 13, 4870. [Google Scholar] [CrossRef]
- Phyo, P.P.; Jeenanunta, C.; Hashimoto, K. Electricity load forecasting in Thailand using deep learning models. Int. J. Electr. Electron. Eng. Telecommun. 2019, 8, 221–225. [Google Scholar] [CrossRef]
- Hagan, M.T.; Behr, S.M. The time series approach to short term load forecasting. IEEE Trans. Power Syst. 1987, 2, 785–791. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Sirsat, M.S.; Cernadas, E.; Alawadi, S.; Barro, S.; Febrero-Bande, M. An extensive experimental survey of regression methods. Neural Netw. 2019, 111, 11–34. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Jin, Z.; Shang, J.; Zhu, Q.; Ling, C.; Xie, W.; Qiang, B. RFRSF: Employee Turnover Prediction Based on Random Forests and Survival Analysis. Lect. Notes Comput. Sci. 2020, 12343 LNCS, 503–515. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: Oxfordshire, UK, 2017. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Jiang, R.; Tang, W.; Wu, X.; Fu, W. A random forest approach to the detection of epistatic interactions in case-control studies. BMC Bioinform. 2009, 10, S65. [Google Scholar] [CrossRef] [Green Version]
- Lahouar, A.; Slama, J.B.H. Day-ahead load forecast using random forest and expert input selection. Energy Convers. Manag. 2015, 103, 1040–1051. [Google Scholar] [CrossRef]
- Dudek, G. Short-Term Load Forecasting using Random Forests. In Proceedings of the 7th IEEE International Conference Intelligent Systems IS’2014, Warsaw, Poland, 24–26 September 2014. [Google Scholar]
- John, V.; Liu, Z.; Guo, C.; Mita, S.; Kidono, K. Real-time lane estimation using deep features and extra trees regression. In Image and Video Technology; Springer: Berlin/Heidelberg, Germany, 2015; pp. 721–733. [Google Scholar]
- Dada, G.I. Analysis of Electric Load Forecasts Using Machine Learning Techniques. Ph.D. Thesis, National College of Ireland, Dublin, Ireland, 2019. [Google Scholar]
- Alawadi, S.; Mera, D.; Fernández-Delgado, M.; Alkhabbas, F.; Olsson, C.M.; Davidsson, P. A comparison of machine learning algorithms for forecasting indoor temperature in smart buildings. Energy Syst. 2020, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Friedman, J. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 1–23. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network framework. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1793–1802. [Google Scholar] [CrossRef]
- Lei, X.; Fang, Z. GBDTCDA: Predicting circRNA-disease associations based on gradient boosting decision tree with multiple biological data fusion. Int. J. Biol. Sci. 2019, 15, 2911. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, J.; Lu, D.; Zhang, X.; Bi, Y.; Cheng, K.; Zheng, M.; Luo, X. Estimation of elimination half-lives of organic chemicals in humans using gradient boosting machine. Biochim. Biophys. Acta (BBA)-Gen. Subj. 2016, 1860, 2664–2671. [Google Scholar] [CrossRef]
- Lu, H.; Cheng, F.; Ma, X.; Hu, G. Short-term prediction of building energy consumption employing an improved extreme gradient boosting model: A case study of an intake tower. Energy 2020, 203, 117756. [Google Scholar] [CrossRef]
- Bogner, K.; Pappenberger, F.; Zappa, M. Machine learning techniques for predicting the energy consumption/production and its uncertainties driven by meteorological observations and forecasts. Sustainability 2019, 11, 3328. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Haghani, A. A gradient boosting method to improve travel time prediction. Transp. Res. Part C Emerg. Technol. 2015, 58, 308–324. [Google Scholar] [CrossRef]
- Touzani, S.; Granderson, J.; Fernandes, S. Gradient boosting machine for modeling the energy consumption of commercial buildings. Energy Build. 2018, 158, 1533–1543. [Google Scholar] [CrossRef] [Green Version]
- Fix, E.; Hodges, J.L. Nonparametric discrimination: Consistency properties. Randolph Field Tex. Proj. 1951, 57, 21–49. [Google Scholar]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Fan, G.F.; Guo, Y.H.; Zheng, J.M.; Hong, W.C. Application of the weighted k-nearest neighbor algorithm for short-term load forecasting. Energies 2019, 12, 916. [Google Scholar] [CrossRef] [Green Version]
- Wahid, F.; Kim, D. A prediction approach for demand analysis of energy consumption using k-nearest neighbor in residential buildings. Int. J. Smart Home 2016, 10, 97–108. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Wang, J.; Hou, R.; Wu, J. A combined model based on data pre-analysis and weight coefficients optimization for electrical load forecasting. Energy 2015, 82, 524–549. [Google Scholar] [CrossRef]
- Lloyd, J.R. GEFCom2012 hierarchical load forecasting: Gradient boosting machines and Gaussian processes. Int. J. Forecast. 2014, 30, 369–374. [Google Scholar] [CrossRef] [Green Version]
- Friedrich, L.; Afshari, A. Short-term Forecasting of the Abu Dhabi Electricity Load Using Multiple Weather Variables. Energy Procedia 2015, 75, 3014–3026. [Google Scholar] [CrossRef] [Green Version]
- Dudek, G. Pattern similarity-based methods for short-term load forecasting-Part 2: Models. Appl. Soft Comput. J. 2015, 36, 422–441. [Google Scholar] [CrossRef]
- Dudek, G. Pattern similarity-based methods for short-term load forecasting-Part 1: Principles. Appl. Soft Comput. J. 2015, 37, 277–287. [Google Scholar] [CrossRef]
- Dudek, G. Pattern-based local linear regression models for short-term load forecasting. Electr. Power Syst. Res. 2016, 130, 139–147. [Google Scholar] [CrossRef]
- Ashfaq, T.; Javaid, N. Short-term electricity load and price forecasting using enhanced KNN. In Proceedings of the 2019 International Conference on Frontiers of Information Technology, Islamabad, Pakistan, 16–18 December 2019; pp. 266–271. [Google Scholar] [CrossRef]
- Lin, Y.; Luo, H.; Wang, D.; Guo, H.; Zhu, K. An ensemble model based on machine learning methods and data preprocessing for short-term electric load forecasting. Energies 2017, 10, 1186. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Cheng, M.; Liu, Y.; Li, D.H.; Wu, R.M. Short-term load forecasting based on big data technologies. Appl. Mech. Mater. 2014, 687–691, 1186–1192. [Google Scholar] [CrossRef]
- Moon, J.; Kim, Y.; Son, M.; Hwang, E. Hybrid short-term load forecasting scheme using random forest and multilayer perceptron. Energies 2018, 11, 3283. [Google Scholar] [CrossRef] [Green Version]
- Khan, P.W.; Byun, Y.C. Adaptive Error Curve Learning Ensemble Model for Improving Energy Consumption Forecasting. Comput. Mater. Contin. 2021, 69, 1893–1913. [Google Scholar] [CrossRef]
- Amarasinghe, P.A.; Abeygunawardana, N.S.; Jayasekara, T.N.; Edirisinghe, E.A.; Abeygunawardane, S.K. Ensemble models for solar power forecasting-a weather classification approach. AIMS Energy 2020, 8, 252–271. [Google Scholar] [CrossRef]
- Abuella, M.; Chowdhury, B. Random forest ensemble of support vector regression models for solar power forecasting. In Proceedings of the 2017 IEEE Power and Energy Society Innovative Smart Grid Technologies Conference, Torino, Italy, 26–29 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, A.A.; Aung, Z. Ensemble learning approach for probabilistic forecasting of solar power generation. Energies 2016, 9, 1017. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Tree-based ensemble methods for predicting PV power generation and their comparison with support vector regression. Energy 2018, 164, 465–474. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
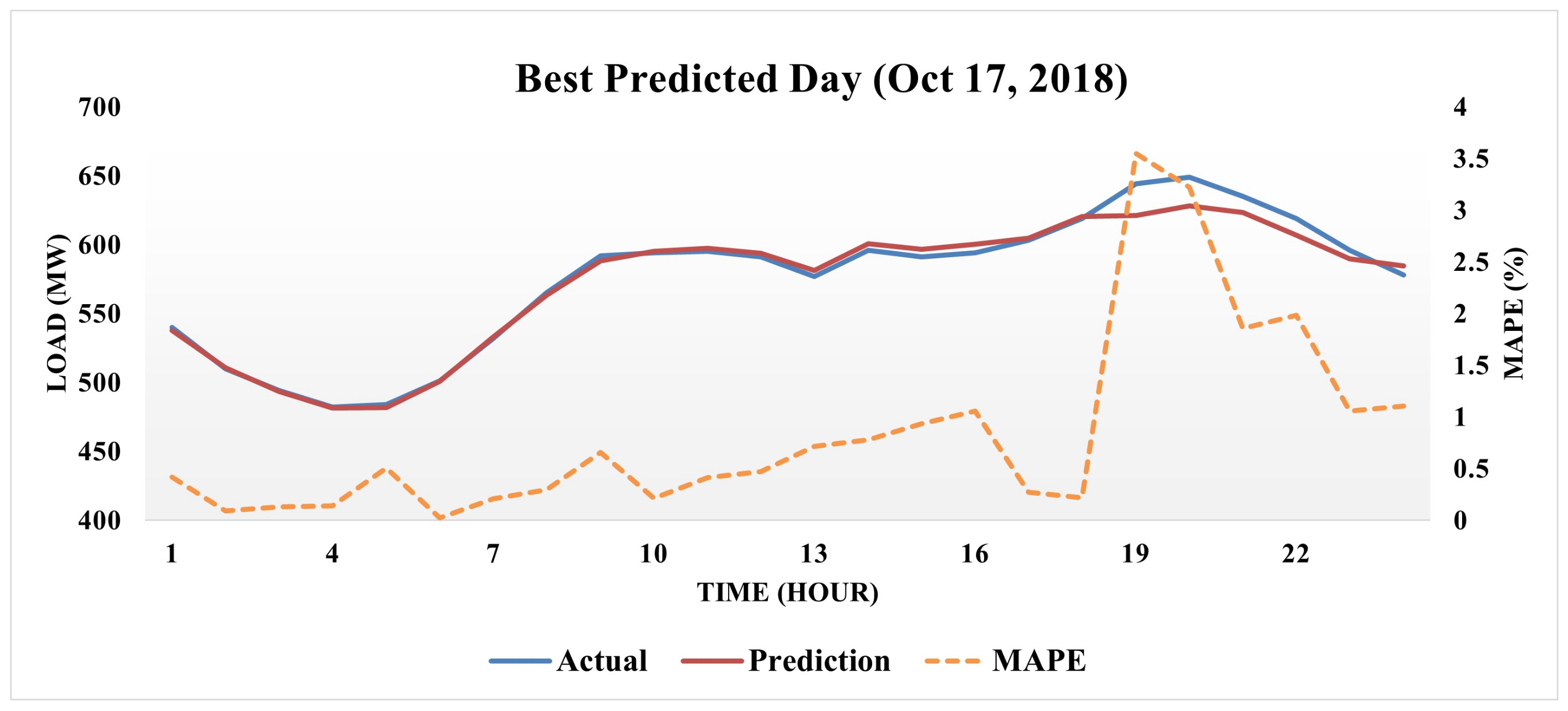{kind=link}
| No | Variables | Min | Max | Mean | SD | CV | Unit |
|---|---|---|---|---|---|---|---|
| 1 | Total_Load | 233 | 951 | 629.56 | 103.32 | 0.16 | MW |
| 2 | Yes_Load | 233 | 951 | 629.56 | 103.32 | 0.16 | MW |
| 3 | Total_TA | −2.40 | 33.80 | 16.81 | 7.98 | 0.47 | C |
| 4 | Total_TD | −10.70 | 28.30 | 11.46 | 9.48 | 0.83 | C |
| 5 | Total_HM | 21 | 99.20 | 72.33 | 14.67 | 0.20 | % |
| 6 | Total_WS | 0 | 22.40 | 3.04 | 1.46 | 0.48 | m/s |
| 7 | Total_WD | 0 | 360 | 190.55 | 84.52 | 0.44 | |
| 8 | Total_PA | 704.30 | 1032.40 | 1011.90 | 11.68 | 0.01 | hPa |
| 9 | Total_DI | 30.10 | 86.50 | 61.97 | 12.35 | 0.20 | - |
| 10 | Total_ST | −7.40 | 33.80 | 16.24 | 8.81 | 0.54 | C |
| 11 | Total_SI | 0 | 2.40 | 0.32 | 0.54 | 1.67 | Mj/m |
| No | ML Algorithm | MAPE (%) | MAE () | MSE () | Time (s) |
|---|---|---|---|---|---|
| 1 | Extra trees regressor (ETR) | 3.10 | 19.37 | 726.74 | 2.79 |
| 2 | Random forest regressor (RFR) | 3.20 | 20.05 | 771.27 | 5.88 |
| 3 | Light gradient boosting machine (LGBM) | 3.40 | 20.88 | 808.37 | 0.40 |
| 4 | Gradient boosting regressor (GBR) | 3.70 | 22.71 | 947.63 | 1.40 |
| 5 | K neighbors regressor (KNN) | 4.00 | 25.06 | 1175.54 | 0.08 |
| 6 | Bayesian ridge (BR) | 4.20 | 25.77 | 1281.17 | 0.02 |
| 7 | Linear regression (LR) | 4.20 | 25.78 | 1281.17 | 0.16 |
| 8 | Lasso regression (Lasso) | 4.10 | 25.73 | 1286.85 | 0.03 |
| 9 | Ridge regression (Ridge) | 4.20 | 25.78 | 1281.17 | 0.02 |
| 10 | Huber regressor (Huber) | 4.10 | 25.44 | 1300.88 | 0.19 |
| 11 | Elastic net (EN) | 4.20 | 25.83 | 1305.45 | 0.03 |
| 12 | Orthogonal matching pursuit (OMP) | 4.30 | 27.07 | 1427.19 | 0.02 |
| 13 | AdaBoost regressor (Ada) | 5.20 | 30.61 | 1474.62 | 0.72 |
| 14 | Decision tree regressor (DT) | 4.40 | 27.26 | 1549.40 | 0.10 |
| 15 | Least angle regression (LAR) | 4.80 | 29.66 | 1648.04 | 0.02 |
| 16 | Passive aggressive regressor (PAR) | 6.60 | 41.37 | 2890.09 | 0.03 |
| 17 | Lasso least angle regression (LLAR) | 13.20 | 79.50 | 9831.52 | 0.02 |
| ETR | RFR | LGBM | GBR | KNN | ARIMA | Proposed VR | |
|---|---|---|---|---|---|---|---|
| June | 3.59 | 3.62 | 3.28 | 3.31 | 3.77 | 11.48 | 3.31 |
| July | 4.50 | 4.59 | 4.47 | 4.38 | 4.25 | 16.97 | 4.24 |
| August | 4.35 | 4.33 | 4.58 | 4.56 | 5.09 | 18.73 | 4.36 |
| September | 4.48 | 4.52 | 4.38 | 4.20 | 4.70 | 13.41 | 4.20 |
| October | 3.34 | 3.24 | 3.03 | 3.11 | 3.60 | 11.15 | 3.14 |
| November | 3.40 | 3.41 | 3.35 | 3.43 | 3.71 | 8.07 | 3.32 |
| December | 4.85 | 4.83 | 4.70 | 4.70 | 5.16 | 12.59 | 4.71 |
| January | 5.34 | 5.33 | 5.26 | 5.27 | 5.44 | 18.05 | 5.20 |
| February | 6.04 | 6.23 | 6.02 | 6.20 | 6.66 | 15.39 | 6.10 |
| March | 5.08 | 5.23 | 4.91 | 4.81 | 5.11 | 10.68 | 4.89 |
| April | 4.58 | 4.67 | 4.45 | 4.40 | 4.67 | 7.44 | 4.43 |
| May | 3.64 | 3.70 | 3.46 | 3.54 | 3.92 | 8.14 | 3.52 |
| Average | 4.42 | 4.46 | 4.31 | 4.32 | 4.66 | 12.68 | 4.28 |
| ETR | RFR | LGBM | GBR | KNN | ARIMA | Proposed VR | |
|---|---|---|---|---|---|---|---|
| June | 22.24 | 22.46 | 20.25 | 20.32 | 22.75 | 62.16 | 20.38 |
| July | 33.47 | 34.09 | 33.35 | 32.58 | 30.77 | 127.91 | 31.50 |
| August | 34.22 | 33.86 | 36.19 | 36.26 | 40.13 | 151.54 | 34.56 |
| September | 28.22 | 28.56 | 27.53 | 26.08 | 29.09 | 77.94 | 26.27 |
| October | 19.25 | 18.75 | 17.48 | 17.98 | 20.75 | 57.60 | 18.20 |
| November | 20.57 | 20.63 | 20.34 | 20.83 | 22.42 | 46.02 | 20.16 |
| December | 34.05 | 34.00 | 33.22 | 33.27 | 36.37 | 92.02 | 33.27 |
| January | 41.16 | 40.97 | 40.55 | 40.71 | 41.54 | 141.64 | 40.01 |
| February | 44.25 | 45.57 | 43.98 | 45.27 | 48.40 | 116.95 | 44.57 |
| March | 35.48 | 36.66 | 34.12 | 33.58 | 35.34 | 77.44 | 34.11 |
| April | 29.46 | 36.66 | 28.52 | 28.16 | 29.81 | 48.49 | 28.41 |
| May | 21.94 | 22.04 | 20.85 | 21.29 | 23.44 | 45.37 | 21.23 |
| Average | 30.30 | 30.57 | 29.64 | 29.63 | 31.66 | 87.16 | 29.33 |
| ETR | RFR | LGBM | GBR | KNN | ARIMA | Proposed VR | |
|---|---|---|---|---|---|---|---|
| June | 925.66 | 957.60 | 811.24 | 834.40 | 919.92 | 6202.86 | 790.07 |
| July | 1925.44 | 2018.45 | 1910.07 | 1831.40 | 1786.87 | 24,061.93 | 1737.92 |
| August | 2112.71 | 2050.42 | 2348.14 | 2309.57 | 3165.23 | 33,180.54 | 2186.10 |
| September | 1356.39 | 1381.26 | 1263.88 | 1180.53 | 1502.92 | 8314.91 | 1175.74 |
| October | 679.66 | 662.24 | 555.97 | 567.94 | 772.93 | 5604.40 | 603.30 |
| November | 724.45 | 739.55 | 704.54 | 728.45 | 887.75 | 3226.72 | 701.97 |
| December | 1778.52 | 1803.59 | 1733.20 | 1736.54 | 2115.47 | 12,465.83 | 1732.65 |
| January | 2729.31 | 2682.77 | 2618.84 | 2648.64 | 2908.46 | 24,611.42 | 2582.60 |
| February | 3289.47 | 3452.91 | 3228.47 | 3345.29 | 3930.38 | 18,199.15 | 3305.67 |
| March | 2039.32 | 2173.71 | 1890.86 | 1859.06 | 2049.58 | 9063.55 | 1881.25 |
| April | 1330.22 | 1399.04 | 1253.99 | 1264.37 | 1429.82 | 4048.37 | 1257.31 |
| May | 790.84 | 801.67 | 732.51 | 734.64 | 895.44 | 3204.19 | 735.05 |
| Average | 1632.80 | 1668.55 | 1580.60 | 1578.79 | 1854.29 | 12,715.92 | 1549.51 |
| ETR | RFR | LGBM | GBR | KNN | ARIMA | Proposed VR | |
|---|---|---|---|---|---|---|---|
| Spring | 4.44 | 4.52 | 4.27 | 4.25 | 4.57 | 8.77 | 4.28 |
| Summer | 4.15 | 4.19 | 4.12 | 4.10 | 4.38 | 15.78 | 3.98 |
| Fall | 3.74 | 3.72 | 3.58 | 3.58 | 4.00 | 10.88 | 3.56 |
| Winter | 5.39 | 5.44 | 5.31 | 5.37 | 5.72 | 15.35 | 5.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Phyo, P.-P.; Byun, Y.-C.; Park, N. Short-Term Energy Forecasting Using Machine-Learning-Based Ensemble Voting Regression. Symmetry 2022, 14, 160. https://doi.org/10.3390/sym14010160
Phyo P-P, Byun Y-C, Park N. Short-Term Energy Forecasting Using Machine-Learning-Based Ensemble Voting Regression. Symmetry. 2022; 14(1):160. https://doi.org/10.3390/sym14010160
Chicago/Turabian StylePhyo, Pyae-Pyae, Yung-Cheol Byun, and Namje Park. 2022. "Short-Term Energy Forecasting Using Machine-Learning-Based Ensemble Voting Regression" Symmetry 14, no. 1: 160. https://doi.org/10.3390/sym14010160